














































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
散列表
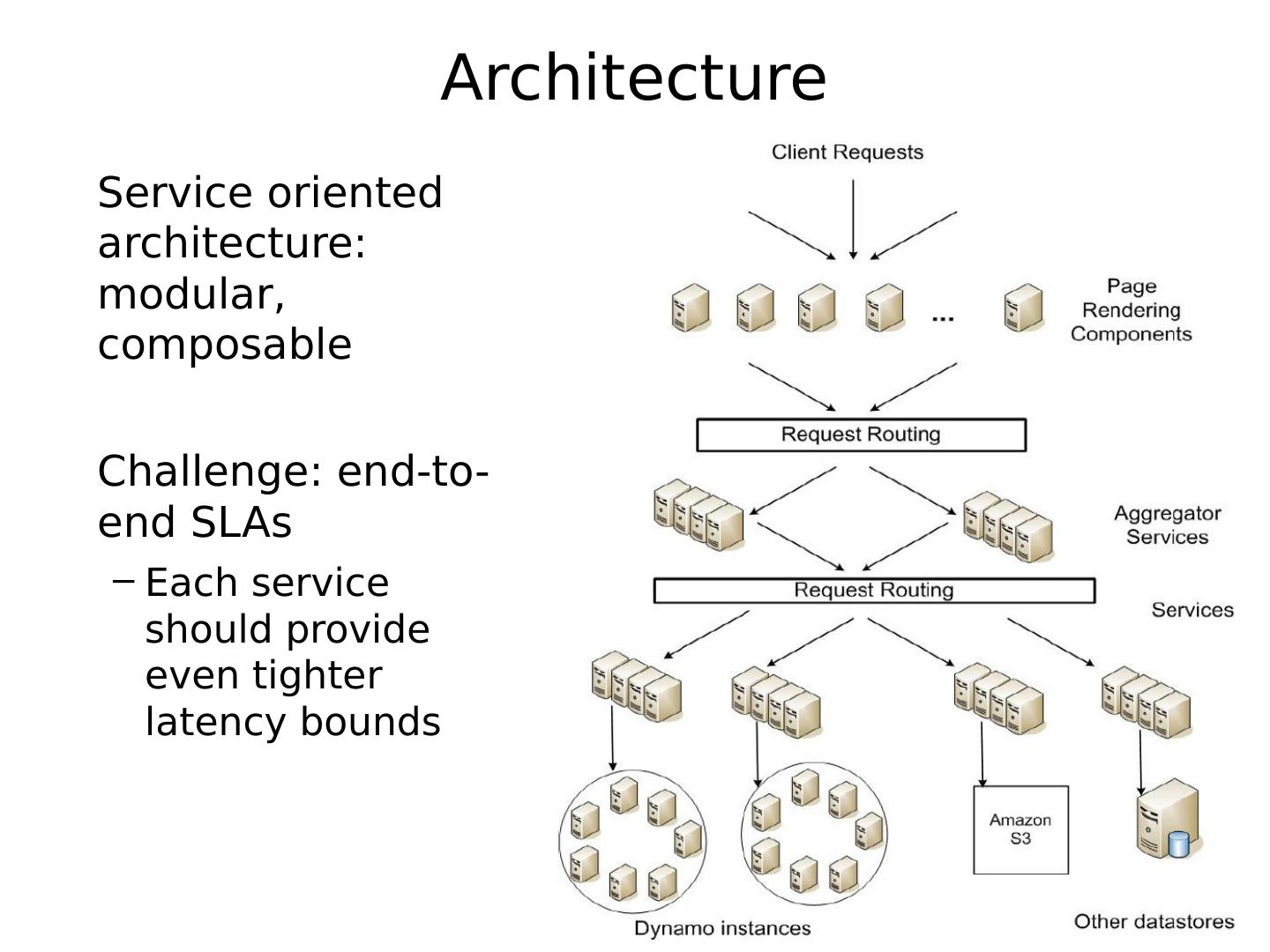
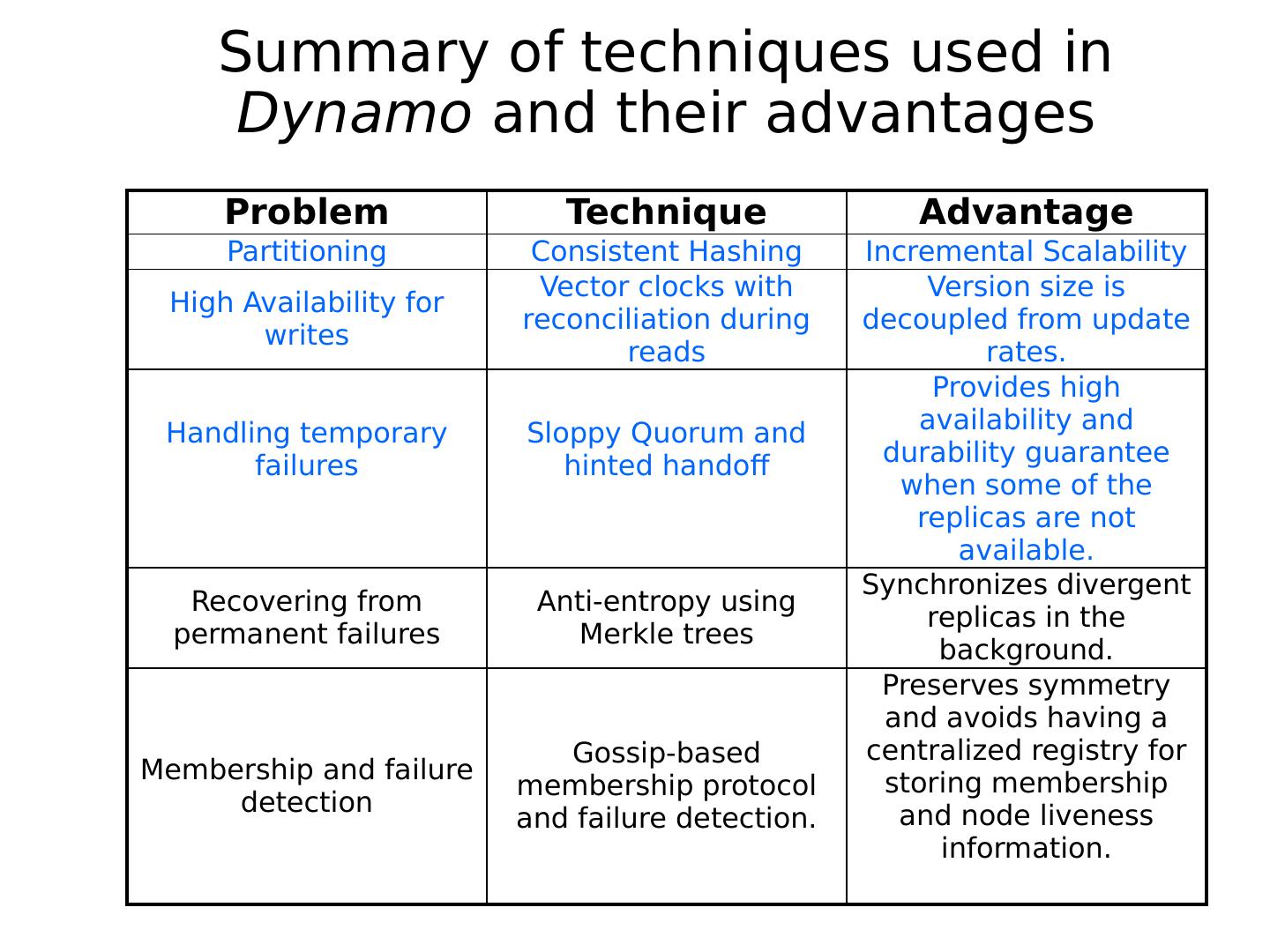
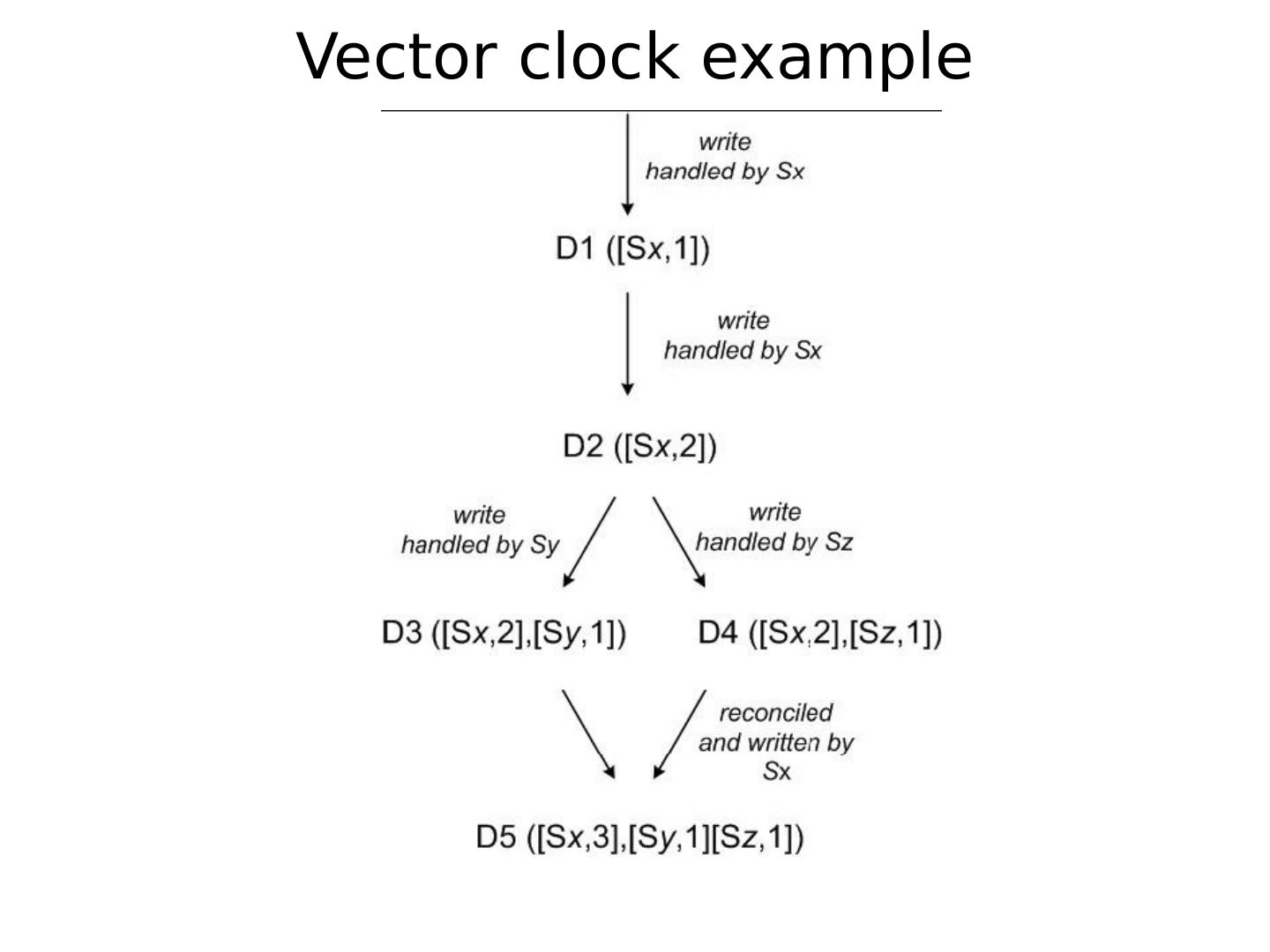
本章节主要介绍散列表的两大类Chord和DynamoDB。Chord是一个算法,也是一个协议。作为一个算法,Chord能够从数学的角度严格证明其正确性和收敛性;作为一个协议,Chord具体定义了每一个环节的消息类型;而 DynamoDB是一个完全托管的NoSQL数据库服务,可以提供快速的、可预期的性能,并且可以实现无缝扩展。本章节给出了两者的定义,从不同角度分析了两者的作用,介绍了其应用以及将两者做出了比较。
展开查看详情
1 .Key-Value Tables: Chord and DynamoDB (Lecture 16, cs262a) Ali Ghodsi and Ion Stoica, UC Berkeley March 14, 2018
2 .Key-Value Tables: Chord and DynamoDB (Lecture 16, cs262a) Ali Ghodsi and Ion Stoica, UC Berkeley March 14, 2018
3 .Key Value Storage Interface put (key, value); // insert/write “ value ” associated with “ key ” value = get (key); // get/read data associated with “ key ” Abstraction used to implement File systems: value content block Sometimes as a simpler but more scalable “ database ” Can handle large volumes of data, e.g., PBs Need to distribute data over hundreds, even thousands of machines
4 .Amazon: Key: customerID Value: customer profile (e.g., buying history, credit card, ..) Facebook, Twitter: Key: UserID Value: user profile (e.g., posting history, photos, friends, …) iCloud /iTunes: Key: Movie/song name Value: Movie, Song Distributed file systems Key: Block ID Value: Block Key Values: Examples
5 .System Examples Google File System, Hadoop Dist. File Systems (HDFS) Amazon Dynamo: internal key value store used to power Amazon.com (shopping cart) Simple Storage System (S3) BigTable/Hbase: distributed, scalable data storage Cassandra : “ distributed data management system ” (Facebook) Memcached: in-memory key-value store for small chunks of arbitrary data (strings, objects)
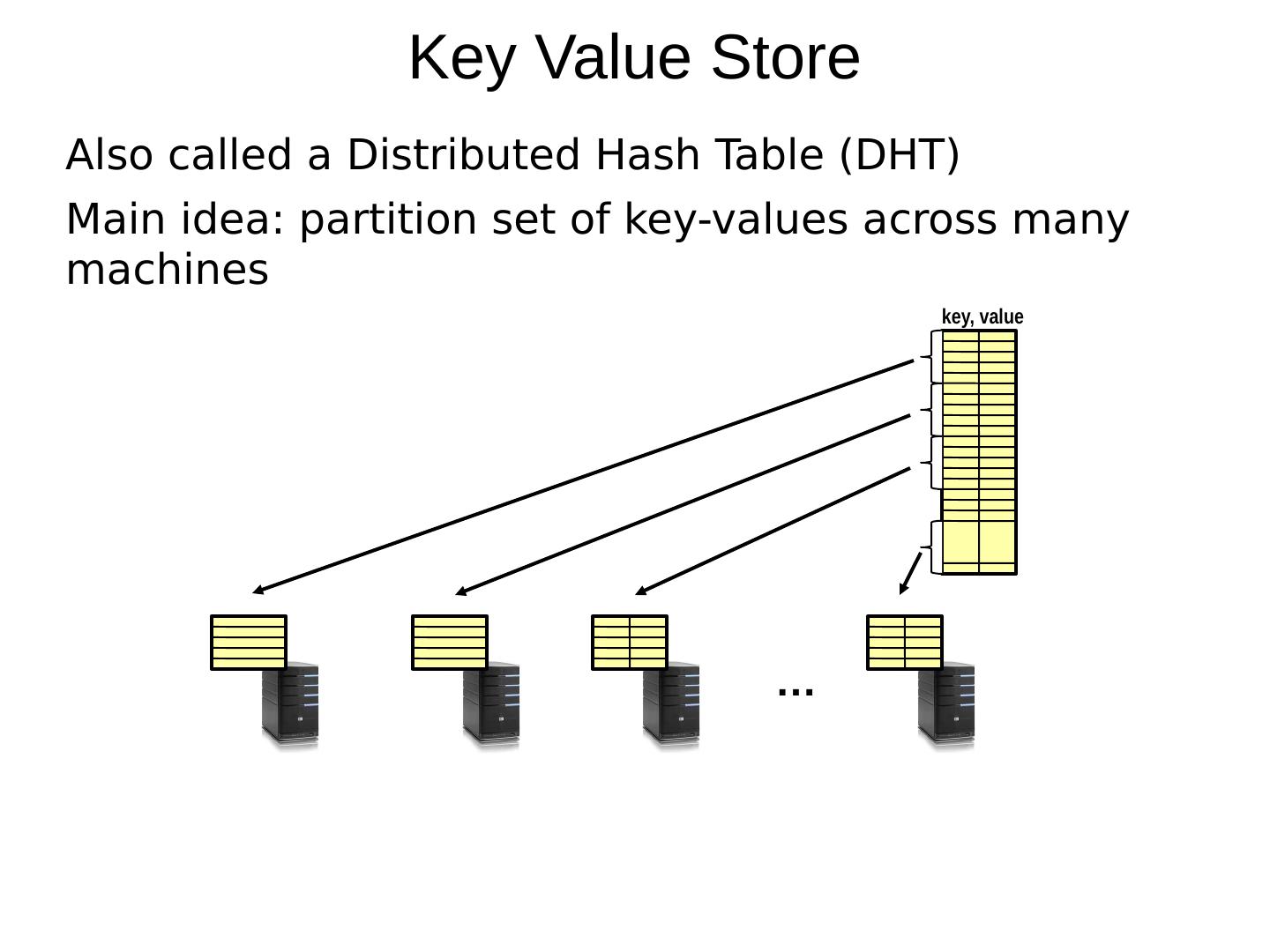
6 .Key Value Store Also called a Distributed Hash Table (DHT) Main idea: partition set of key-values across many machines key, value …
7 .Challenges Fault Tolerance: handle machine failures without losing data and without degradation in performance Scalability: Need to scale to thousands of machines Need to allow easy addition of new machines Consistency: maintain data consistency in face of node failures and message losses Heterogeneity (if deployed as peer-to-peer systems): Latency: 1ms to 1000ms Bandwidth: 32Kb/s to 100Mb/s …
8 .Key Questions put(key, value): where do you store a new (key, value) tuple? get(key): where is the value associated with a given “ key ” stored? And, do the above while providing Fault Tolerance Scalability Consistency
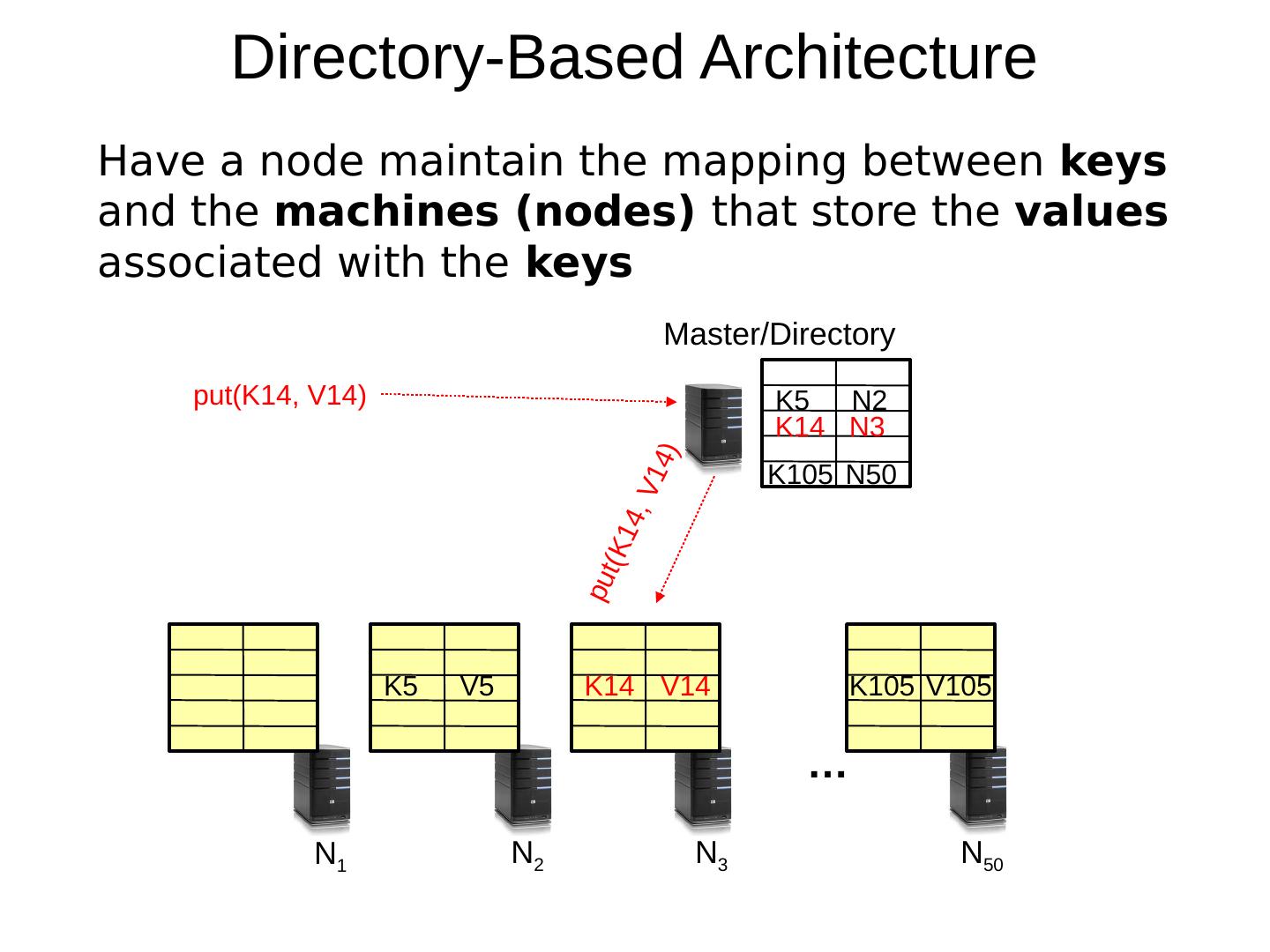
9 .Directory-Based Architecture Have a node maintain the mapping between keys and the machines (nodes) that store the values associated with the keys … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N3 K105 N50 Master/Directory put(K14, V14) put(K14, V14)
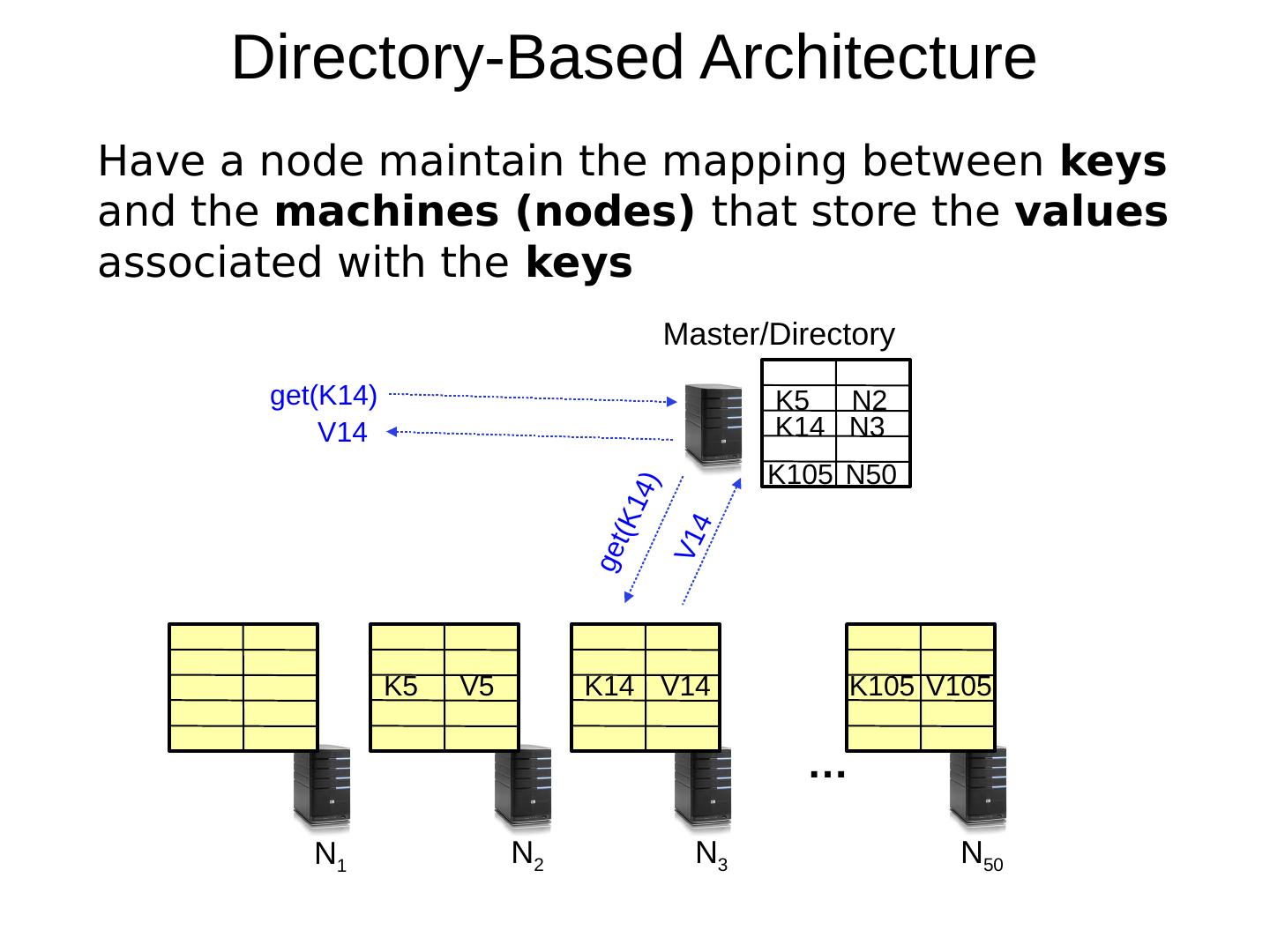
10 .Directory-Based Architecture Have a node maintain the mapping between keys and the machines (nodes) that store the values associated with the keys … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N3 K105 N50 Master/Directory get(K14) get(K14) V14 V14
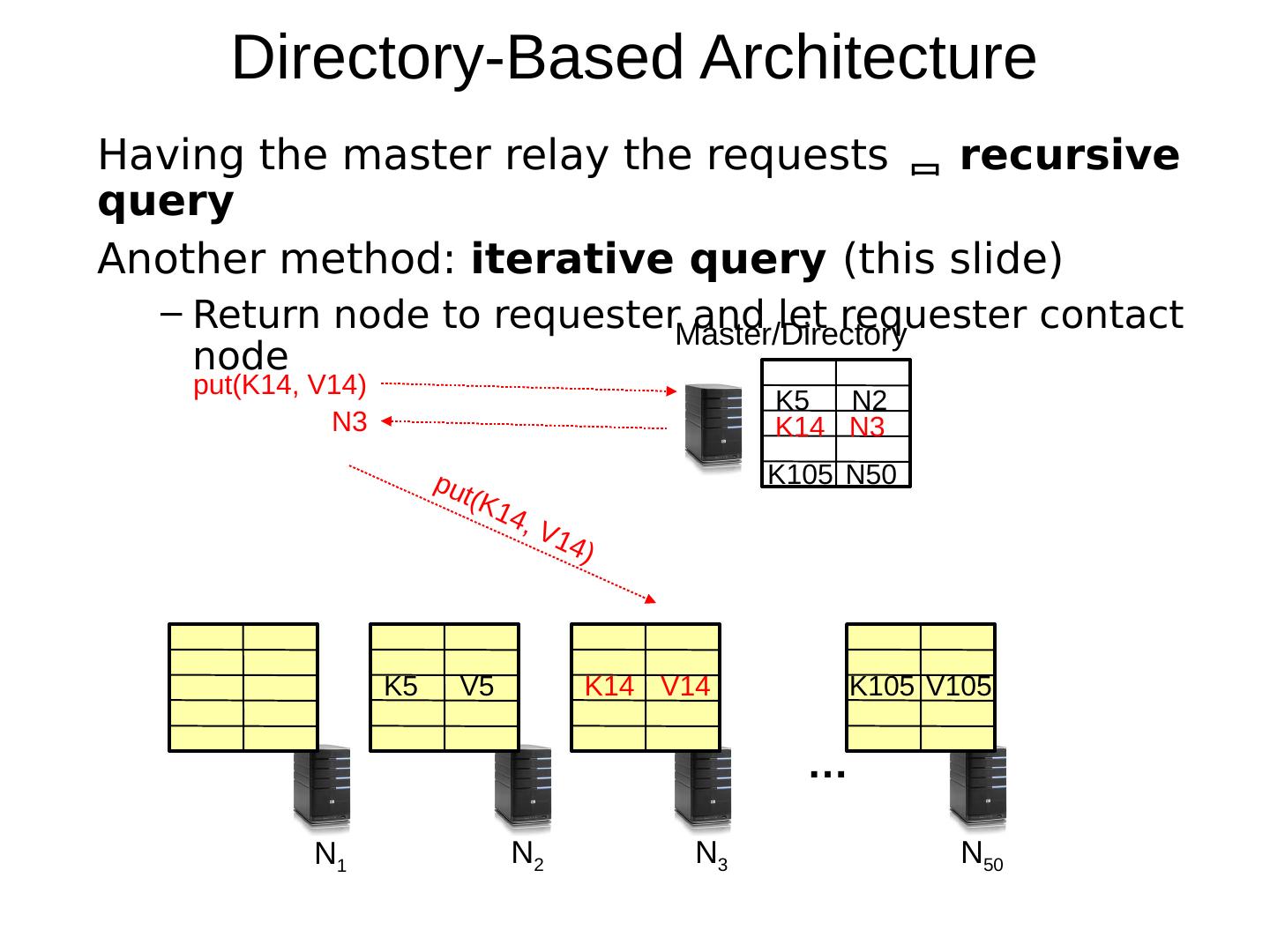
11 .Directory-Based Architecture Having the master relay the requests recursive query Another method: iterative query (this slide) Return node to requester and let requester contact node … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N3 K105 N50 Master/Directory put(K14, V14) put(K14, V14) N3
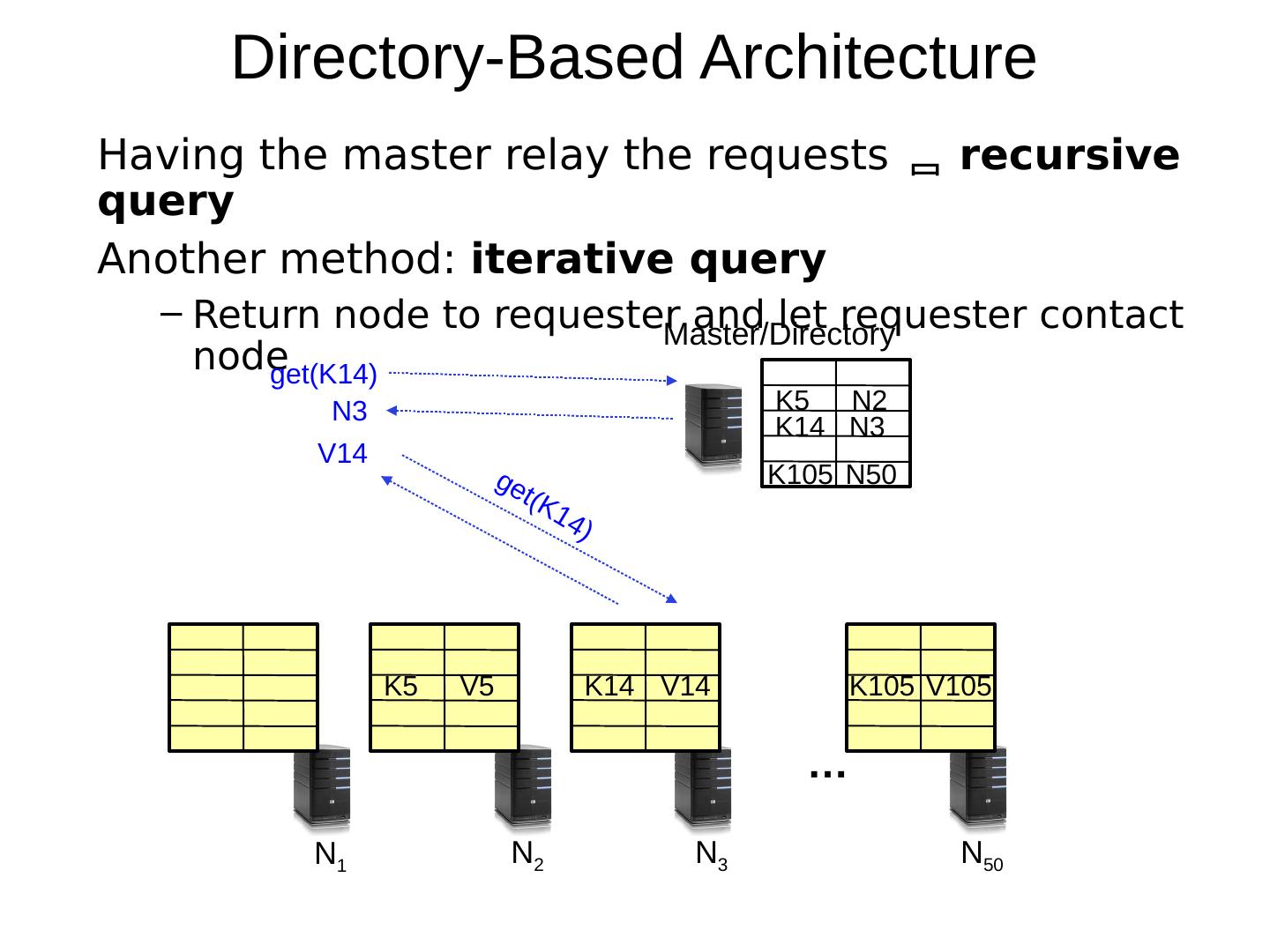
12 .Directory-Based Architecture Having the master relay the requests recursive query Another method: iterative query Return node to requester and let requester contact node … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N3 K105 N50 Master/Directory get(K14) get(K14) V14 N3
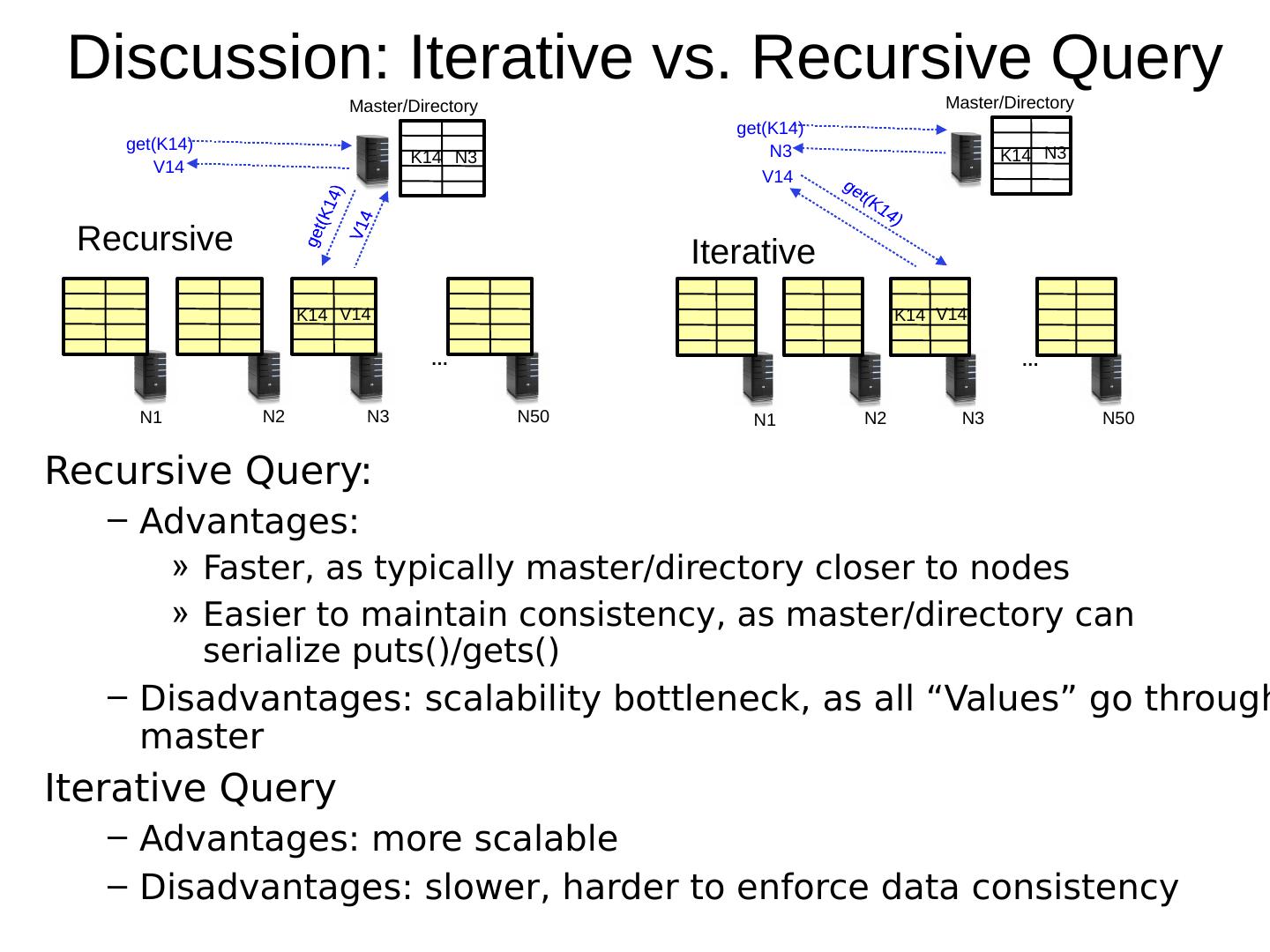
13 .Discussion: Iterative vs. Recursive Query Recursive Query: Advantages: Faster, as typically master/directory closer to nodes Easier to maintain consistency, as master/directory can serialize puts()/gets() Disadvantages: scalability bottleneck, as all “ Values ” go through master Iterative Query Advantages: more scalable Disadvantages: slower, harder to enforce data consistency … N1 N2 N3 N50 K14 V14 K14 N3 Master/Directory get(K14) get(K14) V14 V14 … N1 N2 N3 N50 K14 V14 K14 N3 Master/Directory get(K14) get(K14) V14 N3 Recursive Iterative
14 .Fault Tolerance Replicate value on several nodes Usually, place replicas on different racks in a datacenter to guard against rack failures … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N1,N3 K105 N50 Master/Directory put(K14, V14) put(K14, V14), N1 N1, N3 K14 V14 put(K14, V14)
15 .Fault Tolerance Again, we can have Recursive replication (previous slide) Iterative replication (this slide) … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N1,N3 K105 N50 Master/Directory put(K14, V14) put(K14, V14) N1, N3 K14 V14 put(K14, V14)
16 .Scalability Storage: use more nodes Request throughput: Can serve requests from all nodes on which a value is stored in parallel Master can replicate a popular value on more nodes Master/directory scalability: Replicate it Partition it, so different keys are served by different masters/directories (see Chord)
17 .Scalability: Load Balancing Directory keeps track of the storage availability at each node Preferentially insert new values on nodes with more storage available What happens when a new node is added? Cannot insert only new values on new node. Why? Move values from the heavy loaded nodes to the new node What happens when a node fails? Need to replicate values from fail node to other nodes
18 .Replication Challenges Need to make sure that a value is replicated correctly How do you know a value has been replicated on every node? Wait for acknowledgements from every node What happens if a node fails during replication? Pick another node and try again What happens if a node is slow? Slow down the entire put()? Pick another node? In general, with multiple replicas Slow puts and fast gets
19 .Consistency How close does a distributed system emulate a single machine in terms of read and write semantics? Q: Assume put(K14, V14 ’ ) and put(K14, V14 ’’ ) are concurrent, what value ends up being stored? A: assuming put() is atomic, then either V14 ’ or V14 ’’ , right? Q: Assume a client calls put(K14, V14) and then get(K14) , what is the result returned by get() ? A: It should be V14, right? Above semantics, not trivial to achieve in distributed systems
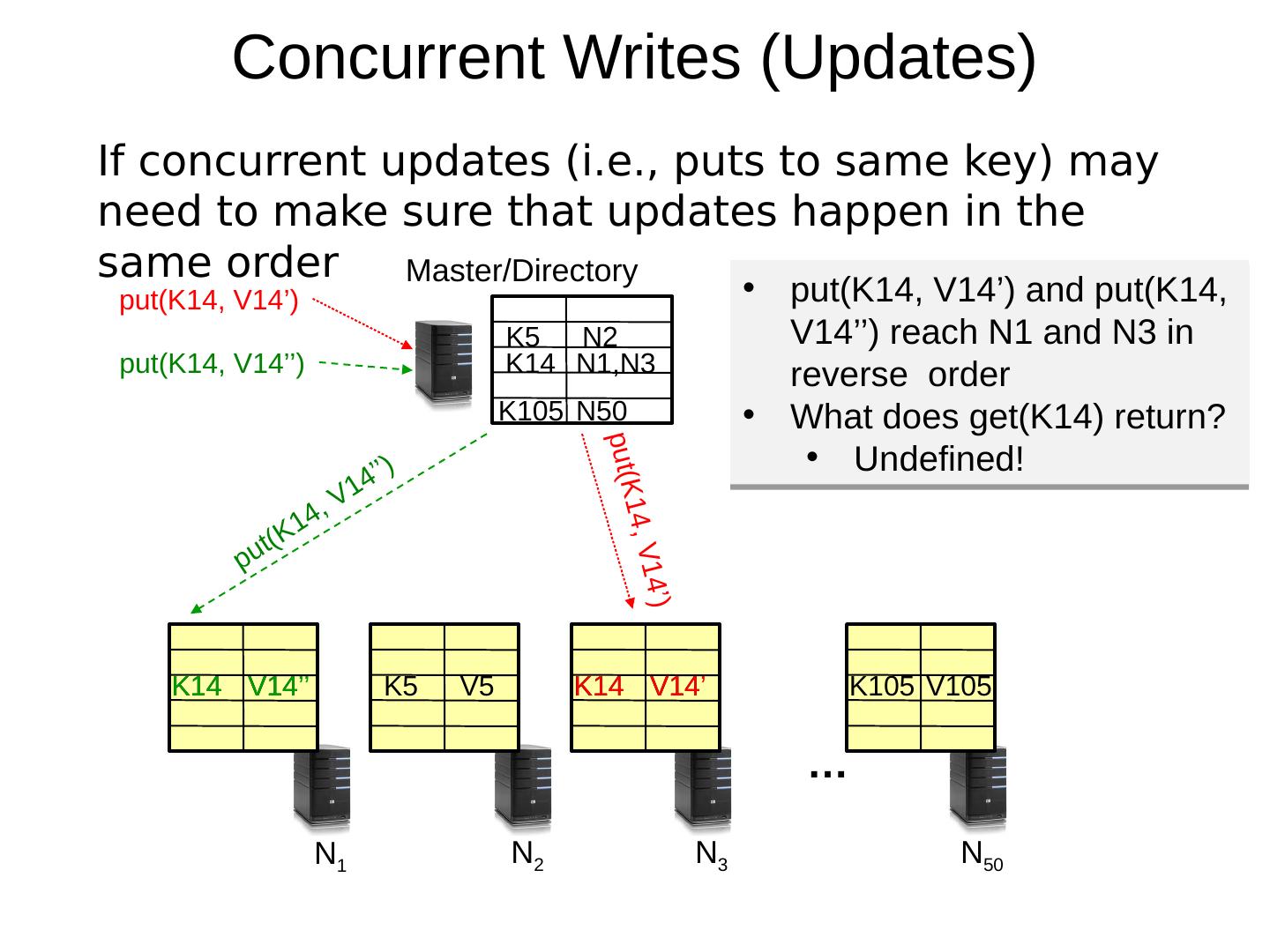
20 .Concurrent Writes (Updates) If concurrent updates (i.e., puts to same key) may need to make sure that updates happen in the same order … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N1,N3 K105 N50 Master/Directory put(K14, V14 ’ ) put(K14, V14 ’ ) K14 V14 put(K14, V14 ’’ ) put(K14, V14’’) K14 V14 ’ K14 V14 ’’ put(K14, V14’) and put(K14, V14’’) reach N1 and N3 in reverse order What does get(K14) return? Undefined!
21 .Concurrent Writes (Updates) If concurrent updates (i.e., puts to same key) may need to make sure that updates happen in the same order … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N1,N3 K105 N50 Master/Directory put(K14, V14 ’ ) put(K14, V14 ’ ) K14 V14 put(K14, V14 ’’ ) put(K14, V14’’) put(K14, V14 ’ ) put(K14, V14 ’’ ) K14 V14 ’’ K14 V14 ’ put(K14, V14’) and put(K14, V14’’) reach N1 and N3 in reverse order What does get(K14) return? Undefined!
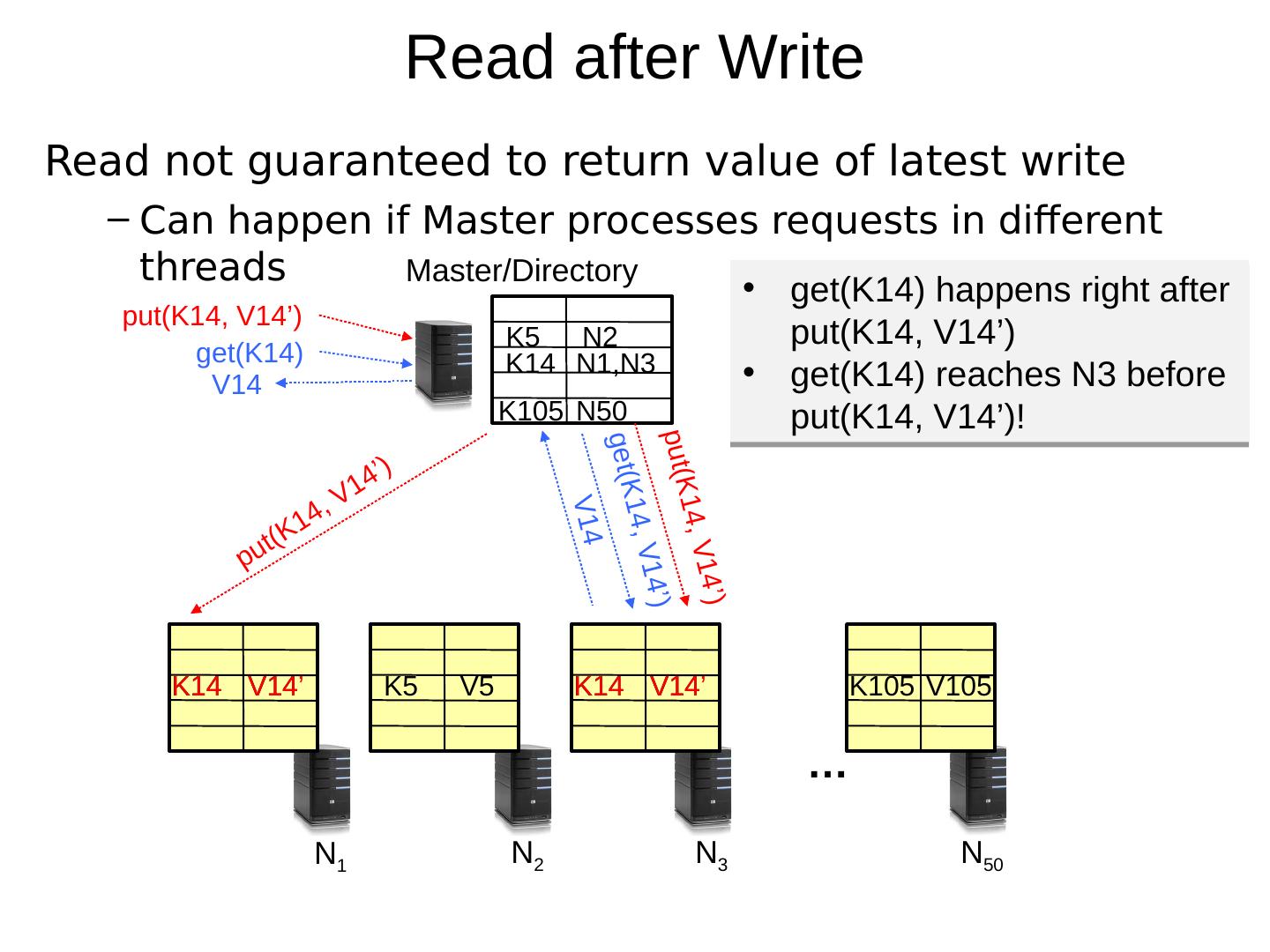
22 .Read after Write Read not guaranteed to return value of latest write Can happen if Master processes requests in different threads … N 1 N 2 N 3 N 50 K5 V5 K14 V14 K105 V105 K5 N2 K14 N1,N3 K105 N50 Master/Directory get(K14) get(K14, V14 ’ ) K14 V14 put(K14, V14 ’ ) put(K14, V14 ’ ) put(K14, V14 ’ ) K14 V14 ’ K14 V14 ’ get(K14) happens right after put(K14, V14’) get(K14) reaches N3 before put(K14, V14’)! V14 V14
23 .Consistency (cont ’ d) Large variety of consistency models (we’ve already seen): Atomic consistency ( linearizability ): reads/writes (gets/puts) to replicas appear as if there was a single underlying replica (single system image) Think “ one updated at a time ” Transactions Eventual consistency: given enough time all updates will propagate through the system One of the weakest form of consistency; used by many systems in practice And many others: causal consistency, sequential consistency, strong consistency, …
24 .Strong Consistency Assume Master serializes all operations Challenge: master becomes a bottleneck Not addressed here Still want to improve performance of reads/writes quorum consensus
25 .Quorum Consensus Improve put() and get() operation performance Define a replica set of size N put() waits for acks from at least W replicas get() waits for responses from at least R replicas W+R > N Why does it work? There is at least one node that contains the update Why you may use W+R > N+1?
26 .Quorum Consensus Example N=3, W=2, R=2 Replica set for K14: {N1, N2, N4} Assume put() on N3 fails N 1 N 2 N 3 N 4 K14 V14 K14 V14 put(K14, V14) ACK put(K14, V14) put(K14, V14) ACK
27 .Quorum Consensus Example Now , for get () need to wait for any two nodes out of three to return the answer N 1 N 2 N 3 N 4 K14 V14 K14 V14 get(K14) V14 get(K14) nill get(K14) V14
28 .Chord
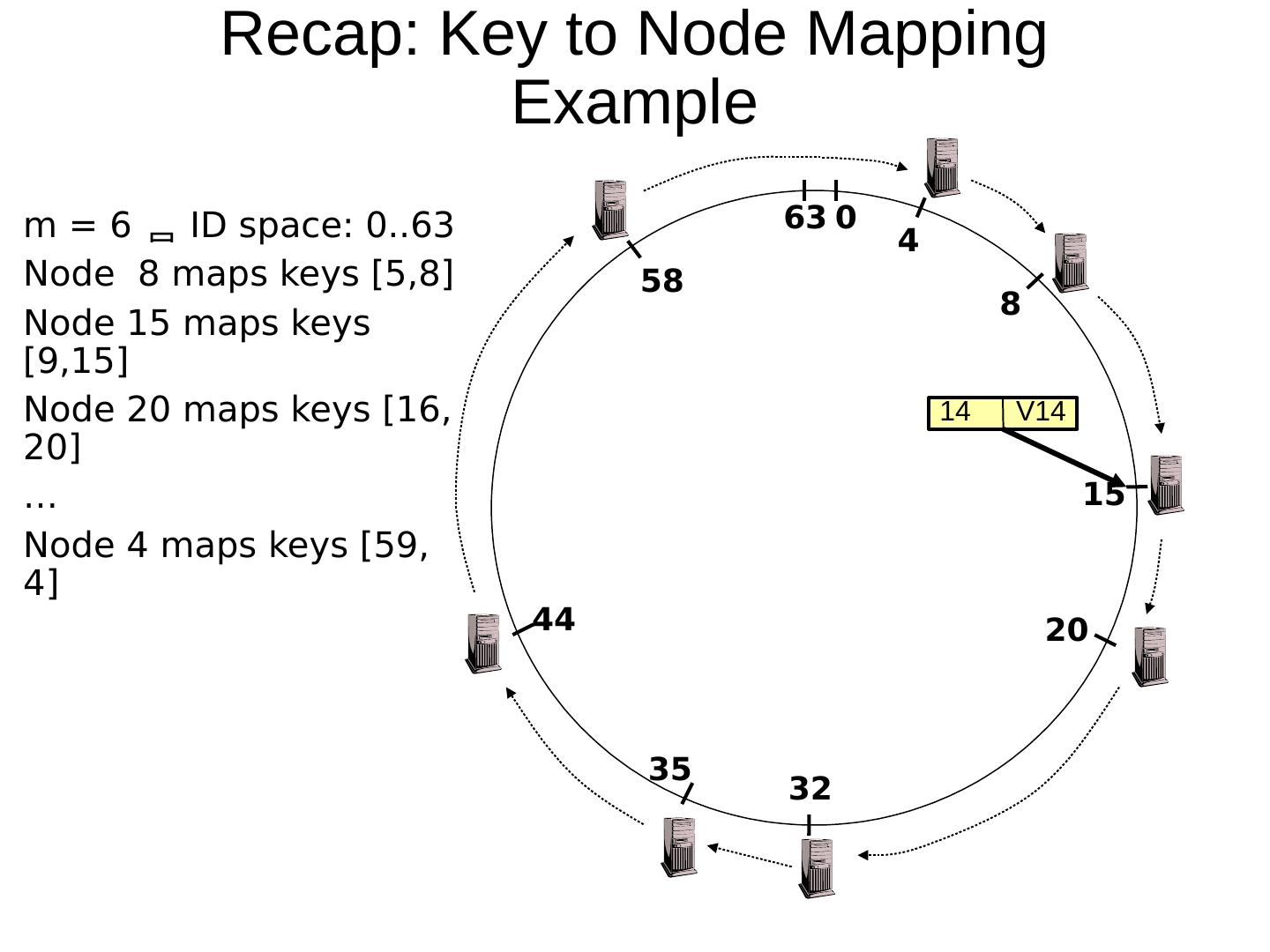
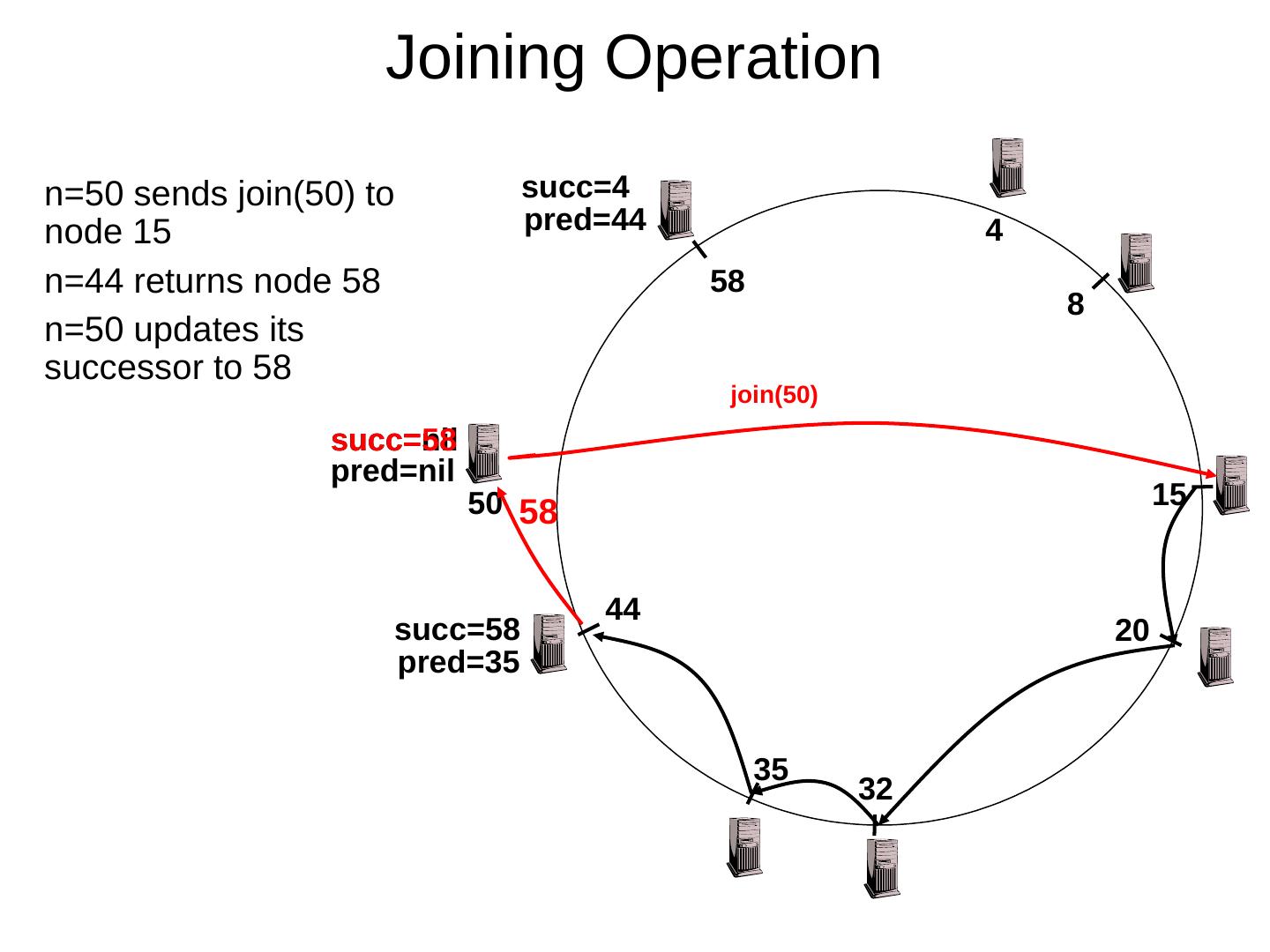
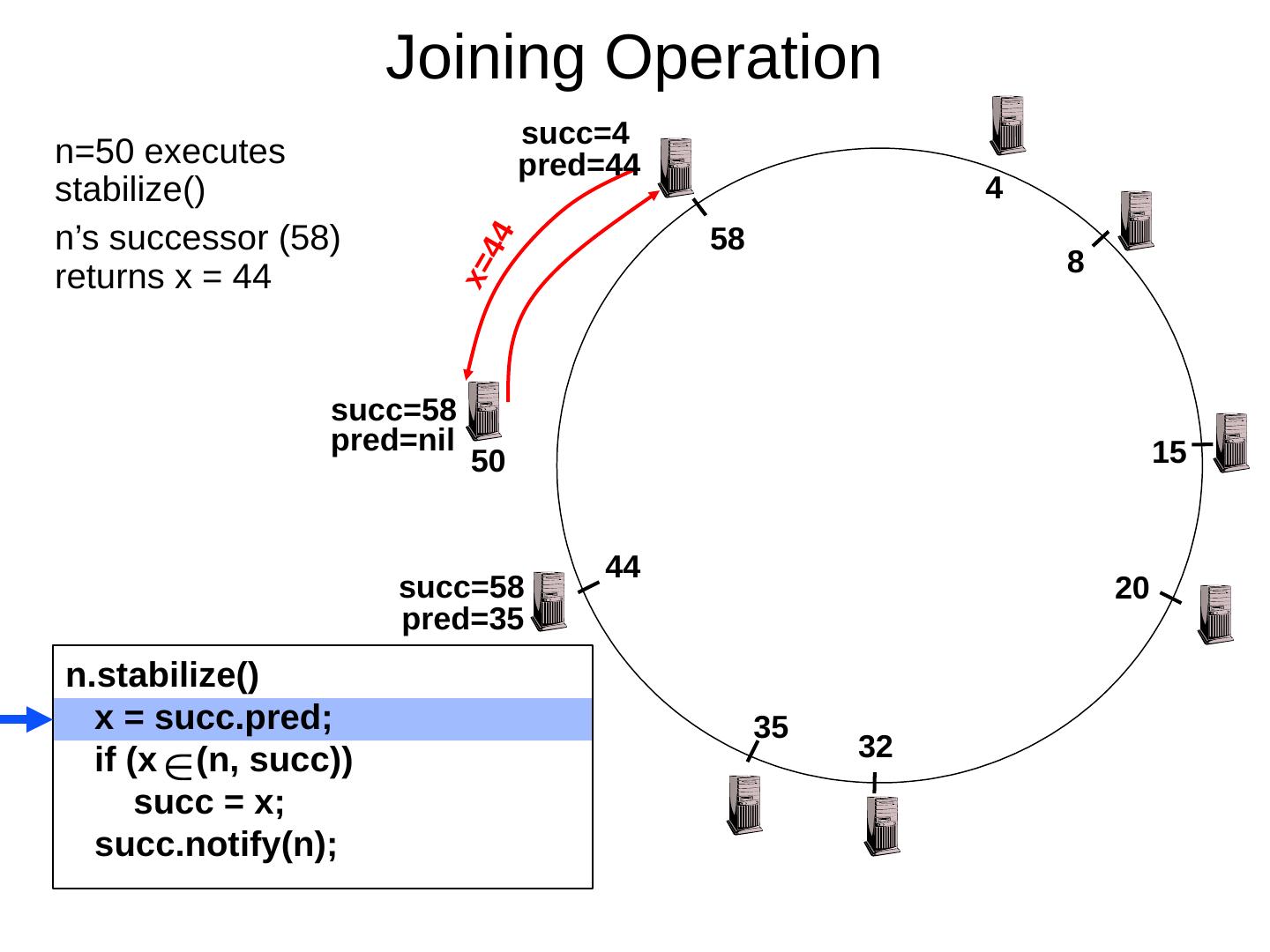
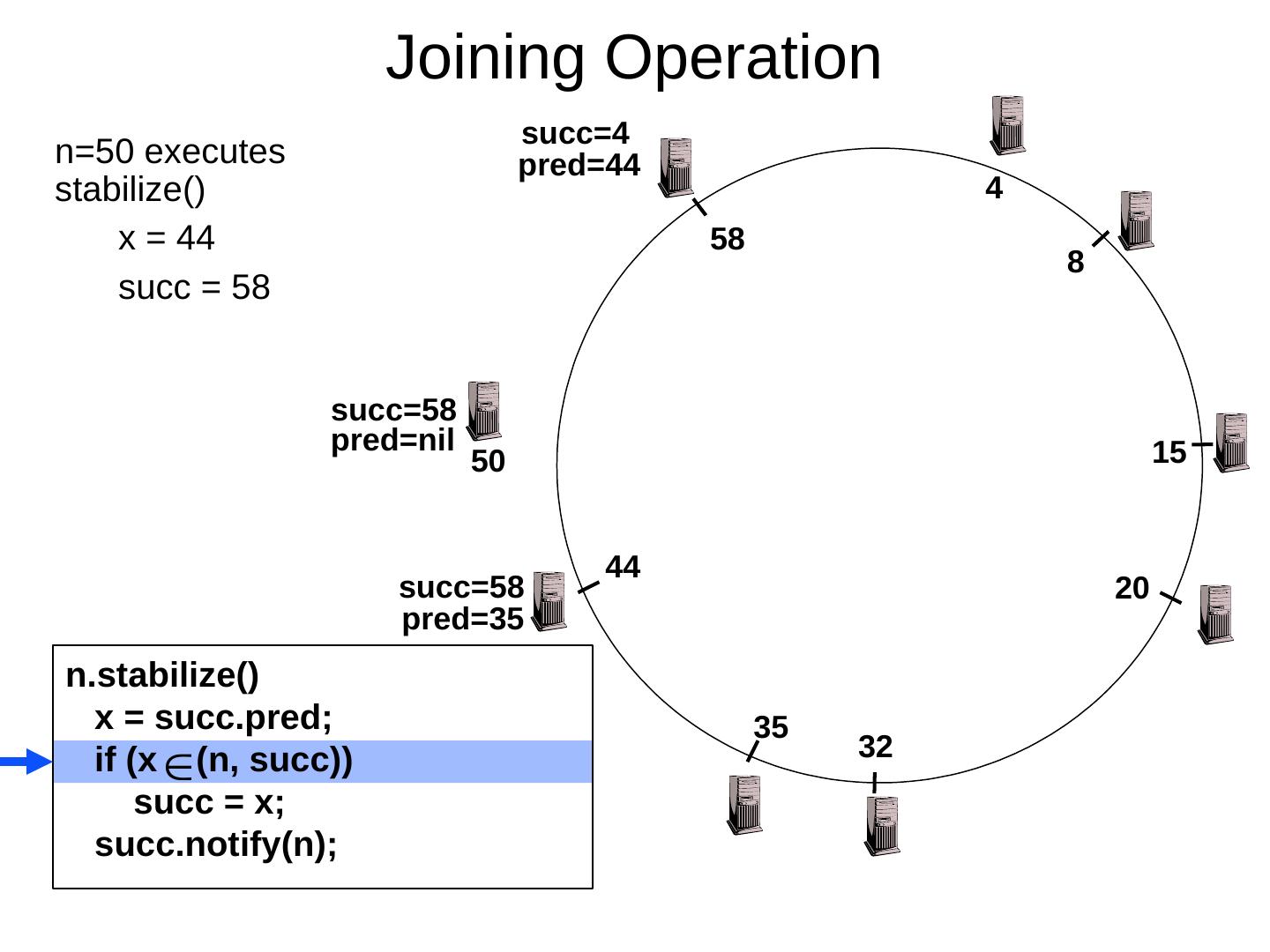
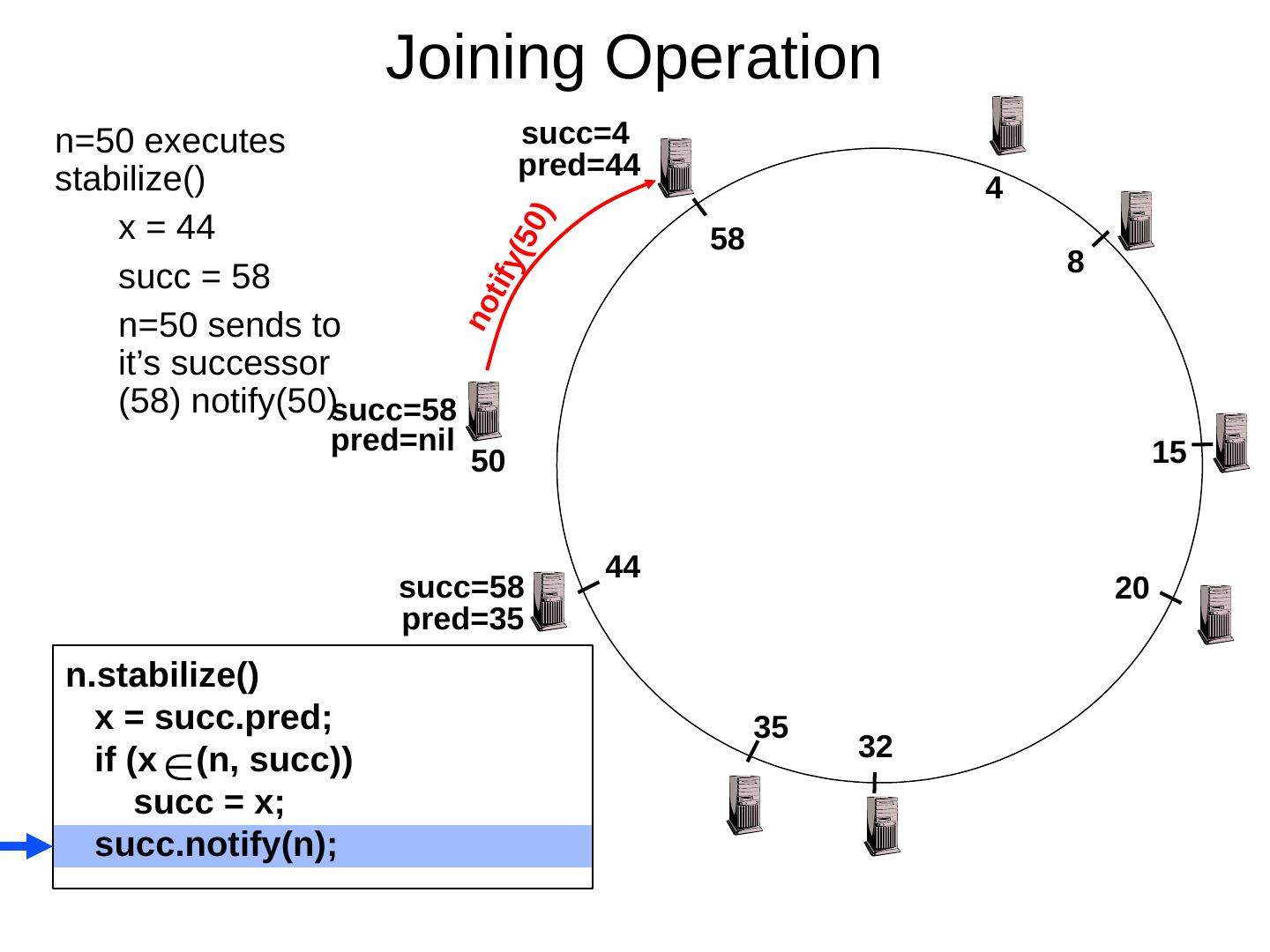
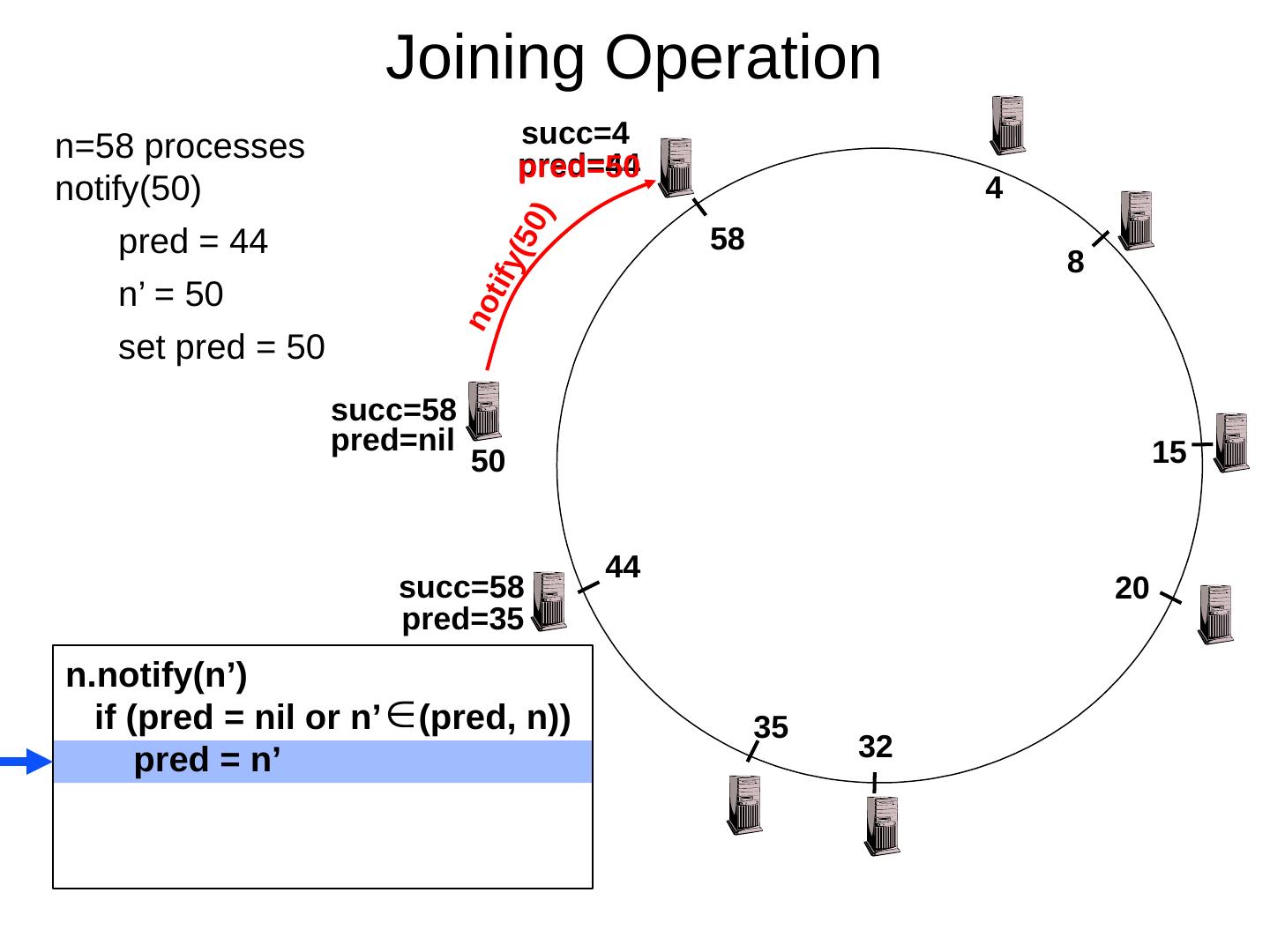
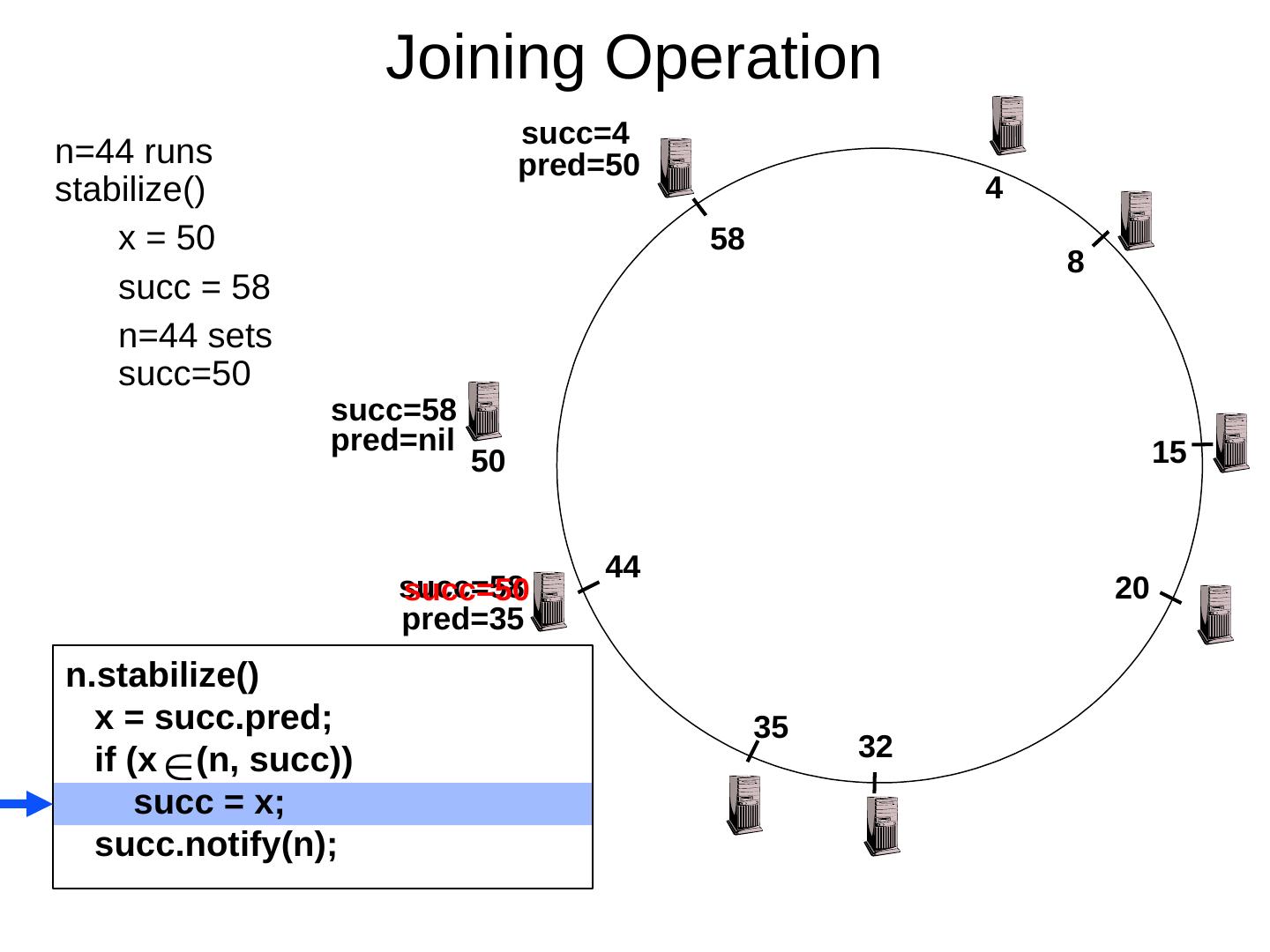
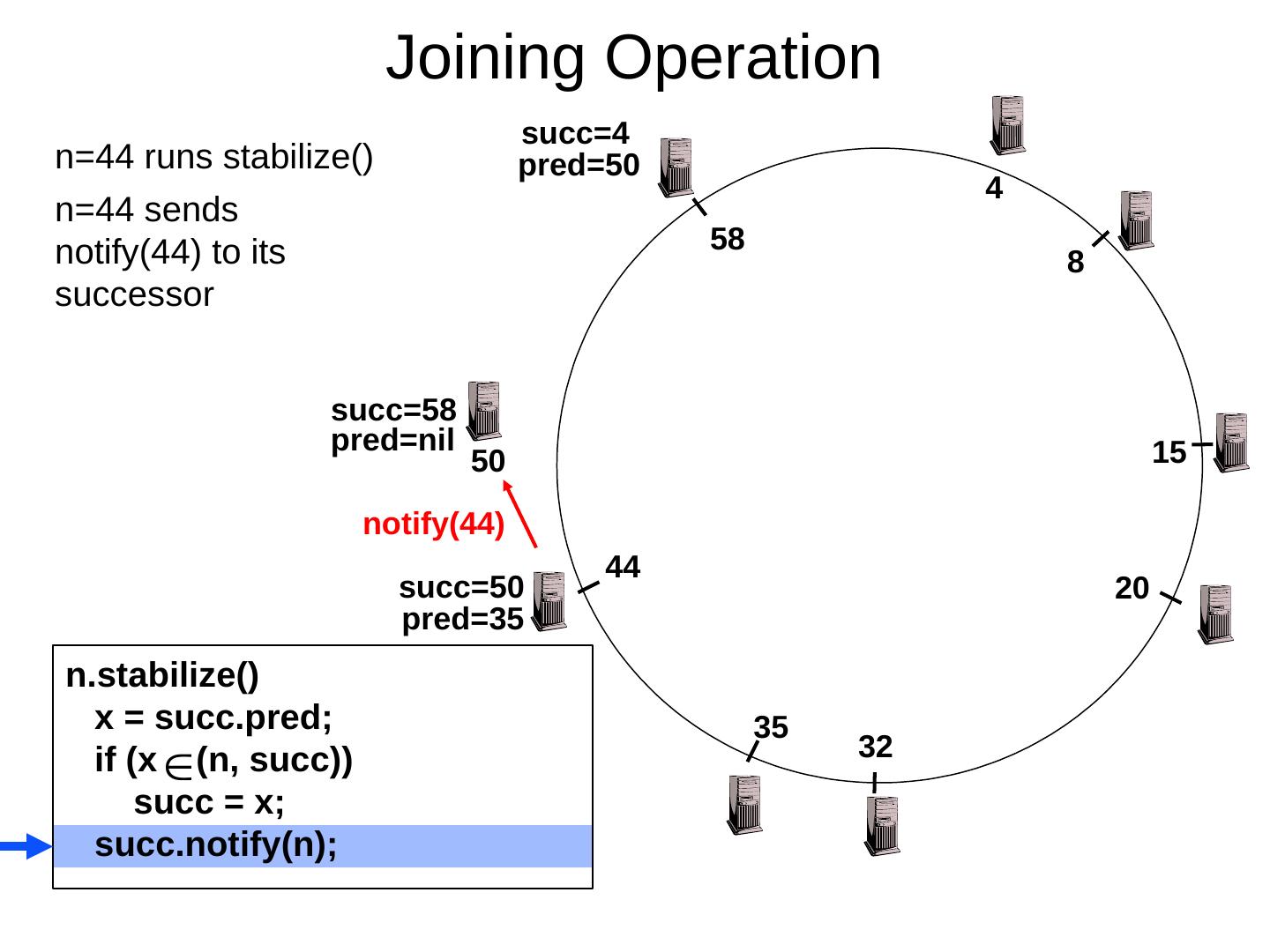
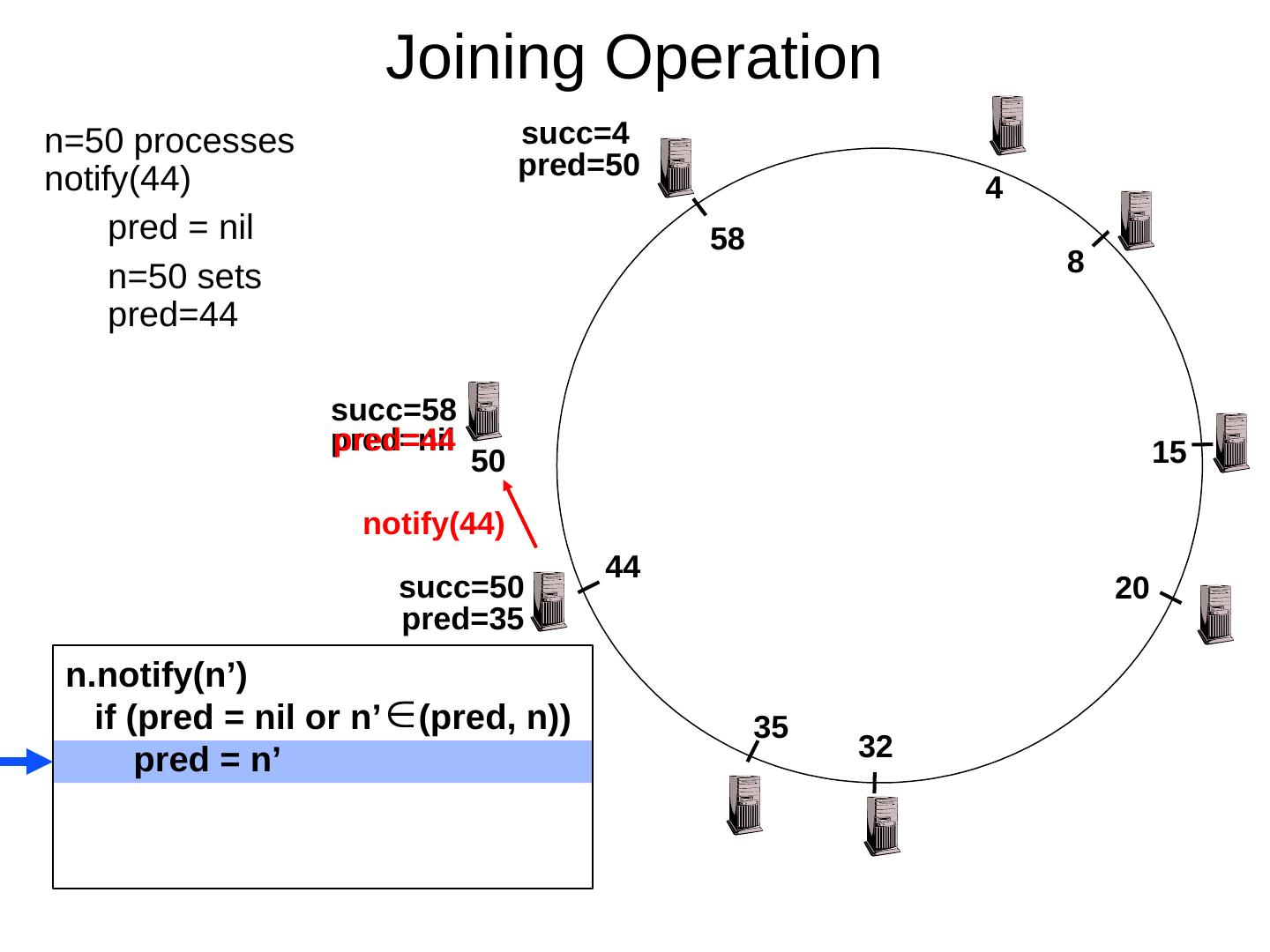
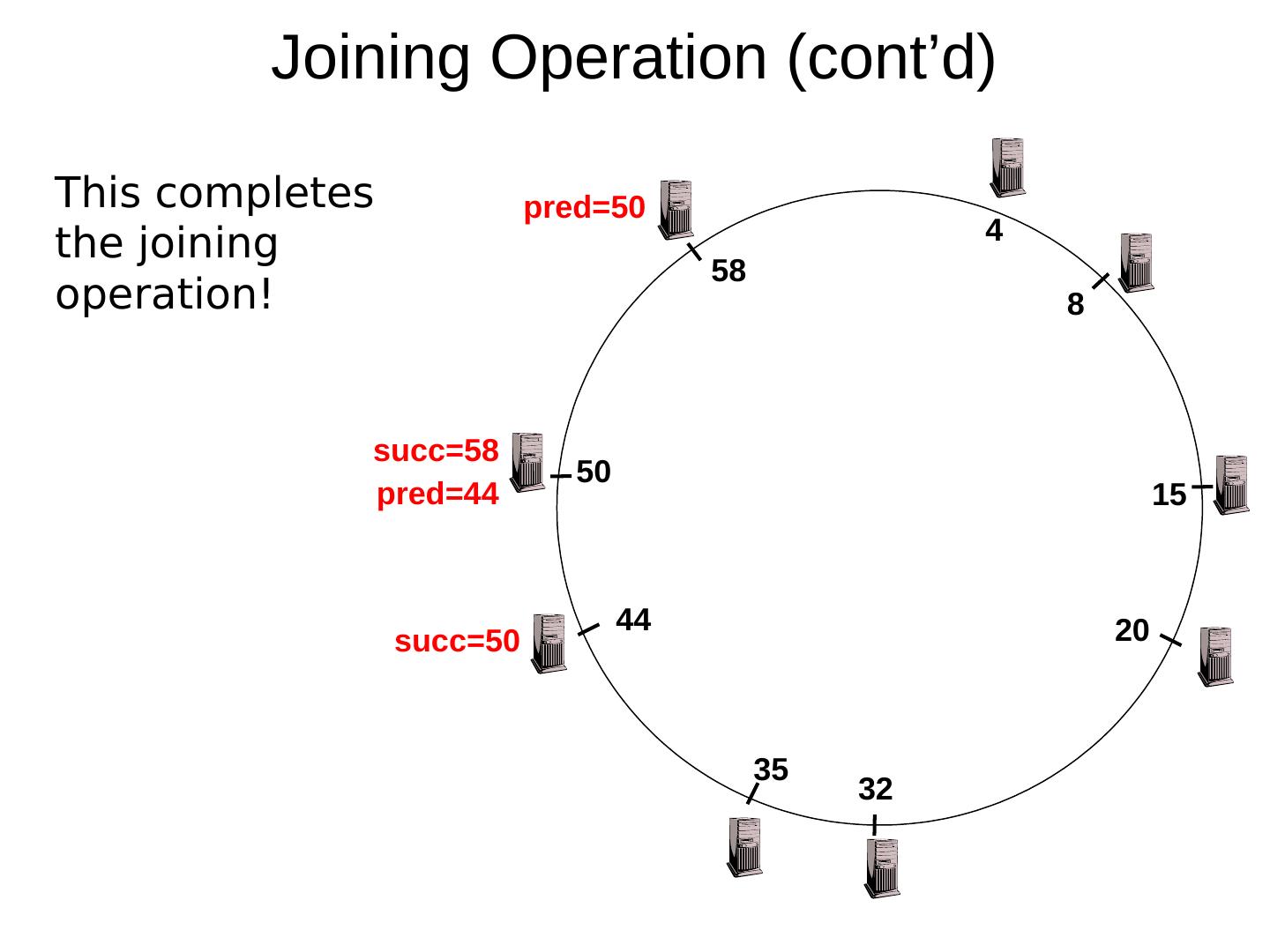
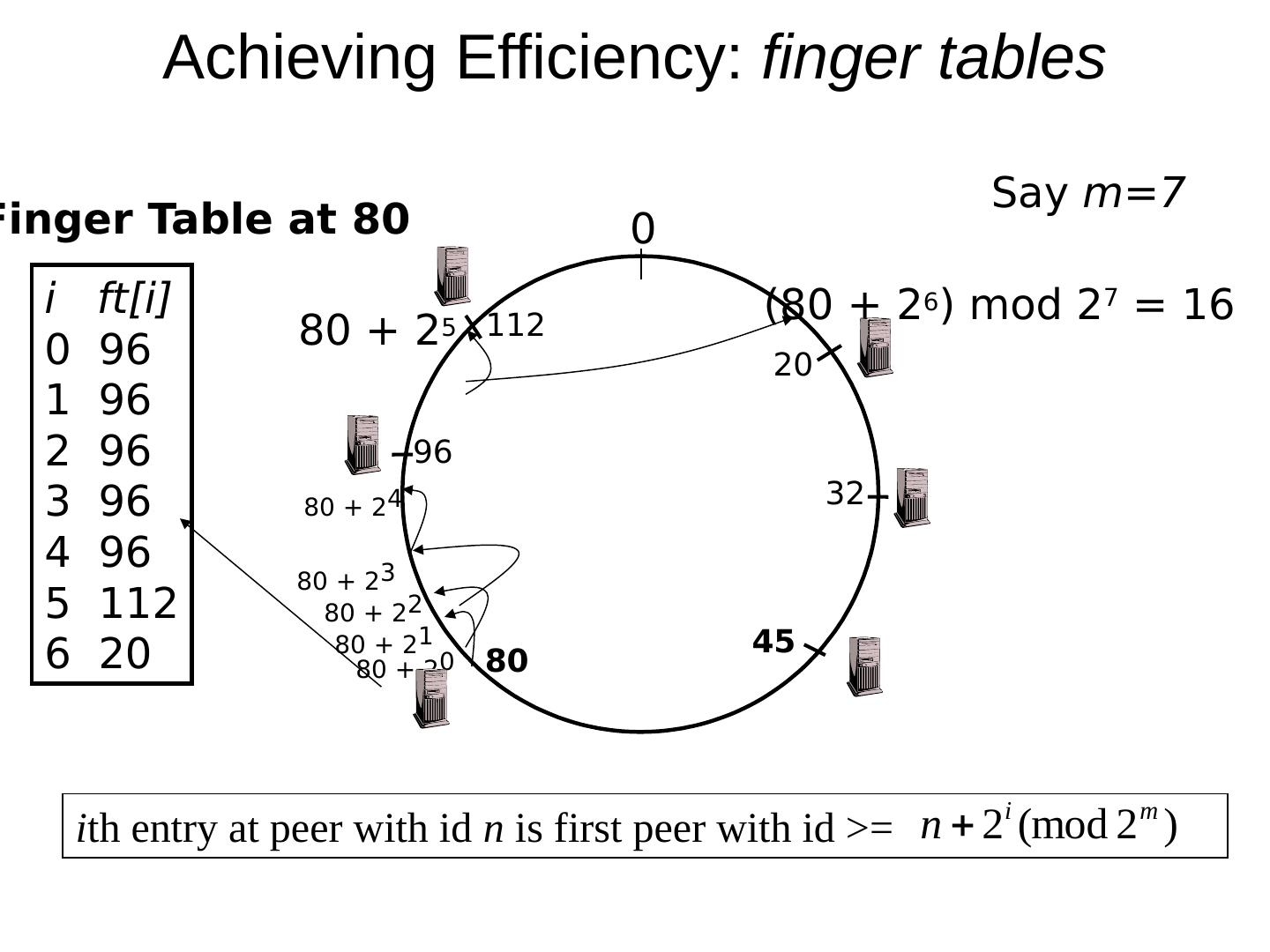
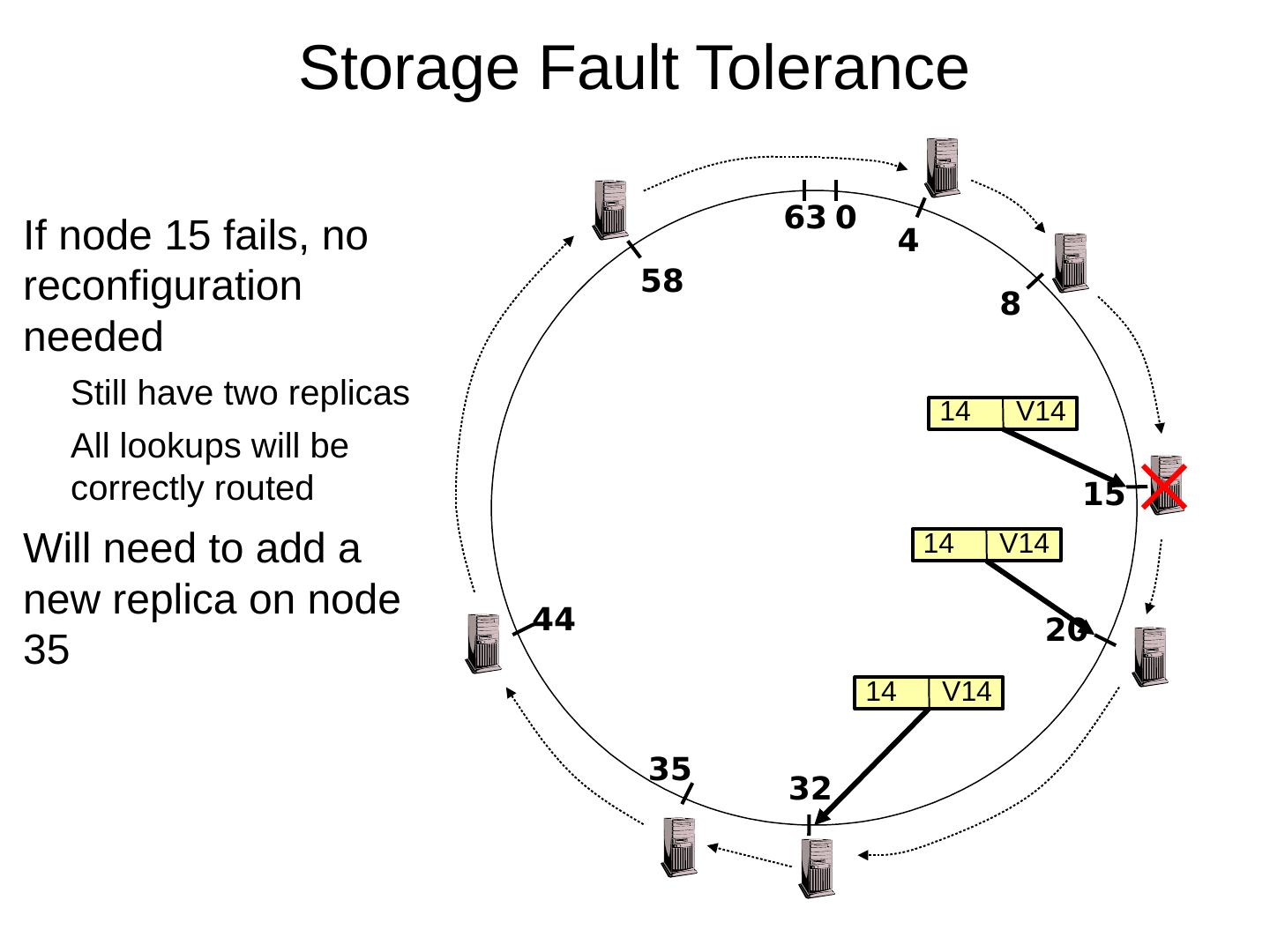
29 .Scaling Up Directory Challenge: Directory contains a number of entries equal to number of (key, value) tuples in the system Can be tens or hundreds of billions of entries in the system! Solution: consistent hashing Associate to each node a unique id in an uni- dimensional space 0..2 m -1 Partition this space across M machines Assume keys are in same uni-dimensional space Each (Key, Value) is stored at the node with the smallest ID larger than Key
3秒后跳转登录页面
去登陆

