




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HP AutoRAID
本章节主要介绍了什么是惠普虚拟存储技术,惠普虚拟存储技术中的AutoRAID技术组件按照与经验丰富的RAID存储管理员用于优化性价比相同的规则编程,对数据的放置进行监视和调整,以实现最优的性能。文中给出了其传输方式,性能优点等。
展开查看详情
1 .HP AutoRAID (Lecture 5, cs262a) Ali Ghodsi and Ion Stoica, UC Berkeley January 31, 2018 ( based on slide from John Kubiatowicz , UC Berkeley)
2 .Array Reliability Reliability of N disks = Reliability of 1 Disk ÷ N 50,000 Hours ÷ 70 disks = 700 hours Disk system MTTF: Drops from 6 years to 1 month! Arrays (without redundancy) too unreliable to be useful! Hot spares support reconstruction in parallel with access : very high media availability can be achieved
3 .RAID Redundant Array of Inexpensive Disks (RAID) Invented at Berkeley 1988: Dave Patterson Garth Gibson (now at CMU, CEO of the Vector Institute, Toronto) Randy Katz Patterson, David ; Gibson, Garth A. ; Katz, Randy (1988). A Case for Redundant Arrays of Inexpensive Disks (RAID ) , SIGMOD ‘88
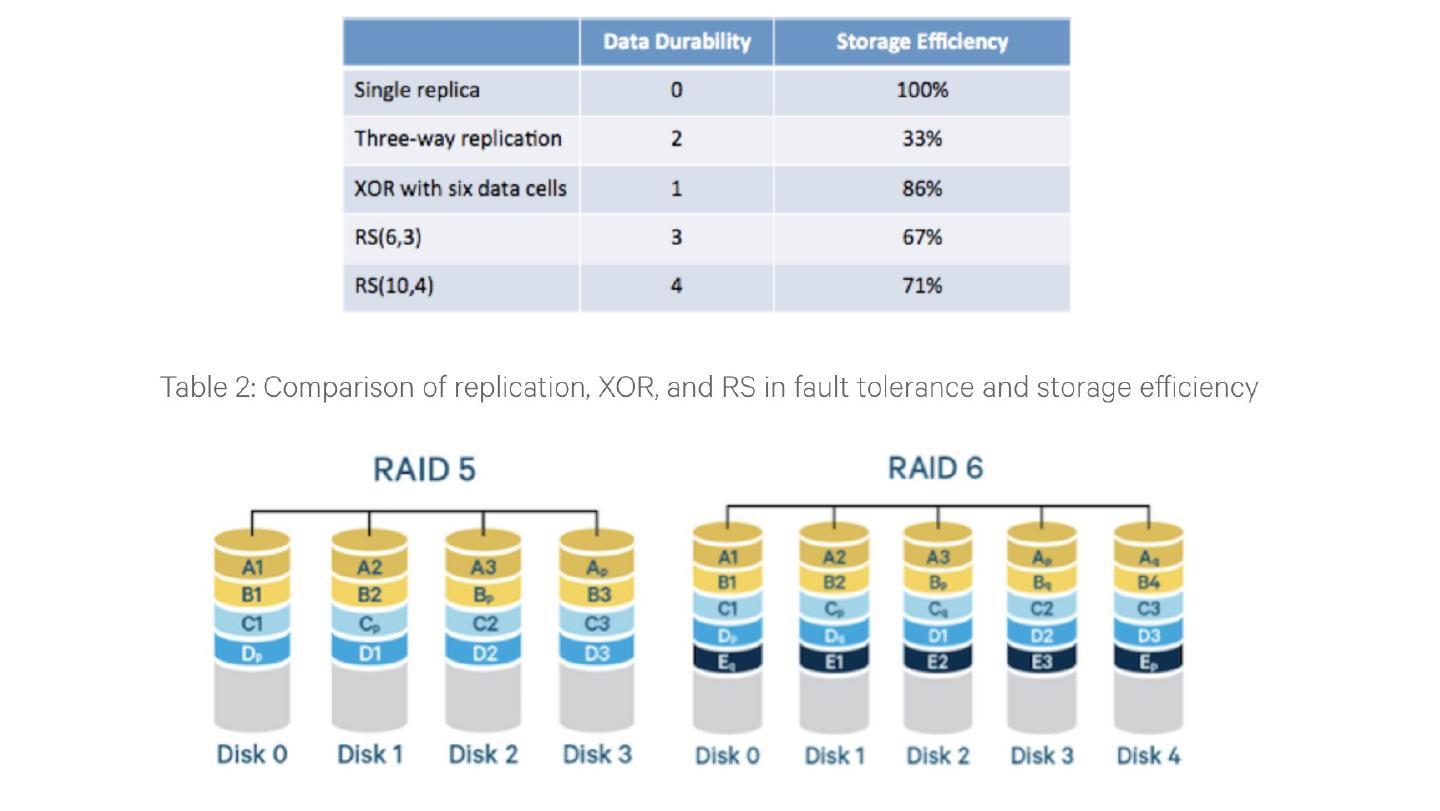
4 .RAID Basics: Levels* of RAID RAID 0: striping with no parity High read/write throughput; theoretically Nx where N is number of disks No data redundancy Levels in RED are used in practice https:// en.wikipedia.org /wiki/ Standard_RAID_levels
5 .RAID Basics: Levels* of RAID RAID 0: striping with no parity RAID 1: Mirroring, simple , fast, but 2 x storage Each disk is fully duplicated onto its " shadow” high availability Read throughput ( 2 x) assuming N disks Writes (1x): two physical writes Levels in RED are used in practice https:// en.wikipedia.org /wiki/ Standard_RAID_levels
6 .
7 .RAID Basics: Levels* of RAID RAID 2: bit-level interleaving with Hamming error-correcting codes d bit Hamming code can detect d-1 errors and correct (d-1)/2 Need s ynchronized disks, i.e., spin at same angular rotation Levels in RED are used in practice https:// en.wikipedia.org /wiki/ Standard_RAID_levels Hamming code
8 .RAID Basics: Levels* of RAID RAID 3: byte-level striping with dedicated parity disk Dedicated parity disk is write bottleneck : every write writes parity Levels in RED are used in practice https:// en.wikipedia.org /wiki/ Standard_RAID_levels p arity disk
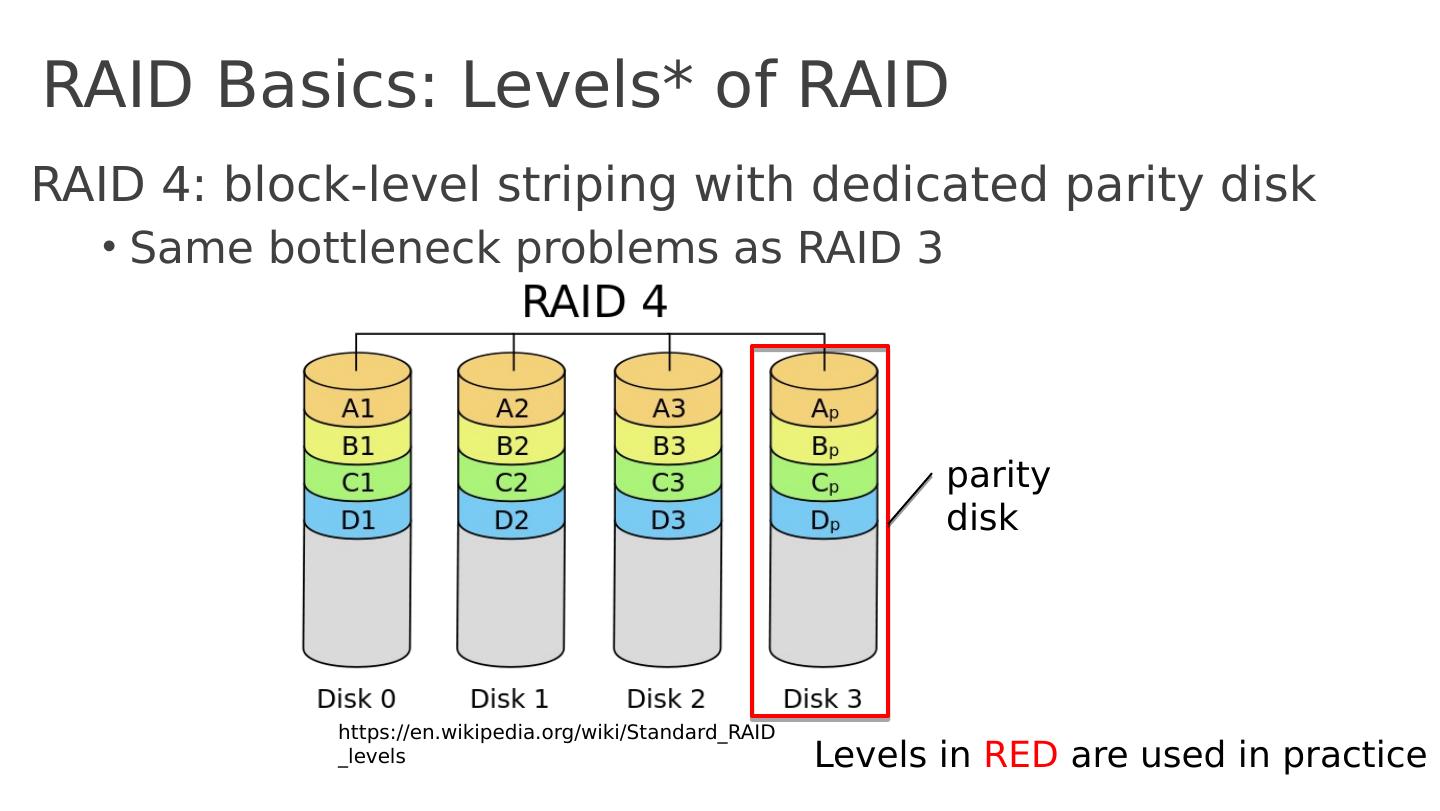
9 .RAID Basics: Levels* of RAID RAID 4 : block-level striping with dedicated parity disk Same bottleneck problems as RAID 3 Levels in RED are used in practice https:// en.wikipedia.org /wiki/ Standard_RAID_levels p arity disk
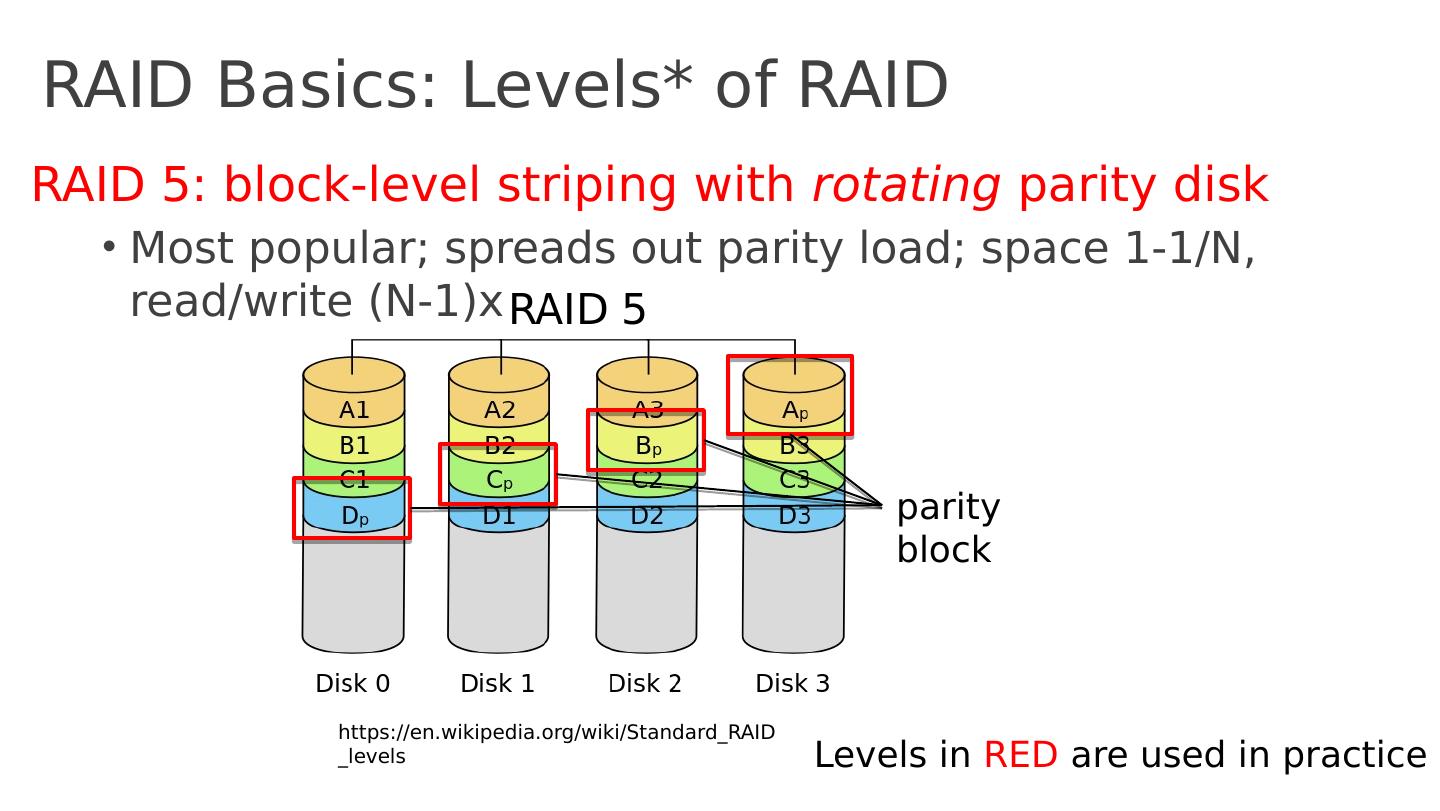
10 .RAID Basics: Levels* of RAID RAID 5: block-level striping with rotating parity disk M ost popular; spreads out parity load; space 1-1/N, read/write (N-1)x Levels in RED are used in practice https:// en.wikipedia.org /wiki/ Standard_RAID_levels p arity block
11 .RAID Basics: Levels* of RAID RAID 5: block-level striping with rotating parity disk M ost popular; spreads out parity load; space 1-1/N, read/write (N-1)x RAID 6: RAID 5 with two parity blocks (tolerates two drive failures) Use with today’s drive sizes! Why? Correlated drive failures (2x expected in 10hr recovery) [Schroeder and Gibson, FAST07] Failures during multi-hour/day rebuild in high-stress environments Levels in RED are used in practice
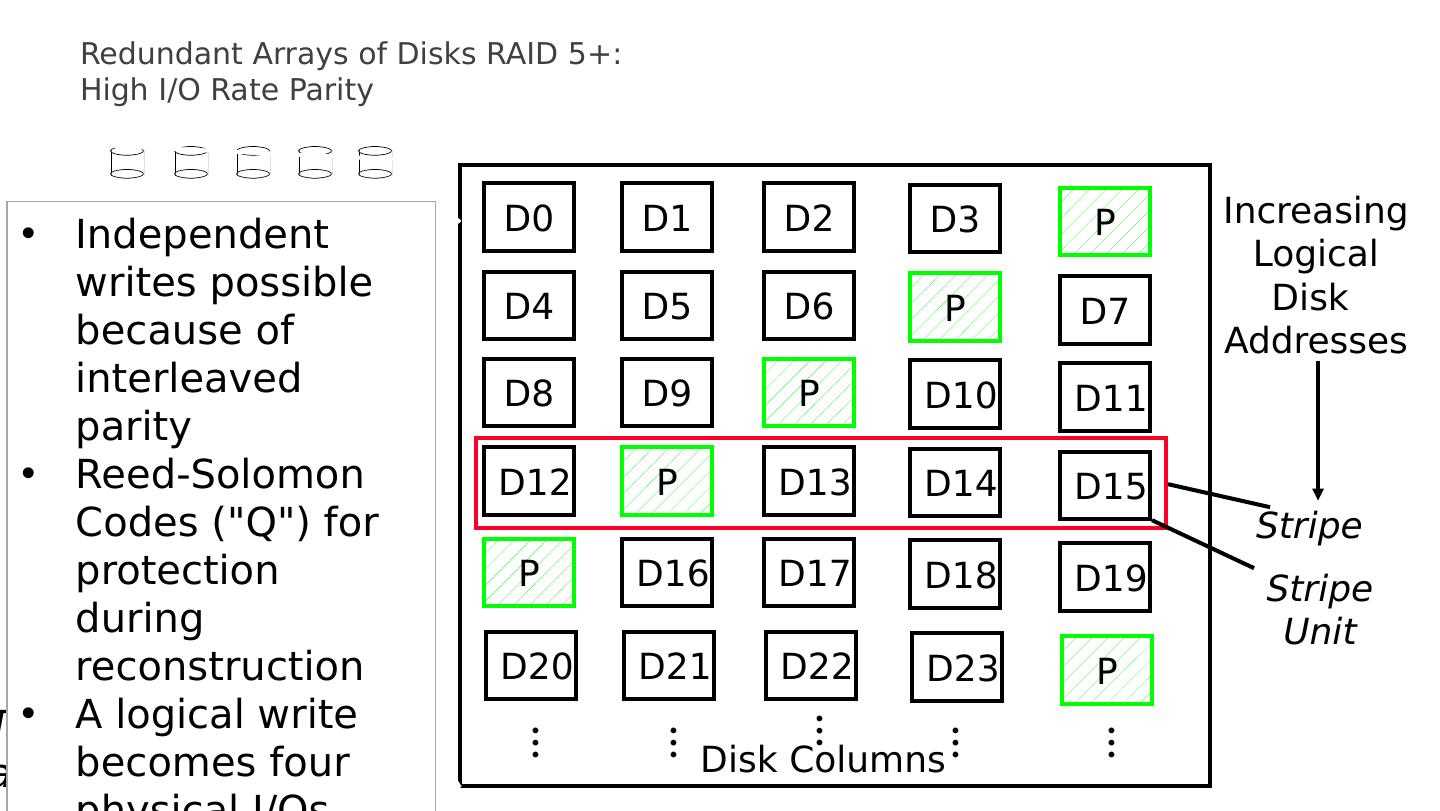
12 .Redundant Arrays of Disks RAID 5+: High I/O Rate Parity D0 D1 D2 D3 P D4 D5 D6 P D7 D8 D9 P D10 D11 D12 P D13 D14 D15 P D16 D17 D18 D19 D20 D21 D22 D23 P Disk Columns Increasing Logical Disk Addresses Stripe Stripe Unit Targeted for mixed applications … … … … … Independent writes possible because of interleaved parity Reed- Solomon Codes ("Q") for protection during reconstruction A logical write becomes four physical I/ Os
13 .Redundant Arrays of Disks RAID 5+: High I/O Rate Parity D0 D1 D2 D3 P D4 D5 D6 P D7 D8 D9 P D10 D11 D12 P D13 D14 D15 P D16 D17 D18 D19 D20 D21 D22 D23 P Disk Columns Increasing Logical Disk Addresses Stripe Stripe Unit Targeted for mixed applications … … … … … Independent writes possible because of interleaved parity Reed- Solomon Codes ("Q") for protection during reconstruction A logical write becomes four physical I/ Os
14 .Redundant Arrays of Disks RAID 5+: High I/O Rate Parity D0 D1 D2 D3 P D4 D5 D6 P D7 D8 D9 P D10 D11 D12 P D13 D14 D15 P D16 D17 D18 D19 D20 D21 D22 D23 P Disk Columns Increasing Logical Disk Addresses Stripe Stripe Unit Targeted for mixed applications … … … … … Independent writes possible because of interleaved parity Reed- Solomon Codes ("Q") for protection during reconstruction A logical write becomes four physical I/ Os
15 .Redundant Arrays of Disks RAID 5+: High I/O Rate Parity D0 D1 D2 D3 P D4 D5 D6 P D7 D8 D9 P D10 D11 D12 P D13 D14 D15 P D16 D17 D18 D19 D20 D21 D22 D23 P Disk Columns Increasing Logical Disk Addresses Stripe Stripe Unit Targeted for mixed applications … … … … … Independent writes possible because of interleaved parity Reed- Solomon Codes ("Q") for protection during reconstruction A logical write becomes four physical I/ Os
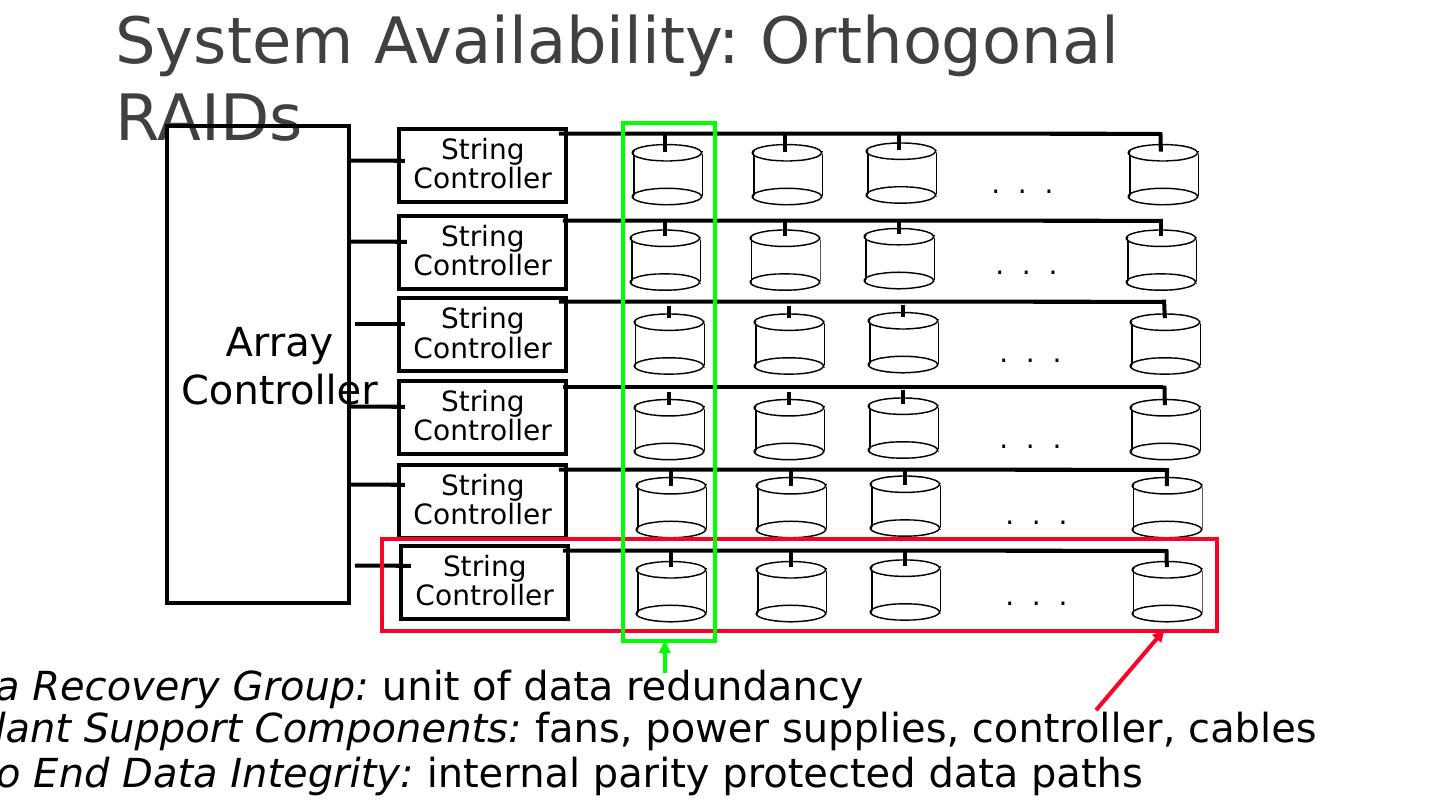
16 .System Availability: Orthogonal RAIDs Array Controller String Controller . . . String Controller String Controller String Controller String Controller String Controller . . . . . . . . . . . . . . . Redundant Support Components: fans, power supplies, controller, cables Data Recovery Group: unit of data redundancy End to End Data Integrity: internal parity protected data paths
17 .System-Level Availability I/O Controller Array Controller . . . . . . . . . Array Controller . . . . . . . . . Recovery Group Goal: No Single Points of Failure host Fully dual redundant I/O Controller host with duplicated paths, higher performance can be obtained when there are no failures
18 .HP AutoRAID – Motivation Goals: automate the efficient replication of data in a RAID RAIDs are hard to setup and optimize Different RAID Levels provide different tradeoffs Automate the migration between levels RAID 1 and 5 : what are the tradeoffs? RAID 1: excellent read performance, good write performance, performs well under failures, expensive RAID 5: cost effective, good read performance, bad write performance, expensive recovery
19 .HP AutoRAID – Motivation Each kind of replication has a narrow range of workloads for which it is best... Mistake ⇒ 1) poor performance, 2) changing layout is expensive and error prone D ifficult to add storage : new disk ⇒ change layout and rearrange data ... Difficult to add disks of different sizes
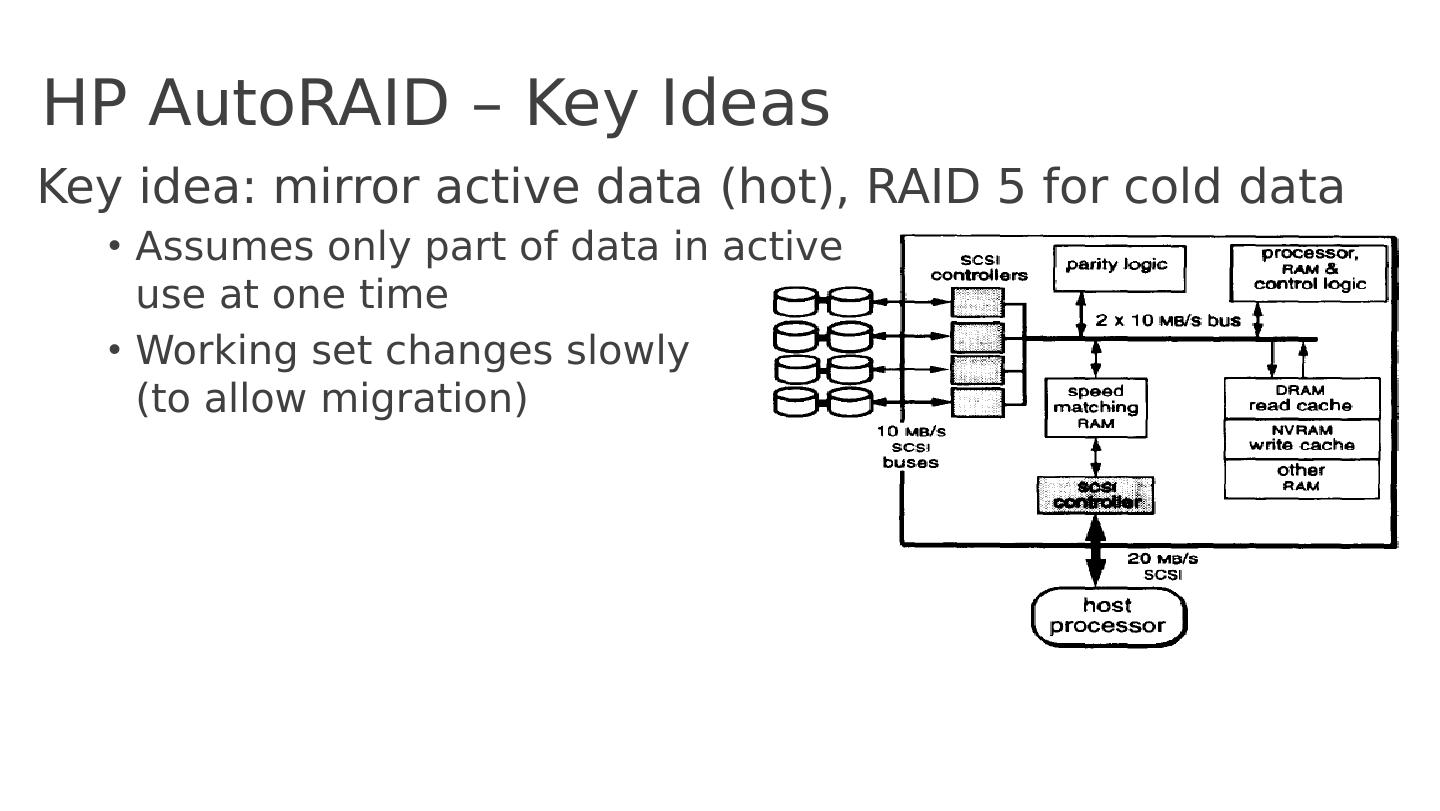
20 .HP AutoRAID – Key Ideas Key idea: mirror active data (hot), RAID 5 for cold data Assumes only part of data in active use at one time Working set changes slowly ( to allow migration )
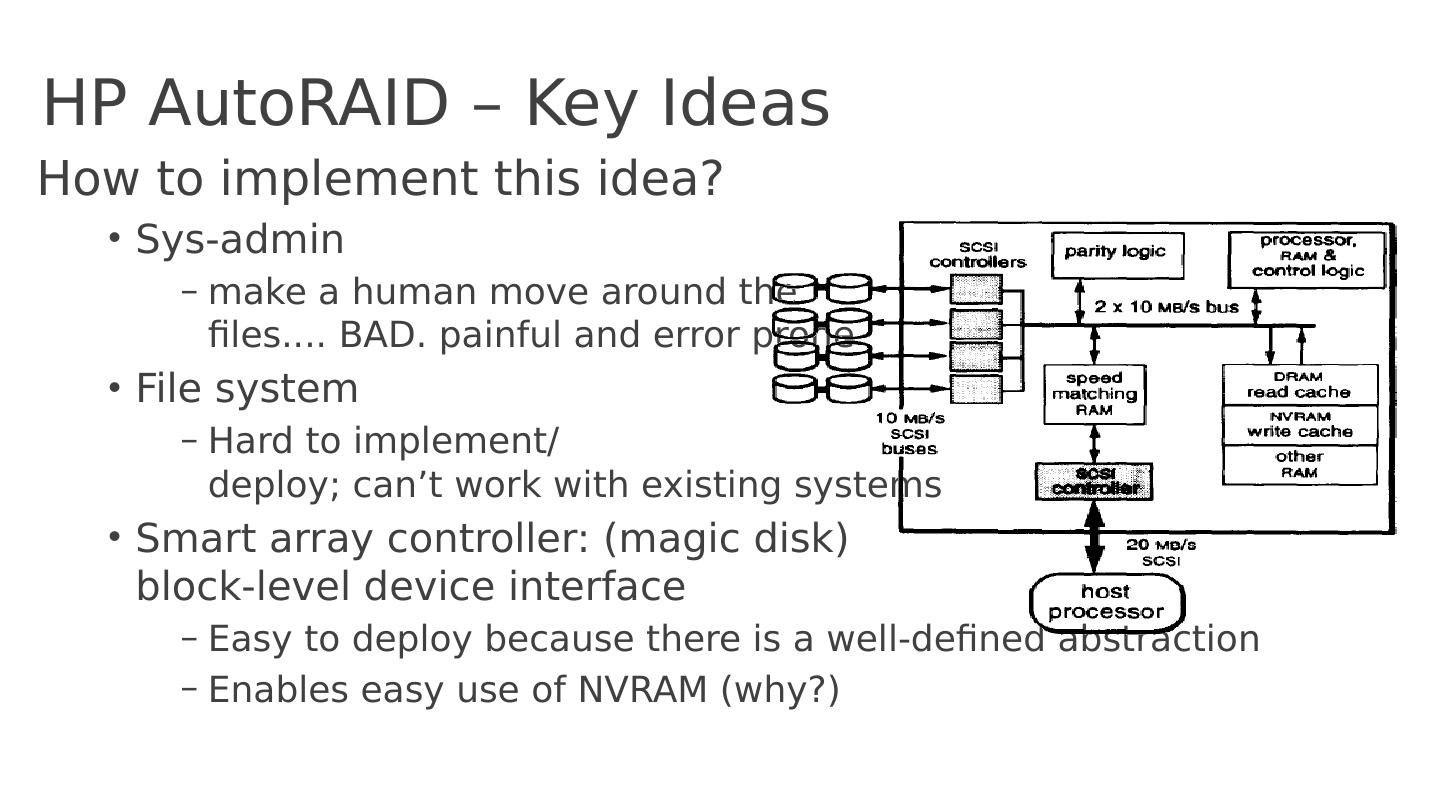
21 .HP AutoRAID – Key Ideas How to implement this idea? Sys-admin make a human move around the files .... BAD. painful and error prone File system H ard to implement / deploy ; can’t work with existing systems Smart array controller: (magic disk) block-level device interface Easy to deploy because there is a well-defined abstraction Enables easy use of NVRAM (why ?)
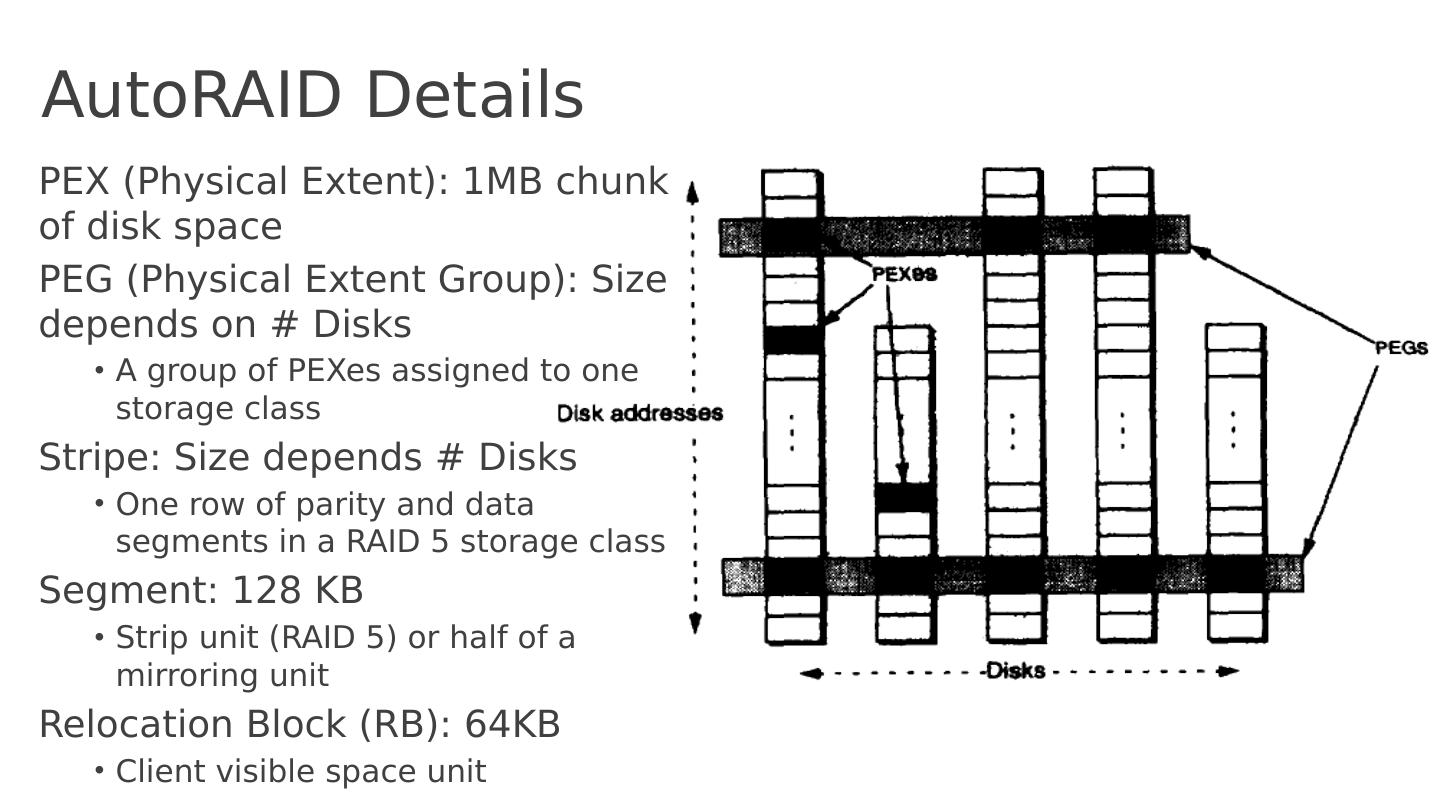
22 .AutoRAID Details PEX (Physical Extent): 1MB chunk of disk space PEG (Physical Extent Group): Size depends on # Disks A group of PEXes assigned to one storage class Stripe: Size depends # Disks One row of parity and data segments in a RAID 5 storage class Segment: 128 KB Strip unit (RAID 5) or half of a mirroring unit Relocation Block (RB): 64KB Client visible space unit
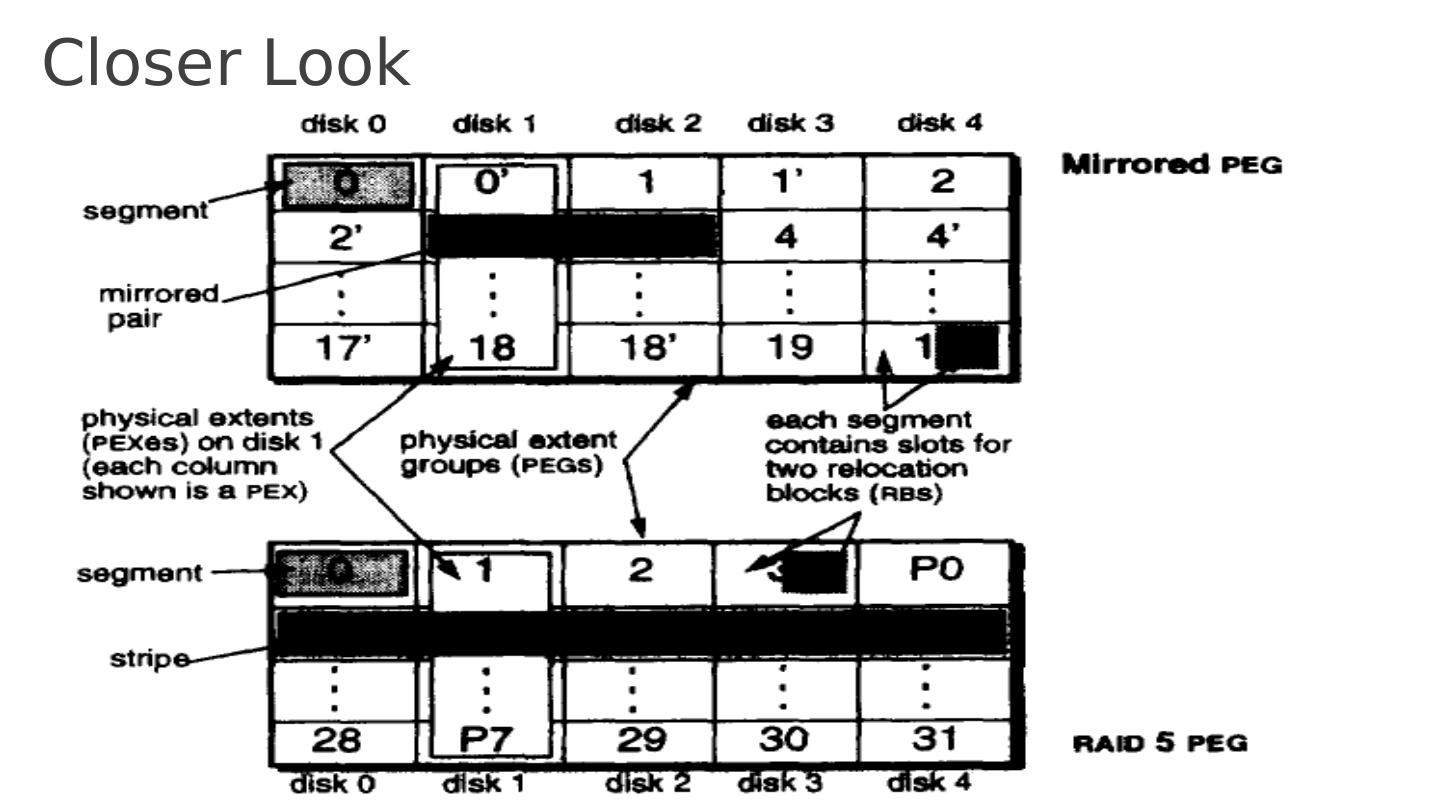
23 .Closer Look
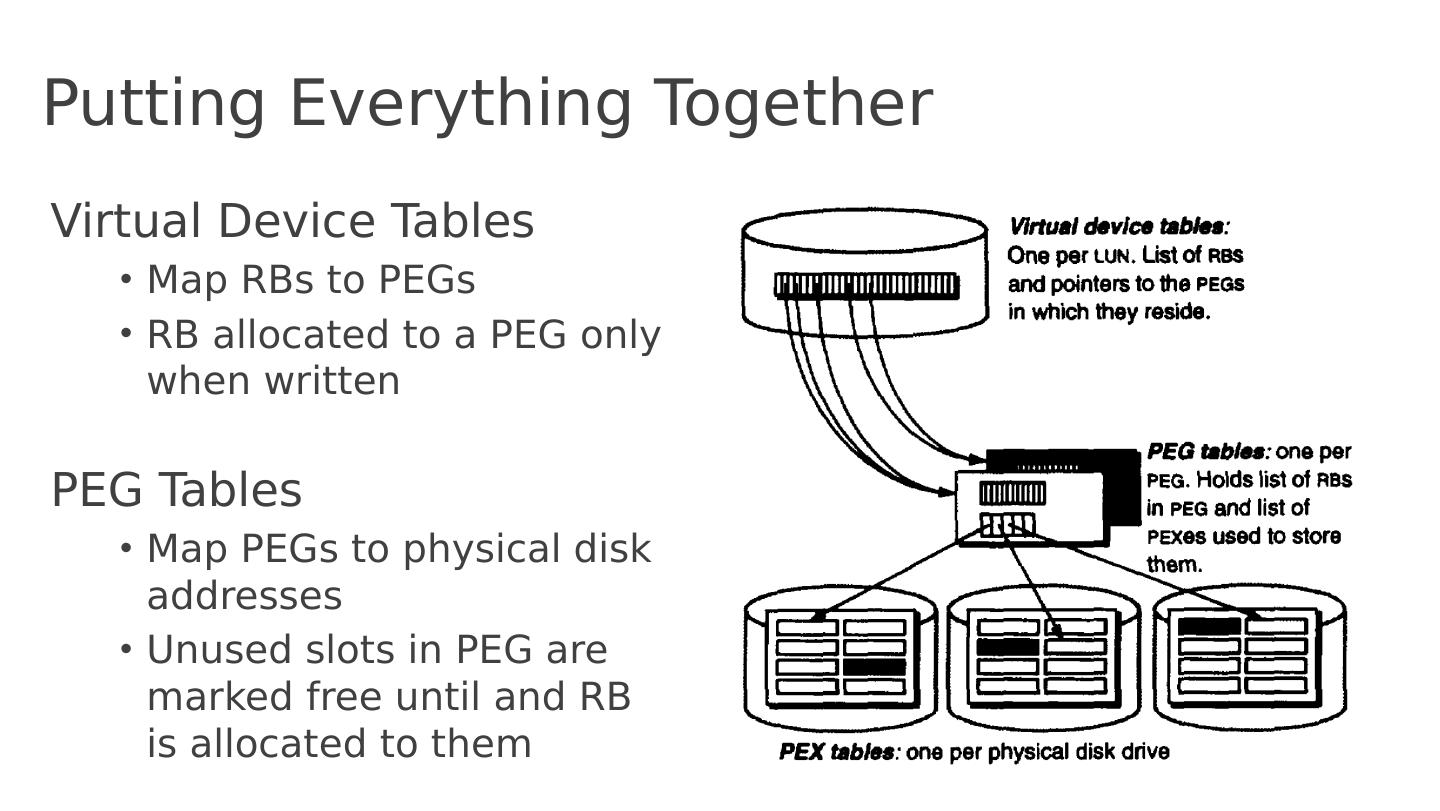
24 .Putting Everything Together Virtual Device Tables Map RBs to PEGs RB allocated to a PEG only when written PEG Tables Map PEGs to physical disk addresses Unused slots in PEG are marked free until and RB is allocated to them
25 .HP AutoRaid – Features Promote/demote in 64KB chunks (8-16 blocks) Hot swap disks, etc. (A hot swap is just a controlled failure) Add storage easily (goes into the mirror pool) U seful to allow different size disks (why? ) No need for an active hot spare (per se); J ust keep enough working space around Log-structured RAID 5 writes Nice big streams, no need to read old parity for partial writes
26 .Questions When to demote? When there is too much mirrored storage (>10%) Demotion leaves a hole (64KB). What happens to it? Moved to free list and reuse Demoted RBs are written to the RAID5 log, one write for data, a second for parity Why log RAID 5 better than update in place? Update of data requires reading all the old data to recalculate parity Log ignores old data (which becomes garbage) and writes only new data/parity stripes How to promote? When a RAID5 block is written... Just write it to mirrored and the old version becomes garbage .
27 .Questions How big should an RB be? Bigger ⇒ Less mapping information, fewer seeks S maller ⇒ fine grained mapping information How do you find where an RB is? Convert addresses to (LUN, offset) and then lookup RB in a table from this pair Map size = Number of RBs and must be proportional to size of total storage How to handle thrashing (too much active write data)? Automatically revert to directly writing RBs to RAID 5!
28 .Issues Disks writes go to two disks (since newly written data is “hot ”) Must wait for both to complete - why? Does the host have to wait for both? No, just for NVRAM Controller uses cache for reads Controller uses NVRAM for fast commit, then moves data to disks What if NVRAM is full? Block until NVRAM flushed to disk, then write to NVRAM
29 .Issues What happens in the background? 1 ) compaction, 2) migration, 3) balancing Compaction : clean RAID 5 and plug holes in the mirrored disks Do mirrored disks get cleaned? Yes, when a PEG is needed for RAID5; i.e., pick a disks with lots of holes and move its used RBs to other disks Resulting empty PEG is now usable by RAID5 What if there aren’t enough holes? Write the excess RBs to RAID5, then reclaim the PEG Migration : which RBs to demote? Least-recently- written (not LRU) Balancing : make sure data evenly spread across the disks. (Most important when you add a new disk)
3秒后跳转登录页面
去登陆

