































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
GFS and BigTable
本章节主要介绍了GFS以及BigTable计算机操作系统技术。GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用;而BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。在本文章中对两者做出了定义,由来,以及将两者做出了比较。
展开查看详情
1 .GFS and BigTable Lecture 17, cs262a Ion Stoica & Ali Ghodsi, UC Berkeley March 19, 2018
2 .Today’s Papers The Google File System , Sanjay Ghemawat , Howard Gobioff , and Shun- Tak Leung , SOSP’03 http ://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003. pdf BigTable : A Distributed Storage System for Structured Data. Fay Chang, Jeffrey Dean, Sanjay Ghemawat , Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes , Robert E. Gruber, OSDI’06 http ://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06. pdf
3 .Google File System
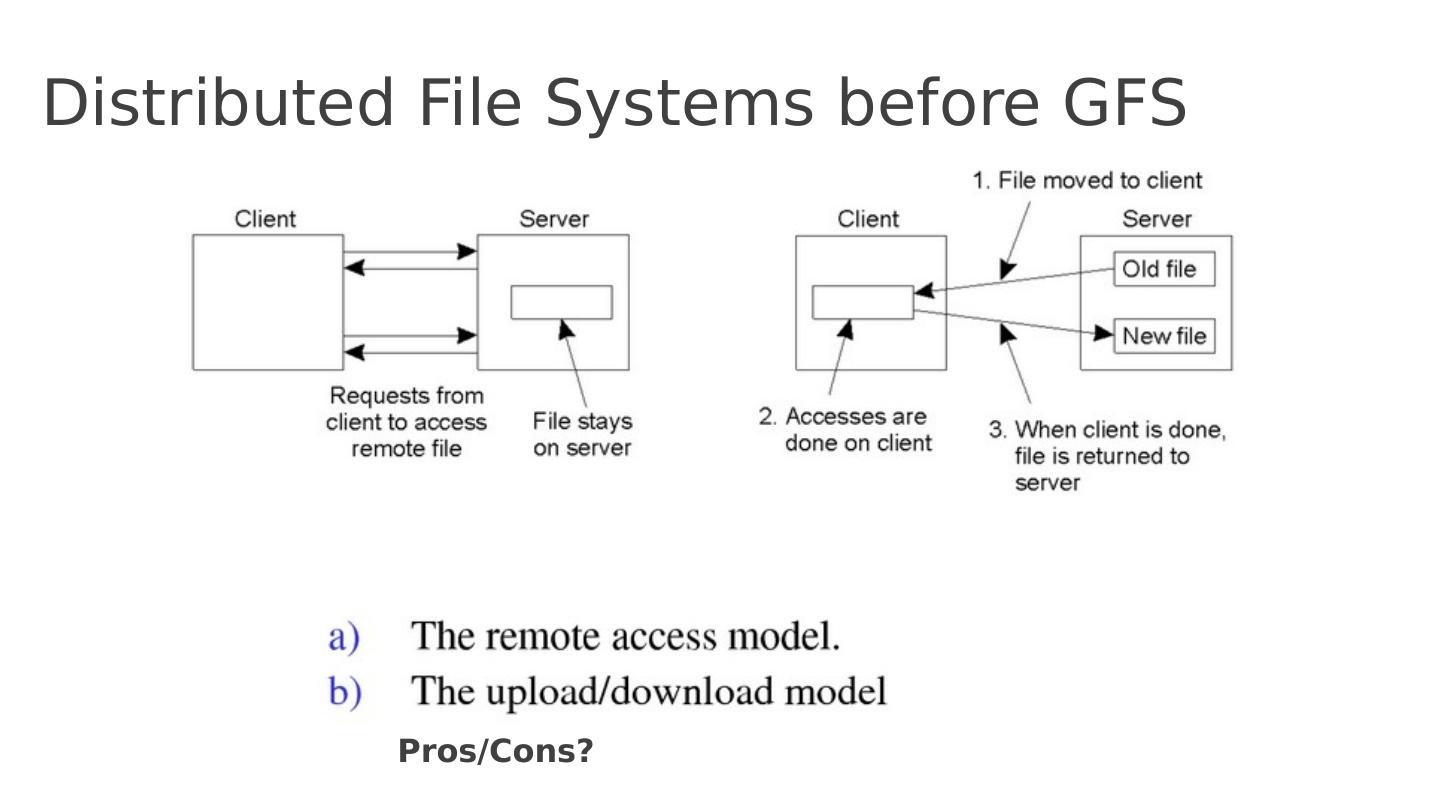
4 .Distributed File Systems before GFS Pros/Cons?
5 .What is Different? Component failures are norm rather than exception, why? F ile system consists of 100s/1,000s commodity storage servers Comparable number of clients Much bigger files, how big? GBs file sizes common TBs data sizes: hard to manipulate billions of KB size blocks
6 .What is Different? Files are mutated by appending new data, and not overwriting Random writes practically non- existent Once written, files are only read sequentially Own both applications and file system can effectively co -designing applications and file system APIs Relaxed consistency model Atomic append operation: allow multiple clients to append data to a file with no extra synchronization between them
7 .Assumptions and Design Requirements (1/2) Should monitor, detect, tolerate, and recover from failures Store a modest number of large files (millions of 100s MB files) Small files supported, but no need to be efficient Workload Large sequential reads S mall reads supported, but ok to batch them Large , sequential writes that append data to files Small random writes supported but no need to be efficient
8 .Assumptions and Design Requirements Implement well-defined semantics for concurrent appends Producer-consumer model Support h undreds of producers concurrently appending to a file Provide atomicity with minimal synchronization overhead Support consumers reading the file as it is written High sustained bandwidth more important than low latency
9 .API Not POSIX, but.. Support usual ops: create, delete , open , close, read, and write Support snapshot and record append operations
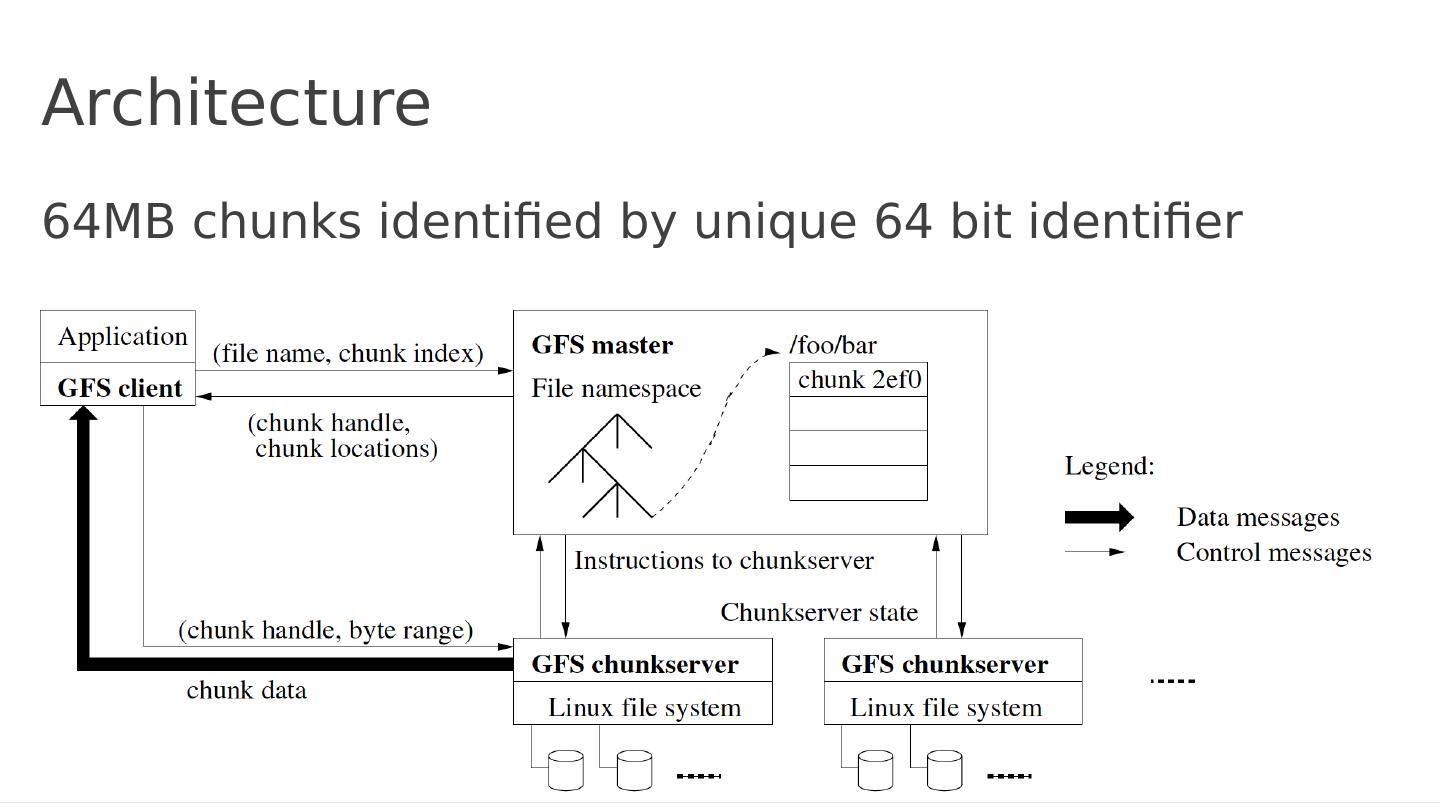
10 .Architecture Single Master (why?)
11 .Architecture 64MB chunks identified by unique 64 bit identifier
12 .Discussion 64MB chunks: pros and cons? How do they deal with hotspots? How do they achieve master fault tolerance? How does master achieve high throughput, perform load balancing, etc ?
13 .Consistency Model Mutation: write/append operation to a chunk Use lease mechanism to ensure consistency: M aster grants a chunk lease to one of replicas (primary) Primary picks a serial order for all mutations to the chunk All replicas follow this order when applying mutations Global mutation order defined first by lease grant order chosen by the master serial numbers assigned by the primary within lease If master doesn’t hear from primary, it grant lease to another replica after lease expires
14 .Write Control and data Flow
15 .Atomic Writes Appends Client specifies only the data GFS picks offset to append data and returns it to client P rimary checks if appending r ecord will exceed chunk max size If yes Pad chunk to maximum size Tell client to try on a new chunk
16 .Master Operation Namespace locking management Each master operation acquires a set o f locks Locks are acquired in a consistent total order to prevent deadlock Replica Placement Spread chunk replicas across racks to maximize availability, reliability, and network bandwidth
17 .Others Chunk creation Equalize disk utilization Limit the number of creations on same chunk server Spread replicas across racks Rebalancing Move replica for better disk space and load balancing. Remove replicas on chunk servers with below average free space
18 .Summary GFS meets Google storage requirements Optimized for given workload Simple architecture: highly scalable, fault tolerant Why is this paper so highly cited? Changed all DFS assumptions on its head Thanks for new application assumptions at Google
19 .BigTable
20 .Motivation Highly available distributed storage for structured data, e.g., URLs: content, metadata, links, anchors, page rank User data: preferences, account info, recent queries Geography: roads, satellite images, points of interest, annotations Large scale Petabytes of data across thousands of servers Billions of URLs with many versions per page Hundreds of millions of users Thousands of queries per second 100TB+ satellite image data
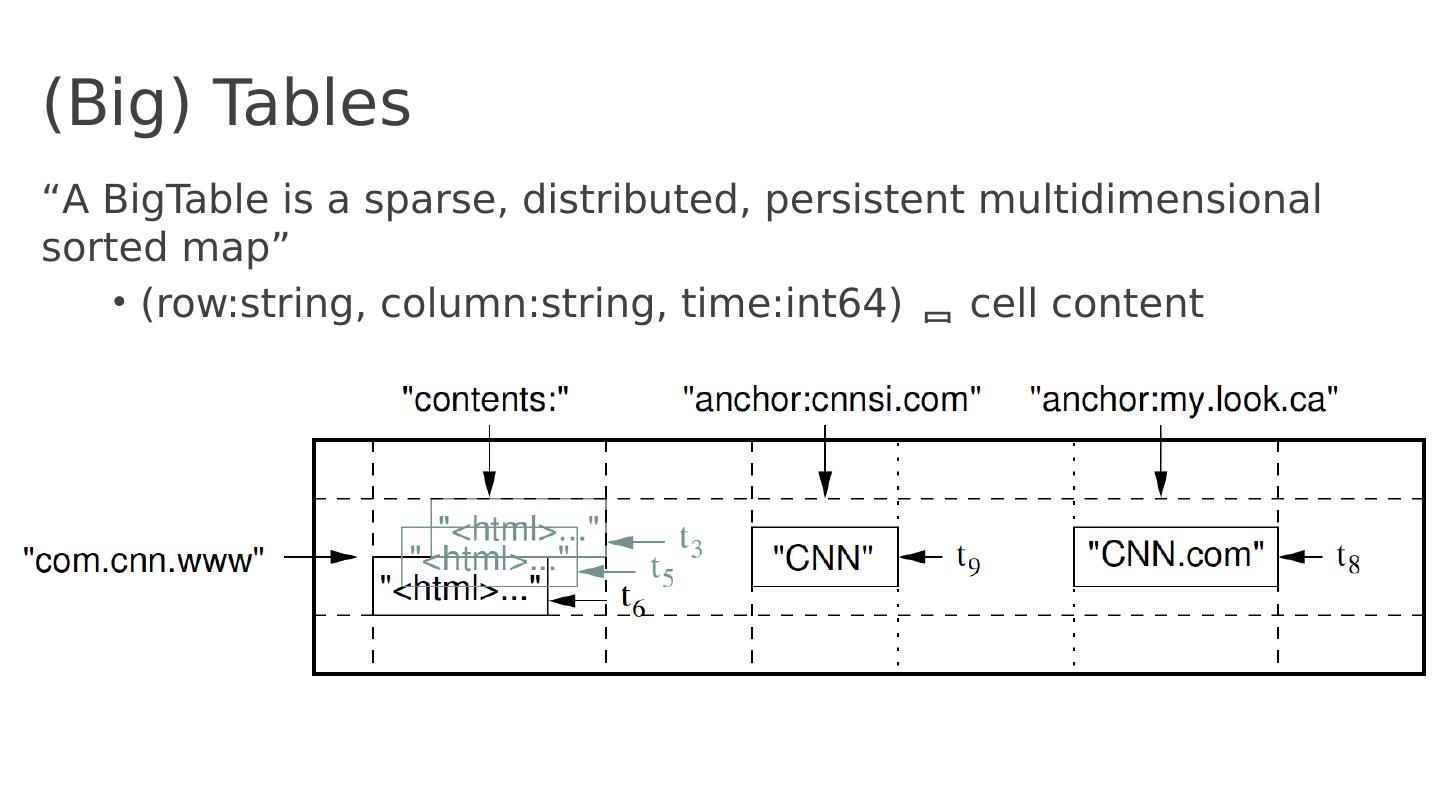
21 .(Big) Tables “A BigTable is a sparse, distributed, persistent multidimensional sorted map ” ( row:string , column:string , time:int64) cell content
22 .Column Families Column Family Group of column keys B asic unit of data access Data in a column family is typically of the same type Data within the same column family is compressed Identified by family:qualifier , e.g., “language”: language_id “anchor”: referring_site Example: <a href = "http://www.w3.org/">CERN< /a> appearing in www.berkeley.edu Referring site Cell content
23 .Timestamps Each cell in a Bigtable can contain multiple versions of same data Version indexed by a 64-bit timestamp: real time or assigned by client Per -column-family settings for garbage collection Keep only latest n versions Or keep only versions written since time t Retrieve most recent version if no version specified If specified, return version where timestamp ≤ requested time
24 .Tablets Table partitioned dynamically by rows into tablets Tablet = range of contiguous rows Unit of distribution and load balancing Nearby rows will usually be served by same server All rows are sorted Accessing nearby rows requires communication with small # of servers Usually, 100 -200 MB per tablet Users can control related rows to be in same tablet by row keys E.g., store maps.google.com / index.html under key com.google.maps / index.html
25 .Another Example from https://www.slideshare.net/romain_jacotin/undestand-google-bigtable-is-as-easy-as-playing-lego-bricks-lecture-by-romain- jacotin
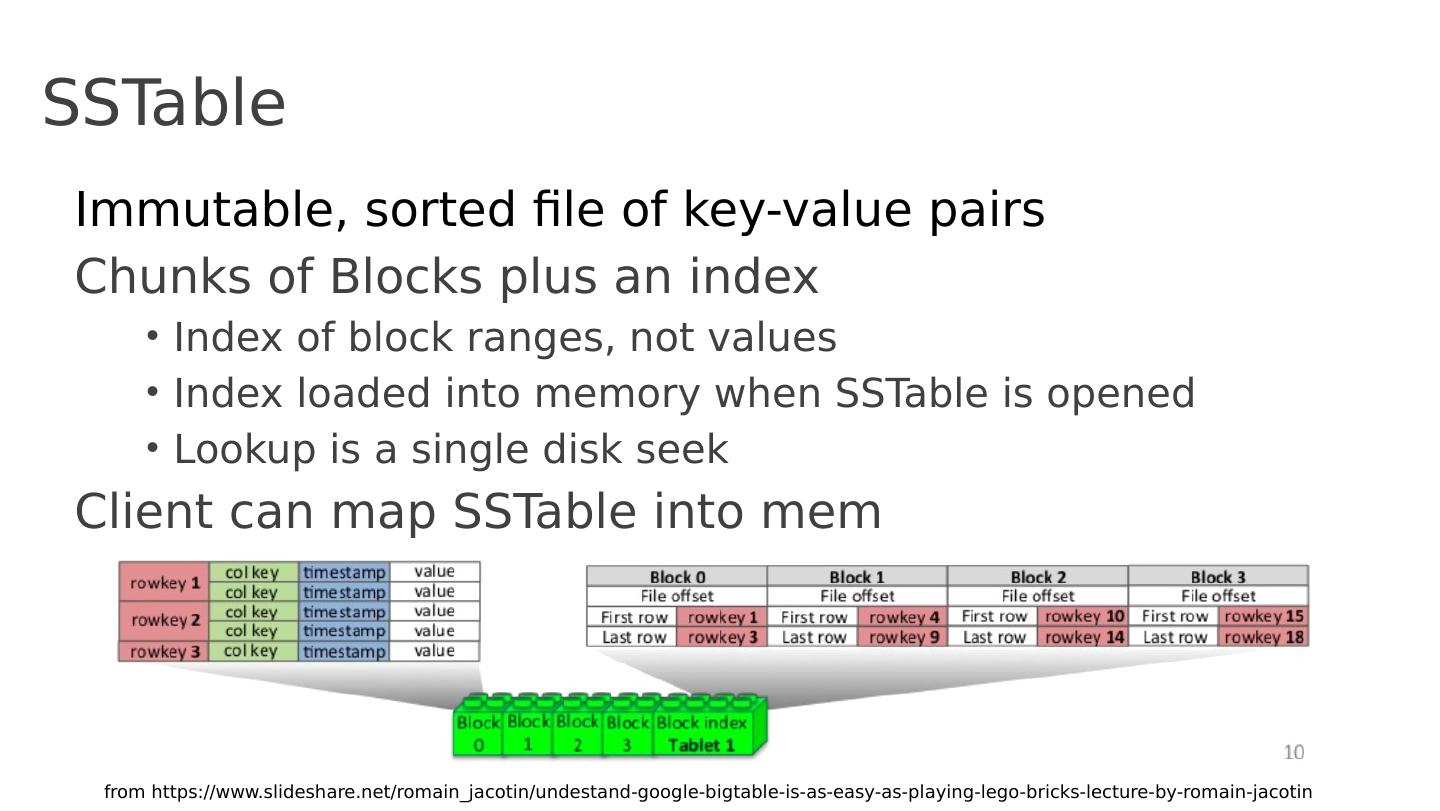
26 .SSTable Immutable, sorted file of key-value pairs Chunks of Blocks plus an index Index of block ranges, not values Index loaded into memory when SSTable is opened Lookup is a single disk seek C lient can map SSTable into mem from https://www.slideshare.net/romain_jacotin/undestand-google-bigtable-is-as-easy-as-playing-lego-bricks-lecture-by-romain- jacotin
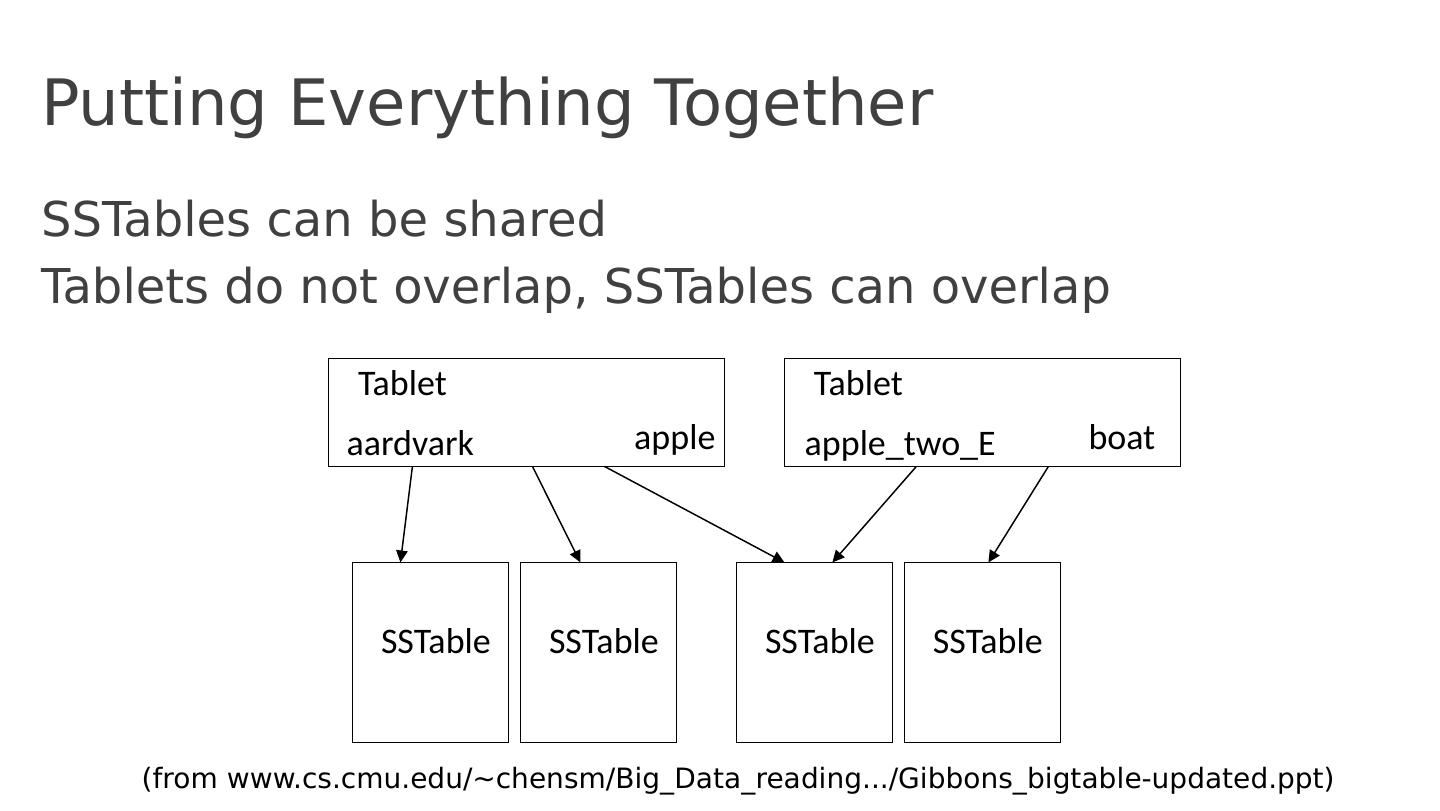
27 .Putting Everything Together SSTables can be shared Tablets do not overlap, SSTables can overlap SSTable SSTable SSTable SSTable Tablet aardvark apple Tablet apple_two_E boat (from www.cs.cmu.edu /~ chensm / Big_Data_reading .../ Gibbons_bigtable- updated.ppt )
28 .API Tables and column families: create, delete, update, control rights Rows: atomic read and write, read -modify-write sequences Values: delete , and lookup values in individual rows Others Iterate over subset of data in table No transactions across rows, but support batching writes across rows
29 .Architecture Google-File-System (GFS) to store log and data files. SSTable file format Chubby as a lock service (another lecture) E nsure at most one active master exists S tore bootstrap location of Bigtable data D iscover tablet servers S tore Bigtable schema information (column family info for each table) S tore access control lists
3秒后跳转登录页面
去登陆

