














































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
日志文件系统
本章节主要介绍了什么是文件,什么是日志,什么是FFS日志文件系统,是一个具有故障恢复能力的文件系统,在这个文件系统中,因为对目录以及位图的更新信息总是在原始的磁盘日志被更新之前写到磁盘上的一个连续的日志上,所以它保证了数据的完整性;与旧的Unix文件系统作对比,给出了他的优点。
展开查看详情
1 .1 Fast File, Log and Journaling File Systems cs262a, Lecture 3 Ali Ghodsi and Ion Stoica (based on presentations from John Kubiatowicz , UC Berkeley, and Arvind Krishnamurthy, from University of Washington )
2 .From Last Lecture
3 .Unix vs. System R : Philosophy Bottom -Up (elegance of system) vs. Top-Down (elegance of semantics) UNIX main function: present hardware to computer programmers small elegant set of mechanisms, and abstractions for developers ( i.e. C programmers) System R: manage data for application programmer complete system that insulated programmers (i.e. SQL + scripting) from the system, while guaranteeing clearly defined semantics of data and queries.
4 .Unix vs. System R: Philosophy Bottom-Up (elegance of system) vs. Top-Down (elegance of semantics) Affects where the complexity goes: to system , or end -programmer ? W hich one is better? In what environments?
5 .Turing Awards Relational databases related: 1981 : Edgar Codd 1988 : Jim Gray 2015 : Mike Stonebraker Unix related 1983: Ken Thomson and Dennis Ritchie 1990: Fernando Corbato
6 .Turing Awards Relational databases related: 1981 : Edgar Codd 1988 : Jim Gray 2015 : Mike Stonebraker Unix related 1983: Ken Thomson and Dennis Ritchie 1990: Fernando Corbato
7 .Why Today’s Papers? After all SSDs are taking over …
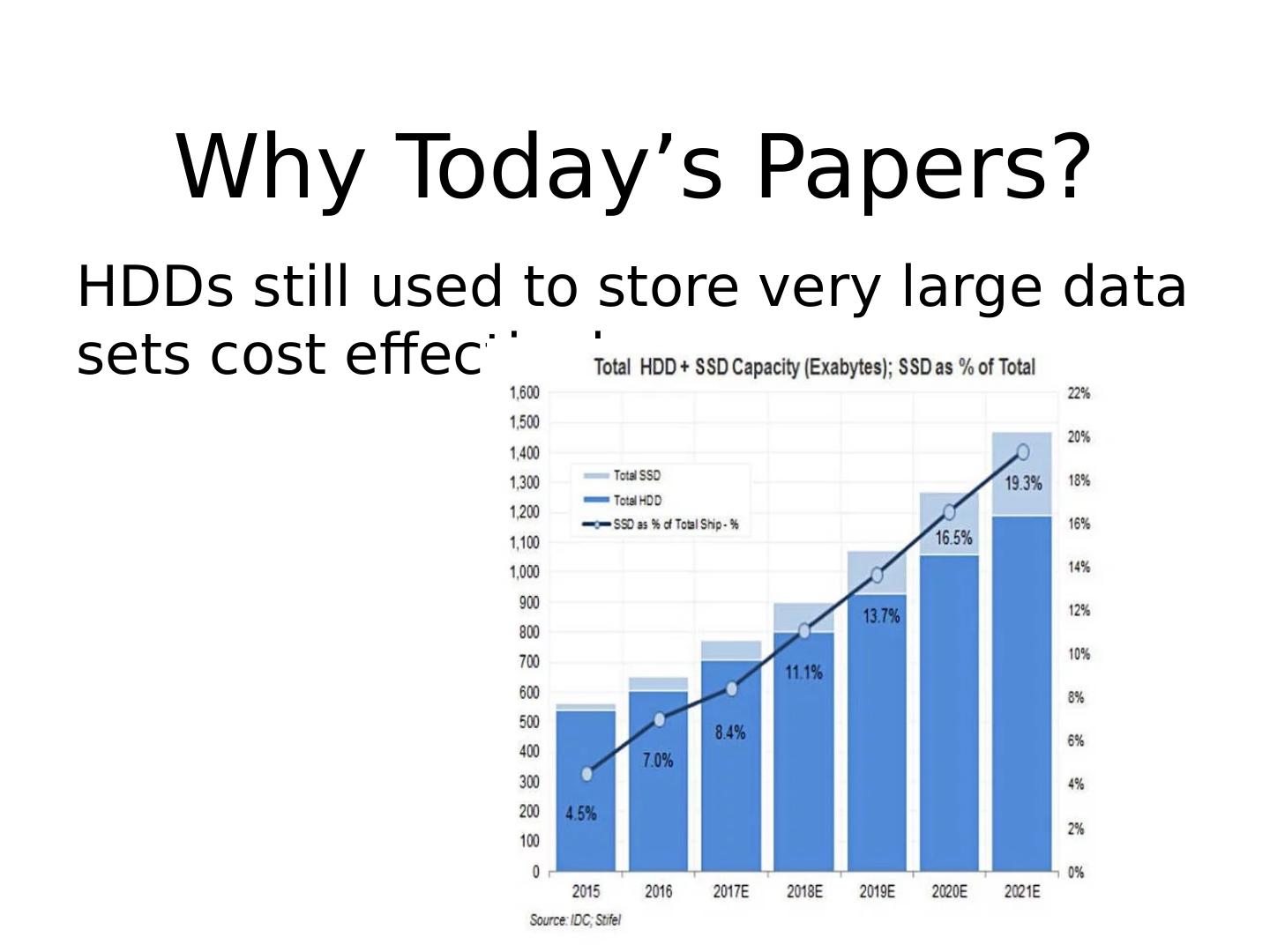
8 .Why Today’s Papers? HDDs still used to store very large data sets cost effectively
9 .Why Today’s Papers? HDDs still used to store very large data sets cost effectively More and more distributed storage systems Performance pattern resemble disks, e.g., Low throughput for random access, high throughput for sequential access Great examples of system engineering Valuable lessons for other application domains
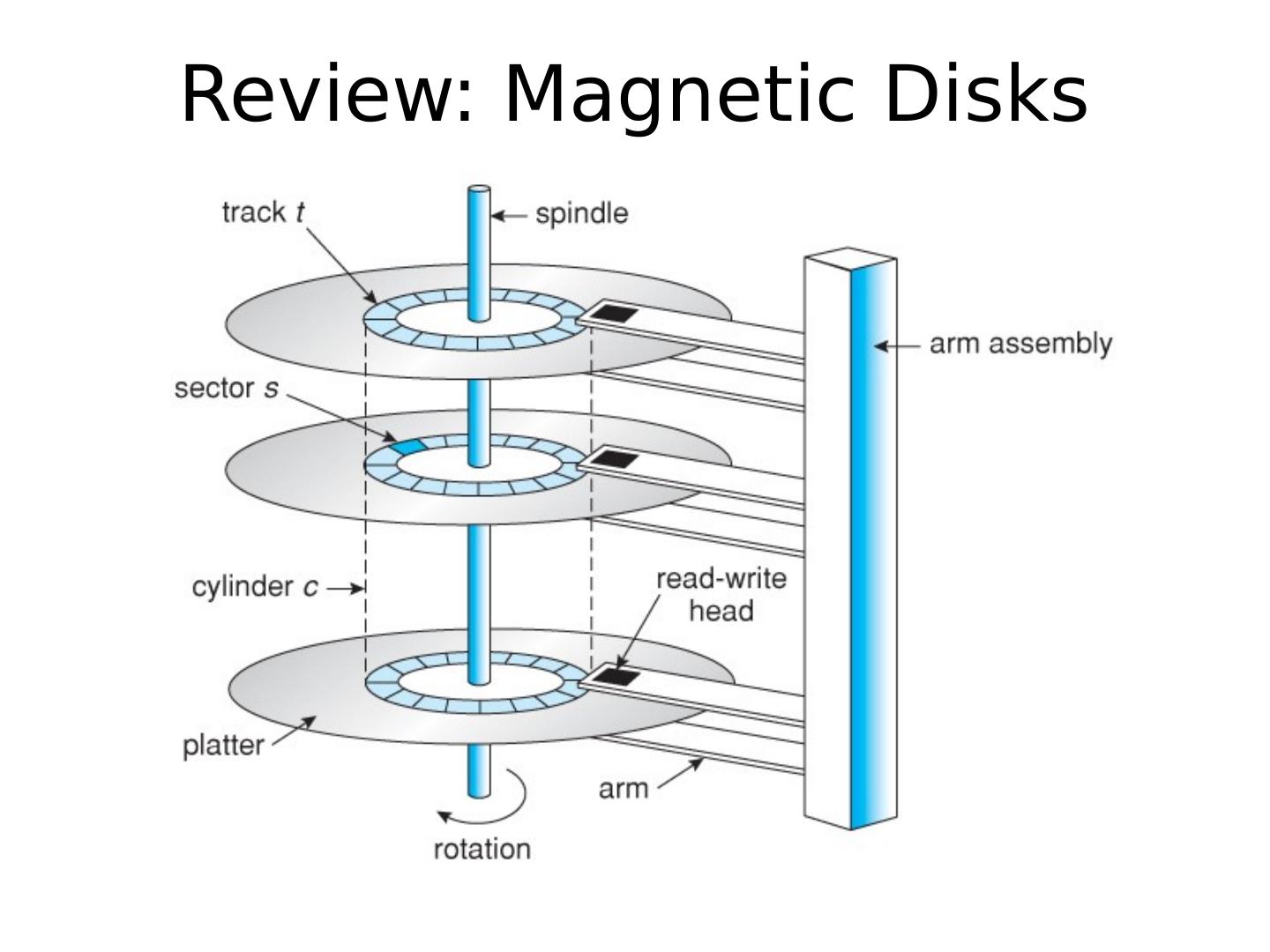
10 .Review: Magnetic Disks
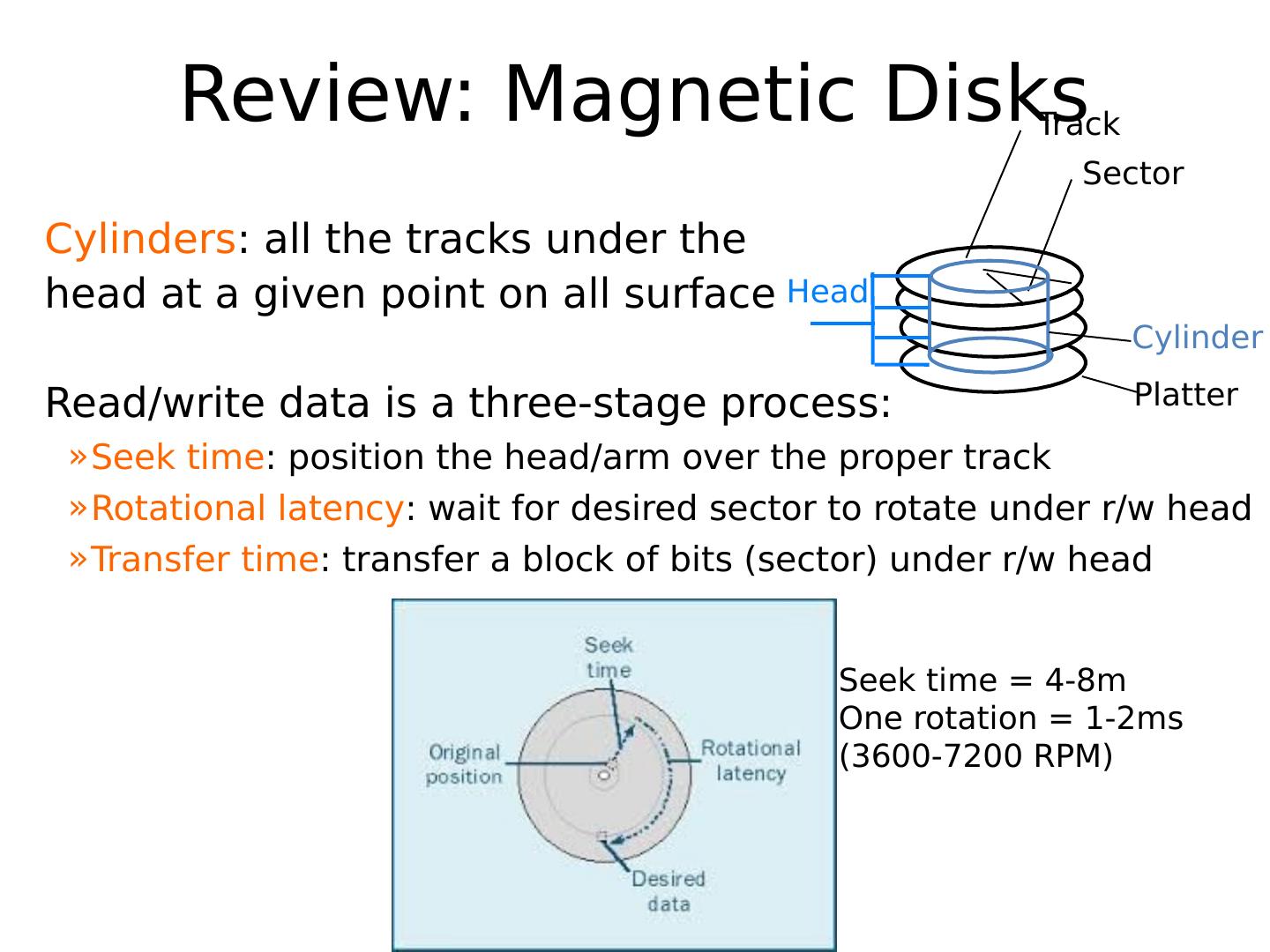
11 .Review: Magnetic Disks Cylinders : all the tracks under the head at a given point on all surface Read/write data is a three-stage process : Seek time : position the head/arm over the proper track Rotational latency : wait for desired sector to rotate under r/w head Transfer time : transfer a block of bits (sector ) under r/w head Sector Track Cylinder Head Platter Seek time = 4-8m One rotation = 1-2ms (3600-7200 RPM)
12 .Review: Magnetic Disks Cylinders : all the tracks under the head at a given point on all surface Read/write data is a three-stage process : Seek time : position the head/arm over the proper track Rotational latency : wait for desired sector to rotate under r/w head Transfer time : transfer a block of bits (sector ) under r/w head Sector Track Cylinder Head Platter Software Queue (Device Driver) Hardware Controller Media Time (Seek+Rot+Xfer) Request Result Disk Latency = Queueing Time + Controller time + Seek Time + Rotation Time + Xfer Time
13 .Review: Magnetic Disks Cylinders : all the tracks under the head at a given point on all surface Read/write data is a three-stage process : Seek time : position the head/arm over the proper track Rotational latency : wait for desired sector to rotate under r/w head Transfer time : transfer a block of bits (sector ) under r/w head Sector Track Cylinder Head Platter Disk Latency = Queueing Time + Controller time + Seek Time + Rotation Time + Xfer Time Highest Bandwidth : Transfer large group of blocks sequentially from one track
14 .Historical Perspective 1956 IBM Ramac — early 1970s Winchester Developed for mainframe computers, proprietary interface Steady shrink in form factor from 24in to 17in 1970s developments 8 inch floppy disk form factor (microcode into mainframe) Emergence of industry standard disk interfaces 1980s : PCs, first generation workstations, and client server computing Centralized storage on file server Accelerate disk downsizing: 8inch inch to 5.25 inch Mass market disk drives become a reality Industry standards: SCSI, IDI; end of proprietary standards 5.25 inch to 3.5 inch drives PCs 1990s: Laptops 2.5inch 2000s: Switch to perpendicular (vs longitudinal) recording 2007: 1TB 2009: 2TB 2016: 12TB IBM Ramac
15 .Recent: Western Digital Ultrastar 12 TB (April, 2017) 8 platters, 16 heads 7200 RPMs Max 255MB/s transfer rate Average latency: 4.2ms Seek time: 8ms Helium filled: reduce friction and power usage
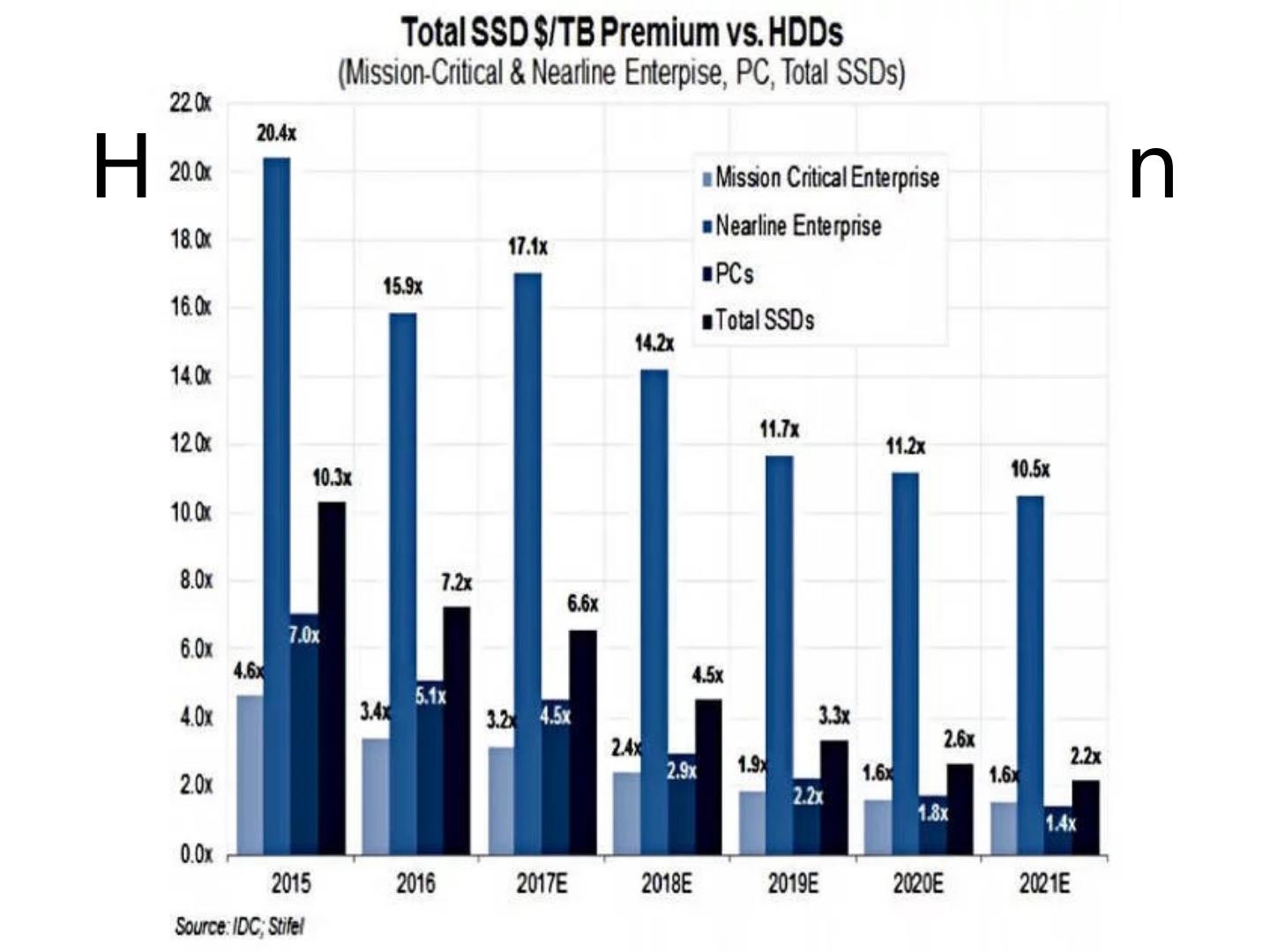
16 .HDD vs SSD Comparison
17 .Largest SSDs 60TB (Seagate, August 16) Dual 16Gbps Seq reads: 1.5GB/s Seq writes: 1GB/s Random Read Ops (IOPS): 150K
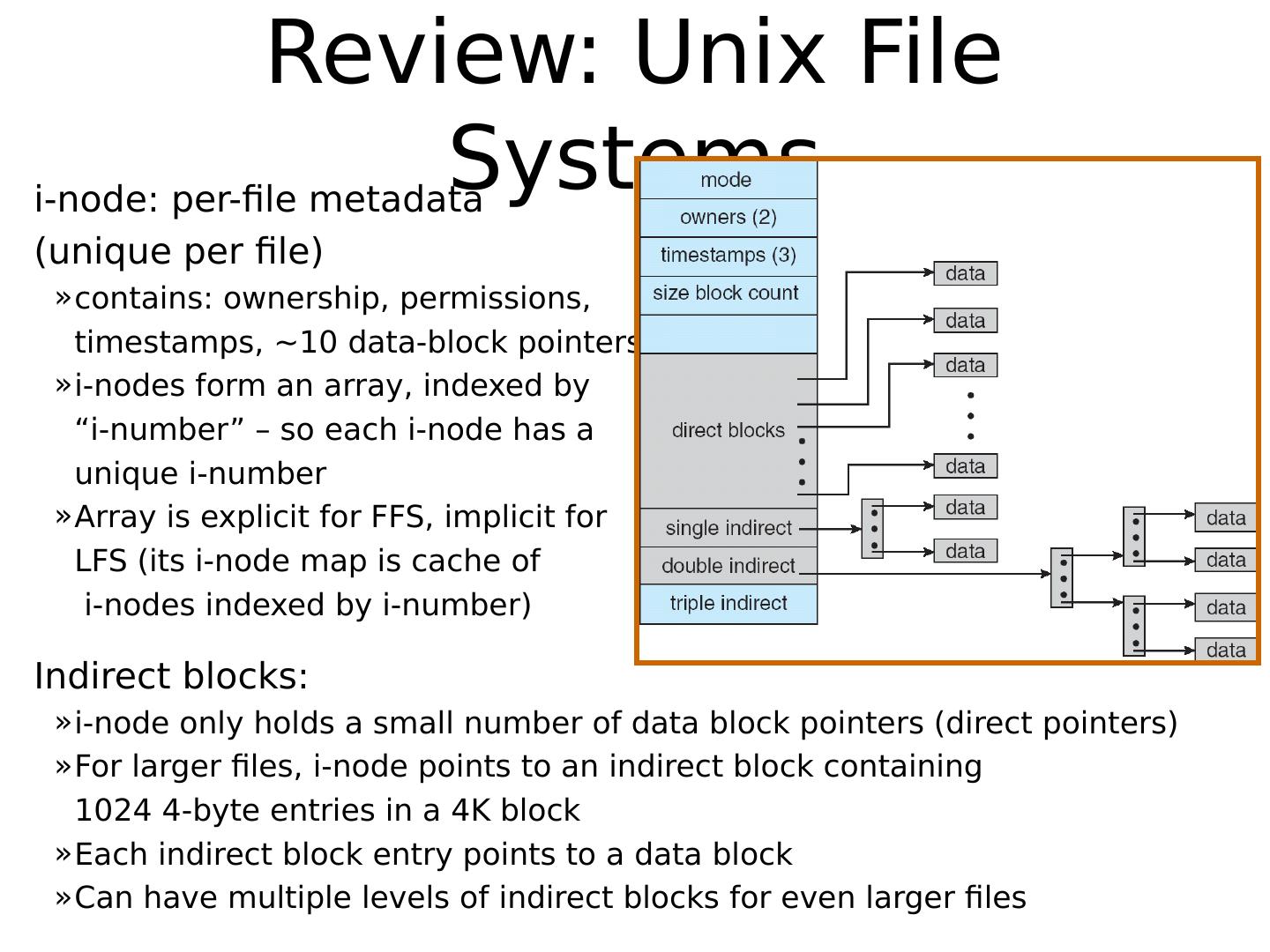
18 .Review: Unix File Systems i -node: per -file metadata ( unique per file) contains: ownership, permissions, timestamps, ~ 10 data-block pointers i -nodes form an array, indexed by “ i -number” – so each i -node has a unique i -number Array is explicit for FFS, implicit for LFS (its i -node map is cache of i -nodes indexed by i -number) Indirect blocks: i -node only holds a small number of data block pointers (direct pointers) For larger files, i -node points to an indirect block containing 1024 4-byte entries in a 4K block Each indirect block entry points to a data block Can have multiple levels of indirect blocks for even larger files
19 .Original Unix File System Simple and elegant, but slow 20KB/s, only 2% from disk theoretical bandwidth (1MB/s) Challenges: Blocks too small: 512 bytes (matched sector size) Many seeks Consecutive blocks of files not close together All i -nodes at the beginning of the disk, all data after that i -nodes of directory not close together Transfer only one block at a time
20 .Old File System Increase block size to 1024: over 2x higher throughput (why?) 2x higher transfer rate F ewer indirect blocks, so fewer seeks Challenges: in time, free list becomes random so performance degrades (because of seeks)
21 .FFS Changes 4096 or 8192 byte block size ( why not larger?) Use cylinder groups (why?) Each contains superblock, i -nodes, bitmap of free blocks, usage summary info B locks divided into small fragments (why?) Don’t fill entire disk (why?)
22 .Parametrized Model New file try to allocate new blocks on same cylinder (why?) Don’t allocate consecutive blocks (why?) How do you compute the space between two blocks that are consecutive in the file?
23 .Layout Principles: Locality of reference to minimize seek latency I mprove the layout of data to optimize larger transfers i nodes of files in same directory together (why?) New directories in cylinder groups that have higher than average free blocks (why?) Try to store all data blocks of a file in the same cylinder group P referably at rotationally optimal positions in the same cylinder Move to other cylinder group when files grow (which one?) Greedy algorithm: same cylinder same cylinder group quadratically hash cylinder group number exhaustive search;
24 .FFS Results 20-40% of disk bandwidth for large reads/writes 10-20x original UNIX speeds Size: 3800 lines of code vs. 2700 in old system 10% of total disk space overhead
25 .FFS System Interface Enhancements Long file names: from 14 to 255 characters Advisory file locks (shared exclusive): Requested by the program: shared or exclusive Effective only if all programs accessing the same file use them Process id of holder stored with lock => can reclaim the lock if process is no longer around Long file names: from 14 to 255 characters Symbolic links (contrast to hard links) Atomic rename capability The only atomic read-modify-write operation, before this there was none Disk quotas
26 .FFS Summary 3 key features: Optimize FS implementation for hardware M easurement-driven design decisions Locality “wins” Limitations : Measurements derived from a single installation I gnored technology trends Lessons: D on’t ignore underlying hardware characteristics Contrasting research approaches: improve what you’ve got vs. design something new (e.g., Log File Systems)
27 .Log Structured & Journaling File Systems
28 .Log-Structured/Journaling File System Radically different file system design Technology motivations: CPUs outpacing disks: I/O becoming more-and-more a bottleneck Large RAM: file caches work well, making most disk traffic writes Problems with (then) existing file systems: Lots of little writes Synchronous: wait for disk in too many places 5 seeks to create a new file (rough order): file i -node (create) file data directory entry file i -node (finalize) directory i -node (modification time)
29 .LFS Basic Idea Log all data and metadata with large , sequential writes Keep an index on log’s contents Use large memory to provide fast access through caching Data layout on disk has “temporal locality” (good for writing), rather than “logical locality” (good for reading) Why is this a good idea?
3秒后跳转登录页面
去登陆

