
















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ARIES
撤销(Undo)数据是反转DML语句结果所需的信息。撤销数据通常被称为“回滚数据”,另外在Oracle数据库中,有一种日志文件叫做重做日志文件,他就是大家俗称的:redolog。本章节主要介绍计算机日志的存储以及恢复。
展开查看详情
1 .Aries (Lecture 6, cs262a) Ali Ghodsi and Ion Stoica, UC Berkeley February 5, 2018 ( based on slide from Joe Hellerstein and Alan Fekete )
2 .Today’s Paper ARIES : A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-ahead Logging , C . Mohan, Don Haderle , Bruce Lindsay, Hamid Pirahesh and Peter Schwarz. Appears in Transactions on Database Systems, Vol 17, No. 1, March 1992, Pages 94-162 Thoughts ?
3 .Review: The ACID properties A tomicity : All actions in the Transaction happen , or none happen C onsistency : If each Transaction is consistent, and the DB starts consistent, it ends up consistent I solation : Execution of one Transaction is isolated from that of other Transactions D urability : If a Transaction commits , its effects persist The Recovery Manager guarantees Atomicity & Durability
4 .Motivation Atomicity: Transactions may abort (“Rollback”) Durability: What if DBMS stops running? (Causes?) crash! Desired Behavior after system restarts: T1, T2 & T3 should be durable T4 & T5 should be aborted (effects not seen ) T1 T2 T3 T4 T5
5 .Intended Functionality At any time, each (visible) data item contains the value produced by the most recent update done by a transaction that committed
6 .Goals Simplicity Operation logging (example?) Flexible storage management Partial rollbacks Flexible buffer management Recovery independence Logical undo Parallelism and fast recovery Minimal overhead
7 .Assumptions Essential concurrency control is in effect For read/write items: Write locks taken and held till commit E.g., Strict 2PL , but read locks not important for recovery For more general types: operations of concurrent transactions commute Updates are happening “in place” i.e. data is overwritten on (or deleted from) its location Unlike multiversion (e.g., shadow pages) approaches Buffer in volatile memory D ata persists on disk
8 .Challenge: REDO Need to restore value 1 to item Last value written by a committed transaction Action Buffer Disk Initially 0 T1 writes 1 1 0 T1 commits 1 0 CRASH 0
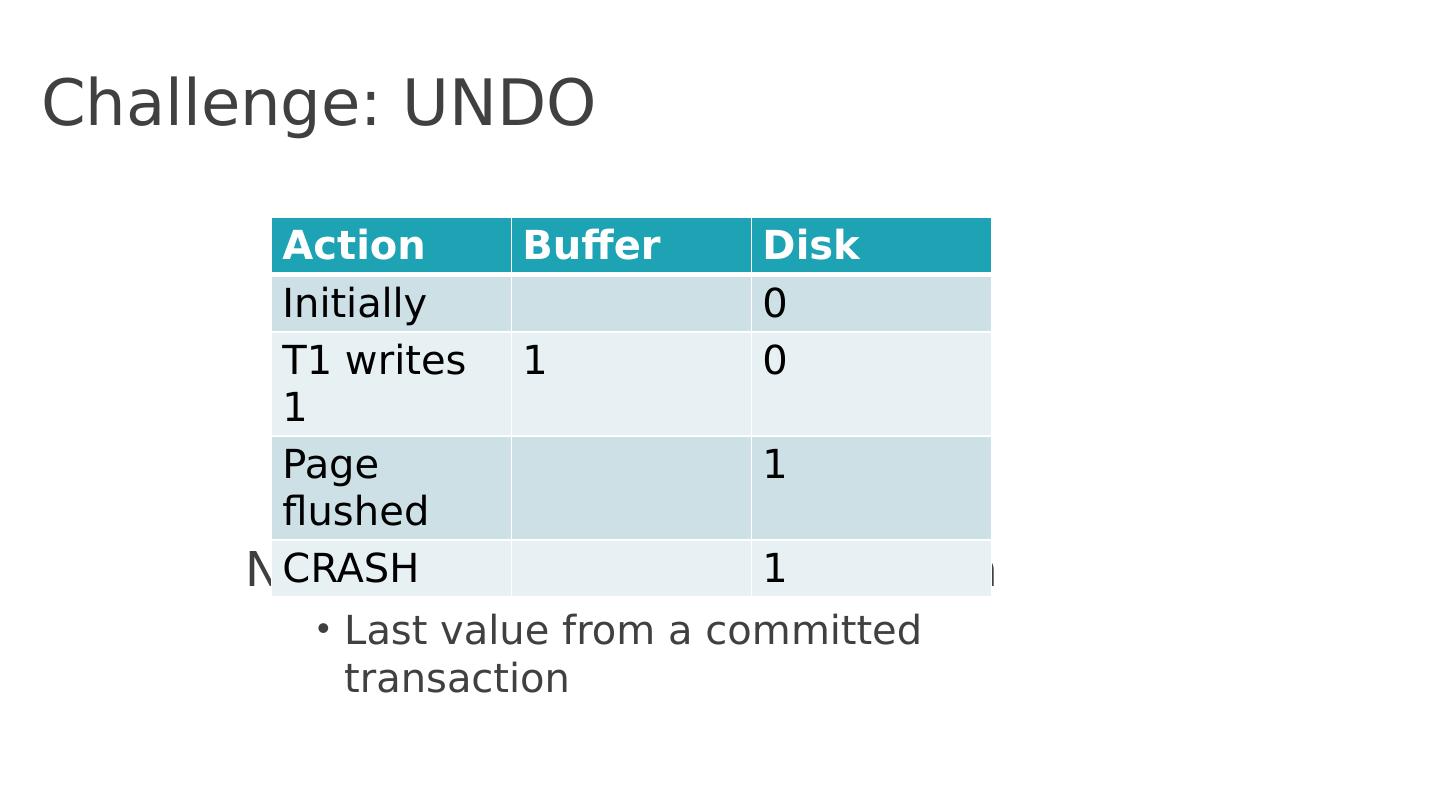
9 .Challenge: UNDO Need to restore value 0 to item Last value from a committed transaction Action Buffer Disk Initially 0 T1 writes 1 1 0 Page flushed 1 CRASH 1
10 .Handling the Buffer Pool What is a simple scheme to guarantee Atomicity & Durability? Force write to disk at commit? Poor response time But provides durability No Steal of buffer-pool frames from uncommited Transactions (“pin”)? Poor throughput But easily ensure atomicity Force No Force No Steal Steal Trivial Desired
11 .More on Steal and Force STEAL (why enforcing Atomicity is hard) To steal frame F: Current page in F (say P) is written to disk; some Transaction holds lock on P What if the Transaction with the lock on P aborts? Must remember old value of P at steal time (to support UNDO ing the write to page P) NO FORCE (why enforcing Durability is hard) What if system crashes before a modified page is written to disk? Write as little as possible, in a convenient place, at commit time, to support REDO ing modifications
12 .Basic Idea: Logging Record REDO and UNDO information, for every update, in a log Sequential writes to log (put it on a separate disk) Minimal info (diff) written to log, so multiple updates fit in a single log page Log : An ordered list of REDO/UNDO actions Log record contains: <XID, pageID , offset, length, old data, new data> and additional control info (which we’ll see soon) For abstract types, have operation( args ) instead of old value new value
13 .Write-Ahead Logging (WAL) The Write-Ahead Logging Protocol: Must force the log record for an update before the corresponding data page gets to disk Must write all log records for a Transaction before commit #1 (undo rule) allows system to have Atomicity #2 (redo rule) allows system to have Durability
14 .ARIES Exactly how is logging (and recovery!) done? Many approaches (traditional ones used in relational systems of 1980s) ARIES algorithms developed by IBM used many of the same ideas, and some novelties that were quite radical at the time Research report in 1989; conference paper on an extension in 1989; comprehensive journal publication in 1992 10 Year VLDB Award 1999
15 .Key ideas of ARIES Log every change ( even UNDOs during Transaction abort ) In restart, first repeat history without backtracking Even REDO the actions of loser transactions Then UNDO actions of losers LSNs in pages used to coordinate state between log, buffer, disk Novel features of ARIES in italics
16 .WAL & the Log Each log record has a unique Log Sequence Number (LSN) LSNs always increasing Each data page contains a pageLSN The LSN of the most recent log record for an update to that page System keeps track of flushedLSN The max LSN flushed so far LSNs pageLSNs RAM flushedLSN pageLSN Log records flushed to disk “Log tail” in RAM DB
17 .WAL constraints Before a page is written, pageLSN £ flushedLSN Commit record included in log; all related update log records precede it in log
18 .Log Records Possible log record types: Update Commit Abort End (signifies end of commit or abort) Compensation Log Records (CLRs) for UNDO actions (and some other tricks!) prevLSN XID type length pageID offset before-image after-image LogRecord fields: update records only
19 .Other Log-Related State Transaction Table: One entry per active Transaction Contains XID, status (running/ commited /aborted), and lastLSN Dirty Page Table: One entry per dirty page in buffer pool Contains recLSN – the LSN of the log record which first caused the page to be dirty
20 .Normal Execution of a Transaction Series of reads & writes , followed by commit or abort We will assume that page write is atomic on disk In practice, additional details to deal with non-atomic writes Strict 2PL (at least for writes) STEAL , NO-FORCE buffer management, with Write-Ahead Logging
21 .Checkpointing Periodically, the DBMS creates a checkpoint , in order to minimize the time taken to recover in the event of a system crash. Write to log: begin_checkpoint record: Indicates when chkpt began. end_checkpoint record: Contains current Transaction table and dirty page table . This is a `fuzzy checkpoint’ : Other Transactions continue to run; so these tables only known to reflect some mix of state after the time of the begin_checkpoint record . No attempt to force dirty pages to disk; effectiveness of checkpoint limited by oldest unwritten change to a dirty page. (So it’s a good idea to periodically flush dirty pages to disk!) Store LSN of chkpt record in a safe place ( master record)
22 .The Big Picture: What’s Stored Where prevLSN XID type length pageID offset before-image after-image LogRecords LOG DB Data pages each with a pageLSN master record Transaction Table lastLSN status Dirty Page Table recLSN flushedLSN RAM
23 .Simple Transaction Abort For now, consider an explicit abort of a Transaction No crash involved We want to “play back” the log in reverse order, UNDO ing updates. Get lastLSN of Transaction from Transaction table Can follow chain of log records backward via the prevLSN field Note: before starting UNDO, could write an Abort log record Why bother?
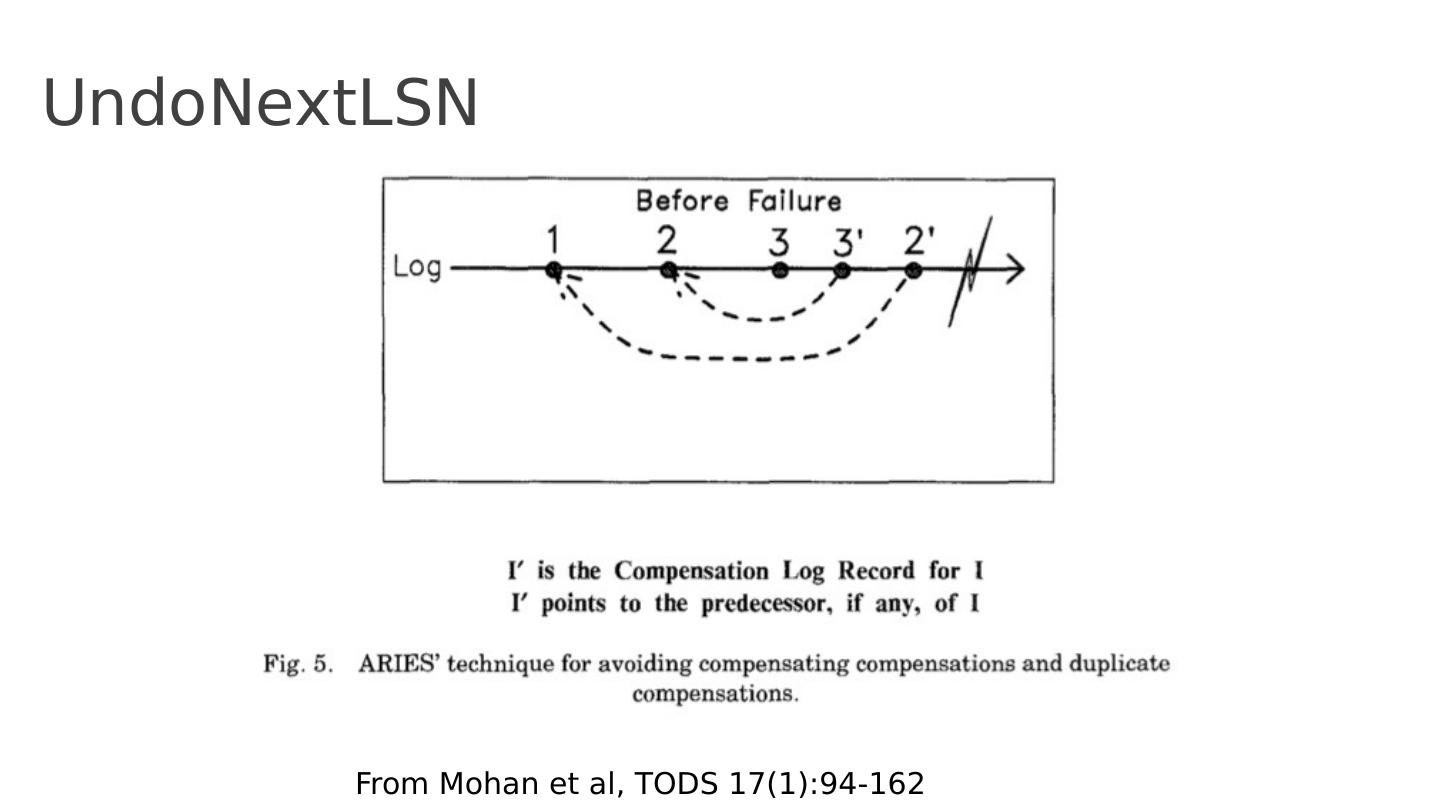
24 .Abort, cont To perform UNDO, must have a lock on data! No problem! Before restoring old value of a page, write a compensation log record (CLR): You continue logging while you UNDO!! CLR has one extra field: undonextLSN Points to next LSN to undo (i.e. prevLSN of the record we’re currently undoing) CLR contains REDO info CLRs never Undone Undo needn’t be idempotent (>1 UNDO won’t happen) But they might be Redone when repeating history (=1 UNDO guaranteed) At end of all UNDOs, write an “end” log record
25 .Transaction Commit Write commit record to log All log records up to Transaction’s lastLSN are flushed Guarantees that flushedLSN ³ lastLSN Note that log flushes are sequential, synchronous writes to disk Many log records per log page Make transaction visible Commit() returns, locks dropped, etc. Write end record to log
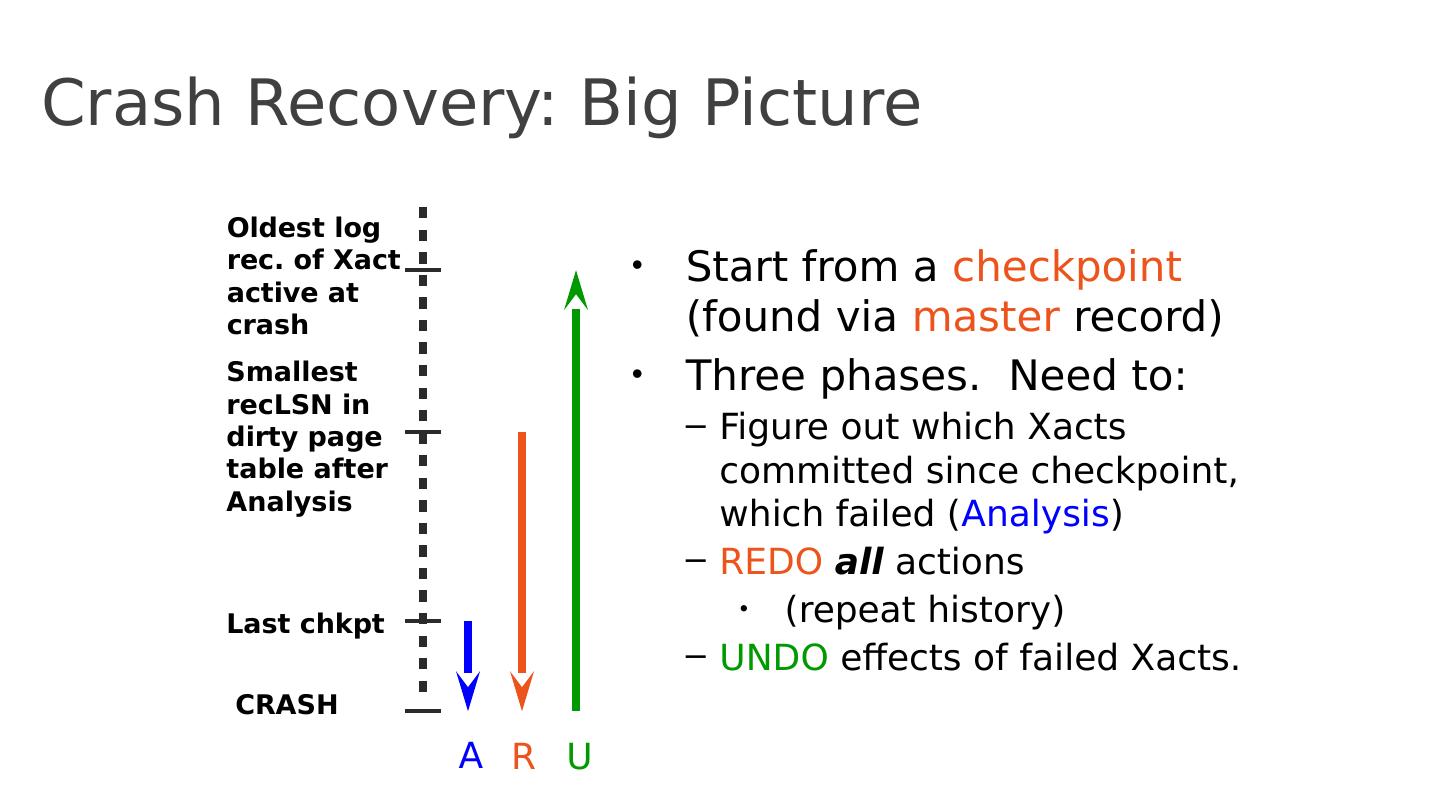
26 .Crash Recovery: Big Picture Start from a checkpoint (found via master record) Three phases. Need to: Figure out which Xacts committed since checkpoint, which failed ( Analysis ) REDO all actions (repeat history) UNDO effects of failed Xacts . Oldest log rec. of Xact active at crash Smallest recLSN in dirty page table after Analysis Last chkpt CRASH A R U
27 .Recovery: The Analysis Phase Reconstruct state at checkpoint via end_checkpoint record Scan log forward from begin_checkpoint End record: Remove Xact from Xact table Other records: Add Xact to Xact table, set lastLSN =LSN , change Xact status on commit Update record: If P not in Dirty Page Table (DPT) Add P to DPT ., set its recLSN =LSN This phase could be skipped; information can be regained in subsequent REDO pass
28 .Recovery: The REDO Phase We repeat History to reconstruct state at crash: Reapply all updates (even of aborted Xacts !), redo CLRs Scan forward from log rec containing smallest recLSN in DPT. For each CLR or update log rec LSN , REDO the action unless page is already more up-to-date than this record: REDO when Affected page is in D.P.T., and has pageLSN (in DB) < LSN. ( if page has recLSN > LSN no need to read page in from disk to check pageLSN ) To REDO an action: Reapply logged action Set pageLSN to LSN . No additional logging!
29 .Invariant State of page P is the outcome of all changes of relevant log records whose LSN is <= P.pageLSN During redo phase, every page P has P.pageLSN >= currently-redoing-LSN Thus at end of redo pass, the database has a state that reflects exactly everything on the (stable) log
3秒后跳转登录页面
去登陆

