










































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
描述语法和语义
本文主要接受编译器的原理、技术和工具,以及计算机语言的词法分析初探、句法分析:功能与责任、上下文无关文法:概念与术语、文法设计与写作等内容。其中还包含有标准语义与操作语义的对比,公理语义的简介分析等。
展开查看详情
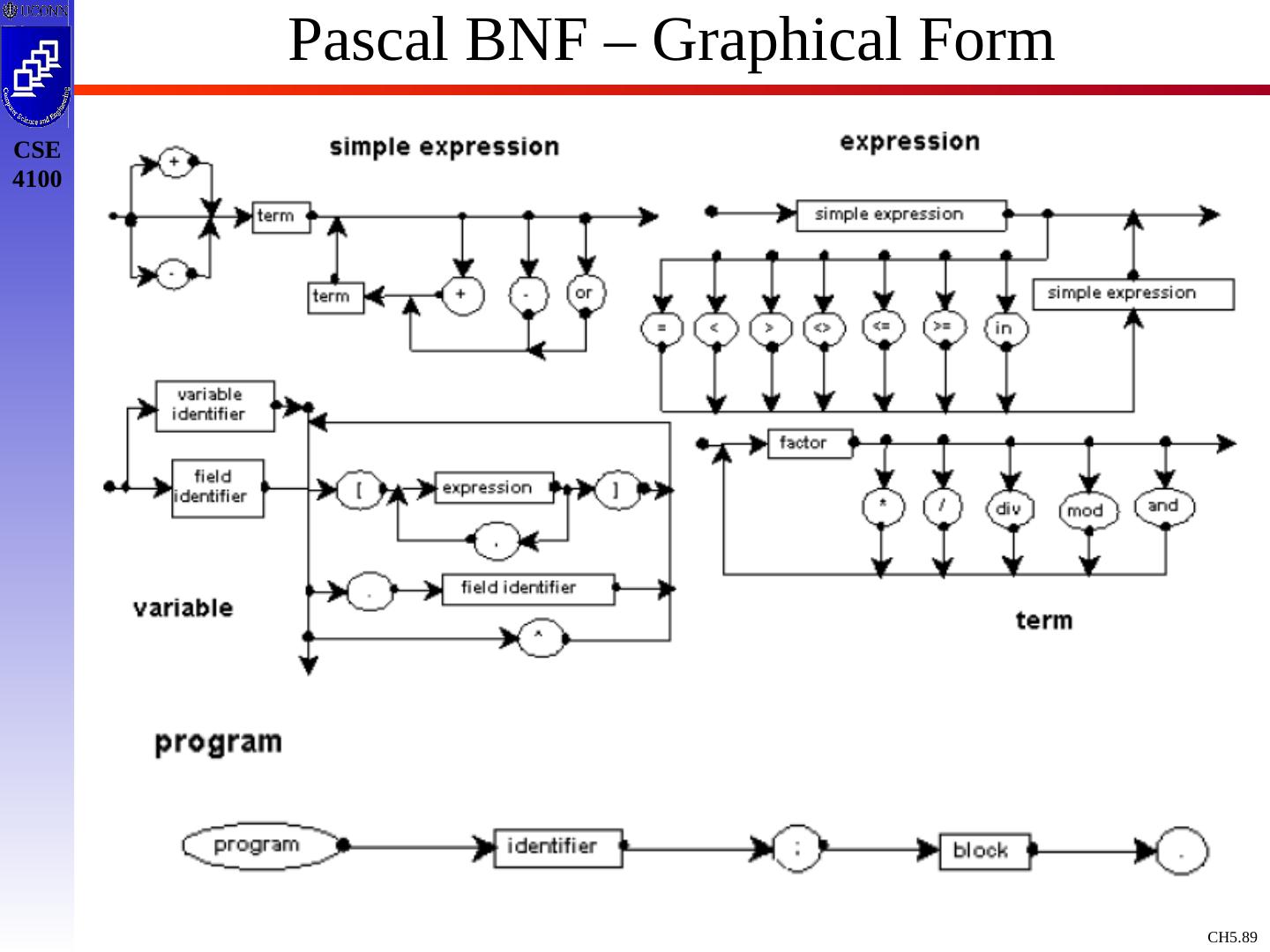
1 .Chapter 3 Describing Syntax and Semantics
2 .Parsing and Grammars From: Chapter 4 of Compilers: Principles, Techniques and Tools , Aho , et al., Addison-Wesley A First look at Lexical Analysis An overview of parsing : Functions & Responsibilities Context Free Grammars: Concepts & Terminology Writing and Designing Grammars
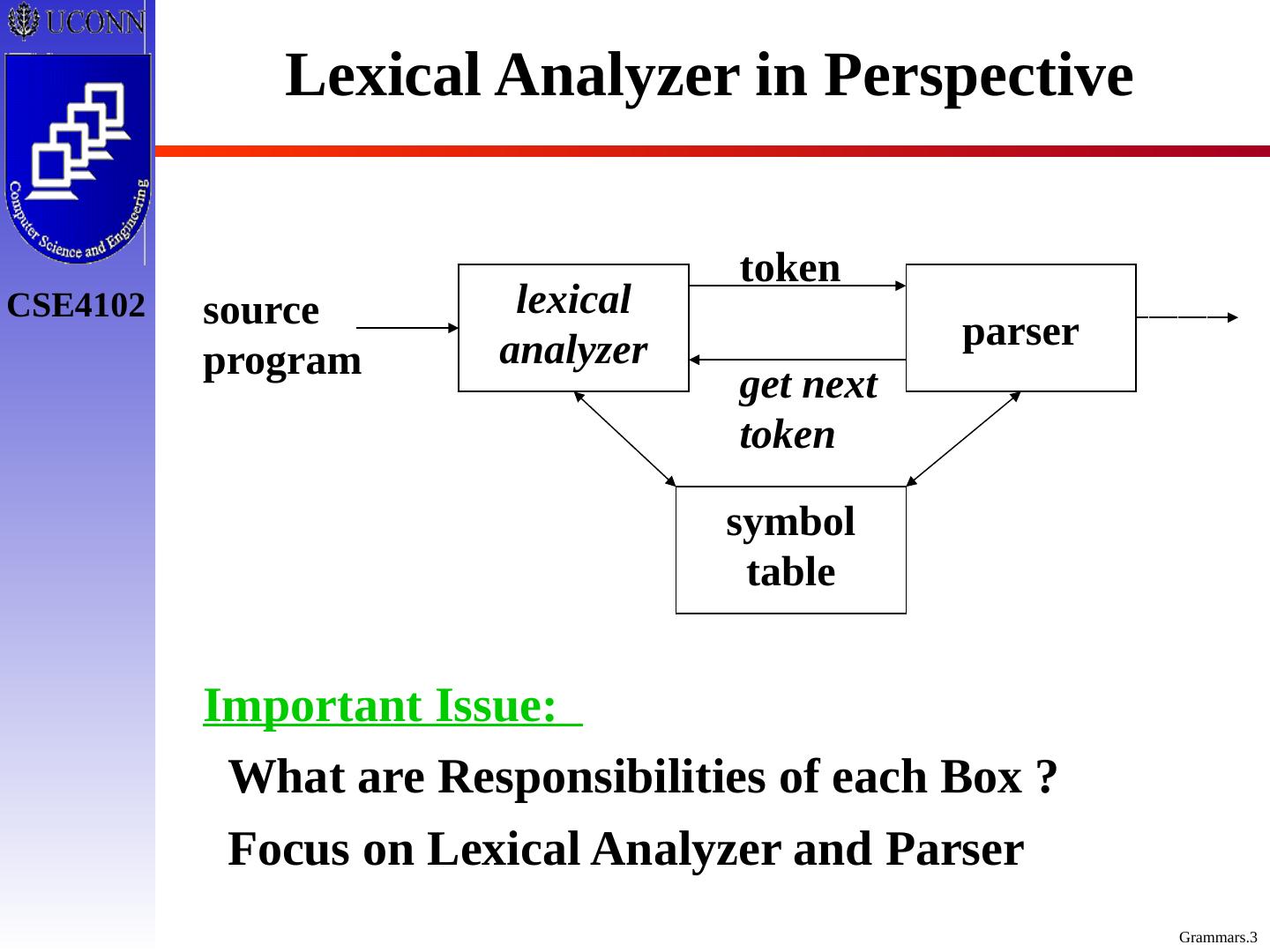
3 .Lexical Analyzer in Perspective lexical analyzer parser symbol table source program token get next token Important Issue: What are Responsibilities of each Box ? Focus on Lexical Analyzer and Parser
4 .Lexical Analyzer in Perspective LEXICAL ANALYZER Scan Input Remove WS, NL, … Identify Tokens Create Symbol Table Insert Tokens into ST Generate Errors Send Tokens to Parser PARSER Perform Syntax Analysis Actions Dictated by Token Order Update Symbol Table Entries Create Abstract Rep. of Source Generate Errors And More…. (We’ll see later)
5 .Introducing Basic Terminology What are Major Terms for Lexical Analysis? TOKEN A classification for a common set of strings Examples Include Identifier, Integer, Float, Assign, LParen, RParen, etc. PATTERN The rules which characterize the set of strings for a token – integers [0-9]+ Recall File and OS Wildcards ([A-Z]*.*) LEXEME Actual sequence of characters that matches pattern and is classified by a token Identifiers: x, count, name, etc… Integers: 345, 20 -12, etc.
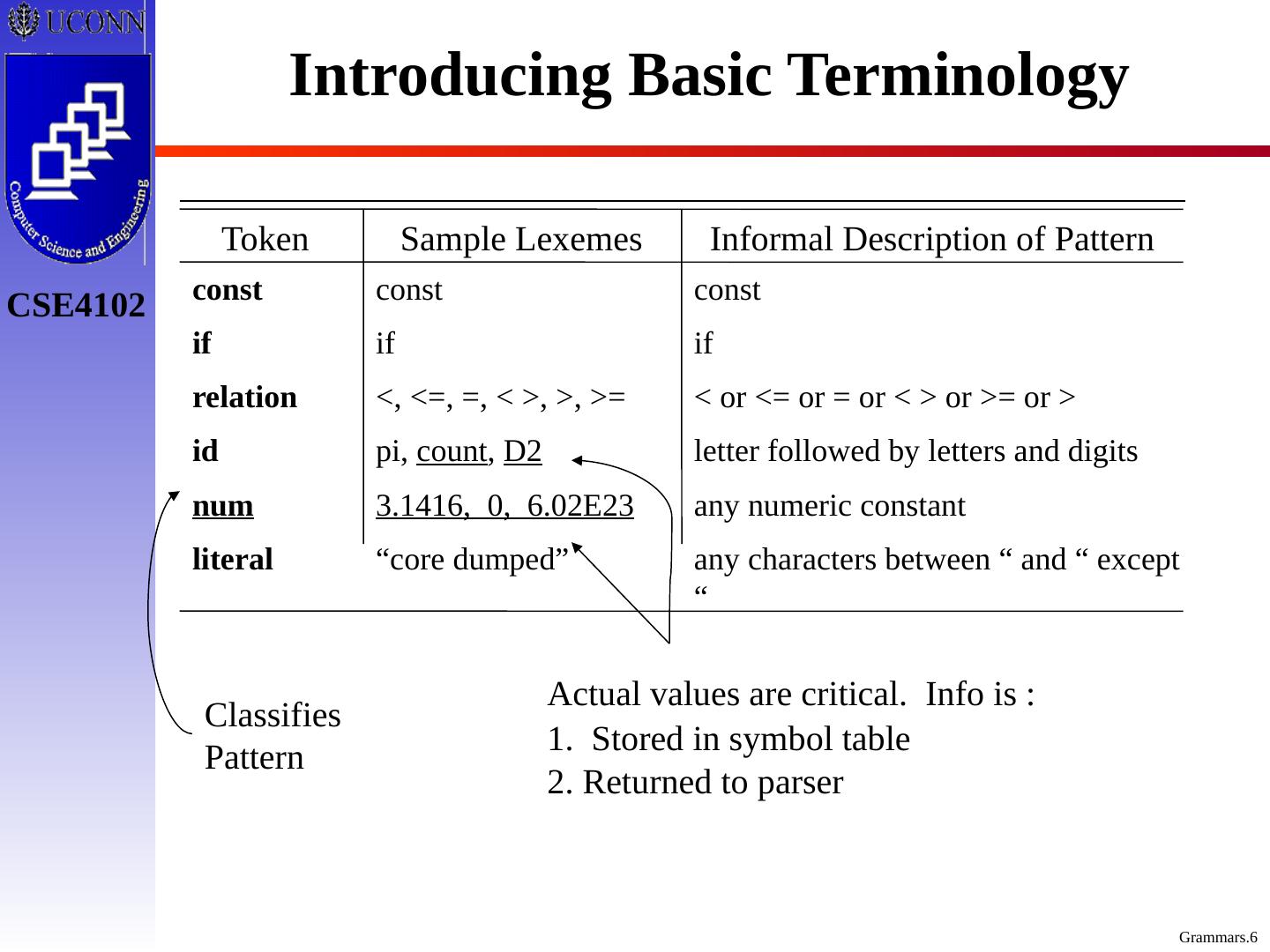
6 .Introducing Basic Terminology Token Sample Lexemes Informal Description of Pattern const if relation id num literal const if <, <=, =, < >, >, >= pi, count , D2 3.1416, 0, 6.02E23 “core dumped” const if < or <= or = or < > or >= or > letter followed by letters and digits any numeric constant any characters between “ and “ except “ Classifies Pattern Actual values are critical. Info is : 1. Stored in symbol table 2. Returned to parser
7 .An Overview of Parsing Why are Grammars to formally describe Languages Important ? Precise, easy-to-understand representations Compiler-writing tools can take grammar and generate a compiler Allow a language to be evolved (new statements, changes to statements, etc.) Languages are not static, but are constantly upgraded to add new features or fix “old” ones ADA ADA9x, C++ Adds: Templates, exceptions, How do grammars relate to parsing process ?
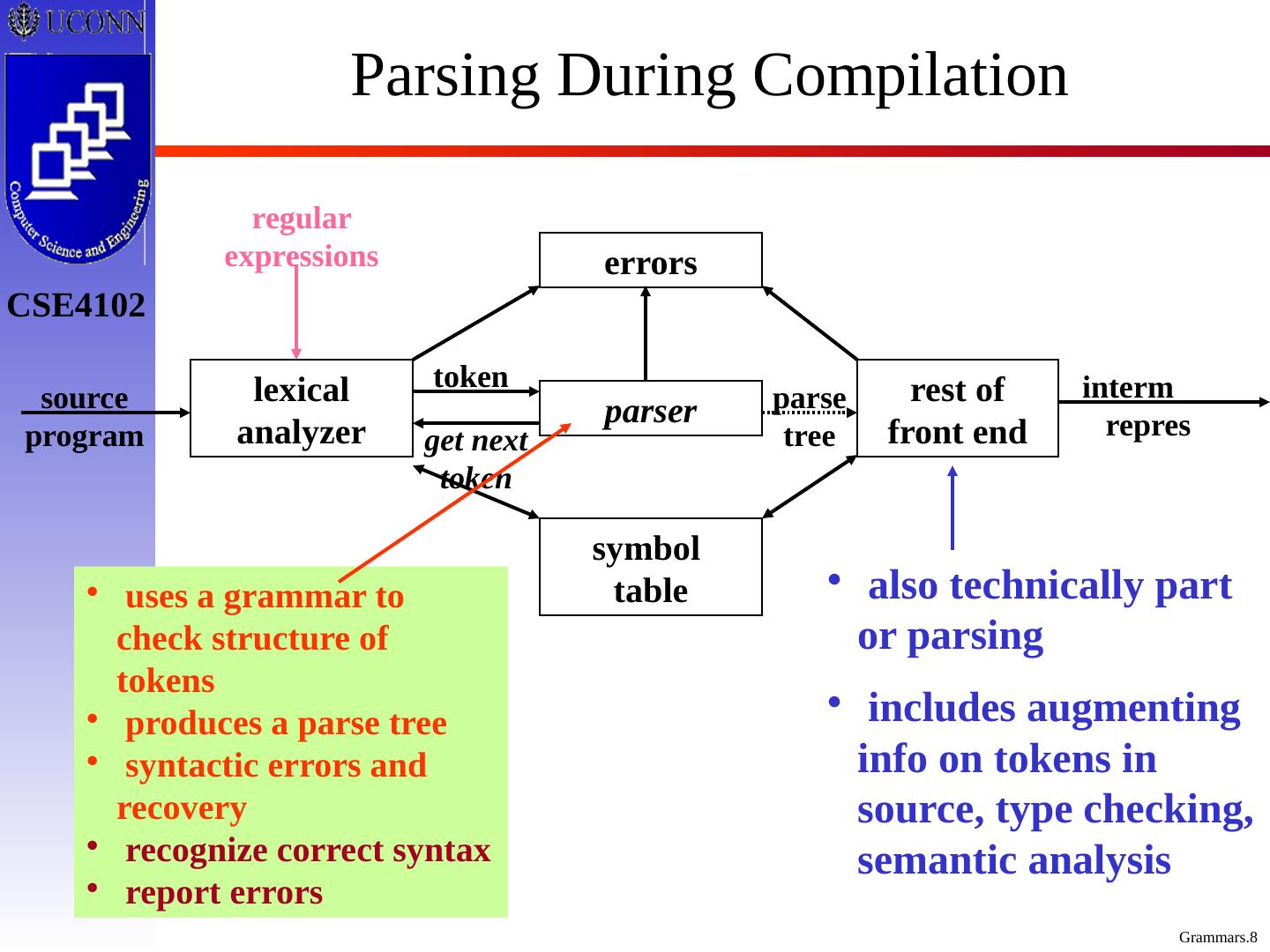
8 .Parsing During Compilation interm repres errors lexical analyzer parser rest of front end symbol table source program parse tree get next token token regular expressions also technically part or parsing includes augmenting info on tokens in source, type checking, semantic analysis uses a grammar to check structure of tokens produces a parse tree syntactic errors and recovery recognize correct syntax report errors
9 .Parsing Responsibilities Syntax Error Identification / Handling Recall typical error types: Lexical : Misspellings Syntactic : Omission, wrong order of tokens Semantic : Incompatible types Logical : Infinite loop / recursive call Majority of error processing occurs during syntax analysis NOTE: Not all errors are identifiable !! Which ones?
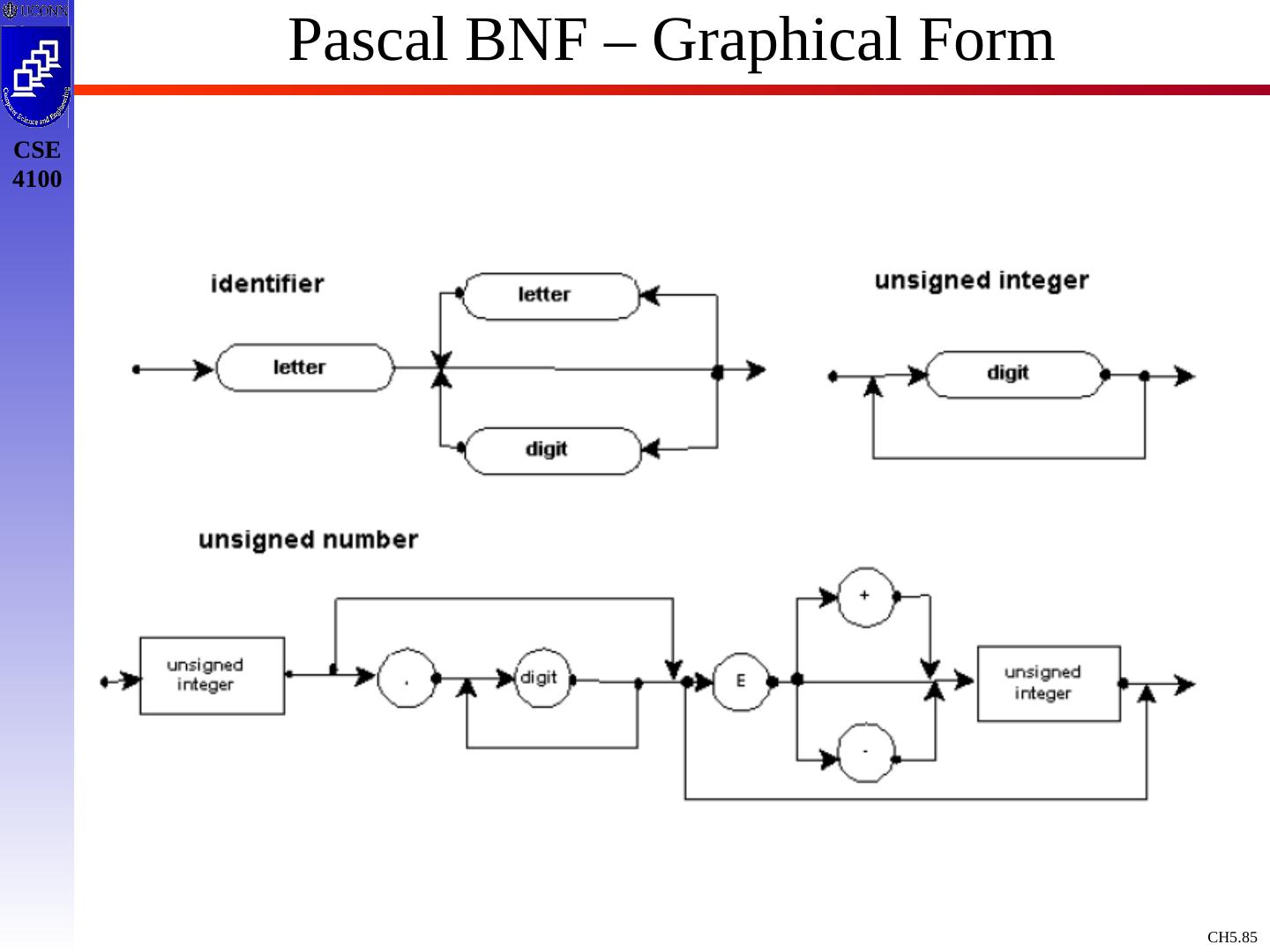
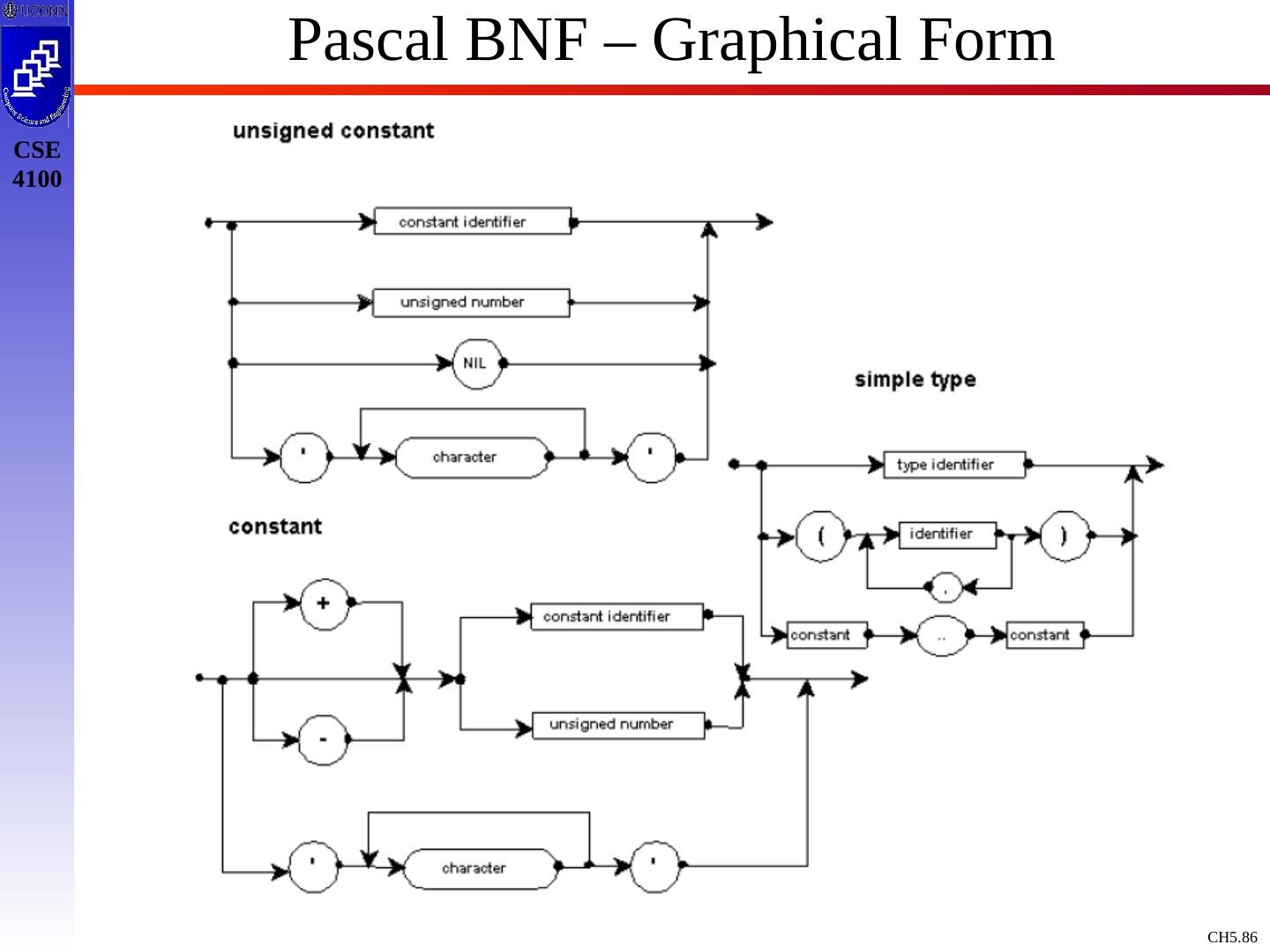
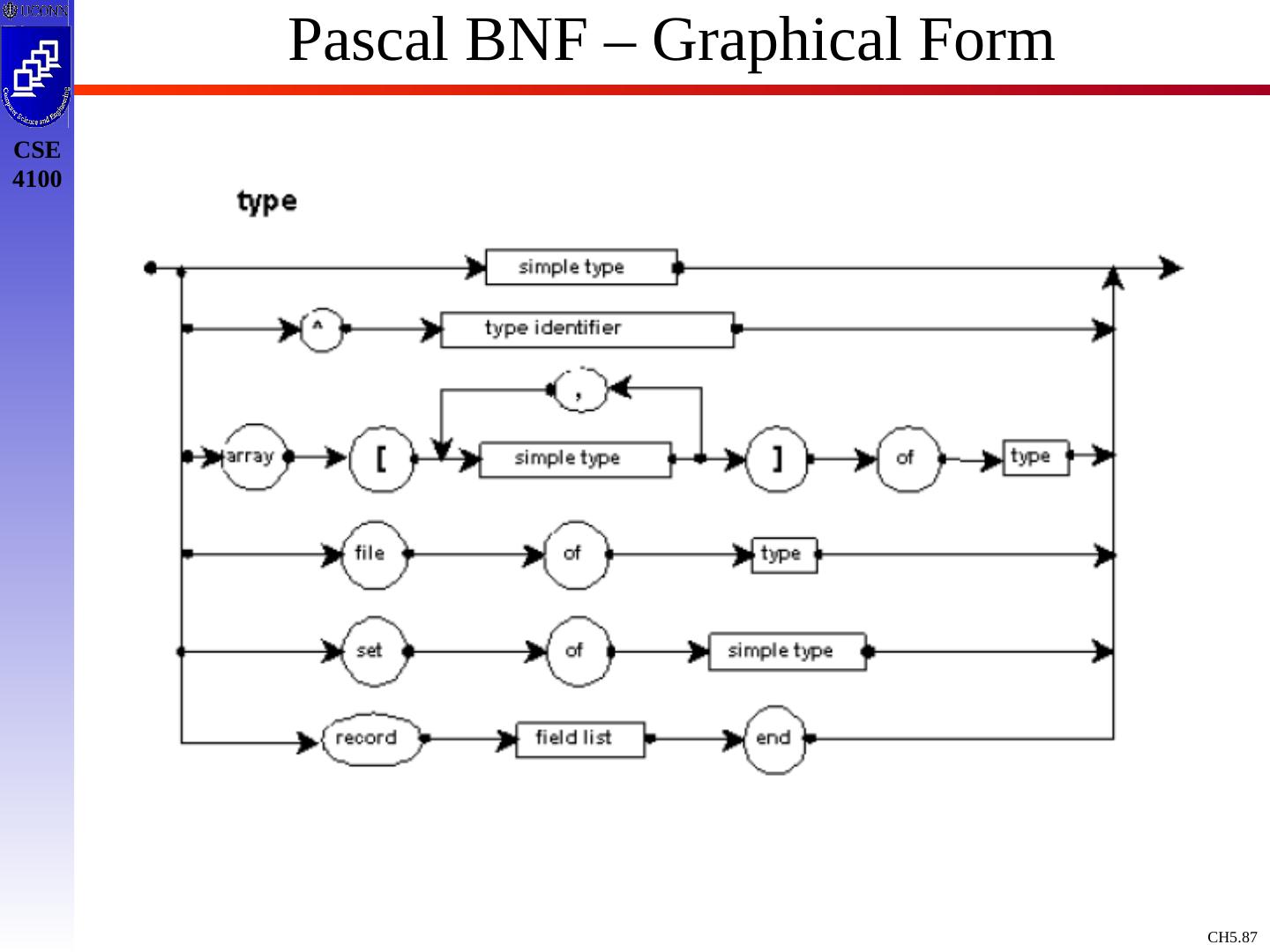
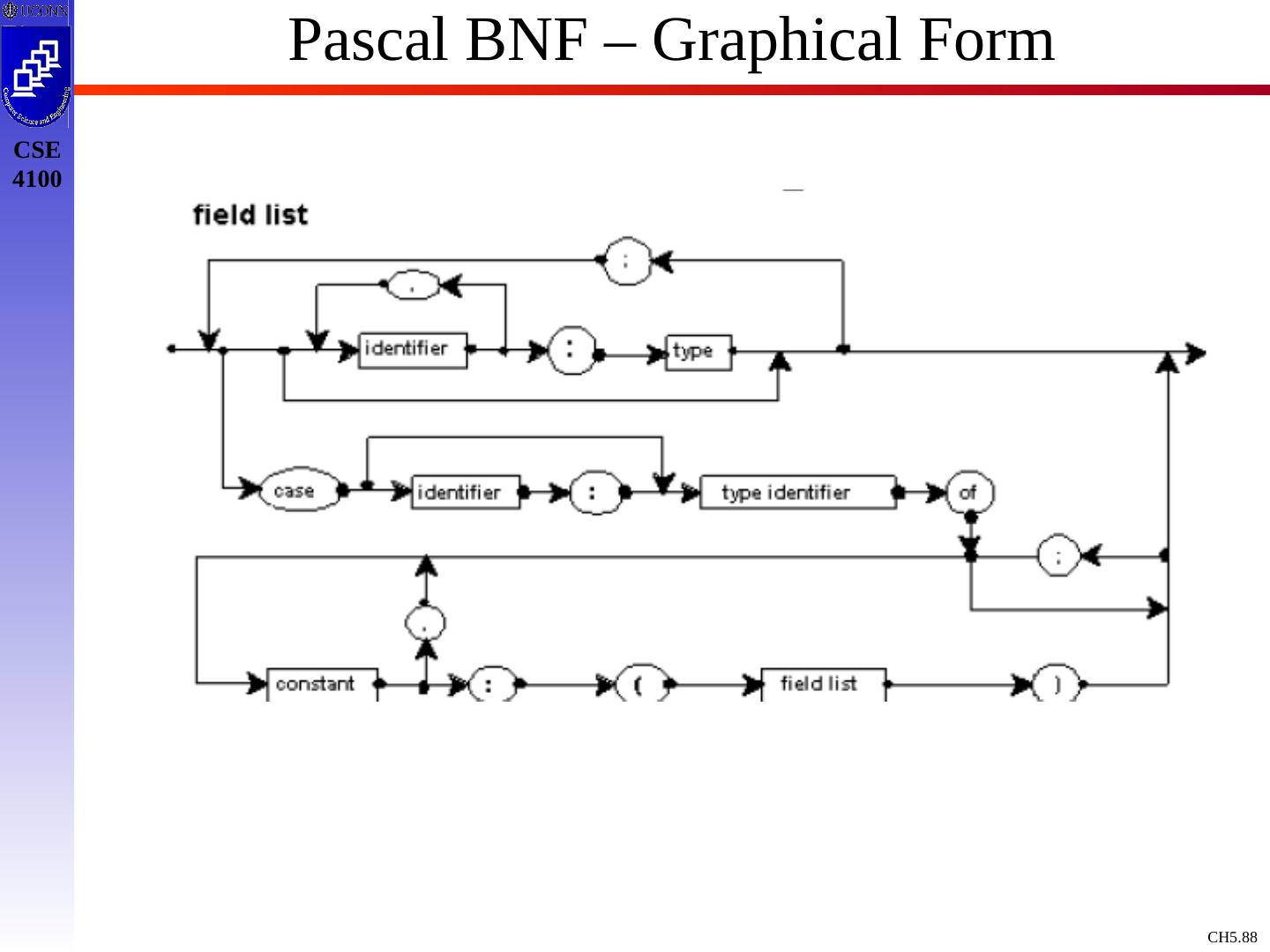
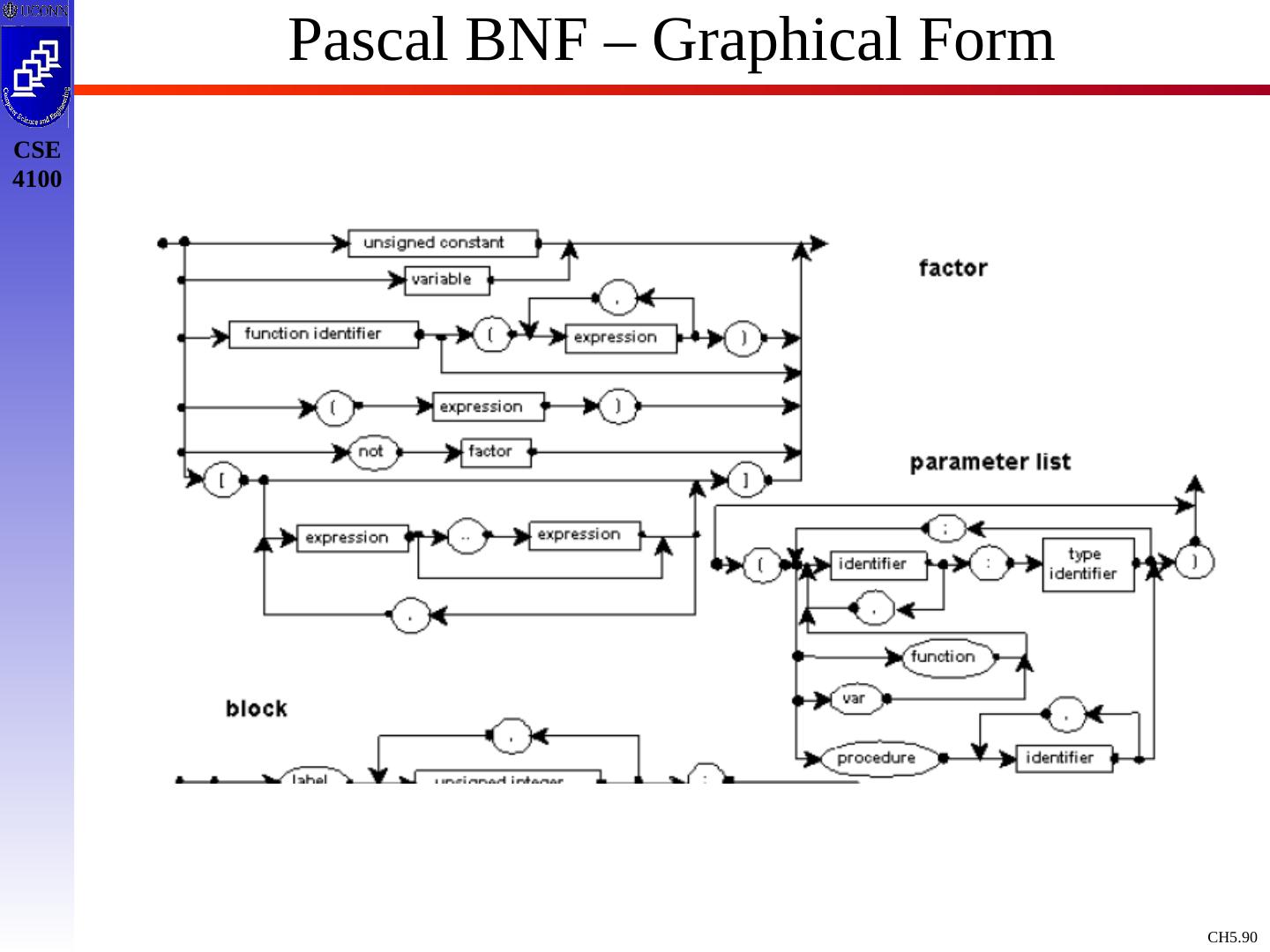
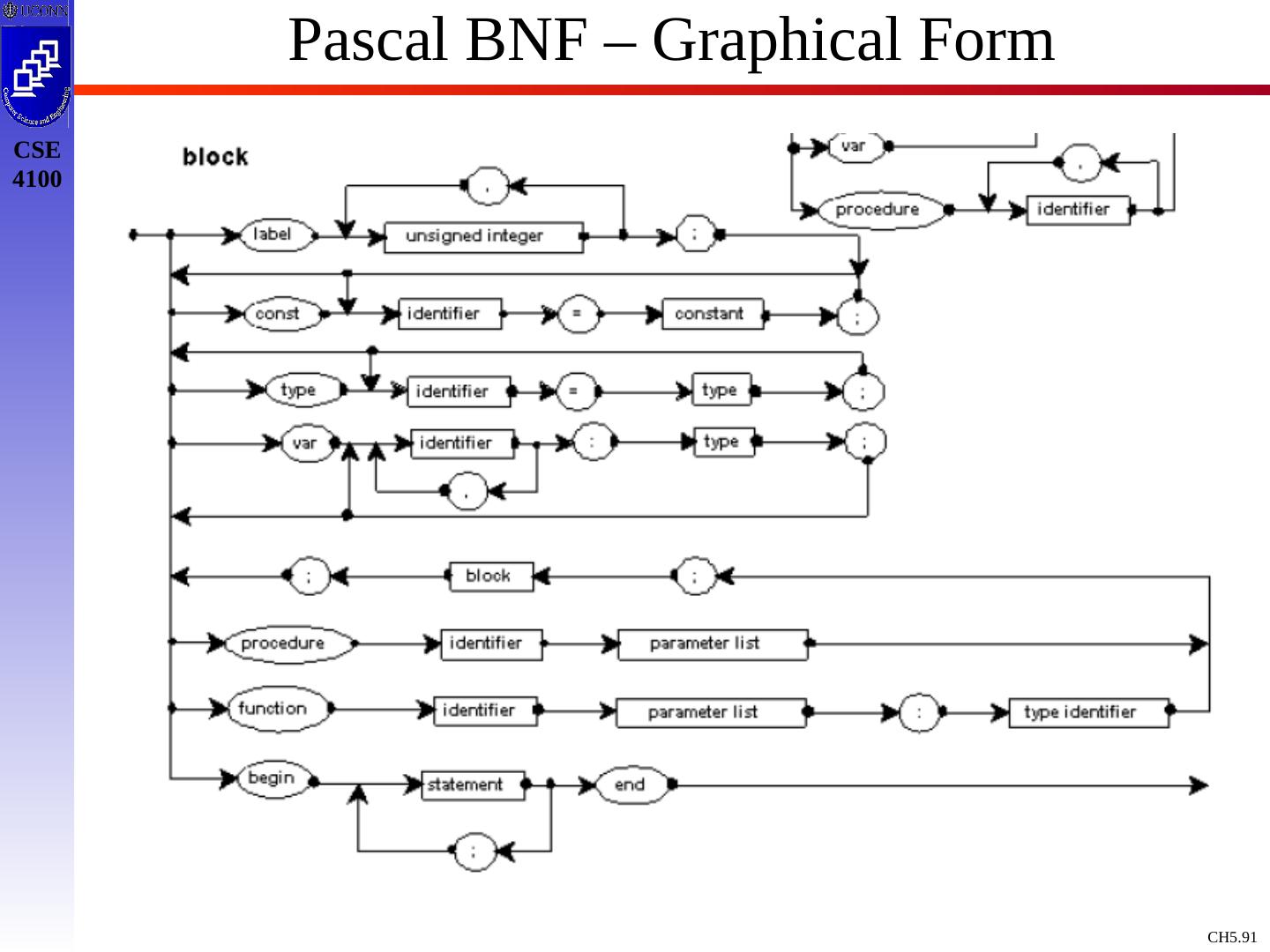
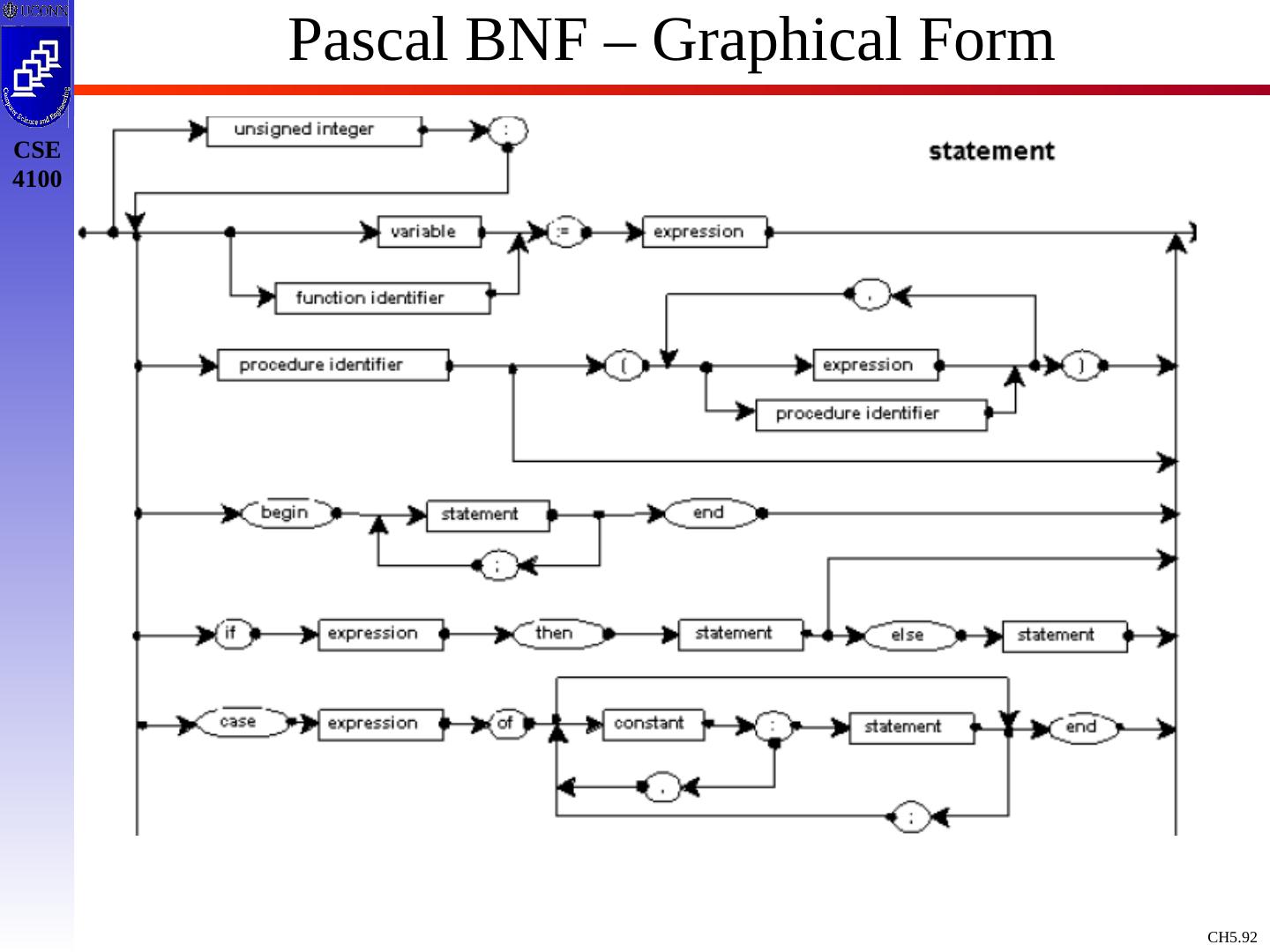
10 .Context Free Grammars : Concepts & Terminology Definition: A Context Free Grammar, CFG, is described by T, NT, S, PR, where: T : Terminals / tokens of the language NT : Non-terminals to denote sets of strings generatable by the grammar & in the language S : Start symbol, S NT, which defines all strings of the language PR : Production rules to indicate how T and NT are combines to generate valid strings of the language. PR: NT (T | NT)* Like a Regular Expression / DFA / NFA, a Context Free Grammar is a mathematical model !
11 .Context Free Grammars : A First Look assign_stmt id := expr ; expr term operator term term id term real term integer operator + operator - What do “ BLUE ” symbols represent? Derivation : A sequence of grammar rule applications and substitutions that transform a starting non-term into a collection of terminals / tokens. Simply stated: Grammars / production rules allow us to “rewrite” and “identify” correct syntax. What do “ BLACK ” symbols represent?
12 .How is Grammar Used ? Given the rules on the previous slide, suppose id := real + int; is input. Is it syntactically correct? How do we know? expr is represented as: expr term operator term Is this accurate / complete? expr expr operator term expr term How does this affect the derivations which are possible?
13 .Let’s Derive : id := id + real – integer ; Derivation Rule that is Used assign_stmt assign_stmt → id := expr ; id := expr ; expr → expr operator term id := expr operator term; expr → expr operator term id := expr operator term operator term; expr → term id := term operator term operator term; term → id id := id operator term operator term; operator → + id := id + term operator term; term → real id := id + real operator term; operator → - id := id + real - term; term → integer id := id + real - integer ; assign_stmt → id := expr ; Expr → expr operator term expr → term term → id term → real term → integer operator → + operator → -
14 .Example Grammar expr expr op expr expr ( expr ) expr - expr expr id op + op - op * op / op Black : NT Blue : T expr : S 9 Production rules To simplify / standardize notation, we offer a synopsis of terminology.
15 .Example Grammar - Terminology Terminals: a,b,c ,+,-,punc,0,1,…,9, blue strings Non Terminals: A,B,C,S, black strings T or NT: X,Y,Z Strings of Terminals: u,v ,…,z in T* Strings of T / NT: , in ( T NT)* Alternatives of production rules: A 1 ; A 2 ; …; A k ; A 1 | 2 | … | 1 First NT on LHS of 1 st production rule is designated as start symbol ! E E A E | ( E ) | - E | id A + | - | * | / |
16 .Grammar Concepts A step in a derivation is zero or one action that replaces a NT with the RHS of a production rule. EXAMPLE : E - E (the means “derives” in one step) using the production rule: E - E EXAMPLE : E E A E E * E E * ( E ) DEFINITION: derives in one step derives in one step derives in zero steps + * EXAMPLES: A if A is a production rule 1 2 … n 1 n ; for all If and then * * * *
17 .How does this relate to Languages? Let G be a CFG with start symbol S. Then S W (where W has no non-terminals) represents the language generated by G, denoted L(G). So WL(G) S W. + + W : is a sentence of G When S (and may have NTs) it is called a sentential form of G. * EXAMPLE: id * id is a sentence Here’s the derivation: E E A E E * E id * E id * id E id * id Sentential forms
18 . lm Leftmost and Rightmost Derivations Leftmost : Replace the leftmost non-terminal symbol E E A E id A E id * E id * id Rightmost : Replace the rightmost non-terminal symbol E E A E E A id E * id id * id rm lm lm lm lm rm rm rm Important Notes: A If A , what’s true about ? If A , what’s true about ? rm Derivations: Actions to parse input can be represented pictorially in a parse tree.
19 .Examples of LM Derivations E E A E | ( E ) | - E | id A + | - | * | / | A leftmost derivation of : id + id * id Another leftmost derivation of : id + id * id E E A E E A E A E id A E A E id +E A E id + id A E id + id * E id + id * id E E A E id A E id + E id + E A E id + id A E id + id * E id + id * id
20 .Examples of RM Derivations E E A E | ( E ) | - E | id A + | - | * | / | A rightmost derivation of : id + id * id Another rightmost derivation of : id + id * id E E A E E A E A E E A E A id E A E * id E A id * id E + id * id id + id * id E E A E E A id E * id E A E * id E A id * id E + id * id id + id * id
21 .Derivations & Parse Tree E E E A E E E A * E E E A id * E E E A id id * E * E E E A E id * E id * id
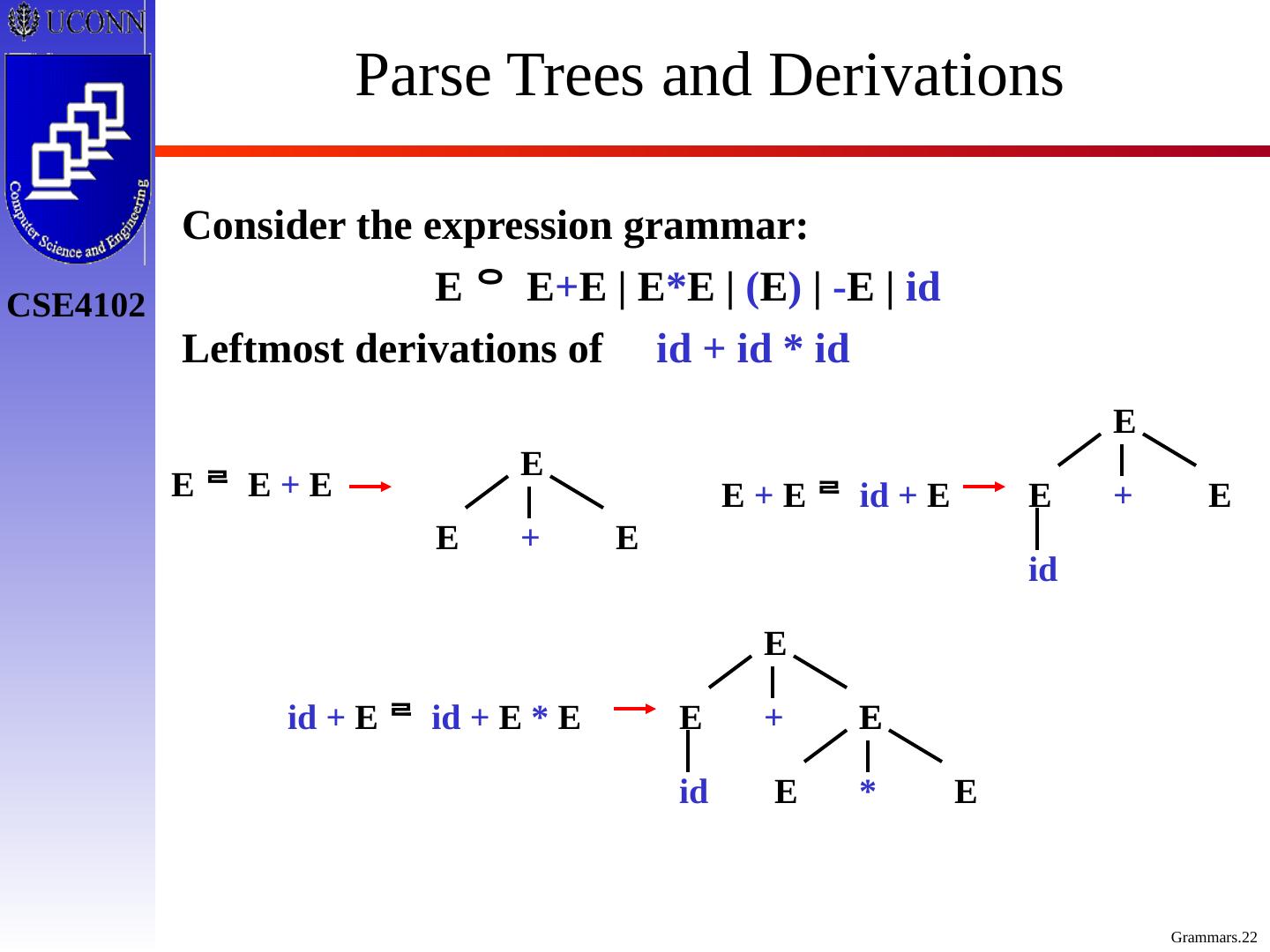
22 .Parse Trees and Derivations Consider the expression grammar: E E + E | E * E | ( E ) | - E | id Leftmost derivations of id + id * id E E + E E + E id + E E E E + id E E E * id + E id + E * E E E E + id E E E +
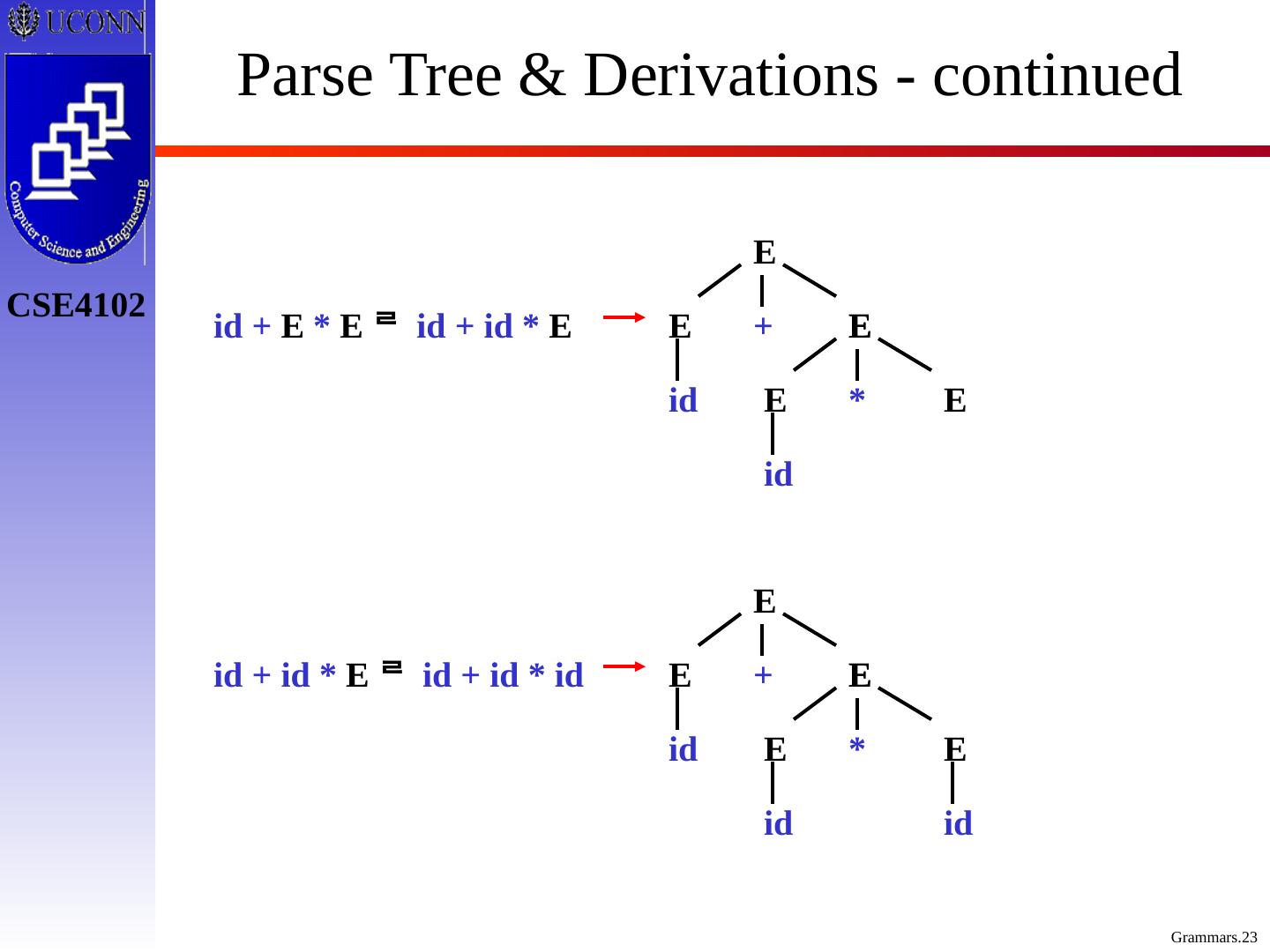
23 .Parse Tree & Derivations - continued E E E * id + E * E id + id * E E E E + id id id + id * E id + id * id E E E * E E E + id id id
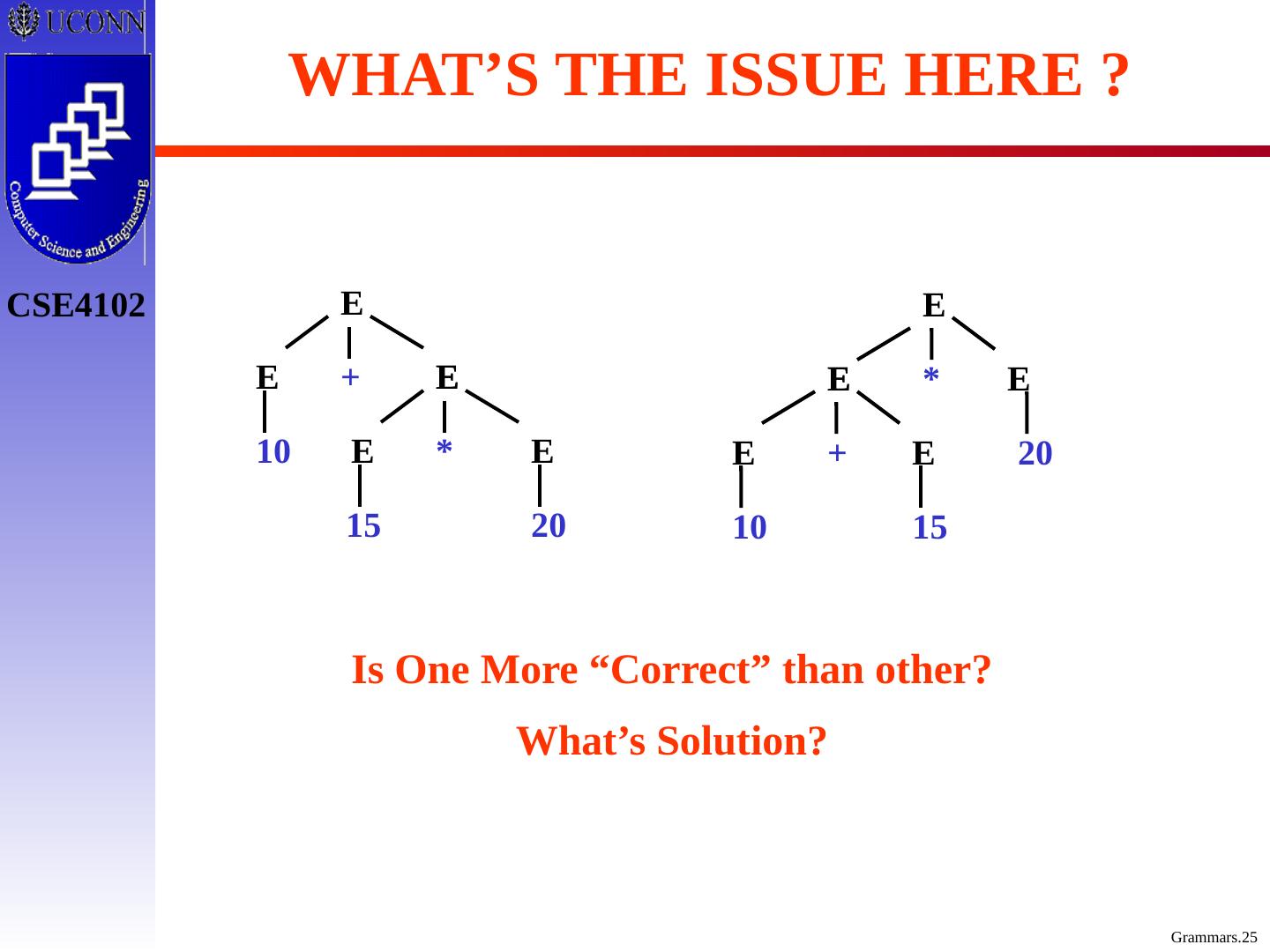
24 .Alternative Parse Tree & Derivation E E * E E + E * E id + E * E id + id * E id + id * id E E E + E E E * id id id WHAT’S THE ISSUE HERE ?
25 .WHAT’S THE ISSUE HERE ? E E E + E E E * 20 10 15 E E E * E E E + 10 20 15 Is One More “Correct” than other? What’s Solution?
26 .Writing and Designing Grammars Explore the Grammar Writing/Design Process Use Examples to Guide Multi-Step Process Understand Higher-Level Organization of Examples Identify “Word” (Tokens) Organize “Words” (Tokens) into “Sentences” Sentences Contain Terminals (Tokens) and Non-Terminals (Generalize the Sentence) This Defines CFG Rule(s) Multiple “Sentences” may be Related All Start with Same Non-Terminal Different Options for Each Grammar Must Cover all Language Features
27 .Consider Pascal Code Segment What is the High-Level Organization? program line variable declarations begin/end. block of sentences (statements) What are the Words/Tokens? program, var , string, text, ;, :, (*, *), begin, while, NOT, EOF, do, etc. What are Some Possible Sentences? assignment expression while do statement program readwritetofiles ; var readfilename : string; writefilename : string; myreadfile : text; mywritefile : text; c : char; gpa : integer; begin (* put files in c:\Dev-Pas directory *) readfilename :=letterGrades.txt; writefilename :=pointGrades.txt; assign( myreadfile , readfilename ); reset( myreadfile ); assign( mywritefile , writefilename ); rewrite( mywritefile ); while NOT EOF ( myreadfile ) do begin readln ( myreadfile , c); case (c) of A : gpa := 4; B : gpa := 3; C : gpa := 2; D : gpa := 1; F : gpa := 0; otherwise gpa := -1; end; (* case *) writeln ( mywritefile , gpa ); end; writeln ( mywritefile ,Completed writing); close( myreadfile ); close( mywritefile ); end.
28 .Sample Pascal Code program readwritetofiles ; var readfilename : string; writefilename : string; myreadfile : text; mywritefile : text; line : packed array [1..120] of char; i , j: integer; num_characters : integer; total_chars : integer; begin (* put files in c:\Dev-Pas directory *) readfilename :=inputfile.txt; writefilename :=outputfile.txt; assign( myreadfile , readfilename ); reset( myreadfile ); assign( mywritefile , writefilename ); rewrite( mywritefile ); total_chars :=0; while NOT EOF ( myreadfile ) do begin readln ( myreadfile , line); num_characters := 0; (* only chars - no blanks*) i:=1; (* i will be total chars+blanks per line*) while ( ord (line[ i ]) <> 0) do i:=i+1; writeln ( mywritefile , i ); for j:=1 to i do if ((line[j] <> ) and ( ord (line[j]) <> 0)) then begin num_characters := num_characters + 1; write( mywritefile , line[j]) end; total_chars := total_chars+num_characters ; writeln ( mywritefile , num_characters ); end; writeln ( mywritefile , total_chars ); writeln ( mywritefile ,Completed writing); close( myreadfile ); close( mywritefile ); end.
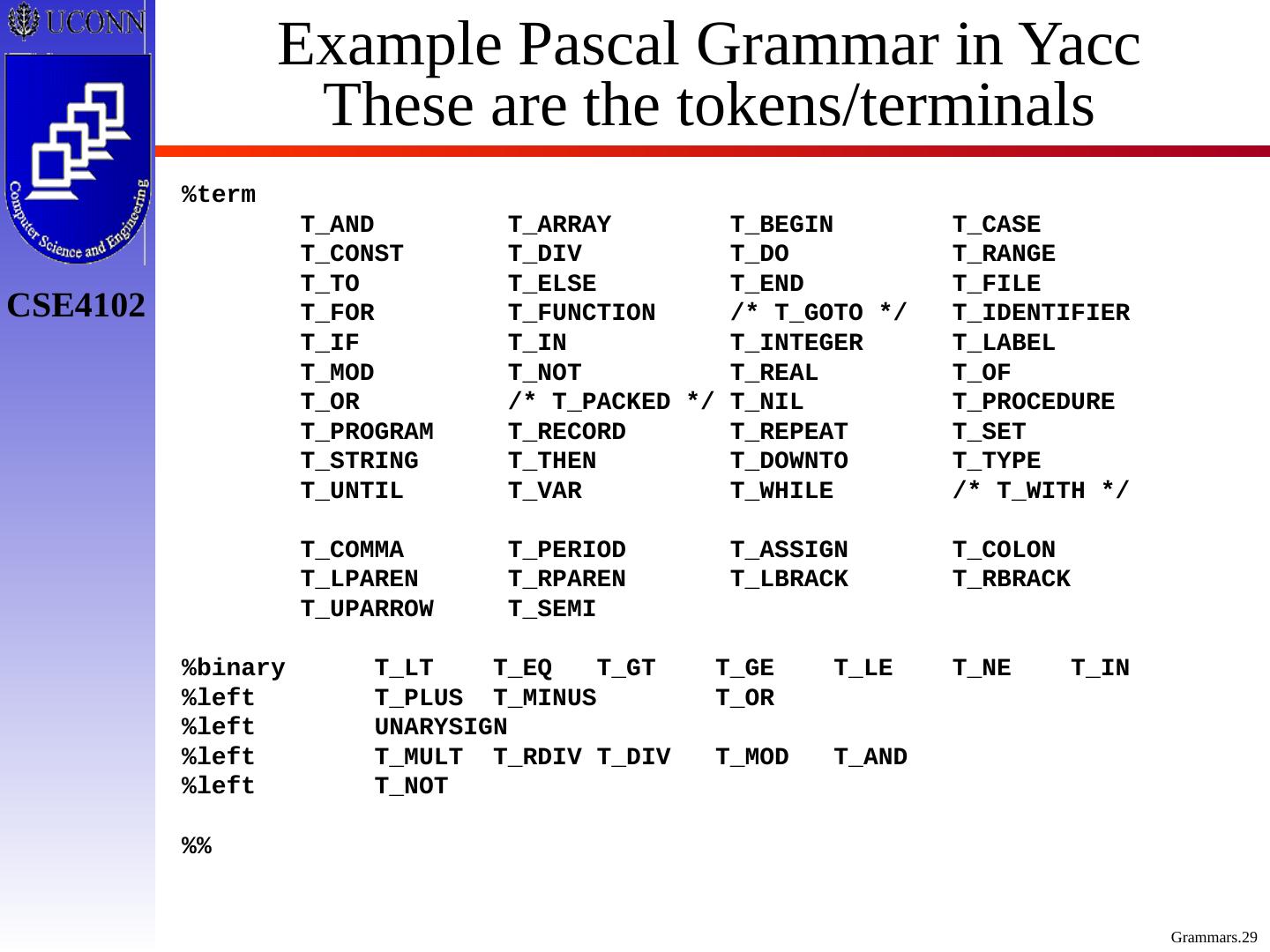
29 .Example Pascal Grammar in Yacc These are the tokens/terminals %term T_AND T_ARRAY T_BEGIN T_CASE T_CONST T_DIV T_DO T_RANGE T_TO T_ELSE T_END T_FILE T_FOR T_FUNCTION /* T_GOTO */ T_IDENTIFIER T_IF T_IN T_INTEGER T_LABEL T_MOD T_NOT T_REAL T_OF T_OR /* T_PACKED */ T_NIL T_PROCEDURE T_PROGRAM T_RECORD T_REPEAT T_SET T_STRING T_THEN T_DOWNTO T_TYPE T_UNTIL T_VAR T_WHILE /* T_WITH */ T_COMMA T_PERIOD T_ASSIGN T_COLON T_LPAREN T_RPAREN T_LBRACK T_RBRACK T_UPARROW T_SEMI % binary T_LT T_EQ T_GT T_GE T_LE T_NE T_IN % left T_PLUS T_MINUS T_OR % left UNARYSIGN % left T_MULT T_RDIV T_DIV T_MOD T_AND % left T_NOT %%
3秒后跳转登录页面
去登陆

