







































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
17computer and network security--Spectre Attacks and security
The course is mainly about Spectre Attacks and the
Future of Security.Generally covered Sought interesting projects,Business evolution,State machine for the security cycle,Addicted to speed,Memory caches,Speculative execution,Conditional branch attack,Conditional branch attack and so on.
展开查看详情
1 .Spectre Attacks and the Future of Security Paul Kocher (paul@paulkocher.com) Stanford CS155 May 29, 2018 If the surgery proves unnecessary, we’ll revert your architectural state at no charge. All trademarks are the property of their respective owners. This presentation is provided without any guarantee or warranty whatsoever.
2 .Intro Stanford undergrad (class of ‘95) Biology major, planning to become a veterinarian Hobby: cryptography & computers Sophomore low on money –> consulting project with Microsoft breaking CD-based SW distribution schemes Met Martin Hellman, attended Stanford Crypto Lunches, read papers, wrote code, worked at RSA in summers… Finished BS in biology (’95) Right place & time Prof. Martin Hellman retired -> referred interesting projects -> delayed vet school Founded Cryptography Research No business plan, no investors
3 .Sought interesting projects Projects (mostly with others): Protocols (incl. SSL v3.0 / TLS “ ”) Side channel attacks Timing attacks Differential power analysis & countermeasures Numerous HW/ASIC projects Pro-bono DES cracking machine (EFF funded) Pay TV (evaluation major design projects) Anti-counterfeiting Risk management architectures Revocation: Co-founded ValiCert (IPO 2001, acquired 2003) Renewability/Forensics: Blu-ray BD+ , Vidity /SCSA… CryptoManager solutions (ASIC, manufacturing, service) Spectre Attacks Advisor/investor to start-ups Devices timing, power, RF vary depending on computation Variations correlate to crypto intermediates break crypto “Obvious in hindsight” but cryptographers != implementers Filed patents on countermeasures (billions of chips impacted) Retained by Taher ElGamal @ Netscape Design philosophy: Simplicity, upgradability Today: most widely-used crypto protocol
4 .Business evolution Complementary leadership team skills: Lots of Stanford talent, including: Ben Jun (Stanford ’96) technical execution Kit Rodgers (Stanford ’96) sales, marketing, business, … 20 years of reinvestment + evolution Consulting Licensing Products Solutions 1995 -> 2015: industry scaling Rambus acquisition in 2011 ($342.5M)
5 .
6 .State machine for the security cycle Secure State Vulnerability reported New release fixes issue (+ adds 2 more) Insecure State No reported problems Developer = Product advertised as secure Customers = Lots of bugs to exploit Attacker = Frantically developing a fix Developer = Vulnerability in the press Customers = Victim acts very cautiously Attacker =
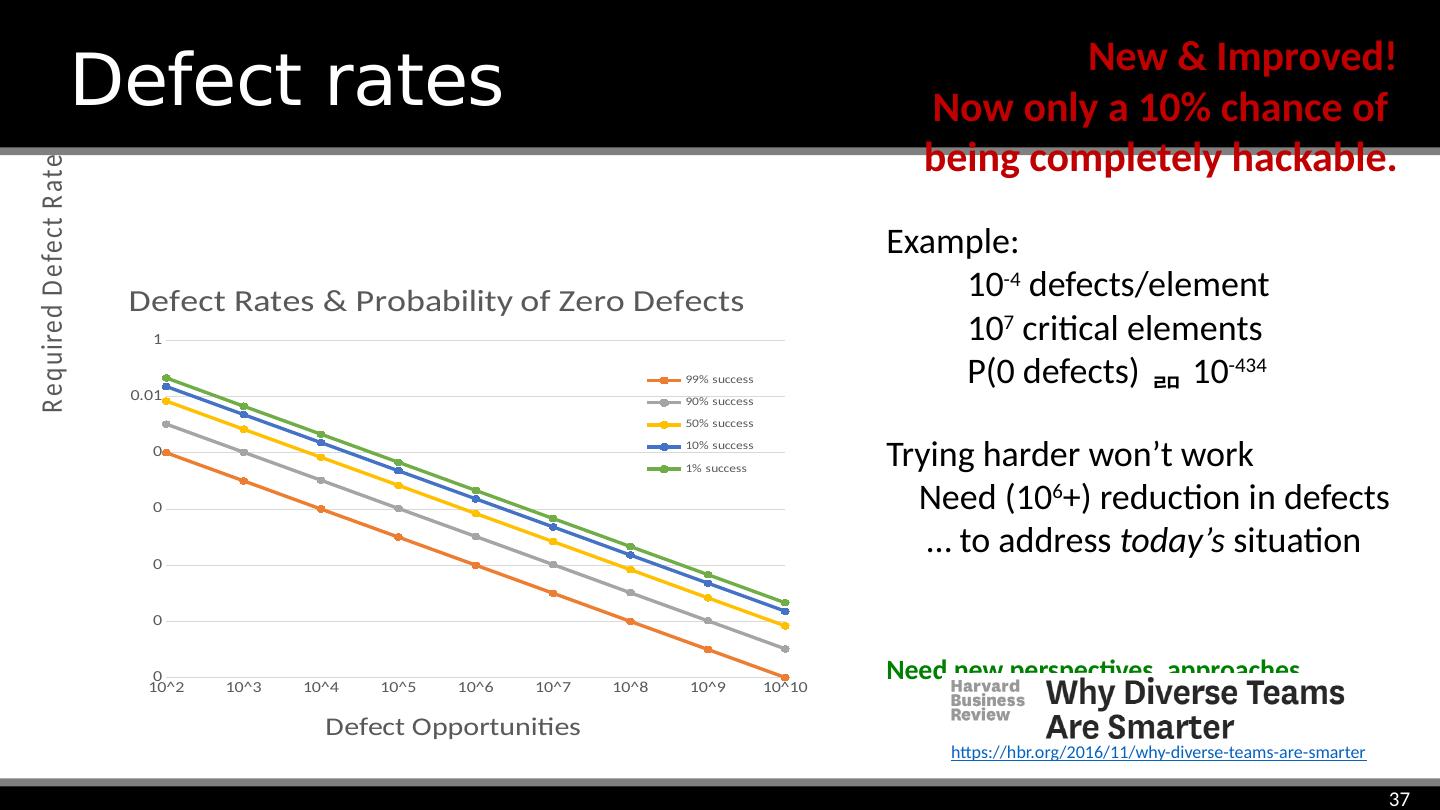
7 .??! Why panic when a big vulnerability is identified? Optimist’s security = P(secure) but ϵ was usually negligible fell from 100% to 0% Image from https://pixabay.com/en/panic-button-panic-button-emergency-1375952/ (Creative Commons CC0 free for commercial use no attribution required) P(secure) fell from ϵ to 0.
8 .??! Why panic when a big vulnerability is identified? Optimist’s security = P(secure) but ϵ was usually negligible fell from 100% to 0% Image from https://pixabay.com/en/panic-button-panic-button-emergency-1375952/ (Creative Commons CC0 free for commercial use no attribution required) P(secure) fell from ϵ to 0.
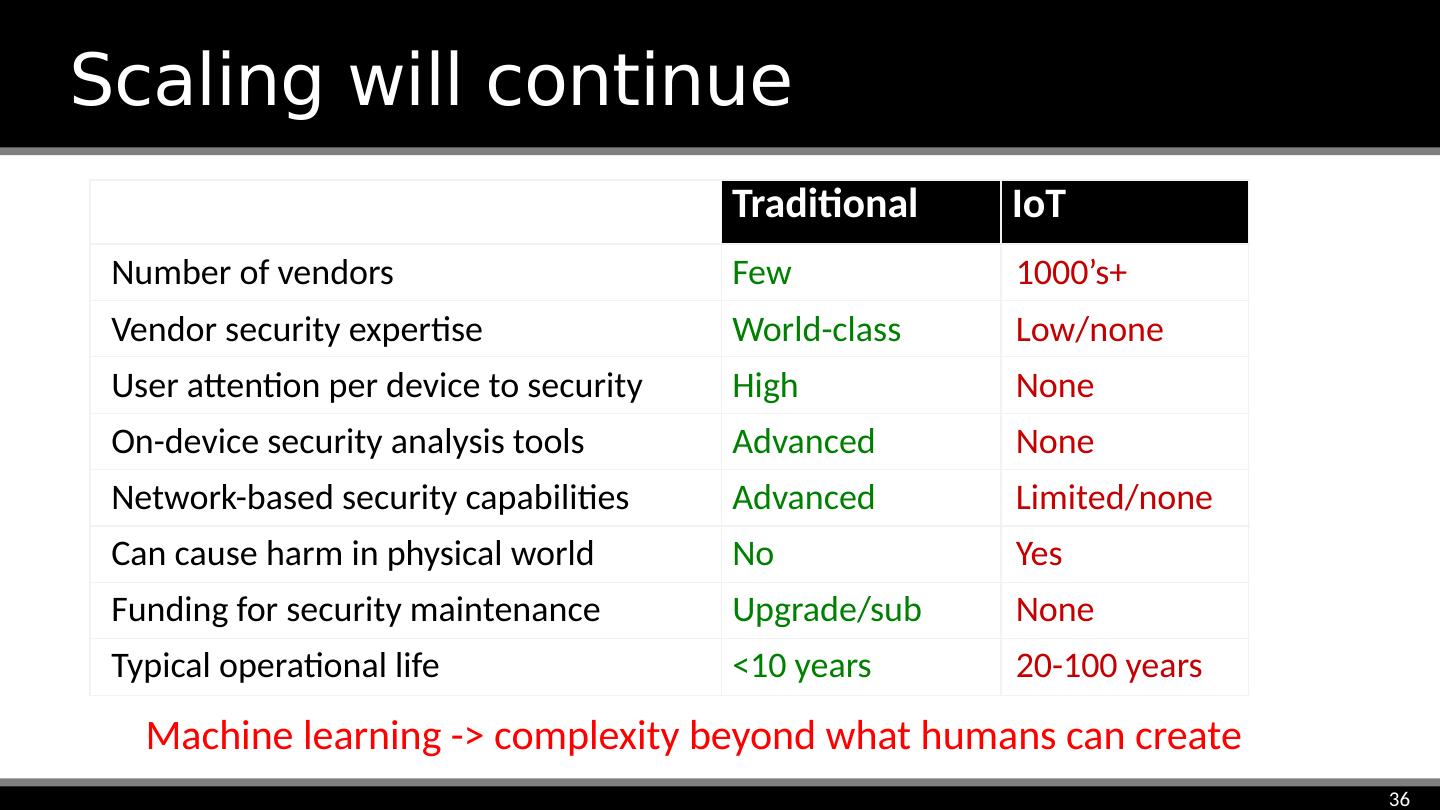
9 .30M 25M 20M 15M 10M 5M 0 $600B $500B $400B $300B $200B $100B $0 30B 25B 20B 15B 10B 0.5B 0 Attacker perspective: Lines of Code in Linux Connected Devices E-commerce in the US Complexity Bugs Devices Targets Economic activity $
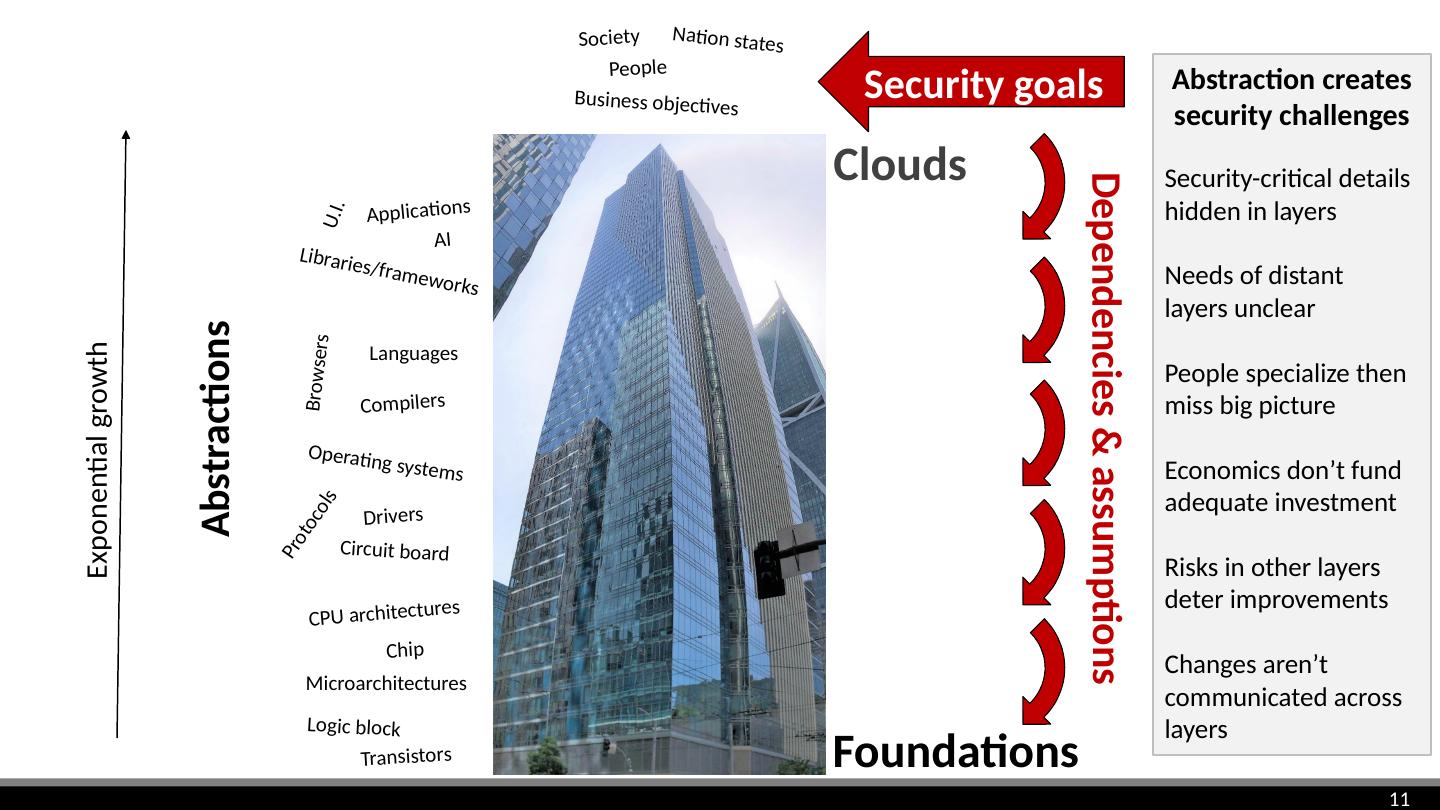
10 .abstraction is a technique for hiding complexity of computer systems. It works by establishing a level of simplicity on which a person interacts with the system, suppressing the more complex details below the current level. https://en.wikipedia.org/wiki/Abstraction_(computer_science)
11 .Abstraction creates security challenges Dependencies & assumptions Security goals Security-critical details hidden in layers Needs of distant layers unclear People specialize then miss big picture Economics don’t fund adequate investment Risks in other layers deter improvements Changes aren’t communicated across layers Exponential growth Microarchitectures Clouds CPU architectures Foundations People Business objectives Society Nation states Logic block Abstractions Operating systems Languages Compilers Protocols Libraries/frameworks Applications Browsers Chip Circuit board Drivers U.I. Transistors AI
12 .Microarchitectures CPU Architecture Machine language Specification (Contract btw CPU & SW) Are there any security implications from speculative execution? -- Mike Hamburg Software Compiler Higher- level lang. Speculative execution
13 .Performance drives CPU purchases Single-thread speed gains require getting more done per clock cycle Memory latency is slow and not improving much Clock rates are maxed out: Pentium 4 reached 3.8 GHz in 2004 How to do more per clock? Reducing memory delays C aches Working during delays Speculative execution Addicted to speed Public domain image of Pentium 4 die by Ritzchens Fritz
14 .Caches hold local (fast) copy of recently-accessed 64-byte chunks of memory Memory caches MAIN MEMORY Big, slow e.g. 16GB SDRAM Set Addr Cached Data ~64B 0 F0016280 31C6F4C0 339DD740 614F8480 B5 F5 80 21 E3 2C.. 9A DA 59 11 48 F2.. C7 D7 A0 86 67 18.. 17 4C 59 B8 58 A7.. 1 71685100 132A4880 2A1C0700 C017E9C0 27 BD 5D 2E 84 29.. 30 B2 8F 27 05 9C.. 9E C3 DA EE B7 D9.. D1 76 16 54 51 5B.. 2 311956C0 002D47C0 91507E80 55194040 0A 55 47 82 86 4E.. C4 15 4D 78 B5 C4.. 60 D0 2C DD 78 14.. DF 66 E9 D0 11 43.. 3 9B27F8C0 8E771100 A001FB40 317178C0 84 A0 7F C7 4E BC.. 3B 0B 20 0C DB 58.. 29 D9 F5 6A 72 50.. 35 82 CB 91 78 8B.. 4 6618E980 BA0CDB40 89E92C00 090F9C40 35 11 4A E0 2E F1.. B0 FC 5A 20 D0 7F.. 1C 50 A4 F8 EB 6F.. BB 71 ED 16 07 1F.. Addr : 2A1C0700 Data: 9E C3 DA EE B7 D3.. Addr : 132E1340 Address: 132E1340 Data: AC 99 17 8F 44 09.. Addr : 132E1340 Data: AC 99 17 8F 44 09.. Fast Slow Fast h( addr ) to map to cache set 132E1340 Evict to make room AC 99 17 8F 44 09.. MEMORY CACHE 2A1C0700 Data: AC 99 17 8F 44 09.. CPU Sends address, Receives data Reads change system state: Next read to newly-cached location is faster Next read to evicted location is slower
15 .Correct result of running instructions = the result of performing instructions in-order CPUs may run instructions out-of-order if this doesn’t affect result Example: Speculative execution a constant b slow_to_obtain c f(a) // start before b finishes if (uncached_value_usually_1 == 1) compute_something () CPUs can also guess likely program path and do speculative execution Example: Branch predictor guesses that if() will be ‘true’ (based on prior history) Starts executing compute_something () speculatively -- but doesn’t save changes When value arrives from memory, if() can be evaluated definitively -- check if guess was correct: Correct: Save speculative work – performance gain Incorrect: Discard speculative work
16 .Speculative Execution CPU regularly performs incorrect calculations, then deletes mistakes Architectural Guarantee Register values eventually match result of in-order execution Set up the conditions so the processor will make a desired mistake Mistake leaks sensitive data into a covert channel (e.g. state of the cache) Fetch the sensitive data from the covert channel Software security assumes the CPU runs instructions correctly… Does making + discarding mistakes violate this assumption?
17 .Conditional branch (Variant 1) attack if (x < array1_size) y = array2[array1[x]*4096]; Assume code in kernel API, where unsigned int x comes from untrusted caller Execution without speculation is safe CPU will not evaluate array2[array1[x]*4096] unless x < array1_size What about with speculative execution?
18 .Conditional branch (Variant 1) attack Before attack: Train branch predictor to expect if() is true (e.g. call with x < array1_size ) Evict array1_size and array2[] from cache if (x < array1_size) y = array2[array1[x]*4096]; Contents don’t matter Memory & Cache Status array1_size = 00000008 Memory at array1 base address: 8 bytes of data (value doesn’t matter) [… lots of memory up to array1 base+N …] 09 F1 98 CC 90... ( something secret) array2[ 0*4096] array2[ 1*4096] array2[ 2*4096] array2[ 3*4096] array2[ 4*4096] array2[ 5*4096] array2[ 6*4096] array2[ 7*4096] array2[ 8*4096] array2[ 9*4096] array2[10*4096] array2[11*4096] Uncached Cached only care about cache status
19 .Conditional branch (Variant 1) attack Attacker calls victim with x =N (where N > 8) Speculative exec while waiting for array1_size Predict that if() is true Read address ( array1 base + x ) w/ out-of-bounds x Read returns secret byte = 09 (fast – in cache) if (x < array1_size) y = array2[array1[x]*4096]; Memory & Cache Status array1_size = 00000008 Memory at array1 base address: 8 bytes of data (value doesn’t matter) [… lots of memory up to array1 base+N …] 09 F1 98 CC 90... ( something secret) array2[ 0*4096] array2[ 1*4096] array2[ 2*4096] array2[ 3*4096] array2[ 4*4096] array2[ 5*4096] array2[ 6*4096] array2[ 7*4096] array2[ 8*4096] array2[ 9*4096] array2[10*4096] array2[11*4096] Uncached Cached Contents don’t matter only care about cache status
20 .Conditional branch (Variant 1) attack Attacker calls victim with x =N (where N > 8) Speculative exec while waiting for array1_size Predict that if() is true Read address ( array1 base + x ) w/ out-of-bounds x Read returns secret byte = 09 (fast – in cache) Request memory at ( array2 base + 09 *4096) Brings array2[ 09 *4096] into the cache Realize if() is false: discard speculative work Finish operation & return to caller Attacker measures read time for array2[ i * 4096 ] Read for i = 09 is fast (cached), revealing secret byte Repeat with many x ( eg ~10KB/s) if (x < array1_size) y = array2[array1[x]*4096]; Memory & Cache Status array1_size = 00000008 Memory at array1 base address: 8 bytes of data (value doesn’t matter) [… lots of memory up to array1 base+N …] 09 F1 98 CC 90... ( something secret) array2[ 0*4096] array2[ 1*4096] array2[ 2*4096] array2[ 3*4096] array2[ 4*4096] array2[ 5*4096] array2[ 6*4096] array2[ 7*4096] array2[ 8*4096] array2[ 9*4096] array2[10*4096] array2[11*4096] Uncached Cached Contents don’t matter only care about cache status
21 .Violating JavaScript’s sandbox index will be in-bounds on training passes, and out-of-bounds on attack passes JIT thinks this check ensures index < length , so it omits bounds check in next line. Separate code evicts length for attack passes Do the out-of-bounds read on attack passes! Keeps the JIT from adding unwanted bounds checks on the next line Leak out-of-bounds read result into cache state! Need to use the result so the operations aren’t optimized away “|0” is a JS optimizer trick (makes result an integer) if (index < simpleByteArray.length ) { index = simpleByteArray [index | 0]; index = (((index * TABLE1_STRIDE)|0) & (TABLE1_BYTES-1))|0; localJunk ^= probeTable [index|0]|0; } 4096 bytes = memory page size Browsers run JavaScript from untrusted websites JIT compiler inserts safety checks, including bounds checks on array accesses Speculative execution can blast through safety checks… Can evict length/ probeTable from JavaScript (easy), timing tricks to detect newly-cached location in probeTable
22 .Conditional branches: 2 destinations (fork in the road) Indirect branches: Can go anywhere (“ jmp [ rax ]”) If destination is delayed, CPU guesses and proceeds speculatively Find an indirect jmp with attacker controlled register(s) … then cause mispredict to a ‘gadget’ that leaks memory at address in register Attack steps Mistrain branch prediction/BTB so speculative execution will go to gadget Evict or flush destination address from the cache to ensure long duration speculative execution Execute victim so it runs gadget speculatively Detect change in cache state to determine memory data Repeat for more bytes Indirect branches Is x < y no yes Jump to address x
23 .Mitigation. noun. “The action of reducing the severity, seriousness, or painfulness of something” Not necessarily a complete solution Mitigations Public domain image by Svetlana Miljkovic Definition from https://en.oxforddictionaries.com/definition/mitigation
24 .LFENCE CPU Variant 1 Mitigation: Speculation-barrier instruction (e.g. LFENCE ) Idea: Software developers insert barrier on all vulnerable code paths in software Efficient: No performance impact on benchmarks or other legacy software Simple & effective App image: CC0 Creative Commons, Free for commercial use , No attribution required https://pixabay.com/en/app-software-contour-settings-1013616/ Abstraction boundaries Insert LFENCEs manually? Often millions of control flow paths Too confusing - speculation runs 188++ instructions, crosses modules Too risky – miss one and attacker can read entire process memory Put LFENCES everywhere? Abysmal performance - LFENCE is very slow (+ no tools) Not in binary libraries, compiler-created code patterns Insert by smart compiler? Transfers blame after breach (CPU -> SW) “you should have put an LFENCE there” -> “Fixed” Software operating systems drivers web servers interpreters/JITs databases : CPU architecture Machine language Compiler Higher-level language Protect all potentially-exploitable patterns = too slow Compilers judged by performance, not security Protect only known-bad bad patterns = unsafe Microsoft Visual C/C++ / Qspectre unsafe for 13 of 15 tests https://www.paulkocher.com/doc/MicrosoftCompilerSpectreMitigation.html (for CPU developer) ?
25 .Intel/AMD (x86): New MSRs created via microcode Low-level control over branch target buffer (O/S only) Performance impact – limited use Retpoline proposal from Google Messy hack -- replace indirect jumps with construction that resists indirect branch poisoning on Haswell Microcode updates to make retpoline safe on Skylake & beyond ARM: No generic mitigation option Fast ARM CPUs broadly impacted, e.g. Cortex-A9, A15, A17, A57, A72, A73, A75... Often no mitigation, but on some chips software may be able to invalidate/disable branch predictor (with “non-trivial performance impact”) See: https://developer.arm.com/support/security-update/download-the-whitepaper Mitigations: Indirect branch variant Mitigations are messy (for all Spectre variants + Meltdown) Software must deal with microarchitectural complexity Mitigations for all variants are really hard to test “All of this is pure garbage” -- Linus Torvolds https://lkml.org/lkml/2018/1/21/192
26 .DOOM with only MOV instructions Public domain image by Svetlana Miljkovic https://github.com/xoreaxeaxeax/movfuscator/tree/master/validation/doom Only MOV instructions No branch instructions One big loop with exception at the end to trigger restart Sub-optimal performance One frame every ~7 hours Oops! Variant 4: Speculative store bypass
27 .Reaction Face image: Creative Commons Attribution 4.0 International license, user: Twitter, https://commons.wikimedia.org/wiki/File:Twemoji2_1f615.svg ‘Optimist’s security’ fell from 100% to 0% “AMD is not susceptible to all three variants. […] there is a near zero risk to AMD processors at this time.”
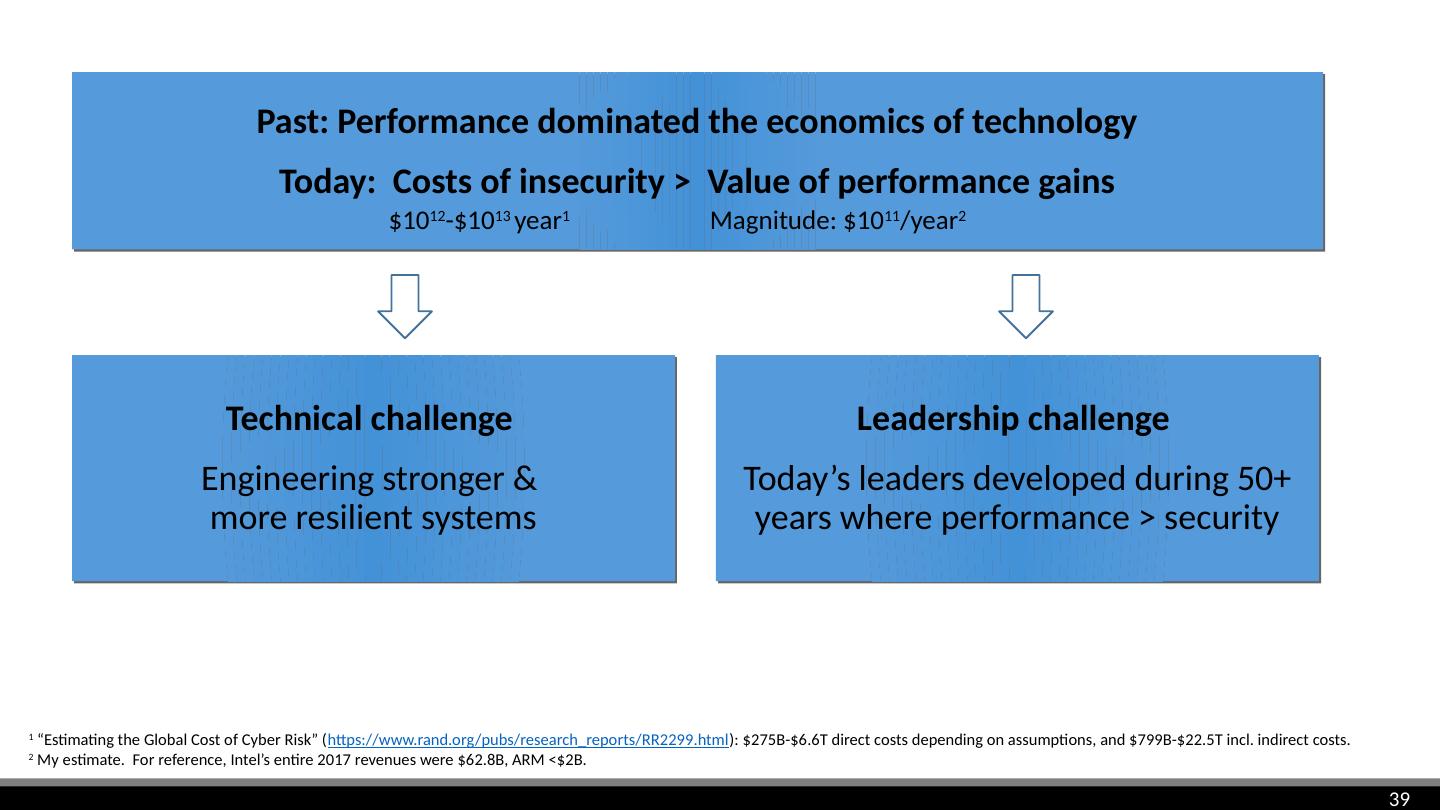
28 .Risk in context Spectre doesn’t change the magnitude of the risk, but adds to the mess Highlights risks in layers with limited mitigation tools Complexity of fixes -> new risks Psychology of unfixed vulnerabilities Because of software bugs, computer security was in a dire situation
29 .Is Spectre a bug? Everything complies with the architecture specs and CPU design textbooks Branch predictor is learning from history, as expected Speculative execution unwinds architectural state correctly Reads are fetching data the victim is allowed to read (unlike Meltdown) Caches are allowed to hold state Covert channels known to exist (+ very hard to eliminate) ?! Architecture Software security gap CPU architecture guarantees are insufficient for security Under-specified -> software & HW developers make different assumptions Computation time, debug counters, timing effects on other threads, analog effects (power, RF, heat…), errors/glitches ( RowHammer , clkscrew …) No way to know if code is secure on today’s chips Future chips may be completely different
3秒后跳转登录页面
去登陆

