展开查看详情
1 .Data Structures and Algorithms in Parallel Computing Lecture 6
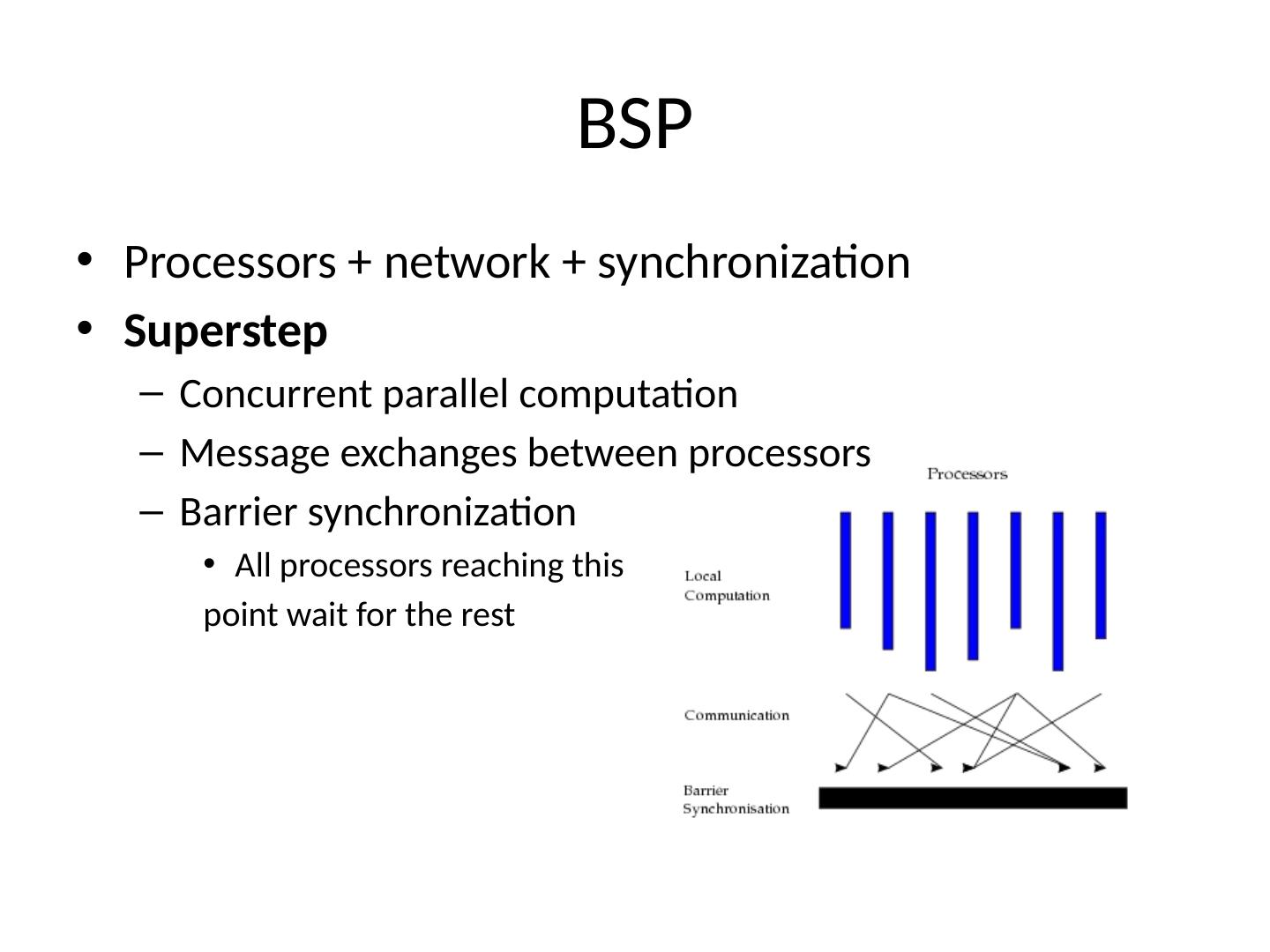
2 .BSP Processors + network + synchronization Superstep Concurrent parallel computation Message exchanges between processors Barrier synchronization All processors reaching this point wait for the rest
3 .Supersteps A BSP algorithm is a sequence of supersteps Computation superstep Many small steps Example: floating point operations (addition, subtraction, etc.) Communication superstep Communication operations each transmitting a data word Example: transfer a real number between 2 processors In theory we distinguish between the 2 types of supersteps In practice we assume a single superstep
4 .Vertex centric model Simple distributed programming model Algorithms are expressed by “ thinking like a vertex ” A vertex contains information about itself and the outgoing edges Computation is expressed at vertex level Vertex execution take place in parallel and are interleaved with synchronized message exchanges
5 .Disadvantages Costly messaging due to vertex logic Porting shared memory algorithms to vertex centric ones may not be trivial Decoupled programming logic from data layout on disk IO penalties
6 .Thinking like a graph Subgraph centric abstraction Express computation at subgraph instead of vertex level Information flows freely inside the subgraph Messages are sent only across subgraphs
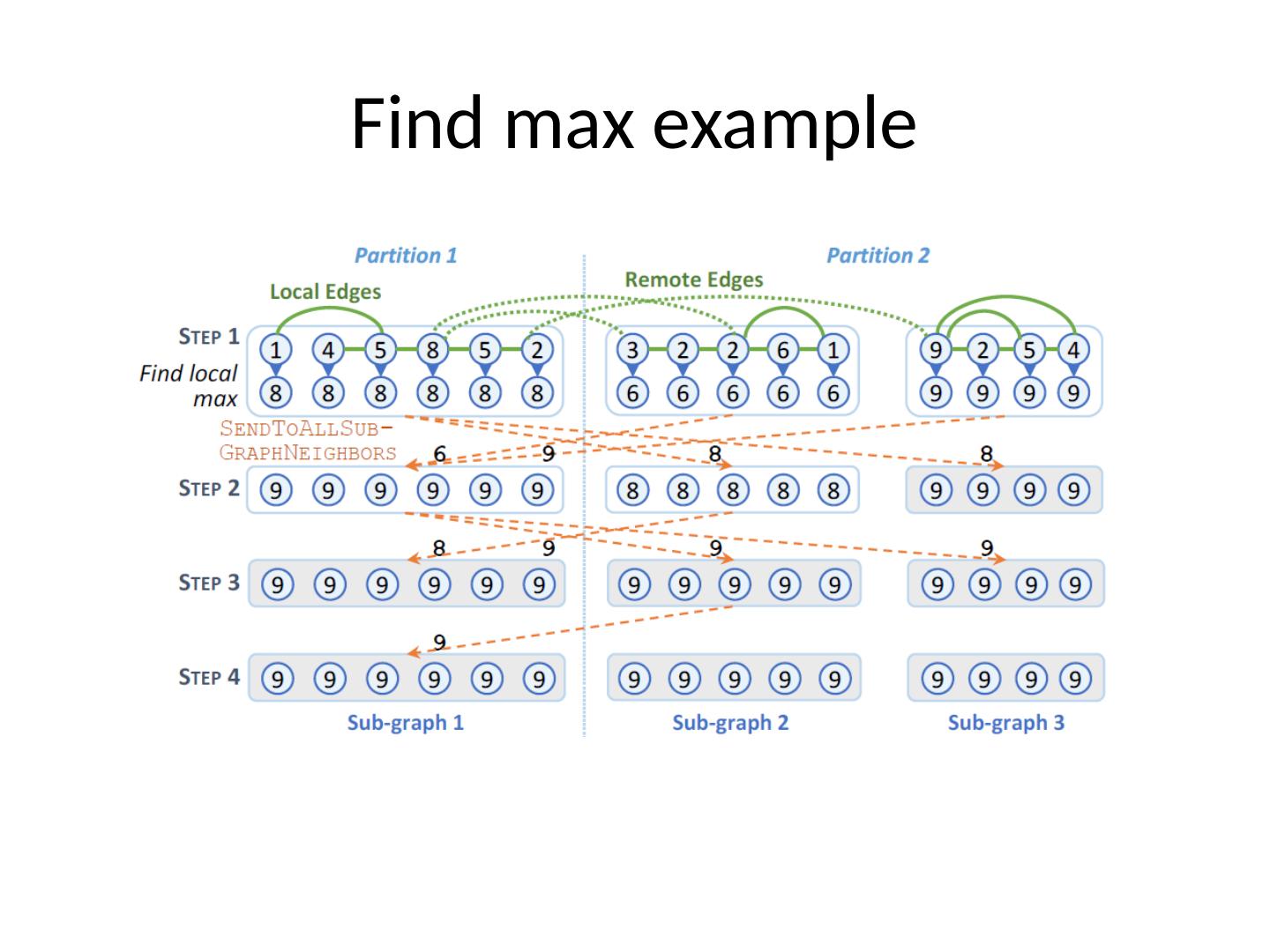
7 .Subgraph centric model Graph is k-partitioned Subgraph is a connected component or a weakly connected component for directed graphs Two subgraphs do not share vertices A partition can store one or more subgraphs Partitions are distributed Subgraph is a meta-vertex Remote edges connect them together Each subgraph is an independent unit of computation
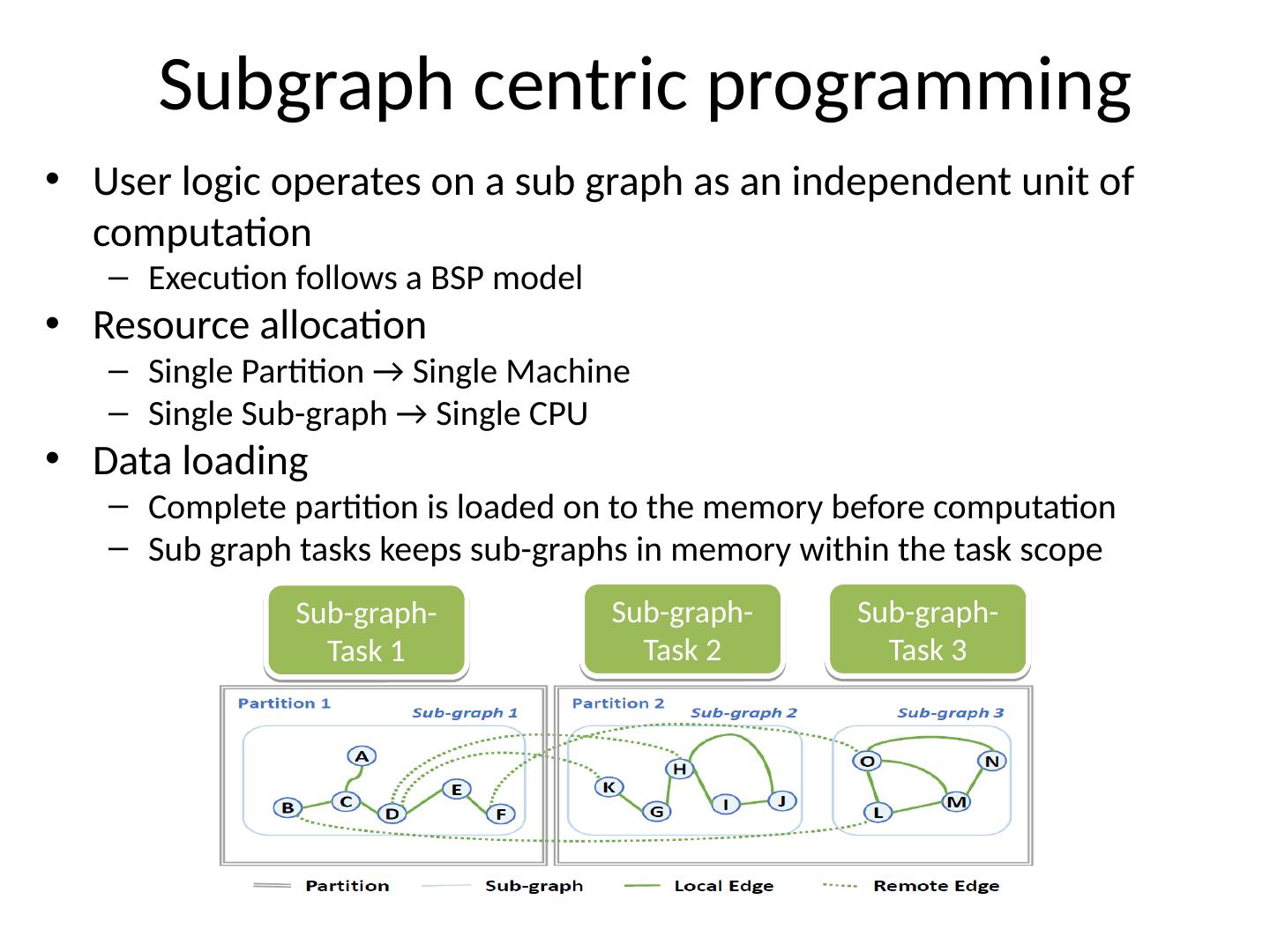
8 .User logic operates on a sub graph as an independent unit of computation Execution follows a BSP model Resource allocation Single Partition → Single Machine Single Sub-graph → Single CPU Data loading Complete partition is loaded on to the memory before computation Sub graph tasks keeps sub-graphs in memory within the task scope Subgraph centric programming Sub-graph-Task 1 Sub-graph-Task 2 Sub-graph-Task 3 8
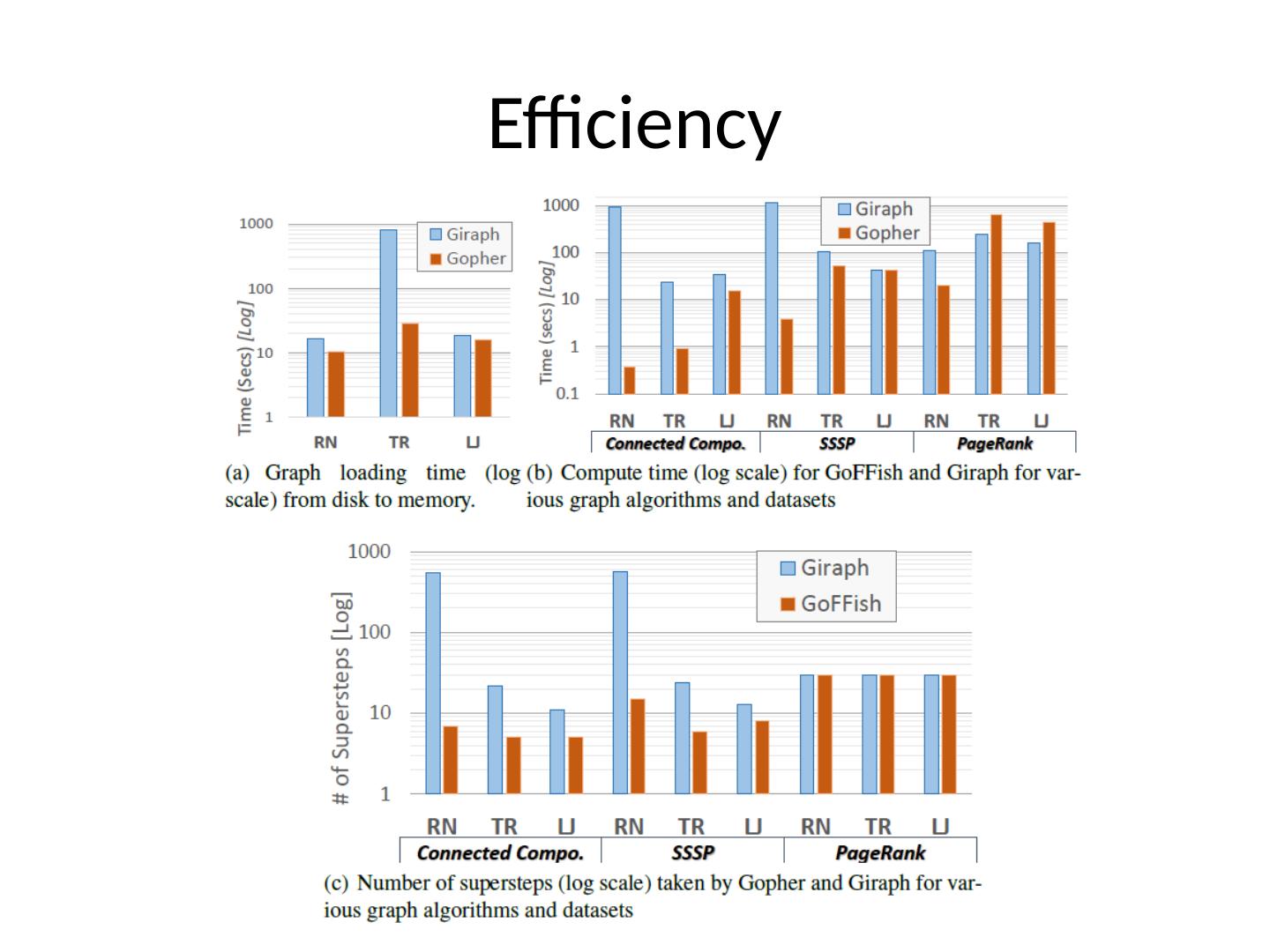
9 .Advantages Messages exchanged Direct access to entire subgraph Messages sent only across partitions Subgraphs are disconnected Pregel has aggregators but they operate after messages are sent Number of supersteps Depending on algorithm the required supersteps can be reduced Limited synchronization overhead Reduces the skew in execution due to unbalanced partitions Reuse of single-machine algorithms Direct reuse of shared memory graph algorithms
10 .GoFFish https:// github.com/usc-cloud/goffish Subgraph programming abstraction Gopher Flexibility of reusing well-known shared memory graph abstractions Leverages subgraph concurrency within a multicore machine and distributed scaling using BSP Efficient distributed storage GoFS Write once read many approach Method naming similar to that of Pregel
13 .Subgraph centric SSSP
14 .Pagerank case study Same number of supersteps to converge as the vertex centric approach Alternative is to use blockrank Assumes some websites to be highly interconnected Like subgraphs Calculates pagerank for vertices by treating blocks (subgraphs) independently (1 SS) Ranks each block based on its relative importance (1 SS) Normalizes the vertex pagerank with the block rank to use as initial value before running the classic pagerank (n SS) Costlier first superstep but faster convergence in the last n supersteps
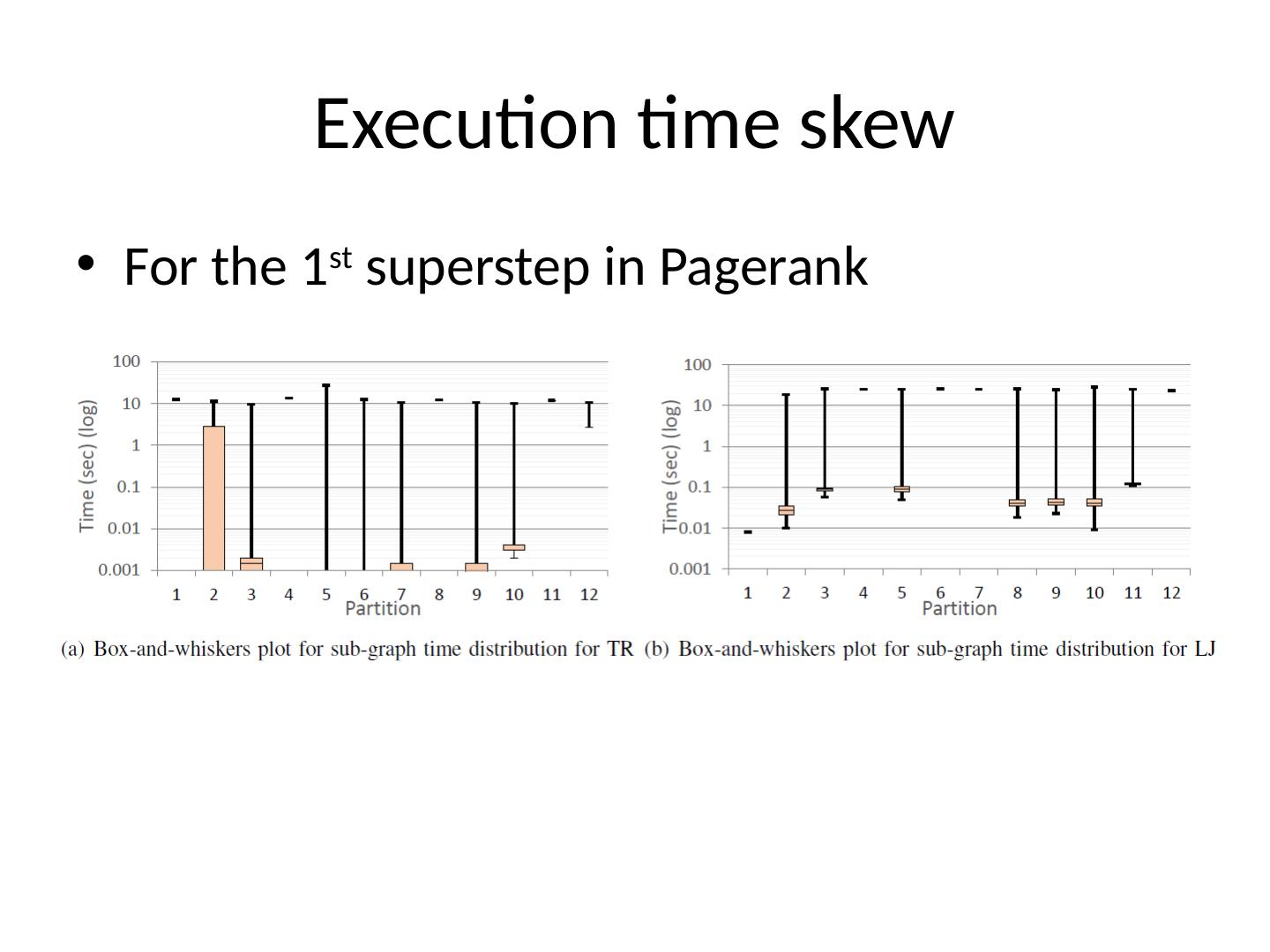
16 .Execution time skew For the 1 st superstep in Pagerank
17 .Subgraph centric w/o the abstraction Louvain community detection Given graph check where there is a “natural division” of vertices Is edge cut realistic enough? Modularity based community detection m c – number of edges inside community c d c – sum of degrees of vertices inside community c M – total number of edges C – set of all communities in graph
18 .Louvain sequential algorithm A greedy modularity maximization approach. Two main steps repeated iteratively while(improvement) { mod = detect-communities() if( (mod – prev_mod ) > T) improvement = true else improvement = false prev_mod = mod collapse-graph() }
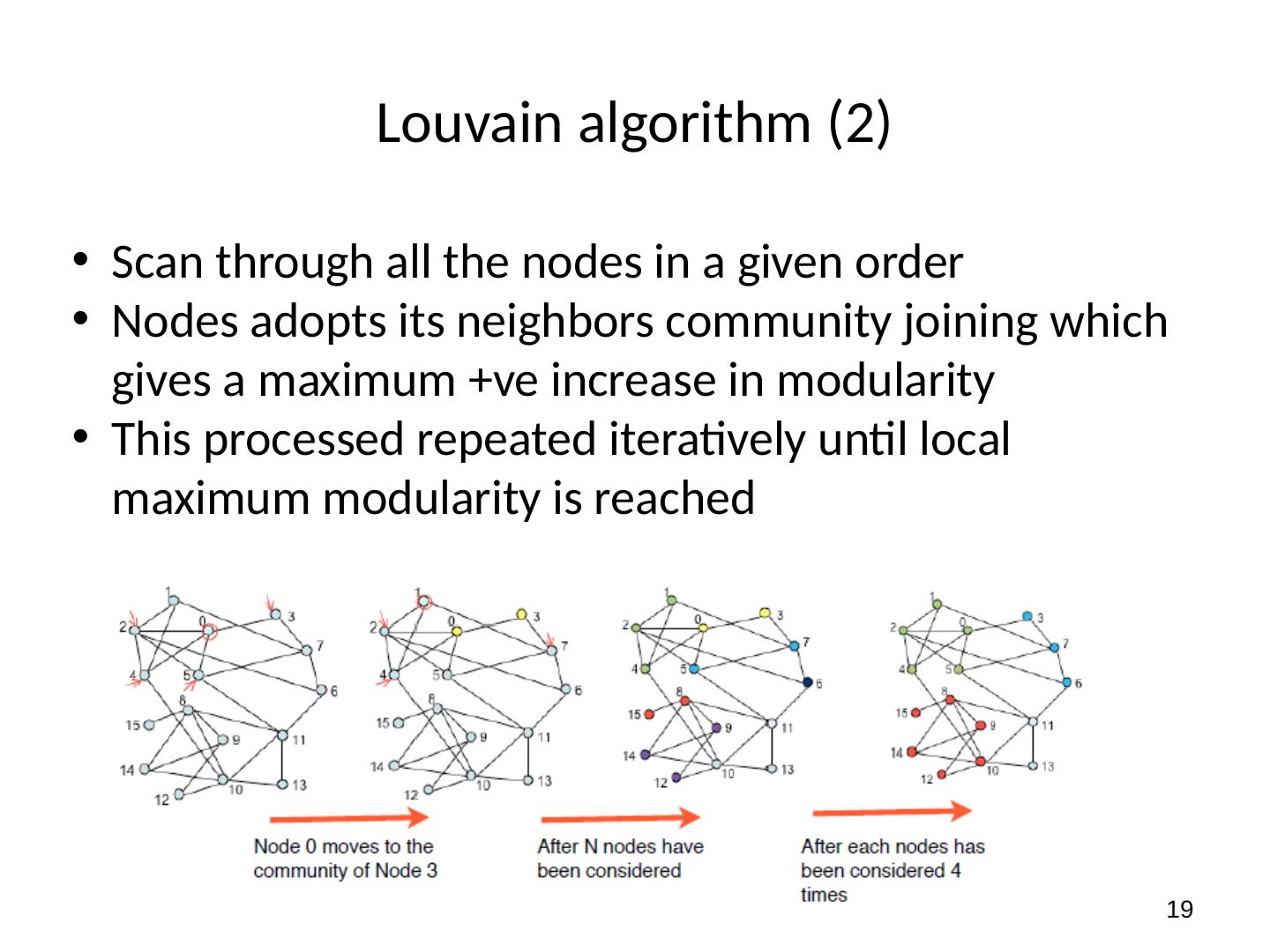
19 .19 Louvain algorithm (2 ) Scan through all the nodes in a given order Nodes adopts its neighbors community joining which gives a maximum + ve increase in modularity This processed repeated iteratively until local maximum modularity is reached
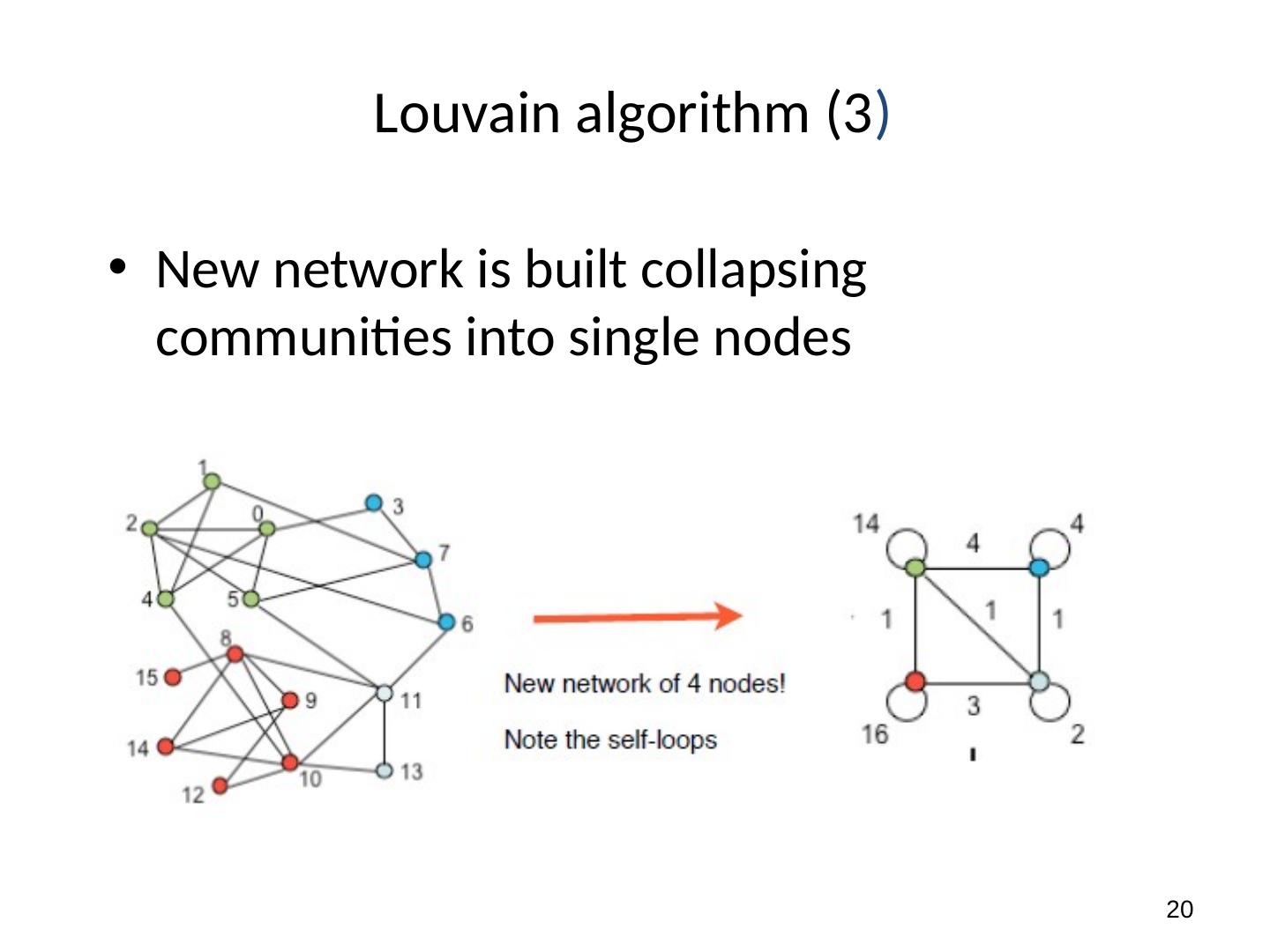
20 .20 Louvain algorithm (3 ) New network is built collapsing communities into single nodes
21 .Observations First iteration is the costliest iteration 79.53 % of total time on average Graph reduced to much smaller graph after the first iteration First iteration community structures are smaller Small number of vertices
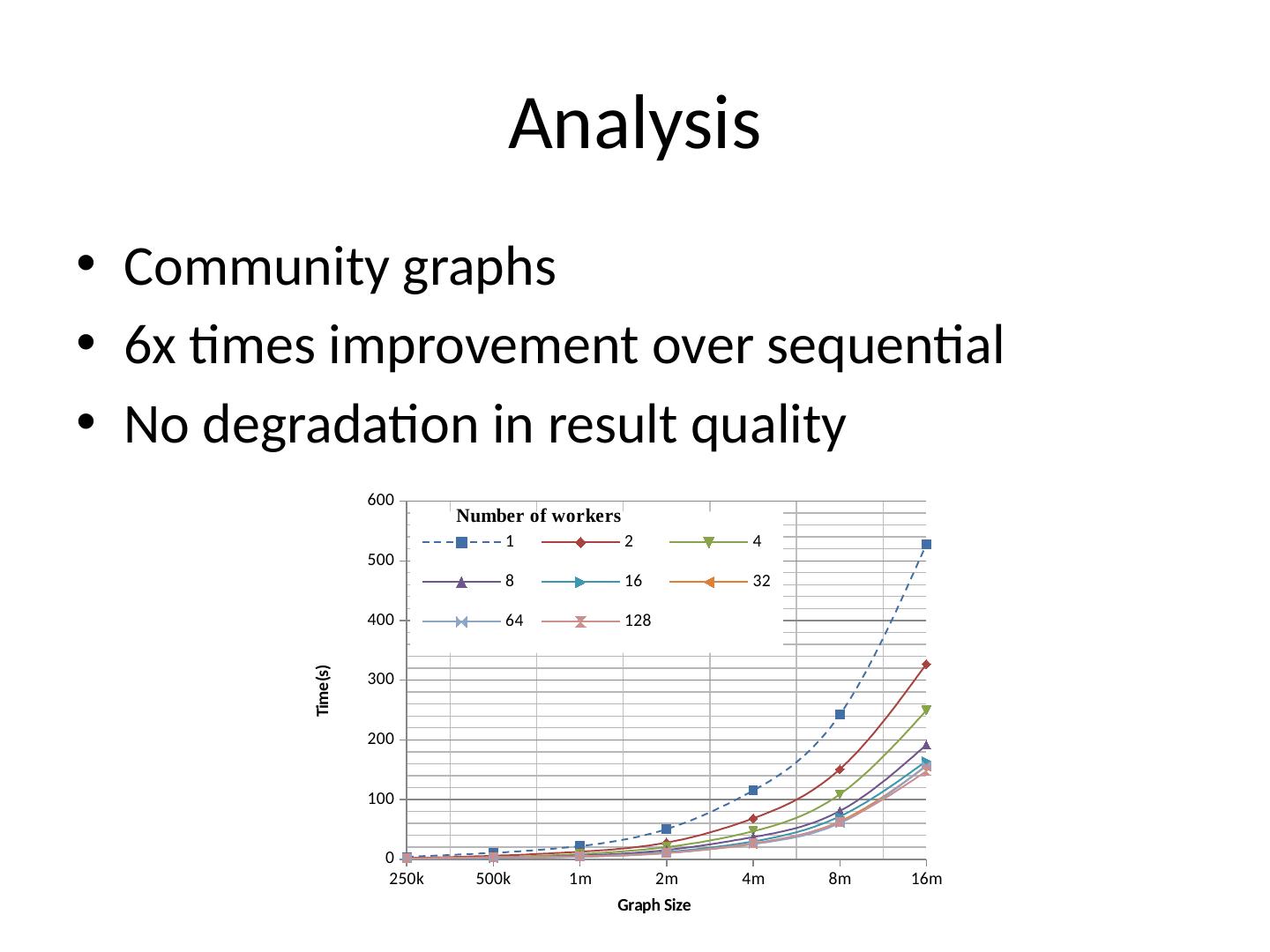
22 .Analysis Community graphs 6x times improvement over sequential No degradation in result quality
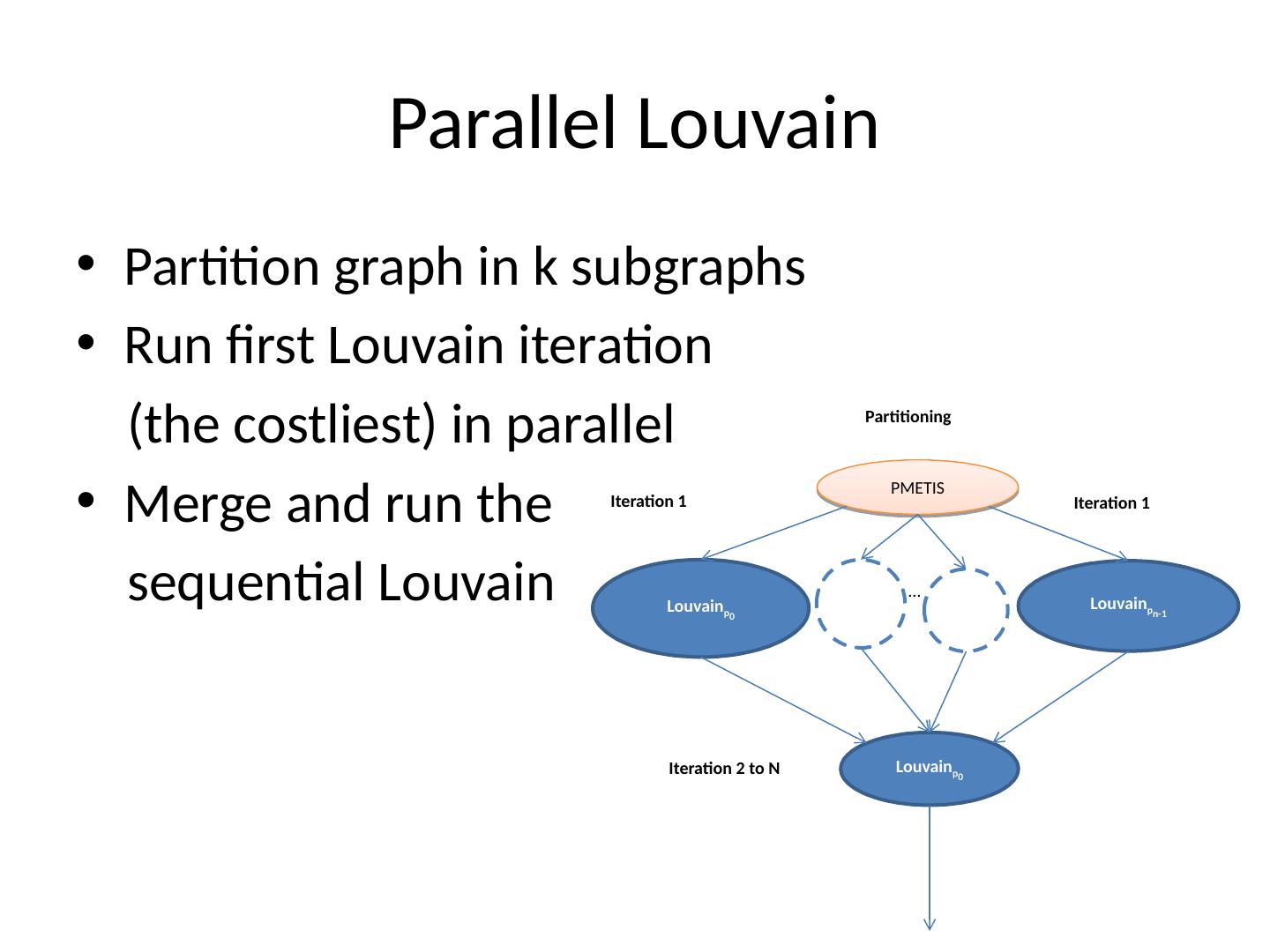
23 .Parallel Louvain Partition graph in k subgraphs Run first Louvain iteration (the costliest) in parallel Merge and run the sequential Louvain PMETIS Partitioning Louvain p 0 Louvain p n-1 Louvain p 0 … Iteration 1 Iteration 2 to N Iteration 1
24 .What’s next? Load balancing Importance of partitioning and graph type Parallel sorting Parallel computational geometry Parallel numerical algorithms …