









- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
OLTP on Hardware Islands
Modern hardware is abundantly parallel and increasingly heterogeneous. The numerous processing cores have nonuniform access latencies to the main memory and to the processor caches, which causes variability in the communication costs. Unfortunately, database systems mostly assume that all processing cores are the same and that microarchitecture differences are not significant enough to appear in critical database execution paths. As we demonstrate in this paper, however, hardware heterogeneity does appear in the critical path and conventional database architectures achieve suboptimal and even worse, unpredictable performance.
展开查看详情
1 . OLTP on Hardware Islands Danica Porobic Ippokratis Pandis† Miguel Branco Pınar Toz ¨ un ¨ Anastasia Ailamaki ´ Ecole Polytechnique Fed´ erale ´ de Lausanne † IBM Almaden Research Center Lausanne, VD, Switzerland San Jose, CA, USA {danica.porobic, miguel.branco, pinar.tozun, anastasia.ailamaki}@epfl.ch ipandis@us.ibm.com ABSTRACT [31, 18, 25, 21, 24]). OLTP applications are mission-critical Modern hardware is abundantly parallel and increasingly for many enterprises with little margin for compromising heterogeneous. The numerous processing cores have non- either performance or scalability. Thus, it is not surpris- uniform access latencies to the main memory and to the ing that all major OLTP vendors spend significant effort processor caches, which causes variability in the communica- in developing highly-optimized software releases, often with tion costs. Unfortunately, database systems mostly assume platform-specific optimizations. that all processing cores are the same and that microarchi- Over the past decades, OLTP systems benefited greatly tecture differences are not significant enough to appear in from improvements in the underlying hardware. Innovations critical database execution paths. As we demonstrate in this in their software architecture have been plentiful but there paper, however, hardware heterogeneity does appear in the is a clear benefit from processor evolution. Uni-processors critical path and conventional database architectures achieve grew predictably faster with time, leading to better OLTP suboptimal and even worse, unpredictable performance. performance. Around 2005, when processor vendors hit the We perform a detailed performance analysis of OLTP de- frequency-scaling wall, they started obtaining performance ployments in servers with multiple cores per CPU (multicore) improvements by adding multiple processing cores to the and multiple CPUs per server (multisocket). We compare same CPU chip, forming chip multiprocessors (multicore or different database deployment strategies where we vary the CMP); and building servers with multiple CPU sockets of number and size of independent database instances running multicore processors (SMP of CMP). on a single server, from a single shared-everything instance Multisockets of multicores are highly parallel and charac- to fine-grained shared-nothing configurations. We quantify terized by heterogeneity in the communication costs: sets, the impact of non-uniform hardware on various deployments or islands, of processing cores communicate with each other by (a) examining how efficiently each deployment uses the very efficiently through common on-chip caches, and commu- available hardware resources and (b) measuring the impact nicate less efficiently with others through bandwidth-limited of distributed transactions and skewed requests on different and higher-latency links. Even though multisocket multicore workloads. Finally, we argue in favor of shared-nothing de- machines dominate in modern data-centers, it is unclear how ployments that are topology- and workload-aware and take well software systems and in particular OLTP systems exploit advantage of fast on-chip communication between islands of hardware capabilities. cores on the same socket. This paper characterizes the impact of hardware topol- ogy on the behavior of OLTP systems running on modern multisocket multicore servers. As recent studies argue and 1. INTRODUCTION this paper corroborates, traditional shared-everything OLTP On-Line Transaction Processing (OLTP) is a multi-billion systems underperform on modern hardware because of (a) dollar industry1 and one of the most important and demand- excessive communication between the various threads [5, 14] ing database applications. Innovations in OLTP continue to and (b) contention among threads [26, 31]. Practitioners deserve significant attention, advocated by the recent emer- report that even commercial shared-everything systems with gence of appliances2 , startups3 , and research projects (e.g. support for non-uniform memory architectures (NUMA) un- 1 derperform [11, 36]. On the other hand, shared-nothing E.g. http://www.gartner.com/DisplayDocument?id= 1044912 deployments [30] face the challenges of (a) higher execution 2 Such as Oracle’s Exadata database machine. costs when distributed transactions are required [16, 9, 12, 3 Such as VoltDB, MongoDB, NuoDB, and others. 27], even within a single node, particularly if the communica- tion occurs between slower links (e.g. across CPU sockets); Permission to make digital or hard copies of all or part of this work for and (b) load imbalances due to skew [33]. personal or classroom use is granted without fee provided that copies are Many real-life workloads cannot be easily partitioned not made or distributed for profit or commercial advantage and that copies across instances or can have significant data and request bear this notice and the full citation on the first page. To copy otherwise, to skews, which may also change over time. In this paper, republish, to post on servers or to redistribute to lists, requires prior specific we examine the impact of perfectly partitionable and non- permission and/or a fee. Articles from this volume were invited to present partitionable workloads, with and without data skew, on their results at The 38th International Conference on Very Large Data Bases, August 27th - 31st 2012, Istanbul, Turkey. shared-nothing deployments of varying sizes as well as shared- Proceedings of the VLDB Endowment, Vol. 5, No. 11 everything deployments. Our experiments show that per- Copyright 2012 VLDB Endowment 2150-8097/12/07... $ 10.00. 1447
2 .fectly partitionable workloads perform significantly better 2.1 Shared-everything Database Deployments on fine-grained shared-nothing configurations but non-parti- Within a database node, shared-everything is any deploy- tionable workloads favor coarse-grained configurations, due ment where a single database instance manages all the avail- to the overhead of distributed transactions. We identify the able resources. As database servers have long been designed overheads as messaging, additional logging, and increased to operate on machines with multiple processors, shared- contention, all of which depend on workload characteristics everything deployments assume equally fast communication such as the percentage of multisite transactions, the number channels between all processors, since each thread needs to ex- of sites touched by each transaction, and the amount of change data with its peers. Until recently, shared-everything work done within each transaction. Additionally, we find was the most popular deployment strategy on a single node. that skewed accesses cause performance to drop significantly All major commercial database systems adopt it. when using fine-grained shared-nothing configurations; this OLTP has been studied extensively on shared-everything effect is less evident on coarser configurations and when using databases. For instance, transactions suffer significant stalls shared-everything deployments. during execution [3, 2, 14]; a result we corroborate in Sec- To our knowledge, this is the first study that systematically tion 6.2. It has also been shown that shared-everything analyzes the performance of shared-everything and shared- systems have frequent shared read-write accesses [5, 14], nothing OLTP configurations of varying size on modern which are difficult to predict [29]. Modern systems enter multisocket multicore machines. The contributions are as numerous contentious critical sections even when execut- follows: ing simple transactions, affecting single-thread performance, requiring frequent inter-core communication, and causing • We provide experimental evidence of the impact of non- contention among threads [26, 25, 18]. These characteris- uniform hardware on the performance of transaction pro- tics make distributed memories (as those of multisockets), cessing systems and conclude that high performance soft- distributed caches (as those of multicores), and prefetch- ware has to minimize contention among cores and avoid ers ineffective. Recent work suggests a departure from the frequent communication between distant cores. traditional transaction-oriented execution model, to adopt • Our experiments show that fine-grained shared-nothing a data-oriented execution model, circumventing the afore- deployments can achieve more than four times as high mentioned properties - and flaws - of traditional shared- throughput as a shared-everything system when the work- everything OLTP [25, 26]. load is perfectly partitionable. By contrast, when the workload is not partitionable and/or exhibits skew, shared- 2.2 Shared-nothing Database Deployments everything achieves twice as high a throughput as shared- Shared-nothing deployments [30], based on fully indepen- nothing. Therefore, there is no unique optimal deployment dent (physically partitioned) database instances that collec- strategy that is independent of the workload. tively process the workload, are an increasingly appealing design even within single node [31, 21, 28]. This is due to the • We demonstrate that a careful assignment of threads to scalability limitations of shared-everything systems, which islands of cores can combine the best features of a broad suffer from contention when concurrent threads attempt to range of system configurations, thereby achieving flexibility access shared resources [18, 25, 26]. in the deployment as well as more predictable and robust The main advantage of shared-nothing deployments is performance. In particular, islands-aware thread assign- the explicit control over the contention within each physi- ment can improve the worst-case scenario by a factor of 2 cal database instance. As a result, shared-nothing systems without hurting the best-case performance much. exhibit high single-thread performance and low contention. In addition, shared-nothing databases typically make bet- The rest of the document is structured as follows. Section 2 ter use of the available hardware resources whenever the presents the background and related work, describing the two workload executes transactions touching data on a single main database deployment approaches. Section 3 identifies database instance. Systems such as H-Store [31] and HyPer recent trends on modern hardware and their implications [21] apply the shared-nothing design to the extreme, deploy- on software design. Section 4 discusses the dependence of ing one single-threaded database instances per CPU core. database systems performance on hardware topology and This enables simplifications or removal of expensive database workload characteristics such as percentage of distributed components such as logging and locking. transactions. Section 5 presents experimental methodology. Shared-nothing systems appear ideal from the hardware Section 6 describes cases favoring fine-grained shared-nothing utilization perspective, but they are sensitive to the ability configurations, and Section 7 analyzes possible overheads to partition the workload. Unfortunately, many workloads when deploying shared-nothing configurations. Finally, Sec- are not perfectly partitionable, i.e. it is hardly possible to tion 8 summarizes the findings and discusses future work. allocate data such that every transaction touches a single instance. Whenever multiple instances must collectively pro- 2. BACKGROUND AND RELATED WORK cess a request, shared-nothing databases require expensive Shared-everything and shared-nothing database designs, distributed consensus protocols, such as two-phase commit, described in the next two sections, are the most widely which many argue are inherently non-scalable [16, 9]. Simi- used approaches for OLTP deployments. Legacy multisocket larly, handling data and access skew is problematic [33]. machines, which gained popularity in the 1990s as symmetric The overhead of distributed transactions urged system multiprocessing servers, had non-uniform memory access designers to explore partitioning techniques that reduce the (NUMA) latencies. This required changes to the database frequency of distributed transactions [12, 27], and to ex- and operating systems to diminish the impact of NUMA, as plore alternative concurrency control mechanisms, such as discussed in Section 2.3. speculative locking [20], multiversioning [6] and optimistic 1448
3 .concurrency control [22, 24], to reduce the overheads when distributed transactions cannot be avoided. Designers of large-scale systems have circumvented problems with dis- tributed transactions by using relaxed consistency models such as eventual consistency [35]. Eventual consistency elim- inates the need for synchronous distributed transactions, but it makes programming transactional applications harder, with consistency checks left to the application layer. The emergence of multisocket multicore hardware adds further complexity to the on-going debate between shared- everything and shared-nothing OLTP designs. As Section 3 Figure 1: Block diagram of a typical machine. Cores describes, multisocket multicores introduce an additional communicate either through a common cache, an level into the memory hierarchy. Communication between interconnect across socket or main memory. processors is no longer uniform: cores that share caches communicate differently from cores in the same socket and of processors by clocking them to higher frequency or by us- other sockets. ing more advanced techniques such as increased instruction- width and extended out-of-order execution. Instead, two 2.3 Performance on Multisocket Multicores approaches are mainly used to increase the processing ca- Past work focused on adapting databases for legacy multi- pability of a machine. The first is to put together multiple socket systems. For instance, commercial database systems processor chips that communicate through shared main mem- provide configuration options to enable NUMA support, but ory. For several decades, such multisocket designs provided this setting is optimized for legacy hardware where each the only way to scale performance within a single node and individual CPU is assumed to contain a single core. With the majority of OLTP systems have historically used such newer multisocket servers, enabling NUMA support might hardware. The second approach places multiple process- lead to high CPU usage and degraded performance [11, 36]. ing cores on a single chip, such that each core is capable An alternative approach is taken by the Multimed project, of processing concurrently several independent instruction which views the multisocket multicore system as a cluster of streams, or hardware contexts. The communication between machines [28]. Multimed uses replication techniques and a cores in these multicore processors happens through on-chip middleware layer to split database instances into those that caches. In recent years, multicore processors have become a process read-only requests and those that process updates. commodity. The authors report higher performance than a single shared- Multisocket multicore systems are the predominant con- everything instance. However, Multimed does not explicitly figuration for database servers and are expected to remain address NUMA-awareness and the work is motivated by popular in the future. Figure 1 shows a simplified block the fact that the shared-everything system being used has diagram of a typical machine that has two sockets with quad- inherent scalability limitations. In this paper, we use a core CPUs.4 Communication between the numerous cores scalable open-source shared-everything OLTP system, Shore- happens through different mechanisms. For example, cores MT [18], which scales nearly linearly with the available cores in the same socket share a common cache, while cores located on single-socket machines; however, we still observe benefits in different sockets communicate via the interconnect (called with shared-nothing deployments based on Shore-MT. QPI for Intel processors). Cores may also communicate A comparison of techniques for executing hash joins in through the main memory if the data is not currently cached. multicore machines [8], corresponding broadly to shared- The result is that the inter-core communication is variable: everything and shared-nothing configurations of different communication in multicores is more efficient than in mul- sizes, illustrates a case where shared-everything has appealing tisockets, which communicate over a slower, power-hungry, characteristics. The operation under study, however, hash and often bandwidth-limited interconnect. joins, has different characteristics from OLTP. Hence, there are two main trends in modern hardware: the Exploiting NUMA effects at the operating system level variability in communication latencies and the abundance of is an area of active research. Some operating system ker- parallelism. In the following two subsections we discuss how nels such as the Mach [1] and exokernels [13], or, more re- each trend affects the performance of software systems. cently, Barrelfish [4], employ the message-passing paradigm. Message-passing potentially facilitates the development of 3.1 Variable Communication Latencies NUMA-aware systems since the communication between The impact of modern processor memory hierarchies on threads is done explicitly through messages, which the op- the application performance is significant because it causes erating system can schedule in a NUMA-aware way. Other variability in access latency and bandwidth, making the proposals include the development of schedulers that detect overall software performance unpredictable. Furthermore, contention and react in a NUMA-aware manner [7, 32]. None it is difficult to implement synchronization or communica- of these proposals is specific to database systems and likely tion mechanisms that are globally optimal in different en- require extensive changes to the database engine. vironments - multicores, multisockets, and multisockets of multicores. We illustrate the problem of optimal synchronization mech- 3. HARDWARE HAS ISLANDS anisms with a simple microbenchmark. Figure 2 plots the Hardware has long departed from uniprocessors, which had 4 Adapted from http://software.intel.com/sites/ predictable and uniform performance. Due to thermal and products/collateral/hpc/vtune/performance analysis power limitations, vendors cannot improve the performance guide.pdf 1449
4 . Millions/sec 400 10 Throughput (KTps) 8 Throughput 300 6 200 4 100 2 0 0 "Spread" "Grouped" OS Spread Group Mix OS threads threads ? ? Figure 2: Allocating threads and memory in a topology-aware manner provides the best perfor- ? ? mance and lower variability. Figure 3: Running the TPCC-Payment workload with throughput of a program running on a machine that has all cores on the same socket achieves 20-30% higher 8 CPUs with 10 cores each (the “Octo-socket” machine of performance than other configurations. Table 2). There are 80 threads in the program, divided into groups of 10 threads, where each group increments a counter Table 1: Throughput and variability when increas- protected by a lock in a tight loop. There are 8 counters in ing counters each protected by a lock. total, matching the number of sockets in the machine. We Counter Total Throughput (M/sec) Std. dev. vary the allocation of the worker threads and plot the total setup counters (Speedup) (%) throughput (million counter increments per second). The Single 1 18.4 9.33% first bar (“Spread” threads) spreads worker threads across Per socket 8 341.7 (18.5x) 0.86% all sockets. The second bar (“Grouped” threads) allocates Per core 80 9527.8 (516.8x) 0.03% all threads in the same socket as the counter. The third bar leaves the operating system to do the thread alloca- tion. Allocating threads and memory in a topology-aware manner results in the best performance and lowest variabil- lelism potentially causes additional contention in multisocket ity. Leaving the allocation to the operating system leads to multicore systems, as a higher number of cores compete for non-optimal results and higher variability.5 shared data accesses. Table 1 shows the results obtained We obtain similar results when running OLTP workloads. on the octo-socket machine when varying the number of To demonstrate the impact of NUMA latencies on OLTP, worker threads accessing a set of counters, each protected we run TPC-C Payment transactions on a machine that has 4 by a lock. An exclusive counter per core achieves lower CPUs with 6 cores each (“Quad-socket” in Table 2). Figure 3 variability and 18x higher throughput than a counter per plots the average throughput and standard deviation across socket, and 517x higher throughput than a single counter multiple executions on a database with 4 worker threads. for the entire machine. In both cases, this is a super-linear In each configuration we vary the allocation of individual speedup. Shared-nothing deployments are better suited to worker threads to cores. The first configuration (“Spread”) handle contention, since they provide explicit control by assigns each thread to a core in a different socket. The sec- physically partitioning data, leading to higher performance. ond configuration (“Group”) assigns all threads to the same In summary, modern hardware poses new challenges to socket. The configuration “Mix” assigns two cores per socket. software systems. Contention and topology have a significant In the “OS” configuration, we let the operating system do impact on performance and predictability of the software. the scheduling. This experiment corroborates the previous Predictably fast transaction processing systems have to take observations of Figure 2: the OS does not optimally allocate advantage of the hardware islands in the system. They need work to cores, and a topology-aware configuration achieves to (a) avoid frequent communication between “distant” cores 20-30% better performance and less variation. The absolute in the processor topology and (b) keep the contention among difference in performance is much lower than in the case of cores low. The next section argues in favor of topology-aware counter incrementing because executing a transaction has OLTP deployments that adapt to those hardware islands. significant start-up and finish costs, and during transaction execution a large fraction of the time is spent on operations other than accessing data. For instance, studies show that 4. ISLANDS: HARDWARE TOPOLOGY- around 20% of the total instructions executed during OLTP AND WORKLOAD-AWARE SHARED- are data loads or stores (e.g. [3, 14]). NOTHING OLTP 3.2 Abundant Hardware Parallelism Traditionally, database systems fall into one of two main Another major trend is the abundant hardware parallelism categories: shared-everything or shared-nothing. The distinc- available in modern database servers. Higher hardware paral- tion into two strict categories, however, does not capture the fact that there are many alternative shared-nothing configu- 5 This observation has been done also by others, e.g. [4], and rations of different sizes, nor how to map each shared-nothing is an area of active research. instance to CPU cores. 1450
5 . CPU 0 CPU 1 CPU 0 CPU 1 CPU 0 CPU 1 Fine-grained Throughput shared-nothing Islands CPU 2 CPU 3 CPU 2 CPU 3 CPU 2 CPU 3 Shared-everything 2 Islands 4 Islands 4 Spread Figure 4: Different shared-nothing configurations on a four-socket four-core machine. Figure 4 illustrates three different shared-nothing configu- % multisite transactions rations. The two left-most configurations, labeled “2 Islands” in workload and “4 Islands”, dedicate different number of cores per in- Figure 5: Performance of various deployment config- stance, but, for the given size, minimize the NUMA effects urations as the percentage of multisite transactions as much as possible. Computation within an instance is increases. done in close cores. The third configuration, ”4 Spread” has the same size per instance as “4 Islands”; however, it does transactions can actually be physically local transactions, not minimize the NUMA effects, as it forces communication since all the required data reside physically in the same across sockets when it is strictly not needed. The first two database instance. Distributed transactions are only required configurations are islands in our terminology, where an island for multisite transactions whose data reside across different is a shared-nothing configuration where each shared-nothing physical database instances. Assuming the same partitioning instance is placed in a topology-aware manner. The third algorithm is used (e.g. [12, 27]), then the more data a configuration is simply a shared-nothing configuration. As database contains the more likely for a transaction to be hardware becomes more parallel and more heterogeneous local. the design space over the possible shared-nothing configu- Given the previous reasoning one could argue that an op- rations increases, and it is harder to determine the optimal timal shared-nothing configuration consists of a few coarse- deployment. grained database instances. This would be a naive assump- On top of the hardware complexity, we have to consider tion as it ignores the effects of hardware parallelism and that the cost of a transaction in a shared-nothing environment variable communication costs. For example, if we consider also depends on whether this transaction is local to a database the contention, then the cost of a (local) transaction of a instance or distributed. A transaction is local when all the coarse-grained shared-nothing configuration Ccoarse is higher required data for the transaction is stored in a single database than the cost of a (local) transaction of a very fine-grained instance. A transaction is distributed when multiple database configuration Cf ine , because the number of concurrent con- instances need to be contacted and slow distributed consensus tenting threads is larger. That is, Tcoarse < Tf ine . If we protocols (such as two-phase commit) need to be employed. consider communication latency, then the cost of a topology- Thus, the throughput also heavily depends on the workload, aware islands configuration Cislands of a certain size is lower adding another dimension to the design space and making than the cost of a topology-unaware shared-nothing configu- the optimal deployment decision nearly “black magic.” 6 ration Cnaive . That is, Tislands < Tnaive . An oversimplified estimation of the throughput of a shared- As a result, this paper makes the case for OLTP Islands, nothing deployment as a function of the number of distributed which are hardware topology- and workload-aware shared- transactions is given by the following. If Tlocal is the perfor- nothing deployments. Figure 5 illustrates the expected behav- mance of the shared-nothing system when each instance exe- ior of Islands, shared-everything, and finer-grained shared- cutes only local transactions, and Tdistr is the performance nothing configurations as the percentage of multisite transac- of a shared-nothing deployment when every transaction re- tions in the workload increases. Islands exploit the properties quires data from more than one database instances, then the of modern hardware by exploring the sets of cores that com- total throughput T is: municate faster with each other. Islands are shared-nothing designs, but partially combine the advantages of both shared- T = (1 − p) ∗ Tlocal + p ∗ Tdistr everything and shared-nothing deployments. Similarly to where p is the fraction of distributed transactions executed. a shared-everything system, Islands provide robust perfor- In a shared-everything configuration all the transactions mance even when transactions in the workload vary slightly. are local (pSE = 0). On the other hand, the percentage of At the same time, performance on well-partitioned work- distributed transactions on a shared-nothing system depends loads should be high, due to less contention and avoidance on the partitioning algorithm and the system configuration. of higher-latency communication links. Their performance, Typically, shared-nothing configurations of larger size execute however, is not as high as a fine-grained shared-nothing sys- fewer distributed transactions, as each database instance tem, since each node has more worker threads operating contains more data. That is, a given workload has a set on the same data. At the other side of the spectrum, the of transactions that access data in a single logical site, and performance of Islands will not deteriorate as sharply as a transactions that access data in multiple logical sites, which fine-grained shared-nothing under the presence of e.g. skew. we call multisite transactions. A single database instance may hold data for multiple logical sites. In that case, multisite 5. EXPERIMENTAL SETUP 6 Explaining, among other reasons, the high compensation In the following sections we perform a thorough evaluation for skilled database administrators. of the benefits of various deployment strategies under a 1451
6 . CPU socket or in different sockets. Unix domain sockets Table 2: Description of the machines used. achieve the highest performance and are used throughout Machine Description the remaining evaluation. Quad-socket 4 x Intel Xeon E7530 @ 1.86 GHz 6 cores per CPU Fully-connected with QPI 5.1 Prototype System 64 GB RAM In order to evaluate the performance of various shared- 64 KB L1 and 256 KB L2 cache per core nothing deployments in multisocket multicore hardware, we 12 MB L3 shared CPU cache implemented a prototype shared-nothing transaction process- Octo-socket 8 x Intel Xeon E7-L8867 @ 2.13GHz ing system on top of the Shore-MT [18] storage manager. 10 cores per CPU We opted for Shore-MT as the underlying system since it Connected using 3 QPI links per CPU provides near linear scalability on single multicores machines. 192 GB RAM Shore-MT is the improved version of the SHORE storage 64 KB L1 and 256 KB L2 cache per core manager, originally developed as an object-relational data 30 MB L3 shared CPU cache store [10]. Shore-MT is designed to remove scalability bottle- necks, significantly improving Shore’s original single-thread 70 Same socket performance. Its performance and scalability are at the Throughput (KMsgs/s) 60 highest end of open-source storage managers [18]. Diff. socket Shore-MT is originally a shared-everything system. There- 50 fore, we extended Shore-MT with the ability to run in shared- 40 nothing configurations, by implementing a distributed trans- action coordinator using the standard two-phase commit 30 protocol. 20 Shore-MT includes a number of state-of-the-art optimiza- 10 tions for local transactions, such as speculative lock inheri- tance [17]. We extended these features for distributed trans- 0 actions, providing a fair comparison between the execution POSIX Pipes FIFO TCP UNIX of local and distributed transactions. Message sockets sockets Queues Figure 6: Throughput of message exchanging (in 5.2 Workload and Experimental Methodology thousands of messages exchanged per second) for In our experiments, we vary the number of instances (i.e. a set of inter-process communication mechanisms. partitions) of the database system. Each instance runs as Unix domain sockets are the highest performing. a separate process. In all experiments, the total amount of input data is kept constant and the data is range-partitioned across all instances of the system. For every experiment, variety of workloads on two modern multisocket multicore with the exception of Section 7.4, we use small dataset with machines, one with four sockets of 6-core CPUs and one with 240,000 rows (∼ 60 MB). We show results using different eight sockets of 10-core CPUs 7 . database configurations, but we always use the same total Hardware and tools. Table 2 describes in detail the hard- amount of data, processors, and memory resources. Only the ware used in the experiments. We disable HyperThreading number of instances and the distribution of resources across to reduce variability in the measurements. The operating instances changes. system is Red Hat Enterprise Linux 6.2 (kernel 2.6.32). In We ensure that each database instance is optimally de- the experiment of Section 7.4, we use two 146 GB 10kRPM ployed. That is, each database process is bound to the cores SAS 2,5” HDDs in RAID-0. within a single socket (minimizing NUMA effects) when pos- We use Intel VTune Amplifier XE 2011 to collect ba- sible, and its memory is allocated in the nearest memory sic micro-architectural and time-breakdown profiling results. bank. As noted in Section 3, allowing the operating system to VTune does hardware counter sampling, which is both accu- schedule processes arbitrarily leads to suboptimal placement rate and light-weight. Our database system is compiled using and thread migration, which degrades performance. GCC 4.4.3 with maximum optimizations. In most experi- The configurations on the graphs are labeled with ”NISL” ments, the database size fits in the aggregate buffer pool size. where N represents the number of instances. For instance, As such, the only I/O is due to the flushing of log entries. 8ISL represents the configuration with 8 database instances, However, since the disks are not capable of sustaining the each of which has 1/8th of the total data and uses 3 processor I/O load, we use memory mapped disks for both data and cores (the machine has 24 cores in total). The number of log files. Overall, we exercise all code paths in the system instances is varied from 1 (i.e. a shared-everything system) and utilize all available hardware contexts. to 24 (i.e. a fine-grained shared-nothing system). Optimiza- IPC mechanisms. The performance of any shared-nothing tions are also applied to particular configurations whenever system heavily depends on the efficiency of its communication possible: e.g. fine-grained shared-nothing allows certain opti- layer. Figure 6 shows the performance in the quad-socket mizations to be applied. Optimizations used are noted along machine of various inter-process communication (IPC) mech- the corresponding experimental results. anisms using a simple benchmark that exchanges messages We run two microbenchmarks. The first consists of read- between two processes, which are either located in the same only transactions that retrieve N rows. The second consists 7 For more details see http://www.supermicro.com/ of read-write transactions updating N rows. For each mi- manuals/motherboard/7500/X8OBN-F.pdf crobenchmark, we run two types of transactions: 1452
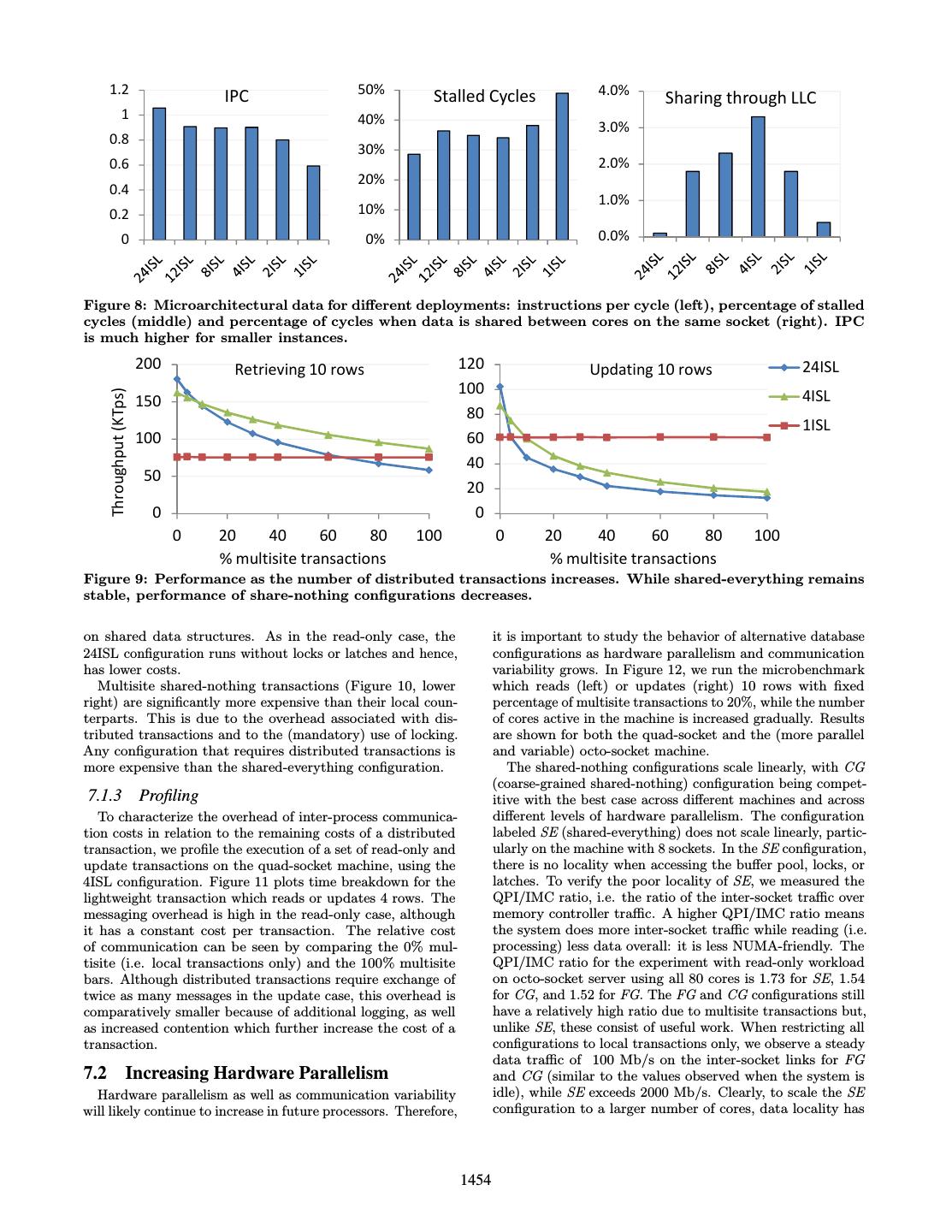
7 . execution leading to shorter code paths, which decreases the 150 number of instruction misses. On the other hand, instances Throughput (Ktps) that span across sockets have a much higher percentage of 100 stalled cycles (shown in the middle of Figure 8), in part due to the significant percentage of—expensive—last-level cache (LLC) misses. Within the same socket, smaller instances 50 have higher ratio of instructions per cycle due to less sharing between cores running threads from the same instance, as shown on the Figure 8 (right). 0 Fine-grained Shared Everything Shared Nothing 7. CHALLENGES FOR FINE-GRAINED PARTITIONING Figure 7: Running the TPC-C benchmark with only A significant number of real life workloads cannot be par- local transactions. Fine-grained shared-nothing is titioned in a way that transactions access a single partition. 4.5x faster than shared everything. Moreover, many workloads contain data and access skews, which may also change dynamically. Such workloads are • Local transactions, which perform its action (read or more challenging for systems that use fine-grained parti- update) on the N rows located in the local partition; tioning and coarser-grained shared-nothing configurations provide a robust alternative. • Multisite transactions, which perform its action (read or update) on one row located in the local partition while 7.1 Cost of Distributed Transactions remaining N − 1 rows are chosen uniformly from the whole Distributed transactions are known to incur a significant data range. Transactions are distributed if some of the cost, and this problem has been the subject of previous input rows happen to be located in remote partitions. research, with e.g. proposals to reduce the overhead of the distributed transaction coordination [20] or to determine an initial optimal partitioning strategy [12, 27]. Our experiment, 6. CASES FAVORING FINE-GRAINED shown in Figure 9, corroborates these results. We run two PARTITIONING microbenchmarks whose transactions read and update 10 This section presents two cases where fine-grained shared- rows respectively on the quad-socket machine. As expected, nothing configurations outperform coarser-grained shared- the configuration 1ISL (i.e. shared-everything) is not affected nothing configurations as well as shared-everything. by varying the percentage of multisite transactions. However, there is a drop in performance of the remaining configurations, 6.1 Perfectly Partitionable Workloads which is more significant in the case of the fine-grained one. If the workload is perfectly partitionable then fine-grained The following experiments further analyze this behavior. shared-nothing provides better performance. An example is shown on Figure 7, obtained using the quad-socket machine, 7.1.1 Read-only Case: Overhead Proportional to the which compares the performance of the shared-everything Number of Participating Instances version of Shore-MT with the fine-grained shared-nothing Figure 10 (upper left) represents the costs of a local read- version of Shore-MT with 24ISL. Both systems run a modified only transaction in various database configurations and as version of the TPC-C benchmark [34] Payment transaction, the number of rows retrieved per transaction increases. The where all the requests are local and, hence, the workload results are obtained on the quad-socket machine. The 24ISL is perfectly partitionable on Warehouses. The fine-grained configuration runs with a single worker thread per instance, shared-nothing configuration outperforms shared-everything so locking and latching are disabled, which leads to roughly by 4.5x, due in large part to contention on the Warehouse 40% lower costs than the next best configuration, corrobo- table in the shared-everything case. Experiments with short- rating previous results [15]. running microbenchmarks in later sections, however, do not The costs of multisite read-only transactions (Figure 10, show such a large difference between shared-everything and upper right) show the opposite trend from the local read- shared-nothing. This is because of the larger number of rows only transactions. In the local case, the costs of a single in the table being accessed, which implies lower contention transaction rise as the size of an instance grows. In the on a particular row. multisite case, however, the costs decrease with the size of an instance. This is due to a decrease in the number of instances 6.2 Read-only Workloads participating in the execution of any single transaction. The Fine-grained shared-nothing configurations are also appro- exception is the shared-everything configuration, which has priate for read-only workloads. In the following experiment higher costs due to inter-socket communication, as discussed we run microbenchmark with local transactions that retrieve in Section 6. 10 rows each. We test multiple configurations ranging from 24ISL to 1ISL in the quad-socket machine. The configuration 7.1.2 Update Case: Additional Logging Overhead Is 24ISL is run without locking or latching. Significant Figure 8 (left) shows that the fine-grained shared-nothing The lower left plot of Figure 10 describes the costs of the configurations, whose instances have fewer threads, make bet- update microbenchmark with local transactions only, on the ter utilization of the CPU. Single-threaded instances, apart quad-socket machine. The cost of a transaction increases from not communicating with other instances, have simpler with the number of threads in the system, due to contention 1453
8 . 1.2 50% 4.0% IPC Stalled Cycles Sharing through LLC 1 40% 3.0% 0.8 30% 0.6 2.0% 20% 0.4 1.0% 0.2 10% 0 0% 0.0% Figure 8: Microarchitectural data for different deployments: instructions per cycle (left), percentage of stalled cycles (middle) and percentage of cycles when data is shared between cores on the same socket (right). IPC is much higher for smaller instances. 200 Retrieving 10 rows 120 Updating 10 rows 24ISL 100 Throughput (KTps) 150 4ISL 80 1ISL 100 60 40 50 20 0 0 0 20 40 60 80 100 0 20 40 60 80 100 % multisite transactions % multisite transactions Figure 9: Performance as the number of distributed transactions increases. While shared-everything remains stable, performance of share-nothing configurations decreases. on shared data structures. As in the read-only case, the it is important to study the behavior of alternative database 24ISL configuration runs without locks or latches and hence, configurations as hardware parallelism and communication has lower costs. variability grows. In Figure 12, we run the microbenchmark Multisite shared-nothing transactions (Figure 10, lower which reads (left) or updates (right) 10 rows with fixed right) are significantly more expensive than their local coun- percentage of multisite transactions to 20%, while the number terparts. This is due to the overhead associated with dis- of cores active in the machine is increased gradually. Results tributed transactions and to the (mandatory) use of locking. are shown for both the quad-socket and the (more parallel Any configuration that requires distributed transactions is and variable) octo-socket machine. more expensive than the shared-everything configuration. The shared-nothing configurations scale linearly, with CG (coarse-grained shared-nothing) configuration being compet- 7.1.3 Profiling itive with the best case across different machines and across To characterize the overhead of inter-process communica- different levels of hardware parallelism. The configuration tion costs in relation to the remaining costs of a distributed labeled SE (shared-everything) does not scale linearly, partic- transaction, we profile the execution of a set of read-only and ularly on the machine with 8 sockets. In the SE configuration, update transactions on the quad-socket machine, using the there is no locality when accessing the buffer pool, locks, or 4ISL configuration. Figure 11 plots time breakdown for the latches. To verify the poor locality of SE, we measured the lightweight transaction which reads or updates 4 rows. The QPI/IMC ratio, i.e. the ratio of the inter-socket traffic over messaging overhead is high in the read-only case, although memory controller traffic. A higher QPI/IMC ratio means it has a constant cost per transaction. The relative cost the system does more inter-socket traffic while reading (i.e. of communication can be seen by comparing the 0% mul- processing) less data overall: it is less NUMA-friendly. The tisite (i.e. local transactions only) and the 100% multisite QPI/IMC ratio for the experiment with read-only workload bars. Although distributed transactions require exchange of on octo-socket server using all 80 cores is 1.73 for SE, 1.54 twice as many messages in the update case, this overhead is for CG, and 1.52 for FG. The FG and CG configurations still comparatively smaller because of additional logging, as well have a relatively high ratio due to multisite transactions but, as increased contention which further increase the cost of a unlike SE, these consist of useful work. When restricting all transaction. configurations to local transactions only, we observe a steady data traffic of 100 Mb/s on the inter-socket links for FG 7.2 Increasing Hardware Parallelism and CG (similar to the values observed when the system is Hardware parallelism as well as communication variability idle), while SE exceeds 2000 Mb/s. Clearly, to scale the SE will likely continue to increase in future processors. Therefore, configuration to a larger number of cores, data locality has 1454
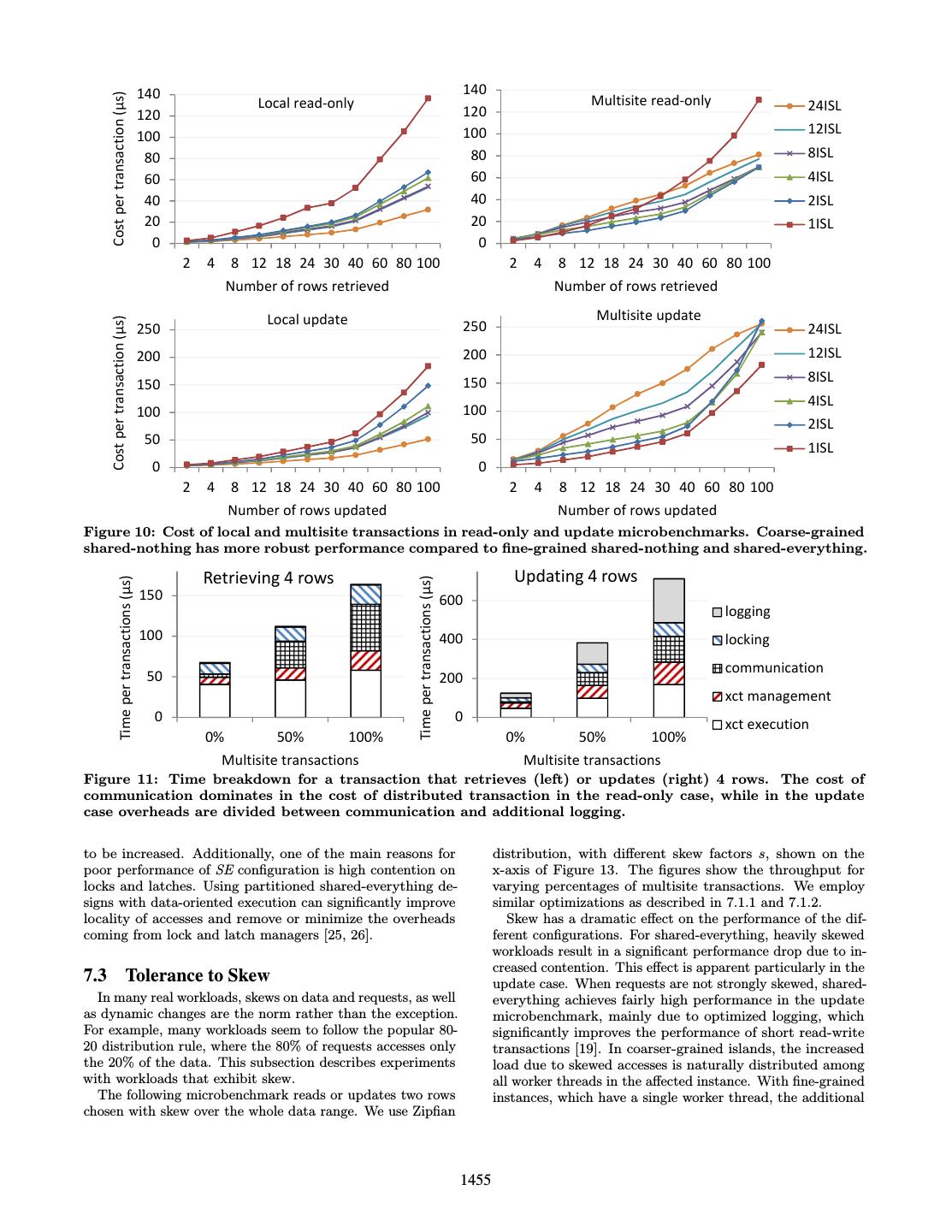
9 . 140 140 Cost per transaction (μs) Local read-only Multisite read-only 24ISL 120 120 100 100 12ISL 80 80 8ISL 60 60 4ISL 40 40 2ISL 20 20 1ISL 0 0 2 4 8 12 18 24 30 40 60 80 100 2 4 8 12 18 24 30 40 60 80 100 Number of rows retrieved Number of rows retrieved Local update Multisite update Cost per transaction (μs) 250 250 24ISL 200 200 12ISL 150 150 8ISL 4ISL 100 100 2ISL 50 50 1ISL 0 0 2 4 8 12 18 24 30 40 60 80 100 2 4 8 12 18 24 30 40 60 80 100 Number of rows updated Number of rows updated Figure 10: Cost of local and multisite transactions in read-only and update microbenchmarks. Coarse-grained shared-nothing has more robust performance compared to fine-grained shared-nothing and shared-everything. Retrieving 4 rows Updating 4 rows Time per transactions (µs) Time per transactions (µs) 150 600 logging 100 400 locking communication 50 200 xct management 0 0 xct execution 0% 50% 100% 0% 50% 100% Multisite transactions Multisite transactions Figure 11: Time breakdown for a transaction that retrieves (left) or updates (right) 4 rows. The cost of communication dominates in the cost of distributed transaction in the read-only case, while in the update case overheads are divided between communication and additional logging. to be increased. Additionally, one of the main reasons for distribution, with different skew factors s, shown on the poor performance of SE configuration is high contention on x-axis of Figure 13. The figures show the throughput for locks and latches. Using partitioned shared-everything de- varying percentages of multisite transactions. We employ signs with data-oriented execution can significantly improve similar optimizations as described in 7.1.1 and 7.1.2. locality of accesses and remove or minimize the overheads Skew has a dramatic effect on the performance of the dif- coming from lock and latch managers [25, 26]. ferent configurations. For shared-everything, heavily skewed workloads result in a significant performance drop due to in- creased contention. This effect is apparent particularly in the 7.3 Tolerance to Skew update case. When requests are not strongly skewed, shared- In many real workloads, skews on data and requests, as well everything achieves fairly high performance in the update as dynamic changes are the norm rather than the exception. microbenchmark, mainly due to optimized logging, which For example, many workloads seem to follow the popular 80- significantly improves the performance of short read-write 20 distribution rule, where the 80% of requests accesses only transactions [19]. In coarser-grained islands, the increased the 20% of the data. This subsection describes experiments load due to skewed accesses is naturally distributed among with workloads that exhibit skew. all worker threads in the affected instance. With fine-grained The following microbenchmark reads or updates two rows instances, which have a single worker thread, the additional chosen with skew over the whole data range. We use Zipfian 1455
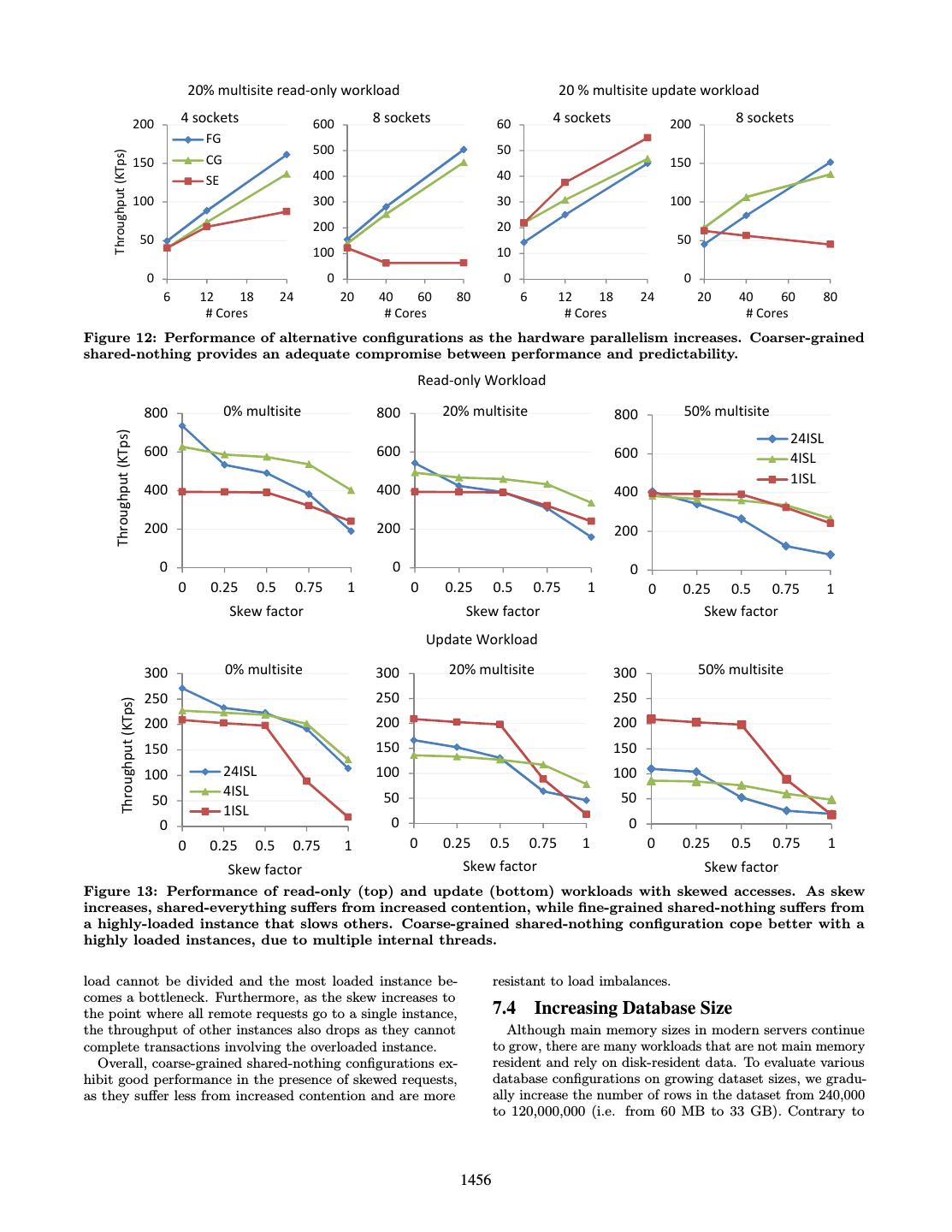
10 . 20% multisite read-only workload 20 % multisite update workload 200 4 sockets 600 8 sockets 60 4 sockets 200 8 sockets FG 500 50 Throughput (KTps) 150 CG 150 SE 400 40 100 300 30 100 200 20 50 50 100 10 0 0 0 0 6 12 18 24 20 40 60 80 6 12 18 24 20 40 60 80 # Cores # Cores # Cores # Cores Figure 12: Performance of alternative configurations as the hardware parallelism increases. Coarser-grained shared-nothing provides an adequate compromise between performance and predictability. Read-only Workload 800 0% multisite 800 20% multisite 800 50% multisite Throughput (KTps) 24ISL 600 600 600 4ISL 1ISL 400 400 400 200 200 200 0 0 0 0 0.25 0.5 0.75 1 0 0.25 0.5 0.75 1 0 0.25 0.5 0.75 1 Skew factor Skew factor Skew factor Update Workload 300 0% multisite 300 20% multisite 300 50% multisite 250 250 250 Throughput (KTps) 200 200 200 150 150 150 100 24ISL 100 100 4ISL 50 50 50 1ISL 0 0 0 0 0.25 0.5 0.75 1 0 0.25 0.5 0.75 1 0 0.25 0.5 0.75 1 Skew factor Skew factor Skew factor Figure 13: Performance of read-only (top) and update (bottom) workloads with skewed accesses. As skew increases, shared-everything suffers from increased contention, while fine-grained shared-nothing suffers from a highly-loaded instance that slows others. Coarse-grained shared-nothing configuration cope better with a highly loaded instances, due to multiple internal threads. load cannot be divided and the most loaded instance be- resistant to load imbalances. comes a bottleneck. Furthermore, as the skew increases to the point where all remote requests go to a single instance, 7.4 Increasing Database Size the throughput of other instances also drops as they cannot Although main memory sizes in modern servers continue complete transactions involving the overloaded instance. to grow, there are many workloads that are not main memory Overall, coarse-grained shared-nothing configurations ex- resident and rely on disk-resident data. To evaluate various hibit good performance in the presence of skewed requests, database configurations on growing dataset sizes, we gradu- as they suffer less from increased contention and are more ally increase the number of rows in the dataset from 240,000 to 120,000,000 (i.e. from 60 MB to 33 GB). Contrary to 1456
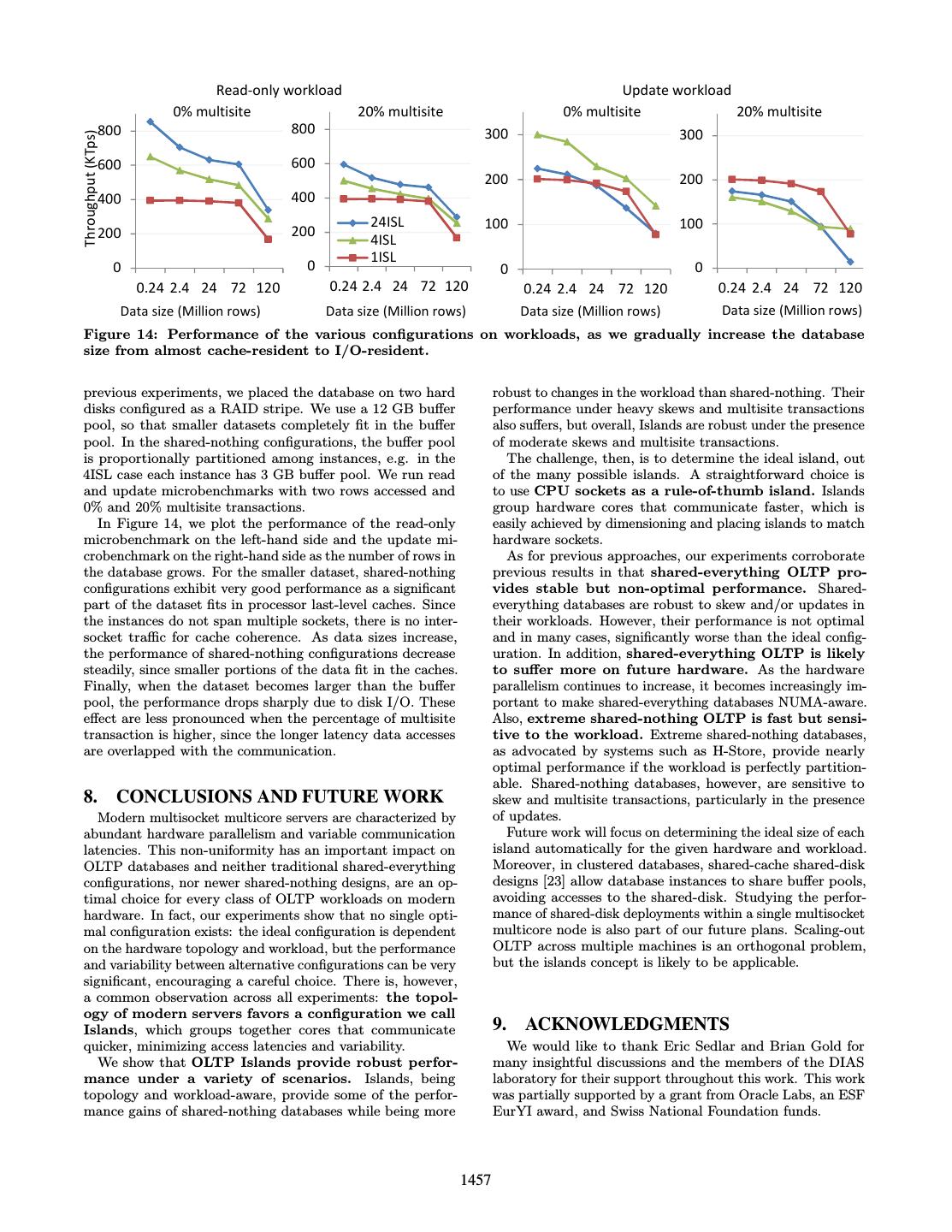
11 . Read-only workload Update workload 0% multisite 20% multisite 0% multisite 20% multisite 800 800 300 300 Throughput (KTps) 600 600 200 200 400 400 24ISL 100 100 200 200 4ISL 1ISL 0 0 0 0 0.24 2.4 24 72 120 0.24 2.4 24 72 120 0.24 2.4 24 72 120 0.24 2.4 24 72 120 Data size (Million rows) Data size (Million rows) Data size (Million rows) Data size (Million rows) Figure 14: Performance of the various configurations on workloads, as we gradually increase the database size from almost cache-resident to I/O-resident. previous experiments, we placed the database on two hard robust to changes in the workload than shared-nothing. Their disks configured as a RAID stripe. We use a 12 GB buffer performance under heavy skews and multisite transactions pool, so that smaller datasets completely fit in the buffer also suffers, but overall, Islands are robust under the presence pool. In the shared-nothing configurations, the buffer pool of moderate skews and multisite transactions. is proportionally partitioned among instances, e.g. in the The challenge, then, is to determine the ideal island, out 4ISL case each instance has 3 GB buffer pool. We run read of the many possible islands. A straightforward choice is and update microbenchmarks with two rows accessed and to use CPU sockets as a rule-of-thumb island. Islands 0% and 20% multisite transactions. group hardware cores that communicate faster, which is In Figure 14, we plot the performance of the read-only easily achieved by dimensioning and placing islands to match microbenchmark on the left-hand side and the update mi- hardware sockets. crobenchmark on the right-hand side as the number of rows in As for previous approaches, our experiments corroborate the database grows. For the smaller dataset, shared-nothing previous results in that shared-everything OLTP pro- configurations exhibit very good performance as a significant vides stable but non-optimal performance. Shared- part of the dataset fits in processor last-level caches. Since everything databases are robust to skew and/or updates in the instances do not span multiple sockets, there is no inter- their workloads. However, their performance is not optimal socket traffic for cache coherence. As data sizes increase, and in many cases, significantly worse than the ideal config- the performance of shared-nothing configurations decrease uration. In addition, shared-everything OLTP is likely steadily, since smaller portions of the data fit in the caches. to suffer more on future hardware. As the hardware Finally, when the dataset becomes larger than the buffer parallelism continues to increase, it becomes increasingly im- pool, the performance drops sharply due to disk I/O. These portant to make shared-everything databases NUMA-aware. effect are less pronounced when the percentage of multisite Also, extreme shared-nothing OLTP is fast but sensi- transaction is higher, since the longer latency data accesses tive to the workload. Extreme shared-nothing databases, are overlapped with the communication. as advocated by systems such as H-Store, provide nearly optimal performance if the workload is perfectly partition- able. Shared-nothing databases, however, are sensitive to 8. CONCLUSIONS AND FUTURE WORK skew and multisite transactions, particularly in the presence Modern multisocket multicore servers are characterized by of updates. abundant hardware parallelism and variable communication Future work will focus on determining the ideal size of each latencies. This non-uniformity has an important impact on island automatically for the given hardware and workload. OLTP databases and neither traditional shared-everything Moreover, in clustered databases, shared-cache shared-disk configurations, nor newer shared-nothing designs, are an op- designs [23] allow database instances to share buffer pools, timal choice for every class of OLTP workloads on modern avoiding accesses to the shared-disk. Studying the perfor- hardware. In fact, our experiments show that no single opti- mance of shared-disk deployments within a single multisocket mal configuration exists: the ideal configuration is dependent multicore node is also part of our future plans. Scaling-out on the hardware topology and workload, but the performance OLTP across multiple machines is an orthogonal problem, and variability between alternative configurations can be very but the islands concept is likely to be applicable. significant, encouraging a careful choice. There is, however, a common observation across all experiments: the topol- ogy of modern servers favors a configuration we call Islands, which groups together cores that communicate 9. ACKNOWLEDGMENTS quicker, minimizing access latencies and variability. We would like to thank Eric Sedlar and Brian Gold for We show that OLTP Islands provide robust perfor- many insightful discussions and the members of the DIAS mance under a variety of scenarios. Islands, being laboratory for their support throughout this work. This work topology and workload-aware, provide some of the perfor- was partially supported by a grant from Oracle Labs, an ESF mance gains of shared-nothing databases while being more EurYI award, and Swiss National Foundation funds. 1457
12 .10. REFERENCES [18] R. Johnson, I. Pandis, N. Hardavellas, A. Ailamaki, [1] M. J. Accetta, R. V. Baron, W. J. Bolosky, D. B. and B. Falsafi. Shore-MT: a scalable storage manager Golub, R. F. Rashid, A. Tevanian, and M. Young. for the multicore era. In EDBT, pages 24–35, 2009. Mach: A new kernel foundation for UNIX development. [19] R. Johnson, I. Pandis, R. Stoica, M. Athanassoulis, and In USENIX Summer, pages 93–112, 1986. A. Ailamaki. Aether: a scalable approach to logging. [2] A. Ailamaki, D. J. DeWitt, M. D. Hill, and D. A. PVLDB, 3(1):681–692, 2010. Wood. DBMSs on a modern processor: Where does [20] E. Jones, D. J. Abadi, and S. Madden. Low overhead time go? In VLDB, pages 266–277, 1999. concurrency control for partitioned main memory [3] L. A. Barroso, K. Gharachorloo, and E. Bugnion. databases. In SIGMOD, pages 603–614, 2010. Memory system characterization of commercial [21] A. Kemper and T. Neumann. HyPer – a hybrid workloads. In ISCA, pages 3–14, 1998. OLTP&OLAP main memory database system based on [4] A. Baumann, P. Barham, P.-E. Dagand, T. Harris, virtual memory snapshots. In ICDE, pages 195–206, R. Isaacs, S. Peter, T. Roscoe, A. Sch¨ upbach, and 2011. A. Singhania. The multikernel: a new OS architecture [22] H. T. Kung and J. T. Robinson. On optimistic for scalable multicore systems. In SOSP, pages 29 – 44, methods for concurrency control. ACM TODS, 2009. 6(2):213–226, 1981. [5] B. M. Beckmann and D. A. Wood. Managing wire [23] T. Lahiri, V. Srihari, W. Chan, N. MacNaughton, and delay in large chip-multiprocessor caches. In MICRO, S. Chandrasekaran. Cache fusion: Extending pages 319–330, 2004. shared-disk clusters with shared caches. In VLDB, [6] P. A. Bernstein and N. Goodman. Multiversion pages 683–686, 2001. concurrency control—theory and algorithms. ACM [24] P.-A. Larson, S. Blanas, C. Diaconu, C. Freedman, TODS, 8(4):465–483, 1983. J. M. Patel, and M. Zwilling. High-performance [7] S. Blagodurov, S. Zhuravlev, A. Fedorova, and concurrency control mechanisms for main-memory A. Kamali. A case for NUMA-aware contention databases. PVLDB, 5(4):298–309, 2011. management on multicore systems. In PACT, pages [25] I. Pandis, R. Johnson, N. Hardavellas, and A. Ailamaki. 557–558, 2010. Data-oriented transaction execution. PVLDB, [8] S. Blanas, Y. Li, and J. M. Patel. Design and 3(1):928–939, 2010. evaluation of main memory hash join algorithms for [26] I. Pandis, P. T¨oz¨ un, R. Johnson, and A. Ailamaki. multi-core cpus. In SIGMOD, pages 37–48, 2011. PLP: page latch-free shared-everything OLTP. PVLDB, [9] E. A. Brewer. Towards robust distributed systems 4(10):610–621, 2011. (abstract). In PODC, pages 7–7, 2000. [27] A. Pavlo, E. P. C. Jones, and S. Zdonik. On predictive [10] M. J. Carey, D. J. DeWitt, M. J. Franklin, N. E. Hall, modeling for optimizing transaction execution in M. L. McAuliffe, J. F. Naughton, D. T. Schuh, M. H. parallel OLTP systems. PVLDB, 5(2):85–96, 2011. Solomon, C. K. Tan, O. G. Tsatalos, S. J. White, and [28] T.-I. Salomie, I. E. Subasu, J. Giceva, and G. Alonso. M. J. Zwilling. Shoring up persistent applications. In Database engines on multicores, why parallelize when SIGMOD, pages 383–394, 1994. you can distribute? In EuroSys, pages 17–30, 2011. [11] K. Closson. You buy a NUMA system, Oracle says [29] S. Somogyi, T. F. Wenisch, N. Hardavellas, J. Kim, disable NUMA! What gives?, 2009. See A. Ailamaki, and B. Falsafi. Memory coherence activity http://kevinclosson.wordpress.com/2009/05/14/you- prediction in commercial workloads. In WMPI, pages buy-a-numa-system-oracle-says-disable-numa-what- 37–45, 2004. gives-part-ii/. [30] M. Stonebraker. The case for shared nothing. IEEE [12] C. Curino, E. Jones, Y. Zhang, and S. Madden. Schism: Database Eng. Bull., 9(1):4–9, 1986. a workload-driven approach to database replication and [31] M. Stonebraker, S. Madden, D. J. Abadi, partitioning. PVLDB, 3(1):48–57, 2010. S. Harizopoulos, N. Hachem, and P. Helland. The end [13] D. R. Engler, M. F. Kaashoek, and J. O’Toole Jr. of an architectural era: (it’s time for a complete Exokernel: an operating system architecture for rewrite). In VLDB, pages 1150–1160, 2007. application-level resource management. In SOSP, pages [32] L. Tang, J. Mars, N. Vachharajani, R. Hundt, and 251–266, 1995. M. L. Soffa. The impact of memory subsystem resource [14] N. Hardavellas, M. Ferdman, B. Falsafi, and sharing on datacenter applications. In ISCA, pages A. Ailamaki. Reactive NUCA: near-optimal block 283–294, 2011. placement and replication in distributed caches. In [33] P. T¨oz¨ un, I. Pandis, R. Johnson, and A. Ailamaki. ISCA, pages 184–195, 2009. Scalable and dynamically balanced shared-everything [15] S. Harizopoulos, D. J. Abadi, S. Madden, and OLTP with physiological partitioning. To appear in M. Stonebraker. OLTP through the looking glass, and The VLDB Journal. what we found there. In SIGMOD, pages 981–992, [34] TPC. TPC benchmark C (OLTP) standard 2008. specification, revision 5.9, 2007. Available at [16] P. Helland. Life beyond distributed transactions: an http://www.tpc.org/tpcc. apostate’s opinion. In CIDR, pages 132–141, 2007. [35] W. Vogels. Eventually consistent. Commun. ACM, [17] R. Johnson, I. Pandis, and A. Ailamaki. Improving 52(1):40–44, 2009. OLTP scalability using speculative lock inheritance. [36] M. Wilson. Disabling NUMA parameter, 2011. PVLDB, 2(1):479–489, 2009. http://www.michaelwilsondba.info/2011/05/disabling- numa-parameter.html. 1458
相关推荐

加关注
3秒后跳转登录页面
去登陆

