












- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
H2O: A Hands-free Adaptive Store
Modern state-of-the-art database systems are designed around a single data storage layout. This is a fixed decision that drives the whole architectural design of a database system, i.e., row-stores, column-stores. However, none of those choices is a universally good solution; different workloads require different storage layouts and data access methods in order to achieve good performance. In this paper, we present the H2O system which introduces two novel concepts.
展开查看详情
1 . H2O: A Hands-free Adaptive Store Ioannis Alagiannis Stratos Idreos‡ Anastasia Ailamaki Ecole Polytechnique Fédérale de Lausanne ‡ Harvard University {ioannis.alagiannis, anastasia.ailamaki}@epfl.ch stratos@seas.harvard.edu ABSTRACT 40 Execution Time (sec) DBMS-C Modern state-of-the-art database systems are designed around a DBMS-R single data storage layout. This is a fixed decision that drives the 30 whole architectural design of a database system, i.e., row-stores, column-stores. However, none of those choices is a universally 20 good solution; different workloads require different storage layouts 10 and data access methods in order to achieve good performance. In this paper, we present the H2 O system which introduces two 0 novel concepts. First, it is flexible to support multiple storage layouts and data access patterns in a single engine. Second, and 2 10 20 30 40 50 60 70 80 90 100 most importantly, it decides on-the-fly, i.e., during query process- Attributes Accessed (%) ing, which design is best for classes of queries and the respective data parts. At any given point in time, parts of the data might Figure 1: Inability of state-of-the-art database systems to main- be materialized in various patterns purely depending on the query tain optimal behavior across different workload patterns. workload; as the workload changes and with every single query, portunities but it also significantly stresses the capabilities of cur- the storage and access patterns continuously adapt. In this way, rent data management engines. More complex scenarios lead to H2 O makes no a priori and fixed decisions on how data should be the need for more complex queries which in turn makes it increas- stored, allowing each single query to enjoy a storage and access ingly more difficult to tune and set-up database systems for modern pattern which is tailored to its specific properties. applications or to maintain systems at a well-tuned state as an ap- We present a detailed analysis of H2 O using both synthetic bench- plication evolves. marks and realistic scientific workloads. We demonstrate that while The Fixed Storage Layout Problem. The way data is stored existing systems cannot achieve maximum performance across all defines how data should be accessed for a given query pattern and workloads, H2 O can always match the best case performance with- thus it defines the maximum performance we may get from a da- out requiring any tuning or workload knowledge. tabase system. Modern state-of-the-art database systems are de- Categories and Subject Descriptors signed around a single data storage layout. This is a fixed de- cision that drives the whole design of the architecture of a data- H.2.2 [Database Management]: Physical Design - Access meth- base system. For example, traditional row-store systems store data ods; H.2.4 [Database Management]: Systems - Query Processing one row at a time [20] while modern column-store systems store General Terms data one column at a time [1]. However, none of those choices is a universally good solution; different workloads require different Algorithms, Design, Performance storage layouts and data access methods in order to achieve good performance. Database systems vendors provide different storage Keywords engines under the same software suite to efficiently support work- Adaptive storage; adaptive hybrids; dynamic operators loads with different characteristics. For example, MySQL supports multiple storage engines (e.g., MyISAM, InnoDB); however, com- 1. INTRODUCTION munication between the different data formats on the storage layer Big Data. Nowadays, modern business and scientific applica- is not possible. More importantly, each storage engine requires a tions accumulate data at an increasingly rapid pace. This data ex- special execution engine, i.e., an engine that knows how to best plosion gives birth to new usage scenarios and data analysis op- access the data stored on each particular format. Example. Figure 1 illustrates an example of how even a well- Permission to make digital or hard copies of all or part of this work for personal or tuned high-performance DBMS cannot efficiently cope with vari- classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full cita- ous workloads. In this example, we test 2 state-of-the-art commer- tion on the first page. Copyrights for components of this work owned by others than cial systems, a row-store DBMS (DBMS-R) and a column-store ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or re- DBMS (DBMS-C). We report the time needed to run a single an- publish, to post on servers or to redistribute to lists, requires prior specific permission alytical select-project-aggregate query in a modern machine. Fig- and/or a fee. Request permissions from permissions@acm.org. ure 1 shows that none of those 2 state-of-the-art systems is a uni- SIGMOD’14, June 22–27, 2014, Snowbird, UT, USA. versally good solution; for different classes of queries (in this case Copyright 2014 ACM 978-1-4503-2376-5/14/06 ...$15.00. http://dx.doi.org/10.1145/2588555.2610502. depending on the number of attributes accessed), a different system
2 .is more appropriate and by a big margin (we discuss the example query patterns, for refining the actual data layouts and for of Figure 1 and its exact set-up in more detail later on). compiling on-the-fly the necessary operators to provide good The root cause for the observed behavior is the fixed data layout access patterns and plans. and the fixed execution strategies used internally by each DBMS. • We show that for dynamic workloads H2 O can outperform These are closely interconnected and define the properties of the solutions based on static data layouts. query engine and, as a result, the final performance. Intuitively, column stores perform better when columns are processed indepen- dently, while row-stores are more suited for queries touching many 2. BACKGROUND AND MOTIVATION attributes. In both systems, the data layout is a static input parame- In this section, we provide the necessary background regarding ter leading to compromised designs. Thus, it restricts these systems the basics of column store and row store layouts and query plans. from adapting when the workload changes. Contrary to common Then we motivate the need for a system that always adapts its stor- belief that column-stores always outperform row-stores for analyt- age and execution strategies. We show that different storage layouts ical queries, we observe that row-stores can show superior perfor- require completely different execution strategies and lead to drasti- mance in a class of workloads which becomes increasingly impor- cally different behavior. tant. Such workloads appear both in business (e.g., network perfor- mance and management applications) and scientific domains (e.g., 2.1 Storage Layout and Query Execution neuro-science, chemical and biological applications) and the com- Row-stores. Traditional DBMS (e.g., Oracle, DB2, SQL Server) mon characteristic is that queries access an increased number of are mainly designed for OLTP-style applications. They follow the attributes from wide tables. For example, neuro-imaging datasets N-ary storage model (NSM) in which data is organized as tuples used to study the structure of human brain consist of more than (rows) and is stored sequentially in slotted pages. The row-store 7000 attributes. In this direction, commercial vendors are continu- data layout is optimized for write-intensive workloads and thus in- ously increasing the support for wide tables e.g., SQL Server today serting new or updating old records is an efficient action. On the allows a total of 30K columns per table while the maximum num- other hand, it may impose an unnecessary overhead both in terms ber of columns per SELECT statement is now at 4096, aiming at of disk and memory bandwidth if only a small subset of the to- serving the requirements of new research fields and applications. tal attributes of a table is needed for a specific query. Regarding Ad-hoc Workloads. If one knows the workload a priori for a query processing, most NSM systems implement the volcano-style given application, then a specialized hybrid system may be used processing model in which data is processed one tuple (or block) which may be perfectly tuned for the given workload [16, 29]. at a time. The tuple at a time model comes with nearly negligible However, if the workload changes a new design is needed to achieve materialization overhead in memory; however, it leads to increased good performance. As more and more applications, businesses instruction misses and a high function call overhead [7, 40]. and scientific domains become data-centric, more systems are con- Column-stores. In contrast, modern column-store DBMS (e.g., fronted with ad-hoc and exploratory workloads where a single de- SybaseIQ [35], Vertica [32], Vectorwise [54], MonetDB [7]) have sign choice cannot cover optimally the whole workload or may been proven the proper match for analytical queries (OLAP ap- even become a bottleneck. As a result modern businesses often plications) since they can efficiently execute queries with specific need to employ several different systems in order to accommodate characteristics such as low projectivity and aggregates. Column- workloads with different properties [52]. stores are inspired by the decomposition storage model (DSM) in H2 O: An Adaptive Hybrid System. An ideal system should be which data is organized as columns and is processed one column able to combine the benefits of all possible storage layouts and ex- at a time. The column-store data layout allows for loading in main ecution strategies. If the workload changes, then the storage layout memory only the relevant attributes for a query and thus signifi- must also change in real time since optimal performance requires cantly reducing I/O cost. Additionally, it can be efficiently com- workload-specific storage layouts and execution strategies. bined with low-level architecture-conscious optimizations and late In this paper, we present the H2 O system that does not make any materialization techniques to further improve performance. On the fixed decisions regarding storage layouts and execution strategies. other hand, reconstructing tuples from multiple columns and up- Instead, H2 O continuously adapts based on the workload. Every dates might become quite expensive. single query is a trigger to decide (or to rethink) how the respective Query Processing. Lets assume the following query. data should be stored and how it should be accessed. New layouts Q1: select a + b + c f rom R where d<v1 and e>v2 are created or old layouts are refined on-the-fly as we process in- In a typical row-store query execution, the system reads the data coming queries. At any given point in time, there may be several pages of relation R and processes single tuples one-by-one accord- different storage formats (e.g., rows, columns, groups of attributes) ing to the operators in the query plan. For Q1, firstly, the query co-existing and several execution strategies used. In addition, the engine performs predicate evaluation for the two conditional state- same piece of data may be stored in more than one formats if differ- ments. Then, if both predicates qualify, it computes the expression ent parts of the query workload need to access it in different ways. in the select clause. The aforementioned steps will be repeated until The result is a query execution engine DBMS that combines Hybrid all the tuples of the table have been processed. storage layouts, Hybrid query plans and dynamic Operators (H2 O). For the same query, a column-store follows a different evaluation Contributions. Our contributions are as follows: procedure. The attributes processed in the query are accessed inde- • We show that fixed data layout approaches can be sub-optimal pendently. Initially, the system reads column d (assuming d is the for the challenges of dynamic workloads. highly selective one) and evaluates the predicate d < X for all the values of column d. The output of this step is a list of tuple IDs of • We show that adaptive data layouts along with hybrid query the qualifying tuples which is used to fetch all the qualifying tuples execution strategies can provide an always tuned system even of e and materialize them in a new intermediate column. Then, the when the workload changes. intermediate column is accessed and the predicate e > Y is evalu- • We discuss in detail lightweight techniques for making on- ated. Finally, a new intermediate list of IDs is created for the qual- the-fly decisions regarding a good storage layout based on ifying tuples considering both predicates in the where clause. The
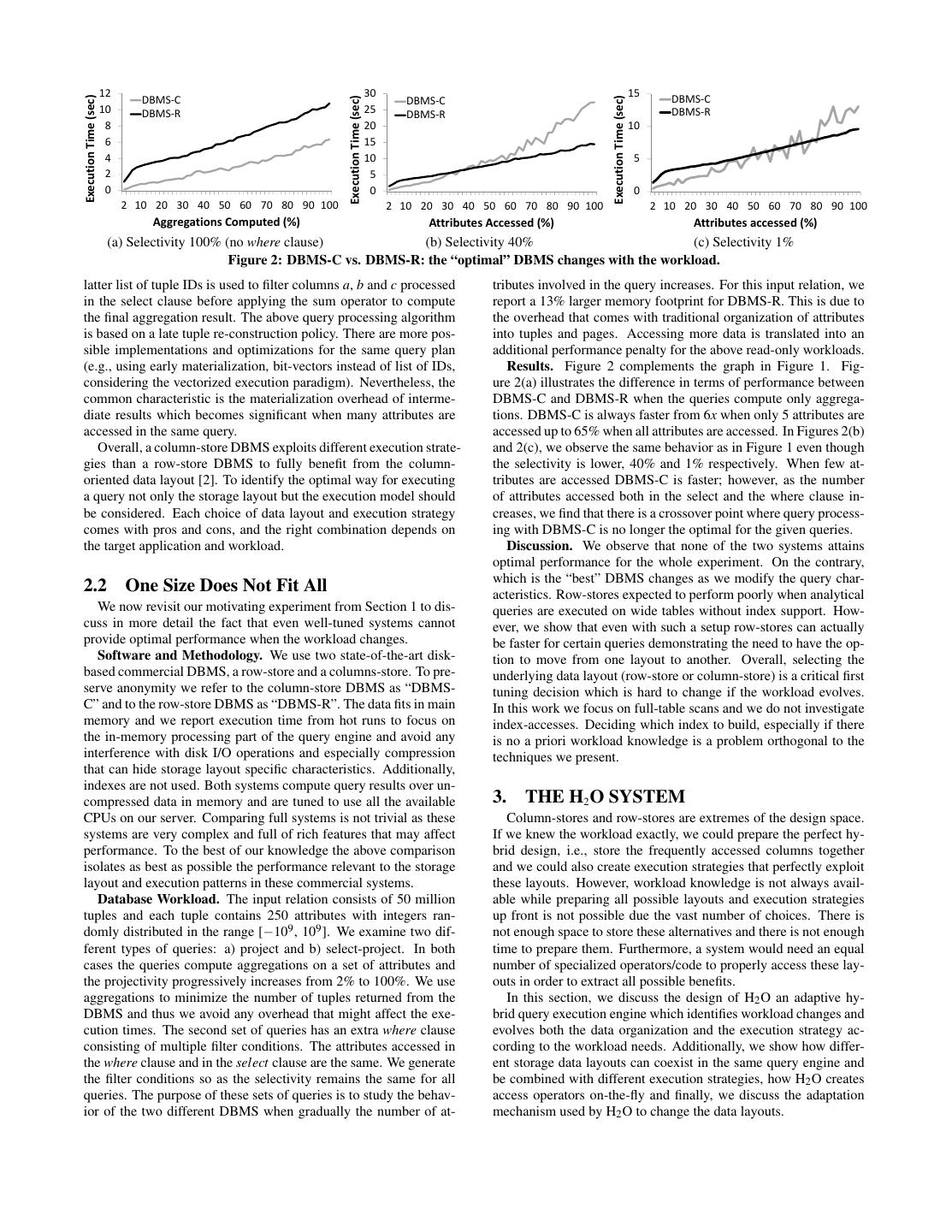
3 .Execution Time (sec) 12 30 15 DBMS-C Execution Time (sec) Execution Time (sec) DBMS-C DBMS-C 10 DBMS-R 25 DBMS-R DBMS-R 8 20 10 6 15 4 10 5 2 5 0 0 0 2 10 20 30 40 50 60 70 80 90 100 2 10 20 30 40 50 60 70 80 90 100 2 10 20 30 40 50 60 70 80 90 100 Aggregations Computed (%) Attributes Accessed (%) Attributes accessed (%) (a) Selectivity 100% (no where clause) (b) Selectivity 40% (c) Selectivity 1% Figure 2: DBMS-C vs. DBMS-R: the “optimal” DBMS changes with the workload. latter list of tuple IDs is used to filter columns a, b and c processed tributes involved in the query increases. For this input relation, we in the select clause before applying the sum operator to compute report a 13% larger memory footprint for DBMS-R. This is due to the final aggregation result. The above query processing algorithm the overhead that comes with traditional organization of attributes is based on a late tuple re-construction policy. There are more pos- into tuples and pages. Accessing more data is translated into an sible implementations and optimizations for the same query plan additional performance penalty for the above read-only workloads. (e.g., using early materialization, bit-vectors instead of list of IDs, Results. Figure 2 complements the graph in Figure 1. Fig- considering the vectorized execution paradigm). Nevertheless, the ure 2(a) illustrates the difference in terms of performance between common characteristic is the materialization overhead of interme- DBMS-C and DBMS-R when the queries compute only aggrega- diate results which becomes significant when many attributes are tions. DBMS-C is always faster from 6x when only 5 attributes are accessed in the same query. accessed up to 65% when all attributes are accessed. In Figures 2(b) Overall, a column-store DBMS exploits different execution strate- and 2(c), we observe the same behavior as in Figure 1 even though gies than a row-store DBMS to fully benefit from the column- the selectivity is lower, 40% and 1% respectively. When few at- oriented data layout [2]. To identify the optimal way for executing tributes are accessed DBMS-C is faster; however, as the number a query not only the storage layout but the execution model should of attributes accessed both in the select and the where clause in- be considered. Each choice of data layout and execution strategy creases, we find that there is a crossover point where query process- comes with pros and cons, and the right combination depends on ing with DBMS-C is no longer the optimal for the given queries. the target application and workload. Discussion. We observe that none of the two systems attains optimal performance for the whole experiment. On the contrary, which is the “best” DBMS changes as we modify the query char- 2.2 One Size Does Not Fit All acteristics. Row-stores expected to perform poorly when analytical We now revisit our motivating experiment from Section 1 to dis- queries are executed on wide tables without index support. How- cuss in more detail the fact that even well-tuned systems cannot ever, we show that even with such a setup row-stores can actually provide optimal performance when the workload changes. be faster for certain queries demonstrating the need to have the op- Software and Methodology. We use two state-of-the-art disk- tion to move from one layout to another. Overall, selecting the based commercial DBMS, a row-store and a columns-store. To pre- underlying data layout (row-store or column-store) is a critical first serve anonymity we refer to the column-store DBMS as “DBMS- tuning decision which is hard to change if the workload evolves. C” and to the row-store DBMS as “DBMS-R”. The data fits in main In this work we focus on full-table scans and we do not investigate memory and we report execution time from hot runs to focus on index-accesses. Deciding which index to build, especially if there the in-memory processing part of the query engine and avoid any is no a priori workload knowledge is a problem orthogonal to the interference with disk I/O operations and especially compression techniques we present. that can hide storage layout specific characteristics. Additionally, indexes are not used. Both systems compute query results over un- compressed data in memory and are tuned to use all the available 3. THE H2 O SYSTEM CPUs on our server. Comparing full systems is not trivial as these Column-stores and row-stores are extremes of the design space. systems are very complex and full of rich features that may affect If we knew the workload exactly, we could prepare the perfect hy- performance. To the best of our knowledge the above comparison brid design, i.e., store the frequently accessed columns together isolates as best as possible the performance relevant to the storage and we could also create execution strategies that perfectly exploit layout and execution patterns in these commercial systems. these layouts. However, workload knowledge is not always avail- Database Workload. The input relation consists of 50 million able while preparing all possible layouts and execution strategies tuples and each tuple contains 250 attributes with integers ran- up front is not possible due the vast number of choices. There is domly distributed in the range [−109 , 109 ]. We examine two dif- not enough space to store these alternatives and there is not enough ferent types of queries: a) project and b) select-project. In both time to prepare them. Furthermore, a system would need an equal cases the queries compute aggregations on a set of attributes and number of specialized operators/code to properly access these lay- the projectivity progressively increases from 2% to 100%. We use outs in order to extract all possible benefits. aggregations to minimize the number of tuples returned from the In this section, we discuss the design of H2 O an adaptive hy- DBMS and thus we avoid any overhead that might affect the exe- brid query execution engine which identifies workload changes and cution times. The second set of queries has an extra where clause evolves both the data organization and the execution strategy ac- consisting of multiple filter conditions. The attributes accessed in cording to the workload needs. Additionally, we show how differ- the where clause and in the select clause are the same. We generate ent storage data layouts can coexist in the same query engine and the filter conditions so as the selectivity remains the same for all be combined with different execution strategies, how H2 O creates queries. The purpose of these sets of queries is to study the behav- access operators on-the-fly and finally, we discuss the adaptation ior of the two different DBMS when gradually the number of at- mechanism used by H2 O to change the data layouts.
4 . a) Column Major Layout b) Row Major Layout c) Group of Columns Query A B C D E A B C D E A B C D E workload Processor a1 b1 c1 d1 e1 a1 b1 c1 d1 e1 a1 b1 c1 d1 e1 a2 b2 c2 d2 e2 a2 b2 c2 d2 e2 a2 b2 c2 d2 e2 Operator a3 b3 c3 d3 e3 a3 b3 c3 d3 e3 a3 b3 c3 d3 e3 Mechanism Adaptation Generator a4 b4 c4 d4 e4 a4 b4 c4 d4 e4 a4 b4 c4 d4 e4 a5 b5 c5 d5 e5 a5 b5 c5 d5 e5 a5 b5 c5 d5 e5 Data Layout Figure 4: Data Layouts. Manager workload. H2 O decides a candidate layout pool by estimating the Figure 3: H2 O architecture. expected benefit and selecting the most fitting solution. Architecture. Figure 3 shows the architecture of H2 O . H2 O sup- Monitoring. H2 O uses a dynamic window of N queries to mon- ports several data layouts and the Data Layout Manager is respon- itor the access patterns of the incoming queries. The window size sible for creating and maintaining the different data layouts. When defines how aggressive or conservative H2 O is and the number of a new query arrives, the Query Processor examines the query and queries from the query history that H2 O considers when evaluating decides how the data will be accessed. It evaluates the alternative the current schema. For a given set of input queries H2 O focuses access plans considering the available data layouts and when the on statistics about attribute usage and frequency of attributes ac- data layout and the execution strategy have been chosen the Op- cessed together. The monitoring window is not static but it adapts erator Generator creates on-the-fly the proper code for the access when significant changes in the statistics happen. H2 O uses the operators. The adaptation mechanism of H2 O is periodically acti- statistics as an indication of the expected queries and to prune the vated to evaluate the current data layouts and propose alternative search space of candidate data layouts. The access patterns are layouts to the Layout Manager. stored in the form of two affinity attribute matrices [38] (one for the where and one for the select clause). Affinity among attributes expresses the extent to which they are accessed together during pro- 3.1 Data Storage Layouts cessing. The basic premise is that attributes accessed together and H2 O supports three types of data layouts: have similar frequencies should be grouped together. Differenti- Row-major. The row-major layout in H2 O follows the typical ating between attributes in the select and the where clause allows way of organizing attributes into tuples and storing tuples sequen- H2 O to consider appropriate data layouts according to the query tially into pages (Figure 4b). Attributes are densely-packed and no access patterns. For example, H2 O can create a data layout for additional space is left for updates. predicates that are often evaluated together. Column-major. In the column-store layout data is organized Alternative Data Layouts. Determining the optimal data lay- into individual columns (Figure 4a). Each column maintains only out for a given workload is equivalent to the well-known prob- the attribute values and we do not store any tuple IDs. lem of vertical partitioning which is NP-hard [48]. Enumerating Groups of Columns. The column-major and row-major layouts through all the possible data layouts is infeasible in practice espe- are the two extremes of the physical data layout design space but cially for tables with many attributes (e.g., a table with 10 attributes not the only options. Groups of columns are hybrid layouts with can be vertically partitioned into 115975 different partitions). Thus, characteristics derived from those extremes. The hybrid layouts are proper heuristic techniques should be applied to prune the immense integral part and the driving force of the adaptive design we have search space without putting at risk the quality of the solution. adopted in H2 O. A group of columns is a vertical partition contain- H2 O starts with the attributes accessed by the queries to gen- ing a subset of the attributes of the original relation (Figure 4c). erate potential data layouts. The initial configuration contains the In H2 O groups of columns are workload-aware vertical parti- narrowest possible groups of columns. When a narrow group of tions used to store together attributes that are frequently accessed columns is accessed by a query, all the attributes in the group are together. Attributes d and e in Figure 4c can be such an example. referenced. Then, the algorithm progressively improves the pro- The width of a group of columns depends on the workload char- posed solution by considering new groups of columns. The new acteristics and can significantly affect the behavior of the system. groups are generated by merging narrow groups with groups gen- Wide groups of columns in which only few attributes are accessed erated in previous iterations. The generation and selection phases decrease memory bandwidth utilization, similarly with a row-major are repeated multiple times until no further improvement is possible layout while a narrow group of columns might come with increased for the input workload. space requirements due to padding. For all the above data layouts, For a given workload W = {q1 , q2 , ..., qn } and a configuration C, we consider fixed length attributes. H2 O evaluates the workload and transformation cost T using the following formula. n 3.2 Continuous Layout Adaptation cost(W,Ci ) = ∑ q j (Ci ) + T (Ci−1 ,Ci ) (1) j=1 H2 O targets dynamic workloads in which data access patterns change and so it needs to continuously adapt. One extreme ap- Intuitively, the initial solution consists of attributes accessed to- proach is to adapt for every query. In this context, every single gether within a query and by merging them together H2 O reduces query can be a potential trigger to change how the respective data the joining overhead of groups. The size of the initial solution is in is stored and how it should be accessed. However, this is feasible the worst case quadratic to the number of narrow partitions and al- in practice only if the cost of generating a new data layout can be lows to effectively prune the search space without putting at risk the amortized over a number of future queries. Covering more than quality of the proposed solution. H2 O considers attributes accessed one query with a new data layout can help to amortize the cost together in the select and the where clause as different potential faster. H2 O gathers statistics regarding the incoming queries. The groups which allows H2 O to examine more executions strategies recent query history is used as a trigger to react in changes of the (e.g., to exploit a group of columns in the where clause to generate
5 .a vector of tuple IDs for the qualifying tuples). H2 O also consid- model [7] in which data is represented as small arrays (vectors). ers the transformation cost from one data layout to another in the Vectors fit in the L1 cache for better cache locality. evaluation method. This is critical, since the benefit of a new data Row-major. The execution strategies for a row-major layout layout depends on the cost of generating it and on how many times follow the volcano execution model. Additionally, predicate evalu- H2 O is going to use it in order to amortize the creation cost. ation is pushed-down to the scan operator for early tuple filtering. Data Reorganization. H2 O combines data reorganization with Column-major. For a column-major layout the execution strat- query processing in order to reduce the time a query has to wait for egy of H2 O materializes intermediate results from filter evaluations a new data layout to be available. Assuming Q1 from Section 2 and into vectors of matching positions. Similarly, it handles the output two data layouts R1(a, b, c) and R2(d, e). The selected data layout of complex arithmetic expressions. For example, in Q1 of Section 2 from the adaptation mechanism requires to merge those two data computing the expression a + b + c results into the materialization layouts into R(a, b, c, d, e). In this case, blocks from R1 and R2 of two intermediate columns, one for a + b and one for the result of are read and stitched together into blocks with tuples (a, b, c, d, e). the addition of the previous intermediate result with c. Then, for each new tuple, the predicates in the where clause are Groups of columns. Regarding group of columns, there is no evaluated and if the tuple qualifies the arithmetic expression in unique execution strategy. Data layouts can apply any of the strate- the select is computed. The early materialization strategy allows gies used for columns-major or row-major layouts. For example, H2 O to generate the data layout and compute the query result with- predicate evaluation can be pushed-down or it can be computed us- out scanning the relation twice. The same strategy is also applied ing vectors of matching positions as in the case of a column-major when the new data layout is a subset of a group of columns. layout. During query processing, H2 O evaluates the alternative ex- H2 O follows a lazy approach to generate new data layouts. It ecution strategies and selects the most appropriate one. does not apply the selected data layout immediately but it waits All executions strategies materialize the output results in mem- until the first query requests a new layout. Then, H2 O creates the ory using contiguous memory blocks in a row-major layout. new data layout as part of the query execution. The source code for the physical operator that generates the new data layout while 3.4 Creating Operators On-the-fly computing the result of the input query is created by applying code The data independence abstraction in databases provides signifi- generation techniques described in Section 3.4. cant flexibility by hiding many low-level details (e.g., how the data Oscillating Workloads. An adaptation algorithm should be able is stored). However, it comes with a hit in performance due to the to detect changes to the workload and act quickly while avoiding considerable interpretation overhead [46]. For example, computing overreacting for temporary changes. Actually, such a trade-off is the qualifying tuples for Q1 from Section 2 using volcano-style pro- part of any adaptation algorithm and it is not specific to H2 O. In cessing requires evaluating a conjunctive boolean expression (d<v1 the case of H2 O, adapting too fast might create additional overhead and e>v2 ) for each one of the tuples. In the generic case, the en- during query processing while slow adaptation might lead to sub- gine needs to be able to compute predicates for all the supported optimal performance. H2 O minimizes the effect of false-positives SQL data types (e.g., integer, double) and additionally complicated due to oscillating workloads by applying the lazy data layouts gen- sub-expressions of arbitrary operators. Thus, a generic operator eration approach described in this subsection. To completely elim- interface leads to spending more time executing function calls and inate the effect of oscillating workloads requires predicting future interpreting code of complex expressions than computing the query queries with high probability; however this is not trivial. H2 O de- result [7]. Column-stores suffer less from the interpretation over- tects workload shifts by comparing new queries with queries ob- head but this comes with the cost of expensive intermediate results served in the previous query window. It examines whether the in- (e.g., need to materialize lists of IDs) and larger source code base put query access pattern is new or if it has been observed with low (e.g., maintain a different operator implementation per data type). frequency. New access patterns are an indication that there might H2 O maintains data into various data layouts and thus to obtain be a shift in the workload. In this case, the adaptation window de- the best performance needs to include the implementation of nu- creases to progressively orchestrate a new adaptation phase while merous execution strategies. when the workload is stable, H2 O increases the adaptation window. For example, having a system that has all the possible code up- front is not possible especially when workload-aware layouts should 3.3 Execution Strategies be combined in the same query plans. The potential combinations Traditional query processing architectures assume not only a fixed of data layouts and access methods are numerous. To compute data layout but predetermined query execution strategies as well. a > X and (a + b) > X requires different physical operators. A For example, in a column-store query plan a predicate in the where generic operator can cover both cases. However, the performance clause is evaluated using vectors of tuple IDs to extract the qualify- will not be optimal due to the interpretation overhead; the over- ing tuples while a query plan for a row-store examines which tuples head of dynamically interpreting complex logic (e.g., expressions qualify one-by-one and then forwards them in the next query oper- of predicates) to low level code. Thus, H2 O creates dynamic oper- ator. In this paper, we show that a data layout should be combined ators for accessing on-the-fly the data referenced from the query with the proper execution strategy in a query plan. To maximize regardless of the way it is internally stored in the system (pure the potential of the selected query plan, tailored code should be cre- columnar or group of columns format). H2 O generates dynamic ated for the query operators in the plan (e.g., in filters it enhances operators not only to reduce the interpretation overhead but also predicate evaluation). Having multiple data layouts in H2 O also in order to combine workload-specific data layouts and execution requires to support the proper execution strategies. Having differ- strategies in the same access operator. ent execution strategies means providing different implementations To generate layout-aware access operators, H2 O uses source code integrated in the H2 O query engine. templates. Each template provides a high-level structure for dif- H2 O provides multiple execution strategies and adaptively se- ferent query plans (e.g., filter tuples with or without list of tuple lects the best combination of data layout and execution strategy ac- IDs). Internally, a template invokes functions that generate the spe- cording to the requirements of the input query. Execution strategies cialized code for specific basic operations; for example, accessing in H2 O are designed according to the vectorized query processing specific attributes in a tuple, evaluate boolean expressions, express
6 . 1 // Compiled equivalent of vectorized primitive output buffer for storing the result of the expression a + b + c for 2 // Input: Column group R(a,b,c,d,e) the qualifying tuples. For each tuple H2 O evaluates in one step the 3 // For each tuple evaluate both predicates in one step two predicates for the conditional statement (Line 9) pushing down 4 // Compute arithmetic expression for qualifying tuples 5 long q1_single_column_group(const int n, the selection to the scan operator. If both predicates are true then 6 const T∗ res, T∗ R, T∗ val1, T∗ val2) { the arithmetic expression in the select clause is computed. The 7 int i, j = 0; code is tailored for the characteristics of the available data layout 8 const T ∗ptr = R; 9 for ( i = 0 ; i < n; i++) { and query. It fully utilizes the attributes in the data layout and thus 10 if ( ptr[3] < ∗val1 && ptr[4] > ∗val2) avoids unnecessary memory accesses. Additionally, it is CPU effi- 11 res[j++] = ptr[0] + ptr[1] + ptr[2]; cient (the filter and the arithmetic expression are computed without 12 ptr = getNextTuple(i); 13 } any overhead) while it does not require any intermediate results. 14 return j; This code can be part of a more complex query plan. 15 } The second on-the-fly code in Figure 6 is generated assuming Figure 5: Generated code for Q1 when all the data is stored in two available groups of columns R1(a, b, c) and R2(d, e) storing a single column group. the attributes in the select and where clause respectively. Since there are two groups of columns we can adopt a different execution 1 // Compiled equivalent of vectorized primitives strategy to optimize performance. In this case, the generated code 2 // Input: Column groups R1(a,b,c) and R2(d,e) 3 // For each batch of tuples call exploits the two column groups by initiating a column-store like 4 nsel = q1_sel_vector(n, sel, R2, val1, val2); execution strategy. The query is computed using two functions; 5 q1_compute_expression(nsel, res, R1, sel); one for tuple selection and one for computing the expression. Ini- 6 7 // Compute arithmetic expression using the positions from sel tially, a selection vector containing the IDs of the qualifying tuples 8 void q1_compute_expression(const int n, is computed. The selection vector is again computed in one step 9 const T∗ res, T∗ R1, int∗ sel) { by evaluating the predicates together. The code that computes the 10 int i = 0; arithmetic expression takes as parameter the selection vector, ad- 11 const T ∗ptr = R1; 12 if (sel == NULL) { ditionally to the group of columns and the values val1 and val2. 13 for ( i = 0 ; i < n; i++) { Then, it evaluates the expression only for the tuple with these IDs 14 res[i] = ptr[0] + ptr[1] + ptr[2]; and thus, avoiding unnecessary computation. On the other hand, 15 ptr = getNextTuple(i); } 16 } else { the materialization of the selection vector is required. 17 for ( i = 0 ; i < n; i++) { 18 ptr = getNextTuple(sel, i); 3.5 Query Cost Model 19 res[sel[i]] = ptr[0] + ptr[1] + ptr[2]; } 20 } To select the optimal combination of data layout and execution 21 } strategy, H2 O evaluates different access methods for the available 22 data layouts and estimates the expected execution cost. The query 23 // Compute selection vector sel for both predicates in R2(d,e) cost estimation is computed using the following formula: 24 int q1_sel_vector(const int n, 25 const T∗ sel, T∗ R2, T∗ val1, T∗ val2) { |L| 26 int i, j = 0; 27 const T ∗ptr = R2; q(L) = ∑ max(costiIO , costiCPU ) (2) 28 for ( i = 0 ; i < n; i++) { i=1 29 if ( ptr[0] < ∗val1 && ptr[1] > ∗val2) For a given query q and a set of data layouts L, H2 O considers the 30 sel[j++] = i; 31 ptr = getNextTuple(i); I/O and CPU cost for accessing the layouts during query process- 32 } ing. The cost model assumes that disk I/O and CPU operations 33 return j; overlap. In practice, when data is read from disk, disk accesses 34 } dominate the overall query cost since disk access latency is orders Figure 6: Generated code for Q1 when the needed attributes of magnitude higher than main-memory latency. are stored into two different column groups. H2 O distinguishes between row-major and column-major lay- outs. Groups of columns are modeled similarly to the row-major complex arithmetic expressions, perform type casting, etc. The layouts. The cost of sequential I/O is calculated as the amount of code generation procedure takes as input the needed data layouts data accessed (e.g., number of tuples multiplied by the average tu- from the data layout manager and the set of attributes required by ple width for a row) divided by the bandwidth of the hard disk the query, selects the proper template and generates as an output while the cost of random I/O additionally considers block accesses the source code of the access operator. The source code is com- and read buffers (e..g, through a buffer pool). piled using an external compiler into a library and then, the new H2 O estimates the CPU cost based on the number of cache misses library is dynamically linked and injected in the query execution incurred when a data layout is processed. Data cache misses have plan. To minimize the overhead of code generation, H2 O stores significant impact (due to cache misses cause CPU-stalls) on query newly generated operators into a cache. If the same operator is re- processing [5] and thus, they can provide a good indication regard- quested by a future query, H2 O accesses it directly from the cache. ing the expected execution cost of query plans. A data cache miss The available query templates in H2 O support select-project-join occurs when a cache line has to be fetched from a higher level in queries and can be extended by writing new query operators. the memory hierarchy, stalling the current instruction until needed Example. Figures 5 and 6 show two dynamically compiled data is available. For a given query Q and a given data layout L equivalents of vectorized primitives for access operators for two the cost model computes the number of data cache misses based different data layouts. on the data layout width, the number of tuples and the number of Figure 5 shows the generated code when all the accessed at- data words accessed for an access pattern following an approach tributes for Q1 (a, b, c, d, e) are stored in the same column group. similar to [16]. The cost of accessing intermediate results is also The on-the-fly code takes as input the group of columns, the con- considered. This is important since not all execution strategies in stant values val1 and val2 used for the predicate evaluation and an H2 O generate intermediate results.
7 .4. EXPERIMENTAL ANALYSIS Row-store Column-store H2 O In this section, we present a detailed experimental analysis of 538.2 sec 283.7 sec 204.7 sec H2 O. We show that H2 O can gracefully adapt to changing work- Table 1: Cumulative Execution Time of the Queries in Figure 7. loads by automatically adjusting the physical data layout and au- tomatically producing the appropriate query processing strategies comparison against the theoretical case of having perfect workload and access code. In addition, we present a sensitivity analysis on knowledge and ample time to prepare the layout for each query. the basic parameters that affect the behavior of H2 O such as which For this experiment, relation R is initially stored in a column- physical layout is best for different types of queries. We examine major format. This is the more desirable starting point as it is eas- how H2 O performs in comparison with approaches that use a static ier to morph to other layouts. However, H2 O can adapt regardless data layout advisor. We use both fine tuned micro-benchmarks and of the initial data layout. The initial data layout affects the query the real-life workload SDSS from the SkyServer project.1 performance of the first few queries only. We discuss such an ex- The main benefit of hybrid data layouts comes during scan oper- periment in detail later on. ations which are responsible for touching the majority of the data. Initially, H2 O executes queries using the available data layout. In our analysis, we focus on scan based queries and we do not con- In this way, we see in Figure 7 that H2 O matches the behavior sider joins. In an efficient modern design a join implemented as in of the column-store system. Periodically, though, H2 O activates memory cache conscious join, e.g., radix join [36], would typically the adaptation mechanism and evaluates the current status of the compute the join using only the join keys with positions (row ids) system (set initially at a window size of 20 queries here but this being the payload. Thus, the actual data layout of the data will have window size also adaptively adjusts as the workload stabilizes or little effect during the join. On the other hand, post join projection changes more rapidly). H2 O identifies groups of columns that are will be affected positively (compared to using full rows) as we can being accessed together in queries (e.g., 5 out of the 20 queries re- fetch the payload columns from hybrid layouts. fer to attributes a1 , a5 , a8 , a9 , a10 ). Then, H2 O evaluates alternative System Implementation. We have designed and implemented data layouts and execution strategies and creates a candidate list of a H2 O prototype from scratch using C++ with all the functional- 4 new groups of columns. H2 O does not create the new layout im- ity of adaptively generating data layouts and the supporting code. mediately. This happens only if a query refers to the attributes in Our code-generation techniques use a layer of C++ macros to gen- this group of columns and can benefit from the creation of the new erate tailored code. The compilation overhead in our experiments data layout. These estimations are performed using the cost model. varies from 10 to 150 ms and depends on the query complexity. Following Query 20, and having the new candidate layouts as Orthogonally to this work, the compilation overhead can be further possible future layouts, in the next 10 queries, 2 out of the 4 can- reduced by using the LLVM framework [34]. In all experiments, didate groups of columns are created. This happens for queries 23 the compilation overhead is included in the query execution time. and 29 and these queries pay the overhead of creating the new data Experimental Setup. All experiments are conducted in a Sandy layout. Query 23 pays a significant part of the creation overhead; Bridge server with a dual socket Intel(R) Xeon(R) CPU E5-2660 (8 however, 4 queries use the new data layouts and enjoy optimal per- cores per socket @ 2.20 GHz), equipped with 64 KB L1 cache and formance. From query 29 up to query 68 no data reorganization 256 KB L2 cache per core, 20 MB L3 cache shared, and 128 GB is required. Another data reorganization takes place after 80 and a RAMrunning Red Hat Enterprise Linux 6.3 (Santiago - 64bit) with new data layout is added to H2 O . kernel version 2.6.32. The server is equipped with a RAID-0 of 7 There are queries for which H2 O cannot match the optimal per- 250 GB 7500 RPM SATA disks. The compiler used is icc 13.0.0. formance. For example a group of columns is better for queries 2 to 8; however, there is no query that triggers the adaptation mech- 4.1 Adapting to Workload Changes anism. In the end of the first evaluation it recognizes the change in the workload and proposes the needed data layouts. For 80% of In this experiment, we demonstrate how H2 O automatically adapts the queries H2 O executes queries using a column group data layout to changes in the workload and how it manages to always stay close while for the rest of the queries it uses a column-major layout. For to the optimal performance (as if we had perfectly tuned the system the given workload a row-major data layout is suboptimal. a priori assuming enough workload knowledge). Overall, we observe that H2 O outperforms both the static column- Micro-benchmark. Here we compare H2 O against a column- store and row-store alternative approaches by 38% and 1.6x re- store implementation and a row-store implementation. In both cases, spectively, as shown in Table 1. More importantly it can adapt to we use our own engines which share the same design principles and workload changes, meaning that it can be used in scenarios where much of the code base with H2 O; thus these comparisons purely re- otherwise more than one systems would be necessary. Query per- flect the differences in data layouts and access patterns. formance in H2 O gets closer to the optimal case without requiring For this experiment we use a relation R of 100 million tuples. a priori workload knowledge. Each tuple consists of 150 attributes with integer values randomly H2 O using Real Workload. In this experiment, we evaluate generated in −109 , 109 . We execute a sequence of 100 queries. H2 O using the SkyServer workload. We test against a scenario The queries are select-project-aggregation queries and each query where we use AutoPart [41], an offline physical, design tool for refers to z randomly selected attributes of R, where z = [10, 30]. vertical partitioning, in order to get the best possible physical de- Figure 7 plots the response time for each query in the work- sign recommendation. For the experiment, we use a subset of the load, i.e., we see the query processing performance as the workload “PhotoObjAll” table which is the most commonly used and 250 of evolves. In addition to H2 O, column-store and row-store, we plot a the SkyServer queries. Figure 8 shows that H2 O manages to out- fourth curve in Figure 7 which represents the optimal performance; perform the choices of the offline tool. By being able to adapt to that is, the performance we would get for each single query if we individual queries as opposed to the whole workload we can opti- had a perfectly tailored data layout as well as the most appropri- mize performance even more than an offline tool. ate code to access the data (without including the cost of creating Dynamic window. In this experiment, we show how H2 O bene- the data layout). We did this manually assuming for the sake of fits from a dynamic adaptation window when the workload changes. 1 http://skyserver.sdss.org We use as input the same relation R as in the previous experiment
8 . Query Response Time (sec) 8 Row-store Column-store Optimal H2O 7 6 5 4 3 2 1 0 0 10 20 30 40 50 60 70 80 90 100 Query Sequence Figure 7: H2 O vs. Row-store vs. Column-store. 800 Query Execution 10 Execution Time (sec) Static window Execution Time (sec) Layout Creation 8 Dynamic window 600 6 400 4 200 2 0 0 AutoPart H2O 0 10 20 30 40 50 60 Query Sequence Figure 8: H2 O vs. AutoPart on the SkyServer workload. Figure 9: Static vs. dynamic adaptation window. in which data this time is organized in a row-major format and a query sequence of 60 queries. Each query refers 5 to 20 attributes. ii. “select max(a), max(b),..., f rom R where <predicates>” for The queries compute arithmetic expressions. The first 15 queries aggregations focus on a set of 20 specific attributes while the other 45 queries to iii. “select a + b + ... f rom R where <predicates>” for arithmetic a different one. We compare two variations of H2 O, with static and expressions with dynamic window. The size of the window is 30 queries. The accessed attributes are randomly generated. The cost of cre- Figure 9 depicts the benefit of the dynamic window. H2 O with ating each group of columns layout is not considered in the mea- dynamic window detects the shift in the workload after the 15th surements. We examine queries with and without where clause. In query and progressively decreases the window size to force a new Figures 10(a-c) we vary the number of attributes accessed from 5 to adaptation phase. The adaptation algorithm is finally triggered in 150 while there is no where clause. In Figures 10(d-f) each query the 25th query generating new groups of columns layouts that can accesses 20 attributes randomly selected from R while one of these efficiently serve the rest of the workload. On the other hand, when attributes is the predicate in the where clause. We progressively using a static window we cannot adapt and we have to wait until vary selectivity from 0.1% to 100%. Figure 10 depicts the results the 30th query before generating new layouts and thus fails to adapt (in all graphs the y-axis is in log scale). We report numbers from quickly to the new workload. Overall, H2 O with dynamic windows hot runs and each data point we report is the average of 5 execu- manages to adapt to changes in the workload following even if they tions. We discuss each case in detail below. do not happen in a periodic way. Projections. Figure 10(a) plots the query execution time for the three alternative data layouts as we increase the projected attributes 4.2 H2O: Sensitivity Analysis while there is no where clause in the queries. The group of columns Next, we discuss a sensitivity analysis of various parameters that layout outperforms the row-major and column-major layouts re- affect the design and behavior of H2 O . For the experiments in this gardless of the number of projected attributes. For projections of section, we use a relation R containing 100 million tuples. Each tu- less than 30 attributes a column-major layout is faster than the row- ple contains 150 attributes with integer values randomly generated major layout; however, when more than 20% of the attributes are in the range −109 , 109 . referenced, performance falls up to 15X due to the high tuple recon- struction cost. As expected performance of the row-major layout 4.2.1 Effect of Data Layouts and of groups of columns matches when all attributes are accessed. In this experiment, we present the behavior of the different data For the same query template (i), in Figure 10(d) we additionally layouts integrated in H2 O using queries with different character- consider the effect of predicates in the where clause. We keep the istics. Queries are executed using column-major, row-major and number of projected attributes the same (20 attributes) while we group of columns layouts. Each group of columns contains only the vary selectivity from 0.1% to 100%. Regardless of the selectivity attributes accessed by the query. All queries are executed using the working with groups of columns is faster than using the other two H2 O custom operators. We use as input a wide table (100 million data layouts. tuples, 150 attributes) to stress test H2 O and examine how some Aggregations. Figure 10(b) shows the response time as we in- representative query types behave as we increased the number of crease the number of aggregations in the queries. Using a column- attributes accessed. We consider simple select project queries and major layout outperforms the other two data layouts. The biggest queries which compute aggregations and arithmetic expressions. performance difference is when 5 aggregations are computed 1.5X Queries are based on variations of the following templates: and 15X from the group of columns layout and the row-major lay- i. “select a, b, ..., f rom R where <predicates>” for projections out respectively. The gap between groups of columns and column-
9 . Execution Time (sec) Execution Time (sec) Execution Time (sec) 100 10 10 10 1 1 1 H2O - Row H2O - Row H2O - Row H2O - Group of Columns H2O - Group of Columns H2O - Group of Columns H2O - Column H2O - Column H2O - Column 0.1 0.1 0.1 5 15 25 35 45 55 65 75 85 95 105 115 125 135 145 5 15 25 35 45 55 65 75 85 95 105 115 125 135 145 5 15 25 35 45 55 65 75 85 95 105 115 125 135 145 # Attributes Projected # Attributes Aggregated # Attributes Accessed (a) (b) (c) 10 10 Execution Time (sec) 10 Execution Time (sec) Execution Time (sec) 1 1 1 H2O - Row H2O - Row H2O - Row H2O - Group of Columns H2O - Group of Columns H2O - Group of Columns H2O - Column H2O - Column H2O - Column 0.1 0.1 0.1 0% 10% 20% 30% 40% 50% 60% 70% 80% 90%100% 0% 10% 20% 30% 40% 50% 60% 70% 80% 90%100% 0% 10% 20% 30% 40% 50% 60% 70% 80% 90%100% Selectivity Selectivity Selectivity (d) (e) (f) Figure 10: Basic operators of H2 O. major layout gets smaller as more aggregations are computed. The selected out of the 30 attributes of the column group. We examine group of columns layout improves the performance in comparison the difference in performance for queries with 1%, 10%, 50% and to the row-major layout by reducing cache misses. 100% selectivity using the same attribute in the where clause. For In Figure 10(e) we vary the selectivity of a query that com- each query, we compare the execution time with the optimal case putes 20 aggregations. The column-major layout and the group in which a tailored data layout has been created containing only the of columns layout clearly outperform the row-major layout. The needed attributes to answer this particular query. column-major layout is slightly faster than the row-major layout for Figure 11 depicts the results. It shows the performance penalty low selectivities but as selectivity increases the group of columns to access the whole column group as opposed to accessing the per- layout is marginally faster. fect column group as a ratio. The graph plots the results for each Arithmetic Expressions. Figure 10(c) plots the execution time query grouped according to the selectivity. We observe that as less for each one of the data layouts as we vary the number of attributes useful attributes are accessed the higher the performance penalty. accessed to compute an arithmetic expression. Group of columns This penalty varies with the number of useful attributes accessed. surpasses the column-major layout from 42% when few attributes For example, when only 5 out of the 30 attributes of the group of are accessed up to 3X when more accesses required. The differ- columns are accessed, we observe the most significant drop in per- ence in performance is due to the cost of having to materialize in- formance, up to 142%. This drop is due to the unnecessary memory termediate results in case of the column-major layout. On the other accesses in comparison with the optimal group of columns. On the hand, combining a group of columns with volcano-style executions other hand, when a query accesses 25 out of the 30 attributes the allows for avoiding this overhead. overhead is almost negligible (3% in the worse case). Figure 10(f) plots execution time for queries based on the third Other than queries having to access only a subset of a column template with where clause. The results show that the group of group, another important case is when a single query needs to ac- columns layout has superior performance for the whole selectivity cess multiple column groups. The question for an adaptive system range since does not require the usage of intermediate results. in this case is whether we should build a new column group to fit Discussion. All the above data layouts are part of H2 O. H2 O com- the query or fetch the data from existing column groups. To study bines them with the proper execution strategies to always achieve this problem, we use an aggregation with filter query Q that refers the best performance. H2 O explores this design space to generate 25 attributes from R. We vary the number of groups of columns the cache friendly operators without intermediate results if possible. query has to access from 2 to 5. In each case, the union of groups of columns contains all the needed attributes. For example, when 2 column groups are accessed, the first column group contains 10 4.2.2 Effect of Groups of Columns of the needed attributes and the second column group the remain- At any given point in time, H2 O maintains multiple layouts. Typ- ing 15 attributes. We experiment with selectivity 1%, 10%, 50% ically these are multiple column groups since plain column-major and 100%. We compare the response time of Q using the optimal or row-major extreme cases. In this way, one reasonable question column group with the cases we have to increase the number of is how does performance vary depending on which column group accessed groups of columns. Figure 12 plots the response of each we access. It might be that we do not always have available the op- query normalized by the response time of queries accessing all the timal column group or we have to fetch the data needed for a single attributes in a single group of columns. Accessing more than one query from multiple column groups or we have to access a given group of columns in the same query does not necessarily impose column group containing more columns than the ones we need. an additional overhead. On the contrary, combining two groups of We first test the case where queries need to access only a sub- columns might even be beneficial for highly selective queries. set of the attributes stored in a column group. Here, we use a Discussion. Accessing only a subset of the attributes of a col- group of 30 randomly selected attributes from R. The queries com- umn group, accessing multiple column groups or accessing mul- pute aggregations with filter following the template presented in tiple groups each one containing a subset of the columns needed the previous subsection, accessing 5, 10, 15, 20 and 25 randomly
10 .Performance Decrease (%) ~142% ~128% ~105% Normalized Response Time 100 1.4 2 Groups 3 Groups 4 Groups 5 Groups 25 attrs 20 attrs 15 attrs 10 attrs 1.2 80 5 attrs 1 60 0.8 40 0.6 0.4 20 0.2 0 0 1% 10% 50% 100% 1% 10% 50% 100% Selectivity Selectivity Figure 11: Accessing a subset of a column group. Figure 12: Accessing more than one group of columns. 10 8 Generated Code Execution Time (sec) Execution Time (sec) Offline 7 8 Online Generic Operator 6 6 5 4 4 3 2 2 1 0 0 Q1 Q2 Q3 Q4 Q1-Row Q2-Row Q1-Group of Q2-Group of Columns Columns Figure 13: Online vs. Offline reorganization. Figure 14: Generic Operator vs. Generated Code. are few of the important scenarios when multiple column groups step. The online case is faster regardless of the storage of the initial co-exist. The previous experiments show that groups of columns relation and the width of the new column group. The improve- can be effective even if not the optimal group of columns is avail- ment varies from 22% to 37% when the initial relation is stored able and thus it is ok to extend monitoring periods and not to react in a columnar layout and from 38% to 61% when the initial data instantly to changes in the workload in this case. Additionally, nar- is in a row-oriented layout. For all cases online reorganization is row groups of columns can be gracefully combined in the same significantly faster than performing the same operation offline. By query operator without imposing significant overhead. overlapping execution and data organization H2 O manages to im- prove significantly the overall execution time of the two tasks. 4.2.3 Data Reorganization H2 O adapts continuously to the workload. One approach would 4.2.4 Importance of Dynamic Operators be to separate the preparation of data layouts from query process- In this experiment, we showcase the benefit of creating tailored ing. Instead H2 O answers an incoming query while adapting the code on-the-fly to match the available data layouts. The set-up is physical layout for this queries. This is achieved by generating an as follows. Q1 is an aggregation and Q2 is an arithmetic expres- operator that integrates the creation of a new data layout and the sion query following the templates presented in Section 4.2.1 and code needed to answer the query in one physical operator accessing 20 out of the 150 attributes of R. We test the execution In this experiment we show that online adaptation brings signif- time achieved by a generic database operator versus an operator icant benefits. The set up is as follows. We assume that two new that uses tailored code created on the fly to match the underly- groups of columns are created from relation R (100 million tuples, ing layout. We examine the effect both for row-major layout and 100 attributes with integer values). The first one contains 10 and groups of columns. The code generation time is included in the the second 25 attributes. In the offline case, the column groups overall query execution time of the dynamically generated operator are created and then queries are executed while in the online case and varies from 63 ms to 84 ms. Figure 14 shows the results. We the column group creation and the query execution overlap. We observe from 16% up to 1.7x performance improvement by creat- test two scenarios. In the first scenario the initial layout is row- ing tailored code which is due to removing the interpretation over- major (Q1 and Q2) while in the second scenario the initial layout is head. This justifies the choices in H2 O in creating fully adaptive column-major (Q3 and Q4). In both cases, we test the cost to trans- layouts and code on the fly. form those initial layouts into the optimal set of column groups for a set of queries. We use two queries in each scenario. Q1 and Q3 trigger the generation of a new group of columns which contains 10 attributes, while Q2 and Q4 create a group of 20 columns. The 5. RELATED WORK queries compute 10 and 20 aggregations (without where clause) re- A large body of recent work both in industry and academia pro- spectively on the attributes of the new layouts. pose different flavors of hybrid solutions to cope with the recent Figure 13 shows the results. The offline bars depict the cumu- data deluge, complex workloads and hardware changes. The need lative response time for creating the column group and executing for hybrid approaches is especially amplified when trying to pro- the query as two separate steps, i.e., first the data layout is created vide a unified solution for workloads with different characteristics. separately and only then we can process the queries. The special- In this section, we review this body of related work and we high- ized operator generated by H2 O performs the same tasks but in one light how our work pushes the state-of-the-art even further.
11 . A Case for Hybrid Systems. Recent research ideas have rec- operations. Blink assigns particular columns into banks trying to ognized the potential of exploring different physical data repre- minimize padding overhead and wasted space. sentations under a unified processing system [43, 11]. Fractured All approaches above provide valuable design alternatives. How- mirrors [43] exploit the benefits of both NSM and DSM layouts ever, one still needs to know the workload before deciding which in the same system. Data is duplicated in both storage layouts system to use and needs multiple of those systems to accommo- and queries are executed using the appropriate mirror. This path date varying workloads. H2 O pushes the state-of-the-art further by has been recently adopted in industry, by the main-memory DBMS providing a design which continuously adapts to the workload. SAP HANA [12] which combines OLTP and OLAP workloads in Auto-tuning Techniques. In the past years, there has been con- the same system. Similarly, SQL Server which provides a row-store siderable work on automated physical design tuning. These tech- memory-optimized database engine for OLTP applications and an niques facilitate the process of automatically selecting auxiliary in-memory data warehouse using ColumnStore Index for OLAP data structures (e.g., indices, materialize views) for a given work- applications [33]. The hybrid approach of mixing of columnar and load to improve performance. Offline approaches [3, 8, 41] assume row-oriented representations in the same tablespace provided by a priori knowledge of the workload and cannot cope with dynamic DB2 with BLU Acceleration [45] is the most related with H2 O. scenarios while online approaches [49] try to overcome this lim- In addition, HyPer [29], a main-memory hybrid workload system, itation by monitoring and periodically tuning the system. Online combines the benefits of OLTP and OLAP database by executing partitioning [28] adapts the database partitions to fit the observed mixed workloads of analytical and transactional queries in parallel workload. However, the above approaches are designed assuming on the same database. Furthermore, recent vision works highlight a static data layout while the execution strategies remain fixed. the importance of hybrid designs. RodentStore [10] envisions a Adapting Storage to Queries with Adaptive Indexing. Adap- hybrid system which can be tuned through a declarative storage al- tive indexing [13, 14, 15, 17, 23, 24, 25, 27, 50] tackles the problem gebra interface while Idreos et al. [22] presents the idea of a fully of evolving workloads in the context of column-stores by building adaptive system that directly reads raw files and stores data in a and refining partial indexes during query processing. The moto of query driven way. adaptive indexing is that the “queries define how the data should The above hybrid approaches expand the capabilities of con- be stored”. We share this motivation here as we also adapt the stor- ventional systems to support mixed workloads assuming, however, age layout on-the-fly based on queries. However, adaptive indexing static (pre-configured) data layouts and thus cannot cope with dy- research has focused on refining the physical order of data within namic workloads. a single column at a time without considering co-locating values Our work here is focused on dynamic environments to enable across columns. The work on partial sideways cracking considers quick reactions and exploration when the workload is not known multiple columns [25] but what it does is to physically reorganize up front and with limited time to invest in initialization costs. It more than one columns in the same way as opposed to enforcing focuses on hybrid data layouts for analytical workloads providing co-location of values from multiple columns as we do here. a fully adaptive approach both at the storage and the execution level In addition, the interest in systems with hybrid storage layouts to efficiently support dynamic workloads. In that respect, we also has given rise to layout-aware workload analysis tools. Data mor- share common ground with other early works in exploration based phing [18] uses a cache miss cost model to select the proper at- techniques, e.g., [6, 10, 22, 26, 30, 37]. tribute grouping within an individual page that maximizes perfor- Layout and Workload-aware Optimizations. When consid- mance for a given workload. The hybrid engine HYRISE [16] ap- ering hybrid architectures, most existing approaches are centered plies the same idea and presents an offline physical deign tool that around storage aspects, i.e., they optimize the way tuples are stored uses a cache misses cost model to evaluate the expected perfor- inside a database page and the proper way of exploiting them dur- mance of different data partitions and proposes the proper verti- ing query processing. Harizopoulos et al. [19] explore performance cal partitioning for a given workload. A storage advisor for SAP trade-offs between column- and row-oriented architectures in the HANA database is presented by Rösch et al. [47] considering both, context of read-optimized systems showing that the DSM layout queries and data characteristics, to propose horizontal and vertical performs better when only few attributes are accessed. Zukowski partitioning schemas. H2 O extends AutoPart [41], an offline ver- et al. [55] present a comprehensive analysis of the overheads of tical partitioning algorithm to work for dynamic scenarios. The DSM and NSM models and show that combining the two layouts above approaches use a static storage layout that is determined in the same plan can be highly beneficial for complex queries. when the relation is created, are optimized assuming a known work- Organizing attributes into groups either inside the data blocks load and cannot adapt to dynamic changes in the workload. In this or the data pages extends the traditional space of NSM and DSM paper, we highlight that no static layout can be optimal for every layouts with cache-friendly layouts allowing for workload specific query and we design a system that can autonomously refine its stor- optimizations. To improve cache locality of traditional NSM, Aila- age layouts and execution strategies as the workload evolves. maki et al. [4] introduce a page layout called PAX. In PAX, data is Just-In-Time Compilation. Compilation of SQL queries into globally organized in NSM pages, while inside the page attributes native code goes back to System R [9]. Recently, there have been are organized into vertical partitions optimizing for reducing the many efforts to take advantage of dynamic translation techniques, number of cache misses. A generalization of PAX layout is pro- such as Just-In-Time (JiT) compilation in the context of DBMS posed in data morphing [18], where the tuples in a page can be to alleviate the interpretation overhead of generic expressions, im- stored in an even more flexible form combining vertical decompo- prove data locality, generate architecture specific source code and sition and arbitrary groups of attributes and increasing spatial lo- thus, significantly enhance performance. JiT techniques have been cality. Multi-resolution Block Storage Model [53] stores attributes applied to main-memory DBMS using the LLVM framework [39, columnwise as PAX maintaining cache efficiency and groups disk 34], column-stores [51], group of column systems [42] and stream blocks into “super-blocks" with tuples stored among the blocks of processing systems [21] to generate code for the whole query ex- a super-block improving I/O performance of scan operations. In ecution plan [31], to revise specific code segments or to generate a similar fashion, Blink [44] vertically partitions columns in byte- building primitives for higher-order composite operators. H2 O ap- aligned column groups called banks, allowing for efficient ALU plies similar techniques to generate layout-aware access operators.
12 .6. CONCLUSIONS [18] R. Hankins and J. Patel. Data morphing: An adaptive, cache-conscious storage technique. In VLDB, 2003. Traditional systems use a static and fixed design regarding data [19] S. Harizopoulos, V. Liang, D. Abadi, and S. Madden. Performance tradeoffs in layouts. However, as applications become more and more data- read-optimized databases. In VLDB, 2006. driven and with ad-hoc workloads it becomes increasingly hard for [20] J. Hellerstein, M. Stonebraker, and J. R. Hamilton. Architecture of a database a single traditional system, i.e., with a fixed layout, to be able to system. Foundations and Trends in Databases, 1(2):141–259, 2007. [21] M. Hirzel et al. IBM streams processing language: Analyzing big data in efficiently cover a multitude of scenarios. In this way, today it is motion. IBM Journal of Research and Development, 57(3/4):7, 2013. not uncommon for businesses to employ more than one systems. [22] S. Idreos, I. Alagiannis, R. Johnson, and A. Ailamaki. Here are my data files. In this paper, we showcase the problem that for analytical queries Here are my queries. Where are my results? In CIDR, 2011. multiple layouts can be beneficial depending on the query work- [23] S. Idreos, M. L. Kersten, and S. Manegold. Database cracking. In CIDR, 2007. load. To get the optimal performance, we not only need the opti- [24] S. Idreos, M. L. Kersten, and S. Manegold. Updating a cracked database. In SIGMOD, 2007. mal layout but also query processing strategies and access operator [25] S. Idreos, M. L. Kersten, and S. Manegold. Self-organizing tuple reconstruction code that are tailored for a given layout. All these together reduce in column-stores. In SIGMOD, 2009. cache misses, instruction misses and interpretation overhead dur- [26] S. Idreos and E. Liarou. dbTouch: Analytics at your fingertips. In CIDR, 2013. ing query execution. We propose H2 O, a system that adaptively [27] S. Idreos, S. Manegold, H. Kuno, and G. Graefe. Merging what’s cracked, cracking what’s merged: adaptive indexing in main-memory column-stores. and continuously adjusts all three of these elements. It generates PVLDB, 4(9), 2011. on-the-fly the appropriate layouts, execution strategies and code to [28] A. Jindal and J. Dittrich. Relax and let the database do the partitioning online. match the workload, as the workload evolves. Using both syn- In BIRTE, 2011. thetic benchmarks and real life experiments, we demonstrate that [29] A. Kemper and T. Neumann. Hyper: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In ICDE, 2011. H2 O gracefully adapts as workloads change and stays close to the [30] M. L. Kersten, S. Idreos, S. Manegold, and E. Liarou. The researcher’s guide to optimal performance without requiring any workload knowledge. the data deluge: Querying a scientific database in just a few seconds. PVLDB, Adaptive systems in which new data layouts are created or old 4(12):1474–1477, 2011. layouts are refined on-the-fly as incoming queries are processed can [31] K. Krikellas, S. Viglas, and M. Cintra. Generating code for holistic query evaluation. In ICDE, 2010. create new exciting research paths. For example, one challenging [32] A. Lamb et al. The Vertica analytic database: C-Store 7 years later. PVLDB, area with potential high impact is to study (adaptive) indexing to- 5(12):1790–1801, 2012. gether with adaptive data layouts and execution strategies. [33] P.-Å. Larson et al. Enhancements to SQL Server column stores. In SIGMOD, 2013. Acknowledgments. The authors would like to thank the anony- [34] C. Lattner and V. Adve. LLVM: A compilation framework for lifelong program mous reviewers for their valuable comments and suggestions on analysis & transformation. In CGO, 2004. how to improve the paper. This work has been supported by the EU [35] R. MacNicol and B. French. Sybase IQ Multiplex - designed for analytics. In FP7, project No. 317858 “BigFoot - Big Data Analytics of Digi- VLDB, 2004. [36] S. Manegold, P. Boncz, and M. Kersten. Optimizing database architecture for tal Footprints” and Swiss National Science Foundation, project No. the new bottleneck: memory access. VLDB J., 9(3):231–246, 2000. CRSII2 136318/1, “Trustworthy Cloud Storage”. [37] A. Nandi and H. V.Jagadish. Guided interaction: Rethinking the query-result paradigm. In VLDB, 2011. [38] S. Navathe, S. Ceri, G. Wiederhold, and J. Dou. Vertical partitioning algorithms 7. REFERENCES for database design. ACM Trans. Database Syst., 9(4):680–710, 1984. [1] D. Abadi, P. Boncz, S. Harizopoulos, S. Idreos, and S. Madden. The design and [39] T. Neumann. Efficiently compiling efficient query plans for modern hardware. implementation of modern column-oriented database systems. Foundations and PVLDB, 4(9):539–550, 2011. Trends in Databases, 5(3):197–280, 2013. [40] S. Padmanabhan, T. Malkemus, R. Agarwal, and A. Jhingran. Block oriented [2] D. Abadi, S. Madden, and N. Hachem. Column-stores vs. row-stores: how processing of relational database operations in modern computer architectures. different are they really? In SIGMOD, 2008. In ICDE, 2001. [3] S. Agrawal, V. Narasayya, and B. Yang. Integrating vertical and horizontal [41] S. Papadomanolakis and A. Ailamaki. AutoPart: Automating schema design for partitioning into automated physical database design. In SIGMOD, 2004. large scientific databases using data partitioning. In SSDBM, 2004. [4] A. Ailamaki, D. DeWitt, M. Hill, and M. Skounakis. Weaving relations for [42] H. Pirk et al. CPU and cache efficient management of memory-resident cache performance. In VLDB, 2001. databases. In ICDE, 2013. [5] A. Ailamaki, D. DeWitt, M. Hill, and D. Wood. DBMSs on a modern [43] R. Ramamurthy, D. DeWitt, and Q. Su. A case for fractured mirrors. VLDB J., processor: Where does time go? In VLDB, 1999. 12(2):89–101, 2003. [6] I. Alagiannis, R. Borovica, M. Branco, S. Idreos, and A. Ailamaki. NoDB: [44] V. Raman et al. Constant-time query processing. In ICDE, 2008. efficient query execution on raw data files. In SIGMOD, 2012. [45] V. Raman et al. DB2 with BLU acceleration: So much more than just a column [7] P. Boncz, M. Zukowski, and N. Nes. MonetDB/X100: Hyper-pipelining query store. PVLDB, 6(11):1080–1091, 2013. execution. In CIDR, 2005. [46] J. Rao, H. Pirahesh, C. Mohan, and G. M. Lohman. Compiled query execution [8] N. Bruno and S. Chaudhuri. Automatic physical database tuning: A engine using JVM. In ICDE, 2006. relaxation-based approach. In SIGMOD, 2005. [47] P. Rösch, L. Dannecker, G. Hackenbroich, and F. Faerber. A storage advisor for [9] D. Chamberlin et al. A history and evaluation of System R. Commun. ACM, hybrid-store databases. PVLDB, 5(12):1748–1758, 2012. 24(10):632–646, 1981. [48] D. Saccà and G. Wiederhold. Database partitioning in a cluster of processors. [10] P. Cudré-Mauroux, E. Wu, and S. Madden. The case for RodentStore: An ACM Trans. Database Syst., 10(1):29–56, 1985. adaptive, declarative storage system. In CIDR, 2009. [49] K. Schnaitter, S. Abiteboul, T. Milo, and N. Polyzotis. COLT: continuous [11] J. Dittrich and A. Jindal. Towards a one size fits all database architecture. In on-line tuning. In SIGMOD, 2006. CIDR, 2011. [50] F. M. Schuhknecht, A. Jindal, and J. Dittrich. The Uncracked Pieces in [12] F. Färber et al. SAP HANA database: data management for modern business Database Cracking. PVLDB, 7(2), 2013. applications. SIGMOD Record, 40(4):45–51, 2011. [51] J. Sompolski, M. Zukowski, and P. Boncz. Vectorization vs. compilation in [13] G. Graefe, F. Halim, S. Idreos, H. A. Kuno, and S. Manegold. Concurrency query execution. In DaMoN, 2011. control for adaptive indexing. PVLDB, 5(7):656–667, 2012. [52] M. Stonebraker and U. Çetintemel. “One size fits all”: An idea whose time has [14] G. Graefe, F. Halim, S. Idreos, H. A. Kuno, S. Manegold, and B. Seeger. come and gone. In ICDE, 2005. Transactional support for adaptive indexing. VLDB J., 23(2):303–328, 2014. [53] J. Zhou and K. Ross. A multi-resolution block storage model for database [15] G. Graefe and H. Kuno. Self-selecting, self-tuning, incrementally optimized design. In IDEAS, 2003. indexes. In EDBT, 2010. [54] M. Zukowski and P. Boncz. Vectorwise: Beyond column stores. IEEE Data [16] M. Grund, J. Krüger, H. Plattner, A. Zeier, P. Cudré-Mauroux, and S. Madden. Eng. Bull., 35(1):21–27, 2012. HYRISE - a main memory hybrid storage engine. PVLDB, 4(2):105–116, 2010. [55] M. Zukowski, N. Nes, and P. Boncz. DSM vs. NSM: CPU performance [17] F. Halim, S. Idreos, P. Karras, and R. Yap. Stochastic database cracking: tradeoffs in block-oriented query processing. In DaMoN, pages 47–54, 2008. Towards robust adaptive indexing in main-memory column-stores. PVLDB, 5(6):502–513, 2012.
相关推荐

加关注
3秒后跳转登录页面
去登陆

