














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Algorithm for a High-performance Memory-resident Database System
Wrth memory prrces droppmg and memory slaes mcreasmg accordrngly, a number of researchers are addressmg the problem of desrgnmg hrgh-performance database systems for managing memory-restdent data In thus paper we address the recovery problem m the context of such a system We argue that exrstmg database recovery schemes fall short of meetmg the reqmrements of such a system, and we present a new recovery mechamsm whrch IS designed to overcome therr
展开查看详情
1 . A Recovery Algorithm for A High-Performance Memory-Resident Database System Tobm J. Lehman Michael J. Carey Computer Sciences Department Computer Sciences Department IBM Almaden Research Center University of Wlsconsm-Madison Abstract resrdent database system can offer srgmficant perfor- mance rmprovements over disk-resrdent database sys- Wrth memory prrces droppmg and memory slaes m- tems through the use of memory-based, instead of drsk- creasmg accordrngly, a number of researchers are ad- based, algortthms [Ammann 85, DeWrtt 84, Dewitt dressmg the problem of desrgnmg hrgh-performance 85, Lehman 86a, Lehman 86b, Lehman 86c, Salem 86, database systems for managing memory-restdent data Shaprro 86, Thompson 861 Wrth the potentral perfor- In thus paper we address the recovery problem m the mance gain, however, comes an Increased dependency context of such a system We argue that exrstmg on the database recovery mechamsm database recovery schemes fall short of meetmg the re- A memory-resident database system IS more vulner- qmrements of such a system, and we present a new re- able to farlures Power loss, chip burnout, hardware covery mechamsm whrch IS designed to overcome therr errors, or software errors (e g , an erroneous program shortcommgs The proposed mechamsm takes advan- causrng a “runaway” CPU) can corrupt the pnmary tage of a few megabytes of rehable memory m order to copy of the database A stable backup copy of the orgamae recovery mformatron on a per “obJect” basrs database must be mamtarned rn order to restore all or As a result, It IS able to amortme the cost of check- part of the memory-resrdent copy after a failure Simple pomts over a controllable number of updates, and rt battery-backup memory IS affordable, but rt 1s not nec- IS also able to separate post-crash recovery mto two essanly rebable and rt 1s not immune to software errors, phases-hrgh-speed recovery of data whrch IS needed so It 1s not a complete eolutron to the memory-resident rmmedrately by transacttons, and background recov- database system recovery problem Large memorres ery of the remammg portions of the database A turn- that are both stable and reha5le are both expensive and ple performance analysrs IS undertaken, and the results potentrally slow-It is drfficult to say Just how expen- suggest our mechamsm should perform well m a hrgh- save or slow these types of memones are because they performance, memory-resrdent database envrronment are not widely avarlable Usmg current technology as a gmde, we bekeve that m the near future stable and reliable memory will be available rn sines on the order of 1 INTRODUCTION tens of megabytes and wrll have read/wnte performance two to four trmes slower than regular memory of the Memory-resrdent database systems are an attractrve same technology-too slow and too small to use for the alternatrve to drsk-resrdent database systems when entire marn memory, but large and fast enough to use the database fits m mam memory ’ A memory- as a stable buffer Using this stable rehable buffer, we attempt to desrgn of a set of recovery algorrthms that Tlus research wa, partially supported by an IBM Fcl- both functron correctly for memory-resrdent database lowrhlp, an IBM Faculty Development Award, and Natlonal systems and perform sufficrently well to warrant bemg Science Foundation Grant Number DCR-8402818 used rn a hrgh-performance database system envrron- ‘It II urually the case that the enttre database wzll not fit m the amount of memory avsllable, but xt may often be ment the case that a large amount of the frequently accessed data 1.1 Lessons Learned From Disk- PermIssIon to copy wlthout fee all or part of this material IS granted Based Recovery Methods provided that the copies are not made or dlstrlbuted for direct commercial advantage, the ACM copyrtght notlce and the title of Memory-resident database systems have recovery needs the pubhcatlon and Its date appear, and notlce 1sgiven that copymg srmrlar to those of drsk-restdent database systems IS by permlsslon of the Assoclatlon for Computing Machmery To Indeed, almost any drsk-onented recovery algorrthm copy otherwise, or to repubhsh, requires a fee and/or specfic --_ permission will fit For the present, we are concerned only with the memory-resident database as a self-contamed umt 0 1987 ACM 0-89791-236-5/87/0005/0104 754 104
2 .would juncfron correctly In a memory-readent database process However, the problem with usmg such an “off system environment In any database system, the mam the shelf” disk-onented recovery scheme for a memory- purpose of the recovery mechamsm 1s to restore the pn- resident database system 1s that the performance of the mary copy of the database to Its most recent consistent recovery mechamsm would probably be poor m those state after a fadure A disk-onented system IS slmdar cases where the entire memory-rendent database, the to a memory-resident system m the handhng of trans- “buffer”, must be wntten to disk (as m a checkpoint action commit, as both types of systems need to record operation) or read from disk (as In a system restart nt- the effects of the transaction on some stable storage de- uatlon) Furthermore, a memory-resident database sys- vice In this sectlon we descnbe how some disk-oriented tem appears to be able to obtain performance gams by recovery designs handle the transaction commit proce- ebmmatlng the buffer manager altogether [Lehman 86a, dure Smce we do not have space m this paper to de- Lehman 88~1, so buffer-oriented recovery algonthms scnbe these algorithms completely, we must refer the must be modified to reflect a “memory-resident” ap- reader to the literature for further details [Kohler 81, proach rather than a “buffer-pool” approach We must Haerder 83, Reuter 841 take a closer look at the requirements of a memory- When a transaction has updated some portlon of the resident system m order to design proper memory- database and 1s ready to make Its changes permanent, resident database recovery algonthms We first exam- there are several ways to handle the commit procedure me previous work on memory-resident database system 1 The transaction could flush all oflts updated pages recovery [Dewitt 84, Ammann 86, Elch 86, Hagmann to the database residing on disk, as In the TWIST 86, Leland 86, Salem 861 algonthm [Reuter 841 2 The transaction could flush all oflts updated pages 1.2 Memory-Resident Database to a separate device, thereby allowmg It to write Recovery Proposals all of the dirty pages m one action usmg chslned I/O, as m the Database Cache algonthm [Elhardt Recovery designs for memory-resident database systems 841 have not been very different from those for disk-resident 3 The transactlon could make shadow copies of up- database systems, with one notable exceptlon IBM’s dated pages to slmpllfy post-crash recovery, while IMS FASTPATH [IBM 79, IBM 841 FASTPATH was still mamtalmng a record-level log of updates, as In the first to mtroduce the notlon of cotnm~t groupr The the System R recovery algonthm [Lone 77, Gray basic idea of commit groups 1s to amortize the cost of log I/O synchromzatlon over several transactions rather 811 than JUSt a smgle transactlon Where a amgle transac- 4 The transaction could wnte a record-level log of tion would normally wait for its log mformatlon to be the updates that It has performed (using the wnte- flushed to disk before comnuttmg and releasing locks, ahead-log protocol [Gray 78]), and penodlcally group commit allows It to prccommaf, whereby Its log m- take checkpotdr to refresh the database and keep formation IS stdl m volatile memory (not yet flushed to the amount of log data small, as m the Lmdsay cl disk), but Its locks are released anyway The log mfor- al algorithm [Lindsay 791 matlon of several transactions accumulates, bemg writ- In [Reuter 841, Reuter analyzed the four methods ten to disk when the log buffer fills up Ftnally, once the mentloned above and found that, for a disk-oriented log lnformatlon arrives safely on disk, the transaction system, method (4) [Lindsay 791 outperformed the rest, officially commits This techmque allows transactions method (3) [Lorle 771 was also found to perform well accessmg the same lnformatlon to “overlap” somewhat, when the page table was memory-rendent These meth- thus mcreasmg concurrency and transaction through- ods are deslgned to produce little processmg overhead put Note that there 1s no danger of a database update during normal transaction processmg, however, some arnvmg at the disk before the correspondmg log record, log processmg IS reqmred for transaction UNDO or sys- as the database update stays (only) In memory, In the tem restart Tks appears to be the best approach for a special case of a checkpomt, the log would be forced high-performance database system, as UNDO process- to disk first DeWltt et at [DeWltt 841 point out that mg 1s typically done only for approumately 3 percent of a stable log buffer memory can also be used to allow all transactlons [Gray 781, and restart 1s needed rarely transactions to commit without log I/O synchromza- m most systems The Database Cache and TWIST al- tlon, at the expense of makmg the log buffer memory gonthms, on the other hand, Involve larger processmg both stable and rehable A stable log buffer provides overheads for normal transaction processmg, as they are the addltlonal advantage of allowlng the recovery mech- designed to provide support for fast UNDO processmg anism to post-process the cornnutted log data, perform- and fast system restarts mg log compression or change accumulation From exammmg disk-onented database systems, In performing database checkpomts, the memory- then, It appears that method (4) would provide a good resident database system recovery proposals do not dlf- baas for a memory-resident algorithm Its wnte-ahead fer much from disk-onented methods, they flush the log protocol usmg record-level log records appears to dirty portion of the buffer to stable storage Dewitt be a good method for handling the transaction commit et al [Dewitt 841 propose first creating a shadow copy 105
3 .of the dirty portron of the database and then writing checkpoint copy of the database and log mformatron rt to disk Erch [Erch 861 proposes writing the dirty The two processors run Independently and commum- portion of the database to drsk when the database sys- cate through a buffer area rn the Stable Log Buffer tem naturally qmesces (though this seems likely to be a The mam CPU performs regular transactron rare event m a high-performance database system) Fr- processing-its only loggmg functron is to write a trans- nally, Hagmann [Hagmann 863 proposes simply stream- action’s log records to the Stable Log Buffer The recov- ing the entire memory copy of the database to disk for ery manager, running on the recovery CPU, reads log a checkpomt In a sense, these methods each treat the records from the Stable Log Buffer that belong to com- database as a single obJect instead of a collection of nutted transactrons and places them mto bms (called smaller obJects-for post-crash recovery, these meth- par~rtcon Qrnr) In the Stable Log Tall accordmg to the ods will reload the entire database and process the log address of the partrtron to whrch they refer Each partl- before the database IS ready for transactron processing tron having outstanding log mformatron IS represented to resume m the Stable Log Tall by such a partrtron bm Each It IS often the case that a transaction can run wrth partition bin holds BED0 log records and other mls- only a small portion of the database present m mem- cellaneous log information pertammg to its partrtron ory A more flexible recovery method would recover Partrtrons having outstandmg log rnformatlon are re- the data that transactrons need In order to run on ferred to as o&we a demand basis, allowing transaction processing and As partition bins become full, they are written out to general recovery to proceed In parallel We propose the log disk, log pages for a given partition are charned a design for a recovery component that provides hrgh- together for recovery purposes Grouping log records speed loggmg, efficient checkpomtmg, and a post-crash accordmg to therr correspondmg partrtrons In the Sta- recovery phase that enables transaction processmg to ble Log Tall allows the recovery manager to keep track resume qurckly In the next section we describe our of the update activity on mdrvrdual partrtrons When new memory-resident database system recovery algo- a partrtron has accumulated a specrtled threshold count rithm In Section three, we provide a simple analysis of log records, It IS marked to be checkpomted, and thus that supports our claim of high performance Section the cost of checkpomt operatrons are amortrzed over a four concludes the paper controlled number of update operations Grouping log records also has another srgmficant advantage-It al- lows partrtrons to be recovered independently 2 A NEW RECOVERY After a crash, the recovery manager restores the database system catalogs and then signals the trans- METHOD action manager to begn processmg As each transac- tion requests access to relatrons and mdrces, the trans- In order to descnbe our recovery scheme more clearly, we need to describe rt m the context of our intended action manager checks to make sure that these obJects are available, and, If not, mrtrates recovery transactrons Marn Memory Database Management System (MM- DBMS) architecture [Lehman 86bJ The mam feature to restore them on a per partition basis In the remainder of this sectron the supportmg hard- of relevance here IS its orgamzatron of memory Every ware for the recovery mechanism IS presented, then, database obJect (relation, index, or system data struc- details of the recovery algonthms, mcludrng regular ture) 1s stored rn its own logmal segment Segments are logging, checkpomtrng, recovery, and archive loggrng, composed of one or more fixed-size partrtlons, whrch are described A simple performance analysis of the are the unit of memory allocatron for the underlying logging, checkpomtmg, and recovery algonthms 1s pro- memory mapping hardware (We use the word partr- vided m Section 3 tron rather than page to avoid any preconcerved notions about the uses of a partition ) Partrtrons represent a complete umt of storage, database entltres (tuples or 2.2 Hardware Organization mdex components) are stored m partitions and do not The hardware architecture for the recovery mechamsm cross partition boundarres r Partrtrons are also used IS composed of a recovery CPU, several megabytes of as the umt of transfer to disk rn checkpoint operatrons reliable, stable main memory, and a set of drsks The re- covery CPU has access to all of the stable memory, and 2.1 Overview of Proposal the mam CPU has access to at least part of the stable memory The two CPU’s could both address all of mem- The proposed memory-resrdent database recovery ory (both volatrle and nonvolatrle), or they could share scheme uses two Independent processors, a mam proces- only the address space of the Stable Log Buffer To al- sor and a recovery processor, stable memory comprrsmg low more flexrbrhty m the actual hardware design, and two different log components, a Stable Log Buffer and also to provide better rsolatron of faults, our algorithms a Stable Log Tall, and disk memory to hold both a require the two CPU’s to share only the address space “Long fields, such as those used to hold voxe or lmsge of the Stable Log Buffer, usmg rt as a commumcatron data, are managed by a separate mechamrm not descrrbed buffer along with Its other uses Also, though the re- here covery duties could be performed by a process running 106
4 . records belongmg to commltted transactlons from the Stable Log Buffer and places them Into partltlon bms m the Stable Log Tall Last, the psrtltlon bm pages of REDO log records m the Stable Log Tall are wrltten to disk when they become full These three steps are dlscussed in more detad below 2.3.1 Writing Log Records TransactIons write log records to two places REDO log records are placed m the Stable Log Buffer and UNDO log records are placed m the volatile UNDO space REDO log records are kept m stable memory so that transactlons can comnut Instantly-they do not need to wait until the REDO log records are flushed to disk UNDO log records are not kept In stable mem- Figure 1 Recovery Mechamsm Arclutecture ory because they are not needed after a transaction commits-the memory-resident database system does not allow modified, uncomnutted data to be wntten to on one of many processors of a multlprocessor, a dedl- the stable disk database A log record corresponds to cated recovery processor (or even a dedicated recovery an entity In a partltlon a relation tuple or an index mult:processor) can take advantage of speclahaatlon by structure component An entity IS referenced by Its havmg closer ties with the log disk controllers and run- memory address (Segment Number, Partltlon Number, nmg a special nummal operating system The disks are and Partltlon Offset) dlvlded into two groups and used for different purposes Both the volatde UNDO space and the Stable Log One set of disks holds checkpomt mformatlon, and the The Buffer (SLB) are managed as a set of fixed-are blocks other set of (duplexed) disks holds log mformatlon These blocks are allocated to transactions on a demand recovery CPU manages the log disks, and both the re- baas, and a gven block will be dedicated to a single covery CPU and the mam CPU manage the checkpoint transaction durmg Its hfetlme As a result, crltlcal sec- disks Figure 1 shows the basic layout of the system tions are used only for block allocatlon - they are not a The two processors have logically different functions part of the log wntmg process itself Because of these The main CPU IS responsible for transaction process- separate lists, transactions do not have to synchronize mg, while the recovery CPU manages logging, check- with each other to wnte to the log Therefore, having pomtmg operations, and archive storage Although the each transaction manage Its own log record hst greatly two sets of tasks could be done by a smgle processor, amehorates the tradltlonal “hot spot” problem of the It 1s apparent that there 1s a large amount of paral- log tall lehsm possible Indeed, although only two processors The chains of log blocks for a transactlon will appear are mentloned, each CPU could even perhaps be a mul- on one of two hsts, the committed transaction list or tlprocessor which further exploits parallehsm wlthm Its the uncommitted transaction hst When a transaction own component In dlscussmg the design, however, we commits, its REDO log block cham IS removed from refer to only two CPU8 the uncommitted list and appended to the committed transaction list, and Its UNDO log block cham 1s du- 2.3 Regular Logging carded (Figure 2) The comnutted transaction hst IS maintained m commit order so that the log records can The loggmg component manages two logs one log holds be sent to disk m this order regular audit trail data such as the contents of the mes- sage that lmtlates the transactlon, time of day, user 2.5.2 Log Record Format data, efc , and the other holds the REDO/UNDO m- formatlon for the transaction The audit trail log IS Log records have different formats depending on the managed In a manner described by Dewitt cf al [De- type of database entity that they correspond to (re- Watt 841 and uses stable memory We concentrate on lation tuples or index components) and on the type of the REDO/UNDO log, as It 1s responsible for mamtam- operation that they represent All log records have four mg database consistency and 1s the maJor focal point main parts of recovery The REDO/UNDO loggmg procedure 1s composed of TAG 1 Bm Index 1 Tran Id 1 Operation three tasks First, transactlons create both REDO and UNDO log records, the REDO log records are placed TAG refers to the type of log record, Ban Indez 1s the mto the Stable Log Buffer, and the UNDO records are index into the part&on bm table where the log record placed into a volatile UNDO space Second, the recov- will be relocated, !Z’ran Id IS the transaction Identifier, ery manager (runmng on the recovery CPU) reads log and Operafron identifies the REDO operation for the 107
5 . Stable Memory Log Tad :-----‘- ___ - _--__-_ _---- SIable Redo lnfomlallal (SIable lag St&r) ’ 7-1 - xidr-4. op-18 Tl - e-3. op_lb Tl - ad&J. op_lc = - addrg. l3 - addr-8. %a op-3s Q _-_ I L ____---_ - - --k-K~ Figure 2 Wrbng Log Records Figure 3 Regular Tmusactlon Loggmg entrty The bm index 1s a drrect index mto the partrtron correspondrng log rnformatron IS no longer needed bm table, and It IS used to locate the proper partrtron for memory recovery bm log page for an entrty’s log record Partrtlons mam- 3 Redundant address mformatron may be stnpped tam then partrtron bm index entnes as part of their from the log records before they are wntten to control rnformatron, so a bm index entry IS easrly lo- drsk, thereby condensing the log cated given the address of any of Its entitles (The next section drscusses this m more detail ) Log records are read from the Stable Log Buffer and Relation log records may specrfy REDO values for placed mto partrtron bms rn the Stable Log Tall (Fig- specrfic entitles, so m one sense they are o&e log ure 3) Each log record IS read, Its bm mdex field IS records However, they may also specrfy operatrons that used to calculate the memory address of the log page of entail updating the stnng space m a partrtron, which 1s the record’s partrtron bin, and the log record IS copied managed as a heap and 1s not locked m a two-phase mto that log page There are two mam possibrhtres for manner, so relation log records are really operat:on log orgamsmg the log bm table there could be an entry m records for a partrtron Index log records specify REDO the table for every exrstrng partrtron m the database, operatrons for mdex components (e g , T Tree nodes or or there could be an entry for every active partrtron Modrfied Linear Hash nodes [Lehman SSc]) A single (Recall that an active partrtron IS one that has been mdex update operatron may affect several mdex compo- updated smce Its last checkpomt, so rt has outstand- nents, so a log record must be wntten for each updated mg log mformatron ) Smce the bm index should not be mdex component To marntam seriahaabrhty and to sparse, bin mdex numbers must be allocated and freed, hke fixed blocks of memory If every partrtron were rep- srmplrfy UNDO processmg for transactrons, mdex com- ponents and relation tuples are locked wrth two-phase resented m the log bm table, then bm index numbers locks [Eswaran 761 that are held until transaction com- would be allocated and de-allocated infrequently-only mlt as often as partrtrons are allocated and de-allocated However, rf only the aciec partrtrons were represented m the log brn table, then bm mdex numbers would be 2.3.3 Grouping Log Records by Partition allocated when partrtlons are activated and reclaimed The mam purpose of the Stable Log Tall IS to pro- when they are de-activated, thereby causmg the brn m- vide a stable storage environment where log records can dex number resource manager to be activated more fre- be grouped accordmg to their correspondmg partrtrons quently For srmphuty m design, we assume that each The recovery manager uses this for several things partrtron has a small permanent entry m the partrtron bm table This requires an informatron block m the 1 The log records correspondmg to a partrtlon are Stable Log Tar1 for each partrtron m the database, but collected m page sme units and wntten to disk only active partltrons requrre the much larger log page The log pages for a partition are linked, thus al- buffer The amount of stable reliable memory required lowing all the pages of a partmular partrtron to be for the Stable Log Tall depends on the total number located easily dunng recovery of partrtrons m the database and the number of active 2 The number of log records for each partrtron IS partitions Each partition uses a small amount-on the recorded, so the checkpomt mechamsm can wnte order of 50 bytes, and each active partition requires a those partrtrons that have a specrtled amount of log page buffer-on the order of 2 to 16 kilobytes (de- log mformatron to disk, thus amortrmng the cost pending on log page suse) of a checkpontt operation over many update opera- Each partrtron has an mformatron block rn Its log bm tions Once a partrtron has been checkpomted, Its contarnmg the followmg entnes 108
6 . Partrtron Address (Segment Number, Partrtron Number) Update Count LSN of First Log Page Log Page Directory The Parid:on Addrcrr IS attached to each page of log records that IS wntten to drsk The entry serves as a consistency check dunng recovery so that the recovery manager can be assured of havmg the correct page It also allows the log pages of a partition to be located when the log 1s used for archive recovery The Update Gouni and the LSN of Arrt Log Page are monitors used to tngger a checkpomt operatron for a Fqure 4 Log Page Drrectorres partition The update count reflects the number of up- dates that have been performed on the partrtron When the update count exceeds a predetermmed threshold, of the pages was read (which IS the Arst page needed the partrtron IS marked for a checkpornt operation The for recovery processmg) Instead, a directory allows log Log Sequence Number of the Arst log page of a partrtron pages to be read rn the order that they are needed dur- shows when the partrtron’s Arst log page was wntten, rt mg recovery The sme of the directory IS chosen to be IS the address of the oldest of the partrtron’s log pages equal to the median number of log pages for an active When a partition IS infrequently updated, It wrll have partrtron so that, dunng recovery, It should often be the few log pages and they wdl be spread out over the en- case that the log pages wrll be able to be read rn order trre log space The avarlable log space remains constant, This allows the log records from one page to be used and It IS reused over time The log space holding cur- while the log records from the next page are being read rently active log mformatron 1s referred to as the log off of the log disk wmdow The log window 1s a Axed amount of log disk If fewer than N (the directory sme) log pages have space that moves forward through the total disk space been wntten, the directory points to all of the log pages as new log pages are wrrtten to it, so some actrve log for the partition (Figure 4(a)) When more than N log mformatron may fall off the end To allow log space pages have been wntten, the directory will be stored rn to be reused, partrtrons are checkpomted If they have every Nth log page old log rnformatron that IS about to fall off the end of the log wmdow (There will actually be a grace penod 2.2.4 Flushing Log Records to the Log Disk between when the checkpomt IS tnggered and when the log space really needs to be reused ) When the log records of a partrtron fill up a log page, the If the log space were mtlnrte, all partition checkpomts records are written to the log disk The recovery CPU would be tnggered by the update count However, since rssues a disk wnte request for that page and allocates the log space IS Amte, infrequently updated partrtlons another page to take Its place (The memory holdmg wdl have to be checkpointed before they are able to the old page IS then released after the drsk wnte has suc- accumulate a sufflcrent number of updates In this case, cessfully Amshed ) The recovery CPU can issue a disk we say that those partrtrons were checkpomted because wnte request with little effort because It IS a dedicated of age This works as follows The recovery manager processor, It 1s using real memory, and rt IS probably mamtams an ordered hst of the Arst log pages of all running a smgle thread of execution (or at least a mm- active partttrons Whenever the log wmdow advances rmal operatmg system) It needs to do little more than due to a log page being wrrtten, this Fcrrt LSN list IS append a disk write request to the drsk device queue checked for any partition whose Arst log page extends that points to the memory page to be wntten beyond the log window boundary When a partrtron becomes active rt IS placed on the First LSN lrst, and 2.4 Regular Checkpointing when It IS checkpomted rt IS removed from the list The head of the hst holds the oldest partrtron, so only a As explained earher, the main purpose of a checkpomt single test on thus hst IS necessary when checking for operation IS to bound the log space used for partrtrons the possrbrlrty of generating a checkpomt due to age by writing to drsk those partitions that have exceeded a The Log Page Dlrecfory holds pointers to a number predetlned number of log records Its secondary purpose of log pages for a pven partrtron (Figure 4) During LSto reclarm the log space of partrtrons that have to be recovery, REDO log records must be apphed m the or- checkpomted because of age When the recovery man- der that they were onqnally written If log pages were ager (running In the recovery CPU) determmes that a chamed In order from most recently to least recently partition should be checkpomted, either due to update wntten, whrch IS the reverse of the order needed, then count or age, rt tells the main CPU that the partrtron log records could not begin to be applied until the last IS ready for a checkpoint vra a commumcatron buffer rn 109
7 . the Stable Log Buffer The recovery manager enters the Stable Log Buffer between transections For each pertltlon’a address m the buffer along with e flag that pertltlon checkpoint request that It finds, It starts represents the status of the checkpomt for that pertl- a checkpomt trensectlon to reed the specified per- tlon, mltlelly this flag 1s m the requerf state, It changes tltlon from the database end wnte It to the check- to the In-progrerr state while the checkpomt IS runmng, point disk, and It also sets the checkpoint status end It finally reaches the fintrhed state after the check- flag to In-progrerr point transaction comnuts A fimshed state entry IS e 3 The checkpoint trensectlon sets e reed lock on the signal to the recovery CPU to flush the remslnmg log pertltlon’s relation and waits until It 1s granted mformetlon for the pertltlon from the Stable Log Tell Notice that e smgle read lock on e relation 1s suf- to the log disk ficient to ensure that Its relation end Index partl- After e partltlon has been checkpomted, though Its tlons are all m e frunraciton conrlrfent state, thus, log mformetlon 1s no longer needed for memory recov- only committed date 1s checkpomted ery, the log mformetlon cannot be discarded because It IS still needed m the archive log to recover from media 4 When the reed lock on the pertltlon’s relation fellure If the pertltlon has any log records rememmg In 1s granted, the checkpolnt trensectlon allocates a the Stable Log Tell, they are flushed to the log disk In block of memory large enough to hold the partl- some sltuetlons, partlculerly when a pertltlon IS check- tlon, copies the partltlon into that memory, end pointed because of age, e partlel page of log records releases the read lock Relation locks are held Just may need to be flushed to the log disk In that case, Its long enough to copy e partltlon et memory speeds, log records are copied to a buffer where they are com- so checkpoint trensectlons will cause mlmmel m- bmed with other log records to create e full page of log terference with normal trensactlons The check- mformetlon, thereby sevmg log space end disk transfer point trensactlon then locates e free ares on the time by wntmg only full or mostly full pages to the log checkpoint disk to hold the partltlon (Since mul- Partltlon checkpomt Images could be kept m well- tiple checkpomt trensectlons may be executing m known locetlons on the checkpoint disks, slmller to e parallel, e wnte latch on the dnk allocation map shadow page scheme, but that would require a disk 1s required for this ) seek to a partltlon’s checkpomt image locetlon for each 5 The updates to the disk allocetlon map end the checkpoint Instead, checkpomt Images are simply writ- partltlon’s catalog entry are logged before the per- ten to the first evellable location on the checkpomt tltlon IS actually wntten to disk Checkpomts of disks end e partltlon’s checkpolnt image location (In catalog pertltlons are done m e manner slmller to the reletlon catalog) IS updated after each checkpoint regular partltlons, except that thar disk locations Therefore, for performance reasons, the disks holding are dupllceted In stable memory and m the disk pertltlon checkpoint images are orgemaed m a pseudo- log (because catalog mformetlon must be kept In urculer queue Frequently updated partltlons will pe- e well-known place so that It can be found easily nodlcelly get written to new checkpoint disk locations, dunng recovery) but reed-only or infrequently updated partltlons may 6 The pertltlon IS written to the checkpoint disk end stay In one locetlon for a long time (We use e pseudo- the checkpomt transectlon commits The memory urculer queue rather than e real clrculer queue so that buffer holdmg the checkpomt copy IS released, the pertltlons that are rarely checkpomted don’t move end new disk location for the partition 1s installed In are skipped over es the head of the queue passes by) Its catalog entry, end the status of the checkpoint The checkpomt disk space should be large enough so operation 1s changed to jin:rhed that there will be sufficiently many free locetlons, or Mer, evedeble to hold new checkpoint images 7 The recovery manager, on seemg the finished state A map of the disks’ storage space 1s kept In the sys- of the checkpoint operetlon, flushes the partltlon’s tem catalogs to allow trensectlons to find the next evell- rememmg log mformetlon from the Stable Log able locetlon for writing e partltlon New checkpomt Buffer to the log disk copies of pertltlons neuer overwnte old copies Instead, the new checkpomt copy IS wntten to a new locetlon 2.5 Post-Crash Memory Recovery (the heed of the queue), end Installed atomlcelly upon commit of the checkpolnt transection The relation Smce the pnmary copy of the database IS memory- catalog contams the disk locetlons of these checkpolnt resident, the only way e trensectlon can run IS If the copies so that they can be located and used to recover mformatlon It needs 1s In mem memory Restoring the partltlons after e crash memory copy of the database entslls restonng the cat- The steps of the checkpoint procedure are as follows alogs and then Indices nght away, then usmg the mfor- metlon m the catalogs to restore the rest of the database 1 The recovery CPU Issues a checkpomt request con- on e demand basis The mformetlon needed to restore temmg e partltlon address end e status flag m the the catalogs 1s a list of catalog partltlon addresses, and Stable Log Buffer this 1s kept In e well-known locetlon--lt IS stored twice, 2 The transection manager, runnmg on the mem m the Stable Log Buffer end m the Stable Log Tell, CPU, checks the checkpomt request queue m the end It 1s penodlcally wntten to the log disk Once the 110
8 . catalogs and thar mdmes have been restored, regular transactron processmg can begm Letter 1 Represents A Transactron could demand the recovery of a index or relatron partrtron m one of two ways /yzgcj 1 It could predeclare the relatrons and mdmes that rt requrred wrth knowledge gamed from query compr- latlon Then, when the relatrons and rndmes were restored m therr entirety the transactron could run 2 It could srmply reference the database dunng the Table 1 Varmble Conventrons course of regular processmg and generate a restore process for those partrtrons that are not yet re- covered Because of reasons having to do wrth could even begn to apply the log records Recall that holdmg latches over process swatches (explarned a &rectory of log pages 1s therefore used here, and smce m [Lehman 87]), rf a transactron made a reference the drrectory sme IS chosen to be equal to the antrcr- to an unrecovered portion of the database whrle pated average number of log pages for a partrtron, It holdmg a latch, It would have to grve up the latch should be possrble m many cases to schedule log page or abort reads m the order that they were orrgmally wrrtten There IS a tradeoff-method (1) IS sample, but It re- Thus, the log records from one page can be apphed to stncts the avarlabrlrty of the database by forcmg the the partrtron whrle the next page of log records are be- transactron to wart untrl the enfrre set of relatrons and mg read When the number of log pages exceeds the mdmes that It requested are avadable before the trans- drrectory sise, It IS possible to get to the first log page # actron can run On the other hand, method (2) allows after I-,,~~~~,“;so!,,~,~~:,,~,l page reads for more avadabrhty by restormg only those needed par- Relatron log records represent operatrone to update trtrons, but It adds complexity and the possrbrhty of a field, insert a tuple, or delete a tuple m a partrtron several transactron aborts durmg restart It appears (More complmated issues mvolvmg changes to relatron that experrmentstron on an actual rmplementatron 1s schema mformatron are beyond the scope of thre drs- requrred to resolve thus Issue cussron ) Index log records represent partsion-rpecsfic Usmg either method, transactrons generate requests operatrons on index components Recall that a smgle to have certam partrtlons restored The transactron mdex update may rnvolve several different actrons to be manager checks the relatron catalog for these entrres applied to one or more index partrtrons For example, to see If they are memory-resrdent If they are not, It a tree update operation can modrfy several tree nodes, mltrates a set of recovery transactrons to recover them, thus generatmg several different log records A pven one per partrtron A relatron catalog entry contams a log record always affects exactly one partrtron hst of partrtron descnptors that make up the relatron, so the transactron manager knows whmh partltrons need to be recovered Each descnptor grves the drsk locatron 2.6 Archive Logging of the partrtron along wrth its current status (memory- The drsk copy of the database 1s basmally the archive resrdent or drsk-resident) copy for the prmary memory copy, but the drsk copy A recovery transactron for a partrtron reads the par- also requrres an archrve copy (probably on tape or op- trtron’s checkpoint copy from the checkpornt drsk and tmal drsk) rn case of disk medra Isrlure Protectmg the issues a request to the recovery CPU to read the par- log disks and database checkpomt drsks comes under trtron’s log records and place them m the Stable Log the well-known area of tradrtronal archive recovery, for Buffer Once the partrtron and Its log records are both which many algorithms are known [Haerder 831, so It IS avadable, the log records are apphed to the partrtron not drscussed here to bnng rt up to Its state precedmg the crash (The processmg of log records can be overlapped wrth the readmg of log pages rf the pages can be read m the correct order ) Then, between regular transactrons, a 3 PERFORMANCE ANAL- system transactron passes through the catalogs and IS- YSIS OF THE RECOV- sues recovery transactrons (at a lower pnonty) for par- trtrons that have not yet been recovered and that have ERY PROPOSAL not been requested by regular transactrons To get an Idea of how this recovery mechanrsm ~111 perform, m thus sectron we examrne the performance 2.5.1 Reading in the Log Records of the three marn operatrons of the recovery compo- The operations specrfied by log records must be appbed nent loggrng, checkpomtmg, and post-crash recovery m the same order that they were ongmally performed First, the logging capacrty of the recovery mechamsm A smgle backwards lmked hst of log pages would force IS calculated to determme the maxrmum rate at whmh the recovery manager to read euery log page before It rt can process log records Second, the frequency of 111
9 . Name Explanatron Value and Umts I recordJookup Read one log record and determme mdex of proper log bm 20 Instructrons / Record I copyAar4 Startup cost of copymg a stnng of bytes 3 Instructrons / Copy I cop, -add Addrtronal cost per byte of copymg a string of bytes 0 125 Instructrons / Byte I wrdc-1nd Cost of rmtlating a disk wnte of a full log bm page 500 Instructions / Page Wrote IpJdl@C Cost of allocating a new log bin page and releasmg the old 100 Instructrons / Page Wnte one Ipage-update Cost of updating the log bm page mformatron 10 Instructrons / Record Ip.pc-ekcck Cost of checking the exrstence of a log brn page 10 Instructrons / Log Record lpvoccrr-LSN Cost of mamtammg the LSN count and checking for pos- 40 Instructrons / Page Wrote sable checkpomts I ckcckpord Cost of srgnalmg the main CPU to start a checkpomt trans- 40 Instructrons / Checkpornt action I record-ror: Total cost of the record sorting process (Calculated) Instructrons / Record Ipp-Wt’it. Total cost of wrrtmg a page from the SLT to the log drsk (Calculated) Instructions / Page Slo,-record Average sme of a log record 24 Bytes / Record Sro* -pep Siae of a log page 8 Kilobytes / Page s peritt1or Siee of a partition 48 Krlobytes / Partrtron N upd& The number of log records that a partltron can accumulate 1000 Log Records / Partition before a checkpomt 1s triggered N~o~-~c~cr Average number of log pages for a partition (Calculated) Log Pages / Partition Rbyic,~~oyps(: Byte rate of the loggng component (Calculated) Bytes / Second R~c,&,-~Osscd Record rate of the loggmg component (Calculated) Log Records / Second Rckcckpod Frequency of checkpomts (Calculated) Checkpomts / Second Preeo+cry MIPS power of the recovery CPU 1 0 M&on Instructrons / Second Table 2 Parameter Deacrrptrons checkpoint transactions IS calculated for various log- complexrty of making It stable and &able ’ gng rates, and the overhead imposed by checkpointmg Instructron counts per operatron are estimated (this transactions 1s calculated as a percentage of the total recovery scheme has not yet been Implemented) and number of transactrons that are running Fmally, the overheads produced by procedure calls, process swrtch- process of post-crash recovery IS outlmed for an mdlvrd- mg and operatmg system mteractron have been some- ual partrtron and performance issues are discussed, and what accounted for by padding the instructron counts then the performance advantage of partrtron-level re- for the operatrons Complrcated microcoded rnstruc- covery is demonstrated by comparing rt with database- trons such as the block move rnstructron are represented level recovery as multrple mstructrons A gencrsc mstructron executed on the recovery processor 1s assumed to execute m one microsecond and a memory reference IS assumed to ex- 3.1 Logging, Checkpointing, and ecute m about one rmcrosecond The reader should Recovery Parameters keep m nund that the mstructron count numbers ap- pear smaller than normal system numbers The recov- Before we begm the analysrs, we introduce the param- ery component IS highly specrahaed and requires only eters that wrll be used throughout this section Table 1 a minrmal operating system, and rt has sole control of grves the conventrons that we use for the names of the the log disks when they are actrvely recervrng log infor- parameters, and Table 2 hsts each parameter of interest matron (The recovery component releases control of along with rts meamng, value (determined as described a log disk when that disk IS transferred to the archive below), and units component to role the contents of the disk onto tape ) The environment used to generate these figures 1s The disk parameters rn Table 2 are based on a two- based on a mrdsmed mainframe with a 6 MIP uniproces- head per surface high-performance disk drive It uses sor for the mam CPU and a smaller 1 MIP umprocessor two read/write heads per surface, so rt has relatively for the recovery CPU ’ The stable r&able memory for low seek times The transfer rate for a track of data the recovery CPU 1s composed of the faster mamframe IS double the transfer rate for mdrvrdual pages, par- memory chrps, but rt 1s four times slower due to the ‘The cost and performance figurer of thts stable memory ‘The speed of the mam CPU 1s not used m any of the are proJected from current technology Ths memory II not cslculatronr presented here, but we mention It to put the available today, but WC b&eve It WIU be widely ardable reader m the proper frame of mmd w&in the next decade 112
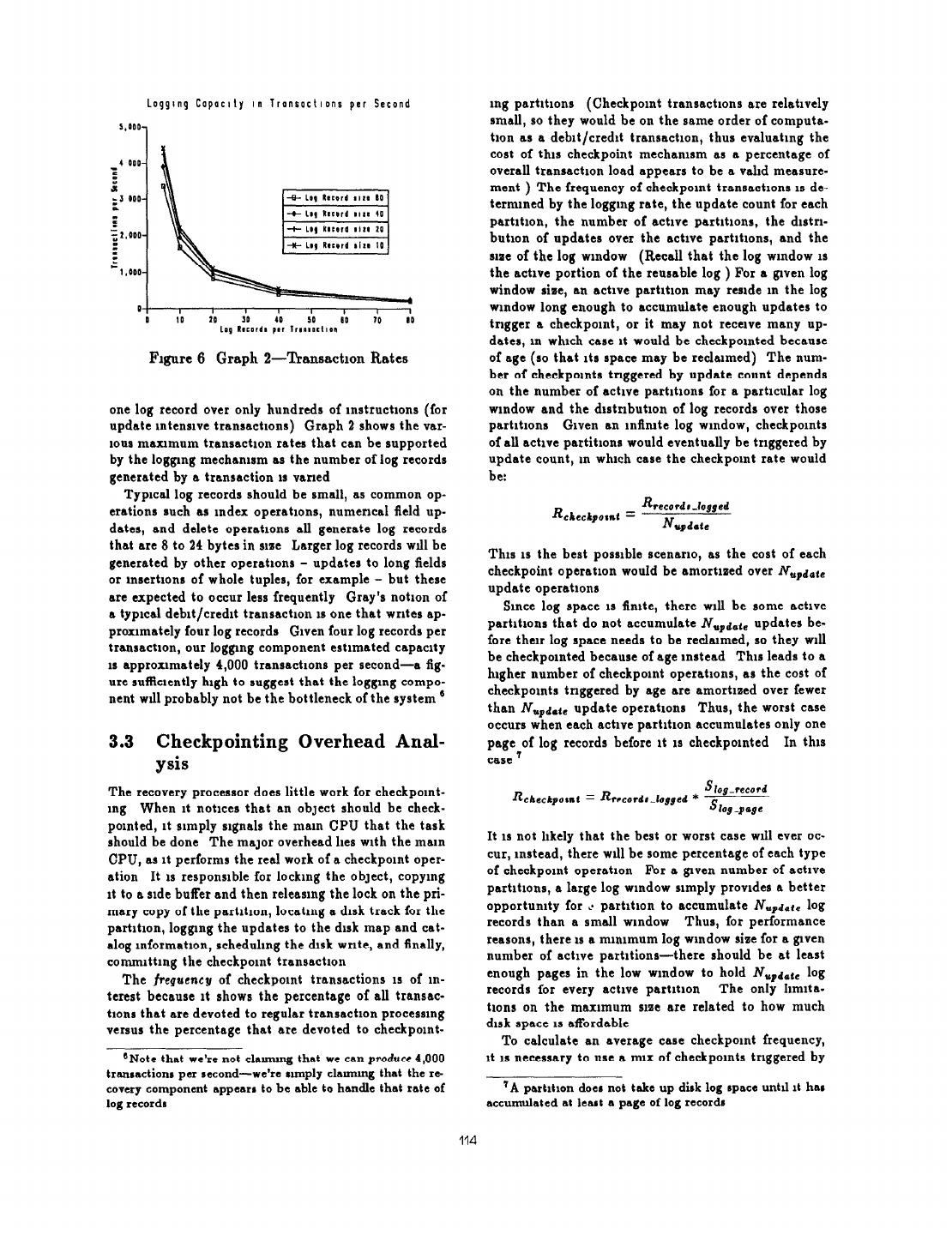
10 . trtrons are wrrtten m whole tracks, whereas log pages are wrrtten mdrvrduslly (requrrmg separate disk opers- tions) To schreve the maxrmum transfer rate possrble Loggrng Copoclty of Recovery Component for wrrtmg log pages, the drsk sectors of the log drsk 15,000, are interleaved, logrcally s4acent sectors are physrcally one sector apart (For srmphuty, sectors are assumed to be the srue of one page ) After wrrtmg one page, a drsk needs a small amount of thrni tame to set up for the next page wnte-more time, we assume, than the trme rt takes to travel from the end of one sector to the begm- rung of the next physrcslly s$scent sector Therefore, by logcally mterleavmg the sectors, the disk has the time of one full sector to reset for the next page wnte We also use different seek times for the checkpornt disks and the log disks The seek time for a partition read IS an average seek time, as a partrtron can be anywhere Figure 6 Graph 1-Loggrng Speed on the disk m relatronshrp to the drsk head dunng the recovery process However, even though the log pages for a psrtrtron wrll be spread out over the log space, spent notrfymg the msln CPU of psrtrtrons that must each page wrll be relstrvely close to rts srbhng, so the be checkpomted seek times between log pages should be somewhat less The cost of the Arst aspect of recovery processmg than the average seek time 1s the cost of the rorf:ng process of moving a single log Prckrng an optrmal srae for partrtrons and log pages record from the Stable Log Buffer to its correct locatron mvolves dealing with a hat of tradeoffs For example, m the Stable Log Tall the log page srae represents a subtle tradeoff between I tCCord~8o~i- &cord-loohup •t &w-cbcck + the space required to hold log pages m the Stable Log Buffer and the frequency of page writes and page allo- Ico,y-‘dcrd t (IcoPy-add * slog-record) •t catrons The partrtron slut affects several factors the Slog-record Ipqe-update t ~pc~cAw * s number of entnes m the Stable Log Tad, since larger log-).#” psrtrtrons mean fewer partrtron entnes, the cost and The second and third aspects of the loggmg process efRcrency of checkpornts, smce larger partrtrons mrght entarl wntmg the psrtrtron bm log pages to disk as they cause a larger percentage of non-updated data to be All up and notifying the msm CPU each time a partition wntten dunng a checkpornt operstlon, and the over- needs to be checkpomted head of managing partitions, since smaller partitions mean mamtammg more entnes per relstron The sraes Ipage-wrate = Lnoc-,rtl t Iproccrr-ZSN t for log pages and partrtrons m Table 2 were chosen from I ChCChpOd the middle of a range of possrble values, given the specr- ‘log-record N update * Acatrons and database reference patterns of a psrtrculsr 30*-p*#C database system, rt may be possrble to pick better page The recovery processor executes a number of mstruc- srxe and psrtrtron snse values trons to move a log record from the Stable Log Buffer to 8 partition bm in the Stable Log Tall Irccor(-ro~r 3.2 Logging Capacity Analysis and rt executes a number of rnstructrons to write a psr- trtron bm log page to disk IrcJc-wc,~e If we combme The logging rate of a recovery mechamsm must be those mstructron costs m terms of mstructrons per byte greater than the rate at which the marn CPU can gen- and drvrde that into the processing power of the system erate log records, or else the recovery mechamsm will (mstructrons per second) then we get the speed of the be the performance bottleneck of the system We estr- loggrng component m bytes per second mate the logging cspscrty of the proposed design usmg a simple snslytrcal model ’ Durmg normal processmg P rk?corery Rbltea-logJcd = I the recovery CPU spends most of Its time moving log record *or: sIopecocd records from the Stable Log Buffer mto partition bins m the Stable Log Tall, rt spends a smaller portion of Graph 1 shows the logpng speed rn log records per its time rmtratmg disk wnte requests for full pages of Rb,icr IO cd second (l.c., .+ for various log record and log records and, an even smaller portion of Its time is log-record disk page sines The number of log records generated ‘Note Space lnmtatlons force us to descnbe only bnefly by a transactron IS of course spphcatron-dependent It the underlymg formulas on which the performance graphs can range from a few log records over hundreds of thou- are based For a more complete and mrratlva dcscnptlon of the formulas, the reader 1s referred to [Lehman 86b] The sands of rnstructrons (for computatron-mtensrve trans- reader II also remmded that Table 2 smnmsrmcs the me-g sctrons) to a few records over several thousand mstruc- of each parameter used m the anslys1s trons (for Gray’s debit/credit transsctrons [Gray 851) to 113
11 . Loqglng Capaclly III TransactIons per Second mg partrtrons (Checkpomt transactrons are relatively small, so they would be on the same order of computa- tion as a debit/credit transactron, thus evaluatrng the cost of this checkpoint mechamsm as a percentage of overall transactron load appears to be a valid measure- ment ) The frequency of checkpomt transactrons 1s de- -S- Loq Record termined by the logging rate, the update count for each + Lmq Record + L,q Rorrrd nizn 20 partrtron, the number of active partrtrons, the drstrr- +I- L,q Record butron of updates over the active partrtrons, and the size of the log window (Recall that the log window 1s the active portion of the reusable log ) For a pven log window size, an active partrtron may reside m the log window long enough to accumulate enough updates to tngger a checkpornt, or it may not receive many up- dates, m whrch case rt would be checkpomted because Fqure 6 Graph 2-Transactron Rates of age (so that Its space may be reclaimed) The num- ber of checkpomts triggered by update count depends on the number of active partrtrons for a particular log one log record over only hundreds of rnstructrons (for window and the drstrrbutron of log records over those update mtensrve transsctrons) Graph 2 shows the var- partrtrons Given an rnilmte log window, checkpomts IOUSmaxrmum transactron rates that can be supported of all active partitrons would eventually be triggered by by the loggmg mechamsm as the number of log records update count, m which case the checkpomt rate would generated by a transaction IS varred be: Typrcal log records should be small, as common op- R tccovdn-logged erations such as mdex operatrons, numerical field up- R checkpod = N update dates, and delete operatrons all generate log records that are 8 to 24 bytes in size Larger log records will be This 1s the best possrble scenano, as the cost of each generated by other operatrons - updates to long fields checkpoint operation would be amortrzed over Nupdale or msertrons of whole tuples, for example - but these update operatrons are expected to occur less frequently Gray’s notron of Since log space IS finite, there will be some actrve a typmal debrt/credrt transactron 1s one that wrrtes ap- partrtrons that do not accumulate N,,&(e updates be- proxrmately four log records Given four log records per fore their log spaceneeds to be reclarmed, so they wrll transactron, our loggmg component estimated capacrty be checkpornted because of age instead This leads to a IS approxrmately 4,000 transactlone per second-a fig higher number of checkpomt operatrons, as the cost of ure sufflcrently high to suggest that the logging compo- checkpomts tnggered by age are amortrzed over fewer nent will probably not be the bottleneck of the system s than N,+& update operatrons Thus, the worst case occurs when each active partrtron accumulates only one 3.3 Checkpointing Overhead Anal- page of log records before rt 1s checkpornted In thus ysis case 7 The recovery processor does little work for checkpomt- S log-record Rchtxkpotnc = Rrrcordc-loJged * mg When rt notices that an obJect should be check- s log-pap pornted, rt srmply signals the mam CPU that the task should be done The maJor overhead lies with the main It 1s not likely that the best or worst case wrll ever oc- CPU, as it performs the real work of a checkpornt oper- cur, instead, there wrll be some percentage of each type ation It 1s responsrble for locking the obJect, copying of checkpomt operatron For a grven number of actrve rt to a side buffer and then releasing the lock on the pri- partrtrons, a large log window srmply provrdes a better mary copy of the partrtron, locating a disk track for the opportunity for ti partition to accumulate N,,z,jcle log partrtron, logging the updates to the disk map and cat- records than a small wrndow Thus, for performance alog mformatron, schedulmg the drsk write, and finally, reasons, there IS a mmrmum log window size for a given commrttmg the checkpomt transactron number of active partitions-there should be at least The frequency of checkpornt transactions IS of m- enough pages in the low window to hold NSpd,,(e log records for every active partrtron The only lrmrta- terest because rt shows the percentage of all transac- trons that are devoted to regular transactron processmg trons on the maxrmum srae are related to how much versus the percentage that are devoted to checkpomt- disk space IS affordable To calculate an average case checkpomt frequency, eNote that we’re not clamung that we cm produce 4,000 rt 1s necessary to use a nux of checkpomts trrggered by transactions per second- we’re sunply clslrmng that the re- covery component sppcars to be able to handle that rate of 7A partrtlon does not take up disk log space until It has log records accumulated at least a page of log records 114
12 . erations to occur for a given trigger percentage, but rt also mcreases the suggested nummum srae of the log so-. CheckpoInt Frequency window A srmrlar effect 1s seen when the log page sure IS doubled or the log record size IS halved, as uther one mcreases the number of log records that an active par- tition must accumulate before rt can have a checkpoint triggered by age (Recall that an active partrtron’s log mformatron will not be wntten to the log disk until rt has accumulated at least one full page of log records rn the Stable Log Tall ) 3.4 Discussion of Post-Crash Parti- tion Recovery The purpose of the partrtron-level recovery algorrthm Frgure 7 Graph 3-Possible Checlcpomt Prequen- IS to allow transactrons to begrn processmg as soon as cles then data IS restored Transactrons issue requests for certain relatrons to be recovered (either “on demand” during the course of the transactron or predeclared at age and tnggered by update count For a grven percent- the begmmng of the transaction) and they are able to age of partltrons that are checkpomted because of age, proceed when their requested relations are avadable, there are a range of possrble checkpomt frequencies, as they do not have to wart for the cnisre database to be re- those partrtrons could have anywhere from a smgle page stored An upper bound on the time needed to recover of updates to almost NuFdPtc updates For comparison a relation 1s the sum of its partition recovery times A purposes we wrll always assume the worst case-that partrtron’s recovery time IS deterrmned by the time rt a partrtron checkpomted because of age has accumu- takes to read its checkpomt image from the checkpomt lated only one page of log records Thus, the equation disk, to read all of its log pages, and to apply those to determine the checkpoint rate for given fractions of log pages to its checkpomt image A partltron’s check- partrtlons being checkpomted because of update count point image and its log pages may be read m parallel, (ftrgdCltUWlt ) and age (fcse) 1s since they are on different disks Also, provided that the log page directory was chosen to be large enough to hold entries for all of the log pages for the partrtron, the log pages can be read m the order that they were orrgmally written, thus allowmg the log records from one log page to be apphed to the partltron In parallel with the reading of other log pages (This assumes, of Rather than try to choose actual numbers for the log course, that the time required to apply a page of log wmdow srue, the number of active partrtrons, and the records to a partition 1s less than the time rt takes to dlstnbutron of log records, we simply examine some drf- read a log page ) s ferent mrxes of checkpomt trigger percentages Graph 3 shows the checkpoint frequenues for various update counts and trigger percentages as the loggrng rate 1s 9.4.1 Comparison with Complete Reload- vaned The log window srae and the number of ac- ing tive partrtrons deternune the number of checkpornts, The main alternative to partrtron-level recovery IS but the logging rate determines how frequently they database-level recovery An interesting point 1s that will occur-the logging rate determines how fast pages database-level recovery 1s a special case of partrtion- of log records go into the log wmdow, and thus, how level recovery, with one very large partrtron (the en- fast they reach the end of the log window, possibly tire database) An attractive feature of partrtron-level tnggermg checkpomt operatrons For an update count recovery 1s that rt 1s flexible enough to perform pure of 1,000, rf the log window size 1s large enough to al- partrtron-level recovery (read a partition, read Its log low 60 percent of the active partitions to accumulate mformatron and recover it), full database-level recov- N ,+,tc log records, then the checkpomt frequency will ery (read all partltrons, read all of the log, recover all be farrly low Assuming an average transactron writes partltlons), or some level m-between An optrmiaatron about 10 log records, this would rndlcate that the check- point transactrons generated at this frequency would to pure partition-level recovery would be to load some srgmficant portion of the log into memory during recov- compose only 1 5 percent of the total transaction load An average number of log records less than 10 would ery so that the seek costs to read these pages would be simply decrease the percentage of checkpoint transac- 8Spacc conrldcrataonr prolublt us from prorxhng a more tions detmled descrlptlon of the recovery costs We refer the m- A larger update count causes fewer checkpomt op- tererted reader to [Lehman Mb] 115
13 .ebrmnsted [Elhardt 841 K Elhardt and R Bayer, “A Database Cache for Hugh Performance and Fast Restart In Database Systems,” ACM !l’ranr on Daiabarc 4 CONCLUSION Syriemr 9, 4, December 1984 [Eswaran 761 K Eswaran, J Gray, R Lone, and I Prevrous work m recovery, both for tradrtronal drsk- Trarger, “The Notrons of Consrstency and Predl- based database systems and for memory-resident sys- cate Locks In a Database System,” Comm of ihe tems, has addressed Issues of loggmg, checkpomtmg and ACM 19, 11, Nov 1976. recovenng a database Many designs have been pro- [Gray 781 J Gray, “Notes on Database Operatmg posed, but none of them have completely satisfied the Systems,” In Operaimg Syrfemr An Advanced needs of a hrgh-performance, memory-resident database CoutJe, Sprmger-Verlag, New York, 1978 system Such a system needs a fast, efficient loggmg mechamsm that can assrmrlate log records as fart or [Gray 811 J Gray, et al, “The Recovery Manager of faster then they can be produced, an efllcrent check- System R,” ACM Compuitng Surseyr 18, 3, June point operatron that can amortrze the cost of a check- 1981 point over many updates to the database, and a post- [Gray 861 J Gray, et al, “One Thousand Transactrons crash recovery mechamsm that IS geared toward allow- Per Second,” Proc IEEE COMPCON, San Fran- mg transactrons to run as qurckly as posrrble after a CISCO,February 1985 crash [Haerder 881 T Haerder and A Reuter, “Prmcr- A desrgn has been presented that meets these three ples of Transactron-Orrented Database Recovery,” cnteria Wrth the use of stable relrable memory and ACM Compuimg Surweyr 15, 4, December 1983 a recovery processor, the logging mechamsm appears to be able to assrnulate log records as fast as they can [Hagmann 861 R Hagmann, “A Crash Recovery be produced Checkpoint operatrons for partrtrons are Scheme for a MemoryResIdent Database Sys- tnggered when the partrtrons have recerved a sIgmAcant tem,” IEEE Tranracilonr on Compuierr C-95, 9, number of updates, and thus the cost of each checkpoint September 1986 1 operatron 1s amortrzed over many updates Recovery of [IBM 791 IBM IMS Verrcon 1 Rekore 1 5 Fari Path data m our desrgn 1s onented toward transactron re- Feaiure Dercrtpi:on and Dercgn Gucde, IBM World sponse time After a crash, relations that are requested Trade Systems Centers (G320-6776), 1979 by transactrons are recovered first so that these trans- [IBM 841 An IBM Gwde Lo IMS/VS Vi RJ Daia En- actrons can begn processmg nght away The remammg try Daiabare (DEDB) Foe&y, IBM Internatronal relatrons are recovered m the background on a low pri- Systems Centers (GG24-1633-O), 1984 orrty bans [Kohler 811 W Kohler, “A Survey of Techniques for Synchromzatron and Recovery m Decentrabzed Computer Systems,” ACM Compuicng Surueyr iJ, 6 Acknowledgements ,8, June 1981 Our thanks to Jrm Gray, John Palmer, Jrm Stamos and [Lehman 86a] T Lehman and M Carey, “Query Pro- the SIGMOD referees for therr helpful comments and cessmg In Mam Memory Database Management suggestrons on rmprovmg thnr paper Systems,” Proc ACM SIGMOD Conf , May 1986 [Lehman 80b] T Lehman, Dercgn and Perfor- mance Ewluairon of a Mom Memory Relaisonal 6 REFERENCES Daiabare Syeiem, Ph D Drssertatron, Umversrty of Wrsconsm-Madrson, August 1986 [Amman 861 A Ammann, M Hanrahan, and R [Lehman 86~1 T Lehman and M Carey, “A Study Knshnamurthy, “Design of a Memory Resrdent of Index Structures for Marn Memory Database DBMS,” Proc IEEE COMPCON, San Francisco, Management Systems,” Proc Idih Conf Very February 1986 Large Daia Barer, August 1986 [Dewitt 841 D DeWrtt, et al, “Implementatron [Lehman 871 T Lehman and M Carey, “Concur- Techmques for Marn Memory Database Systems,” rency Control in Memory-Rendent Database Sys- Proc ACM SIGMOD Conf , June 1984 tems,” (submitted for publication) [Dewitt 861 D DeWrtt and R Gerber, “Multrpro- [Leland 861 M Leland and W Roome, “The Srhcon cessor Hash-Based Join Algonthms,” Proc llih Database Machme,” Proc 4th Ini Workrhop on Conf Very Large Dolo B~ICI, Stockholm, Swe- Doiobore Machmer, Grand Bahama Bland, March den, August 1986 1985 [Eich 861 M Erch, MMDB Recoaery, Southern [Lindsay 791 B Lindsay, et al, Noier on Dtrircbuled Methodrst Umv Dept of Computer Scrences Dolaborer, IBM Research Report RJ 2671, San Tech Rep [86-CSE-11, March 1986 Jose, C&&forma, 1979 116
14 .[Lorie 771 R Lone, “PhysIcal Integnty In a Large Segmented Database,” ACM Tranr on Daiabare Syriemr Z, 1, March 1977 [Reuter 801 A Reuter, “A Past TransactIon-onented Loggmg Scheme for UNDO Recovery,” IEEE Tranr Soffwate Eng SE-b, July 1980 [Reuter 841 A Reuter, “Performance Analysis of Re- covery Techmques,” ACM Tranr on Database Syrlemr 9, 4, December 1984 [Salem 861 K Salem and H Garcia-Mohna, Crarh Recooery Mechantrmr for Macn Siorage Daiabare Syrlemr, Pnnceton Umv Computer Science Dept Tech Rep CS-Tech Rep [034086, Apnl 1986 [Shapiro 861 L Shapiro, “Jam Processmg m Database Systems with Large Main Memones,” ACM !Ranr on Dafabare Syr- iemr, September 1986 [Thompson 861 W Thompson, Masn Memory Daiabare Algordhmr for Muk8procerror8, Ph D Dlssertatlon, Umv Cahforma-Davis, June 1986 117
相关推荐

加关注
3秒后跳转登录页面
去登陆

