









- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
XStream: a Signal-Oriented Data StreamManagement System
Sensors capable of sensing phenomena at high data rates on the order of tens to hundreds of thousands of samples per second are now widely deployed in many industrial, civil engineering, scientific, networking, and medical applications. In aggregate, these sensors easily generate several million samples per second that must be processed within milliseconds or seconds.The computation required includes both signal processing and event stream processing. XStream is a stream processing system for such applications. XStream introduces a new data type, the signal segment, which allows applications to manipulate is ochronous (regularly spaced in time) collections of sensor samples more conveniently and efficiently than the asynchronous representation used in previous work.
展开查看详情
1 . XStream: a Signal-Oriented Data Stream Management System Lewis Girod 1, Yuan Mei, Ryan Newton, Stanislav Rost, Arvind Thiagarajan Hari Balakrishnan, Samuel Madden Computer Science and Artificial Intelligence Laboratory, MIT 32 Vassar St, Cambridge, MA, 02139, USA 1ldgirod@csail .mit .edu Abstract- Sensors capable of sensing phenomena at high data are not provided, and must be implemented as user-defined rates on the order of tens to hundreds of thousands of samples functions in external languages. per second are now widely deployed in many industrial, civil To understand these two limitations more concretely, we engineering, scientific, networking, and medical applications. In aggregate, these sensors easily generate several million samples discuss a synthetic benchmark, STATFILTER. This query com- per second that must be processed within milliseconds or seconds. putes statistics over streams of audio data that have been regu- The computation required includes both signal processing and larly sampled in time (are isochronous). This benchmark con- event stream processing. XStream is a stream processing system sists of two sequentially connected filter operators. The first for such applications. operator calculates the standard deviation of the last 4096 XStream introduces a new data type, the signal segment, which samples, and passes the window onward if it is greater than allows applications to manipulate isochronous (regularly spaced in time) collections of sensor samples more conveniently and a threshold a. The second operator works similarly, passing efficiently than the asynchronous representation used in previous only windows whose average value is less than Q. work. XStream includes a memory manager and scheduler op- Let's consider how such an application might be imple- timizations tuned for processing signal segments at high speeds. mented in a conventional SPE. First, the streams carry one In benchmark comparisons, we show that XStream outperforms a leading commercial stream processing system by more than tuple for each input sample, with <sample, timestamp> three orders of magnitude. On one application, the commercial as the schema. The first filter collects the next 4096 tuples in system processed 72.7 Ksamples/sec, while XStream processed a window, and must either stride through the data or strip the 97.6 Msamples/sec. timestamps out to compute the standard deviation. For each window that satisfies the predicate over standard deviation, the I. INTRODUCTION tuples in that window are passed, one at a time, as an output stream to the second filter. The second filter again collects a XStream is a stream processing system that is designed window of 4096 tuples and conditionally outputs tuples from to efficiently support high-rate signal processing applications. windows that satisfy the average predicate. The motivating applications for this system come from a va- In contrast, the streams in the XStream implementation are riety of industrial, scientific, and engineering domains. These tuples containing chunks of sample data called signal seg- applications use embedded vibration, seismic, pressure, mag- ments, or SigSegs. Rather than performing per-operator win- netic, acoustic, network, and medical sensors to sample data dowing, the SigSegs are formatted into blocks of 4096 samples that are on the order of millions of samples per second in by a special re-window operator. Timing information is sum- aggregate. Such high-rate sample streams need to be processed marized as part of each SigSeg data type. Per tuple timestamps and analyzed within milliseconds or at most seconds of being are not necessary because all samples are separated by the produced, using a mix of event stream and signal process- same amount of time. Each filter is invoked once per tuple, ing operations. Example operations include selecting out time but since each tuple contains a SigSeg, it processes the entire ranges and samples of interest, applying signal processing block at once. When a SigSeg is passed to the next operator, transforms to them, correlating them with other signals, time- the entire SigSeg of tuples is passed by reference, reducing aligning them with other signals, and applying a variety of overhead further. application-specific aggregate operations on the signals. XStream achieves a 1000 x performance gain for this type of Existing stream processing engines (SPEs) [1], [2], [3], [4], query, relative to a commercial SPE: the commercial system [5], [6] provide some of the features needed to express these processed 72.7 Ksamples/sec, while XStream processed applications, but suffer from two limitations. First, they do 97.6 Msamples/sec. This gain is the result of several design not scale to the rates that many signal processing applications choices that enhance XStream's performance for signal- need to support (often several million samples per second) oriented queries, in particular an ADT designed to efficiently on conventional PC-class machines. Second, existing SPEs manipulate signal data, a set of operators, a memory manager, do not provide an operator set that is adequate for signal and a scheduler optimizes for that ADT. We expand on these processing for example, operations like FFTs and Wavelets results in Section IV. 978-1-4244-1837-4/08/$25.00 (© 2008 IEEE 1180 ICDE 2008
2 . Raw Data Stream Data after "windowing" into SigSegs Sensor on 1 OOms nal processing functions in existing SPEs relies heavily on (4400 samples) Sensor off 2000 sample SigSeg the use of user-defined functions (UDFs). However, because these UDFs are written and compiled separately from queries, 1 Second query optimizers cannot "see inside" UDFs. If, on the other Off time reflected in sequence gap hand, we write the entire application in a single language, we gain the ability to perform global optimizations. For example, Fig. 1. Example illustrating how a raw data stream, with 100 ms of data the compiler can fuse UDFs or specialize them to the specific every second, sampled at 44 KHz, is packaged into 2000-element SigSegs. contexts in which they are invoked. Such a framework makes it easy to ensure type-safety, and removes the necessity for awkward type conversions and parameter marshaling when In a recent position paper at CIDR [7], we outlined the calling UDFs. basic system architecture and functional query language of a system that makes it easy to express signal-oriented streaming This paper focuses on the first two points mentioned above. applications. In this paper, we describe the details of XStream, An overview of the WaveScript language was given in a po- focusing on the features that achieve high performance. These sition paper [7]; a detailed evaluation of the compiler opti- performance gains result from design choices arising from mizations and programmer productivity benefits are subjects three important observations: of on-going work. 1) Isochronous data is the common case: We have observed A. Contributions that many sensor-based streaming applications produce high- rate data isochronously (e.g., once per microsecond). Rep- This paper describes and evaluates the implementation of resenting and processing these data streams as timestamped XStream. It makes the following contributions: tuples is inefficient, since the timestamp of each sample is . The SigSeg ADT, which enables high performance ma- implicit from its position in the stream. Many block-oriented nipulation of signal-oriented data, and a memory manager signal processing operators such as FFTs perform optimally that supports (large) SigSegs efficiently. when operating on densely packed arrays. For such operators, . A scheduler that dispatches tuples to operators in a processing data interleaved with timestamps presents a major (mostly) depth-first traversal of the query plan, avoiding hurdle. Additionally, conventional streaming operators such as expensive scheduling decisions. temporal joins suffer when working at the granularity of indi- . A detailed experimental evaluation of several mi- vidual samples, because of the sheer number of comparisons crobenchmarks analyzing XStream, including a compar- that must be made. To address this, we define a new abstract ison to a commercial SPE. data type which we call a signal segment, or SigSeg. A SigSeg We begin with a few motivating applications, and then de- encapsulates a finite sequence of isochronous samples into an scribe the implementation of SigSegs and the XStream en- array-like data structure with associated timing metadata, as gine in Section III. We evaluate XStream by presenting mi- shown in Fig. 1. XStream applications manipulate SigSegs as crobenchmarks of engine performance in Section III, and a first-class objects. detailed evaluation of the XStream engine with benchmark 2) Scheduler and tuple passing overhead is a bottleneck: comparisons to a commercial SPE in Section IV. Left unchecked, scheduling and tuple passing overhead can easily dwarf the costs of the actual computations performed II. MOTIVATING APPLICATIONS on the data stream. We demonstrate this in Table I (Sec- To motivate our design decisions, we summarize three ap- tion IV-A), in which our performance benchmarks show that plications that we have implemented using XStream: pipeline engine overhead is often multiple orders of magnitude greater leak detection, network monitoring, and acoustic localization. than the actual cost of data processing operators, even in a All three applications process high-rate input data (many kilo- commercial SPE. We design XStream's engine to minimize hertz to megahertz), whose aggregate in a deployment would the engine overhead. The XStream memory manager takes be several million samples per second. Although space con- advantage of isochrony to manage SigSegs efficiently, allowing straints preclude covering these implementations in detail, we applications to pass, append, and subdivide SigSegs with low quote performance numbers from our XStream-based imple- overhead. In particular, it avoids expensive copying operations mentations, using the benchmarking setup described in Sec- whenever possible, while supporting dynamic manipulation of tion IV. signal data. In addition, passing data in SigSegs rather than 1) Pipeline Monitoring: Pipeline monitoring uses vibration individual tuples substantially reduces the context switching and/or acoustic sensors deployed along water pipelines to de- overhead in the scheduler. The XStream runtime also includes tect incipient ruptures. Cracks in pipes cause small disrup- a novel design for a "depth-first" scheduler that dispatches tions that can be detected at multiple sensors to determine tuples to operators in a (mostly) depth-first traversal of the the approximate locations of leaks. When deployed in the wa- wiring diagram, avoiding expensive scheduling decisions. ter distribution networks underneath cities, these technologies 3) unified query language A enables whole-program opti- might save millions of dollars a year by preventing leaks and mization: Implementing the SigSeg ADT and associated sig- outages [8], [9]. Typical data rates are tens to hundreds of 1181
3 . Senso 0 <Samples> Rewindow <Samples> L _TrimPeak(MIN) ! <Peak, Rest> LeakDetect «Pe k, ReFilter I t,' I<Re |st>i................-...<Rest> <Peak2, Re t2 p <P eak, ReR IrkP e st>t-t I<leak, <up trans time >_ Fig. 2. DETECTAUDIO workflow. Fig. 3. PIPELINE workflow. kilohertz from each sensor; deployments typically consist of about ten sensors each. Wavelet analysis is used to identify triggered whenever the summary signal exceeds a threshold Q signatures characteristic of leak reflections, which are located standard deviations above the current noise estimate. based on time difference of arrivals. Our XStream implemen- Whenever an event is detected, the time range corresponding tation of processed vibration data at 4.3 Msamples/sec. to the event is passed as the control input to a sync operator. 2) Network Monitoring: Recently, several groups have ap- All four channels of raw signal data are fed into the inputs of plied signal processing methods to network monitoring [10], the sync operator; for every detection range submitted on the [11]. In our application we analyze wireless bit errors at differ- control input, sync emits a tuple containing a SigSeg from ent receivers in an 802.1 ig network, in an effort to reconstruct each input channel corresponding to the requested detection the original packets from multiple corrupted copies. In the range. analysis, we align the (possibly corrupted) bit-streams from Fig. 3 shows a diagram of the PIPELINE benchmark. Most multiple observations of each packet, and compute pairwise of the work is done by the haarwavelet operator, which correlations. The most correlated receivers for each source finds the energy in particular frequency bands. PIPELINE com- are identified by clustering, and receivers from different clus- bines several standard WaveScript operators (e.g., rewindow, ters are selected to maximize the likelihood of reconstructing zip, haarwavelet and trimpeak) with LeakDetect, corrupted packets. Our XStream implementation processed a a custom operator that determines the presence of a leak in packet stream at 241.5 Kpackets/sec. the pipeline. 3) Acoustic Localization: In a typical acoustic localization application, several small arrays of omni-directional micro- III. XSTREAM IMPLEMENTATION phones are placed in the environment surrounding a target. Fig. 4 shows the XStream architecture. This paper focuses Typical data rates are 48 kSamples/sec from each channel, on the right-hand side of the diagram: the XStream engine with each array hosting 4 or more channels. These systems that efficiently implements the SigSeg ADT and schedules a typically run a low-cost local detection stage, followed by compiled query plan with low overhead. The implementation a more expensive multi-node localization and classification of SigSegs and the scheduler are described in detail in the stage. These systems apply to a number of domains, including following sections. animal tracking [12], [13], signal enhancement for improved event recognition [14], and military applications such as sniper A. The SigSeg ADT identification [15]. Our XStream implementation processed 4 As in most streaming databases, all data in XStream is channel audio data at 7.5 Msamples/sec. represented as streams of tuples with pass-by-value seman- tics. These streams are used to pass data between XStream A. DETEcTAUDIO and PIPELINE Benchmarks operators; typically a data source operator creates a stream as To provide a more realistic performance assessment for it reads data from sensors, the network, or a file, and feeds XStream, we developed two benchmarks based on our it into a query plan. Individual operators process this stream motivating applications: DETECTAUDIO and PIPELINE. In and in turn generate new streams. this section we describe these algorithms in more detail. The main addition to the data model is that tuples may Fig. 2 shows a block diagram of our XStream implemen- contain SigSegs, which are used to pass signal data between tation. The sensor inputs consist of four independent audio operators. Conceptually, SigSegs provide an array-like inter- channels, receiving 16-bit audio data from a microphone array face that provides access to a subsection of a signal. SigSegs at 48 KHz. The application passes one of the channels to a also conform to a pass-by-value semantics, although (as we streaming event detector. This data stream is windowed into describe in Section III-B), for efficiency reasons the imple- blocks of 32 samples each, and each window is passed to a Fast mentation passes them by reference with copy-on-write. Ele- Fourier Transform (FFT) to compute a frequency map. The ments of SigSegs are assumed to be regularly spaced in time, algorithm then calculates a "detection score" by computing a though individual tuples in a stream may arrive completely weighted sum of the magnitudes of the frequency bins. asynchronously. (Hence, the data model of a stream processor The resulting summary signal is passed to a Constant False like Aurora [1] or STREAM [2] which have no SigSegs- Alarm Rate (CFAR) algorithm [14]. The CFAR algorithm as- can be fully modeled as a stream of XStream tuples.) Each sumes a Gaussian noise model N(,u, u2) and computes on- SigSeg also contains a reference to a timebase, an object that line estimates of the model parameters ,u and (X. Detection is specifies the rate and phase of the signal. Tuples in XStream do 1182
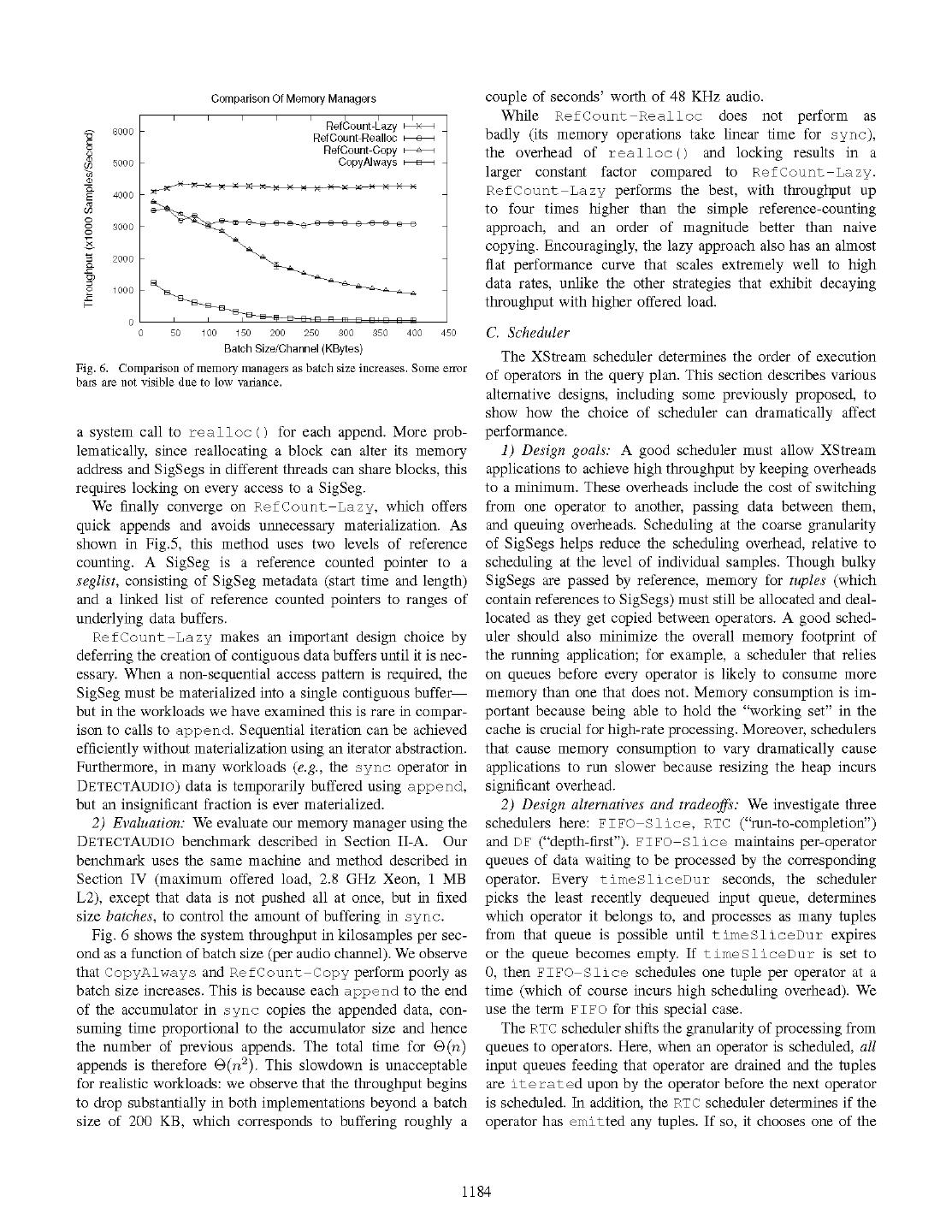
4 . Errors WavseSrpt Rsl SigSeg SigSeg Program Type Inference XStream Engine (D G, Query Plan Scheduler Threads CZ Partial U/) Evaluate] dla o :~~~~~~~~~ Query Plan daTa ,, - - - -- - - . . eyiBufe .. I~~~~ *_I-- I t J-__ Underlying Data Buffer -7 - E E Optimize - Reference counted pointer Generate C Memory Manager Timebase Service W Logical sample range L-------- Int Query- Plan -_-_-__________-__ -_-_______________________ __-_----- --- - List pointer Installs Query Plan Fig. 5. The Refcount-Lazy data structure. Fig. 4. The XStream architecture. 1) Design alternatives and tradeoffs: To motivate our de- sign choices in this implementation, we present four succes- not intrinsically contain timestamps, though many application sive versions, each making an incremental change over the schemas do include timestamps. previous, and yielding a performance improvement. SigSegs make it possible to pass windows of data between We first consider CopyAlways, a naive implementation operators as first class objects. This, combined with the iso- in which SigSegs contain a copy of the signal data. In this chrony of SigSegs, offers three benefits: version, SigSegs are passed between operators by copying, and . First, since SigSegs carry windows of data between oper- append and subseg are also implemented by copying. This ators, individual operators are not required to define their strategy is a good basis for comparison, with simple semantics own window at their input. even in the presence of concurrency. * Second, operations that buffer data or change the window- To establish the overhead of copying, we compared the ing of data are very efficient. The rewindow operator cost of creating a copy of a SigSeg to two common signal uses copy-free subset and append operations to transform processing operations: FFT and X. X. We found that while the windowing of a stream of SigSegs. copy cost is insignificant compared to heavier algorithms such . Third, since SigSegs are isochronous, storage overhead is as a 256 point FFT, the cost of making a copy consistently dramatically reduced by eliminating explicit per-sample dwarfs X. X by a factor of 10. This suggests that a lighter- timestamps, and enabling operators to index into a SigSeg weight method of passing SigSegs is required to support fine- by timestamp in constant time. grained modularity in the query plan. Our second implementation, Re fCount, is a straightfor- To achieve this, SigSegs add three additional methods to the ward extension to CopyAlways that stores signal data in standard array API: a reference-counted buffer. Re fCount implements standard . subseg(si'gseg, start, len): returns a new SigSeg repre- copy-on-write semantics: mutating a SigSeg normally requires senting a sub-range of the input sigseg. copying, but can be optimized to be in-place if no other . append(sigseg, sigseg): returns a new SigSeg represent- SigSegs share the same data block. The append operation ing the union of two adjacent SigSegs. poses more of a challenge. We consider three possible . timebase(sigseg): returns the SigSeg's timebase, used to implementations of append: relate a signal index to a timestamp. . Ref Count-Copy, which maintains a contiguous buffer on append by allocating a new block and copying. B. Memory Manager and SigSegs . RefCount-Realloc, which uses realloc () to ex- tend the allocation of the "earlier" buffer without copying, The principal goal of the XStream memory manager is an and then appends data from the "later" buffer. efficient implementation of the SigSeg API capable of scaling . RefCount-Lazy, which relaxes the requirement that to data rates of millions of samples per second. In particular, the underlying buffers are contiguous, instead taking a the memory manager must provide efficient ways to: lazy approach to materialization. Each SigSeg maintains * Create SigSegs at a data source (e.g., a microphone or a list of reference counted pointers to data blocks sorted pressure sensor) or from intermediate results of compu- by time. In-place destructive appends are fast since they tation (e.g., output of an FFT). simply splice lists. . Pass SigSegs between operators in the query plan. Our experiments with the acoustic monitoring application * Manipulate SigSegs using append and subseg. quickly ruled out the first design, which suffered an unac- . Materialize SigSegs into contiguous data buffers to sup- ceptable slowdown from appends within the sync operator port algorithms with non-sequential access patterns. (Fig. 6). The second design also suffers from the overhead of 1183
5 . Comparison Of Memory Managers couple of seconds' worth of 48 KHz audio. I I While RefCount -Realloc I~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ does not perform as RefCount-Lazy x>< 6000 RefCount-Realloc o badly (its memory operations take linear time for sync), 0 C-) a) RefCount-Copy CopyAlways A E the overhead of realloc () and locking results in a 5000 F U) a) larger constant factor compared to RefCount-Lazy. Q- E 4000 RefCount-Lazy performs the best, with throughput up CZ U) to four times higher than the simple reference-counting 3000 - approach, and an order of magnitude better than naive I copying. Encouragingly, the lazy approach also has an almost 2000 P 0 Q- flat performance curve that scales extremely well to high 0 1 000 data rates, unlike the other strategies that exhibit decaying F-- throughput with higher offered load. 0 50 100 150 200 250 300 350 400 C. Scheduler 450 Batch Size/Channel (KBytes) The XStream scheduler determines the order of execution Fig. 6. Comparison of memory managers as batch size increases. Some error bars are not visible due to low variance. of operators in the query plan. This section describes various alternative designs, including some previously proposed, to show how the choice of scheduler can dramatically affect a system call to realloc () for each append. More prob- performance. lematically, since reallocating a block can alter its memory 1) Design goals: A good scheduler must allow XStream address and SigSegs in different threads can share blocks, this applications to achieve high throughput by keeping overheads requires locking on every access to a SigSeg. to a minimum. These overheads include the cost of switching We finally converge on RefCount-Lazy, which offers from one operator to another, passing data between them, quick appends and avoids unnecessary materialization. As and queuing overheads. Scheduling at the coarse granularity shown in Fig.5, this method uses two levels of reference of SigSegs helps reduce the scheduling overhead, relative to counting. A SigSeg is a reference counted pointer to a scheduling at the level of individual samples. Though bulky seglist, consisting of SigSeg metadata (start time and length) SigSegs are passed by reference, memory for tuples (which and a linked list of reference counted pointers to ranges of contain references to SigSegs) must still be allocated and deal- underlying data buffers. located as they get copied between operators. A good sched- RefCount-Lazy makes an important design choice by uler should also minimize the overall memory footprint of deferring the creation of contiguous data buffers until it is nec- the running application; for example, a scheduler that relies essary. When a non-sequential access pattern is required, the on queues before every operator is likely to consume more SigSeg must be materialized into a single contiguous buffer memory than one that does not. Memory consumption is im- but in the workloads we have examined this is rare in compar- portant because being able to hold the "working set" in the ison to calls to append. Sequential iteration can be achieved cache is crucial for high-rate processing. Moreover, schedulers efficiently without materialization using an iterator abstraction. that cause memory consumption to vary dramatically cause Furthermore, in many workloads (e.g., the sync operator in applications to run slower because resizing the heap incurs DETECTAUDIO) data is temporarily buffered using append, significant overhead. but an insignificant fraction is ever materialized. 2) Design alternatives and tradeoffs: We investigate three 2) Evaluation: We evaluate our memory manager using the schedulers here: FIFO-Slice, RTC ("run-to-completion") DETECTAUDIO benchmark described in Section I1-A. Our and DF ("depth-first"). FIFO -Slice maintains per-operator benchmark uses the same machine and method described in queues of data waiting to be processed by the corresponding Section IV (maximum offered load, 2.8 GHz Xeon, 1 MB operator. Every timeSliceDur seconds, the scheduler L2), except that data is not pushed all at once, but in fixed picks the least recently dequeued input queue, determines size batches, to control the amount of buffering in sync. which operator it belongs to, and processes as many tuples Fig. 6 shows the system throughput in kilosamples per sec- from that queue is possible until timeSliceDur expires ond as a function of batch size (per audio channel). We observe or the queue becomes empty. If timeSliceDur is set to that CopyAlways and RefCount-Copy perform poorly as 0, then FIFO-Slice schedules one tuple per operator at a batch size increases. This is because each append to the end time (which of course incurs high scheduling overhead). We of the accumulator in sync copies the appended data, con- use the term FIFO for this special case. suming time proportional to the accumulator size and hence The RTC scheduler shifts the granularity of processing from the number of previous appends. The total time for 0(n) queues to operators. Here, when an operator is scheduled, all appends is therefore 9(n2). This slowdown is unacceptable input queues feeding that operator are drained and the tuples for realistic workloads: we observe that the throughput begins are iterated upon by the operator before the next operator to drop substantially in both implementations beyond a batch is scheduled. In addition, the RTC scheduler determines if the size of 200 KB, which corresponds to buffering roughly a operator has emitted any tuples. If so, it chooses one of the 1184
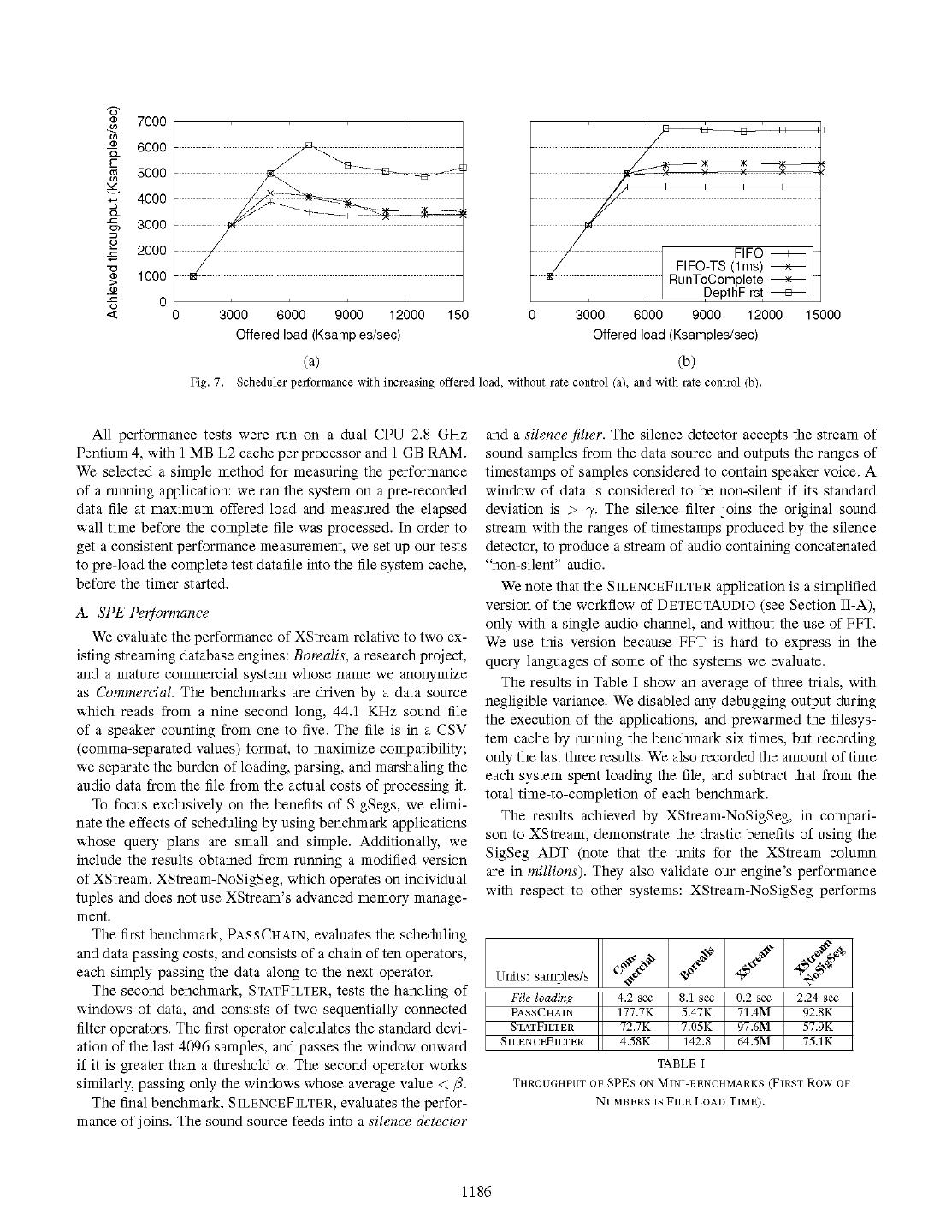
6 .successor operators to execute immediately afterwards, while system.) the other successor operators are enqueued for execution in We assume that the admission-controlled results represent the scheduler's queue of pending operators. If not, the operator the true peak performance of the scheduler algorithms. As has completed, and the scheduler is free to pick the next, least expected, the F I FO scheduler performs the worst, topping out recently scheduled operator with pending tuples to run. Both around 4.5M samples/second. The FIFO -Slice scheduler F I FO- S i ce and RTC should exhibit good instruction cache with slice = 28 ,us (labeled FIFO-TS in the figure) performs locality. 11% better. The RTC performs 20% better than FIFO, while The DF scheduler starts by pushing a set of tuples from DF is faster by about 51%. an input stream through an operator and then directly invokes We now look at the relative peak performance of the sched- the successor operator in the query plan whenever the operator ulers. After the FIFO scheduler finishes running an operator emits a tuple. Thus, the DF call graph is a depth-first traversal on an input tuple, it is highly likely to switch to a different of the query plan. This scheme does not require an operator operator. The overhead of switching results in some "cache- scheduled next to allocate and deallocate memory for tuples busting" both the instruction cache (operator code) and the (unlike in the previous cases, where tuples need to be copied) data cache (input queues and operator state) on the CPU ex- because synchronously executing operators can pass tuples perience churn. Both FIFO-Slice and RTC mitigate this by reference. But some queuing is unavoidable because the problem; in fact, RTC drains all the queues and automatically query plan is rarely a linear processing chain, and backtracking transitions to the one of the successors, so performs a little to an operator in the depth-first traversal requires data to be better than FIFO- Slice. The DF scheduler has poor cache queued. Because a XStream query plan may contain cycles, locality, but is able to more than compensate for it by avoiding the DF scheduler maintains the stack of the execution so far the expensive allocation, deallocation, and copying associated and enqueues those operators which would close the loop on with emitting tuples into input queues. In fact, in a pure engine to the scheduler queue for later execution. Once the depth-first benchmark (EngineBench) consisting of a 1000 pass-through traversal for a set of tuples has completed, the DF scheduler operators, the DF scheduler can be 5.8x faster than the other selects the least recently processed operator with enqueued schedulers. data to run next. To confirm our intuition regarding the CPU cache behavior, 3) Evaluation: We evaluate the performance of our sched- we profiled the cache usage of these schedulers, and found ulers on the DETECTAUDIo application described in Section that the execution of EngineBench using the FIFO scheduler II-A. We perform two sets of experiments: a scalability exper- resulted in 47x the rate of misses in the LI data cache - iment that measures the performance of the schedulers under compared to RTC. Also, it produces 20x the LI instruction increasing offered load and a peak-performance experiment cache misses relative to RTC. DF has about 50% of the in- that measures end-to-end performance of different XStream struction cache miss rate as FIFO and a similar data cache applications. These experiments use the same machine and miss rate because it switches rapidly between operators. methodology described in Section IV. We would like to point out that, although the DF scheduler Fig. 7(a) displays the results of scalability experiments, as performs best in the majority of the benchmarks, there are the offered load increases beyond the maximum processing some rare cases where it does not. Some applications involve capacity of each scheduler. The figure shows a drop-off in "heavy-hitter" operators which generate a lot of output, which the sustained throughput as the offered load increases. We must be scheduled sparingly and whose output must be con- determined that this degradation is due to the buildup in in- sumed quickly. In such scenarios, schemes like FIFO which put queues when the system is overloaded. As queue sizes schedule the operators in the query plan more uniformly than increase, a large amount of memory must be allocated and DF I, have a better chance of avoiding memory allocation deallocated to keep up, which causes the heap maintained by "spikes" which we have determined to be detrimental to per- the GNU C library's malloc implementation to grow and formance. We show one such case in Section IV-B. shrink, placing a heavy burden on Linux's virtual memory manager. Smaller amounts of allocation and deallocation could IV. EVALUATION be handled entirely within a heap cache, or even the CPU cache. In the previous section, we described the implementation To solve this problem, we augment our schedulers with of XStream and presented some results to illustrate the per- source rate control, which synchronously admits a maximum formance of each individual component. In this section, we of tupleBurst tuples from each source, waits until all the present data to specifically quantify the performance gains that operators reach completion, and then repeats. This has the stem from our system design. We demonstrate these perfor- effect of limiting the total amount of memory used by the mance gains within the XStream framework and also provide XStream engine at any time. Fig. 7(b) shows that admission some comparative results for both the Borealis [16] engine control causes each scheduler's response to increased load to and a commercial system, to show that the same ideas can be flat rather than collapsing. (Alternatively, we could have produce a similar gain in other stream processing systems. limited the maximum size of the input queues and used back- pressure to throttle the rate of allocation/deallocation in the 1DF's decisions are dictated by the query plan connectivity. 1185
7 . C') 7000 C') cn 6000 E CZ) 5000 4000 ----- a- ~~~~~~~~~~~~~~~~~ -F 3000 0) I -o 2000 - FIFO FIFO-TS (lms) x 1000 - RunToComplete -K .C_ DepthFirst -E-- 0 0 3000 6000 9000 12000 150 0 3000 6000 9000 12000 15000 Offered load (Ksamples/sec) Offered load (Ksamples/sec) (a) (b) Fig. 7. Scheduler performance with increasing offered load, without rate control (a), and with rate control (b). All performance tests were run on a dual CPU 2.8 GHz and a silence filter. The silence detector accepts the stream of Pentium 4, with 1 MB L2 cache per processor and 1 GB RAM. sound samples from the data source and outputs the ranges of We selected a simple method for measuring the performance timestamps of samples considered to contain speaker voice. A of a running application: we ran the system on a pre-recorded window of data is considered to be non-silent if its standard data file at maximum offered load and measured the elapsed deviation is > -y. The silence filter joins the original sound wall time before the complete file was processed. In order to stream with the ranges of timestamps produced by the silence get a consistent performance measurement, we set up our tests detector, to produce a stream of audio containing concatenated to pre-load the complete test datafile into the file system cache, "non-silent" audio. before the timer started. We note that the SILENCEFILTER application is a simplified A. SPE Performance version of the workflow of DETEcTAUDIO (see Section Il-A), only with a single audio channel, and without the use of FFT. We evaluate the performance of XStream relative to two ex- We use this version because FFT is hard to express in the isting streaming database engines: Borealis, a research project, query languages of some of the systems we evaluate. and a mature commercial system whose name we anonymize The results in Table I show an average of three trials, with as Commercial. The benchmarks are driven by a data source negligible variance. We disabled any debugging output during which reads from a nine second long, 44.1 KHz sound file the execution of the applications, and prewarmed the filesys- of a speaker counting from one to five. The file is in a CSV tem cache by running the benchmark six times, but recording (comma-separated values) format, to maximize compatibility; only the last three results. We also recorded the amount of time we separate the burden of loading, parsing, and marshaling the each system spent loading the file, and subtract that from the audio data from the file from the actual costs of processing it. total time-to-completion of each benchmark. To focus exclusively on the benefits of SigSegs, we elimi- nate the effects of scheduling by using benchmark applications The results achieved by XStream-NoSigSeg, in compari- son to XStream, demonstrate the drastic benefits of using the whose query plans are small and simple. Additionally, we include the results obtained from running a modified version SigSeg ADT (note that the units for the XStream column are in millions). They also validate our engine's performance of XStream, XStream-NoSigSeg, which operates on individual tuples and does not use XStream's advanced memory manage- with respect to other systems: XStream-NoSigSeg performs ment. The first benchmark, PASSCHAIN, evaluates the scheduling and data passing costs, and consists of a chain of ten operators, each simply passing the data along to the next operator. Units: samples/s | The second benchmark, STATFILTER, tests the handling of File loading 4.2 sec 8.1 sec 0.2 sec 2.24 sec windows of data, and consists of two sequentially connected PASSCHAIN 177.7K 5.47K 71.4M 92.8K filter operators. The first operator calculates the standard devi- STATFILTER 72.7K 7.05K 97.6M 57.9K ation of the last 4096 samples, and passes the window onward SILENCEFILTER 4.58K 142.8 64.5M 75.1K if it is greater than a threshold a. The second operator works TABLE I similarly, passing only the windows whose average value < . THROUGHPUT OF SPEs ON MINI BENCHMARKS (FIRST Row OF The final benchmark, SILENCEFILTER, evaluates the perfor- NUMBERS IS FILE LOAD TIME). mance of joins. The sound source feeds into a silence detector 1186
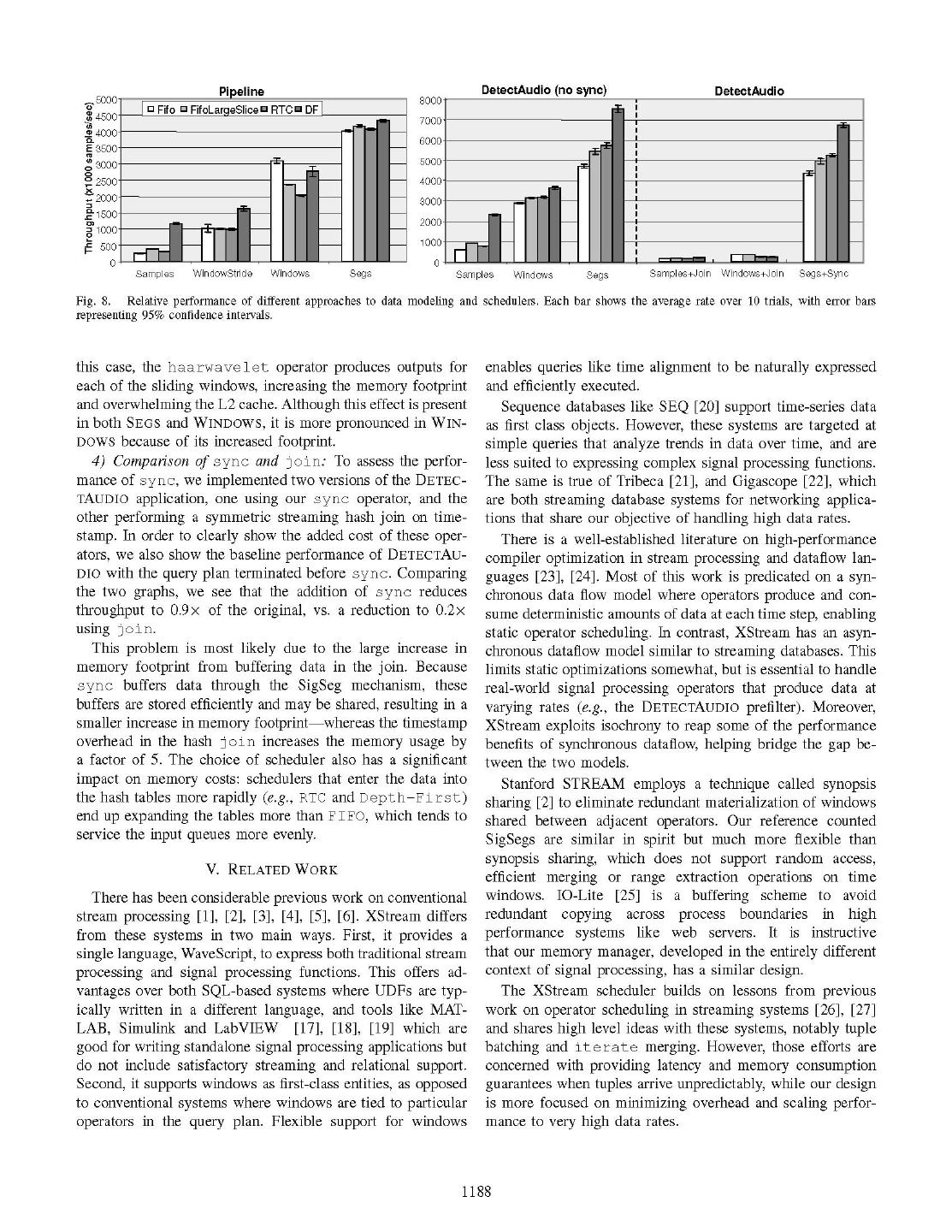
8 .on par with the commercial SPE. XStream loads the file faster To show the differential impact of sync and join opera- because the commercial SPE's input file parser is more elab- tors, we created additional versions of DETECTAUDIO: one orate. We suspect that Commercial does better than XStream version that cuts off the query plan directly before sync, on PASSCHAIN because of its internal query optimizations, and another that implements the complete DETECTAUDIO ap- such as operator merging. On the other hand, the numbers in plication, substituting join for sync in the WINDOW and Table I clearly indicate the advantages of the sync operator SAMPLES cases. We now describe each of these cases in detail, over generic joins, even in a system which uses tuple-by-tuple starting from SAMPLES and adding optimizations. stream processing. 1) Window-passing optimization: Processing high-rate data Our results show that XStream outperforms the commercial one sample at a time places incurs a large queuing and schedul- system by a factor of more than 400 in simple message pass- ing overhead. In our first optimization, an operator that would ing, a factor of more than 1340 in windowing and statistics op- emit N individual tuples now packs those tuples into a SigSeg erations, and a factor of 14000 (four factors of magnitude) in and thus passes them by reference in a single emit call. Note time-based joins. XStream outperforms Borealis by more than that although we use a SigSeg to enable sharing and pass-by- four factors of magnitude in simple benchmarks, and more reference, the SigSeg is defined on <time, value> tuples than five factors of magnitude in temporal joins. Why does so the data is interleaved with timestamps. This optimization our system outperform the existing systems so drastically? is analogous to the synopsis sharing optimization of Stanford XStream uses the isochrony of signal data to store a single STREAM [2]. timestamp per SigSeg. The competing systems store a times- Comparing the results in Fig. 8 (PIPELINE), we see tamp per every tuple. In addition to the timestamp, some of that there is an increase in performance from SAMPLES to the systems attach extraneous metadata to every tuple. For WINDOWSTRIDE, with some variation among schedulers. example, Borealis attaches a 53 byte header to every sample Since the Depth-First scheduler bypasses inter-operator it passes around, greatly increasing the chance of cache misses. queues wherever it can, it far outperforms the others on XStream takes advantage of memory management optimiza- SAMPLES where queue and scheduler costs dominate. The tions: passing signal data by reference (via SigSegs), and using window-passing optimization is a clear win: Depth-First a single copy of any piece of signal data throughout the system. improves by 1.4x, while the other schedulers improve by a The other systems suffer from the overhead of extraneous factor of 3. memory management and copying. 2) Column-order optimization: When we implement signal XStream implements sync, an efficient form of time-based processing operations such as haarwavelet over windows join which operates on time ranges as opposed to samples. of <time, value> tuples, we have the option to process the Other systems join on a sample-by-sample basis, which is data by "striding" through the row-major data, or to first copy considerably more costly in terms of the number of timestamp the data into a column-major vector. In our tests, WINDOW- comparisons. STRIDE executes haarwavelet directly on row-major data while WINDOWS first copies the data into column order, and B. Performance Benefits of SigSegs then copies it back into tuple form. By comparing WINDOW- In this section, we present data to specifically quantify the STRIDE to WINDOWS, we can see that re-ordering the data performance gains that stem from using SigSegs. We have yields a 2x improvement for all schedulers except DF, which found that SigSegs affect performance in four ways: (1) they yields 1.7 x. This effect is caused by a larger memory footprint eliminate per-sample processing which incurs a high schedul- and by cache exhaustion, as discussed in Section Ill-C. ing overhead, (2) they represent data in column-major order, 3) Cost of interleaved time-stamps: While operators such thus compacting it for a lower cache footprint, (3) they reduce as haarwavelet are more heavily influenced by cache per- the memory footprint by eliminating redundant time-stamp formance, the performance of the system in general is af- information, and (4) they enable sync, an optimized j oin fected by the memory footprint. Maintaining sampled data construct. as <time, value> is very inefficient. We can see the ef- To separately quantify each of these factors, we imple- fect of maintaining interleaved time-stamps by comparing the mented special versions of our PIPELINE and DETECTAUDIO performance of SEGS and WINDOWS. In this implementation, applications in which we enable each improvement in turn, timestamps are 64 bit integers doubling the memory foot- with the results shown in Fig. 8. These versions are named print of PIPELINE (since samples are double) and tripling as follows: that of DETECTAUDIO (since samples are float). Averaging . SAMPLES: passes each sample between operators as a over all schedulers, eliminating time-stamps yields a 1.6 x separate <time,value> tuple. improvement in PIPELINE, and a 1.8x improvement in DE- * WINDOWSTRIDE: passes whole windows of <time, TECTAUDIO. value> tuples between operators. We implemented this Note that different scheduling disciplines also affect per- only for PIPELINE. formance. In particular, disciplines that attempt to drain the . WINDOWS: same as above, but re-orders to column-order queue of an operator run the risk of increasing the memory before heavy operators (e.g., f ft). footprint if the operator emits more data than it consumes. . SEGS: the SigSeg-based version. This explains the performance penalty incurred by RTC; in 1187
9 . o-5000 0 Fifo * FifoLargeSlice RTC * DF| * 8000- 0 451000 ~ ~~ ~ ~ ~ ~ ~ ~ ~ ~~~~~~~00 E 4000| (D 3500 ;| Samples WindowStride Windows Segs Samples Windows Segs Samples+Join Windows+Join Segs+Sync Fig. 8. Relative performance of different approaches to data modeling and schedulers. Each bar shows the average rate over 10 trials, with error bars representing 95% confidence intervals. this case, the haarwavelet operator produces outputs for enables queries like time alignment to be naturally expressed each of the sliding windows, increasing the memory footprint and efficiently executed. and overwhelming the L2 cache. Although this effect is present Sequence databases like SEQ [20] support time-series data in both SEGS and WINDOWS, it is more pronounced in WIN- as first class objects. However, these systems are targeted at DOWS because of its increased footprint. simple queries that analyze trends in data over time, and are 4) Comparison of sync and joinn: To assess the perfor- less suited to expressing complex signal processing functions. mance of sync, we implemented two versions of the DETEC- The same is true of Tribeca [21], and Gigascope [22], which TAUDIo application, one using our sync operator, and the are both streaming database systems for networking applica- other performing a symmetric streaming hash join on time- tions that share our objective of handling high data rates. stamp. In order to clearly show the added cost of these oper- There is a well-established literature on high-performance ators, we also show the baseline performance of DETECTAu- compiler optimization in stream processing and dataflow lan- DIO with the query plan terminated before sync. Comparing guages [23], [24]. Most of this work is predicated on a syn- the two graphs, we see that the addition of sync reduces chronous data flow model where operators produce and con- throughput to 0.9x of the original, vs. a reduction to 0.2x sume deterministic amounts of data at each time step, enabling using join. static operator scheduling. In contrast, XStream has an asyn- This problem is most likely due to the large increase in chronous dataflow model similar to streaming databases. This memory footprint from buffering data in the join. Because limits static optimizations somewhat, but is essential to handle sync buffers data through the SigSeg mechanism, these real-world signal processing operators that produce data at buffers are stored efficiently and may be shared, resulting in a varying rates (e.g., the DETEcTAUDIO prefilter). Moreover, smaller increase in memory footprint whereas the timestamp XStream exploits isochrony to reap some of the performance overhead in the hash join increases the memory usage by benefits of synchronous dataflow, helping bridge the gap be- a factor of 5. The choice of scheduler also has a significant tween the two models. impact on memory costs: schedulers that enter the data into Stanford STREAM employs a technique called synopsis the hash tables more rapidly (e.g., RTC and Depth-First) sharing [2] to eliminate redundant materialization of windows end up expanding the tables more than FIFO, which tends to shared between adjacent operators. Our reference counted service the input queues more evenly. SigSegs are similar in spirit but much more flexible than synopsis sharing, which does not support random access, V. RELATED WORK efficient merging or range extraction operations on time There has been considerable previous work on conventional windows. 1O-Lite [25] is a buffering scheme to avoid stream processing [1], [2], [3], [4], [5], [6]. XStream differs redundant copying across process boundaries in high from these systems in two main ways. First, it provides a performance systems like web servers. It is instructive single language, WaveScript, to express both traditional stream that our memory manager, developed in the entirely different processing and signal processing functions. This offers ad- context of signal processing, has a similar design. vantages over both SQL-based systems where UDFs are typ- The XStream scheduler builds on lessons from previous ically written in a different language, and tools like MAT- work on operator scheduling in streaming systems [26], [27] LAB, Simulink and LabVIEW [17], [18], [19] which are and shares high level ideas with these systems, notably tuple good for writing standalone signal processing applications but batching and iterate merging. However, those efforts are do not include satisfactory streaming and relational support. concerned with providing latency and memory consumption Second, it supports windows as first-class entities, as opposed guarantees when tuples arrive unpredictably, while our design to conventional systems where windows are tied to particular is more focused on minimizing overhead and scaling perfor- operators in the query plan. Flexible support for windows mance to very high data rates. 1188
10 . Our paper shares high-level ideas with a previous short [7] L. Girod, K. Jamieson, Y Mei, R. Newton, S. Rost, A. Thiagarajan, position paper [7]. That paper made the case for integrating H. Balakrishnan, and S. Madden, "The case for WaveScope: A signal- oriented data stream management system (position paper)," in Proceed- relational and signal processing functions in a data stream ings of Third Biennial Conference on Innovative Data Systems Research processing system for high-rate applications. It sketched the (CIDR07), 2007. high-level details of a language and mentioned the run-time [8] I. Stoianov, D. Dellow, C. Maksimovic, and N. Graham, "Field validation of the application of hydraulic transients for leak detection in trans- component, but left the design and implementation of the mission pipelines," in Proceedings of the International Conference on system and language for future work. In addition to describing Advances in Water Supply Management. CCWI-Computing and Control these details, this paper describes how XStream applications for the Water Industry, London, UK, September 2003. [9] I. Stoianov, L. Nachman, S. Madden, and T. Tokmouline, "PIPENET: from three different domains are written in WaveScript and A wireless sensor network for pipeline monitoring," in IPSN '07: Pro- evaluates their performance. ceedings of the sixth international conference on Information processing in sensor networks. New York, NY, USA: ACM Press, 2007. [10] A. Lakhina, M. Crovella, and C. Diot, ""diagnosing network-wide traffic VI. CONCLUSION anomalies"," in SIGCOMM, Portland, OR, August 2004. [11] Y-C. Cheng, J. Bellardo, P. Benko, A. C. Snoeren, G. M. Volker, and This paper described the architecture and implementation S. Savage, "Jigsaw: Solving the puzzle of enterprise 802.11 analysis," of XStream, a system that combines event stream and sig- in SIGCOMM, Pisa, Italy, August 2006. nal processing. XStream aims to improve both programmer [12] H. Wang et al., "Acoustic sensor networks for woodpecker localiza- tion," in SPIE Conference on Advanced Signal Processing Algorithms, productivity, by making it easy to develop user-defined pro- Architectures and Implementations, Aug. 2005. cessing functions, and achieve high performance, processing [13] A. Ali, T. Collier, L. Girod, K. Yao, C. Taylor, and D. T. Blumstein, "An several million samples per second on a standard PC. XStream empirical study of acoustic source localization," in IPSN '07: Proceed- ings of the sixth international conference on Information processing in incorporates a new basic data type to represent isochronous sensor networks. New York, NY, USA: ACM Press, 2007. signal segments and uses the WaveScript language to express [14] V. Trifa, "A framework for bird songs detection, recognition and queries and write custom operators. The XStream runtime uses localization using acoustic sensor networks," Master's thesis, Ecole Polytechnique Federale de Lausanne, 2006. an efficient SigSeg memory manager and a depth-first operator [15] A. Ledeczi et al., "Countersniper system for urban warfare," ACM scheduler to achieve high performance. Transactions on Sensor Networks, vol. 1, no. 2, pp. 153-177, Nov. 2005. We described three real-world applications and measured [16] D. J. Abadi, Y. Ahmad, M. Balazinska, U. Cetintemel, M. Cherniack, J.- H. Hwang, W. Lindner, A. S. Maskey, A. Rasin, E. Ryvkina, N. Tatbul, their performance, obtaining both end-to-end results and a Y. Xing, and S. Zdonik, "The design of the borealis stream processing detailed experimental analysis of the various components of engine," in CIDR, 2005. the XStream engine. These results showed the benefits of our [17] (2007) Matlab product homepage. [Online]. Available: http://www. mathworks.com/products/matlab/ system architecture and data model. They are also encouraging [18] (2007) Simulink product homepage. [Online]. Available: http://www. in comparison to traditional SPEs: our benchmark measure- mathworks.com/products/simulink/ ments show that, XStream is between 400 and 14000 times [19] (2007) Labview product homepage. [Online]. Available: http://www.ni. com/labview/ faster than a commercial SPE. On similar conventional PC [20] P. Seshadri, M. Livny, and R. Ramakrishnan, "The design and imple- hardware, XStream applications are able to implement non- mentation of a sequence database system," in VLDB, 1996. trivial real applications running at speeds between 4.8 and [21] M. Sullivan and A. Heybey, "Tribeca: A system for managing large databases of network traffic," in Proceedings of the USENIX Annual 7 million samples per second. Thus, our architecture is well- Technical Conference, New Orleans, LA, June 1998. suited for high-rate processing for an important emerging class [22] C. Cranor, T. Johnson, 0. Spataschek, and V. Shkapenyuk, "Gigascope: of signal-oriented streaming applications. a stream database for network applications," in SIGMOD, 2003. [23] W. Thies, M. Karczmarek, and S. Amarasinghe, "Streamit: A language for streaming applications," in ICCC, April 2002. VII. ACKNOWLEDGEMENTS [24] R. Stephens, "A survey of stream processing," Acta Informatica, vol. 34, no. 7, pp. 491-541, 1997. This work was supported by the National Science Founda- [25] V. S. Pai, P. Druschel, and W. Zwaenepoel, "10-Lite: a unified I/O tion under Awards Number CNS-0520032 and CNS-0720079. buffering and caching system," ACM Transactions on Computer Systems, vol. 18, no. 1, pp. 37-66, 2000. [26] D. Carney, U. Cetintemel, A. Rasin, S. Zdonik, M. Cherniack, and REFERENCES M. Stonebraker, "Operator scheduling in a data stream manager," in VLDB, 2003. [1] D. Carney, U. Cetintemel, M. Cherniak, C. Convey, S. Lee, G. Seidman, [27] B. Babcock, S. Babu, M. Datar, R. Motwani, and D. Thomas, "Operator M. Stonebraker, N. Tatbul, and S. Zdonik, "Monitoring streams a new scheduling in data stream systems," The VLDB Journal, vol. 13, no. 4, class of data management applications," in VLDB, 2002. pp. 333-353, 2004. [2] A. Arasu, B.Babcock s.SBabu, J. Cieslewicz, M. Datar, K Ito, R. Motwani, U. Srivastava, and J. Widom, "Stream: The stanford data stream management system," in Book Chapter, 2004. [3] s. Chandrasekaran, 0. Cooper, A. Deshpande, M. J. Franklin, J. M. Hellerstein, W. Hong, S. Krishnamurthy, S. R. Madden, V. Raman, F. Reiss, and M. A. Shah, "Telegraphcq: Continuous dataflow processing for an uncertain world," in CIDR, 2003. [4] (2007) Streambase corporate homepage. [Online]. Available: http: //www.streambase.com/ [5] (2007) Coral8 corporate homepage. [Online]. Available: http://www. coral8.com/ [6] (2007) Aleri corporate homepage. [Online]. Available: http://www.aleri. com/ 1189
3秒后跳转登录页面
去登陆

