












- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Data Ingestion for the Connected World
In this paper, we argue that in many “Big Data” applications, getting data into the system correctly and at scale via traditional ETL (Extract, Transform, and Load) processes is a fundamental roadblock to being able to perform timely analytics or make real-time decisions. The best way to address this problem is to build a new architecture for ETL which takes advantage of the push-based nature of a stream processing system. We discuss the requirements for a streaming ETL engine and describe a generic architecture which satisfies those requirements. We also describe our implementation of streaming ETL using a scalable messaging system(Apache Kafka), a transactional stream processing system(S-Store), and a distributed poly store (Intel’s Big DAWG)
展开查看详情
1 . Data Ingestion for the Connected World John Meehan Nesime Tatbul Jiang Du Cansu Aslantas Intel Labs and MIT University of Toronto Stan Zdonik tatbul@csail.mit.edu jdu@cs.toronto.edu Brown University {john,cpa,sbz}@cs.brown.edu ABSTRACT We argue that for modern applications in which latency In this paper, we argue that in many “Big Data” applica- matters, ETL should be conceived as a streaming problem. tions, getting data into the system correctly and at scale via New data arrives and is immediately handed to processing traditional ETL (Extract, Transform, and Load) processes is elements that prepare data and load it into a DBMS. We a fundamental roadblock to being able to perform timely an- believe that this requires a new architecture and that this alytics or make real-time decisions. The best way to address architecture places some fundamental requirements on the this problem is to build a new architecture for ETL which underlying stream processing system. An analytics system takes advantage of the push-based nature of a stream pro- for demanding applications like IoT are based on the exis- cessing system. We discuss the requirements for a streaming tence of a time-sensitive data store that captures a picture ETL engine and describe a generic architecture which sat- of the world that is as accurate as possible. If correctness isfies those requirements. We also describe our implemen- criteria are not met, the contents of the analytics system can tation of streaming ETL using a scalable messaging system drift arbitrarily far from the true state of the world. (Apache Kafka), a transactional stream processing system While this paper is primarily about data ingestion at scale, (S-Store), and a distributed polystore (Intel’s BigDAWG), we note that for many modern applications, the data in ques- as well as propose a new time-series database optimized to tion are time-series. We point out that paying special atten- handle ingestion internally. tion to this important data type can have strong benefits, and we are currently pursuing this line of work. 1. INTRODUCTION 2. MOTIVATING EXAMPLES Data ingestion is the process of getting data from its source to its home system as efficiently and correctly as pos- sible. This has always been an important problem and has 2.1 Internet of Things been targeted by many previous research initiatives, such as There is a strong need to support real-time data inges- data integration, deduplication, integrity constraint mainte- tion, particularly for demanding new applications such as nance, and bulk data loading. Data ingestion is frequently IoT. Many of the standard problems of data ingestion (like discussed under the name of Extract, Transform, and Load data cleaning and data integration) remain in these new ap- (ETL). plications, but the scale at which these tasks must operate Modern applications put new requirements on ETL. Tra- changes the way we must conceive of the solution. ditionally, ETL is constructed as a pipeline of batch pro- For instance, take self-driving vehicles as an example of an cesses, each of which takes its input from a file and writes IoT deployment. Today’s cars have many on-board sensors its output to another file for consumption by the next pro- such as accelerometers, position sensors (e.g., GPS, phone), cess in the pipeline, etc. The reading and writing of files fuel consumption sensors and at least one on-board com- is cumbersome and very slow. Older applications, such as puter. In the future, cars will also be equipped with com- data warehouses, were not particularly sensitive to the la- munication ability to send messages to other vehicles or to tency introduced by this process. They did not need the the cloud via sophisticated middleware (streaming system). most absolutely current data. Newer applications like IoT In cities, it is easy to imagine that this may scale to mil- (Internet of Things), on the other hand, seek to provide an lions of cars. Such a system will need to offer many services, accurate model of the real world in order to accommodate including, for example, a warning and a list of nearby gas real-time decision making. stations when the fuel tank level is below some threshold. In this situation, it is easy to see why the traditional data integration process is not sufficient. The value of sensor data decreases drastically over time, and the ability to make decisions based on that data is only useful if the analysis is done in near real-time. There is a necessity to maintain the order of the time-series data, but to do so in a way that This article is published under a Creative Commons Attribution License does not require waiting hours for a large batch to become (http://creativecommons.org/licenses/by/3.0/), which permits distribution available. Additionally, time-series data can become very and reproduction in any medium as well allowing derivative works, pro- vided that you attribute the original work to the author(s) and CIDR 2017. large very quickly, particularly if sensor sample rates are CIDR’17 January 8–11, 2017, Chaminade, CA, USA high. Storing this data can become extremely expensive,
2 . micro-batches throughout the day. Assuming the ETL system outputs the same final results, there is no downside to taking a streaming approach. How- ever, the act of breaking large batches into smaller ones in- troduces new data dependencies. Take for instance the Dim- Security, DimAccount, and DimTrade tables, each of which are described in Figure 1(a). Note that the DimTrade table contains foreign keys on both the DimSecurity and DimAc- count tables (other foreign keys also exist in these tables, but for simplicity, we will focus on this subset) [21]. When new rows are defined within the DimTrade table, reference must be made to the other two tables to assign the SK SecurityID and SK AccountID keys, which means that the correspond- ing rows must already exist in their respective tables. Stream processing is an ideal way to handle these data dependencies. The operations for managing additions to (a) Partial Schema the DimSecurity, DimAccount, and DimTrade tables can be arranged in a specific order by using a streaming dataflow graph. For example, assume a batching mechanism groups the creation of security S, account A, and a trade request T from account A for purchasing shares of security S. The dataflow graph illustrated in Figure 1(b) maintains the data dependencies of this batch while allowing processing flexi- bility. The batch is first processed by a CreateSecurities dataflow graph, then CreateAccount, and finally, CreateT ra- des. Dividing ETL processing into small, ordered transactions has the added benefit of making the process more granu- lar for the purposes of distributed processing. Ordinarily, the operations creating the trade, company, and security relations may take place in a single, large transaction. How- ever, these transactions can require look-ups on data that are sharded on different keys, and thus likely require a large cross-node transaction in a distributed system. Streaming ETL could allow these large distributed transactions to be (b) Partial Dataflow Graph broken into several small single-sited transactions without Figure 1: TPC-DI damaging correctness due to its push-based, ordered pro- cessing. Thus, the transactions creating the trade, company, and it is likely that the entirety of the time-series data does and security relations can each run separately on different not need to be stored to extract the relevant analytics. nodes, independent of one another save for their order of We postulate that with a completely fresh look at the data execution. integration process, the analytics, cleaning, and transforma- tion of time-series data can all be performed by one system 3. STREAMING ETL REQUIREMENTS in near real-time. As with any data integration system, streaming ETL must first and foremost be concerned with the correctness and pre- 2.2 Streaming TPC-DI dictability of its results. Simultaneously, a streaming ETL While sensor data and other streaming data sources are system must be able to scale with the number of incoming a natural use-case, we believe that streaming ETL can have data sources and process data in as timely a fashion as pos- benefits for traditional data ingestion as well. Take for in- sible. With these goals in mind, we can divide the require- stance a retail brokerage firm application, emulated by TPC- ments for a streaming ETL system into three categories: DI. TPC-DI is a data integration benchmark created by the ETL requirements, streaming requirements, and infrastruc- TPC team to measure the performance of various enterprise- ture requirements. level ingestion solutions [18]. It focuses on the extraction and transformation of data from a variety of sources and 3.1 ETL Requirements source formats (e.g., CSV, XML, etc.). These various flat files are processed in large batches, and the results are inte- 3.1.1 Data Collection grated as one unified data model in a data warehouse. A typical example of an ETL workload generally includes While TPC-DI was originally designed as a benchmark a large number of heterogeneous data sources that may have for traditional data ingestion, it can be re-imagined as a different schemas and originate from a variety of sources. streaming ETL use case. The obvious benefit of the con- While heterogeneity in data collection is a well-known prob- version to streaming is quicker access to incremental re- lem and has been addressed by traditional ETL and data sults. Traditional ETL systems process large batches of data integration solutions, it is more challenging to apply these overnight, while a streaming version could process smaller solutions at the scale required for a large number of stream-
3 .ing data sources, as in IoT. In the case of streaming data actual order of data generation. With so many sources and sources, data must be collected, queued, and routed to the incoming tuples, tuples can be out of time-stamp order or appropriate processing channel. A data collection mecha- they can be missing altogether. Waiting for things to be nism should have the ability to transform traditional ETL sorted out before proceeding can introduce an unacceptable data sources (e.g., flat files) into streaming ETL sources. In level of latency. this case, the traditional data sources need to be collected by One problem that arises in a network setting with disor- streaming clients that can batch and create input streams. der in tuple arrival is determining when a logical batch of Data collection should scale with the number of data sources tuples has completely arrived. In such a setting, some ear- to avoid losing information or becoming a bottleneck for pro- lier solutions required that the system administrator specify cessing. a timeout value [5]. Timeout is defined as a maximum value In addition to simply collecting data, some of the data for how long the system should wait to fill a batch. If the cleaning computation can be pushed to the data collection timeout value is exceeded, the batch closes and if any subse- network. For example, in an IoT application that collects quent tuples for this batch arrive later, they are discarded. data over a large network of sources, the gateway routers We can imagine that for streams that represent time-series and switches can help with some of the computation via (the vast majority of streaming sources in IoT), if a batch filtering and smoothing of signal data [19]. Another op- times out, the system could predict what the missing values tion when router programming is not readily available is to in that batch would look like based on historical data. In use field-programmable gate arrays (FPGAs) for the same other words, we can use predictive techniques (e.g., regres- functionality. Some network interface cards also support sion) to make a good guess on the missing values. embedded FPGAs. Even though the computational capa- bilities and memory sizes of these edge programming nodes 3.2.2 Dataflow Ordering are very limited, for large-scale applications such as IoT, As previously stated, data ingestion is traditionally ac- the benefit of using this method is quick scalability with the complished in large batches. In the interest of improving network size. performance, streaming data ingestion seeks to break large batches into much smaller ones. The same goes for oper- 3.1.2 Bulk Loading ations; rather than accomplishing data transformation in It has long been recognized that loading large amounts of large transactions, streaming data ingestion breaks opera- data into a DBMS should not be done in a tuple-at-a-time tions into several smaller operations that are connected as a manner. The overhead cost of inserting data using SQL is user-defined DAG known as a dataflow graph. significantly higher than inserting data in bulk. Further- In order to ensure that these smaller operations on smaller more, indexing the new data presents a significant issue for batches still produce the same result as their larger counter- the warehouse. Therefore, a streaming ETL engine must parts, ordering constraints need to be enforced on how the have the ability to bulk load freshly transformed data into dataflow graph executes. Streaming data management sys- the data warehouse. tems are no stranger to ordering constraints. Intuitively, Another tactic to increase the overall input bandwidth batches must be processed in the order in which they ar- of the system is to suppress the indexing and materialized rive. Additionally, the dataflow graph must execute in the view generation of the warehouse until some future time. expected order for each batch. These constraints should The warehouse would have to be prepared to answer queries be strict enough to ensure correctness while also providing in a two-space model in which older data is indexed and enough flexibility to achieve parallelism. newer data is not. This would require two separate query plans. The two spaces would be merged periodically and 3.2.3 Exactly-Once Processing asynchronously. When a stream-processing system fails and is rebuilding its state via replay, duplicate tuples may be created to those 3.1.3 Heterogeneous Data Types generated before the failure. This is counter-productive and Modern data ingestion architectures should provide built- endangers the integrity of the data. Data ingestion attempts in support for dealing with diverse target storage systems. to remove duplicate records, but without exactly-once pro- The heterogeneity of the storage systems in today’s big data cessing, our system may insert the very thing that dedupli- ecosystem has led to the need for using multiple disparate cation addresses. Similarly, it is expected that no tuples are backends or federated storage engines (e.g., the BigDAWG lost during either normal operation or failure. polystore [7]). The presence of multiple heterogeneous desti- Exactly-once guarantees apply to the activation of oper- nations calls for a data routing capability within the stream- ations within a dataflow graph, as well as the messaging ing ETL engine. Furthermore, if semantically related batch- between engines that comprise the streaming ETL ecosys- es are being loaded to multiple targets, it may be critical to tem. Any data migration to and from the streaming ETL coordinate their loading to help the data warehouse main- engine must also occur once and only once. In both inter- tain a consistent global view. and intrasystem messaging, the requirement of exactly-once processing in a streaming ETL engine prevents the loss or 3.2 Streaming Requirements duplication of tuples or batches in case of recovery. 3.2.1 Out-of-Order and Missing Tuples 3.3 Infrastructure Requirements This topic relates to data cleaning, but has particular im- portance to IoT. When receiving data from many millions 3.3.1 Local Storage of devices talking simultaneously, it becomes very difficult Any ETL or data ingestion pipeline needs to maintain lo- to guarantee that the data’s arrival order corresponds to the cal storage for temporary staging of new batches of data
4 .while they are being prepared for loading into the back- OLAP system in order to avoid becoming a bottleneck. It end data warehouse. For example, in an IoT use case, is important that the data ingestion also be able to keep up a large number of streaming time-series inputs from dis- with increasing quantities of data sources and items. This tributed sources may need to be buffered to ensure their means providing the ability to scale up processing across correct temporal ordering and alignment. Furthermore, in many nodes and accommodating a variable number of con- a distributed streaming ETL setting with multiple related nections. Disk and/or memory storage must also be able to dataflow graphs, there will likely be a need to support shared scale to suit expanding datasets. in-memory storage. While this raises the need for transac- tional access to local storage, it can also potentially provide 3.3.4 Data Freshness and Latency a queryable, locally consistent view of the most recent data One of the key reasons to develop a streaming ETL system for facilitating real-time analytics at the OLAP backend. is to improve the end-to-end latency from receiving a data The streaming ETL engine should also have the ability item to storing it in a data warehouse. When running ana- to take over some of the responsibility of the warehouse. lytical queries on the data warehouse, we take into account For instance, it can store (cache) some of the data that is the freshness of the data available in the warehouse. Data computed on the input streams. This data can be pulled freshness can be measured with respect to the most recent as needed into the warehouse or as a part of future stream data available to queries run in the data warehouse. The processing. For example, it is possible to store the head of more frequently new data arrives, the fresher the warehouse a stream in the ETL engine and the tail in the warehouse. data is. If the most recent data is only available in the data This is largely because recent data is more likely to be rele- ingestion cache, a query’s data freshness can be improved vant for data ingestion than older data. by pulling that data as it begins. In addition to temporary staging of new data, local stor- The end-to-end latency to ingest new data items is also age may also be required for caching older data that has al- related to data freshness. Refreshing the data frequently ready made its way into the data warehouse. For example, in the data warehouse will not help unless new data items in our TPC-DI scenario, each incoming batch of new tuples can be ingested quickly. Often, achieving the best possible requires look-ups in several warehouse tables for getting rel- latency is not as crucial as obtaining an optimal balance be- evant metadata, checking referential integrity constraints, tween high throughput within a reasonable latency bound. etc. Performing these look-ups on a local cache would be Latency bounds can be variable degrees of strict. For ex- more efficient than retrieving them from the backend ware- ample, it may be important that time-sensitive sensor data house every time (provided that the data in the cache is be processed immediately, as its value may quickly diminish read-mostly to keep data consistency inexpensive). with time. Traditional ETL, on the other hand, frequently has more relaxed latency bounds. 3.3.2 ACID Transactions Together, these requirements provide a roadmap for what ETL processes are fundamentally concerned with the cre- is expected from streaming ETL. Next, we explore a generic ation of state, and transactions are crucial for maintaining architecture to build a streaming ETL system for a variety correctness of that state. Incoming tuples are cleaned and of uses. transformed in a user-defined manner, and the output is assumed to be consistent and correct. A streaming ETL en- 4. THE NEW ARCHITECTURE gine will be processing multiple streams at once, and each In developing the architecture of a streaming ETL engine, dataflow instance may try to make modifications to the same we wished to create a generic design that can suit a vari- state simultaneously. Additionally, as discussed in Section ety of data ingestion situations. This generic architecture 3.3.1, staged tuples may be queried by the outside world, is illustrated in Figure 2. We envision four primary compo- and cached tuples are maintained from a data warehouse. nents: data collection, streaming ETL, OLAP backend, and In all of these cases, data isolation is necessary to ensure a data migrator that provides a reliable connection between that any changes do not conflict with one another. the ETL and OLAP components. Similarly, it is expected that the atomicity of operations is maintained in an ETL system. ETL is executed in batches, 4.1 Data Collection and it would be incorrect to install a fraction of the batch Data may be collected from one or many sources. In an into a data warehouse. IoT workload, for example, data is ingested from thousands Perhaps most importantly, all state must be fully recov- of different data sources at once. Each source submits new erable in the event of a failure. This is relevant to individ- tuples onto a stream (likely sending them through a socket), ual ETL operations; in the event of a failure, the system which are then received by a data collector mechanism. This should be able to recover to its most recent consistent sta- data collector primarily serves as a messaging queue. It tus. Recovery also pertains to migration between the vari- must route tuples to the proper destination while continu- ous components in an ETL stack. If the data ingestion and ously triggering the proper ETL process as new data arrives warehousing are handled by different components, then the (Section 3.1.1). Additionally, the data collector must be dis- migration between the two must also be fully recoverable. tributed, scaling to accommodate more clients as the number ACID transactions provide all of these guarantees, and of data sources increases. Fault tolerance is also required to are a crucial element to any ETL system. ensure that no tuples are lost during system failure. The data collector is responsible for assigning logical batch- 3.3.3 Scalability es of tuples, which will be consumed together by the ETL Most modern OLAP systems scale roughly linearly in or- engine. While time-series order is naturally maintained with der to accommodate the increasing size of datasets. Ide- respect to each data source, global ordering can be much ally, data ingestion should scale at the same rate as the trickier in the presence of thousands of streams (Section
5 . Figure 2: Streaming ETL Architecture 3.2.1). It is the data collector’s responsibility to ensure that 4.3 OLAP Backend the global ordering of the tuples is maintained. The OLAP backend consists of a query processor and one or several OLAP engines. The need to support several 4.2 Streaming ETL OLAP systems is rooted in variations in data type; some data are best analyzed in a row-store, some a column-store, Once data has been batched in the data collector, it is some an array database, etc (Section 3.1.3). Each OLAP pushed to the streaming ETL engine. The streaming ETL engine contains its own data warehouse, as well as a delta engine features a full library of traditional ETL tools, includ- data warehouse which stores any changes to be made to ing data cleaning and transformation operators. These ETL the dataset. The delta data warehouse contains the same operators are largely dependent on the use-case that the schema as the full warehouse, but may be missing indexes system is designed to handle. For instance, traditional ETL or materialized views in order to allow for faster ingestion may require full SQL support in order to select and compare (Section 3.1.2). The streaming ETL engine writes all up- against historic table data, while a time-series workload is dates to this delta data warehouse, and the OLAP engine more likely to require tools for signal processing, such as fast periodically merges these changes into the full data ware- Fourier transformations. house. Through a user-defined dataflow graph of operators, in- The OLAP backend also requires a query processor, prefer- coming batches are massaged into normalized data ready ably one that is able to access all of the underlying OLAP for integration with a data warehouse. Frequently, reference engines. If this is not possible, multiple query processors will need to be made to existing data in the warehouse (e.g., may be needed. When a data warehouse is queried, the cor- to look-up and assign foreign keys). For these instances, the responding delta table must also be queried (assuming that streaming ETL engine requires the ability to cache estab- some of the results are not yet merged). Potentially, if the lished data from the warehouse, as constant look-ups from user is looking for the most recent data, the query processor the warehouse itself will quickly become very expensive. may query the staging tables in the streaming ETL engine Once the data has been fully cleaned and transformed, it as well. The user should have the ability to choose whether remains staged in the streaming ETL engine until it is ready to include staged results, as they may affect query perfor- to be migrated. The migration may occur when the data mance. Replication between the streaming ETL and OLAP warehouse is ready to receive the data and pulls it, or when engine is also an option, but it comes at the cost of needing the streaming engine is ready to push to the warehouse. to maintain two consistent versions of the same data items. Because there may be multiple data warehouses storing a variety of data types, the streaming ETL engine must be able to route outgoing data to the appropriate warehouse, 4.4 Durable Migration much like the data collection mechanism routes its output. Batches are frequently moved between the Streaming ETL Additionally, the streaming ETL engine must be scalable and OLAP Backend components, and a mechanism is needed to support expanding amounts of data, and fault-tolerant to ensure that there is no data lost in transit. Failures that to ensure that its results are recoverable in the event of a occur as a batch is moved between components should re- failure (Sections 3.3.3 and 3.2.3). sult in the data being rolled back and restored to its original In addition to the ETL library, the streaming ETL en- location. Additionally, the migration mechanism should be gine also contains various support features found in most able to support the most strict isolation guarantees of its databases. For instance, to ensure consistency of the outgo- components. We believe that ACID state management is ing data, a transaction manager is included (Section 3.3.2). crucial for a Streaming ETL component, and therefore the Local storage is needed for both staging and caching, and migration mechanism should fully support ACID transac- dataflow scheduling and recovery are managed within the tions as well (Section 3.3.2). engine (Sections 3.3.1 and 3.2.2). Migration is expensive, and it is important that it primar-
6 .ily takes place at a time when the individual components are not overloaded. For instance, the OLAP Backend may fre- quently handle long-running queries that are both disk and CPU intensive. Similarly, there may be scenarios in which the Streaming ETL engine is overworked. In order to avoid reduced performance of either the data ingestion or ware- house analytics, flexibility in both the timing and quantity of data in bulk loading is necessary. Assuming that the in- gestion and analytics take place in different locations, there are two options for choosing when to migrate between the two: Push. Data may be periodically pushed from the ingestion storage to the data warehouse. This may either be done at Figure 3: Relational ETL Implementation a regular frequency, or can occur when the workload on the data ingestion is lighter than usual. routed to the appropriate dataflow graph within the stream- Pull. The data warehouse itself can periodically pull fresh ing ETL engine. In contrast to our architecture description, data from the data ingestion storage. This would occur all batching currently takes place within the streaming ETL either directly before an analytical query (if optimal data component. In future iterations of the data ingestion stack, freshness is the priority) or at periods in which fewer ana- the data collection component can be extended to handle lytical queries are running (if query performance is the pri- more complicated message handling, including the batch- ority). ing of near-simultaneous tuples and perhaps simple filtering Developers should have the option to implement either operations. a push- or pull-based migration model, depending on the structure of their ETL workload. If the Streaming ETL 5.1.2 Streaming ETL - S-Store is the bottleneck, or if fresh data is a high priority, then Choosing a streaming data management system that best new data should periodically be pushed to the OLAP back- fits streaming ETL is complicated, as there are advantages end when it is ready (Section 3.3.4). If long-running OLAP and disadvantages to each. Few single systems meet all queries are the priority, then the backend should pull new requirements described in Section 3. For instance, Spark data when there is downtime. Streaming [26] and Twitter Heron [14], two modern stream- ing systems, offer highly scalable processing with low la- 5. RELATIONAL ETL IMPLEMENTATION tency. They provide data-driven processing and streaming primitives, and either seems like a natural choice for the When implementing our streaming ETL architecture, we streaming ETL component. However, when it comes to state wanted to consider the two primary use-cases listed in Sec- management, neither system has a strong story. Neither pro- tion 2: relational ETL (TPC-DI) and time-series ETL (IoT). vide support for shared, mutable state, so both would need While the architecture in Figure 2 can be used for either, the some sort of external storage component. The addition of implementation may vary significantly. another database system for state management would intro- Relational data ingestion requires the transformation of duce an extreme amount of overhead, since most operations incoming time-series data to suit the needs of one or sev- in traditional ETL involve reading or writing persistent data eral OLAP backends that are highly specialized. Typically on a regular basis. these use-cases involve the mutation of relational data in S-Store, on the other hand, is a new streaming database a way that maintains constraints on the data, such as for- system built explicitly to handle shared, mutable state [15]. eign keys. In this section, we discuss the implementation Unlike traditional streaming systems, S-Store models data- of our streaming ETL architecture for use in a relational flow graphs as a series of transactions, each of which ensure a ETL context. We use three research technologies to imple- consistent view of the modified state upon commit. S-Store ment our core streaming ETL components - Apache Kafka is built on top of the main-memory OLTP system H-Store [13], S-Store [15], and Intel’s BigDAWG polystore [7]. The [11], and integrates streaming functionality such as streams, implementation is illustrated in Figure 3. windows, triggers, and dataflows. It provides three funda- mental guarantees which together are exclusively available in 5.1 Components S-Store: ACID transactions, dataflow ordering, and exactly- once processing [20]. These guarantees in conjunction with 5.1.1 Data Collection - Kafka its streaming functionality make S-Store an ideal fit for a A streaming system needs a messaging infrastructure at streaming ETL engine. its entrance to get data into the system. Kafka is a good As an OLTP system at its core, S-Store uses relational initial choice. Apache Kafka is a highly-scalable publish- tables as its primary method of storage. It provides many subscribe messaging system able to handle thousands of of the standard elements to be expected in a DBMS, in- clients and hundreds of megabytes of reads and writes per cluding indexes and materialized views. S-Store uses user- second [13] . Kafka’s combination of availability and durabil- defined stored procedures as its transactional operations. ity makes it a good candidate for our data collection mecha- Each stored procedure is defined using a mixture of Java nism, as it is able to queue new tuples to push to the stream- and SQL. This allows for a good deal of flexibility, as data ing ETL engine. cleaning operations can be quite complex. Presently, in our implementation, Kafka serves exclusively While S-Store is well-suited for the task of managing stream- as a messaging queue for individual tuples, each of which are ing ETL, it does require careful database design in order to
7 . (a) Pseudo-SQL of DimTrade Ingestion [21] Figure 4: BigDAWG 1.0 Architecture achieve scalability. As with most shared-nothing architec- tures, S-Store performs best when data items that are ac- cessed together are co-located as often as possible, as dis- tributed transactions are extremely expensive. Incoming data is batched in order to improve performance; typically the larger the batch, the better the performance in terms of raw throughput. However, large batches come with a trade-off of increased latency, as the system must wait for more data to arrive before processing a full batch. S-Store (b) Dataflow Graph of DimTrade Ingestion database design applies to the transactions within a dataflow graph as well. Typically an S-Store dataflow graph is com- posed of many transactions with only a few operations apiece Figure 5: DimTrade Ingestion in TPC-DI rather than few transactions with many operations. By breaking up large operations into smaller components, it both S-Store and Postgres until both sides of the migration becomes possible to run several single-sited transactions in have completed, BigDAWG is able to ensure that a batch place of a large distributed transaction. This is particularly of data is either fully migrated or completely rolled back, relevant when data is needed from multiple tables, each of thereby avoiding data loss or duplication issues. which is hashed on a different key. It is important to note that while data can be migrated from S-Store to BigDAWG or vice versa, we chose not to 5.1.3 OLAP Backend and Migration - Postgres and implement cross-system replication at this time. This is to BigDAWG ensure that we are only maintaining a single copy of the Because S-Store provides local storage, OLAP operations data at once, thereby avoiding data consistency issues as- could, in theory, be integrated into the streaming ETL com- sociated with replication. We leave cross-system replication ponent. However, most OLAP engines are specialized and to future work. However, queries sent by the user can be are able to perform much more sophisticated analytics oper- automatically routed to the correct OLAP warehouse, and ations with much better performance. Because this paper is may include UNIONed data from a delta warehouse or from primarily focused on ingestion rather than analytics, Post- the staging storage of the streaming ETL engine. Complex gres was chosen as a backend database for simplicity’s sake. queries that require data from both S-Store and Postgres can While using Postgres as an OLAP database is straightfor- be performed by first migrating the relevant data fully into ward, the complication is the migration of data between the one engine or the other, and then performing the operation streaming ETL and OLAP engines. To address this con- there. cern, we chose the built-in data migrator provided by the BigDAWG polystore. 5.2 Migration Experiments (TPC-DI) Intel’s BigDAWG is a polystore of multiple disparate data- base systems, each of which specializes in one type of data 5.2.1 Experiment Setup (e.g., relational, array, streaming, etc.) [7]. BigDAWG One of the key questions facing a streaming ETL system provides unified querying and data migration across each is how frequently data should be migrated to the data ware- of its databases, presenting them to the user as a single house. As discussed in Section 4.4, there are two methods system. To facilitate this, BigDAWG includes several “is- of determining when this migration occurs: either the inges- lands of information”, each of which contains multiple sys- tion engine periodically pushes the data to the warehouse, tems that share a common query language. For instance, or the warehouse pulls the data from the ingestion engine all relational databases are connected to “relational island”, when it is needed. Thus, we devised an experiment to test which is queried using standard SQL. The architecture of the pros and cons of each. BigDAWG is shown in Figure 4. To test the performance of our inaugural system, we im- BigDAWG provides the flexibility needed to handle mul- plemented a portion of the TPC-DI workload described in tiple OLAP data warehouses under one roof. Because S- Section 2.2. In the streaming ETL engine (S-Store), we Store is also integrated with BigDAWG, migration between implemented the operations required to ingest tuples from S-Store and any OLAP system supported by the polystore is Trade.txt into the DimTrade table, as described in Figure 5. easy to implement and efficient [16]. Most importantly, the The necessary transformations can be broken down into a migration between both components is transactional. By us- handful of SQL operations, several of which perform lookups ing two-phase commit and maintaining open transactions on on other dimension tables which are each partitioned on a
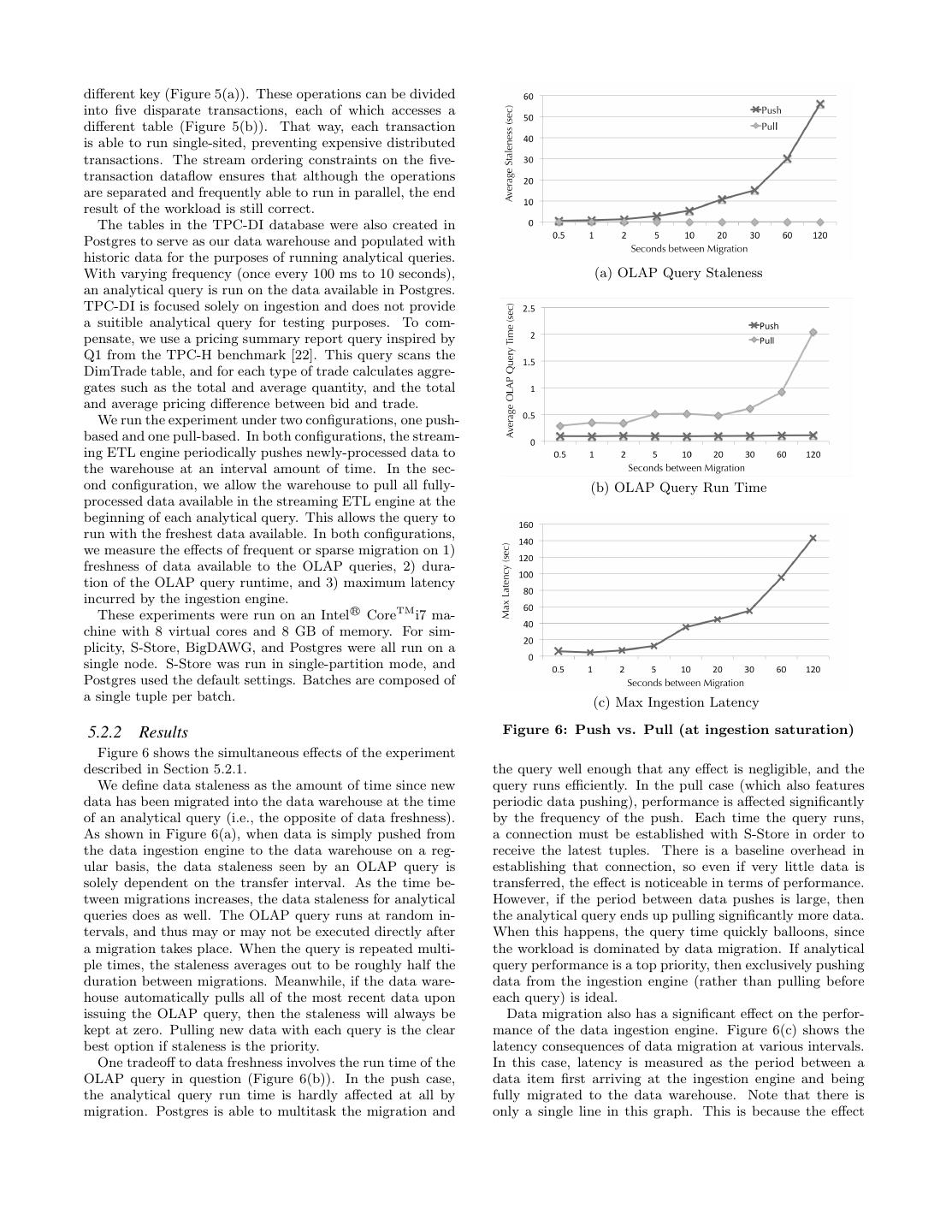
8 .different key (Figure 5(a)). These operations can be divided into five disparate transactions, each of which accesses a different table (Figure 5(b)). That way, each transaction is able to run single-sited, preventing expensive distributed transactions. The stream ordering constraints on the five- transaction dataflow ensures that although the operations are separated and frequently able to run in parallel, the end result of the workload is still correct. The tables in the TPC-DI database were also created in Postgres to serve as our data warehouse and populated with historic data for the purposes of running analytical queries. With varying frequency (once every 100 ms to 10 seconds), (a) OLAP Query Staleness an analytical query is run on the data available in Postgres. TPC-DI is focused solely on ingestion and does not provide a suitible analytical query for testing purposes. To com- pensate, we use a pricing summary report query inspired by Q1 from the TPC-H benchmark [22]. This query scans the DimTrade table, and for each type of trade calculates aggre- gates such as the total and average quantity, and the total and average pricing difference between bid and trade. We run the experiment under two configurations, one push- based and one pull-based. In both configurations, the stream- ing ETL engine periodically pushes newly-processed data to the warehouse at an interval amount of time. In the sec- ond configuration, we allow the warehouse to pull all fully- (b) OLAP Query Run Time processed data available in the streaming ETL engine at the beginning of each analytical query. This allows the query to run with the freshest data available. In both configurations, we measure the effects of frequent or sparse migration on 1) freshness of data available to the OLAP queries, 2) dura- tion of the OLAP query runtime, and 3) maximum latency incurred by the ingestion engine. These experiments were run on an Intel R CoreTM i7 ma- chine with 8 virtual cores and 8 GB of memory. For sim- plicity, S-Store, BigDAWG, and Postgres were all run on a single node. S-Store was run in single-partition mode, and Postgres used the default settings. Batches are composed of a single tuple per batch. (c) Max Ingestion Latency 5.2.2 Results Figure 6: Push vs. Pull (at ingestion saturation) Figure 6 shows the simultaneous effects of the experiment described in Section 5.2.1. the query well enough that any effect is negligible, and the We define data staleness as the amount of time since new query runs efficiently. In the pull case (which also features data has been migrated into the data warehouse at the time periodic data pushing), performance is affected significantly of an analytical query (i.e., the opposite of data freshness). by the frequency of the push. Each time the query runs, As shown in Figure 6(a), when data is simply pushed from a connection must be established with S-Store in order to the data ingestion engine to the data warehouse on a reg- receive the latest tuples. There is a baseline overhead in ular basis, the data staleness seen by an OLAP query is establishing that connection, so even if very little data is solely dependent on the transfer interval. As the time be- transferred, the effect is noticeable in terms of performance. tween migrations increases, the data staleness for analytical However, if the period between data pushes is large, then queries does as well. The OLAP query runs at random in- the analytical query ends up pulling significantly more data. tervals, and thus may or may not be executed directly after When this happens, the query time quickly balloons, since a migration takes place. When the query is repeated multi- the workload is dominated by data migration. If analytical ple times, the staleness averages out to be roughly half the query performance is a top priority, then exclusively pushing duration between migrations. Meanwhile, if the data ware- data from the ingestion engine (rather than pulling before house automatically pulls all of the most recent data upon each query) is ideal. issuing the OLAP query, then the staleness will always be Data migration also has a significant effect on the perfor- kept at zero. Pulling new data with each query is the clear mance of the data ingestion engine. Figure 6(c) shows the best option if staleness is the priority. latency consequences of data migration at various intervals. One tradeoff to data freshness involves the run time of the In this case, latency is measured as the period between a OLAP query in question (Figure 6(b)). In the push case, data item first arriving at the ingestion engine and being the analytical query run time is hardly affected at all by fully migrated to the data warehouse. Note that there is migration. Postgres is able to multitask the migration and only a single line in this graph. This is because the effect
9 .on the data ingestion is the same regardless of push or pull; only the interval between migrations is important. At sat- uration, new incoming data items must wait for migration to finish before they can be ingested (because this particu- lar ingestion engine implementation requires a full partition lock during migration). In cases where the interval between migrations is high, more data must be migrated at once, and therefore the maximum amount of time a batch may wait is extremely high. While this effect may be less pronounced in an implementation with looser locking constraints, ingestion performance would still be affected. In both scenarios (push vs. pull) and all three contexts Figure 7: Metronome Architecture (staleness, run time, and max ingestion latency), the sit- uation is significantly improved by smaller, more frequent improved and optimized for an IoT use-case. Using the re- migrations. Setting the time between migrations to be some- quirements and architecture that we have established for a where between one and five seconds gives optimal results for streaming ETL system, we can create an all-in-one inges- each context. Frequent migrations also mean that data pulls tion and analytics engine specifically for time-series data. for queries that require high degrees of data freshness have We call this system Metronome. good performance as well. There are a wide variety of use-cases which prominently 5.3 IoT Proof-of-Concept (MIMIC II) feature time-series. Classically, time series are used for fore- casting (i.e., prediction) and pattern matching (e.g., outlier In addition to our TPC-DI experiments for relational ETL, detection). Additionally, when treated as a signal, time se- we are also able to create a workload that imitates an IoT ries can participate in FFTs, convolutions, and filtering. We use-case on our current streaming ETL system implemen- believe that by treating time-series as the primary data type, tation. As described in our previous work, we have imple- a single data model can be used for all of these situations. mented a real-time alert monitoring system over streaming We will then be able to specialize the generic data model by patient waveforms from an ICU [20]. This is based on the implementing operations that are specific to each time-series MIMIC II dataset, which includes a variety of ICU data such use-case. as different types of heart-rate data [4]. Unlike most stream processing systems, Metronome’s fun- In our demonstration, we ingest ECG and PAP heart-rate damental data type is a finite sequence of values (a window) data in real-time and run two queries to search for abnor- that represents a contiguous piece of a time-series. Rather mal patterns. One query ensures that PAP levels are above than relational tables, time-series store data in a named se- a given threshold, while the second looks for specific pat- quence of values indexed by time. A time-series is primarily terns within the ECG waveform. In the event of either case, updated by appending new values at higher time-index po- an alert is sent to medical devices intended to notify profes- sitions, with tertiary support for updating values in specific sionals. The MIMIC dataflow also includes transformation cases (such as error correction). and ingestion into SciDB [6], an array database, via Big- Because both the streaming ETL operations and the on- DAWG. There, the waveform is stored in a warehouse for line analytics processing are concerned with time-series data, later analysis. we believe that Metronome has the capability to handle an While we were able to successfully implement the work- integrated streaming ETL architecture which includes both load, we noticed some limitations. Though S-Store is de- real-time data ingestion and time-series analytics. Figure 7 signed to handle ordered batch data (which share many illustrates the basic architecture of Metronome. Each of the properties with time-series data) in a streaming context, its functionalities from Section 4 are supported. However, be- query support is extremely rooted in relational databases. cause the entire dataflow stack is optimized within a single It is not truly optimized to perform complex time-series- system, components of the streaming ETL architecture do specific operations. SciDB contains a similar problem; while not directly map one-to-one with components of Metronome. time-series can be stored as a one-dimensional array, an ar- Streaming data ingestion for time-series shares many sim- ray database lacks support for complicated time-series quer- ilarities to that of relational data, and has the same require- ies. Also, because both S-Store and SciDB center around ments listed in Section 3. However, with the change in fun- strong support for mutable state rather than append-heavy damental data type, the priorities for these requirements time-series workloads, there are other missed opportunities change substantially. For instance, relational data priori- for optimization. tizes functionality that allows for update-in-place, such as Our MIMIC II implementation led us to the conclusion ACID transactions. For time-series however, workloads are that a new, single system could be created to both ingest append-mostly; as new data arrives, it gets appended to the and analyze time-series at scale. We discuss our plans for end of an existing time-series. As a result, the isolation guar- such a system in the next section. antees of ACID can be relaxed without significant risk to correctness and at the benefit of performance. Traditional 6. FUTURE WORK: TIME-SERIES ETL ETL requirements such as bulk loading and heterogeneity While ETL for relational data involves mutation of shared can also be de-prioritized, as the incoming time-series data state, IoT datasets primarily require consideration of time- is always stored as a time-series and that storage is local to series data, which tends to be very insert-heavy and requires Metronome. operators capable of efficiently analyzing waveforms. We be- While some requirements can be relaxed, the need for lieve that the system we built in this paper can be further others becomes even more pronounced. Streaming require-
10 .ments, in particular, are extremely important. For instance, fault tolerance. when receiving information from thousands of devices in an Shen et al. propose a stream-based distributed data man- IoT workload, out-of-order tuples are a frequent occurrence agement architecture for IoT applications [19]. This a three- that needs to be directly addressed by the data collection layer (edge-fog-cloud) architecture like ours. However, the mechanism. Each sensor likely generates its own times- main emphasis is on embedding lightweight stream process- tamps, and even if the clocks are extremely accurate, they ing on network devices located at the edge layer (like our are almost certainly offset from one another. Additionally, data collection layer) with support for various types of win- data items may become delayed in-transit to Metronome. dow joins that can address the disorder and time alignment Thus, the data collection mechanism must be responsible for issues common in IoT streams. synchronizing incoming tuples into simultaneous batches. It There has been a large body of work in the database com- is also unreasonable for a full batch to be held from process- munity that relates to time-series data management. As an ing as the system waits for tuples that it knows are missing example for one of the earliest time-series database systems, or lost. Instead, the data collection mechanism should be KDB+ is a commercial, column-oriented database based on able to use historic data to predict what those missing tu- the Q vector programming language [3, 2]. KDB+ is pro- ples are whenever possible. prietary and is highly specialized to the financial domain, As discussed in Section 3.3.3, scalability is also a crucial and therefore, is not suitable for the kinds of IoT applica- factor when considering data collection and analysis in a tions that we propose to study in this proposal. There are single system. Because resources will be directly shared be- several examples of recent time-series databases, including tween the two, it is very important that long-running ana- InfluxDB [1], Gorilla [17], and OpenTSDB [25]. Each of lytics queries do not strongly affect ingestion performance, these provide valuable insight into time-series databases but or vice versa. To accomplish this, it is necessary to intelli- do not meet our ingestion requirements and are not a great gently determine when to migrate data between components fit for the kinds of IoT applications that we consider. based on resource availability, in much the same way as the prototype implementation. 8. CONCLUSIONS Using the lessons learned in our implementation of stream- This paper makes the case for streaming ETL as the ba- ing ETL, we believe that Metronome can be a novel, next- sis for improving the currency of the warehouse, even when generation approach to the ingestion and analysis of time- the implied ingestion rate is very high. We have discussed series data at an IoT scale. the major functional requirements such a streaming ETL approach should address, including embedded local storage 7. RELATED WORK and transactional guarantees. We have then described a sys- There has been a plethora of research in ETL-style data tem architecture designed to meet these requirements using ingestion [12, 23]. The conventional approach is to use file- a transactional stream processing system as its base tech- based tools to periodically ingest large batches of new or nology for ingestion. Our proof-of-concept implementation changed data from operational systems into backend data using the S-Store system [15] shows the viability of this ap- warehouses. This is typically done at coarse granularity, dur- proach in real-world use cases such as brokerage firm inges- ing off-peak hours (e.g., once a day) in order to minimize the tion (TPC-DI) and medical sensor monitoring (MIMIC II). burden on both the source and the backend systems. More IoT points out how in many applications the streams can recently, there has been a shift towards micro-batch ETL be viewed as time-series. We believe that high-speed inges- (a.k.a., “near real-time” ETL), in which the ETL pipelines tion support is necessary, but that we can do even better are invoked at higher frequencies to maintain a more up-to- when the input streams are known to be time-series. Thus, date data warehouse [24]. It has been commonly recognized our future research directions include evaluating and com- that fine-granular ETL comes with consistency challenges paring the performance of our approach against other ETL [10, 8]. In most of these works, ETL system is the main alternatives using IoT-scale benchmarks as well as enhancing source of updates to the warehouse, whereas the OLAP sys- our approach with time-series data management support. tem takes care of the query requests. Thus, consistency largely refers to the temporal lag among the data sources 9. ACKNOWLEDGMENTS and the backend views which are used to answer the queries. This research was funded in part by the Intel Science and In such a model, it is difficult to enable a true “real-time” Technology Center for Big Data, and by the NSF under analytics capability. In contrast, the architecture we pro- grant NSF IIS-1111423. pose in this paper allows queries to have access to the most recent data in the ETL pipeline in addition to the warehouse data, with more comprehensive consistency guarantees. Im- 10. REFERENCES [1] InfluxDB. https://www.influxdata.com/. plementing the ETL pipeline on top of an in-memory trans- actional stream processing system is the key enabler for this. [2] Kdb+ Database and Language Primer. Modern big data management systems have also looked https://a.kx.com/q/d/primer.htm. into the ingestion problem. For example, AsterixDB high- [3] Kx Systems. http://www.kx.com/. lights the need for fault-tolerant streaming and persistence [4] MIMIC II Data Set. https://physionet.org/mimic2/. for ingestion, and embeds data feed management into its [5] D. Abadi et al. Aurora: A New Model and big data stack so as to achieve higher performance than glu- Architecture for Data Stream Management. VLDB ing together separate systems for stream processing (Storm) Journal, 12(2), August 2003. and persistent storage (MongoDB) [9]. Our architecture ad- [6] P. G. Brown. Overview of SciDB: Large Scale Array dresses this need by using a single streaming ETL system for Storage, Processing and Analysis. In SIGMOD, June streaming and storage with multiple guarantees that include 2010.
11 . [7] A. Elmore et al. A Demonstration of the BigDAWG Polystore System. PVLDB, 8(12), August 2015. [8] L. Golab and T. Johnson. Consistency in a Stream Warehouse. In CIDR, January 2011. [9] R. Grover and M. Carey. Data Ingestion in AsterixDB. In EDBT, March 2015. [10] T. Jorg and S. Dessloch. Near Real-Time Data Warehousing using State-of-the-art ETL Tools. In BIRTE Workshop, August 2009. [11] R. Kallman et al. H-Store: A High-Performance, Distributed Main Memory Transaction Processing System. PVLDB, 1(2), August 2008. [12] R. Kimball and J. Caserta. The Data Warehouse ETL Toolkit. Wiley Publishing, 2004. [13] J. Kreps, N. Narkhede, and J. Rao. Kafka: A Distributed Messaging System for Log Processing. In NetDB Workshop, June 2011. [14] S. Kulkarni et al. Twitter Heron: Stream Processing at Scale. In SIGMOD, June 2015. [15] J. Meehan et al. S-Store: Streaming Meets Transaction Processing. PVLDB, 8(13), September 2015. [16] J. Meehan et al. Integrating Real-Time and Batch Processing in a Polystore. In IEEE HPEC Conference, September 2016. [17] T. Pelkonen, S. Franklin, J. Teller, P. Cavallaro, Q. Huang, J. Meza, and K. Veeraraghavan. Gorilla: A Fast, Scalable, In-memory Time Series Database. PVLDB, 8(12):1816–1827, 2015. [18] M. Poess et al. TPC-DI: The First Industry Benchmark for Data Integration. PVLDB, 7(13), August 2014. [19] Z. Shen et al. CSA: Streaming Engine for Internet of Things. IEEE Data Engineering Bulletin, Special Issue on Next-Generation Stream Processing, 38(4), December 2015. [20] N. Tatbul et al. Handling Shared, Mutable State in Stream Processing with Correctness Guarantees. IEEE Data Engineering Bulletin, Special Issue on Next-Generation Stream Processing, 38(4), December 2015. [21] Transaction Processing Performance Council (TPC). TPC Benchmark DI (Version 1.1.0). http://www.tpc.org/tpcdi/, Nov. 2014. [22] Transaction Processing Performance Council (TPC). TPC Benchmark H (Version 2.17.1). http://www.tpc.org/tpch/, Nov. 2014. [23] P. Vassiliadis. A Survey of Extract-Transform-Load Technology. International Journal of Data Warehousing and Mining, 5(3), July 2009. [24] P. Vassiliadis and A. Simitsis. Near Real-Time ETL. In S. Kozielski and R. Wrembel, editors, New Trends in Data Warehousing and Data Analysis. Springer, 2009. [25] T. W. Wlodarczyk. Overview of Time Series Storage and Processing in a Cloud Environment. In IEEE CloudCom Conference, pages 625–628, 2012. [26] M. Zaharia et al. Discretized Streams: Fault-tolerant Streaming Computation at Scale. In SOSP, November 2013.
3秒后跳转登录页面
去登陆

