































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
IEEE-Next-Gen-Streaming
事件模型(TEM)是一种新的计算无关模型,其目标是帮助非程序员。定义和管理事件驱动应用程序的逻辑。模型的设计是基于包含一组图表和规范化表来定义事件业务逻辑的构建块在一个应用程序中,一组定义正确的模型应该满足断言集合的原则和一个词汇表来表达所有的商业概念,建立TEM模型的有效性。并通过一组相关的完整性原则进行保证,并自动转换为执行通过代码生成器。
展开查看详情
1 .Bulletin of the Technical Committee on Data Engineering December 2015 Vol. 38 No. 4 IEEE Computer Society Letters Letter from the Editor-in-Chief . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . David Lomet 1 Letter from the Special Issue Editors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . David Maier, Badrish Chandramouli 2 Special Issue on Next-Generation Stream Processing Kafka, Samza and the Unix Philosophy of Distributed Data . . . . . . . . . . . . . . . . . . Martin Kleppmann, Jay Kreps 4 Streaming@Twitter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Maosong Fu, Sailesh Mittal, Vikas Kedigehalli, Karthik Ramasamy, Michael Barry, Andrew Jorgensen, Christopher Kellogg, Neng Lu, Bill Graham, Jingwei Wu 15 Apache Flink™: Stream and Batch Processing in a Single Engine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Paris Carbone, Stephan Ewen, Seif Haridi, Asterios Katsifodimos, Volker Markl, Kostas Tzoumas 28 CSA: Streaming Engine for Internet of Things . . . . . . . . . . . . . . . . . . . . . . . . . . . . Zhitao Shen, Vikram Kumaran, Michael J. Franklin, Sailesh Krishnamurthy, Amit Bhat, Madhu Kumar, Robert Lerche, Kim Macpherson 39 Trill: Engineering a Library for Diverse Analytics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Badrish Chandramouli, Jonathan Goldstein, Mike Barnett, James F. Terwilliger 51 Language Runtime and Optimizations in IBM Streams . . . . . . . . . . Scott Schneider, Bu˘gra Gedik, Martin Hirzel 61 FUGU: Elastic Data Stream Processing with Latency Constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Thomas Heinze, Yuanzhen Ji, Lars Roediger, Valerio Pappalardo, Andreas Meister, Zbigniew Jerzak, Christof Fetzer 73 Exploiting Sharing Opportunities for Real-time Complex Event Analytics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Elke A. Rundensteiner, Olga Poppe, Chuan Lei, Medhabi Ray, Lei Cao, Yingmei Qi, Mo Liu, Di Wang 82 Handling Shared, Mutable State in Stream Processing with Correctness Guarantees . . . . . . . . . . . . Nesime Tatbul, Stan Zdonik, John Meehan, Cansu Aslantas, Michael Stonebraker, Kristin Tufte, Chris Giossi, Hong Quach 94 “The Event Model” for Situation Awareness . . . . . . . . . . . . Opher Etzion, Fabiana Fournier, Barbara von Halle 105 Towards Adaptive Event Detection Techniques for the Twitter Social Media Data Stream . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Michael Grossniklaus, Marc H. Scholl, Andreas Weiler 116 Conference and Journal Notices TCDE Membership Form . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . back cover
2 .Editorial Board TCDE Executive Committee Editor-in-Chief Chair David B. Lomet Xiaofang Zhou Microsoft Research School of Information Tech. & Electrical Eng. One Microsoft Way The University of Queensland Brisbane, QLD 4072, Australia Redmond, WA 98052, USA zxf@itee.uq.edu.au lomet@microsoft.com Executive Vice-Chair Associate Editors Masaru Kitsuregawa Christopher Jermaine The University of Tokyo Department of Computer Science Tokyo, Japan Rice University Secretary/Treasurer Houston, TX 77005 Thomas Risse Bettina Kemme L3S Research Center School of Computer Science Hanover, Germany McGill University Vice Chair for Conferences Montreal, Canada Malu Castellanos HP Labs David Maier Palo Alto, CA 94304 Department of Computer Science Advisor Portland State University Kyu-Young Whang Portland, OR 97207 Computer Science Dept., KAIST Xiaofang Zhou Daejeon 305-701, Korea School of Information Tech. & Electrical Eng. Committee Members The University of Queensland Amr El Abbadi Brisbane, QLD 4072, Australia University of California Santa Barbara, California Distribution Erich Neuhold Brookes Little University of Vienna IEEE Computer Society A 1080 Vienna, Austria 10662 Los Vaqueros Circle Alan Fekete Los Alamitos, CA 90720 University of Sydney eblittle@computer.org NSW 2006, Australia Wookey Lee The TC on Data Engineering Inha University Membership in the TC on Data Engineering is open to Inchon, Korea all current members of the IEEE Computer Society who Chair, DEW: Self-Managing Database Sys. are interested in database systems. The TCDE web page is Shivnath Babu http://tab.computer.org/tcde/index.html. Duke University The Data Engineering Bulletin Durham, NC 27708 The Bulletin of the Technical Committee on Data Engi- Co-Chair, DEW: Cloud Data Management neering is published quarterly and is distributed to all TC Hakan Hacigumus members. Its scope includes the design, implementation, NEC Laboratories America modelling, theory and application of database systems and Cupertino, CA 95014 their technology. VLDB Endowment Liason Letters, conference information, and news should be sent Paul Larson to the Editor-in-Chief. Papers for each issue are solicited Microsoft Research by and should be sent to the Associate Editor responsible Redmond, WA 98052 for the issue. Opinions expressed in contributions are those of the au- SIGMOD Liason thors and do not necessarily reflect the positions of the TC Anastasia Ailamaki ´ Ecole Polytechnique F´ed´erale de Lausanne on Data Engineering, the IEEE Computer Society, or the authors’ organizations. Station 15, 1015 Lausanne, Switzerland The Data Engineering Bulletin web site is at http://tab.computer.org/tcde/bull_about.html. i
3 .Letter from the Editor-in-Chief Delayed Publication This December, 2015 issue of the Bulletin is, as some of you may notice, being published in July of 2016, after the March and June, 2016 issues have been published. Put simply, the issue is late, and the March and June issues were published in their correct time slots. The formatting of the issue, and the surrounding editorial material, e.g. the inside front cover and copyright notice, are set to the December, 2015 timeframe. Indeed, the only mention of this inverted ording of issues is in this paragraph. Things do not always go as planned. However, I am delighted that the current issue is being published, and I have high confidence that you will enjoy reading about next-generation stream processing, the topic of the issue. The Current Issue At one point a few years ago, the research community had lost interest in stream processing. The first streaming systems had been built and these early systems demonstrated their feasibility. Commercial interest had been generated, with a number of start-ups and major vendors entering the market. Even using a declarative database- style query language had become an accepted part of the technology landscape. Job done, right? Actually, wrong! As we have seen with the database field itself, innovation and a changing technological environment can lead to an “encore” of interest in a field. Such is the case with stream processing. The issue title: “Next- Generation Stream Processing” captures that. The issue itself captures a whole lot more about the state of the field. Streaming systems have evolved, sometimes in revolutionary ways. Applications of streaming technology have exploded, both in number and in importance. As much as at any time in the past, the streams area is a hive of activity. New technology is opening new application areas, while new application areas create a pull for new technology. David Maier has worked with Badrish Chandramouli to assemble this current issue devoted to presenting the diversity of work now in progress in the streaming area. Streaming technology is at the core of much of their recent research. This makes them ideal editors for the current issue. They have brought together papers that not only provide insights into new streaming technology, but also illustrate where technology might be taking us in its enabling of new applications. Streams are here as a permanent part of the technology environment in a way similar to databases. Thanks to both David and Badrish for bringing this issue together on a topic that will, I am convinced, become a fixture of both the research and the application environment of our field. David Lomet Microsoft Corporation 1
4 .Letter from the Special Issue Editors The precursors of data-stream systems began to show up in the late 1980s and early 1990s in the form of “reactive” extensions to data management systems. With such extensions, there was a reversal of sorts between the roles of data and query. Database requests – in the form of continuous queries, materialized views, event- condition-action rules, subscriptions, and so forth – became persistent entities that responded to newly arriving data. The initial generation of purpose-built stream systems addressed many issues: appropriate languages, deal- ing with unbounded input, handling delay and disorder, dealing with high data rates, load balancing and shed- ding, resiliency, and, to some extent, distribution and parallelism. However, integration with other system com- ponents, such as persistent storage and messaging middleware, was often rudimentary or left to the application programmer. The most recent generation of stream systems have the benefit of a better understanding of application re- quirements and execution platforms, by virtue of lessons learned through experimentation with earlier systems. Scaling, in cloud, fog, and cluster environments, has been at the forefront of design considerations. Systems need to scale not just in terms of stream rate and number of streams, but also to large numbers of queries. Application tuning, operation, and maintenance have also come to the forefront. Support for tradeoffs among throughput, latency, accuracy, and availability is important for application requirements, such as meeting service- level agreements. Resource management at run time is needed to enable elasticity of applications as well as for managing multi-tenancy both with other stream tasks and other application components. Many stream applica- tions require long-term deployment, possibly on the order of years. Thus, the ability to maintain the underlying stream systems as well as evolve applications that run on them is critical. State management is also a concern, both within stream operators and in interactions with other state managers, such as transactional storage. There has also been a focus on broadening the use of stream-processing systems, but through programming models for non-specialists and by supporting more complex analyses over streams, such as machine-learning techniques. This issue is devoted to this next generation of stream-processing, looking at particular systems, specific optimization and evaluation techniques, and programming models. The first three papers discuss frameworks that support composing reliable and distributed stream (and batch) processing networks out of individual operators, but are somewhat agnostic about what the particular operators are. Samza (Kleppman, et al.) is a stream-processing framework developed initially at LinkedIn that supports stream operators loosely coupled using the Kafka message broker. The use of Kafka reduces dependencies between stream stages, and provides replicated logs that support multiple consumers running at different rates. The next paper (Fu, et al.) introduces Heron, whose API is compatible with Twitters early streaming platform, Storm. Heron features support sustained deployment and maintenance, such as resource reservations and task isolation. The paper discusses alternative back-pressure mechanisms, and how Heron supports at-least-once and at-most-once messaging semantics. Apache Flink (Carbone, et al.) is a framework that supports a general pipelined dataflow architecture that handles both live stream and historical batch data (and combinations) for sim- ple queries as well as complex iterative scripts as found in machine-learning. The paper discusses mechanisms for trading latency with throughput; the use of in-stream control events to help checkpointing, track progress and coordinate iterations; and low-interference fault-tolerance taking consistent snapshots across operators without pausing execution. The next three papers deal with complete systems that include specific query languages. In Connected Streaming Analytics (CSA) from Cisco (Shen, et al.), stream-processing components can be embedded in net- work elements such as routers and switches to support Internet-of-Things applications. Given this execution environment, it is important that stream queries not interfere with high-priority network tasks. CSA uses a con- tainer mechanism to constrain resources and promote portability. The language is SQL with window extensions. CSA supports different kinds of window joins: best-effort join combines data immediately on receipt, whereas coordinated join matches items based on application time, which may require buffering. Trill (Chandramouli, et 2
5 .al.) shares goals with Flink in seeking a single engine that can work for online, incremental and offline process- ing, and supports latency-throughput tradeoffs as appropriate for different contexts. It takes a library approach that allows mutual embedding with applications written in high-level languages. Trill queries are written in a LINQ-based language that supports tempo-relational operations, along with timestamp manipulation capabil- ities. For performance, it uses a columnar in-memory representation of data batches. The subsequent paper looks at language runtime support for the IBM Stream Processing Language (SPL) (Schneider, et al.). The SPL runtime provides certain execution guarantees, such as isolation of operator state and in-order delivery, and sat- isfies performance goals such as long-term query execution without degradation and efficient parallel execution. Performance optimizations include both “fusion” (combining operators into a single Processing Element) and “fission” (replicating a portion of the query graph). The next three papers consider stream-processing optimizations and guarantees. While several of the sys- tems in the foregoing papers provide a means to make performance tradeoffs, in practice it can be difficult for a user to determine the best way to adjust the control knobs. The FUGU stream-processing system (Heinze, et al.) employs strategies that automate the adjustment of these parameters, based on on-line profiling of query execution and user-provided latency specifications. The paper from Worchester Polytechnic Institute (Runden- steiner, et al.) looks at several methods to improve performance of pattern-matching queries, using a variety of sharing strategies. Examples are Event-Sequence Pattern Sharing, which determines temporal correlations between sub-patterns in order to decide whether sharing is beneficial, and Shared Event-Pattern Aggregation, which looks for shared aggregation opportunities at the sub-pattern level. Several early stream systems had the ability to access stored data in some form, for example, to augment stream events with information from a look-up table. However, these systems gave limited consistency guarantees, either between the stream and the stored data, or between shared access to stored data across stream operators. The S-Store system (Tatbul, et al.) develops a stream-processing model that provides several correctness guarantees, such as traditional ACID semantics, order-of-execution conditions and exactly-once semantics. The last two papers are oriented towards application development. Most stream systems require queries to be written in a special request language or a general-purpose programming language, either of which is a hurdle for non-CS experts. The Event Model (TEM) (Etzion, et al.) allows a user to specify an event-driven application by concentrating on application logic, expressed in diagrams and associated condition tables. The TEM environment can fill in low-level details and manage the conversion to a particular stream-processing system. “Live” analytics are a major driver of next-generation stream systems. Our final paper looks at mining for events in a text stream (Grossniklaus, et al.). It adopts a tool-kit approach that allows easy implementation of many of the published approaches in this domain. In addition, it describes an evaluation platform for comparing alternative event-detection techniques. David Maier, Badrish Chandramouli Portland State University (Maier), Microsoft Corporation (Chandramouli) 3
6 . Kafka, Samza and the Unix Philosophy of Distributed Data Martin Kleppmann Jay Kreps University of Cambridge Confluent, Inc. Computer Laboratory Abstract Apache Kafka is a scalable message broker, and Apache Samza is a stream processing framework built upon Kafka. They are widely used as infrastructure for implementing personalized online services and real-time predictive analytics. Besides providing high throughput and low latency, Kafka and Samza are designed with operational robustness and long-term maintenance of applications in mind. In this paper we explain the reasoning behind the design of Kafka and Samza, which allow complex applications to be built by composing a small number of simple primitives – replicated logs and stream operators. We draw parallels between the design of Kafka and Samza, batch processing pipelines, database architecture, and the design philosophy of Unix. 1 Introduction In recent years, online services have become increasingly personalized. For example, in a service such as LinkedIn there are many activity-based feedback loops, automatically adapting the site to make it more relevant to individual users: recommendation systems such as “people you may know” or “jobs you might be interested in” [30], collaborative filtering [33] or ranking of search results [23, 26] are personalized based on analyses of user behavior (e.g. click-through rates of links) and user-profile information. Other feedback loops include abuse prevention (e.g. blocking spammers, fraudsters and other users who violate the terms of service), A/B tests and user-facing analytics (e.g. “who viewed your profile”). Such personalization makes a service better for users, as they are likely to find what they need faster than if the service presented them with static information. However, personalization has also opened new challenges: a huge amount of data about user activity needs to be collected, aggregated and analyzed [8]. Timeliness is important: after the service learns a new fact, the personalized recommendations and rankings should be swiftly updated to reflect the new fact, otherwise their utility is diminished. In this paper we describe Kafka and Samza, two related projects that were originally developed at LinkedIn as infrastructure for solving these data collection and processing problems. The projects are now open source, and maintained within the Apache Software Foundation as Apache Kafka1 and Apache Samza2 , respectively. Copyright 2015 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering 1 http://kafka.apache.org/ 2 http://samza.apache.org/ 4
7 .1.1 Implementing Large-Scale Personalized Services In a large-scale service with many features, the maintainability and the operational robustness of an implemen- tation are of paramount importance. The system should have the following properties: System scalability: Supporting an online service with hundreds of millions of registered users, handling mil- lions of requests per second. Organizational scalability: Allowing hundreds or even thousands of software engineers to work on the system without excessive coordination overhead. Operational robustness: If one part of the system is slow or unavailable, the rest of the system should continue working normally as much as possible. Large-scale personalized services have been successfully implemented as batch jobs [30], for example using MapReduce [6]. Performing a recommendation system’s computations in offline batch jobs decouples them from the online systems that serve user requests, making them easier to maintain and less operationally sensitive. The main downside of batch jobs is that they introduce a delay between the time the data is collected and the time its effects are visible. The length of the delay depends on the frequency with which the job is run, but it is often on the order of hours or days. Even though MapReduce is a lowest-common-denominator programming model, and has fairly poor perfor- mance compared to specialized massively parallel database engines [2], it has been a remarkably successful tool for implementing recommendation systems [30]. Systems such as Spark [34] overcome some of the performance problems of MapReduce, although they remain batch-oriented. 1.2 Batch Workflows A recommendation and personalization system can be built as a workflow, a directed graph of MapReduce jobs [30]. Each job reads one or more input datasets (typically directories on the Hadoop Distributed Filesystem, HDFS), and produces one or more output datasets (in other directories). A job treats its input as immutable and completely replaces its output. Jobs are chained by directory name: the same name is configured as output directory for the first job and input directory for the second job. This method of chaining jobs by directory name is simple, and is expensive in terms of I/O, but it provides several important benefits: Multi-consumer. Several different jobs can read the same input directory without affecting each other. Adding a slow or unreliable consumer affects neither the producer of the dataset, nor other consumers. Visibility. Every job’s input and output can be inspected by ad-hoc debugging jobs for tracking down the cause of an error. Inspection of inputs and outputs is also valuable for audit and capacity planning purposes, and monitoring whether jobs are providing the required level of service. Team interface. A job operated by one team of people can produce a dataset, and jobs operated by other teams can consume the dataset. The directory name thus acts as interface between the teams, and it can be reinforced with a contract (e.g. prescribing the data format, schema, field semantics, partitioning scheme, and frequency of updates). This arrangement helps organizational scalability. Loose coupling. Different jobs can be written in different programming languages, using different libraries, but they can still communicate as long as they can read and write the same file format for inputs and outputs. A job does not need to know which jobs produce its inputs and consume its outputs. Different jobs can be run on different schedules, at different priorities, by different users. 5
8 .Data provenance. With explicitly named inputs and outputs for each job, the flow of data can be tracked through the system. A producer can identify the consumers of its dataset (e.g. when making forward- incompatible changes), and a consumer can identify its transitive data sources (e.g. in order to ensure regulatory compliance). Failure recovery. If the 46th job in a chain of 50 jobs failed due to a bug in the code, it can be fixed and restarted at the 46th job. There is no need to re-run the entire workflow. Friendly to experimentation. Most jobs modify only to their designated output directories, and have no other externally visible side-effects such as writing to external databases. Therefore, a new version of a job can easily be run with a temporary output directory for testing purposes, without affecting the rest of the system. 1.3 From Batch to Streaming When moving from a high-latency batch system to a low-latency streaming system, we wish to preserve the attractive properties listed in Section 1.2. By analogy, consider how Unix tools are composed into complex programs using shell scripts [21]. A workflow of batch jobs is comparable to a shell script in which there is no pipe operator, so each program must read its input from a file on disk, and write its output to a different (temporary) file on disk. In this scenario, one program must finish writing its output file before another program can start reading that file. To move from a batch workflow to a streaming data pipeline, the temporary files would need to be replaced with something more like Unix pipes, which support incrementally passing one program’s output to another program’s input without fully materializing the intermediate result [1]. However, Unix pipes do not have all the properties we want: they connect exactly one output to exactly one input (not multi-consumer), and they cannot be repaired if one of the processes crashes and restarts (no failure recovery). Kafka and Samza provide infrastructure for low-latency distributed stream processing in a style that resem- bles a chain of Unix tools connected by pipes, while also preserving the aforementioned benefits of chained batch jobs. In the following sections we will discuss the design decisions that this approach entails. 1.4 Relationship of Kafka and Samza Kafka and Samza are two separate projects with a symbiotic relationship. Kafka provides a message broker service, and Samza provides a framework for processing messages. A Samza job uses the Kafka client library to consume input streams from the Kafka message broker, and to produce output streams back to Kafka. Although either system can be used without the other, they work best together. We introduce Kafka in more detail in Section 2, and Samza in Section 3. At the time of writing, there is an effort underway to add a feature called Kafka Streams to the Kafka client library [31]. This feature provides a stream processing capability similar to Samza, but it differs in that Kafka Streams does not prescribe a deployment mechanism, whereas Samza currently relies on Hadoop YARN. Most other high-level architecture choices are similar in Samza and Kafka Streams; for purposes of this paper, they can be regarded as equivalent. 2 Apache Kafka Kafka has been described in detail in prior work [8, 16, 19, 32]. In this section we present a brief high-level overview of the principles behind Kafka’s design. Kafka provides a publish-subscribe messaging service, as illustrated in Figure 1. Producer (publisher) clients write messages to a named topic, and consumer (subscriber) clients read messages in a topic. 6
9 . append Producer client Partition 0 1 2 3 4 5 6 7 8 9 10 11 12 Topic A Producer client Partition 1 1 2 3 4 5 6 7 8 9 10 Partition 0 1 2 3 4 Consumer group read sequentially Consumer client Topic B Partition 1 1 2 3 4 5 6 7 8 9 offsets: (B.1: 4, B.2: 7) Consumer client Partition 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 offsets: (B.3: 11) Figure 1: A Kafka topic is divided into partitions, and each partition is a totally ordered sequence of messages. A topic is divided into partitions, and messages within a partition are totally ordered. There is no ordering guarantee across different partitions. The purpose of partitioning is to provide horizontal scalability: different partitions can reside on different machines, and no coordination across partitions is required. The assignment of messages to partitions may be random, or it may deterministic based on a key, as described in Section 3.2. Broker nodes (Kafka servers) store all messages on disk. Each partition is physically stored as a series of segment files that are written in an append-only manner. A Kafka partition is also known as a log, since it resembles a database’s transaction commit log [12]: whenever a new message is published to a topic, it is appended to the end of the log. The Kafka broker assigns an offset to the message, which is a per-partition monotonically increasing sequence number. A message in Kafka consists of a key and a value, which are untyped variable-length byte strings. For richer datatypes, any encoding can be used. A common choice is Apache Avro,3 a binary encoding that uses explicit schemas to describe the structure of messages in a topic, providing a statically typed (but evolvable) interface between producers and consumers [10, 15]. A Kafka consumer client reads all messages in a topic-partition sequentially. For each partition, the client tracks the offset up to which it has seen messages, and it polls the brokers to await the arrival of messages with a greater offset (akin to the Unix tool tail -f, which watches a file for appended data). The offset is periodically checkpointed to stable storage; if a consumer client crashes and restarts, it resumes reading from its most recently checkpointed offset. Each partition is replicated across multiple Kafka broker nodes, so that the system can tolerate the failure of nodes without unavailability or data loss. One of a partition’s replicas is chosen as leader, and the leader handles all reads and writes of messages in that partition. Writes are serialized by the leader and synchronously replicated to a configurable number of replicas. On leader failure, one of the in-sync replicas is chosen as the new leader. 2.1 Performance and Scalability Kafka can write millions of messages per second on modest commodity hardware [14], and the deployment at LinkedIn handles over 1 trillion unique messages per day [20]. Message length is typically low hundreds of 3 http://avro.apache.org/ 7
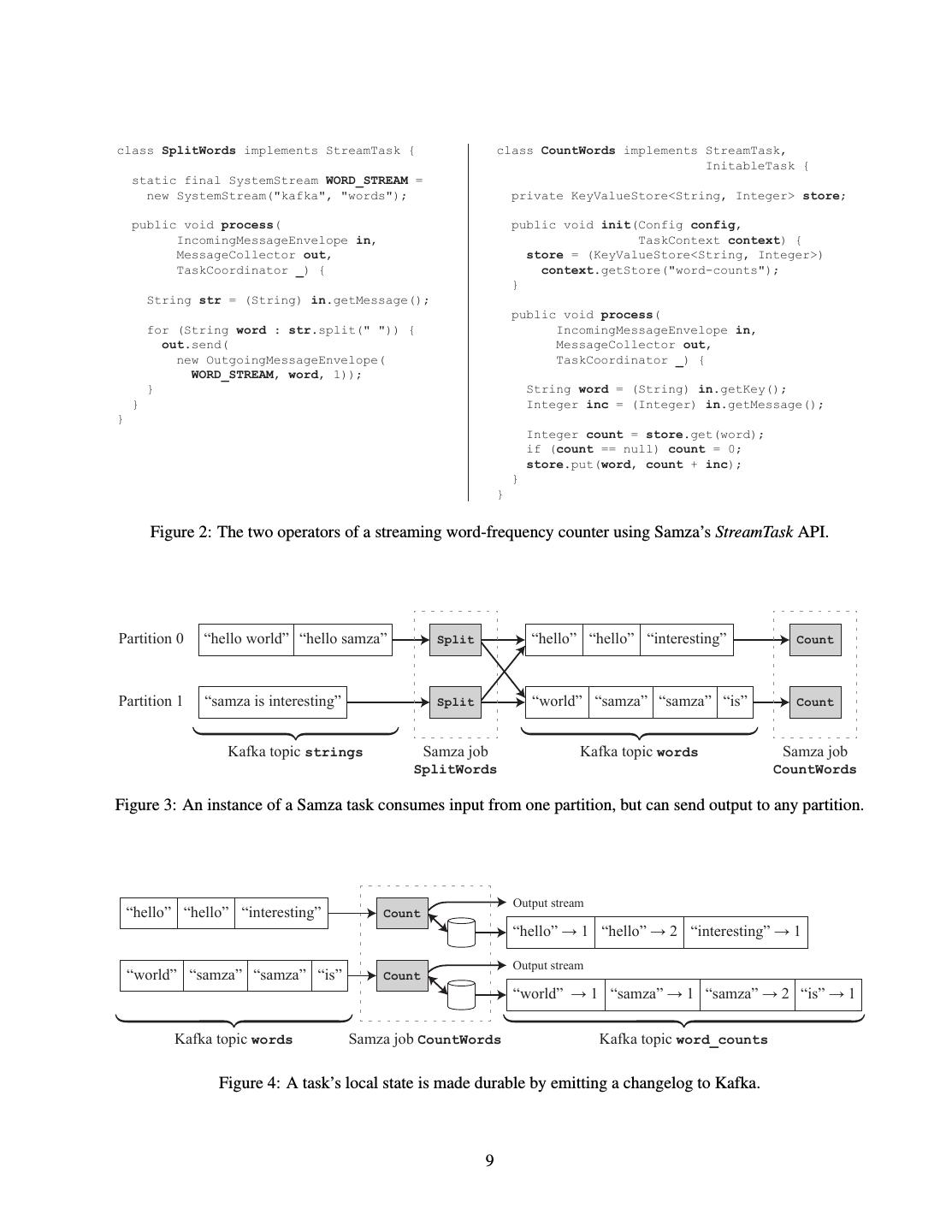
10 .bytes, although smaller or larger messages are also supported. In many deployments, Kafka is configured to retain messages for a week or longer, limited only by available disk space. Segments of the log are discarded when they are older than a configurable threshold. Alternatively, Kafka supports a log compaction mode, in which the latest message with a given key is retained indefinitely, but earlier messages with the same key are garbage-collected. Similar ideas are found in log-structured filesys- tems [25] and database storage engines [18]. When multiple producers write to the same topic-partition, their messages are interleaved, so there is no inherent limit to the number of producers. The throughput of a single topic-partition is limited by the computing resources of a single broker node – the bottleneck is usually either its NIC bandwidth or the sequential write throughput of the broker’s disks. Higher throughput can be achieved by creating more partitions and assigning them to different broker nodes. As there is no coordination between partitions, Kafka scales linearly. It is common to configure a Kafka cluster with approximately 100 topic-partitions per broker node [22]. When adding nodes to a Kafka cluster, some partitions can be reassigned to the new nodes, without changing the number of partitions in a topic. This rebalancing technique allows the cluster’s computing resources to be increased or decreased without affecting partitioning semantics. On the consumer side, the work of consuming a topic can be shared between a group of consumer clients (illustrated in Figure 1). One consumer client can read several topic-partitions, but any one topic-partition must be read sequentially by a consumer process – it is not possible to consume only a subset of messages in a partition. Thus, the maximum number of processes in a consumer group equals the number of partitions of the topic being consumed. Different consumer groups maintain their offsets independently, so they can each read the messages at their own pace. Thus, like multiple batch jobs reading the same input directory, multiple groups of consumers can independently read the same Kafka topic without affecting each other. 3 Apache Samza Samza is a framework that helps application developers write code to consume streams, process messages, and produce derived output streams. In essence, a Samza job consists of a Kafka consumer, an event loop that calls application code to process incoming messages, and a Kafka producer that sends output messages back to Kafka. In addition, the framework provides packaging, cluster deployment (using Hadoop YARN), automatically restarting failed processes, state management (Section 3.1), metrics and monitoring. For processing messages, Samza provides a Java interface StreamTask that is implemented by application code. Figure 2 shows how to implement a streaming word counter with Samza: the first operator splits every input string into words, and the second operator counts how many times each word has been seen. For a Samza job with one input topic, the framework instantiates one StreamTask for each partition of the input topic. Each task instance independently consumes one partition, no matter whether the instances are running in the same process, or distributed across multiple machines. As processing is always logically partitioned by input partition, even if several partitions are physically processed on the same node, a job’s allocated computing resources can be scaled up or down without affecting partitioning semantics. The framework calls the process() method for each input message, and the application code may emit any number of output messages as a result. Output messages can be sent to any partition, which allows re-partitioning data between jobs. For example, Figure 3 illustrates the use of partitions in the word-count example: by using the word as message key, the SplitWords task ensures that all occurrences of the same word are routed to the same partition of the words topic (analogous to the shuffle phase of MapReduce [6]). Unlike many other stream-processing frameworks, Samza does not implement its own network protocol for transporting messages from one operator to another. Instead, a job usually uses one or more named Kafka topics as input, and other named Kafka topics as output. We discuss the implications of this design in Section 4. 8
11 .class SplitWords implements StreamTask { class CountWords implements StreamTask, InitableTask { static final SystemStream WORD_STREAM = new SystemStream("kafka", "words"); private KeyValueStore<String, Integer> store; public void process( public void init(Config config, IncomingMessageEnvelope in, TaskContext context) { MessageCollector out, store = (KeyValueStore<String, Integer>) TaskCoordinator _) { context.getStore("word-counts"); } String str = (String) in.getMessage(); public void process( for (String word : str.split(" ")) { IncomingMessageEnvelope in, out.send( MessageCollector out, new OutgoingMessageEnvelope( TaskCoordinator _) { WORD_STREAM, word, 1)); } String word = (String) in.getKey(); } Integer inc = (Integer) in.getMessage(); } Integer count = store.get(word); if (count == null) count = 0; store.put(word, count + inc); } } Figure 2: The two operators of a streaming word-frequency counter using Samza’s StreamTask API. Partition 0 “hello world” “hello samza” Split “hello” “hello” “interesting” Count Partition 1 “samza is interesting” Split “world” “samza” “samza” “is” Count Kafka topic strings Samza job Kafka topic words Samza job SplitWords CountWords Figure 3: An instance of a Samza task consumes input from one partition, but can send output to any partition. Output stream “hello” “hello” “interesting” Count ³KHOOR´ : ³KHOOR´ : ³LQWHUHVWLQJ´ : Output stream “world” “samza” “samza” “is” Count ³ZRUOG´ : ³VDP]D´ : ³VDP]D´ : ³LV´ : Kafka topic words Samza job CountWords Kafka topic word_counts Figure 4: A task’s local state is made durable by emitting a changelog to Kafka. 9
12 .3.1 State Management Many stream-processing jobs need to maintain state, e.g. in order to perform joins (Section 3.2) or aggregations (such as the counters in CountWords, Figure 2). Any transient state can simply be maintained in instance variables of the StreamTask; since messages of a partition are processed sequentially on a single thread, these data structures need not be thread-safe. However, any state that must survive the crash of a stream processor must be written to durable storage. Samza implements durable state through the KeyValueStore abstraction, exemplified in Figure 2. Each StreamTask instance has a separate store that it can read and write as required. Samza uses the RocksDB4 embedded key-value store, which provides low-latency, high-throughput access to data on local disk. To make the embedded store durable in the face of disk and node failures, every write to the store is also sent to a dedicated topic-partition in Kafka, as illustrated in Figure 4. This changelog topic acts as a durable replication log for the store: when recovering after a failure, a task can rebuild its store contents by replaying its partition of the changelog from the beginning. Kafka’s log compaction mode (see Section 2.1) prevents unbounded growth of the changelog topic: if the same key is repeatedly over- written (as with a counter), Kafka eventually garbage-collects overwritten values, and retains the most recent value for any given key indefinitely. Rebuilding a store from the log is only necessary if the RocksDB database is lost or corrupted. Writing the changelog to Kafka is not merely an efficient way of achieving durability, it can also be a useful feature for applications: other stream processing jobs can consume the changelog topic like any other stream, and use it to perform further computations. For example, the word counts topic of Figure 4 could be consumed by another job to determine trending keywords (in this case, the changelog stream is also the CountWords operator’s output – no separate output topic is required). 3.2 Stream Joins One characteristic form of stateful processing is a join of two or more input streams, most commonly an equi- join on a key (e.g. user ID). One type of join is a window join, in which messages from input streams A and B are matched if they have the same key, and occur within some time interval ∆t of one another. Alternatively, a stream may be joined against tabular data: for example, user clickstream events could be joined with user profile data, producing a stream of clickstream events with embedded information about the user. Stream-table joins can be implemented by querying an external database within a StreamTask, but the net- work round-trip time for database queries soon becomes a bottleneck, and this approach can easily overload the external database [13]. A better option is to make the table data available in the form of a log-compacted stream. Processing tasks can consume this stream to build an in-process replica of a database table partition, using the same approach as the recovery of durable local state (Section 3.1), and then query it with low latency. For example, in the case of a database of user profiles, the log-compacted stream would contain a snapshot of all user profiles as of some point in time, and an update message every time a user subsequently changes their profile information. Such a stream can be extracted from an existing database using change data capture [5, 32]. When joining partitioned streams, Samza expects that all input streams are partitioned in the same way, with the same number of partitions n, and deterministic assignment of messages to partitions based on the same join key. The Samza job then co-partitions its input streams: for any partition k (with 0 ≤ k < n), messages from partition k of input stream A and from partition k of input stream B are delivered to the same StreamTask instance. The task can then use local state to maintain the data that is required to perform the join. Multi-way joins on several different keys may require different partitioning for each join. Such joins can be implemented with a multi-stage pipeline, where the output of each job partitions messages according to the next stage’s join key. The same approach is used in MapReduce workflows. 4 http://rocksdb.org/ 10
13 .4 Discussion In Sections 2 and 3 we outlined the architecture of Kafka and Samza. We now examine the design decisions behind that architecture in the light of our goals discussed in Section 1, namely creating large-scale personalized services in a way that is scalable, maintainable and operationally robust. 4.1 Use of Replicated Logs Stream processing with Samza relies heavily on fault-tolerant, partitioned logs as implemented by Kafka. Kafka topics are used for input, output, messaging between operators, durability of local state, replicating database tables, checkpointing consumer offsets, collecting metrics, and disseminating configuration information. An append-only log with optional compaction is one of the simplest data structures that is useful in prac- tice [12]. Kafka focuses on implementing logs in a fault-tolerant and scalable way. Since the only access methods supported by a log are an appending write and a sequential read from a given offset, Kafka avoids the complexity of implementing random-access indexes. By doing less work, Kafka is able to provide much better performance than systems with richer access methods [14, 16]. Kafka’s focus on the log abstraction is reminis- cent of the Unix philosophy [17]: “Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new ‘features’.” Real systems do require indexes and caches, but these can be derived from the log by a Kafka consumer that writes messages to an indexed store, either in-process (for local access) or to a remote database (for access by other applications). Because all consumers see messages in the same partition in the same order, deterministic consumers can independently construct views that are consistent with each other – an approach known as state machine replication [27]. The truth is in the log, and a database is a cached subset of the log [9]. 4.2 Composing Stream Operators Each Samza job is structurally simple: it is just one step in a data processing pipeline, with Kafka topics as inputs and outputs. If Kafka is like a streaming version of HDFS, then Samza is like a streaming version of MapReduce. The pipeline is loosely coupled, since a job does not know the identity of the jobs upstream or downstream from it, only the topic names. This principle again evokes a Unix maxim [17]: “Expect the output of every program to become the input to another, as yet unknown, program.” However, there are some key differences between Kafka topics and Unix pipes. In particular, Kafka preserves the advantages of batch workflows discussed in Section 1.2: a topic can have any number of consumers that do not interfere with each other (including consumers operated by different teams, or special consumers for debugging or monitoring), it tolerates failure of producers, consumers or brokers, and a topic is a named entity that can be used for tracing data provenance. Kafka topics deliberately do not provide backpressure: the on-disk log acts as an almost-unbounded buffer of messages. If a slow consumer falls behind the producer, the producers and other consumers continue operating at full speed. Thus, one faulty process does not disrupt the rest of the system, which improves operational reliability. Since Kafka stores all messages on disk anyway, buffering messages for a slow consumer does not incur additional overhead. The slow consumer can catch up without missing messages, as long as it does not fall behind further than Kafka’s retention period of log segments, which is usually on the order of days or weeks. Moreover, Kafka offers the ability for a consumer to jump back to an earlier point in the log, or to rebuild the entire state of a database replica by consuming from the beginning of a log-compacted topic. This facility makes it feasible to use stream processors not only for ephemeral event data, but also for database-like use cases. Even though the intermediate state between two Samza stream processing operators is always materialized to disk, Samza is able to provide good performance: a simple stream processing job can process over 1 million messages per second on one machine, and saturate a gigabit Ethernet NIC [7]. 11
14 .4.3 Unix as a Role Model Unix and databases are both data management systems [24], allowing data to be stored (in files or tables) and processed (through command-line tools or queries). Unix tools are famously well suited for implementing ad- hoc, experimental, short-running data processing tasks [21], whereas databases have traditionally been the tool of choice for building complex, long-lived applications. If our goal is to build stream processing applications that will run reliably for many years, is Unix really a good role model? The database tradition favors clean high-level semantics (the relational model) and declarative query lan- guages. While this approach has been very successful in many domains, it has not worked well in the context of building large-scale personalized services, because the algorithms required for these use cases (such as statis- tical machine learning and information retrieval methods) are not amenable to implementation using relational operators [28, 29]. Moreover, different use cases have different access patterns, which require different indexing and storage methods. It may be necessary to store the same data in both a traditional row-oriented fashion with indexes, as well as columnar storage, pre-aggregated OLAP cubes, inverted full-text search indexes, sparse matrices or array storage. Rather than trying to implement everything in a single product, most databases specialize in implementing one of these storage methods well (which is hard enough already). In the absence of a single database system that can provide all the necessary functionality, application de- velopers are forced to combine several data storage and processing systems that each provide a portion of the required application functionality. However, many traditional database systems are not designed for such compo- sition: they focus on providing strong semantics internally, rather than integration with external systems. Mech- anisms for integrating with external systems, such as change data capture, are often ad-hoc and retrofitted [5]. By contrast, the log-oriented model of Kafka and Samza is fundamentally built on the idea of composing heterogeneous systems through the uniform interface of a replicated, partitioned log. Individual systems for data storage and processing are encouraged to do one thing well, and to use logs as input and output. Even though Kafka’s logs are not the same as Unix pipes, they encourage composability, and thus Unix-style thinking. 4.4 Limitations Kafka guarantees a total ordering of messages per partition, even in the face of crashes and network failures. This guarantee is stronger than most “eventually consistent” datastores provide, but not as strong as serializable database transactions. The stream-processing model of computation is fundamentally asynchronous: if a client issues a write to the log, and then reads from a datastore that is maintained by consuming the log, the read may return a stale value. This decoupling is desirable, as it prevents a slow consumer from disrupting a producer or other consumers (Section 4.2). If linearizable data structures are required, they can fairly easily be implemented on top of a totally ordered log [3]. If a Kafka consumer or Samza job crashes and restarts, it resumes consuming messages from the most recently checkpointed offset. Thus, any messages processed between the last checkpoint and the crash are processed twice, and any non-idempotent operations (such as the counter increment in CountWords, Figure 2) may yield non-exact results. There is work in progress to add a multi-partition atomic commit protocol to Kafka [11], which will allow exactly-once semantics to be achieved. Samza uses a low-level one-message-at-a-time programming model, which is very flexible, but also harder to use, more error-prone and less amenable to automatic optimization than a high-level declarative query language. Work is currently in progress in the Kafka project to implement a high-level dataflow API called Kafka Streams, and the Samza project is developing a SQL query interface, with relational operators implemented as stream processing tasks. These higher-level programming models enable easier development of applications that fit the model, while retaining the freedom for applications to use the lower-level APIs when required. 12
15 .5 Conclusion We present the design philosophy behind Kafka and Samza, which implement stream processing by composing a small number of general-purpose abstractions. We draw analogies to the design of Unix, and batch processing pipelines. The approach reflects broader trends: the convergence between batch and stream processing [1, 4], and the decomposition of monolithic data infrastructure into a collection of specialized services [12, 28]. In particular, we advocate a style of application development in which each data storage and processing com- ponent focuses on “doing one thing well”. Heterogeneous systems can be built by composing such specialised tools through the simple, general-purpose interface of a log. Compared to monolithic systems, such composable systems provide better scalability properties thanks to loose coupling, and allow easier adaptation of a system to a wide range of different workloads, such as recommendation systems. Acknowledgements Large portions of the development of Kafka and Samza were funded by LinkedIn. Many people have contributed, and the authors would like to thank the committers on both projects: David Arthur, Sriharsha Chintalapani, Yan Fang, Jakob Homan, Joel Koshy, Prashanth Menon, Neha Narkhede, Yi Pan, Navina Ramesh, Jun Rao, Chris Riccomini, Gwen Shapira, Zhijie Shen, Chinmay Soman, Joe Stein, Sriram Subramanian, Garry Turkington, and Guozhang Wang. Thank you to Garry Turkington, Yan Fang and Alastair Beresford for feedback on a draft of this article. References [1] Tyler Akidau, Robert Bradshaw, Craig Chambers, Slava Chernyak, et al. The dataflow model: A practical approach to balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data processing. Proceedings of the VLDB Endowment, 8(12):1792–1803, August 2015. doi:10.14778/2824032.2824076. [2] Shivnath Babu and Herodotos Herodotou. Massively parallel databases and MapReduce systems. Foundations and Trends in Databases, 5(1):1–104, November 2013. doi:10.1561/1900000036. [3] Mahesh Balakrishnan, Dahlia Malkhi, Ted Wobber, Ming Wu, et al. Tango: Distributed data structures over a shared log. In 24th ACM Symposium on Operating Systems Principles (SOSP), pages 325–340, November 2013. doi:10.1145/2517349.2522732. [4] Raul Castro Fernandez, Peter Pietzuch, Jay Kreps, Neha Narkhede, et al. Liquid: Unifying nearline and offline big data integration. In 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015. [5] Shirshanka Das, Chavdar Botev, Kapil Surlaker, Bhaskar Ghosh, et al. All aboard the Databus! In 3rd ACM Symposium on Cloud Computing (SoCC), October 2012. [6] Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified data processing on large clusters. In 6th USENIX Symposium on Operating System Design and Implementation (OSDI), December 2004. [7] Tao Feng. Benchmarking Apache Samza: 1.2 million messages per second on a single node, Au- gust 2015. URL http://engineering.linkedin.com/performance/benchmarking-apache-samza-12- million-messages-second-single-node. [8] Ken Goodhope, Joel Koshy, Jay Kreps, Neha Narkhede, et al. Building LinkedIn’s real-time activity data pipeline. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 35(2):33–45, June 2012. [9] Pat Helland. Immutability changes everything. In 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015. [10] Martin Kleppmann. Schema evolution in Avro, Protocol Buffers and Thrift, December 2012. URL http://martin. kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html. [11] Joel Koshy. Transactional messaging in Kafka, July 2014. URL https://cwiki.apache.org/confluence/ display/KAFKA/Transactional+Messaging+in+Kafka. [12] Jay Kreps. I Heart Logs. O’Reilly Media, September 2014. ISBN 978-1-4919-0932-4. 13
16 .[13] Jay Kreps. Why local state is a fundamental primitive in stream processing, July 2014. URL http://radar.oreilly.com/2014/07/why-local-state-is-a-fundamental-primitive-in-stream- processing.html. [14] Jay Kreps. Benchmarking Apache Kafka: 2 million writes per second (on three cheap machines), April 2014. URL https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million- writes-second-three-cheap-machines. [15] Jay Kreps. Putting Apache Kafka to use: a practical guide to building a stream data platform (part 2), February 2015. URL http://blog.confluent.io/2015/02/25/stream-data-platform-2/. [16] Jay Kreps, Neha Narkhede, and Jun Rao. Kafka: a distributed messaging system for log processing. In 6th Interna- tional Workshop on Networking Meets Databases (NetDB), June 2011. [17] M D McIlroy, E N Pinson, and B A Tague. UNIX time-sharing system: Foreword. The Bell System Technical Journal, 57(6):1899–1904, July 1978. [18] Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. The log-structured merge-tree (LSM-Tree). Acta Informatica, 33(4):351–385, June 1996. doi:10.1007/s002360050048. [19] Todd Palino. Running Kafka at scale, March 2015. URL https://engineering.linkedin.com/kafka/ running-kafka-scale. [20] Kartik Paramasivam. How we’re improving and advancing Kafka at LinkedIn, September 2015. URL http://engineering.linkedin.com/apache-kafka/how-we%E2%80%99re-improving-and-advancing- kafka-linkedin. [21] Rob Pike and Brian W Kernighan. Program design in the UNIX environment. AT&T Bell Laboratories Technical Journal, 63(8):1595–1605, October 1984. doi:10.1002/j.1538-7305.1984.tb00055.x. [22] Jun Rao. How to choose the number of topics/partitions in a Kafka cluster?, March 2015. URL http://www. confluent.io/blog/how-to-choose-the-number-of-topicspartitions-in-a-kafka-cluster/. [23] Azarias Reda, Yubin Park, Mitul Tiwari, Christian Posse, and Sam Shah. Metaphor: A system for related search recommendations. In 21st ACM International Conference on Information and Knowledge Management (CIKM), October 2012. [24] Dennis M Ritchie and Ken Thompson. The UNIX time-sharing system. Communications of the ACM, 17(7), July 1974. doi:10.1145/361011.361061. [25] Mendel Rosenblum and John K Ousterhout. The design and implementation of a log-structured file system. ACM Transactions on Computer Systems (TOCS), 10(1):26–52, February 1992. doi:10.1145/146941.146943. [26] Sriram Sankar. Did you mean “Galene”?, June 2014. URL https://engineering.linkedin.com/search/did- you-mean-galene. [27] Fred B Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput- ing Surveys, 22(4):299–319, December 1990. [28] Margo Seltzer. Beyond relational databases. Communications of the ACM, 51(7):52–58, July 2008. doi:10.1145/1364782.1364797. [29] Michael Stonebraker and U˘gur C¸etintemel. “One size fits all”: An idea whose time has come and gone. In 21st International Conference on Data Engineering (ICDE), April 2005. [30] Roshan Sumbaly, Jay Kreps, and Sam Shah. The “Big Data” ecosystem at LinkedIn. In ACM International Confer- ence on Management of Data (SIGMOD), July 2013. [31] Guozhang Wang. KIP-28 — add a processor client, July 2015. URL https://cwiki.apache.org/confluence/ display/KAFKA/KIP-28+-+Add+a+processor+client. [32] Guozhang Wang, Joel Koshy, Sriram Subramanian, Kartik Paramasivam, et al. Building a replicated log- ging system with Apache Kafka. Proceedings of the VLDB Endowment, 8(12):1654–1655, August 2015. doi:10.14778/2824032.2824063. [33] Lili Wu, Sam Shah, Sean Choi, Mitul Tiwari, and Christian Posse. The browsemaps: Collaborative filtering at LinkedIn. In 6th Workshop on Recommender Systems and the Social Web (RSWeb), October 2014. [34] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, et al. Resilient distributed datasets: A fault- tolerant abstraction for in-memory cluster computing. In 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), April 2012. 14
17 . Streaming@Twitter Maosong Fu, Sailesh Mittal, Vikas Kedigehalli, Karthik Ramasamy, Michael Barry, Andrew Jorgensen, Christopher Kellogg, Neng Lu, Bill Graham, Jingwei Wu Twitter, Inc. Abstract Twitter generates tens of billions of events per hour when users interact with it. Analyzing these events to surface relevant content and to derive insights in real-time is a challenge. To address this, we developed Heron, a new real time distributed streaming engine. In this paper, we first describe the design goals of Heron and show how the Heron architecture achieves task isolation and resource reservation to ease debugging, troubleshooting, and seamless use of shared cluster infrastructure with other critical Twitter services. We subsequently explore how a topology self adjusts using back pressure so that the pace of the topology goes as its slowest component. Finally, we outline how Heron implements at-most- once and at-least-once semantics and we describe a few operational stories based on running Heron in production. 1 Introduction Stream-processing platforms enable enterprises to extract business value from data in motion, similar to batch processing platforms that facilitated the same with data at rest [42]. The goal of stream processing is to enable real-time or near real-time decision making by providing capabilities to inspect, correlate and analyze data as it flows through data-processing pipelines. There is an emerging trend to transition from predominant batch analytics to streaming analytics driven by a combination of increased data collection in real-time and the need to make decisions instantly. Several scenarios in different industries require stream processing capabilities that can process millions and even hundreds of millions of events per second. Twitter is no exception. Twitter is synonymous with real-time. When a user tweets, his or her tweet can reach millions of users instantly. Twitter users post several hundred million tweets every day. These tweets vary in diversity of content [28] including but not limited to news, pass along (information or URL sharing), status updates (daily chatter), and real-time conversations surrounding events such as the Super Bowl, and the Oscars. Due to the volume and variety of tweets, it is necessary to surface relevant content in the form of break-out moments and trending #hashtags to users in real time. In addition, there are several real-time use cases including but not limited to analyzing user engagements, extract/transform/load (ETL), and model building. In order to power the aforementioned crucial use cases, Twitter developed an entirely new real-time dis- tributed stream-processing engine called Heron. Heron is designed to provide Copyright 2015 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering 15
18 . • Ease of Development and Troubleshooting: Users can easily debug and identify the issues in their topologies (also called standing queries), allowing them to iterate quickly during development. This improvement in visibility is possible because of the fundamental change in architecture in Heron from thread based to process based. Users can easily reason about how their topologies work, and profile and debug their components in isolation. • Efficiency and Performance: Heron is 2-5x more efficient than Storm [40]. This improvement resulted in significant cost savings for Twitter both in capital and operational expenditures. • Scalability and Reliability: Heron is highly scalable both in the ability to execute large numbers of components for each topology and the ability to launch and track large numbers of topologies. This large scale results from the clean separation of topology scheduling and monitoring. • Compatibility with Storm: Heron is API compatible with Storm and hence no code change is required for migration. • Simplified and Responsive UI: The Heron UI gives a visual overview of each topology. The UI uses metrics to show at a glance where the hot spots are and provides detailed counters for tracking progress and troubleshooting. • Capacity Allocation and Management: Users can take a topology from development to production in a shared-cluster infrastructure instantly, since Heron runs as yet another framework of the scheduler that manages capacity allocation. The remainder of this paper is organized as follows. Section 2 presents related work on streaming systems. The following section, Section 3 describes the Heron data model. Section 4 describes the Heron architecture followed by how the architecture meets the design goals in Section 5. Section 6 discusses some of the operational aspects that we encountered while running Heron at Twitter specifically back-pressure issues in Section 6.1, load shedding in Section 6.2, and Kestrel spout issues in Section 6.3. Finally, Section 7 contains our conclusions and points to a few directions for future work. 2 Related Work The importance of stream-processing systems was recognized in the late 1990s and early 2000s. From then on, these systems have gone through three generations of evolution. First-generation systems were either main- memory database systems or rule engines that evaluate rules expressed as condition-action pairs when new events arrive. When a rule is triggered, it might produce alerts or modify the internal state, which could trigger other rules. These systems were limited in functionality and also did not scale with large-data-volume streams. Some of the systems in this generation include HiPAC [29], Starburst [43], Postgres [37], Ode [31], and NiagaraCQ [27]. Second-generation systems were focused on extending SQL for processing streams by exploiting the simi- larities between a stream and a relation. A stream is considered as an instantaneous relation [22] and streams can be processed using relational operators. Furthermore, the stream and stream results can be stored in relations for later querying. TelegraphCQ [25] focused on developing novel techniques for processing streams of con- tinuous queries over large volume of data using Postgres. Stanford stream manager STREAM [21] proposed a data model integrating streams into SQL. Aurora [18] used operator definitions to form a directed acyclic graph (DAG) for processing stream data in a single node system. Borealis [17] extended Aurora for distributed stream processing with a focus on fault tolerance and distribution. Cayuga [30] is a stateful publishe-subscribe system that developed a query language for event processing based on an algebra using non-deterministic finite state automaton. 16
19 . Because these second-generation systems were not designed to handle incoming data in a distributed fashion, a need for a third generation arose as Internet companies began producing data at a high velocity and volume. These third-generation systems were developed with the key focus on scalable processing of streaming data. Yahoo S4 [3] is one of the earliest distributed streaming systems that is near real-time, scalable and allows for easy implementation of streaming applications. Apache Storm [40] is a widely popular distributed streaming system open sourced by Twitter. It models a streaming analytics job as a DAG and runs each node of the DAG as several tasks distributed across a cluster of machines. MillWheel [19] is a key-value based streaming system that supports exactly once semantics. It uses BigTable [26] for storing state and checkpointing. Apache Samza [4] developed at LinkedIn, is a real-time, asynchronous computational framework for stream processing. It uses several independent single-stage computational tasks for stitching together a topology similar to Storm. Each stage reads one or more streams from Apache Kafka [32] and writes the output stream to Kafka for stitching together a processing DAG. Apache Spark [5] supports streaming using a high-level abstraction called a discretized stream, Spark runs short tasks to process these discretized streams and output results to other systems. In contrast, Apache Flink [2] uses a distributed streaming dataflow engine and asynchronous snapshots for achieving exactly once semantics. Pulsar [35] is a real time analytics engine open sourced by eBay and its unique feature is its SQL interface. Some of the other notable systems include S-Store [34] Akka [1], Photon [20], and Reactive Streams [11]. In addition to these platforms, several commercial streaming systems are available in the market [7], [8], [9], [12], [13]i, [14], and [15]. 3 Heron Data Model Heron uses a directed acyclic graph (DAG) for representing a real-time computation. The graph is referred to as a topology. Each node in the topology contains processing logic, and the links between the nodes indicate how the data flows between them. These data flows are called streams. A stream is an unbounded sequence of tuples. Nodes take one or more streams and transform them into one or more new new streams. There are two types of nodes: spouts and bolts. Spouts are the sources of streams. For example, a Kafka [32] spout can tap into a Kafka queue and emit it as a stream. A bolt consumes tuples from streams, applies its processing logic and emits tuples in outgoing streams. Typical processing logic includes filtering, joining and aggregation of streams. An example topology is shown in Figure 1. Figure 1: Heron Topology In this topology, the spouts S1 taps into its data source and emits two streams consumed by the first stage 17
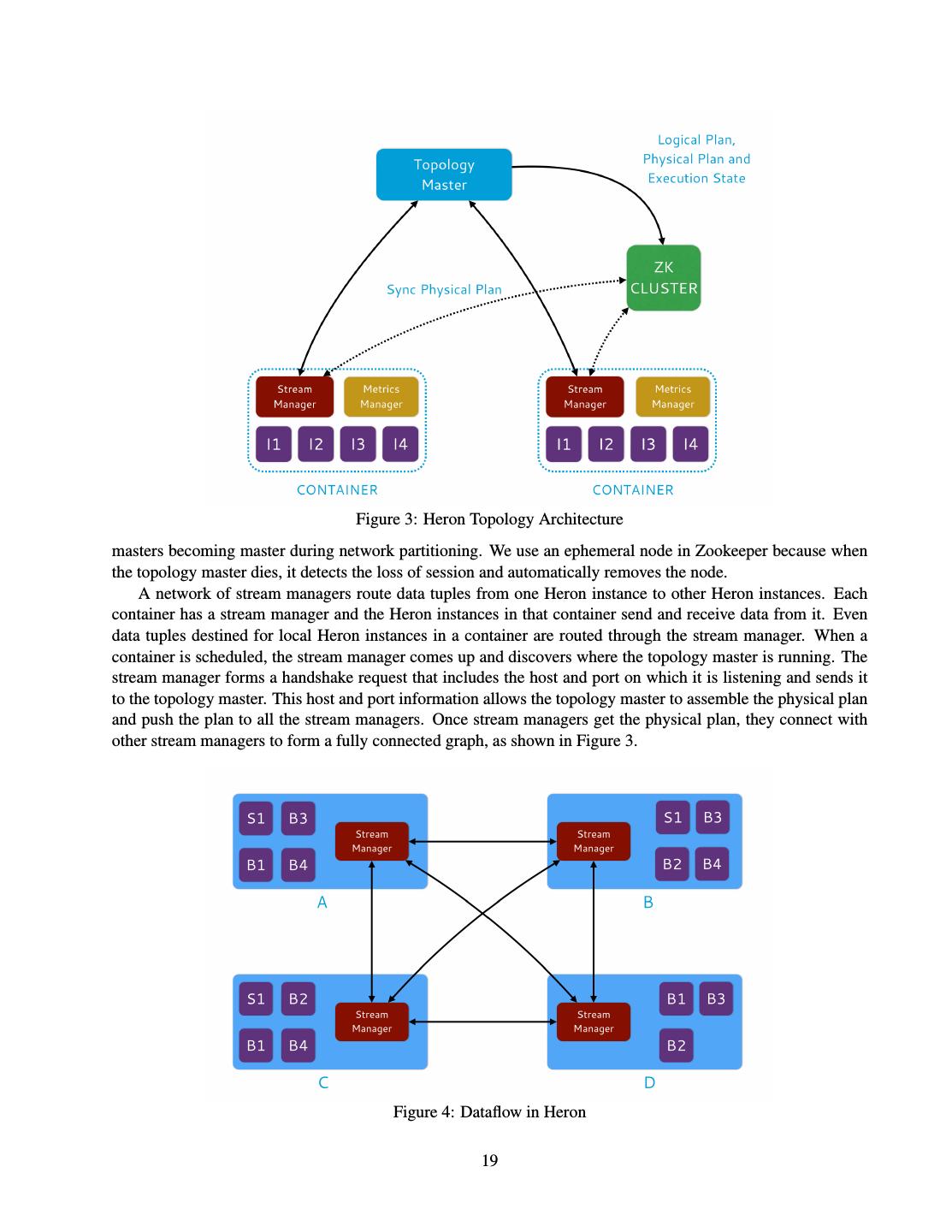
20 .bolts B1, and B2. These bolts transform the streams and emit three new streams feeding bolts B3 and B4. Since the incoming data rate might be higher than the processing capability of a single process or even a single machine, each spout and bolt of the topology is run as multiple tasks. The number of tasks for each spout and bolt is specified in the topology configuration by the programmer. Such a task specification is referred to as the degree of parallelism. The topology shown in Figure 1, when instantiated at run time is illustrated in Figure 2. The topology, the task parallelism for each node and the specification about how data should be routed form the physical execution plan of the topology. Figure 2: Physical Execution of a Heron Topology 4 Heron Architecture The design goals for Heron are multifold. First, the spout and bolt tasks need to be executed in isolation. Such isolation will provide the ability to debug and profile a task when needed. Second, the resources allocated to the topology should not be exceeded during the execution of the topology. This requirement enables Heron topologies to be run in a shared cluster environment alongside other critical services. Third, the Heron API should be backward compatible with Storm and a migrated topology should run unchanged. Fourth, Heron topologies should adjust themselves automatically when some of their components are executing slowly. Fifth, Heron should be able to provide high throughput and low latency. While these goals are often mutually exclusive, Heron should expose the appropriate knobs so that users can balance throughput and latency needs. Sixth, Heron should support the processing semantics of at most once and at least once. Finally, Heron should be able to achieve high throughput and/or low latency while consuming a minimal amount of resources. To meet the aforementioned design goals, Heron uses the architecture as shown in Figure 3. A user writes his or her topology using the Heron API and submits to a scheduler. The scheduler acquires the resources (CPU and RAM) as specified by the topology and spawns multiple containers on different nodes. The first container, referred to as the master container, runs the topology master. The other containers each run a stream manager, a metrics manager and several processes called instances that execute the processing logic of spouts and bolts. The topology master is responsible for managing the entire topology. Furthermore, it assigns a role or group based on the user who launched the topology. This role is used to track the resource usage of topologies across different teams and calcuate the cost of running them for reporting. In addition, the topology master acts as the gateway to access the metrics and status of the topology. Once the topology master comes up in the master container, it advertises its location in the form of a host and port via an ephemeral Zookeeper [6] node. This node allows other containers to discover the location of the topology master and also prevents multiple topology 18
21 . Figure 3: Heron Topology Architecture masters becoming master during network partitioning. We use an ephemeral node in Zookeeper because when the topology master dies, it detects the loss of session and automatically removes the node. A network of stream managers route data tuples from one Heron instance to other Heron instances. Each container has a stream manager and the Heron instances in that container send and receive data from it. Even data tuples destined for local Heron instances in a container are routed through the stream manager. When a container is scheduled, the stream manager comes up and discovers where the topology master is running. The stream manager forms a handshake request that includes the host and port on which it is listening and sends it to the topology master. This host and port information allows the topology master to assemble the physical plan and push the plan to all the stream managers. Once stream managers get the physical plan, they connect with other stream managers to form a fully connected graph, as shown in Figure 3. Figure 4: Dataflow in Heron 19
22 . A Heron instance runs the processing logic in spouts or bolts. Each Heron instance is a process running a single spout task or a bolt task. The instance process runs two threads –the gateway thread and the task-execution thread. The gateway thread communicates with the stream manager to send and receive data tuples from the stream manager. The task-execution thread runs the user code of the spout or bolt. When the gateway thread receives tuples, it passes them to the task-execution thread. The task-execution thread applies the processing logic and emits tuples, if needed. These emitted tuples are sent to the gateway thread, which passes them to the stream manager. In addition to tuples, the task-execution thread collects several metrics. These are passed to the gateway thread, which routes them to the metrics manager. The metrics manager is responsible for collecting metrics from all instances and exporting them to the metrics-collection system. The metrics-collection system stores those raw metrics and allows for later analysis. Since there are several popular metrics-collection systems, the metrics manager exposes a generic abstraction. This abstraction facilitates ease of implementation for routing metrics to various different metrics-collection systems. 5 Achieving Design Goals As mentioned in the previous section, Heron was developed with certain design goals in mind. In this section, we examine how we achieved each one of them in detail. 5.1 Task Isolation Since a Heron instance executes a single task in a dedicated process, it is entirely isolated from other spout and bolt tasks. Such task isolation provides several advantages. First, it is easy to debug an offending task, since the logs from its instance are written to a file of its own providing a time ordered view of events. This ordering helps simplify debugging. Second, one can use performance-tracking tools (such as YourKit [16], etc) to identify the functions consuming substantial time, when a spout or bolt task is running slowly. Third, it allows examination of the memory of the process to identify large objects and provide insights. Finally, it facilitates the examination of execution state of all threads in the process to identify synchronization issues. 5.2 Resource Reservation In Heron, a topology requests its resources in the form of containers, and the scheduler spawns those contain- ers on the appropriate machines. Each container is assigned the requested number of CPU cores and memory. Once a certain amount of resources (CPU and RAM) are assigned to a topology, Heron ensures that they are not exceeded. This monitoring is needed when Heron topologies are run alongside other critical services in a shared infrastructure. Furthermore, when fragments of multiple topologies are executing in the same ma- chine, resource reservation ensures that one topology does not influence other topologies by consuming more resources temporarily. If resource reservation is not enforced, it would lead to unpredictability in the behavior of other topologies, making it harder to track the underlying performance issues. Each container is mapped to a Linux cgroup. This ensures that the container does not exceed the allocated resources. If there is an attempt to temporarily consume more resources, the container will be throttled, leading to a slowdown of the topology. 5.3 Self Adjustment A typical problem seen in streaming systems, similar to what is seen in batch systems, is that of stragglers. Since the topology can process data only as fast as its slowest component, stragglers cause lag in the input data to build up. In such scenarios, a streaming system tends to drop data at different stages of the DAG. This dropping of results in either data loss or replay of data multiple times. A topology needs to adjust its pace depending on the 20
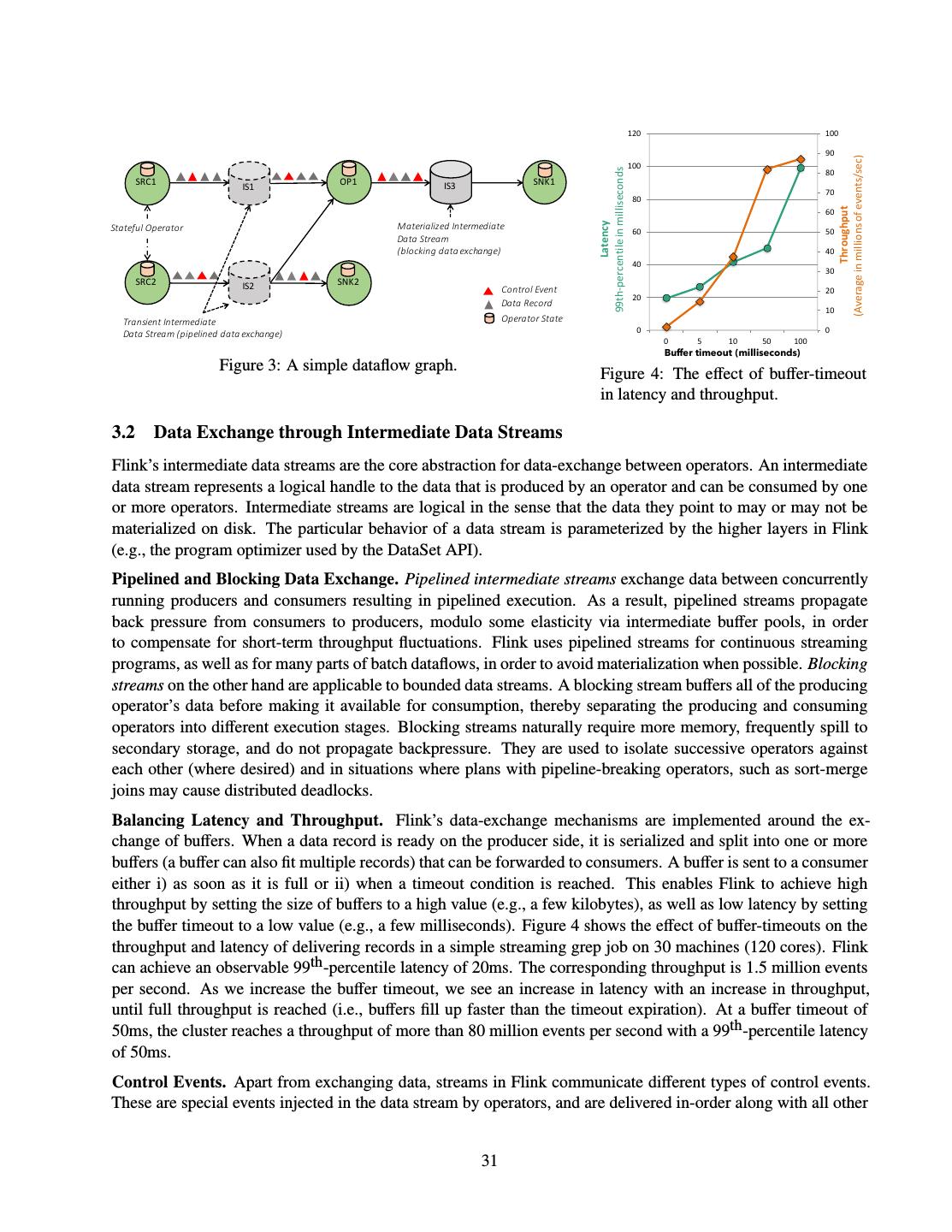
23 .prevailing situations. Some of these situations are data skew, where a bolt instance is receiving more data than it can process, and when a fragment of the topology is scheduled on a slow node. During such scenarios, some feedback mechanism should be incorporated to slow down the topology tem- porarily so that the data drops are minimized. Heron implements a full fledged back-pressure mechanism to ensure that the topology is self adjusting. We investigated two back-pressure approaches –TCP-based back pressure and spout-based back pressure. The TCP protocol uses slow-start and sliding-window mechanisms to ensure that the sender is transmitting at the rate the receiver can consume. Hence it is natural to ask whether Heron could leverage the TCP protocol for back pressure. But due to the multiplexing nature of the stream manager, where multiple logical transport channels are mapped on a single physical channel, TCP-based back pressure could slow upstream or downstream spouts or bolts. To illustrate this possibility, consider the physical execution of the topology in Figure 1 with four containers as shown in Figure 5. Assume that an instance of Bolt B3 in Container A is going slow. As shown in Figure 1, Bolt B3 receives input from Bolt B1 which means all instances of Bolt B3 will receive input from all instances of B1. Hence, the stream manager in Container A will receive input from bolt instances of B1 running in Containers C and D. Since the instance of Bolt B3 in Container A is going slow, its stream manager will not take any additional input from the stream managers of the containers C and D. Since the connection between stream managers use TCP sockets, eventually the socket send buffers in stream managers in Containers C and D will fill up. As a result, the data exchange between Bolt B1 and B2 (shown in green) in containers C and D with bolt B4 (shown in green) in Container A is affected. We found that for some topologies, such situations could eventually drive the throughput to zero. Figure 5: TCP Back Pressure We considered another approach called spout-based back pressure. This approach is based on the observation that spouts are the sources of data and we can manage when they emit or suspend the injection of data. In other words, whenever a stream manager detects one of the instances is going slow, it will explicitly send an initiate- back-pressure message to all the other stream managers. When a stream manager receives this message, it examines the physical plan and, if there are any spouts running in the container, it will not consume data from them. To illustrate, again consider the physical execution of topology in Figure 1 as shown in Figure 6. When the Bolt B3 in Container A goes slower, its stream manager sends the initiate-back-pressure message to stream 21
24 .managers of all the containers. Upon receiving this message, the stream managers in Containers B and C do not consume data from their spouts, in this case, Spout S1 (shown in blue). This action reduces the data inflow into the topology thereby self adjusting. Once the Bolt B3 picks up pace, its stream manager sends a relieve-back- pressure message to all other stream managers. They act on this message by starting to consume from their local spouts. More details about the back pressure mechanism can be found in Kulkarni, et al. [33]. Figure 6: Spout Back Pressure 5.4 Processing Semantics In order to provide predictability, a stream processing system needs to provide guarantees on the data that passes through it. Heron supports two different types of processing semantics: • At most once: In this semantics, the processing is best effort. In the presence of node or process failures, the data processed by the streaming system could be lost. Hence, the number of data tuples processed might be lower than the actual number of data tuples, which could affect the results. • At least once: In this semantics, the system guarantees that the data is processed at least once. If the data is dropped during node or process failures, it is reprocessed. It is possible that the same data tuple is processed more than once. Hence, the number of data tuples processed might be higher than the actual number of data tuples, again potentially affecting the results. Incorporating at-most-once semantics in Heron is straight forward. A Heron topology continuously pro- cesses data and, during processing, the data moves from instance to stream manager and between stream man- agers. When an instance in a container fails, the state accumulated by the bolt or spout is lost. After restart, it connects with the stream manager and continues to receive and process data thereby, accumulating new state. Similarly, when a stream manager in a container dies, it restarts and reconnects to other stream managers and resumes processing. If an entire container fails due to node failure, the container is relocated to another node. Once the stream manager and instances in the relocated container come up, the data processing continues. Dur- ing relocation, the data intended for the failed stream manager from other stream managers could be dropped or if the data is buffered, the buffers could overflow, eventually dropping data. 22
25 .6 Heron in Practice Heron has been in production at Twitter for over two years. It is used for diverse use cases such as real-time business intelligence, real-time machine-learning, real-time classification, real-time engagements, computing real-time trends, real-time media, and real-time monitoring. In this section, we will explore some of operational issues that occur in practice and how we solve them. 6.1 Back Pressure Spout-based back pressure helped us reduce data loss significantly as stragglers are the norm in multi-tenant distributed systems. The Heron back-pressure recovery mechanism allows us to process data at a maximal rate such that the recovery times are very low. Since most topologies are provisioned with extra capacity to handle increased traffic during well-known events (such as the Super Bowl and the Oscars), the recovery rate is usually much higher than the steady state. In cases where the topologies have not been provisioned to handle increased traffic, the back pressure mechanisms act as a shock absorber to handle any temporary spikes. In cases where these spikes are not temporary, back pressure also allows users to add more capacity and restart their topologies with minimal loss of data. We have encouraged topology writers to test their back pressure (and recovery) mechanism in staging envi- ronments by artificially creating traffic spikes (e.g., by reading from older offsets in Kafka). This practice allows them to understand the dynamic behavior of back pressure and measure the recovery time. To monitor this pro- cess in real time, several metrics have been exposed on the dashboard. Back pressure also helps topology writers in tuning their topology. Since we do not have auto tuning (yet), users are required to use trial and error to get the correct values for resource allocation and parallelism of the components. By looking at the back pressure metrics, they can identify which of the components are under back pressure and correspondingly increase the resources or parallelism until there is no back pressure in steady state. In our experience, we have found that in most scenarios, back pressure recovers without manual intervention. However, there are cases where a particular component in topology gets scheduled on a faulty host or goes into irrecoverable garbage-collection cycles (for various reasons). Under such scenarios, users get paged, upon which they usually restart those components to get the problem fixed. While most users see back pressure as a requirement, some users prefer dropping data as they only care about the latest data. To handle such cases, we added the load-shedding feature in spouts as decribed in the following section. 6.2 Load Shedding Load shedding has been studied extensively in the context of second-generation streaming systems [23, 24, 36, 38, 39, 41]. Most of the proposed alternatives fall into two broad categories, sampling-based approaches and data-dropping-based approaches. The idea behind sampling-based approaches is that if the system can automatically downsample an incoming stream in a predictable way, the user can potentially scale up the results of the computation in order to compensate. For example, if a Heron topology is counting widgets and the stream is being downsampled by 50%, the user can simply multiply the widget counts by two for each widget that is present in the stream and therefore still get approximately correct results. The common theme of sampling approaches is that a more uniformly sampled stream is easier to reason about and a user could also use the information about the sampling rate to scale the output of the computations, which is a very desirable property. However, for sampling to be useful to applications, it would be important that the sampling was done on a global level. If each spout instance was individually sampling at different times and different rates the value of uniform sampling to applications programmers is pretty much negated. The system would lose the property that it is easy to reason about the sampling that is happening and also the ability to properly scale the output of the 23
26 .computation based on the sampling rate. Due to these limitations and its considerably higher complexity, we did not implement the sampling-based approach. On the other hand, the idea behind dropping-based approaches is that the system will simply drop older data and prefer more recent data when the Heron topology is unable to keep up. Heron spouts are modified such that the user can configure a lag threshold and a lag-adjustment value. The lag threshold will indicate how much lag is tolerable before the spout drops any data. The lag-adjustment value will indicate how much of the old data the system will drop when this threshold is reached. Given the two values described above, the system will monitor the lag for each individual spout instance and periodically skip ahead by the lag adjustment value whenever the lag is above the threshold value. A key point here is that the decision to drop data is a completely local decision in each spout instance. There will be no attempt made to synchronize amongst different spouts or otherwise coordinate such that the spouts work together in deciding what data to drop. Each spout drops data from its associated Kafka or Eventbus partition and no communication between spouts will occur. 6.3 Kestrel Spout Kestrel [10] is a simple distributed message-queuing system. Each Kestrel host handles a set of reliable, and ordered, message queues. A Kestrel cluster consists of several such hosts with no communication between them. Whenever a client is interested in enqueuing or dequeuing an item, it randomly picks a host, thereby providing reliable, loosely ordered message queue behavior. An attractive property of Kestrel is its ability to scale, since servers do not communicate with each other and have no need for any coordination. Unlike Kafka [32], Kestrel is stateful. In order to maintain state, Kestrel replicates data for every consumer. In other words, Kestrel assumes only one consumer per physical queue. An item in the queue is removed only after a client dequeues and then acknowledges it. If two different instances of a consumer are consuming from the same Kestrel queue, it is guaranteed that they will never receive same item, given that they acknowledge their respective items. If the item is not acknowledged within a specified amount of time, it is placed back in the queue for the next instance to receive. We started with the open source Kestrel spout and it worked reasonably well. However, as traffic grew, Heron topologies using Kestrel spouts faced several issues, such as: • One or more Kestrel hosts would start accumulating data and not drain. The immediate resolution is to manually mark those servers as read only until they drain, and enable writes once the number of items to be consumed goes below a certain threshold. This approach presents an operational challenge, especially during non-working hours. When a host is not getting drained, it affects the performance of other queues it needs to service as well. One possible solution is to set maxItems (the maximum number of items held in queue) and maxAge (maximum amount of time an item stays in the queue before it is deleted) limits on the queues to be small, so that the size of queue does not grow to affect other queues on the host. But this solution results in data loss for the job consuming this queue. • A Kestrel spout would pack the Kestrel client (or connection) along with the data in a tuple. This would cause the spout to become stateless, because when the tuple came back to the spout to get acknowledged, it just extracted the client from the tuple and acknowledged it back to Kestrel host to retire the tuple. The problem with this approach was that the tuple size grew, and it carried extra load for no reason, which resulted in extra data transfers, and more serialization and deserialization costs. • A Kestrel spout would create a new connected client every time it requested the next batch of items from Kestrel. While this behavior has no effect on topologies with low throughput, for more data-heavy topolo- gies, the number of connections to a host grew without bound. Some of the spout-related configurations, 24
27 . such as maximum spout pending (limits the number of tuples in flight in a topology, so the spouts do not re- quest an unbounded number of tuples) often hid this problem. Furthermore, creation of many connections exacerbated garbage-collection issues. The root cause for one or more Kestrel hosts not draining was triggered by the use of Zookeeper to discover Kestrel hosts. Specifically, the Kestrel spout used a service factory for creating a connection to one of the Kestrel hosts in the server set, The factory did not provide any guarantees that all the hosts would be connected and read evenly. As a result, some of the servers were occasionally left out, causing items from those servers to not be consumed. Our initial solution was to fetch all the hosts from the Kestrel server set, and read from each server in a round-robin fashion. This practice ensured that no server is left unread, while giving all the hosts equal priority. This approach worked even during times of high load, because it is assumed that to achieve steady state, the read rate has to be higher than the write rate. So even in case of high load, round robin would drain the full queues, and bring the system to steady state. Soon we saw an issue where instead of one Kestrel host lagging, all of the hosts were backing up. This issue was traced to one host being unable to respond and because of the round robin policy, all the hosts were read at the pace of the slowest one. The actual slow down of the host was due to disk writes for logging. Hence, an approach was needed to decouple a slow host from others temporarily. To solve the issue, each spout instance is assigned a configurable number of Kestrel hosts. These assignments were not mutually exclusive, and had overlaps. The three main properties of these assignments are: • Each spout instance reads from a subset (more than one) of Kestrel hosts. • Each Kestrel host is read by a subset (more than one) spout instances. • If any two Kestrel hosts, A and B, are read by one spout instance, then there exists a spout instance that reads from host A and not B, and another instance that reads from host B and not A. The last property ensures that if one Kestrel host slows down, the rest of the hosts will be read without any penalties. And using round-robin reads ensures that the slow host will not be left out, and will still be drained. The issue of passing a Kestrel client was fixed by mapping each tuple to its Kestrel client using a combination of a generated unique identifier and the original item identifier provided by the Kestrel host. This approach also prevented the creation of several client objects by reusing existing Kestrel client objects. Finally, we added configuration parameters to control both the number of connections per Kestrel host from a spout instance and the number of pending items per connection, which helped in playing nice with Kestrel. 7 Conclusion Heron has become the de-facto real-time streaming system at Twitter. It runs several hundred development and production topologies and been in production for more than two years. Several teams in Twitter use Heron for making real-time data-driven decisions that are business critical. Heron is used for several diverse use cases ranging from ETL to building machine-learning models and is expanding rapidly. These use cases require additional future work to evolve Heron. First, manual resource assignment for a topology when it goes production currently requires several itera- tions. Each iteration involves changing the configuration parameters, recompiling and redeploying. For large topologies, each iteration is very expensive. We want to explore an elegant solution for estimating initial re- source requirements using a combination of data-source characteristics, sampling and linear regression. Second, the topologies are often overprovisioned to accommodate peak loads during popular events to avoid manual intervention. This policy led to resource wastage and hence we are investigating approaches where the topology can expand automatically and shrink depending on traffic variations. Third, we want to support a declarative 25
28 .query paradigm that allows users to write queries faster and be more productive. Fourth, in some uses cases, we have to guarantee data processing by the topology is exactly once. The problems of auto-scaling and exactly once will require distributed partitionable state and additional Heron APIs. 8 Acknowledgements Thanks to David Maier and Kristin Tufte for providing comments on the initial draft of the paper that helped improved its presentation. Thanks to Jeff Naughton, Deep Medhi and Jignesh Patel for reading the pre-final draft and help improve the presentation. Thanks to Arun Kejariwal for help with LaTeX including setting it up, patiently answering several questions and providing several comments on the first draft. References [1] Akka. http://akka.io/. [2] Apache Flink. https://flink.apache.org/. [3] Apache S4. http://incubator.apache.org/s4/. [4] Apache Samza. https://samza.apache.org/. [5] Apache Spark. https://spark.apache.org/. [6] Apache Zookeeper. http://zookeeper.apache.org/. [7] Apama Streaming Analytics. http://www.softwareag.com/corporate/products/apama_webmethods/ analytics/overview/default.asp. [8] Informatica Vibe Data Stream. https://www.informatica.com/products/data-integration/real-time- integration/vibe-data-stream.html#fbid=v8VRdfhc8YI. [9] InfoSphere Streams: Capture and analyze data in motion. http://www-03.ibm.com/software/products/en/ infosphere-streams. [10] Kestrel: A simple, distributed message queue system. http://twitter.github.io/kestrel. [11] Reactive Streams. http://incubator.apache.org/s4/. [12] SAP Event Stream Processor. http://www.sap.com/pc/tech/database/software/sybase-complex-event- processing/index.html. [13] SQLstream Blaze. http://www.sqlstream.com/blaze/. [14] TIBCO StreamBase. http://www.streambase.com/. [15] Vitria OI For Streaming Big Data Analytics. http://www.vitria.com/solutions/streaming-big-data- analytics/benefits/. [16] YourKit. https://www.yourkit.com/. [17] D. J. Abadi, Y. Ahmad, M. Balazinska, M. Cherniack, J. hyon Hwang, W. Lindner, A. S. Maskey, E. Rasin, E. Ryvk- ina, N. Tatbul, Y. Xing, and S. Zdonik. The design of the Borealis stream processing engine. In Proceedings of the Conference on Innovative Data Systems Research, pages 277–289, 2005. [18] D. J. Abadi, D. Carney, U. C¸etintemel, M. Cherniack, C. Convey, S. Lee, M. Stonebraker, N. Tatbul, and S. Zdonik. Aurora: A new model and architecture for data stream management. The VLDB Journal, 12(2), Aug. 2003. [19] T. Akidau, A. Balikov, K. Bekiro˘glu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom, and S. Whittle. Millwheel: Fault-tolerant stream processing at internet scale. Proceedings of the VLDB Endowment, 6(11):1033–1044, Aug. 2013. [20] R. Ananthanarayanan, V. Basker, S. Das, A. Gupta, H. Jiang, T. Qiu, A. Reznichenko, D. Ryabkov, M. Singh, and S. Venkataraman. Photon: Fault-tolerant and scalable joining of continuous data streams. In Proceedings of the 2013 International Conference on Management of Data, pages 577–588, 2013. [21] A. Arasu, B. Babcock, S. Babu, M. Datar, K. Ito, I. Nishizawa, J. Rosenstein, and J. Widom. STREAM: The stanford stream data manager (demonstration description). In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, pages 665–665, 2003. [22] B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom. Models and issues in data stream systems. In Proceedings of the Symposium on Principles of Database Systems, pages 1–16, Madison, Wisconsin, 2002. 26
29 .[23] B. Babcock, M. Datar, and R. Motwani. Load shedding techniques for data stream systems. In Proceedings of the 2003 Workshop on Management and Processing of Data Streams MPDS, 2003. [24] B. Babcock, M. Datar, and R. Motwani. Load shedding in data stream systems. In C. Aggarwal, editor, Data Streams, volume 31 of Advances in Database Systems, pages 127–147. Springer US, 2007. [25] S. Chandrasekaran, O. Cooper, A. Deshpande, M. J. Franklin, J. M. Hellerstein, W. Hong, S. Krishnamurthy, S. R. Madden, F. Reiss, and M. A. Shah. TelegraphCQ: Continuous dataflow processing. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, pages 668–668, 2003. [26] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: A distributed storage system for structured data. ACM Transactions on Computer Systems, 26(2), June 2008. [27] J. Chen, D. J. Dewitt, F. Tian, and Y. Wang. Niagara CQ: A scalable continuous query system for internet databases. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, pages 379–390, 2000. [28] S. Dann. Twitter content classification. First Monday, 15(12), December 2010. http://firstmonday.org/ojs/ index.php/fm/article/view/2745/2681. [29] U. Dayal, B. Blaustein, A. Buchmann, U. Chakravarthy, M. Hsu, R. Ledin, D. McCarthy, A. Rosenthal, S. Sarin, M. J. Carey, M. Livny, and R. Jauhari. The HiPAC project: Combining active databases and timing constraints. SIGMOD Rec., 17(1):51–70, March 1988. [30] A. Demers, J. Gehrke, M. Hong, B. Panda, M. Riedewald, V. Sharma, and W. White. Cayuga: A general purpose event monitoring system. In Proceedings of the Conference on Innovative Data Systems Research, 2007. [31] N. Gehani and H. V. Jagdish. Ode as an active database: Constraints and triggers. In Proceedings of the 17th International Conference on Very Large Data Bases, Barcelona, Spain, 1991. [32] N. N. Jay Kreps and J. Rao. Kafka: A distributed messaging system for log processing. In SIGMOD Workshop on Networking Meets Databases, 2011. [33] S. Kulkarni, N. Bhagat, M. Fu, V. Kedigehalli, C. Kellogg, S. Mittal, J. M. Patel, K. Ramasamy, and S. Taneja. Twitter Heron: Streaming at scale. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 2015. [34] J. Meehan, N. Tatbul, S. Zdonik, C. Aslantas, U. Cetintemel, J. Du, T. Kraska, S. Madden, D. Maier, A. Pavlo, M. Stonebraker, K. Tufte, and H. Wang. S-Store: streaming meets transaction processing. Proceedings of VLDB Endowment, 8(13):2134–2145, Sept. 2015. [35] S. Murthy and T. Ng. Announcing Pulsar: Real-time Analytics at Scale. http://www.ebaytechblog.com/2015/ 02/23/announcing-pulsar-real-time-analytics-at-scale, Feb. 2015. [36] S. Senthamilarasu and M. Hemalatha. Load shedding using window aggregation queries on data streams. Interna- tional Journal of Computer Applications, 54(9):42–49, September 2012. [37] M. Stonebraker and G. Kemnitz. The POSTGRES next generation database management system. Communications of the ACM, 34(10):78–92, October 1991. [38] N. Tatbul, U. C¸etintemel, S. Zdonik, M. Cherniack, and M. Stonebraker. Load shedding in a data stream manager. In Proceedings of the 29th International Conference on Very Large Data Bases, pages 309–320, 2003. [39] N. Tatbul and S. Zdonik. Window-aware Load Shedding for Aggregation Queries over Data Streams. In Proceedings of the 32nd International Conference on Very Large Data Bases (VLDB’06). [40] A. Toshniwal, S. Taneja, A. Shukla, K. Ramasamy, J. M. Patel, S. Kulkarni, J. Jackson, K. Gade, M. Fu, J. Donham, N. Bhagat, S. Mittal, and D. Ryaboy. Storm@twitter. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, pages 147–156, 2014. [41] Y.-C. Tu, S. Liu, S. Prabhakar, and B. Yao. Load shedding in stream databases: A control-based approach. In Proceedings of the 32nd International Conference on Very Large Data Bases, pages 787–798, 2006. [42] J. Vijayan. Streaming Analytics: Business Value from Real-Time Data. http://www.datamation.com/data- center/streaming-analytics-business-value-from-real-time-data.html. [43] J. Widom. The Starburst rule system: Language design, implementation, and applications. IEEE Data Engineering Bulletin, Special Issue on Active Databases, 15:1–4, 1992. 27
3秒后跳转登录页面
去登陆

