



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Data Stream Management Issues A Survey
除非显式地添加时间戳属性,否则传统数据库存储没有预先约定的时间概念的相对静态记录集。虽然这个模型完全代表商业目录或储存库。
对于个人信息,许多当前和正在出现的应用程序需要支持对快速变化的数据流的在线分析。人们已经认识到传统DBMS在支持流式应用程序方面的局限性,这促使人们研究如何增强现有技术,并建立新的系统来管理流式数据。
展开查看详情
1 . Data Stream Management Issues – A Survey∗ Lukasz Golab ¨ M. Tamer Ozsu School of Computer Science University of Waterloo Waterloo, Canada {lgolab, tozsu}@uwaterloo.ca Technical Report CS-2003-08 April 2003 ∗ This research is partially supported by the Natural Sciences and Engineering Research Council (NSERC) of Canada. 1
2 .Abstract • The inability to store a complete stream suggests the use of approximate summary structures, re- Traditional databases store sets of relatively static records ferred to in the literature as synopses [1] or digests with no pre-defined notion of time, unless timestamp [104]. As a result, queries over the summaries may attributes are explicitly added. While this model ad- not return exact answers. equately represents commercial catalogues or reposito- ries of personal information, many current and emerg- • Streaming query plans may not use blocking op- ing applications require support for on-line analysis of erators that must consume the entire input before rapidly changing data streams. Limitations of tradi- any results are produced. tional DBMSs in supporting streaming applications have • Due to performance and storage constraints, back- been recognized, prompting research to augment existing tracking over a data stream is not feasible. On-line technologies and build new systems to manage streaming stream algorithms are restricted to making only data. The purpose of this paper is to review recent work one pass over the data. in data stream management systems, with an emphasis on data models, continuous query languages, and query • Applications that monitor streams in real-time must evaluation and optimization techniques. We also give ex- react quickly to unusual data values. amples of streaming queries in various applications and review related work in modeling lists and sequences. • Long-running queries may encounter changes in sys- tem conditions throughout their execution lifetimes (e.g. variable stream rates). 1 Introduction • Shared execution of many continuous queries is needed Traditional databases have been used in applications that to ensure scalability. require persistent data storage and complex querying. Usually, a database consists of a set of unordered objects Proposed data stream systems resemble the abstract that are relatively static, with insertions, updates and architecture shown in Figure 1. An input monitor regu- deletions occurring less frequently than queries. Queries lates the input rates, perhaps by dropping packets if the are executed when posed and the answer reflects the system is unable to keep up. Data are typically stored current state of the database. However, the past few in three partitions: temporary working storage (e.g. for years have witnessed an emergence of applications that window queries), summary storage for stream synopses, do not fit this data model and querying paradigm. In- and static storage for meta-data (e.g. physical location of stead, information naturally occurs in the form of a se- each source). Long-running queries are registered in the quence (stream) of data values; examples include sensor query repository and placed into groups for shared pro- data [13, 68], Internet traffic [45, 87], financial tickers cessing, though one-time queries over the current state of [22, 104], on-line auctions [5], and transaction logs such the stream may also be posed. The query processor com- as Web usage logs and telephone call records [26]. municates with the input monitor and may re-optimize A data stream is a real-time, continuous, ordered (im- the query plans in response to changing input rates. Re- plicitly by arrival time or explicitly by timestamp) se- sults are streamed to the users or temporarily buffered. quence of items. It is impossible to control the order in Users may then refine their queries based on the latest which items arrive, nor is it feasible to locally store a results. stream in its entirety. Likewise, queries over streams run In this paper, we review recent work in data stream continuously over a period of time and incrementally re- processing, including data models, query languages, con- turn new results as new data arrive. First defined in the tinuous query processing, and query optimization. Re- Tapestry system [89], these are known as long-running, lated surveys include Babcock et al. [8], which discusses continuous, standing, and persistent queries [22, 66]. The issues in data stream processing in the context of the unique characteristics of data streams and continuous STREAM project, and a tutorial by Garofalakis et al. queries dictate the following requirements of data stream [40], which reviews algorithms for data streams. management systems: The remainder of this paper surveys requirements of streaming applications (Section 2), models and query • The data model and query semantics must allow languages for data streams (Section 3), streaming op- order-based and time-based operations (e.g. queries erators (Section 4), query processing and optimization over a five-minute moving window). (Section 5), and related data models and query languages 2
3 . containing the latitude and longitude of each sta- tion, and connect all points that have reported the Working Storage same temperature with lines. Input Summary Query Output Monitor Storage Processor Buffer • Analyze a stream of recent power usage statistics Query reported to a power station (group by location, e.g. Static Reposi- Storage tory city block) and adjust the power generation rate if Streaming Streaming necessary [23]. Inputs Outputs Updates to User Static Data Queries 2.2 Network Traffic Analysis Figure 1: Abstract reference architecture for a data Ad-hoc systems for analyzing Internet traffic in near-real stream management system. time are already in use, e.g. [27, 45, 87]. As in sen- sor networks, joining data from multiple sources, packet (Section 6). We conclude in Section 7 with a list of cur- monitoring, packet filtering, and detecting unusual con- rent academic projects related to data stream manage- ditions (e.g. congestion or denial of service) are required. ment. Support for historical queries and on-line mining is also needed, perhaps to compare current traffic traces with stored patterns corresponding to known events such as 2 Streaming Applications a denial-of-service attack. Other requirements include monitoring recent requests for popular URLs or find- We begin by reviewing a collection of current and pro- ing those customers who consume the most bandwidth. posed data stream applications in order to define a set These are particularly important as Internet traffic pat- of query types that a data stream management system terns are believed to obey the Power Law distribution, should support. More examples may be found in the whose consequence is that a considerable amount of band- Stream Query Repository [85] and in NEXMark [93]—a width is consumed by a small set of “heavy” users. The proposed benchmark for data stream systems. following are typical queries in network traffic analysis: • Traffic matrices: Determine the total amount of 2.1 Sensor Networks bandwidth used by each source-destination pair and Sensor networks may be used for geophysical monitor- group by distinct IP address, subnet mask, and ing, highway congestion monitoring, movement tracking, protocol type. Note that IP traffic is statistically medical monitoring of life signs, and supervision of man- multiplexed, therefore a traffic stream must be logi- ufacturing processes. These applications involve complex cally demultiplexed in order to reconstruct the un- filtering and activation of an alarm upon discovering un- derlying TCP/IP sessions [27]. Moreover, divid- usual patterns in the data. Aggregation and joins over ing the stream into sessions involves temporal se- multiple streams are required to analyze data from many mantics, e.g. a session ends if the two parties have sources, while aggregation over a single stream may be not sent packets to each other for more than one needed to compensate for individual sensor failures (due minute. to physical damage or depletion of battery power). Sen- sor data mining may require access to some historical • Compare the number of distinct source-destination data. Representative queries include the following: pairs in the (logical) streams containing the second and third steps, respectively, of the three-way TCP • Activate a trigger if several sensors in the same area handshake. If the counts differ by a large margin, report measurements that exceed a given thresh- then a denial-of-service attack may be taking place old. and permissions to connect are not being acknowl- edged by the (spoofed) clients. • Drawing temperature contours on a weather map: Perform a join of temperature streams (on the tem- perature attribute) produced by weather monitor- 2.3 Financial Tickers ing stations. Join the results with a static table On-line analysis of stock prices involves discovering cor- relations, identifying trends and arbitrage opportunities, 3
4 .and forecasting future values [104]. Traderbot, a typical There are some differences, but these are related to work- Web-based financial ticker, allows users to pose queries load characteristics (e.g. stream arrival rates or amount such as these [90]: of historical data to be stored) and not to the under- lying model. We list below a set of fundamental con- • High Volatility with Recent Volume Surge: Find tinuous query operations over streaming data, keeping all stocks priced between $20 and $200, where the in mind that new streaming applications, possibly with spread between the high tick and the low tick over additional requirements, may be proposed in the future. the past 30 minutes is greater than three percent of the last price, and where in the last five minutes • Selection: All streaming applications require sup- the average volume has surged by more than 300%. port for complex filtering. • NASDAQ Large Cap Gainers: Find all NASDAQ • Nested aggregation [42]: Complex aggregates, in- stocks trading above their 200-day moving average cluding nested aggregates (e.g. comparing a mini- with a market cap greater than $5 Billion that have mum with a running average) are needed to com- gained in price today between two and ten percent pute trends in the data. since the opening, and are within two percent of today’s high. • Multiplexing and demultiplexing: Physical streams may need to be decomposed into a series of logical • Trading Near 52-week High on Higher Volume: Find streams and conversely, logical streams may need all stocks whose prices are within two percent of to be fused into one physical stream (similar to their respective 52-week highs that trade at least group-by and union, respectively). one million shares per day. • Frequent item queries: These are also known as top-k or threshold queries, depending on the cut- 2.4 Transaction Log Analysis off condition. On-line mining of Web usage logs, telephone call records, • Stream mining: Operations such as pattern match- and Automated Bank Machine transactions also conform ing, similarity searching, and forecasting are needed to the data stream model. The goal is to find interesting for on-line mining of streaming data. customer behaviour patterns, identify suspicious spend- ing behaviour that could indicate fraud, and forecast fu- • Joins: Support should be included for multi-stream ture data values. As in other streaming applications, this joins and joins of streams with static meta-data. requires joining multiple streams, complex filtering, and statistical analysis. The following are some examples: • Windowed queries: All of the above query types may be constrained to return results inside a win- • Find all Web pages on a particular server that have dow (e.g. the last 24 hours or the last one hundred been accessed in the last fifteen minutes with a rate packets). that is at least 40% greater than the running daily average. 3 Data Models and Query Lan- • Examine Web server logs in real-time and re-route users to backup servers if the primary servers are guages for Streams overloaded. As demonstrated above, data stream applications require • Roaming diameter [26]: Mine cellular phone records support for continuous queries and order-related opera- and for each customer, determine the greatest num- tors such as moving windows. In this section, we survey ber of distinct base stations used during one tele- proposed data models and query languages for streaming phone call. applications. 2.5 Analysis of Requirements 3.1 Data Models The preceding examples show significant similarities in A real-time data stream is a sequence of data items that data models and basic operations across applications. arrive in some order and may be seen only once [57]. Since items may arrive in bursts, a data stream may 4
5 .instead be modeled as a sequence of lists of elements window”. If the update interval is larger than the [91, 92]. Individual stream items may take the form of window size, the result is a series of non-overlapping relational tuples or instantiations of objects. In relation- tumbling windows [14]. based models (e.g. STREAM [75]), items are transient tuples stored in virtual relations, possibly horizontally 3.2 Continuous Query Semantics partitioned across remote nodes. In object-based mod- els (e.g. COUGAR [13] and Tribeca [87]), sources and Any monotonic persistent query that is incrementally up- item types are modeled as (hierarchical) data types with datable may be implemented as a continuous query over associated methods. a traditional database. In an append-only database, all Stream items may arrive out of order and/or in a pre- conjunctive queries are monotonic: once a tuple is added, processed form, giving rise to the following list of possible it either satisfies the query or it does not and the satis- models [46]: faction condition does not change over time. In con- trast, adding negation may violate monotonicity (e.g. se- 1. Unordered cash register : Items from various do- lect from a stream of e-mail messages all those messages mains arrive in no particular order and without that have not yet received a reply)1 . Similarly, if the any preprocessing. database is not append-only, then no query is monotonic as updated tuples may cease to satisfy a given query. 2. Ordered cash register : Individual items from var- Less restrictive semantics of monotonic and non-mono- ious domains are not preprocessed but arrive in tonic continuous queries over data streams have been de- some known order. rived by Arasu et al. in [5]. Assuming for simplicity that 3. Unordered aggregate: Individual items from the time is represented as a set of natural numbers and that same domain are preprocessed and only one item all continuous queries are re-evaluated at each clock tick, per domain arrives, in no particular order. let A(Q, t) be the answer set of a continuous query Q at time t, τ be the current time, and 0 be the starting time. 4. Ordered aggregate: Individual items from the same The answer set of a monotonic continuous query Q at domain are preprocessed and one item per domain time τ is: arrives in some known order. τ In many cases, only an excerpt of a stream is of in- A(Q, τ ) = (A(Q, t) − A(Q, t − 1)) ∪ A(Q, 0) (1) terest at any given time, giving rise to window models, t=1 which may be classified according the the following three That is, it suffices to re-evaluate the query over newly criteria [17, 42]: arrived items and append qualifying tuples to the result. In contrast, non-monotonic queries may need to be re- 1. Direction of movement of the endpoints: Two fixed computed from scratch during every re-evaluation, giving endpoints define a fixed window, two sliding end- rise to the following semantics: points (either forward or backward, replacing old items as new items arrive) define a sliding window, τ while one fixed endpoint and one moving endpoint A(Q, τ ) = A(Q, t) (2) (forward or backward) define a landmark window. t=0 There are a total of nine possibilities as each of the two endpoints could be fixed, moving forward, or 3.3 Stream Query Languages moving backward. Three querying paradigms for streaming data have been 2. Physical vs. logical: Physical, or time-based win- proposed in the literature. Relation-based systems use dows are defined in terms of a time interval, while SQL-like languages to query timestamped relations, usu- logical, (also known as count-based or tuple-based ) ally with enhanced support for windows and ordering. windows are defined in terms of the number of tu- Object-based languages also resemble SQL, but include ples. support for streaming abstract data types (ADTs) and associated signal processing methods. Procedural sys- 3. Update interval: Eager re-evaluation updates the tems construct queries by defining data flow through window upon arrival of each new tuple, while batch 1 Note that it may be possible to remove negation from some processing (lazy re-evaluation) induces a “jumping queries with a suitable rewriting. 5
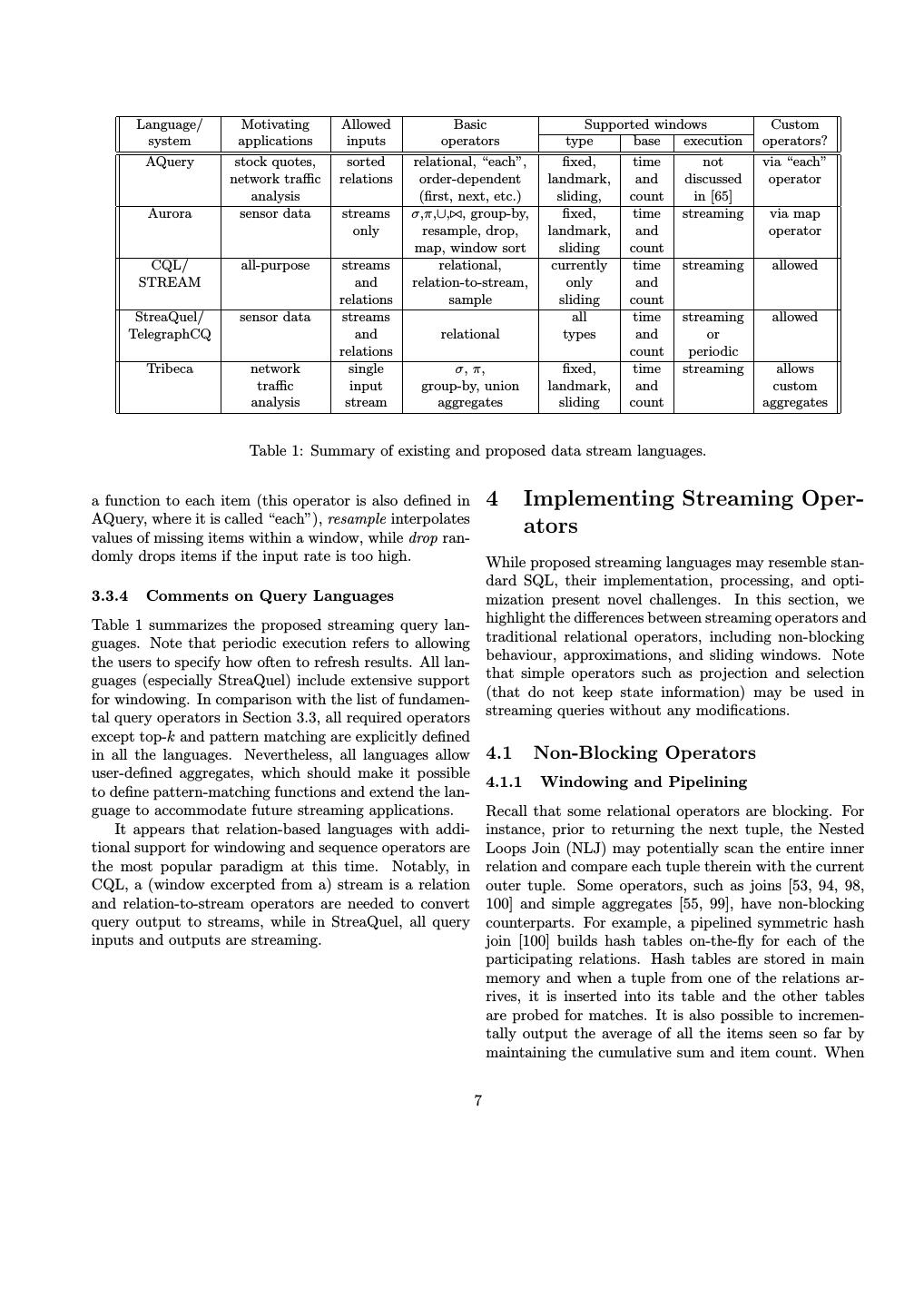
6 .various operators. We describe the three groups of lan- as arrays, on which order-dependent operators such as guages below and give example queries to illustrate their next, previous (abbreviated prev), first, and last may be differences, at times using simplified syntax to improve applied. For example, a continuous query over a stream readability. A summary is provided in Table 1. of stock quotes that reports consecutive price differences of IBM stock may be specified as follows: 3.3.1 Relation-Based Languages SELECT price - prev(price) Three proposed relation-based languages are CQL [5, 75], FROM Trades ASSUMING ORDER timestamp StreaQuel [15, 17], and AQuery [65]. CQL (Continuous WHERE company = ’IBM’ Query Language) is used in the STREAM system, and includes sliding windows and operators that translate re- The clause ASSUMING ORDER defines the ordering field lations to streams. It is possible to PARTITION a win- of the table. Note that performing this query in conven- dow on an attribute and specify the width of a window tional sequence languages (discussed in Section 6) re- (e.g. ROWS 100 or RANGE 100 MINUTES). For example, if quires a self join of the Trades relation with a copy of a stream S contains telephone call records, the following itself that is shifted by one position. query computes the average length of the ten most recent long-distance calls for each customer: 3.3.2 Object-Based Languages SELECT AVG(S.call_length) One approach to object-oriented stream modeling is to FROM S [PARTITION BY S.customer_id classify stream contents according to a type hierarchy. ROWS 10 This method is used in the Tribeca network monitor- WHERE S.type = ’Long Distance’] ing system, which implements Internet protocol layers as hierarchical data types [87]. Another possibility is to Queries over entire streams may specify [UNBOUNDED] model the sources as ADTs, as in the COUGAR sys- or [NOW] in the window type, with the latter being used tem for managing sensor data [13]. Each type of sen- for monotonic queries (e.g. selections) that need not con- sor is modeled by an ADT, whose interface consists of sider any old items. Moreover, there are three relation- signal-processing methods supported by this type of sen- to-stream operators, which can be used to explicitly spec- sor. The proposed query language has SQL-like syntax ify the query semantics (as defined in Equations (1) and and also includes a $every() clause that indicates the (2)). Additionally, the sampling rate may be explicitly query re-execution frequency; however, few details on the defined, e.g. ten percent, by following a reference to a language are available in the published literature, so we stream with the statement 10 % SAMPLE. do not include a summary of COUGAR’s query language StreaQuel, the query language of TelegraphCQ, also in Table 1. For a simple example, a query that runs every provides advanced windowing capabilities. Each query sixty seconds and returns temperature readings from all definition is followed by a for-loop construct with a vari- sensors on the third floor of a building could be specified able t that iterates over time. The loop contains a Win- as follows: dowIs statement that specifies the type and size of the window. Let S be a stream and let ST be the start time SELECT R.s.getTemperature() of a query. To specify a sliding window over S with size FROM R five that should run for fifty days, the following for-loop WHERE R.floor = 3 AND $every(60). may be appended to the query: 3.3.3 Procedural Languages for(t=ST; t<ST+50; t++) WindowIs(S, t-4, t) An alternative to declarative query languages is to let the user specify how the data should flow through the sys- Changing to a landmark window could be done by tem. In the Aurora system [14], users construct query replacing t-4 with some constant in the WindowIs state- plans via a graphical interface by arranging boxes (cor- ment. Changing the for-loop increment condition to t= responding to query operators) and joining them with di- t+5 would cause the query to re-execute every five time rected arcs to specify data flow, though the system may units. later re-arrange, add, or remove operators in the opti- AQuery consists of a query algebra and an SQL-based mization phase. Aurora includes several operators that language for ordered data. Table columns are treated are not explicitly defined in other languages: map applies 6
7 . Language/ Motivating Allowed Basic Supported windows Custom system applications inputs operators type base execution operators? AQuery stock quotes, sorted relational, “each”, fixed, time not via “each” network traffic relations order-dependent landmark, and discussed operator analysis (first, next, etc.) sliding, count in [65] Aurora sensor data streams σ,π,∪, , group-by, fixed, time streaming via map only resample, drop, landmark, and operator map, window sort sliding count CQL/ all-purpose streams relational, currently time streaming allowed STREAM and relation-to-stream, only and relations sample sliding count StreaQuel/ sensor data streams all time streaming allowed TelegraphCQ and relational types and or relations count periodic Tribeca network single σ, π, fixed, time streaming allows traffic input group-by, union landmark, and custom analysis stream aggregates sliding count aggregates Table 1: Summary of existing and proposed data stream languages. a function to each item (this operator is also defined in 4 Implementing Streaming Oper- AQuery, where it is called “each”), resample interpolates values of missing items within a window, while drop ran- ators domly drops items if the input rate is too high. While proposed streaming languages may resemble stan- dard SQL, their implementation, processing, and opti- 3.3.4 Comments on Query Languages mization present novel challenges. In this section, we Table 1 summarizes the proposed streaming query lan- highlight the differences between streaming operators and guages. Note that periodic execution refers to allowing traditional relational operators, including non-blocking the users to specify how often to refresh results. All lan- behaviour, approximations, and sliding windows. Note guages (especially StreaQuel) include extensive support that simple operators such as projection and selection for windowing. In comparison with the list of fundamen- (that do not keep state information) may be used in tal query operators in Section 3.3, all required operators streaming queries without any modifications. except top-k and pattern matching are explicitly defined in all the languages. Nevertheless, all languages allow 4.1 Non-Blocking Operators user-defined aggregates, which should make it possible 4.1.1 Windowing and Pipelining to define pattern-matching functions and extend the lan- guage to accommodate future streaming applications. Recall that some relational operators are blocking. For It appears that relation-based languages with addi- instance, prior to returning the next tuple, the Nested tional support for windowing and sequence operators are Loops Join (NLJ) may potentially scan the entire inner the most popular paradigm at this time. Notably, in relation and compare each tuple therein with the current CQL, a (window excerpted from a) stream is a relation outer tuple. Some operators, such as joins [53, 94, 98, and relation-to-stream operators are needed to convert 100] and simple aggregates [55, 99], have non-blocking query output to streams, while in StreaQuel, all query counterparts. For example, a pipelined symmetric hash inputs and outputs are streaming. join [100] builds hash tables on-the-fly for each of the participating relations. Hash tables are stored in main memory and when a tuple from one of the relations ar- rives, it is inserted into its table and the other tables are probed for matches. It is also possible to incremen- tally output the average of all the items seen so far by maintaining the cumulative sum and item count. When 7
8 . Method Functions References Counting Order statistics, frequent items [30, 48, 73] Hashing Distinct value counts, frequent items [34, 38] Sampling Order statistics, distinct value counts, frequent items, [30, 34, 37, 43, 73, 74] testing near-sortedness Sketches Frequency moments, distinct value counts, aggregates, [2, 18, 25, 32, 36, 39, 42, 46, 59] histograms, frequent items Wavelets Aggregates [41, 46, 49] Table 2: Approximate data stream algorithms classified according to method of generating synopses. a new item arrives, the item count is incremented, the Function References new item’s value is added to the sum, and an updated Aggregates [32, 42] average is computed by dividing the sum by the count. Distinct value counts [2, 25, 38, 43] There remains the issue of memory constraints if an oper- Frequency moments [2, 36, 39, 59] ator requires too much working memory, so a windowing Frequent items [18, 30, 34, 73] scheme may be needed to bound the memory require- Histograms [50, 51] ments. Order Statistics [43, 48, 74] Testing near-sortedness [37] 4.1.2 Exploiting Stream Constraints Another way to unblock query operators is to exploit con- Table 3: Approximate data stream algorithms classified straints over the input streams. Schema-level constraints according to function. include synchronization among timestamps in multiple streams, clustering (duplicates arrive contiguously), and 4.2 Streaming Algorithms ordering [11]. If two streams have nearly synchronized timestamps, an equi-join on the timestamp can be per- As shown above, unblocking a query operator may be ac- formed in limited memory: a scrambling bound B may complished by re-implementing it in an incremental form, be set such that if a tuple with timestamp τ arrives, then restricting it to operate over a window, and exploiting no tuple with timestamp greater than τ − B may arrive stream constraints. However, there may be cases where later [75]. an incremental version of an operator does not exist or is Constraints at the data level may take the form of inefficient to evaluate, where even a sliding window is too control packets inserted into a stream, called punctua- large to fit in main memory, or where no suitable stream tions [91, 92]. Punctuations are constraints (encoded as constraints are present. In these cases, compact stream data items) that specify conditions for all future items. summaries may be stored and approximate queries may For instance, a punctuation may arrive asserting that be posed over the summaries. This implies a trade-off all the items henceforth shall have the A attribute value between accuracy and the amount of memory used to larger than ten. This punctuation could be used to par- store the summaries. An additional restriction is that tially unblock a group-by query on A since all the groups the processing time per item (amortized) should be kept where A ≤ 10 are guaranteed not to change for the re- small, especially if the inputs arrive at a fast rate. Table 2 mainder of the stream’s lifetime, or until another punc- classifies approximate algorithms for the infinite stream tuation arrives and specifies otherwise. Punctuations model according to the method used to summarize the may also be used to synchronize multiple streams in stream, while Table 3 groups the algorithms according that a source may send a punctuation asserting that to function. it will not produce any tuples with timestamp smaller Counting methods, used mainly to compute quan- than τ [5]. There are several open problems concern- tiles and frequent item sets, typically store frequency ing punctuations—given an arbitrary query, is there a counts of selected item types (perhaps chosen by sam- punctuation that unblocks this query? If so, is there an pling) along with error bounds on their true frequencies. efficient algorithm for finding this punctuation? Hashing may also be used to summarize a stream, espe- cially when searching for frequent items—each item type 8
9 .may be hashed to n buckets by n distinct hash functions When the timestamp of the oldest basic window expires, and may be considered a potentially frequent flow if all its synopsis is removed, a fresh window is added to the of its hash buckets are large. Sampling is a well known front, and the aggregate is incrementally re-computed. data reduction technique and may be used to compute This method has been used to compute correlations be- various queries to within a known error bound. How- tween streams [104] and to find frequently appearing ever, some queries (e.g. finding the maximum element in items [29], but results are refreshed only after the stream a stream) may not be reliably computed by sampling. fills the current basic window; if the available memory is Sketches were initially proposed by Alon et al. [2] and small, the refresh interval is large. Moreover, some statis- have since then been used in various approximate algo- tics may not be incrementally computable from a set of rithms. Let f (i) be the number of occurrences of value synopses. i in a stream. A sketch of a data stream is created by One way to stream new results after each new item taking the inner product of f with a vector of random arrives is to maintain a windowed sample [9] and esti- values chosen from some distribution with a known ex- mate the answer from the sample. Another is to bound pectation. Moreover, wavelet transforms (that reduce the error caused by delayed expiration of basic windows. the underlying signal to a small set of coefficients) have Datar et al. [28] show that restricting the sizes of the been proposed to approximate aggregates over infinite basic windows to powers of two and imposing a limit on streams. the number of basic windows of each size yields a space- optimal algorithm that approximates simple aggregates 4.3 Data Stream Mining to within using logarithmic space (with respect to the sliding window size). This algorithm has been used to As is the case in traditional query operators, on-line approximately compute the sum [10, 44] as well as vari- stream mining operators must be incrementally updat- ance and k-medians clustering [28]. able without making multiple passes over the data. Re- cent results in (possibly approximate) algorithms for on- 4.4.2 Windowed Joins line stream mining include computing stream signatures and representative trends [26], decision trees [33, 58], The symmetric hash join [100] and an analogous sym- forecasting [103], k-medians clustering [19, 52], nearest metric NLJ may be extended to operate over two [62] or neighbour queries [63], and regression analysis [23] A more [47] sliding windows by periodically scanning the comprehensive discussion of similarity detection, pattern hash tables (or whole windows in case of the NLJ) and matching, and forecasting in sensor data mining may be removing stale items. Interesting trade-offs appear in found in a tutorial by Faloutsos [35]. that large hash tables are expensive to maintain if tuple expiration is performed too frequently [47]. 4.4 Sliding Window Algorithms Many infinite stream algorithms do not have obvious 5 Continuous Query Processing counterparts in the sliding window model. For instance, and Optimization while computing the maximum value in an infinite stream is trivial, doing so in a sliding window of size N requires Having surveyed issues in designing continuous query Ω(N ) space—consider a sequence of non-increasing val- languages and implementing streaming operators, we now ues, in which the oldest item in any given window is the discuss problems related to processing and optimizing maximum and must be replaced whenever the window continuous queries. In what follows, we outline emerging moves forward. Thus, the fundamental problem is that research in cost metrics, query plans, quality-of-service as new items arrive, old items must be simultaneously guarantees, and distributed optimization of streaming evicted from the window. queries. 4.4.1 Windowed Aggregates 5.1 Memory Requirements Simple aggregates over sliding windows may be com- As already discussed, some query operators (e.g. joins) puted in limited memory by dividing the window into may require infinite working memory, even when rewrit- small portions (called basic windows in [104]) and only ten into an incremental form. Consequently, a possible storing a synopsis and a timestamp for each portion. first step in processing a continuous query is to decide 9
10 .whether it may be answered exactly in bounded memory to optimize for the highest output rate or to find or whether it should be approximated based on stream a plan that takes the least time to output a given summaries. Computing the memory requirements of con- number of tuples [97]. In related work, Urhan and tinuous queries has been studied by Arasu et al. [4] for Franklin discuss scheduling of pipelined hash joins monotonic conjunctive queries with grouping and aggre- in order to quickly produce the initial portion of gation. Consider two unbounded relational data streams: the result [95]. S(A, B, C) and T (D, E). The query πA (σA=D∧A>10∧D<20 (S × T )) may be evaluated in bounded memory whether • Power usage: In a wireless network of battery- or not the projection preserves duplicates. To preserve operated sensors, energy consumption may be min- duplicates, for each integer i between 11 and 19, it suf- imized if each sensor’s power consumption char- fices to maintain the count of tuples in S such that A = i acteristics (when transmitting and receiving) are and the count of tuples in T such that D = i. To remove known [70, 101]. duplicates, it is necessary to store flags indicating which tuples have occurred such that S.A = i and T.D = i for 5.3 Continuous Query Plans i ∈ [11, 19]. Conversely, the query πA (σA=D (S × T )) is In relational DBMSs, all operators are pull-based: an op- not computable in finite memory either with or without erator requests data from one of its children in the plan duplicates. tree only when needed. In contrast, stream operators Interestingly, πA (σA>10 S) is computable in finite mem- consume data pushed to the system by the sources. One ory only if duplicates are preserved; any tuple in S with approach to reconcile these differences, as considered in A > 10 is added to the answer as soon as it arrives. On Fjords [68] and STREAM [8], is to connect operators the other hand, the query πA (σB<D∧A>10∧A<20 (S × T )) with queues, allowing sources to push data into a queue is computable in bounded memory only if duplicates are and operators to retrieve data as needed. Problems in- removed: for each integer i between 11 and 19, it suffices clude scheduling operators so as to minimize queue sizes to maintain the current minimum value of B among all and queuing delays in the presence of bursty streams the tuples in S such that A = i and the current maximum [7], and maintaining quality-of-service guarantees [14]. value of D over all tuples in T . Another challenge in continuous query plans deals with supporting historical queries. Designing disk-based data 5.2 Cost Metrics and Statistics structures and indices to exploit access patterns of stream Traditional DBMSs use selectivity information and avail- archives is an open problem [15]. able indices to select plans that require fewest disk ac- cesses. This cost metric, however, does not apply to 5.4 Processing Multiple Queries (possibly approximate) continuous queries over infinite Two approaches have been proposed to execute similar streams, where processing cost per-unit-time is more ap- continuous queries together: sharing query plans (e.g. propriate [62]. Below, we list possible cost metrics for NiagaraCQ [22]) and indexing query predicates (CACQ streaming queries along with necessary statistics that [71] and PSoup [16]). In the former, queries belonging to must be maintained. the same group share a plan, which produces the union • Accuracy and reporting delay vs. memory usage: of the results needed by each query in the group. A Allocating more memory for synopses should im- final selection is then applied to the shared result set. prove accuracy, while sampling and load shedding Problems include dynamic re-grouping as new queries are [88] decrease memory usage by increasing the er- added to the system [20], choosing whether to push se- ror. It is necessary to know the accuracy of each lections below joins or pull them above (the latter allows operator as a function of the available memory, and many queries to share one materialized join, but perfor- how to combine such functions to obtain the overall mance may suffer if the join is expensive to maintain) accuracy of a plan. Furthermore, batch processing [21], shared evaluation of windowed joins with various [8] may be done instead of re-evaluating a query window sizes [54], and plan sharing for complex queries. whenever a new item arrives, at a cost of increased In the indexing approach, query predicates are stored reporting delay. in a table. When a new tuple arrives for processing, its attribute values are extracted and looked up in the query • Output rate: If the stream arrival rates and output table to see which queries are satisfied by this tuple. Data rates of query operators are known, it is possible 10
11 .and queries are treated as duals, reducing query process- All-purpose strategies aim at decreasing communica- ing to a multi-way join of the query predicate table and tion costs by performing computations at the sources. the data tables. The indexing approach works well for These include re-ordering of query operators across sites simple SPJ queries, but is currently not applicable to, [24, 84] and specifically, performing simple query func- e.g. windowed aggregates [16]. tions (e.g. filtering, aggregation or signal compression [64]) locally at a sensor or a network router [27, 56, 69, 72, 5.5 Query Optimization 102]. For example, if each remote node pre-aggregates its results by sending to the co-ordinator the sum and count 5.5.1 Query Rewriting of its values, the co-ordinator may then take the cumu- A useful rewriting technique in relational databases deals lative sum and cumulative count, and compute the over- with re-ordering a sequence of binary joins in order to all average. Other techniques include selecting leader minimize a particular cost metric. There has been some nodes to stream pre-processed results to the front-end preliminary work in join ordering for data streams in the [102], caching [16, 31, 101], and sending updates to the context of the rate-based model [97, 98] and in main- co-ordinator only if new data values differ significantly memory sliding window joins [47]. In general, each of the from previously reported values [76]. query languages outlined in Section 3 introduces rewrit- Distributed techniques for ad-hoc sensor networks ex- ings for its new operators, e.g. selections and projections ploit the fact that query dissemination and result collec- commute over sliding windows [5, 17]. tion in a wireless sensor network proceed along a routing tree (or a DAG) via a shared wireless channel. [69, 72]. The two main objectives are decreasing the number of 5.5.2 Adaptivity transmissions in order to extend battery life and deal- The cost of a query plan may change for three reasons: ing with poor wireless connectivity. For example, if a change in processing time of an operator, change in se- sensor reports its maximum local value x in response to lectivity of a predicate, and change in the arrival rate a MAX query, a neighbouring sensor that overhears this of a stream [6]. Initial efforts on adaptive query plans transmission need not respond if its local maximum is include mid-query re-optimization [61] and query scram- smaller than x (assuming that the neighbouring sensor bling, where the objective was to pre-empt any opera- has not powered down). Dealing with poor connectivity tors that become blocked and schedule other operators includes sending redundant copies of data packets, e.g. instead [3, 96]. To further increase adaptivity, instead of a sensor could broadcast its maximum value to several maintaining a rigid tree-structured query plan, the Ed- other nodes, not just the node along the path to the dies approach (introduced in [6], extended to multi-way root. However, this does not work for other aggregates joins in [79], and applied to continuous queries in [16, 71]) such as SUM and COUNT, as duplicate values would con- performs scheduling of each tuple separately by routing taminate the result. In these cases, a sensor may “split” it through the operators that make up the query plan. its local sum and send partial sums to each of its neigh- In effect, the query plan is dynamically re-ordered to bours. Even if one packet is lost, the remainder of the match current system conditions. This is accomplished sum should still reach the root. by tuple routing policies that attempt to discover which operators are fast and selective, and those operators are scheduled first. There is, however, an important trade- 6 Related Models and Query Lan- off between the resulting adaptivity and the overhead guages required to route each tuple separately. While data stream applications have begun to appear in 5.6 Distributed Query Processing the last several years, there has been some prior work on modeling (off-line) lists, sequences, and time series. We In sensor networks, Internet traffic analysis, and Web discuss those next. usage logs, multiple data streams are expected to arrive from remote sources, suggesting a distribution of query 6.1 List-Based Models operators among the participating nodes. We classify distribution strategies according to the envisioned appli- Two types of list models have been defined in the litera- cation: some are all-purpose, while others are designed ture: functional and object-oriented. Functional systems specifically for sensor networks. (e.g. Tangram [67, 77]) operate on (possibly infinite) lists 11
12 .by means of functional transformations called transduc- 6.3 Sequence Models ers, of which there are five types: 6.3.1 Modeling and Querying Sequences 1. Enumerators produce new lists. The SEQ sequence model and algebra were introduced by 2. Maps apply a function to each item in a list. Seshadri et al. in [81, 82, 83]. SEQ defines an ordering function from the integers (or another ordered domain 3. Filters correspond to selection predicates. such as calendar dates) to each item in the sequence. 4. Accumulators compute aggregates over a list or a Some operators, such as selection, projection, various set sliding window. operations, and aggregation (including moving windows) are carried over from the relational model. There are five 5. Pattern Detectors consist of regular expressions on new operators: values inside a list. Object-oriented models (e.g. AQUA [86]) define a • The Group construct is a group-by operator that LIST object to be composed of a set of CELLs and a divides a sequence into sub-sequences. set of directed edges joining the cells. Supported opera- • The Positional Offset returns an output sequence tions resemble transducers: select (filter), apply (map), that is identical to the input sequence except that and sub select (selection of a regular-expression-like pat- the ordering domain has been shifted by a specified tern within a list). There are also two novel operators: number of positions. descendants and ancestors, which return the portion of a list preceding and following a match, respectively. Each • The Positional Join joins two sequences on the or- operator preserves the ordering of the list. dering attribute. • The Collapse operator is a many-to-one surjective 6.2 Time Series Models function from one ordering domain to another. For A time-series extension to SQL, called SQL-TS [80], mod- instance, a sequence of daily stock quotes may be els time series as relations sorted by timestamps and ex- collapsed into a sequence of average (or top, or min- tends SQL by allowing the following constructs to be imum) weekly stock quotes. included in the FROM clause: • The Expand operator is the “inverse” of Collapse. • A CLUSTER BY clause which effectively demultiplexes However, note that collapsing and then expanding a stream into separate logical streams. a sequence S does not return S unless the original • A SEQUENCE BY clause which sorts the time series sequence is also stored. on the provided timestamp. Relational equivalences for projections and selections • An AS clause used to bind tuples to variable names. apply, as does the predicate push-down heuristic. There As in regular expressions, recurring patterns may are also additional equivalences between sequence oper- be expressed with a star. ators. For instance, the positional offset can be “pushed through” any operator and the projection may be pushed Each tuple that is bound to a variable is logically mod- through any sequence operator, so long as all the at- eled to contain pointers to the previous and next tuples tributes that participate in the sequence operator are in the time series, forming a doubly linked list. For in- included in the projection. stance, to find the maximal periods during which the The SEQ model has been implemented in SRQL (Sort- price of a stock fell more than 50 percent, the following ed Relational Query Language) [78]. Sequences are im- SQL-TS query may be used: plemented as logically or physically sorted multi-sets (re- SELECT X.name, X.date as START_DATE, lations) and the language attempts to exploit the sort Z.previous.date as END_DATE order. Four new operators have been added: FROM stock_quotes CLUSTER BY name • The Sequence operator creates a new sequence by SEQUENCE BY date choosing an ordering field(s) for a particular rela- AS (X, *Y, Z) tional table. WHERE Y.price < Y.previous.price AND Z.previous.price < 0.5 * X.price 12
13 . • The Shiftall operator joins a sequence R with a V.name E.name copy of itself, R whose ordering field is shifted with v3 e3 respect to R v4 e5 v5 e5 • The Shift operator is similar to ShiftAll but only joins a sequence R with the ordering field of R instead of all the fields of R . Table 5: Result of the earthquake query. • WindowAggregate computes sliding window aggre- gates. incrementally updatable (i.e. updates take time propor- tional to the size of the view, not to the length of the These operators implement the SEQ model, with the underlying sequence) if sequence items arrive in increas- exception of Expand and Collapse, which require tem- ing order of the sequence numbers, and if the view def- poral capabilities beyond SQL’s power. For an example inition algebra does not include joins of two sequences, taken from [78], consider a sequence of Volcano eruptions unless these are equi-joins on the sequencing attribute with schema V(time, name) and a sequence of earth- with one of the sequencing fields projected out. More- quakes with schema E(time, name, magnitude). Sup- over, the algebra must not have a group-by operator with pose that the sequences are instantiated as seen in Ta- an aggregate that may not be computed incrementally. ble 4. To find for each volcano eruption the most recent The Chronicle model does not consider sliding windows. earthquake that was greater than 7 on the Richter scale, the following SRQL query may be posed: 7 Conclusions SELECT V.name, E.name FROM Volcano as V, Earthquake as E We have shown that designing an effective data stream WHERE E.time <= V.time management system requires extensive modifications of AND (SHIFT(E,1).time > V.time nearly every part of a traditional database, creating many OR SHIFT(E,1).time IS NULL) interesting database problems such as adding time, or- AND E.magnitude > 7 der, and windowing to data models and query languages, implementing approximate operators, combining push- Volcanoes Earthquakes based and pull-based operators in query plans, adaptive query re-optimization, and distributed query processing. time name time name magnitude Recent interest in these problems has generated a num- 3 v1 1 e1 8 4 v2 2 e2 2 ber of academic projects. There exist at least the follow- 5 v3 5 e3 8 ing systems: 8 v4 6 e4 9 • Aurora [14, 24] is a workflow-oriented system that 9 v5 7 e5 8 allows users to build query plans by arranging boxes (operators) and arrows (data flow among opera- Table 4: Volcano and Earthquake sequences. tors). Web site: http://www.cs.brown.edu/ research/aurora. That is, the earthquake times are shifted by one po- • COUGAR [12, 13] is a sensor database that models sition (e.g. the time of e1 becomes 2 and the time of sensors as ADTs and their output as time series. e2 becomes 5 and so on until e5, whose time becomes Recent work in the COUGAR project deals with NULL) and this shifted time must be more recent than query processing inside the sensor network [101, the time of a volcano eruption to guarantee the most re- 102]. Web site: http://www.cs.cornell.edu/ cent earthquake. The result of this query is shown in database/cougar. Table 5. • Gigascope [27] is a distributed network monitor- 6.3.2 Materialized Views over Sequences ing architecture that proposes pushing some query operators to the sources (e.g. routers). The Chronicle data model includes relations and sequenc- ing attributes, and deals with maintaining materialized • NiagaraCQ [22] is a continuous query system de- views over sequences [60]. It is shown that views are signed for monitoring dynamic Web content. The 13
14 . system executes multiple continuous queries (ex- [6] R. Avnur, J. Hellerstein. Eddies: Continuously Adap- pressed in XML-QL) over streaming data in groups, tive Query Processing. In Proc. ACM Int. Conf. on where each group of similar queries shares an exe- Management of Data, 2000, pp. 261–272. cution plan. Web site: http://www.cs.wisc.edu/ [7] B. Babcock, S. Babu, M. Datar, R. Motwani. Chain: niagara. Operator Scheduling for Memory Minimization in Data Stream Systems. To appear in Proc. ACM Int. Conf. on • OpenCQ [66] is another continuous query system Management of Data, June 2003. for monitoring streaming Web content. Its focus [8] B. Babcock, S. Babu, M. Datar, R. Motwani, J. Widom. is on scalable event-driven query processing. Web Models and Issues in Data Streams. In Proc. ACM site: http://disl.cc.gatech.edu/CQ SIGACT-SIGMOD Symp. on Principles of Database Systems, 2002, pp. 1–16. • StatStream [104] is a stream monitoring system de- signed to compute on-line statistics across many [9] B. Babcock, M. Datar, R. Motwani. Sampling from a streams. Web site: http://cs.nyu.edu/cs/ Moving Window over Streaming Data. In Proc. 13th faculty/shasha/papers/statstream.html. SIAM-ACM Symp. on Discrete Algorithms, 2002, pp. 633–634. • STREAM [75] is an all-purpose relation-based sys- [10] B. Babcock, M. Datar, R. Motwani, L. O’Callaghan. tem with an emphasis on memory management and Maintaining Variance and k-Medians over Data Stream approximate query answering. Web site: Windows. To appear in Proc. ACM SIGACT-SIGMOD http://www-db.stanford.edu/stream. Symp. on Principles of Database Systems, June 2003. [11] S. Babu, J. Widom. Exploiting k-Constraints to • TelegraphCQ [15] is a proposed continuous query Reduce Memory Overhead in Continuous Queries processing system that focuses on shared query eval- over Data Streams. Stanford University Techni- uation and adaptive query processing. Web site: cal Report 2002-52, November 2002. Available at http://telegraph.cs.berkeley.edu. http://dbpubs.stanford.edu:8090/pub/2002-52. • Tribeca [87] is an early on-line Internet traffic mon- [12] P. Bonnet, J. Gehrke, P. Seshadri. Querying the Physi- itoring tool. cal World. In IEEE Personal Communications, 7(5):10– 15, Oct. 2000. [13] P. Bonnet, J. Gehrke, P. Seshadri. Towards Sensor References Database Systems. In Proc. 2nd Int. Conf. on Mobile Data Management, 2001, pages 3–14. [1] S. Acharya, P. B. Gibbons, V. Poosala, S. Ramaswamy. Join synopses for approximate query answering. In [14] D. Carney, U. Cetinternel, M. Cherniack, C. Convey, S. Proc. ACM Int. Conf. on Management of Data, 1999, Lee, G. Seidman, M. Stonebraker, N. Tatbul, S. Zdonik. pp. 275–286. Monitoring streams—A New Class of Data Manage- ment Applications. In Proc. 28th Int. Conf. on Very [2] N. Alon, Y. Matias, M. Szegedy. The Space Complex- Large Data Bases, 2002, pp. 215–226. ity of Approximating the Frequency Moments. In Proc. 28th ACM Symp. on Theory of Computing, 1996, pp. [15] S. Chandrasekaran, O. Cooper, A. Deshpande, M. J. 20–29. Franklin, J. M. Hellerstein, W. Hong, S. Krishna- murthy, S. Madden, V. Raman, F. Reiss, M. Shah. [3] L. Amsaleg, M. J. Franklin, A. Tomasic, T. Urhan. TelegraphCQ: Continuous Dataflow Processing for an Scrambling Query Plans to Cope with Unexpected De- Uncertain World. In Proc. 1st Biennial Conf. on Inno- lays. In Proc. Int. Conf. on Parallel and Distributed vative Data Syst. Res, 2003, pp. 269–280. Information Systems, 1996, pp. 208–219. [16] S. Chandrasekaran, M. J. Franklin. Streaming Queries [4] A. Arasu, B. Babcock, S. Babu, J. McAlister, J. over Streaming Data. In Proc. 28th Int. Conf. on Very Widom. Characterizing Memory Requirements for Large Data Bases, 2002, pp. 203–214. Queries over Continuous Data Streams. In Proc. ACM SIGACT-SIGMOD Symp. on Principles of Database [17] S. Chandrasekaran, S. Krishnamurthy, S. Mad- Systems, 2002, pp. 221–232. den, A. Deshpande, M. J. Franklin, J. M. Heller- stein, M. Shah. Windows Explained, Windows [5] A. Arasu, S. Babu, J. Widom. An Abstract Seman- Expressed. Submitted for publication, 2003. Avail- tics and Concrete Language for Continuous Queries able at http://www.cs.berkeley.edu/~sirish/ over Streams and Relations. Stanford University Tech- research/streaquel.pdf. nical Report 2002-57, November 2002. Available at http://dbpubs.stanford.edu:8090/pub/2002-57. 14
15 .[18] M. Charikar, K. Chen, M. Farach-Colton. Finding fre- [30] E. Demaine, A. Lopez-Ortiz, J. I. Munro. Frequency quent items in data streams. In Proc. 29th Int. Col- Estimation of Internet Packet Streams with Limited loquium on Automata, Languages and Programming, Space. In Proc. European Symposium on Algorithms, 2002, pp. 693–703. 2002, pp. 348–360. [19] M. Charikar, L. O’Callaghan, R. Panigrahy. Better [31] A. Deshpande, S. Nath, P. Gibbons, S. Seshan. Cache- Streaming Algorithms for Clustering Problems. To ap- and-Query for Wide Area Sensor Databases. To appear pear in Proc. 35th ACM Symp. on Theory of Comput- in Proc. ACM Int. Conf. on Management of Data, June ing, June 2003. 2003. [20] J. Chen, D. DeWitt. Dynamic Re-Grouping of [32] A. Dobra, M. Garofalakis, J. Gehrke, R. Rastogi. Pro- Continuous Queries. Manuscript, 2002. Avail- cessing Complex Aggregate Queries over Data Streams. able at http://www.cs.wisc.edu/niagara/ In Proc. ACM Int. Conf. on Management of Data, 2002, Publications.html. pp. 61–72. [21] J. Chen, D. J. DeWitt, J. F. Naughton. Design and [33] P. Domingos, G. Hulten. Mining High-Speed Data Evaluation of Alternative Selection Placement Strate- Streams. In Proc. 6th ACM SIGKDD Int. Conf. on gies in Optimizing Continuous Queries. In Proc. 18th Knowledge Discovery and Data Mining, 2000, pp. 71– Int. Conf. on Data Engineering, 2002, pp. 345–357. 80. [22] J. Chen, D. DeWitt, F. Tian, Y. Wang. NiagaraCQ: [34] C. Estan, G. Varghese. New Directions in Traffic Mea- A Scalable Continuous Query System for Internet surement and Accounting. In Proc. ACM SIGCOMM Databases. In Proc. ACM Int. Conf. on Management Internet Measurement Workshop, 2001, pp. 75–80. of Data, 2000, pp. 379–390. [35] C. Faloutsos. Sensor Data Mining: Similarity Search and Pattern Analysis. Tutorial in 28th Int. Conf. on [23] Y. Chen, G. Dong, J. Han, B. W.Wah, J. Wang. Multi- Very Large Data Bases, 2002. Dimensional Regression Analysis of Time-Series Data Streams. In Proc. 28th Int. Conf. on Very Large Data [36] J. Feigenbaum, S. Kannan, M. Strauss, M. Bases, 2002, pp. 323–334. Viswanathan. An Approximate L1-Difference Al- gorithm for Massive Data Streams. In Proc. 40th [24] M. Cherniack, H. Balakrishnan, M. Balazinska, D. Car- Symp. on Foundations of Computer Science, 1999. pp. ney, U. Cetintemel, Y. Xing, S. Zdonik. Scalable Dis- 501–511. tributed Stream Processing. In Proc. 1st Biennial Conf. on Innovative Data Syst. Res, 2003. [37] J. Feigenbaum, S. Kannan, M. Strauss, M. Viswanathan. Testing and Spot Checking Data [25] G. Cormode, M. Datar, P. Indyk, S. Muthukrishnan. Streams. . In Proc. 11th SIAM-ACM Symp. on Comparing Data Streams Using Hamming Norms (How Discrete Algorithms, 2000, pp. 165–174. to Zero In). In Proc. 28th Int. Conf. on Very Large Data Bases, 2002, pp. 335–345. [38] P. Flajolet, G. N. Martin. Probabilistic Counting. In 24th Annual Symp. on Foundations of Computer Sci- [26] C. Cortes, K. Fisher, D. Pregibon, A. Rogers, F. Smith. ence, 1983, pp. 76–82, 1983. Hancock: A Language for Extracting Signatures from [39] J. Fong, M. Strauss. An Approximate Lp-difference Al- Data Streams. In Proc. 6th ACM SIGKDD Int. Conf. gorithm for Massive Data Streams. In Journal of Dis- on Knowledge Discovery and Data Mining, 2000, pp. crete Mathematics and Theoretical Computer Science, 9–17. 4(2):301–322, 2001. [27] C. Cranor, Y. Gao, T. Johnson, V. Shkapenyuk, O. [40] M. Garofalakis, J. Gehrke, R. Rastogi. Querying and Spatscheck. GigaScope: High Performance Network Mining Data Streams: You Only Get One Look. Tuto- Monitoring with an SQL Interface. In Proc. ACM Int. rial in ACM Int. Conf. on Management of Data, 2002. Conf. on Management of Data, 2002, p. 623. [41] M. Garofalakis, P. Gibbons. Wavelet Synopses with Er- [28] M. Datar, A. Gionis, P. Indyk, R. Motwani. Maintain- ror Guarantees. In Proc. ACM Int. Conf. on Manage- ing Stream Statistics over Sliding Windows. In Proc. ment of Data, 2002, pp. 476–487. 13th SIAM-ACM Symp. on Discrete Algorithms, 2002, pp. 635–644 [42] J. Gehrke, F. Korn, D. Srivastava. On Computing Cor- related Aggregates Over Continual Data Streams. In [29] D. DeHaan, E. D. Demaine, L. Golab, A. Lopez- Proc. ACM Int. Conf. on Management of Data, 2001, Ortiz, J. I. Munro. Towards Identifying Frequent Items pp. 13–24. in Sliding Windows. University of Waterloo Tech- [43] P. Gibbons, S. Tirthapura. Estimating Simple Func- nical Report CS-2003-06, March 2003. Available at tions on the Union of Data Streams. In Proc. ACM http://db.uwaterloo.ca/~lgolab/frequent.pdf. Symp. on Parallel Algorithms an Architectures, 2001, pp. 281–291. 15
16 .[44] P. Gibbons, S. Tirthapura. Distributed Streams Al- [57] M. Henzinger, P. Raghavan, S. Rajagopalan. Comput- gorithms for Sliding Windows. In 14th Annual ACM ing on Data Streams. In DIMACS series in Discrete Symp. on Parallel Algorithms and Architectures, 2002, Mathematics and Theoretical Computer Science, vol. pp. 63–72. 50, pp. 107–118, 1999. [45] A. C. Gilbert, Y. Kotidis, S. Muthukrishnan, M. J. [58] G. Hulten, L. Spencer, P. Domingos. Mining Time- Strauss. QuickSAND: Quick Summary and Analysis Changing Data Streams. In Proc. 7th ACM SIGKDD of Network Data. DIMACS Technical Report 2001-43, Int. Conf. on Knowledge Discovery and Data Mining, Dec. 2001. Available at http://citeseer.nj.nec.com/ 2001, pp. 97–106. gilbert01quicksand.html. [59] P. Indyk. Stable distributions, pseudorandom genera- [46] A. C. Gilbert, Y. Kotidis, S. Muthukrishnan, M. J. tors, embeddings and data stream computations. In Strauss. Surfing Wavelets on Streams: One-Pass Sum- Proc. Annual IEEE Symp. on Foundations of Computer maries for Approximate Aggregate Queries. In Proc. Science, 2000, pp. 189–197. 27th Int. Conf. on Very Large Data Bases, 2001, pp. [60] H. V. Jagadish, I. S. Mumick, A. Silberschatz. View 79–88. Maintenance Issues for the Chronicle Data Model. In [47] ¨ L. Golab, M. T. Ozsu. Processing Sliding Win- Proc. ACM SIGACT-SIGMOD Symp. on Principles of dow Multi-Joins in Continuous Queries over Database Systems, 1995, pp. 113–124. Data Streams. University of Waterloo Techni- [61] N. Kabra, D. J. DeWitt. Efficient Mid-query Re- cal Report CS-2003-01, Feb. 2003. Available at optimization of Sub-optimal Query Execution Plans. In http://db.uwaterloo.ca/~ddbms/publications/ Proc. ACM Int. Conf. on Management of Data, 1998, stream/multijoins.pdf. pp. 106–117. [48] J. Greenwald, F. Khanna. Space Efficient On-Line [62] J. Kang, J. Naughton, S. Viglas. Evaluating Window Computation of Quantile Summaries. In Proc. ACM Joins over Unbounded Streams. To appear in Proc. 19th Int. Conf. on Management of Data, 2001, pp. 58–66. Int. Conf. on Data Engineering, 2003. [49] S. Guha, P. Indyk, S. Muthukrishnan, M. Strauss. His- [63] F. Korn, S. Muthukrishnan, D. Srivastava. Reverse togramming Data Streams with Fast Per-Item Process- Nearest Neighbor Aggregates over Data Streams. In ing. In Proc. 29th Int. Colloquium on Automata, Lan- Proc. 28th Int. Conf. on Very Large Data Bases, 2002, guages and Programming, 2002, pp. 681–692. pp. 814–825. [50] S. Guha, N. Koudas. Approximating a Data Stream [64] I. Lazaridis, S. Mehrotra. Capturing Sensor-Generated for Querying and Estimation: Algorithms and Perfor- Time Series with Quality Guarantees. To appear in mance Evaluation. In Proc. 18th Int. Conf. on Data Proc. 19th Int. Conf. on Data Engineering, 2003. Engineering, 2002, pp. 567–576. [65] A. Lerner, D. Shasha. AQuery: Query Language for [51] S. Guha, N. Koudas, K. Shim. Data-Streams and His- Ordered Data, Optimization Techniques, and Experi- tograms. In Proc. 33rd Annual ACM Symp. on Theory ments. TR2003-836, Courant Institute of Mathematical of Computing, 2001, pp. 471–475 Sciences, New York University, March 2003. Available [52] S. Guha, N. Mishra, R. Motwani, L. O’Callaghan. Clus- at http://csdocs.cs.nyu.edu/Dienst/Repository/ tering Data Streams. In Proc. IEEE Symp. on Founda- 2.0/Body/ncstrl.nyu_cs%2fTR2003-836/pdf. tions of Computer Science, pp. 359–366. [66] L. Liu, C. Pu, W. Tang. Continual Queries for Internet- [53] P. Haas, J. Hellerstein. Ripple Joins for Online Aggre- Scale Event-Driven Information Delivery. In IEEE gation. In Proc. ACM Int. Conf. on Management of Trans. Knowledge and Data Eng., 11(4): 610–628, Data, 1999, pp. 287-298. 1999. [54] M. A. Hammad, M. J. Franklin, W. G. Aref, A. K. [67] B. Livezey, R. R. Muntz. ASPEN: A Stream Processing Elmagarmid. Scheduling for shared window joins over Environment. In Proc. PARLE (2), 1989, pp. 374–388. data streams. Submitted for publication, Feb. 2003. [68] S. Madden, M. J. Franklin. Fjording the Stream: An [55] J. M. Hellerstein, P. Haas, H. Wang. Online Aggrega- Architecture for Queries Over Streaming Sensor Data. tion. In Proc. ACM Int. Conf. on Management of Data, In Proc. 18th Int. Conf. on Data Engineering, 2002, pp. 1997, pp. 171–182. 555–566. [56] J. M. Hellerstein, W. Hong, S. Madden, K. Stanek. [69] S. Madden, M. J. Franklin, J. M. Hellerstein, W. Hong. Beyond Average: Toward Sophisticated Sensing with TAG: a Tiny AGgregation Service for Ad-Hoc Sensor Queries. To appear in Proc. 2nd Int. Workshop on In- Networks. In Proc. 5th Annual Symp. on Operating Sys- formation Processing in Sensor Networks, Apr. 2003. tems Design and Implementation, 2002. 16
17 .[70] S. Madden, M. J. Franklin, J. M. Hellerstein, W. Hong. [83] P. Seshadri, M. Livny, R. Ramakrishnan. The Design The Design of an Acquisitional Query Processor For and Implementation of a Sequence Database System. In Sensor Networks. To appear in Proc. ACM Int. Conf. Proc. 22nd Int. Conf. on Very Large Data Bases, 1996, on Management of Data, June 2003. pp. 99–110. [71] S. Madden, M. Shah, J. Hellerstein, V. Raman. Contin- [84] M. A. Shah, J. M. Hellerstein, S. Chandrasekaran, M. uously Adaptive Continuous Queries Over Streams. In J. Franklin. Flux: An Adaptive Partitioning Operator Proc. ACM Int. Conf. on Management of Data, 2002, for Continuous Query Systems. To appear in Proc. 19th pp. 49–60. Int. Conf. on Data Engineering, 2003. [72] S. Madden, R. Szewczyk, M. J. Franklin, D. Culler. [85] Stream Query Repository. Supporting Aggregate Queries Over Ad-Hoc Wireless www-db.stanford.edu/stream/sqr. Sensor Networks. In Proc. 4th IEEE Workshop on Mo- [86] B. Subramanian, T. W. Leung, S. L. Vandenberg, S. B. bile Computing Systems and Applications, 2002, pp. 49– Zdonik. The AQUA Approach to Querying Lists and 58. Trees in Object-Oriented Databases. In Proc. 11th Int. [73] G. S. Manku, R. Motwani. Approximate Frequency Conf. on Data Engineering, 1995, pp. 80–89. Counts over Data Streams. In Proc. 28th Int. Conf. on [87] M. Sullivan, A. Heybey. Tribeca: A System for Man- Very Large Data Bases, 2002, pp. 346–357. aging Large Databases of Network Traffic. In Proc. [74] G.S. Manku, S. Rajagopalan, B.G. Lindsay. Random USENIX Annual Technical Conf. , 1998. Sampling Techniques for Space Efficient Online Com- [88] N. Tatbul, U. Cetintemel, S. Zdonik, M. putation of Order Statistics of Large Datasets. In Proc. Cherniack, M. Stonebraker. Load Shedding ACM Int. Conf. on Management of Data, 1999, pp. in a Data Stream Manager. Technical Re- 251–262. port, Brown University, Feb. 2003. Available at http://www.cs.brown.edu/~tatbul/papers/ [75] R. Motwani, J. Widom, A. Arasu, B. Babcock, S. tatbul_tr.pdf. Babu, M. Datar, G. Manku, C. Olston, J. Rosenstein, R. Varma. Query Processing, Approximation, and Re- [89] D. Terry, D. Goldberg, D. Nichols, B. Oki. Continuous source Management in a Data Stream Management Queries over Append-Only Databases. In Proc. ACM System. In Proc. 1st Biennial Conf. on Innovative Data Int. Conf. on Management of Data, 1992, pp. 321–330. Syst. Res, 2003, pp. 245–256. [90] Traderbot. www.traderbot.com. [76] C. Olston, J. Jiang, J. Widom. Adaptive Filters for [91] P. Tucker, D. Maier, T. Sheard, L. Fegaras. Continuous Queries over Distributed Data Streams. To Punctuating Continuous Data Streams. Techni- appear in Proc. ACM Int. Conf. on Management of cal Report, Oregon University, 2001. Available Data, June 2003. at http://www.cs.brown.edu/courses/cs227/ [77] D.S. Parker. Stream Data Analysis in Prolog. In L. papers/TM02-punctuating.pdf. Sterling, ed., The Practice of Prolog, Cambridge, MA: [92] P. Tucker, D. Maier, T. Sheard, L. Fegaras. En- MIT Press, 1990. hancing relational operators for querying over punc- tuated data streams. Manuscript, 2002. Available [78] R. Ramakrishnan, D. Donjerkovic, A. Ranganathan, K. at http://www.cse.ogi.edu/dot/niagara/pstream/ S. Beyer. SRQL: Sorted Relational Query Language. punctuating.pdf. In Proc. 10th Int. Conf. on Scientific and Statistical Database Management, 1998, pp. 84–97. [93] P. Tucker, T. Tufte, V. Papadimos, D. Maier. NEXMark—a Benchmark for Query- [79] V. Raman, A. Deshpande, J. Hellerstein. Using State ing Data Streams. Manuscript, 2002. Avail- Modules for Adaptive Query Processing. To appear in able at http://www.cse.ogi.edu/dot/niagara/ Proc. 19th Int. Conf. on Data Engineering, 2003. pstream/nexmark.pdf. [80] R. Sadri, C. Zaniolo, A. M. Zarkesh, J. Adibi. Opti- [94] T. Urhan, M. J. Franklin. XJoin: A Reactively- mization of Sequence Queries in Database Systems. In Scheduled Pipelined Join Operator. In IEEE Data En- Proc. ACM SIGACT-SIGMOD Symp. on Principles of gineering Bulletin, 23(2):27–33, June 2000. Database Systems, 2001, pp. 71–81. [95] T. Urhan, M. J. Franklin. Dynamic Pipeline Scheduling [81] P. Seshadri, M. Livny, R. Ramakrishnan. Sequence for Improving Interactive Query Performance. In Proc. Query Processing. In Proc. ACM Int. Conf. on Man- 27th Int. Conf. on Very Large Data Bases, 2001, pp. agement of Data, 1994, pp. 430–441. 501–510. [82] P. Seshadri, M. Livny, R. Ramakrishnan. SEQ: A [96] T. Urhan, M. J. Franklin, L. Amsaleg. Cost-based Model for sequence Databases. In Proc. 11th Int. Conf. Query Scrambling for Initial Delays. In Proc. ACM Int. on Data Engineering, 1995, pp. 232–239. Conf. on Management of Data, 1998, pp. 130–141. 17
18 .[97] S. Viglas and J. Naughton. Rate-Based Query Opti- mization for Streaming Information Sources. In Proc. ACM Int. Conf. on Management of Data, 2002, pp. 37–48. [98] S. Viglas, J. Naughton, J. Burger. Maximiz- ing the Output Rate of Multi-Join Queries over Streaming Information Sources. Available at http://www.cs.wisc.edu/niagara/papers/ mjoin.pdf. [99] H. Wang, C. Zaniolo. ATLaS: A Native Exten- sion of SQL for Data Mining and Stream Computa- tions. UCLA CS Technical Report, 2002. Available at http://citeseer.nj.nec.com/551711.html. [100] A. Wilschut, P. Apers. Dataflow query execution in a parallel main-memory environment. In Proc. 1st Int. Conf. Parallel and Distributed Information Systems, 1991, pp. 68–77. [101] Y. Yao and J. Gehrke. The Cougar Approach to In- Network Query Processing in Sensor Networks. In SIG- MOD Record, 31(3):9–18, Sep. 2002. [102] Y. Yao and J. Gehrke. Query Processing for Sensor Net- works. In Proc. 1st Biennial Conf. on Innovative Data Syst. Res, 2003, pp. 233–244. [103] B.-K. Yi, N. Sidiropoulos, T. Johnson, H. V. Jagadish, C. Faloutsos, A. Biliris. Online Data Mining for Co- Evolving Time Sequences. In Proc. 16th Int. Conf. on Data Engineering, 2000, pp. 13–22. [104] Y. Zhu, D. Shasha. StatStream: Statistical Monitoring of Thousands of Data Streams in Real Time. In Proc. 28th Int. Conf. on Very Large Data Bases, 2002, pp. 358–369. 18
3秒后跳转登录页面
去登陆

