展开查看详情
1 . 我们毕业啦
基于 IBFBP 的 ipv6 路由查
找算法
其实是答辩的标题地方
高鹰
�
2 . 论文摘要
研究背景
研究内容
CONTANTS 研究结果
论文总结
�
3 .论文摘
It was the best of times, it was the worst of times; it was the age of
要
wisdom, it was the age of foolishness.
�
4 .论文摘要 研究背景 研究内容 研究结果 论文总结
总结目前 IPv6 路由查找算法优缺点,提出了
一种新的 IPv6 路由查找算法 -IBFBP 。
该算法结合 IBF 与 BP 神经网络,将 IPv6 不同
长度网络 ID 作为 IBF 的输入,以关键字的特
征标志创建标志库 LB 进行学习,提前判断是
否发生误判。
将位数组用 counter 计数数组来代替,支持可
、
删除操作,进而进行 BP 神经网络学习过程。
理论分析和实验结果表明,该算法比已有神经
网络路由查找算法降低了误判率和搜索成本,
提高了查找效率。
�
5 .研究背
It was the best of times, it was the worst of times; it was the age of
景
wisdom, it was the age of foolishness.
�
6 .论文绪论 研究背景 研究内容 研究结果 论文总结
IPV4 地址消耗殆尽,提出 IPV6 ,地址数量巨
大
用户网络要求提高,路由条目大量增加
挺高硬件性能困难,成本高,算法成为关键
对 BF 算法进行改进并结合 BP 神经网络
�
7 .研究方
It was the best of times, it was the worst of times; it was the age of
法
wisdom, it was the age of foolishness.
�
8 .论文绪论 研究背景 研究内容 研究结果 论文总结
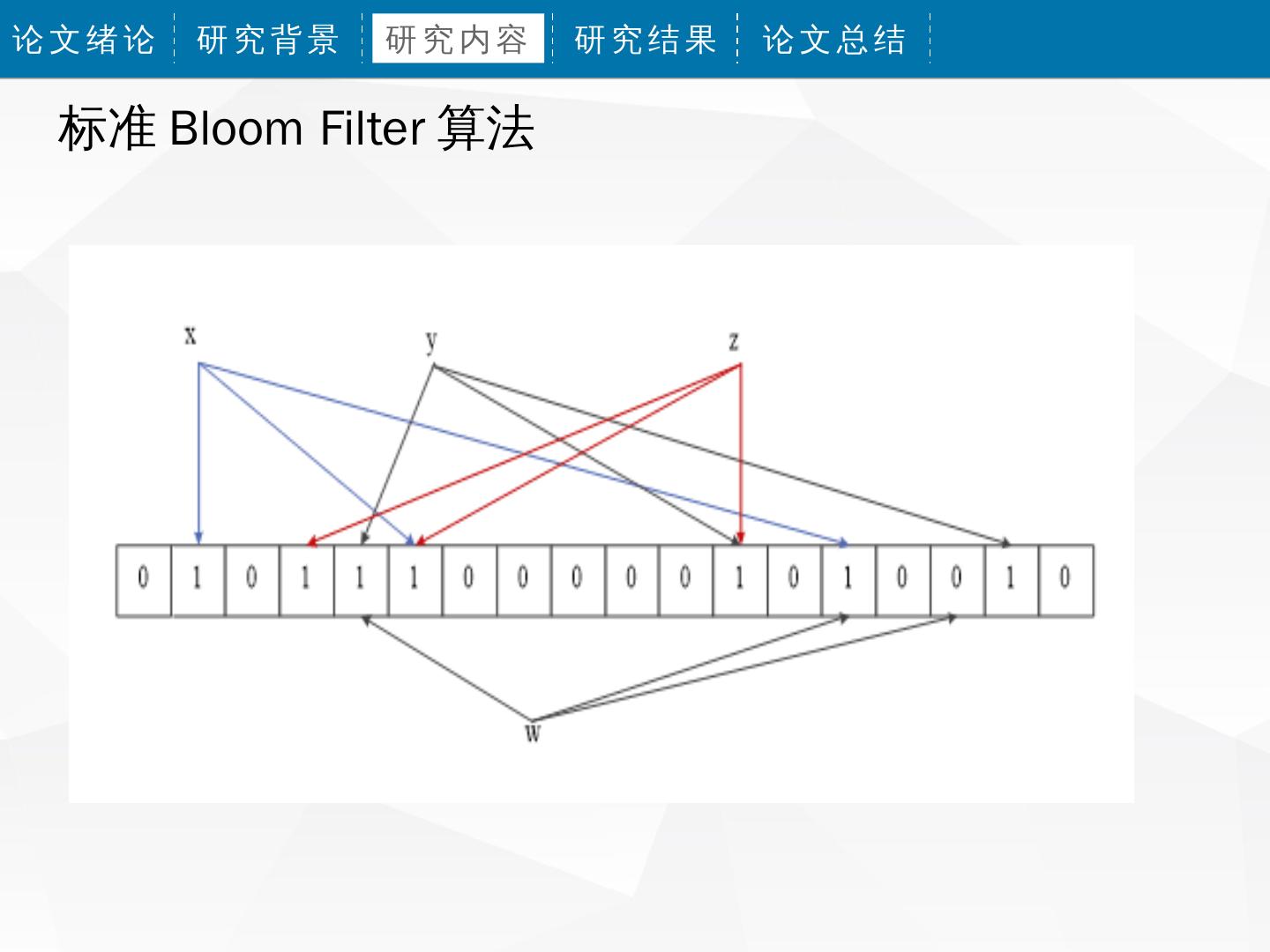
标准 Bloom Filter 算法
�
9 .论文绪论 研究背景 研究内容 研究结果 论文总结
标准 Bloom Filter 算法
1 、存在误判,当插入 x 、 y 、 z 这三个元素之后,
再来查询 w ,会发现 w 不在集合之中,而如果 w 经
过三个 hash 函数计算得出的结果所得索引处的位全
是 1 ,那么 Bloom Filter 就会告诉你, w 在集合之
中,实际上这里是误报, w 并不在集合之中。
2 、标准的 Bloom Filter 算法,只支持插入和查找。
当表达的集合是静态集合时,标准的 Bloom Filter 可
以正常工作,但是如果要表达的集合是变动的,标准
Bloom Filter 的弊端就显现出来了,无法从 Bloom
Filter 集合中删除一个元素。因为该元素对应的位会
牵动到其他的元素。
�
10 .论文绪论 研究背景 研究内容 研究结果 论文总结
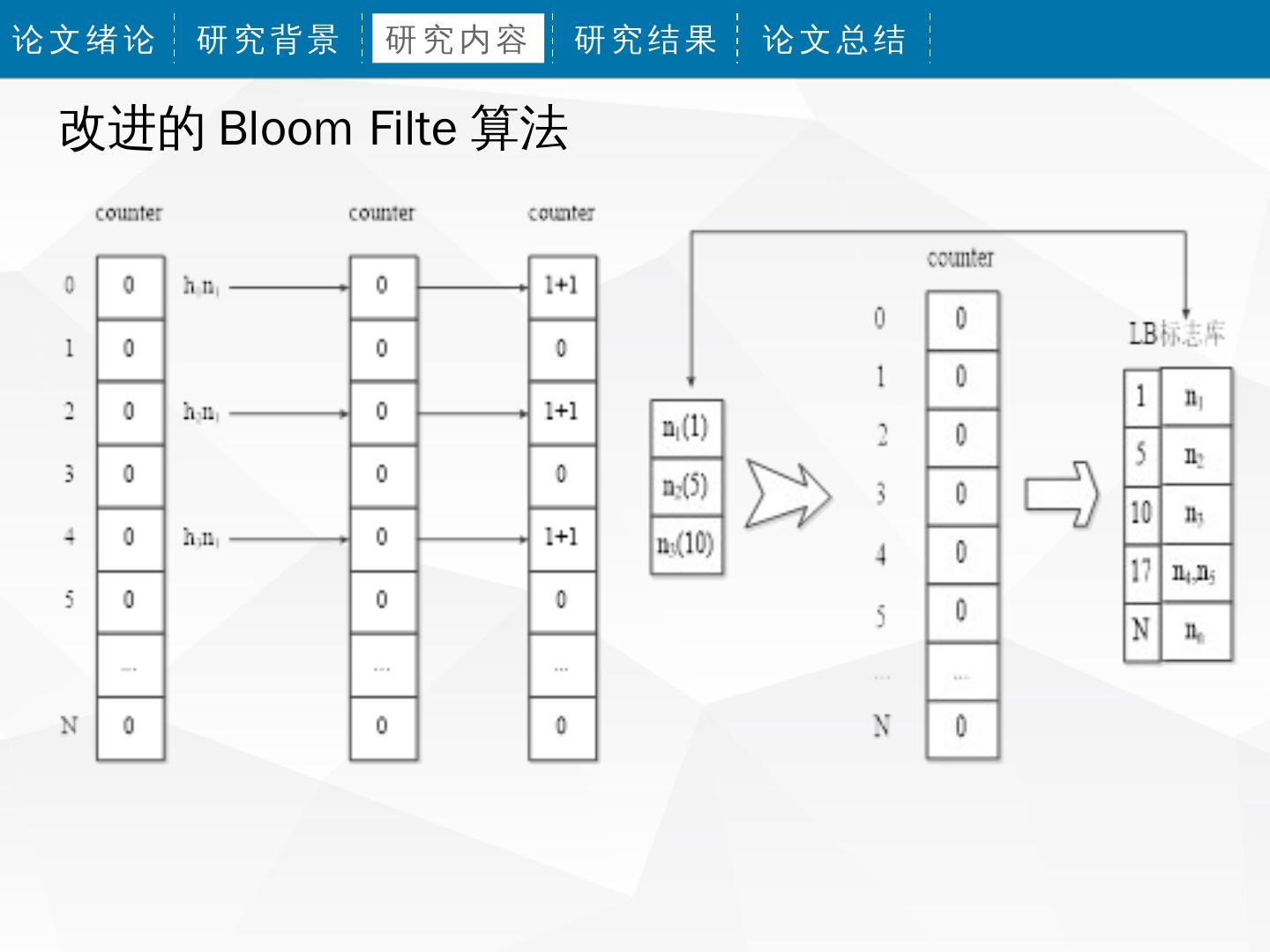
改进的 Bloom Filte 算法
�
11 .论文绪论 研究背景 研究内容 研究结果 论文总结
建立过滤器
{
定义过滤器 filter
声 明 ( 集 合 A , hash 函 数 h , 整 数
m , counter V )
返回 过滤器 filter
初始化 counter V= 0
Foreach 集合 A 中元素 a
Foreach hash 哈希函数 h
counter V[hash h(a)]=1+1
结束 foreach
结束 foreach
以哈希函数关键字的特征建立一个标志
返回 过滤器 filter 库且以关键字的最小值作为标志来区分
}
建立标志库 LB
{
声明标志库 LB (集合 B , hash 函数, LB )
在插入元素时给对应的 k 个 counter 的值
返回 LB
Foreach 集合 B 中元素 b
分别加 1 ,删除元素时给对应的 k 个
Foreach hash 哈希函数 h counter 的值分别减 1 ,从而实现对元素
分配每一个 min[h(b)] 于 LB ,
所有 b 产生相同的 min[h(b)] 放在 LB 相同的区间 的删除
结束 foreach
结束 foreach
返回 LB
}
新集合比对阶段
产生测试 Test
{
声明 ( 测试值 T , filter , LB , hash h,counter V)
返回值 Yes or Misdiagnosis or mismatching
Foreach hash h
If counter V[h(T)]=0 returns mismatching
If counter V[h(T)]!=0
after finding B
If min[h(T)]!=B returns Misdiagnosis
If min[h(T)]=B returns Yes
结束 foreach
�
12 .论文绪论 研究背景 研究内容 研究结果 论文总结
IBFBP 算法
�
13 .论文绪论 研究背景 研究内容 研究结果 论文总结
输入:输入 IP 地址获取路由条目
输出:路由下一跳信息
步骤:
① 输入 IP 地址获取路由条目;
② 提取网络前缀进行学习;
③ 获取路由条目给 Route ;
④ 获取路由前缀长度给 Prefix length ;
⑤ 获取路由前缀给 Prefix ;
⑥ 路由下一跳索引给 Next hop ;
⑦ 进行 IBF 算法 counter 计数数组与标志库匹配判断是否发生
误判,如果发生误判则返回步骤①重新输入,如果没有发生误
判作为 BP 神经网络的输入执行下一步;
⑧BP 神经网络网络学习;
⑨ 输出下一跳地址。
�
14 .研究结
It was the best of times, it was the worst of times; it was the age of
果
wisdom, it was the age of foolishness.
�
15 .论文绪论 研究背景 研究内容 研究结果 论文总结
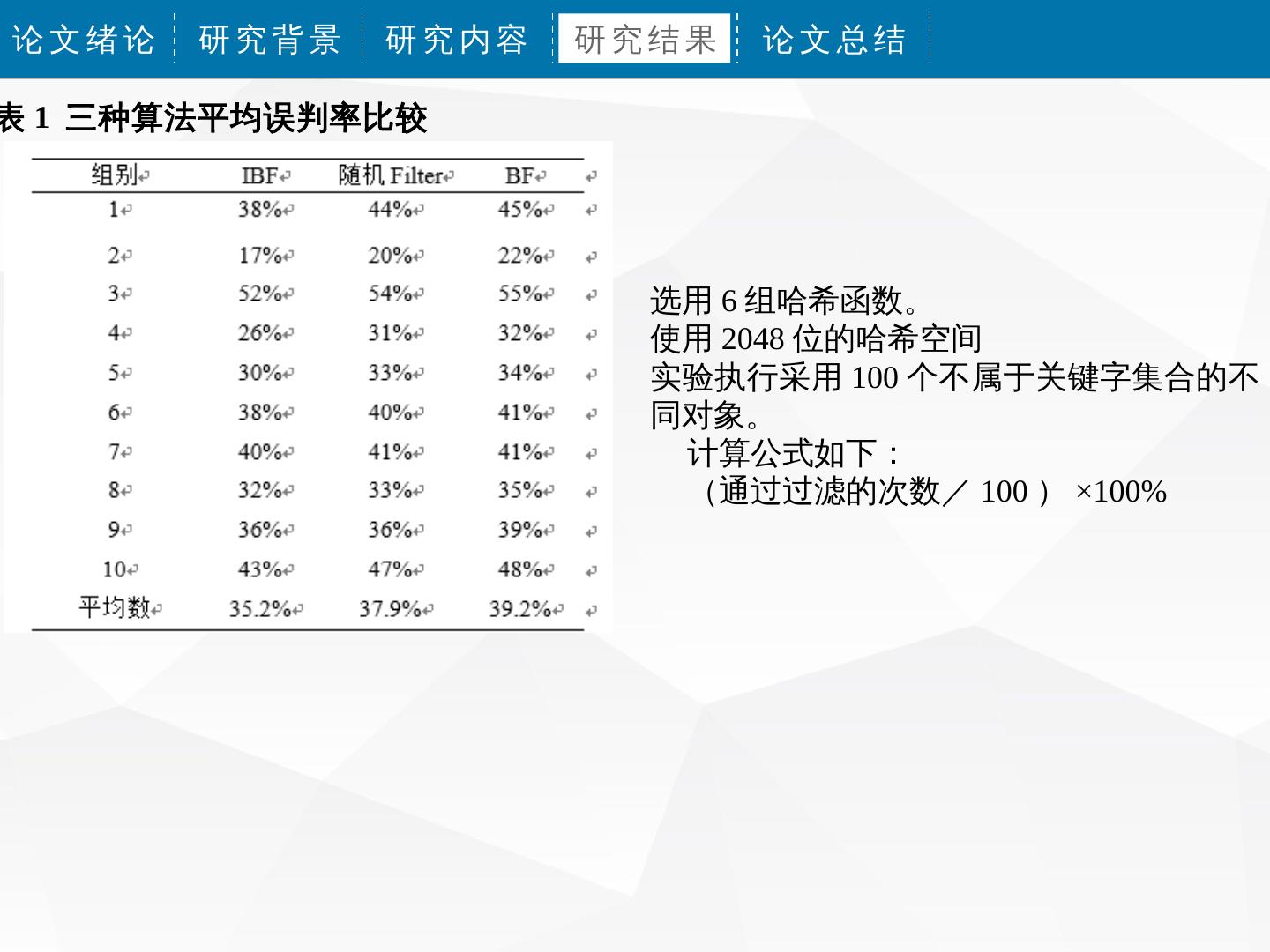
表 1 三种算法平均误判率比较
选用 6 组哈希函数。
使用 2048 位的哈希空间
实验执行采用 100 个不属于关键字集合的不
同对象。
计算公式如下:
(通过过滤的次数/ 100 ) ×100%
�
16 .论文绪论 研究背景 研究内容 研究结果 论文总结
8
60 x 10
8
经 典 神 经 网 络 RINP
经典神经网络
多 层 神 经 网 络 RINP
7 多层神经网络
50 IBFBP神经网络 RINP
IBFBP神经网络
6
40
5
路由条目
30 4
3
20
2
10
1
0 0
15 20 25 30 35 40 15 20 25 30 35 40
前缀长度 前缀长度
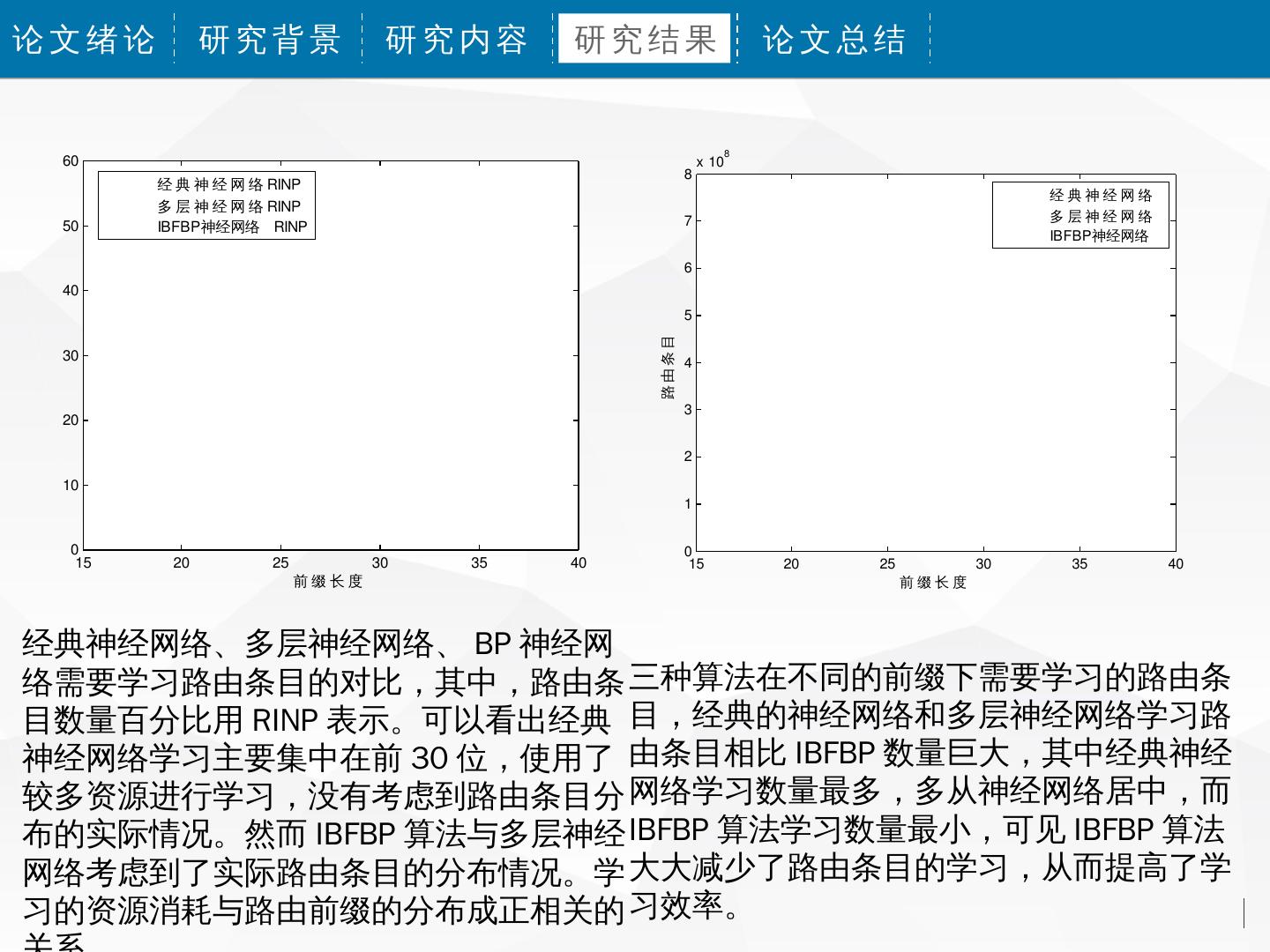
经典神经网络、多层神经网络、 BP 神经网
络需要学习路由条目的对比,其中,路由条 三种算法在不同的前缀下需要学习的路由条
目数量百分比用 RINP 表示。可以看出经典 目,经典的神经网络和多层神经网络学习路
神经网络学习主要集中在前 30 位,使用了 由条目相比 IBFBP 数量巨大,其中经典神经
较多资源进行学习,没有考虑到路由条目分 网络学习数量最多,多从神经网络居中,而
布的实际情况。然而 IBFBP 算法与多层神经 IBFBP 算法学习数量最小,可见 IBFBP 算法
网络考虑到了实际路由条目的分布情况。学 大大减少了路由条目的学习,从而提高了学
习的资源消耗与路由前缀的分布成正相关的 习效率。
�
17 .论文总
It was the best of times, it was the worst of times; it was the age of
结
wisdom, it was the age of foolishness.
�
18 .论文绪论 研究背景 研究内容 研究结果 论文总结
本文提出了一种基于 IBFBP 的 IPv6 路由算法,对标准
BF 算法进行了改进,通过将 IPv6 不同长度网络 ID 作
为 IBF 的输入,以关键字的特征标志创建标志库
( LB )进行学习,将查询元素与 LB 进行匹配,如果
没有则说明是误判,通过这种方法提前判断出误判的
发生,大大降低了误判率,而且避免了无用的检测过
滤,从而降低了检测成本,节约了检测时间。利用
counter 计数数组来代替位数组,在插入元素时给对应
的 k 个 counter 的值分别加 1 ,删除元素时给对应的 k
个 counter 的值分别减 1 ,从而实现对元素的删除。每
个神经网络,不需要学习所有的 IP 地址,只需要学习
网络 ID ,从而该算法学习的路由条目减少了,从而提
高了路由学习效率。
�