展开查看详情
1 .Druid SQL和Security在美团点评的实践
高大月@美团点评
2019-03
�
2 .内容大纲
・Druid在美团的现状和挑战
・Druid SQL的应用和改进
・Druid Security的实践经验
・总结
�
3 .Druid应用现状
・2个集群,70多个数据节点(物理机)
・0.12版本,数据摄入主要采用Tranquility
・500多张表,100TB存储,最大的表日摄入消息量在百亿级别
・日查询量1700万次,TP99响应低于1秒的表占到80%
・支撑外卖、酒店、旅游、金融、广告等主要业务线
�
4 .Druid平台化挑战
・易用性
- 新用户花多长时间能用Druid实现他的业务需求?
- 遇到问题后用户能不能自己定位和解决问题?
・安全性
- 数据是业务最重要的资产之一,如何保障业务的数据安全?
・稳定性
- 面对不熟悉的业务逻辑,如何在一个多租户环境中定位和解决问题?
- 我们能给业务提供什么样的SLA承诺?
�
5 .内容大纲
・Druid在美团的现状和挑战
・Druid SQL的应用和改进
・Druid Security的实践经验
・总结
�
8 .Druid SQL简介
・0.10新增的核心模块
・基于Calcite实现的SQL到JSON翻译层
- 简单、稳定、性能开销低
- 功能受限于JSON查询的能力
・支持 HTTP 和 JDBC 两种调用方式
・几乎能表达所有JSON查询能实现的逻辑
- 例如:嵌套GroupBy,union all,近似TopN
- 自动选择最适合的queryType
�
9 .SQL例子
近似TopN 半连接
嵌套GroupBy
�
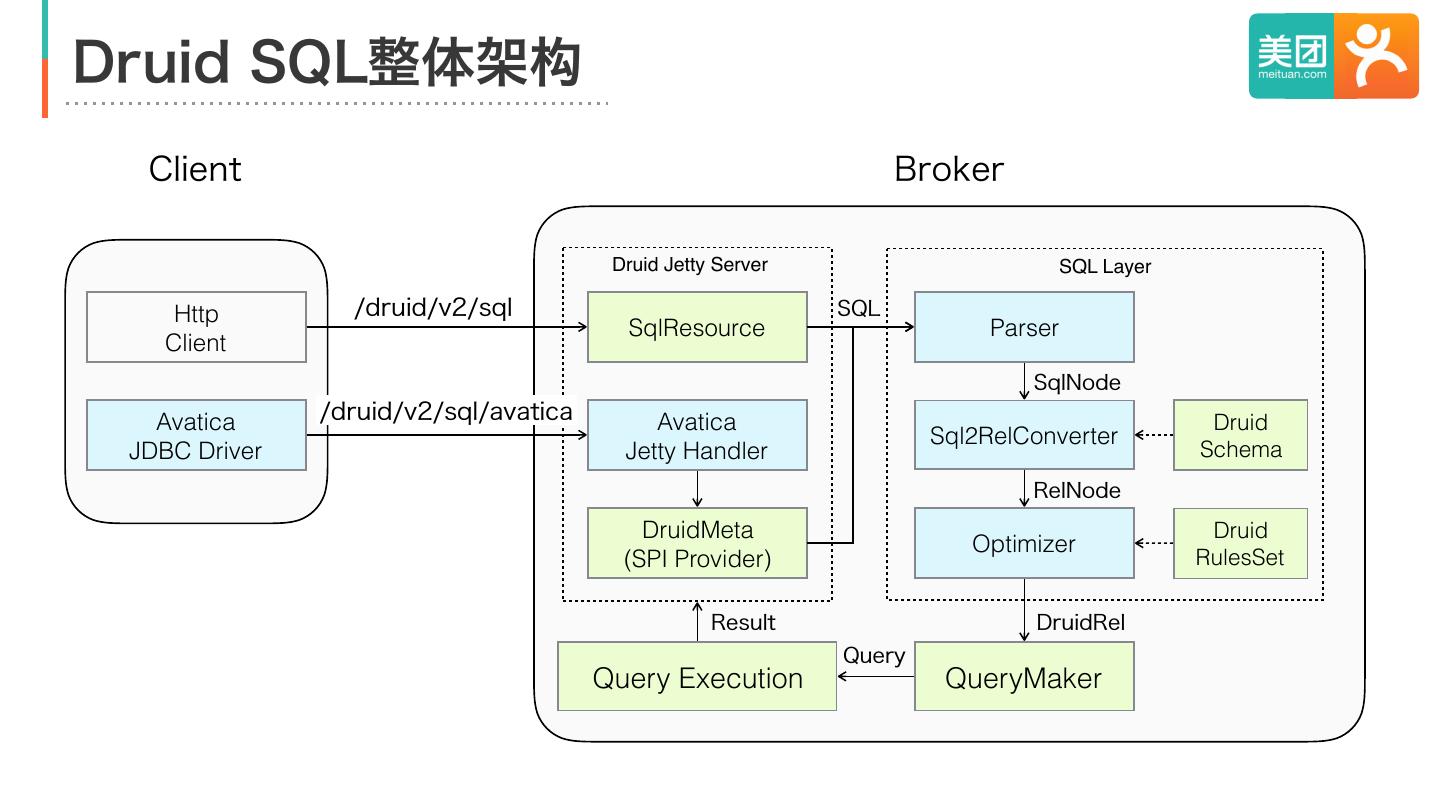
10 .Druid SQL整体架构
Client Broker
Druid Jetty Server SQL Layer
Http /druid/v2/sql SQL
SqlResource Parser
Client
SqlNode
Avatica /druid/v2/sql/avatica Avatica Druid
Sql2RelConverter
JDBC Driver Jetty Handler Schema
RelNode
DruidMeta Druid
Optimizer
(SPI Provider) RulesSet
Result DruidRel
Query
Query Execution QueryMaker
�
11 .API选择: HTTP or JDBC
・HTTP API
- 客户端处理逻辑相对较多
- 适用于所有编程语言
- Broker无状态,运维较简单
・JDBC
- 对于Java应用接入更简单,但仅适用于Java
- Broker有状态,负载均衡实现更复杂
- 还有一些未解决的BUG (#4826)
�
12 .改进一:DruidSchema性能优化(1/2)
・社区版计算Datasource schema的方式
- 通过SegmentMetadataQuery获取每个segment的schema
- 按照segment创建时间合并schema
- 在segment发生变化时重新计算
・性能和稳定性问题
- 启动时间过长:60万segment,计算schema需要半小时
- GC压力大:缓存/刷新schema导致常驻内存和分配速率增加
- 扩展性差:元数据Query量级与(#broker × #segment)成正比
�
13 .改进一:DruidSchema性能优化(2/2)
・观察
- schema变更是低频操作,大部分segment的schema是相同的
- 业务通常希望使用最新segment的schema来查询
・解决方案
- 每个表只使用最近一段时间的segment来推导schema
・效果
- 60万个segment,schema计算耗时降低到20秒
- Broker GC压力显著降低
�
14 .改进二:添加SQL的请求日志和监控指标(1/2)
・SQL查询带来的运维变化
- 慢查询定位
- SLA计算
- 流量回放
・目标
- SQL和对应的原生查询能互相关联
- 可扩展的SQL请求日志实现
�
15 .改进二:添加SQL的请求日志和监控指标(2/2)
・解决方案 (#6302)
- 为每个SQL请求分配唯一的sqlQueryId
- 扩展了RequestLogger接口,支持输出SQL请求日志
- SQL和JSON查询通过sqlQueryId和nativeQueryIds关联
- 两个新metrics:"sqlQuery/time" 和 "sqlQuery/bytes"
�
16 .改进三:强制用户指定__time条件
・背景
- Druid实现高性能的关键之一是根据时间戳提前过滤segments
- 然而写SQL容易忘记添加时间戳的过滤条件,造成扫全表
・解决方案 (#6246)
- Planner生成的JSON查询如果没有有效的intervals,就直接报错
- druid.sql.planner.requireTimeCondition=true
�
17 .内容大纲
・Druid在美团的现状和挑战
・Druid SQL的应用和改进
・Druid Security的实践经验
・总结
�
18 .Druid Security需求
・背景
- Druid(0.10)所有API都没有访问控制,业务数据安全得不到保障
・需求&目标
- 所有API都要经过认证
- 实现DB粒度的权限控制
- 所有数据访问都有审计日志
- 业务能平滑升级到安全集群
- 对代码的改动侵入性小
�
19 .社区Security功能简介
・端到端的传输层加密 (0.11)
・可扩展的认证框架
- Allow All (0.11)
- Kerberos (0.11)
- Basic Auth (0.12)
- Anonymous (0.13)
・可扩展的鉴权框架
- Role-based Access Control扩展 (0.12)
�
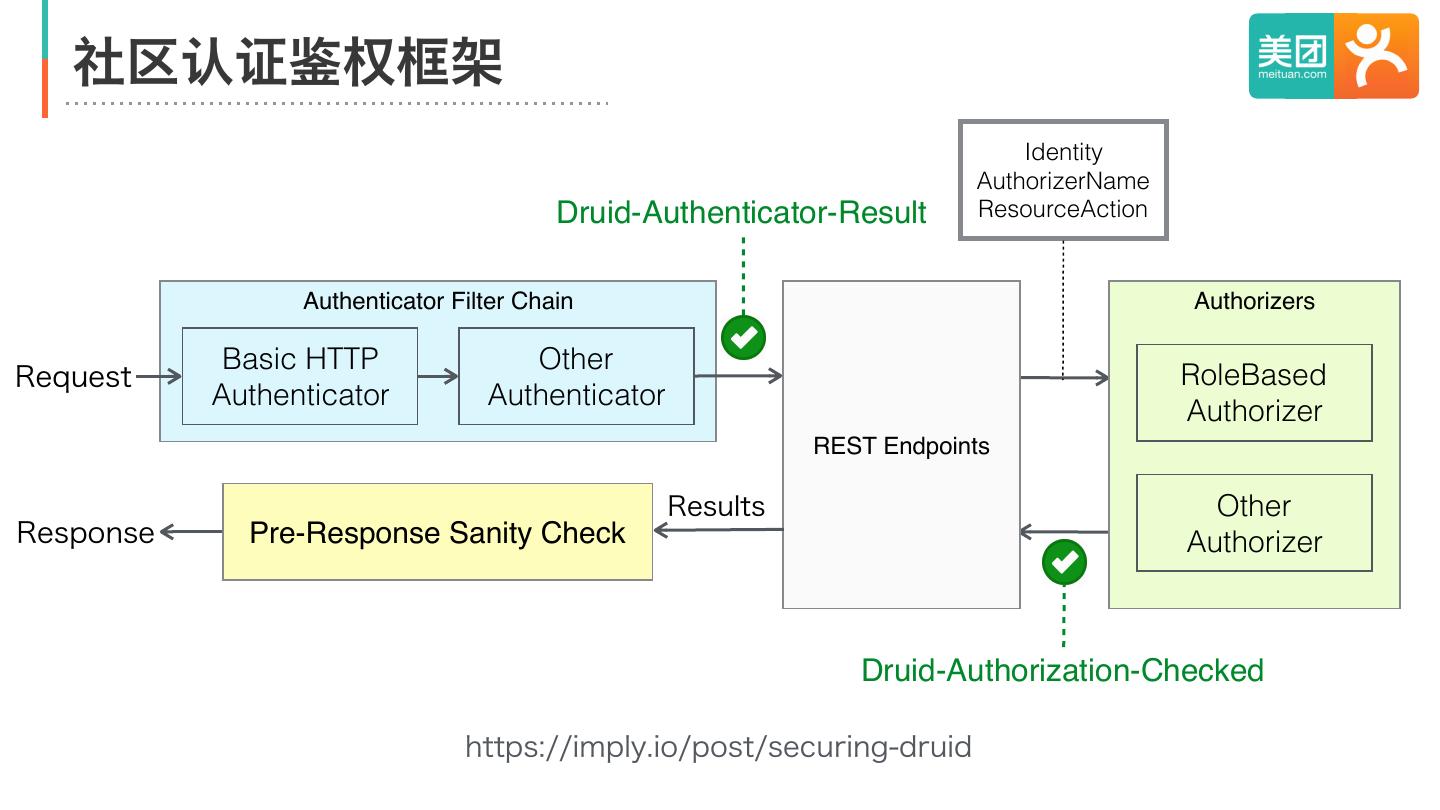
20 . 社区认证鉴权框架
Identity
AuthorizerName
Druid-Authenticator-Result ResourceAction
Authenticator Filter Chain Authorizers
Basic HTTP Other
Request RoleBased
Authenticator Authenticator
Authorizer
REST Endpoints
Results Other
Response Pre-Response Sanity Check Authorizer
Druid-Authorization-Checked
https://imply.io/post/securing-druid
�
22 .社区方案的不足
・Web控制台对BA认证的支持较差
・未认证用户的权限不能修改 (0.13修复)
・权限管理只提供了low-level API,使用不方便
・缺少审计日志
�
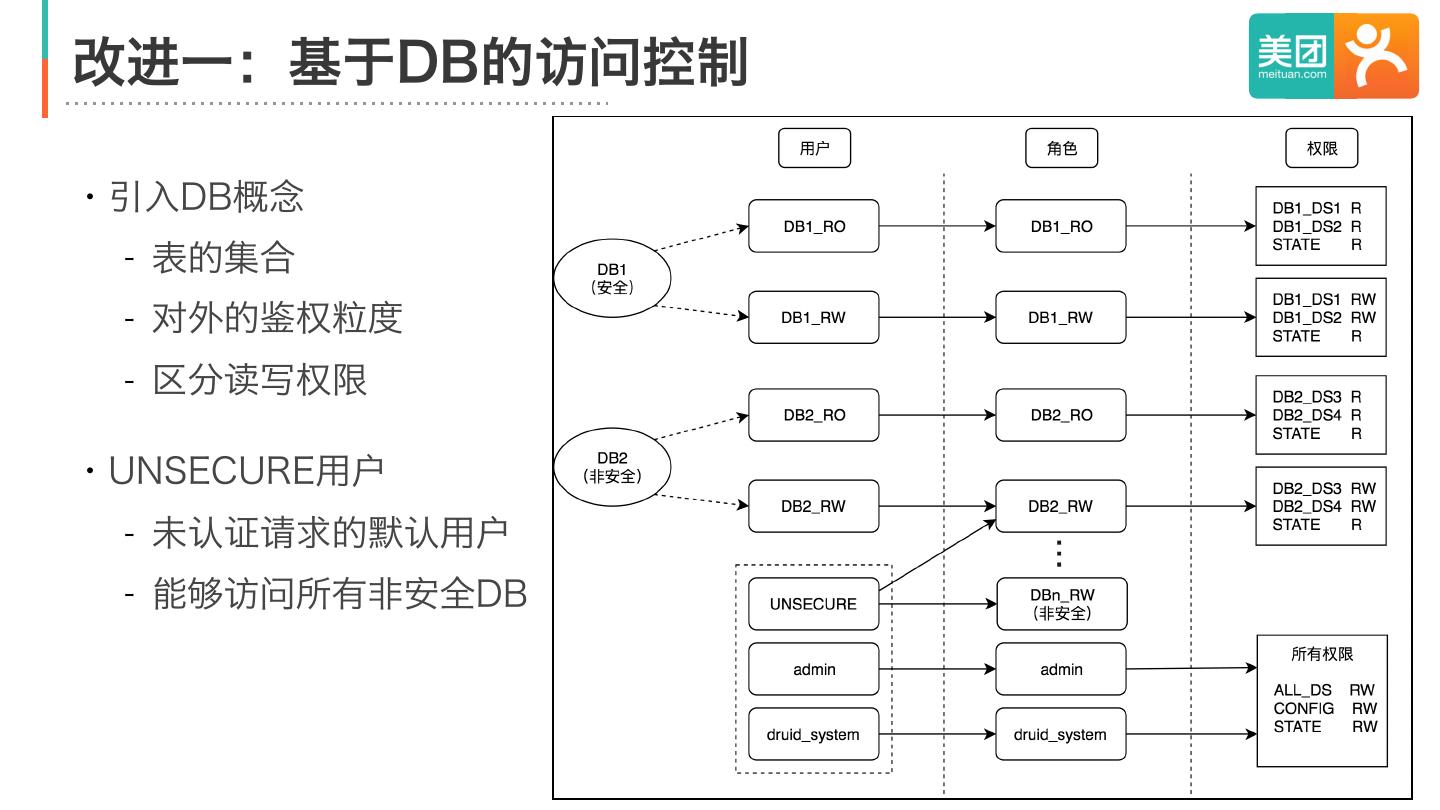
23 .改进一:基于DB的访问控制
・引入DB概念
- 表的集合
- 对外的鉴权粒度
- 区分读写权限
・UNSECURE用户
- 未认证请求的默认用户
- 能够访问所有非安全DB
�
24 .改进二:自动管理权限DB
初始化权限
新建DB 修改权限DB
任务接⼊入平台 Druid集群
新建DS (admin用户)
将DB切换成安全
DB和DataSource映射关系 用户/角色/权限
平台 metadata
DB storage
�
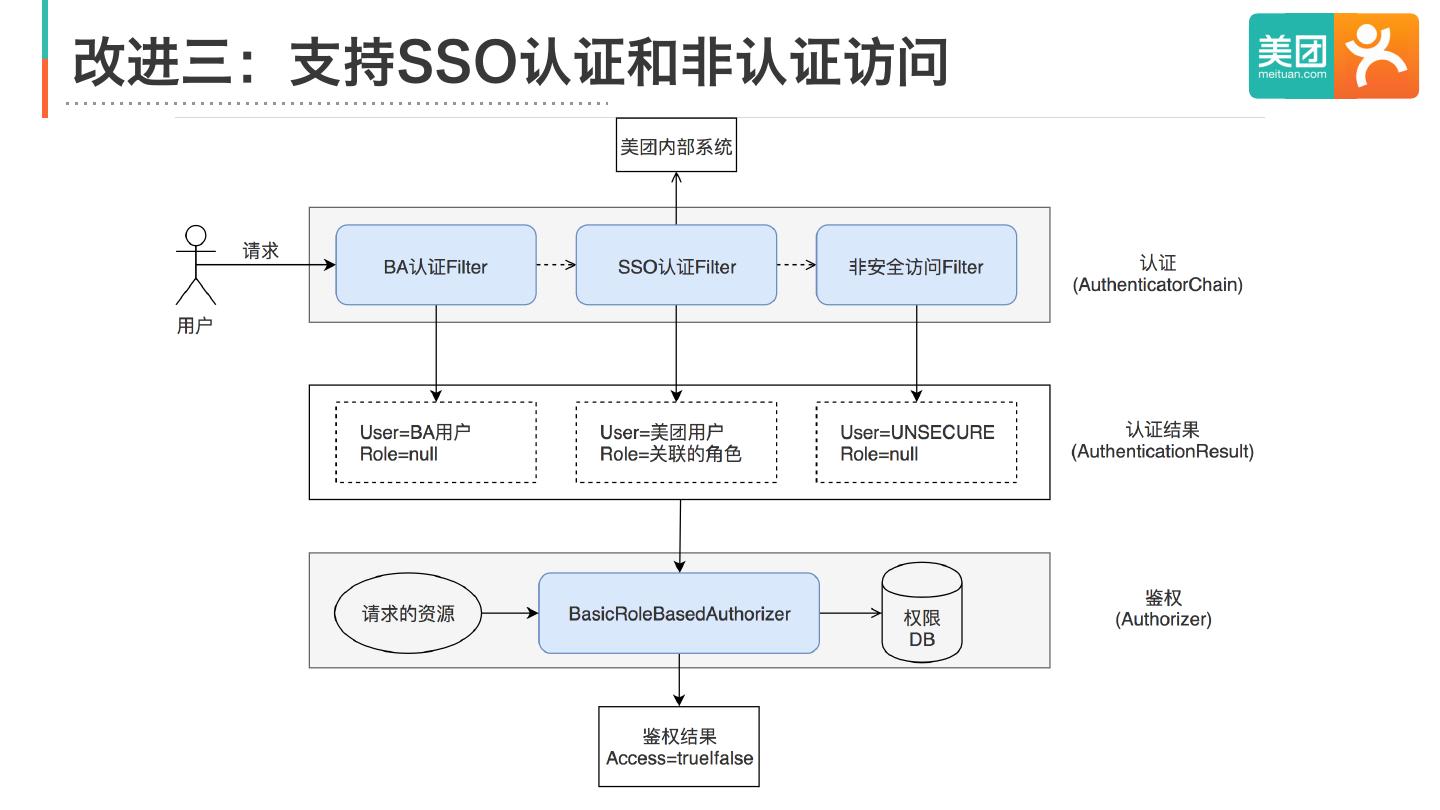
26 .注意事项
・使用0.13以上版本(或者cherrypick高版本的bugfix)
・上线流程
- 启用basic-security功能,用allowAll兜底
- 初始化权限DB,创建匿名用户并授权
- 将allowAll替换为anonymous
- 逐步回收匿名用户的权限
・上线顺序:coordinator -> overlord -> broker -> historical -> middleManager
�
27 .内容大纲
・Druid在美团的现状和挑战
・Druid SQL的应用和改进
・Druid Security的实践经验
・总结
�
28 .关于SQL
・如果你还在用原生的JSON查询语言,强烈建议试一试
・社区不断在改进和优化,建议使用最新版本 (0.14即将发布)
・Druid SQL本质上是一个语言翻译层
- 对查询性能和稳定性没有太大影响
- 受限于Druid本身的查询处理能力,支持的SQL功能有限
・要留意的坑
- 大集群的Schema推导效率
- Broker需要等Schema初始化后再提供服务 (#6742)
�
29 .关于Security
・Druid包含以下Security特性,建议升级到最新版本使用
- 传输层加密
- 认证鉴权框架
- BA和Kerberos认证
- RBAC鉴权
・认证鉴权框架足够灵活,可根据自身需求扩展
・经历生产环境考验,完成度和稳定性足够好
・上线前要充分考虑兼容性和节点更新顺序
�