

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
深入了解TiDB优化器
从原理上带大家深入了解 TiDB SQL 优化器中的关键模块,比如应用一堆逻辑优化规则的逻辑优化部分,基于代价的物理优化部分,还有和代价估算密切相关的统计信息等。
展开查看详情
1 .TiDB SQL Optimizer Presented by zhangjian@pingcap.com
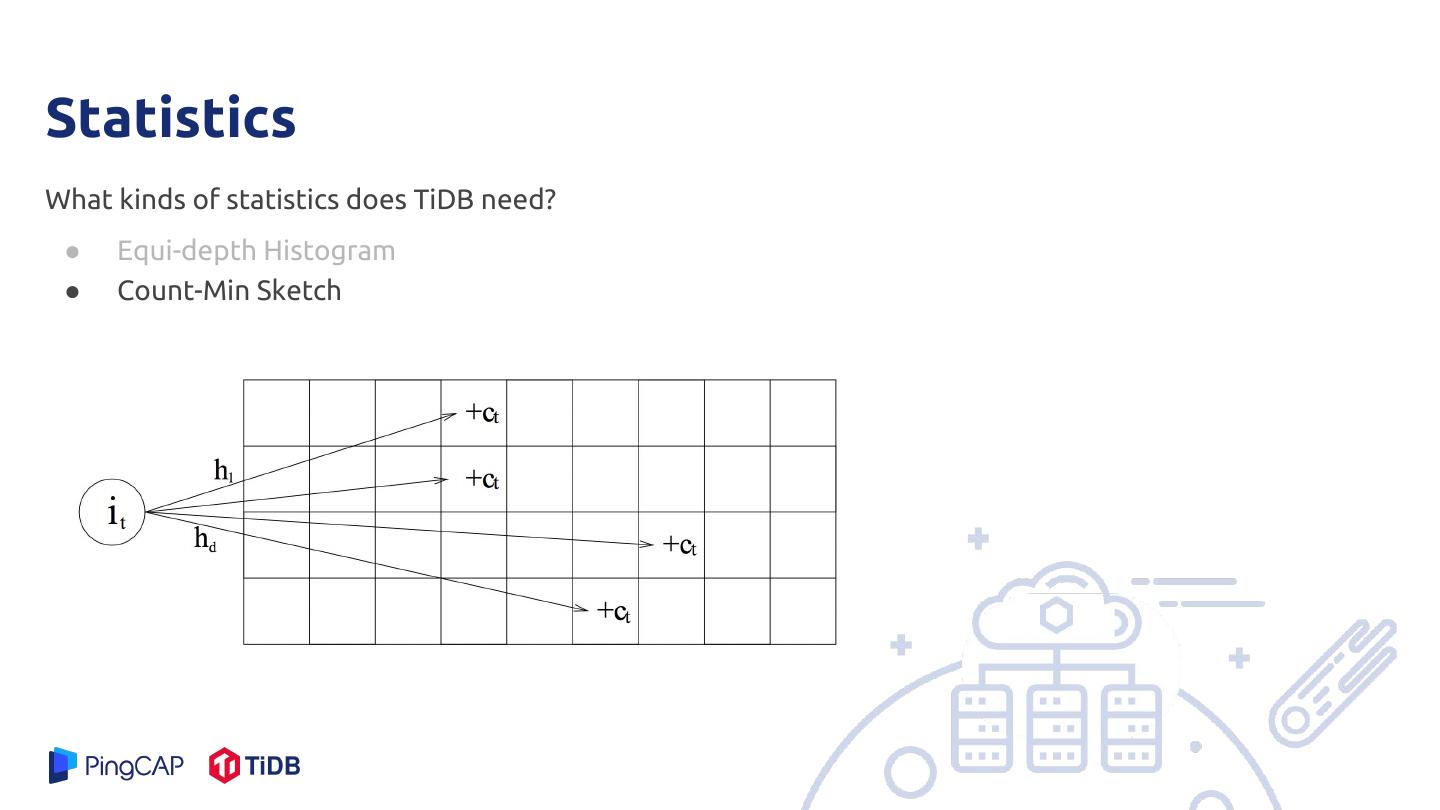
2 .Agenda ● TiDB Overview ● Query Optimizer ● Statistics ● Future Works PingCAP.com
3 .Part I - TiDB Overview
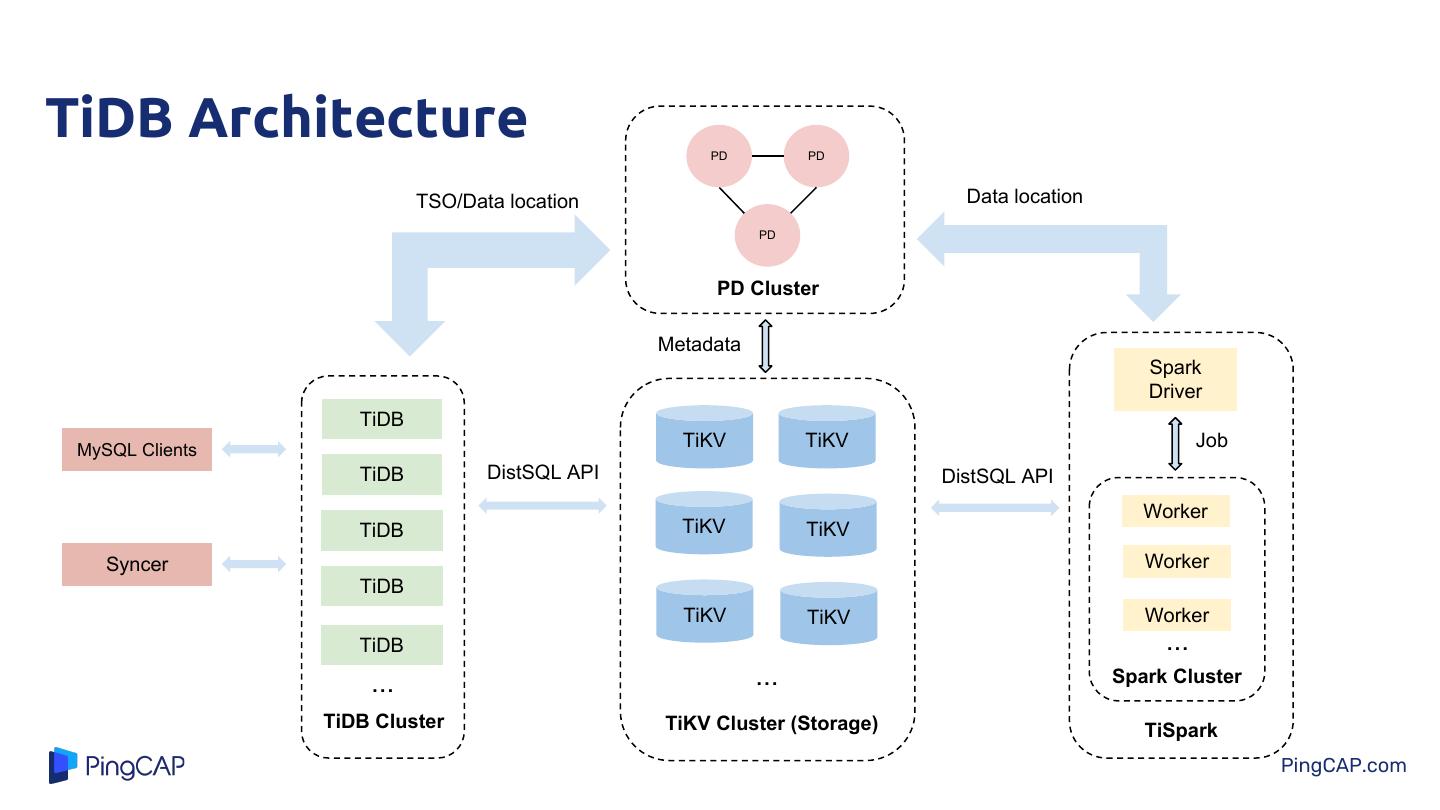
4 .TiDB Architecture PD PD TSO/Data location Data location PD PD Cluster Metadata Spark Driver TiDB MySQL Clients TiKV TiKV Job TiDB DistSQL API DistSQL API Worker TiDB TiKV TiKV Syncer Worker TiDB TiKV TiKV Worker TiDB ... ... ... Spark Cluster TiDB Cluster TiKV Cluster (Storage) TiSpark PingCAP.com
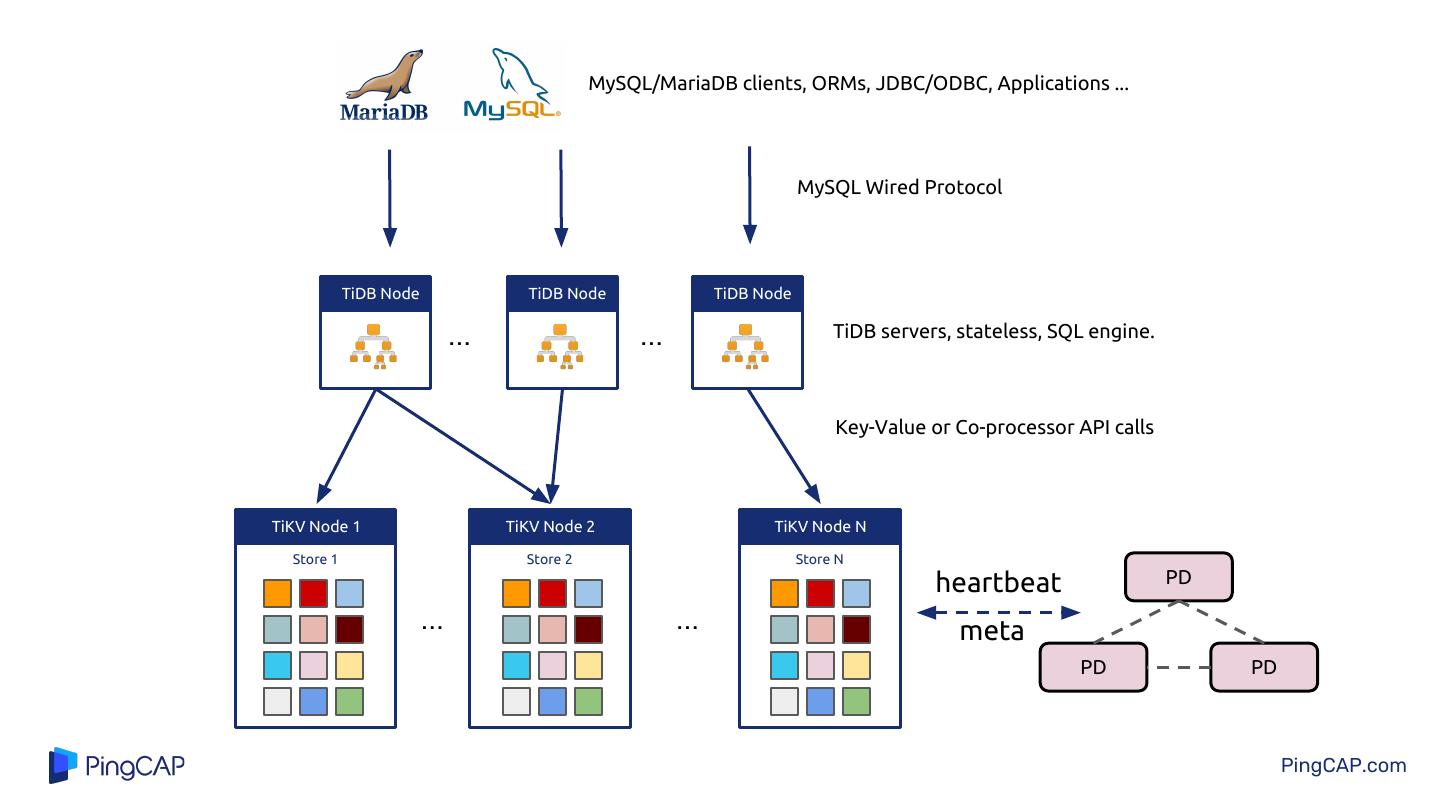
5 . MySQL/MariaDB clients, ORMs, JDBC/ODBC, Applications ... MySQL Wired Protocol TiDB Node TiDB Node TiDB Node ... ... TiDB servers, stateless, SQL engine. Key-Value or Co-processor API calls TiKV Node 1 TiKV Node 2 TiKV Node N Store 1 Store 2 Store N heartbeat PD ... ... meta PD PD PingCAP.com
6 .Data organization within TiDB ● For a row in a Table, row data is encoded in key-value pairs with the format below: t<<tableID>>_r<<rowID>> => [col1, col2, col3, col4] ● If there is secondary index, the index data of a row is encoded in this way: t<<tableID>>_i<<indexID>>_indexedColumnsValue => rowID Or t<<tableID>>_i<<indexID>>_indexedColumnsValue_rowID => nil PingCAP.com
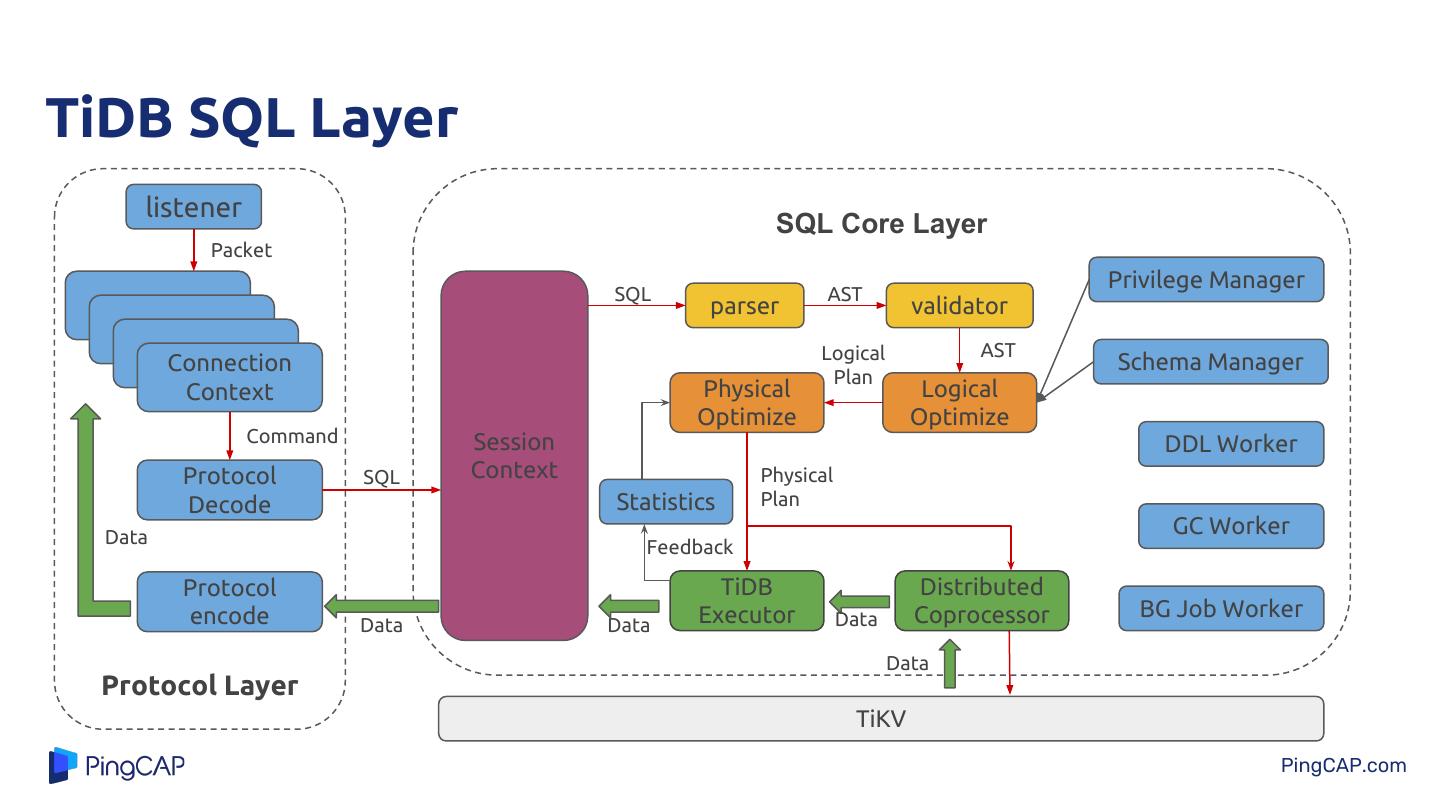
7 .TiDB SQL Layer listener SQL Core Layer Packet Privilege Manager SQL AST parser validator Logical AST Connection Schema Manager Plan Context Physical Logical Optimize Optimize Command Session DDL Worker Protocol SQL Context Physical Decode Statistics Plan Data GC Worker Feedback Protocol TiDB Distributed encode Executor Data Coprocessor BG Job Worker Data Data Data Protocol Layer TiKV PingCAP.com
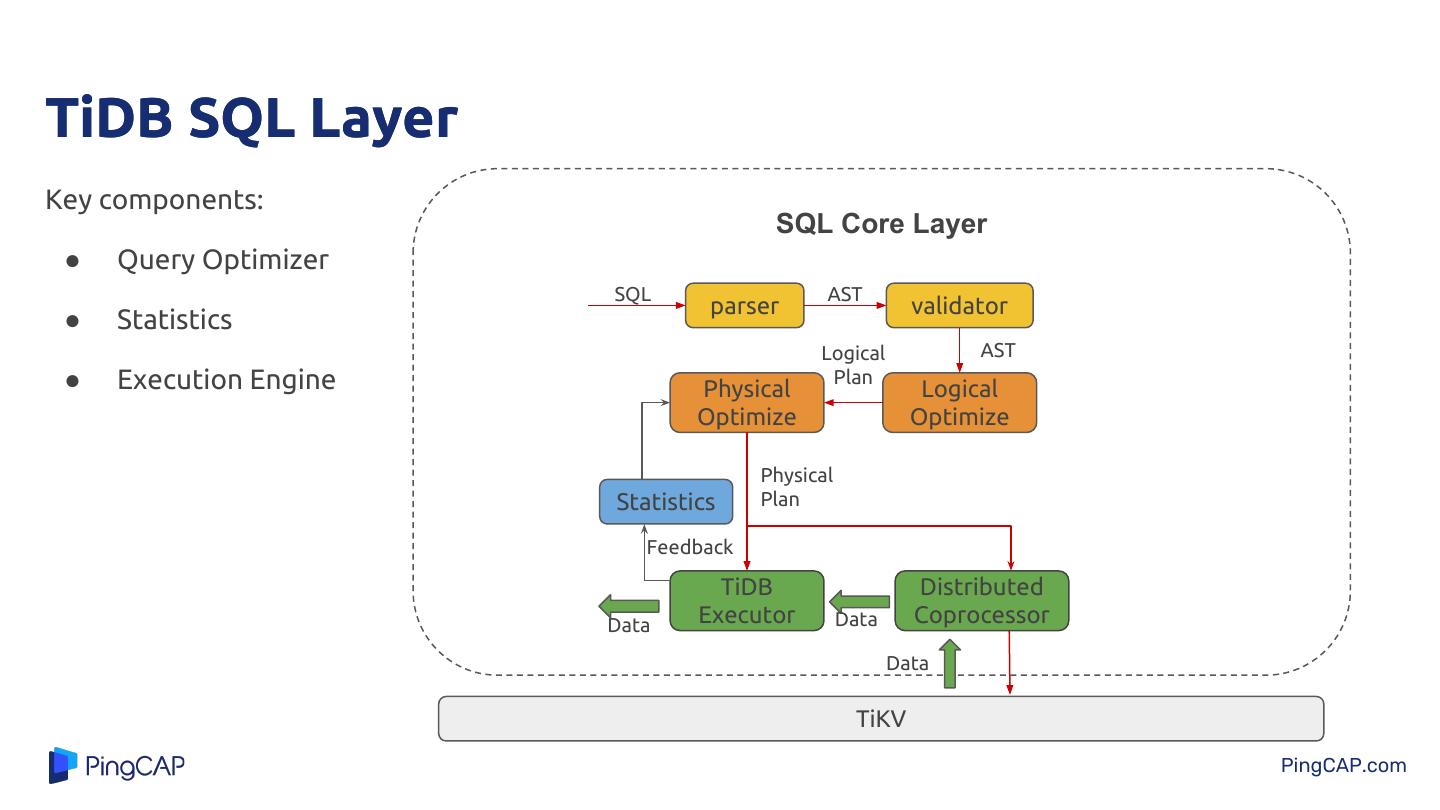
8 .TiDB SQL Layer Key components: SQL Core Layer ● Query Optimizer SQL AST parser validator ● Statistics Logical AST ● Execution Engine Physical Plan Logical Optimize Optimize Physical Statistics Plan Feedback TiDB Distributed Data Executor Data Coprocessor Data TiKV PingCAP.com
9 .Part II - Query Optimizer
10 .Query Optimizer A Query Execution Plan Example: TiDB(root@127.0.0.1:test) > explain select count(*) from t1, t2 where t1.a=t2.a; +--------------------------+----------+------+---------------------------------------------------------------------+ | id | count | task | operator info | +--------------------------+----------+------+---------------------------------------------------------------------+ | StreamAgg_13 | 1.00 | root | funcs:count(1) | | └─MergeJoin_33 | 12500.00 | root | inner join, left key:test.t1.a, right key:test.t2.a | | ├─IndexReader_25 | 10000.00 | root | index:IndexScan_24 | | │ └─IndexScan_24 | 10000.00 | cop | table:t1, index:a, range:[NULL,+inf], keep order:true, stats:pseudo | | └─IndexReader_28 | 10000.00 | root | index:IndexScan_27 | | └─IndexScan_27 | 10000.00 | cop | table:t2, index:a, range:[NULL,+inf], keep order:true, stats:pseudo | +--------------------------+----------+------+---------------------------------------------------------------------+ 6 rows in set (0.00 sec) Ref: Understand the Query Execution Plan PingCAP.com
11 .Query Optimizer Find a reasonable plan in a reasonable time ● Operator Pushdown ● Access Path Selection ● Join Order/Algorithm Selection ● Subquery Evaluation ● ... PingCAP.com
12 .Query Optimizer/Try PointGet Plan For simple point get queries 1. unique_key = xx 2. Single table SELECT/UPDATE/DELETE Benefit 1. Reduce the query optimization overhead 2. The PointGet executor is also very efficient
13 .Query Optimizer/Try PointGet Plan Example: TiDB(root@127.0.0.1:test) > create table t(a double primary key, b double); Query OK, 0 rows affected (0.02 sec) TiDB(root@127.0.0.1:test) > insert into t values(1.1, 1.2), (2.1, 2.2), (3.1, 3.2); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 TiDB(root@127.0.0.1:test) > desc select * from t where a = 1.1; +-------------+-------+------+------------------+ | id | count | task | operator info | +-------------+-------+------+------------------+ | Point_Get_1 | 1.00 | root | table:t, index:a | +-------------+-------+------+------------------+ 1 row in set (0.00 sec)
14 .Query Optimizer Phase 1: Logical Optimization ● Logical ● Equal ● Beneficial What rules does TiDB have?
15 .Query Optimizer ● Column Pruning ● Outer Join Simplification ● Partition Pruning ● Subquery Decorrelation ● Group By Elimination ● Predicate Push Down ● Max/Min Eliminatation ● Aggregate Push Down ● Project Emination ● TopN/Limit Push Down ● Outer Join Elimination ● Join Reorder ● ...
16 .Query Optimizer/Max Min Elimination Convert a single Max to descending ordered scan TiDB(root@127.0.0.1:test) > desc select max(a) from t; +--------------------------+-------+------+--------------------------------------------------------------------------+ | id | count | task | operator info | +--------------------------+-------+------+--------------------------------------------------------------------------+ | StreamAgg_13 | 1.00 | root | funcs:max(test.t.a) | | └─Limit_17 | 1.00 | root | offset:0, count:1 | | └─IndexReader_34 | 1.00 | root | index:Limit_33 | | └─Limit_33 | 1.00 | cop | offset:0, count:1 | | └─IndexScan_32 | 1.00 | cop | table:t, index:a, range:[-inf,+inf], keep order:true, desc, stats:pseudo | +--------------------------+-------+------+--------------------------------------------------------------------------+ 5 rows in set (0.00 sec)
17 .Query Optimizer/Outer Join Elimination ● Parent operator only needs outer columns ● Join Key on inner side is unique select t1.* from t1 left join t2 on t1.a=t2.unique_key select * from t1;
18 .Query Optimizer/Outer Join Elimination ● Parent operator only needs outer columns ● Join Key on inner side is unique ● Parent only needs the distinct outer columns select sum(distinct t1.a) from t1 left join t2 on t1.b=t2.b group by t1.b; select sum(distinct t1.a) from t1;
19 .Query Optimizer/Subquery Decorrelation aggregate -> outer join TiDB(root@127.0.0.1:test) > desc select * from t1 where t1.a < (select sum(t2.a) from t2 where t2.b = t1.b); +------------------------------+----------+------+-----------------------------------------------------------------------------------------------------------+ | id | count | task | operator info | +------------------------------+----------+------+-----------------------------------------------------------------------------------------------------------+ | Projection_10 | 9990.00 | root | test.t1.a, test.t1.b | | └─HashLeftJoin_11 | 9990.00 | root | inner join, inner:HashAgg_21, equal:[eq(test.t1.b, test.t2.b)], other cond:lt(cast(test.t1.a), sum(t2.a)) | | ├─TableReader_15 | 9990.00 | root | data:Selection_14 | | │ └─Selection_14 | 9990.00 | cop | not(isnull(test.t1.b)) | | │ └─TableScan_13 | 10000.00 | cop | table:t1, range:[-inf,+inf], keep order:false, stats:pseudo | | └─HashAgg_21 | 7992.00 | root | group by:col_2, funcs:sum(col_0), firstrow(col_1) | | └─TableReader_22 | 7992.00 | root | data:HashAgg_16 | | └─HashAgg_16 | 7992.00 | cop | group by:test.t2.b, funcs:sum(test.t2.a), firstrow(test.t2.b) | | └─Selection_20 | 9990.00 | cop | not(isnull(test.t2.b)) | | └─TableScan_19 | 10000.00 | cop | table:t2, range:[-inf,+inf], keep order:false, stats:pseudo | +------------------------------+----------+------+-----------------------------------------------------------------------------------------------------------+ 10 rows in set (0.00 sec)
20 .Query Optimizer/Aggregate Push Down Push Aggregate through Join ● only beneficial when the aggregate can reduce the size of join table ● disabled by default, set tidb_opt_agg_push_down to 1 to enable it
21 .Query Optimizer/Aggregate Push Down TiDB(root@127.0.0.1:test) > desc select sum(t1.a) from t1 join t2 on t1.a=t2.a group by t1.a; +------------------------------+----------+------+----------------------------------------------------------------+ | id | count | task | operator info | +------------------------------+----------+------+----------------------------------------------------------------+ | HashAgg_11 | 8000.00 | root | group by:test.t1.a, funcs:sum(join_agg_0) | | └─HashRightJoin_13 | 10000.00 | root | inner join, inner:HashAgg_18, equal:[eq(test.t1.a, test.t2.a)] | | ├─HashAgg_18 | 8000.00 | root | group by:col_2, funcs:sum(col_0), firstrow(col_1) | | │ └─TableReader_19 | 8000.00 | root | data:HashAgg_14 | | │ └─HashAgg_14 | 8000.00 | cop | group by:test.t1.a, funcs:sum(test.t1.a), firstrow(test.t1.a) | | │ └─TableScan_17 | 10000.00 | cop | table:t1, range:[-inf,+inf], keep order:false, stats:pseudo | | └─TableReader_23 | 10000.00 | root | data:TableScan_22 | | └─TableScan_22 | 10000.00 | cop | table:t2, range:[-inf,+inf], keep order:false, stats:pseudo | +------------------------------+----------+------+----------------------------------------------------------------+ 8 rows in set (0.00 sec)
22 .Query Optimizer/TopN Limit Push Down Push it through Outer Join TiDB(root@127.0.0.1:test) > desc select * from t1 left outer join t2 on t1.a=t2.a order by t1.a limit 3; +------------------------------+----------+------+-------------------------------------------------------------------------+ | id | count | task | operator info | +------------------------------+----------+------+-------------------------------------------------------------------------+ | TopN_12 | 3.00 | root | test.t1.a:asc, offset:0, count:3 | | └─HashLeftJoin_16 | 3.75 | root | left outer join, inner:TableReader_31, equal:[eq(test.t1.a, test.t2.a)] | | ├─TopN_17 | 3.00 | root | test.t1.a:asc, offset:0, count:3 | | │ └─TableReader_25 | 3.00 | root | data:TopN_24 | | │ └─TopN_24 | 3.00 | cop | test.t1.a:asc, offset:0, count:3 | | │ └─TableScan_23 | 10000.00 | cop | table:t1, range:[-inf,+inf], keep order:false, stats:pseudo | | └─TableReader_31 | 10000.00 | root | data:TableScan_30 | | └─TableScan_30 | 10000.00 | cop | table:t2, range:[-inf,+inf], keep order:false, stats:pseudo | +------------------------------+----------+------+-------------------------------------------------------------------------+ 8 rows in set (0.01 sec)
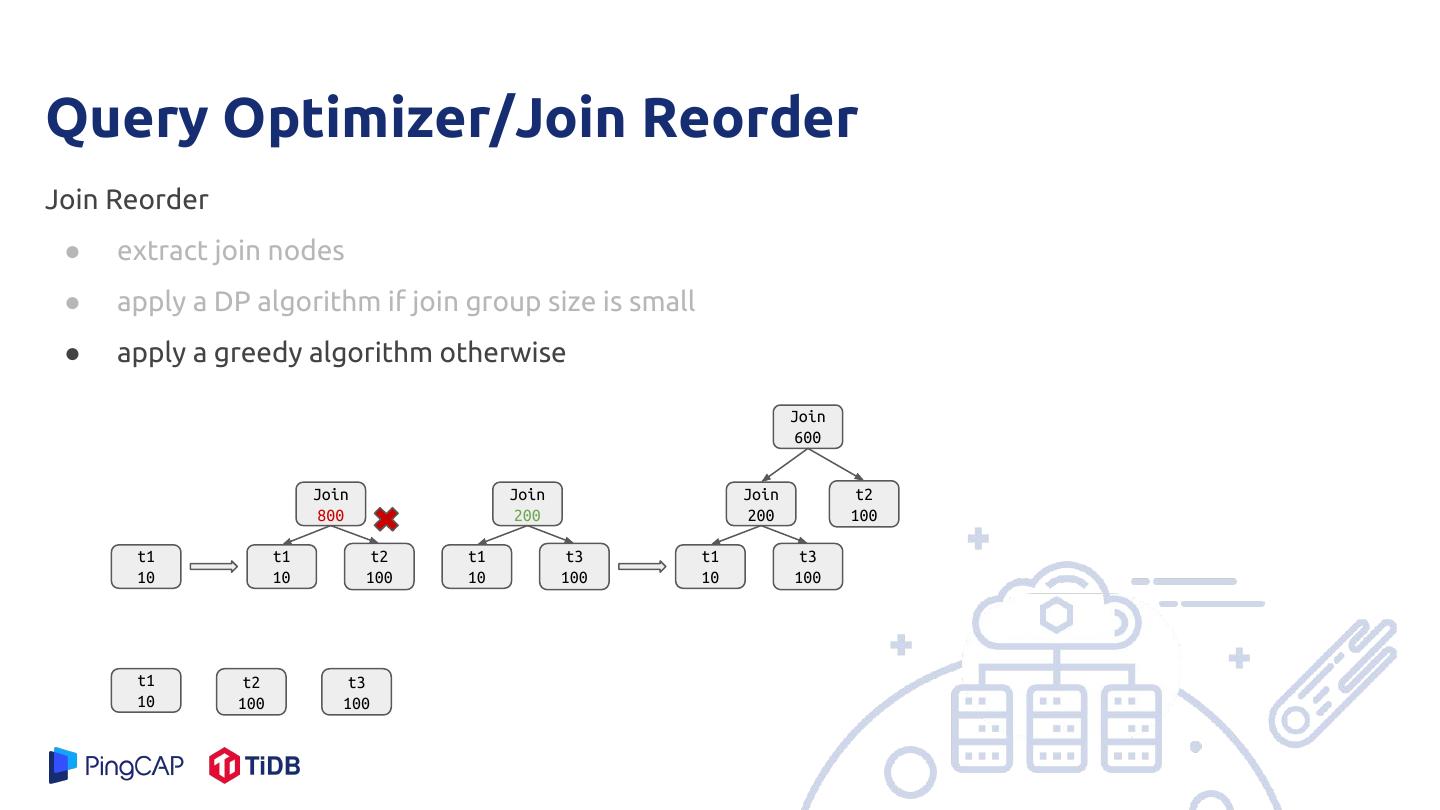
23 .Query Optimizer/Join Reorder Join Reorder ● extract join nodes
24 .Query Optimizer/Join Reorder Join Reorder ● extract join nodes ● apply a DP algorithm if join group size is small use bitmask to represent join nodes 1. 6(110) represents a join group with node 1 and 2 2. f[6] represents the best join order for join group {1, 2} 3. f[group] = min{join(f[sub], f[group-sub])}
25 .Query Optimizer/Join Reorder Join Reorder ● extract join nodes ● apply a DP algorithm if join group size is small ● apply a greedy algorithm otherwise Join 600 Join Join Join t2 800 200 200 100 t1 t1 t2 t1 t3 t1 t3 10 10 100 10 100 10 100 t1 t2 t3 10 100 100
26 .Query Optimizer Phase 1: Logical Optimization Phase 2: Physical Optimization
27 .Query Optimizer Physical Property: ● task type ● data order ● data distribution(not implemented yet) A Dynamic Programming Progress: ● (Logical Plan, Required Physical Property) -> Physical Plan ● A top-down search approach ● Memorization the search result
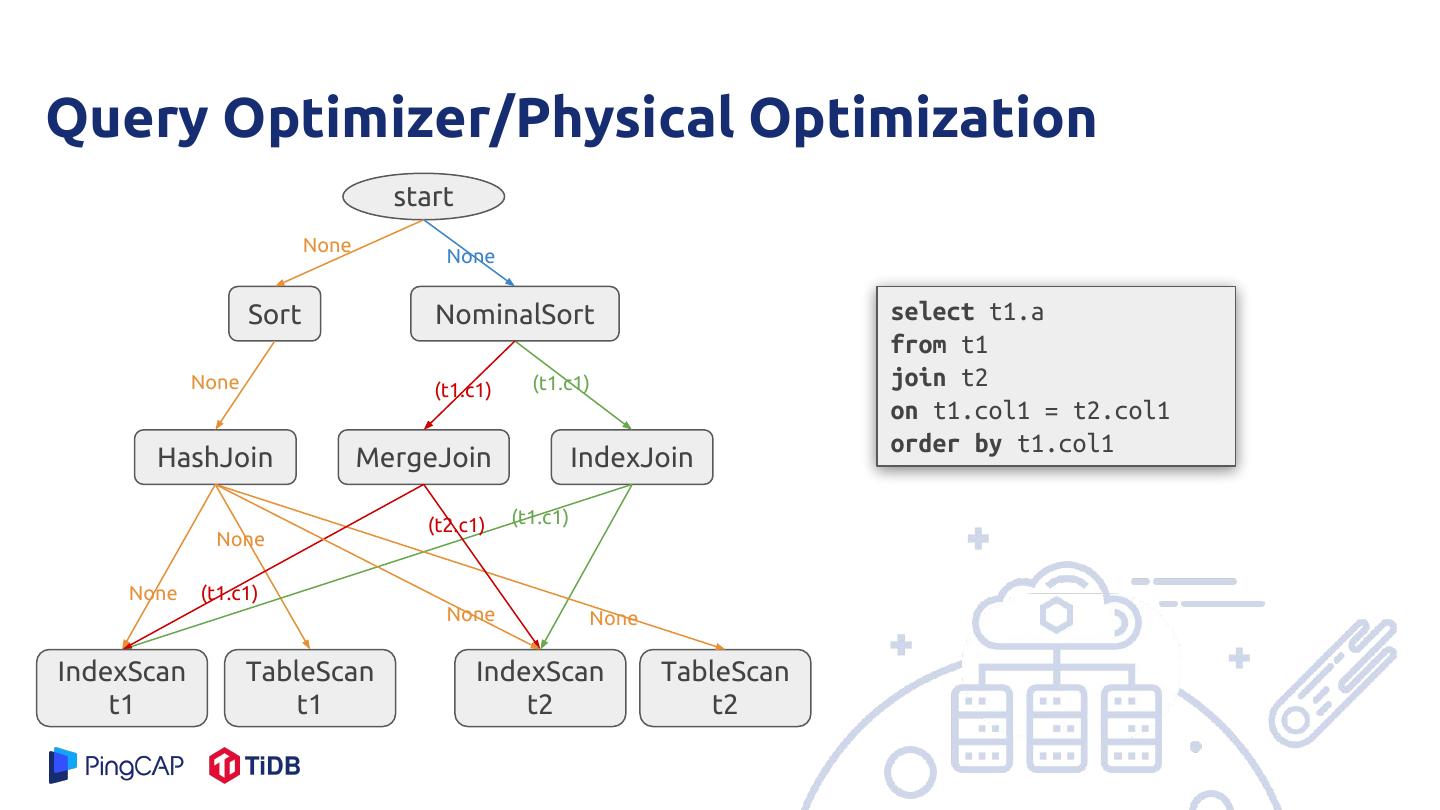
28 .Query Optimizer/Physical Optimization start None None Sort NominalSort select t1.a from t1 None (t1.c1) (t1.c1) join t2 on t1.col1 = t2.col1 order by t1.col1 HashJoin MergeJoin IndexJoin (t2.c1) (t1.c1) None None (t1.c1) None None IndexScan TableScan IndexScan TableScan t1 t1 t2 t2
29 .Query Optimizer/Physical Optimization select a Skyline Index Pruning from t where t.a = 1 ● is order property satisified? and t.b = 2 ● is single or double scan? order by t.a ● how many index columns are covered? Access Path Chossen ● idx1(a) ● idx2(a, b)
3秒后跳转登录页面
去登陆

