






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Druid精确去重的设计与实现
Druid在快手落地近一年时间,支持了公司绝大部分OLAP分析需求。为了保障性能,稳定性,功能性等要求,快手对Druid内核进行大量改进,建设周边系统,以及开发新feature。本次分享主要介绍快手Druid精确去重功能的设计与实现,以及部分实用功能的改进。
展开查看详情
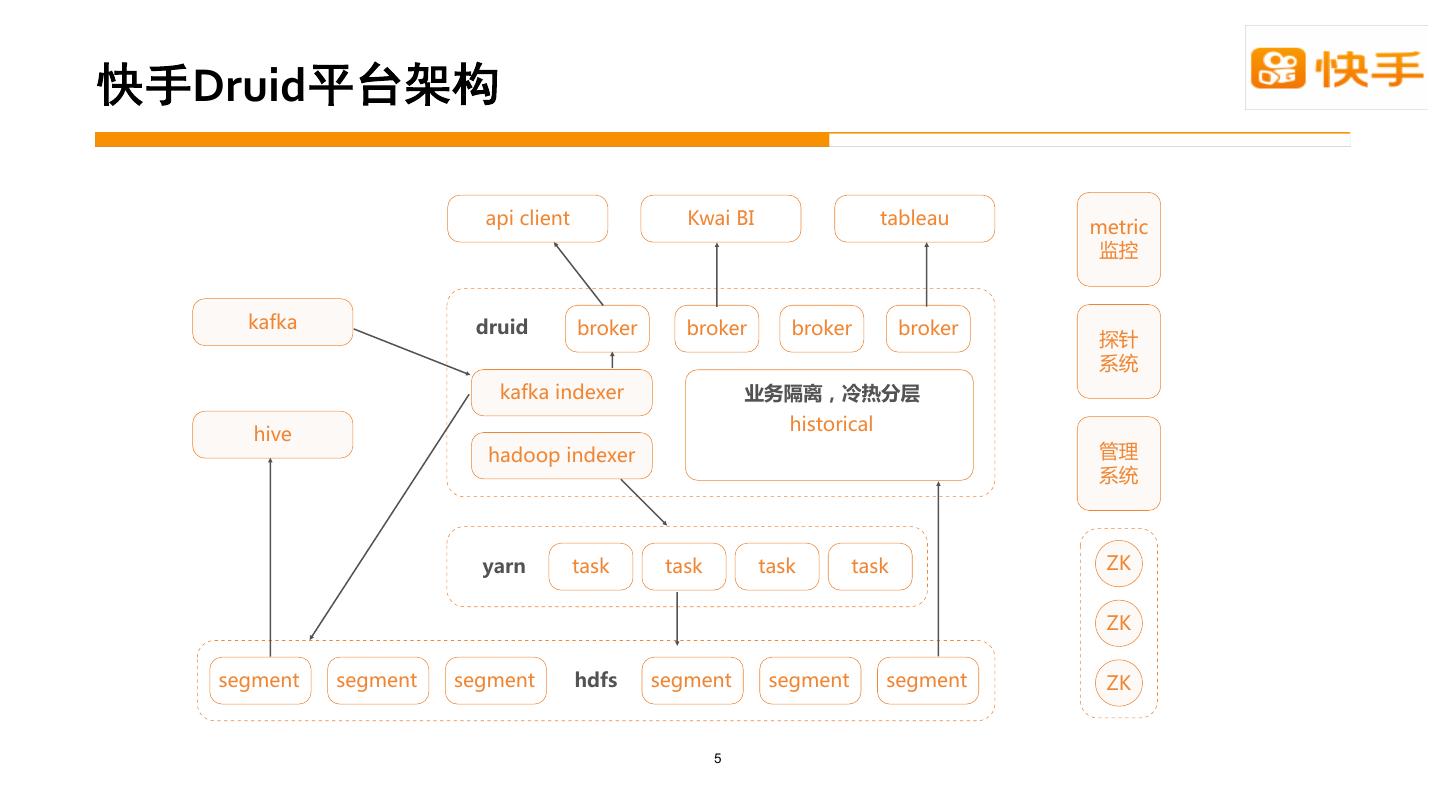
1 .Druid 3 26 1 9 - 0
2 .n n n Druid n OLAP n hadoop/kylin/druid contributor 2
3 .o Druid o Druid o Druid o Druid Roadmap o Q&A 3
4 .0 c a d Q L d LD d d d D d S 1d 1d + / 1 + 4
5 .Druid 5
6 .Druid o n cardinality agg, , hll, hash cpu n group by n DistinctCount p hash partition p interval o n HyperUniques/Sketch: hll cardinality agg o 10
7 . -hashset Year City o 2016 bejing Year distinct City n o 2016 shanghai segment1 2016 {beijing,shanghai} n 2017 beijing 2017 chongqing segment2 2017 {beijing, chongqing} o n Shard & no merge n Shuffle o Druid {beijing,shanghai,chongqing}.size()=3 5000W String, 10B, 500MB, HashSet 5G 11
8 . - +bitmap City int Year City beijing 1 o 2016 bejing shanghai 2 n , 2016 shanghai chongqing 3 n n Kylin 2017 beijing 2017 chongqing o Year distinct City n segment1 2016 {1,2} n segment2 2017 {1, 3} o {1,2,3}.size()=3 42 , bitmap max 500M 12
9 . -Redis o n o n Id POC: 5w/s n n Redis 13
10 . - MR o n n o n o n MR n int 14
11 . - AppendTrie o KYLIN AppendTrie o ALL AS STRING o Append n id n id 15
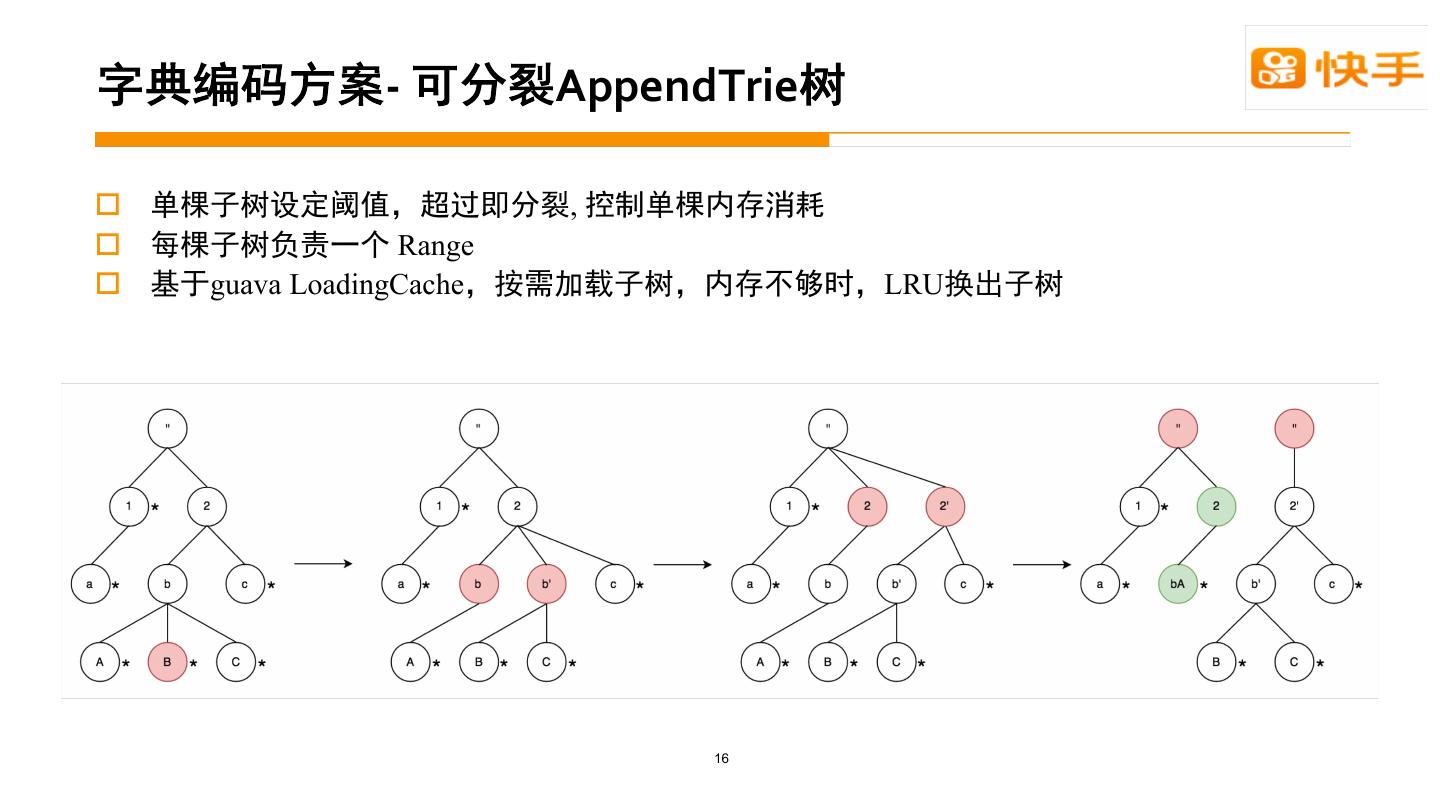
12 . - AppendTrie o , o Range o guava LoadingCache LRU 16
13 . - o MVCC( hdfs ) n n working n n TTL o zookeeper n n DataSourceName+ColumnName 17
14 . - unique o ComplexMetricSerde n Serde o Aggregator n o BufferAggregator n Aggregator Aggregator Buffer o AggregatorFactory n n Aggregator 18
15 . - o DetermineConfigurationJob DetermineConfigurationJob ZK n segment BuildDictJob map map map o BuildDictJob n Map reducer reduce reduce p Map combine HDFS n reducer /dict/ds1/column1 n ZK /dict/ds1/column2 o IndexGeneratorJob IndexGeneratorJob n Map int map map map n Reducer int, bitmap n reducer segment reduce reduce Segments files 19
16 . - o unique o unique o issue:6716 20
17 .o (UHC) n IndexGenerator ClusterBy UHC n map uhc o n DataSource n IndexGenerator map 21
18 .bitmap o targetPartitionSize numShards n segment o batchOr or n I/O or cache line miss n batchOr p inplace or p naive_or p priorityqueue_or , bitmap benchmark 22
19 .bitmap -Croaring JNI o Croaring- high performance low-level implementation n Simd (avx2) n java 80% o 100w bitmap or n Java 13s n JNI Croaring: memcpy 6.5s+ 7.5s=14s n Croaring ImmutableRoaringBitmap inplace 23
20 .o Broker Historical HTTP gzip plain json gzip, cpu gzip 24
21 .o 8 author_id 10 150w o 10 historical Segment base 1 50s targetPartitionSize=15w 10 7s batchOr 10 4s gzip 10 2s 25
22 . 0 0 D 3 D ) 3 ) 3 ) 3 ( ( ( 3 D ) 3 ) 3 ) 3 3 ( ( ( 27
23 .- 28
24 . - issue:6715 segment: hour query: minute segment: hour query: hour segment: day query: day 29
25 . - DataSource p99 p99 ds1 16% 33% 5s->2s 150% ds2 3% 60% 6s->2s 200% ds3 28% 99% 10s->5s 100% ds4 1% 99% 8s->1s 700% ds5 1% 95% 3s->0.3s 900% 30
26 . Historical o 12 * 2T SATA HDD (10w segments 10TB size) o druid.segmentCache.lazyLoadOnStart (pr: 6988) n Guava Suppliers.memoize n 40min -> 2min 20X faster before after 31
27 .Kafka index - taskCount o Kafka index taskCount n KafkaSupervisor DynamicTaskCountNotice n task cpu use& kafka lag 25% taskCount n supervisor 32
28 .Kafka index – o Middle Manager indexing task slot n Kafka indexing task Hadoop indexing task n task task 33
29 .o Overlord MySQL n druid_segments (dataSource, used, end) n 10s -> 1s o Coordinator MySQL n Segments p coordinator druid_segments p druid_segments (used,created_date) p 1.7min -> 30ms n p segment TreeSet load segment ConcurrentHashSet 1 set p apply rules LoadRule p cleanup overshadow p 3min -> 30s 34
3秒后跳转登录页面
去登陆

