Spark生态圈——大数据领跑者
分享
点赞
1
收藏
1
下载 7
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
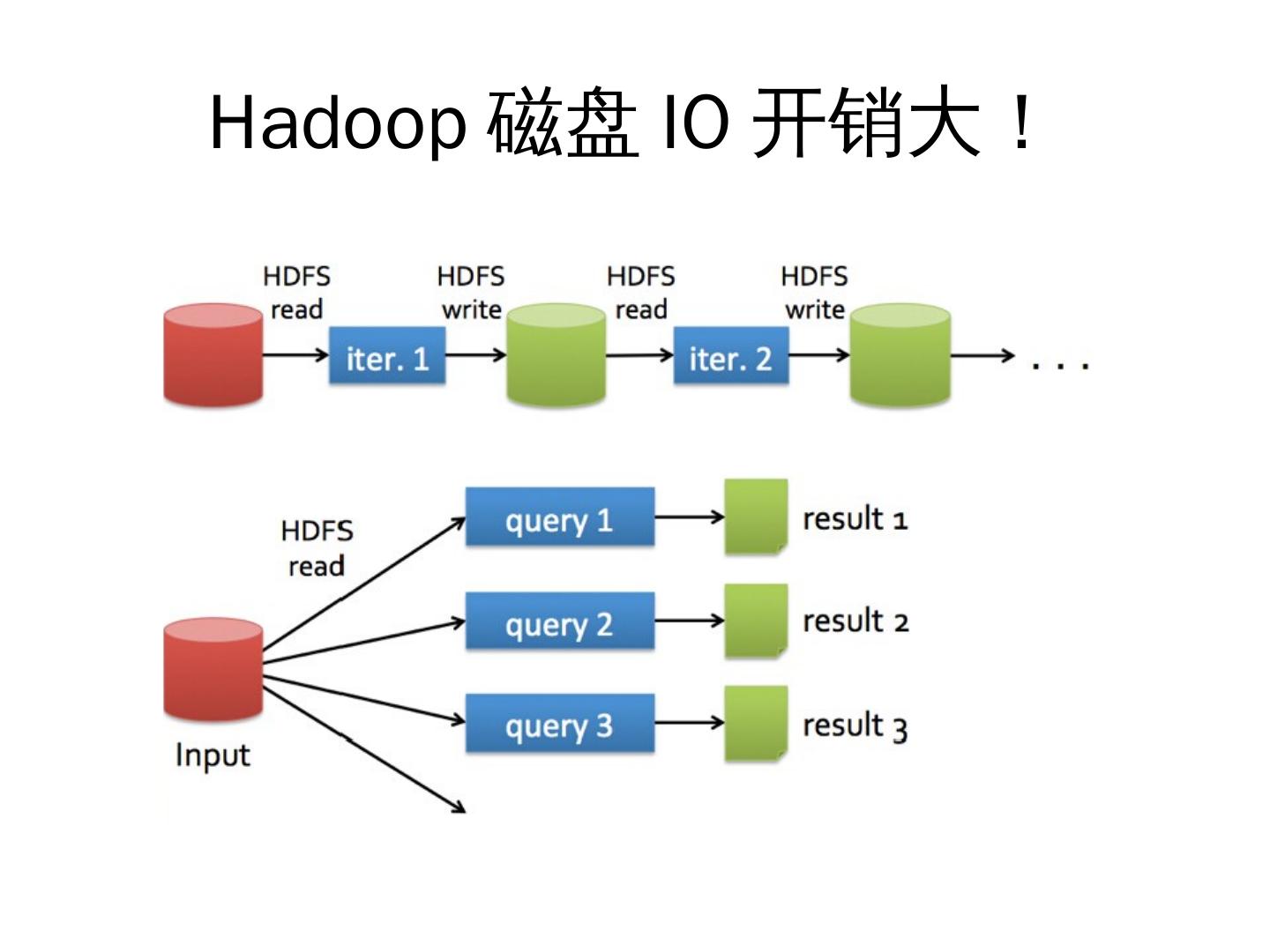
随着时代的潮流,传统的分布式已经无法满足现在的数据处理要求,Hadoop的磁盘IO开销很大,对比Spark,计算内存快,支持scala,Java,Python三种语言,良好的容错性,一栈式处理,都远远的提升了数据处理的性能。
展开查看详情
1 .Spark 生态圈——大数据领跑
者
报告人:岳灵茜
�
2 .• Spark
• GraphX (重点)
• SparkStreaming
�
3 . 时代的需要—— spark 家族
• 随着人们对计算速度和规模的要求不断扩
大,以及数据挖掘,机器学习,大规模图
算法等的兴起,当前单机的计算能力已经
远远不能满足人们的需求。
• 传统的分布式计算的复杂的编程接口,困
难的调试,无法容错
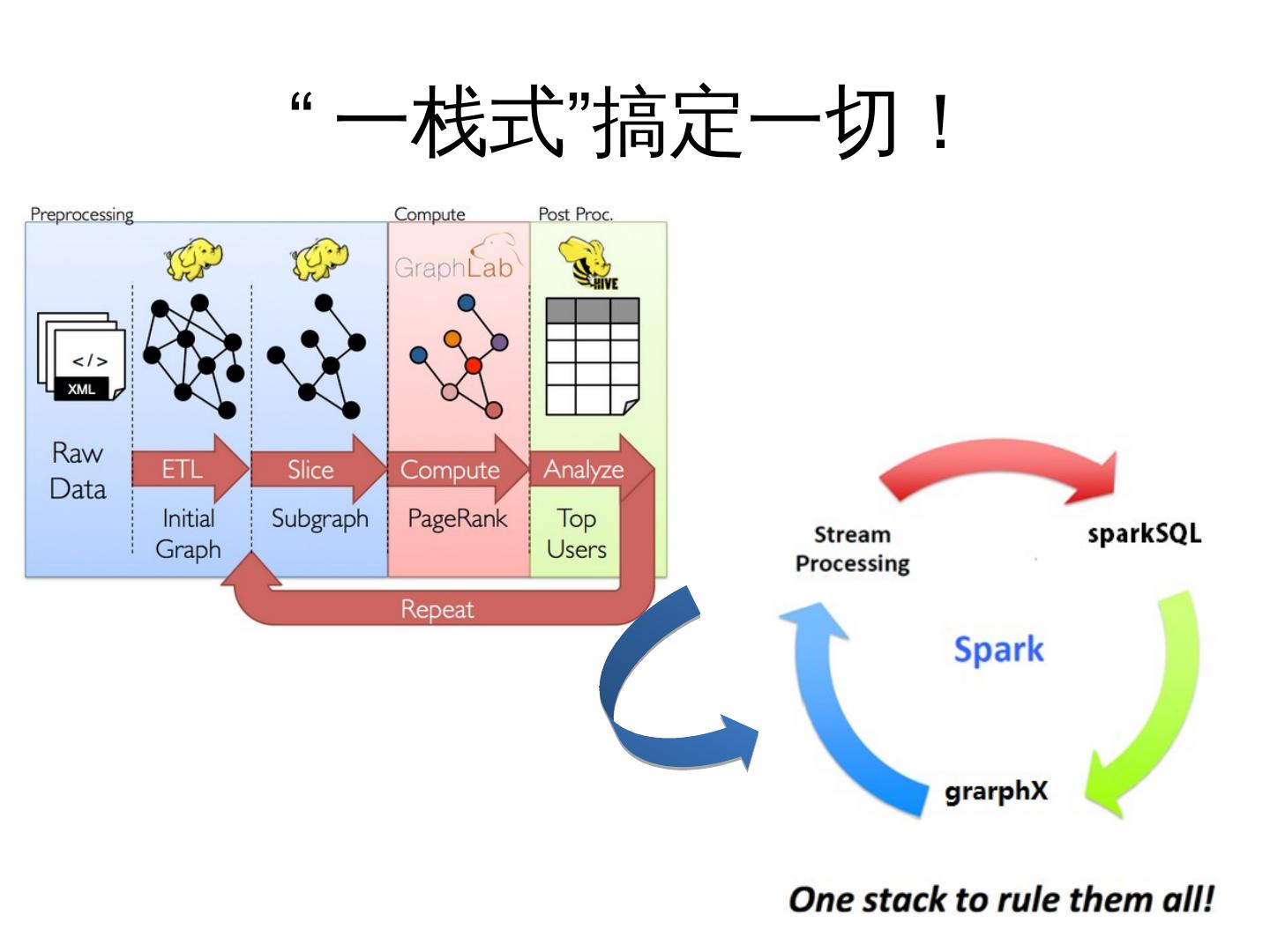
• 无法“一栈式”处理
�
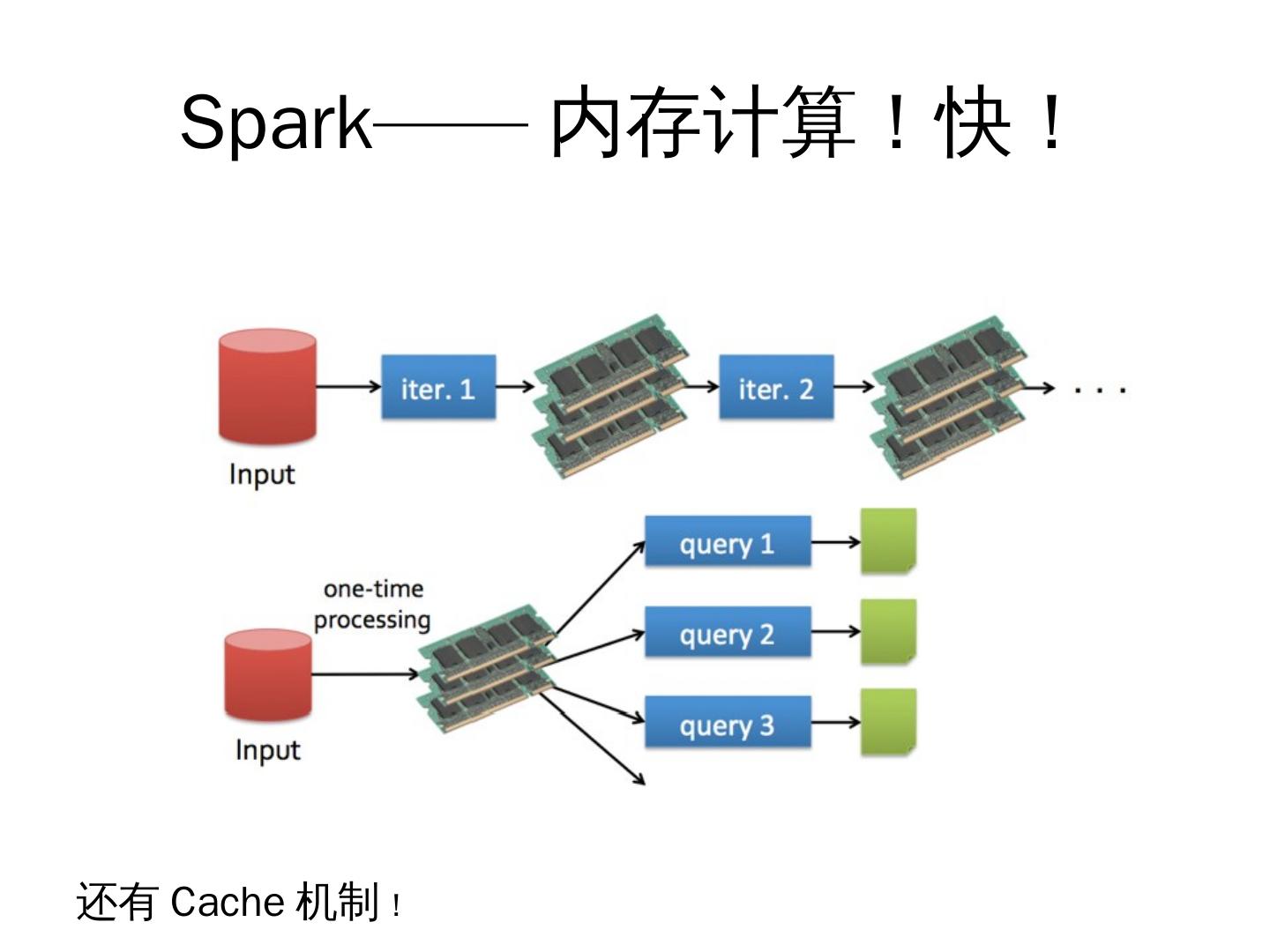
5 . Spark—— 内存计算!快!
还有 Cache 机制!
�
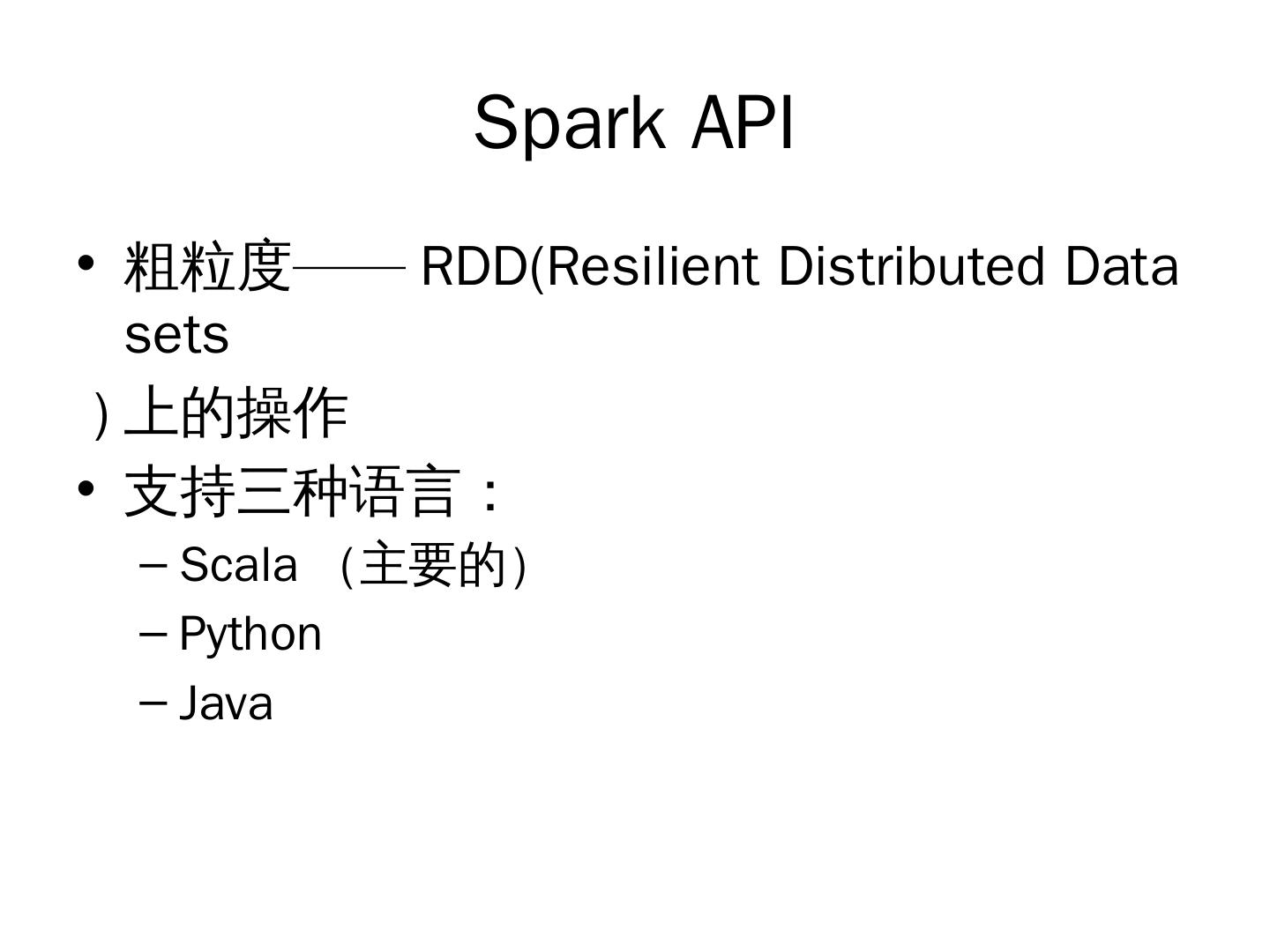
6 . Spark API
• 粗粒度—— RDD(Resilient Distributed Data
sets
) 上的操作
• 支持三种语言:
– Scala (主要的)
– Python
– Java
�
7 .Spark 编程接口(举例说明)
Transformations Action
• map(func)
• filter(func) • reduce(func)
• union(otherDataset) • collect()
• reduceByKey(func, [numT • count()
asks])
• foreach(func)
• repartitionAndSortWithi
nPartitions(partitioner)
�
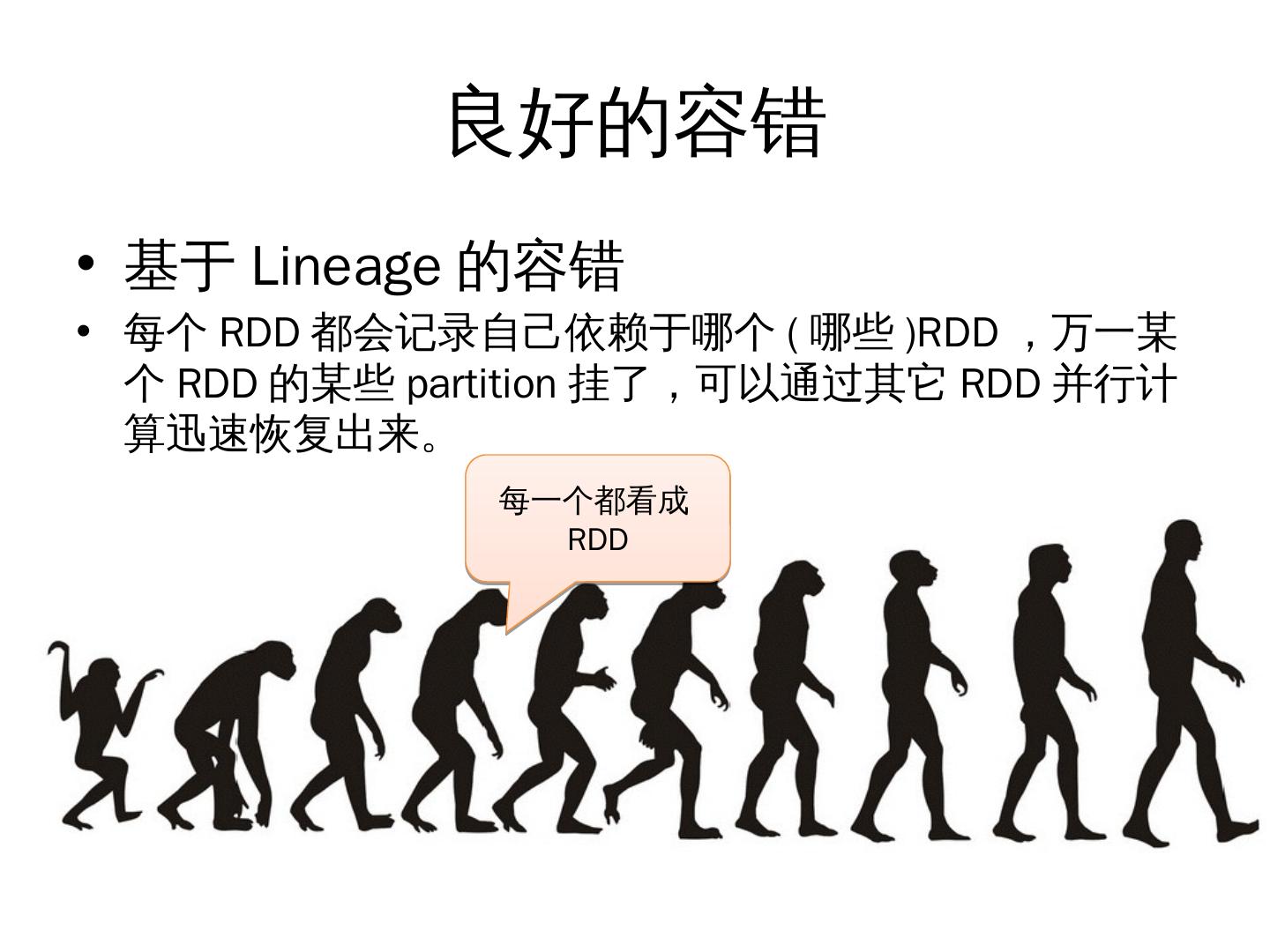
9 . 良好的容错
• 基于 Lineage 的容错
• 每个 RDD 都会记录自己依赖于哪个 ( 哪些 )RDD ,万一某
个 RDD 的某些 partition 挂了,可以通过其它 RDD 并行计
算迅速恢复出来。
每一个都看成
RDD
�
10 . 到底什么是 RDD ?
• Resilient Distributed Dataset 弹性分布式数
据集
• 每个 RDD 对象包含如下信息:
– 分区
– 依赖
– 函数
– 最佳位置 ( 可选 )
– 分区策略 ( 可选 )
�
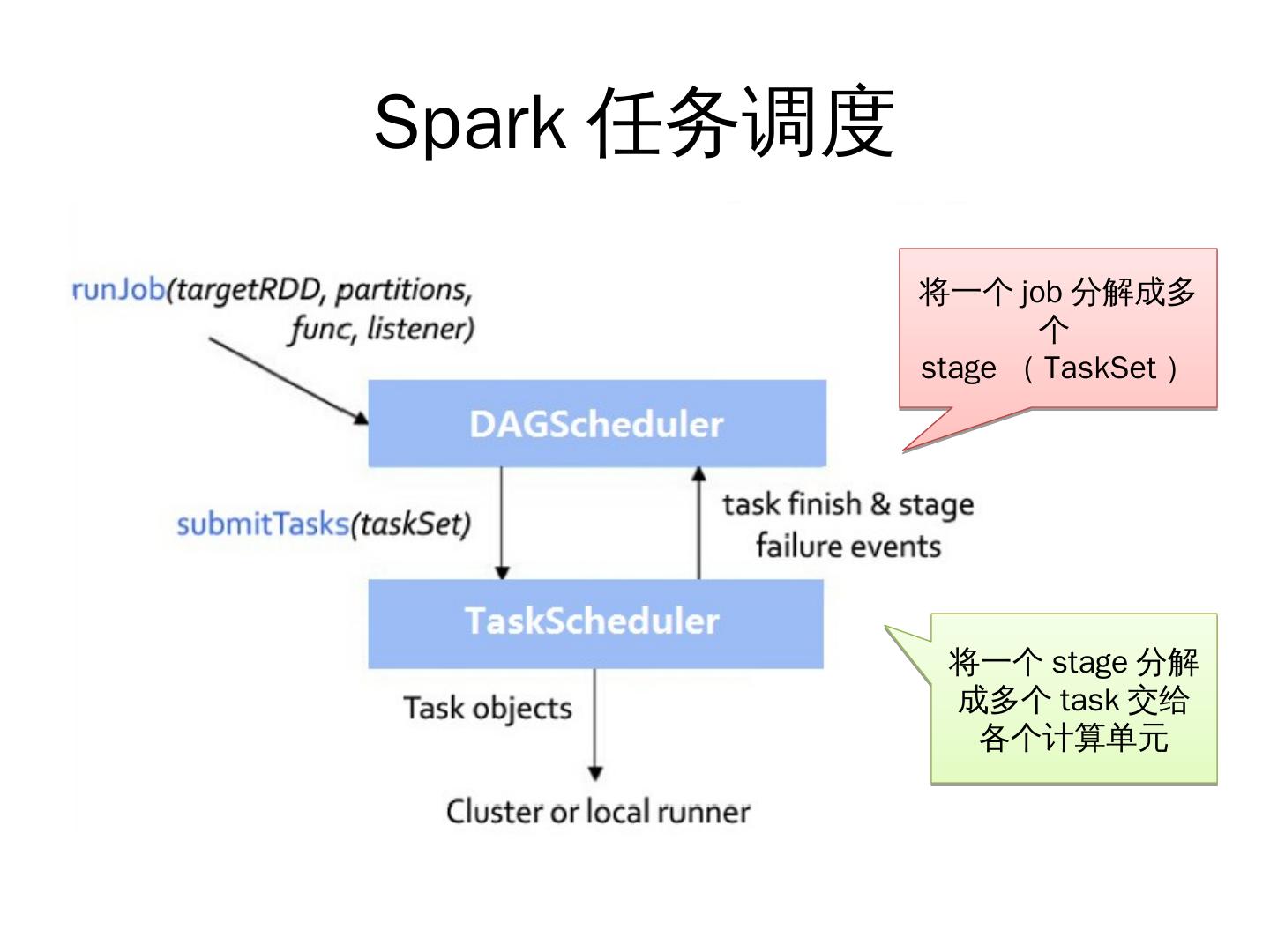
11 .Spark 任务调度
将一个 job 分解成多
个
stage ( TaskSet )
将一个 stage 分解
成多个 task 交给
各个计算单元
�
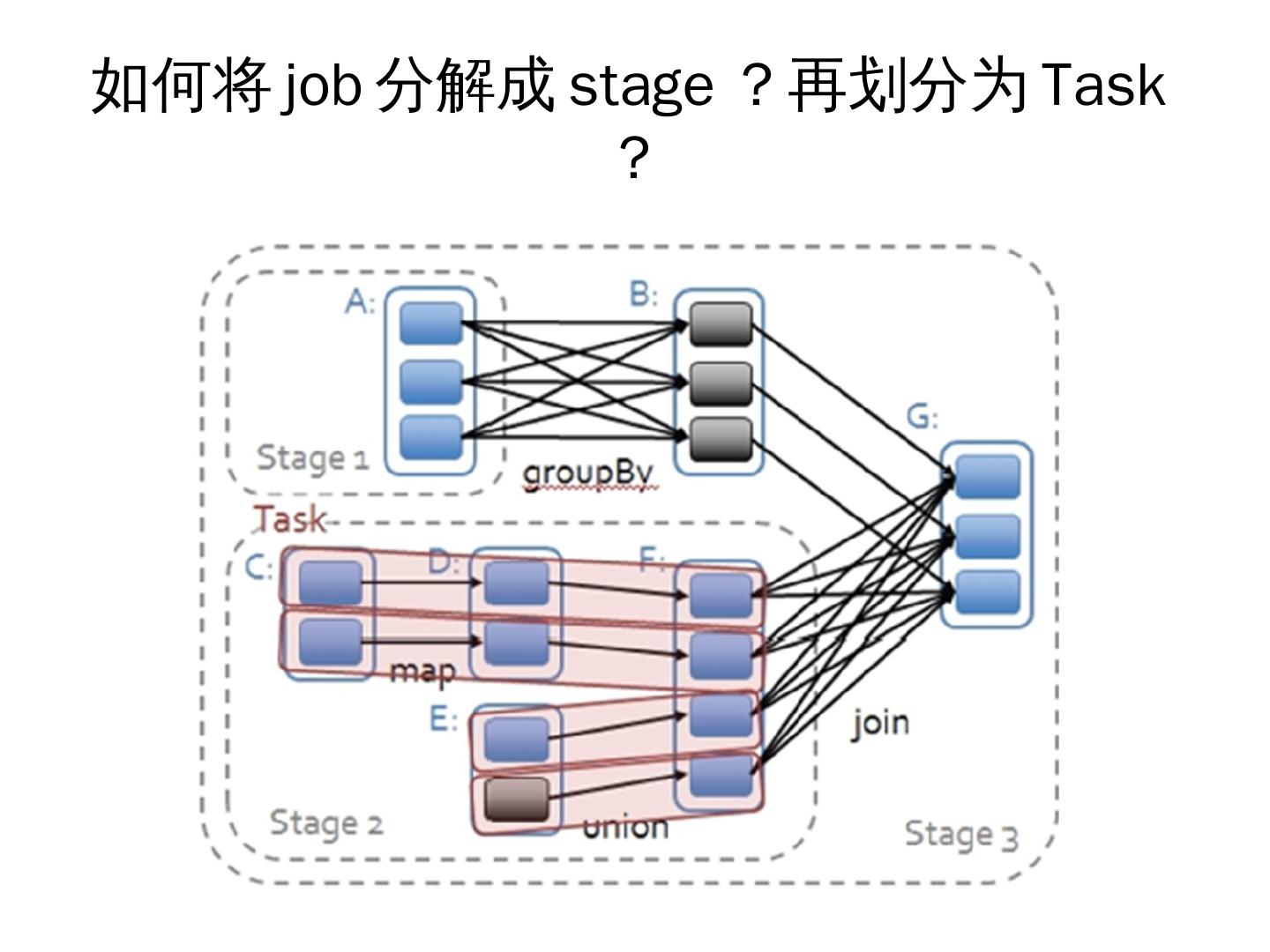
12 .如何将 job 分解成 stage ?再划分为 Task
?
�
13 . Spark 组件
• GraphX—— 图计算
• SparkStreaming—— 流式处理
• SparkSQL——Hive on spark
• MLlab—— 机器学习
�
14 . GraphX—— 图数据的并行计算
• GraphX 是一个新的 sparkAPI 为图和图的并
行计算而准备的
• 其前身为 Bagel—— 即为 spark 能支持 pre
gel 而提供的一套 API
�
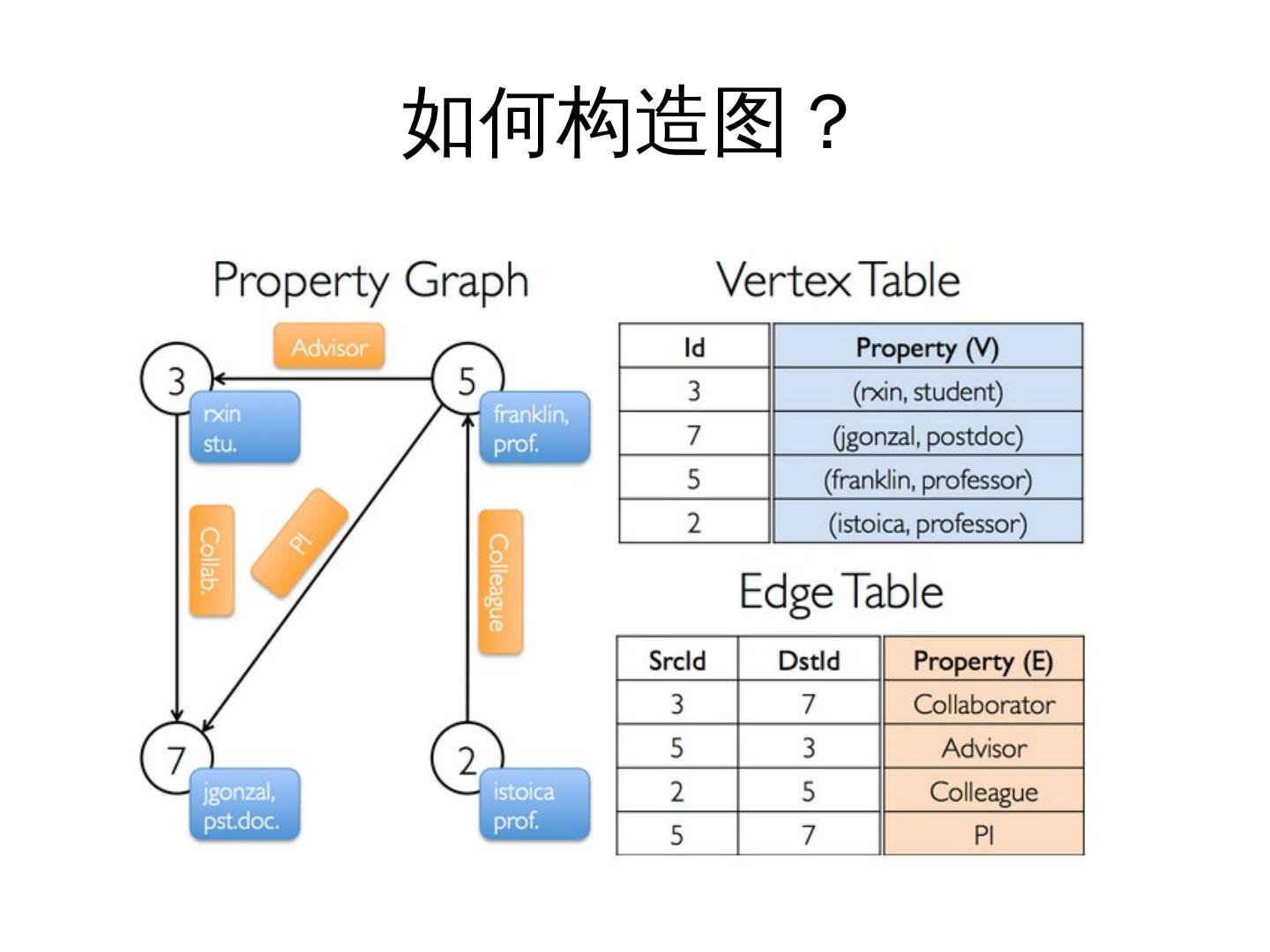
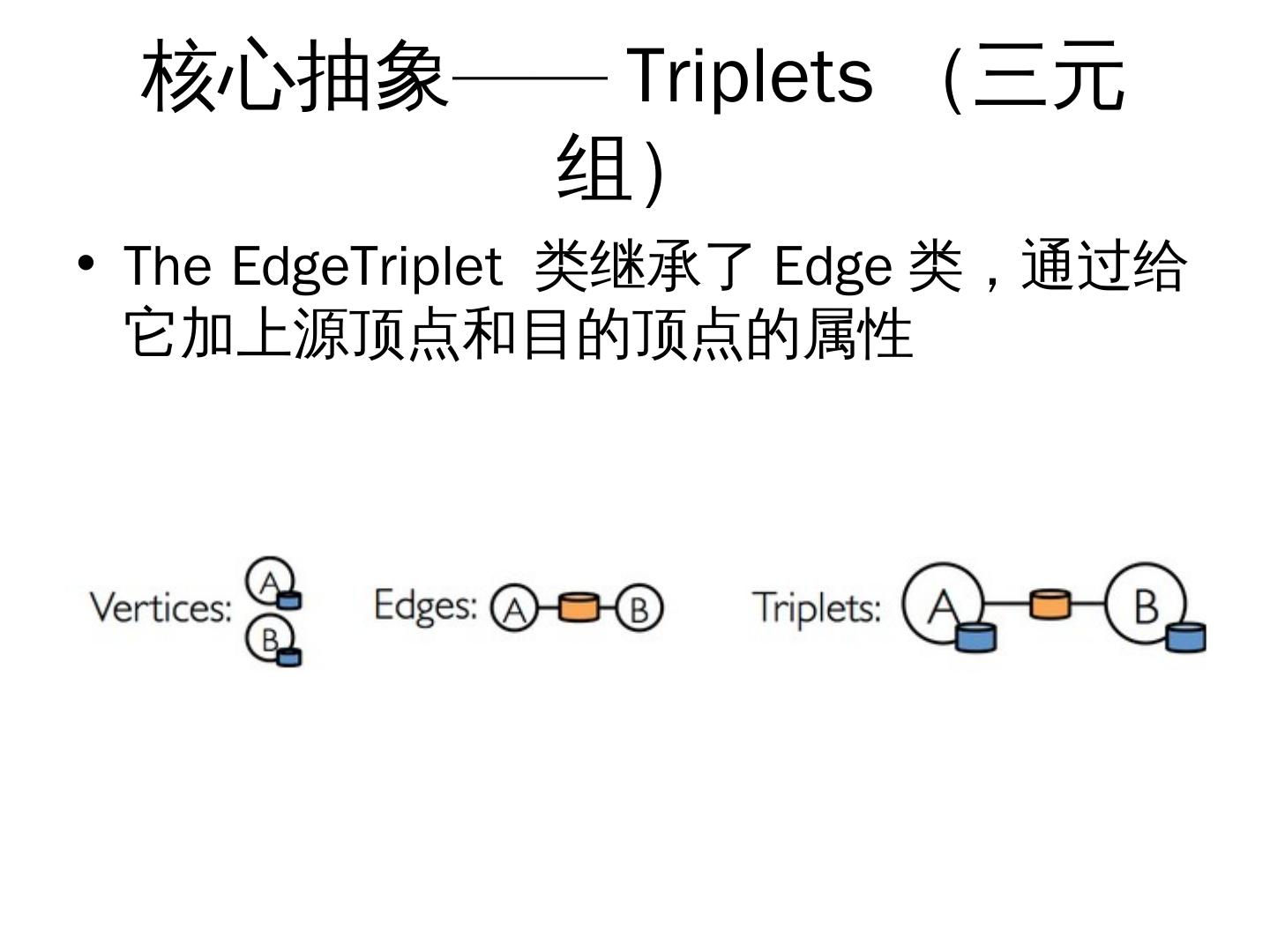
16 . 核心抽象—— Triplets (三元
组)
• The EdgeTriplet 类继承了 Edge 类,通过给
它加上源顶点和目的顶点的属性
�
17 . 对图的操作
• GraphX 提供了多种类型的操作:
– Information about the Graph
– Views of the graph as collections
– Functions for caching graphs
– Change the partitioning heuristic
– Transform vertex and edge attributes
– Modify the graph structure
– Join RDDs with the graph
– Aggregate information about adjacent triplets
– Iterative graph-parallel computation
– Basic graph algorithms
�
18 . 对传统计算框架的支持
• 为了便于编程, GraphX 提供了对传统框架
编程接口的支持
• 例如 Map-Reduce 和 Pregel
�
19 . Spark 对 Pregel 的支持
• Pregel 是 Google 提出的一个用于分布式图计
算的计算框架
• 从高层次看 Pregel 是 BSP 模型,就是“计算” -
“ 通信” -“ 计算”模式
– 作用于每个顶点的处理逻辑 vertexProgram
– 消息发送,用于相邻节点间的通讯 sendMessage
– 消息合并逻辑 messageCombining
• Spark 对 pregel 的支持—— GraphOps. pregel
方法
�
20 . 例子
• 以下是计算单源最短路径程序的片段
�
21 . Spark 对 MapReduce 的支持
• 对图的每一个 triplets 执行传入的 map 函数
和 reduce 函数
• GraphOps 类的 aggregateMessages 方法
�
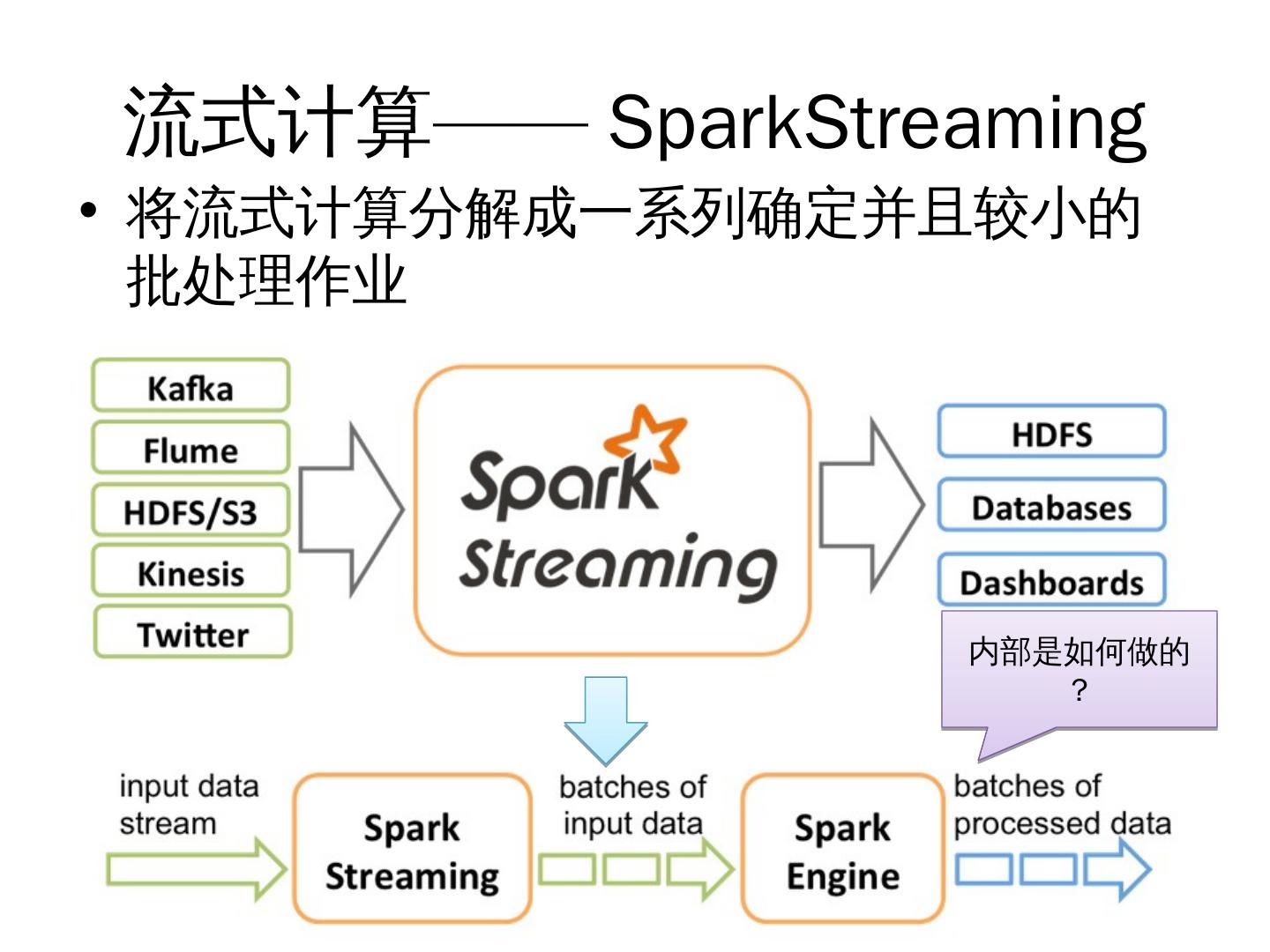
23 .流式计算—— SparkStreaming
• 将流式计算分解成一系列确定并且较小的
批处理作业
内部是如何做的
?
�
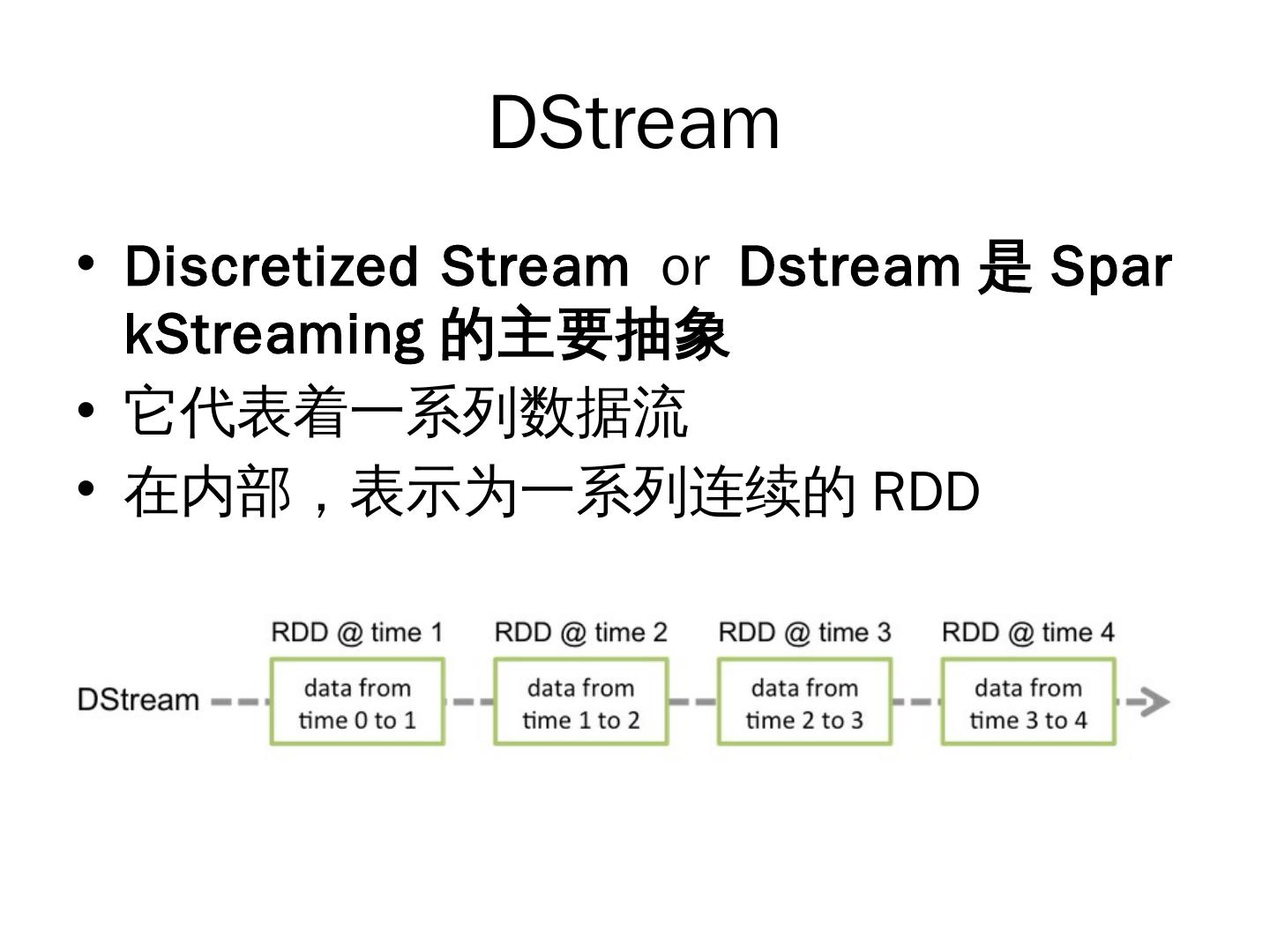
24 . DStream
• Discretized Stream or Dstream 是 Spar
kStreaming 的主要抽象
• 它代表着一系列数据流
• 在内部,表示为一系列连续的 RDD
�
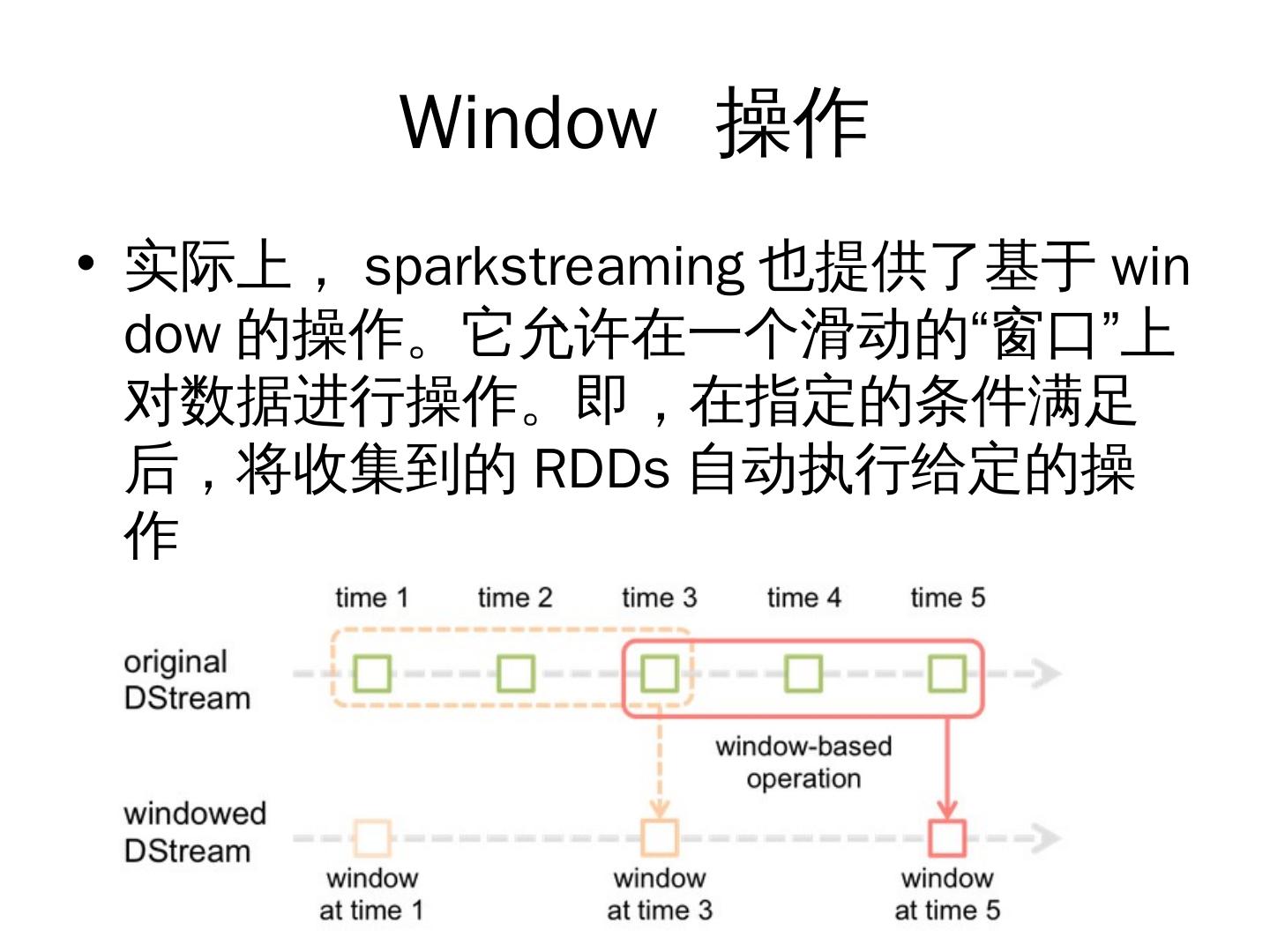
25 . Window 操作
• 实际上, sparkstreaming 也提供了基于 win
dow 的操作。它允许在一个滑动的“窗口”上
对数据进行操作。即,在指定的条件满足
后,将收集到的 RDDs 自动执行给定的操
作
�
26 . 数据的输入
• 数据的获取
– 支持从不断增加的文件中获取(本地或 HDF
S)
– 支持从网络中获取
�