











































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
09 Tapestry——用于服务部署的弹性全球范围覆盖
本篇文档主要介绍了Tapestry——用于服务部署的弹性全球范围覆盖,具体介绍了什么是Tapestry、什么是DOLR、问题的背景、DOLR网络API的四部分、路由与对象定位、路由网、在路由网格中提供弹性、对象发布和定位、动态节点算法、结点插入、组件体系结构、评价、稳定Tapestry上的微基准测试等知识。
展开查看详情
1 .Tapestry:A Resilient Global- Scale Overlay for Service Deployment Zhao, Huang, Stribling, Rhea, Joseph, Kubiatowicz Presented by Rebecca Longmuir
2 .What is Tapestry? A peer-to-peer overlay routing infrastructure offering efficient, scalable, location- independent routing of message directly to nearby copies of an object or service using only localized resources. An extensible infrastructure that provides decentralized object location and routing(DOLR)
3 .What is DOLR? Interface focusing on routing of message to endpoints such as nodes or object replicas. Virtualizes resources, since endpoints are named by opaque identifiers encoding nothing about physical location Allows for message delivery in instable underlying infrastructure. Developers only need to think about the dynamics of the network for optimization
4 .Some background Nodes participate in the overlay and are assigned nodeIDs uniformly at random from a large identifier space. More than one node maybe be on one physical host. Application-specific endpoints are assigned globally unique identifiers(GUIDs) select from the same identifier space.
5 .More background NodeN has nodeID Nid and an object O has GUID OG. Every message contains an application- specific identifier Aid
6 .Four part DOLR networking API PUBLISHOBJECT(OG,Aid): Publish or make available, object O on the local node. This is a best effort call and receives no confirmation UNPUBLISHOBJECT(OG,Aid): Best effort attempt to remove location mappings for O ROUTETOOBJECT(OG,Aid): Routes message to location of object with GUID OG ROUTETONODE(N,Aid,Exact): Routes message to application Aid on node N. “Exact” specifies whether destination ID needs to be matched exactly to deliver payload
7 .Routing and Object Location Tapestry dynamically maps each identifier G to an Unique live node called the identifier's root GR If node N exists with Nid = G then this is the root of G Messages are delivered by using a routing table consisting of nodeIDs and IP addresses of nodes it communicates with referred to as neighbors. Routing involves sending messages forward across neighbor links to nodes whose nodeIDs are progressively closer
8 .Routing Mesh Tapestry uses local tables at each node, called neighbor maps, to route overlay messages to the destination ID digit by digit A node N has a neighbor map with multiple levels, where each level contains links to nodes matching a prefix up to a digit position in the ID and contains a number of entries equal to the ID’s base
9 .Routing Mesh The primary ith entry in the jth level is the ID and location of closest node that begins with the prefix(N,j-1)+i for example the 3259 is the ninth entry of the fourth level for 325AE It is this idea of closest node that proves the locality properties of Tapestry
10 .Routing Mesh Since the nth hop shares a prefix of length >=n with the destination node, Tapestry looks in the (n+1)th level map for the entry matching the next digit in the destination ID This guarantees that any existing node is reached in at most logBN logical hops where N is the namespace size and the IDs are of base B and assuming consistent neighbor maps. If a digit cannot be matched than Tapestry looks for a close digit using ‘surrogate routing’ where each nonexistent ID is mapped to some live node with a similar ID
11 .Providing resilience in the Routing Mesh Make use of redundant routing paths Each Primary neighbor is augmented by backup links sharing the same prefix There are c x B pointers on a level(c is the number of neighbor links that differ only at the nth digit on the nth routing level) The total size of the neighbor maps is c x B x logBN The expected total number of back pointers is c x B x logBN
12 .Object Publication and Location Eachroot node inherits a unique spanning tree for routing Thisis utilized to locate objects by sending out soft-state directory information across nodes
13 .Object Publication and Location A server S, storing an object O periodically publishes this object by routing a publish message toward OR Each node along the publication path stores a pointer mapping For replicas of an object that are on separate sever each server publishes its copy Node location is stored for replicas in sorted order of network latency
14 .Object Publication and Location A client locates an object by routing a message to OR Each node checks to see if it has location map for the object If a node has a location map it send the request to the servicing node S, otherwise, it sends the message onward to OR
15 .Object Publication and Location Each hop toward the root reduces the number of nodes satisfying the next hop prefix constraint by a factor of the identifier base The path to the root is a function of the destination ID only not the source ID The closer a query gets to the object the more likely it is to cross the paths with the objects published path and the sooner it will reach the object
16 .Dynamic Node Algorithms Thereare many mechanisms in place to maintain consistency and to make sure objects are not lost Many of the control messages require acknowledgments and are retransmitted as needed
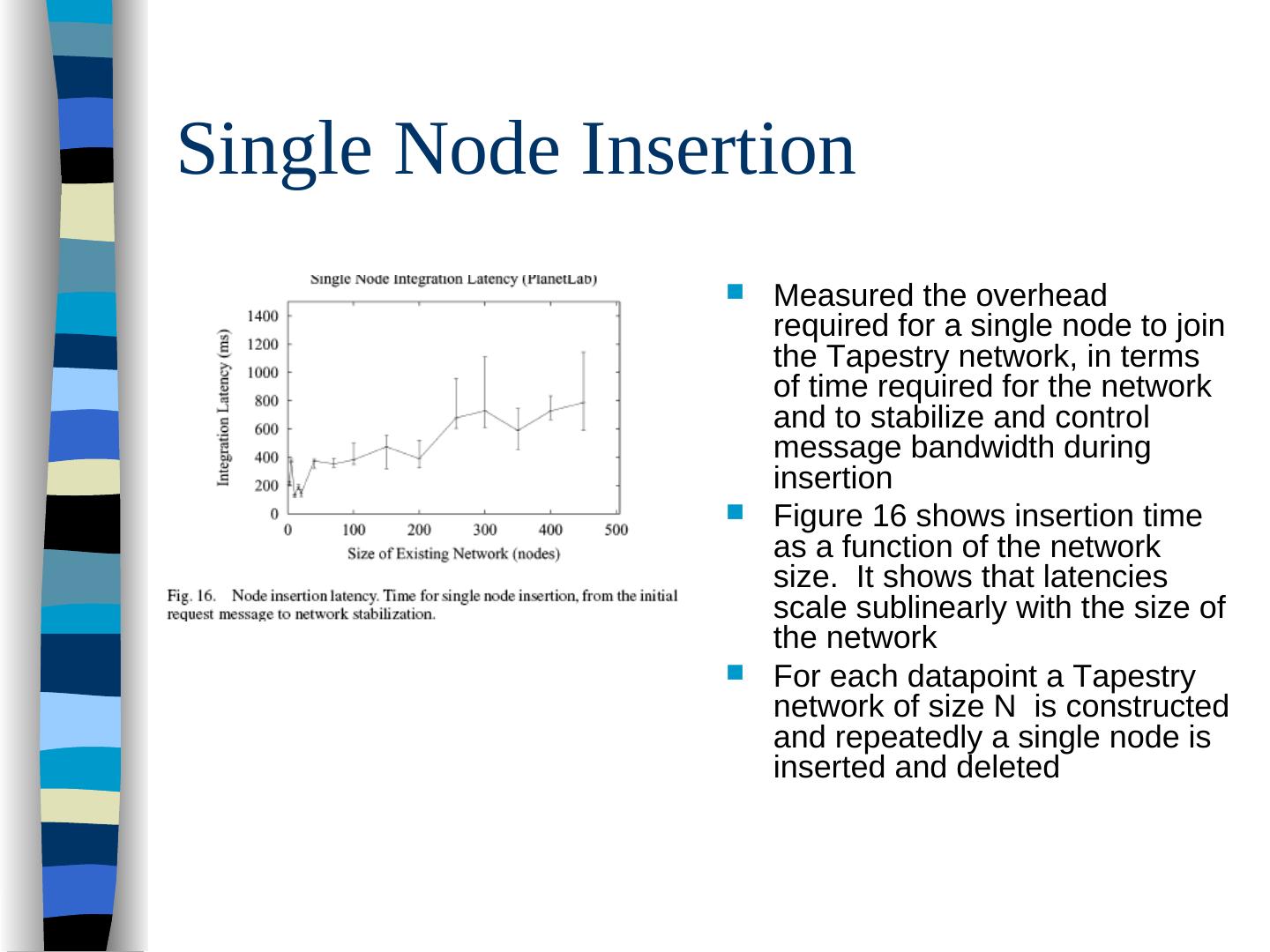
17 .Node Insertion (four components) Need-to-know nodes are notified of N, because N fills a null entry in their routing tables N might become the new object root for existing objects. References to those objects must be moved to N to maintain object availability The algorithms must construct a near optimal routing table for N Nodes near N are notified and may consider using N in their routing tables as an optimization
18 .Node Insertion Begins at N’s surrogate S (the “root” node that Nid maps to in the existing network) S determines the longest prefix length it shares with Nid this length is p S sends out an Acknowledge Multicast message to all existing nodes sharing the same prefix The nodes that get the message add N to their routing tables and transfer references of locally rooted pointers as needed
19 .Node Insertion N’s initial neighbor set for it’s routing table are the nodes reached by the multicast Beginning at level p N does an interactive nearest neighbor search N uses the neighbor set to fill level p, trims this set to size k and requests that the k nodes send there backpointers N decrements p and repeats the process until all levels are filled
20 .Multiple nodes inserting at once Every node A in the multicast keeps track of every node B that is still multicasting down to its neighbors This lets any node C that is multicasting to A know of B’s existence Also multicast keep track of the holes in the new node’s routing table and check their tables for any entries that can fill in these holes
21 .Voluntary Node Deletion When a node N leaves it tells all of the nodes making the set D that are it’s backpointers that it is leaving and of replacement nodes at each level from N’s routing table The notified nodes send a republish object traffic to both N and its replacement N routes reference of locally rooted objects to their new roots and lets D know when it is done
22 .Involuntary Node Deletion Tapestry improves object availability and routing in failure prone networks by building redundancy into the routing tables and object location references Nodes send periodic beacons to detect outgoing links and node failures. When these problems are notices repair of the routing mesh starts and redistribution and replication of the object location references begins This is also helped by soft-state republishing of object references
23 .Component Architecture Transport layer provides the abstraction of communication channels from one overlay node to another Neighbor Link provides secure but unreliable datagram facilities to layers above, including the fragmentation and reassembly of large messages Neighbor Links also provides fault detection through keep alive message, plus latency and loss rate estimation Neighbor Link optimizes message processing by parsing the message headers and only deserializing the message contents when required
24 .Component Architecture The router implements functionality unique to Tapestry This layer includes the routing table and local object points The router examines the destination GUID of the message that is receives and determines the next hop using the routing table and local object pointers Message are passed back to the neighbor link layer for delivery
25 .Component Architecture Flow chart of the object location process Also keep in mind the routing table and object pointer database are constantly changing as the network changes because of nodes entering or leaving or latency in the network
26 .Tapestry Upcall Interface To support functions that require greater control of details than the DOLR API can provide Tapestry supports an extensible upcall mechanism Three primary calls provide the interaction between Tapestry and application handlers(G is a generic ID) – Deliver(G, Aid, Msg): Invoked on incoming messages destined for the local node – Forward(G,Aid,Msg): Invoked on incoming upcall-enabled messages – Route(G,Aid, Msg, NextHopNode): Invoked by the application handler to forward a message on to the NextHopNode
27 .Tapestry Upcall Interface Tapestry sends the message to the application via Forward(). The handler is responsible for calling Route() with the final destination. Finally, Tapestry invokes Deliver() on messages destined for the local node to complete routing
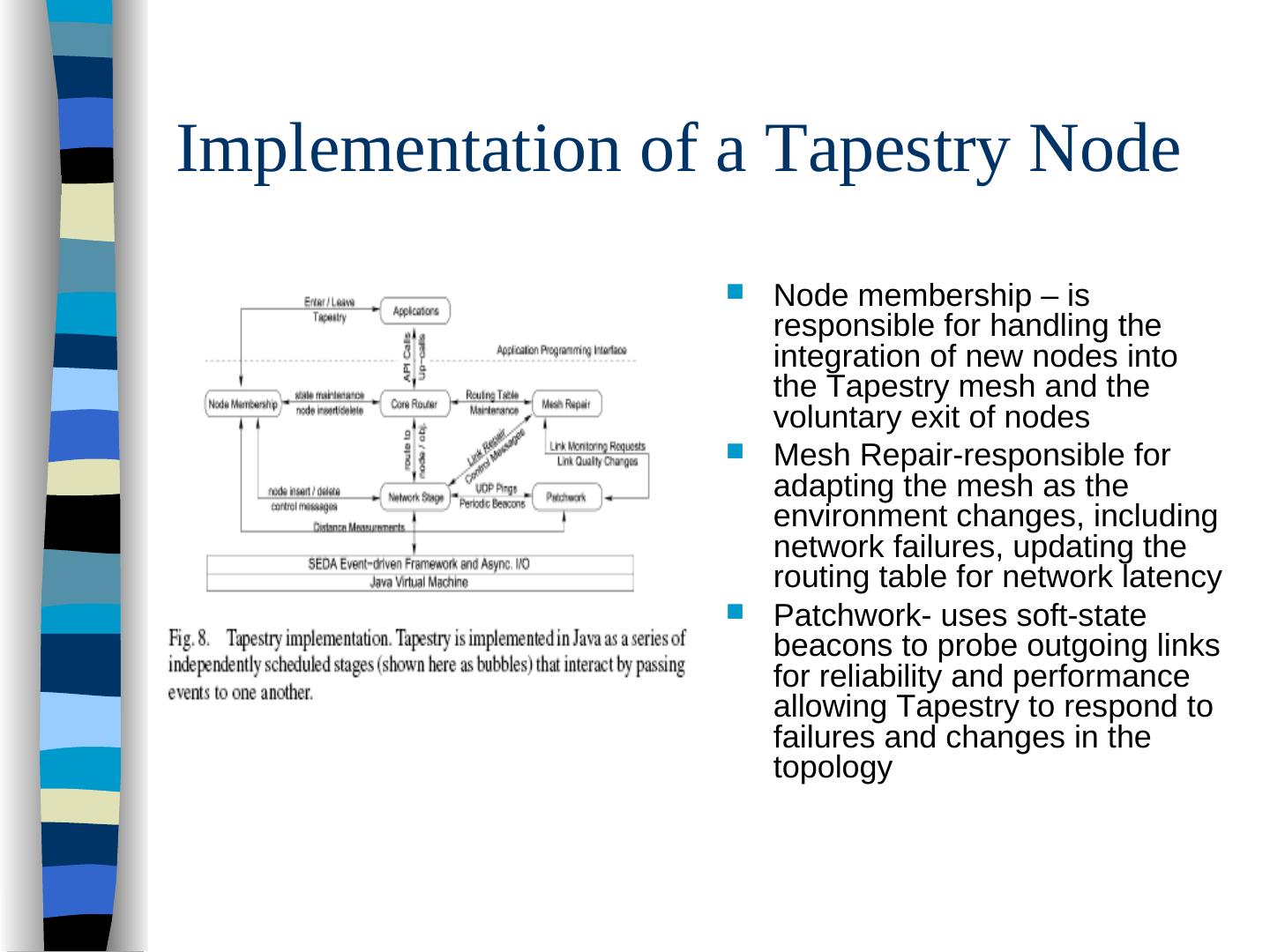
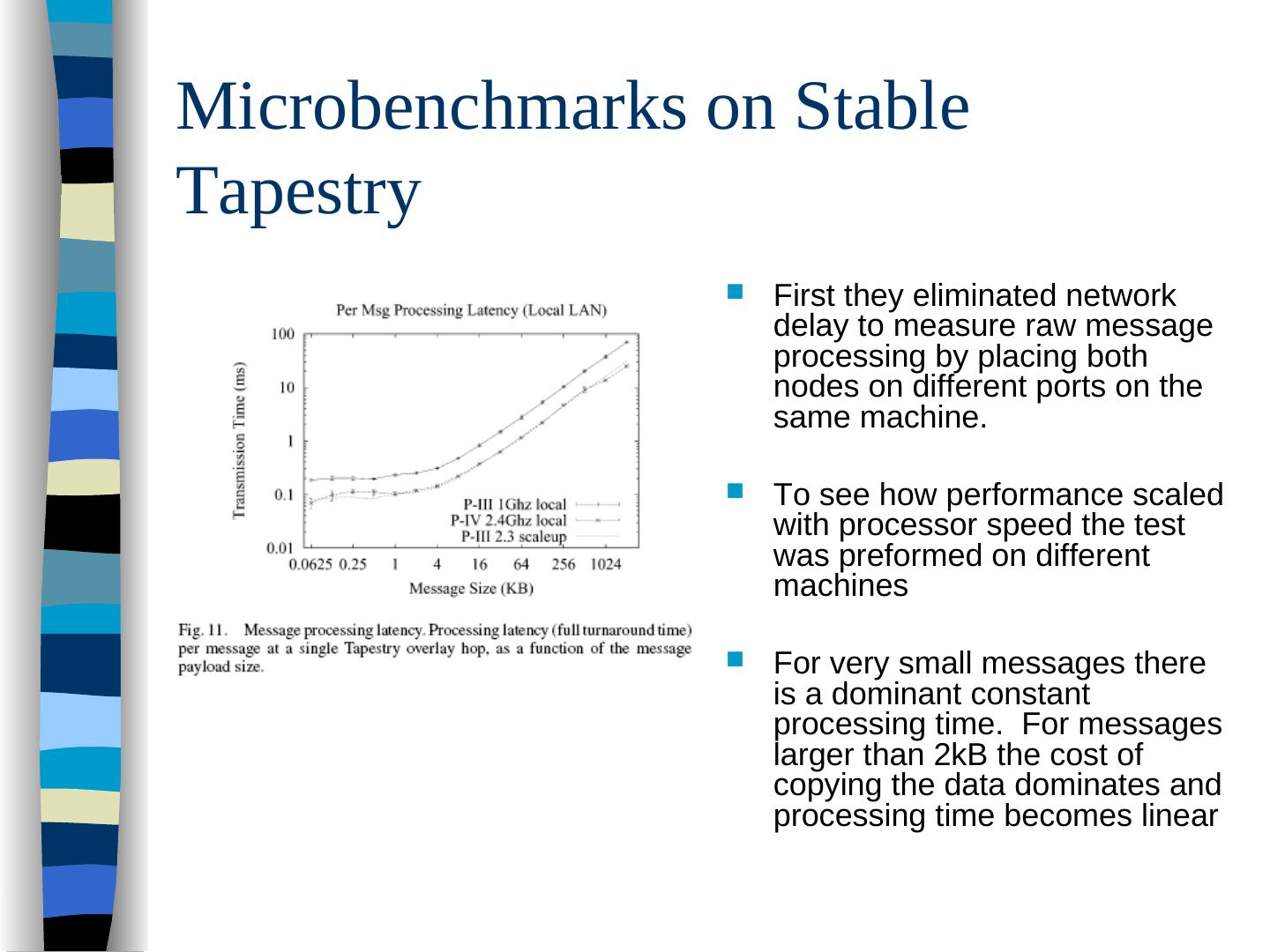
28 .Implementation of a Tapestry Node Tapestry is implemented as an event- driven system for high throughput and scalability This requires an asynchronous I/O layer as well as an efficient model for internal communication and control between components
29 .Implementation of a Tapestry Node Network stage – is a combination of part of the transport layer and part of the neighbor link layer, providing neighbor communication that is not provided by the operating system. It also works with the Patchwork monitoring to measure loss rates and latency Core router - utilizes the routing and object reference tables to handle application driven messages. It is the critical path for all messages entering or exiting the system
3秒后跳转登录页面
去登陆

