展开查看详情
1 .Pipelined processors and Hazards
Two options
Processor
HLL
Compiler ALU
LU Output
Program
Control unit
1. Either the control unit can be smart, i,e. it can delay
instruction phases to avoid hazards. Processor cost
increases.
2. The compiler can be smart, i.e. produce optimized
codes either by inserting NOPs or by rearranging
instructions. The cost of the compiler goes up.
�
2 .Instruction Reorganization by Compiler
To avoid data hazards, the control unit can insert bubbles.
As an alternative, the compiler can use NOP instructions.
Example: Compute a: = b + c; d: = e + f
(a, b, c, d, e, f are stored in the memory)
LW R1, b LW R1, b
LW R2, c LW R2, c
ADD R3, R1, R2 NOP
SW a, R3 NOP
LW R1, e ADD R3, R1, R2
LW R2, f NOP
SUB R3, R1, R2 SW a, R3
SW d, R3 LW R1, e
LW R2,f
NOP
NOP
SUB R3, R1, R2
NOP
SW d, R3
Original code Code generated by a smart compiler
�
3 . Instruction Reorganization by Compiler
The compiler can further speedup by reorganizing the
instruction stream and minimizing the no of NOP’s.
Example: Compute a: = b + c; d: = e + f
LW R1,b LW R1,b
LW R2,c L W R2,c
ADD R3, R1, R2 LW R4, e
SW a, R3 LW R5, f
LW R1, e ADD R3,R1,R2
LW R2,f NOP
SUB R3, R1, R2 SW a, R3
SW d, R3 SUB R6, R5, R4
NOP
SW d, R6
NOP
Original code Code reorganized by a smart compiler
(Control unit remains unchanged)
Note the reassignment of registers
�
4 .Virtual memory
P M
I D
L1 L2
Goals
1. Creates the illusion of a address space much
larger than the physical memory
2. Make provisions for protection
The main idea is that if a virtual address is not mapped into
the physical memory, then it has to be fetched from the disk.
The unit of transfer is a page (or a segment). Observe the
similarities (as well as differences) between virtual memory
and cache memory. Also, recall how slow is the disk (~ ms)
to the main memory (50 ns). So each miss (called a page
fault or a segment fault) has a large penalty.
�
5 .What is a page? What is a segment?
A page is a fixed size fragment (say 4KB or 8 KB) of code or
data. A segment is a logical component of the code (like a
subroutine) or data (like a table). The size is variable.
VM Types
Segmented, paged, segmented and paged.
Page size 4KB –64 KB
Hit time 50-100 CPU clock cycles
Miss penalty 106 - 107 clock cycles
Access time 0.8 x 106 –0.8 x 107 clock cycles
Transfer time
0.2 x 106 –0.2 x 107 clock cycles
Miss rate 0.00001% - 0.001%
Virtual address 4 GB -16 x 1018 byte
Space size
�
6 .A quick look at different types of VM
Segment sizes
are not fixed
A segment
Page sizes
are fixed
Page frame A page
or block
Segments can
be paged
�
7 .Address Translation
Page Number Offset Virtual address
page
table
Physical address
Block Number Offset
Page Table format for Direct Map
Page Presence Block no./ Disk addr Other attributes
No. bit like protection
0 1 7 Read only
1 0 Sector 6, Track 18
2 1 45 Not cacheable
3 1 4
4 0 Sector 24,Track 32
Page Table format for Associative Map
Pg, Blk, P Block no./ Disk addr Other attributes
0, 7, 1 7 Read only
1, ?, 0 Sector 6, Track 18
2, 45, 1 45 Not cacheable
3, 4, 1 4
4, ?, 0 Sector 24, Track 32
�
8 .Address translation overhead
Hit time involves one extra table lookup. Can we
reduce this overhead?
Average Memory Access Time = Hit time (no page fault)
+ Miss rate (page fault rate) x Miss penalty
Examples of VM performance
Hit time = 50 ns.
Page fault rate = 0.001%
Miss penalty = 2 ms
Tav = 50 + 10-5 x 2 x 106 ns = 70 ns.
�
9 .Improving VM Performance
1. Hit time involves one extra table lookup. Hit time
can be reduced using a TLB
(TLB = Translation Lookaside Buffer).
2. Miss rate can be reduced by allocating enough
memory to hold the working set. Otherwise,
thrashing is a possibility.
3. Miss penalty can be reduced by using disk cache
�
10 .Page Replacement policy
Determines which page needs to be discarded to
accommodate an incoming page. Common policies
are
♦ Least Recently Used (LRU)
♦ Least Frequently Used (LFU)
♦ Random
Writing into VM
Write-back makes more sense. The page table
must keep track of dirty pages. There is no
overhead to discard a clean page, but to discard
dirty pages, they must be written back to the disk.
�
11 .Working Set
Consider a page reference string
0, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 2, … 100,000 references
The size of the working set is 2 pages.
Page thrashing
Fault
Rate
Enough to Available M
hold the
working set
Always allocate enough memory to hold the working
set of a program (Working Set Principle)
Disk cache
Modern computers allocate up a large fraction of the
main memory as file cache. Similar principles apply to
disk cache that drastically reduces the miss penalty.
�
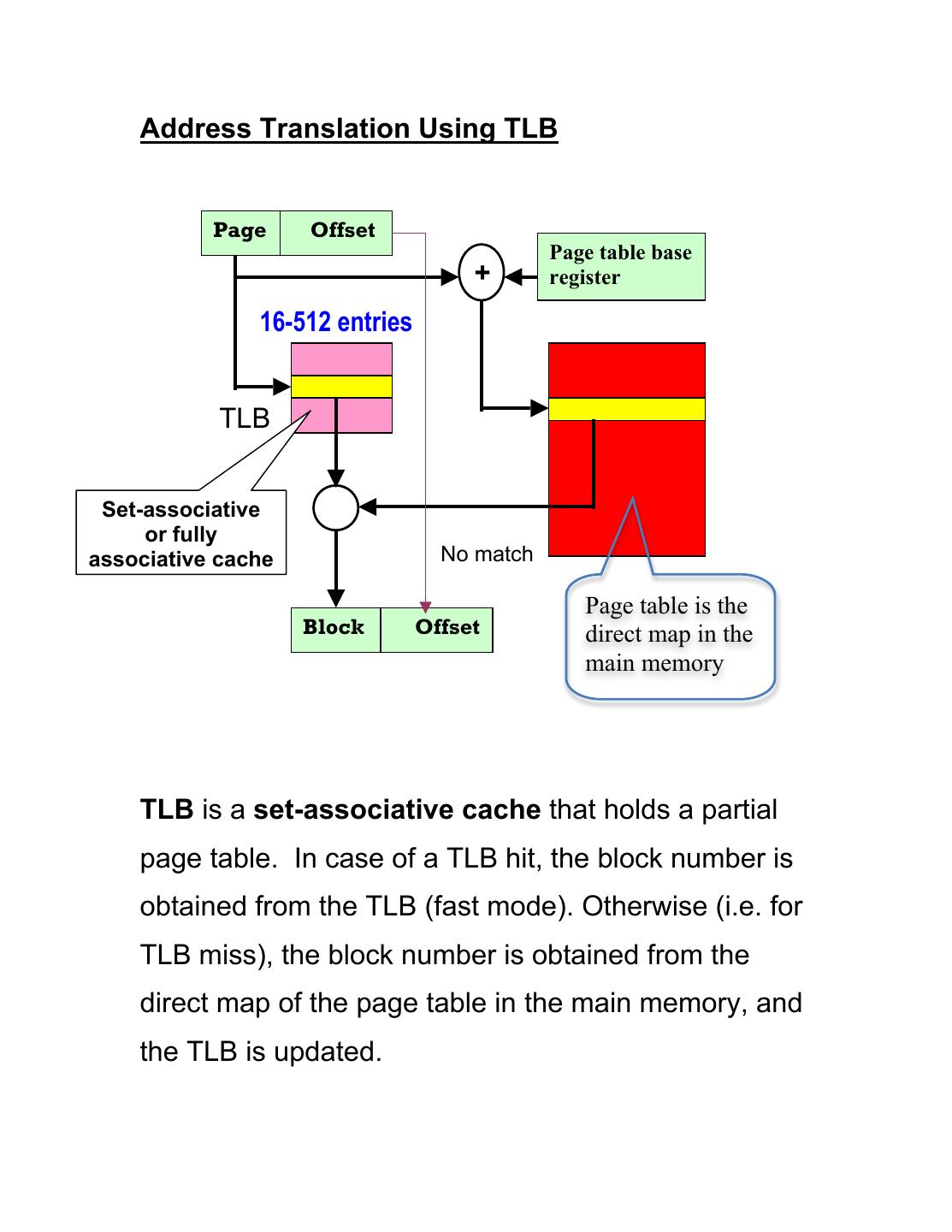
12 . Address Translation Using TLB
Page Offset
Page table base
+ register
16-512 entries
TLB
M
Set-associative
or fully
associative cache No match
Page table is the
Block Offset direct map in the
main memory
TLB is a set-associative cache that holds a partial
page table. In case of a TLB hit, the block number is
obtained from the TLB (fast mode). Otherwise (i.e. for
TLB miss), the block number is obtained from the
direct map of the page table in the main memory, and
the TLB is updated.
�