20 计算机组成--流水线式MIPS
分享
点赞
0
收藏
1
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 王木木
王木木
/
发布于
/
2122
人观看
本篇文档主要介绍了流水线式MIPS、一致性、指令执行速度的提升、指令执行时间的计算、流水线中的危害、避免数据危险的方法(插入气泡、需要对数据通路进行一些修改)、控制风险、MIPS的五个周期。
展开查看详情
1 .Pipelined MIPS
While a typical instruction takes 3-4 cycles (i.e.
3-4 CPI), a pipelined processor targets 1 CPI
(and gets close to it).
It shows the rough division of responsibilities.
The buffers between stages are not shown.
�
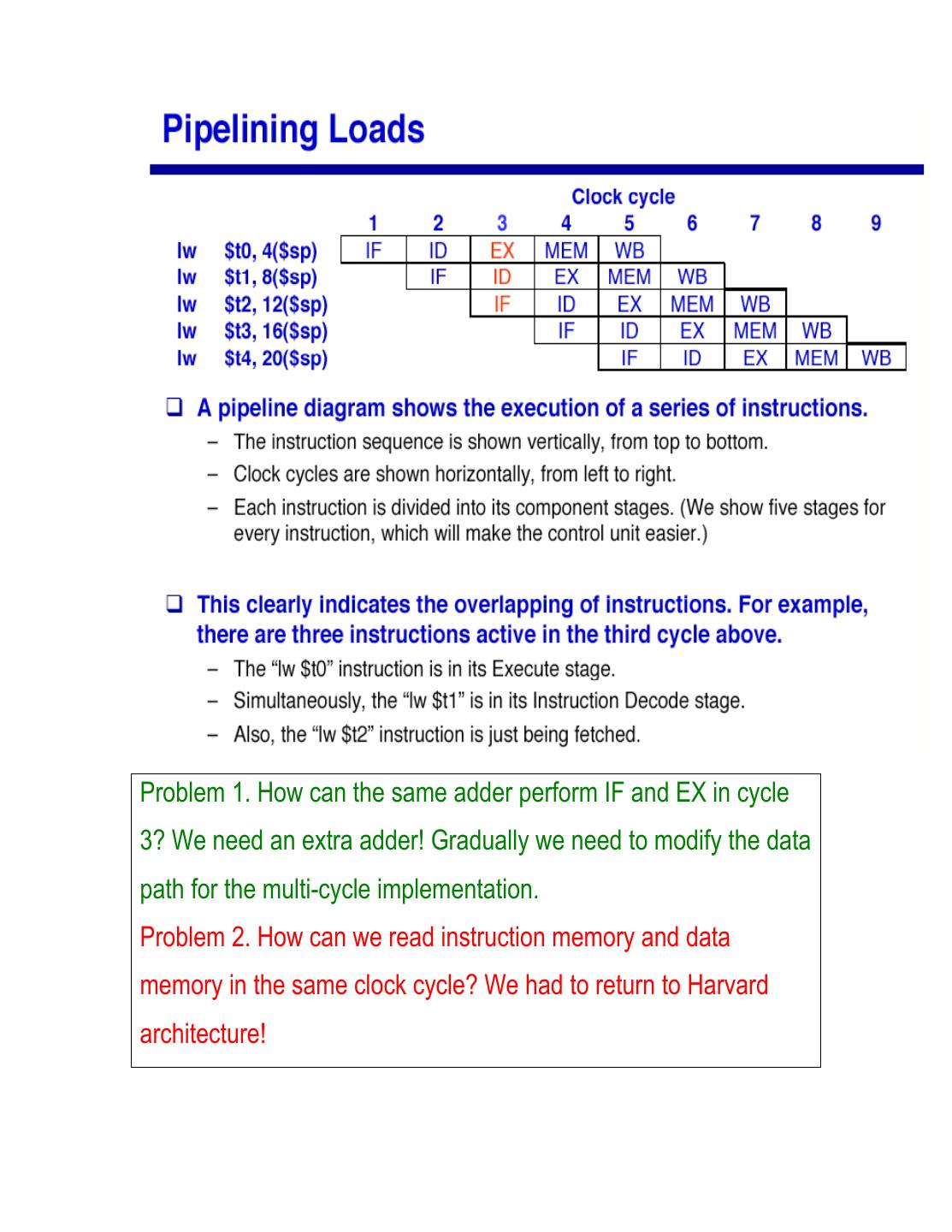
2 .Problem 1. How can the same adder perform IF and EX in cycle
3? We need an extra adder! Gradually we need to modify the data
path for the multi-cycle implementation.
Problem 2. How can we read instruction memory and data
memory in the same clock cycle? We had to return to Harvard
architecture!
�
3 .Uniformity is simplicity
�
4 .Speedup
The steady state throughput is determined by
the time t needed by one stage.
The length of the pipeline determines the
pipeline filling time
If there are k stages, and each stage takes t
time units, then the time needed to execute N
instructions is
k.t + (N-1).t
Estimate the speedup when N=5000 and k=5
�
5 .Hazards in a pipeline
Hazards refer to conflicts in the execution of a
pipeline. On example is the need for the same
resource (like the same adder) in two
concurrent actions. This is called structural
hazard. To avoid it, we have to replicate
resources. Here is another example:
lw $s1, 4($sp) IF ID EX MEM WB
add $s0, $s1, $s2 IF ID EX MEM WB
Notice the second instruction tries to read $s1
before the first instruction complete the load!
This is known as data hazard.
�
6 .Avoiding data hazards
One solution is in insert bubbles (means
delaying certain operation in the pipeline)
lw $s1, 4($sp) IF ID EX MEM WB
add $s0, $s1, $s2 IF nop nop nop ID
Another solution may require some
modification in the datapath, which will raise
the hardware cost
Hazards slow down the instruction execution
speed.
�
7 .Control hazard
sub $s1, $t1, $t2 IF ID EX MEM WB
beq $s1, $zero L IF ID EX MEM
some instruction here IF ID EX
Will the correct
instruction be fetched?
There is no guarantee! The next instruction
has to wait until the predicate ($s1=0) is
resolved. Look at the tasks performed in the
five steps – the predicate is evaluated in the
EX step. Until then, the control unit will
insert nop (also called bubbles) in the
pipeline.
�
8 . The Five Cycles of MIPS
(Instruction Fetch)
IR:= Memory[PC]; PC:= PC+4
(Instruction decode and Register fetch)
A:= Reg[IR[25:21]], B:=Reg[IR[20:16]]
ALUout := PC + sign-extend(IR[15:0]]
(Execute|Memory address|Branch completion)
Memory refer: ALUout:= A+ IR[15:0]
R-type (ALU): ALUout:= A op B
Branch: if A=B then PC:= ALUout
(Memory access | R-type completion)
LW: MDR:= Memory[ALUout]
SW: Memory[ALUout]:= B
R-type: Reg[IR[15:11]]:= ALUout
(Write back)
LW: Reg[[20:16]]:= MDR
�
9 .sub $s1, $t1, $t2 IF ID EX MEM WB
beq $s1, $zero L IF ID EX MEM
Some instruction here IF o IF ID
No action
performed here
An alternative approach to deal with this is for
the compiler (or the assembler) to insert NOP
instructions, or reorder the instructions.
�