17 计算机组成--高速缓存的写入
分享
点赞
0
收藏
0
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 王木木
王木木
/
发布于
/
2081
人观看
本篇文档主要介绍了高速缓存的写入,具体介绍了写命中,写入的方式、写失效、最先进的内存层次结构--多级缓存、多级缓存的读操作、写操作的命中、写操作的失效、属性、多级缓存下平均读取时间的估算、缓存块的最佳大小。
展开查看详情
1 .Writing into Cache
Case 1. Write hit
x
X x (store X: X is in C)
Write through Write back
Write into C & M Write into C only. Update M
only when discarding the block
containing x
Q1. Isn’t write-through inefficient?
Not all cache accesses are for write.
Q2. What about data consistency in write-back cache?
If M is not shared, then who cares?
Most implementations of Write through use a Write Buffer.
How does it work?
�
2 .Case 2. Write miss
x
X ? (Store X, X is NOT in C)
Write allocate Write around
Allocate a C-block to X. Write directly into
Load the block containing X bypassing C
X from M to C.
Then write into X in C.
.
�
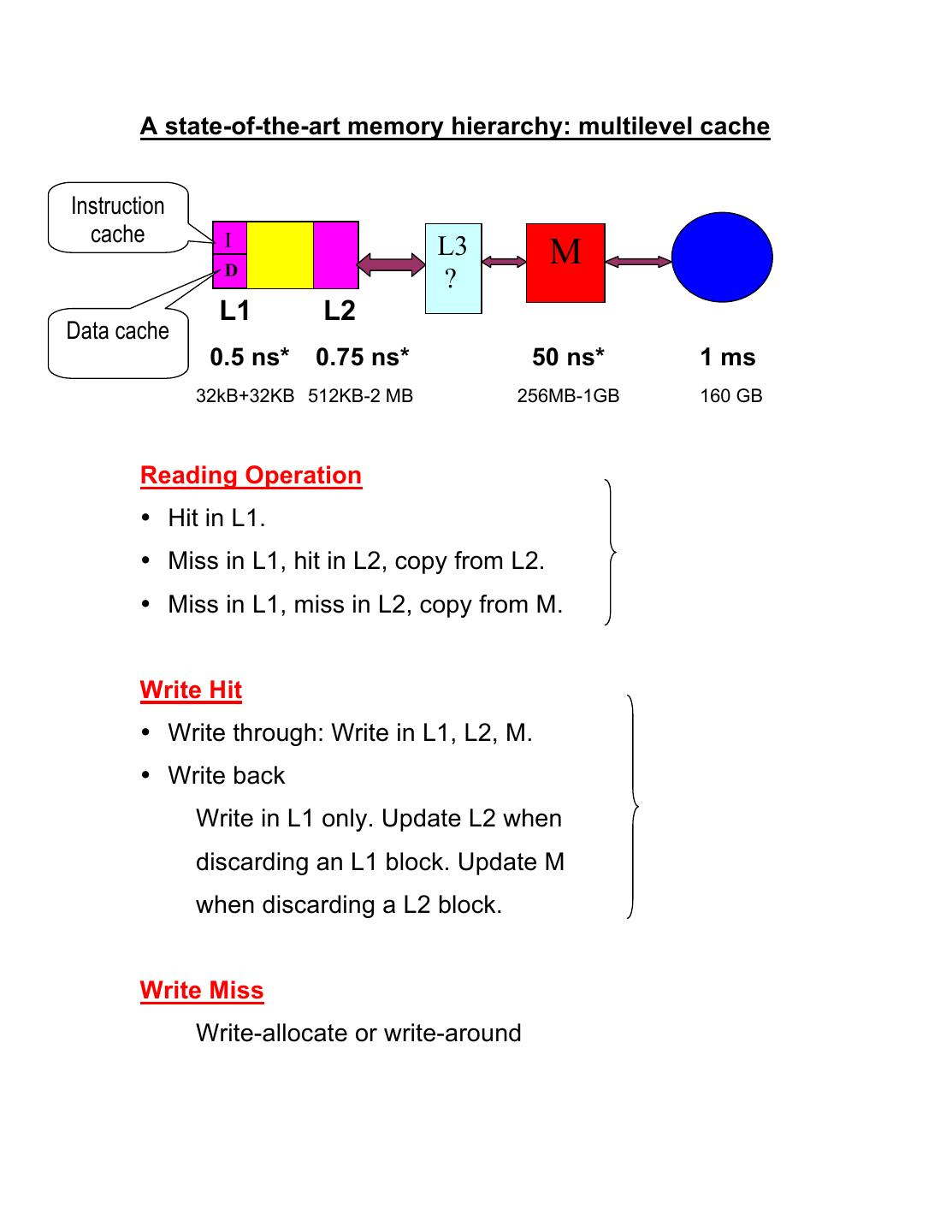
3 . A state-of-the-art memory hierarchy: multilevel cache
Instruction
cache I
D
L3 M
?
L1 L2
Data cache
0.5 ns* 0.75 ns* 50 ns* 1 ms
32kB+32KB 512KB-2 MB 256MB-1GB 160 GB
Reading Operation
• Hit in L1.
• Miss in L1, hit in L2, copy from L2.
• Miss in L1, miss in L2, copy from M.
Write Hit
• Write through: Write in L1, L2, M.
• Write back
Write in L1 only. Update L2 when
discarding an L1 block. Update M
when discarding a L2 block.
Write Miss
Write-allocate or write-around
�
4 .Inclusion Property
P M
I D
L1 L2
In a consistent state,
• Every valid L1 block can also be found in L2.
• Every valid L2 block can also be found in M.
Average memory access time =
(Hit time)L1 + (Miss rate)L1 x (Miss penalty)L1
(Miss penalty)L1 = (Hit time)L2 + (Miss rate) L2 x
(Miss penalty)L2
Performance improves with additional level(s) of
cache if we can afford the cost.
�
5 .Optimal Size of Cache Blocks
Tav
Miss Miss Avg.
Penalty Rate Mem
Access
Time
Block size Block size Block size
Large block size supports program locality and
reduces the miss rate.
But the miss penalty grows linearly, since more
bytes are copied from M to C after a miss.
Tav = Hit time + Miss rate x Miss penalty.
The optimal block size is 8-64 bytes. Usually, I-
cache has a higher hit ratio than D-cache. Why?
�