



























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
传统分布式文件系统也可以适应海量数据增长
主要是面向结构化数据和事务处理的关系型数据库. 扩展到面向非 .... 新型分布式文件系统采用数据计算与存储绑定的新策略,可有效应对海量数据增长. X86 PC集群.
展开查看详情
1 .网络新技术之大数据
2 .5. 大数据技术 5.1 大数据的定义 5.2 大数据的技术特征 5.3 大数据的典型应用 5.4 大数据的发展趋势
3 .一组数据 3 亿用户 , 每天上亿条微博 . 2015 年全球移动终端产生的数据量 6300PB Facebook 每天要存储大约 100TB 的用户数据; NASA 美国宇航局 每天要处理约 24TB 的数据 微信国内用户 4 亿,国外用户突破 7 千万,每天产生数据 百度每天处理数据量 100PB
4 .大 数据时代的爆炸增长 想驾驭这庞大的数据,我们必须了解大数据的特征。 地球上至今总共的数据量 : 在 2006 年,个人用户才刚刚迈进 TB 时代 ,全球一共新产生了约 180EB 的 数据 ; 在 2011 年,这个数字达到了 1.8ZB 。 而有市场 研究 机构预测: 到 2020 年,整个世界的数据总量将会增长 44 倍,达到 35.2ZB ( 1ZB=10 亿 TB )! 1PB (拍字节 ) = 2^50 字节 1EB (艾字节 ) = 2^60 字节 1ZB (泽字节) = 2^70 字节
5 .大数据概念和特征 什么是大数据 (Big data) ? 维 基百科的 定义 : 大 数据指难以用常用的软件工具在 可容忍时间 内抓取、管理以及处理的数据 集 ( 一般单个 数据集大小在 10T 左右 ) 。 大 数据之所以在 最近走红 ,主要归结于互联网、移动设备、物联网和 云 计算 等快速崛起,全球数据量大大提升 。 “大数据” 是继云计算、物联网之后 IT 产业又一次颠覆性的技术变革 2006 年左右,数据量已足够大,但是当时大数据不红, why ?
6 .为什么叫大 数据:一是数量大 YB:2 的 80 次方, ZB 的 1000 倍 Z B:2 的 7 0 次方, E B 的 1000 倍 E B:2 的 6 0 次方, P B 的 1000 倍 P B:2 的 50 次方, T B 的 1000 倍 T B:2 的 4 0 次方, G B 的 1000 倍 G B:2 的 3 0 次方, M B 的 1000 倍 绝大部分应用在这两个数量级
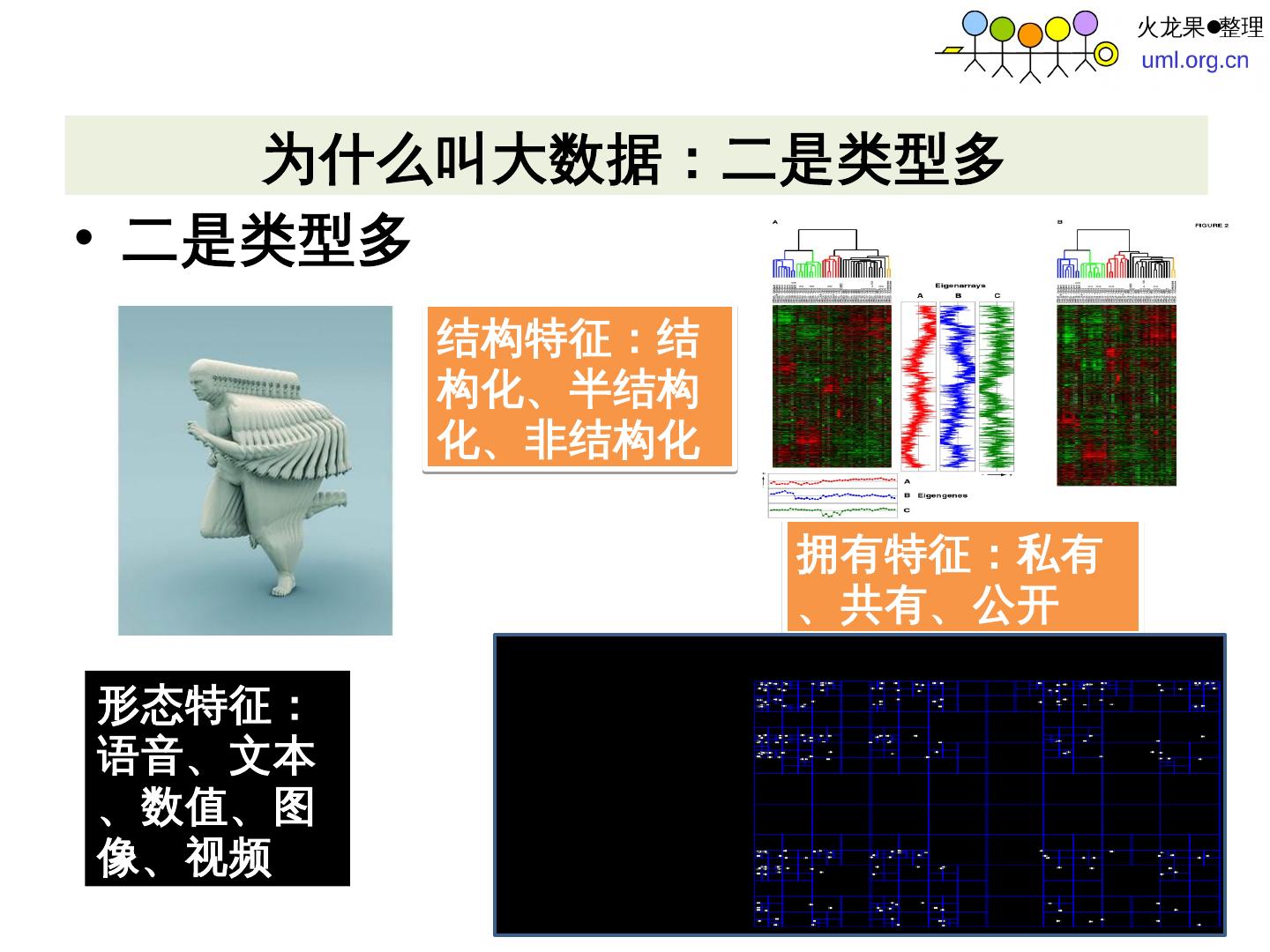
7 .二是类型多 结构特征:结构化、半结构化、非结构化 拥有特征 :私有、共有、公开 形态特征:语音、文本、数值、图像、视频 为什么叫大数据:二是类型多
8 .三是更接近 把握信息资源的本质 大数据真正开始把信息变成资源 有 的文章将大数据看作石油,大数据研究与自然资源利用发现、开采、提炼存在一定的 相似之处 研究 大数据,首先要研究各种有用的信息在何处,就是找 矿 其次 是把满足特定需求的信息收集过来,就是 开矿 第三 是把收集的信息按应用需求进行结构化处理,就是提炼,如同石油必须经过炼化才能变成消费用的汽油、柴油或作为原料用的聚乙烯、 聚丙烯 第四 是将这样的信息与具体 的 应 用 结合,使之发挥作用,这就是基于大数据的应用系统,或称之为围绕应用的大数据管理系统,如同汽油通过加油站加到消费者的汽车内,石化原料变成衣服、设备或其部件 。
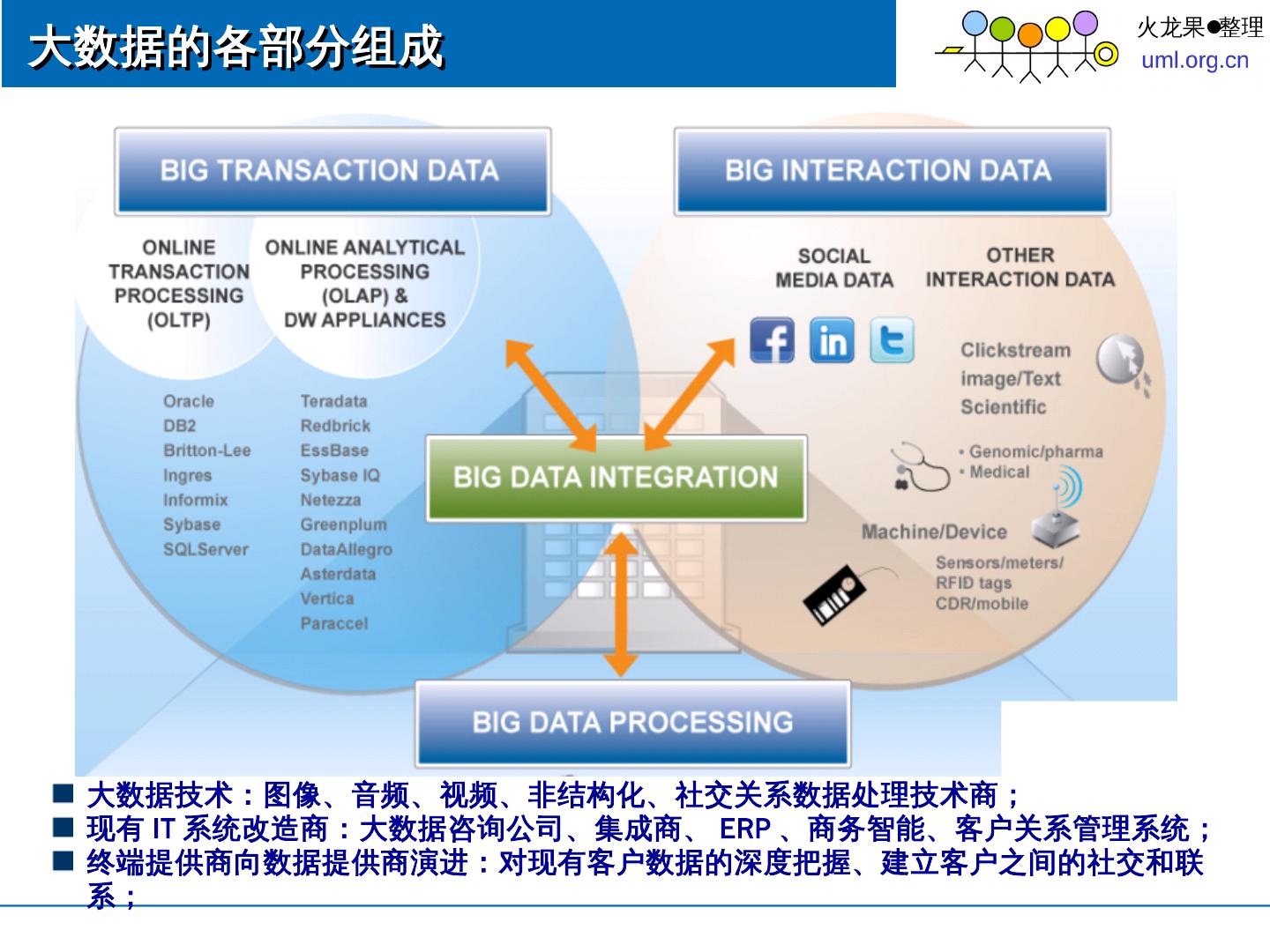
9 .大数据的各部分组成 大数据技术:图像、音频、视频、非结构化、社交关系数据处理技术商; 现有 IT 系统改造商:大数据咨询公司、集成商、 ERP 、商务智能、客户关系管理系统; 终端提供商向数据提供商演进:对现有客户数据的深度把握、建立客户之间的社交和联系;
10 .展现方式:大型控制中心、移动终端 在多样性、体量、速度三大特征的指引下,大数据将有新型的展现方式:大型控制中心和移动终端,实现数据的实时处理和快速决策。
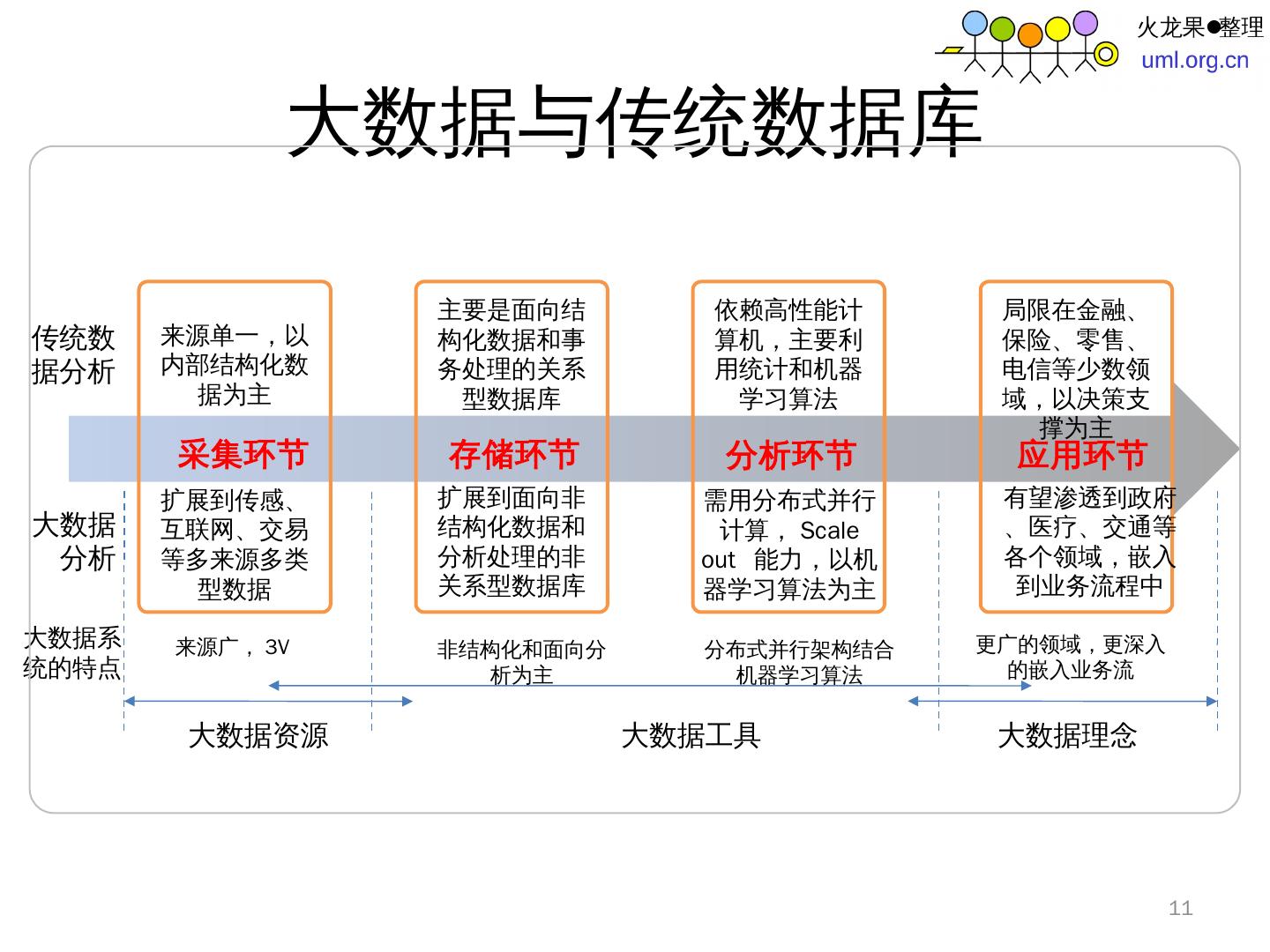
11 .大数据与传统数据库 11 采集环节 存储环节 分析环节 应用环节 传统数据分析 大数据分析 扩展到传感、互联网、交易等多来源多类型数据 来源单一,以内部结构化数据为主 主要是面向结构化数据和事务处理的关系型数据库 扩展到面向非结构化数据和分析处理的非关系型数据库 依赖高性能计算机,主要利用统计和机器学习算法 需用分布式并行计算, Scale out 能力,以机器学习算法为主 局限在金融、保险、零售、电信等少数领域,以决策支撑为主 有望渗透到政府、医疗、交通等各个领域,嵌入到业务流程中 来源广, 3V 非结构化和面向分析为主 分布式并行架构结合机器学习算法 更广的领域,更深入的嵌入业务流 大数据系统的特点 大数据资源 大数据工具 大数据理念
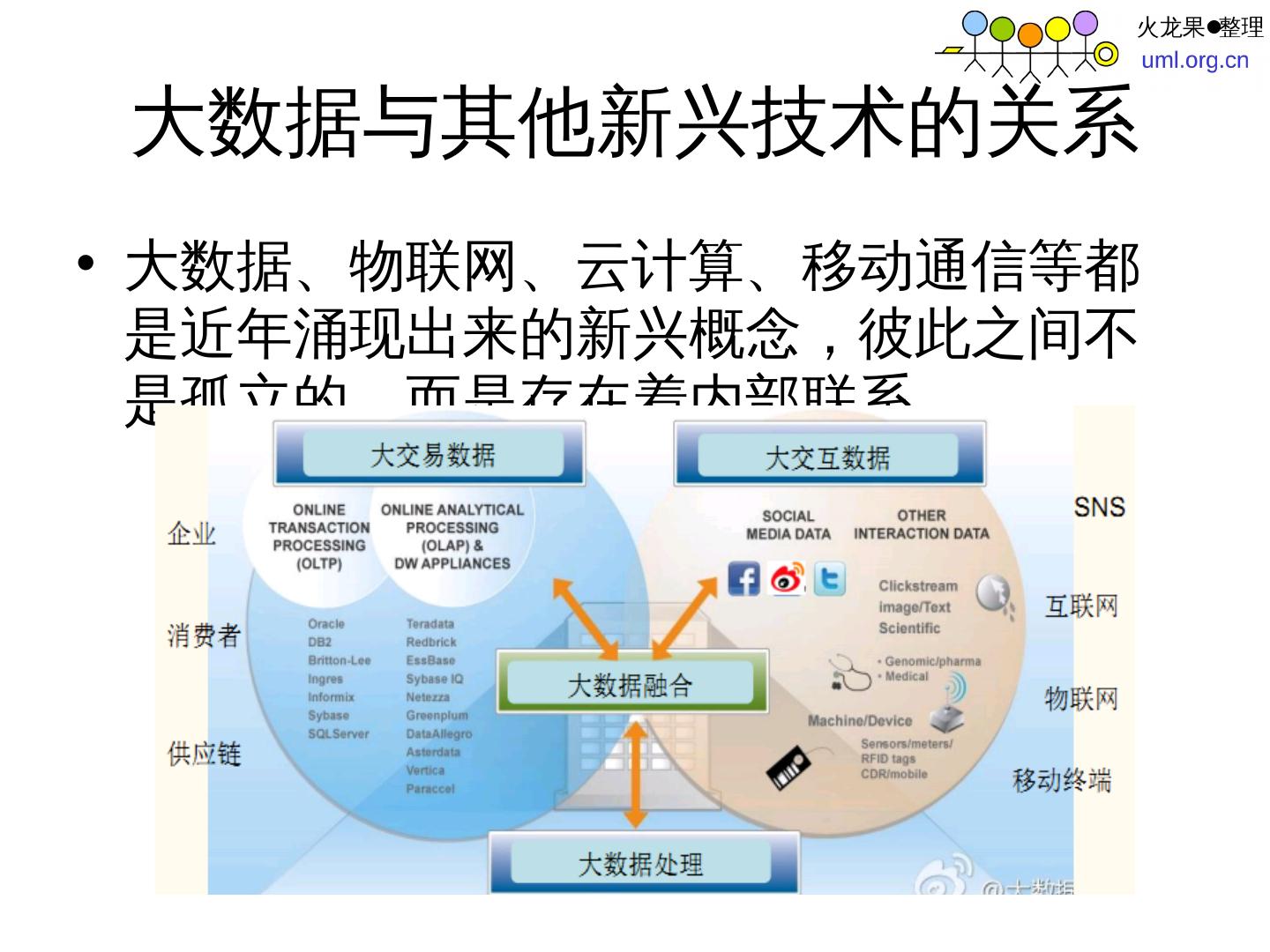
12 .大数据与其他新兴技术的关系 大数据、物联网、云计算、移动通信等都是近年涌现出来的新兴概念,彼此之间不是孤立的,而是存在着内部联系。
13 .大数据带来的思维方式的变化 处理的对象往往是全部数据,而不是部分数据的采样 采样的不合理会导致预测结果的偏差,在大数据时代,依靠强大的数据处理能力,应该去处理全部的数据。 不再执迷于精确性 精确的、规范化的、可以被传统数据库处理的数据只占全部数据的 5% ,必须接受不精确性才能处理另外 95% 的数据。 错误的数据是客观存在的,竭力避免它就失去了应有的客观性和公平性。 大 数据的简单算法比小数据的复杂算法更有效。 更加关注相关性,而不是因果性 预测依靠的是相关性。 很多情况下知道“是什么”即可,不必知道“为什么”。
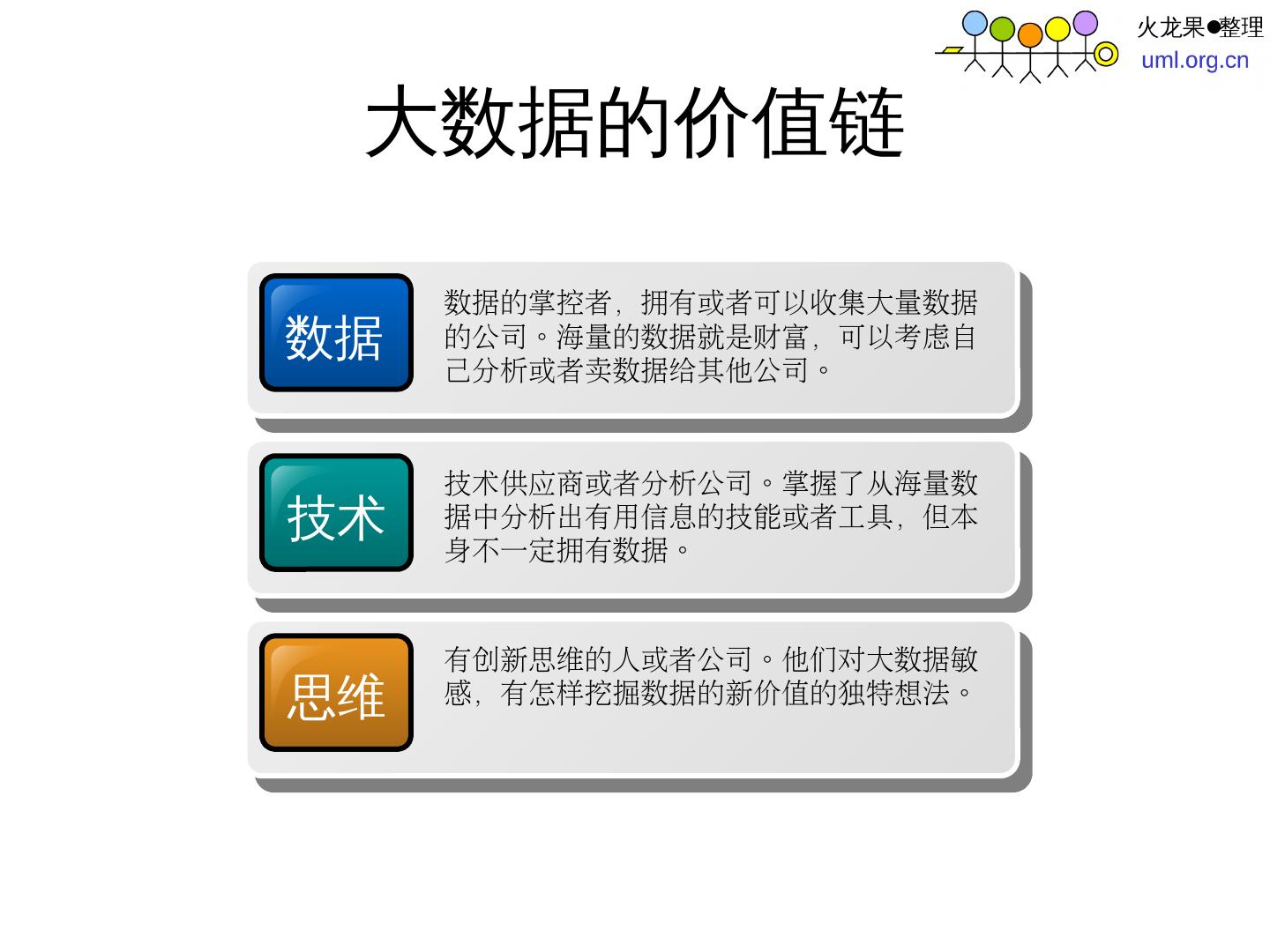
14 .大数据的价值链 数据 数据的掌控者,拥有或者可以收集大量数据的公司。海量的数据就是财富,可以考虑自己分析或者卖数据给其他公司。 技术 技术供应商或者分析公司。掌握了从海量数据中分析出有用信息的技能或者工具,但本身不一定拥有数据。 思维 有创新思维的人或者公司。他们对大数据敏感,有怎样挖掘数据的新价值的独特想法。
15 .第 15 页 大数据基础架构要求 可预测的低延迟 高 事务参数 灵活的数据结构 获取 组织 分析 决策 高吞吐量 就地 准备 所有数据源和结构 深度分析 敏捷开发 高度可伸缩性 实时 流数据 运营影响
16 .第 15 页 大数据基础架构要求 可预测的低延迟 高 事务参数 灵活的数据结构 获取 组织 分析 决策 高吞吐量 就地 准备 所有数据源和结构 深度分析 敏捷开发 高度可伸缩性 实时 流数据 运营影响
17 .大数据的技术特征 数 据结构: 结构化数据与非结构化数据 数据库数据模型:关系型数据库与非关系型数据库 数据处理特性: OLTP 与 OLAP 数据一致性:强一致性与最终一致 性 数 据存储方式:行式存储与列式存储 数据库存储与处理架构: SMP 与 MPP 数据存储架构:传统分布式文件与新型分布式文件 数 据处理架构:基于并行计算的分布式数据处理技 术( MapReduce ) - 17 -
18 .数 据的结构 — 结 构 化、 非结构 化、半结构化数 据 结构化数据和非结构化数据都是客观存在,大 数据技 术需要涵盖两者 - 18 - 对比项 结构化数据 非结构化数据 半非结构化数据 定义 有数据结构描述信息的数据 不方便用固定结构来表现的数据 介于完全结构化数据和完全无结构的数据之间的数据 结构与内容的关系 先有结构、再有数据 只有数据,没有结构 先有数据,再有结构 示例 各类表格 图形、图像、音频、视频信息 HTML 文档,它一般是自描述的,数据的结构和内容混在一起
19 .数据库数据模型 — 关系型数据库与非关 系型数据库 在大数据技术 中 " 非 关系 型 " 数 据库技术是必不可少 的, 但 关系数据库也是不可或缺的 - 19 - 对比项 关系型数据库 非关系型数据库 定义 创建在关系模型基础上,借助于集合代数等数学概念和方法来处理数据库中的数据 关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成 没有标准定义 包括:表存储数据库、键值存储数据库、面向文档的数据库等 接口语言 SQL ( Structured Query Language ,结构化查询语言),对数据库中的数据进行查询、操作和管理 无统一标准 包括:各自定义的 API 、类 SQL 、 MR 等 典型案例 Oracel 、 DB2 、 Sybase 、 SQL Server 、 Mysql 、 Postgresql 等 新型的 MPP RDB ( Greenplum )也属于关系型数据库 Hbase 、 MongoDB 、 Redis
20 .数据处理特 性 —OLTP 与 OLAP OLTP 以业务操作型为主, OLAP 以业务分析性为主,两者对技术的要求很难兼顾 - 20 - 比较项 联机事务处理 OLTP ( On-Line Transaction Processing ) 联机分析处理 OLAP ( On-Line Analytical Processing ) 基本类型 业务操作型 业务分析型 数据特 性 对一条记录数据会多次修改, 支持大量并发用户添加和修改数据 数据写入后基本不再修改,能较好地支持大量并发用户进行大数据量查询 技术特性 确保数据的一致性 确保事务的完整性 数据读写实时性高 支持多维数据以及对多维数据的复杂分析 大数据量 数据量 GB-TB 级 TB-PB 级 典型示例 银行业务系统 / 数据库 各类决策分析系统 / 数据库
21 .数据一致性:强一致性与最终一致性 强一致性和最终一致性都是指客户端 向数据库系 统写入数据后 ,数据库系 统能够提供的数据一致性的表现 - 21 - 对比项 强一致性(即时一致性) 最终一致性 弱一致性 场景定义 假定三个进程 A 、 B 、 C 是互相独立的,且都在对存储系统进行读写操作 数据一致性表现 A 写入数据到存储系统后,存储系统能够保证后续任何时刻发起读操作的 B 、 C 可以读到 A 写入的数据 A 写入数据到存储系统后,经过一定时间,或者在某个特定操作后, B 、 C 最终会读到 A 写入的数据 A 写入数据到存储系统后,存储系统不能够保证后续发起读操作的 B 、 C 可以读到 A 写入的数据 示例 OLTP 需要强一致性 OLAP 需最终一致性 绝大多数应用不能够容忍弱一致性
22 .数据存储方 式 — 行式存储与 列 式存储 - 22 - 传统关系型数据库主要采用行存储模式,海量数据的高效存储和访问要求引发了从行存储模式向列存储模式的转 变 行 存储 用户 生日 聊天记录 日均在线时长 用户 1 1981-10-3 Xxxx yyyy ... 2 用户 2 1990-5-15 Mm nnn … 3.7 用户 1 1981-10-3 Xxxx yyyy ... 2 用户 2 1990-5-15 Mm nnn … 3.7 列 存储 用户 1 1981-10-3 用户 2 1990-5-15 用户 1 Xxxx yyyy .. 用户 2 Mm nnn .. 用户 1 2 用户 2 3.7 行存储 列存储 存储 一行中各列一起存放,单行集中存储 一行中各列独立存放,单列集中存储 索引效率 海量数据索引既占用大量空间,且索引效率会随着数据增长越来越低 基于列自动索引,海量数据查询效率高,不产生额外存储 空间效率 同一行不同列数据类型不同,压缩效率低 空值列依然占据空间 列同数据类型,压缩效率高 空值不占空间 I/O 查某列必须读出整行, I/O 负荷高、速度慢 只需读出某列数据, I/O 低速度快 结构 表结构改变影响很大 可随时动态增加列 适用场景 数据写入后需要修改和删除,基于行的反复查询,多用于 OLTP 数据库 批量数据一次写入和基于少量列的反复查询,多用于 OLAP 数据库 样例数据表
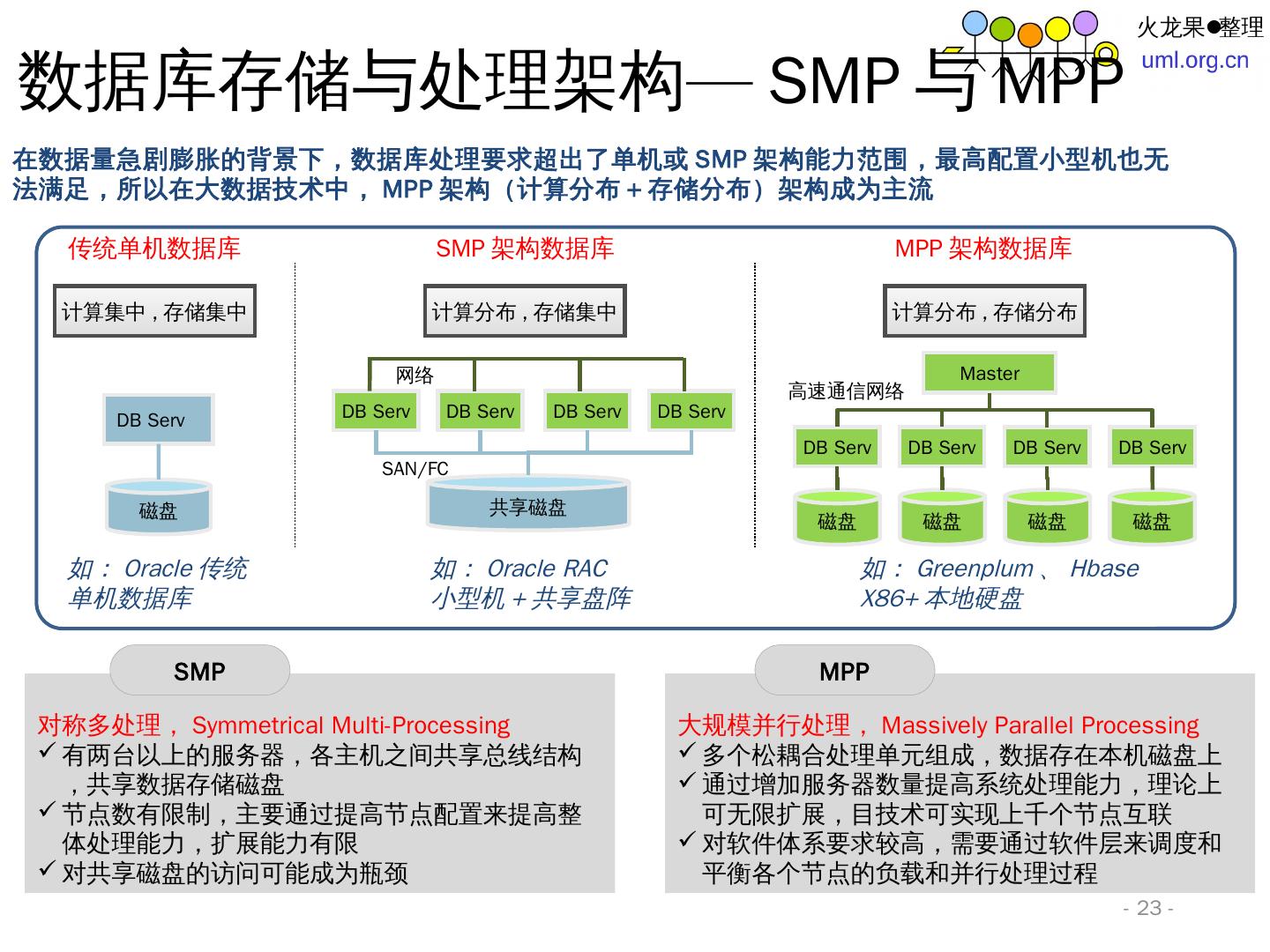
23 .- 23 - 在数据量急剧膨胀的 背景下 ,数据库处理要 求超出 了单机或 SMP 架构能力范围,最高配 置小 型 机也 无法满 足, 所以在大数据技术中 , MPP 架构 ( 计 算分 布 + 存 储分 布)架构成 为主 流 数据库存储与处理架构 —SMP 与 MPP 计算分 布 , 存 储集 中 DB Serv 共 享磁盘 DB Serv DB Serv DB Serv 网络 SAN/FC 计算集 中 , 存 储集 中 DB Serv 磁盘 计算分 布 , 存 储分布 DB Serv DB Serv DB Serv DB Serv 高 速通信网 络 磁盘 磁盘 磁盘 磁盘 Master 如 : Oracle 传统 单机数据库 如 : Oracle RAC 小 型机 + 共享盘阵 如 : Greenplum 、 Hbase X86+ 本地硬盘 传统单机数据库 SMP 架构数据库 MPP 架构数据库 对称多处 理, Symmetrical Multi-Processing 有两台以上的服务器,各主机之 间共 享总线结构,共享数据存储磁盘 节点数有 限制 ,主要 通 过提高节点配置来提高整体处理能力,扩展能力有限 对共享磁盘的访问可能成为瓶颈 SMP 大规模并行处 理, Massively Parallel Processing 多个 松 耦 合处 理单元组 成,数据存在本机磁盘上 通过增加服 务器数量提高系统处理能力,理论 上可无限 扩展 ,目技 术可实现上千个节点互联 对软件体系要求较高,需要通过软件层来调度和平衡各个节点的负载和并行处理过 程 MPP
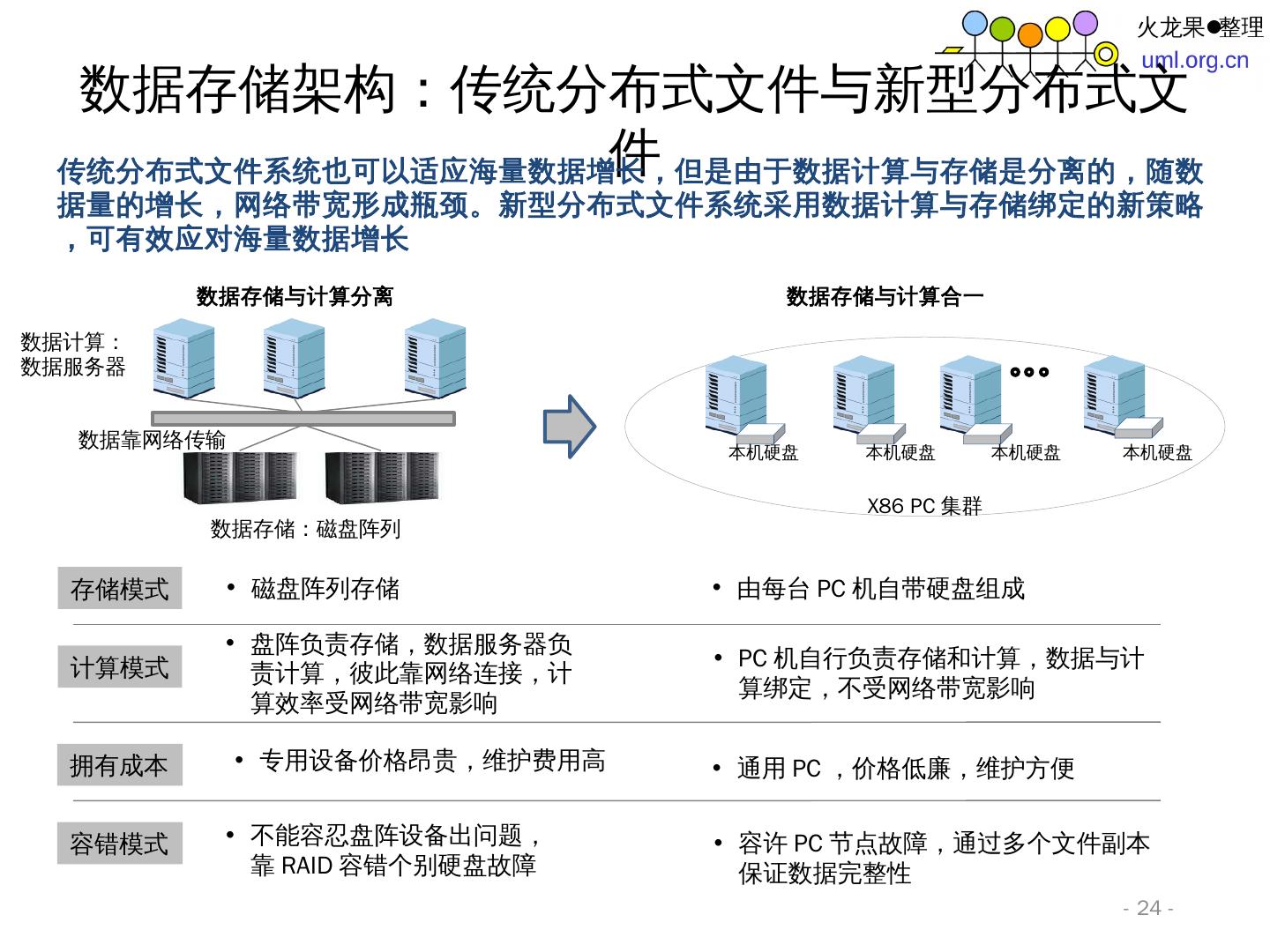
24 .数据存储架构:传统分布式文件与新型分布 式文件 - 24 - 传统分布式文件系 统也可 以适应海量数据增长,但是由于数据计算与存储是分离的,随数据 量的增 长,网络带宽形成瓶 颈。新 型分布式文件系统采用数据计算与存储绑定的新策略,可有效应对海量数据增 长 X86 PC 集群 数据存 储:磁盘阵 列 数据存储与计算合一 数据 计 算: 数据服务器 数据靠网络传输 本 机硬盘 本 机硬盘 本 机硬盘 本 机硬盘 计算模式 拥有成本 盘阵负责存储,数据服务器负责计算,彼此靠网络连接,计算效率受网络带宽影响 PC 机自行负责存储和计算,数据与计算绑定,不受网络带宽影响 专用设备价格昂贵,维护费用高 通用 PC ,价格低廉,维护方便 存储模式 磁盘阵列存储 由每台 PC 机自带硬盘组成 容错模式 不能容忍盘阵设备出问题,靠 RAID 容错个别硬盘故障 容许 PC 节点故障,通过多个文件副本保证数据完整性 数据存储与计算分离
25 .新 型分布式文件系统 — Hadoop HDFS - 25 - Hadoop HDFS 是新型分布式文件系统的典型代表,提供高可靠、高扩展、高吞吐能力的海量文件数据存储 元数据节点 Namenode 文件名,文件块,文件块所在数据节点, … 文件元数据 1 2 3 数据节点 Datanode 数据节点 Datanode 数据节点 Datanode 数据节点 Datanode 先读取 文件 元数据,知道文件在哪 后读取各个文件块 管理文件分布存储 优点 支持任意超大文件存储;硬件节点可不断扩展,低成本存储 对上层应用屏蔽分布式部署结构,提供统一的文件系统访问接口,感觉就是一个大硬盘;应用无需知道文件具体存放位置,使用简单; 文件分块存储( 1 块 缺省 64MB) ,不同块可分布在不同机器节点上,通过元数据记录文件块位置;应用顺序读取各个块 系统设计为高容错性,允许廉价 PC 故障;每块文件数据在不同机器节点上保存 3 份;这种备份的另一个好处是可方便不同应用就近读取,提高访问效率 缺点 适合大数据文件保存和分析, 不适合小文件 ,由于分布存储需要从不同节点读取数据,效率反而没有集中存储高;一次写入多次读取, 不支持文件修改 是最基础的大数据技术,基于文件系统层面提供文件访问能力,不如数据库技术强大,但也是海量数据库技术的底层依托 文件系统接口完全不同于传统文件系统,应用需要重新开发 上层应用 Yahoo Amazon Facebook Ebay 淘宝 百度 中国移动飞信 中国移动大云 行业 应用 技术特点
26 .基于并行计算的分布式数据处理技 术 ( MapReduce ) MapReduce 是解 决海量数 据处 理的并行编程环 境 - 26 - TaskTracker ( MapTask ) TaskTracker ( MapTask ) TaskTracker ( MapTask ) TaskTracker ( ReduceTask ) TaskTracker ( ReduceTask ) 中间结果 中间结果 中间结果 输出数据 输出数据 JobTracker 用户程序 ( JobClient ) 提交作业 任务调度 任务调度 状态监控 状态监控 1 2 3 MapReduce 技术特性 自 动并行化 :系统自动进行作业并行化处 理 自动可靠处理 :系统自动处理节点 / 任务的故障检测和恢复 灵活扩展 :节点可以灵活加入和退出,系统自动感知节点状态并进行处理 高性能 :计算任务将被调度至数据所在的节点,减少网络开销,提升执行性能 MapReduce
27 .基于并行计算的分布式数据处理技 术 ( MapReduce ) MapReduce 是解 决海量数 据处 理的并行编程环 境 - 26 - TaskTracker ( MapTask ) TaskTracker ( MapTask ) TaskTracker ( MapTask ) TaskTracker ( ReduceTask ) TaskTracker ( ReduceTask ) 中间结果 中间结果 中间结果 输出数据 输出数据 JobTracker 用户程序 ( JobClient ) 提交作业 任务调度 任务调度 状态监控 状态监控 1 2 3 MapReduce 技术特性 自 动并行化 :系统自动进行作业并行化处 理 自动可靠处理 :系统自动处理节点 / 任务的故障检测和恢复 灵活扩展 :节点可以灵活加入和退出,系统自动感知节点状态并进行处理 高性能 :计算任务将被调度至数据所在的节点,减少网络开销,提升执行性能 MapReduce
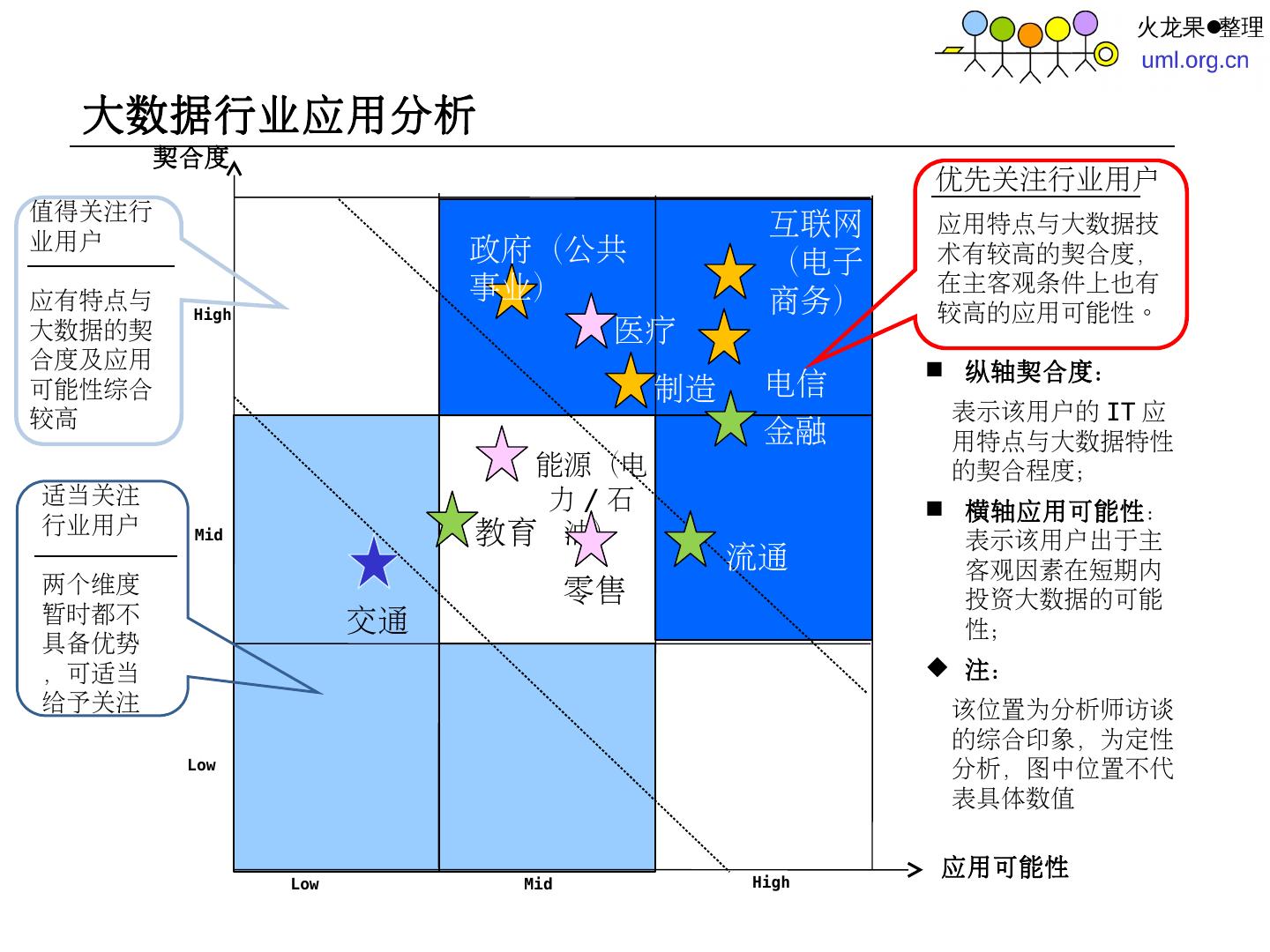
28 .大数据行业应用分析 应用可能性 电信 政府(公共事业) 交通 金融 医疗 教育 能源(电力 / 石油) 纵轴契合度: 表示该用户的 IT 应用特点与大数据特性的契合程度; 横轴应用可能性 :表示该用户出于主客观因素在短期内投资大数据的可能性; 注: 该位置为分析师访谈的综合印象,为定性分析,图中位置不代表具体数值 High Mid Low Low Mid High 优先关注行业用户 应用特点与大数据技术有较高的契合度,在主客观条件上也有较高的应用可能性。 值得关注行业用户 应有特点与大数据的契合度及应用可能性综合较高 适当关注行业用户 两个维度暂时都不具备优势,可适当给予关注 互联网(电子商务) 契合度 流通 零售 制造
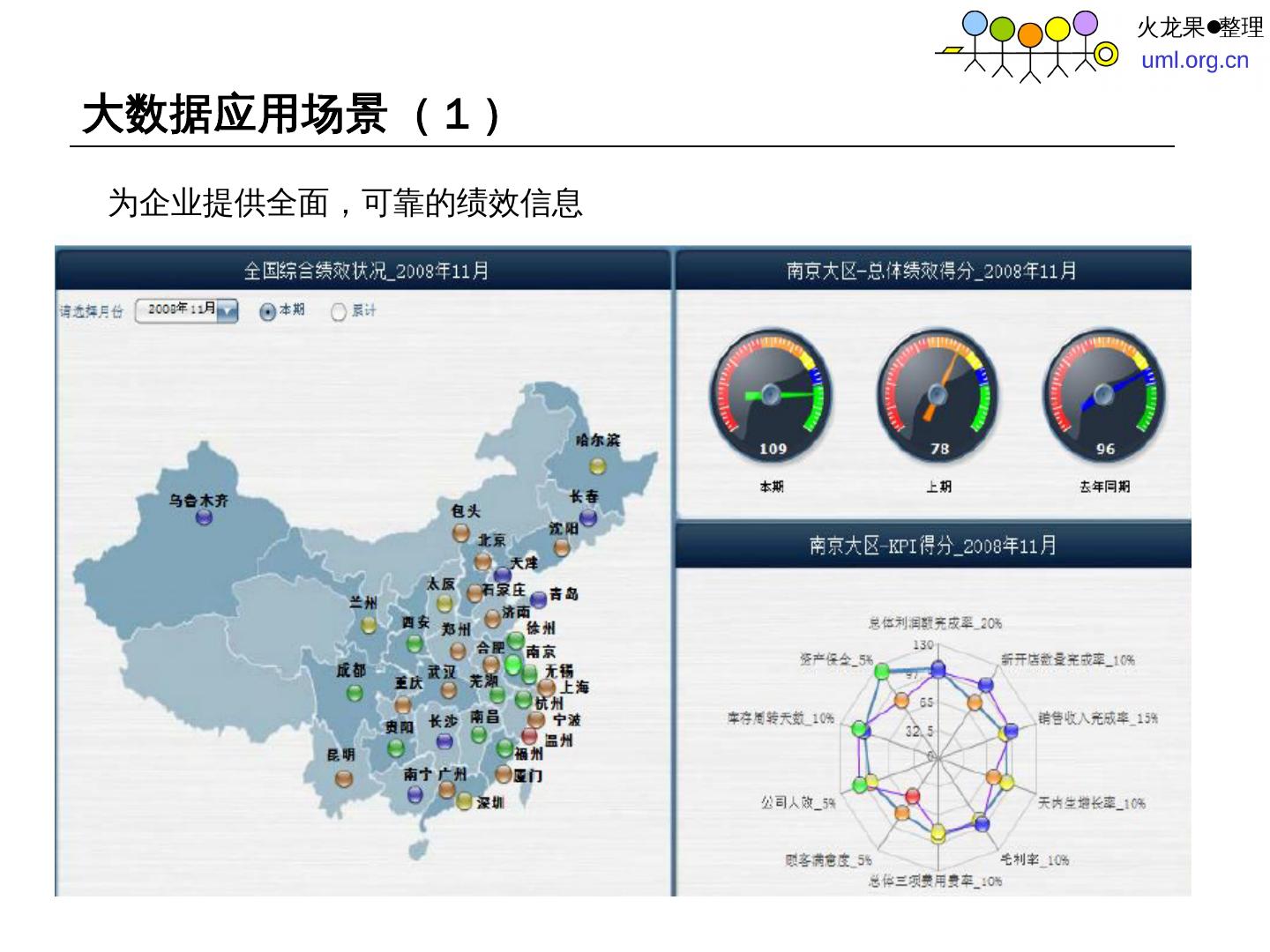
29 .大 数据应用场景( 1 ) 为企业提供全面,可靠的绩效信息
3秒后跳转登录页面
去登陆

