






































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
目标检测与识别
本节介绍了包括目标识别中的难点:实现鲁棒识别、计算量大、在小样本条件下学习;物体识别方法:检测(detection),表示(representation)、分类(classification or categorization)( K近邻(KNN)、神经网络(NN)、支持向量机(SVM)等);人脸识别的技术实现;深度学习引导
展开查看详情
1 .第十二章 目标检测与识别 Lecture 12 Object Detection and Recognition
2 .目标检测和识别 怎样检测和识别图像中物体,如汽车、牛等?
3 .目标识别的应用
4 .难点之一 : 如何鲁棒识别?
5 .类内差异( intra-class variability )
6 .类间相似性( inter-class similarity )
7 .难点之二:计算量大 一幅图像中像素个数多,目前每秒约产生 300G 像素 的图像 /视频数据。 - Google 图片搜索中已有几十亿幅图像 - 全球数字照相机一年产生 180 亿张以上的图片 ( 2004 年) - 全球一年销售约 3 亿部照相手机( 2005 ) 人的物体识别能力是强大的 - 灵长类动物约使用大脑皮层的一半来处理视觉信息 [Felleman and van Essen 1991]Felleman and van Essen 1991] - 可以识别 3,000-30,000 种物体 - 物体姿态可允许 30 度以上的自由度。
8 .难点之三:如何在小样本条件下学习
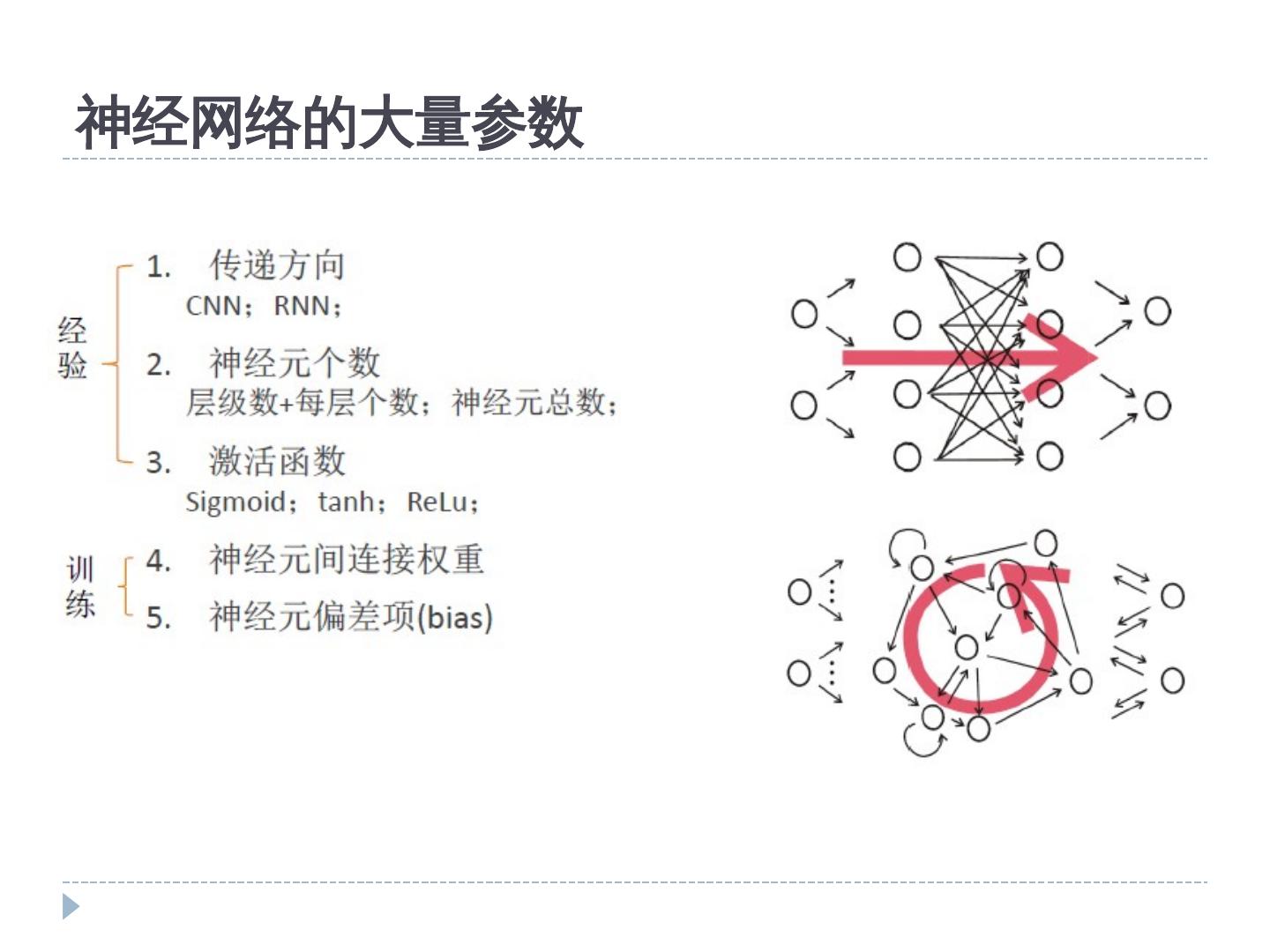
9 .物体识别方法 检测 (detection)vs. detection)vs. vs. 不检测 表示 (detection)vs. representation)vs. - 颜色、纹理、边缘、梯度、局部特征、深度、 运动等等。 分类 (detection)vs. classification or categorization)vs. - K 近邻( KNN ) - 神经网络( NN ) 生成学习 - 支持向量机( SVM ) ( Generative - Boosting(detection)vs. Adaboost 等 )vs. learning ) vs. 判别 - 隐马尔科夫模型( HMM ) 学习 - 其他 ( discriminative learning )
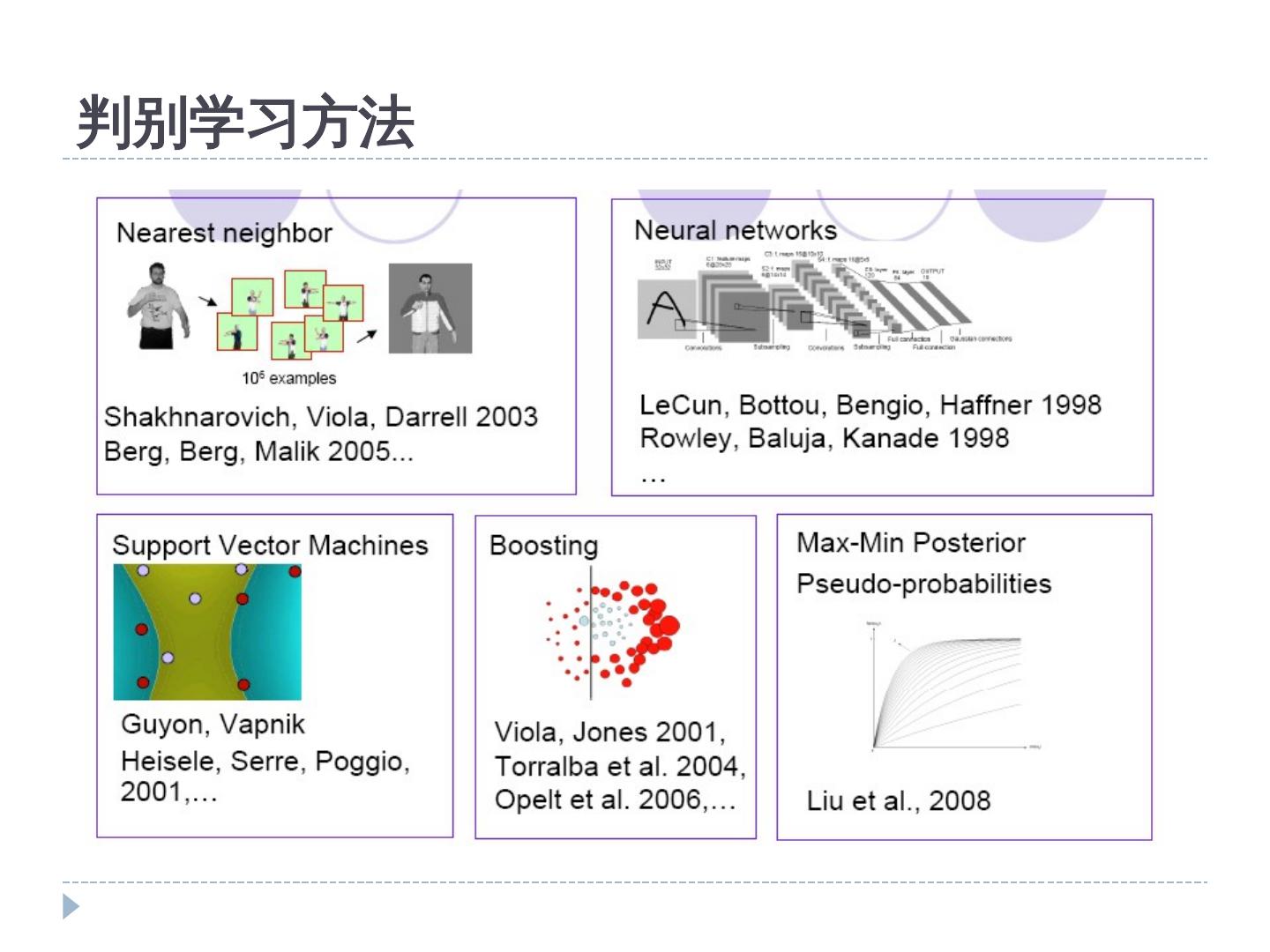
10 .生成学习 vs. 判别学习 两种分类器学习模式 生成学习 --- 目标是学习到符合训练数据的类别模型 --- 如 EM 算法 (detection)vs. Maximum Likelihood)vs. 判别学习 在训练阶段即考虑类别之间的判别信息 包括 Support Vector Machines (detection)vs. SVMs)vs. , Boosting, Minimum Classification Error (detection)vs. MCE)vs. , Maximum Mutual Information (detection)vs. MMI)vs. , Lager Margin (detection)vs. LM)vs. , and etc. 判别学习算法比生成学习算法表现出更好的分类性能 。
11 .判别学习方法
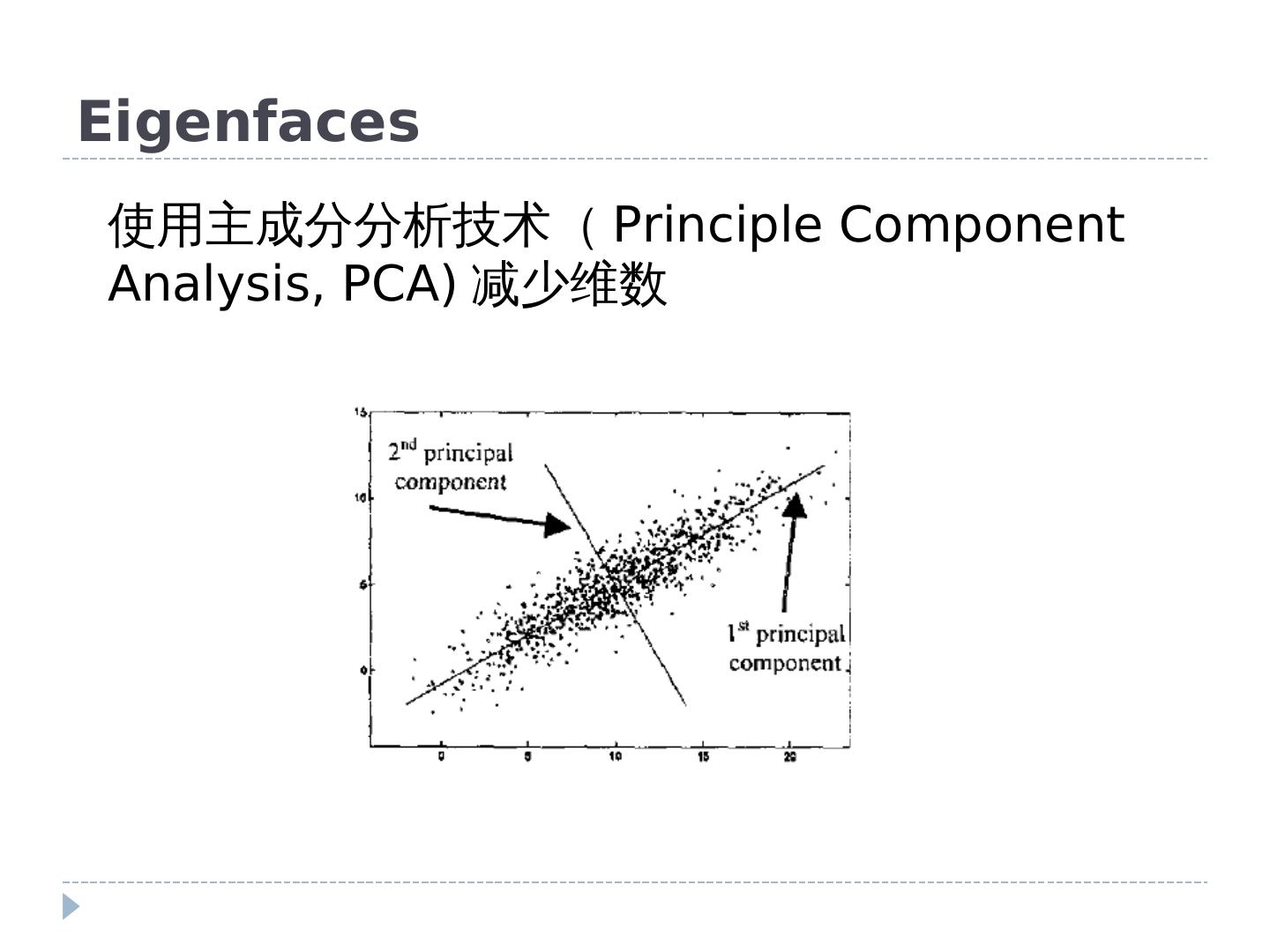
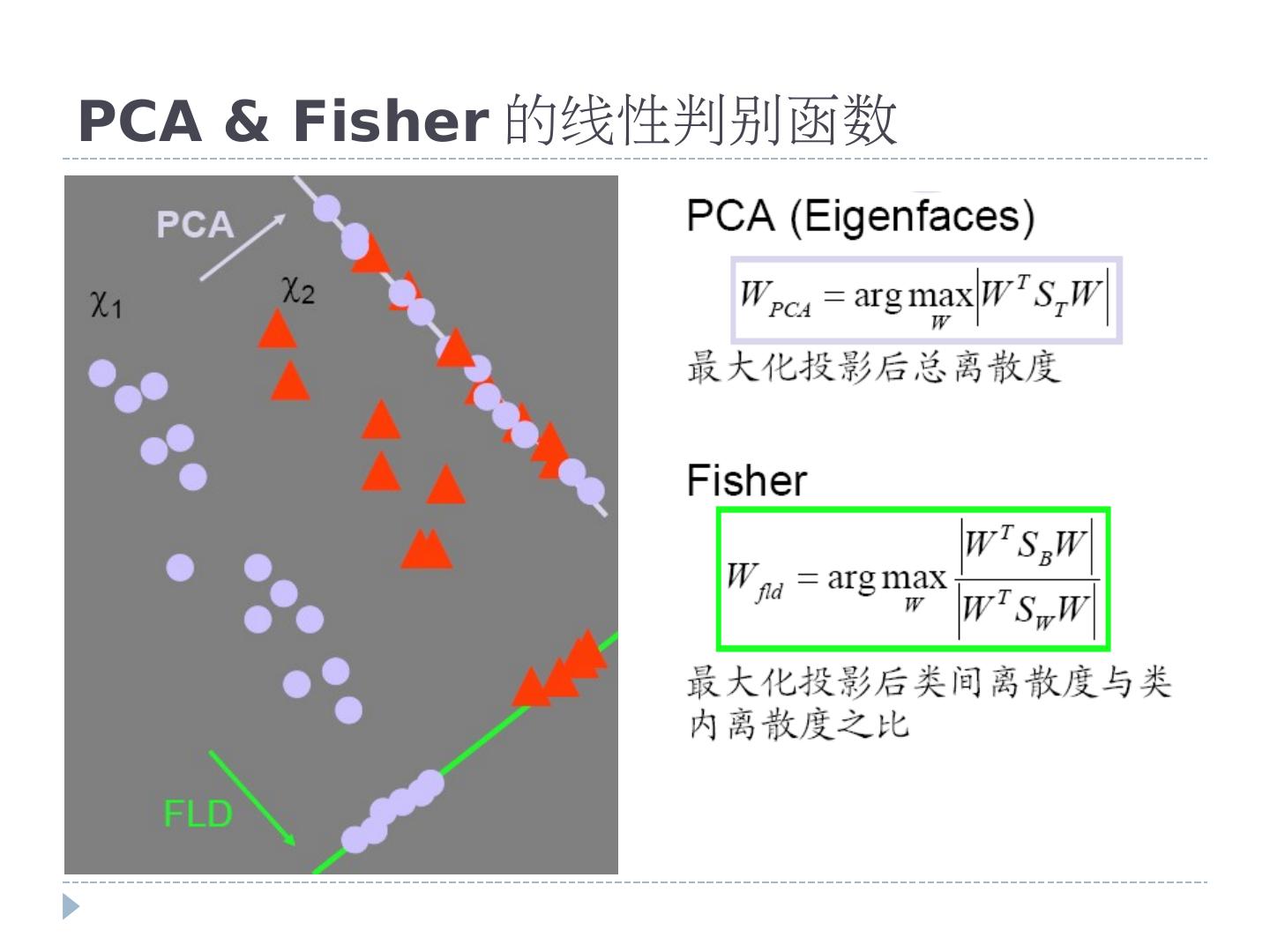
12 .第二节 人脸检测与识别
13 .1. 物体检测 基于二分类器 Car/non-car Classifier No, notcar. Yes, a car. 13
14 .物体检测 在复杂背景下,通过滑动窗口( sliding window s )搜索感兴趣的物体。 Car/non-car Classifier 14
15 .物体检测 Step1. 获取训练数据 Step2. 提取特征 Step3. 训练分类器 Step4. 利用分类器进行检测
16 .人脸检测( Face detection ) Viola-Jones 人脸检测算法(基于 AdaBoost )
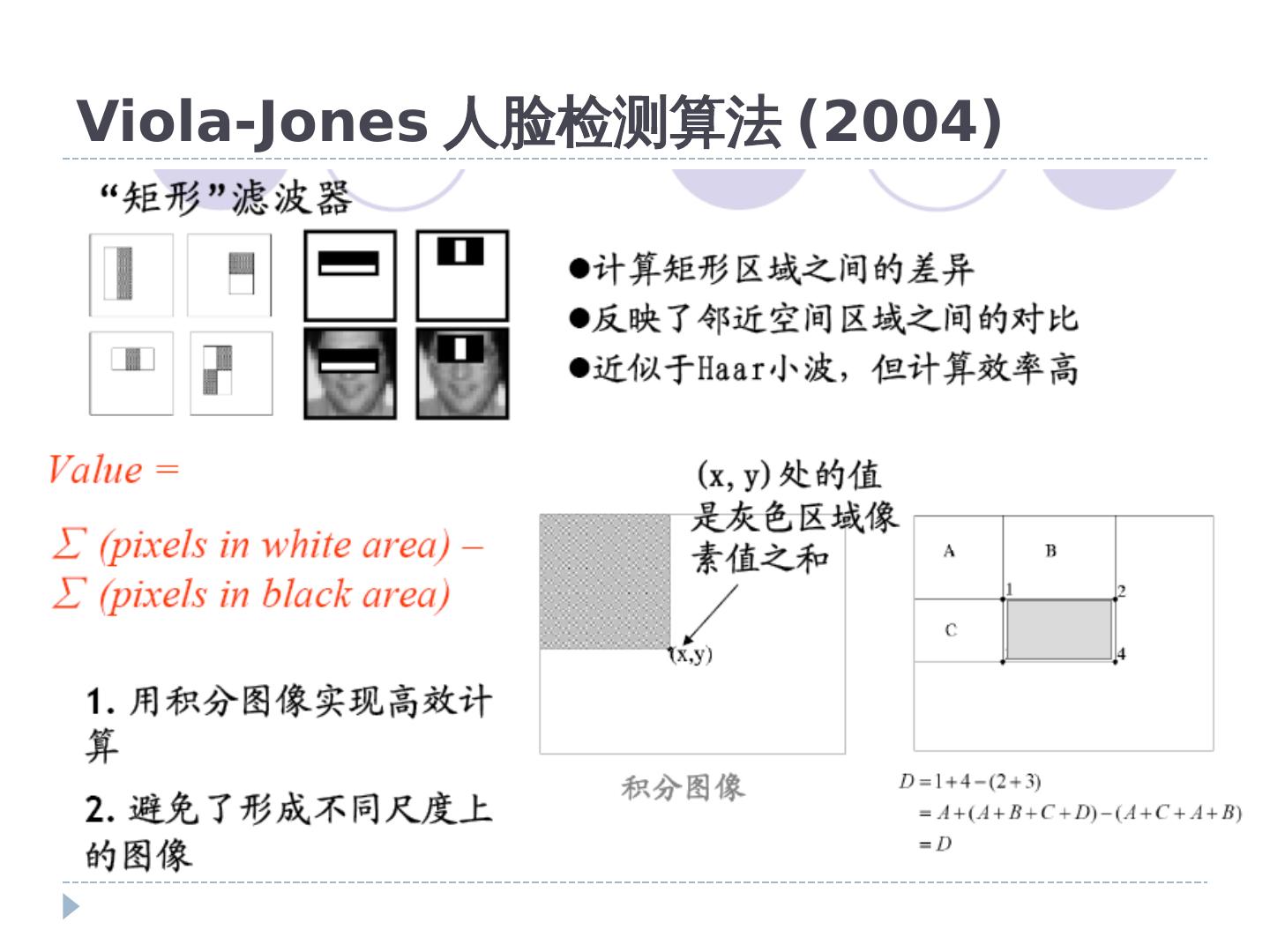
17 .Viola-Jones 人脸检测算法 (2004)
18 .滤波器设计
19 .Adaboost Adaboost 是一种迭代算法,其核心思想是针对同一 个训练集训练不同的分类器 ( 弱分类器 ) ,然后把这些 弱分类器集合起来,构成一个更强的最终分类器 ( 强分 类器 ) 。 其算法本身是通过改变数据分布来实现的,它根据每 次训练集之中每个样本的分类是否正确,以及上次的 总体分类的准确率,来确定每个样本的权值。将修改 过权值的新数据集送给下层分类器进行训练,最后将 每次训练得到的分类器最后融合起来,作为最后的决 策分类器。 使用 adaboost 分类器可以排除一些不必要的训练数 据特徵,并将关键放在关键的训练数据上面。
20 .Boosting Example
21 .Boosting Example
22 .Boosting Example
23 .Boosting Example
24 .Boosting Example
25 .Boosting Example
26 .Adaboost 学习目标:选择能够最有效地区分人脸与非人脸的矩形特征 及其阈值
27 .Adaboost 组合弱分类器( weak learners ),得到更为精确 的集成分类器( ensemble classifier )。 弱分类器:性能仅比随机分类稍好 根据矩形特征定义弱分类器 :
28 .Adaboost 算法步骤 初始给每个训练样本以同等权重 循环执行以下步骤: 根据当前加权训练集,选择最佳弱分类器 提升被当前弱分类器错分的训练样本的权重 按照各弱分类器分类精度对其加权,然后将各个 弱分类器形成线性组合,得到最终分类器。
29 . Viola-Jones 算法中的 AdaBoost 每一次 boosting 迭代如下 : 评价每一个样本上的每一种矩形特征 为每一种矩形特征选择最佳分类阈值 选择最优的矩形特征及其阈值组合 改变样本权重 计算复杂度 : O(detection)vs. MNT)vs. M :特征数, N :样本数 , T :阈值数
3秒后跳转登录页面
去登陆

