展开查看详情
1 .Elasticsearch 在日志分析领域 应用和运维实践 阿里巴巴高级工程师 赵汉青
2 .目录 Elasticsearch 及相关产品 介绍 1 基于 ELK + Kafka 的日志分析系统 2 3 Elasticsearch 优化经验 4 阿里云 Elasticsearch 服务 5 Elasticsearch 运维实践
3 .Elasticsearch 及相关产品介绍 Elasticsearch :分布式实时分析搜索引擎。 查询近实时 。 内存消耗小 , 搜索速度快 。 可扩展性强。 高可用。 Elasticsearch
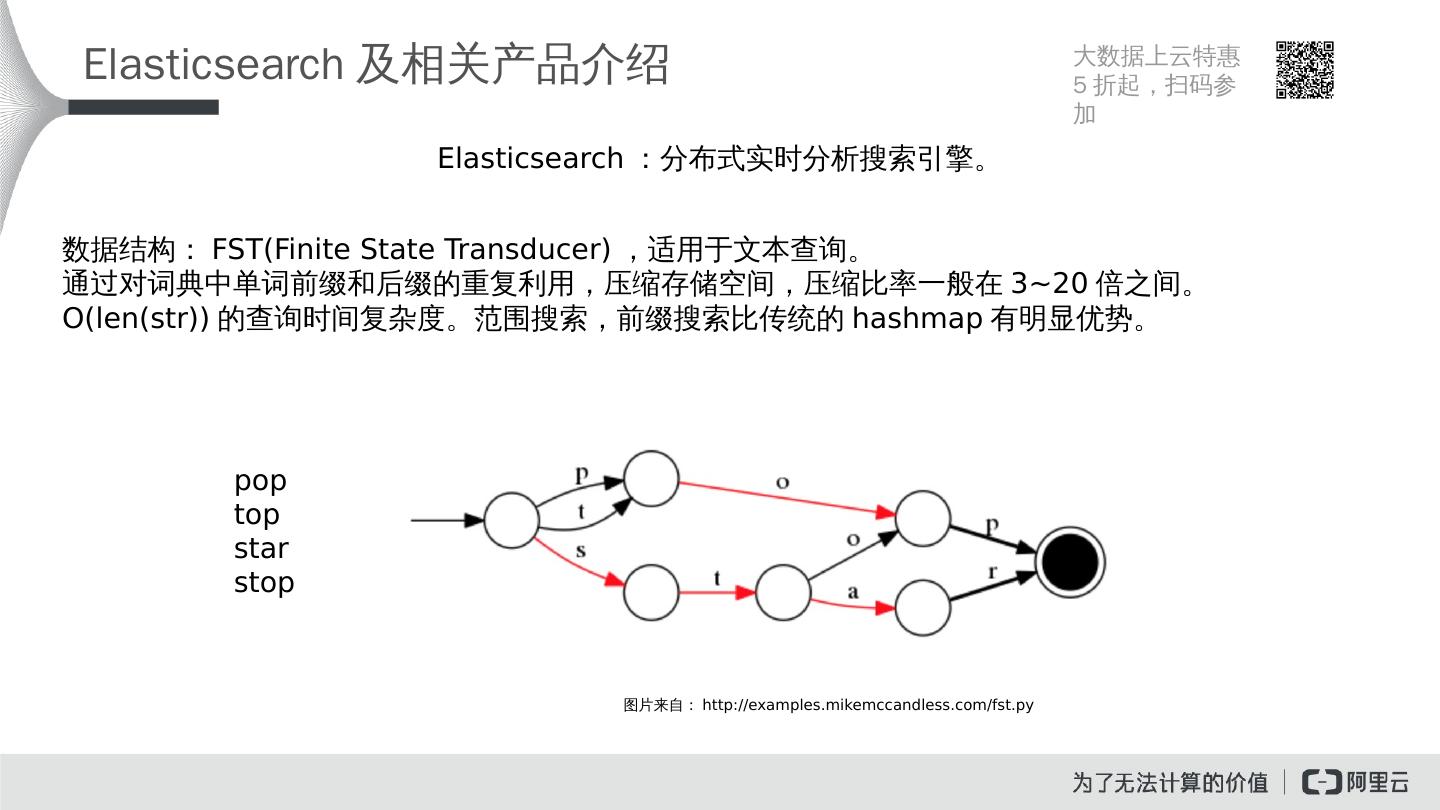
4 .Elasticsearch 及相关产品介绍 Elasticsearch :分布式实时分析搜索引擎。 数据结构: FST(Finite State Transducer) ,适用于文本查询。 通过对词典中单词前缀和后缀的重复利用,压缩存储空间,压缩比率一般在 3~20 倍之间。 O( len ( str )) 的查询时间复杂度。范围搜索,前缀搜索比传统的 hashmap 有明显优势。 pop top star stop 图片来自: http:// examples.mikemccandless.com / fst.py
5 .Elasticsearch 及相关产品介绍 Elasticsearch :分布式实时分析搜索引擎。 数据结构: BKDTree (Block k-d tree) ,适用于数值型,地理信息( geo )等多维度数据类型。 K=1, 二叉搜索树,查询复杂度 log(N) K=2, 确定切分维度,切分点选这个维度的中间点
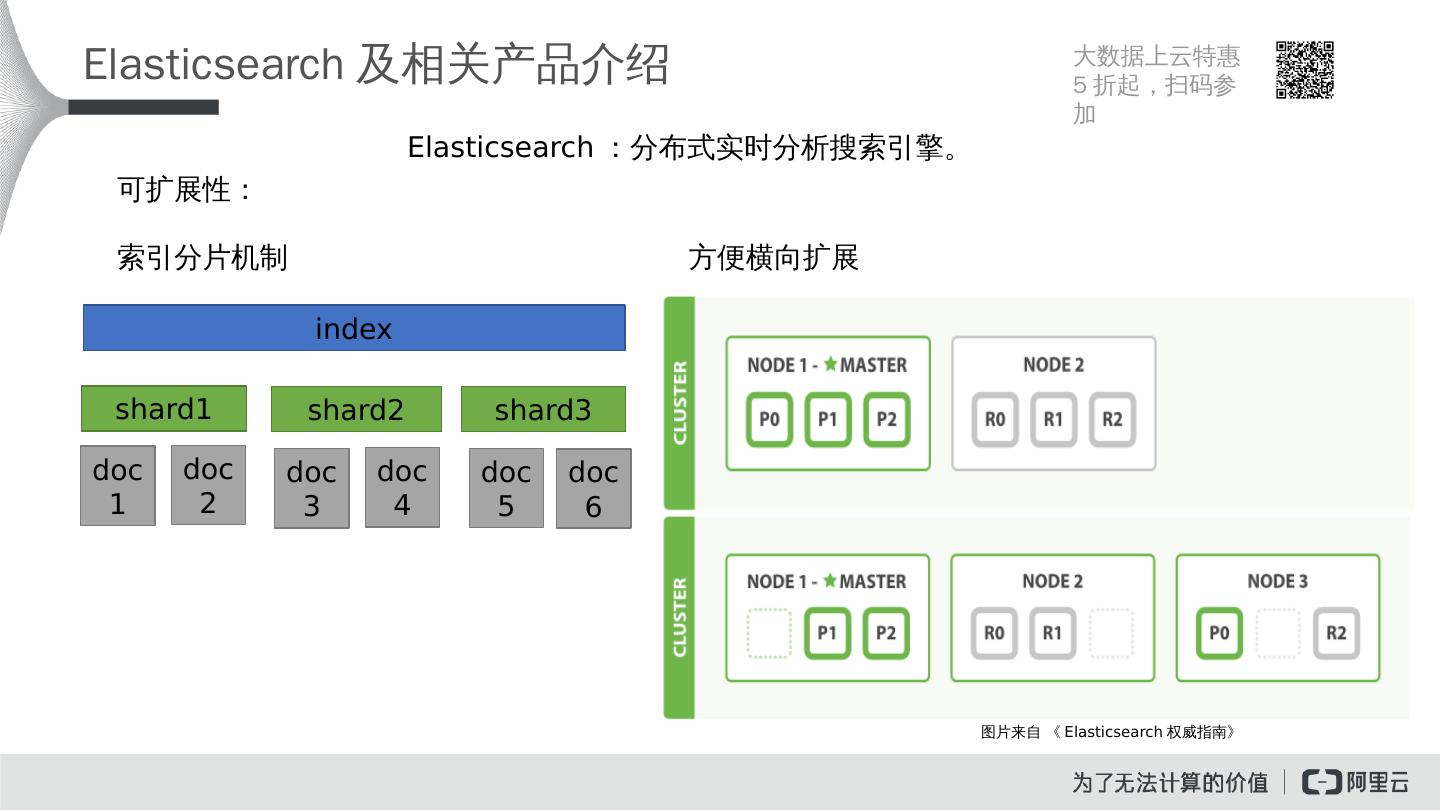
6 .Elasticsearch 及相关产品介绍 Elasticsearch :分布式实时分析搜索引擎。 可扩展性: 索引分片机制 方便横向扩展 index shard1 shard 2 shard 3 doc1 doc 2 doc 3 doc 4 doc5 doc6 图片来自 《 Elasticsearch 权威指南 》
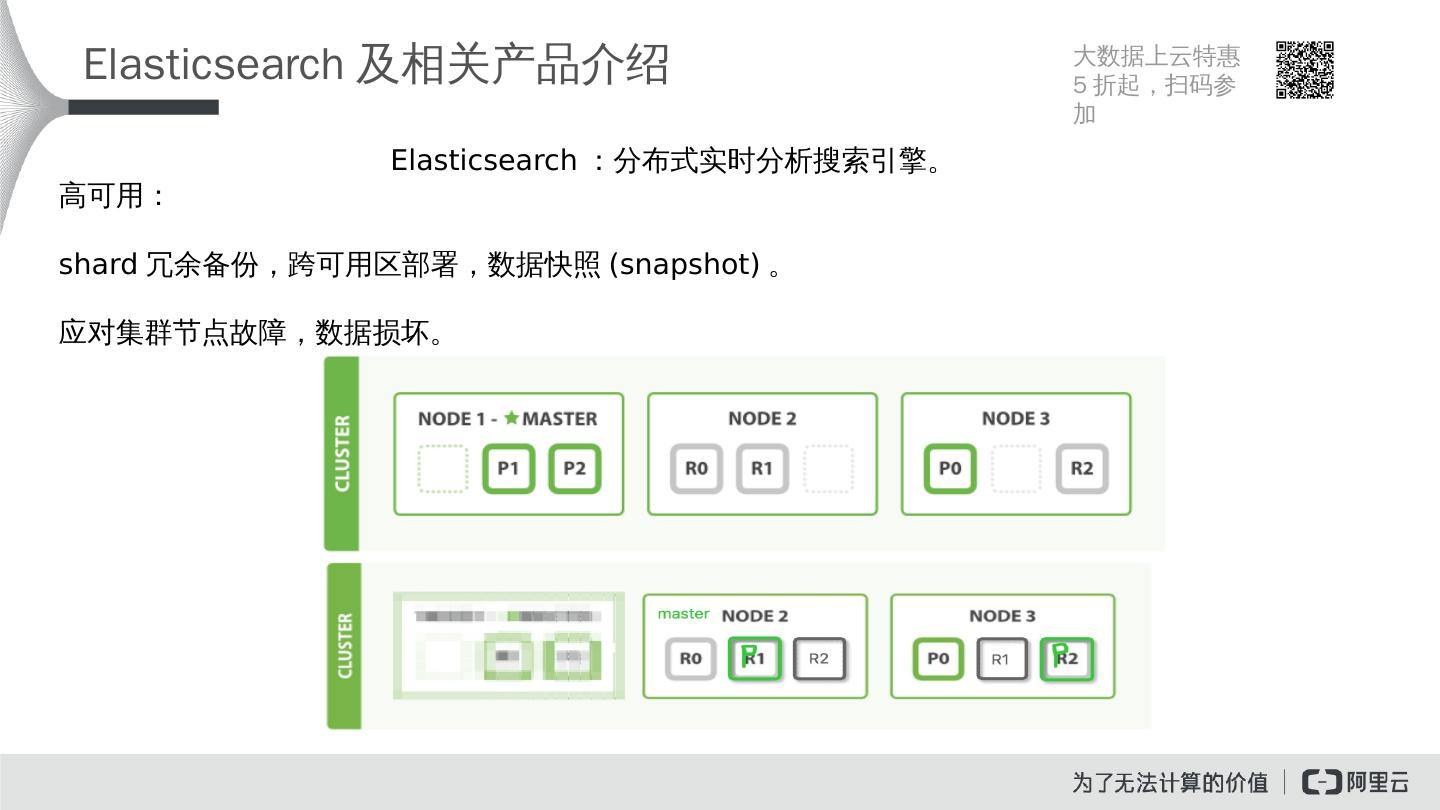
7 .Elasticsearch 及相关产品介绍 Elasticsearch :分布式实时分析搜索引擎。 高可用: shard 冗余备份,跨可用区部署,数据快照 (snapshot) 。 应对集群节点故障,数据损坏。
8 .Elasticsearch 及相关产品介绍 Kibana : 数据可视化,与 elasticsearch 交互。 Elasticsearch: 存储,索引,搜索。 Logstash: 数据收集,过滤,转换。 Beats: 比 logstash 更轻巧 , 更多样化 : Filebeat, Metricbeat, Packetbeat, Winlogbeat … Kibana Elasticsearch Logstash Beats Elastic Stack:
9 .目录 2 Elasticsearch 及相关产品介绍 1 3 4 5 基于 ELK + Kafka 的日志分析系统 Elasticsearch 优化经验 阿里云 Elasticsearch 服务 Elasticsearch 运维实践
10 .基于 ELK+Kafka 的 日志分析系统 Elasticsearch 使用的典型场景:日志分析
11 .基于 ELK+Kafka 的日志分析系统 l ogstash 优点 提供了大量的用于数据过滤,转换的插件。 drop: 丢掉不需要的数据。 g rok : 正则匹配抓取数据。 d ate : 从数据中解析 date 属性,用作 Elasticsearch document 的 timestamp 。 metrics: 获取 logstash 的 metrics 。 c odec.multiline :多行数据合成一条记录。 fingerprint : 防止插入重复的数据。 Logstash 缺点:收集 log 效率低,耗资源。 Filebeat: 弥补的缺点,但自身插件较少。
12 .基于 ELK+Kafka 的日志分析系统 为何用 kafka 进行 日志 传输? Kafka 有数据缓存能力。 Kafka 数据可重复消费。 Kafka 本身高可用,防止数据丢失。 Kafka 的 throughput 更好。 Kafka 使用广泛。 实践经验: 不同的 service ,创建不同的 topic 。 根据 service 的日志量,设定 topic partition 个数。 按照 kafka partition 的个数和消费该 topic 的 logstash 的个数,配置 consumer_threads 。 尽量明确 logstash 和对应消费的 topic ( s) ,配置消费的 topic 少用通配符。
13 .基于 ELK+Kafka 的日志分析系统 集群 规划的 基本问题: 总数据量大小:每天流入多少数据,保存多少天数据。 单节点配置:每个节点多少索引,多少 shard ,每个 shard 大小控制在多少。 根据总数据量和单节点配置,得出集群总体规模。
14 .基于 ELK+Kafka 的日志分析系统 问题分析 1 : 每日增加的数据量:每日新增的 log 量*备份个数 。 如果 enable 了 _ all 字段,则在上面的基础上再翻一倍。 比如每天新增 1T 的 log ,每个 shard 有 1 个备份, enable _all ,则 Elasticsearch 集群的实际数据增加量约等于 4T 。 如果每天需要存 4T 数据,假如保存 30 天的数据,需要的最低存储是 120T ,一般还会加 20% 的 buffer 。 至少 需要准备 144T 的存储空间。 根据日志场景的特点,可做 hot-node, warm - node 划分。 hot-node 通常用 SSD 磁盘, warm-node 采用普通机械盘。
15 .基于 ELK+Kafka 的日志分析系统 问题分析 2 : 单节点,根据经验通常 CPU :Memory的配比是1:4。 Memory : Disk 的配比为 1 : 24 。 Elasticsearch heap 的 xmx 设置通常不大于 32g 。 Memory 和 shard 的配比在 1 : 20 ~ 1:25 之间。 每个shard的大小不超过 5 0g 。
16 .基于 ELK+Kafka 的日志分析系统 案例分析: 产线上出现服务 failover , backup 集群日志量会忽然增大, kafka 里的数据量也突然增多,单位时间内 logstash 消费 kafka 注 入 Elasticsearch 的数据量也会增大,如果某些正在插入数据的 primary shard 集中在一个 node 上,该 node 会因为需要索引的数据量过大、同时响应多个 logstash bulk 请求等因素,导致该 node 的 Elasticsearch 服务过于繁忙 。 若无法响应 master 节点发来的请求(比如 cluster health heartbeat ), master 节点会因为等待该节点的响应而被 block ,导致别的节点认为 master 节点丢失,从而触发一系列非常反应,比如重选 master 。 若无法及时响应 logstash 请求, logstash connect elasticsearch 便会出现 timeout , l ogstash 会认得这个 Elasticsearch 为 dead ,同时不再消费 kafka 。 Kafka 发现在同一个 consumer group 里面某个 consumer 消失了,便会触发整个 consumer group 做 rebalance ,从而影响别的 logstash 的消费, 影响整个集群的吞吐量。
17 .基于 ELK+Kafka 的日志分析系统 案例分析: 典型 羊群效应,需要消除头羊带 来的影响。 可通过 elasticsearch API: GET /_cat/thread_pool / bulk?v&h =name , host,active,queue,rejected,completed 定位哪个节点比较忙: queue 比较大, rejected 不断增加。 然后通过 GET /_cat/shards 找到该 node 上活跃的 shard 。 最后再通过 POST /_cluster/reroute API 把 shard 移到 load 比较低的 node 上,缓解该 node 的压力。
18 .目录 3 2 4 1 5 Elasticsearch 及相关产品介绍 基于 ELK + Kafka 的日志收集系统 Elasticsearch 优化经验 阿里云 Elasticsearch 服务 Elasticsearch 运维实践
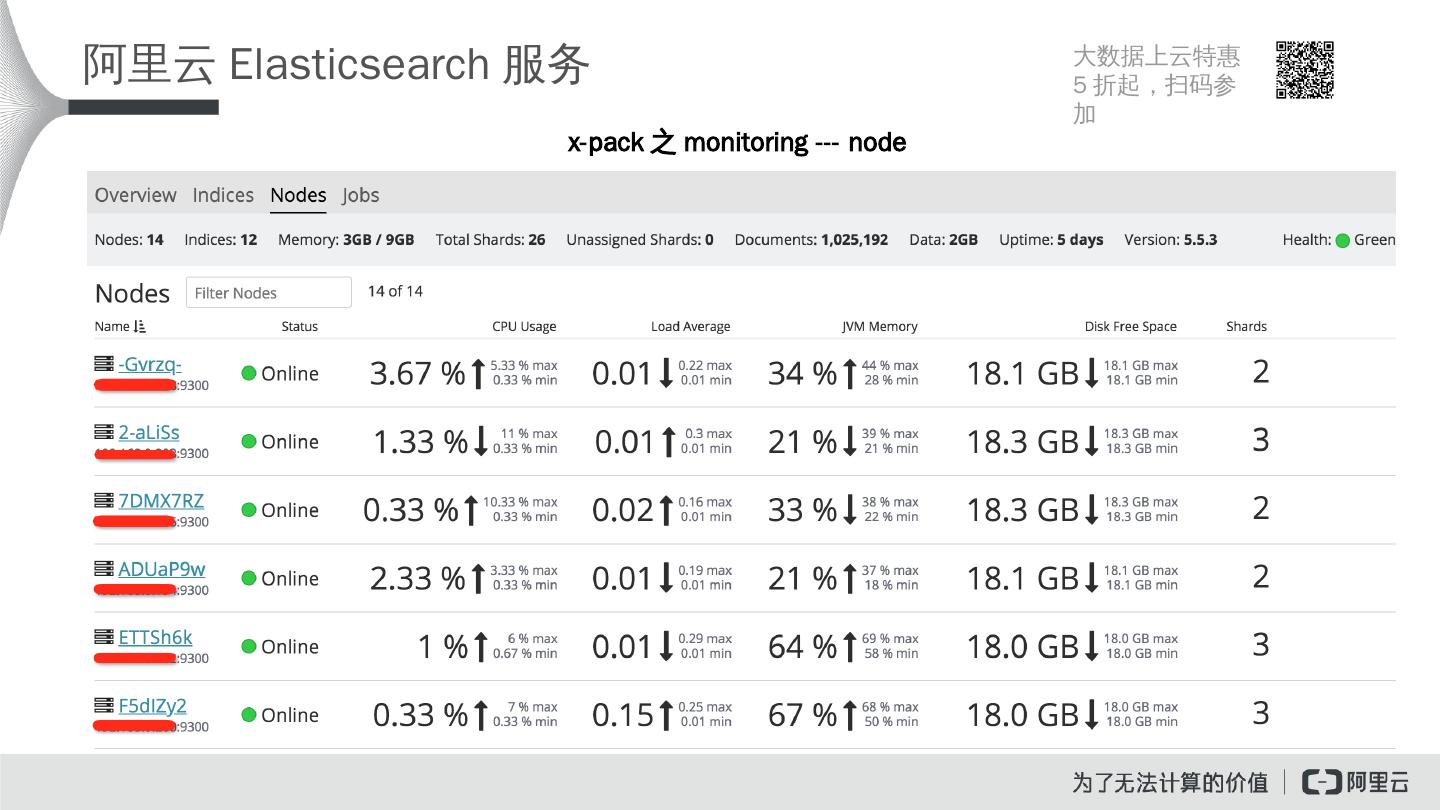
19 .Elasticsearch 运维实践 运维 Elasticsearch 集群 ,主要关注下面几个指标: 1. 集群健康状态。 2 . 集群索引和搜索 性能。 3. 节点 cpu , memory, disk 使用情况。
20 .Elasticsearch 运维实践 集群 green ,正常。 集群 yellow ,主要是有 replica shard 未分配。 集群 red ,是因为有 primary shard 未分配。 主要原因:集群 node disk 使用率超过 watermark ( 默认 85% )。 可通过 api GET /_cat/ allocation 查看 node 的磁盘使用率。 可通过 api GET /_cluster/ settings 查看 cluster.routing.allocation.enable 是否被禁止。 可通过 api GET /_cluster/allocation/ explain? pretty 查看 shard 未分配到 node 的具体原因。
21 .Elasticsearch 运维实践 indexing rate, indexing latency , search rate, search latency 。
22 .Elasticsearch 运维实践 监控 节点的 cpu , memory, disk 使用情况。 推荐监控工具 : cerebro ( https:// github.com / lmenezes / cerebro )
23 .目录 4 3 5 2 1 Elasticsearch 及相关产品介绍 基于 ELK + Kafka 的日志收集系统 Elasticsearch 运维实践 Elasticsearch 优化经验 阿里云 Elasticsearch 服务
24 .Elasticsearch 优化经验 索引优化: 1. 提前创建索引。 2. 避免索引稀疏, index 中 document 结构最好保持一致,如果 document 结构不一致,建议分 index ,用一个有少量 shard 的 index 存放 field 格式不同的 document 。 3 . 在加载大量数据时可设置 refresh_interval =-1 , index.number_of_replicas =0 ,索引完成后再设回 来。 4 . load 和 IO 压力不大的情况,用 bulk 比单条的 PUT/DELETE 操作索引效率更高 。 5 . 调整 index buffer( indices.memory.index_buffer_size ) 。 6. 不需要 score 的 field ,禁用 norms ; 不需要 sort 或 aggregate 的 field ,禁用 doc_value 。
25 .Elasticsearch 优化经验 查询 优化: 使用 routing 提升某一维度数据的查询速度。 避免返回太大量的搜索结果集,用 limit 限制。 如果 heap 压力不大,可适当增加 node query cache( indices.queries.cache.size ) 。 增加 shard 备份可提高查询并发能力,但要注意 node 上的 shard 总量。 定期合并 segment 。
26 .目录 5 4 3 2 1 Elasticsearch 及相关产品介绍 基于 ELK + Kafka 的日志收集系统 Elasticsearch 优化经验 阿里云 Elasticsearch 服务 Elasticsearch 运维实践
27 .阿里云 Elasticsearch 服务 Security Monitoring Alerting Reporting Graph Machine Learning Kibana Elasticsearch Logstash Beats +
28 .阿里云 Elasticsearch 服务 x -pack 之 security
29 .阿里云 Elasticsearch 服务 x -pack 之 monitoring