



















































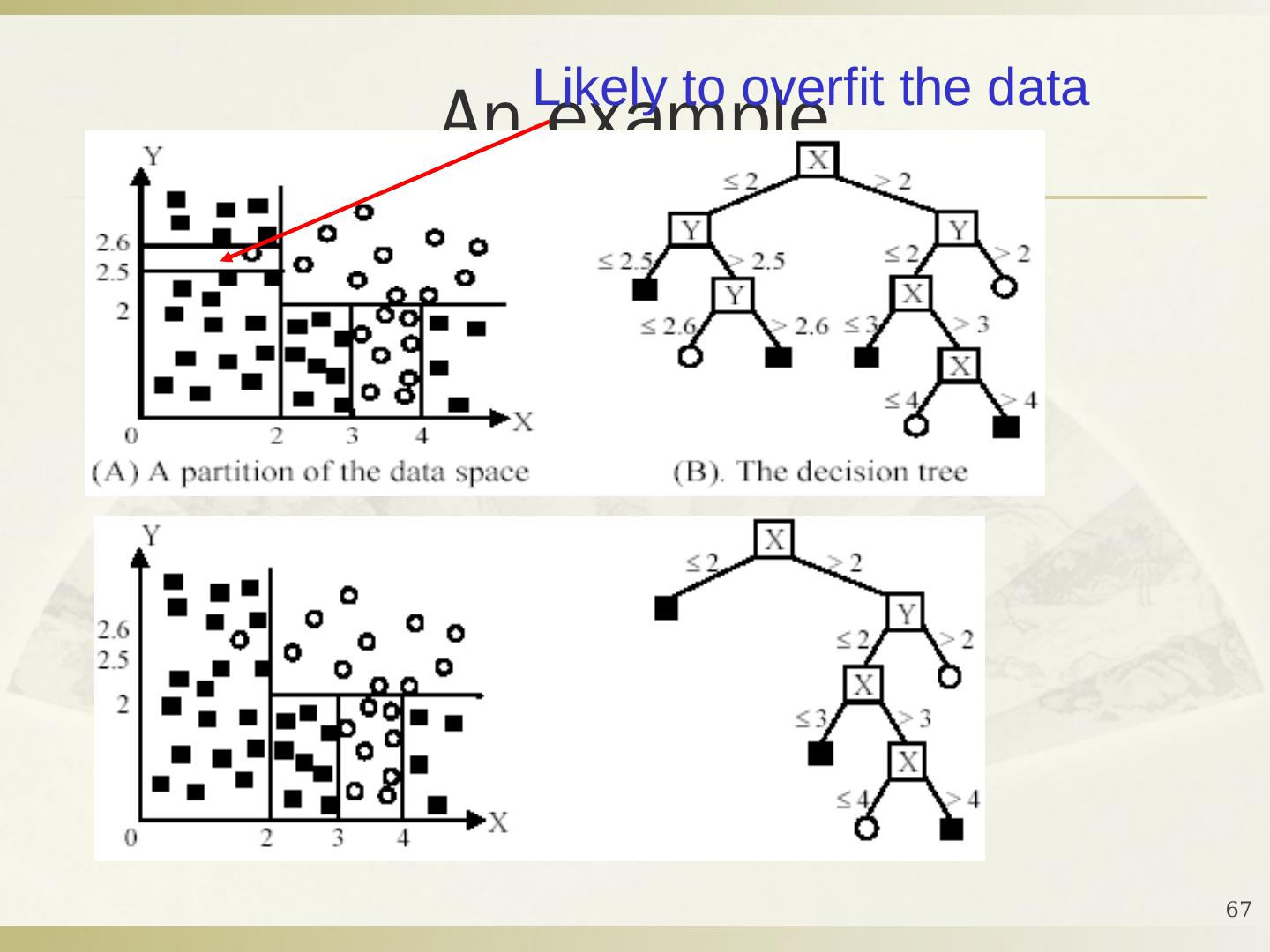
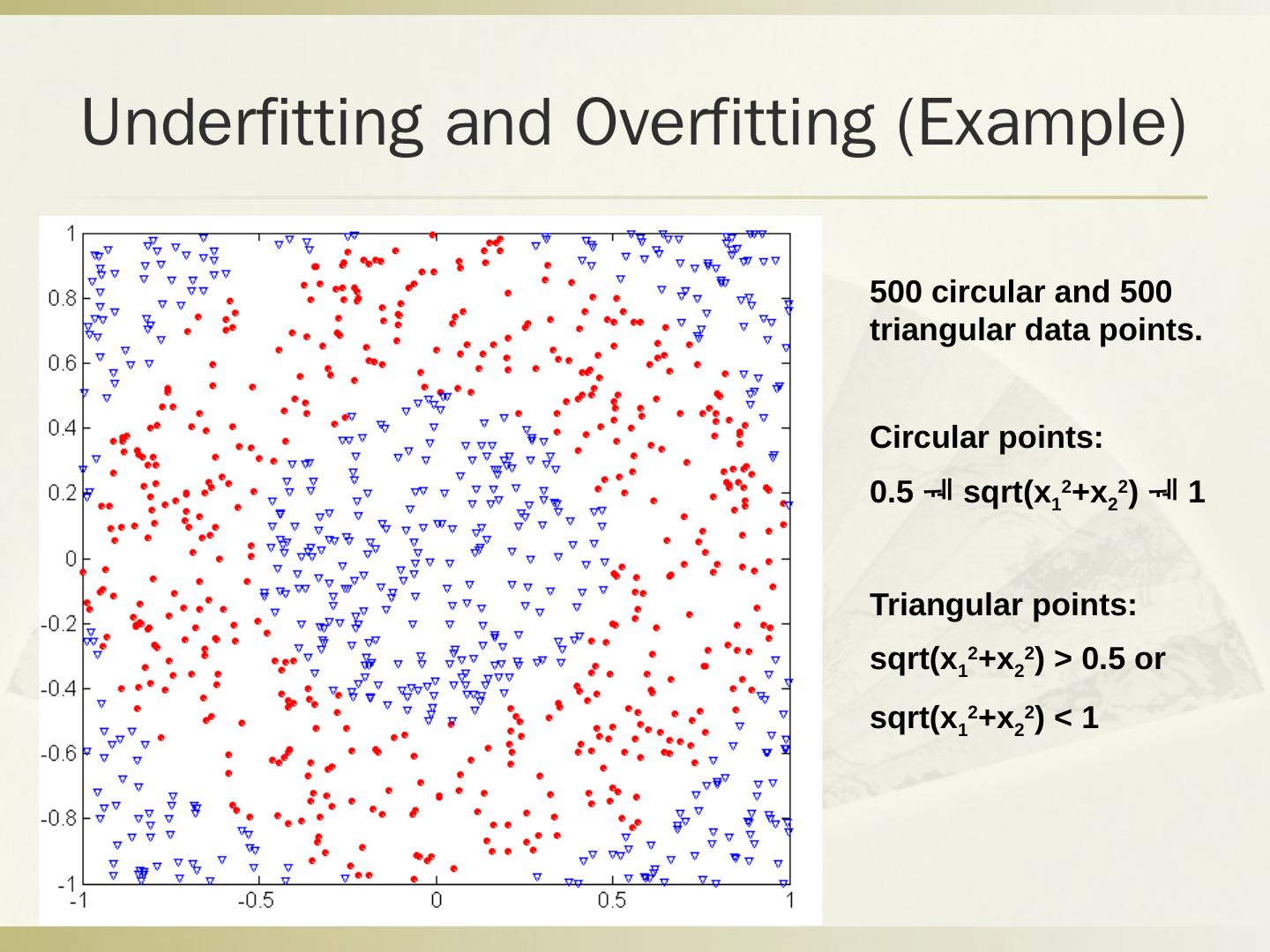
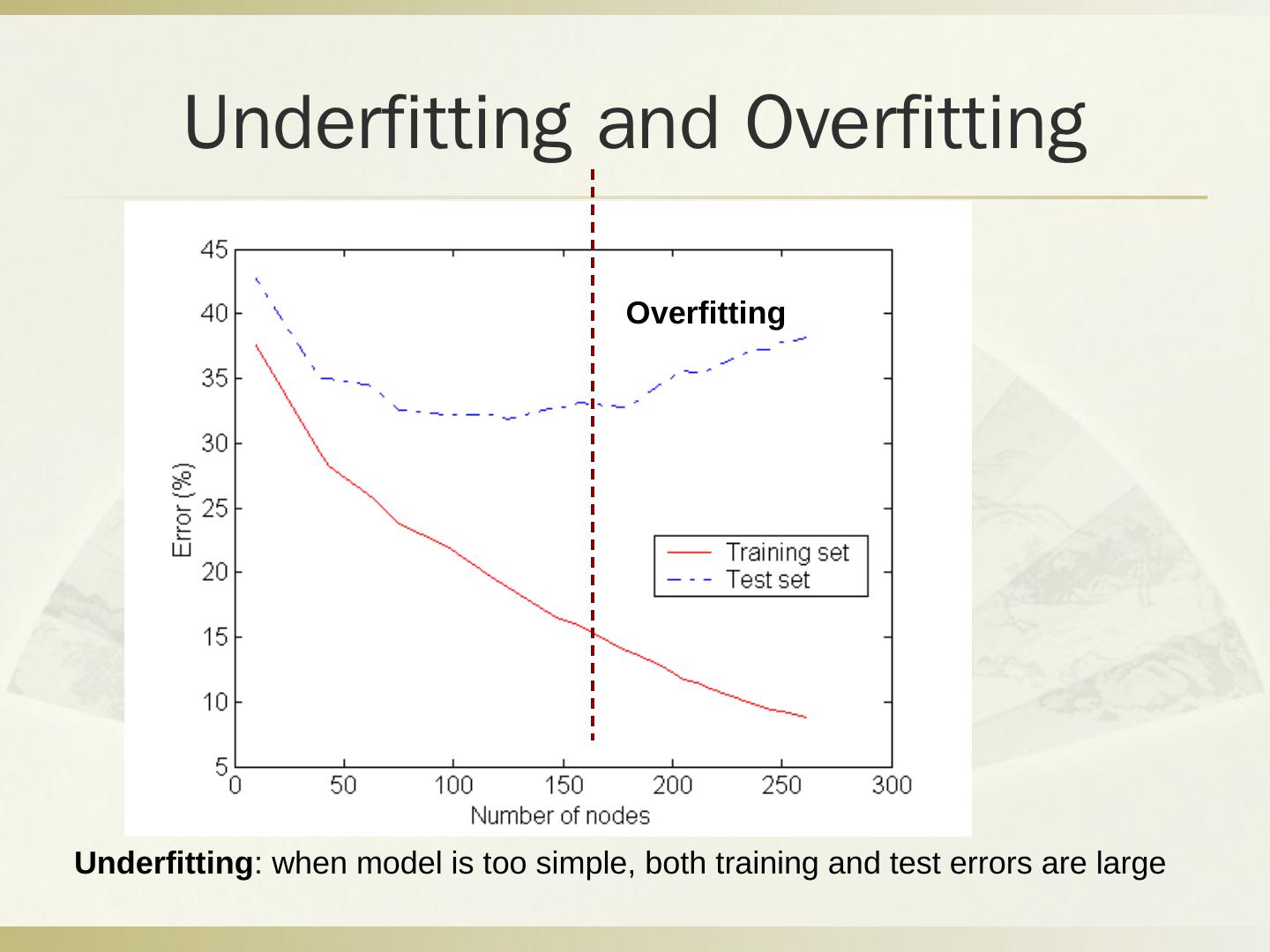
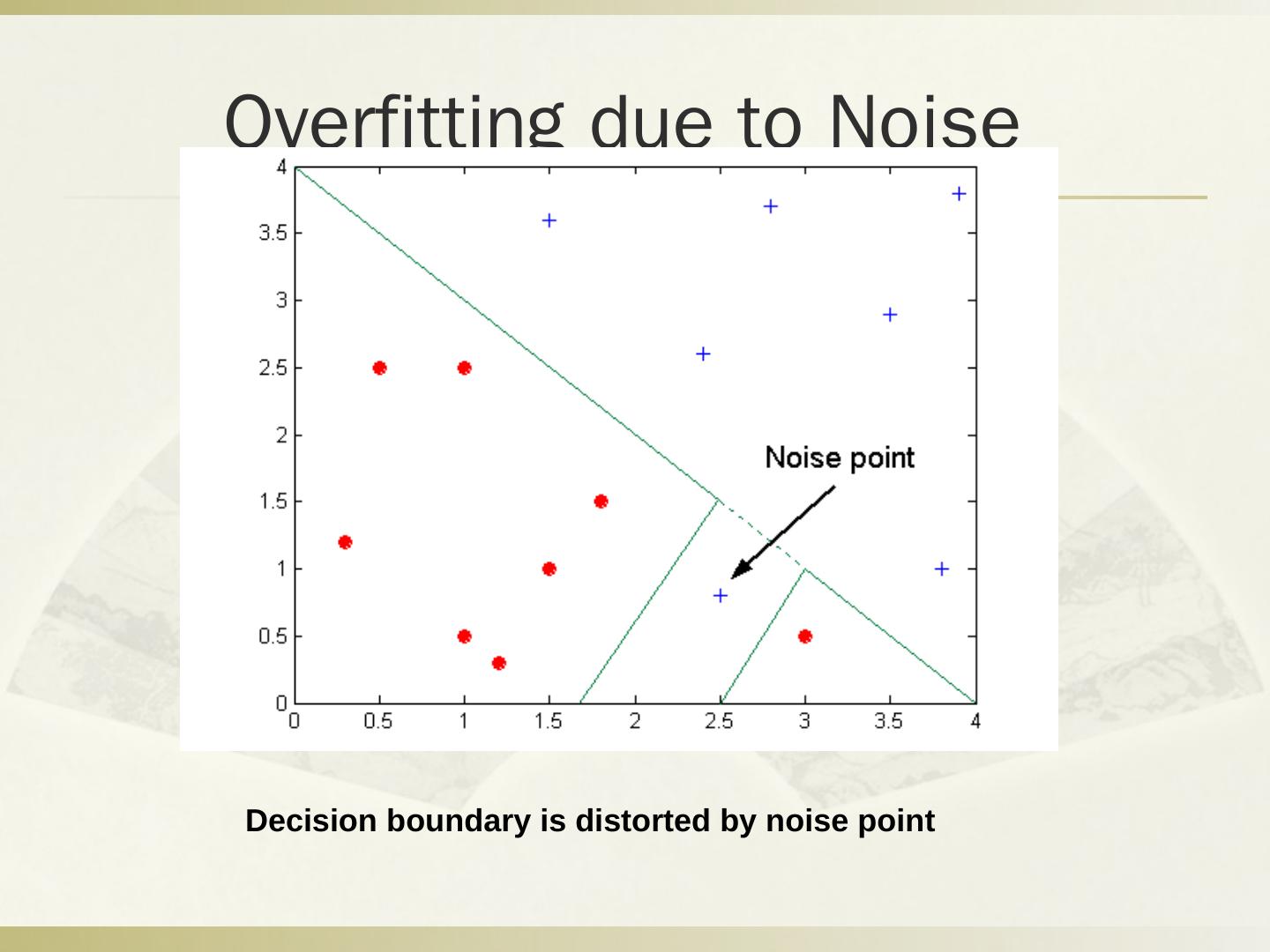





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
AI:分类方法
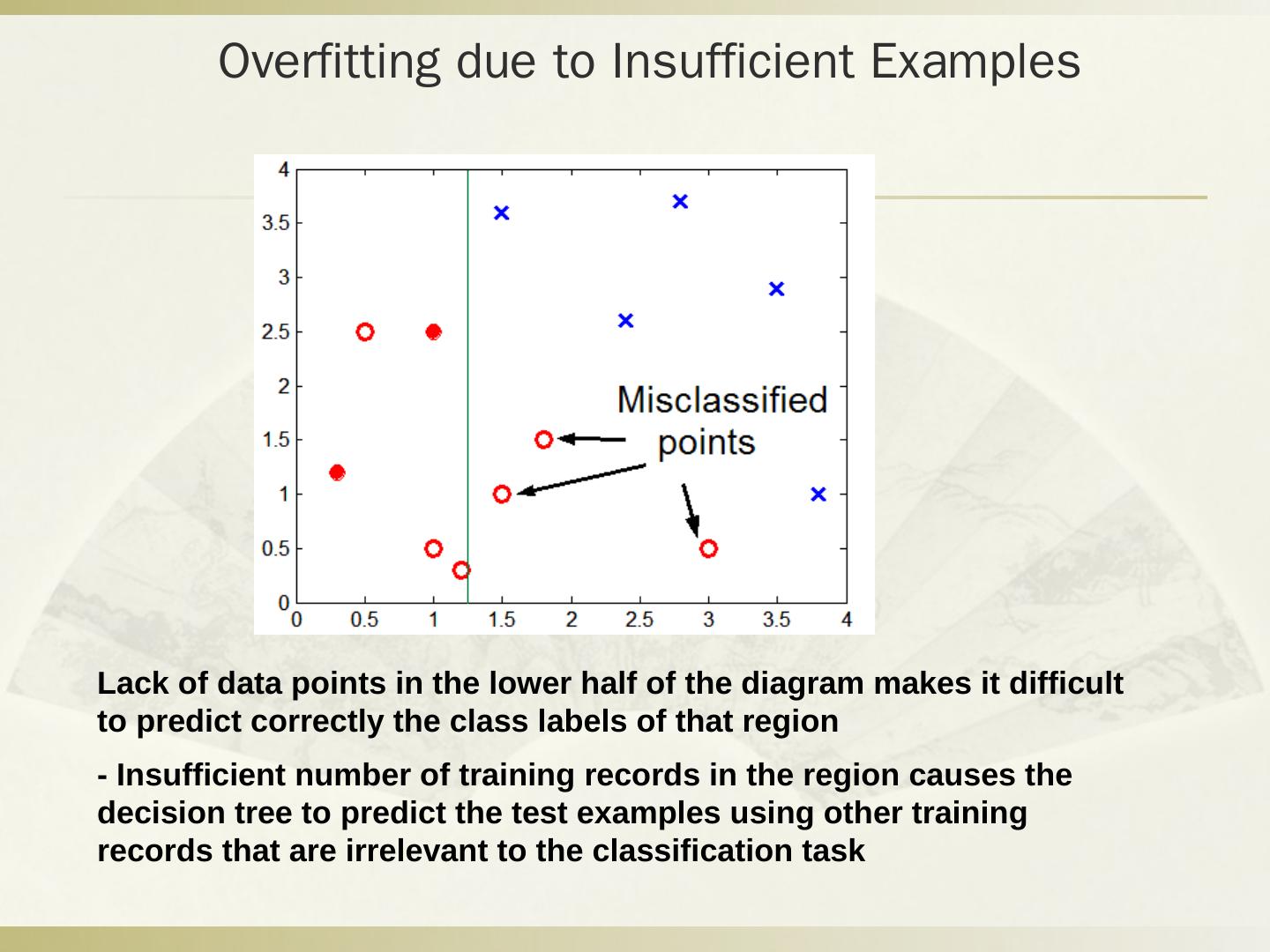
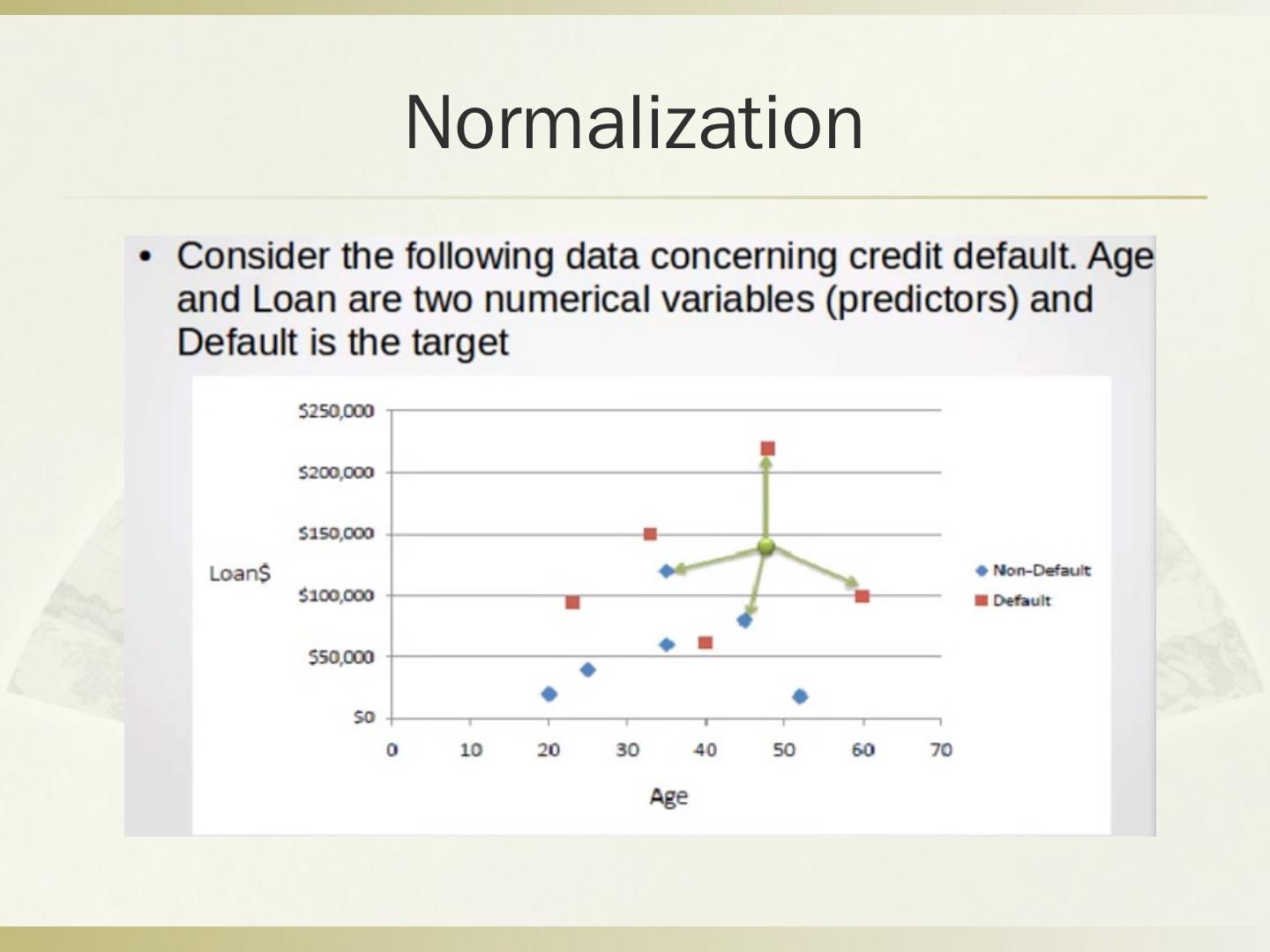
分类的目的是学会一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的类别中。介绍了主要的分类方法:贝叶斯分类、决策树分类方法、基于距离的分类算法。其中,贝叶斯分类器是最小错误率意义上的优化。并且举例说明朴素贝叶斯模型的应用。举例说明决策树分类方法以及基于连续属性的分割。随后介绍了避免过拟合分类的方法。最后介绍了最邻近规则分类(KNN)以及相关概念。
展开查看详情
1 .2016年10月17日星期一 DMKD Sides By MAO 1 第四章 分类方法 内容提要 分类的基本概念与步骤 基于距离的分类算法 决策树分类方法 贝叶斯分类
2 .2016年10月17日星期一 DMKD Sides By MAO 2 分类的目的是学会一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的类别中。 分类可用于预测。从利用历史数据纪录中自动推导出对给定数据的推广描述,从而能对未来数据进行类预测。 分类和统计学中的回归是既相互联系,有有一定区别的概念。分类输出的是离散的类别值,而回归输出的是连续数值。 分类具有广泛的应用,例如医疗诊断、信用卡系统的信用分级、图像模式识别等。
3 .2016年10月17日星期一 DMKD Sides By MAO 3 分类器的构造依据的方法很广泛: 统计方法:包括贝叶斯法和非参数法等。 机器学习方法:包括决策树法和规则归纳法。 神经网络方法。 其他,如粗糙集等(在前面绪论中也介绍了相关的情况)。
4 .2016年10月17日星期一 DMKD Sides By MAO 4 分类方法的类型 从使用的主要技术可以把分类方法归结为四种类型 : 贝叶斯分类 方法 决策树分类 方法 基于距离的分类方法 规则 归纳方法。
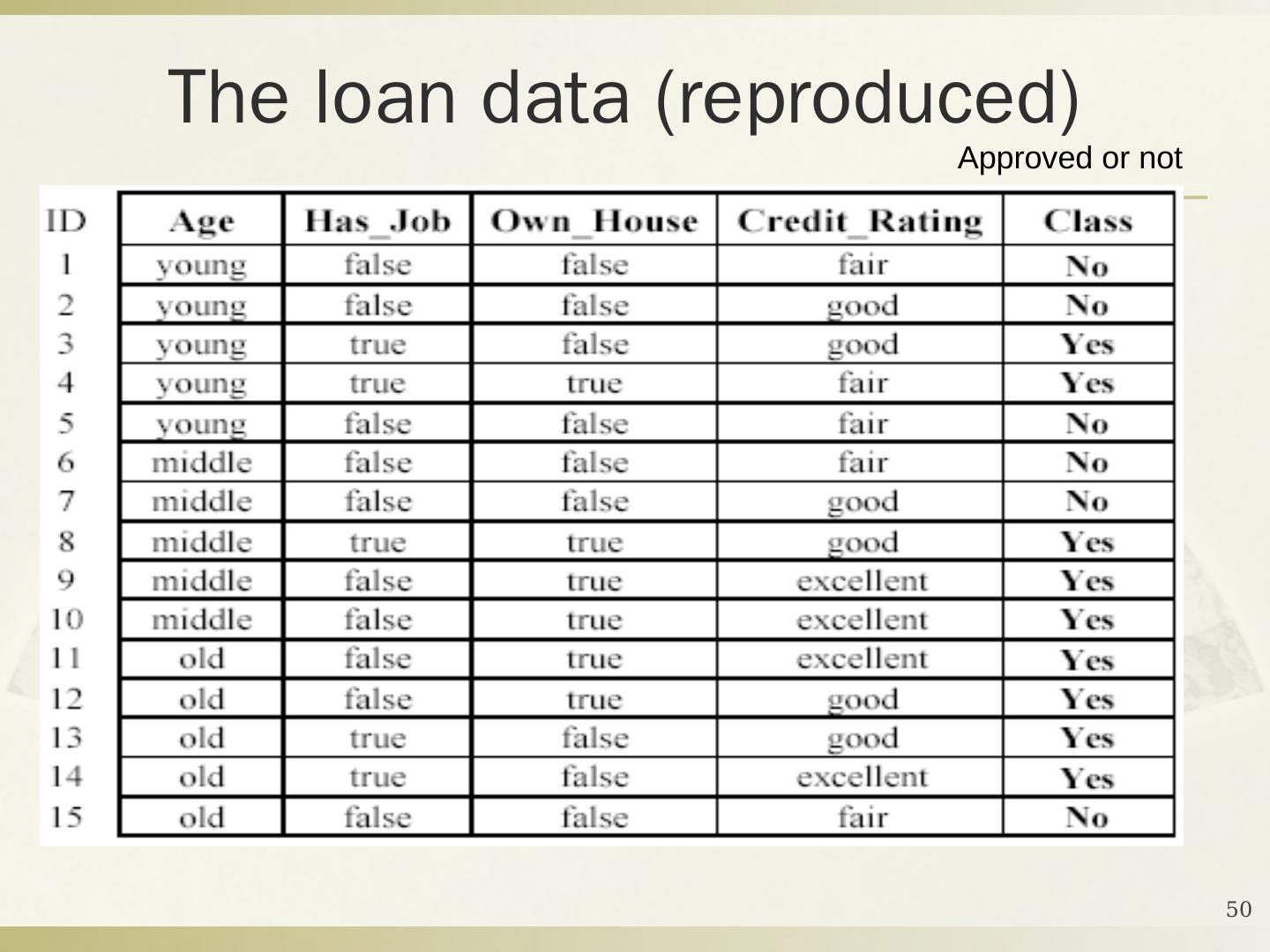
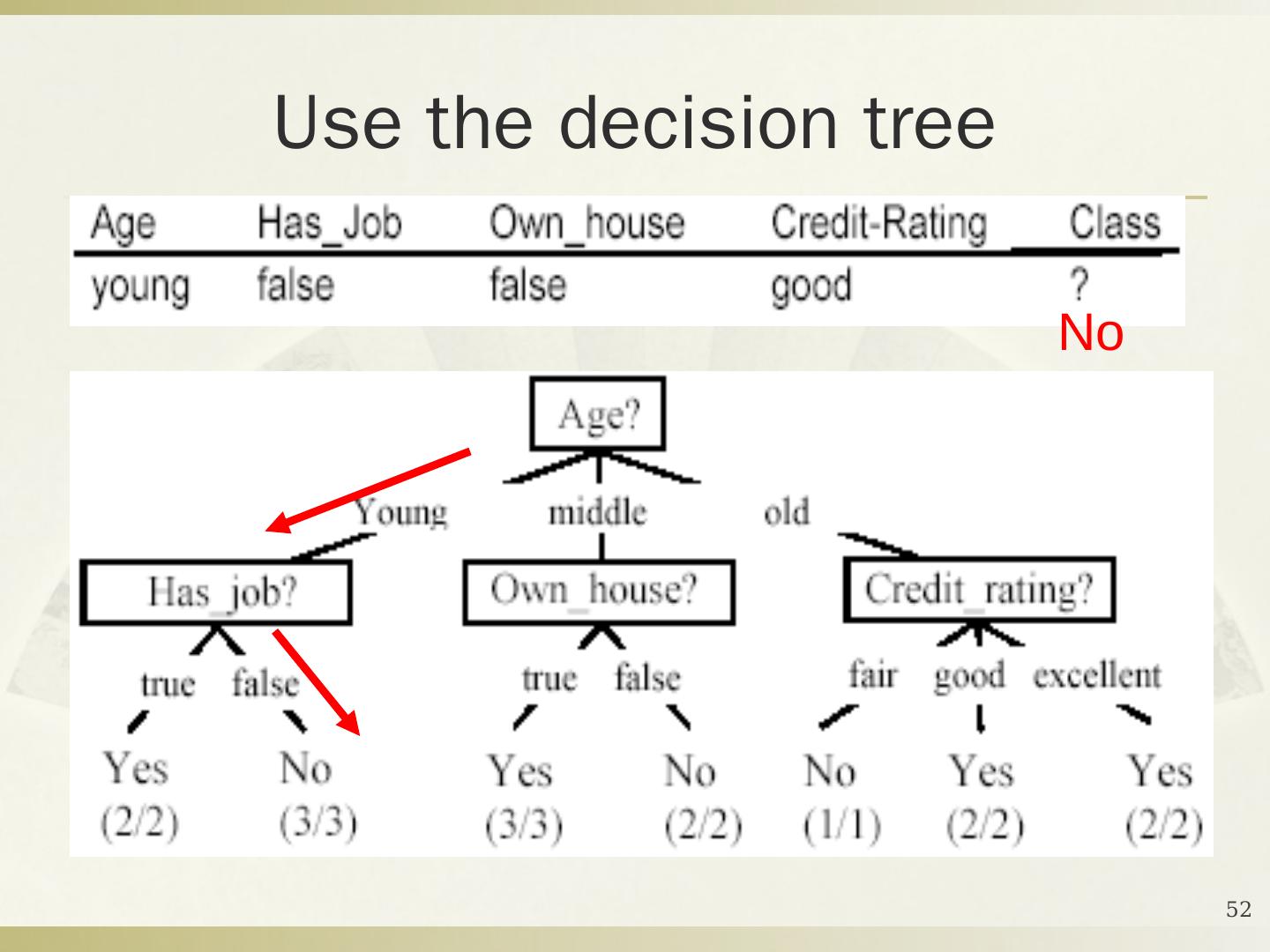
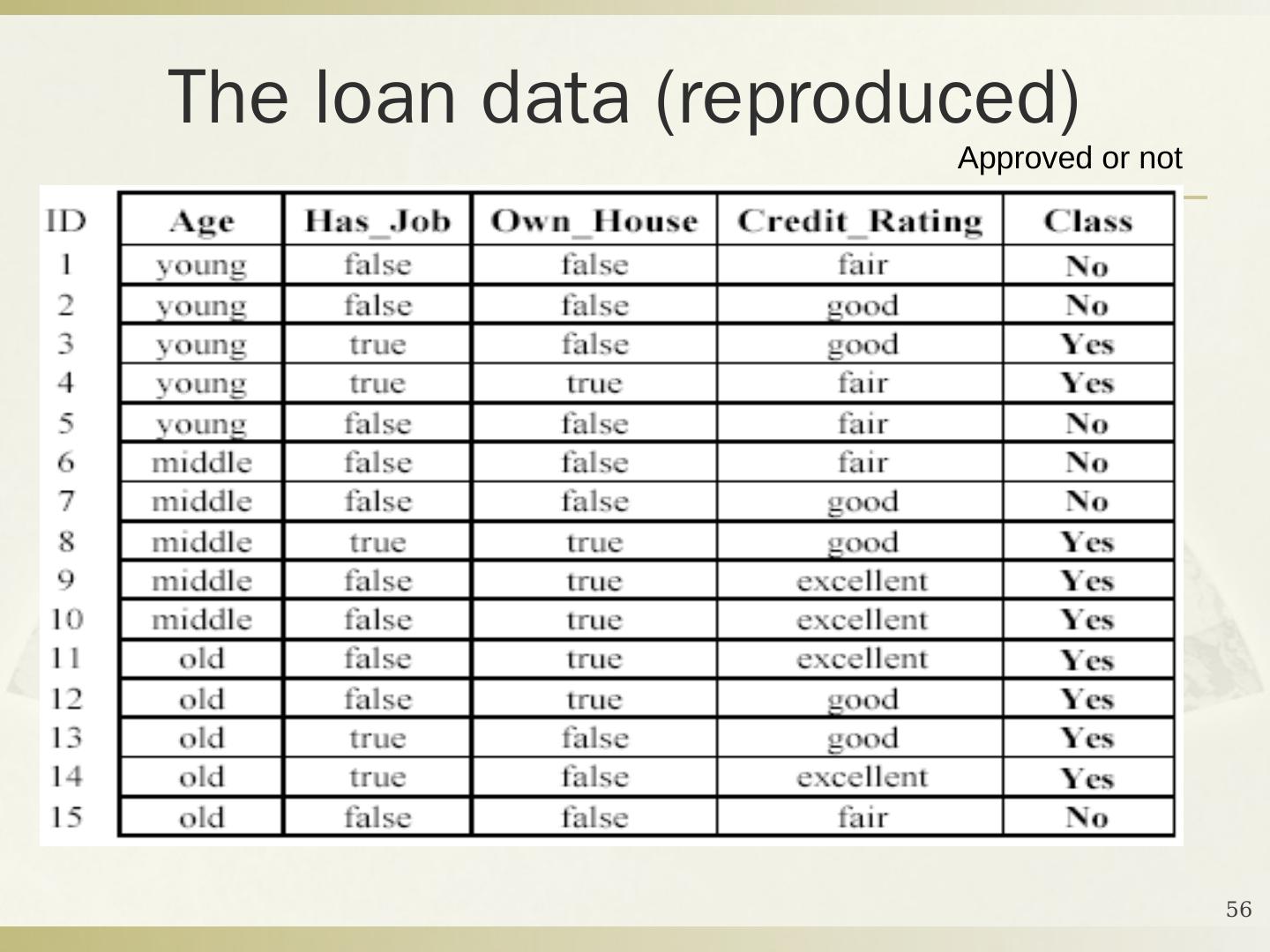
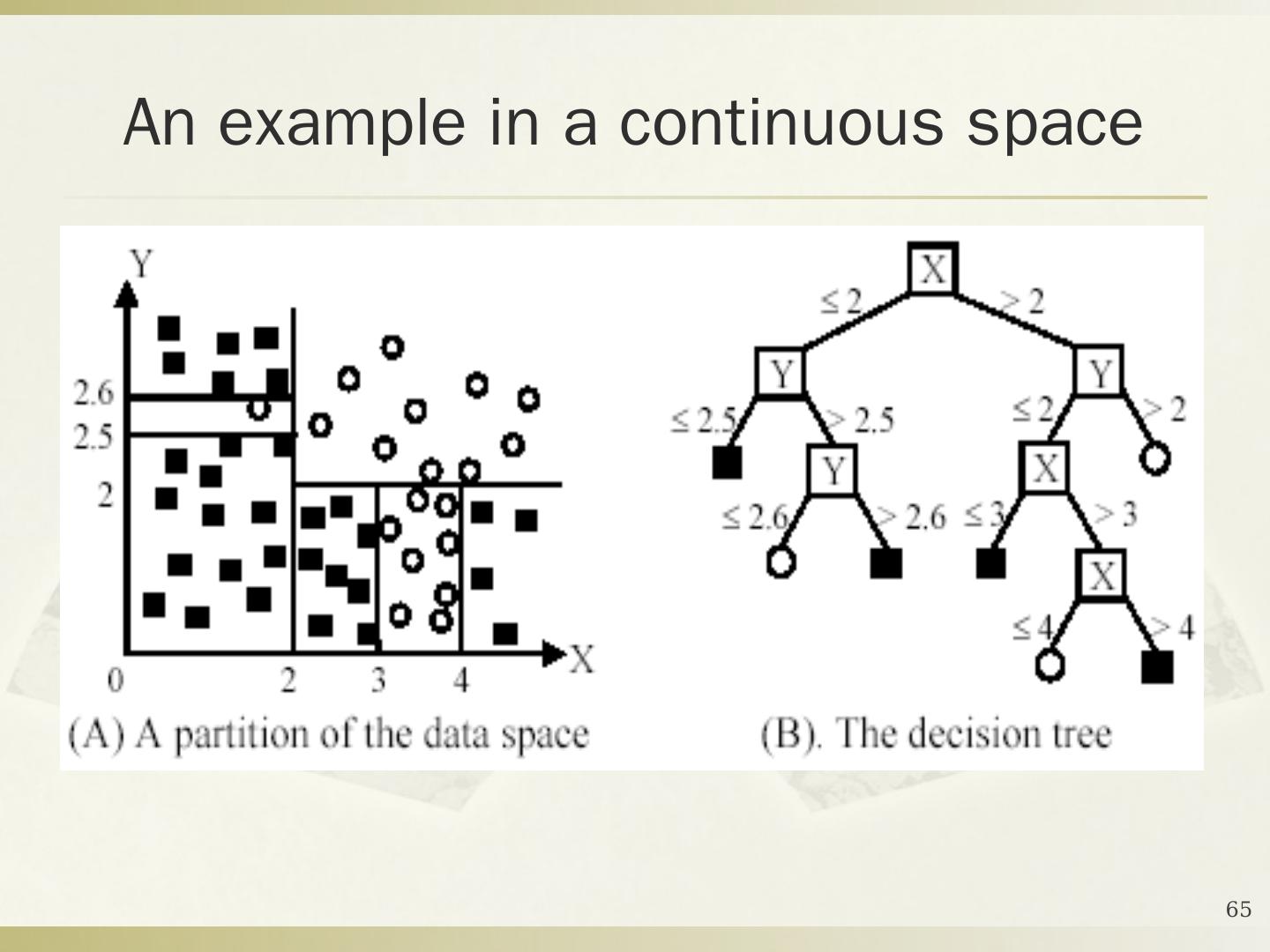
5 .2016年10月17日星期一 DMKD Sides By MAO 5 定义 4-1 给定一个数据库 D ={ t 1 , t 2 , … , t n } 和一组类 C ={ C 1 , … , C m } ,分类问题是去确定一个映射 f : D C ,使得每个元组 t i 被分配到一个类中。一个类 C j 包含映射到该类中的所有元组,即 C j ={ t i | f ( t i )= C j , 1≤ i ≤ n ,而且 t i D } 。 解决分类问题的关键是构造一个合适的分类器:从数据库到一组类别集的映射。一般地,这些类是被预先定义的、非交叠的。 构造分类器,需要有一个训练样本数据集作为 输入 。分类的目的是分析输入数据,通过训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。 数据分类 (Data Classification) 分为两个步骤 : 建模和使用。
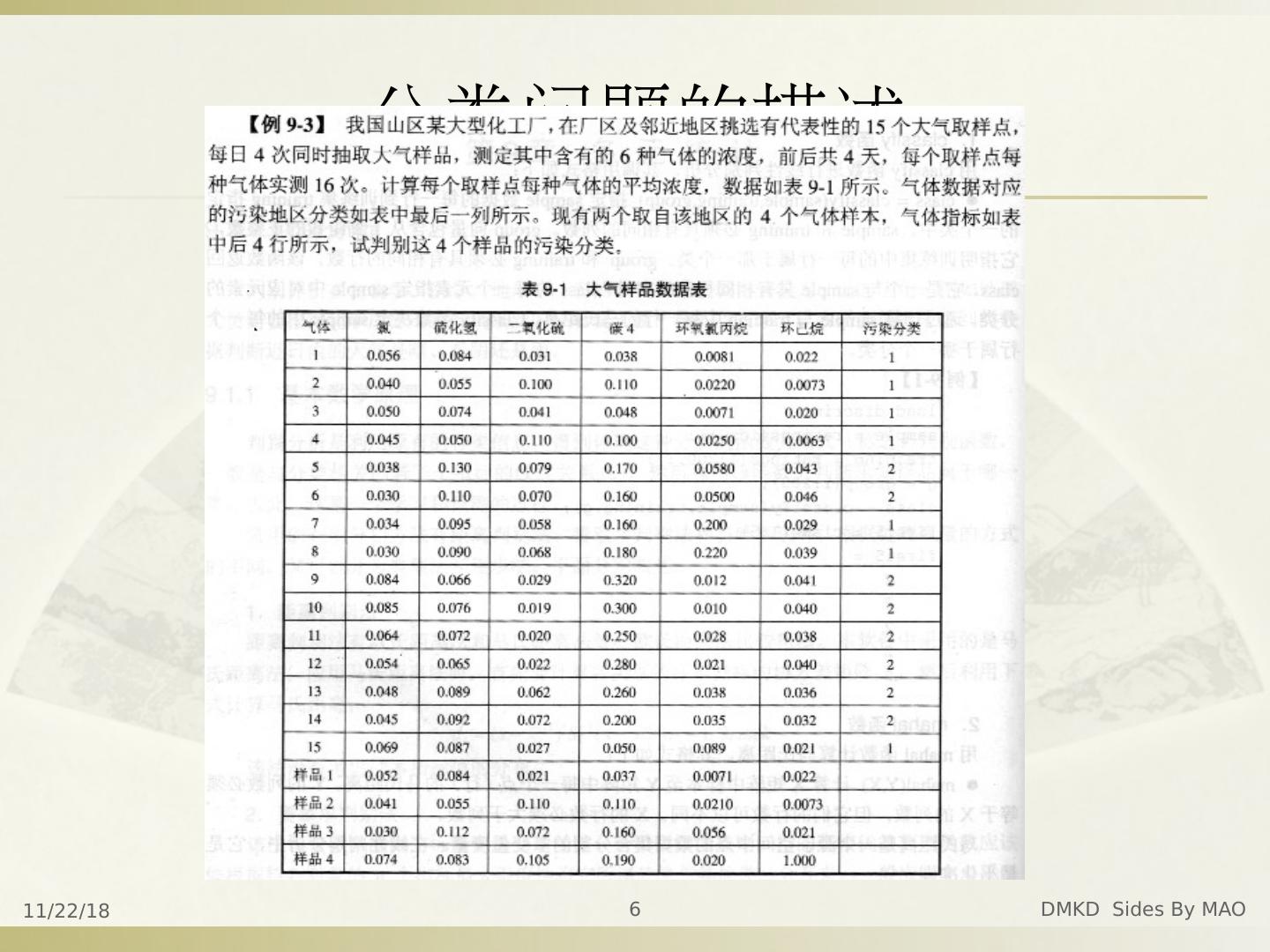
6 .2016年10月17日星期一 DMKD Sides By MAO 6 分类问题的描述
7 .7 分类方法的类型 从使用的主要技术可以把分类方法归结为四种类型 : 贝叶斯分类 方法 决策树分类 方法 基于距离的分类 方法
8 .1.1 分类的基本概念 1.2 贝叶斯分类概述 1. 贝叶斯分类
9 .1.1 分类的基本概念 背景 近几十年来, Internet 互联网的普及使得人们获得和存储数据的能力得到逐步的提高,数据规模不断壮大。面对“数据丰富而知识匮乏”的挑战,数据挖掘技术应运而生。数据挖掘是一门多学科的交叉领域,涉及统计学,机器学习、神经网络、模式识别、知识库系统、信息检索、高性能计算和可视化等学科。而数据挖掘中的分类技术是一项非常重要的技术。
10 .Q1 什么是分类 超市中的物品分类 生活中的垃圾分类
11 .Q1 什么是分类 生活信息的分类 由此可见,分类是跟我们的生活息息相关的东西,分类让生活更加有条理,更加精彩 .
12 .Q1 什么是分类 分类就是把一些新的数据项映射到给定类别的中的某一个类别,比如说当我们发表一篇文章的时候,就可以自动的把这篇文章划分到某一个文章类别。 分类也称为有监督学习(supervised learning),与之相对于的是无监督学习(unsupervised learning),比如聚类。 分类与聚类的最大区别在于,分类数据中的一部分的类别是已知的,而聚类数据的类别未知。 分类在数据挖掘中的学术定义
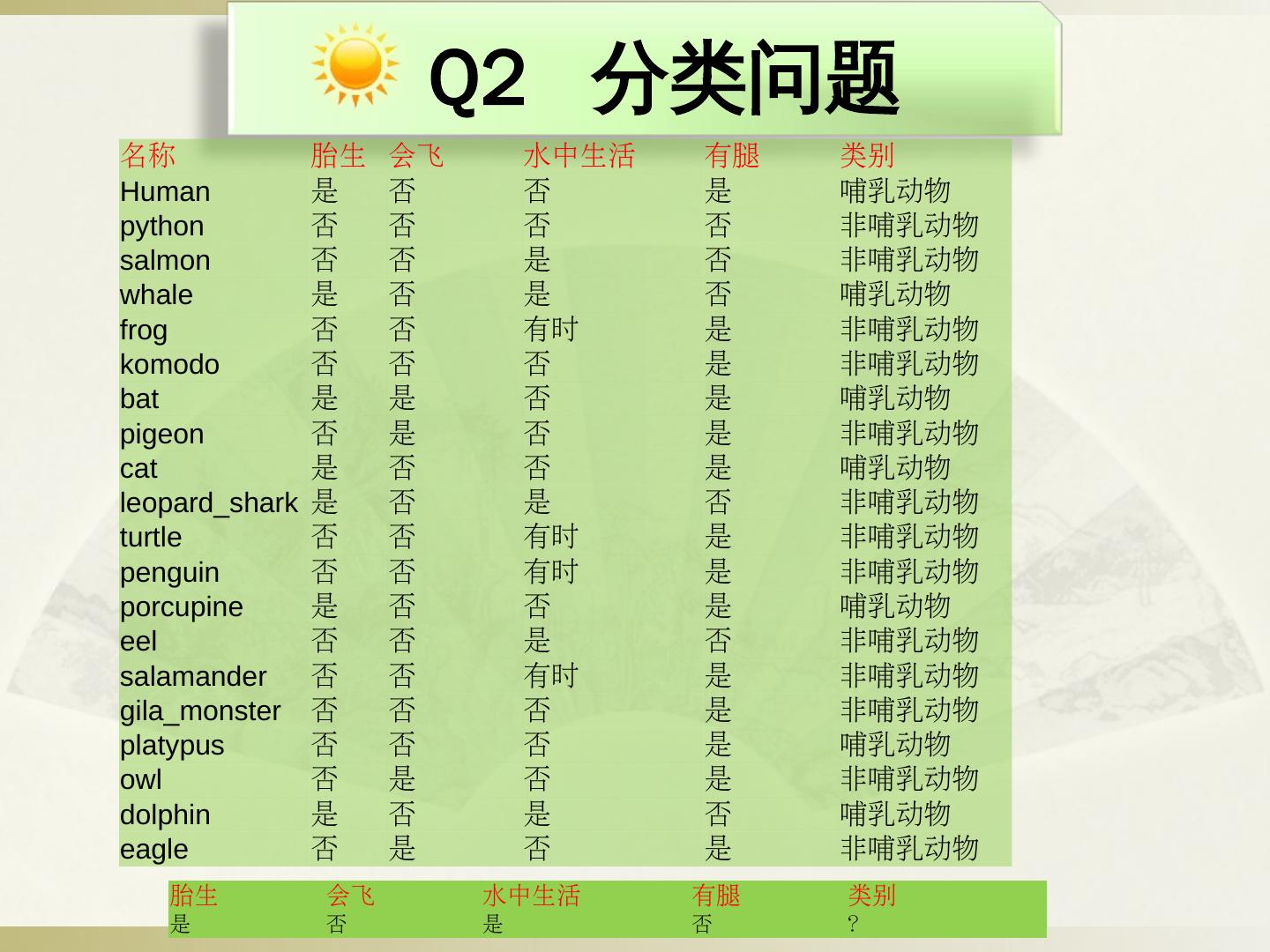
13 .Q2 分类问题 名称 胎生 会飞 水中生活 有腿 类别 Human 是 否 否 是 哺乳动物 python 否 否 否 否 非哺乳动物 salmon 否 否 是 否 非哺乳动物 whale 是 否 是 否 哺乳动物 frog 否 否 有时 是 非哺乳动物 komodo 否 否 否 是 非哺乳动物 bat 是 是 否 是 哺乳动物 pigeon 否 是 否 是 非哺乳动物 cat 是 否 否 是 哺乳动物 leopard_shark 是 否 是 否 非哺乳动物 turtle 否 否 有时 是 非哺乳动物 penguin 否 否 有时 是 非哺乳动物 porcupine 是 否 否 是 哺乳动物 eel 否 否 是 否 非哺乳动物 salamander 否 否 有时 是 非哺乳动物 gila_monster 否 否 否 是 非哺乳动物 platypus 否 否 否 是 哺乳动物 owl 否 是 否 是 非哺乳动物 dolphin 是 否 是 否 哺乳动物 eagle 否 是 否 是 非哺乳动物 胎生 会飞 水中生活 有腿 类别 是 否 是 否 ?
14 .Q2 分类的流程 动物种类 体型 翅膀数量 脚的只数 是否产蛋 是否有毛 类别 狗 中 0 4 否 是 哺乳动物 猪 大 0 4 否 是 哺乳动物 牛 大 0 4 否 是 哺乳动物 麻雀 小 2 2 是 是 鸟类 天鹅 中 2 2 是 是 鸟类 大雁 中 2 2 是 是 鸟类 动物A 大 0 2 是 无 ? 动物B 中 2 2 否 是 ? 根据现有的知识,我们得到了一些关于哺乳动物和鸟类的信息,我们能否对新发现的物种,比如动物A,动物B进行分类?
15 .动物种类 体型 翅膀数量 脚的只数 是否产蛋 是否有毛 类别 狗 中 0 4 否 是 哺乳动物 猪 大 0 4 否 是 哺乳动物 牛 大 0 4 否 是 哺乳动物 麻雀 小 2 2 是 是 鸟类 天鹅 中 2 2 是 是 鸟类 大雁 中 2 2 是 是 鸟类 步骤一:将样本转化为等维的数据特征(特征提取)。 所有样本必须具有相同数量的特征 兼顾特征的全面性和独立性 Q2 分类的流程
16 .动物种类 体型 翅膀数量 脚的只数 是否产蛋 是否有毛 类别 狗 中 0 4 否 是 哺乳动物 猪 大 0 4 否 是 哺乳动物 牛 大 0 4 否 是 哺乳动物 麻雀 小 2 2 是 是 鸟类 天鹅 中 2 2 是 是 鸟类 大雁 中 2 2 是 是 鸟类 步骤二:选择与类别相关的特征(特征选择)。 比如,绿色代表与类别非常相关,黑色代表部分相关,浅蓝色代表完全无关 Q2 分类的流程
17 .1.2 贝叶斯分类概述 背景 贝叶斯分类基于贝叶斯定理,贝叶斯定理是由 18 世纪概率论和决策论的早起研究者 Thomas Bayes 发明的,故用其名字命名为贝叶斯定理。 分类算法的比较研究发现,一种称为朴素贝叶斯分类法的简单贝叶斯分类法可以与决策树和经过挑选的神经网络分类器相媲美。用于大型数据库,贝叶斯分类法也已表现出高准确率和高速度。 目前研究较多的贝叶斯分类器主要有四种,分别是: Naive Bayes 、 TAN 、 BAN 和 GBN 。 Thomas Bayes
18 .1.2 贝叶斯分类概述 背景 贝叶斯分类基于贝叶斯定理,贝叶斯定理是由 18 世纪概率论和决策论的早起研究者 Thomas Bayes 发明的,故用其名字命名为贝叶斯定理。 分类算法的比较研究发现,一种称为朴素贝叶斯分类法的简单贝叶斯分类法可以与决策树和经过挑选的神经网络分类器相媲美。用于大型数据库,贝叶斯分类法也已表现出高准确率和高速度。 目前研究较多的贝叶斯分类器主要有四种,分别是: Naive Bayes 、 TAN 、 BAN 和 GBN 。 Thomas Bayes
19 . 贝叶斯公式提供了从先验概率 P(A) 、 P(B) 和 P(B|A) 计算后验概率 P(A|B) 的方法: P(A|B)=P(B|A)*P(A)/P(B) , P(A|B) 随着 P(A) 和 P(B|A) 的增长而增长,随着 P(B) 的增长而减少,即如果 B 独立于 A 时被观察到的可能性越大,那么 B 对 A 的支持度越小。 贝叶斯公式
20 .贝叶斯法则 机器学习的任务:在给定训练数据 D 时,确定假设空间 H 中的最佳假设。 最佳假设:一种方法是把它定义为在给定数据 D 以及 H 中不同假设的先验概率的有关知识下的 最可能假设 。贝叶斯理论提供了一种计算假设概率的方法,基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据本身。
21 .贝叶斯分类的原理 贝叶斯分类器的分类原理是通过某对象的 先验概率 ,利用 贝叶斯公式 计算出其 后验概率 ,即该对象属于某一类的概率,选择具有最大 后验概率 的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。 根据贝叶斯定理: 由于 P ( X )对于所有类为 常数 ,只需要 P ( X | H )* P ( H )最大即可。
22 . 朴素贝叶斯 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。 通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。 黑人 非洲人 概率最大
23 . 第一阶段 —— 准备工作阶段 ,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。 第二阶段 —— 分类器训练阶段 ,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。 第三阶段 —— 应用阶段 。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。 朴素贝叶斯分类的流程
24 . 朴素贝叶斯分类实例 检测 SNS 社区中不真实账号 下面讨论一个使用朴素贝叶斯分类解决实际问题的例子。 这个问题是这样的,对于 SNS 社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为 SNS 社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对 SNS 社区的了解与监管。 如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类。 下面我们一步一步实现这个过程。 是真是假?
25 .首先设 C=0 表示真实账号, C=1 表示不真实账号。 1 、确定特征属性及划分 这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。 我们选择三个特征属性: a1 :日志数量 / 注册天数 a2 :好友数量 / 注册天数 a3 :是否使用真实头像 在 SNS 社区中这三项都是可以直接从数据库里得到或计算出来的。 下面给出划分: a1 : {a<=0.05, 0.05<a<0.2, a>=0.2} a2 : {a<=0.1, 0.1<a<0.8, a>=0.8} a3 : {a=0 (不是) ,a=1 (是) }
26 . 2 、获取训练样本 这里使用运维人员曾经人工检测过的 1 万个账号作为训练样本。 3 、计算训练样本中每个类别的频率 用训练样本中真实账号和不真实账号数量分别除以一万,得到: P(C = 0) = 8900/10000 = 0.89 P(C = 1) = 1100/10000 = 0.11 4 、计算每个类别条件下各个特征属性划分的频率 P(a1<=0.05| C = 0) = 0.3 P(a1<=0.05| C = 1) = 0.8 P(0.05<a1<0.2|C = 0) = 0.5 P(0.05<a1<0.2| C = 1) = 0.1 P(a1>0.2| C = 0) = 0.2 P(a1>0.2| C = 1) = 0.1 P(a2<=0.1| C = 0) = 0.1 P(a2<=0.1| C = 1) = 0.7 P(0.1<a2<0.8 | C=0) = 0.7 P(0.1<a2<0.8 | C=1) = 0.2 P(a2>0.8| C = 0) = 0.2 P(a2>0.8| C = 0) = 0.1 P(a3 = 0|C = 0) = 0.2 P(a3 = 1|C = 0) = 0.8 P(a3 = 0|C = 1) = 0.9 P(a3 = 1|C = 1) = 0.1
27 . 5 、使用分类器进行鉴别 下面我们使用上面训练得到的分类器鉴别一个账号,属性如下 a1: 日志数量与注册天数的比率为 0.1 a2 : 好友数与注册天数的比率为 0.2 a3: 不使用真实头像 (a = 0) P(C = 0)P( x|C = 0) = P(C = 0) P(0.05<a1<0.2|C = 0)P(0.1<a2<0.8|C = 0)P(a3=0|C = 0) = 0.89*0.5*0.7*0.2 = 0.0623 P(C = 1)P( x|C = 1) = P(C = 1) P(0.05<a1<0.2|C = 1)P(0.1<a2<0.8|C = 1)P(a3=0|C = 1) = 0.11*0.1*0.2*0.9 = 0.00198 可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。
28 . 朴素贝叶斯模型 发源于古典数学理论,有着坚实的数学基础,以 及稳定的分类效率。同时, NBC 模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上, NBC 模型与其他分类方法相比具有最小的误差率。但是朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。于是诞生了一种更高级、应用范围更广的 —— 贝叶斯网络 。
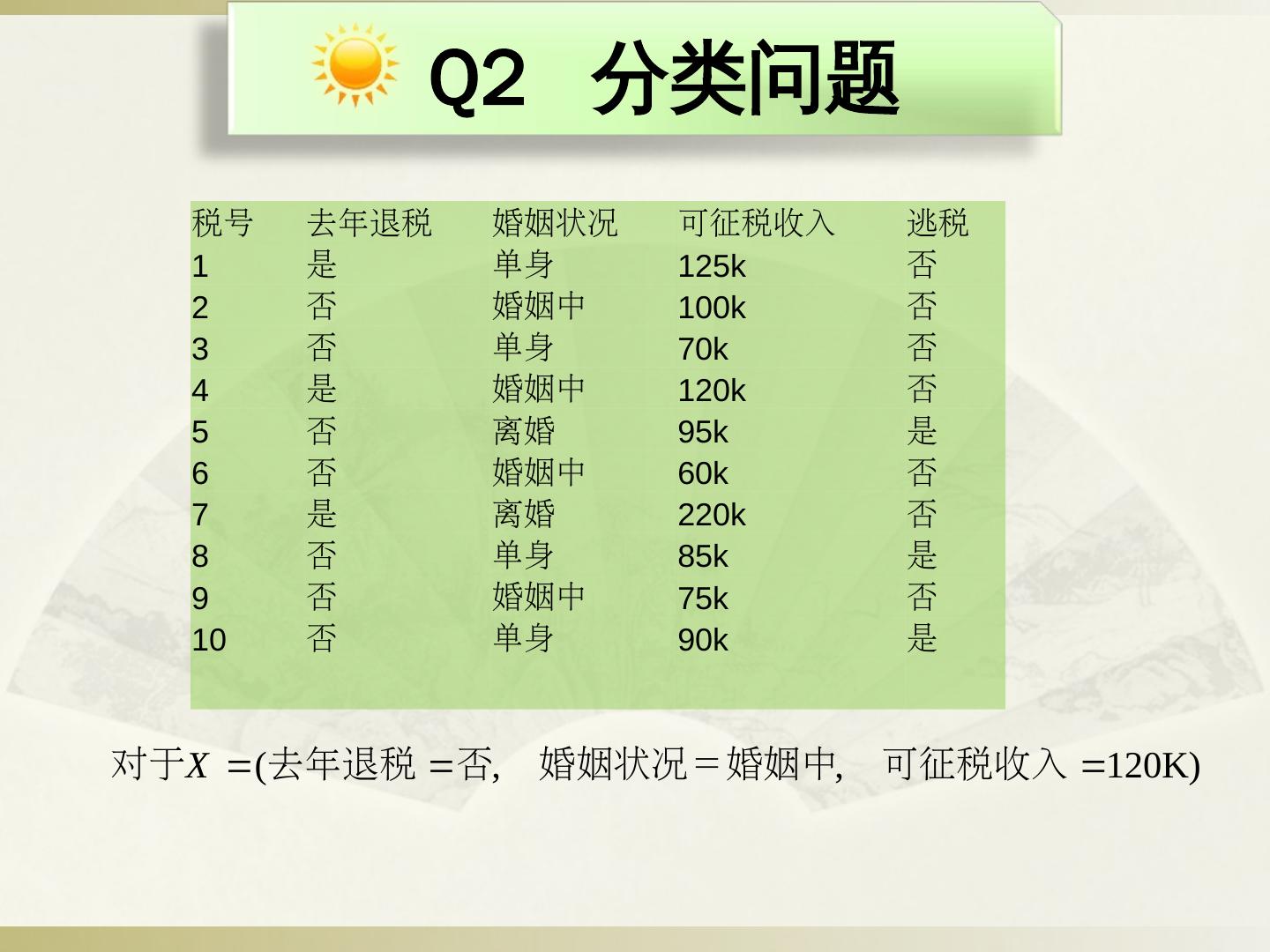
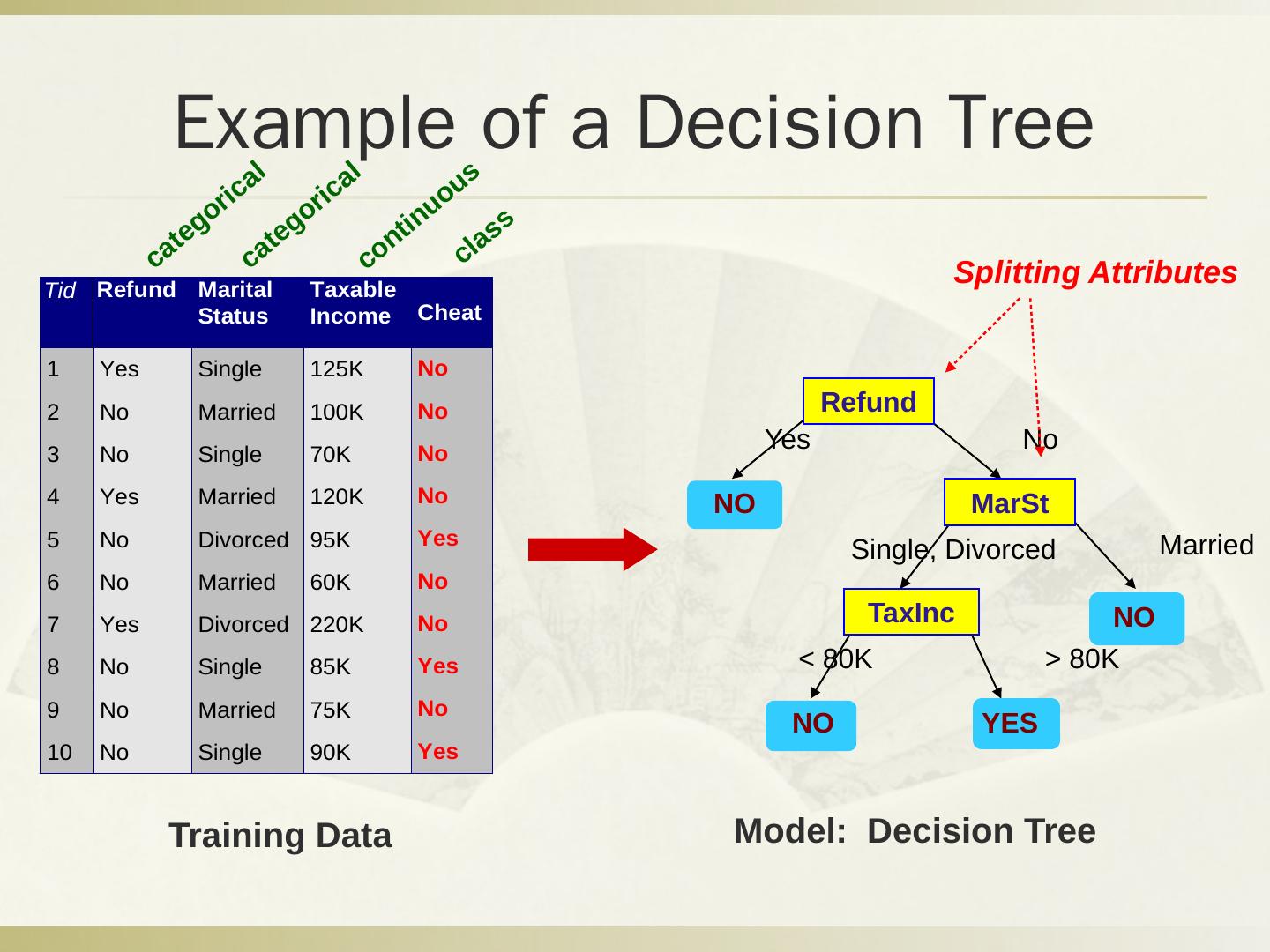
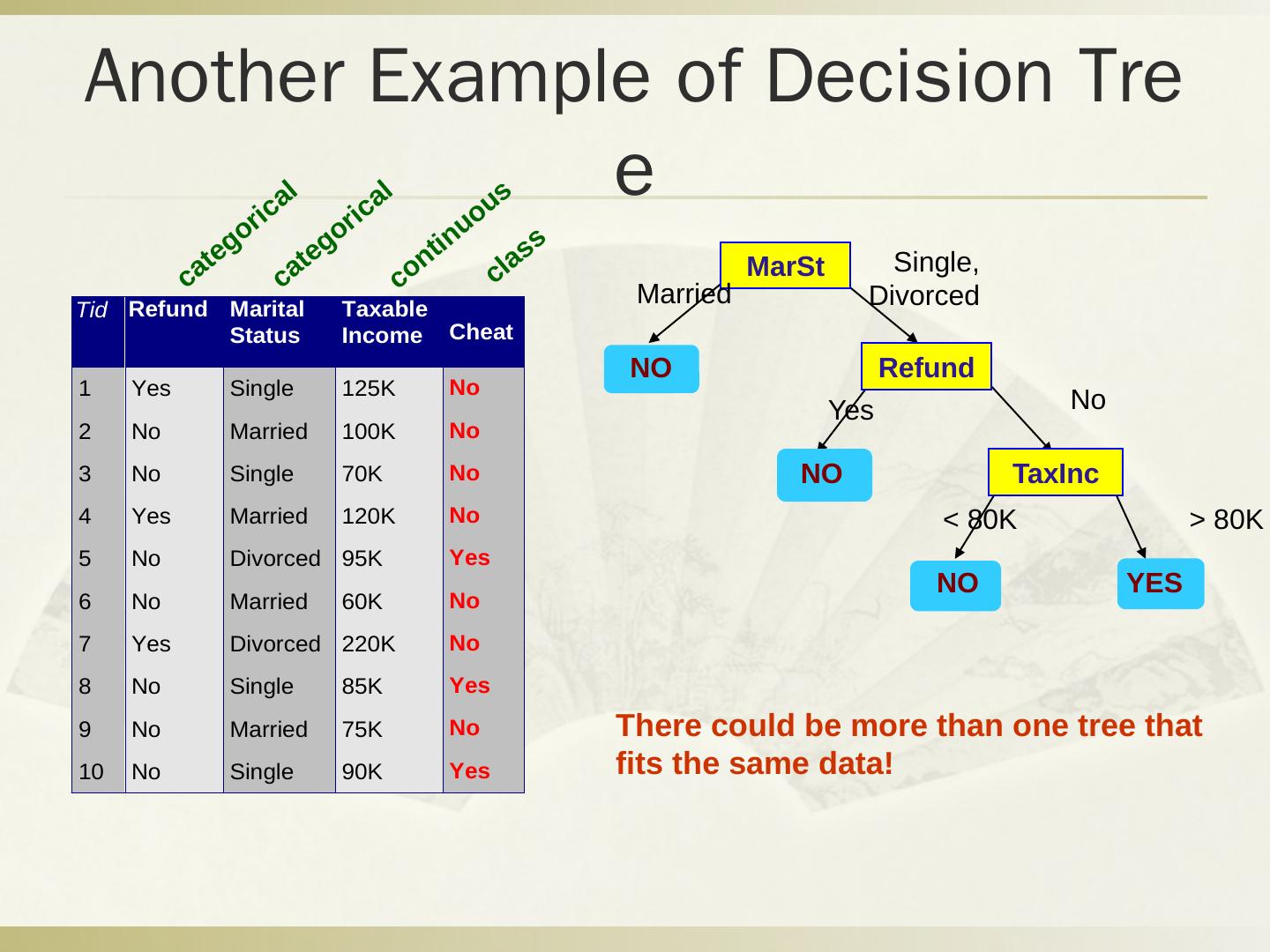
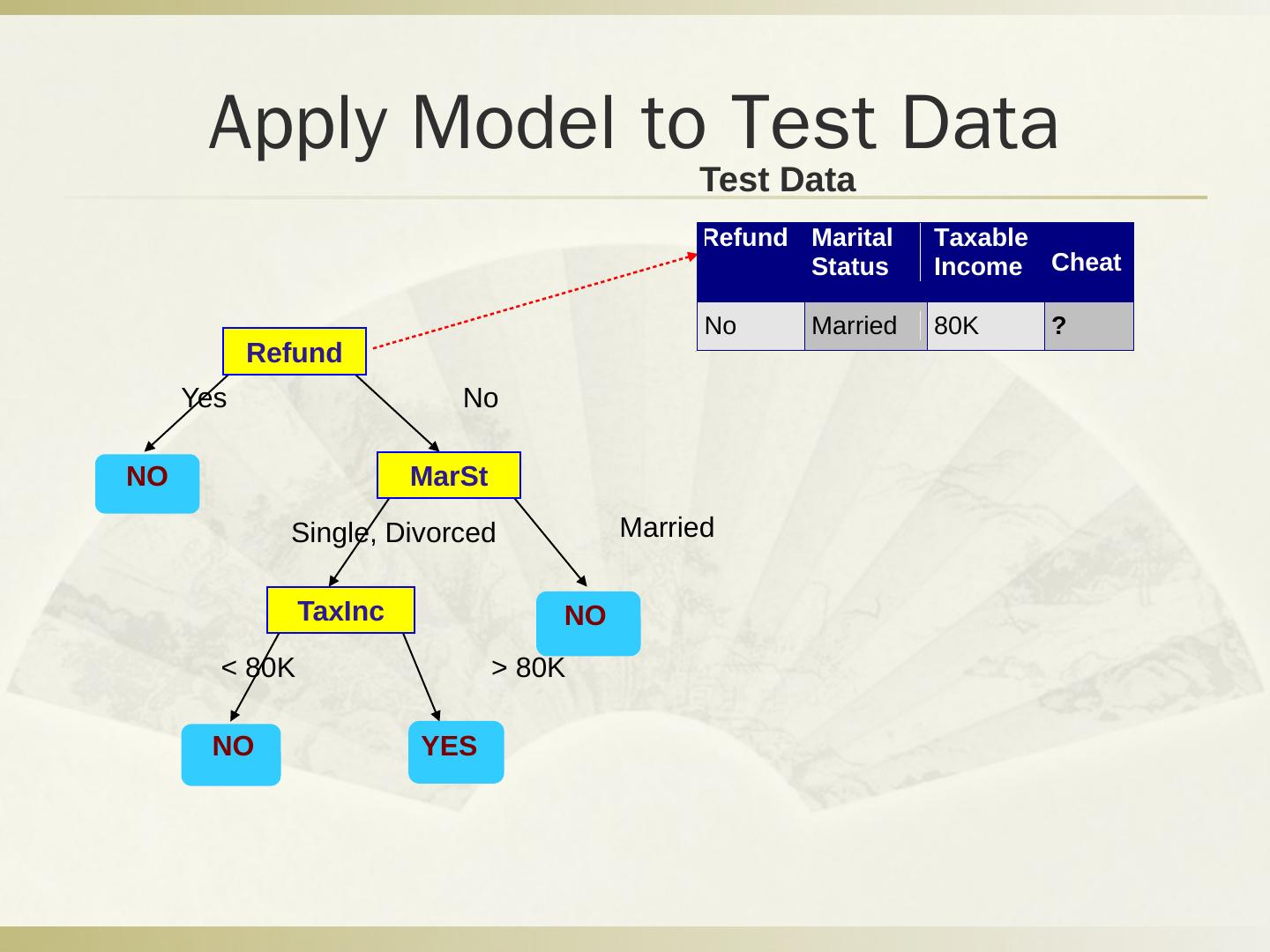
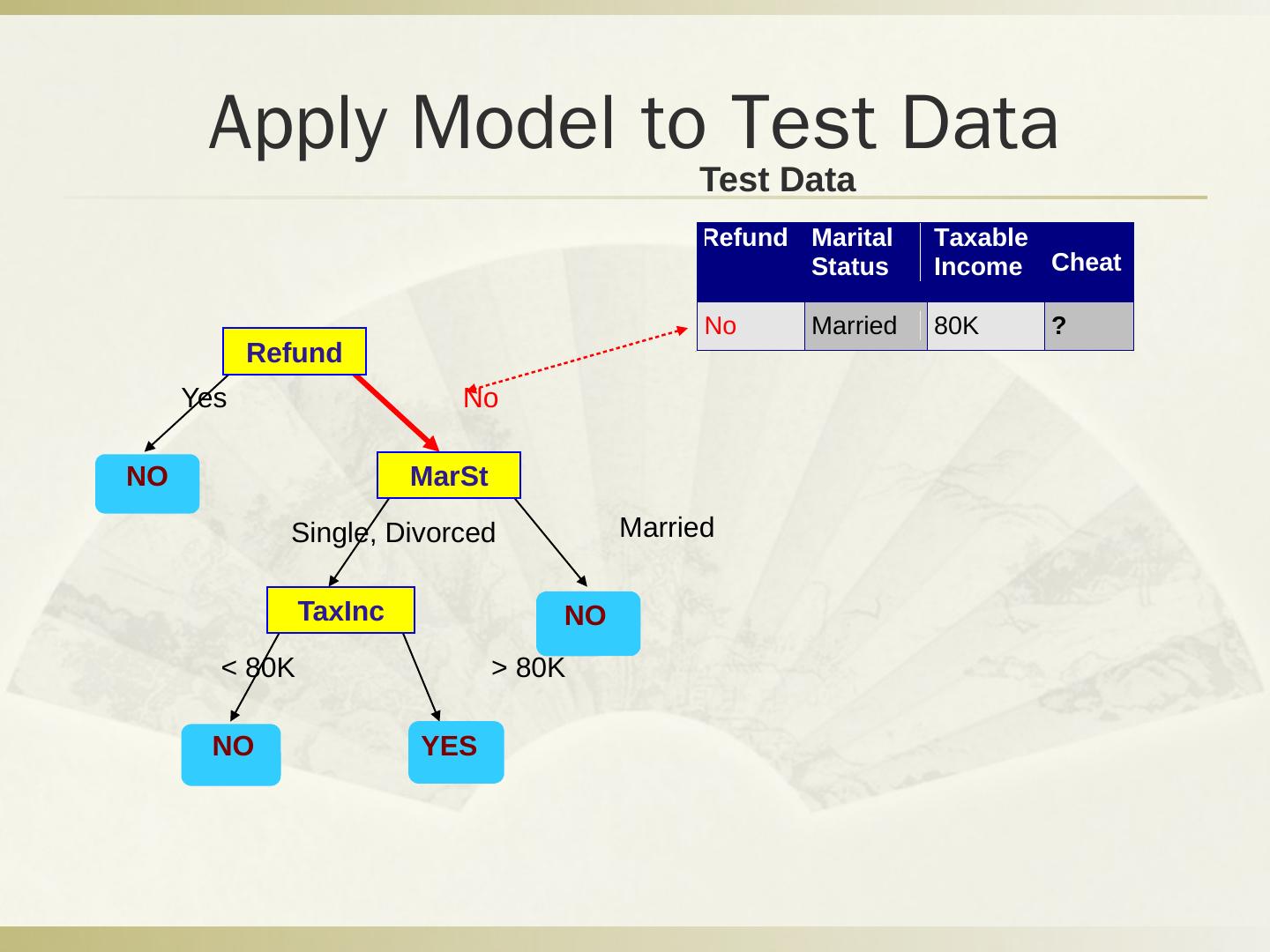
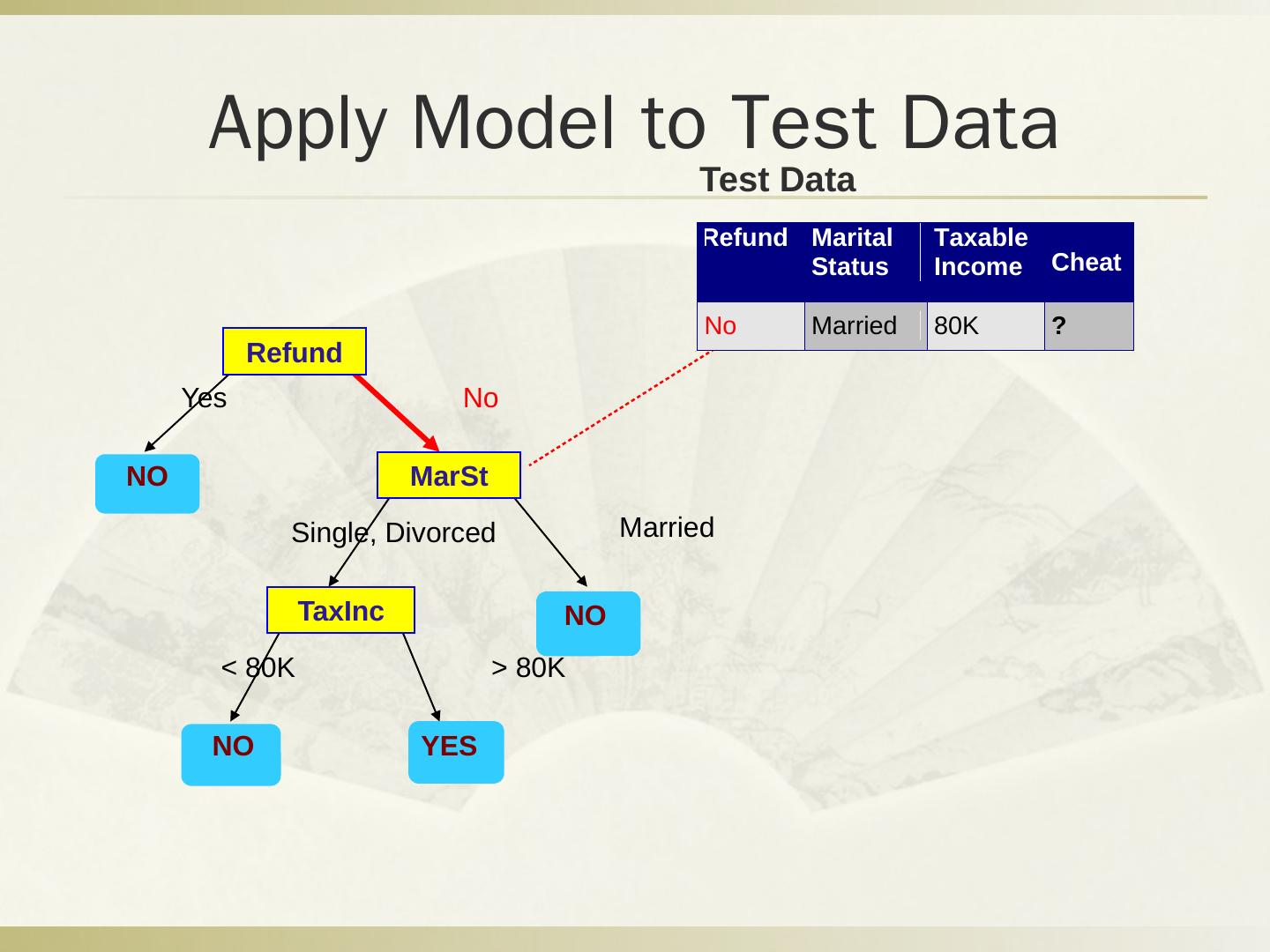
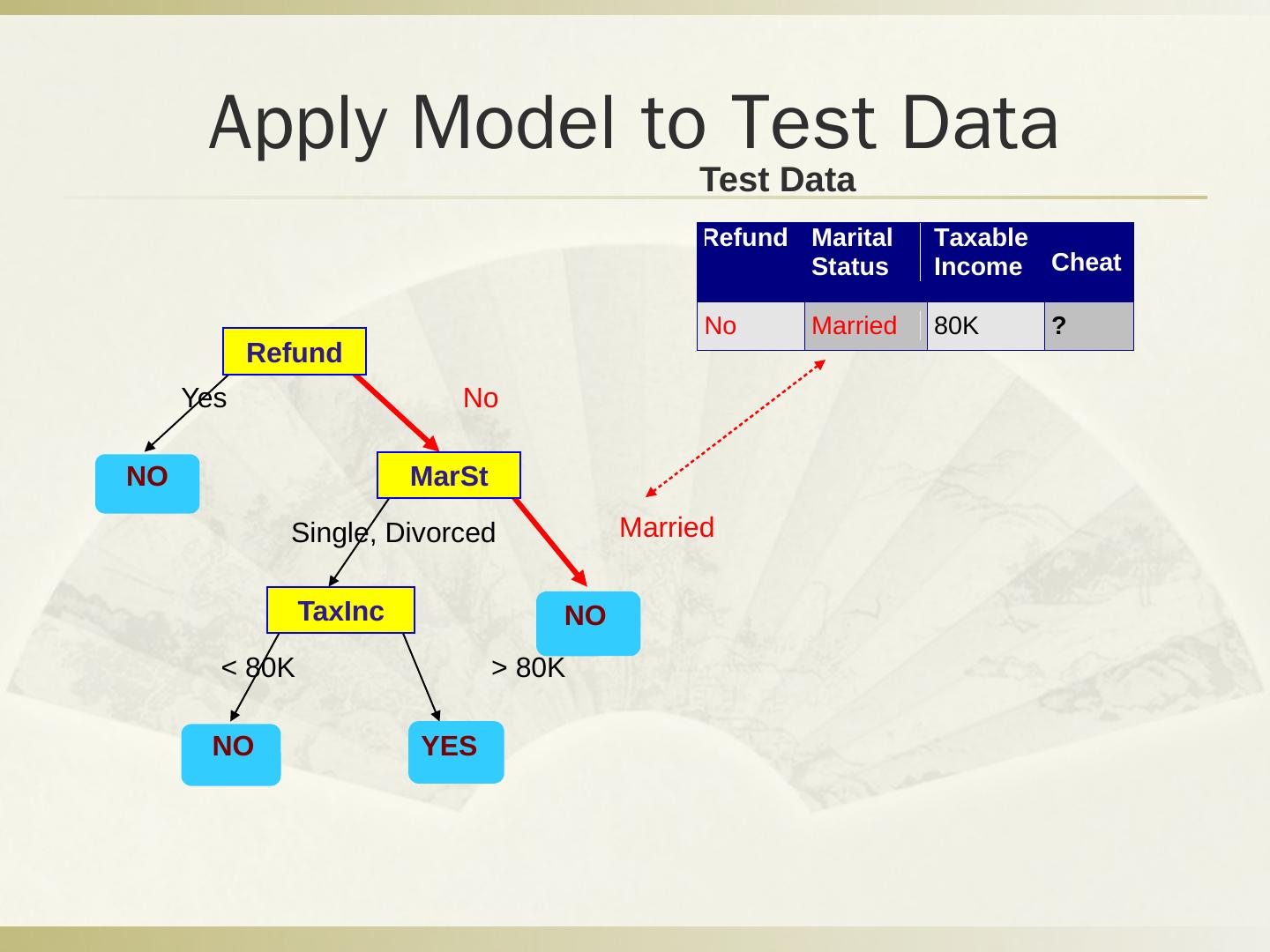
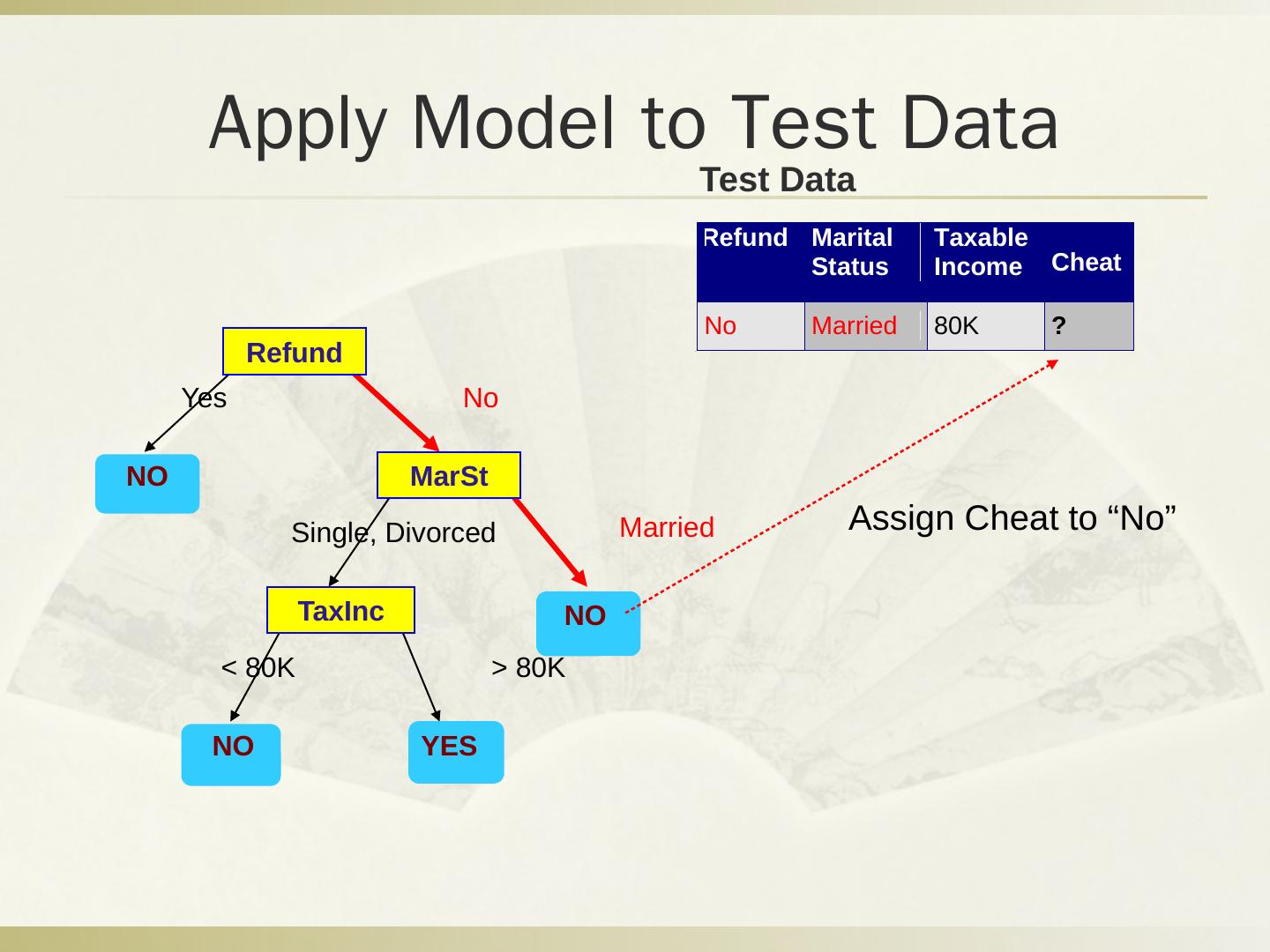
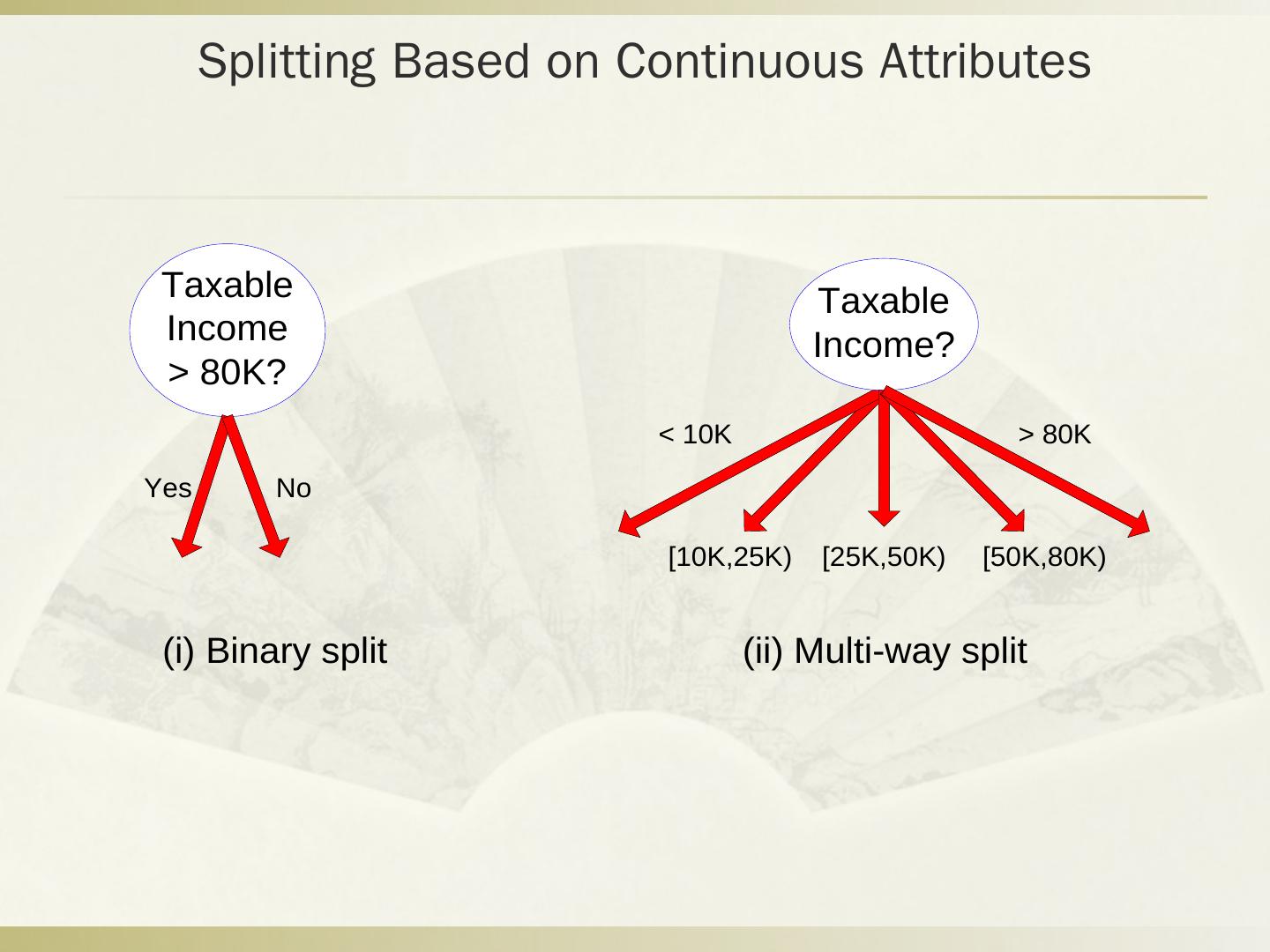
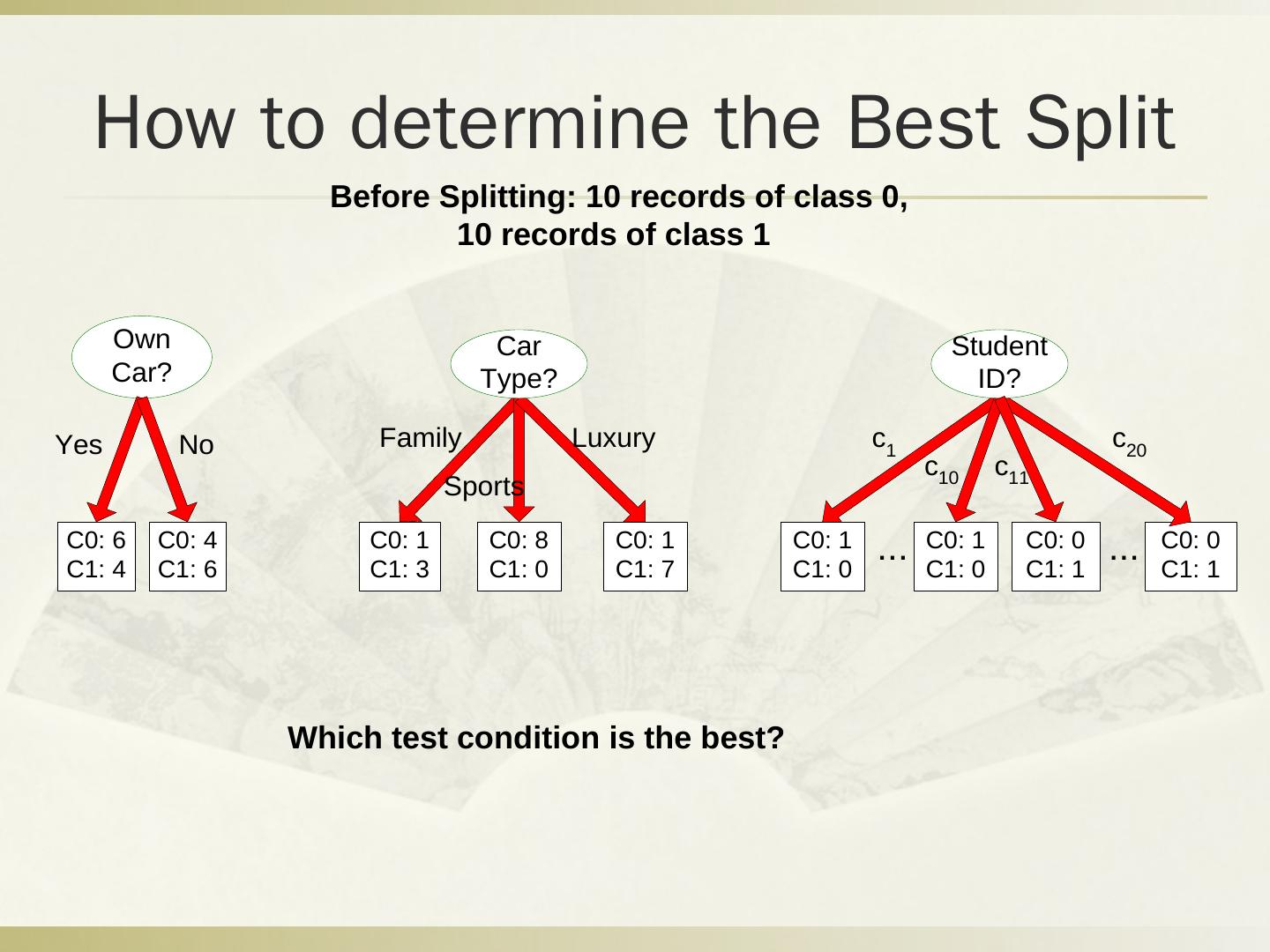
29 .Q2 分类问题 税号 去年退税 婚姻状况 可征税收入 逃税 1 是 单身 125k 否 2 否 婚姻中 100k 否 3 否 单身 70k 否 4 是 婚姻中 120k 否 5 否 离婚 95k 是 6 否 婚姻中 60k 否 7 是 离婚 220k 否 8 否 单身 85k 是 9 否 婚姻中 75k 否 10 否 单身 90k 是
3秒后跳转登录页面
去登陆

