













































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Sparser: Apache Spark中非结构化数据格式的快速解析
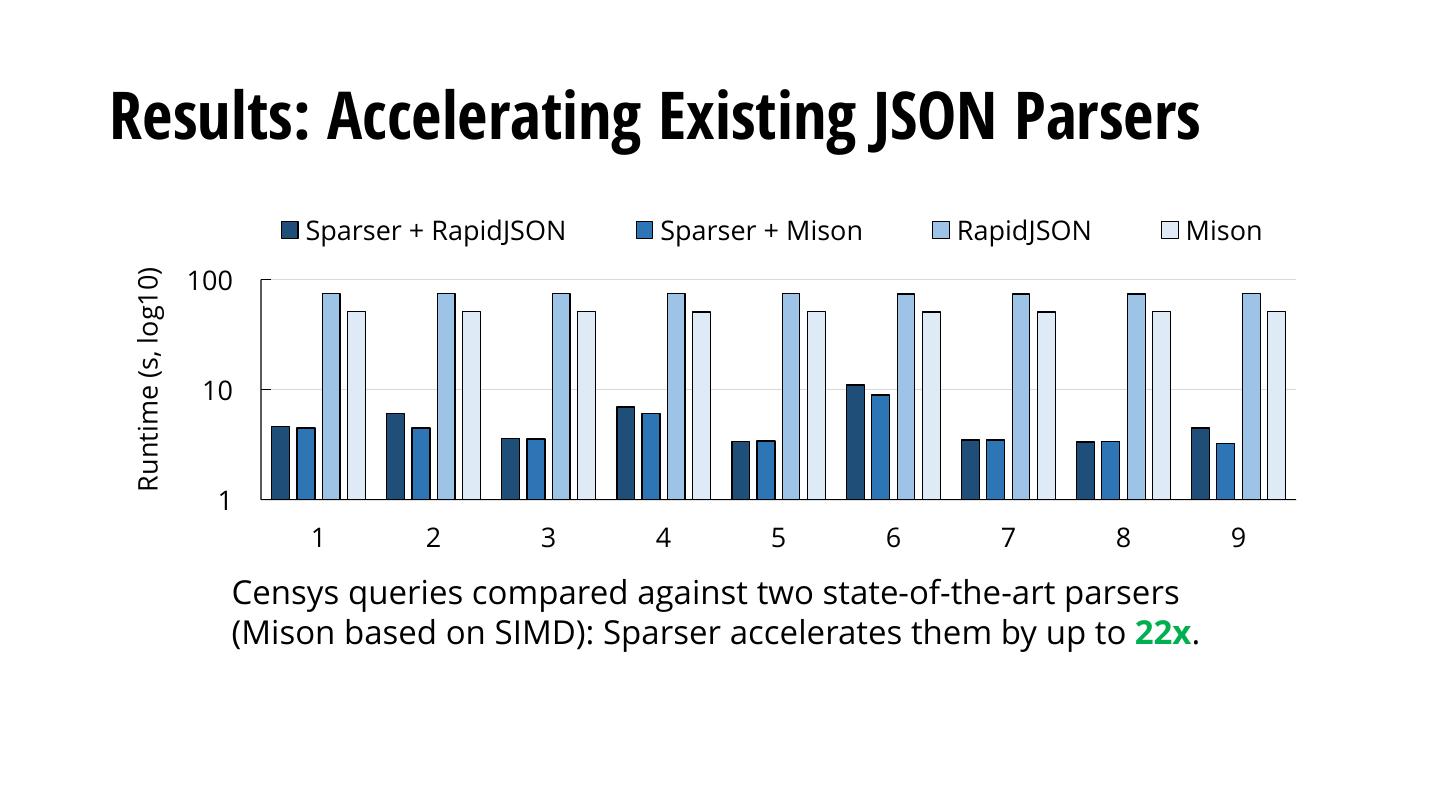
在本文中,我们介绍了Spark,一个新的解析库,用于Sjk中的JSON、CSV和AVRO文件。通过在解析记录之前积极地过滤它们,Sparser在几个真实的Spark SQL工作负载上实现了高达9倍的端到端运行时改进。使用Spark的数据源API,Sparser提取由Spark SQL查询指定的过滤表达式;然后将这些表达式编译为快速、SIMD加速的“预过滤器”,它可以以比当前在S中可用的JSON和CSV解析器快一个数量级的速度丢弃数据园。
展开查看详情
1 .Sparser: Fast Analytics on Raw Data by Avoiding Parsing Shoumik Palkar, Firas Abuzaid, Peter Bailis, Matei Zaharia
2 . Motivation Bigger unstructured datasets and faster hardware. Data Volume Speed Time Time
3 .Parsing unstructured data before querying it is often very slow.
4 .Today: Spark Data Sources API Push part of query into the data source. Spark Core Engine
5 .Today: Spark Data Sources API Push part of query into the data source. + E.g., column pruning directly in Parquet data loader - Little support for unstructured formats (e.g., can’t avoid JSON parsing) Spark Core Engine Data Source API
6 .Parsing: A Computational Bottleneck 150000 113836 Cycles/ 5KB Record 100000 Example: Existing state-of-the- art JSON parsers 100x slower 56796 50000 than scanning a string! 360 *Similar results on binary formats 0 like Avro and Parquet RapidJSON Mison Index String Scan Parsing Contruction Parsing seems to be a necessary evil: how do we get around doing it? State-of-the-art Parsers
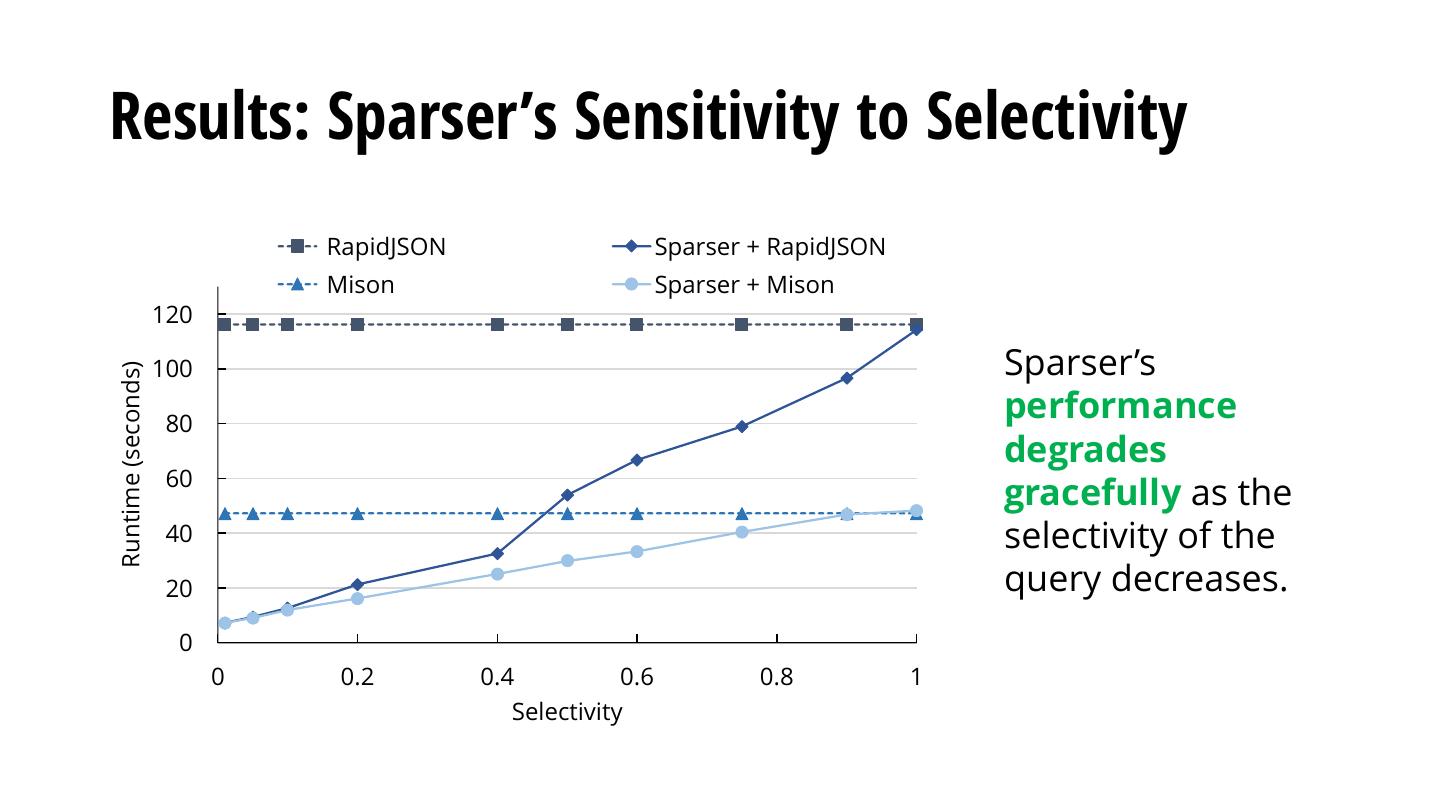
7 .Key Opportunity: High Selectivity Databricks Censys 1 0.8 High selectivity especially true for exploratory analytics. 0.6 CDF 0.4 0.2 Data Source API provides access to query filters at data source! 0 1.E-09 1.E-05 1.E-01 Selectivity 40% of customer Spark queries at Databricks select < 20% of data 99% of queries in Censys select < 0.001% of data
8 .How can we exploit high selectivity to accelerate parsing?
9 .Sparser: Filter Before You Parse Sparser: Filter before parsing first using fast filtering functions with false positives, but no false negatives Parse Raw Data Filter Raw Data Filter Raw Data Today: parse full input à slow! Raw Data Filter Parse Raw Data
10 .Demo Count Tweets where text contains “Trump” and “Putin”
11 . Sparser in Spark SQL val df = spark.read.format(“json”) Spark Core Engine Data Source API
12 . Sparser in Spark SQL val df = spark.read.format(“edu.stanford.sparser.json”) Sparser Data Source Reader (Also supports Avro, Parquet!) Spark Core Engine Data Source API Sparser Filtering Engine
13 .Sparser Overview
14 . Sparser Overview Raw Filter (“RF”): filtering function on a bytestream with false positives but no false negatives. Use an optimizer to combine RFs into a cascade. Other Full 0x54 0x72 0x75 0x6d 0x70 RF Pass! RFs Parser T r u m b “TRUM” Example: Tweets WHERE But is it in the “text” field? Is the text contains “Trump” full word “Trump”?
15 .Key Challenges in Using RFs 1. How do we implement the RFs efficiently? 2. How do we efficiently choose the RFs to maximize parsing throughput for a given query and dataset? Rest of this Talk • Sparser’s API • Sparser’s Raw Filter Designs (Challenge 1) • Sparser’s Optimizer: Choosing a Cascade (Challenge 2) • Performance Results on various file formats (e.g., JSON, Avro)
16 .Sparser API
17 .Sparser API Filter Example WHERE user.name = “Trump” Exact String Match WHERE likes = 5000
18 .Sparser API Filter Example WHERE user.name = “Trump” Exact String Match WHERE likes = 5000 Contains String WHERE text contains “Trum”
19 .Sparser API Filter Example WHERE user.name = “Trump” Exact String Match WHERE likes = 5000 Contains String WHERE text contains “Trum” Contains Key WHERE user.url != NULL
20 .Sparser API Filter Example WHERE user.name = “Trump” Exact String Match WHERE likes = 5000 Contains String WHERE text contains “Trum” Contains Key WHERE user.url != NULL WHERE user.name = “Trump” Conjunctions AND user.verified = true WHERE user.name = “Trump” Disjunctions OR user.name = “Obama”
21 .Sparser API Filter Example WHERE user.name = “Trump” Exact String Match WHERE likes = 5000 Contains String WHERE text contains “Trum” Contains Key WHERE user.url != NULL WHERE user.name = “Trump” Conjunctions AND user.verified = true WHERE user.name = “Trump” Disjunctions OR user.name = “Obama” Currently does not support numerical range-based predicates.
22 .Challenge 1: Efficient RFs
23 .Raw Filters in Sparser SIMD-based filtering functions that pass or discard a record by inspecting raw bytestream 150000 113836 Cycles/ 5KB Record 100000 56796 50000 360 0 RapidJSON Parsing Mison Index Contruction Raw Filter
24 .Example RF: Substring Search Search for a small (e.g., 2, 4, or 8-byte) substring of a query predicate in parallel using SIMD Example query: text contains “Trump” Input : “text”:“I just met Mr. Trumb!!!” Shift 1 : TrumTrumTrumTrumTrumTrumTrum------- Shift 2 : -TrumTrumTrumTrumTrumTrumTrum------ Length 4 Substring Shift 3 : --TrumTrumTrumTrumTrumTrumTrum----- packed in SIMD register Shift 4 : ---TrumTrumTrumTrumTrumTrumTrum---- False positives (found “Trumb” by accident), but no false negatives (No “Trum” ⇒ No “Trump”) On modern CPUs: compare 32 characters in parallel in ~4 cycles (2ns). Other RFs also possible! Sparser selects them agnostic of implementation.
25 .Key-Value Search RF Searches for key, and if key is found, searches for value until some stopping point. Searches occur with SIMD. Only applicable for exact matches Useful for queries with common substrings (e.g., favorited=true) Key: name Value: Trump Delimiter: , Ex 1: “name”: “Trump”, (Pass) Ex 2: “name”: “Actually, Trump” (Fail) Ex 3: “name”: “My name is Trump” (Pass, False positive) Second Example would result in false negative if we allow substring matches Other RFs also possible! Sparser selects them agnostic of implementation.
26 .Challenge 2: Choosing RFs
27 . Choosing RFs To decrease false positive rate, combine RFs into a cascade Filter Raw Data Filter Raw Data Filter Raw Data Raw Data Raw Data Filter Filter vs. vs. Filter Raw Data Raw Data Raw Filter Parse Data Raw Parse Parse Raw Data Data Sparser uses an optimizer to choose a cascade
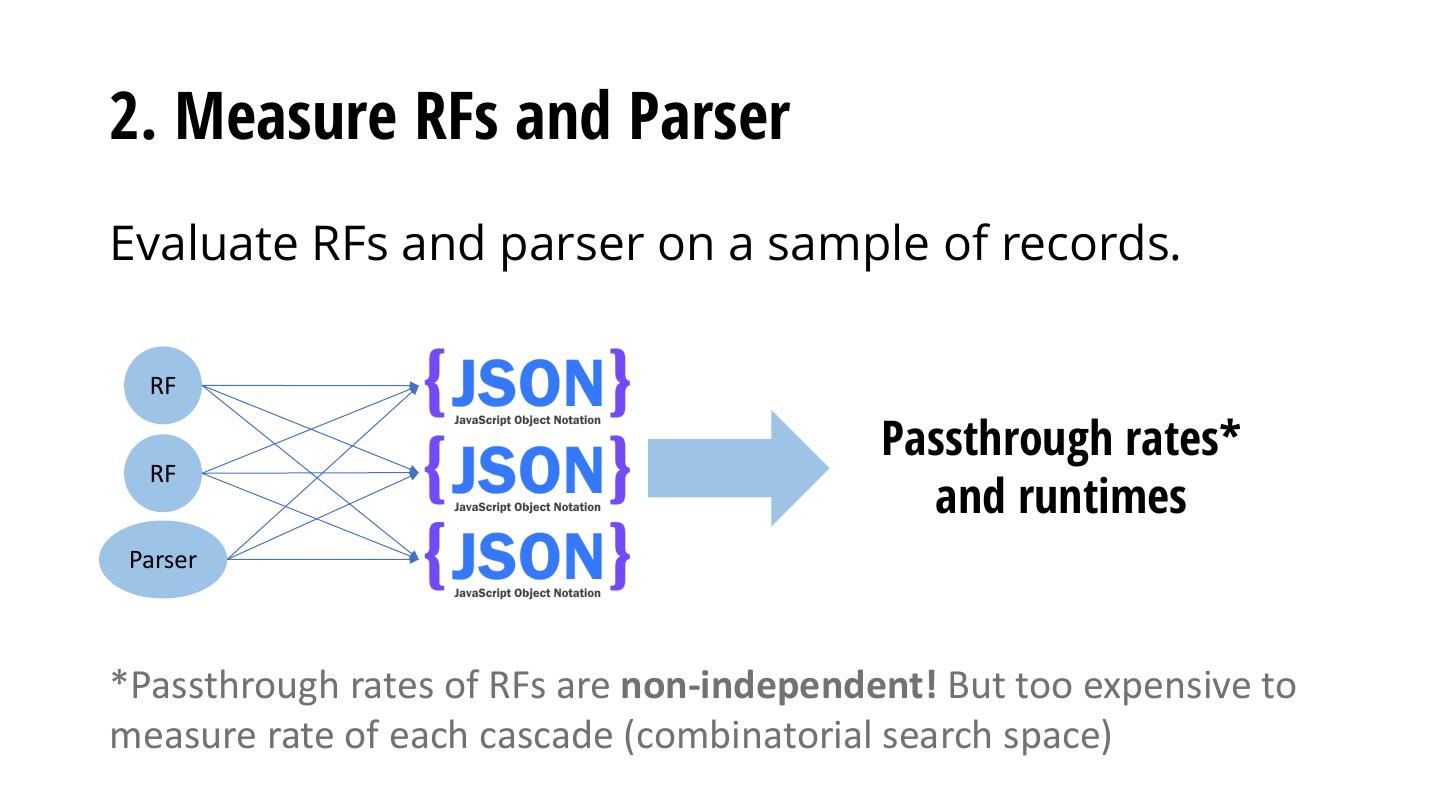
28 .Sparser’s Optimizer (name = "Trump" AND text contains "Putin") raw bytestream 0010101000110101 Step 1: Compile Step 2: Measure Step 3: Score and Step 4: Apply Possible RFs from Params on Sample Choose Cascade Chosen Cascade predicates of Records S1 S2 S3 RF 1 X RF1: "Trump" C (RF1) = 4 RF 1 0 1 1 RF2: "Trum" C (RF1àRF2) = 1 RF fails RF 2 1 0 1 RF3: "rump" C (RF2àRF3) = 6 … RF 2 X RF4: "Tr" for sampled RF fails C (RF1àRF3) = 9 RF5: "Putin" records: … Filtered bytes … 1 = passed 0 = failed sent to full parser
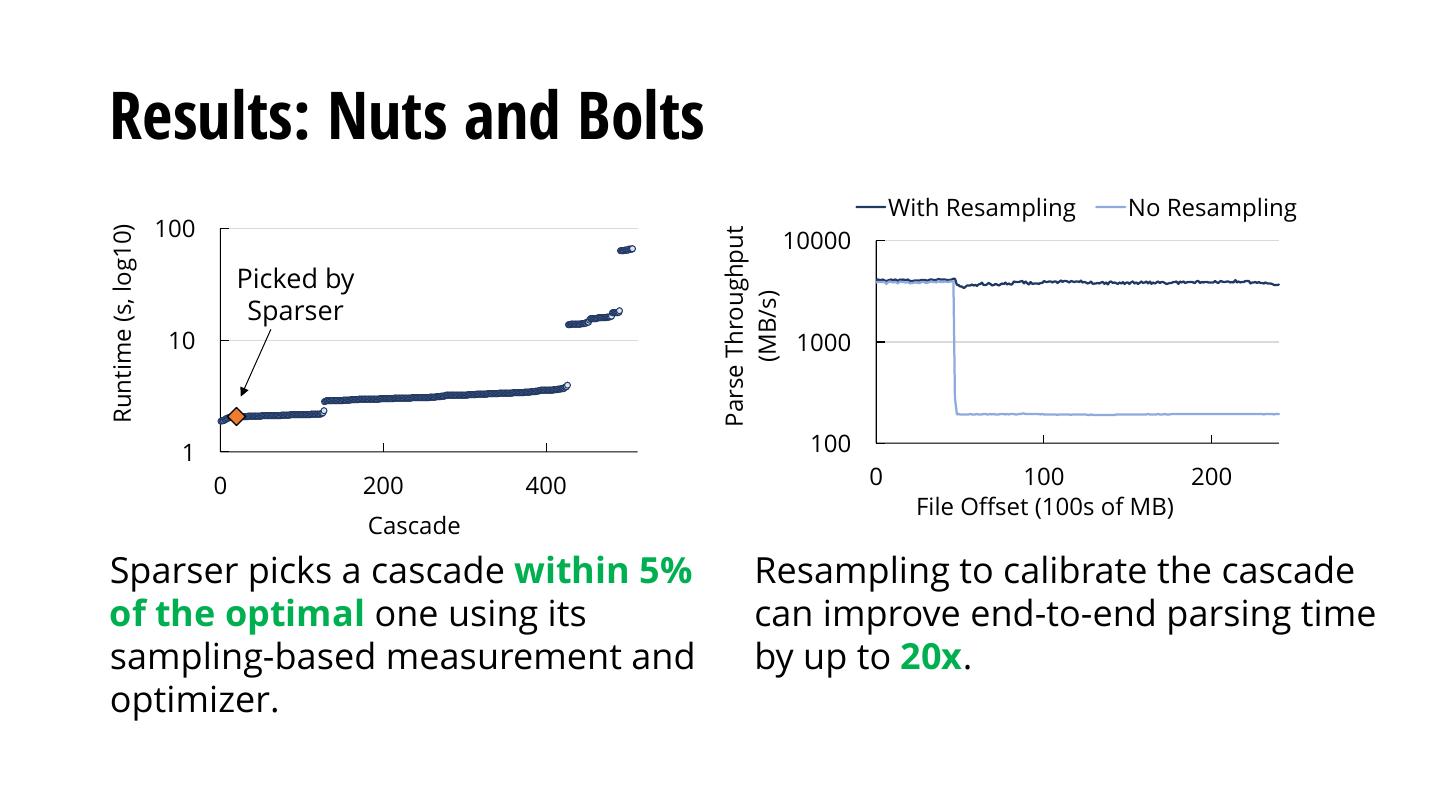
29 .Sparser’s Optimizer: Configuring RF Cascades Three high level steps: 1. Convert a query predicate to a set of RFs 2. Measure the passthrough rate and runtime of each RF and the runtime of the parser on sample of records 3. Minimize optimization function to find min-cost cascade
3秒后跳转登录页面
去登陆

