






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
荷兰铁路的维修预测
在本文中,我们介绍如何使用压缩机原木来检测列车制动管中空气泄漏的发生。从日志中提取压缩机运行时间和空闲时间,并用逻辑回归器建模,以便在正常运行模式下区分这两个类。空气泄漏将导致空闲时间变得更短,因为空气压力需要更频繁地调平,这可以用logistic模型检测。然后,利用基于密度的聚类技术,可以识别此类事件的序列,同时由于诸如停电之类的环境现象而忽略异常值。
展开查看详情
1 .Predictive Maintenance at the Dutch Railways Air leakage detection in train breaking pipes Ivo Everts, GoDataDriven (Amsterdam, NL) #DSSAIS16
2 .Tünde Alkemade Stefan Hendriks Ivo Everts Wouter Hordijk Jelte Hoekstra Inge Kalsbeek Giovanni Lanzani Wan-Jui Lee Janelle Zoutkamp Inka Locht Kee Man Nick Oosterhof Margot Peters Cyriana Roelofs Mattijs Suurland #DSSAIS16 !2
3 .Tünde Alkemade Stefan Hendriks Ivo Everts Wouter Hordijk Jelte Hoekstra Inge Kalsbeek Giovanni Lanzani Wan-Jui Lee Janelle Zoutkamp Inka Locht Kee Man Nick Oosterhof Margot Peters Cyriana Roelofs Mattijs Suurland Published paper in June 2017 'Contextual Air Leakage Detection in Train Braking Pipes' @ 'Advances in Artificial Intelligence: From Theory to Practice' #DSSAIS16 !2
4 . Tünde Alkemade Stefan Hendriks Ivo Everts Wouter Hordijk Jelte Hoekstra Inge Kalsbeek Giovanni Lanzani Wan-Jui Lee Janelle Zoutkamp Inka Locht Kee Man Nick Oosterhof Margot Peters Cyriana Roelofs Mattijs Suurland Published paper in June 2017 'Contextual Air Leakage Detection in Train Braking Pipes' @ 'Advances in Artificial Intelligence: From Theory to Practice' Implemented the paper using PySpark; teamwork for data delivery, proper productionizing, way of working #DSSAIS16 !2
5 . Tünde Alkemade Stefan Hendriks Ivo Everts Wouter Hordijk Consulting data scientist @ GoDataDriven Jelte Hoekstra Inge Kalsbeek Giovanni Lanzani MSc in AI; PhD in Computer Vision Wan-Jui Lee Janelle Zoutkamp Did lot of scientific programming Inka Locht Now mostly Python, Hadoop, Spark, Keras Kee Man Nick Oosterhof Margot Peters Cyriana Roelofs Mattijs Suurland Published paper in June 2017 'Contextual Air Leakage Detection in Train Braking Pipes' @ 'Advances in Artificial Intelligence: From Theory to Practice' Implemented the paper using PySpark; teamwork for data delivery, proper productionizing, way of working #DSSAIS16 !2
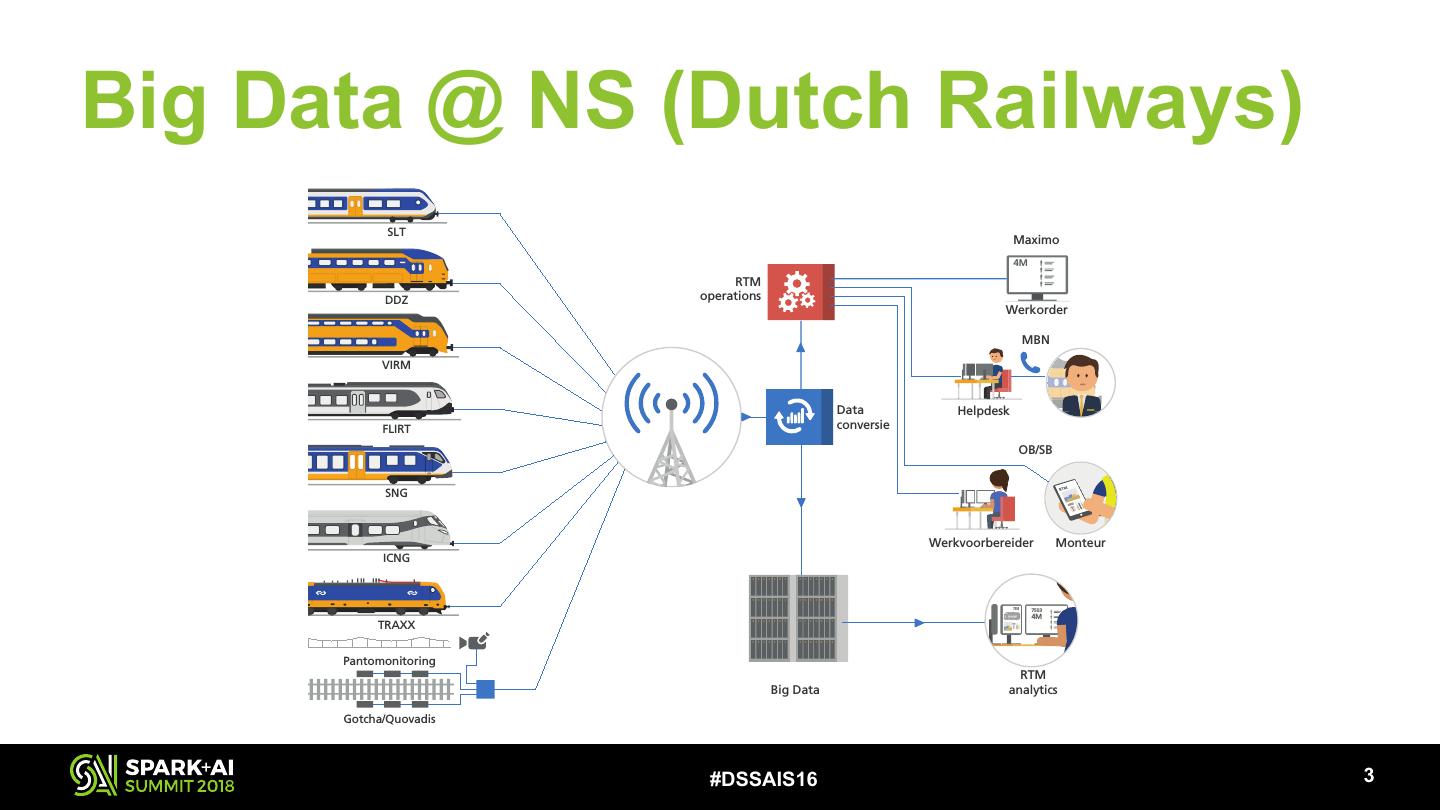
6 .Big Data @ NS (Dutch Railways) SLT Maximo 4M RTM DDZ operations Werkorder MBN VIRM Data Helpdesk FLIRT conversie OB/SB SNG Werkvoorbereider Monteur ICNG 7503 7503 4M TRAXX Pantomonitoring RTM Big Data analytics Gotcha/Quovadis #DSSAIS16 !3
7 .Outline • Data ingestion • Air leakage detection • Other use cases #DSSAIS16 !4
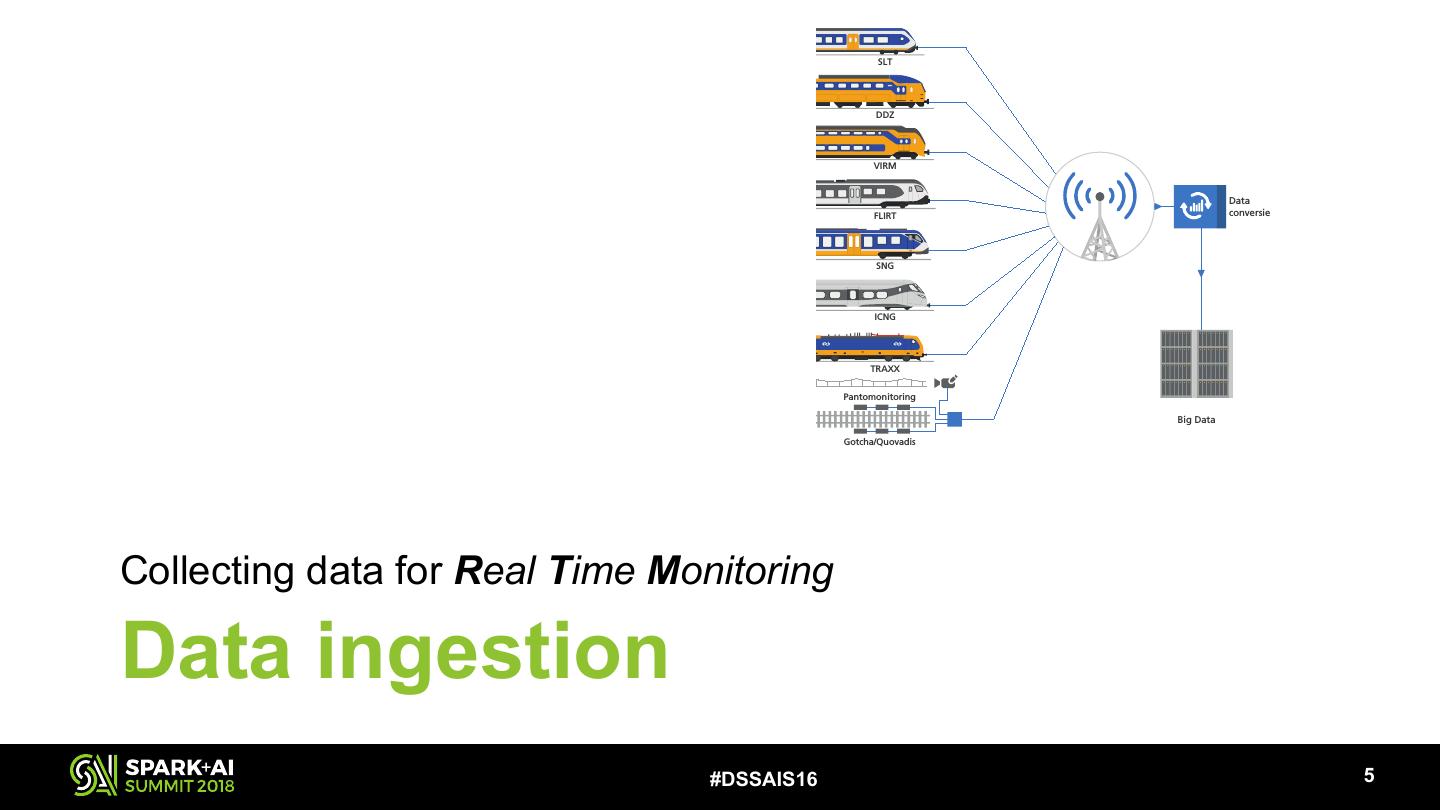
8 . SLT Maximo 4M RTM DDZ operations Werkorder MBN VIRM Data Helpdesk FLIRT conversie OB/SB SNG Werkvoorbereider Monteur ICNG 7503 7503 4M TRAXX Pantomonitoring RTM Big Data analytics Gotcha/Quovadis Collecting data for Real Time Monitoring Data ingestion #DSSAIS16 !5
9 .Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records #DSSAIS16 !6
10 .Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records #DSSAIS16 !6
11 .Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records #DSSAIS16 !6
12 . Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records # fetch args table_name = sys.argv[1] origin = sys.argv[2] # read xml string from stdin xml_string = ''.join(sys.stdin.readlines()) # parse 'm and print to stdout data = xml2table(xml_string, table_name, origin, start_dt, end_dt) print(data.to_csv(encoding='utf-8', header=False, index=False, #DSSAIS16 !6
13 . Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records # fetch args table_name = sys.argv[1] origin = sys.argv[2] # read xml string from stdin xml_string = ''.join(sys.stdin.readlines()) # parse 'm and print to stdout data = xml2table(xml_string, table_name, origin, start_dt, end_dt) print(data.to_csv(encoding='utf-8', header=False, index=False, #DSSAIS16 !6
14 . Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records def get_history_df(hdfs_binary_files, output_table_name): rdd = (hdfs_binary_files .map(unzip_xml) .flatMap(lambda x: xml2rows(x, output_table_name))) return None if rdd.isEmpty() else rdd.toDF() ... ... # read binary files and parse 'm hdfs_binary_files = (sc.binaryFiles('{}*'.format(file_group)) # fetch args .persist(StorageLevel.MEMORY_AND_DISK_SER) table_name = sys.argv[1] .repartition(num_executors)) origin = sys.argv[2] sdf = get_history_df(hdfs_binary_files, args.output_table_name) # read xml string from stdin xml_string = ''.join(sys.stdin.readlines()) # parse 'm and print to stdout data = xml2table(xml_string, table_name, origin, start_dt, end_dt) print(data.to_csv(encoding='utf-8', header=False, index=False, #DSSAIS16 !6
15 . Data ingestion Real time data Historic data ~20GB per day; 22B records 22B records def get_history_df(hdfs_binary_files, output_table_name): rdd = (hdfs_binary_files .map(unzip_xml) .flatMap(lambda x: xml2rows(x, output_table_name))) return None if rdd.isEmpty() else rdd.toDF() ... ... # read binary files and parse 'm hdfs_binary_files = (sc.binaryFiles('{}*'.format(file_group)) # fetch args .persist(StorageLevel.MEMORY_AND_DISK_SER) table_name = sys.argv[1] .repartition(num_executors)) origin = sys.argv[2] sdf = get_history_df(hdfs_binary_files, args.output_table_name) # read xml string from stdin xml_string = ''.join(sys.stdin.readlines()) # parse 'm and print to stdout data = xml2table(xml_string, table_name, origin, start_dt, end_dt) >> Better suited for large datasets print(data.to_csv(encoding='utf-8', header=False, index=False, >> Easier to (re)partition and append >> Preference for a unified approach #DSSAIS16 !6
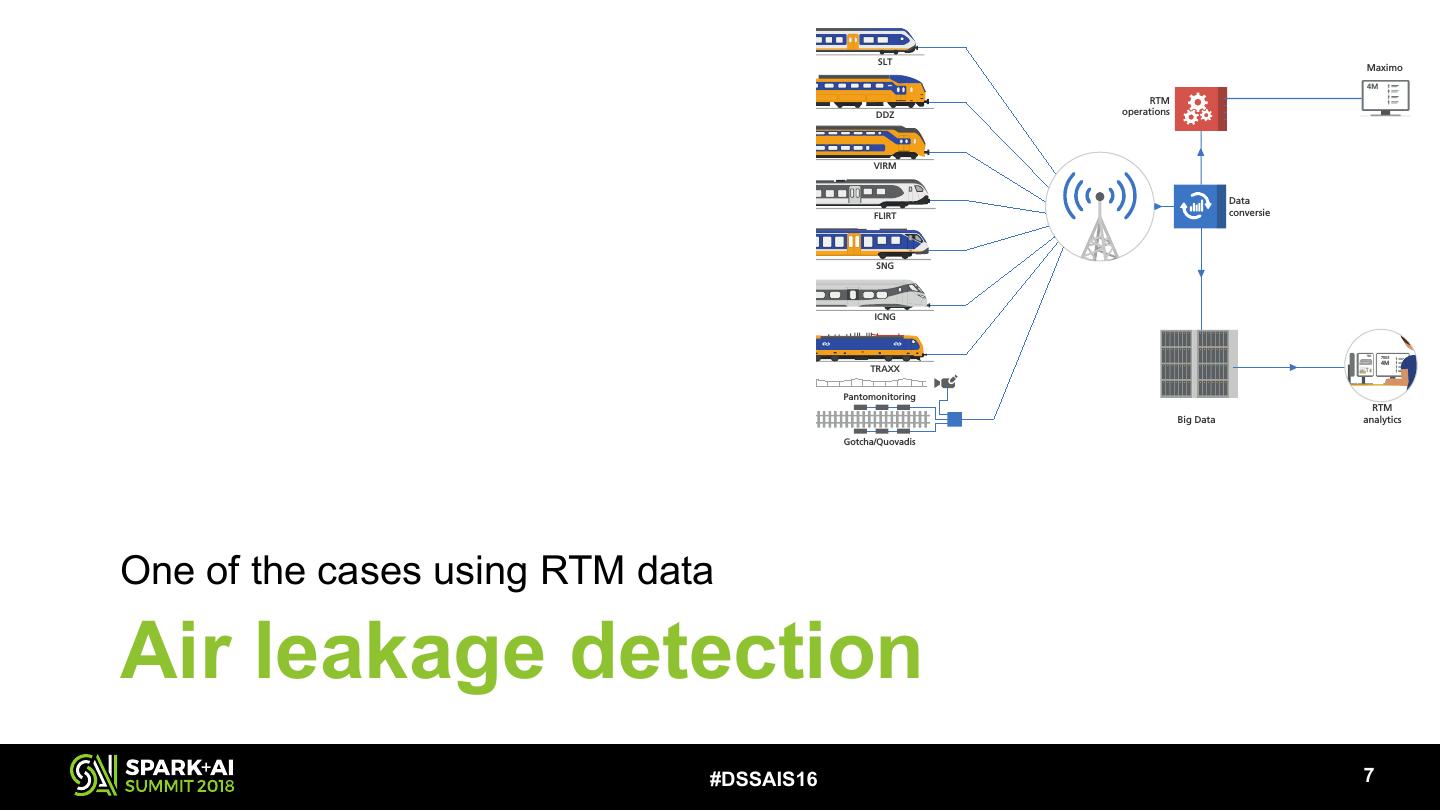
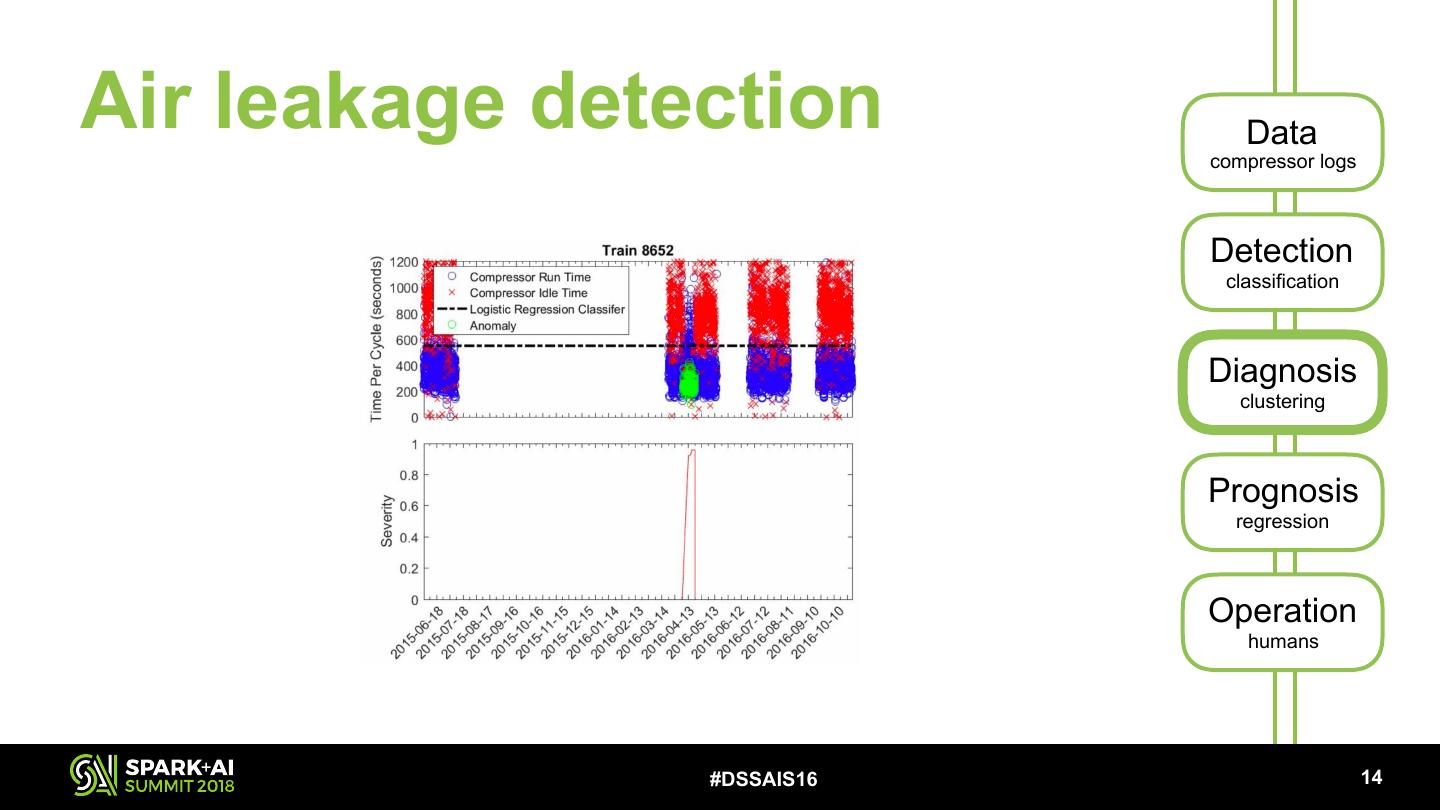
16 . SLT Maximo 4M RTM DDZ operations Werkorder MBN VIRM Data Helpdesk FLIRT conversie OB/SB SNG Werkvoorbereider Monteur ICNG 7503 7503 4M TRAXX Pantomonitoring RTM Big Data analytics Gotcha/Quovadis One of the cases using RTM data Air leakage detection #DSSAIS16 !7
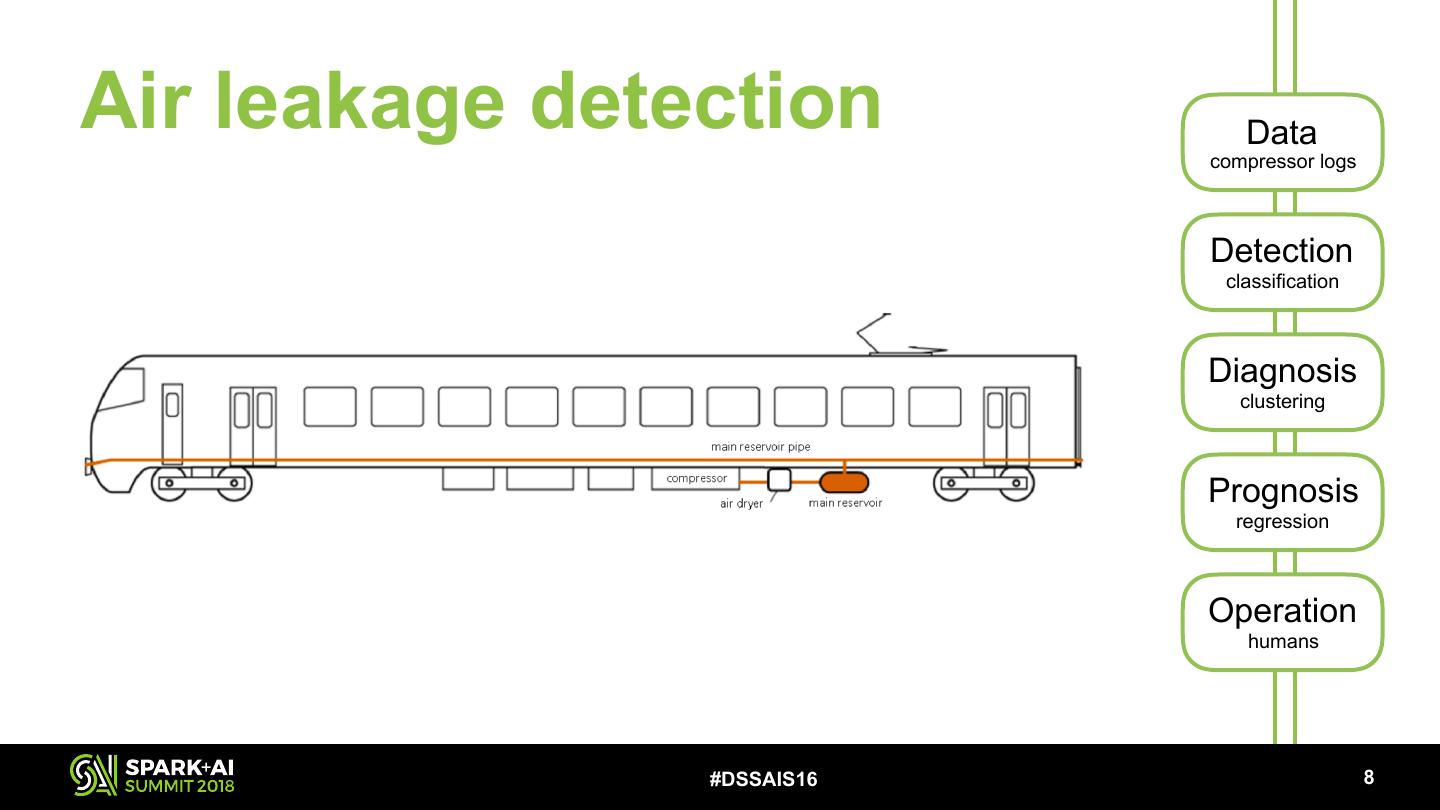
17 .Air leakage detection Data compressor logs Detection classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !8
18 .Air leakage detection Data compressor logs Detection classification Diagnosis clustering Prognosis regression Operation humans We extract median compressor run- and idle- times per hour #DSSAIS16 !9
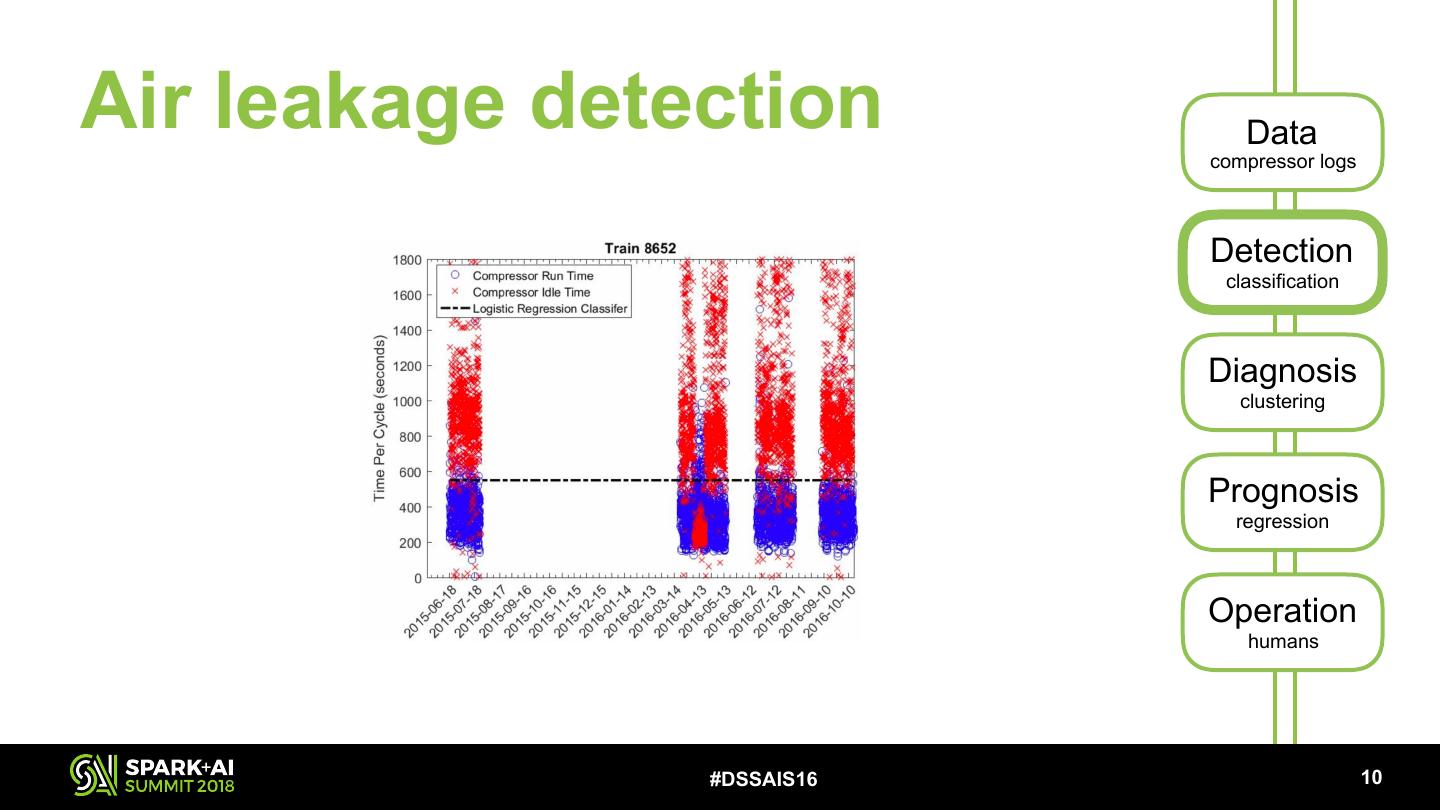
19 .Air leakage detection Data compressor logs Detection classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !10
20 . Air leakage detection Data compressor logs One model per train => compressor durations collected with a groupBy() and modelled in a UDF using scikit-learn Detection classification to obtain the per-class probabilities: Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !11
21 . Air leakage detection Data compressor logs One model per train => compressor durations collected with a groupBy() and modelled in a UDF using scikit-learn Detection classification to obtain the per-class probabilities: Diagnosis clustering Anomalies Prognosis regression Operation humans #DSSAIS16 !11
22 . Air leakage detection Data compressor logs One model per train => compressor durations collected with a groupBy() and modelled in a UDF using scikit-learn Detection classification to obtain the per-class probabilities: Diagnosis clustering Anomalies # group data per train and collect data LOL train_data = (df.groupBy('rolling_stock_number') Prognosis .agg(F.collect_list('median_duration').alias('median_duration'), regression F.collect_list('label').alias('label'))) # define UDF and fit model logistic_regression = F.udf(lambda X, y: sklearn_wrapper(X, y), ArrayType(FloatType())) Operation model_data = (train_data.withColumn('logistic_model_parameters', humans logistic_regression(train_data.median_duration, train_data.label))) #DSSAIS16 !11
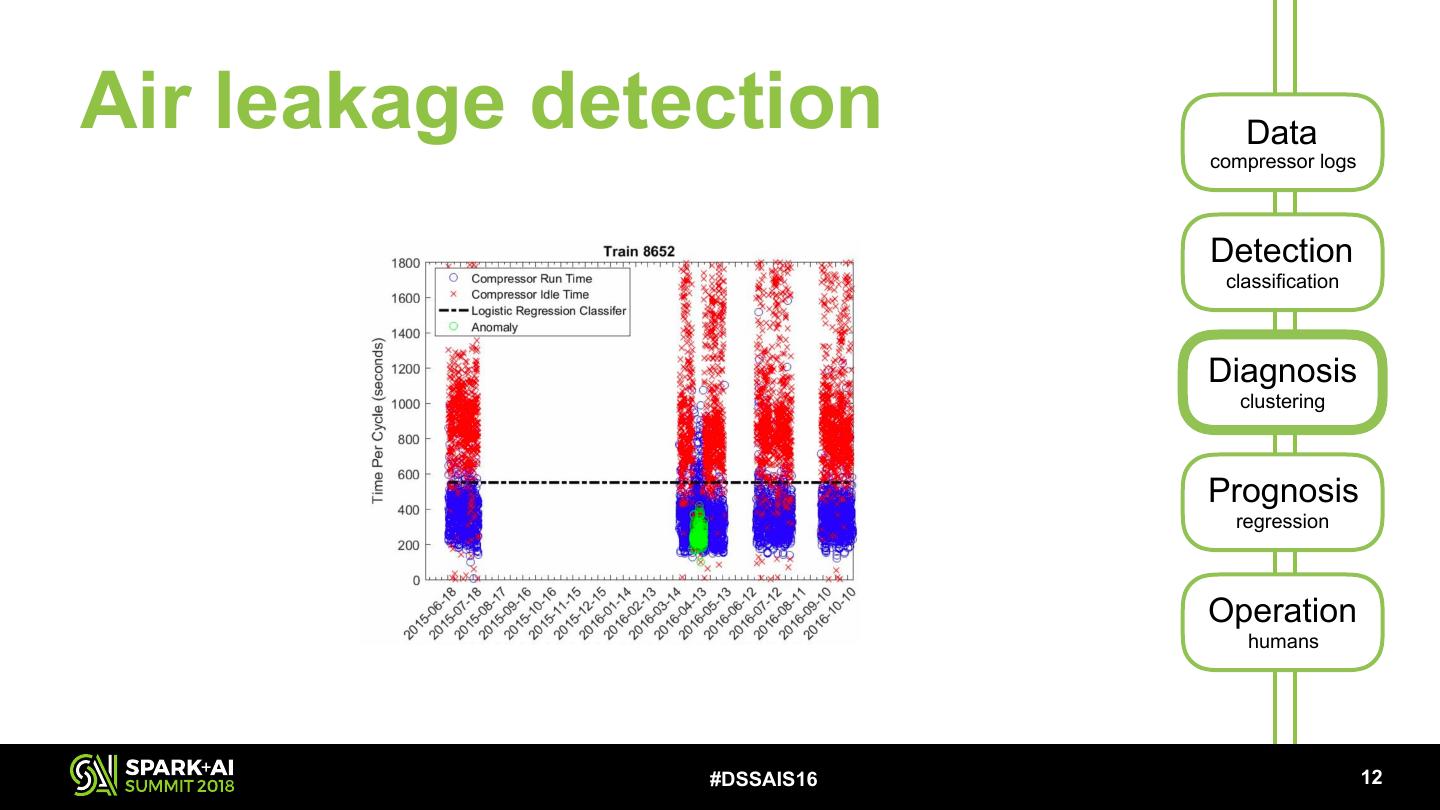
23 .Air leakage detection Data compressor logs Detection classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !12
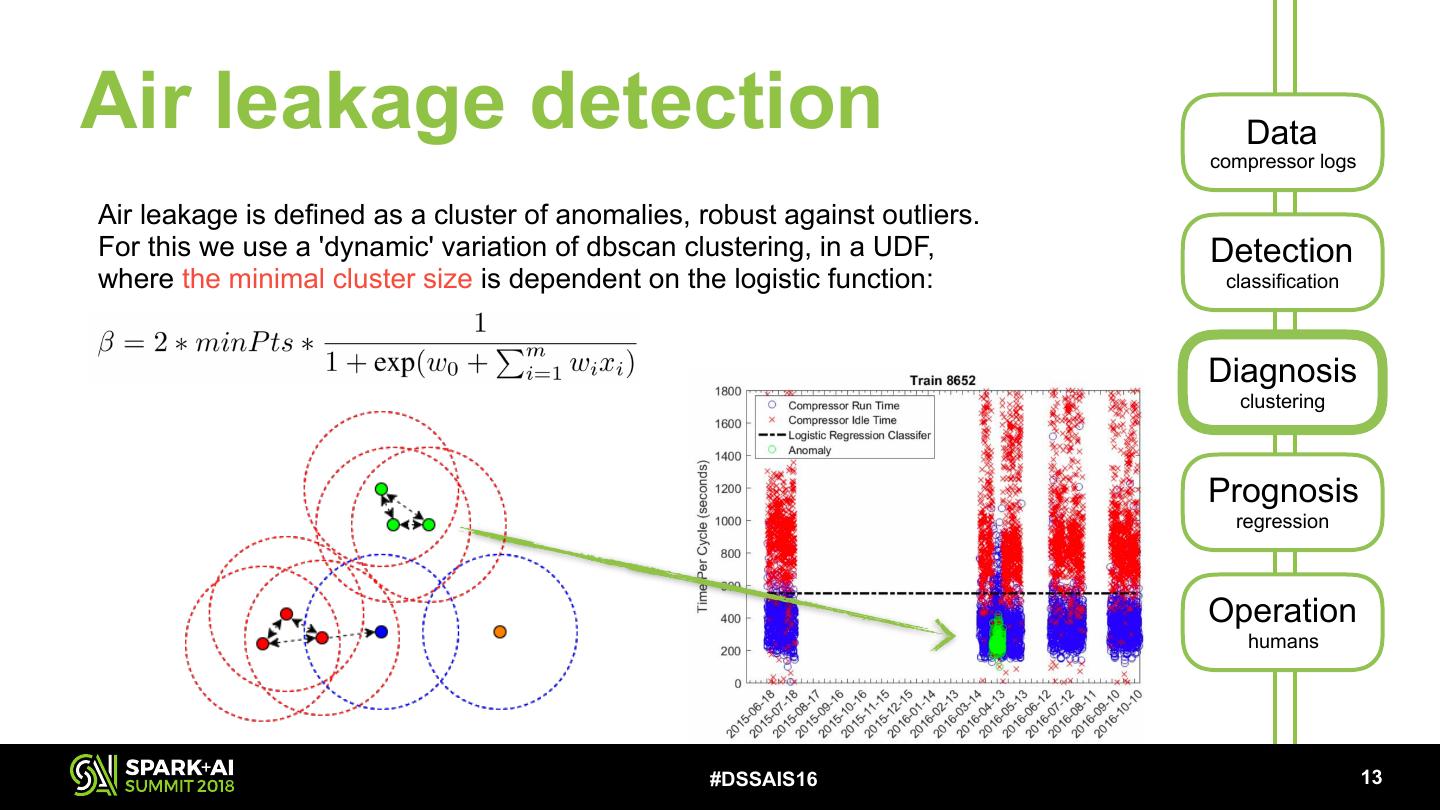
24 .Air leakage detection Data compressor logs Air leakage is defined as a cluster of anomalies, robust against outliers. For this we use a 'dynamic' variation of dbscan clustering, in a UDF, Detection where the minimal cluster size is dependent on the logistic function: classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !13
25 .Air leakage detection Data compressor logs Air leakage is defined as a cluster of anomalies, robust against outliers. For this we use a 'dynamic' variation of dbscan clustering, in a UDF, Detection where the minimal cluster size is dependent on the logistic function: classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !13
26 .Air leakage detection Data compressor logs Detection classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !14
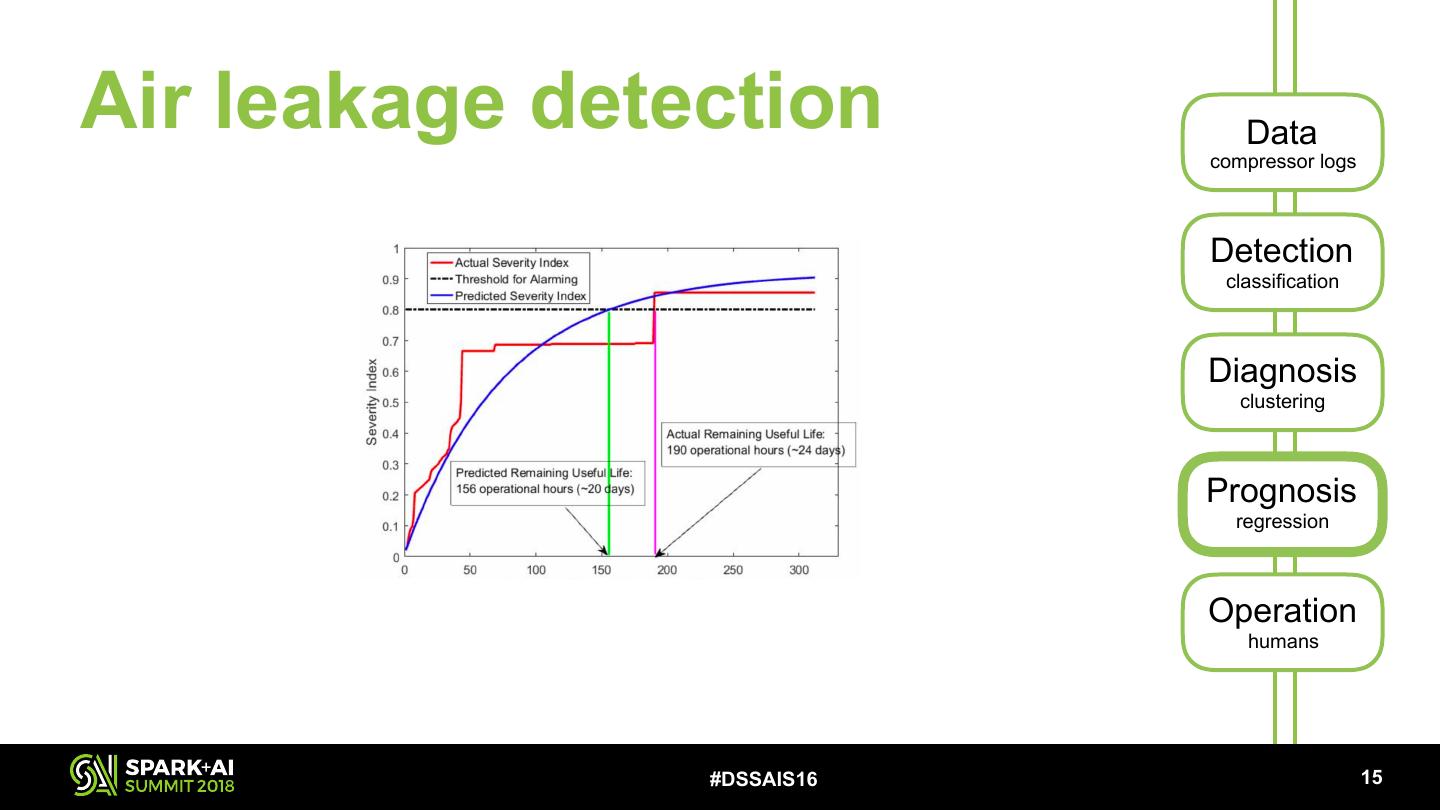
27 .Air leakage detection Data compressor logs Detection classification Diagnosis clustering Prognosis regression Operation humans #DSSAIS16 !15
28 .Air leakage detection Data compressor logs In the current implementation Detection classification we train one regressor for all trains, so a pure Spark implementation is possible Diagnosis clustering # import relevant classes from sparkml Prognosis from pyspark.ml.feature import VectorAssembler regression from pyspark.ml.regression import LinearRegression ... # prepare and run linear regression assembler = VectorAssembler(inputCols=x_cols, outputCol='features') Operation humans input = assembler.transform(train_data).select(['label', 'features']) output = LinearRegression().setSolver('l-bfgs').fit(input) #DSSAIS16 !16
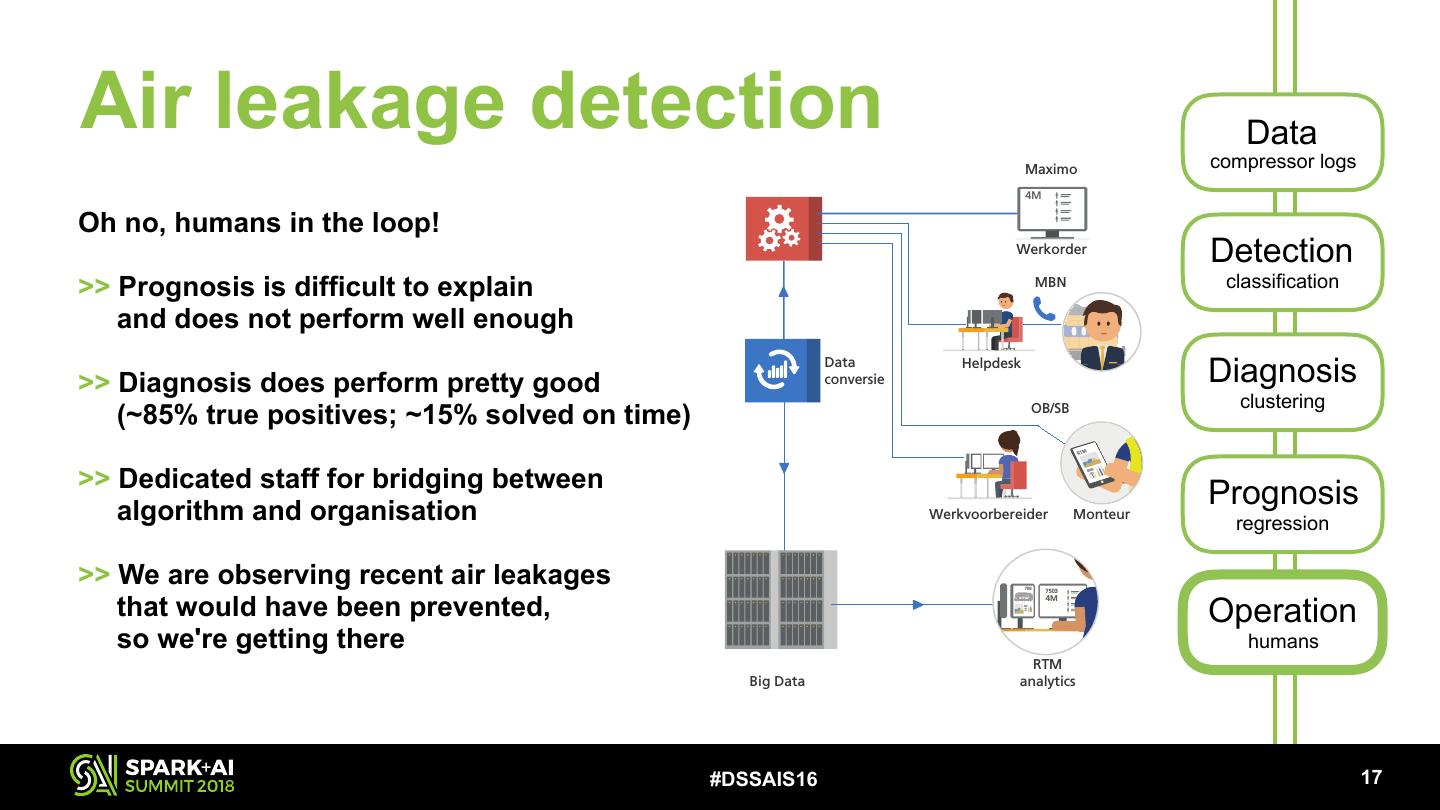
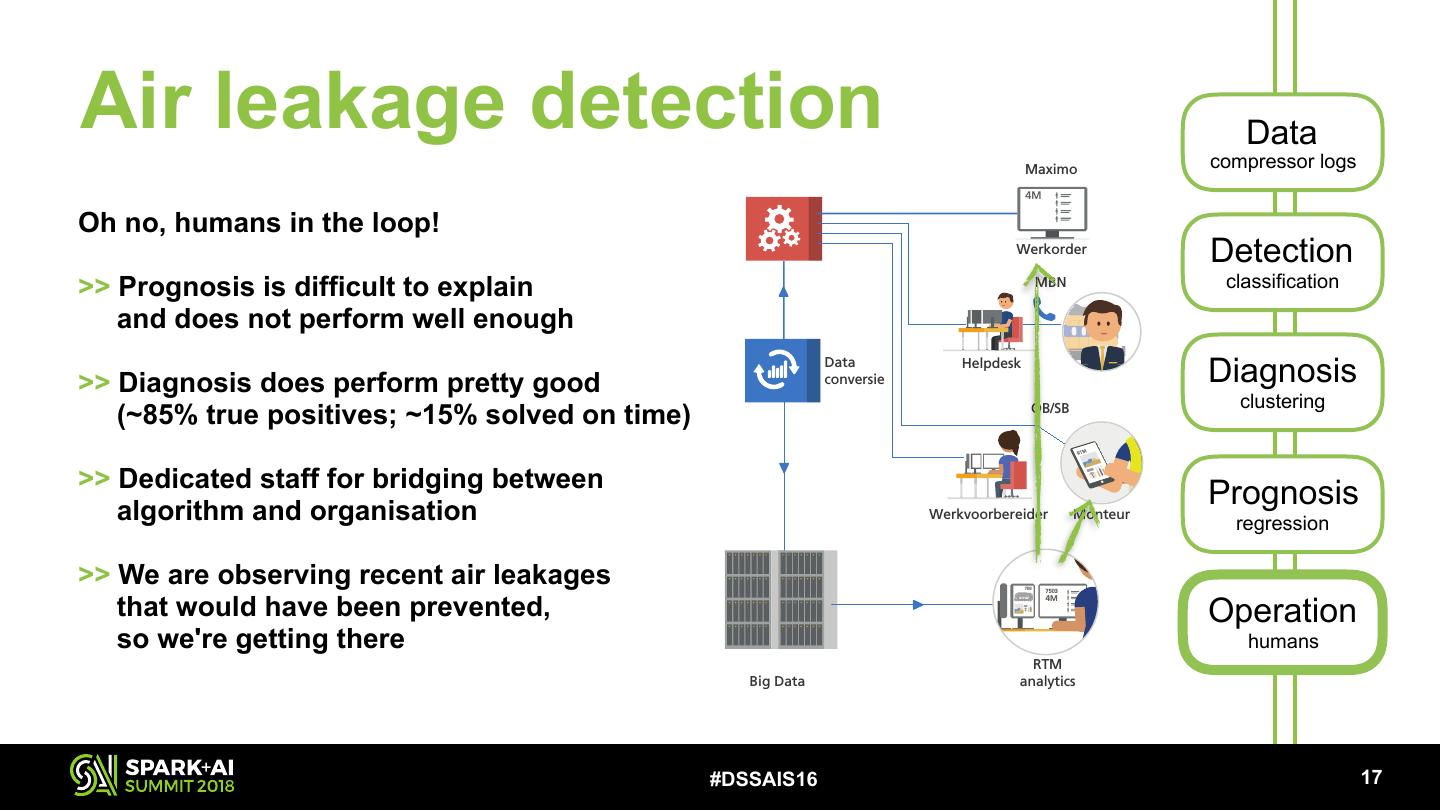
29 .Air leakage detection Data SLT Maximo compressor logs 4M Oh no, humans inDDZ the loop! RTM operations Werkorder Detection >> Prognosis is difficult to explain MBN classification and does not perform VIRM well enough >> Diagnosis does perform pretty good FLIRT Data conversie Helpdesk Diagnosis clustering (~85% true positives; ~15% solved on time) OB/SB SNG >> Dedicated staff for bridging between algorithm and organisation Werkvoorbereider Monteur Prognosis ICNG regression >> We are observing recent air leakages 7503 7503 that would have been prevented, Operation 4M TRAXX so we're getting there Pantomonitoring humans RTM Big Data analytics Gotcha/Quovadis #DSSAIS16 !17
3秒后跳转登录页面
去登陆

