










































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
利用Ray RLlib实现分布式强化学习
增强学习(RL)算法涉及不同组件的深度嵌套,其中每个组件通常显示分布式计算的机会。当前的RL库提供了整个程序级别上的并行性,将所有组件耦合在一起,并使现有实现难以扩展、组合和重用。
展开查看详情
1 .Scalable Reinforcement Learning with RLlib Eric Liang and Richard Liaw #ray #rllib
2 .Talk overview Reinforcement Leveraging Ray RLlib and learning (RL) for distributed AI Abstractions for scalable RL ray.readthedocs.io 2
3 .Reinforcement Learning is centered around interaction action environment policy agent observation + reward ray.readthedocs.io 3
4 .Applications of RL ray.readthedocs.io 4
5 .How do we improve RL? More data from More Compute interaction Improved Performance ray.readthedocs.io 5
6 .Distributed RL Distributed Hyperparameter Optimization Experience Experience Buffer Buffer Learners Interaction ray.readthedocs.io 6
7 . Abstractions for How to do Reinforcement Learning distributed Distributed Execution Environment RL? Hardware ray.readthedocs.io 7
8 . Abstractions for Reinforcement Learning Ray Distributed Execution Environment Provides task parallel API, actor API, and DataFrame API Hardware ray.readthedocs.io 8
9 . Ray provides a Task parallel API @ray.remote def zeros(shape): zeros zeros return np.zeros(shape) id1 id2 @ray.remote def dot(a, b): return np.dot(a, b) dot id1 = zeros.remote([5, 5]) id3 id2 = zeros.remote([5, 5]) id3 = dot.remote(id1, id2) result = ray.get(id3) ray.readthedocs.io 9
10 .Ray also provides an actor API @ray.remote(num_gpus=1) class Counter(object): def __init__(self): Counter self.value = 0 def inc(self): self.value += 1 inc id4 return self.value c = Counter.remote() id4 = c.inc.remote() inc id5 id5 = c.inc.remote() result = ray.get([id4, id5]) ray.readthedocs.io 10
11 .Ray Architecture Overview Worker Worker Driver Worker Worker Worker Object Store Object Store Object Store Local Scheduler Local Scheduler Local Scheduler Global Scheduler Global Scheduler Global Scheduler Global Scheduler ray.readthedocs.io 11
12 .Ray Architecture Overview Worker Worker Driver Worker Worker Worker Object Store Object Store Object Store Local Scheduler Local Scheduler Local Scheduler Global Scheduler Global Control Store Global Scheduler Global Control Store Global Scheduler Global Scheduler Global Control Store ray.readthedocs.io 12
13 .You can run Ray on Spark Worker Worker Driver Worker Worker Worker Object Store Object Store Object Store Local Scheduler Local Scheduler Local Scheduler Spark executor Spark driver Spark executor $ pip install ray > sc.parallelize(1 to 100).mapPartitions(_ => "ray start --redis-address=DRIVER_ADDR"!!) ray.readthedocs.io 13
14 .Ray Libraries Pandas on Ray Ray tasks and actors Hardware resources ray.readthedocs.io 14
15 .What is RLlib Your algorithms RLlib algorithms RLlib RLlib abstractions Ray tasks and actors Hardware resources ray.readthedocs.io 15
16 .RLlib is easy to get started with ./train.py --env=CartPole-v0 --run=DQN ray.readthedocs.io 16
17 .RLlib has a simple Python API from ray.rllib.dqn import DQNAgent env_creator = lambda config: my_env() agent = DQNAgent(env_creator=creator) while True: print(agent.train()) ray.readthedocs.io 17
18 .RLlib efficiently scales to multi-core and clusters ray.readthedocs.io 18
19 .Unified framework for scalable RL Distributed PPO Ape-X Distributed (vs OpenMPI) DQN, DDPG Evolution Strategies (vs Redis-based) ray.readthedocs.io 19
20 .RLlib algorithms and optimizers RLlib Policy Optimizers: Current RLlib Algorithms: AsyncOptimizer Policy Gradients (PG) SyncLocalOptimizer Proximal Policy Optimization (PPO) all scale from SyncLocalReplayOptimizer Asynchronous Advantage Actor-Critic (A3C) laptop to LocalMultiGPUOptimizer clusters Deep Q Networks (DQN) ApexOptimizer Evolution Strategies (ES) Deep Deterministic Policy Gradients (DDPG) Ape-X Distributed Prioritized Experience Replay, including both DQN and DPG variants work in progress: IMPALA work in progress: TRPO Community Contributions ray.readthedocs.io 20
21 .RLlib makes implementing algorithms simple • Developer specifies policy, postprocessor, loss Neural network Python function Tensor ops in in TF / PyTorch / etc. TF / Pytorch class rllib.PolicyGraph ray.readthedocs.io 21
22 .Scale RL algorithms with RLlib • Use RLlib to define your learning algorithm • Use RLlib to scale training to a cluster ray.readthedocs.io 22
23 .RLlib abstractions rllib.PolicyEvaluator exchange / replay samples, gradients, replica rllib.PolicyGraph weights to optimize policy replica replica rllib.PolicyOptimizer replica Ray actor ray.readthedocs.io 23
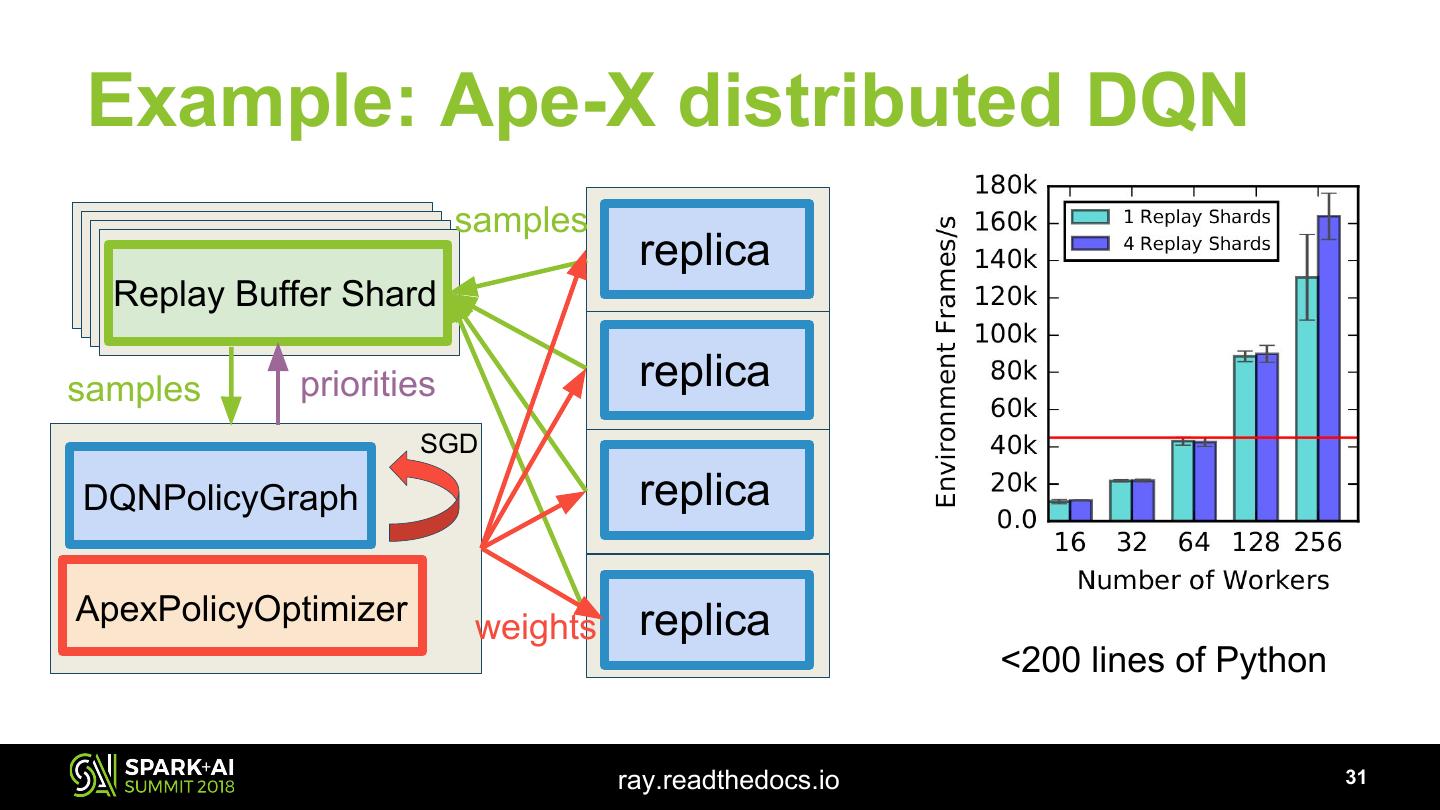
24 . RLlib example algorithms 1. Simple parallel policy gradient 2. Ape-X distributed experience prioritization ray.readthedocs.io 24
25 . Example: Policy gradient CartPole task: keep pole balanced on cart 1. Defining the policy network policy network_out = FullyConnectedNetwork(obs, size=[64, 64]) # 2 outputs def action_distribution = CategoricalDistribution(network_out) # e.g., P(LEFT) = 0.8, P(RIGHT) = 0.2 action_op = action_distribution.sample() # e.g., LEFT using current_obs = env.reset() # e.g., [1.2, -1.5] policy action = session.run(action_op, feed_dict={obs: current_obs}) # returns LEFT or RIGHT next_obs, reward, done = env.step(action) sample experiences = [ ([1.2, -1.5], LEFT, [1.1, -0.2], +1, False), data ([1.1, -0.2], RIGHT, [1.2, -0.8], +1, False), ([1.2, -0.8], LEFT, [1.1, -1.1], -10, True) ] # batch of experiences ray.readthedocs.io 25
26 . Example: Policy gradient CartPole task: keep pole balanced on cart 2. Experience postprocessing experiences_in = [ ([1.2, -1.5], LEFT, [1.1, -0.2], +1, False), sample input ([1.1, -0.2], RIGHT, [1.2, -0.8], +1, False), ([1.2, -0.8], LEFT, [1.1, -1.1], -10, True) ] experiences_out = [ ([1.2, -1.5], LEFT, [1.1, -0.2], -6.2, False), sample ([1.1, -0.2], RIGHT, [1.2, -0.8], -8.0, False), output ([1.2, -0.8], LEFT, [1.1, -1.1], -10, True) ] temporal discounting: propagate consequences of actions ray.readthedocs.io 26
27 .Example: Policy gradient CartPole task: keep pole balanced on cart 3. Defining the loss function policy, experiences Loss() float loss = -tf.reduce_mean(dist.logp(action) * advantages) train_op = tf.train.GradientDescentOptimizer.minimize(loss) ray.readthedocs.io 27
28 .Parallel Policy Gradient with RLlib class PolicyGradientGraph(rllib.TFPolicyGraph): def __init__(self, obs_space, action_space): self.obs, self.adv = tf.placeholder(), tf.placeholder() model = FullyConnectedNetwork(self.obs, size=[64, 64]) dist = rllib.action_distribution(action_space, model) self.act = dist.sample() self.loss = -tf.reduce_mean(dist.logp(self.act) * self.adv) def postprocess(self, batch): return rllib.compute_advantages(batch) ray.readthedocs.io 28
29 .Parallel Policy Gradient with RLlib # Setup distributed workers workers = [rllib.PolicyEvaluator.remote( env="CartPole-v0", policy_graph=PolicyGradientGraph) for _ in range(10)] # Choose policy optimizer optimizer = rllib.AsyncPolicyOptimizer(workers) # Training loop while True: optimizer.step() print(optimizer.foreach_policy(lambda p: p.get_stats())) ray.readthedocs.io 29
3秒后跳转登录页面
去登陆

