

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
用Apache Spark、Python 3和机器学习构建可伸缩记录链接系统
在这次讲座中,我们将分享我们的经验,用Apache Spark、Python 3和简单的机器学习技术构建SpRink。我们将介绍使用此堆栈的好处和坏处,从使用干净的API和随时可用的库到处理讨厌的Sparkbug、困难和糟糕的训练数据。
展开查看详情
1 .Building a Scalable Record Linkage System with Apache Spark, Python 3, and Machine Learning Nicholas Chammas and Eddie Pantridge MassMutual #Py6SAIS
2 .The Business Problem • What: Comprehensive view of the customer • Why: Marketing and underwriting • Problem: • Customer information scattered across many systems • No global key to link them all together • Variations in name and address #Py6SAIS !2
3 .The Technical Challenge • 330M+ records that need to be linked • Records come from various systems with differing schemas • No global key; SSN generally not available • No differential extracts of source systems • Need to link everything, all at once, every night #Py6SAIS !3
4 .Record Linkage Prior Art • Dedupe • Mature, sophisticated • Local processing • Previous team found did not scale enough #Py6SAIS !4
5 .Record Linkage Prior Art • Splinkr 2 • In-house system built on Spark’s RDD API in late 2015 / early 2016 • 8+ hours to run; problems with stability, code maintainability, and link quality • Successful as an experiment, but needed replacement for production #Py6SAIS !5
6 .Splinkr 3 • All-new project started in late 2016, targeting Spark’s DataFrame API • Goal: Build a production-ready record linkage system, leveraging the lessons from Splinkr 2 #Py6SAIS !6
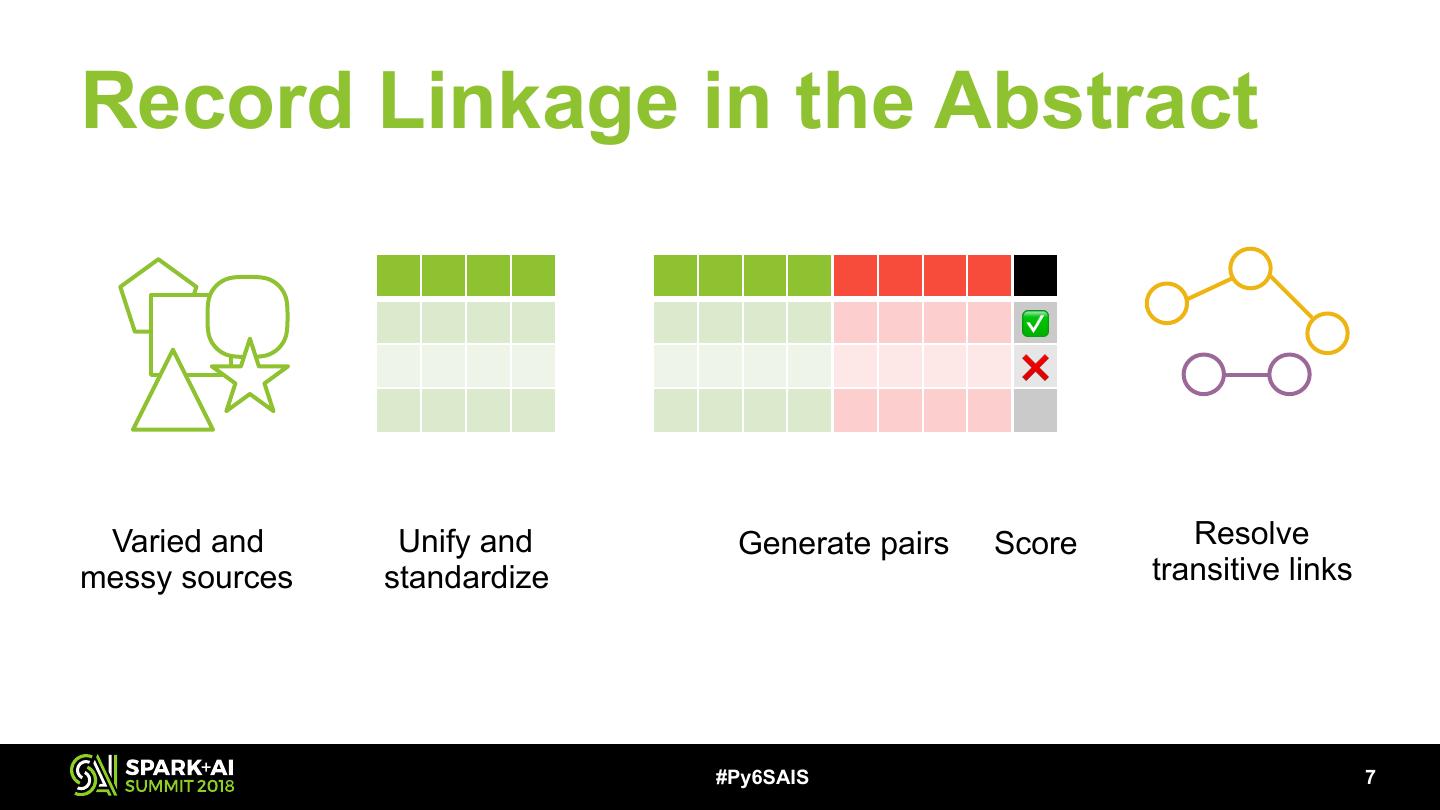
7 .Record Linkage in the Abstract ✅ ❌ Varied and Unify and Generate pairs Score Resolve messy sources standardize transitive links #Py6SAIS !7
8 .Standardizing the Incoming Data Full Name … ZIP Nick Chammas 02138 First Name Last Name … ZIP First Name Last Name … ZIP Nick Chammas 02138 Nicholas Chammas 02138-1516 Nicholas Chammas 02138 #Py6SAIS !8
9 .Generating Pairs Efficiently • 330M records means (330M choose 2) ≈ 1016 possible pairs • Need heuristic to quickly cut that 1016 down without losing many matches • We accomplish this by extracting a “blocking key” • We generate pairs only for records in the same block #Py6SAIS !9
10 .Generating Pairs Efficiently • Example: • Record: John Roberts, 20 Main St, Plainville MA 01111 • Blocking key: JR01111 • Will be paired with: Jonathan Ray … 01111 • Won’t be paired with: Frank Sinatra … 07030 #Py6SAIS !10
11 .Generating Pairs Efficiently • Blocking as a crude model for predicting matches • We want a recall of 1.0 • Don’t care about precision • Drastically shrink search space • Blocking cuts down generated pairs from 1016 to 108 #Py6SAIS !11
12 .Generating Pairs Efficiently blocked_people = ( people .withColumn( '_blocking_key', blocking_key_udf('first_name', 'last_name', 'zip') ) ) #Py6SAIS !12
13 .Generating Pairs Efficiently people_pairs = ( blocked_people.alias('p1') .join( blocked_people.alias('p2'), on='_blocking_key') .where( concat(col('p1.source_name'), col('p1.source_pk')) < concat(col('p2.source_name'), col('p2.source_pk')) ) ) #Py6SAIS !13
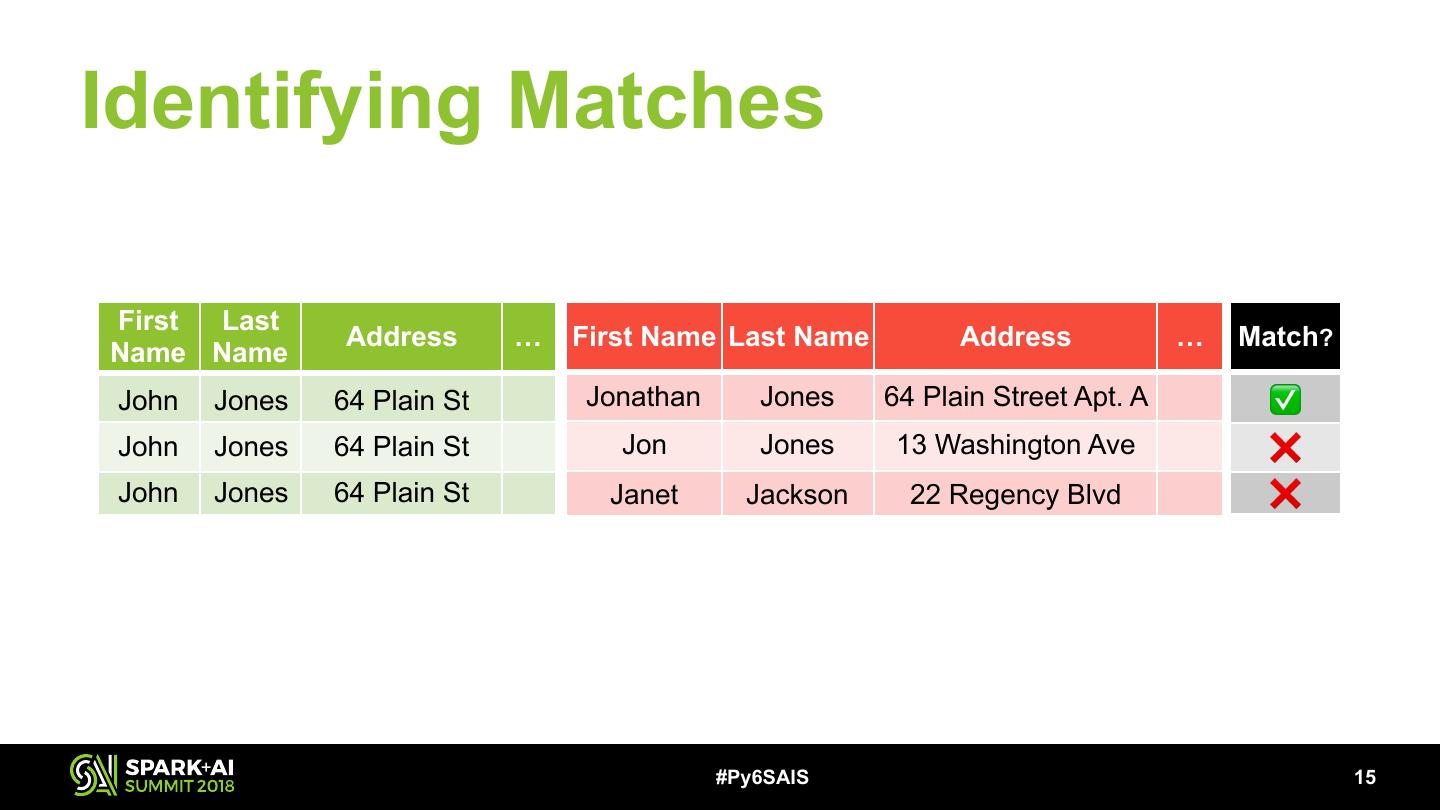
14 .Identifying Matches • Logistic regression model (Spark ML Guide) • Trained on records where SSN was available • Model features: • Phonetic equality on full name and city • String distance on full name, address, and city • Exact match on state and ZIP • Jellyfish: Python library providing implementations of Metaphone, Jaro-Winkler, … #Py6SAIS !14
15 .Identifying Matches First Last Address … First Name Last Name Address … Match? Name Name John Jones 64 Plain St Jonathan Jones 64 Plain Street Apt. A ✅ John Jones 64 Plain St Jon Jones 13 Washington Ave ❌ John Jones 64 Plain St Janet Jackson 22 Regency Blvd ❌ #Py6SAIS !15
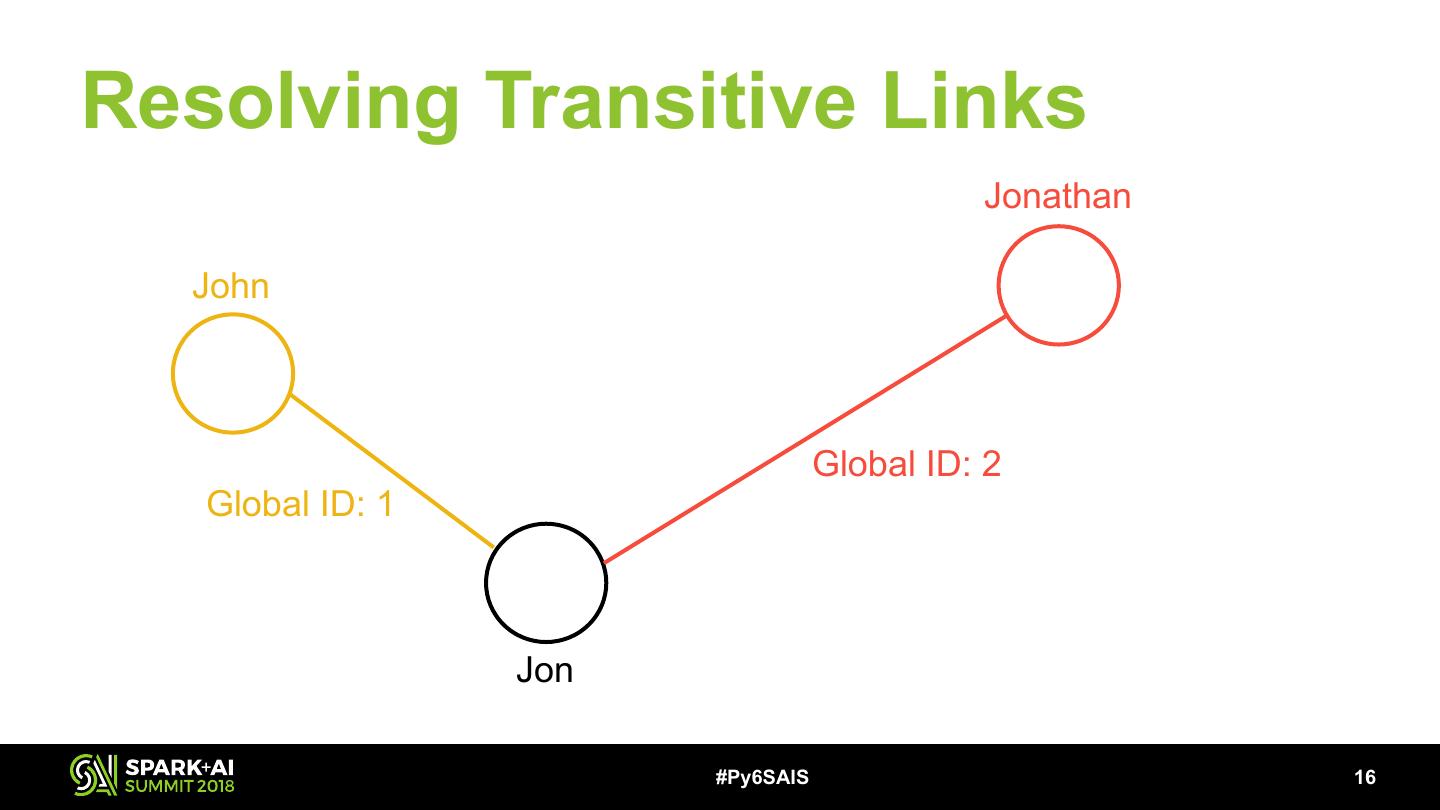
16 .Resolving Transitive Links Jonathan John Global ID: 2 Global ID: 1 Jon #Py6SAIS !16
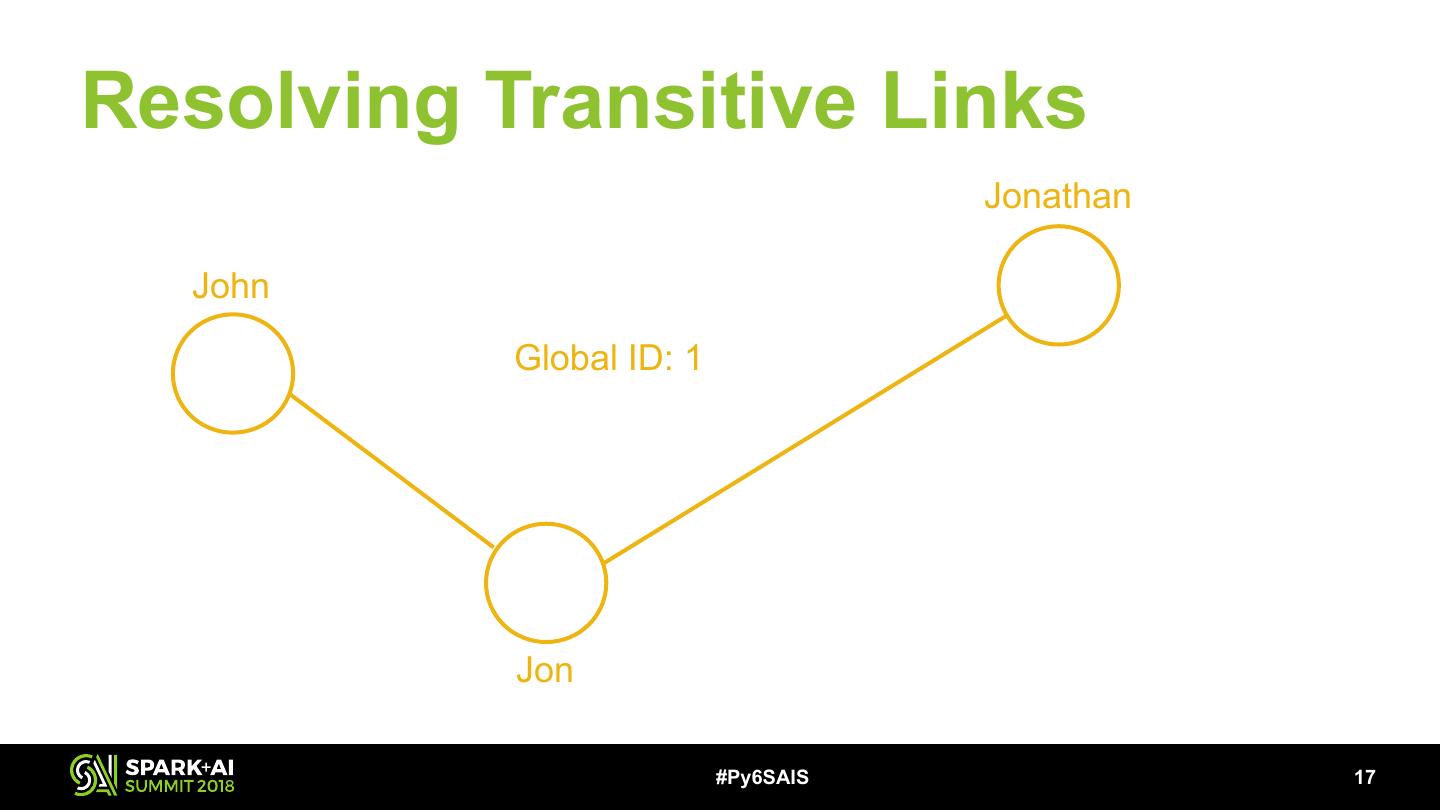
17 .Resolving Transitive Links Jonathan John Global ID: 1 Jon #Py6SAIS !17
18 .Resolving Transitive Links from graphframes import GraphFrame graph = GraphFrame(vertices, edges) connected_components = (graph.connectedComponents()) globally_linked_people = ( connected_components .select( col('component').alias('global_id'), 'person', )) #Py6SAIS !18
19 .Splinkr 3 at Launch • Cut runtime from 8+ hours (Splinkr 2) to 1.5 hours on same hardware • Model performance better than previous in-house systems • Code base easier to read thanks to declarative style of DataFrame API • Less code weight by leveraging Spark and Python packages #Py6SAIS !19
20 .Experiments with Neural Networks • Prompted by idea shared during Riot Games talk at Spark Summit 2017 • Goals: • Handle edge cases better than logistic regression model • Simplify code while maintaining model performance #Py6SAIS !20
21 .Experiments with Neural Networks • Experimented with convolutional neural networks • Model trained on raw text; no explicit features extracted • Minor hacking required to integrate Keras model into Spark #Py6SAIS !21
22 .Experiments with Neural Networks • Results: • Marginal increase in accuracy; recall up, precision down • Neural network did not seem to learn anything not already captured by logistic regression • Code simplified at expense of interpretability, memory requirements, and run time #Py6SAIS !22
23 .Biggest Hurdles in Building Splinkr 3 • Poor quality labels on our training data • SSN is not a great way to generate training pairs • Poor training data limited potential for linkage improvements • Manual cleanup helped, but turking or synthetic training data would have been better #Py6SAIS !23
24 .Biggest Hurdles in Building Splinkr 3 • Bugs and API gaps working with Spark 2.0 • Code generation bugs (SPARK-18492, SPARK-18866) • Optimizer problems related to UDFs (SPARK-18254, SPARK-18589) • GraphFrames Python 3 compatibility (graphframes#85) • GraphFrames correctness bug (graphframes#159) #Py6SAIS !24
25 .Take-aways from Building Splinkr 3 • Spark makes building a scalable linkage pipeline approachable • Declarative style of DataFrame API facilitates good design • Access to Spark and Python ecosystems saves time (GraphFrames, Jellyfish) #Py6SAIS !25
26 .Take-aways from Building Splinkr 3 • Good training data is critical and worth the upfront investment • Good heuristics are often a better starting point than machine learning (Google’s ML Engineering Rule #1) • Building with cutting-edge tools (at the time, Spark 2.0) comes with risk #Py6SAIS !26
27 .Building a Scalable Record Linkage System with Apache Spark, Python 3, and Machine Learning Nicholas Chammas and Eddie Pantridge MassMutual #Py6SAIS
3秒后跳转登录页面
去登陆

