展开查看详情
1 .Building Deep Reinforcement Learning
Applications on Apache Spark
with Analytics Zoo using BigDL
Yuhao Yang
Intel Data Analytics Technologies
�
2 .Agenda
Analytics Zoo overview
Reinforcement learning overview
Reinforcement learning with Analytics zoo
future directions
�
3 .Analytics Zoo
• Analytics + AI Platform for Apache Spark and BigDL
• Open source, Scala/Python, Spark 1.6 and 2.X
Analytics Zoo High level API, Industry pipelines, App demo & Util
BigDL MKL, Tensors, Layers, optim Methods, all-reduce
Apache Spark RDD, DataFrame, Scala/Python
https://github.com/intel-analytics/analytics-zoo
�
4 .Analytics Zoo
High level pipeline APIs
nnframes: Spark DataFrames and ML Pipelines for DL
Keras-style API
autograd: custom layer/loss using auto differentiation
Transfer learning
�
5 .Analytics Zoo
Built-in deep learning pipelines & models
Object detection: API and pre-trained SSD and Faster-RCNN
Image classification: API and pre-trained VGG, Inception, ResNet, MobileNet, etc.
Text classification API with CNN, LSTM and GRU
Recommendation API with NCF, Wide and Deep etc.
�
6 .Analytics Zoo
End-to-end reference use cases
reinforcement learning
anomaly detection
sentiment analysis
fraud detection
image augmentation
object detection
variational autoencoder
…
�
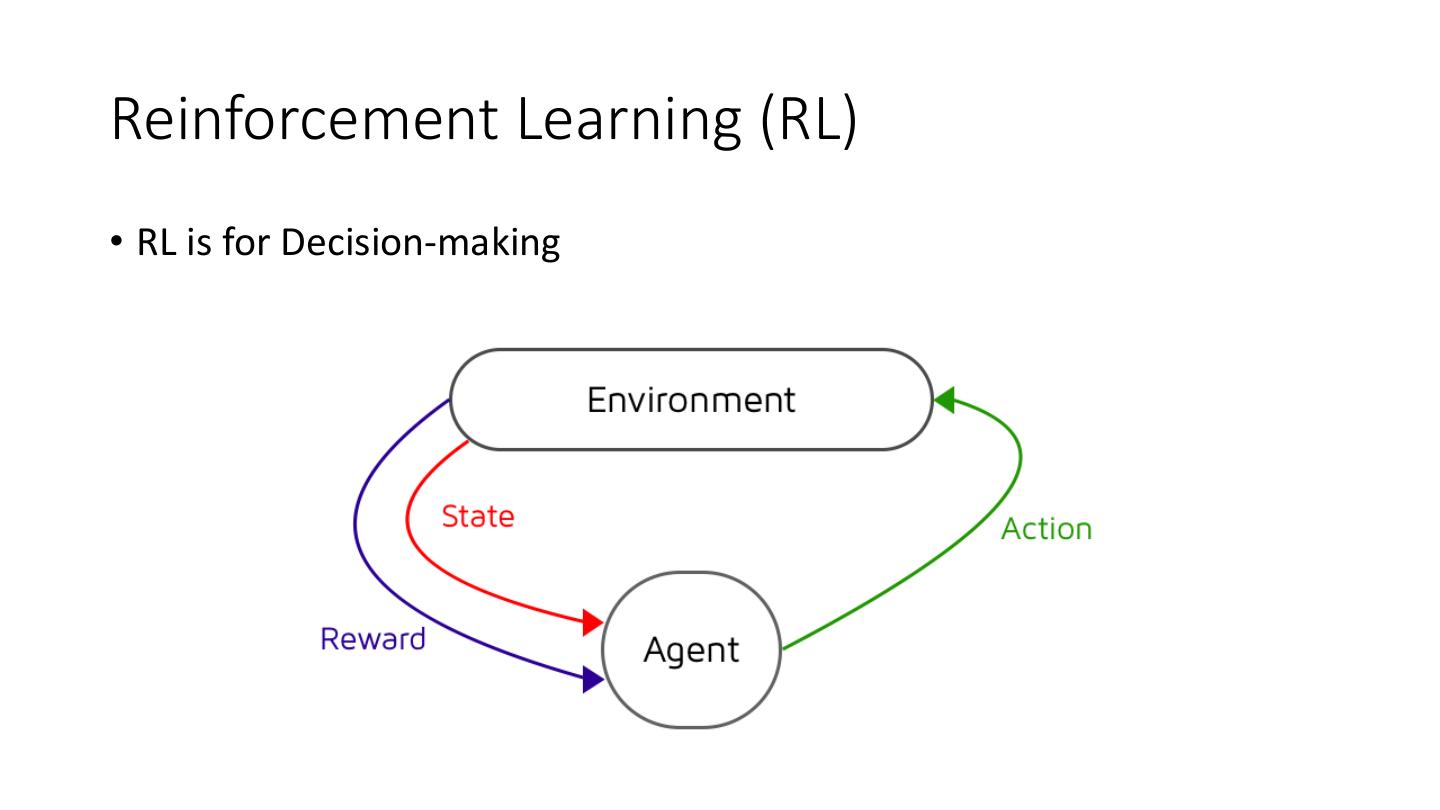
7 .Reinforcement Learning (RL)
• RL is for Decision-making
�
8 .Examples of RL applications
• Play: Atari, poker, Go, ...
• Interact with users: recommend, Healthcare, chatbot, personalize, ..
• Control: auto-driving, robotics, finance, …
�
9 .Deep Reinforcement Learning (DRL)
Agents take actions (a) in state (s) and receives rewards (R)
Goal is to find the policy (π) that maximized future rewards
http://people.csail.mit.edu/hongzi/content/publications/DeepRM-HotNets16.pdf
�
11 .Approaches to Reinforcement Learning
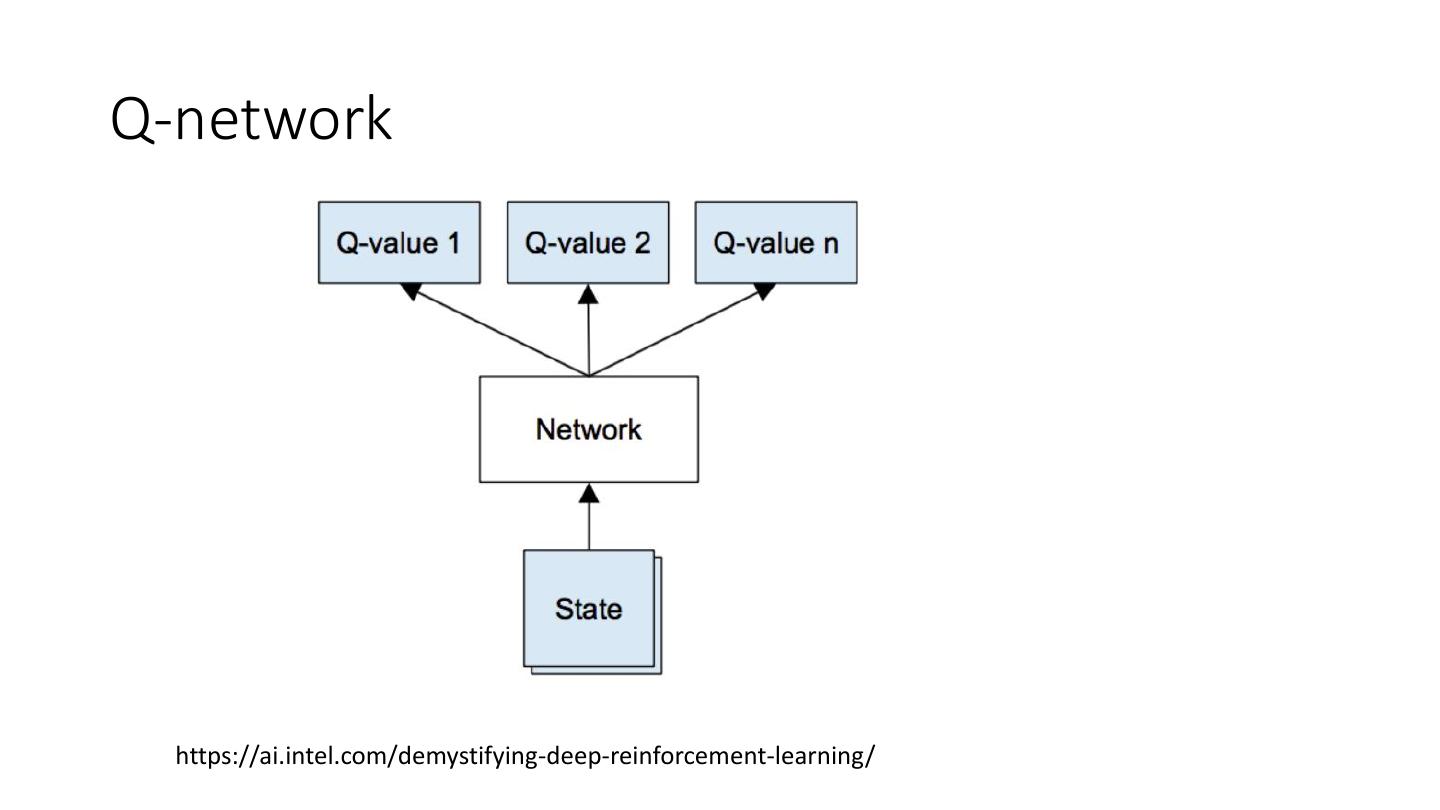
• Value-based RL
• Estimate the optimal value function Q*(S,A)
• Output of the Neural network is the value for Q(S, A)
• Policy-based RL
• Search directly for the optimal policy π*
• Output of the neural network is the probability of each action.
• Model-based RL
�
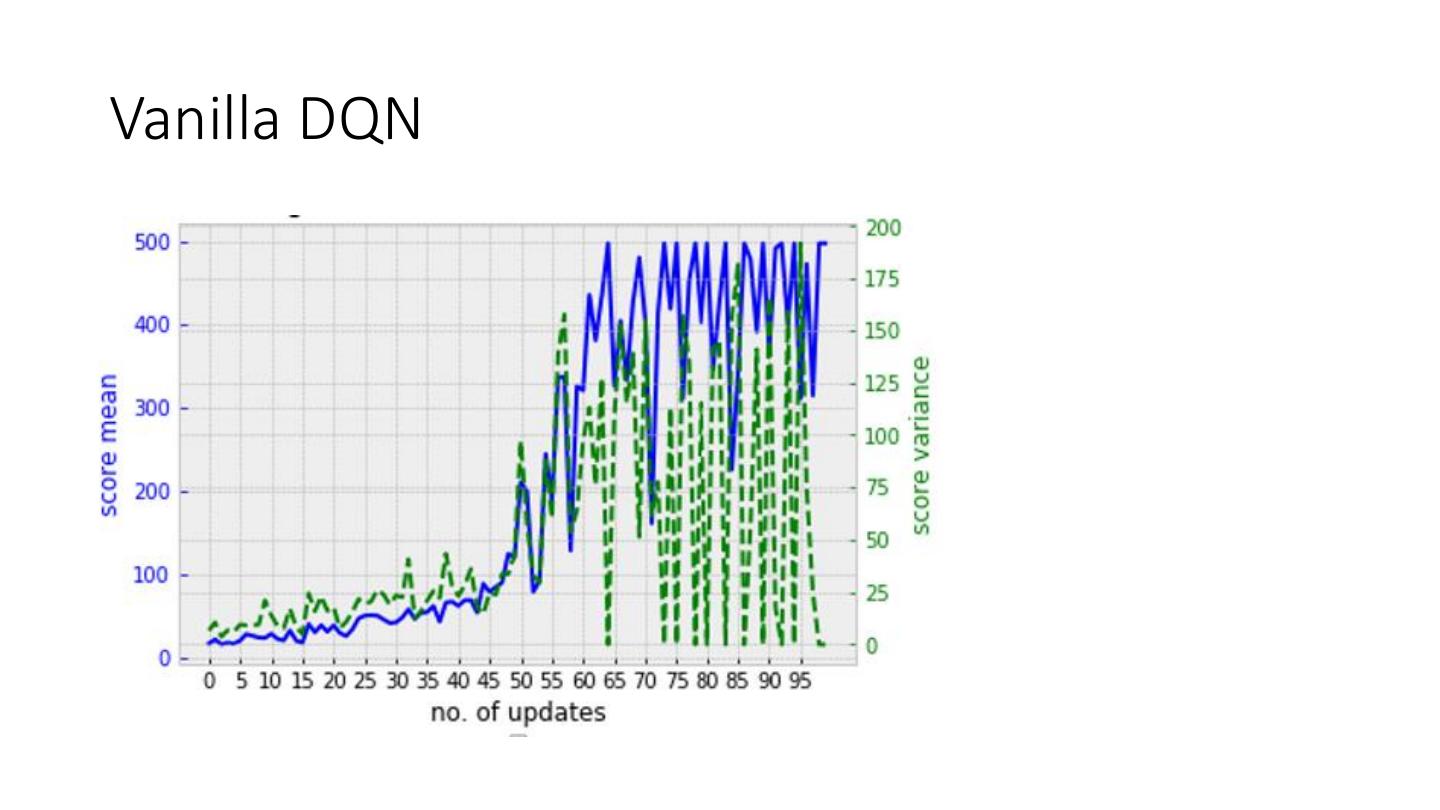
13 .Examples
• 1. Simple DQN to demo API and train with Spark RDD.
• 2. Distributed REINFORCE
�
14 .Q-network
https://ai.intel.com/demystifying-deep-reinforcement-learning/
�
15 .Bellman Equation
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Resources_files/deep_rl.pdf
�
16 .DQN critical routines
for e in range(EPISODES):
state = env.reset()
state = np.reshape(state, [1, state_size])
for time in range(500):
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
if len(agent.memory) > batch_size:
agent.replay(batch_size)
�
17 .Parallelize the neural network training
def replay(self, batch_size):
X_batch = np.array([0,0,0,0])
y_batch = np.array([0,0])
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma *
np.amax(self.model.predict_local(next_state)[0]))
target_f = self.model.predict_local(state)
target_f[0][action] = target
X_batch = np.vstack((X_batch, state))
y_batch = np.vstack((y_batch, target_f))
rdd_sample = to_RDD(X_batch,y_batch)
self.model.fit(rdd_sample, None, nb_epoch=10, batch_size=batch_size)
�
18 .Analytics Zoo Keras-style Model
�
20 .Policy gradients
• In Policy Gradients, we usually use a neural network (or other
function approximators) to directly model the action probabilities.
• we tweak the parameters θ of the neural network so that “good”
actions will be sampled more likely in the future.
�
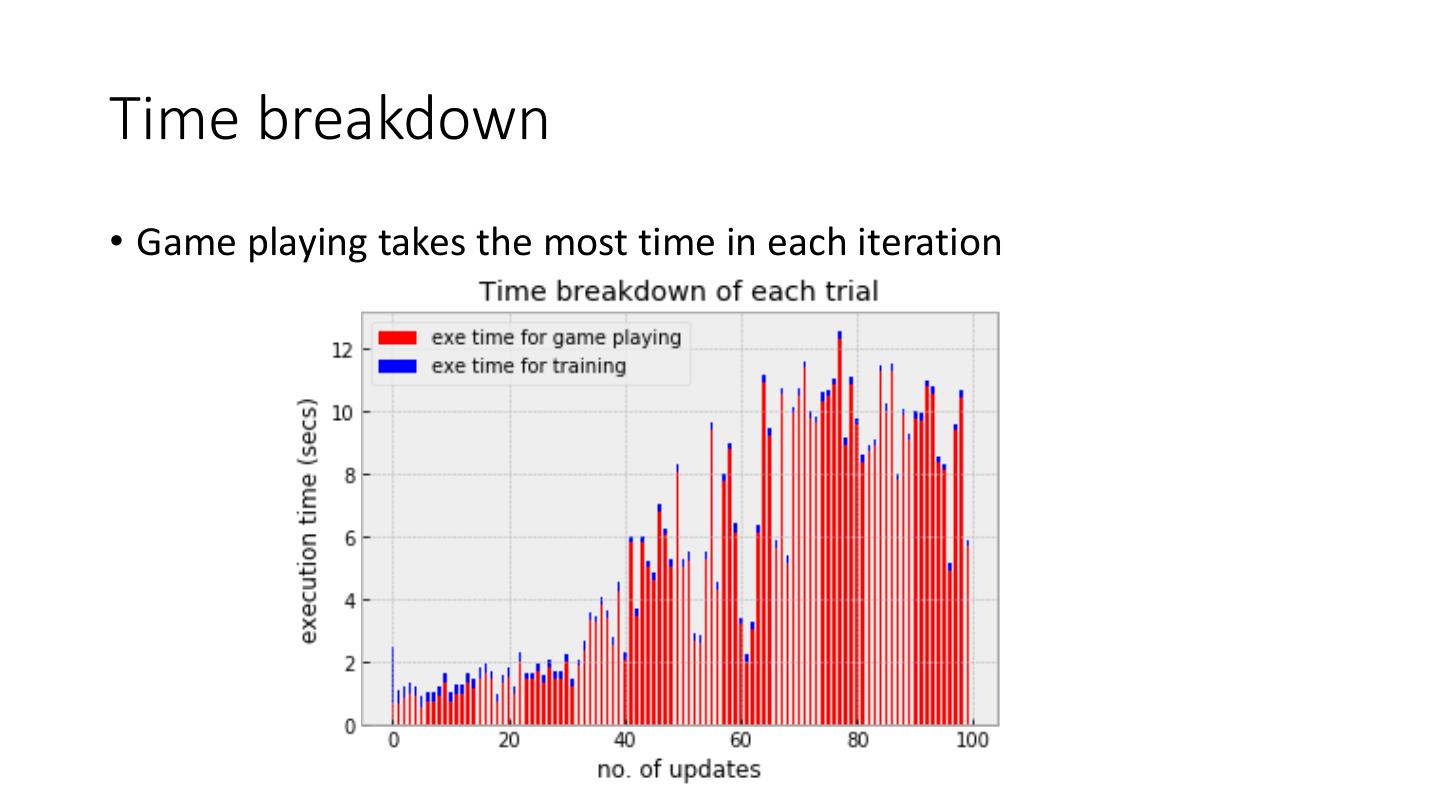
22 .Time breakdown
• Game playing takes the most time in each iteration
�
23 . Distributed REINFORCE
# create and cache several agents on each partition as specified by parallelism
# and cache it
with DistributedAgents(sc, create_agent=create_agent, parallelism=parallelism) as a:
agents = a.agents # a.agents is a RDD[Agent]
optimizer = None
num_trajs_per_part = int(math.ceil(15.0 / parallelism))
mean_std = []
for i in range(60):
with SampledTrajs(sc, agents, model, num_trajs_per_part=num_trajs_per_part) as trajs:
trajs = trajs.samples \ # samples is a RDD[Trajectory]
.map(lambda traj: (traj.data["observations"],
traj.data["actions"],
traj.data["rewards"]))
�
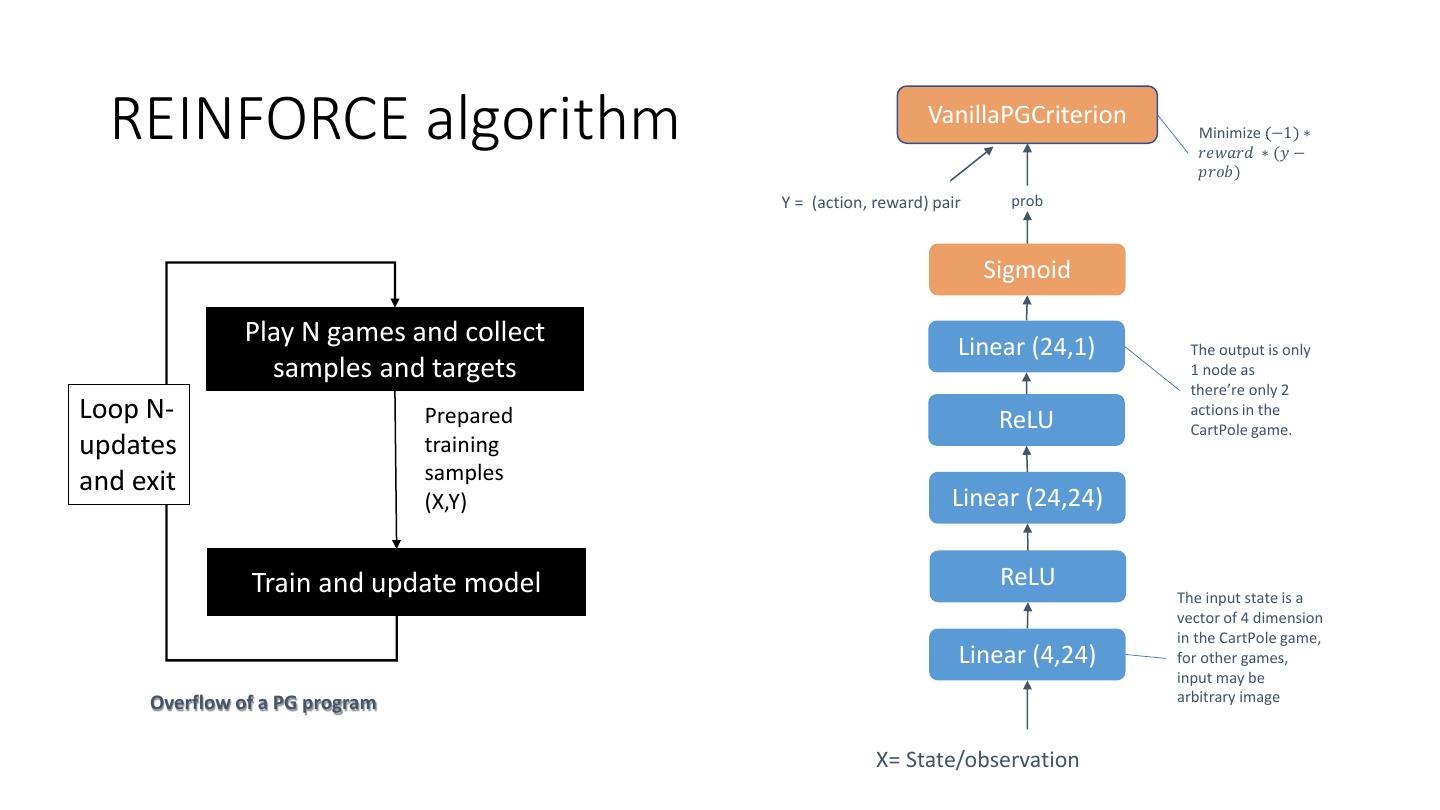
24 . REINFORCE algorithm VanillaPGCriterion
Minimize −1 ∗
𝑟𝑒𝑤𝑎𝑟𝑑 ∗ (𝑦 −
𝑝𝑟𝑜𝑏)
Y = (action, reward) pair prob
Sigmoid
Play N games and collect Linear (24,1) The output is only
samples and targets 1 node as
there’re only 2
Loop N- Prepared ReLU
actions in the
CartPole game.
updates training
and exit samples
(X,Y) Linear (24,24)
Train and update model ReLU
The input state is a
vector of 4 dimension
in the CartPole game,
Linear (4,24) for other games,
input may be
Overflow of a PG program arbitrary image
X= State/observation
�
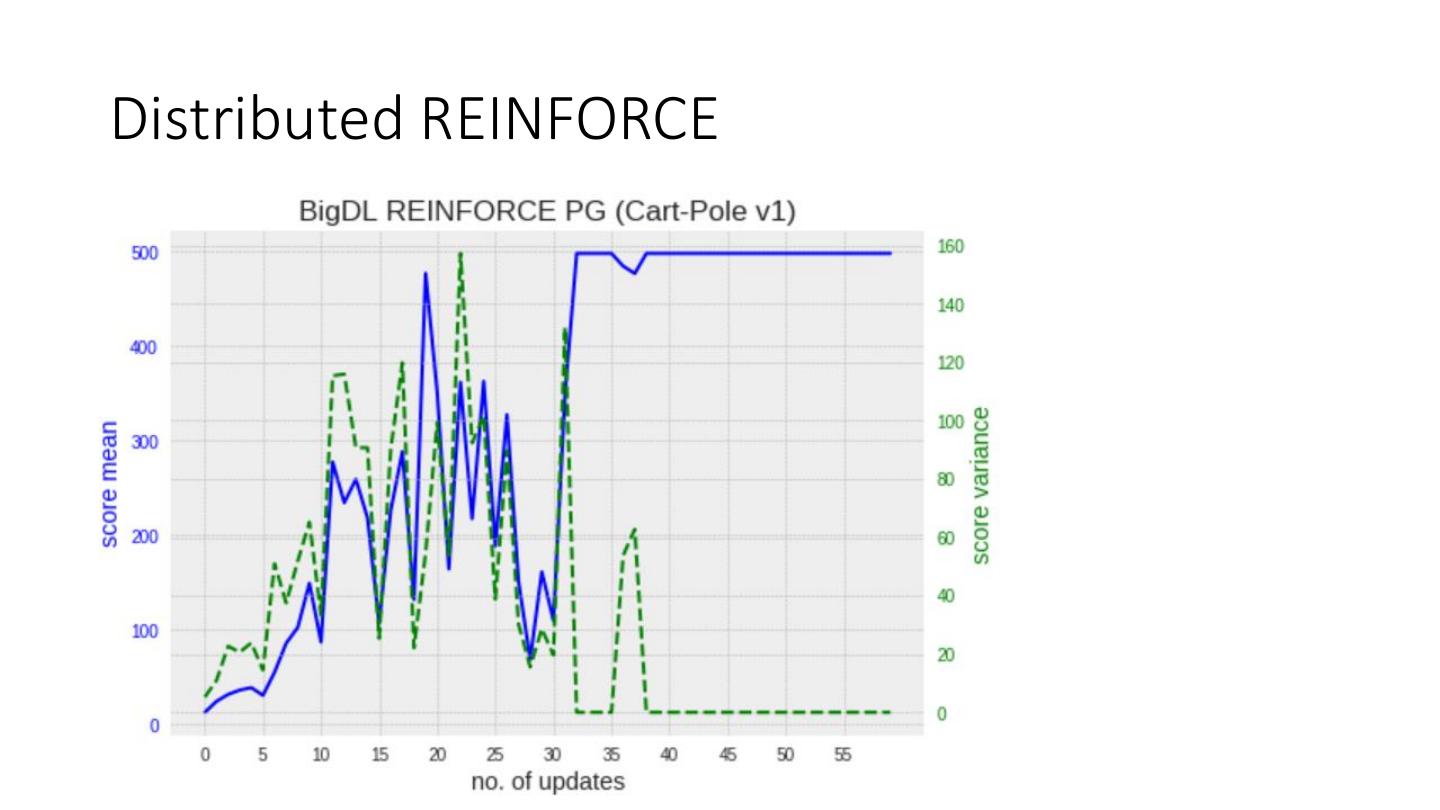
25 .Distributed REINFORCE
�
26 .Other RL algorithms
• Flappy bird with DQN
• Discrete and continuous PPO
• A2C (in roadmap)
�
27 .Q&A
Analytics Zoo High level API, Industry pipelines, App demo & Util
https://github.com/intel-analytics/analytics-zoo
Thanks Shane Huang and Yang Wang for working on RL implementations.
�