



















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
避免Apache Spark 和 Cassandra AntiPatterns中的错误
向那些几乎每一个基本的Apache Spark都错误的人学习,这样你就不必这么做了!我们将介绍一些用户最常做的事,这些事最终会导致不必要的痛苦,并解释如何避免它们。
展开查看详情
1 . Spark and Cassandra Anti-Patterns Russell Spitzer © DataStax, All Rights Reserved.
2 .Russell (left) and Cara (right) • Software Engineer • Spark-Cassandra Integration since Spark 0.9 • Cassandra since Cassandra 1.2 • 3 Year Scala Convert • Still not comfortable talking about Monads in public
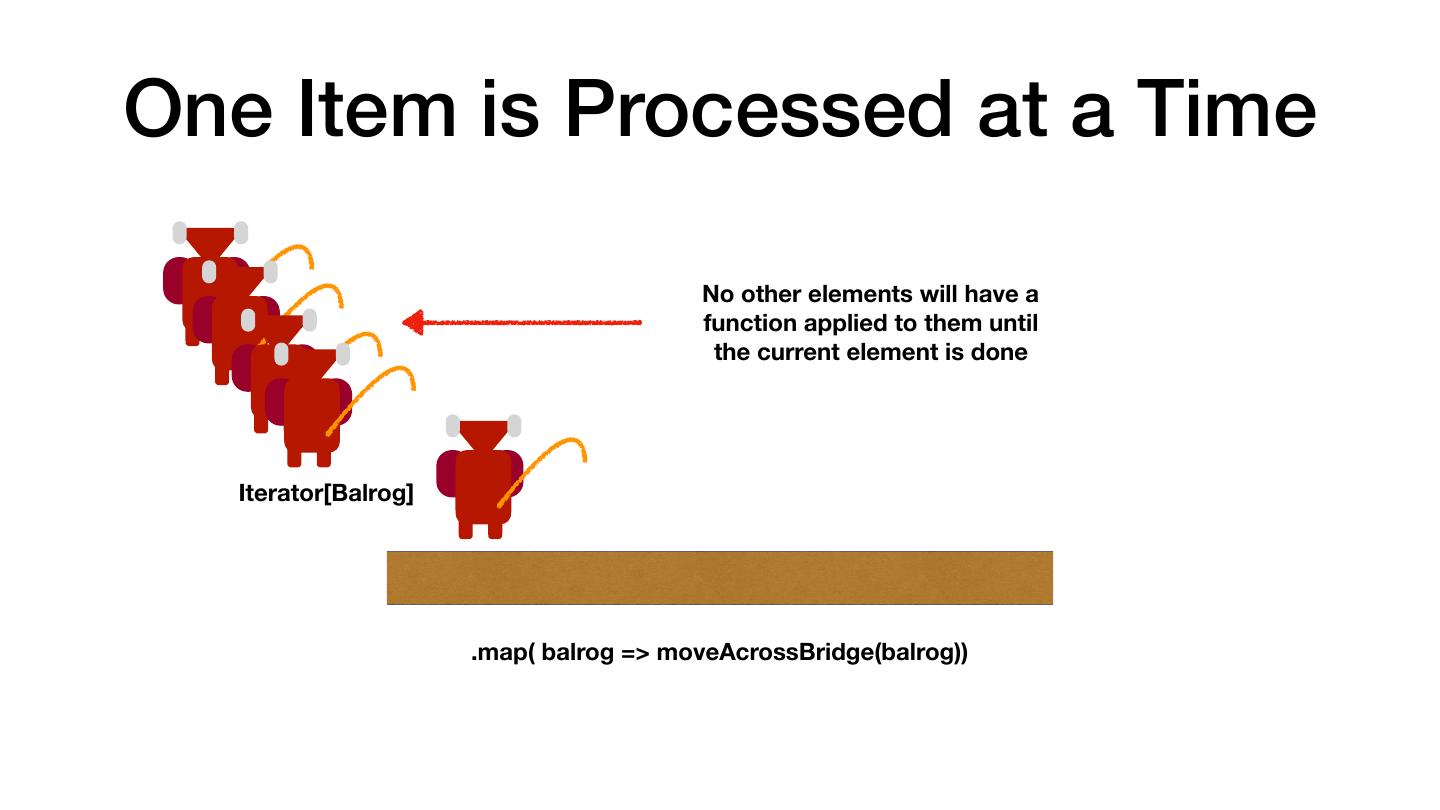
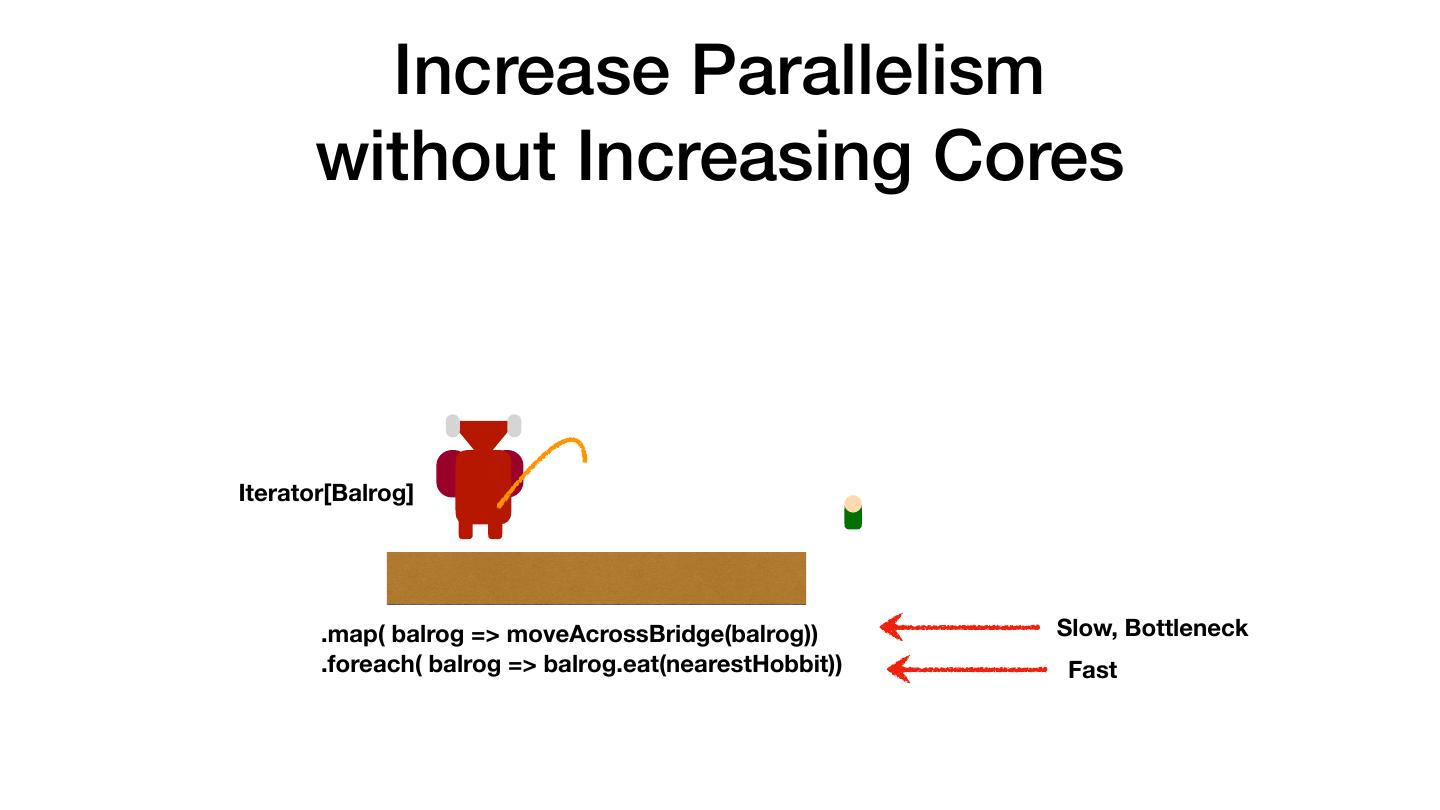
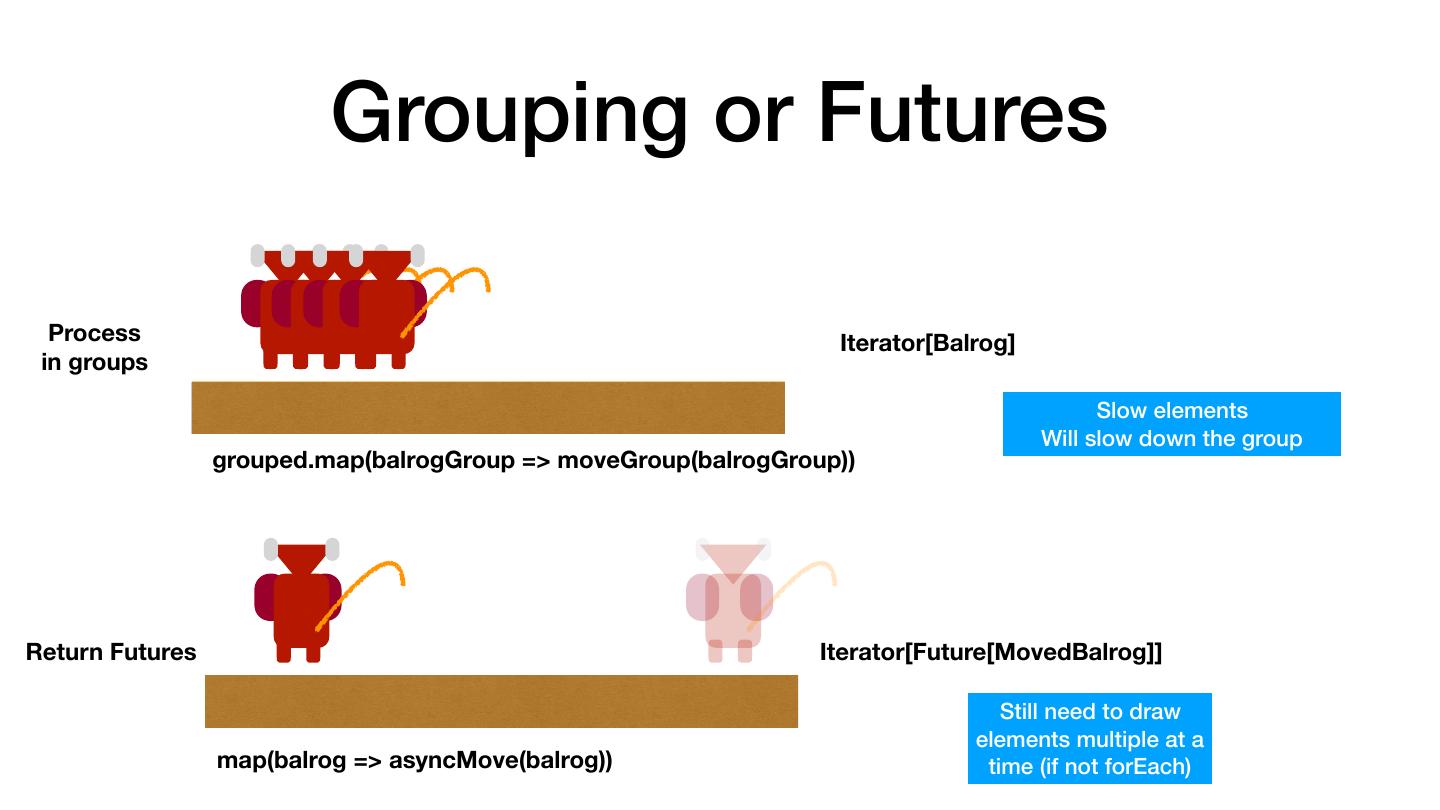
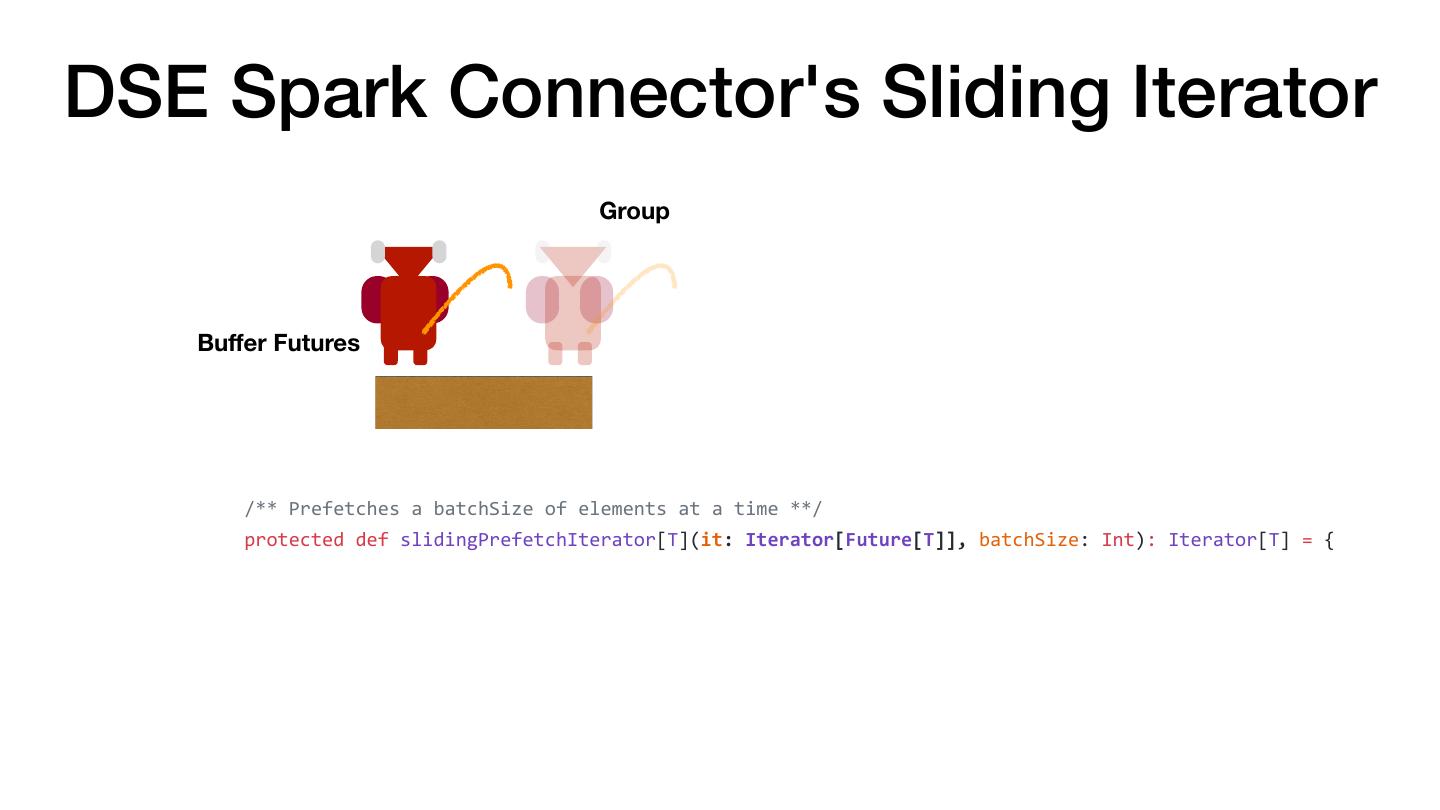
3 .Avoiding the Sharp Edges • Out of Memory Errors • RPC Failures • "It is Slow" • Serialization • Understanding what Catalyst does After working with customers for several years, most problems boil down to a few common scenarios.
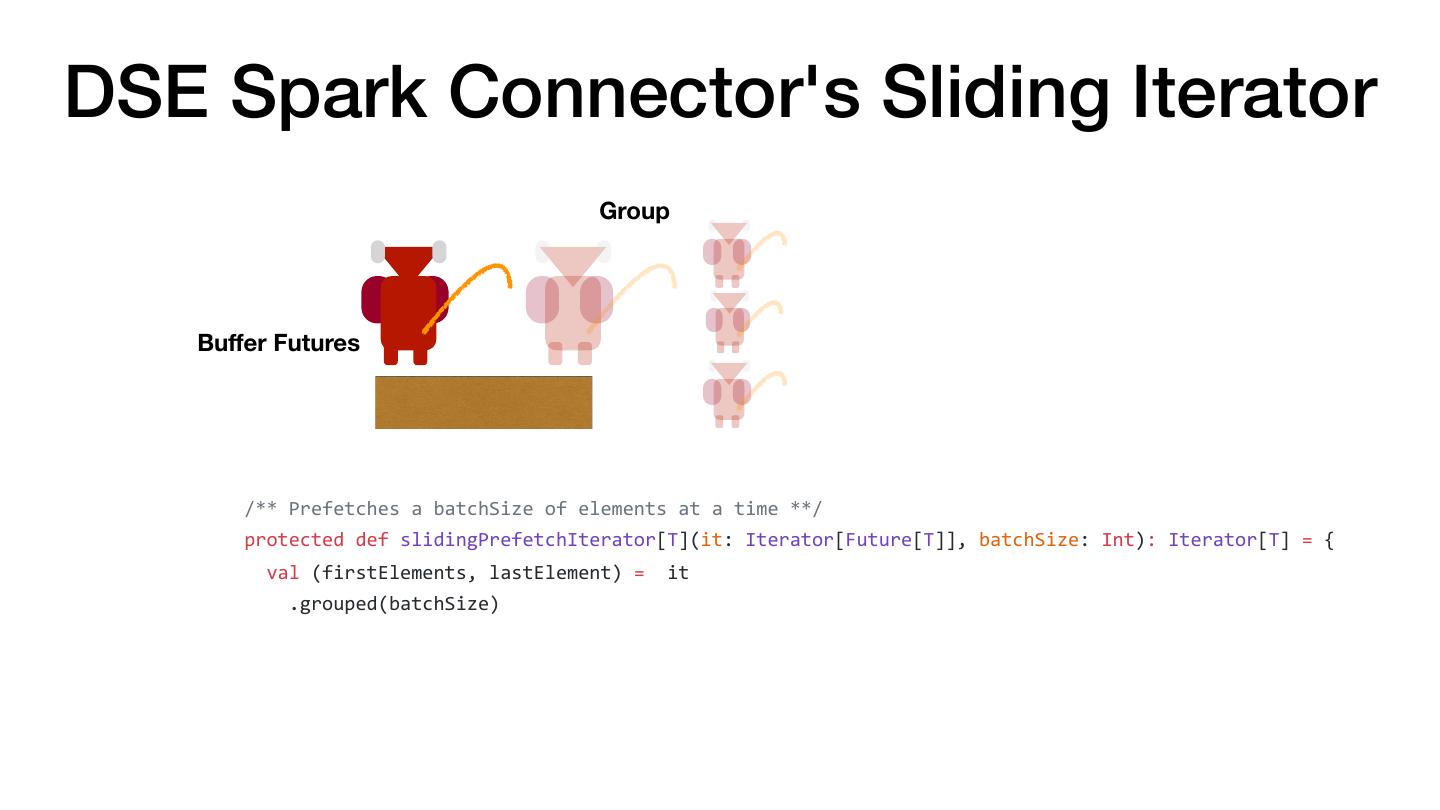
4 .Most Common Performance Pitfall val there = rdd.map(doStuff).collect() val backAgain = someWork.map(otherStuff) val thereAgain = sc.parallelize(backAgain) OOM Slow RPC Failures The Hobbit (1977)
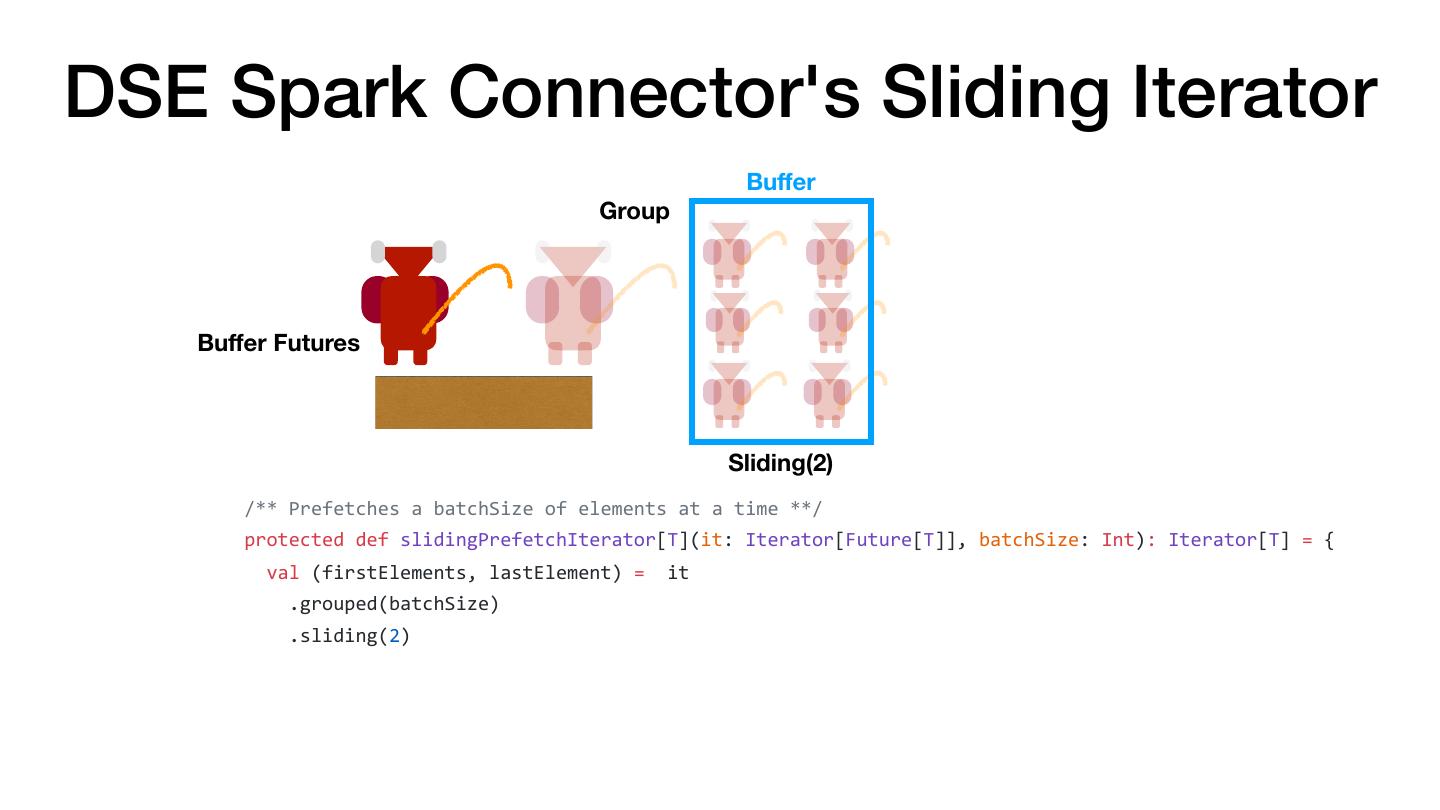
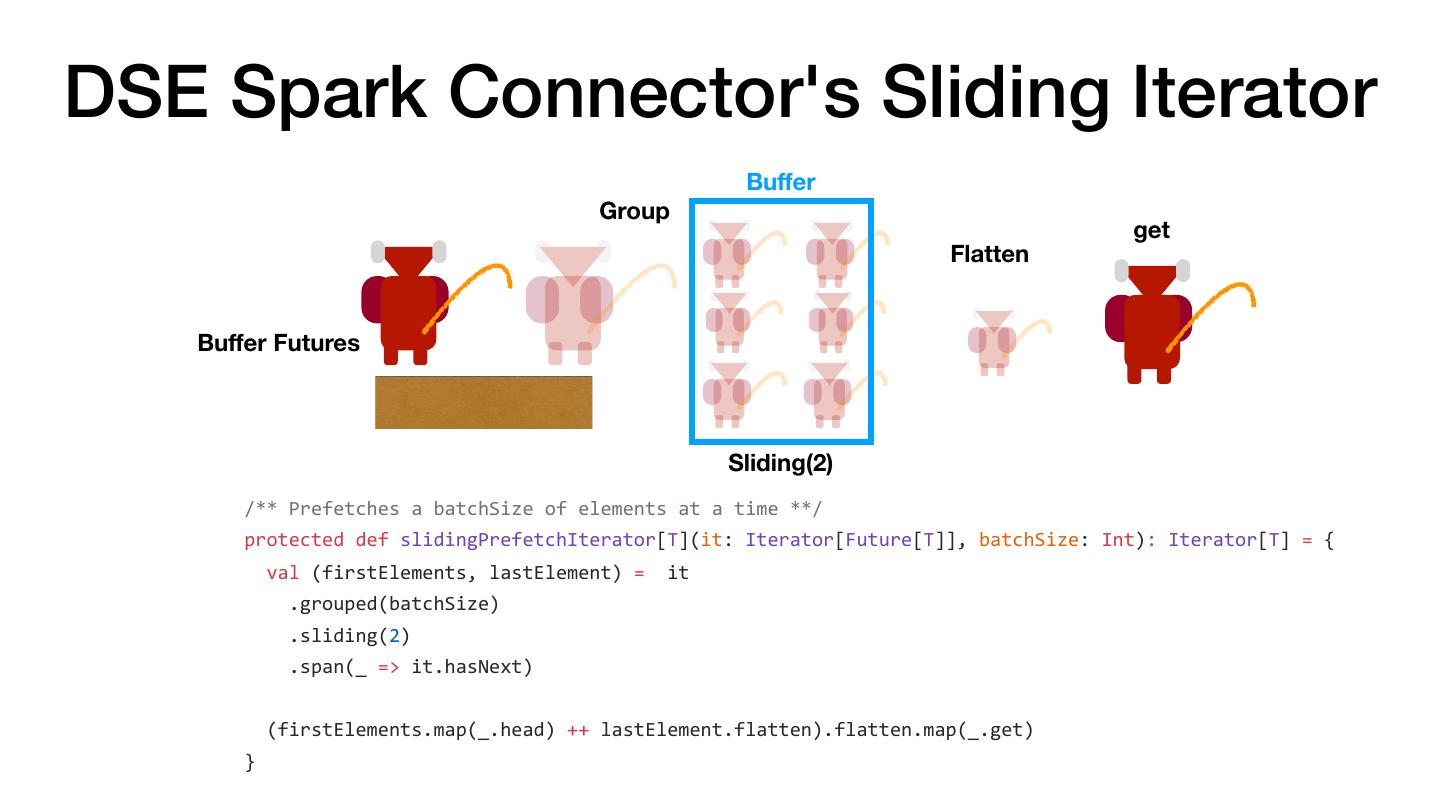
5 . There and Back Again: Don't Collect and Parallelize Don't Do val there = rdd.map(doStuff).collect() val backAgain = someWork.map(otherStuff) val thereAgain = sc.parallelize(backAgain) Instead val there = rdd .map(doStuff) .map(otherStuff) The Hobbit (1977)
6 . There and Back Again: Don't Collect and Parallelize Don't Do val there = rdd.map(doStuff).collect() val backAgain = someWork.map(otherStuff) val thereAgain = sc.parallelize(backAgain) Instead val there = rdd .map(doStuff) .map(otherStuff) The Hobbit (1977)
7 . Why Not? 1. You are using Spark for a Reason Your Cluster Driver JVM Parallelize Collect Lord of the Rings, 2001-2003
8 . Why Not? 1. You are using Spark for a Reason Your Cluster Driver JVM Parallelize Collect Dependable Easy to work with Easy to understand Not very big Only 1 Lord of the Rings, 2001-2003
9 . Why Not? 1. You are using Spark for a Reason Your Cluster Driver JVM Parallelize Collect Dependable Easy to work with Easy to understand Not very big Only 1 The Entire Reason Behind Using Spark Lord of the Rings, 2001-2003
10 . Why Not? 1. You are using Spark for a Reason Your Cluster Driver JVM Parallelize OOM Collect Dependable Easy to work with Easy to understand Not very big Only 1 The Entire Reason Behind Using Spark Lord of the Rings, 2001-2003
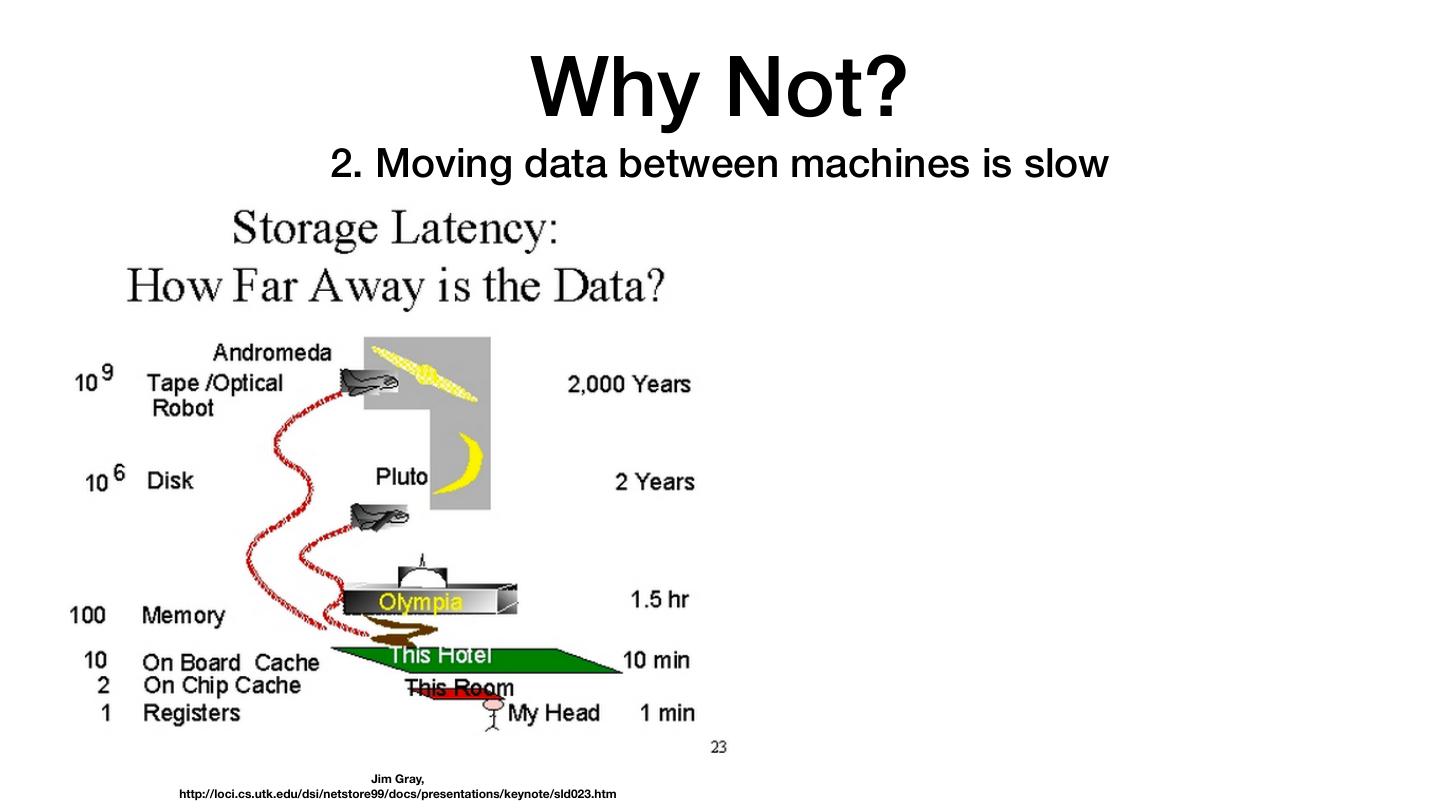
11 . Why Not? 2. Moving data between machines is slow Jim Gray, http://loci.cs.utk.edu/dsi/netstore99/docs/presentations/keynote/sld023.htm
12 . Why Not? 2. Moving data between machines is slow Jim Gray, http://loci.cs.utk.edu/dsi/netstore99/docs/presentations/keynote/sld023.htm
13 . Why Not? 2. Moving data between machines is slow The Lord of the Rings, 1978 Jim Gray, http://loci.cs.utk.edu/dsi/netstore99/docs/presentations/keynote/sld023.htm
14 . Why Not? 3. Parallelize sends data in task metadata parallelize()
15 . Why Not? 3. Parallelize sends data in task metadata List[Dwarves] -> RDD[Dwarves] ? ENIAC Programmers, 1946, University of Pennsylvania
16 . Why Not? 3. Parallelize sends data in task metadata List[Dwarves] -> RDD[Dwarves] Minimum of one Dwarf per Partition RPC Warns on Task Metadata over 100kb
17 . Why Not? 3. Parallelize sends data in task metadata scala> val treasure = 1 to 100 map (_ => "x" * 1024) scala> sc.parallelize(Seq(treasure)).count WARN 2018-05-21 14:13:08,035 org.apache.spark.scheduler.TaskSetManager: Stage 0 contains a task of very large size (105 KB). The maximum recommended task size is 100 KB. res0: Long = 1 Storing indefinitely growing state in a single object will continue growing in size until you run into heap problems. J.R.R. Tolkien, “Conversation with Smaug” (The Hobbit, 1937)
18 . Keep the work Distributed Don't Do val there = rdd.map(doStuff).collect() val backAgain = someWork.map(otherStuff) val thereAgain = sc.parallelize(backAgain) 1.We won't be doing distributed work 2.We end up sending things over the wire 3.Parallelize doesn't handle large objects well 4.We don't need to! Everyday val there = rdd .map(doStuff) .map(otherStuff) The Hobbit (1977)
19 . Start Distributed if Possible Other alternatives to Parallelize Start Data out Distributed (Cassandra, HDFS, S3, …) The Hobbit (1977)
20 .Predicate Pushdowns Failing! SELECT * FROM escapes WHERE time = 11-27-1977 No Slow Pushdown
21 . What have I got in my pocket? Make your literals' types explicit! SELECT * FROM escapes WHERE time = 11-27-1977 Catalyst No precious predicate pushdowns
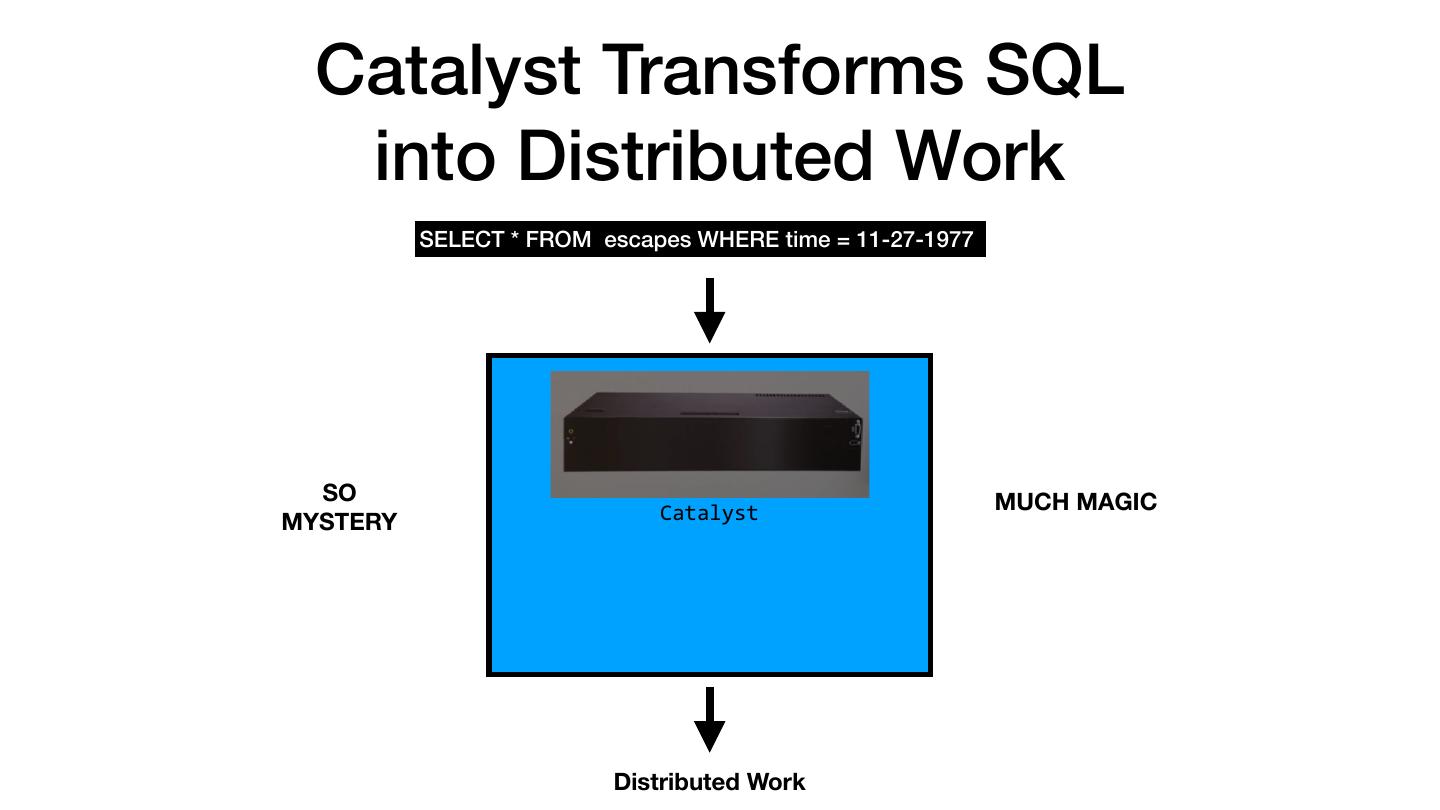
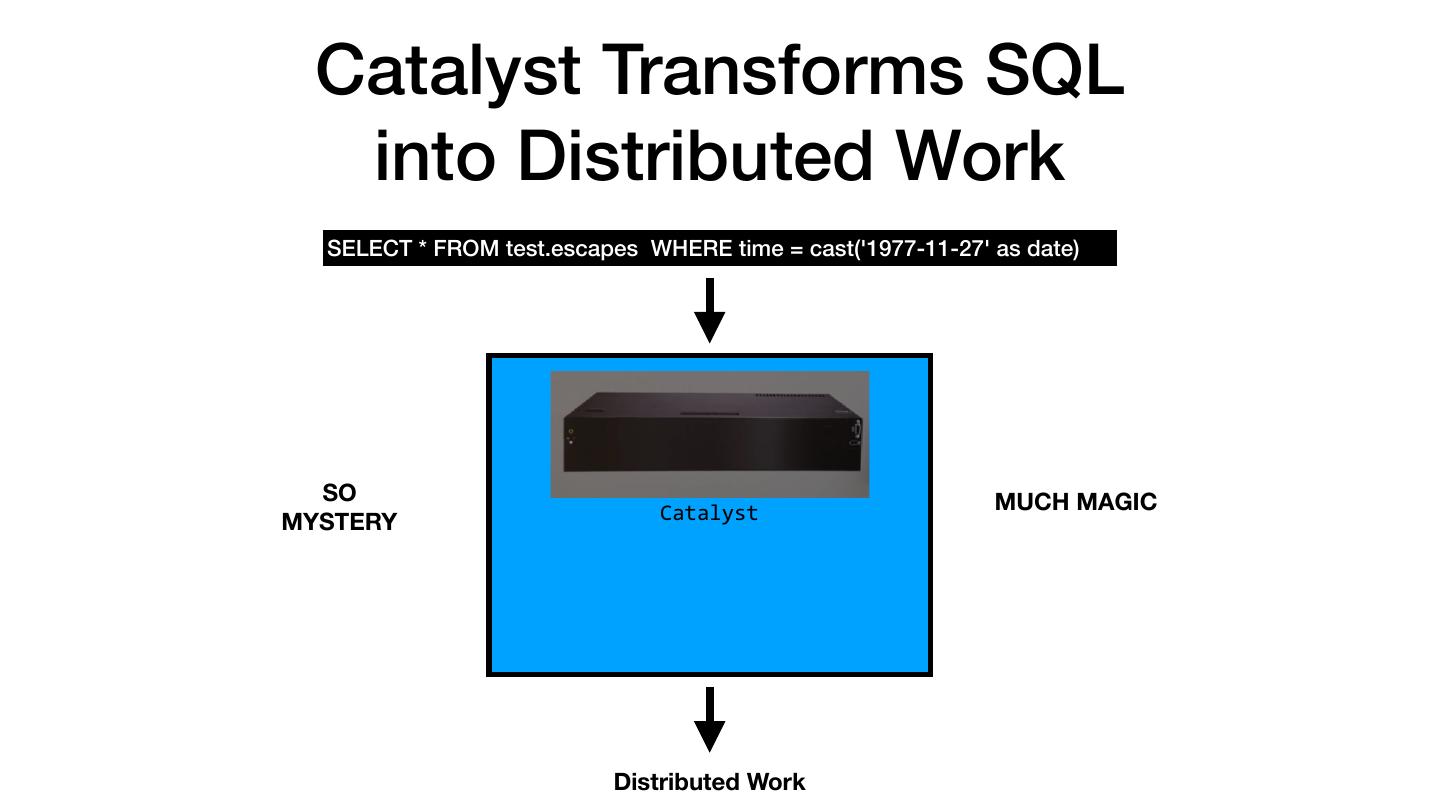
22 . Catalyst Transforms SQL into Distributed Work SELECT * FROM escapes WHERE time = 11-27-1977 ? ? ? SO MUCH MAGIC MYSTERY Catalyst Distributed Work
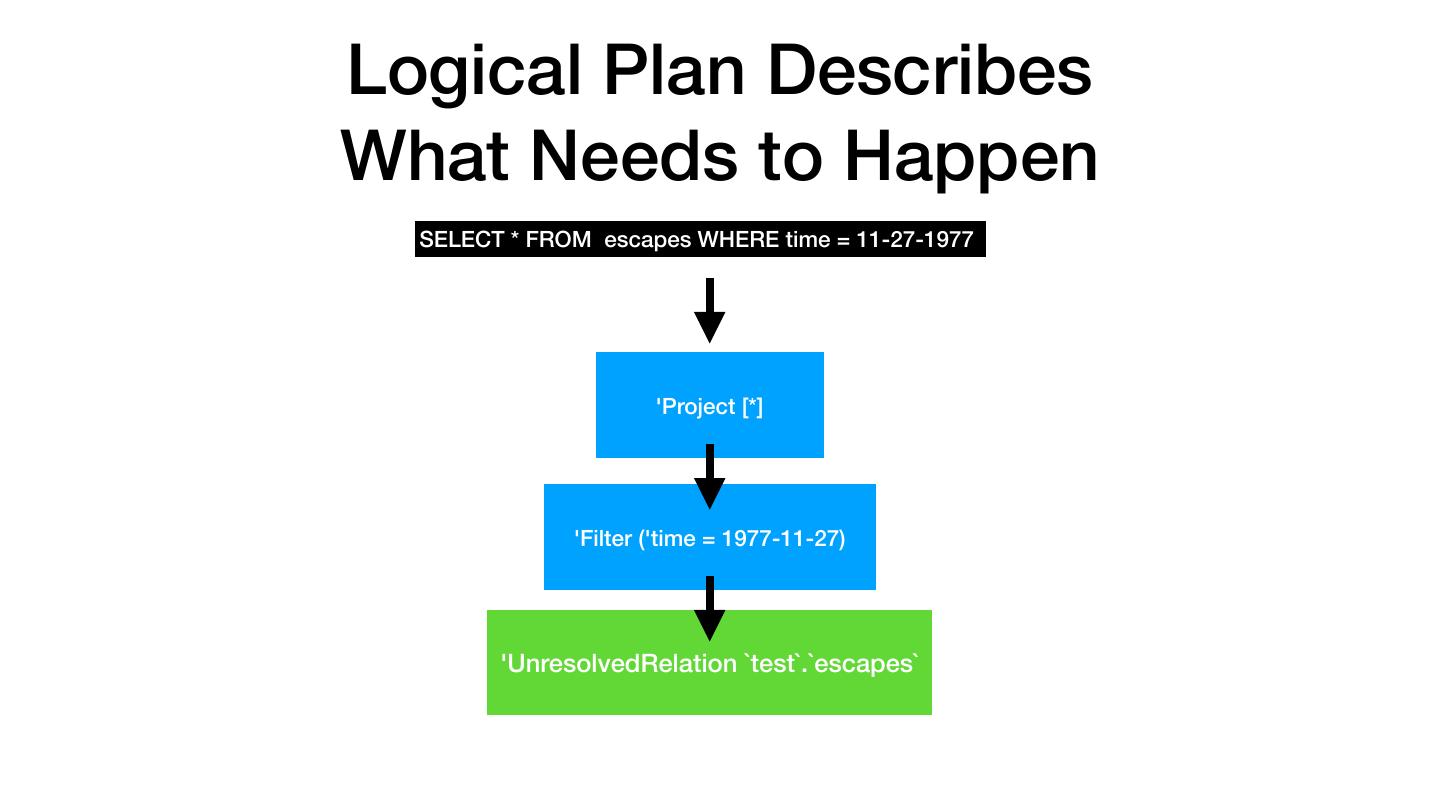
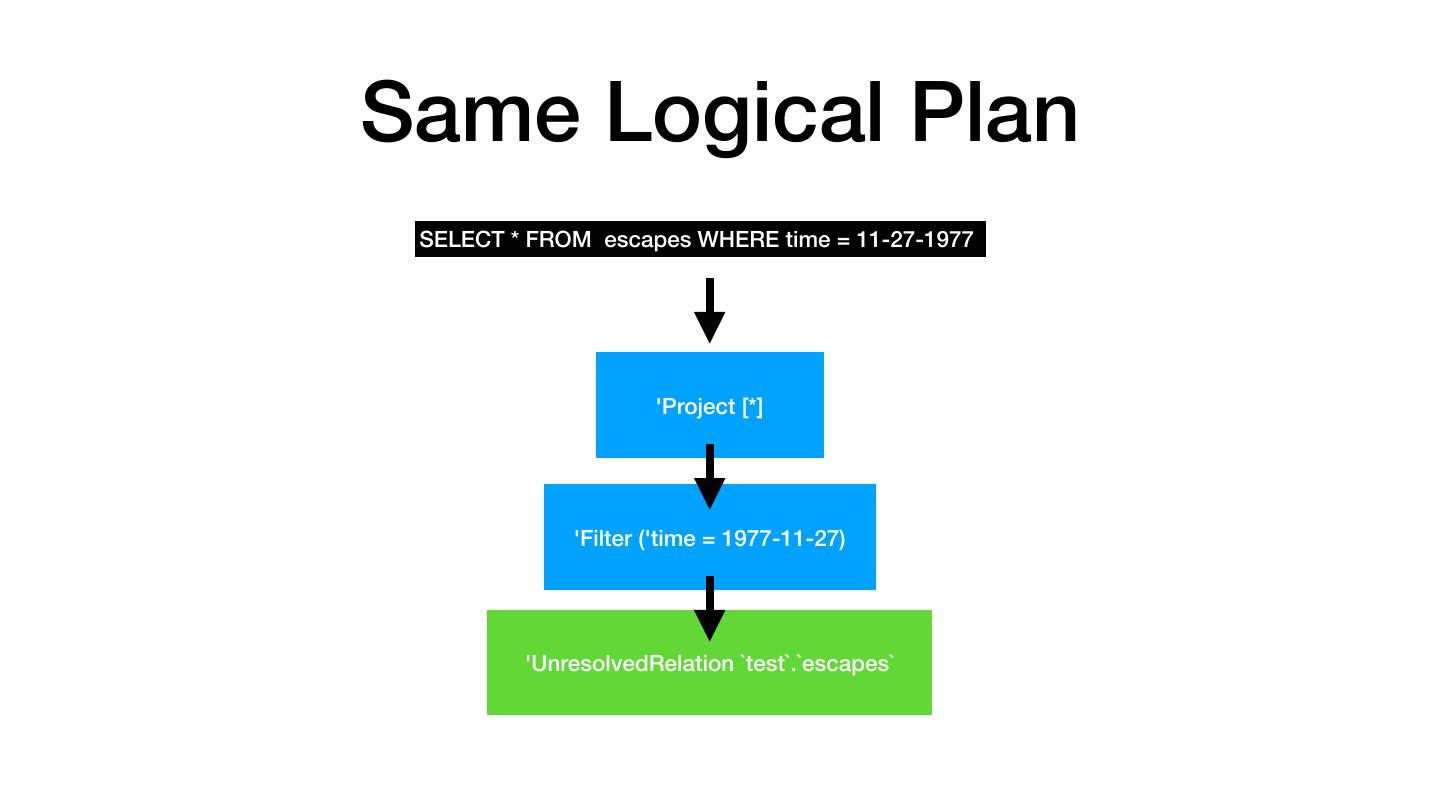
23 .Logical Plan Describes What Needs to Happen SELECT * FROM escapes WHERE time = 11-27-1977 'Project [*] 'Filter ('time = 1977-11-27) 'UnresolvedRelation `test`.`escapes`
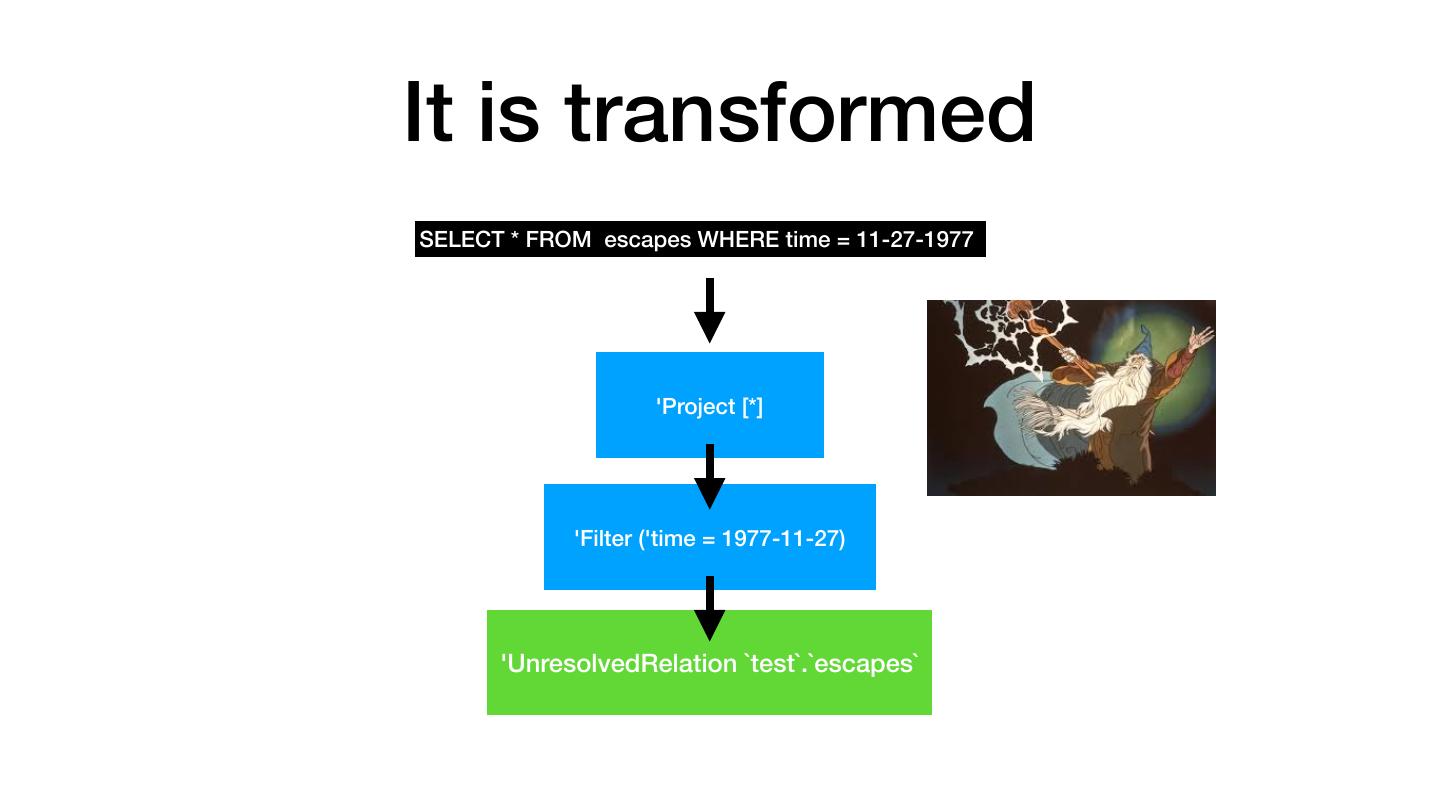
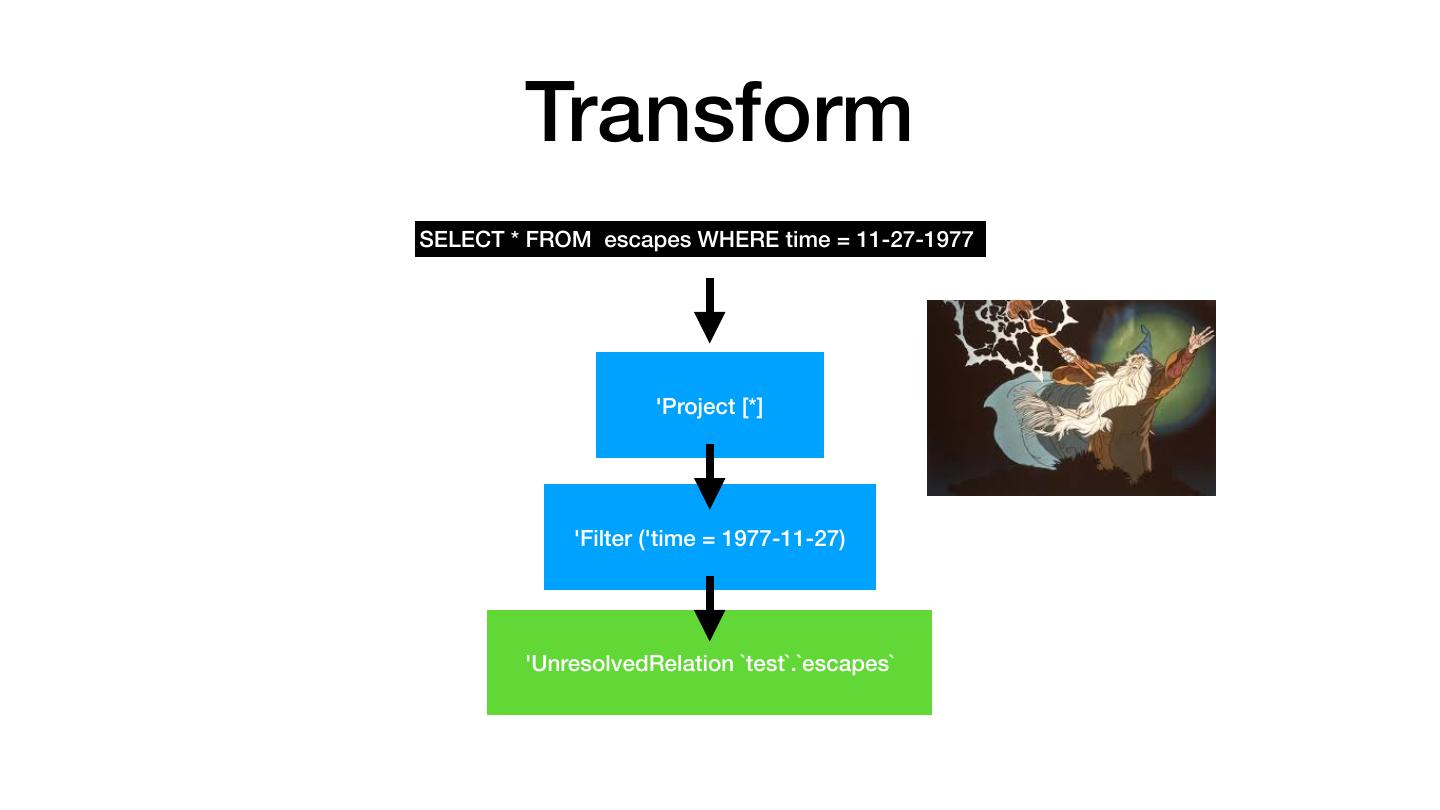
24 .It is transformed SELECT * FROM escapes WHERE time = 11-27-1977 'Project [*] 'Filter ('time = 1977-11-27) 'UnresolvedRelation `test`.`escapes`
25 .Into a Physical Plan which defines How it will be accomplished SELECT * FROM escapes WHERE time = 11-27-1977 *Filter (cast(time#5 as string) = 1977-11-27) *Scan CassandraSourceRelation test.escapes[time#5,method#6] ReadSchema: struct<time:date,method:string>
26 .Into a Physical Plan which defines How it will be accomplished SELECT * FROM escapes WHERE time = 11-27-1977 *Filter (cast(time#5 as string) = 1977-11-27) *Scan CassandraSourceRelation test.escapes[time#5,method#6] ReadSchema: What happened to struct<time:date,method:string> predicate pushdown?
27 .Catalyst Needs to make Types Match '1977-11-27' Compare this to time#5
28 . Catalyst Needs to make Types Match '1977-11-27' time#5 This is a string? This is a date?
29 . Catalyst Needs to make Types Match '1977-11-27' time#5 This is a string? This is a date? MAKE THEM BOTH STRINGS Cast(time#5 as String)
3秒后跳转登录页面
去登陆

