


















































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark作为图书馆开发人员
作为一名开发人员、数据工程师或数据科学家,您已经看到了Apache Spark的表达能力如何足以让您优雅高效地解决问题,从而能够扩展处理更多数据。但是,如果您一次又一次地解决相同的问题,那么您可能希望捕获和分发您的解决方案,以便您能够关注新问题,并且其他人能够重用和重新混合它们:您希望开发扩展Spark的库。
展开查看详情
1 .Apache Spark for library developers William Benton Erik Erlandson willb@redhat.com eje@redhat.com @willb @manyangled
2 .The Silex and Isarn libraries Reusable open-source code that works with Spark, factored from internal apps. We’ve tracked Spark releases since Spark 1.3.0. See https://silex.radanalytics.io and http://isarnproject.org
3 .
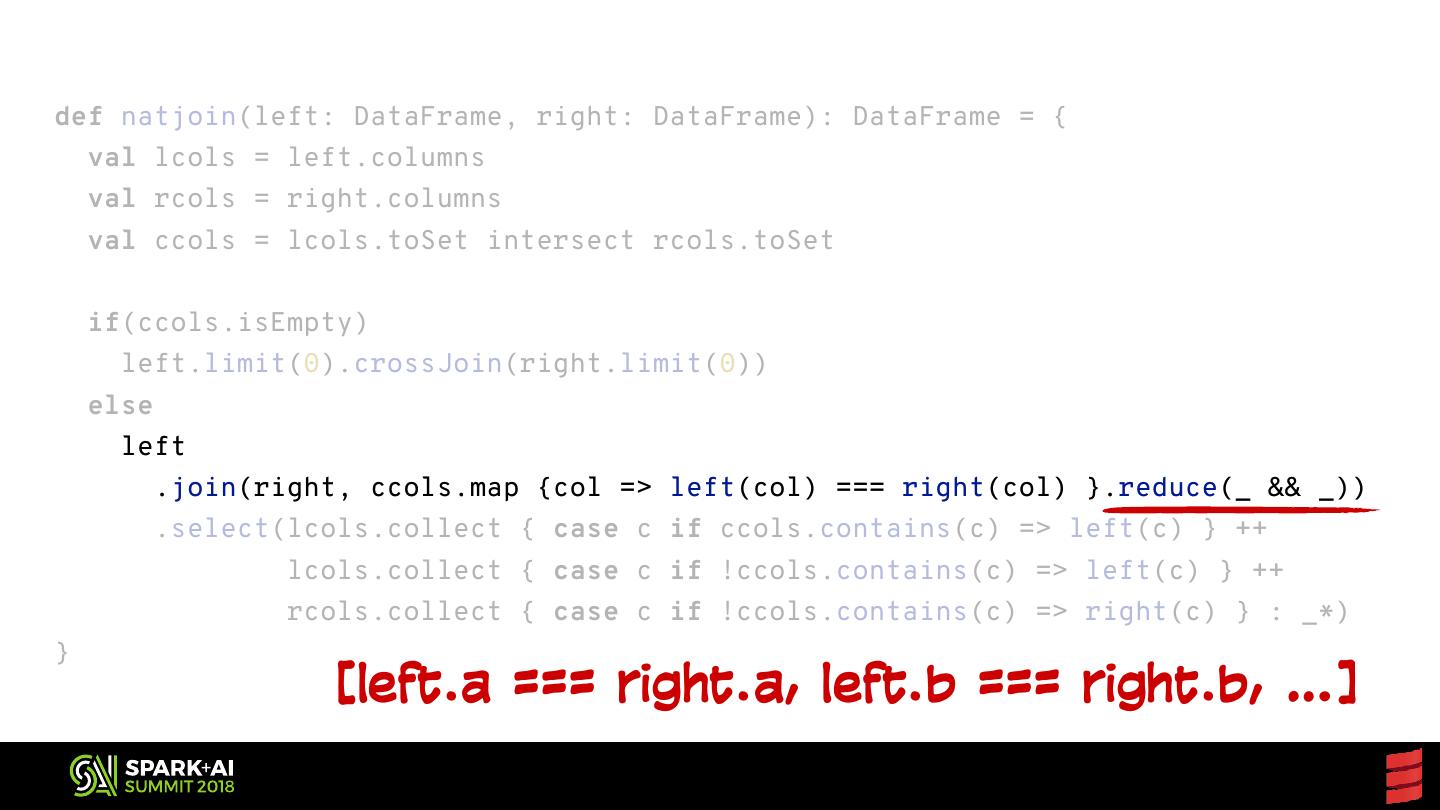
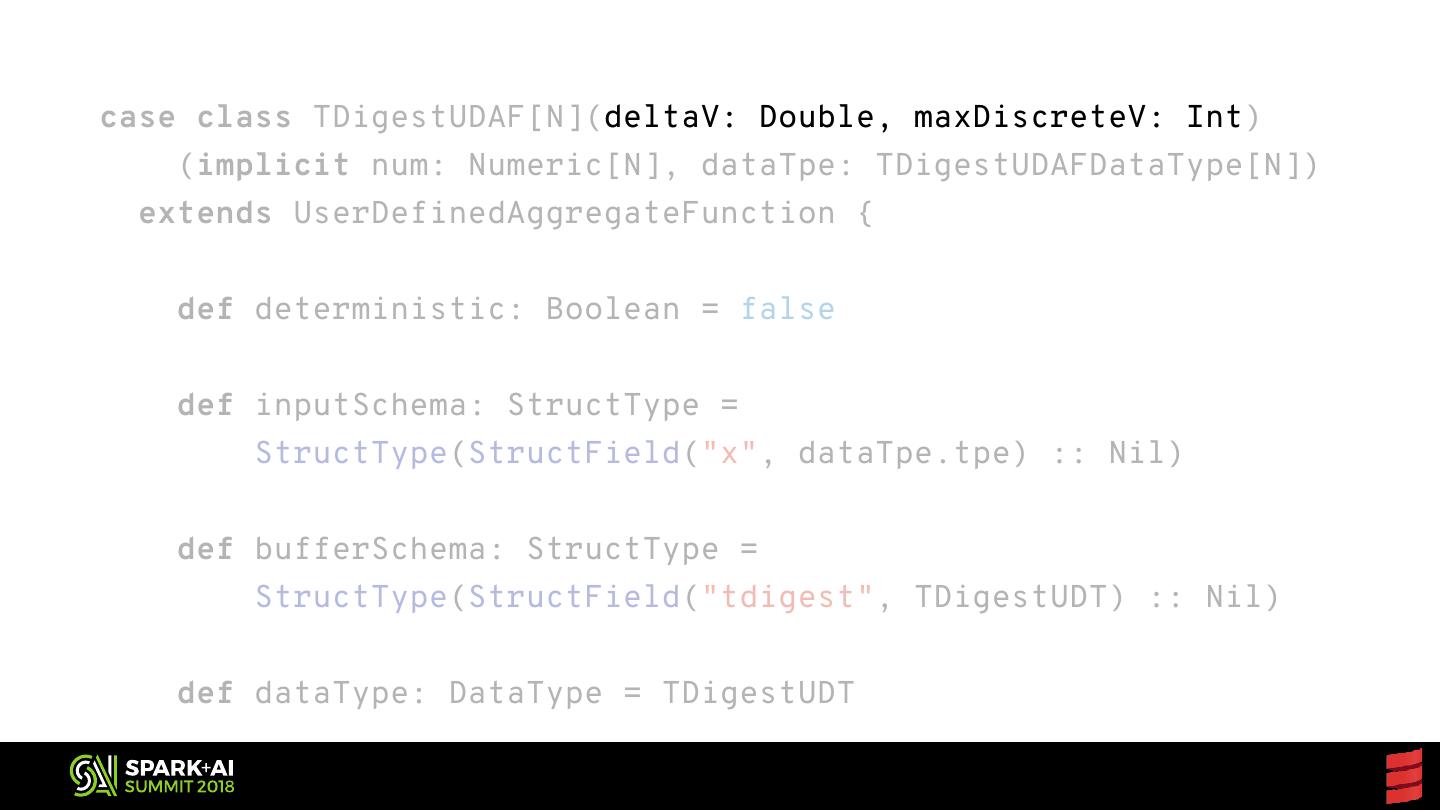
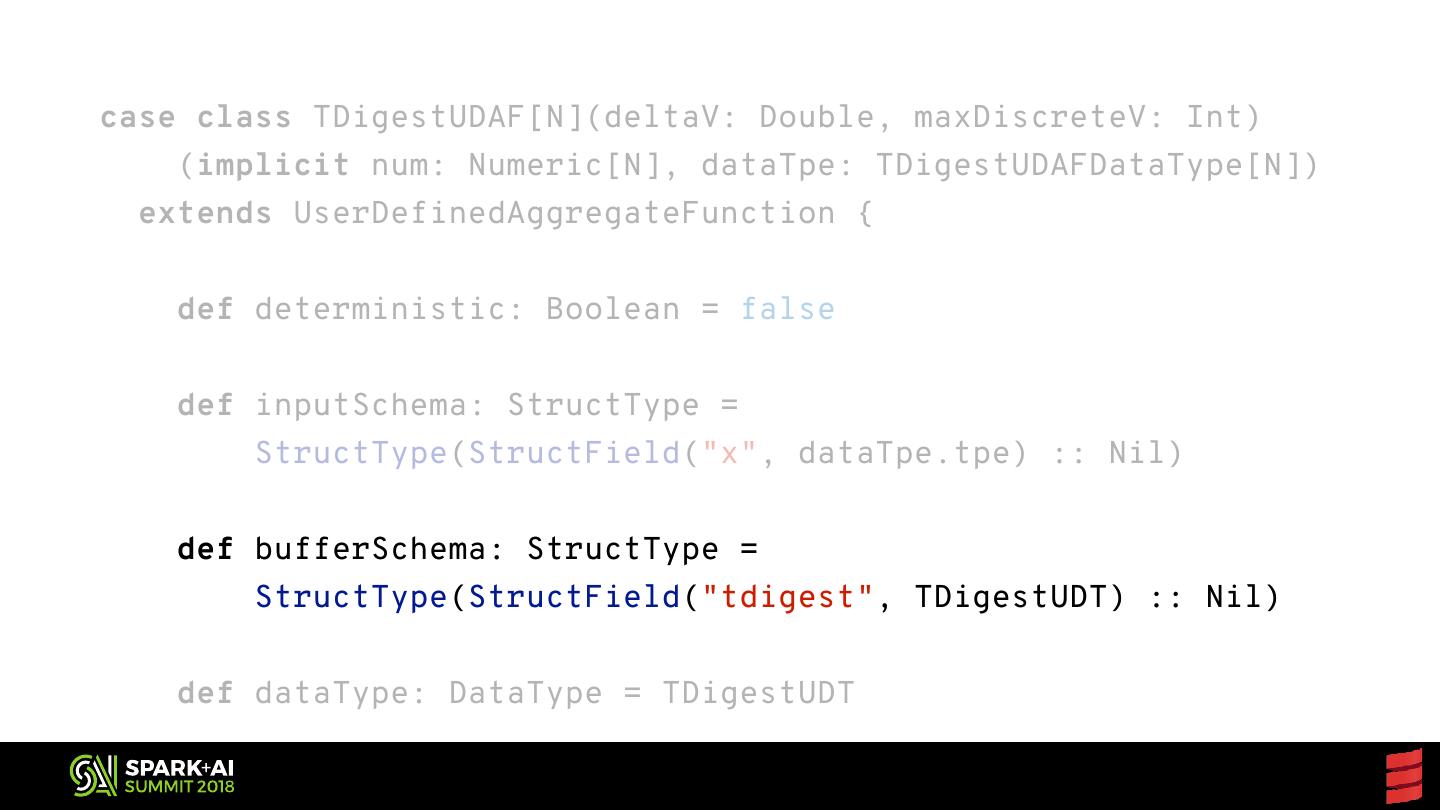
4 .Forecast Basic considerations for reusable Spark code Generic functions for parallel collections Extending data frames with custom aggregates Exposing JVM libraries to Python Sharing your work with the world
5 .Basic considerations
6 .
7 .
8 .
9 .
10 .
11 .
12 .
13 .
14 .
15 .Today’s main themes
16 .Cross-building for Scala in your SBT build definition: scalaVersion := "2.11.11" crossScalaVersions := Seq("2.10.6", "2.11.11") in your shell: $ sbt +compile $ sbt "++ 2.11.11" compile
17 .Cross-building for Scala in your SBT build definition: scalaVersion := "2.11.11" crossScalaVersions := Seq("2.10.6", "2.11.11") in your shell: $ sbt +compile # or test, package, publish, etc. $ sbt "++ 2.11.11" compile
18 .Cross-building for Scala in your SBT build definition: scalaVersion := "2.11.11" crossScalaVersions := Seq("2.10.6", "2.11.11") in your shell: $ sbt +compile # or test, package, publish, etc. $ sbt "++ 2.11.11" compile
19 .“Bring-your-own Spark” in your SBT build definition: libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "2.3.0" % Provided, "org.apache.spark" %% "spark-sql" % "2.3.0" % Provided, "org.apache.spark" %% "spark-mllib" % "2.3.0" % Provided, "joda-time" % "joda-time" % "2.7", "org.scalatest" %% "scalatest" % "2.2.4" % Test)
20 .“Bring-your-own Spark” in your SBT build definition: libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "2.3.0" % Provided, "org.apache.spark" %% "spark-sql" % "2.3.0" % Provided, "org.apache.spark" %% "spark-mllib" % "2.3.0" % Provided, "joda-time" % "joda-time" % "2.7", "org.scalatest" %% "scalatest" % "2.2.4" % Test)
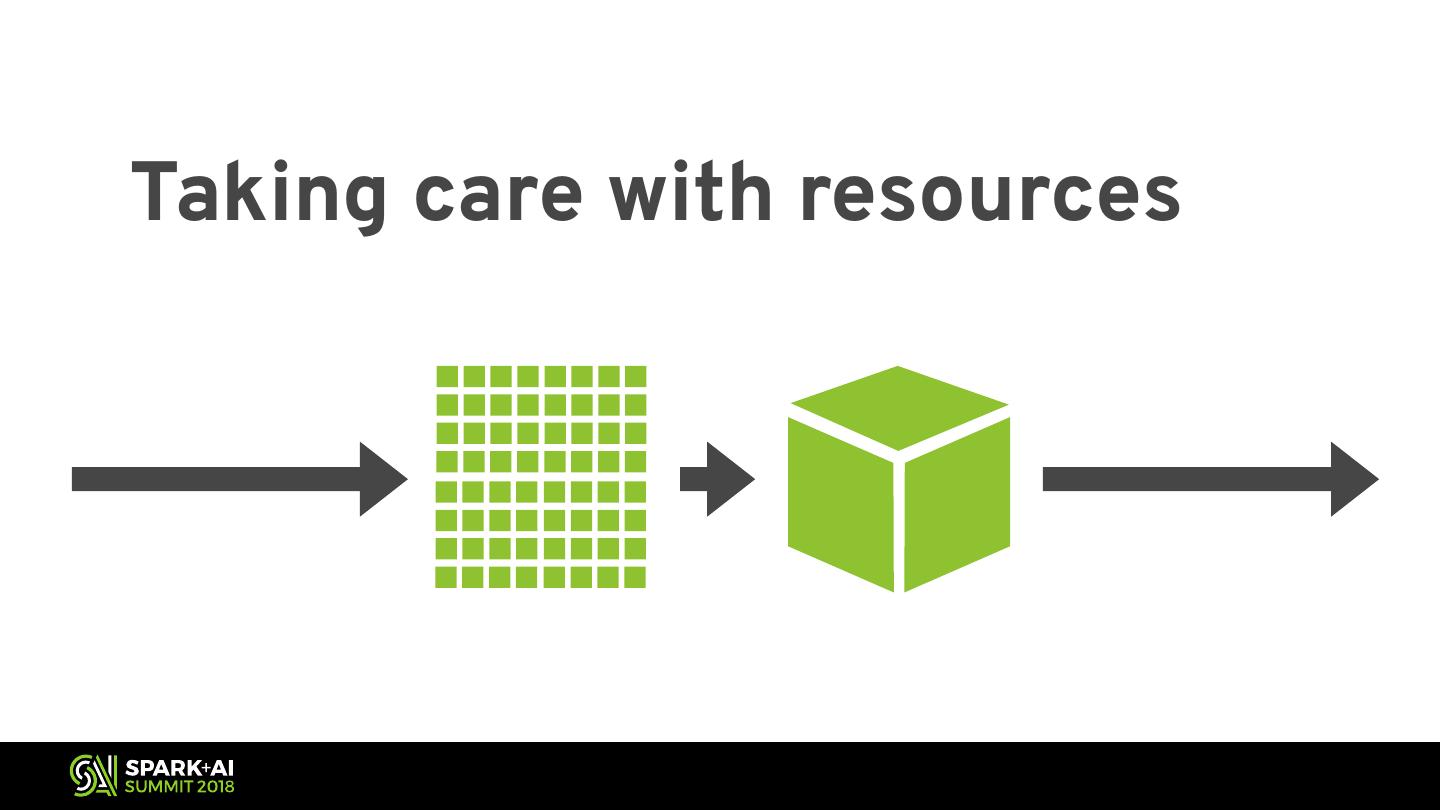
21 .Taking care with resources
22 .Taking care with resources
23 .Taking care with resources
24 .Caching when necessary def defstep(rdd: step(rdd:RDD[_]) RDD[_])= ={ { val valwasUncached wasUncached= =rdd.storageLevel rdd.storageLevel====StorageLevel.NONE StorageLevel.NONE rdd.cache() ifif(wasUncached) (wasUncached){ {rdd.cache() rdd.cache()} } result result= =trainModel(rdd) trainModel(rdd) ifif(wasUncached) (wasUncached){ {rdd.unpersist() rdd.unpersist()} } result result }}
25 .Caching when necessary def defstep(rdd: step(rdd:RDD[_]) RDD[_])= ={ { val valwasUncached wasUncached= =rdd.storageLevel rdd.storageLevel====StorageLevel.NONE StorageLevel.NONE rdd.cache() ifif(wasUncached) (wasUncached){ {rdd.cache() rdd.cache()} } result result= =trainModel(rdd) trainModel(rdd) ifif(wasUncached) (wasUncached){ {rdd.unpersist() rdd.unpersist()} } result result }}
26 .Caching when necessary def defstep(rdd: step(rdd:RDD[_]) RDD[_])= ={ { val valwasUncached wasUncached= =rdd.storageLevel rdd.storageLevel====StorageLevel.NONE StorageLevel.NONE rdd.cache() ifif(wasUncached) (wasUncached){ {rdd.cache() rdd.cache()} } result result= =trainModel(rdd) trainModel(rdd) ifif(wasUncached) (wasUncached){ {rdd.unpersist() rdd.unpersist()} } rdd.unpersist() result result }}
27 .Caching when necessary def step(rdd: RDD[_]) = { val wasUncached = rdd.storageLevel == StorageLevel.NONE if (wasUncached) { rdd.cache() } result = trainModel(rdd) if (wasUncached) { rdd.unpersist() } result }
28 .Caching when necessary def step(rdd: RDD[_]) = { val wasUncached = rdd.storageLevel == StorageLevel.NONE if (wasUncached) { rdd.cache() } result = trainModel(rdd) if (wasUncached) { rdd.unpersist() } result }
29 .var nextModel = initialModel for (int i = 0; i < iterations; i++) { val current = sc.broadcast(nextModel) val newState = nextModel = modelFromState(newState) current.unpersist }
3秒后跳转登录页面
去登陆

