


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
用Apache Spark加速脑组织模拟数据分析
在过去的几年中,不断增长的计算能力使得具有较高计算需求的大型科学实验成为可能,例如脑组织模拟。一般来说,更大的模拟意味着产生大量的数据,需要由神经科学家进行分析。目前,神经科学家在Python脚本的帮助下分析模拟报告,这归功于它的编程简单性和数据库的性能。
展开查看详情
1 .Accelerating Data Analysis of Brain Tissue Simulations with Apache Spark Judit Planas, Blue Brain Project - EPFL #Py5SAIS
2 .Outline • Introduction • Motivation • Analysis of simulations with Spark • Evaluation • Conclusions #Py5SAIS 2
3 .Introduction #Py5SAIS 3
4 .Blue Brain Project • Blue Brain Project (BBP): Swiss initiative targeting the digital reconstruction and simulation of the brain, hosted in Geneva (Switzerland) • BBP is a multi-disciplinary team of people coming from different backgrounds, like neuroscience, computer engineering, physics, mathematics or chemistry #Py5SAIS 4
5 . Computational Neuroscience Systems Molecular Neurophysiology Computational neuroscience neuroscience neuroscience Neurophilosophy Neuropharmacology Neuroscience study areas Neurology Neuropsychology Neuroanatomy And many others… #Py5SAIS 5
6 .BBP’s Target Contributions to Neuroscience • Help scientists understand how the brain works internally • Recently, BBP has been able to reproduce the electrical behavior of a neocortex fragment by means of a computer reconstruction[1] – Brain volume: 1/3 mm3 – 30’000 neurons – 40 million synapses (connections between neurons) – This model has revealed novel insights into the functioning of the neocortex • Supercomputer-based simulation of the brain provides a new tool to study the interaction within the different brain regions • Understanding the brain not only will help the diagnosis and treatment of brain diseases, but also will contribute to the development of neurorobotics, neuromorphic computing and AI #Py5SAIS 6
7 . Simulation Neuroscience at Different Levels Morphologically detailed Subcellular (molecular) Model Point neurons neurons NEST NEURON STEPS Simulator Spiking neural Supports cells with Detailed models of networks, focused complex anatomical neuronal signaling Example on dynamics, size and biophysical pathways at and structure properties molecular level HW Platform Full scale K supercomp. 20 racks BG/Q Full scale on Sango Human Brain % 2.3 % 0.1 % 1.2 x 10-9 % # Neurons 1.86 x 109 82 x 106 1 Biological Time 1s 10 ms 30 ms Simulation Time 3275 s 220 s 26.8 s Sim Time Norm.: 0.003 ms 0.28 ms 1.3 x 106 s 1 neuron, 1 thread, 1 s bio time All these values are approximate and should NOT be used for technical purposes [2, 3, 4] #Py5SAIS 7
8 .Motivation #Py5SAIS 8
9 . Brain Tissue Simulation Process • The following steps are usually involved in brain tissue simulations: Visualization Configuration Simulation Analysis / Filtering Scripting Analysis #Py5SAIS 9
10 .Our Challenge • Simulations can produce GBs – TBs of data very quickly – E.g.: Plastic neocortex simulation • Recording 1 variable • 30 s of biological time ~50 GB of output data [ x N ] • 31’000 neurons ⭐ But… >1 variables are recorded ⭐ And… Biological time is much longer • Most scientists use sequential scripts to analyze their data – Most preferred language is Python – They do not have time / knowledge to improve their scripts – Existing analysis tools exploit thread-level parallelism on single node #Py5SAIS 10
11 .Our Requirements • Python-friendly • Scalable • GBs – TBs of data will be analyzed • Scientist workflow should not be impacted nor modified significantly • Compatible with existing tools and scripts Visualization Configuration Simulation Analysis / Filtering Scripting Analysis #Py5SAIS 11
12 .Analysis of Simulations with Spark #Py5SAIS 12
13 .Spark Could Be Our Solution • Spark meets most of our requirements • How can we leverage from Spark? – Once simulation data is generated, it can be read by a Spark cluster – Then, scientist scripts and available tools can execute queries on these data Binary File Reader GPFS #Py5SAIS 13
14 .Simulation Data Analysis with Spark Pros Cons • Python support • NumPy support critical for us • Scalable across cluster – RDDs: OK • Can be hidden from final user – DFs: need data conversion • Fits our type of queries • Missing native reader for custom binary format • SQL support can be useful • UDFs in Python add overhead • Compatible with on-site systems • On-site system’s GPFS cannot be migrated to HDFS But still worth to investigate! J #Py5SAIS 14
15 .Evaluation #Py5SAIS 15
16 . What Do We Evaluate? Selected combinations RDD Parallel structure DF Automatic We want to Data partitioning compare Manual the NumPy array difference between: Data container Binary (byte array) Python list Binary format (BBP) Data source Parquet #Py5SAIS 16
17 .Selected Combinations RDD RDDkey DFbin DFpylist Parallel RDD RDD DF DF structure Data Manual, based Automatic Automatic Automatic partitioning on GID Binary Data container NP array NP array Python list (byte array) • Data source is specified in the label: BBP (custom layout, binary) or Parquet #Py5SAIS 17
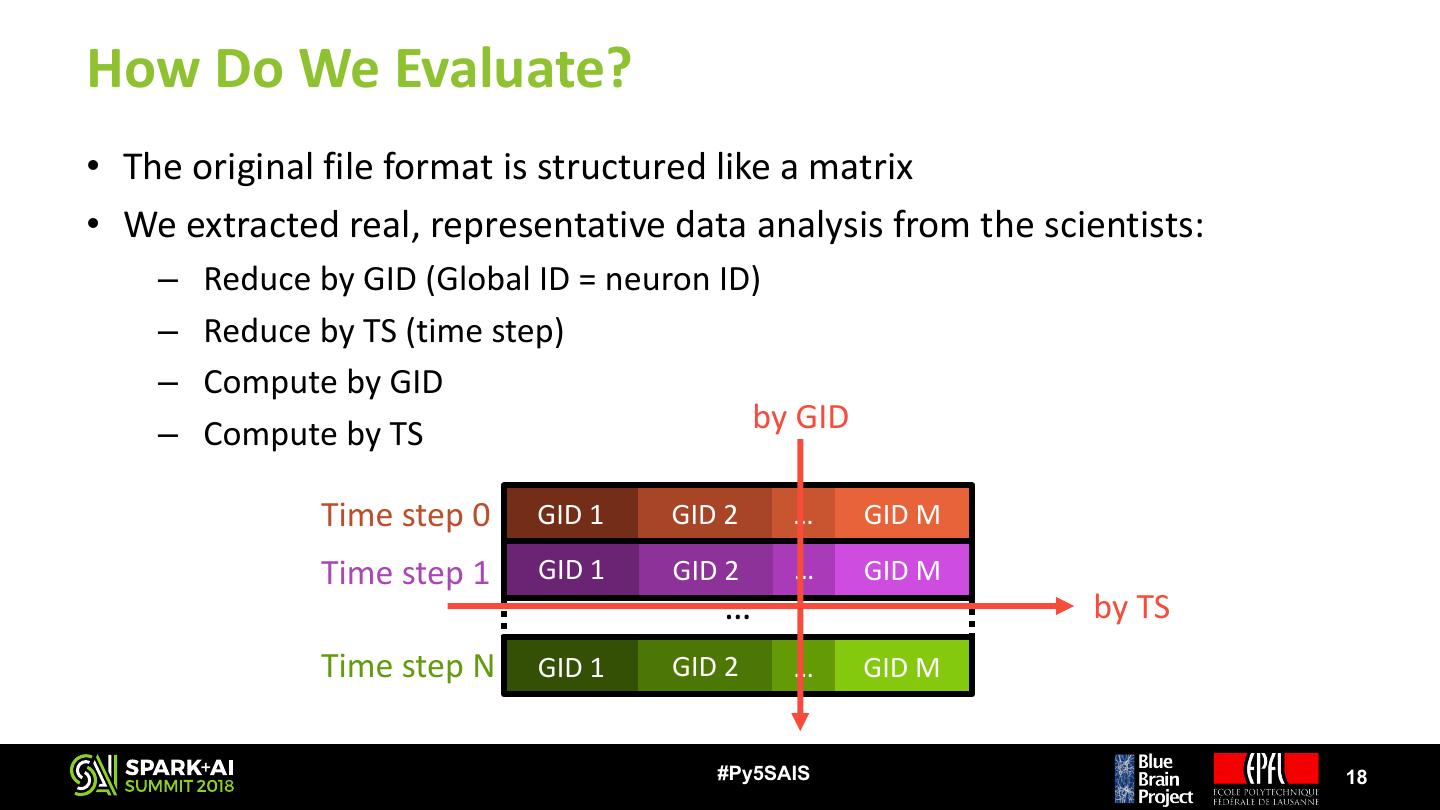
18 .How Do We Evaluate? • The original file format is structured like a matrix • We extracted real, representative data analysis from the scientists: – Reduce by GID (Global ID = neuron ID) – Reduce by TS (time step) – Compute by GID – Compute by TS by GID Time step 0 GID 1 GID 2 … GID M Time step 1 GID 1 GID 2 … GID M … by TS Time step N GID 1 GID 2 … GID M #Py5SAIS 18
19 .Where Do We Evaluate? Hardware Platform Software • On-site cluster • Red Hat Enterprise Linux 7.3 • 40+ compute nodes • Java OpenJDK RE 1.8 • InfiniBand EDR 100 GB • Apache Spark 2.2.1 • GPFS file system Runtime Configuration • Each node: • Exclusive access to allocated nodes – 2 x Intel Xeon 6140 • Spark slaves use all cores – 72 threads (2 x 18 cores with HT) – 384 GB DRAM • Spark master runs on separate node – 2 x SSD P4500, 1 TB each • Dataset size: 2 TB #Py5SAIS 19
20 . Memory Footprint DFpylist - BBP RDD - Parquet RDDkey - Parquet DFbin - BBP DFbin - Parquet RDDkey - BBP RDD - BBP 300.00 • Original dataset size (files): 47 GB • RDD – BBP is the only version that Node Memory Footprint [GB] 250.00 stays close to original files size 200.00 • Any other data source / data structure increases memory consumption from 150.00 3 – 6 times 100.00 • DFpylist crashes due to lack of 50.00 memory while performing the computation by GID (unable to 0.00 continue with memory test) #Py5SAIS 20
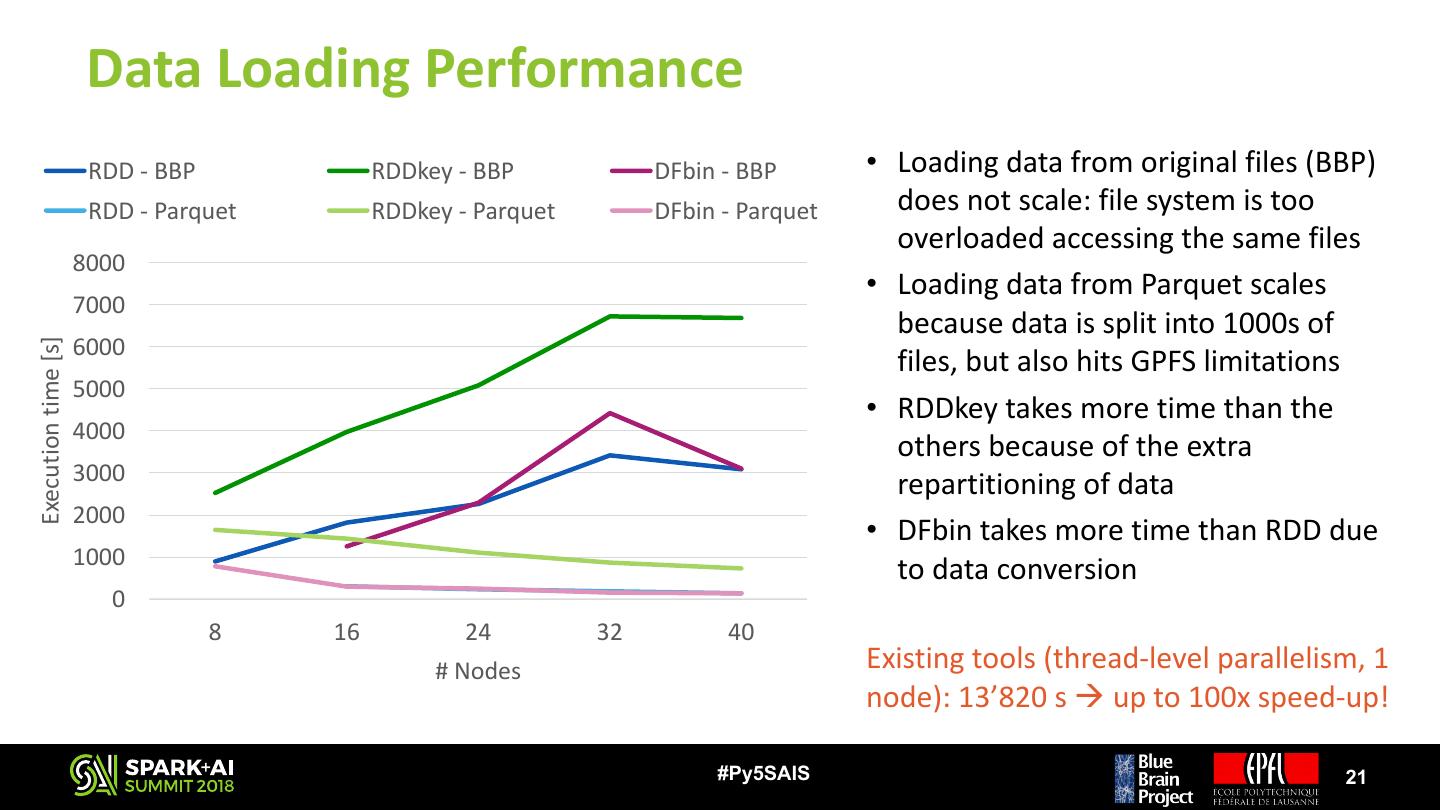
21 . Data Loading Performance RDD - BBP RDDkey - BBP DFbin - BBP • Loading data from original files (BBP) RDD - Parquet RDDkey - Parquet DFbin - Parquet does not scale: file system is too overloaded accessing the same files 8000 • Loading data from Parquet scales 7000 because data is split into 1000s of 6000 Execution time [s] files, but also hits GPFS limitations 5000 • RDDkey takes more time than the 4000 others because of the extra 3000 repartitioning of data 2000 • DFbin takes more time than RDD due 1000 to data conversion 0 8 16 24 32 40 # Nodes Existing tools (thread-level parallelism, 1 node): 13’820 s à up to 100x speed-up! #Py5SAIS 21
22 . Existing tools (TLP, 1 node): 5 s à worse Reduction by GID/TS Performance or same perf à needs investigation RDD - BBP RDDkey - BBP DFbin - BBP RDD - Parquet RDDkey - Parquet DFbin - Parquet 900 60.00 800 Reduce by GID Reduce by TS 50.00 700 Execution time [s] Execution time [s] 600 40.00 500 30.00 400 300 20.00 200 10.00 100 0 0.00 8 16 24 32 40 8 16 24 32 40 # Nodes # Nodes • RDDkey is the fastest thanks to the manual • Reduce by TS was run right after Reduce by partitioning: better data distribution GID: we believe that partial results were • DFbin is the slowest due to data conversions cached and, thus, is significantly faster #Py5SAIS 22
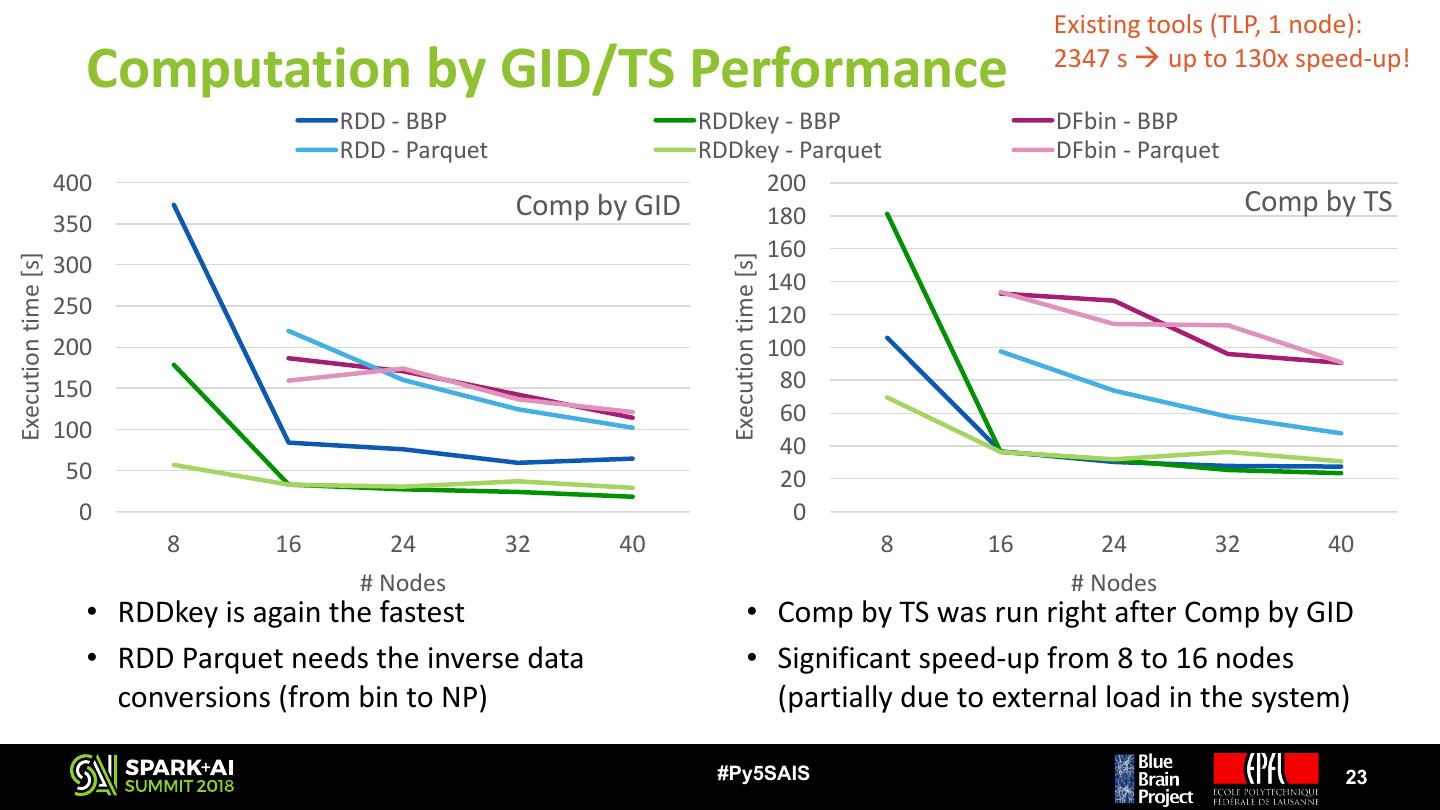
23 . Existing tools (TLP, 1 node): Computation by GID/TS Performance 2347 s à up to 130x speed-up! RDD - BBP RDDkey - BBP DFbin - BBP RDD - Parquet RDDkey - Parquet DFbin - Parquet 400 200 Comp by GID 180 Comp by TS 350 160 300 Execution time [s] Execution time [s] 140 250 120 200 100 150 80 60 100 40 50 20 0 0 8 16 24 32 40 8 16 24 32 40 # Nodes # Nodes • RDDkey is again the fastest • Comp by TS was run right after Comp by GID • RDD Parquet needs the inverse data • Significant speed-up from 8 to 16 nodes conversions (from bin to NP) (partially due to external load in the system) #Py5SAIS 23
24 .Conclusions #Py5SAIS 24
25 .Conclusions • Spark improves the performance of our data analysis (up to 130x) • There are a few corner cases to investigate on our side • Design decisions (data structure, origin, …) can make a huge impact in memory consumption and performance • Spark data partitioning does a good job, but additional knowledge on data contents can help in a better partitioning • But there are a few points that could be further improved… #Py5SAIS 25
26 .Discussion Points • NumPy support would make things easier for us – Use of Pandas DataFrames cannot be applied to our use case • Ability to control number of executors per node dynamically at runtime: – Use few executors per node when loading data from GPFS – Use full node when doing data analysis and computations #Py5SAIS 26
27 .Acknowledgments & References • BBP In Sillico Experiments and HPC teams for the support and feedback provided • An award of computer time was provided by the ALCF Data Science Program (ADSP). This research used resources of the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357. [1] Henry Markram et al. Reconstruction and Simulation of Neocortical Microcircuitry. Cell, Vol. 163, Issue 2, pp 456 – 492 [2] Kunkel, Susanne et al. Spiking network simulation code for petascale computers. Frontiers in neuroinformatics, Vol. 8, p 78 [3] Ovcharenko, A. et al. Simulating Morphologically Detailed Neuronal Networks at Extreme Scale. In PARCO, pp. 787-796 [4] Chen, Weiliang et al. Parallel STEPS: Large Scale Stochastic Spatial Reaction-Diffusion Simulation with High Performance Computers. Frontiers in neuroinformatics, Vol. 11, p 13 #Py5SAIS 27
3秒后跳转登录页面
去登陆

