






















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
结构化流中状态流处理的深入研究
状态处理是分布式容错流处理中最具挑战性的方面之一。结构化流中的DataFrameAPI使得开发人员非常容易隐式地表达他们的状态逻辑(流聚合)或显式地表达它们的状态逻辑(mapGroupsWithState)。然而,引擎盖下有许多移动部件,这使得所有的魔法成为可能。在这篇文章中,我将深入探讨状态化处理如何在结构化流中工作。
展开查看详情
1 .A Deep Dive into Stateful Stream Processing in Structured Streaming Tathagata “TD” Das @tathadas Spark Summit 2018 5th June, San Francisco
2 . Structured Streaming stream processing on Spark SQL engine fast, scalable, fault-tolerant rich, unified, high level APIs deal with complex data and complex workloads rich ecosystem of data sources integrate with many storage systems
3 . you should not have to reason about streaming
4 . you should write simple queries & Spark should continuously update the answer
5 .Treat Streams as Unbounded Tables data stream unbounded input table new data in the data stream = new rows appended to a unbounded table
6 .Anatomy of a Streaming Query Example Read JSON data from Kafka Parse nested JSON ETL Store in structured Parquet table Get end-to-end failure guarantees
7 .Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) Source .option("subscribe", "topic") Specify where to read data from .load() Built-in support for Files / Kafka / Kinesis* returns a Spark DataFrame Can include multiple sources of (common API for batch & streaming data) different types using join() / union() *Available only on Databricks Runtime
8 .Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() Kafka DataFrame key value topic partition offset timestamp [binary] [binary] "topic" 0 345 1486087873 [binary] [binary] "topic" 3 2890 1486086721
9 .Anatomy of a Streaming Query spark.readStream.format("kafka") Transformations .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() Cast bytes from Kafka records to a .selectExpr("cast (value as string) as json") string, parse it as a json, and .select(from_json("json", schema).as("data")) generate nested columns 100s of built-in, optimized SQL functions like from_json user-defined functions, lambdas, function literals with map, flatMap…
10 .Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) Sink .option("subscribe", "topic") Write transformed output to .load() external storage systems .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) Built-in support for Files / Kafka .writeStream .format("parquet") Use foreach to execute arbitrary .option("path", "/parquetTable/") code with the output data Some sinks are transactional and exactly once (e.g. files)
11 .Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) Processing Details .option("subscribe", "topic") .load() Trigger: when to process data .selectExpr("cast (value as string) as json") - Fixed interval micro-batches .select(from_json("json", schema).as("data")) - As fast as possible micro-batches .writeStream .format("parquet") - Continuously (new in Spark 2.3) .option("path", "/parquetTable/") .trigger("1 minute") .option("checkpointLocation", "…") Checkpoint location: for tracking the .start() progress of the query
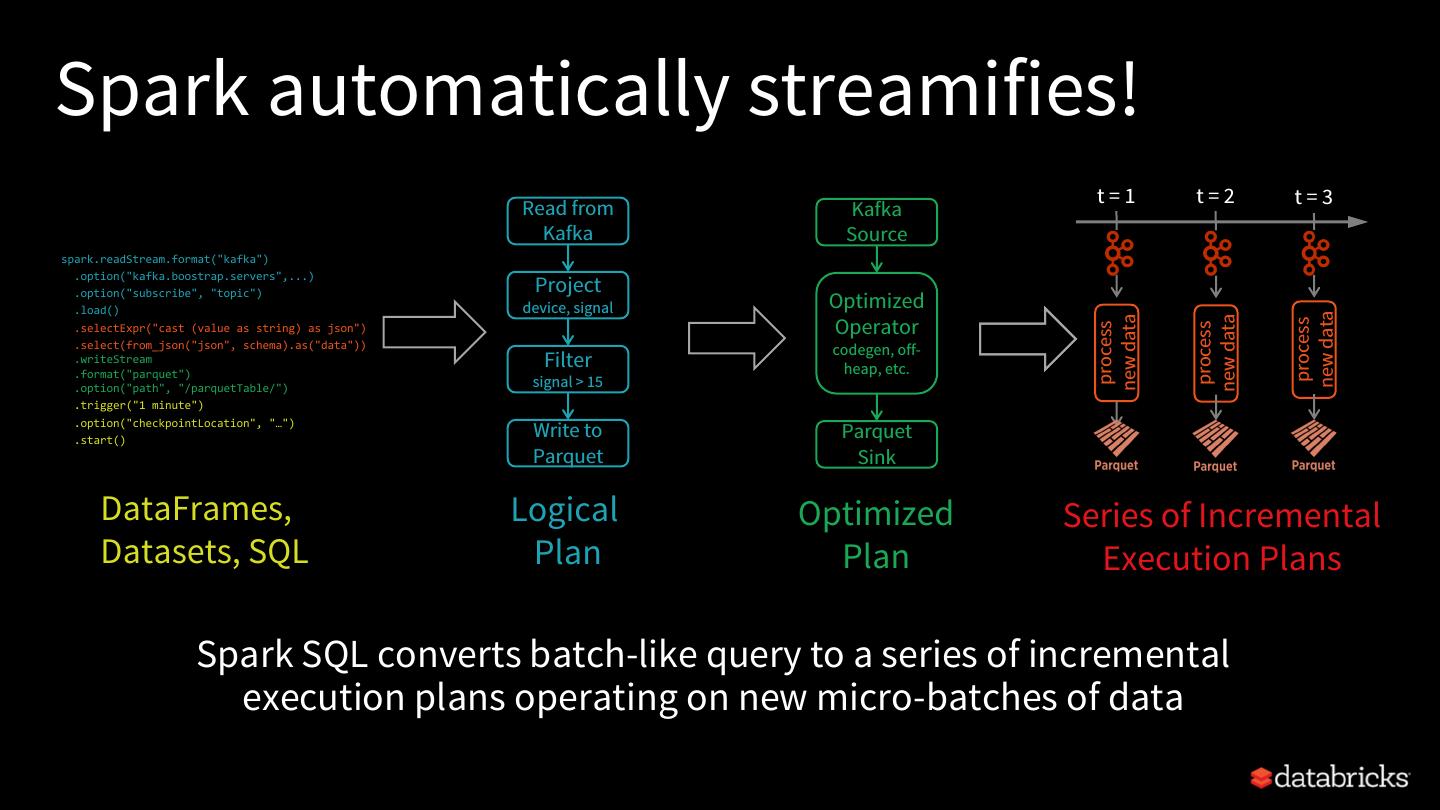
12 .Spark automatically streamifies! t=1 t=2 t=3 Read from Kafka Kafka Source spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) Project .option("subscribe", "topic") .load() device, signal Optimized new data Operator new data new data process process process .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) codegen, off- .writeStream .format("parquet") Filter heap, etc. .option("path", "/parquetTable/") signal > 15 .trigger("1 minute") .option("checkpointLocation", "…") .start() Write to Parquet Parquet Sink DataFrames, Logical Optimized Series of Incremental Datasets, SQL Plan Plan Execution Plans Spark SQL converts batch-like query to a series of incremental execution plans operating on new micro-batches of data
13 .Fault-tolerance with Checkpointing t=1 t=2 t=3 Checkpointing new data new data Saves processed offset info to stable storage new data process process process Saved as JSON for forward-compatibility write Allows recovery from any failure ahead Can resume after limited changes to your log streaming transformations (e.g. adding new end-to-end filters to drop corrupted data, etc.) exactly-once guarantees
14 . Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") ETL .load() .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .writeStream Raw data from Kafka available .format("parquet") .option("path", "/parquetTable/") as structured data in seconds, .trigger("1 minute") ready for querying .option("checkpointLocation", "…") .start()
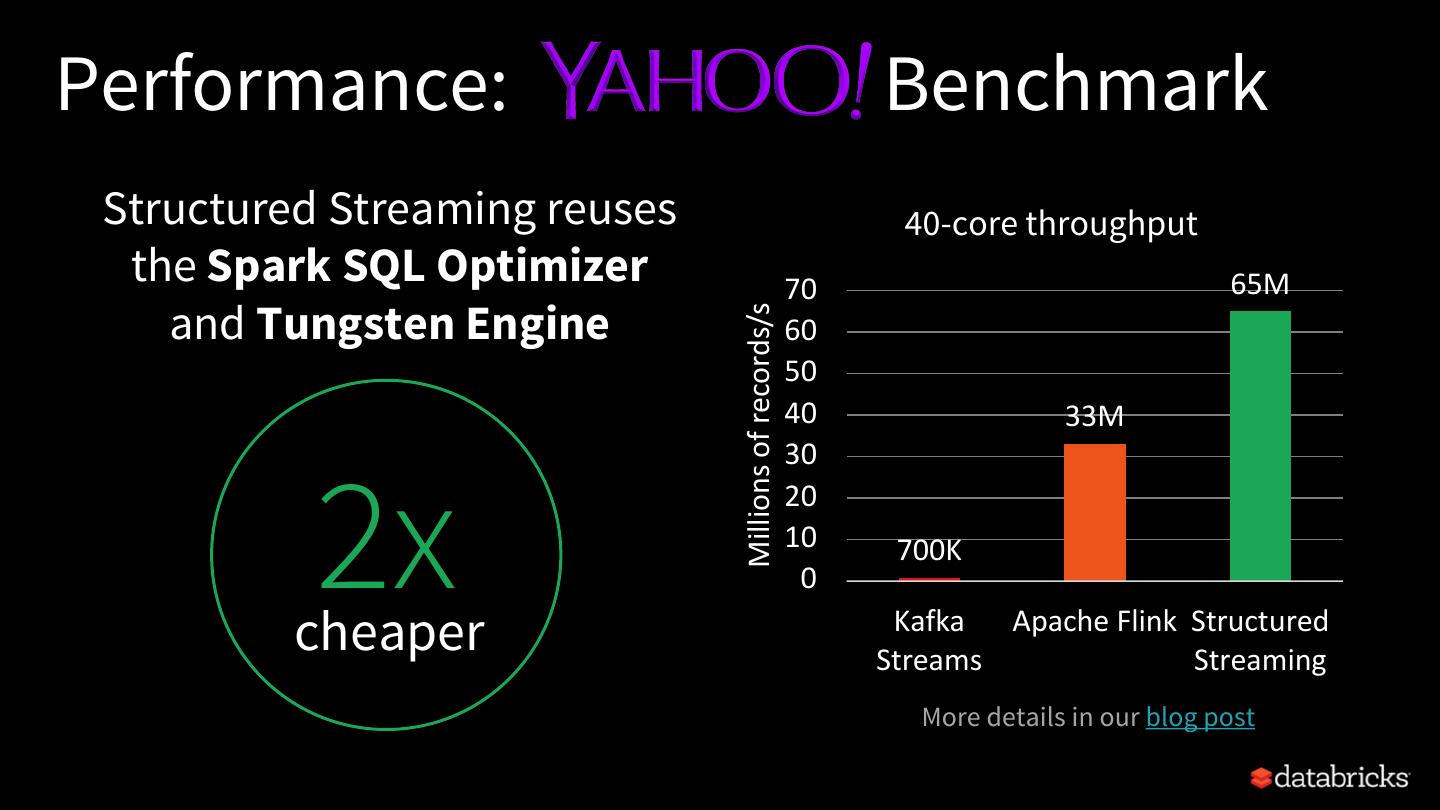
15 .Performance: Benchmark Structured Streaming reuses 40-core throughput the Spark SQL Optimizer 70 65M and Tungsten Engine Millions of records/s 60 50 40 33M 30 2x 20 10 700K 0 cheaper faster Kafka Apache Flink Structured Streams Streaming More details in our blog post
16 . Stateful Stream Processing
17 .What is Stateless Stream Processing? Stateless streaming queries (e.g. stateless ETL) process each record streaming independent of other records Spark df.select(from_json("json", schema).as("data")) .where("data.type = 'typeA') Every record is parsed into a structured form and then selected (or not) by the filter
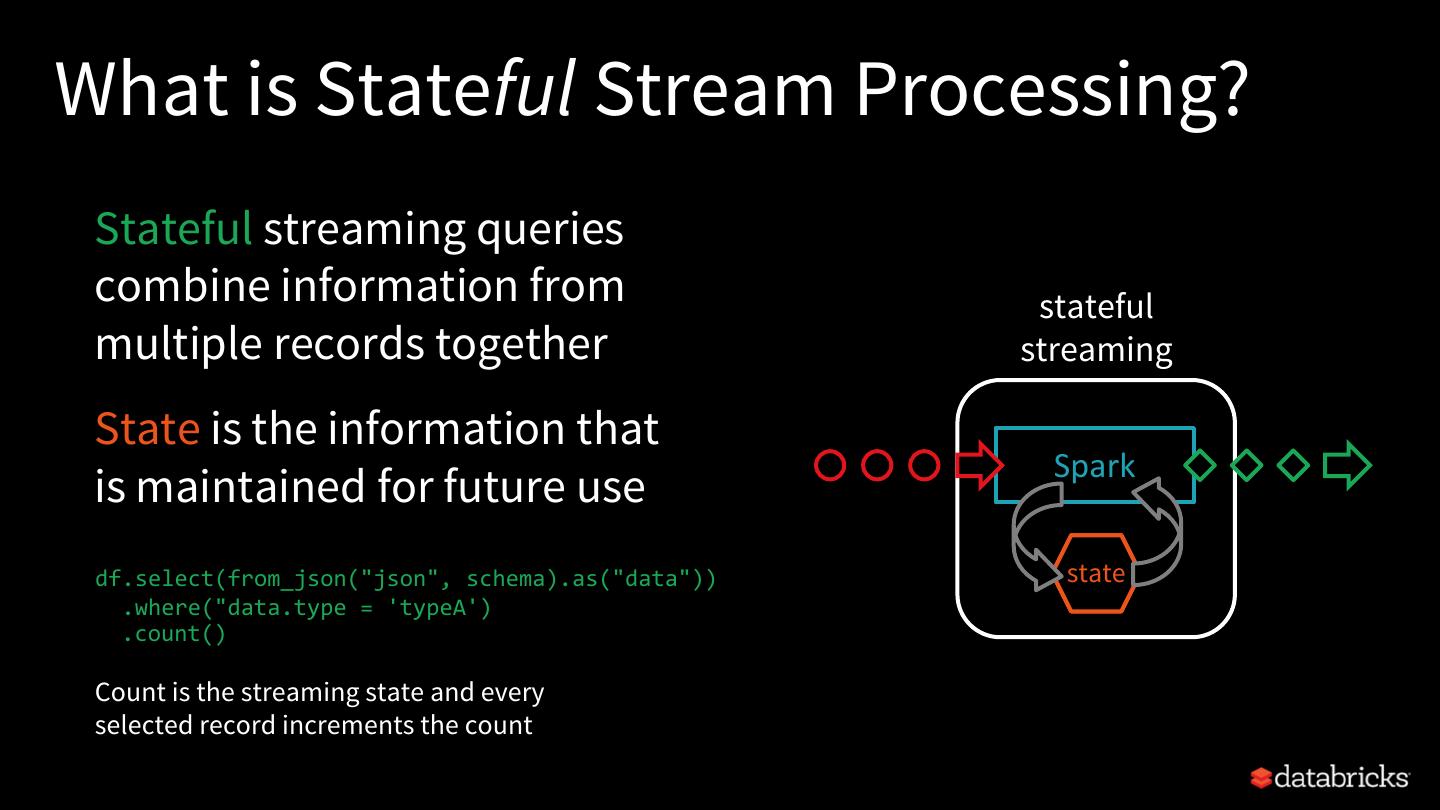
18 .What is Stateful Stream Processing? Stateful streaming queries combine information from stateful multiple records together streaming State is the information that Spark is maintained for future use df.select(from_json("json", schema).as("data")) state .where("data.type = 'typeA') .count() Count is the streaming state and every selected record increments the count
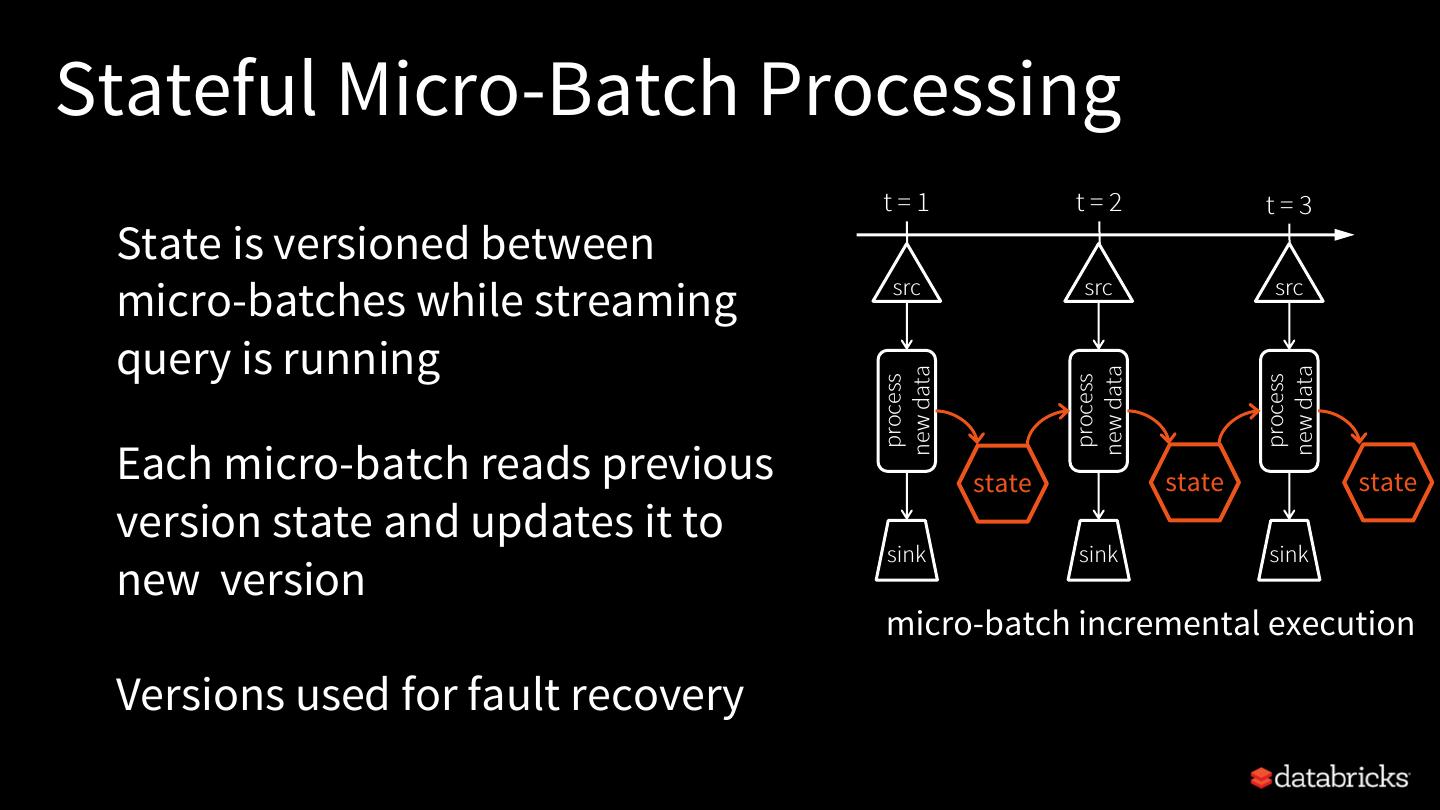
19 .Stateful Micro-Batch Processing t=1 t=2 t=3 State is versioned between micro-batches while streaming src src src query is running new data new data new data process process process Each micro-batch reads previous state state state version state and updates it to sink sink sink new version micro-batch incremental execution Versions used for fault recovery
20 .Distributed, Fault-tolerant State State data is distributed across executors State stored in the executor memory state Micro-batch tasks update the state driver tasks Changes are checkpointed with version to executor 1 given checkpoint location (e.g. HDFS) Recovery from failure is automatic state executor 2 Exactly-once fault-tolerance guarantees! HDFS
21 . Philosophy of Stateful Operations
22 . Two types of Stateful Operations Automatic State User-defined State Cleanup Cleanup
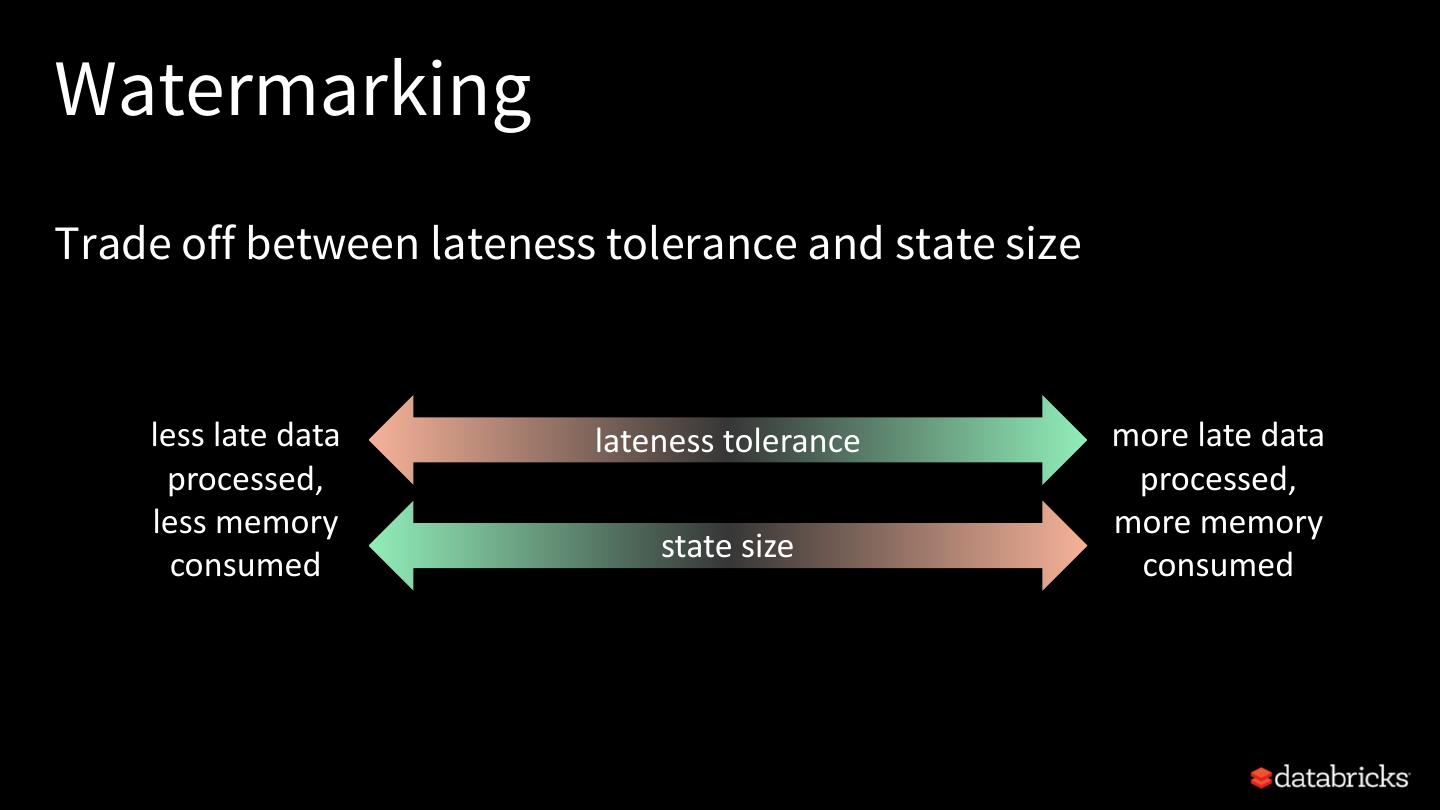
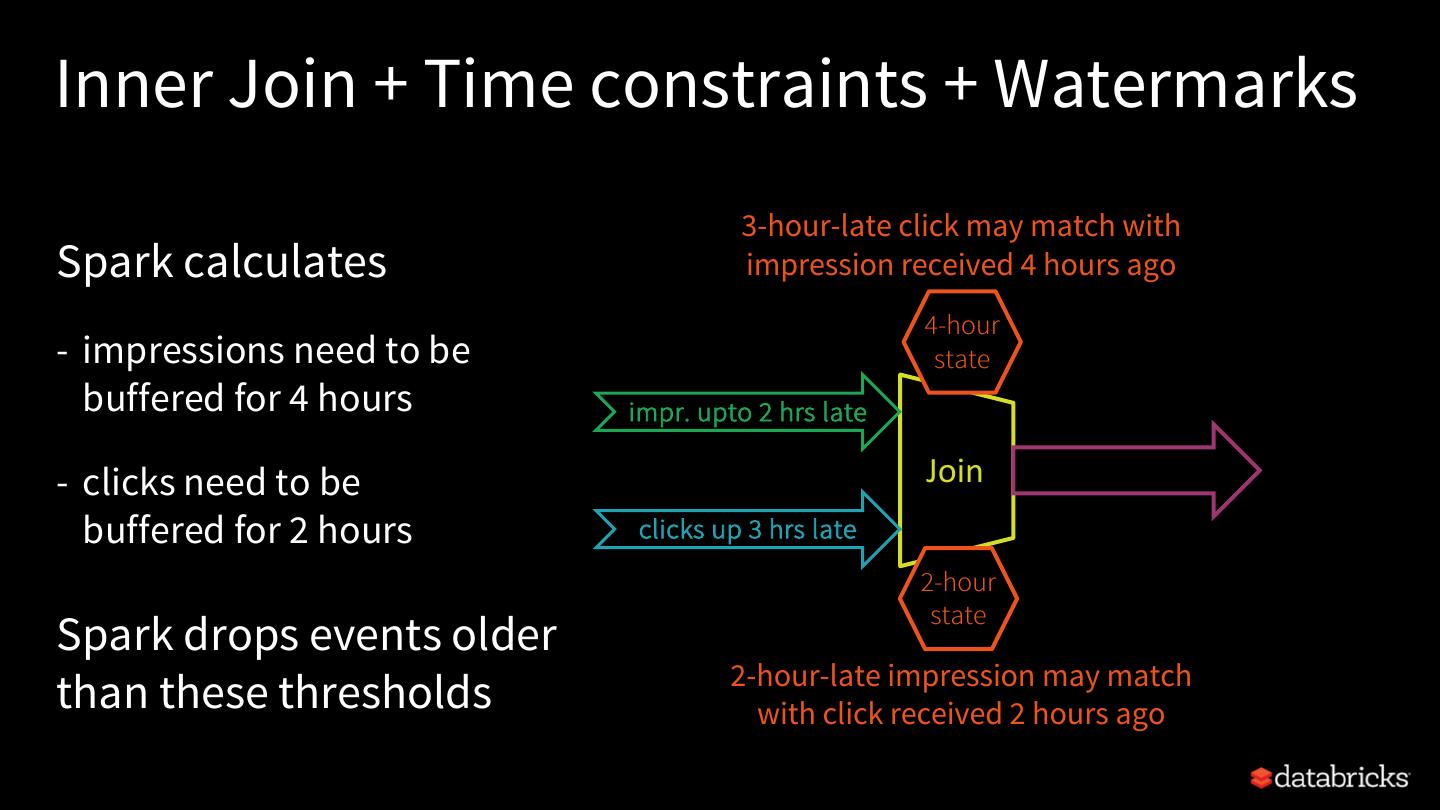
23 . Automatic State User-defined State Cleanup Cleanup For SQL operations with well- For user-defined, arbitrary defined semantics stateful operations State cleanup is automatic No automatic state cleanup with watermarking because we precisely know when state User has to explicitly data is not needed any more manage state
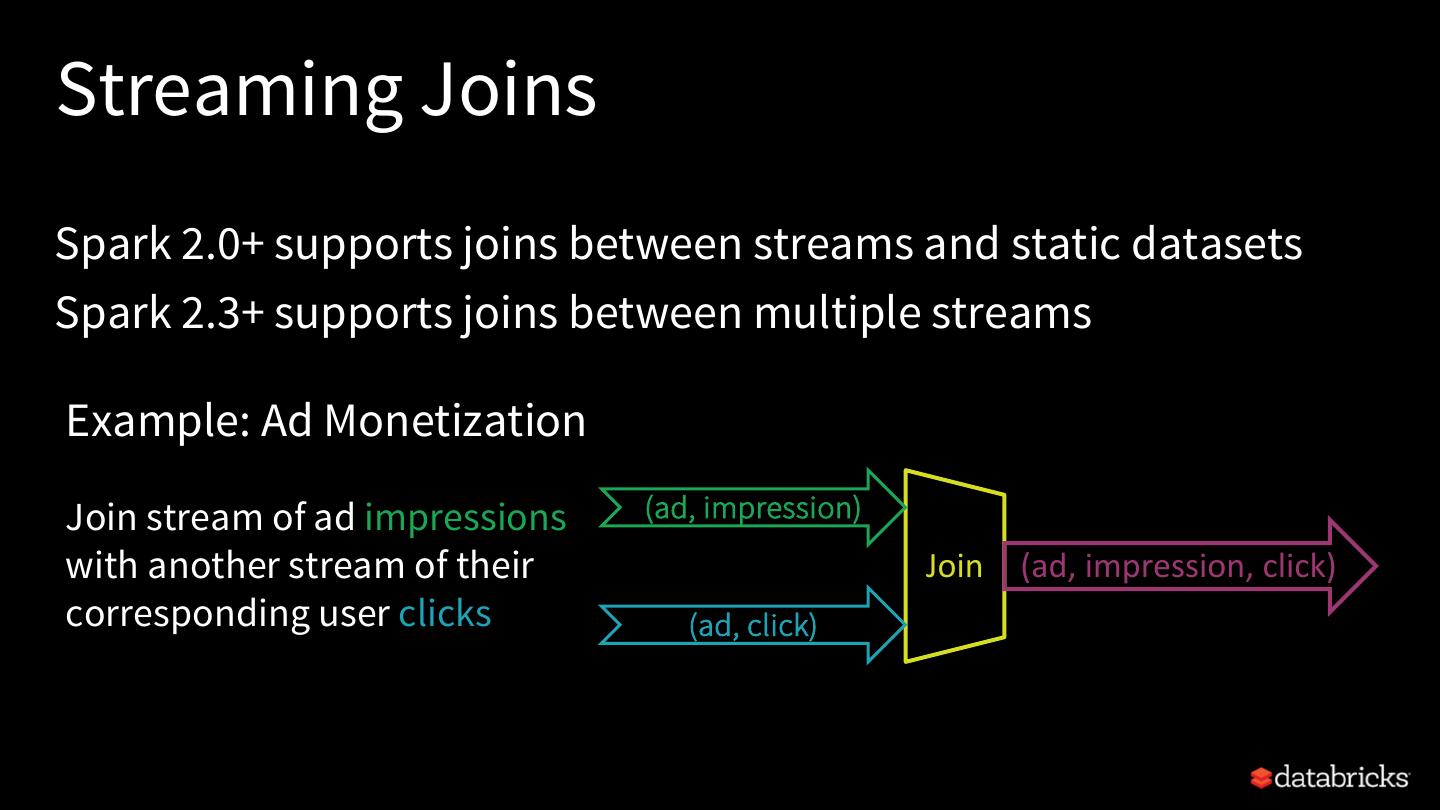
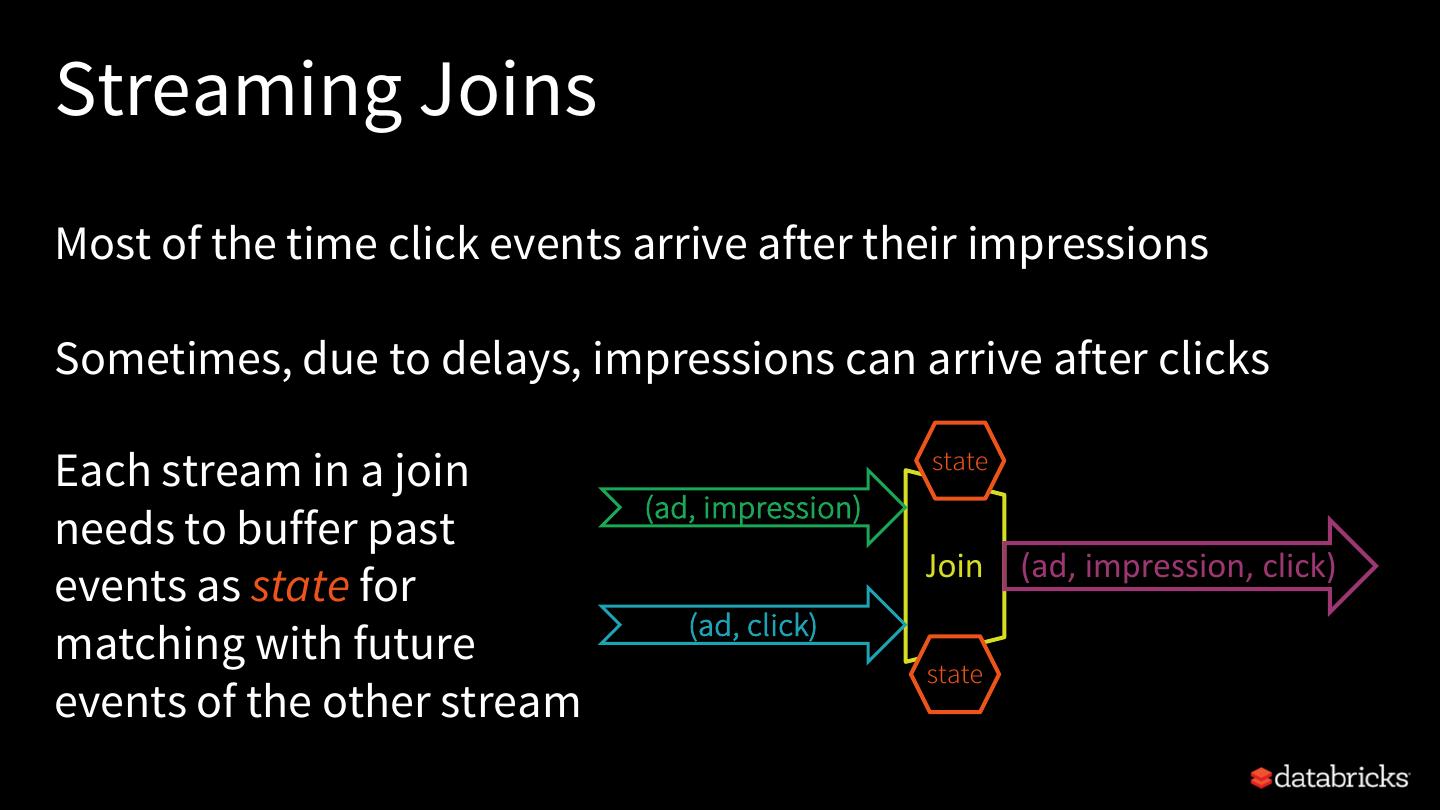
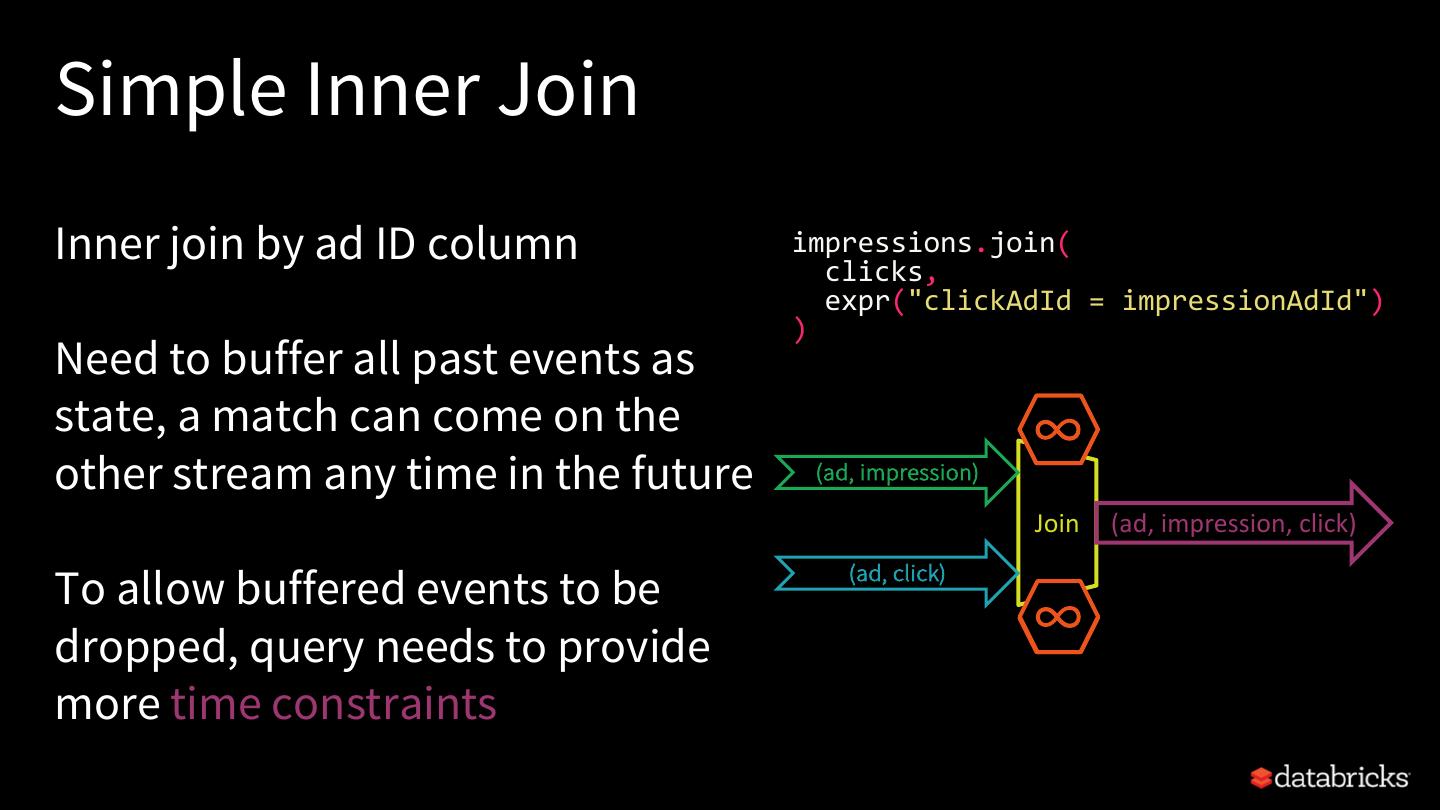
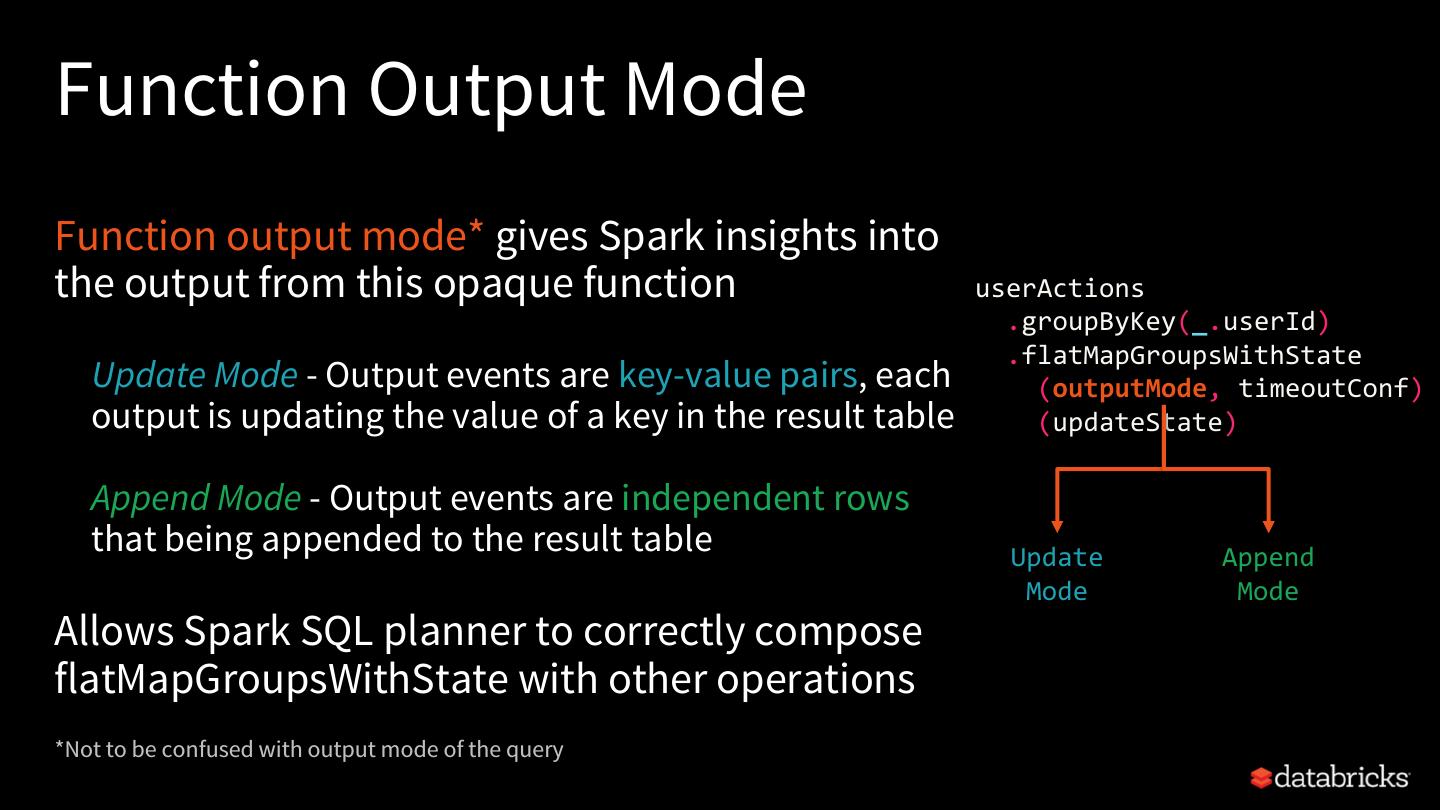
24 .Automatic State User-defined State Cleanup Cleanup aggregations streaming sessionization deduplications with mapGroupsWithState and flatMapGroupsWithState joins
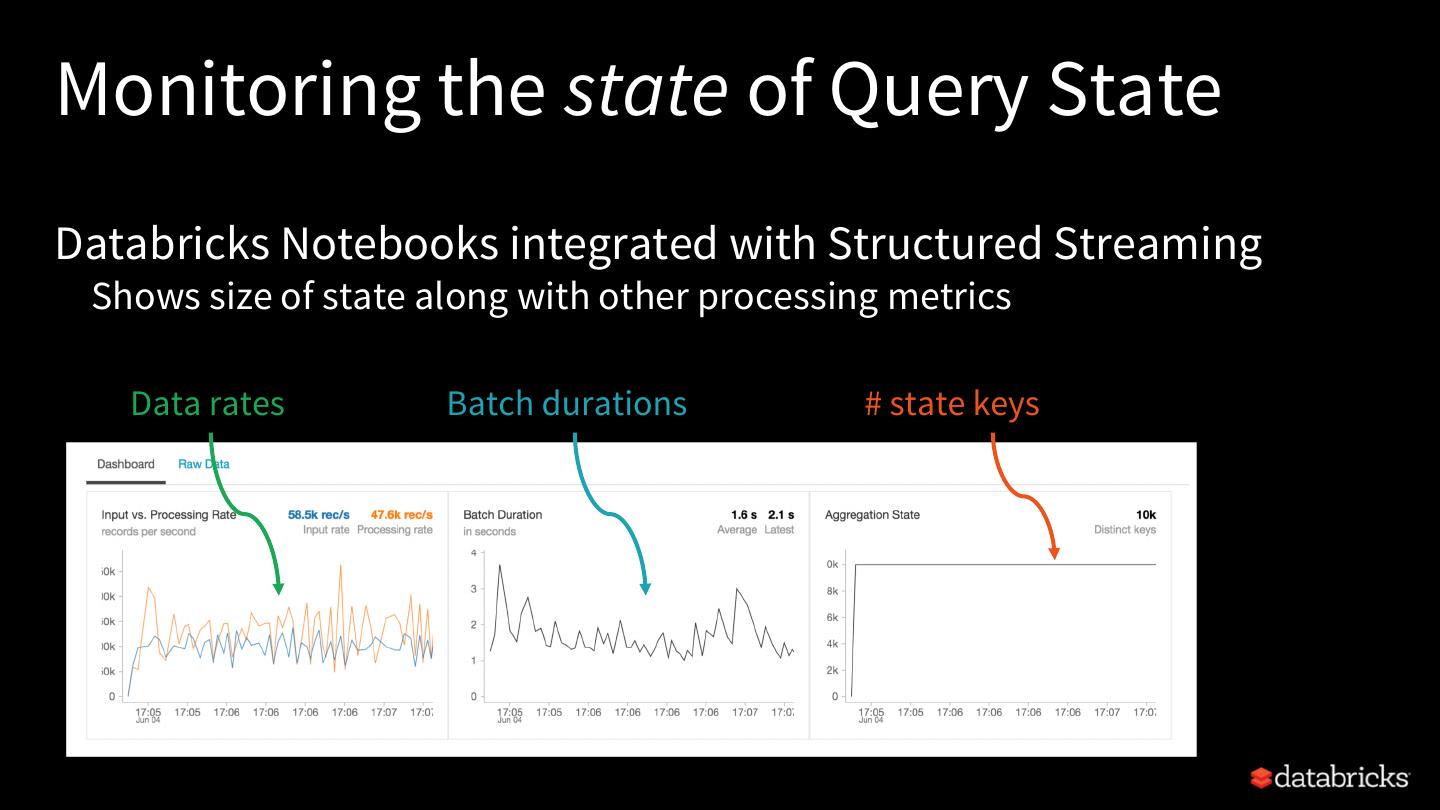
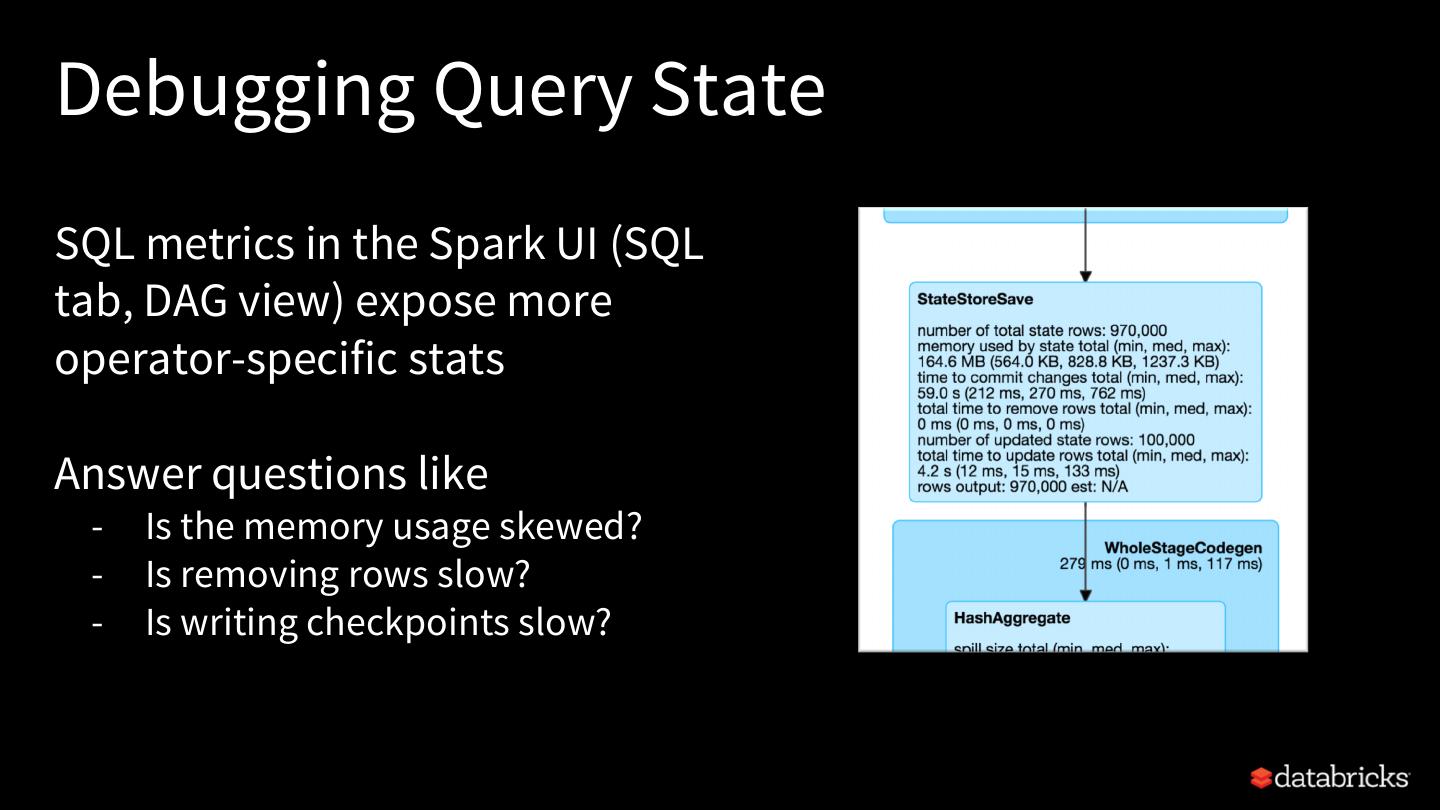
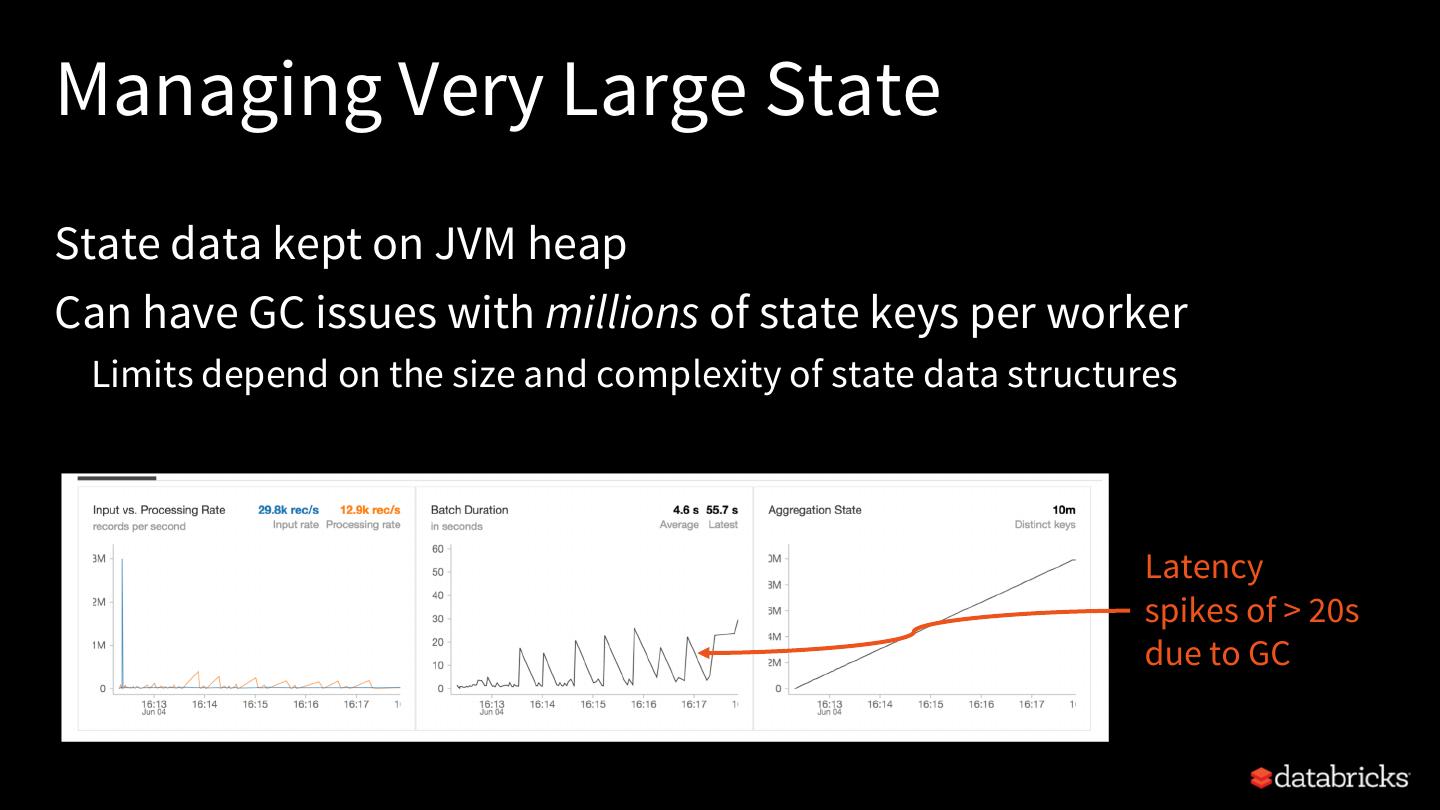
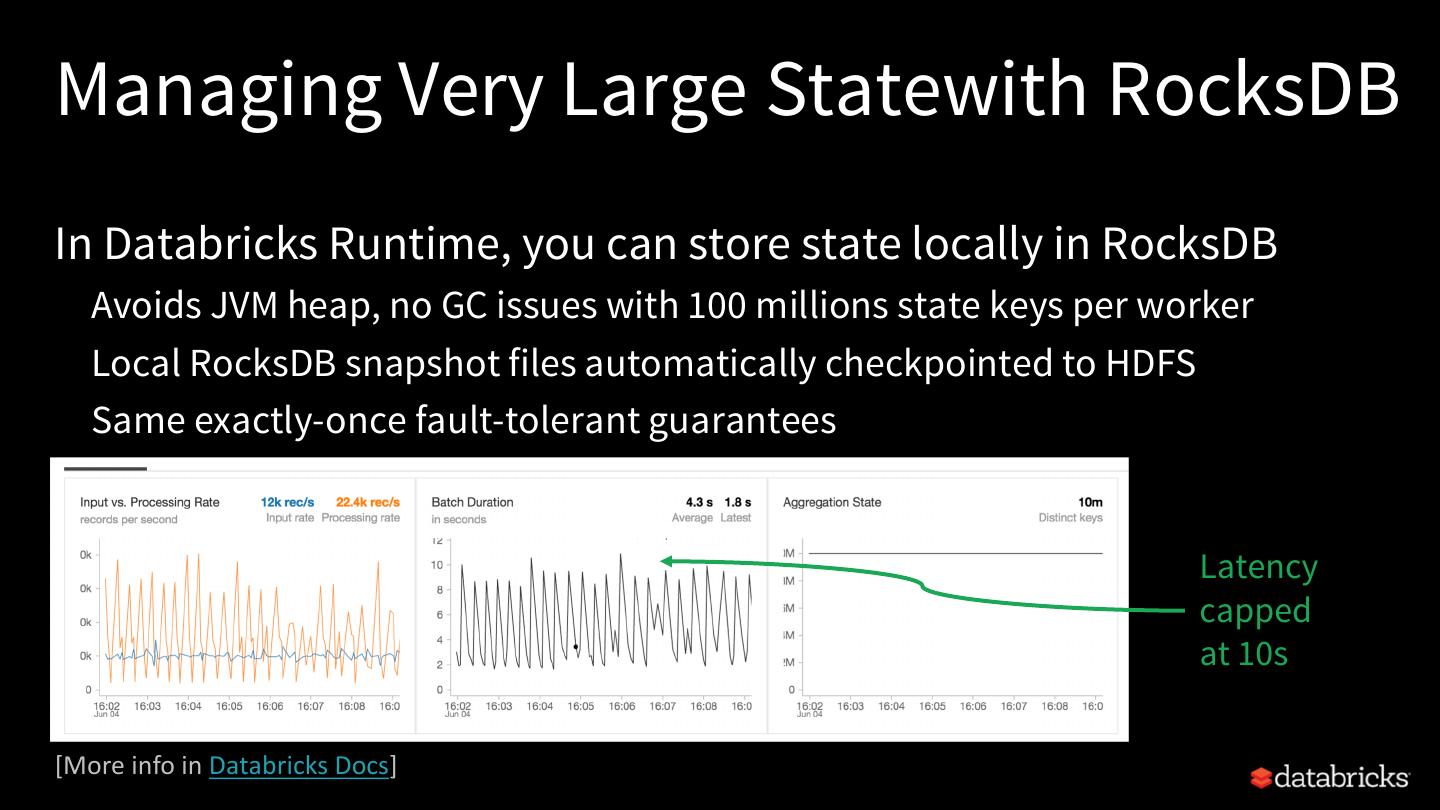
25 .Rest of this talk Explore built-in stateful operations How to use watermarks to control state size How to build arbitrary stateful operations How to monitor and debug stateful queries
26 .Streaming Aggregation
27 .Aggregation by key and/or time windows events Aggregation by key only .groupBy("key") .count() events Aggregation by event time windows .groupBy(window("timestamp","10 mins")) .avg("value") events Aggregation by both .groupBy( col(key), window("timestamp","10 mins")) Supports multiple aggregations, .agg(avg("value"), corr("value")) user-defined functions (UDAFs)!
28 .Automatically handles Late Data Keeping state allows 13:00 14:00 15:00 16:00 17:00 late data to update 12:00 - 13:00 1 12:00 - 13:00 3 12:00 - 13:00 3 12:00 - 13:00 5 12:00 - 13:00 3 counts of old windows 13:00 - 14:00 1 13:00 - 14:00 2 13:00 - 14:00 2 13:00 - 14:00 2 14:00 - 15:00 5 14:00 - 15:00 5 14:00 - 15:00 6 15:00 - 16:00 4 15:00 - 16:00 4 16:00 - 17:00 3 But size of the state increases red = state updated with late data indefinitely if old windows are not dropped
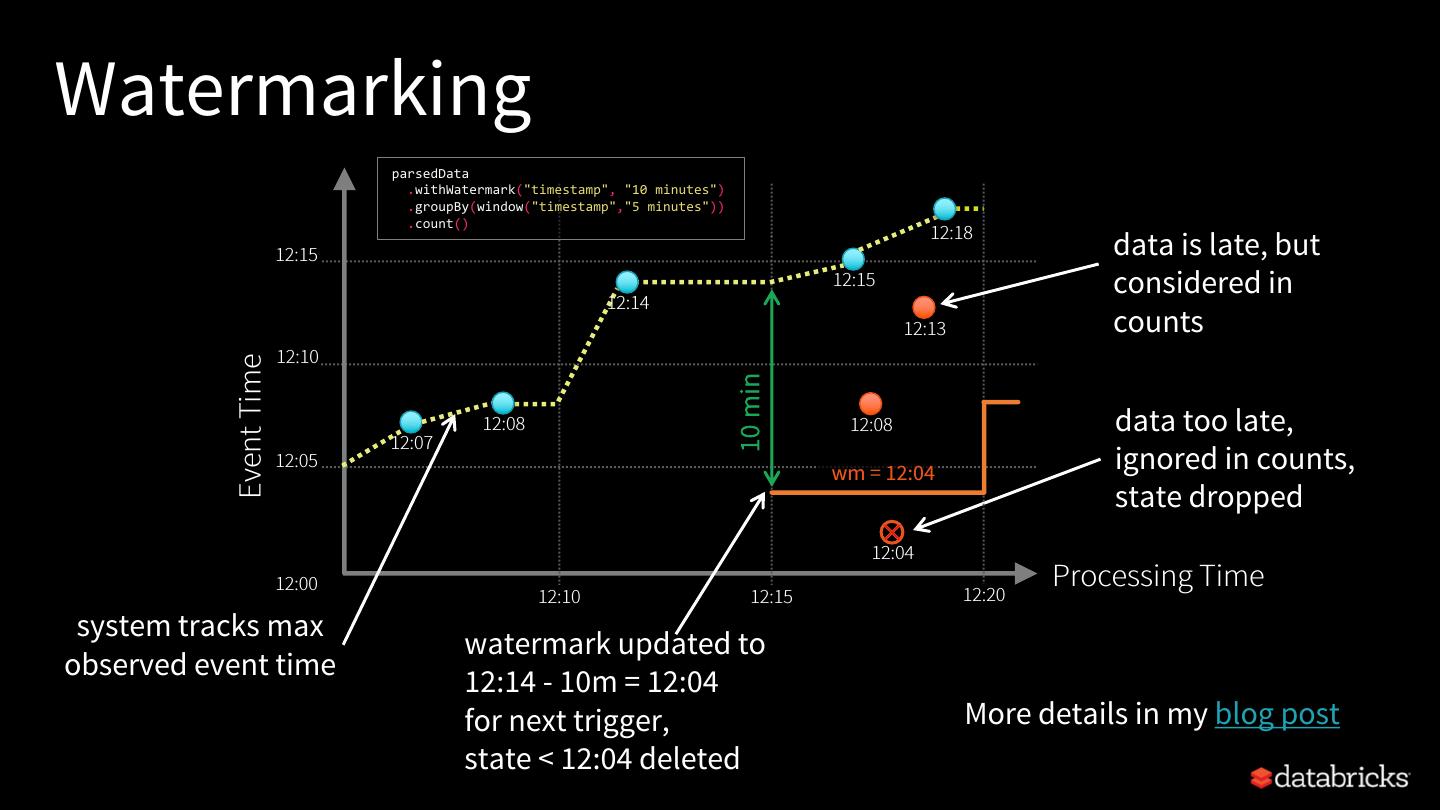
29 .Watermarking event time Watermark - moving threshold of how late data is expected to be max event time and when to drop old state 12:30 PM trailing gap Trails behind max event time of 10 mins seen by the engine watermark data older 12:20 PM than Watermark delay = trailing gap watermark not expected
3秒后跳转登录页面
去登陆

