

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
内存连贯性,缓存一致性和同步的研究探讨
本文继续讲述了内存连贯性,缓存一致性和同步的有关知识,对内存连贯性,缓存一致性和同步的研究探讨,讨论了同步系统的来源是什么?内存连贯性,缓存一致性二者之间的优缺点及联系。
展开查看详情
1 . Advanced Operating Systems (CS 202) Memory Consistency, Cache Coherence and Synchronization (Part II) Jan, 30, 2017 (some cache coherence slides adapted from Ian Watson; some memory consistency slides from Sarita Adve)
2 . What is synchronization? • Making sure that concurrent activities don’t access shared data in inconsistent ways • int i = 0; // shared Thread A Thread B i=i+1; i=i-1; What is in i? 2
3 . What are the sources of concurrency? • Multiple user-space processes – On multiple CPUs • Device interrupts • Workqueues • Tasklets • Timers 3
4 . Pitfalls in scull • Race condition: result of uncontrolled access to shared data if (!dptr->data[s_pos]) { dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL); if (!dptr->data[s_pos]) { goto out; } } Scull is the Simple Character Utility for Locality Loading (an example device driver from the Linux Device Driver book)
5 . Pitfalls in scull • Race condition: result of uncontrolled access to shared data if (!dptr->data[s_pos]) { dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL); if (!dptr->data[s_pos]) { goto out; } }
6 . Pitfalls in scull • Race condition: result of uncontrolled access to shared data if (!dptr->data[s_pos]) { dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL); if (!dptr->data[s_pos]) { goto out; } }
7 . Pitfalls in scull • Race condition: result of uncontrolled access to shared data if (!dptr->data[s_pos]) { dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL); Memory leak if (!dptr->data[s_pos]) { goto out; } }
8 . Synchronization primitives • Lock/Mutex – To protect a shared variable, surround it with a lock (critical region) – Only one thread can get the lock at a time – Provides mutual exclusion • Shared locks – More than one thread allowed (hmm…) • Others? Yes, including Barriers (discussed in the paper) 8
9 . Synchronization primitives (cont’d) • Lock based – Blocking (e.g., semaphores, futexes, completions) – Non-blocking (e.g., spin-lock, …) • Sometimes we have to use spinlocks • Lock free (or partially lock free J) – Atomic instructions – seqLocks – RCU – Transactions (next time) 9
10 . Naïve implementation of spinlock • Lock(L): While(test_and_set(L)); //we have the lock! //eat, dance and be merry • Unlock(L) L=0; 10
11 . Why naïve? • Works? Yes, but not used in practice • Contention – Think about the cache coherence protocol – Set in test and set is a write operation • Has to go to memory • A lot of cache coherence traffic • Unnecessary unless the lock has been released • Imagine if many threads are waiting to get the lock • Fairness/starvation 11
12 . Better implementation Spin on read • Assumption: We have cache coherence – Not all are: e.g., Intel SCC • Lock(L): while(L==locked); //wait if(test_and_set(L)==locked) go back; • Still a lot of chattering when there is an unlock – Spin lock with backoff 12
13 . Bakery Algorithm struct lock { int next_ticket; int now_serving; } • Acquire_lock: int my_ticket = fetch_and_inc(L->next_ticket); Still too much chatter while(L->new_serving!=my_ticket); //wait //Eat, Dance and me merry! • Release_lock: L->now_serving++; Comments? Fairness? Efficiency/cache coherence? 13
14 . Anderson Lock (Array lock) • Problem with bakery algorithm: – All threads listening to next_serving • A lot of cache coherence chatter – But only one will actually acquire the lock – Can we have each thread wait on a different variable to reduce chatter? 14
15 . Anderson’s Lock • We have an array (actually circular queue) of variables – Each variable can indicate either lock available or waiting for lock • Only one location has lock available Lock(L): my_place = fetch_and_inc (queuelast); while (flags[myplace mod N] == must_wait); Unlock(L) flags[myplace mod N] = must_wait; flags[mypalce+1 mod N] = available; Fair and not noisy – compare to spin-on-read and bakery algorithm 15 Any negative side effects?
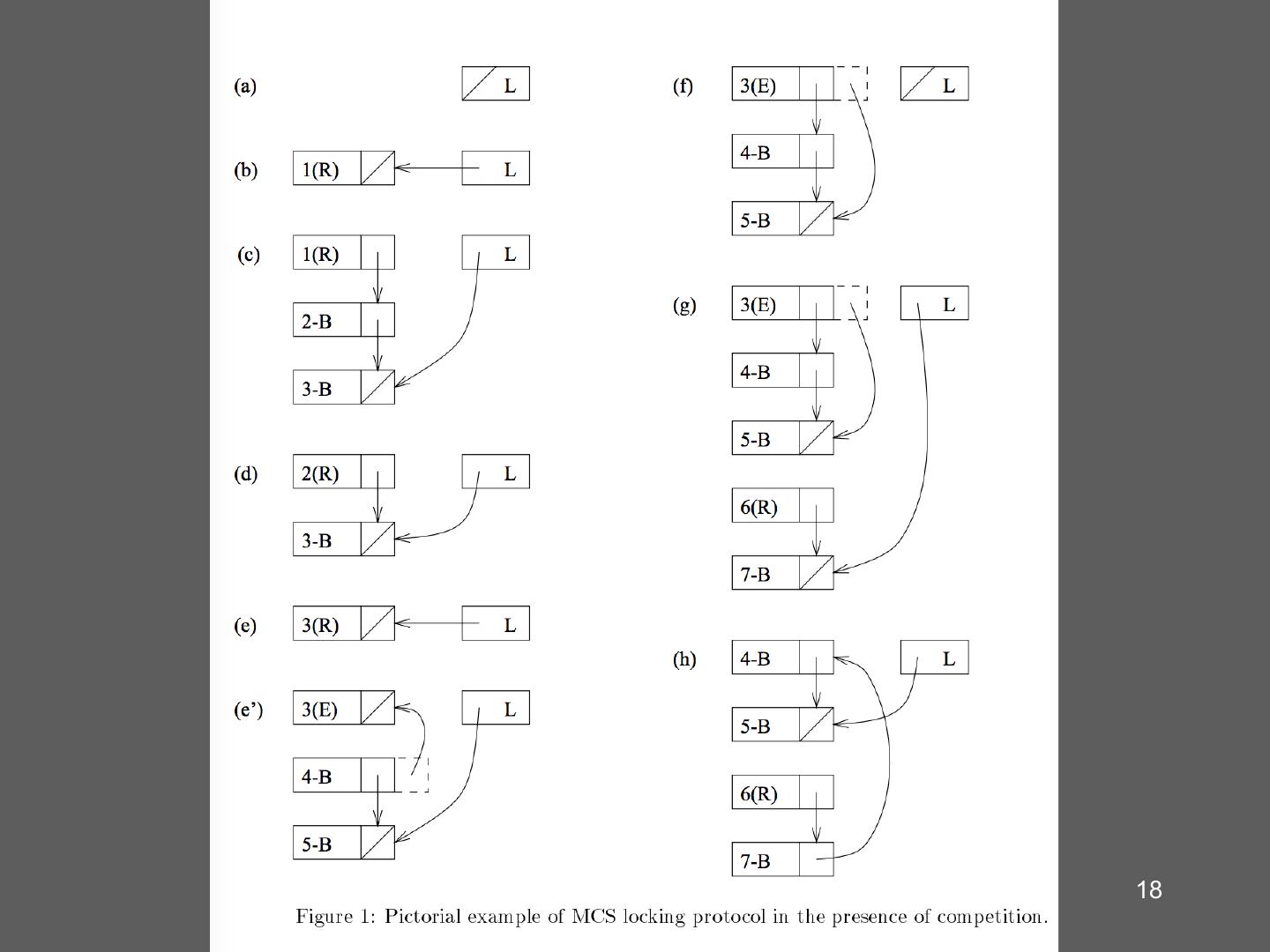
16 . MCS Lock Lock • Each node has: struct node { Lock me bool got_it; Current Next; //successor} Lock me Lock(L, me) Unlock(L,me) join(L); //use fetch-n-store remove me from L while(got_it == 0); signal successor (setting got it to 0) 16
17 . Race condition! • What if there is a new joiner when the last element is removing itself 17
18 .18
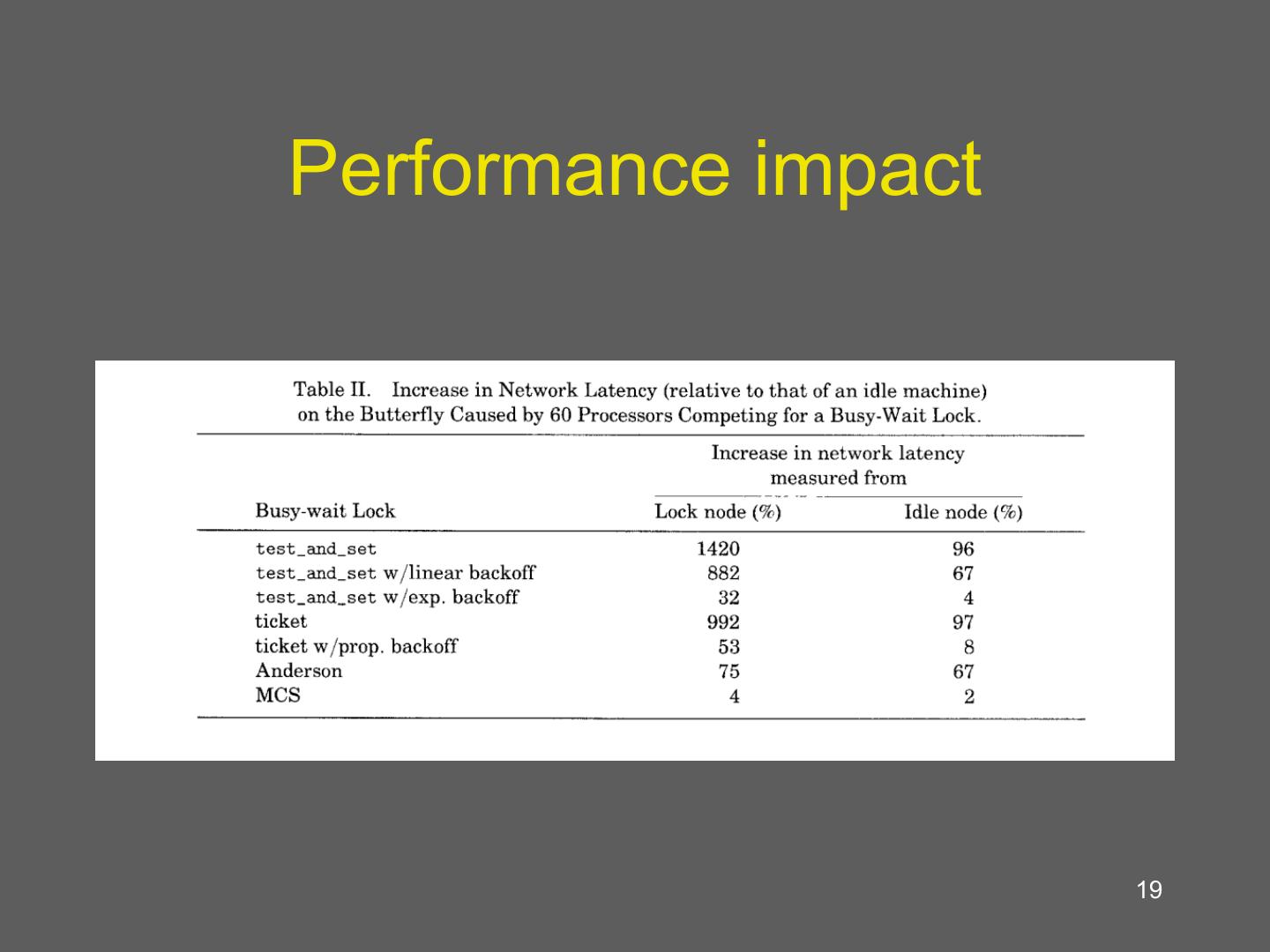
19 .Performance impact 19
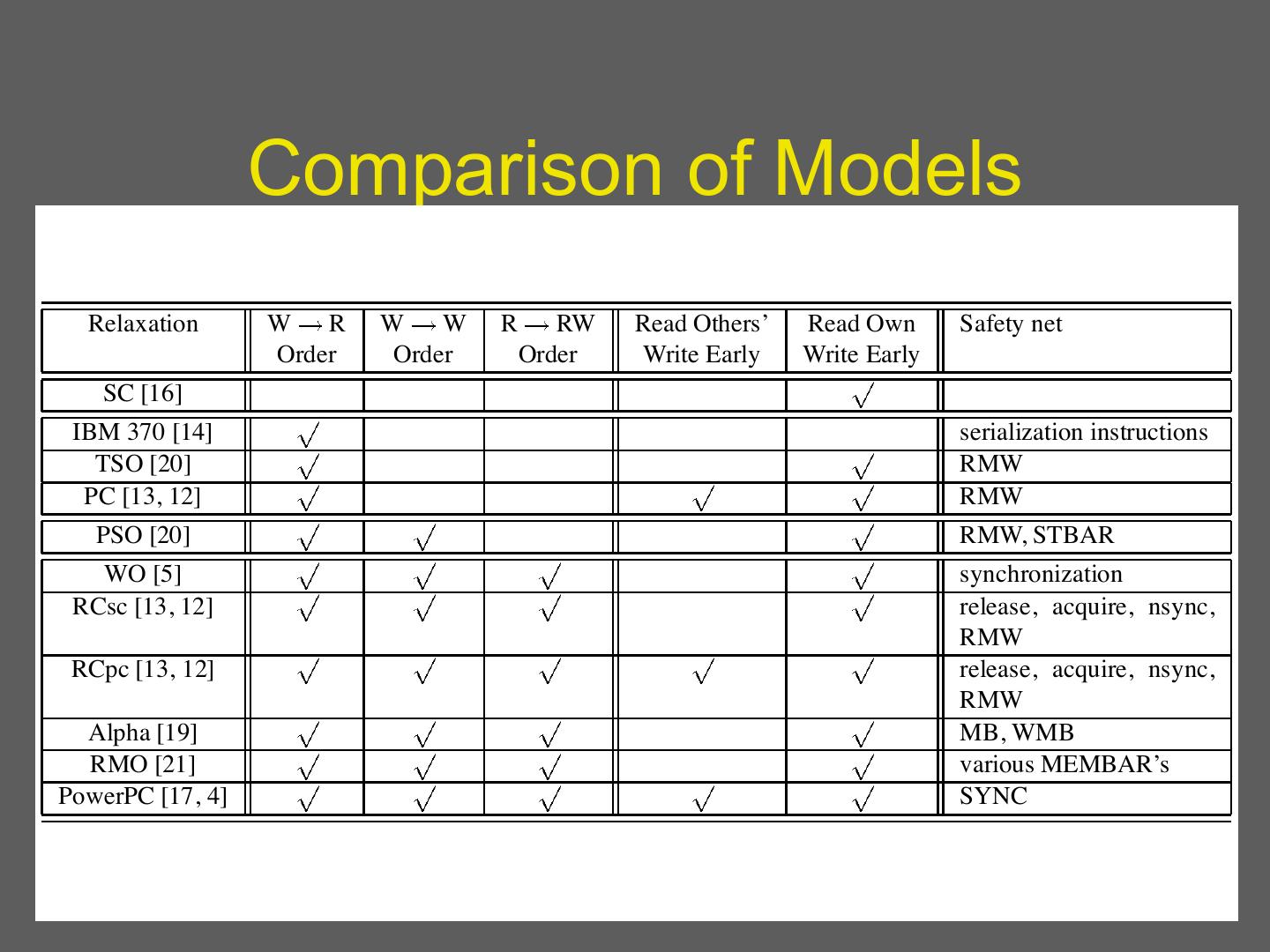
20 .Concurrency and Memory Consistency References: • Shared Memory Consistency Models: A Tutorial, Sarita V. Adve & Kourosh Gharachorloo, September 1995 • A primer on memory consistency and cache coherence, Sorin, Hill and wood, 2011 (chapters 3 and 4) • Memory Models: A Case for Rethinking Parallel Languages and Hardware, Adve and Boehm, 2010 20
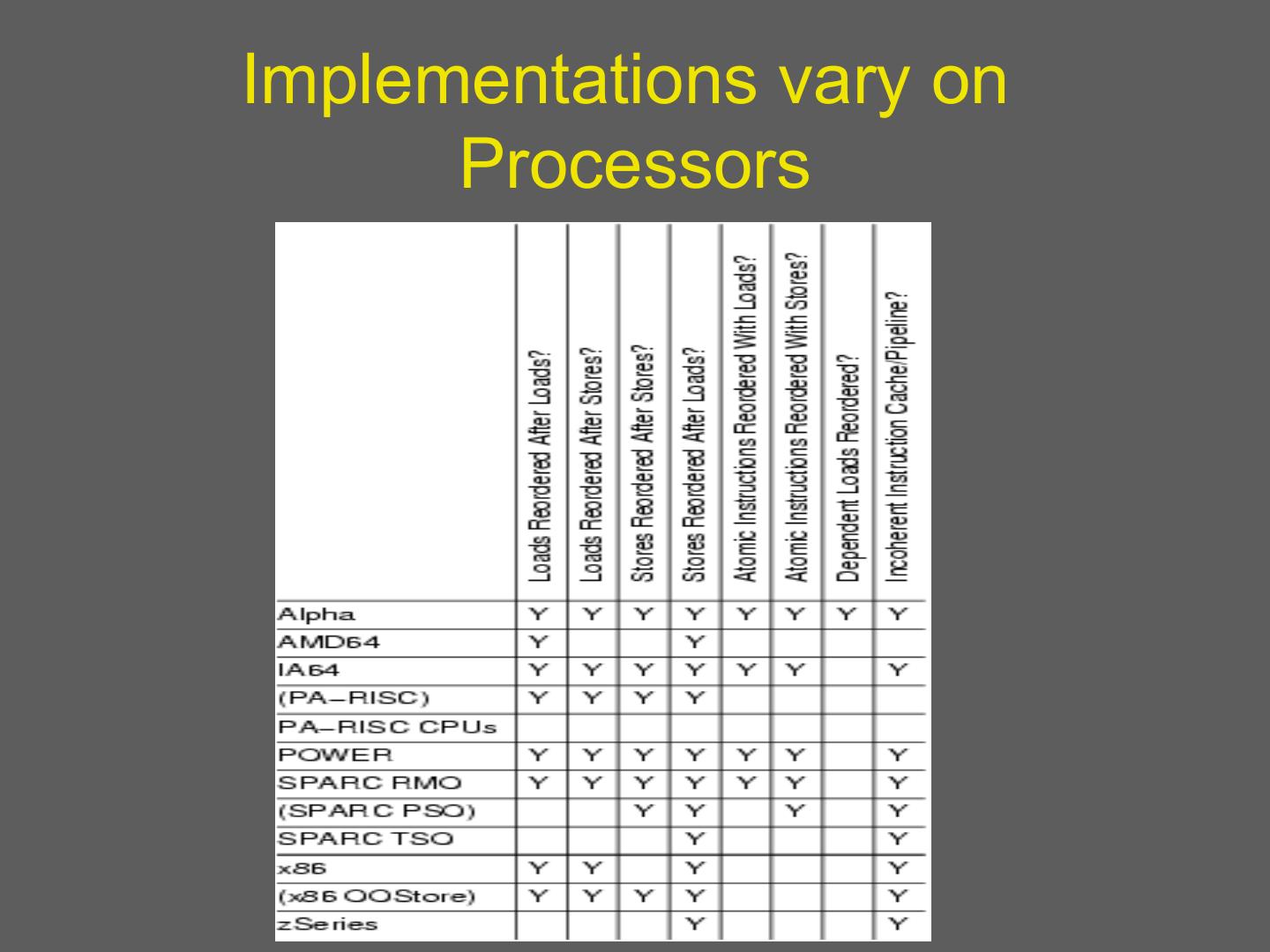
21 . Memory Consistency • Formal specification of memory semantics • Guarantees as to how shared memory will behave on systems with multiple processors • Ordering of reads and writes • Essential for programmer (OS writer!) to understand 21
22 . Why Bother? • Memory consistency models affect everything – Programmability – Performance – Portability • Model must be defined at all levels • Programmers and system designers care 22
23 . Uniprocessor Systems • Memory operations occur: – One at a time – In program order • Read returns value of last write – Only matters if location is the same or dependent – Many possible optimizations • Intuitive! 23
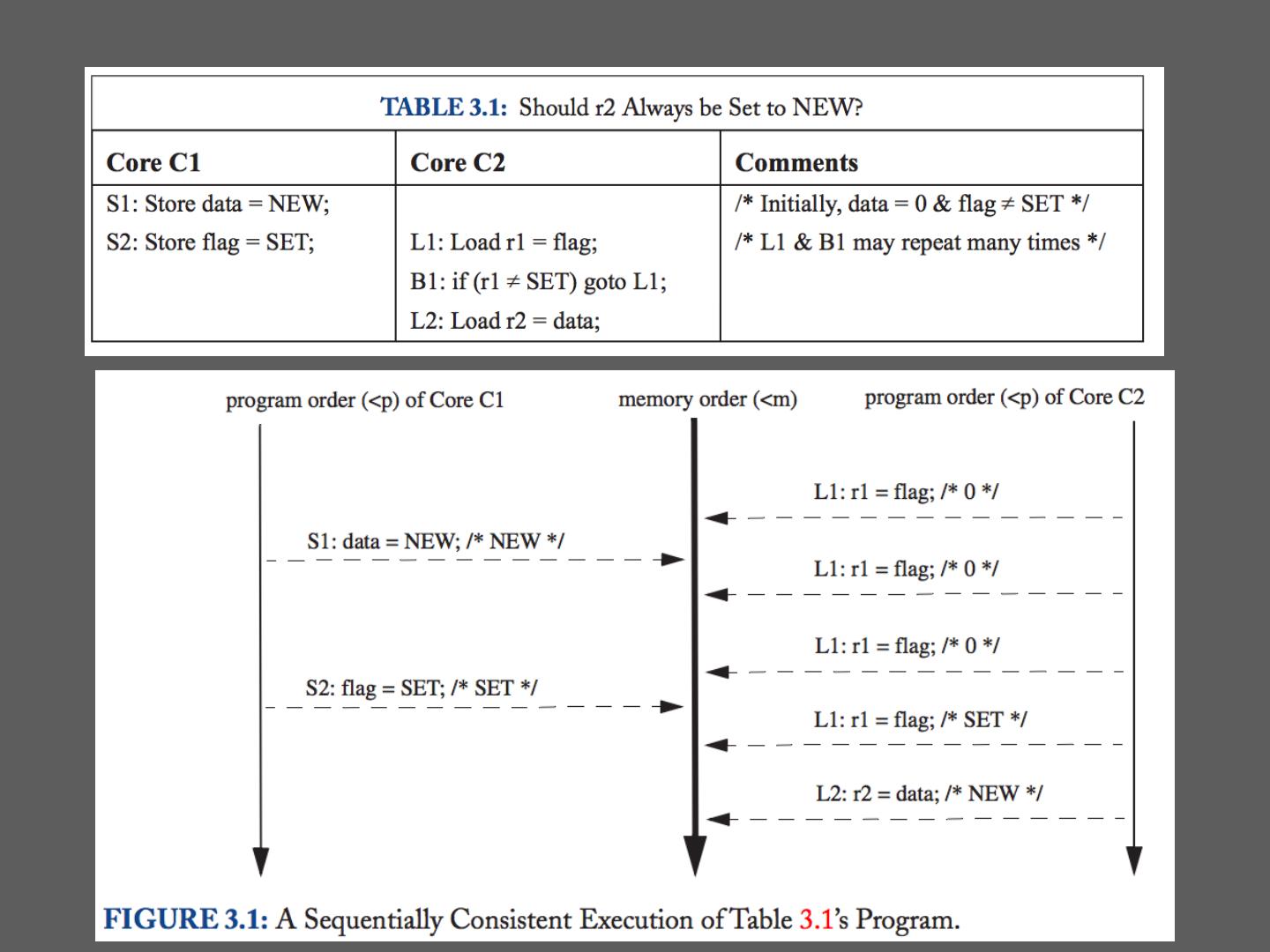
24 .Multiprocessor: Example 24
25 . Cont’d • S2 and S1 reordered – Why? How? 25
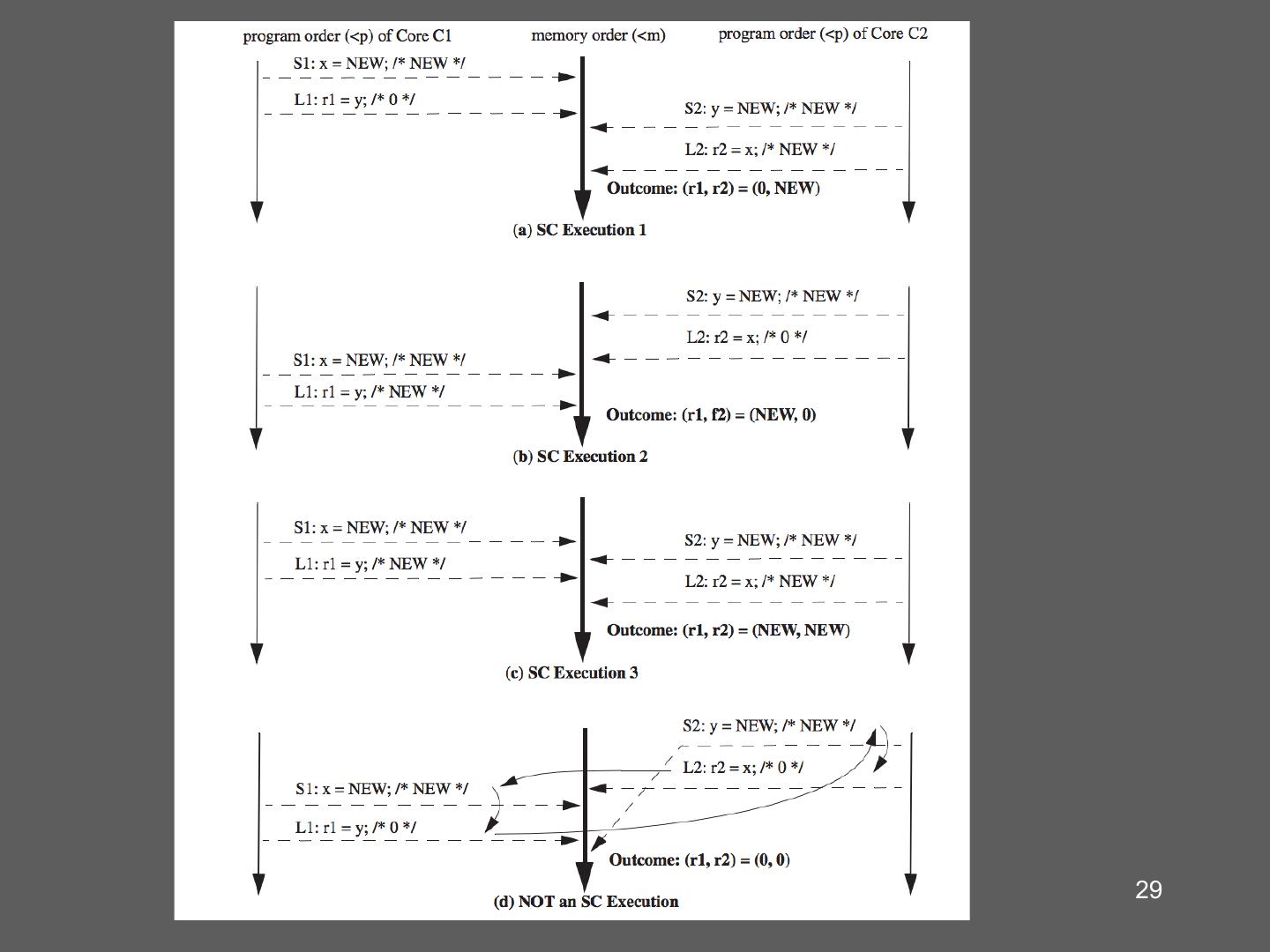
26 .Example 2 26
27 . Sequential Consistency … P1 P2 P3 Pn • The result of any execution is the same as if all operations were executed on a single processor • Operations on each processor occur in the Memory sequence specified by the executing program 27
28 .One execution sequence 28
29 .29
3秒后跳转登录页面
去登陆

