
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
微核系列的基本内容
本章具体介绍了微核的基本内容,通过学习L3、L4的内容讨论微内核系列基本概念,提出了关于微核建设的方法,提出了本文的主张。介绍了Threads and IPC的内容及其作用。
展开查看详情
1 .Advanced Operating Systems (CS 202) Scheduling (1) Jan, 23, 2017
2 . Administrivia • Lab has been released – You may work in pairs – Some more details about how to test your implementation may be added • But feel free to come up with your own • Sorry about short lead time for critiques – Will try to release reading one week ahead – We will drop your worse 2 critiques 2
3 .ON MICROKERNEL CONSTRUCTION (L3/4) 3
4 . L4 microkernel family • Successful OS with different offshoot distributions – Commercially successful • OKLabs OKL4 shipped over 1.5 billion installations by 2012 – Mostly qualcomm wireless modems – But also player in automative and airborne entertainment systems • Used in the secure enclave processor on Apple’s A7 chips – All iOS devices have it! 100s of millions 4
5 . Big picture overview • Conventional wisdom at the time was: – Microkernels offer nice abstractions and should be flexible – …but are inherently low performance due to high cost of border crossings and IPC – …because they are inefficient they are inflexible • This paper refutes the performance argument – Main takeaway: its an implementation issue • Identifies reasons for low performance and shows by construction that they are not inherent to microkernels – 10-20x improvement in performance over Mach • Several insights on how microkernels should (and shouldn’t) be built – E.g., Microkernels should not be portable 5
6 . Paper argues for the following • Only put in anything that if moved out prohibits functionality • Assumes: – We require security/protection – We require a page-based VM – Subsystems should be isolated from one another – Two subsystems should be able to communicate without involving a third 6
7 . Abstractions provided by L3 • Address spaces (to support protection/separation) – Grant, Map, Flush – Handling I/O • Threads and IPC – Threads: represent the address space – End point for IPC (messages) – Interrupts are IPC messages from kernel • Microkernel turns hardware interrupts to thread events • Unique ids (to be able to identify address spaces, threads, IPC end points etc..) 7
8 . Debunking performance issues • What are the performance issues? 1. Switching overhead • Kernel user switches • Address space switches • Threads switches and IPC 2. Memory locality loss • TLB • Caches 8
9 . Mode switches • System calls (mode switches) should not be expensive – Called context switches in the paper • Show that 90% of system call time on Mach is “overhead” – What? Paper doesn’t really say • Could be parameter checking, parameter passing, inefficiencies in saving state… – L3 does not have this overhead 9
10 . Thread/address space switches • If TLBs are not tagged, they must be flushed – Today? x86 introduced tags but they are not utilized • If caches are physically indexed, no loss of locality – No need to flush caches when address space changes • Customize switch code to HW • Empirically demonstrate that IPC is fast 10
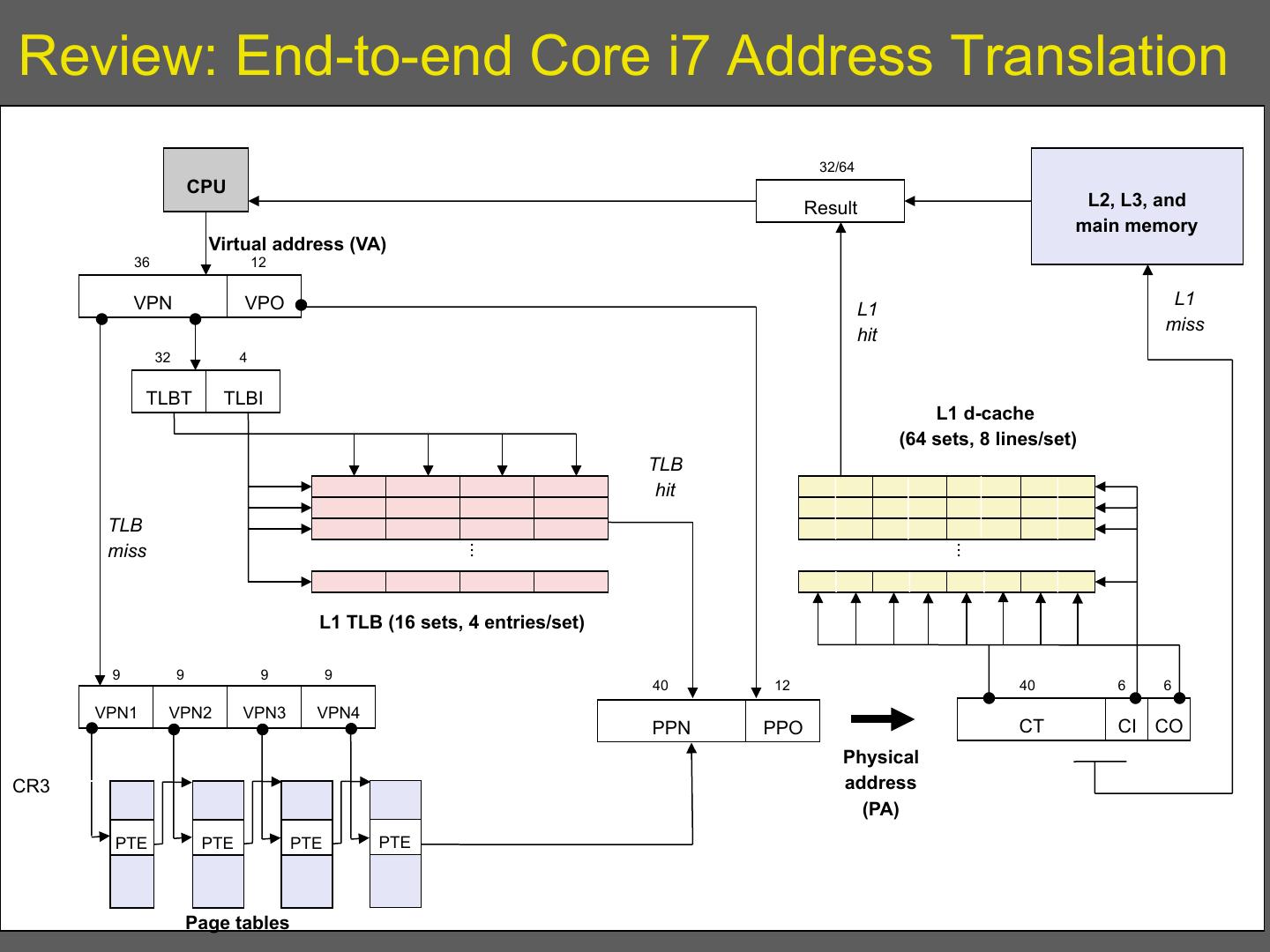
11 .Review: End-to-end Core i7 Address Translation 32/64 CPU Result L2, L3, and main memory Virtual address (VA) 36 12 VPN VPO L1 L1 miss hit 32 4 TLBT TLBI L1 d-cache (64 sets, 8 lines/set) TLB hit L2, L3, and TLB main memory miss ... ... L1 TLB (16 sets, 4 entries/set) 9 9 9 9 40 12 40 6 6 VPN1 VPN2 VPN3 VPN4 PPN PPO CT CI CO Physical CR3 address (PA) PTE PTE PTE PTE Page tables
12 . Tricks to reduce the effect • TLB flushes due to AS switch could be very expensive – Since microkernel increases AS switches, this is a problem – Tagged TLB? If you have them – Tricks with segments to provide isolation between small address spaces • Remap them as segments within one address space • Avoid TLB flushes 12
13 . Memory effects • Chen and Bershad showed memory behavior on microkernels worse than monolithic • Paper shows this is all due to more cache misses • Are they capacity or conflict misses? – Conflict: could be structure – Capacity: could be size of code • Chen and Bershad also showed that self- interference more of a problem than user-kernel interference • Ratio of conflict to capacity much lower in Mach – à too much code, most of it in Mach
14 . Conclusion • Its an implementation issue in Mach • Its mostly due to Mach trying to be portable • Microkernel should not be portable – It’sthe hardware compatibility layer – Example: implementation decisions even between 486 and Pentium are different if you want high performance – Think of microkernel as microcode 14
15 .Today: CPU Scheduling 15
16 . The Process • The process is the OS abstraction for execution – It is the unit of execution – It is the unit of scheduling – It is the dynamic execution context of a program – A process is sometimes called a job or a task • A process is a program in execution – Programs are static entities with the potential for execution – Process is the animated/active program • Starts from the program, but also includes dynamic state 16
17 .Process Address Space 0xFFFFFFFF Stack SP Dynamic Heap Address (Dynamic Memory Alloc) Space Static Data (Data Segment) Static Code PC (Text Segment) 0x00000000 17
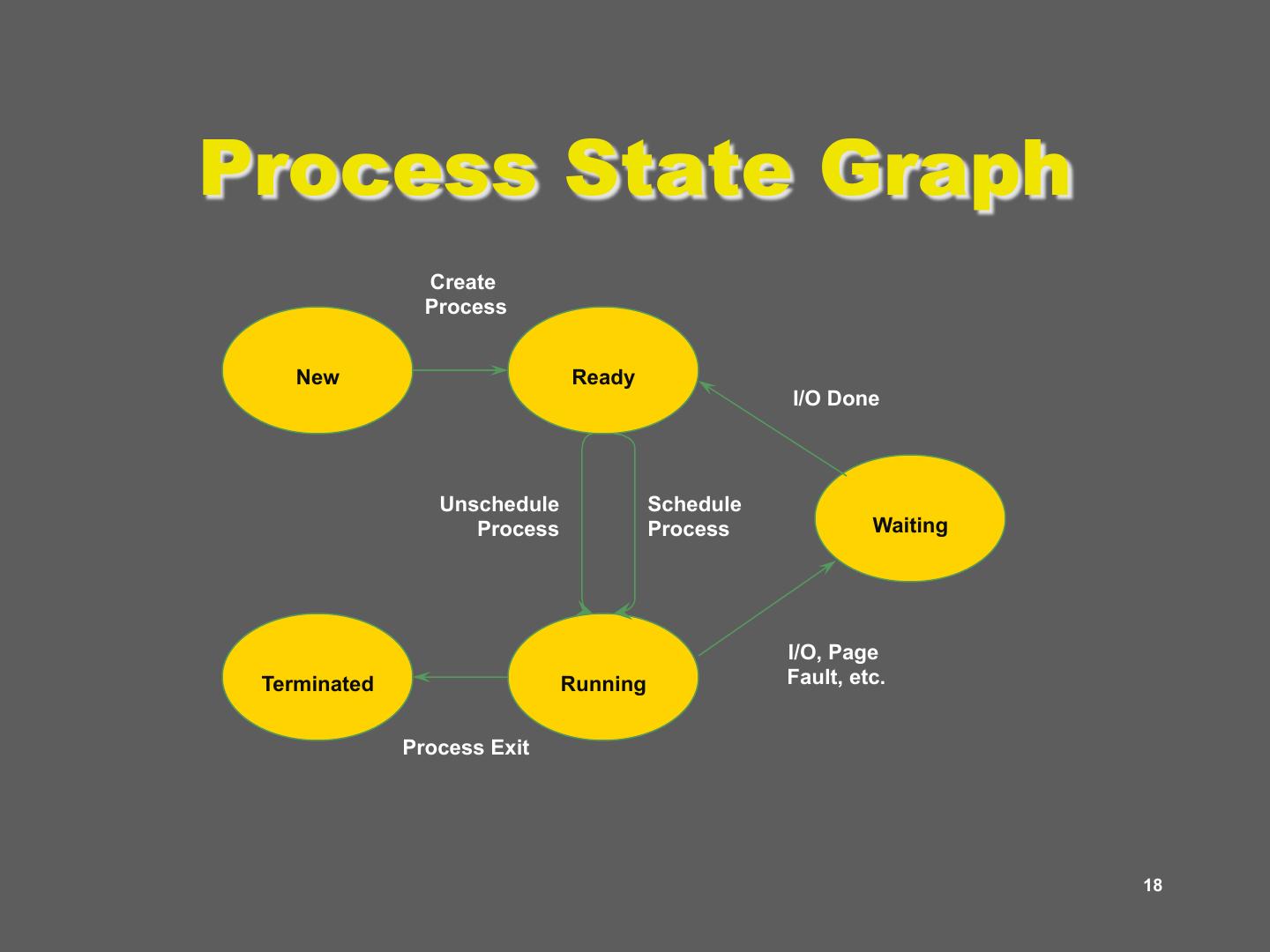
18 .Process State Graph Create Process New Ready I/O Done Unschedule Schedule Process Process Waiting I/O, Page Terminated Running Fault, etc. Process Exit 18
19 . Threads • Separate dual roles of a process – Resource allocation unit and execution unit – A thread defines a sequential execution stream within a process (PC, SP, registers) – A process defines the address space, and resources (everything but threads of execution) • A thread is bound to a single process – Processes, however, can have multiple threads • Threads become the unit of scheduling – Processes are now the containers in which threads execute – Processes become static, threads are the dynamic entities 19
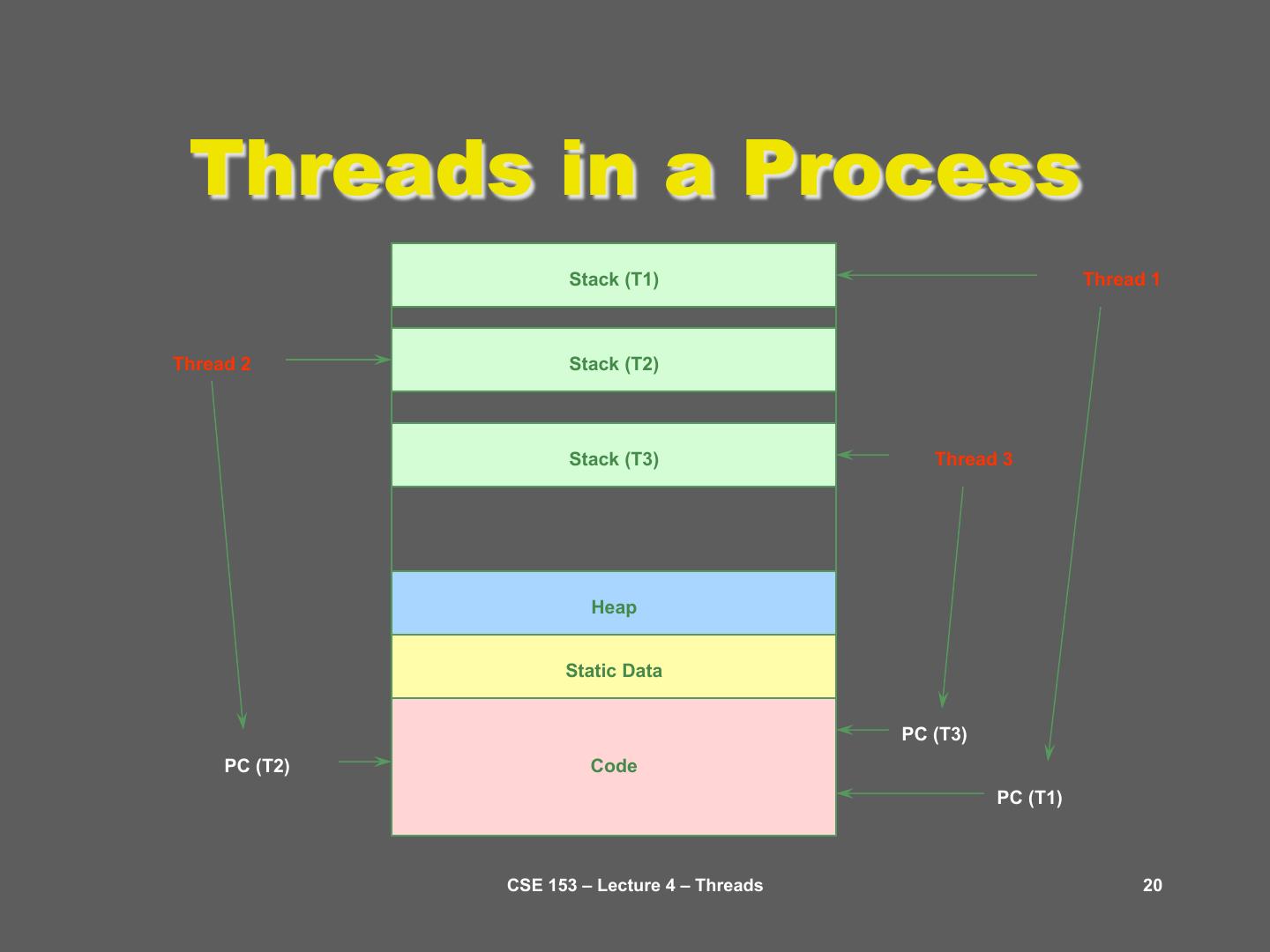
20 . Threads in a Process Stack (T1) Thread 1 Thread 2 Stack (T2) Stack (T3) Thread 3 Heap Static Data PC (T3) PC (T2) Code PC (T1) CSE 153 – Lecture 4 – Threads 20
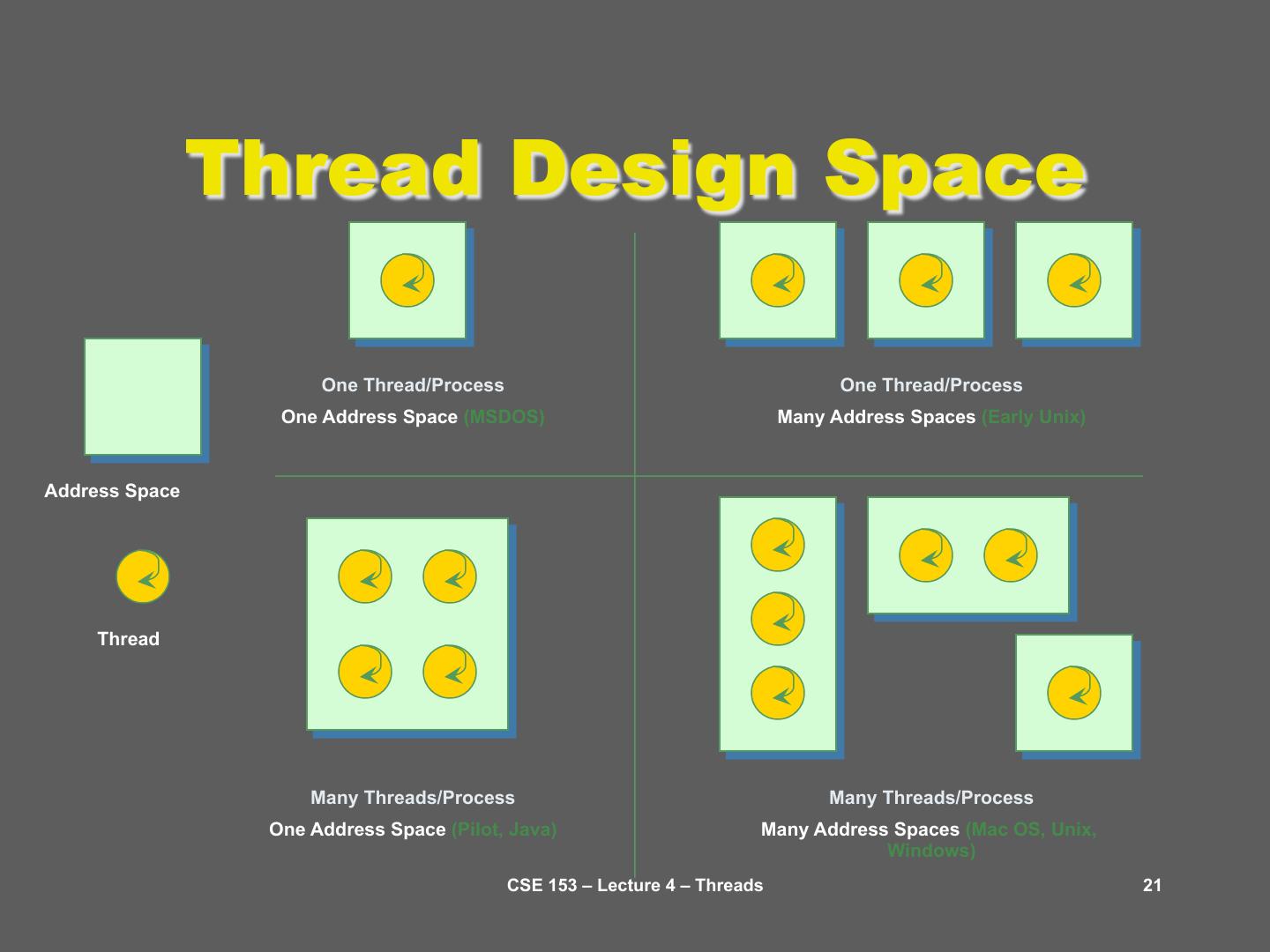
21 . Thread Design Space One Thread/Process One Thread/Process One Address Space (MSDOS) Many Address Spaces (Early Unix) Address Space Thread Many Threads/Process Many Threads/Process One Address Space (Pilot, Java) Many Address Spaces (Mac OS, Unix, Windows) CSE 153 – Lecture 4 – Threads 21
22 . Today: CPU Scheduling • Scheduler runs when we context switching among processes/threads on the ready queue – What should it do? Does it matter? • Making the decision on what thread to run is called scheduling – What are the goals of scheduling? – What are common scheduling algorithms? – Lottery scheduling • Scheduling activations – User level vs. Kernel level scheduling of threads 22
23 . Scheduling • Right from the start of multiprogramming, scheduling was identified as a big issue – CCTS and Multics developed much of the classical algorithms • Scheduling is a form of resource allocation – CPU is the resource – Resource allocation needed for other resources too; sometimes similar algorithms apply • Requires mechanisms and policy – Mechanisms: Context switching, Timers, process queues, process state information, … – Scheduling looks at the policies: i.e., when to switch and which process/ thread to run next 23
24 . Preemptive vs. Non- preemptive scheduling • In preemptive systems where we can interrupt a running job (involuntary context switch) – We’re interested in such schedulers… • In non-preemptive systems, the scheduler waits for a running job to give up CPU (voluntary context switch) – Was interesting in the days of batch multiprogramming – Some systems continue to use cooperative scheduling – Example algorithms: RR, Shortest Job First (how to determine shortest), … 24
25 . Scheduling Goals • What are some reasonable goals for a scheduler? • Scheduling algorithms can have many different goals: – CPU utilization – Job throughput (# jobs/unit time) – Response time (Avg(Tready): avg time spent on ready queue) – Fairness (or weighted fairness) – Other? • Non-interactive applications: – Strive for job throughput, turnaround time (supercomputers) • Interactive systems – Strive to minimize response time for interactive jobs • Mix? 25
26 . Goals II: Avoid Resource allocation pathologies • Starvation no progress due to no access to resources – E.g., a high priority process always prevents a low priority process from running on the CPU – One thread always beats another when acquiring a lock • Priority inversion – A low priority process running before a high priority one – Could be a real problem, especially in real time systems • Mars pathfinder: http://research.microsoft.com/en-us/um/people/mbj/ Mars_Pathfinder/Authoritative_Account.html • Other – Deadlock, livelock, convoying … 26
27 . Non-preemptive approaches • Introduced just to have a baseline • FIFO: schedule the processes in order of arrival – Comments? • Shortest Job first – Comments? 27
28 . Preemptive scheduling: Round Robin • Each task gets resource for a fixed period of time (time quantum) – If task doesn’t complete, it goes back in line • Need to pick a time quantum – What if time quantum is too long? • Infinite? – What if time quantum is too short? • One instruction?
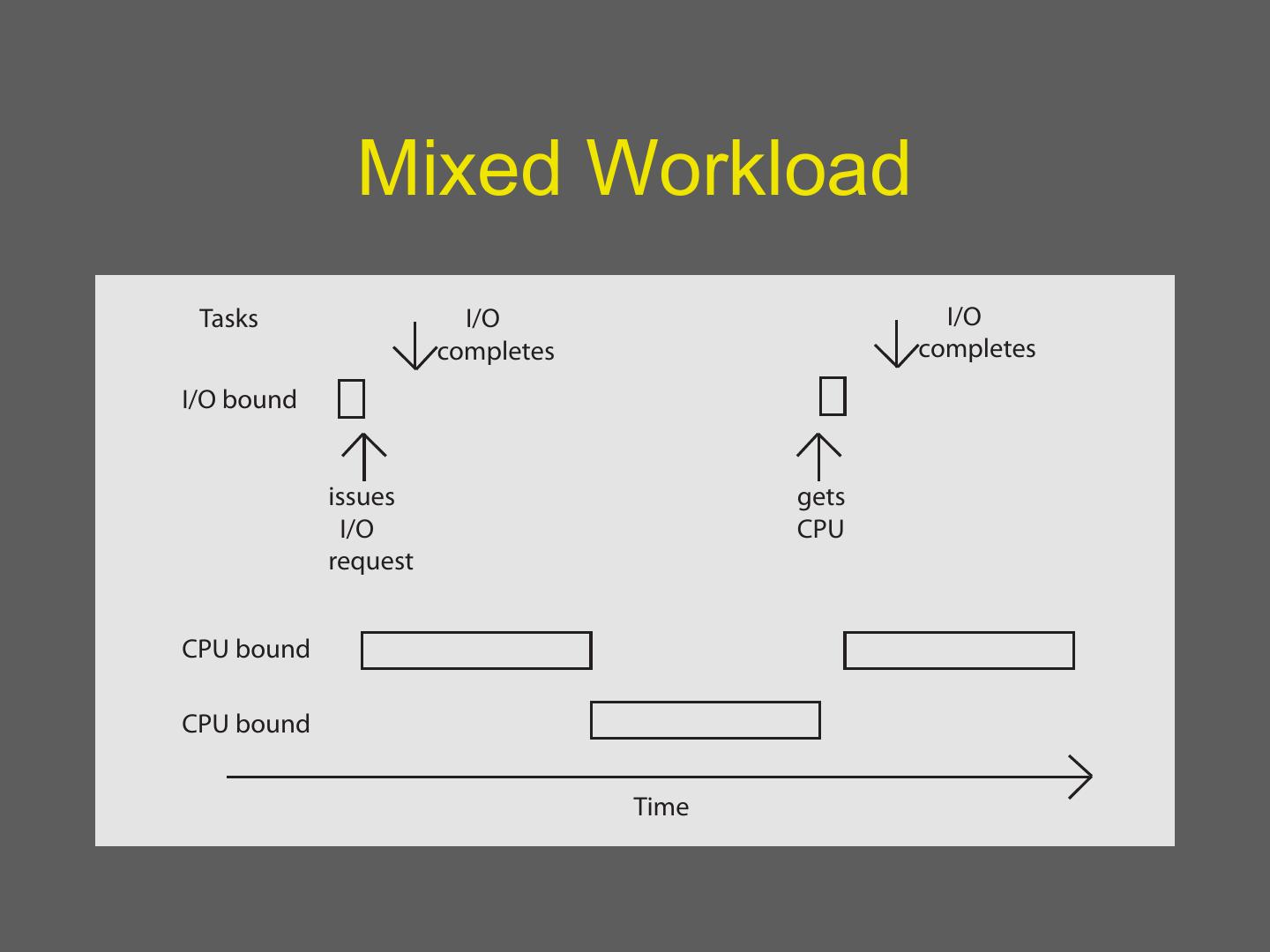
29 . Mixed Workload Tasks I/O I/O completes completes I/O bound issues gets I/O CPU request CPU bound CPU bound Time
3秒后跳转登录页面
去登陆

