















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
NFS(Network File System)简介
本文主要学习NFS(Network File System)即网络文件系统的基本概念,发展历程及应用。网络文件系统具有快速高效的碰撞恢复的特点,NFS是design decision 的关键。
展开查看详情
1 . Filesystems Lecture 11 Credit: Uses some slides by Jehan-Francois Paris, Mark Claypool and Jeff Chase
2 .DESIGN AND IMPLEMENTATION OF THE SUN NETWORK FILESYSTEM R. Sandberg, D. Goldberg S. Kleinman, D. Walsh, R. Lyon Sun Microsystems
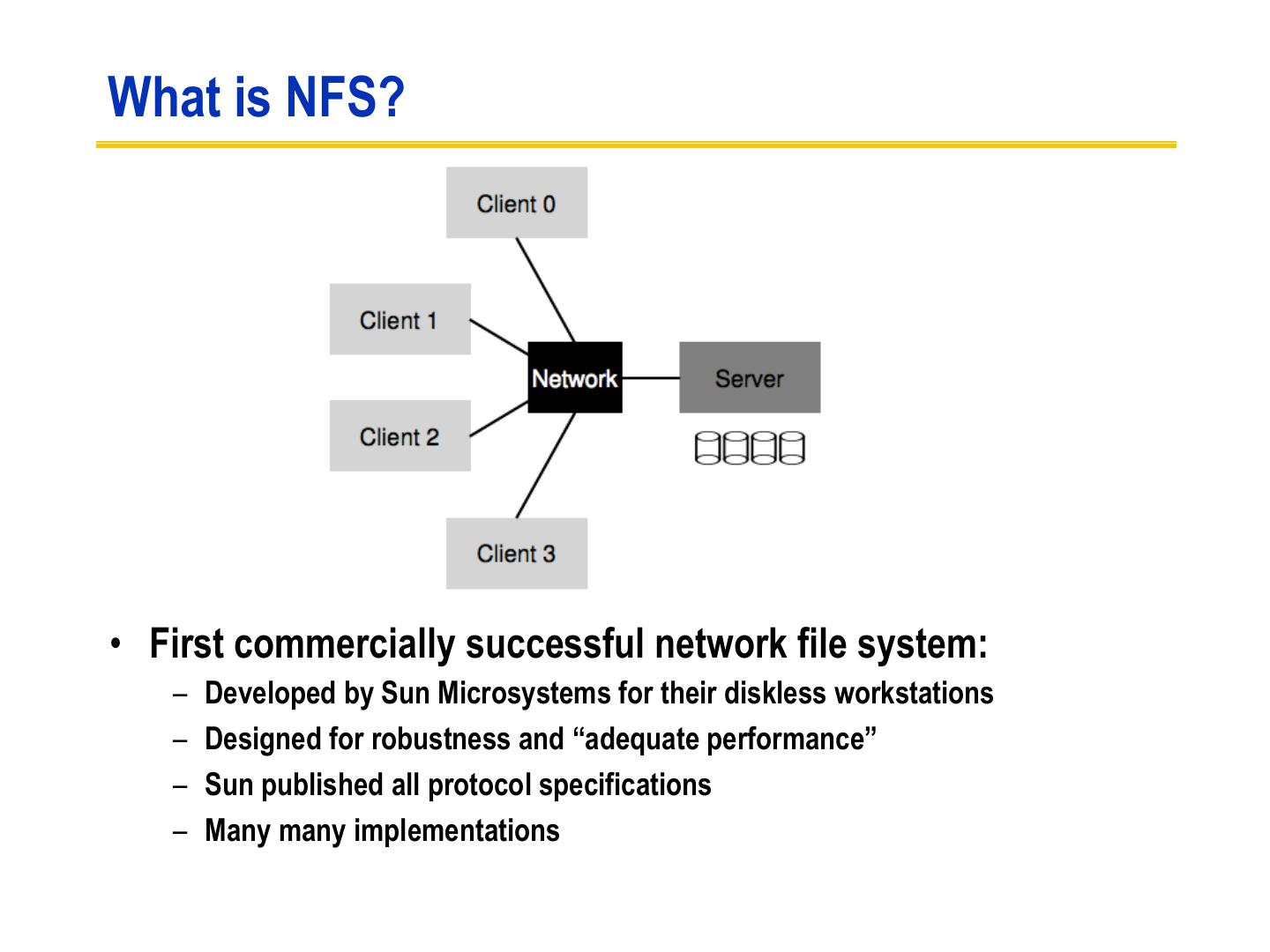
3 .What is NFS? • First commercially successful network file system: – Developed by Sun Microsystems for their diskless workstations – Designed for robustness and “adequate performance” – Sun published all protocol specifications – Many many implementations
4 .Overview and Objectives • Fast and efficient crash recovery – Why do crashes occur? • To accomplish this: – NFS is stateless – key design decision » All client requests must be self-contained – The virtual filesystem interface » VFS operations » VNODE operations
5 .Additional objectives • Machine and Operating System Independence – Could be implemented on low-end machines of the mid-80’s • Transparent Access – Remote files should be accessed in exactly the same way as local files • UNIX semantics should be maintained on client – Best way to achieve transparent access • “Reasonable” performance – Robustness and preservation of UNIX semantics were much more important
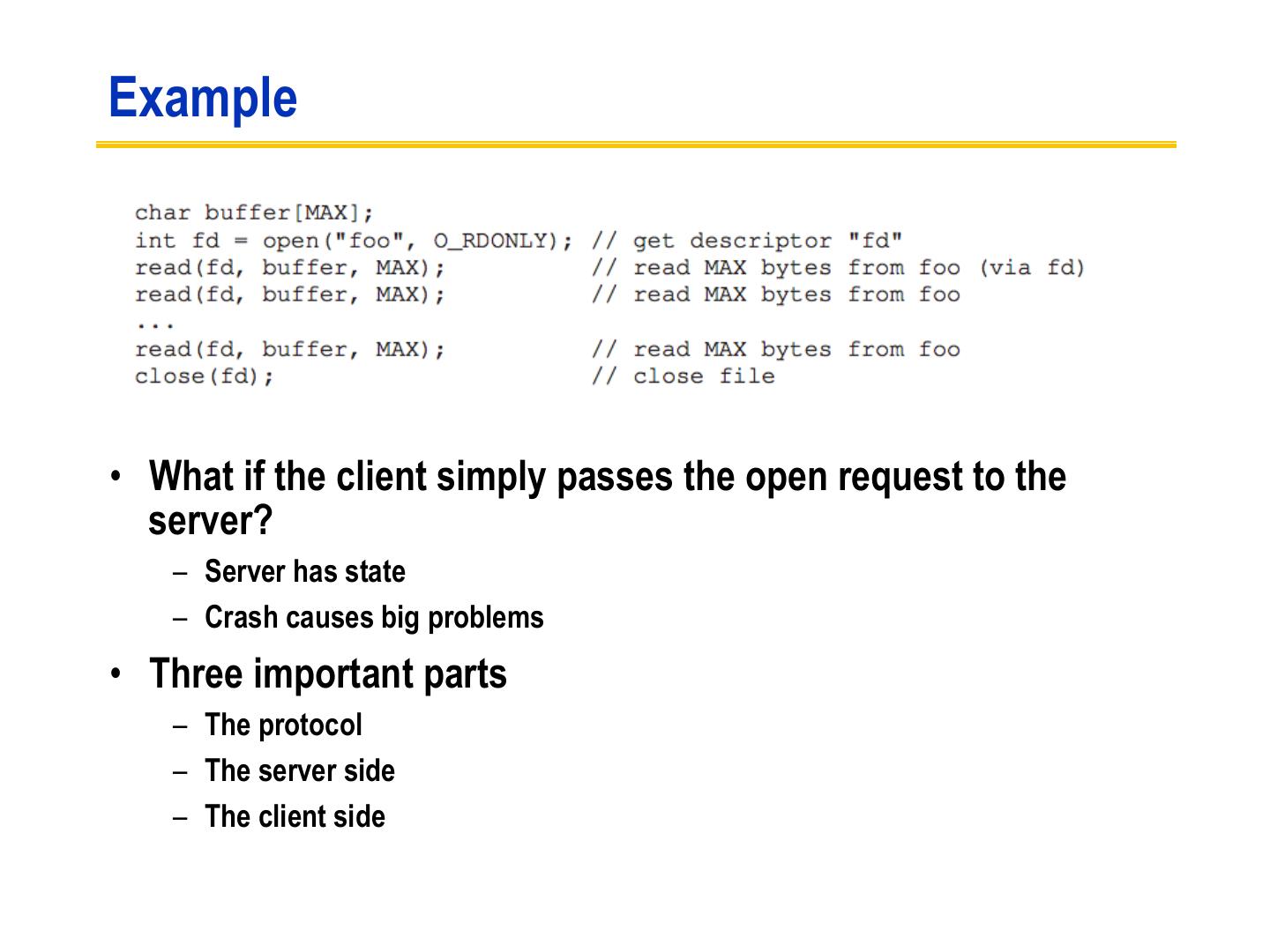
6 .Example • What if the client simply passes the open request to the server? – Server has state – Crash causes big problems • Three important parts – The protocol – The server side – The client side
7 .The protocol (I) • Uses the Sun RPC mechanism and Sun eXternal Data Representation (XDR) standard • Defined as a set of remote procedures • Protocol is stateless – Each procedure call contains all the information necessary to complete the call – Server maintains no “between call” information
8 .Advantages of statelessness • Crash recovery is very easy: – When a server crashes, client just resends request until it gets an answer from the rebooted server – Client cannot tell difference between a server that has crashed and recovered and a slow server • Client can always repeat any request
9 .NFS as a “Stateless” Service • A classical NFS server maintains no in-memory hard state. » The only hard state is the stable file system image on disk. – no record of clients or open files – no implicit arguments to requests » E.g., no server-maintained file offsets: read and write requests must explicitly transmit the byte offset for each operation. – no write-back caching on the server – no record of recently processed requests – etc., etc.... • Statelessness makes failure recovery simple and efficient.
10 .Consequences of statelessness • Read and writes must specify their start offset – Server does not keep track of current position in the file – User still use conventional UNIX reads and writes • Open system call translates into several lookup calls to server • No NFS equivalent to UNIX close system call
11 .Important pieces of protocol
12 .From protocol to distributed file system • Client side translates user requests to protocol messages to implement the request remotely • Example:
13 .The lookup call (I) • Returns a file handle instead of a file descriptor – File handle specifies unique location of file » Volume identifier, inode number and generation number • lookup(dirfh, name) returns (fh, attr) – Returns file handle fh and attributes of named file in directory dirfh – Fails if client has no right to access directory dirfh
14 .The lookup call (II) – One single open call such as fd = open(“/usr/joe/6360/list.txt”) will be result in several calls to lookup lookup(rootfh, “usr”) returns (fh0, attr) lookup(fh0, “joe”) returns (fh1, attr) lookup(fh1, “6360”) returns (fh2, attr) lookup(fh2, “list.txt”) returns (fh, attr) • Why all these steps? – Any of components of /usr/joe/6360/list.txt could be a mount point – Mount points are client dependent and mount information is kept above the lookup() level
15 .Server side (I) • Server implements a write-through policy – Required by statelessness – Any blocks modified by a write request (including i-nodes and indirect blocks) must be written back to disk before the call completes
16 .Server side (II) • File handle consists of – Filesystem id identifying disk partition – I-node number identifying file within partition – Generation number changed every time i-node is reused to store a new file • Server will store – Filesystem id in filesystem superblock – I-node generation number in i-node
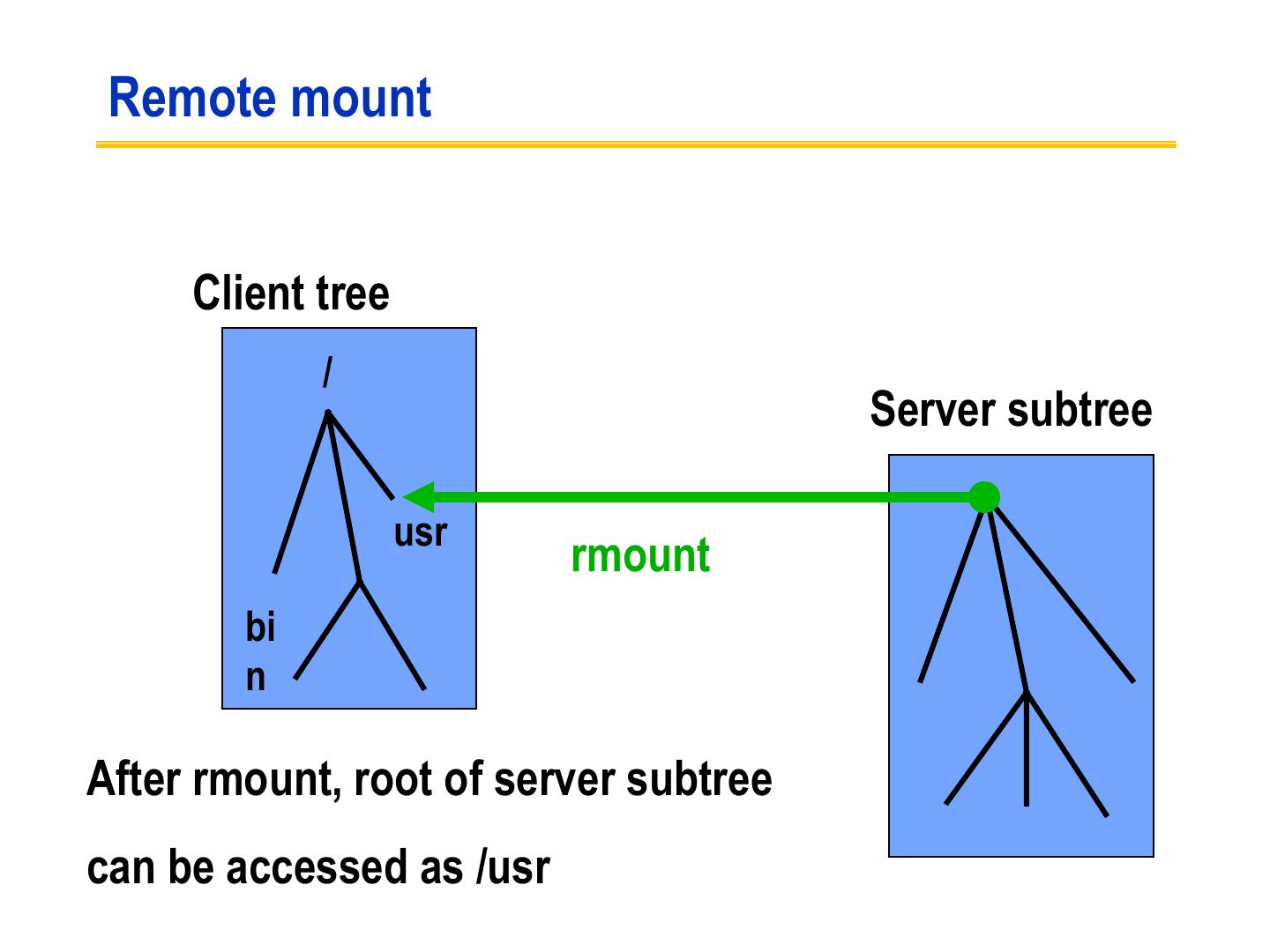
17 .Client side (I) • Provides transparent interface to NFS • Mapping between remote file names and remote file addresses is done a server boot time through remote mount – Extension of UNIX mounts – Specified in a mount table – Makes a remote subtree appear part of a local subtree
18 . Remote mount Client tree / Server subtree usr rmount bi n After rmount, root of server subtree can be accessed as /usr
19 .Client side (II) • Provides transparent access to – NFS – Other file systems (including UNIX FFS) • New virtual filesystem interface supports – VFS calls, which operate on whole file system – VNODE calls, which operate on individual files • Treats all files in the same fashion
20 .Client side (III) User UNIX system callsinterface is unchanged VNODE/VFS Common interface Other FS NFS UNIX FS RPC/XDR disk LAN
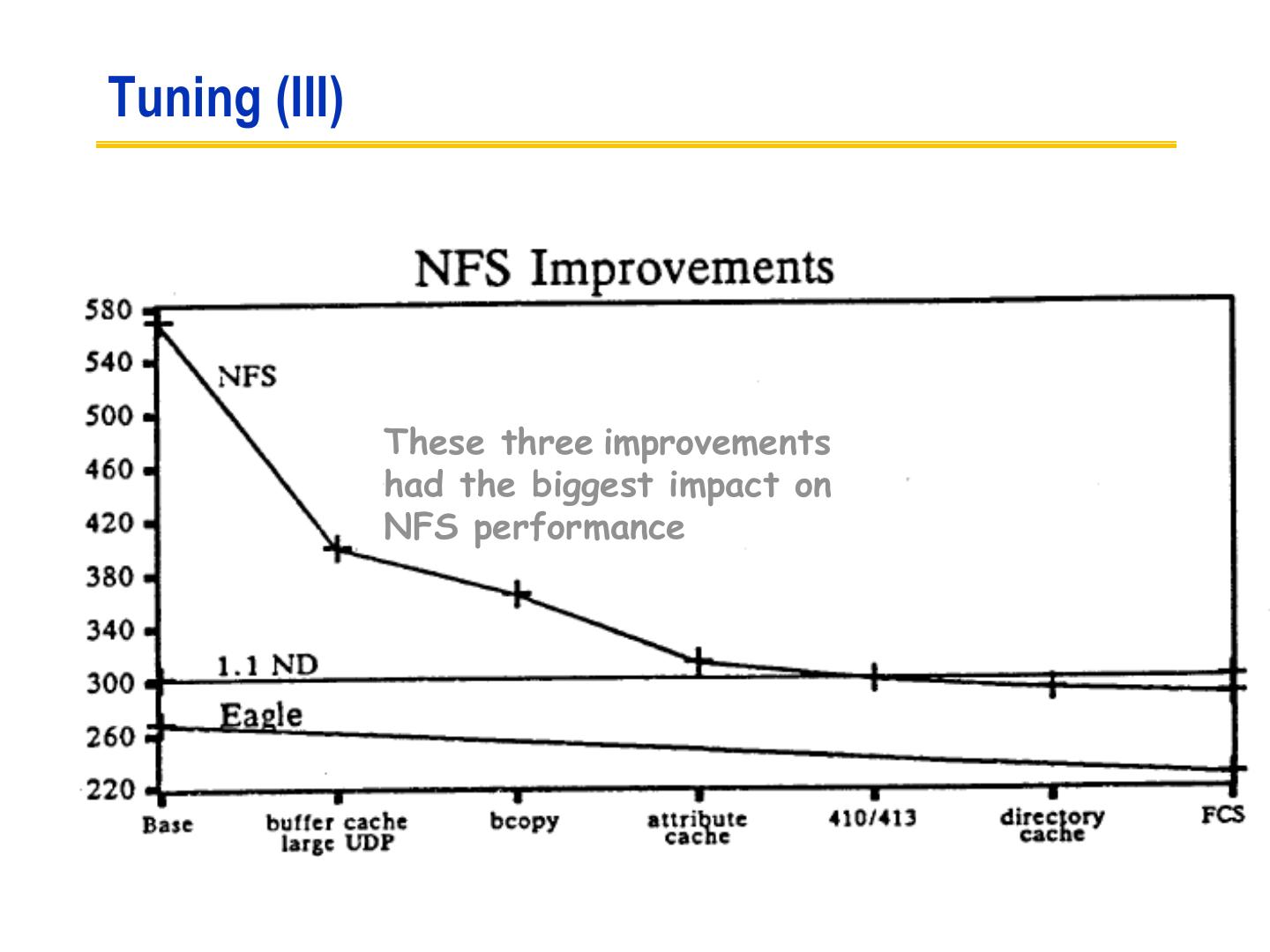
21 .More examples
22 .Continued
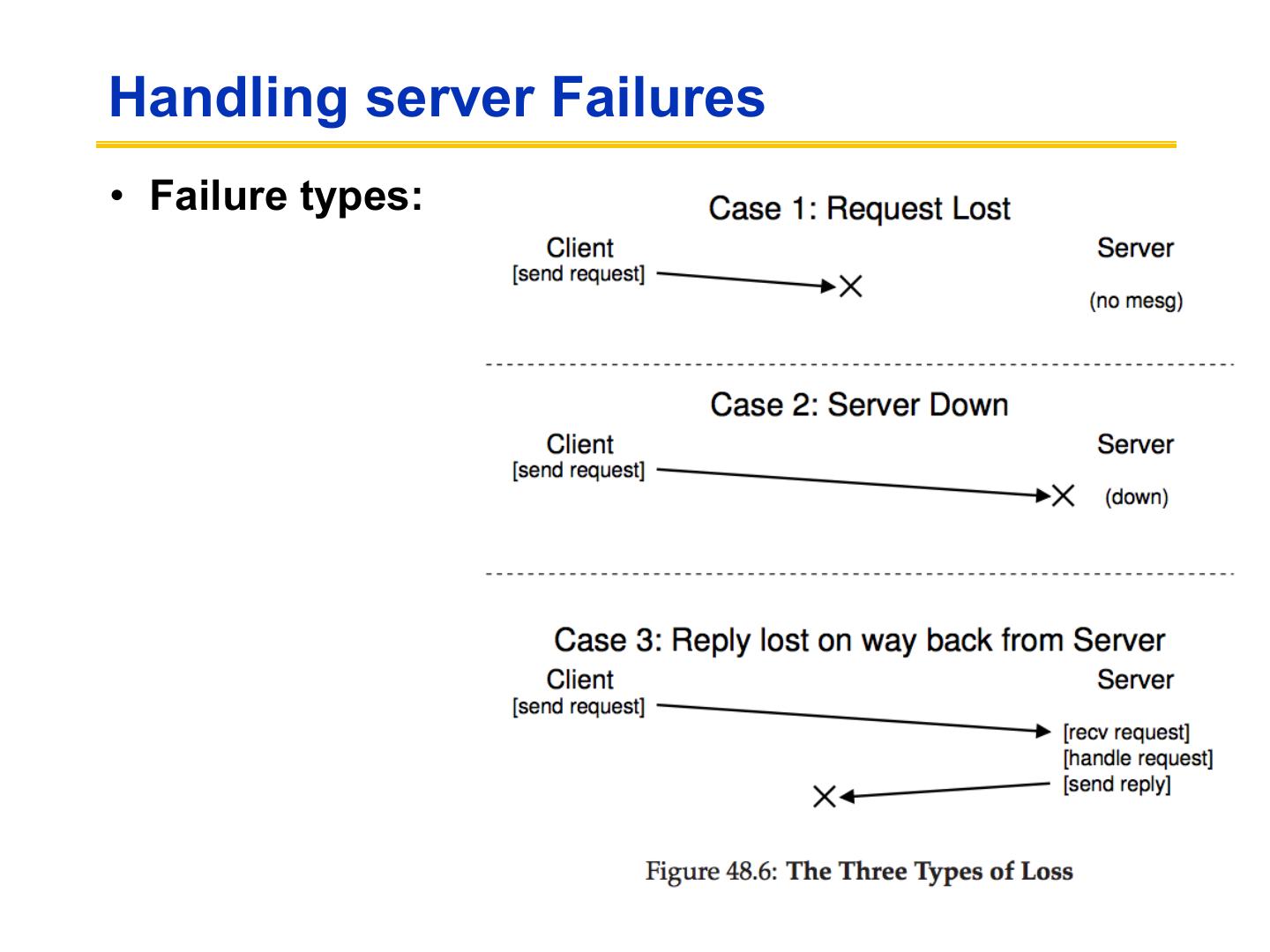
23 .Handling server Failures • Failure types:
24 .Recovery in Stateless NFS • If the server fails and restarts, there is no need to rebuild in-memory state on the server. – Client reestablishes contact (e.g., TCP connection). – Client retransmits pending requests. • Classical NFS uses a connectionless transport (UDP). – Server failure is transparent to the client; no connection to break or reestablish. » A crashed server is indistinguishable from a slow server. – Sun/ONC RPC masks network errors by retransmitting a request after an adaptive timeout. » A dropped packet is indistinguishable from a crashed server.
25 .Drawbacks of a Stateless Service • The stateless nature of classical NFS has compelling design advantages (simplicity), but also some key drawbacks: – Recovery-by-retransmission constrains the server interface. » ONC RPC/UDP has execute-at-least-once semantics (“send and pray”), which compromises performance and correctness. – Update operations are disk-limited. » Updates must commit synchronously at the server. – NFS cannot (quite) preserve local single-copy semantics. » Files may be removed while they are open on the client. » Server cannot help in client cache consistency. • Let’s explore these problems and their solutions...
26 . Problem 1: Retransmissions and Idempotency • For a connectionless RPC transport, retransmissions can saturate an overloaded server. » Clients “kick ‘em while they’re down”, causing steep hockey stick. • Execute-at-least-once constrains the server interface. – Service operations should/must be idempotent. » Multiple executions should/must have the same effect. – Idempotent operations cannot capture the full semantics we expect from our file system. » remove, append-mode writes, exclusive create
27 .Solutions to the Retransmission Problem • 1. Hope for the best and smooth over non- idempotent requests. » E.g., map ENOENT and EEXIST to ESUCCESS. • 2. Use TCP or some other transport protocol that produces reliable, in-order delivery. » higher overhead...and we still need sessions. • 3. Implement an execute-at-most once RPC transport. » TCP-like features (sequence numbers)...and sessions. • 4. Keep a retransmission cache on the server [Juszczak90]. » Remember the most recent request IDs and their results, and just resend the result....does this violate statelessness? » DAFS persistent session cache.
28 .Problem 2: Synchronous Writes • Stateless NFS servers must commit each operation to stable storage before responding to the client. – Interferes with FS optimizations, e.g., clustering, LFS, and disk write ordering (seek scheduling). » Damages bandwidth and scalability. – Imposes disk access latency for each request. » Not so bad for a logged write; much worse for a complex operation like an FFS file write. • The synchronous update problem occurs for any storage service with reliable update (commit).
29 .Speeding Up Synchronous NFS Writes • Interesting solutions to the synchronous write problem, used in high-performance NFS servers: – Delay the response until convenient for the server. » E.g., NFS write-gathering optimizations for clustered writes (similar to group commit in databases). » Relies on write-behind from NFS I/O daemons (iods). – Throw hardware at it: non-volatile memory (NVRAM) » Battery-backed RAM or UPS (uninterruptible power supply). » Use as an operation log (Network Appliance WAFL)... » ...or as a non-volatile disk write buffer (Legato). – Replicate server and buffer in memory (e.g., MIT Harp).
3秒后跳转登录页面
去登陆

