































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Turbo码的介绍
Turbo码又称并行级联卷积码(PCCC,Parallel Concatenated Convolutional Code),它巧妙地将卷积码和随机交织器结合在一起,在实现随机编码思想的同时,通过交织器实现了由短码构造长码的方法,并采用软输出迭代译码来逼近最大似然译码。可见,Turbo码充分利用了Shannon信道编码定理的基本条件,因此得到了接近Shannon极限的性能。
展开查看详情
1 . 第六章 Turbo 码 虽然软判决译码、级联码和编码调制技术都对信道码的设计和发 展产生了重大影响,但是其增益与 Shannon 理论极限始终都存在 2~ 3dB 的差距。因此,在 Turbo 码提出以前,信道截止速率 R0 一直被 认为是差错控制码性能的实际极限,Shannon 极限仅仅是理论上的极 限,是不可能达到的。 根据 Shannon 有噪信道编码定理,在信道传输速率 R 不超过信道 容量 C 的前提下,只有在码组长度无限的码集合中随机地选择编码 码字并且在接收端采用最大似然译码算法时,才能使误码率接近为 零。但是最大似然译码的复杂性随编码长度的增加而加大,当编码长 度趋于无穷大时,最大似然译码是不可能实现的。所以人们认为随机 性编译码仅仅是为证明定理存在性而引入的一种数学方法和手段,在 实际的编码构造中是不可能实现的。 在 1993 年于瑞士日内瓦召开的国际通信会议(ICC'93)上,两位任 教于法国不列颠通信大学的教授 C.Berrou、A.Glavieux 和他们的缅 甸籍博士生 P.thitimajshima 首次提出了一种新型信道编码方案—— Turbo 码,由于它很好地应用了 shannon 信道编码定理中的随机性 编、译码条件,从而获得了几乎接近 shannon 理论极限的译码性能。
2 . Claude Berrou Dave Forney Turbo 码又称并行级联卷积码 (PCCC,Parallel Concatenated Convolutional Code),它巧妙地将卷积码和随机交织器结合在一起, 在实现随机编码思想的同时,通过交织器实现了由短码构造长码的方 法,并采用软输出迭代译码来逼近最大似然译码。可见,Turbo 码充 分利用了 Shannon 信道编码定理的基本条件,因此得到了接近 Shannon 极限的性能。 在介绍 Turbo 码的首篇论文里,发明者 Berrou 仅给出了 Turbo 码的基本组成和迭代译码的原理,而没有严格的理论解释和证明。因 此,在 Turbo 码提出之初,其基本理论的研究就显得尤为重要。 J.Hagenauer 首先系统地阐明了迭代译码的原理,并推导了二进制分 组码与卷积码的软输入软输出译码算法。由于在 Turbo 码中交织器 的出现,使其性能分析异常困难,因此 S.Benedetto 等人提出了均匀 交织(UI,Uniform interleaver)的概念,并利用联合界技术给出了 Turbo 码的平均性能上界。D.Divsalar 等人也根据卷积码的转移函 数,给出了 Turbo 码采用 MLD 时的误比特率上界。对于 Turbo 码 来说,标准联合界在信噪比较小时比较宽松,只有在信噪比较大时才
3 .能实现对 Turbo 码性能的度量。因此,T.M.Duman、I.Sason 和 D.Divsalar 等人在 Gallager 限等已有性能界技术的基础上进行改 进.扩展了 Turbo 码性能界的紧致范围。D.Divsalar 等人还根据递归 系统卷积码的特点提出了有效自由距离的概念,并说明在设计 Turbo 码时应该使码字有效自由距离尽可能大。L.C.Perez 等人从距离谱的 角度对 Turbo 码的性能进行了分析,证明可以通过增加交织长度或 采用本原反馈多项式增加分量码的自由距离来提高 Turbo 码的性能。 他们还证明了 Turbo 码虽然自由距离比较小,但其低重量码字的数 目较少,从而解释了低信噪比条件下 Turbo 码性能优异的原因,并 提出了交织器增益的概念。S.Dolinar 的研究表明,Turbo 码的最小 距离码字主要由重量为 2 的输入信息序列生成,是形成错误平台的主 要原因。为提高高信噪比条件下 Turbo 码的性能,就必须提高低重 输入信息序列的输出码重。J.Seghers 系统地分析了 Turbo 码的距离 特性。由于交织器的存在,无法给出 Turbo 码自由距离的严格数学 表示,相应地也出现了许多分析和计算 Turbo 码最小距离、重量分 布和性能上限的方法。A.Ambroze 还构造了 Turbo 码的树图,用来 作为计算码字距离谱的工具。此外,R. Tanner、E.Offer 和 K.Engdahl 分别从代数和统计的角度对 Turbo 码进行了分析。考虑到 Turbo 码 的延时问题,E. Hall 等人提出了面向流的 Turbo 码。也可以用其他 系统模型采描述 Turbo 码及其迭代译码过程:T.Richardson 把 Turbo 码作为一个动力学系统进行描述;A. Khandani 则把 Turbo 码考虑成 一个周期性的线性系统;J.Laertyy, X.Ge 和 F. Kschischang 描述了
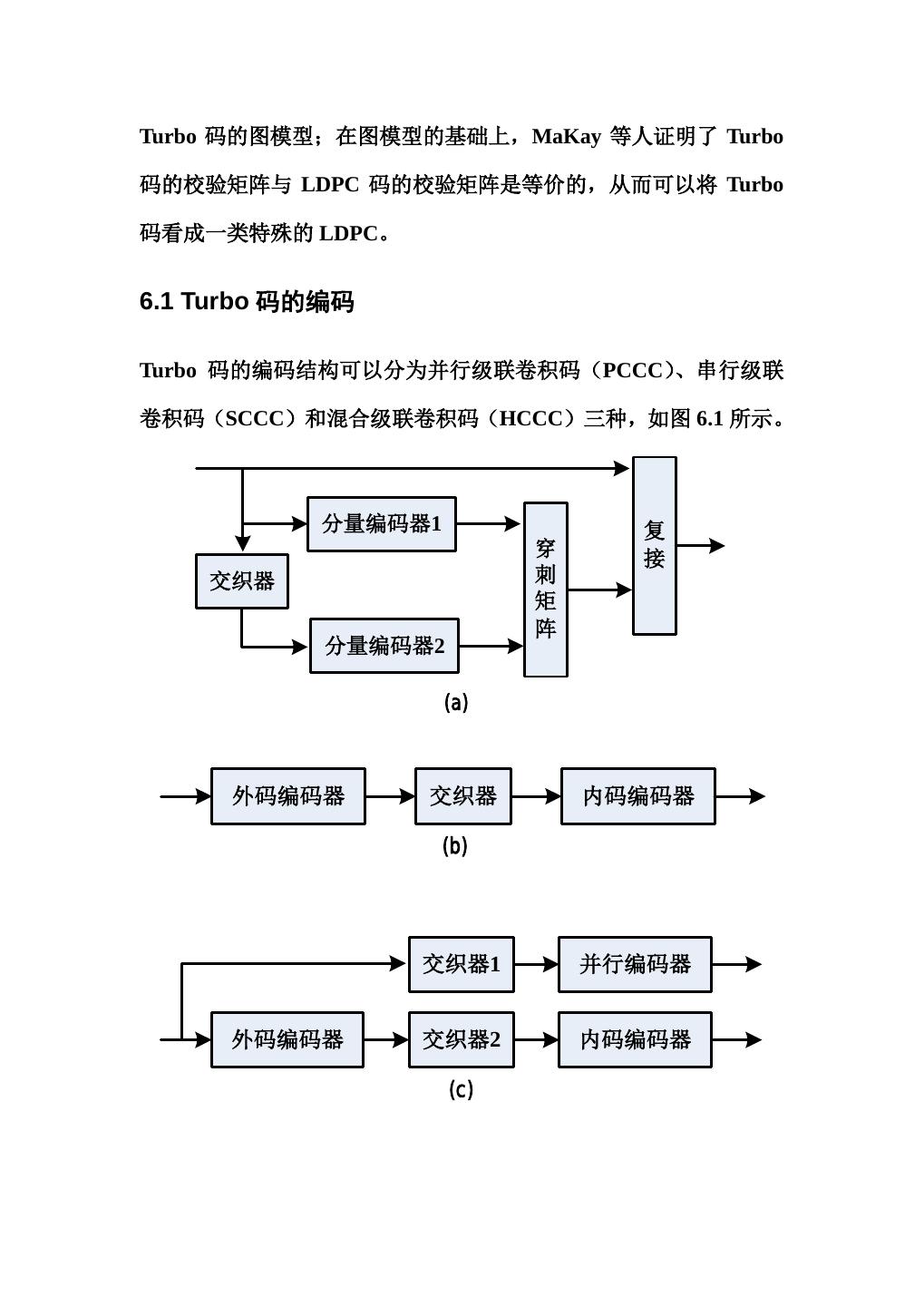
4 .Turbo 码的图模型;在图模型的基础上,MaKay 等人证明了 Turbo 码的校验矩阵与 LDPC 码的校验矩阵是等价的,从而可以将 Turbo 码看成一类特殊的 LDPC。 6.1 Turbo 码的编码 Turbo 码的编码结构可以分为并行级联卷积码(PCCC)、串行级联 卷积码(SCCC)和混合级联卷积码(HCCC)三种,如图 6.1 所示。 分量编码器1 复 穿 接 交织器 刺 矩 阵 分量编码器2 (a) 外码编码器 交织器 内码编码器 (b) 交织器1 并行编码器 外码编码器 交织器2 内码编码器 (c)
5 . 外码编码器 交织器1 内码编码器1 交织器2 (d) 内码编码器2 图 6.1 Turbo 码的几种编码结构(a)PCCC(b)SCCC(c)HCCC-I (d)HCCC-II 1993 年,C.Berrou 提出的 Turbo 码就是 PCCC 结构,主要由分 量编码器、交织器、穿刺矩阵和复接器组成。分量码一般选择为递归 系统卷积(RSC)码,当然也可以选择分组码、非递归卷积(NRC) 码以及非系统卷积(NSC)码。通常两个分量码采用相同的生成矩阵 (也可不同) 。若两个分量码的码率分别为 R1 和 R2,则 Turbo 码的 码率为: R1 R2 R= (6.1) R1 + R2 − R1 R2 在 AWGN 信道上对 PCCC 的性能仿真证明,当 BER 随 SNR 的 增加下降到一定程度时,就会出现下降缓慢甚至不再降低的情况,一 般称为误码平台(error floor) 。为解决这个问题,1996 年,S.Benedetto 提出了串行级联卷积码(SCCC)的概念,它综合了 Forney 串行级 联码(RS 码+卷积码)和 Turbo 码(PCCC)的特点,在适当的信 噪比范围内,通过迭代译码可以达到非常优异的译码性能。Benedetto
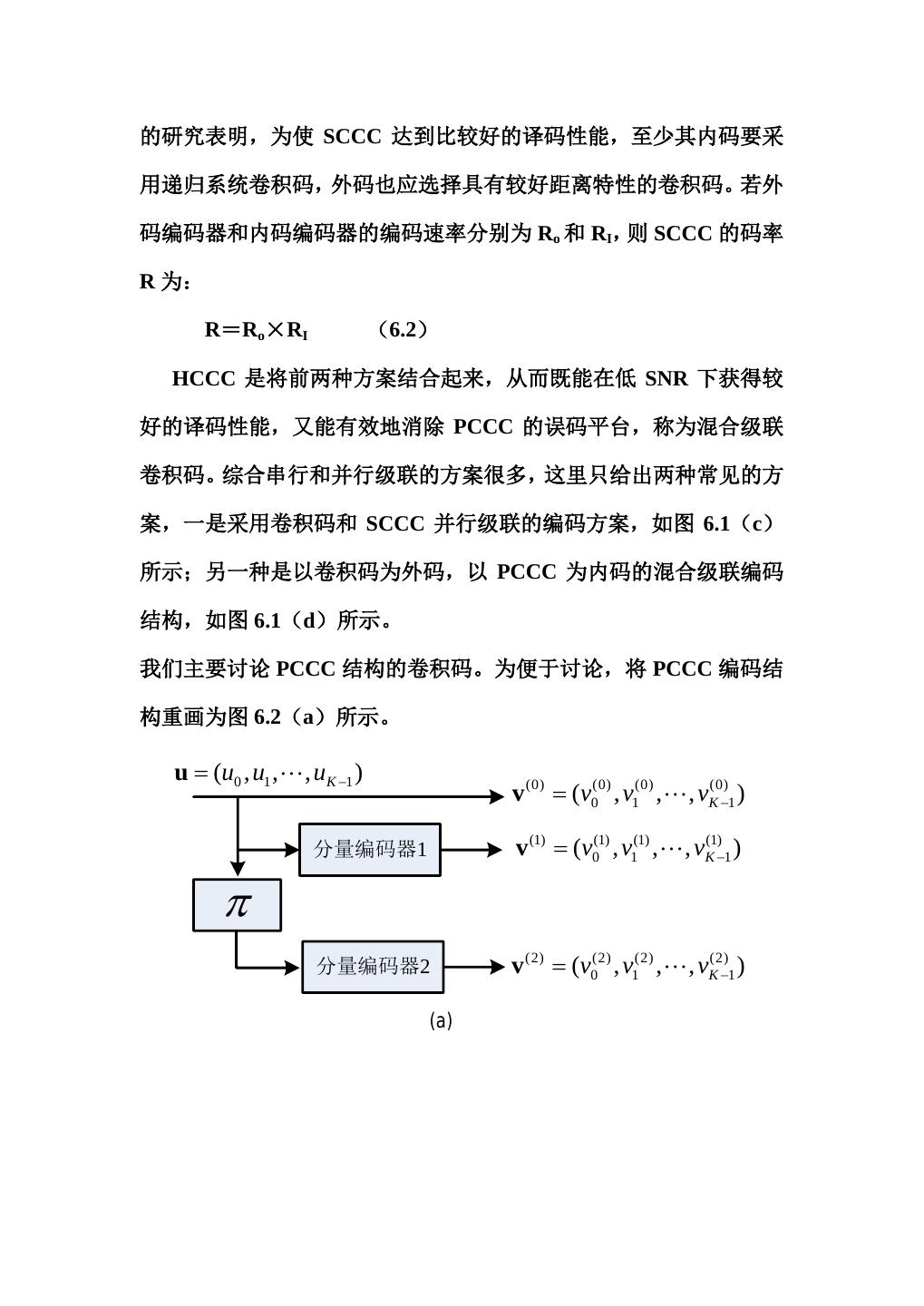
6 .的研究表明,为使 SCCC 达到比较好的译码性能,至少其内码要采 用递归系统卷积码,外码也应选择具有较好距离特性的卷积码。若外 码编码器和内码编码器的编码速率分别为 Ro 和 RI,则 SCCC 的码率 R 为: R=Ro×RI (6.2) HCCC 是将前两种方案结合起来,从而既能在低 SNR 下获得较 好的译码性能,又能有效地消除 PCCC 的误码平台,称为混合级联 卷积码。综合串行和并行级联的方案很多,这里只给出两种常见的方 案,一是采用卷积码和 SCCC 并行级联的编码方案,如图 6.1(c) 所示;另一种是以卷积码为外码,以 PCCC 为内码的混合级联编码 结构,如图 6.1(d)所示。 我们主要讨论 PCCC 结构的卷积码。为便于讨论,将 PCCC 编码结 构重画为图 6.2(a)所示。 u = (u0 , u1 , , uK −1 ) v (0) = (v0(0) , v1(0) , , vK(0)−1 ) 分量编码器1 v (1) = (v0(1) , v1(1) , , vK(1)−1 ) π 分量编码器2 v (2) = (v0(2) , v1(2) , , vK(2)−1 ) (a)
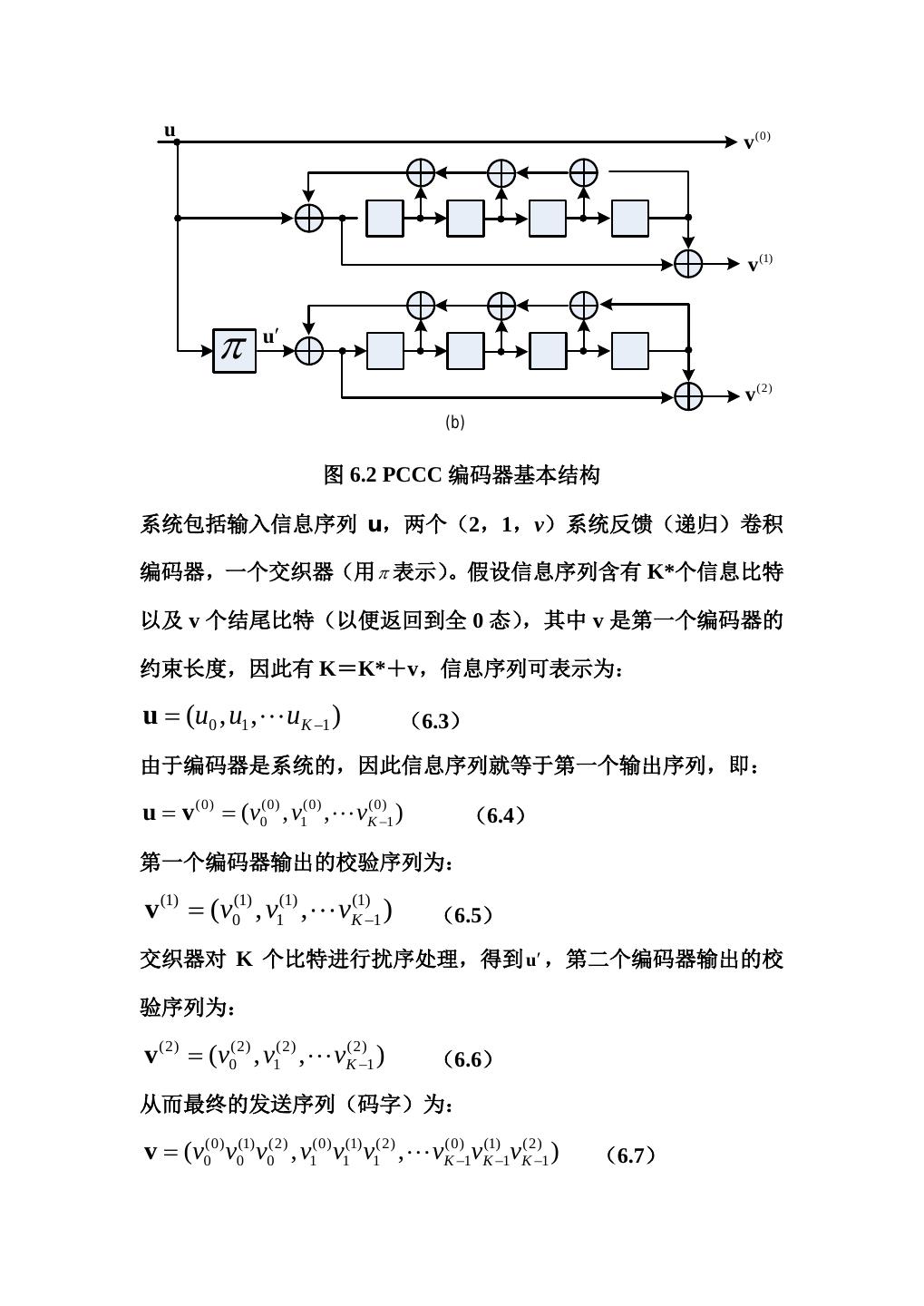
7 . u v (0) v (1) π u′ v (2) (b) 图 6.2 PCCC 编码器基本结构 系统包括输入信息序列 u,两个(2,1,v)系统反馈(递归)卷积 编码器,一个交织器(用 π 表示) 。假设信息序列含有 K*个信息比特 以及 v 个结尾比特(以便返回到全 0 态) ,其中 v 是第一个编码器的 约束长度,因此有 K=K*+v,信息序列可表示为: u = (u0 , u1 , uK −1 ) (6.3) 由于编码器是系统的,因此信息序列就等于第一个输出序列,即: = u v= (0) (v0(0) , v1(0) , vK(0)−1 ) (6.4) 第一个编码器输出的校验序列为: v (1) = (v0(1) , v1(1) , vK(1)−1 ) (6.5) 交织器对 K 个比特进行扰序处理,得到 u′ ,第二个编码器输出的校 验序列为: v (2) = (v0(2) , v1(2) , vK(2)−1 ) (6.6) 从而最终的发送序列(码字)为: v = (v0(0) v0(1) v0(2) , v1(0) v1(1) v1(2) , vK(0)−1vK(1)−1vK(2)−1 ) (6.7)
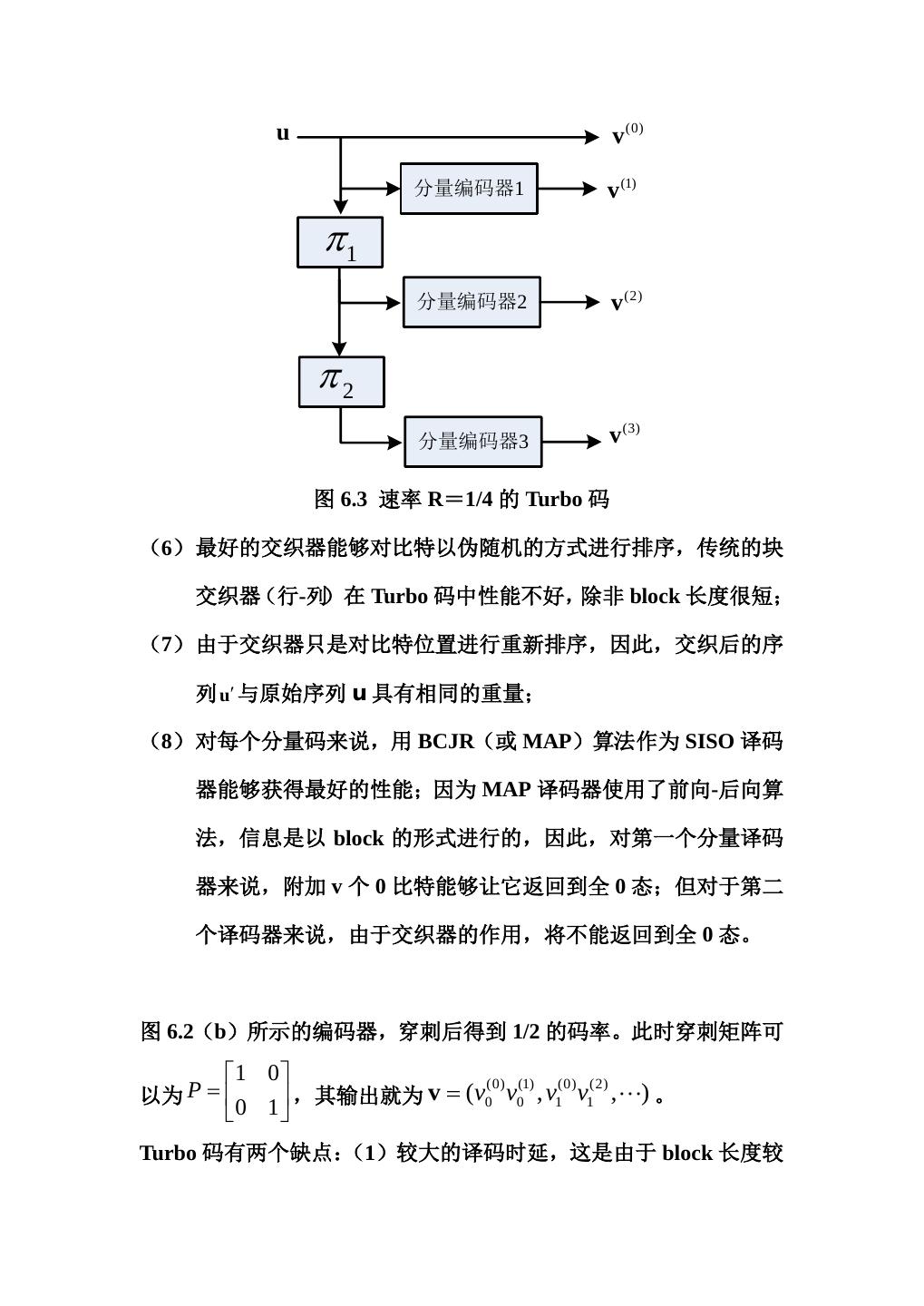
8 .因此,对该编码器来说,码字长度 N=3K,Rt=K*/N=(K-v)/3K, 当 K 比较大时,约为 1/3。 在图 6.2(b)中,两个分量码都是(2,1,4)系统反馈编码器,具 有相同的生成矩阵,为: G ( D= ) [1 (1 + D 4 ) /(1 + D + D 2 + D 3 + D 4 )] (6.8) 对于 Turbo 码来说,需要注意以下几点: (1) 为了得到靠近 Shannon 限的系统性能,信息分组长度(交织器 大小)K 一般比较大,通常至少几千个比特。 (2) 对于分量码来说,一般选择相同结构,且约束长度较短,通常 v≤4。 (3) 递归分量码(由系统反馈编码器产生)会比非递归分量码(前 馈编码器)有更好的性能; (4) 高码率可通过穿刺矩阵产生,如图 6.2(b)中,可通过交替输 (1) (2) 出v 和v 得到 1/2 的编码速率。 (5) 通过增加分量码和交织器也可得到较低编码速率的 Turbo 码, 如图 6.3 所示。
9 . u v (0) 分量编码器1 v (1) π1 分量编码器2 v (2) π2 分量编码器3 v (3) 图 6.3 速率 R=1/4 的 Turbo 码 (6) 最好的交织器能够对比特以伪随机的方式进行排序,传统的块 交织器(行-列)在 Turbo 码中性能不好,除非 block 长度很短; (7) 由于交织器只是对比特位置进行重新排序,因此,交织后的序 列 u′ 与原始序列 u 具有相同的重量; (8) 对每个分量码来说,用 BCJR(或 MAP)算法作为 SISO 译码 器能够获得最好的性能;因为 MAP 译码器使用了前向-后向算 法,信息是以 block 的形式进行的,因此,对第一个分量译码 器来说,附加 v 个 0 比特能够让它返回到全 0 态;但对于第二 个译码器来说,由于交织器的作用,将不能返回到全 0 态。 图 6.2(b)所示的编码器,穿刺后得到 1/2 的码率。此时穿刺矩阵可 1 0 以为 P = ,其输出就为 v = (v0 v0 , v1 v1 ,) 。 (0) (1) (0) (2) 0 1 Turbo 码有两个缺点: (1)较大的译码时延,这是由于 block 长度较
10 .大、译码需要多次迭代造成的。这样对于实时业务或高速数据的传输 (2)BER 在 10-5 后会出现误码平台,这是由于 Turbo 就非常不利; 码的重量分布造成的。对于某些对 BER 要求较高的应用就不适合, 当然通过交织器的设计能够提供码字的最小距离,从而降低误码平 台。 ======================================= 例 6.1:结尾卷积码的重量谱 考虑(2,1,4)非系统前馈卷积码,编码器生成矩阵为: G ff ( D) =[1 + D + D 2 + D 3 + D 4 1 + D 4 ] (6.9) 该码的最小自由距离是 6,对应的输入信息序列为(110…) 。如果该 编码器转为系统反馈形式,生成矩阵为: G fb ( D= ) [1 (1 + D 4 ) /(1 + D + D 2 + D 3 + D 4 )] (6.10) 由于码是相同的,因此自由距离仍是 6,但在这种情况下,最小重量 码字是由信息序列(10000100…)产生的 ,即 u(D)=1+D5。两个不同 的编码器得到相同的码,但信息序列和码字之间的映射关系不同。 【说 明:Turbo 码编码的对象是长度固定的数据序列,即在编码过程中首 先将输入信息数据分成长度与交织长度相同的数据序列,然后对每个 数据序列进行编码。如果 Turbo 码的分量码在数据序列编码结束时 利用结尾比特使得网格图状态归零,则 Turbo 码可等效为一个分组 码。 】设每个编码器信息长度为 K*=K-4,附加 4 个比特让编码器 返回到全 0 态,此时,我们就可得到(N,K*)=(2K,K-4)的 分组码,码率为 R=(K-4)/2K,当 K 很大时,约等于 1/2。这个分组
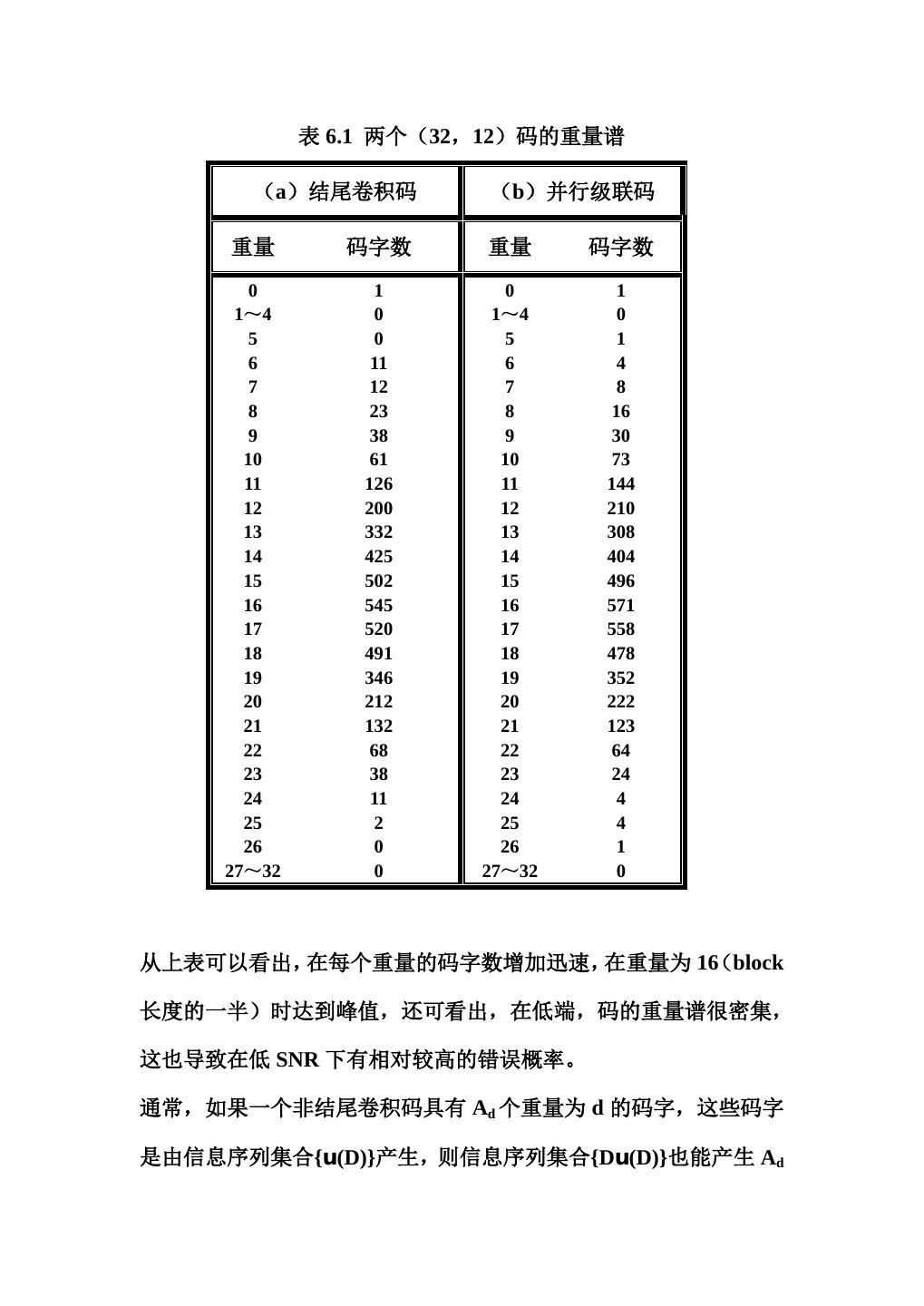
11 .码含有 K-5 个重量为 6 的码字,因为这些码字的信息序列可以从 K -5 个任意位置开始,都可以得到相同的码字。类似的分析显示,对 于重量为 7 及其他较低重量,码字数都很多。在表 6.1(a)里,给出 了(32,12)码的所有重量谱,其中 K=16。
12 . 表 6.1 两个(32,12)码的重量谱 (a)结尾卷积码 (b)并行级联码 重量 码字数 重量 码字数 0 1 0 1 1~4 0 1~4 0 5 0 5 1 6 11 6 4 7 12 7 8 8 23 8 16 9 38 9 30 10 61 10 73 11 126 11 144 12 200 12 210 13 332 13 308 14 425 14 404 15 502 15 496 16 545 16 571 17 520 17 558 18 491 18 478 19 346 19 352 20 212 20 222 21 132 21 123 22 68 22 64 23 38 23 24 24 11 24 4 25 2 25 4 26 0 26 1 27~32 0 27~32 0 从上表可以看出,在每个重量的码字数增加迅速,在重量为 16(block 长度的一半)时达到峰值,还可看出,在低端,码的重量谱很密集, 这也导致在低 SNR 下有相对较高的错误概率。 通常,如果一个非结尾卷积码具有 Ad 个重量为 d 的码字,这些码字 是由信息序列集合{u(D)}产生,则信息序列集合{Du(D)}也能产生 Ad
13 .个重量为 d 的码字,依此类推。结尾卷积码本质上也具有相同的特 性。换句话说,卷积码是时不变的,这个特性能够说明为什么在结尾 卷积码中低重量码字数较多。 当一个伪随机交织器用于产生一个并行级联码时,又会如何? ======================================= ======================================= 例 6.2:并行级联码的重量谱 选用式(6.10)所示的系统反馈卷积编码器,输入序列长度 K=16, 长度为 16 的交织图案为: ∏ = [0,8,15,9, 4, 7,11,5,1,3,14, 6,13,12,10, 2] 16 (6.11) 扰序后的输入序列用相同的校验生成器 (1 + D 4 ) /(1 + D + D 2 + D 3 + D 4 ) 进行编码,因此会得到不同的校验序列。为了与例 6.1 进行比较,我 们用周期 T=2 的穿刺矩阵: 1 0 P= (6.12) 0 1 进行处理,这样同样会得到一个(32,12)的码,该码的重量谱如表 6.1(b)所示。观察(a)和(b)我们可以看出两者有明显的不同, 自由距离由 6 减小到 5,但只有 1 个码字,更重要的是,重量为 6~9 的码字数明显减少了,这表示在并行级联码中,低重量码字向高重量 码字偏移了,这种偏移称为谱细化(spectral thinning) 。例如,重量 为 2 的输入信息序列 u=(1000010…0) ,这样会得到低重量校验序 列 v(1)=(11001100…0) ,因此,没有交织器,结尾卷积码产生的码
14 .字重量为 6。交织后的输入序列假定为 u′ =(100000010…0) ,则产 生的校验序列为 v(2)=(1100101111000110) ,复 用 v(1)和 v(2),用式 (6.12)式进行穿刺,得到的校验序列为(1100100101000100)。这 样,对于同是重量为 2 的输入序列,在并行级联码中就产生了重量为 8 的码字。 值得注意的问题: (1) 不同的交织器和穿刺矩阵会产生不同的结果; (2) 谱细化对最小自由距离的影响很小,但却能大大减小低重量码 字的数目; (3) 随着分组长度和交织器大小 K 的增加,并行级联卷积码的重量 谱近似于一个随机分布。 ======================================= 由此可看出,交织器在 Turbo 码中起着关键的作用,传统的块交织 在 Turbo 中并不适用,一定要做到伪随机化,这样构造出的码重量 谱就近似于一个二项式分布,Shannon 曾证明过,只有随机(二项式) 重量分布的码是性能达到 Shannon 限的前提。产生随机交织图案的 方法很多,例如用如下简单算法: km(m + 1) cm ≡ (mod K ), 0 ≤ m < K (6.13) 2 来产生一个序号映射函数 cm → cm +1(mod K ) ,其中 K 是交织器大小,k 是一个奇数。例如,K=16,k=1,可得到: (c0,c1,…,c15)=(0,1,3,6,10,15,5,12,4,13,7,2,14,11,9,8) (6.14)
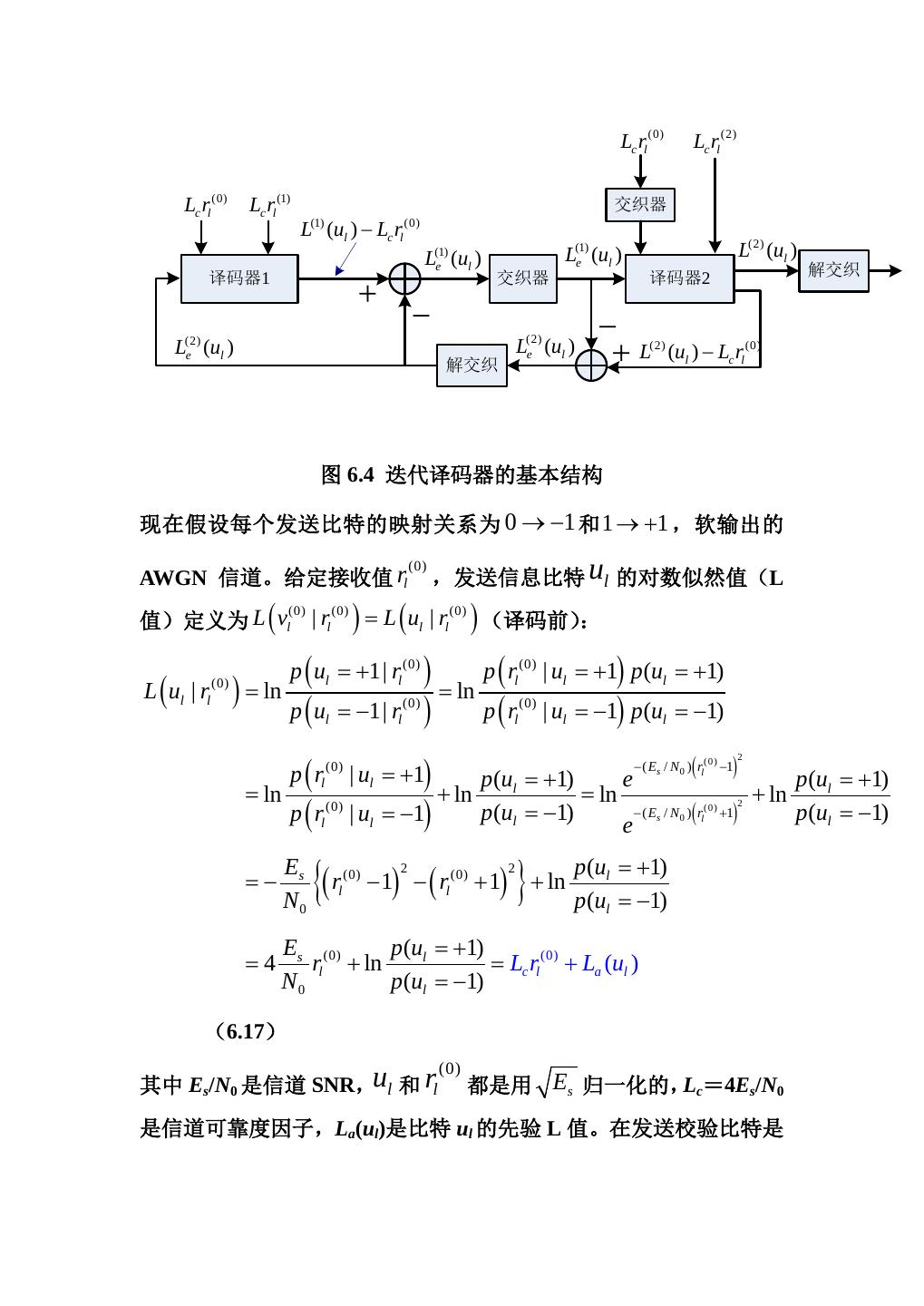
15 . 这意味着交织后序列 u′ 中的序号 0(输入比特 u0′ )与原始序列 u 中 的序号 1 相对应(即 u0′ = u1 ), u′ 中的 1 与 u 中的序号 3 相对应, 这样交织器为: ∏ = [1,3,14, 6,13,12,10, 2, 0,8,15,9, 4, 7,11,5] 16 (6.15) C0 C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15 U’ 0 1 3 6 10 15 5 12 4 13 7 2 14 11 9 8 U 1 3 6 10 15 5 12 4 13 7 2 14 11 9 8 0 按照 U’的升序(0,1,2,…,15)重新排列,所对应的 U 序列值就是 交织图案: 1、3、14、6、13、12、10、2、0、8、15、9、4、7、11、5 该交织图案如果向右循环移动 8 位,就得到式(6.11)所示的交织图 案。对于 K 是 2 的指数,可以证明这些交织器具有与随机交织类似 的统计特性,因此用于 Turbo 码中具有很好的性能。 6.2 Turbo 码的迭代译码 Turbo 码的迭代译码器基本结构如图 6.4 所示(假设速率 R=1/3、没 有穿刺的并行级联码) ,它使用了两个 SISO 译码器(MAP 算法) 。 在每个时间单元 l,从信道接收到三个输出值,一个是对应着信息比 (0) (1) 特 ul = vl ,用 rl (2) 表示,其他两个对应着校验比特 vl 和 vl (0) ,分 (1) (2) 别用 rl 和 rl 表示,这样接收到的向量(3K 维)为: r = ( r0(0) r0(1) r0(2) , r1(0) r1(1) r1(2) , rK(0)−1rK(1)−1rK(2)−1 ) (6.16)
16 . Lc rl (0) Lc rl (2) Lc rl (0) Lc rl (1) 交织器 L (ul ) − Lc rl (1) (0) L(1) L(1) e (ul ) L(2) (ul ) e (ul ) 解交织 译码器1 交织器 译码器2 + - - (2) L (ul ) e L(2) e (ul ) + L (ul ) − Lc rl (2) (0) 解交织 图 6.4 迭代译码器的基本结构 现在假设每个发送比特的映射关系为 0 → −1 和 1 → +1 ,软输出的 ,发送信息比特 ul 的对数似然值(L (0) AWGN 信道。给定接收值 rl (0) 值)定义为 L vl | rl (0) ( = L ul | rl (0) (译码前): ) ( ) p ( ul = +1| rl (0) ) p ( rl (0) | ul = +1) p (ul = +1) L ( ul | rl ) ln= = (0) ln p ( ul = −1| rl (0) ) p ( rl (0) | ul = −1) p (ul = −1) p ( rl | ul = +1) ( ) 2 (0) − ( Es / N 0 ) rl( 0 ) −1 p (ul = +1) e p (ul = +1) = ln + ln = ln + ln p ( rl (0) | ul = −1) p (ul = −1) − ( E / N )( r +1) p (ul = −1) 2 (0) s 0 l e = E − s N0 {( r l (0) − 1) − ( rl (0 ) + 1) + ln 2 2 } p (ul = +1) p (ul = −1) Es (0) p (ul = +1) = 4 rl + ln = Lc rl (0) + La (ul ) N0 p (ul = −1) (6.17) (0) 其中 Es/N0 是信道 SNR,ul 和 rl 都是用 Es 归一化的,Lc=4Es/N0 是信道可靠度因子,La(ul)是比特 ul 的先验 L 值。在发送校验比特是
17 .vl( j ) 的情况下,给定接收到的值为 rl ( j ) ,j=1,2,L 值(译码前)为: L ( vl( j ) | rl ( j ) ) =Lc rl ( j ) + La ( vl( j ) ) =Lc rl ( j ) , j = 1, 2 (6.18) 因为在一个线性码中信息比特等概,校验比特为+1 和-1 的概率也 是相同的,因此校验比特的先验 L 值为 0,即: p ( vl( j ) = +1) La ( v =) ln p v( j ) = −= ( j) 0,=j 1, 2 l ( l 1) (6.19) (注意:对于译码器 1 的第一次迭代, La (ul ) 也等于 0,之后,信 息比特的先验 L 值就被另一个译码器输出的外部 L 值所取代,后面 会讲到) 。 (0) (1) (1) 接收到的信道 L 值(软信息) Lc rl (for ul)和 Lc rl (for vl ) (0) (2) 进入译码器 1,交织后的信道 L 值(软信息)Lc rl (for ul)和 Lc rl (for vl(2) )进入译码器 2,译码器 1 的输出包括 2 项: (1) 给定接收到的向量(部分) r1 r0(0) r0(1) , r1(0) r1(1) , rK(0)−1rK(1)−1 以及先验输入向量 L a La (u0 ), La (u1 ), La (u K −1 ) ,每个信 (1) (1) (1) (1) 息 比 特 的 后 验 L 值 ( 译 码 后 ) 为 p ( ul = +1| r1 , L(1) a ) L (ul ) = ln (1) ; p ( ul = −1| r1 , L(1) a ) (2) 与 每 个 信 息 比 特 相 关 的 外 部 后 验 概 率 值 ( 译 码 后 ) L(1) (1) (0) + L(2) e (ul ) = L (ul ) − Lc rl e (ul ) ,该信息经交织后送给译 (2) 码器 2,作为先验值 La (ul ) 。 同样地,译码器 2 的输出也包括两项:
18 . p ( ul = +1| r2 , L(2) a ) = (2) ,其中 r2 p ( ul = −1| r2 , L(2) a ) (1) L (ul ) ln (2) 是(部分)接收向量, L a 是先验输入向量; (2) Le (ul ) = L (ul ) − Lc rl + L(1) (2) (2) (0) e (ul ) 是译码器 2 产生的外部 (1) 后验 L 值,经过解交织后,作为先验值 La (ul ) 反馈作为译码 器 1 的输入。 (0) (1) 这样,每个译码器的输入包含三项:软信道 L 值 Lc rl 、Lc rl (或 Lc rl (2) )、 以 及 从 另 一 个 译 码 器 传 送 的 外 部 后 验 L 值 e (ul ) = La (ul ) (或 Le (ul ) = La (ul ) ) L(2) (1) (1) (2) 。注意:在译码器 1 的 初始迭代时,外部后验 L 值 Le (ul ) = La (ul ) 就是初始先验 L 值 (2) (1) La (ul )(对于等概信息比特,该值为 0),在译码器 1 的随后迭代中, (1) (2) 先验 L 值 La (ul ) 就用接收到的外部后验 L 值 Le (ul )(进行解交织 处理后)代替;对于译码器 2,其第一次迭代和随后的迭代都是相同 (1) 的,外部后验 L 值一直都是 Le (ul ) 。译码迭代处理,每个译码器 将其外部 L 值传送给另一个译码器,形成一个 Turbo 的效果,如图 6.5 所示,使得译码结果越来越可靠。
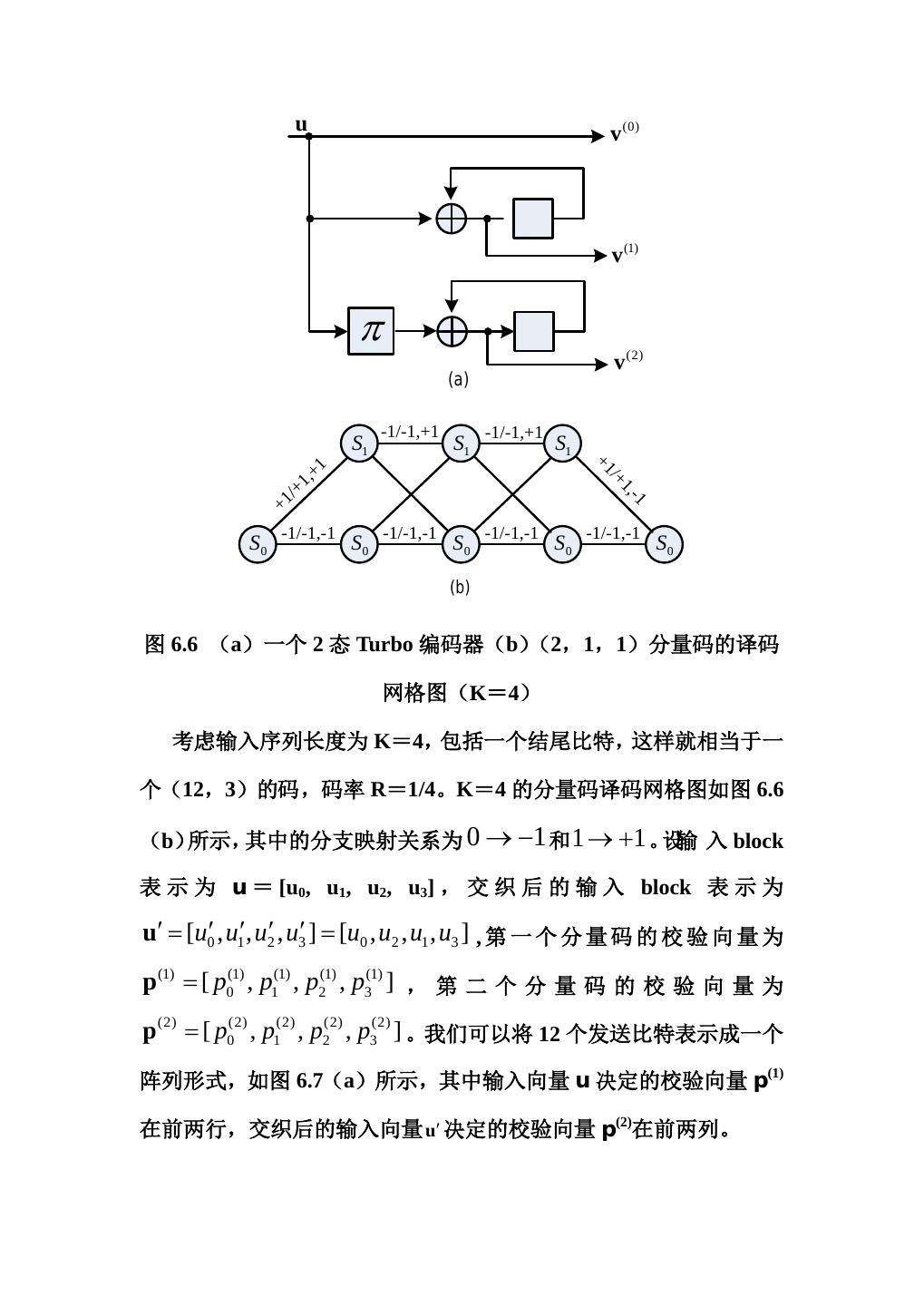
19 . 图 6.5 汽车发动机的 Turbo 结构 经过一定次数的迭代后,译码后的信息比特就从译码器 2 输出的后验 (2) L 值 L (ul ) 中判决得到,如果该 L 值为正,就判为+1,否则就判 为-1。 值得一提的是:Turbo 的很多特性与 LDPC 很类似,如编码方案都 是产生随机重量分布的码、译码方法都是在迭代过程中利用了后验概 率似然值、都利用了外部信息的概念等。实际上,正是由于 Turbo 码的出现,才使得人们对 LDPC 码的优点有了重新的认识。 ====================================== 例 6.3:使用 Log-MAP 算法进行迭代译码 考虑一个 PCCC 结构的 Turbo 码,它是由两个(2,1,1)系统 递归卷积码构成,如图 6.6(a)所示,生成矩阵为: G(D)=[1 1/(1+D)] (6.20)
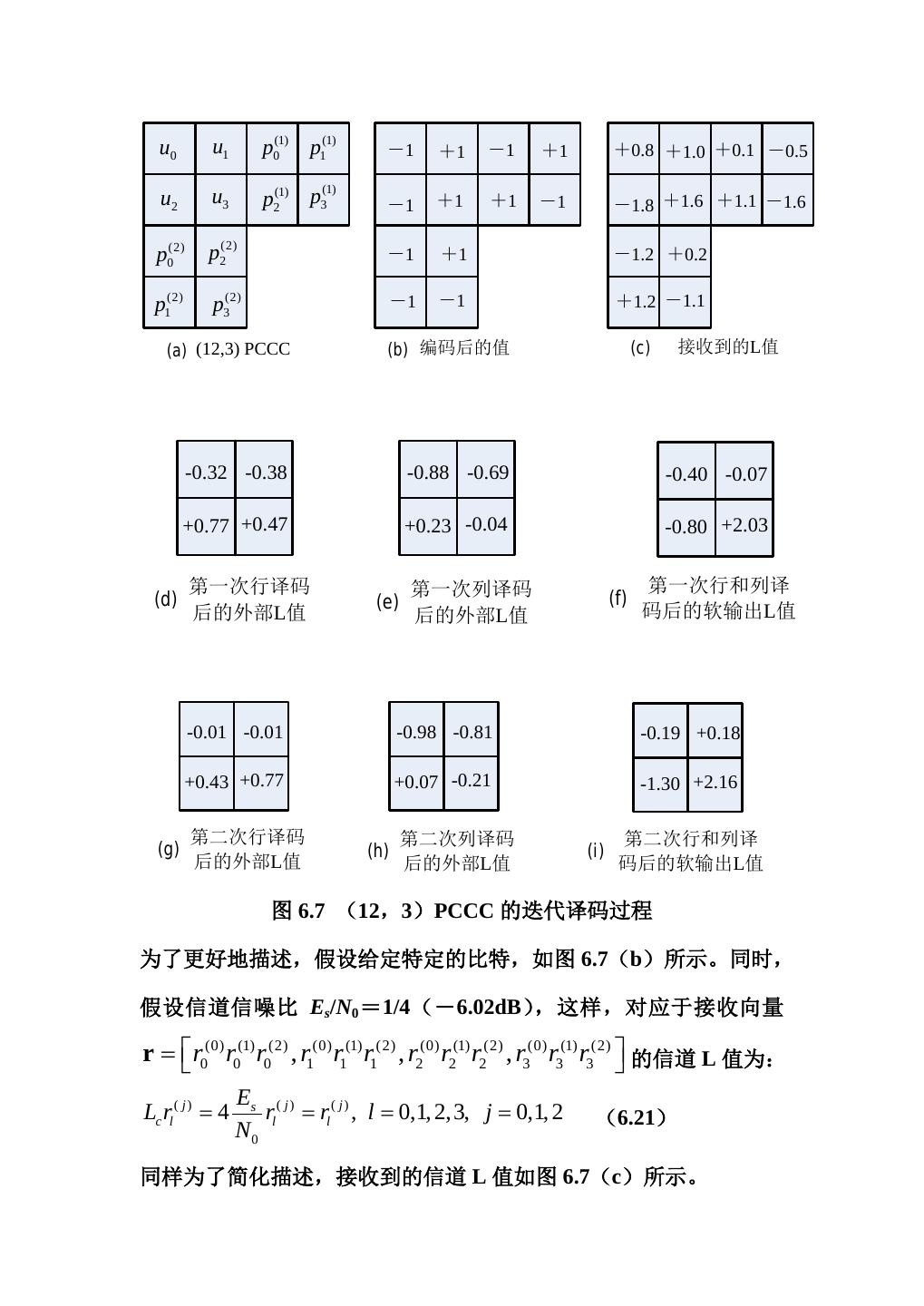
20 . u v (0) v (1) π v (2) (a) -1/-1,+1 -1/-1,+1 S1 S1 S1 +1 +1 /+ 1, 1, /+ -1 +1 -1/-1,-1 -1/-1,-1 -1/-1,-1 -1/-1,-1 S0 S0 S0 S0 S0 (b) 图 6.6 (a)一个 2 态 Turbo 编码器(b)(2,1,1)分量码的译码 网格图(K=4) 考虑输入序列长度为 K=4,包括一个结尾比特,这样就相当于一 个(12,3)的码,码率 R=1/4。K=4 的分量码译码网格图如图 6.6 (b)所示,其中的分支映射关系为 0 → −1 和 1 → +1 。设输 入 block 表 示 为 u = [u0, u1, u2, u3] , 交 织 后 的 输 入 block 表 示 为 =u′ [u= ′ ′ ′ ′ [u0 , u2 , u1 , u3 ] , 第 一 个 分 量 码 的 校 验 向 量 为 0 , u1 , u2 , u3 ] p (1) = [ p0(1) , p1(1) , p2(1) , p3(1) ] , 第 二 个 分 量 码 的 校 验 向 量 为 p (2) = [ p0(2) , p1(2) , p2(2) , p3(2) ] 。我们可以将 12 个发送比特表示成一个 阵列形式,如图 6.7(a)所示,其中输入向量 u 决定的校验向量 p(1) 在前两行,交织后的输入向量 u′ 决定的校验向量 p(2)在前两列。
21 . u0 u1 p0(1) p1(1) -1 +1 -1 +1 +0.8 +1.0 +0.1 -0.5 (1) u2 u3 p2(1) p3 -1 +1 +1 -1 -1.8 +1.6 +1.1 -1.6 p0(2) p2(2) -1 +1 -1.2 +0.2 p1(2) p3(2) -1 -1 +1.2 -1.1 (a) (12,3) PCCC (b) 编码后的值 (c) 接收到的L值 -0.32 -0.38 -0.88 -0.69 -0.40 -0.07 +0.77 +0.47 +0.23 -0.04 -0.80 +2.03 第一次行译码 第一次列译码 第一次行和列译 (d) (e) (f) 后的外部L值 后的外部L值 码后的软输出L值 -0.01 -0.01 -0.98 -0.81 -0.19 +0.18 +0.43 +0.77 +0.07 -0.21 -1.30 +2.16 第二次行译码 第二次列译码 第二次行和列译 (g) (h) (i) 后的外部L值 后的外部L值 码后的软输出L值 图 6.7 (12,3)PCCC 的迭代译码过程 为了更好地描述,假设给定特定的比特,如图 6.7(b)所示。同时, 假设信道信噪比 Es/N0 =1/4(-6.02dB),这样,对应于接收向量 r = r0(0) r0(1) r0(2) , r1(0) r1(1) r1(2) , r2(0) r2(1) r2(2) , r3(0) r3(1) r3(2) 的信道 L 值为: Es ( j ) L= c rl ( j) 4 = rl rl= ( j) = , l 0,1, 2,3, j 0,1, 2 (6.21) N0 同样为了简化描述,接收到的信道 L 值如图 6.7(c)所示。
22 .在译码器 1 的第一次迭代中(行译码) ,应用 log-MAP 算法到 2 态(2, (1) 1,1)码的网格图中,来计算每个输入比特的后验 L 值 L (ul ) ,以 (1) 及对应的传送给译码器 2 的外部后验 L 值 Le (ul ) 。类似地,在译 码器 2 的第一次迭代中,log-MAP 算法用从译码器 1 收到的外部后 (1) 验 L 值 Le (ul ) 来计算每个比特的后验 L 值 L(2) (ul ) ,以及对应的 (2) 传送给译码器 1 的外部后验 L 值 Le (ul ) 。随后的译码就这样迭代进 行。 ======================================= 我们用 log-MAP 算法对后验 L 值 L(ul ) 和 在继续讨论这个例子之前, 外部后验 L 值 Le (ul ) 的一般式进行推导。为了简化表示,定义发送 向量为 v=(v0, v1, v2, v3),其中 vl=(ul,pl), l=0,1,2,3, ul 是输入比特,pl 是校验比特。类似地,接收到的向量表示为 r=(r0, r1, r2, r3),其中 rl = (rul , rpl ) ,l=0,1,2,3, rul 是接收到的信元,对应于发送的输入 比特 ul; rpl 是接收到的信元,对应于发送的输入比特 pl;输入比特 的后验 L 值为(见第五章公式 5.67 和 5.72) : p (ul = +1| r ) L(ul ) = ln p (ul = −1| r ) ∑ ( s′, s )∈Σ+= p ( sl s=′, sl +1 s, r ) (6.22) = ln l ∑ ( s′, s )∈Σl−=p ( sl s=′, sl +1 s , r ) + 其中 Σ l 表示在 l 时刻状态为 sl = s′ ,l+1 时刻状态为 sl +1 = s ,这 种状态转移是由输入比特 ul = +1 所引起的,所有这些状态对的集合 + 就构成 Σ l 。
23 . p ( s′, s, r ) = eαl ( s′) +γ l ( s′, s ) + βl +1 ( s ) * * * (6.23) 其中 α l * ( s′) 、 γ l* ( s′, s) 和 βl*+1 ( s) 是 MAP 算法中 α 、 γ 和 β 的对 。注意:α l ( s′) 、γ l 数域表达(见第五章公式 5.88) * * ( s′, s ) 和 βl*+1 ( s) 分别表示 l 时刻之前、l 时刻和 l 时刻之后的接收序列对 l 时刻输入比 特估计的影响。 对一个连续输出 AWGN 信道,信噪比为 Es/N0,我们可得到: ul La (ul ) Lc 分支度量: γ l ( s′, = + rl ⋅ v l , = * s) l 0,1, 2,3 (6.24a) 2 2 前向度量:α = * l +1 ( s ) max *s′∈σ l γ l* ( s′, s ) + α l* ( s′= ) , l 0,1, 2,3(6.24b) = 后向度量: βl* ( s′) max *s∈σ l +1 γ l* ( s′, s ) + βl*+1 ( s ) (6.24c) 初始条件为: α= β= 0 , α 0* ( S1 ) = β 4* ( S1 ) = −∞ 。 * * 0 ( S0 ) 4 ( S0 ) 分支度量进一步可写为: γ l* ( s′, s ) = ul La (ul ) Lc 2 + 2 ( ul rul + pl rpl ) u p (6.25) = l La (ul ) + Lc rul + l Lc rpl , =l 0,1, 2,3 2 2 从图 6.6(b)可看出,为了确定比特 u0 的后验 L 值,在式(6.22) 中的每个和式只有 1 项,因为此时在网格图中只有 1 个+1 和-1 的 比特转移,因此,比特 u0 的后验 L 值可表示为:
24 .L(u0 ) =ln p ( s′ =S0 , s =S1 , r ) − ln p ( s′ =S0 , s =S0 , r ) =α 0* ( S0 ) + γ 0* ( s′ =S0 , s =S1 ) + β1* ( S1 ) − α 0* ( S0 ) + γ 0* ( s′ =S0 , s =S0 ) + β1* ( S0 ) 1 1 + La (u0 ) + Lc ru0 + Lc rp0 + β1 ( S1 ) − = * 2 2 (6.26a) 1 1 − La (u0 ) + Lc ru0 − Lc rp0 + β1 ( S0 ) * 2 2 = Lc ru0 + La (u0 ) + Le (u0 ) 其中 Le (u0 ) ≡ Lc rp0 + β1* ( S1 ) − β1* ( S0 ) (6.26b) 表示 u0 的外部后验 L 值。式(6.26a)表明,在 log-MAP 译码器的 输出端计算出的 u0 的后验 L 值包括三部分: Lc ru0 :对应于比特 u0 的接收到的信道 L 值,是译码器输入的一部分。 La (u0 ) :u0 的先验 L 值,也是译码器输入的一部分。除了译码器 1 的第一次迭代,该项等于从另一个译码器输出接收到的 u0 的外部后 (对于译码器 1 的第一次迭代, La (u0 ) = 0 ) 验 L 值。 Le (u0 ) :u0 的外部后验 L 值,不依赖于 Lc ru 或 La (u0 ) 。该项送给 0 另一个译码器作为先验输入。 类似地,我们可计算比特 u1 的后验 L 值,从图 6.6(b)可看出,在 式(6.22)中的每个和式都有 2 项,因为此时在网格图中有 2 个+1 和-1 的比特转移,因此,比特 u1 的后验 L 值可表示为:
25 .L(u1 ) = ln [ p ( s′ = S0 , s = S1 , r ) + p ( s′ = S1 , s = S0 , r ) ] − ln [ p ( s′ = S0 , s = S0 , r ) + p ( s′ = S1 , s = S1 , r ) ] = { max* α1* ( S0 ) + γ 1* ( s′ =S0 , s =S1 ) + β 2* ( S1 ) , α1* ( S1 ) + γ 1* ( s′ =S1 , s =S0 ) + β 2* ( S0 ) } { − max *α1* ( S0 ) + γ 1* ( s′ =S0 , s =S0 ) + β 2* ( S0 ) , α1* ( S1 ) + γ 1* ( s′ =S1 , s = } S1 ) + β 2* ( S1 ) =Lc ru1 + La (u1 ) + Le (u1 ) (6.27a) 其中 1 1 Le (u1 ) = max * + Lc rpl + α1* ( S0 ) + β 2* ( S1 ) , − Lc rpl + α1* ( S1 ) + β 2* ( S0 ) 2 2 1 1 − max * − Lc rpl + α1* ( S0 ) + β 2* ( S0 ) , + Lc rpl + α1* ( S1 ) + β 2* ( S1 ) 2 2 (6.27b) 【特别说明:在上面的推导中,使用了一个等式即: max*(z+x, z+y)=z+max*(x,y)】 同样会得到 u2 和 u3 的后验 L 值: L(u2 ) =Lc ru2 + La (u2 ) + Le (u2 ) (6.28a) 其中 1 1 Le (u2 ) = max * + Lc rp2 + α s* ( S0 ) + β3* ( S1 ) , − Lc rp2 + α 2* ( S1 ) + β3* ( S0 ) 2 2 1 1 − max * − Lc rp2 + α 2* ( S0 ) + β3* ( S0 ) , + Lc rp2 + α 2* ( S1 ) + β 3* ( S1 ) 2 2
26 .(6.28b) L(u3 ) =Lc ru3 + La (u3 ) + Le (u3 ) (6.29a) 1 1 Le (u3 ) = − 2 Lc rp3 + α * 3 ( S1 ) + β * 4 ( S 0 ) − − 2 Lc rp3 + α * 3 ( S 0 ) + β * 4 ( S 0 ) = α 3* ( S1 ) − α 3* ( S0 ) (6.29b) 注意:接收到的校验信元 rp3 不会影响 Le (u3 ) ,在图 6.6(b)可看 出,在 l=3 时刻两个分支 p3=0,因此 rp3 没有携带任何有助于译码 的信息。 在计算外部后验 L 值 Le (ul ) ,l=0,1,2,3 时,需要用到前向度量和后 向度量。利用式(6.24)和(6.25) ,并对信息比特 L 值和校验比特 L 值采用简化表示,即:Lul ≡ Lc rul + La (ul ) 和 L pl ≡ Lc rpl ,l=0,1,2,3, 可得到: a1* ( S0 ) = 1 ( − Lu0 + L p0 2 ) (6.30a) a1* ( S1 ) = 1 ( + Lu0 + L p0 2 ) (6.30b) 1 1 a2* ( S= 0) ( ) ( ) max * − Lu1 + Lp1 + a1* ( S0 ) , + Lu1 − Lp1 + a1* ( S1 ) 2 2 (6.30c) 1 1 a2* ( S= 1 ) max * + Lu1 +(L p1 + a1 * ) ( S ) , 0 − Lu − L ( p1 + a1 * ( S ) ) 1 2 2 1 (6.30d)
27 . 1 1 a3* ( S0= ( ) ( ) max * − Lu2 + Lp2 + a2* ( S0 ) , + Lu2 − Lp2 + a2* ( S1 ) ) 2 2 (6.30e) 1 1 a3* ( S= 1 ) max * + Lu2 + ( L p2 + a2 * ( S ) , 0 )− Lu − L p2 + a2 * (( S1 ) ) 2 2 2 (6.30f) − ( Lu + L p ) 1 β3* ( S0 ) = (6.30g) 2 3 3 + ( Lu − L p ) 1 β3* ( S1 ) = (6.30h) 2 3 3 1 1 ) max * − ( Lu + L p ) + β3* ( S0 ) , + ( Lu + Lp ) + β3* ( S1 ) β 2* ( S0= 2 2 2 2 2 2 (6.30i) 1 1 β 2* ( S= 1) max * + ( Lu − L p ) + β3* ( S0 ) , − ( Lu − L p ) + β3* ( S1 ) 2 2 2 2 2 2 (6.30j) 1 1 β1* ( S= 0) max * − ( Lu + L p ) + β 2* ( S0 ) , + ( Lu + Lp ) + β 2* ( S1 ) 2 2 1 1 1 1 (6.30k) 1 1 β1* ( S= 1) max * + ( Lu − L p ) + β 2* ( S0 ) , − ( Lu − L p ) + β 2* ( S1 ) 2 2 1 1 1 1 (6.30l) 对所有 l,校验比特的先验 L 值 La ( pl ) = 0 ,因为对于等概信息比特 的线性码,校验比特也是等概的;而且,与信息比特不同,校验比特 的 L 值不被迭代译码算法所更新, 即在整个译码过程中校验比特的 L
28 .值保持不变。因此, L pl =Lc rpl + La ( pl ) =Lc rpl 。最后计算外部 后验 L 值: L p0 + β1* ( S1 ) − β1* ( S0 ) Le (u0 ) = (6.31a) 1 1 ) max * + Lp1 + α1* ( S0 ) + β 2* ( S1 ) , − L p1 + α1* ( S1 ) + β 2* ( S0 ) Le (u1= 2 2 1 1 − max * − L p1 + α1* ( S0 ) + β 2* ( S0 ) , + L p1 + α1* ( S1 ) + β 2* ( S1 ) 2 2 (6.31b) 1 1 ) max * + L p2 + α 2* ( S0 ) + β3* ( S1 ) , − L p2 + α 2* ( S1 ) + β3* ( S0 ) Le (u2 = 2 2 1 1 − max * − L p2 + α 2* ( S0 ) + β3* ( S0 ) , + L p2 + α 2* ( S1 ) + β3* ( S1 ) 2 2 (6.31c) L= e (u3 ) α * 3 ( S1 ) − α * 3 ( S0 ) (6.31d) 我们注意到,在计算外部 L 值 Le (ul ) 时, Lul 并没有在公式中出现, 这表示比特 ul 的外部 L 值不直接依赖于 ul 的先验 L 值。 ====================================== 继续例 6.3 设接收到的信道 L 值如图 6.7(c)所示,根据式(6.30)和(6.31), 我们可计算出外部后验 L 值。在译码器 1(行译码)对比特 u0、u1、 u2、u3 进行第一次迭代译码时,考虑到在 Lul 中初始化先验 L 值为 0, 从式(6.30)可得到:
29 . 1 − ( 0.8 + 0.1) = a1* ( S0 ) = −0.45 (6.32a) 2 1 + ( 0.8 + 0.1) = a1* ( S1 ) = +0.45 (6.32b) 2 1 1 a2* ( S= 0 ) max* − (1.0 − 0.5 ) − 0.45 , + 2 (1.0 + 0.5 ) + 0.45 = 1.34 2 (6.32c) 1 1 a2* ( S= 1) max* + (1.0 − 0.5 ) − 0.45 , − (1.0 + 0.5 ) + 0.45= 0.44 2 2 (6.32d) 1 1 S0 ) max* − ( −1.8 + 1.1) + 1.34 , + ( −1.8 − 1.1) + 0.44= a3* (= 1.76 2 2 (6.32e) 1 1 S1 ) max* + ( −1.8 + 1.1) + 1.34 , − ( −1.8 − 1.1) + 0.44= a3* (= 2.23 2 2 (6.32f) 1 − (1.6 − 1.6 ) = β3* ( S0 ) = 0 (6.32g) 2 1 + (1.6 + 1.6 ) = β3* ( S1 ) = 1.6 (6.32h) 2 1 1 S0 ) max* − ( −1.8 + 1.1) + 0 , + ( −1.8 + 1.1) + 1.6= β 2* (= 1.59 2 2 (6.32i) 1 1 S1 ) max* + ( −1.8 − 1.1) + 0 , − ( −1.8 − 1.1) + 1.6= β 2* (= 3.06 2 2 (6.32j)
3秒后跳转登录页面
去登陆

