

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
LDPC码简介
LDPC码自身的矩阵结构引入了交织特性,而且其采用迭代译码的方法,使其性能比以往的线性分组码有很大程度的提高。由于其基本原理是基于最原始的线性分组码,因此它有强大的数学工具作为其理论依据,几乎融图论、组合数学、概率论、矩阵论、代数、几何、代数数论、黎曼几何于一炉。LDPC码的译码主要方法有比特翻转(Bit-Flipping)译码、加权大数逻辑(Weighted Majority-Logic)译码、和积(Sum-Product)算法等。
展开查看详情
1 . 第八章 LDPC 码 8.1 研究 LDPC 码的原因 BCH 码 码 循环码 编 码 道 RS码 码 组 线性 积 信 系统卷 分 码 卷 奇偶 积码 Turbo 码 LDPC 校验 码 非循环 非系统 码 非线 码 卷积码 性码 汉明 码 Mackay等人的再发 现 可以看到,信道编码的发展可以简单的归纳为分组码卷积吗分组 码这样一个过程(在这里按其结构将 Turbo 码也归入卷积码的范畴)。 其中 Turbo 码的出现以及迭代译码的思想引入使得信道编解码产生 了前所未有的飞跃,但 Turbo 码之后卷积码却没有更大的发展,究其 原因就是其没有完备的理论基础,使得人们不能给出其性能上严密的 数学解释。于是在那之后可以说是一种退化或者是返朴归真,Mackay 等人再次发掘了 Gallager 于 1962 年提出的一种具有稀疏校验矩阵的 分组纠错码,即 LDPC 码。 LDPC 码自身的矩阵结构引入了交织特性,而且其采用迭代译码的 方法,使其性能比以往的线性分组码有很大程度的提高。由于其基本 原理是基于最原始的线性分组码,因此它有强大的数学工具作为其理 论依据,几乎融图论、组合数学、概率论、矩阵论、代数、几何、代 数数论、黎曼几何于一炉。在通信的其它领域,我们很难再找到某个
2 .方向可以有如此深厚的理论基础与之媲美。我的一个学生就认为:理 论上的完备性与数学上的优美表达正是编码的魅力所在。 但理论上的完备性并不能使其直接应用于实际,因此从码字构造 的方向来说,如何将 LDPC 码应用于实际工作才是值得深入研究的。 为了保证其实现性,性能上就要有所妥协。 在编码方面,以准循环 LDCP 码,即 QC-LDPC 码为例,为了降低 硬件上的存储空间以及易于编码,就要以牺牲 LDPC 码先天的优势— —交织特性为代价,这样便做出了性能与实现上的折中。但这种折中 是有意义的,为 LDPC 码的实际应用开辟了道路。而且,通过某些方 法,可以使设计出的码字在易于存储实现的同时,还能保证一定的性 能。 在译码方面,种种方法都可以归结为和积算法(SPA)的变形,都 是在其基础上做出改进,从而保证译码性能前提下使译码器尽可能的 简单。相对于 Turbo 码,LDPC 码的解码迭代次数还是过高,这样在 实际应用中的竞争力便大打折扣。于是,怎样在保证性能的前提下降 低译码时间是现在译码研究的主要工作。 8.2 LDPC 码简介 1996 年 Mackay、Spielman 和 Wiberg 几乎同时发现:Gallager 早在 1962 年提出的低密度校验码(简称 LDPC 码,也称 Gallager 码) 也是一个好码,具有更低的线性译码复杂度。Gallager 提出 LDPC 码 后一直没有得到编码界的重视,只有 1981 年 Tanner 从图论的角度研
3 .究过 LDPC 码。 自 Mackay 等“再发现”LDPC 码后,人们的进一步研究表明:给 予非规则双向图的 LDPC 长码的性能可以优于 Turbo 码,而且这样的 码的性能可以非常接近 Shannon 限。一个原因在于 LDPC 码具有良好 的距离特性、较小的译码错误概率和较低的译码复杂度,且码长大于 200 时不存在错误平台,码率容易调整,实验结果中几乎均为可检测 错误,所以 LDPC 码无论在理论上还是在实际上都具有极其重要的价 值。LDPC 码的重新发现是继 Turbo 码后在纠错码领域又一重大进展。 (1)编码方面的简介 无论 Gallager 还是 Mackay 都是用随机的方法构造 LDPC 码,用 随机法构造的 LDPC 码的码字参数选择灵活,但对于高码率、中短长 度的 LDPC 码用随机法进行构造,要避免短循环是困难的,其没有一 定的码结构,编码复杂度高,于是人们考虑用代数法构造 LDPC 码。 LDPC 码代数构造可采用几何方法、图论方法、实验设计方法、 置换方法来设计。不同的构造方法都是为了实现以下几个目的:增大 图中最小循环长度,即 Girth 值。优化非规则码的节点分布,减小编 码复杂度,构造的 LDPC 码要有好的码性能。 M.G.Luby 等指出,非规则 H 矩阵构造的码字性能优于相应的规 则 H 矩阵构造的码字。在寻找好的码结构方面,Mackay 等提出:能 快速编码的 LDPC 矩阵通常具有下三角形结构。 T.J.Richardson 探讨了如何构造编码矩阵,使编码时间与码块长 度实际上符合线性关系(线形时间编码),而非通常认为的平方关系。
4 . Y.Kou 和 S.Lin 等探讨了基于有限几何学的 LDPC 码结构。S.Lin 研 究团队的 B.Ammar 等提出用均衡不完全区组设计方法(BIBD)构造 好的 LDPC 码。 (2)译码方面的简介 Gallager 曾给出两种 LDPC 码的迭代译码算法:硬判决和软判决 算法。后者虽有好的性能,但太复杂,消息传递算法可以认为是二者 的折衷。消息传递算法(MP,Message Passing)有时也称置信传播 (BP,Belief Propagation)算法。在 MP 译码算法中,节点到节点的 消息是通过 Tanner 图传递的。 译码算法的改进和优化离不开译码性能的分析。在译码性能分析 的研究方面, T.J.Richardson 等开发了一种在码块无限长假设条件下, 跟踪 LDPC 码 Tanner 图中消息概率的技术,称为“密度进化”算法的 数值程序,来近似估计噪声门限(在该门限以下可望成功地采用 BP 算法),提出了一种通用方法来确定任何二元输入无记忆信道中采用 MP 译码的 LDPC 码的性能。特别对于 BP 译码算法,该方法可提供任 何所需精度的性能估计。 S.Y.Chung 等将消息离散化,通过计算机迭代搜索寻找最优的节 点次数分布,特别适合于非规则码的分析,在二进制输入 AWGN 信 道下,设计码率 1/2、码长 107 的非规则 LDPC 码在错误概率 10-6 时离 Shannon 限仅 0.0045dB。这是迄今为止报到处的性能最接近 Shannon 限的信道编码。 8.3 LDPC 码的基本概念
5 . LDPC 码是用一个稀疏的非系统的校验矩阵 H 定义的线性码。 行重:H 矩阵每行中“1”的个数,其值远远小于 H 矩阵的列数。 列重:H 矩阵每列中“1”的个数。 LDPC 码可以按照 H 矩阵分为规则(regular)和非规则(irregular) 两种。规则 LDPC 码中,各行的行重是一致的,各列的列重也是一致 的,而行重或者列重不一致就称为非规则 LDPC 码。 下面给出规则 LDPC 码的定义: 一个(n, j, k)的规则 LDPC 码由它的校验矩阵 H 定义,校验矩阵 有 n 列,m 行,列重 j,行重 k,其中 m= n ⋅ j / k ,j<k,j<<m,k<<n。 LDPC 码的 H 矩阵一般都是用非系统形式给出的。例如我们生成一 个(6,2,4)的校验矩阵: 1 1 0 1 1 0 H = 1 0 1 0 1 1 0 1 1 1 0 1 如例所示的规则 H 矩阵行重为 4,列重为 2。 同一般的线性分组码,H 矩阵的码率可以如下计算: R=(n-m)/n=(k-j)/k;则图 4 的矩阵可以用来实现码率 1/2 的编码。 LDPC 码的校验矩阵的行对应着校验方程(校验节点),列对应 着传输的比特(比特节点),它们之间的关系可以用 Tanner 图来表 示,图的左边有 n 个节点,每个节点表示码字的信息位,称为信息节 点{xj, j=1, 2, …, n},是码字的比特位,对应于校验矩阵的各列,信息 节点也成为变量节点;右边有 m 个节点,每个节点表示码字的一个
6 .校验集,称为校验节点{ri, i=1, 2, …, m},代表校验方程,对应于校验 节点的各行;与校验矩阵中“1”元素相对应的左右两节点之间存在 连接边。我们将这条边两端的节点称为相邻节点,每个节点相连的变 数成为该节点的度(Degree),每个信息节点与 j 个校验节点相连, 称为该变量节点的度为 j;每个校验节点与 k 个信息节点相连,称为 校验节点的度为 k。例如上面的 H 矩阵对应的 Tanner 图如下: x1 x2 r1 = x1 + x2 + x4 + x5 x3 r2 = x1 + x3 + x5 + x6 x4 r3 = x2 + x3 + x4 + x6 x5 x6 图 1 Tanner 图 LDPC 码校验矩阵 H 中,一个很重要的概念:H 矩阵的最小圈长, 即 girth。一个 4 循环(girth=4)在图 1 中表示为:
7 . x1 x2 r1 = x1 + x2 + x4 + x5 x3 r2 = x1 + x3 + x5 + x6 x4 r3 = x2 + x3 + x4 + x6 x5 x6 图 2 Girth 值为 4 的短循环 对应于 H 矩阵,此 4 循环可以表达为: 1 1 0 1 1 0 H = 1 0 1 0 1 1 0 1 1 1 0 1 同理,对于 6 循环我们有: 1 0 1 H1 = 1 1 0 0 1 1 上式所示的矩阵 H1 表示校验矩阵 H 中的一个子矩阵。 短循环对于矩阵性能的影响: 在 LDPC 码的译码算法中,我们都 假设传递的消息满足彼此独立的假设。当 H 矩阵中存在长度为 2L 的 环路时,则这些消息只在前 L 轮迭代过程中满足独立性假设(注意:
8 .解码的迭代过程包括一次比特节点更新和一次校验节点更新)。因此 短循环的存在会影响 LDPC 码的解码性能。 另外简单的解释:例如在图 2 所示的 H 矩阵中,存在一个 4 循环 于是这个 4 循环对应的校验方程为: r1 = x1 + x2 + x4 + x5 r2 = x1 + x3 + x5 + x6 由于 4 循环的存在,我们可以看到,上面两个校验方程含有共同 的比特节点 x1 与 x5,直观地说,如果这两个校验方程均出错,则我 们无法确定 x1 与 x5 中究竟哪个出错,所以从这个角度也可以说明短 循环对于性能带来的影响。 8.4 LDPC 码的编码方法 LDPC 码属于线性分组码,利用其校验矩阵 H 可以生成编码矩阵 G, 从而可以生成码字,其校验矩阵 H 可以体现 LDPC 码的特点与性能, 所以我们首先介绍 H 矩阵的构造方法。 8.4.1 LDPC 码校验矩阵 H 的构造 Gallager 的 H 矩阵构造方法 每一行有 j 个 1;——满足行重要求 每一列有 k 个 1;——满足列重要求 任意两列具有共同 1 的个数不大于 1;——满足 girth 值大于 4 j 和 k 分别与 H 矩阵中的列数和行数相比小得多;——满足 H 矩阵的稀疏性
9 . 设矩阵 H0 为: 利用 H0,我们可以通过列交换的方法得到校验矩阵 H: 例如下图就是由这种方法构造出的校验矩阵: Mackay 的构造方法 此方法中,校验矩阵的列重为 j,每行的平均重量为 k(即此方法 所构造出的 H 矩阵),且任意两列具有共同 1 的个数不大于 1(保证 不存在 4 循环)。 构造法 1A
10 . 这是一种基本的构造方法,每一列具有固定的列重 j。随机构造矩 阵,使其平均行重为 k,且任意两列具有共同 1 的个数不大于 1。构 造矩阵如图 3 所示: 3 3 图 3(j=3,k=6,R=1/2) 可以按照上面的方法生成一个 H 矩阵,例如 1 0 0 0 0 0 1 1 1 1 1 0 1 1 0 1 0 1 1 1 0 0 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 1 0 0 1 0 1 1 1 构造法 2A 与构造法 1A 类似,引入一些列重为 2 的列,使得 H 矩阵的 girth 值增大,其中列重为 2 的列数为 m/2,这一部分是由两个 m/2×m/2 的单位阵上下重叠起来构成的。如下图所示: 3
11 . 图4 可以按照上面的方法生成一个 H 矩阵,例如 1 0 0 0 0 0 1 1 1 1 1 0 0 1 0 1 0 1 1 1 0 0 0 0 0 0 1 1 1 0 0 0 1 0 0 1 1 0 0 0 1 1 1 0 0 1 0 0 0 1 0 1 0 1 0 0 1 0 1 1 0 0 1 0 1 0 0 1 0 1 1 1 构造法 1B 和 2B 从构造法 1A 和 2A 中删除一些仔细选择的列,使得 H 矩阵中 girth 值满足相应的要求。 超轻矩阵 将 Mackay 的构造方法推广,进一步增加列重为 2 的列数,即用 更多的更小的单位矩阵连续重叠。现将两个 m/2×m/2 的单位矩阵重 叠,再是 m/4×m/4 的单位矩阵重叠,以此类推,最终最多是 m 个 列重为 2 的列。如下图所示。 3 图5 例如,
12 . 1 0 0 0 0 0 1 1 1 1 1 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 0 0 0 1 0 1 1 0 0 1 1 0 1 0 1 0 1 1 1 8.4.2 QC-LDPC 码的构造 在构造 LDPC 码校验矩阵时,随机构造方法不利于硬件实现,于 是人们想到利用几何代数的方法来构造 LDPC 码的校验矩阵,于是就 产生了 QC-LDPC 码,即准循环 LDPC 码(Quasi-Cyclic LDPC codes)。 首先,这类码有严谨的数学结构,构造和性能分析更加精确,甚至最 小汉明距离都是可以计算的;其次,和随机构造的 LDPC 码相比,它 具有更低的误码平台;第三,这类码字具有准循环结构,极大地降低 了编码复杂度,也为译码提供了更方便的选择。 QC-LDPC 码的数学基础 首先,介绍 QC-LDPC 码的数学基础,以及重要的定理。 群:群(G)是具有二元运算的集合,并且适合一下条件: 结合律成立,即 (ab)c = a (bc), ∀a, b, c ∈ G ; G 中存在一个元 e: ea = ae = a, ∀a ∈ G ; −1 对 G 中的任意元 a,存在 a ∈ G ,使 aa −1 −1 = a= a e。 环:有两个二元运算(分别叫做加法和乘法)的代数系统 ( A, +, ⋅) 叫做一个环,如果 ( A, + ) 是一个加法群;
13 . ( A, ⋅) 是一个半群(只对结合律成立); 乘法对加法的左、右分配律都成立。 域:一个交换的除环叫做一个域 一个重要的定理:(费马定理) 设 p 为素数,则有:ap-1=1 (mod p),即 ap=a (mod p)。□ QC-LDPC 码的定义 定义 H 矩阵的 m×n 的母矩阵 M(H),将 M(H)中的 0 与 1 分别用 aij L*L 的全 0 子矩阵与 L*L 的循环子矩阵 p 替换,就可得到校验矩阵 H, 其中循环移位子矩阵 P 定义为 0 1 0 0 0 0 1 0 P = 0 0 0 1 1 0 0 0 例如定义一个全 1 母矩阵为: 1 1 1 1 1 1 1 1 M(H) = 1 1 1 1 m×n 将上式中的每个 1 替换成一个 L×L 的子矩阵 p ,得到一个 aij mL×nL 的 H 矩阵:
14 . pa11 pa12 p a1(n-1) pa1n a p 21 p 2(n-1) p a pa22 a 2n H= pam1 pam2 p am(n-1) pamn 其中 aij (i=1,2,…,m; j=1,2,…,n)为移位项。将单位阵向右循环移 aij 位 aij 得到循环子矩阵 p 。在存储 H 矩阵的时候,我们只需要存储 上式中每一个 aij 的值,而不需要存储每个 1 的位置。 基于有限几何(Finite Geometries)的 LDPC 码的构造方法 有限几何指的是一个由点和边组成的集合,a 为其中一个 m 元组 点,即 a ∈ GF (q ) 。 m 在构造 LDPC 码的时候,有限几何 G 是由 n 个点和 m 条边组成, n 和 m 分别对应于 H 矩阵的列数和行数。我们要构造规则的 H 矩阵, 所以这些点和边具有下列性质: 每一条边含有 j 个点——对应 H 矩阵的行重 每一个点都位于 k 条边上——对应 H 矩阵的列重 任意两个点仅仅通过一条边相连——确保没有 4 循环 任意两条边或平行或只相交于一点 对于这样的有限几何 G,所构造 H 矩阵的行和列分别对应其中的 边和点,当 H 矩阵中 hi,j=1 时,表示 G 中的第 i 条边包含了第 j 个点。 基于有限环的构造方法 有限环构造的优点: 由定义可知,环与域的区别在于除法和对于乘法的交换律。因此
15 .环的限制比域小得多。更重要的是环的基数可以做到连续,这样使得 所构造的码长可以连续。 基于这种理论我们可以构造出 girth 值为 10,且码长连续的 LDPC 码 H 矩阵。 8.4.3 LDPC 码的线性编码 基本编码方法 通过矩阵的初等变换,把 H 矩阵变化成系统形式:H′ = [P , I] ; T 得到该 H 矩阵对应的生成矩阵 G = [I, P] ; 用信息比特去乘生成矩阵 G,就得到了编码后的码字; 2 此方法的复杂度为 O(n ) 。 Richardson 的 LDPC 码编码算法 1) 公式推导: 通过行列置换将 H 矩阵化为近似下三角形状,即: A ( m- g )×( n-m ) B ( m- g )× g T( m- g )×( m- g ) H= , C g ×( n - m ) Dg×g E g ×( m - g ) m×n 其中 T 为下三角阵。 即 H 可以转化为:
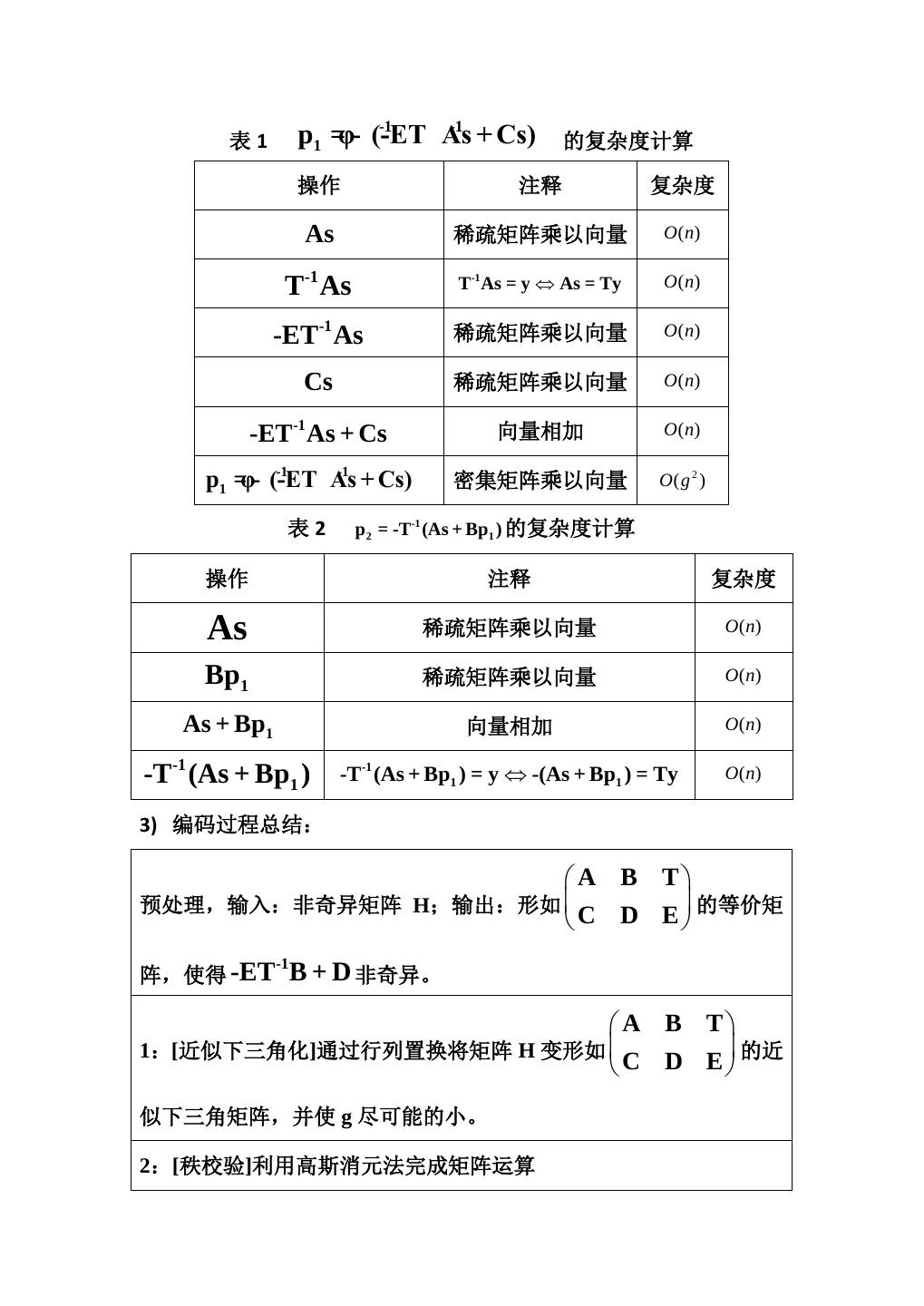
16 . 图6 I 0 用式 -ET-1 I 所示矩阵左乘矩阵 H,得到 A B T -1 -1 -ET A -ET B + D 0 s x = p1 假设码字为 p ,其中 s 表示信息符号,p1 和 p2 表示校验 2 符号。 于是由 Hx=0 有: As + Bp1 + Tp 2 = 0 (-ET-1 A + C)s + (-ET-1B + D)p1 = 0 定义: φ = (-ET B + D) , 并且假设 φ 非奇异,于是有: -1 p1 =φ- (-ET As + Cs) , p 2 = -T (As + Bp1 ) -1 -1 -1 2) 复杂度分析:
17 . 表1 p1 =φ- (-ET -1 As -1 + Cs) 的复杂度计算 操作 注释 复杂度 As 稀疏矩阵乘以向量 O ( n) T-1 As T-1 As = y ⇔ As = Ty O ( n) -ET-1 As 稀疏矩阵乘以向量 O ( n) Cs 稀疏矩阵乘以向量 O ( n) -ET-1 As + Cs 向量相加 O ( n) p1 =φ- (-ET -1 As -1 + Cs) 密集矩阵乘以向量 O( g 2 ) 表2 p 2 = -T-1 (As + Bp1 ) 的复杂度计算 操作 注释 复杂度 As 稀疏矩阵乘以向量 O ( n) Bp1 稀疏矩阵乘以向量 O ( n) As + Bp1 向量相加 O ( n) -T-1 (As + Bp1 ) -T-1 (As + Bp1 ) = y ⇔ -(As + Bp1 ) = Ty O ( n) 3) 编码过程总结: A B T 预处理,输入:非奇异矩阵 H;输出:形如 的等价矩 C D E -1 阵,使得 -ET B + D 非奇异。 A B T 1:[近似下三角化]通过行列置换将矩阵 H 变形如 的近 C D E 似下三角矩阵,并使 g 尽可能的小。 2:[秩校验]利用高斯消元法完成矩阵运算
18 . I 0 A B T A B T -1 = -ET I C D E -ET-1 A -ET-1B + D 0 检验矩阵 -ET-1B + D 是否非奇异,如果奇异,则进一步进行行列置换 使之非奇异。 A B T 编码:输入:形如 的非奇异矩阵,并且 -ET-1B + D 非奇 C D E s x = p1 异,向量 s;输出:向量 ,使得 Hx=0。 p 2 1:通过表 1 计算 p1 2:通过表 2 计算 p 2 此方法的复杂度为 O ( n + g 2 ) ,为了降低编码复杂度,应当使 g 尽量小。 8.5 通过 H 矩阵的设计简化编码复杂度 在利用 LDPC 码 H 矩阵编码的时候,一般都需要先得到 G 矩阵, 随后生成所需要的码字。在 H 矩阵转化为 G 矩阵的过程中所需要的 计算量是相当大的。而且在硬件存储方面,H 矩阵为稀疏矩阵,需要 存储每个 1 的位置,但是 G 矩阵是一个密集矩阵加上一个单位阵的 形式,这就需要开辟很大的存储空间。所以如果编码时不需要生成 G 矩阵,而直接通过 H 矩阵编码,这样就将编码复杂度大大简化。 最简单的方法 这种方法是构造 Hsys 形式的 H 矩阵。即先构造一个矩阵 H1,随后
19 .在 H1 的后面添加一个单位阵构造出 H 矩阵。即: 图7 利用这种 H 矩阵可以实现线性时间编码。 递推编码的方法 由于上面的方法最右边存在一个单位阵,导致最右边列重为 1, 即最右边每个比特只参与一个校验方程。这样使得校验节点对比特节 点的保护就不够,造成性能上的降低。于是为了增加对右边比特的保 护,我们可以采用下面 H 矩阵构造方式。 将 H 矩阵构造为如下形式: p1,1 p1,2 p1,(n-m) p1,(n-m+1) 0 0 0 p p 2,2 p 2,(n-m) p 2,(n-m+1) p 2,(n-m+2) 0 0 H= 2,1 pm,1 pm,2 pm,(n-m) pm,(n-m+1) pm,(n-m+2) pm,(n-m+3) pm,n 其中 pi,j 为利用单位阵移位生成的循环子矩阵。这种循环子矩阵有一 个非常好的性质: pi,jpi,jT=I;即 pi,j-1=pi,jT。这样我们就可以通过对矩阵求转置而得到 矩阵的逆,大大简化了计算量。 对于上式所示的 H 矩阵,由其校验方程 Hx = 0 ,可得:
20 . p1,(n-m+1)c1 = p1,1 x1 + p1,2 x 2 + + p1,(n-m) xn-m p 2,(n-m+1)c1 + p 2,(n-m+2)c 2 = p 2,1 x1 + p 2,2 x 2 + + p 2,(n-m) xn-m ; pm,(n-m+1)c1 + pm,(n-m+2)c 2 + + pm,ncm = pm,1 x1 + pm,2 x 2 + + pm,(n-m) xn-m T c1 = p1,(n-m+1) (p1,1 x1 + p1,2 x 2 + + p1,(n-m) xn-m ) c 2 = p T2,(n-m+2) (p 2,1 x1 + p 2,2 x 2 + + p 2,(n-m) xn-m + p 2,(n-m+1)c1 ) 则 ; cm = pm,n T (pm,1 x1 + pm,2 x 2 + + pm,(n-m) xn-m + pm,(n-m+1)c1 + pm,(n-m+2)c 2 + ) x1 x x = n-m 其中 c1 ,利用递推算法可以得到相应的 c1 , c 2 , , cm 。 cm 8.6 LDPC 码的译码 主要方法有比特翻转(Bit-Flipping)译码、加权大数逻辑(Weighted Majority-Logic)译码、和积(Sum-Product)算法等。
3秒后跳转登录页面
去登陆

