










































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Hadoop文件系统
本文主要介绍了Hadoop文件系统及其应用。我们从Hadoop系统的起源开始讲起,通过学习Hadoop系统的发展历程,探讨其在实际中的应用。
展开查看详情
1 . Hadoop File System 1 SLIDES MODIFIED FROM PRESENTATION BY B. RAMAMURTHY 2/27/17
2 .Moving Computation is Cheaper than Moving Data
3 . Motivation: Big Data! What is BigData ? - Google (over 20~ PB/day) Where does it come from ? Why to take so much of pain ? - Information everywhere, but where is the knowledge? Existing systems (vertical scalibility) Why Hadoop (horizontal scalibility)?
4 . Origin of Hadoop MapReduce paper in OSDI 2014 (Google) ¡ new programming paradigm to handle data at internet scale ¡ Google developed GFS Hadoop/HDFS open source version of MapReduce ¡ Hadoop started as a part of the Nutch project. ¡ In Jan 2006 Doug Cutting started working on Hadoop at Yahoo ¡ Factored out of Nutch in Feb 2006 ¡ Yahoo gave it to Apache First release of Apache Hadoop in September 2007 ¡ Jan 2008 - Hadoop became a top level Apache project
5 . What is Hadoop ? Flexible infrastructure for large scale computation & data processing on a network of commodity hardware Completely written in java Open source & distributed under Apache license Hadoop Common, HDFS & MapReduce
6 . Hadoop distributions Amazon Cloudera MapR HortonWorks Microsoft Windows Azure. IBM InfoSphere Biginsights Datameer EMC Greenplum HD Hadoop distribution Hadapt
7 . Google/GFS Assumptions 7 Based on Google workloads ¡ Also the assumptions driving HDFS 1. Hardware failure common 2. Files are large, and numbers are limited (millions not billions) 3. Two main types of reads: large streaming reads and small random reads 4. Sequential writes that append to files 5. Files rarely modified (simplifies coherence) 6. High sustained bandwidth preferred to low latency 2/27/17
8 . What is Hadoop ? Flexible infrastructure for large scale computation & data processing on a network of commodity hardware Completely written in java Open source & distributed under Apache license Hadoop Common, HDFS & MapReduce
9 . Basic Features: HDFS 9 Highly fault-tolerant ¡ Thousands of server machines ¡ Failure norm rather than exception High throughput ¡ Internet scale workloads ¡ Move compute to data (e.g., MapReduce) Suitable for applications with large data sets Streaming access to file system data Can be built out of commodity hardware ¡ Compare to RAID 2/27/17
10 . Data Characteristics 10 Large data sets and files: gigabytes to terabytes size ¡ Tens of millions of files in a single instance Applications need streaming access to data ¡ Batch processing rather than interactive user access. Scale to thousands of nodes in a cluster Write-once-read-many: a file once created rarely needs to changed ¡ Assumption simplifies coherence ¡ Internet workloads (e.g., map-reduce or web-crawler) fits model 2/27/17
11 . MapReduce 11 combine part0 map reduce Cat split reduce part1 split map combine Bat map part2 split combine reduce Dog map Other split Words (size: TByte) 2/27/17
12 .Architecture 12 2/27/17
13 . Whats new for us? 13 Why not just run NFS? ¡ Scalability ¡ Performance ¡ Elasticity ¡ Reliability Is it a different form of RAID? 2/27/17
14 . Namenode and Datanodes 14 HDFS exposes a file system Each file is split into one or more A single Namenode Maintains metadata and name space Regulates access to files by clients Carries out rebalancing and fault recovery Many DataNodes, usually one per node in a cluster DataNodes manage storage attached to the nodes that they run on Serves read, write requests, performs block creation, deletion, and replication upon instruction from Namenode Communicates to Namenode via heartbeats Namenode communicates back through replies; otherwise clients talk directly to datanodes 2/27/17
15 . HDFS Architecture 15 Metadata(Name, replicas..) Metadata ops Namenode (/home/foo/data,6. .. Client Block ops Read Datanodes Datanodes replication B Blocks Rack1 Write Rack2 Client 2/27/17
16 . File system Namespace 16 Hierarchical file system with directories and files ¡ Create, remove, move, rename etc. File system API started as unix compatible ¡ “faithfulness to standards was sacrificed in favor of improved performance …” Any meta information changes to the file system recorded by the Namenode. 2/27/17
17 . Data Replication 17 HDFS is designed to store very large files across machines in a large cluster. Each file is a sequence of blocks. All blocks in the file except the last are of the same size. Blocks are replicated for fault tolerance. Block size and replicas are configurable per file. The Namenode receives a Heartbeat and a BlockReport from each DataNode in the cluster. BlockReport contains all the blocks on a Datanode. 2/27/17
18 . Replica Placement 18 The placement of the replicas is critical to HDFS reliability and performance. Rack-aware replica placement: ¡ Goal: improve reliability, availability and network bandwidth utilization ¡ Research topic Many racks, communication between racks are through switches. Replicas are typically placed on unique racks ¡ Simple but non-optimal ¡ Writes are expensive ¡ Replication factor is 3 Replicas are placed: one on a node in a local rack, one on a different node in the local rack and one on a node in a different rack. 2/27/17
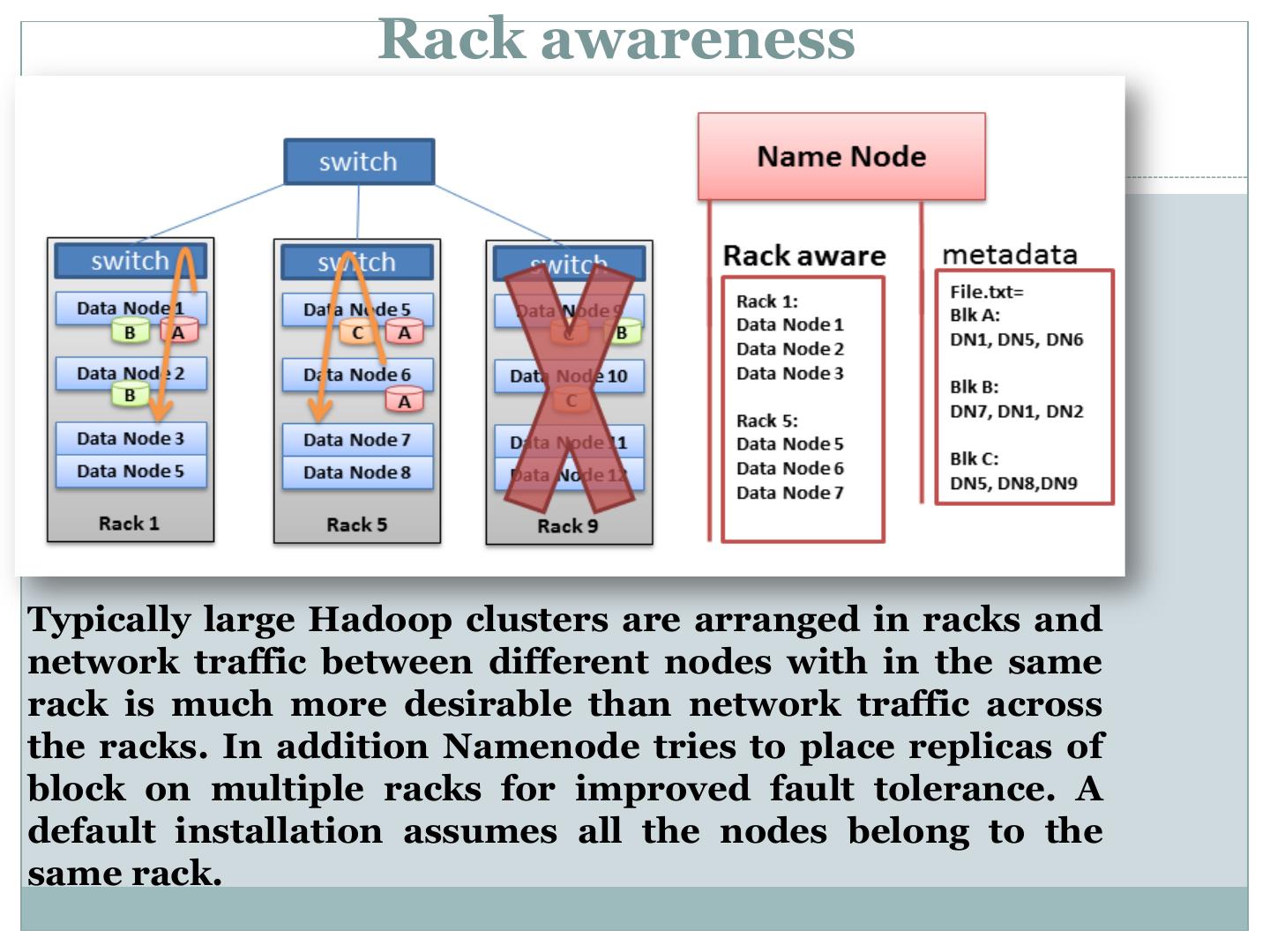
19 . Rack awareness Typically large Hadoop clusters are arranged in racks and network traffic between different nodes with in the same rack is much more desirable than network traffic across the racks. In addition Namenode tries to place replicas of block on multiple racks for improved fault tolerance. A default installation assumes all the nodes belong to the same rack.
20 . Filesystem Metadata 20 The HDFS namespace is stored by Namenode. Namenode uses a transaction log called the EditLog to record every change that occurs to the filesystem meta data. ¡ For example, creating a new file. ¡ Change replication factor of a file ¡ EditLog is stored in the Namenode’s local filesystem ¡ Metadata only Entire filesystem namespace including mapping of blocks to files and file system properties is stored in a file FsImage. Stored in Namenode’s local filesystem. 2/27/17
21 . Namenode 21 Keeps image of entire file system namespace and file Blockmap in memory. 4GB of local RAM is sufficient When Namenode starts up it gets the FsImage and Editlog from its local file system update FsImage with EditLog information and then stores a copy of the FsImage on the filesytstem as a checkpoint. Periodic checkpointing is done. So that the system can recover back to the last checkpointed state in case of a crash. 2/27/17
22 . Datanode 22 A Datanode stores data in files in its local file system. Datanode has no knowledge about HDFS filesystem It stores each block of HDFS data in a separate file. Datanode does not create all files in the same directory. It uses heuristics to determine optimal number of files per directory and creates directories appropriately: ¡ Research issue? When the filesystem starts up it generates a list of all HDFS blocks and send this report to Namenode: Blockreport. 2/27/17
23 .Protocol 23 2/27/17
24 . The Communication Protocol 24 All HDFS communication protocols are layered on top of the TCP/IP protocol A client establishes a connection to a configurable TCP port on the Namenode machine. It talks ClientProtocol with the Namenode. The Datanodes talk to the Namenode using Datanode protocol. RPC abstraction wraps both ClientProtocol and Datanode protocol. Namenode is simply a server and never initiates a request; it only responds to RPC requests issued by DataNodes or clients. 2/27/17
25 .Robustness 25 2/27/17
26 . Objectives 26 Primary objective of HDFS is to store data reliably in the presence of failures. Three common failures are: Namenode failure, Datanode failure and network partition. 2/27/17
27 . DataNode failure and heartbeat 27 A network partition can cause a subset of Datanodes to lose connectivity with the Namenode. Namenode detects this condition by the absence of a Heartbeat message. Namenode marks Datanodes without Hearbeat and does not send any IO requests to them. Any data registered to the failed Datanode is not available to the HDFS. Also the death of a Datanode may cause replication factor of some of the blocks to fall below their specified value. 2/27/17
28 . Re-replication 28 Re-replication (creating more replicas) is sometimes needed Re-replication could be invoked due to: ¡ A Datanode is unavailable, ¡ A replica is corrupted, ¡ A hard disk on a Datanode fails, or ¡ The replication factor on the block may be increased. 2/27/17
29 . Cluster Rebalancing 29 HDFS architecture is compatible with data rebalancing schemes. A scheme might move data from one Datanode to another if the free space on a Datanode falls below a certain threshold. In the event of a sudden high demand for a particular file, a scheme might dynamically create additional replicas and rebalance other data in the cluster. 2/27/17
3秒后跳转登录页面
去登陆

