














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Concurrency (Continued)同步
本文主要讲述了操作系统的设计,操作系统的概念框架,定时器触发线程切换,并发线程的系统介绍等。
展开查看详情
1 . Operating System as Design CS162 Operating Systems and Compilers Word Processing Web Browsers Systems Programming Email Lecture 7 Databases Web Servers Application / Service Concurrency (Continued), Portable OS Library OS Synchronization User System Call Interface System Portable OS Kernel September 18th, 2017 Software Platform support, Device Drivers Ion Stoica Hardware x86 PowerPC ARM http://cs162.eecs.Berkeley.edu PCI 802.11 a/b/g/n Graphics Ethernet (10/100/1000) SCSI IDE 9/18/17 CS162 ©UCB Fall 2017 Lec 7.2 Conceptual Framework Recall: MT Kernel 1T Process ala Pintos/x86 Process 1 Process N threads threads code • Physical Addresses Shared data Mem. Mem. – So: Processes and Address Translation IO IO magic # … magic### magic### magic### … … • Single CPU Must Be list list# list# list# Kernel priority# priority# state state priority# stack# status# stack# status# stack# status# priority Shared !d# !d# !d# stack CPU CPU CPU CPU status tid state state state state – So: Threads User code code • Processes Aren’t Trusted data data CPU – So: Kernel/Userspace Split OS *** sched. • Threads Might Not heap heap PC 1 thread Cooperate IP SP at a time – So: Use timer interrupts User User K SP CPU to context switch stack stack Proc Regs PL: # (1 core) (”preemption”) • Each user process/thread associated with a kernel thread, described by a 4KB page object containing TCB and kernel stack for the kernel thread 9/18/17 CS162 ©UCB Fall 2017 Lec 7.3 9/18/17 CS162 ©UCB Fall 2017 Lec 7.4 Page 1
2 . In User thread, w/ Kernel thread waiting User → Kernel code code data data magic### magic### magic### magic # magic### magic### magic### magic### magic # list# priority# list# priority# list# priority# list list# priority# list# priority# list# priority# list# priority# list Kernel Kernel stack# stack# stack# stack# stack# status# !d# stack# status# !d# status# !d# priority status# !d# stack# status# !d# status# !d# status# !d# priority stack stack status status tid tid User User code code code code data data data data heap *** heap heap *** heap IP IP SP SP User User User User K SP K SP stack stack stack stack Proc Regs PL: 3 Proc Regs PL: 0 • x86 CPU holds interrupt SP in register • Mechanism to resume k-thread goes through interrupt vector • During user thread execution, associated kernel thread is “standing by” 9/18/17 CS162 ©UCB Fall 2017 Lec 7.5 9/18/17 CS162 ©UCB Fall 2017 Lec 7.6 User → Kernel via interrupt vector Pintos Interrupt Processing intrNN_stub() Wrapper for 0 generic handler *** 0 intr_entry: push 0x20 (int #) save regs as frame magic### magic### magic### jmp intr_entry set up kernel env. list# priority# list# priority# list# priority# 0x20 stack# stack# status# stack# status# status# call intr_handler Kernel !d# !d# !d# push 0x21 (int #) jmp intr_entry intr_exit: User code code 255 *** restore regs intr vector iret data data 255 Hardware stubs.S heap *** heap interrupt IP vector SP User User K SP stack stack Proc Regs PL: 3 • Interrupt transfers control through the Interrupt Vector (IDT in x86) • iret restores user stack and PL 9/18/17 CS162 ©UCB Fall 2017 Lec 7.7 9/18/17 CS162 ©UCB Fall 2017 Lec 7.8 Page 2
3 . Recall: cs61C THE STACK FRAME Pintos Interrupt Processing interrupt.c Basic Structure of a Function Intr_handler(*frame) intrNN_stub() Wrapper for ! Prologue - classify generic handler - dispatch entry_label: addi $sp,$sp, -framesize 0 *** - ack IRQ sw $ra, framesize-4($sp) # save $ra save other regs if need be " " ! intr_entry: - maybe thread yield ! ra push 0x20 (int #) save regs as frame Body!!... (call other functions…) ! jmp intr_entry set up kernel env. 0x20 ! The Stack (review) call intr_handler Epilogue ! memory push 0x21 (int #) restore other regs if need be ! Stack frame includes: jmp intr_entry lw $ra, framesize-4($sp) # restore $ra " Return “instruction” address intr_exit: timer_intr(*frame) addi $sp,$sp, framesize " Parameters restore regs 0 tick++ jr $ra" *** " Space for other local variables0xFFFFFFFF" iret thread_tick() frame" 255 CS61C L10 Introduction to MIPS : Procedures I (18) Garcia, Spring 2014 © UCB ! Stack frames contiguous 0x20 timer.c blocks of memory; stack pointer tells where bottom of stack frame is frame" Hardware stubs.S ! When procedure ends, stack frame interrupt is tossed off the stack; frees frame" vector memory for future stack frames frame" $sp" Pintos intr_handlers CS61C L11 Introduction to MIPS : Procedures II & Logical Ops (3) Garcia, Spring 2014 © UCB 9/18/17 CS162 ©UCB Fall 2017 Lec 7.9 9/18/17 CS162 ©UCB Fall 2017 Lec 7.10 In Kernel thread Timer may trigger thread switch • thread_tick code – Updates thread counters data – If quanta exhausted, sets yield flag magic### magic### magic### magic### magic # • thread_yield list# list# list – On path to rtn from interrupt list# list# priority# priority# priority# priority# Kernel stack# stack# stack# status# !d# stack# status# !d# status# !d# status# !d# priority stack status – Sets current thread back to READY tid User – Pushes it back on ready_list code code – Calls schedule to select next thread to run upon iret data data • Schedule heap *** heap – Selects next thread to run IP – Calls switch_threads to change regs to point to stack for thread SP to resume User User K SP – Sets its status to RUNNING stack stack Proc Regs PL: 0 – If user thread, activates the process • Kernel threads execute with small stack in thread structure – Returns back to intr_handler • Scheduler selects among ready kernel and user threads 9/18/17 CS162 ©UCB Fall 2017 Lec 7.11 9/18/17 CS162 ©UCB Fall 2017 Lec 7.12 Page 3
4 . Thread Switch (switch.S) Switch to Kernel Thread for Process code code data data magic### magic### magic### magic # magic### magic### magic### magic### magic # list# priority# list# priority# list# priority# list list# priority# list# priority# list# priority# list# priority# list Kernel Kernel stack# stack# stack# stack# stack# status# !d# stack# status# !d# status# !d# priority status# !d# stack# status# !d# status# !d# status# !d# priority stack stack status status tid tid User User code code code code data data data data heap *** heap heap *** heap IP IP SP SP User User User User K SP K SP stack stack stack stack Proc Regs PL: 0 Proc Regs PL: 0 • switch_threads: save regs on current small stack, change SP, return from destination threads call to switch_threads 9/18/17 CS162 ©UCB Fall 2017 Lec 7.13 9/18/17 CS162 ©UCB Fall 2017 Lec 7.14 Pintos Return from Processing Kernel → User interrupt.c code Intr_handler(*frame) intrNN_stub() Wrapper for generic handler - classify data - dispatch 0 *** - ack IRQ intr_entry: - maybe thread yield magic### magic### magic### magic # push 0x20 (int #) save regs as frame list# priority# list# priority# list# priority# list Kernel stack# stack# jmp intr_entry status# stack# status# status# priority 0x20 set up kernel env. !d# !d# !d# stack call intr_handler status push 0x20 (int #) tid jmp intr_entry User intr_exit: timer_intr(*frame) code code restore regs 0 tick++ *** iret thread_tick() data data 255 0x20 timer.c heap *** heap Hardware stubs.S interrupt IP thread_yield() vector SP - schedule User User Resume Some Thread K SP stack stack Proc Regs PL: 3 Pintos schedule() intr_handlers - switch • Interrupt return (iret) restores user stack and PL 9/18/17 CS162 ©UCB Fall 2017 Lec 7.15 9/18/17 CS162 ©UCB Fall 2017 Lec 7.16 Page 4
5 . Rest of Today’s Lecture Recall: Thread Abstraction • The Concurrency Problem Programmer Abstraction Physical Reality • Synchronization Operations Threads • Higher-level Synchronization Abstractions – Semaphores, monitors, and condition variables 1 2 3 4 5 1 2 3 4 5 Processors 1 2 3 4 5 1 2 Running Ready Threads Threads • Infinite number of processors • Threads execute with variable speed – Programs must be designed to work with any schedule 9/18/17 CS162 ©UCB Fall 2017 Lec 7.17 9/18/17 CS162 ©UCB Fall 2017 Lec 7.18 Multiprocessing vs Multiprogramming Correctness for systems with concurrent threads • Remember Definitions: • If dispatcher can schedule threads in any way, programs must work – Multiprocessing ≡ Multiple CPUs or cores or hyperthreads (HW per- under all circumstances instruction interleaving) – Can you test for this? – Multiprogramming ≡ Multiple Jobs or Processes – How can you know if your program works? – Multithreading ≡ Multiple threads per Process • Independent Threads: – No state shared with other threads • What does it mean to run two threads “concurrently”? – Deterministic ⇒ Input state determines results – Scheduler is free to run threads in any order and interleaving: FIFO, – Reproducible ⇒ Can recreate Starting Conditions, I/O Random, … – Scheduling order doesn’t matter (if switch() works!!!) • Cooperating Threads: A – Shared State between multiple threads Multiprocessing B – Non-deterministic C – Non-reproducible A B C • Non-deterministic and Non-reproducible means that bugs can be intermittent Multiprogramming A B C A B C B – Sometimes called “Heisenbugs” 9/18/17 CS162 ©UCB Fall 2017 Lec 7.19 9/18/17 CS162 ©UCB Fall 2017 Lec 7.20 Page 5
6 . Interactions Complicate Debugging Why allow cooperating threads? • Is any program truly independent? • Advantage 1: Share resources – Every process shares the file system, OS resources, network, etc. – One computer, many users – Extreme example: buggy device driver causes thread A to crash – One bank balance, many ATMs “independent thread” B » What if ATMs were only updated at night? – Embedded systems (robot control: coordinate arm & hand) • Non-deterministic errors are really difficult to find • Advantage 2: Speedup – Example: Memory layout of kernel+user programs – Overlap I/O and computation » depends on scheduling, which depends on timer/other things » Many different file systems do read-ahead » Original UNIX had a bunch of non-deterministic errors – Multiprocessors – chop up program into parallel pieces – Example: Something which does interesting I/O • Advantage 3: Modularity » User typing of letters used to help generate secure keys – More important than you might think – Chop large problem up into simpler pieces » To compile, for instance, gcc calls cpp | cc1 | cc2 | as | ld » Makes system easier to extend 9/18/17 CS162 ©UCB Fall 2017 Lec 7.21 9/18/17 CS162 ©UCB Fall 2017 Lec 7.22 High-level Example: Web Server Threaded Web Server • Instead, use a single process • Multithreaded (cooperating) version: serverLoop() { connection = AcceptCon(); ThreadFork(ServiceWebPage(), connection); } • Looks almost the same, but has many advantages: – Can share file caches kept in memory, results of CGI scripts, other things • Server must handle many requests – Threads are much cheaper to create than processes, so this has a • Non-cooperating version: lower per-request overhead serverLoop() { connection = AcceptCon(); ProcessFork(ServiceWebPage(), connection); • What about Denial of Service attacks or digg / Slashdot effects? } • What are some disadvantages of this technique? 9/18/17 CS162 ©UCB Fall 2017 Lec 7.23 9/18/17 CS162 ©UCB Fall 2017 Lec 7.24 Page 6
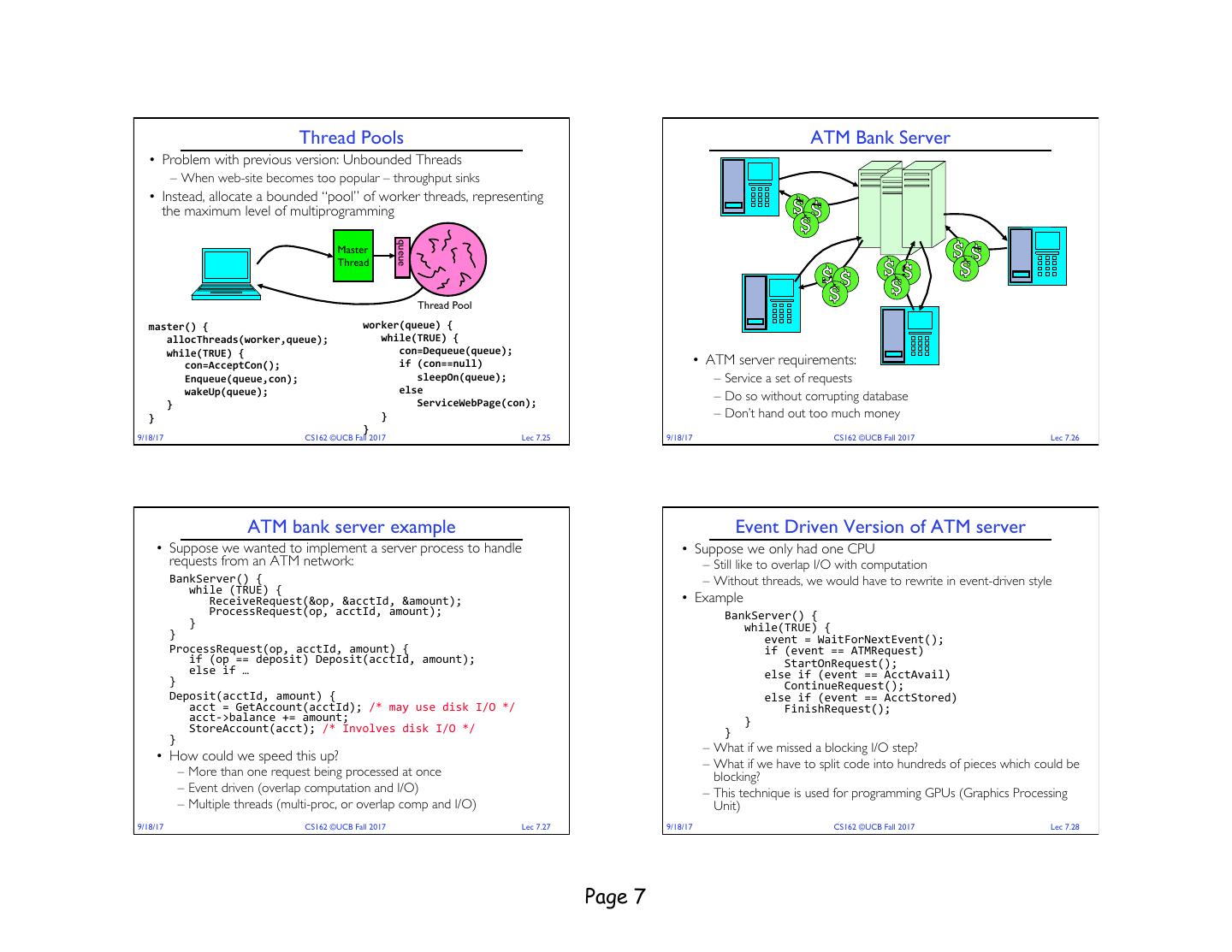
7 . Thread Pools ATM Bank Server • Problem with previous version: Unbounded Threads – When web-site becomes too popular – throughput sinks • Instead, allocate a bounded “pool” of worker threads, representing the maximum level of multiprogramming queue Master Thread Thread Pool master() { worker(queue) { allocThreads(worker,queue); while(TRUE) { while(TRUE) { con=Dequeue(queue); con=AcceptCon(); if (con==null) • ATM server requirements: Enqueue(queue,con); sleepOn(queue); – Service a set of requests wakeUp(queue); else ServiceWebPage(con); – Do so without corrupting database } } } – Don’t hand out too much money } 9/18/17 CS162 ©UCB Fall 2017 Lec 7.25 9/18/17 CS162 ©UCB Fall 2017 Lec 7.26 ATM bank server example Event Driven Version of ATM server • Suppose we wanted to implement a server process to handle • Suppose we only had one CPU requests from an ATM network: – Still like to overlap I/O with computation BankServer() { – Without threads, we would have to rewrite in event-driven style while (TRUE) { ReceiveRequest(&op, &acctId, &amount); • Example ProcessRequest(op, acctId, amount); BankServer() { } while(TRUE) { } event = WaitForNextEvent(); ProcessRequest(op, acctId, amount) { if (event == ATMRequest) if (op == deposit) Deposit(acctId, amount); StartOnRequest(); else if … else if (event == AcctAvail) } ContinueRequest(); Deposit(acctId, amount) { else if (event == AcctStored) acct = GetAccount(acctId); /* may use disk I/O */ FinishRequest(); acct->balance += amount; } StoreAccount(acct); /* Involves disk I/O */ } } – What if we missed a blocking I/O step? • How could we speed this up? – What if we have to split code into hundreds of pieces which could be – More than one request being processed at once blocking? – Event driven (overlap computation and I/O) – This technique is used for programming GPUs (Graphics Processing – Multiple threads (multi-proc, or overlap comp and I/O) Unit) 9/18/17 CS162 ©UCB Fall 2017 Lec 7.27 9/18/17 CS162 ©UCB Fall 2017 Lec 7.28 Page 7
8 . Can Threads Make This Easier? Problem is at the Lowest Level • Threads yield overlapped I/O and computation without having to • Most of the time, threads are working on separate data, so “deconstruct” code into non-blocking fragments scheduling doesn’t matter: – One thread per request Thread A Thread B • Requests proceeds to completion, blocking as required: x = 1; y = 2; Deposit(acctId, amount) { • However, what about (Initially, y = 12): acct = GetAccount(actId); /* May use disk I/O */ Thread A Thread B acct->balance += amount; StoreAccount(acct); /* Involves disk I/O */ x = 1; y = 2; } x = y+1; y = y*2; • Unfortunately, shared state can get corrupted: – What are the possible values of x? Thread 1 Thread 2 • Or, what are the possible values of x below? load r1, acct->balance load r1, acct->balance Thread A Thread B add r1, amount2 x = 1; x = 2; store r1, acct->balance – X could be 1 or 2 (non-deterministic!) add r1, amount1 store r1, acct->balance – Could even be 3 for serial processors: » Thread A writes 0001, B writes 0010 → scheduling order ABABABBA 9/18/17 CS162 ©UCB Fall 2017 Lec 7.29 9/18/17 yields 3! CS162 ©UCB Fall 2017 Lec 7.30 Atomic Operations Correctness Requirements • Threaded programs must work for all interleavings of thread • To understand a concurrent program, we need to know what the instruction sequences underlying indivisible operations are! – Cooperating threads inherently non-deterministic and non- • Atomic Operation: an operation that always runs to completion or reproducible not at all – Really hard to debug unless carefully designed! • Examples: – It is indivisible: it cannot be stopped in the middle and state cannot be modified by someone else in the middle – Fundamental building block – if no atomic operations, then have no way for threads to work together • On most machines, memory references and assignments (i.e. loads and stores) of words are atomic – Consequently – weird example that produces “3” on previous slide can’t happen • Many instructions are not atomic – Double-precision floating point store often not atomic – VAX and IBM 360 had an instruction to copy a whole array 9/18/17 CS162 ©UCB Fall 2017 Lec 7.31 9/18/17 CS162 ©UCB Fall 2017 Lec 7.32 Page 8
9 . Administrivia • Group/Section assignments finalized! • BREAK – If you are not in group, talk to us immediately! • Attend assigned sections – Need to know your TA! » Participation is 8% of your grade » Should attend section with your TA • First design doc due next Wednesday – This means you should be well on your way with Project 1 – Watch for notification from your TA to sign up for design review • Basic semaphores work in PintOS! – However, you will need to implement priority scheduling behavior both in semaphore and ready queue 9/18/17 CS162 ©UCB Fall 2017 Lec 7.33 9/18/17 CS162 ©UCB Fall 2017 Lec 7.34 Motivation: “Too Much Milk” Definitions • Great thing about OS’s – analogy between problems in OS and problems in real life • Synchronization: using atomic operations to ensure cooperation between threads – Help you understand real life problems better – For now, only loads and stores are atomic – But, computers are much stupider than people – We are going to show that its hard to build anything useful with only • Example: People need to coordinate: reads and writes Time Person A Person B 3:00 Look in Fridge. Out of milk • Mutual Exclusion: ensuring that only one thread does a particular 3:05 Leave for store thing at a time 3:10 Arrive at store Look in Fridge. Out of milk – One thread excludes the other while doing its task 3:15 Buy milk Leave for store 3:20 Arrive home, put milk away Arrive at store • Critical Section: piece of code that only one thread can execute at 3:25 Buy milk once. Only one thread at a time will get into this section of code 3:30 Arrive home, put milk away – Critical section is the result of mutual exclusion – Critical section and mutual exclusion are two ways of describing the same thing 9/18/17 CS162 ©UCB Fall 2017 Lec 7.35 9/18/17 CS162 ©UCB Fall 2017 Lec 7.36 Page 9
10 . More Definitions Too Much Milk: Correctness Properties • Lock: prevents someone from doing something – Lock before entering critical section and • Need to be careful about correctness of concurrent before accessing shared data programs, since non-deterministic – Unlock when leaving, after accessing shared data – Impulse is to start coding first, then when it doesn’t work, pull hair out – Wait if locked – Instead, think first, then code » Important idea: all synchronization involves waiting – Always write down behavior first • For example: fix the milk problem by putting a key on the refrigerator • What are the correctness properties for the “Too much milk” – Lock it and take key if you are going to go buy milk problem??? – Fixes too much: roommate angry if only wants OJ – Never more than one person buys – Someone buys if needed #$@% • Restrict ourselves to use only atomic load and store @#$@ operations as building blocks – Of Course – We don’t know how to make a lock yet 9/18/17 CS162 ©UCB Fall 2017 Lec 7.37 9/18/17 CS162 ©UCB Fall 2017 Lec 7.38 Too Much Milk: Solution #1 Too Much Milk: Solution #1 • Use a note to avoid buying too much milk: • Use a note to avoid buying too much milk: – Leave a note before buying (kind of “lock”) – Leave a note before buying (kind of “lock”) – Remove note after buying (kind of “unlock”) – Remove note after buying (kind of “unlock”) – Don’t buy if note (wait) – Don’t buy if note (wait) • Suppose a computer tries this (remember, only memory read/write • Suppose a computer tries this (remember, only memory read/write are atomic): are atomic): if (noMilk) { Thread A Thread B if (noNote) { if (noMilk) { leave Note; if (noMilk) { buy milk; if (noNote) { remove note; if (noNote) { } leave Note; } buy Milk; remove Note; } } leave Note; buy Milk; remove Note; } } 9/18/17 CS162 ©UCB Fall 2017 Lec 7.39 9/18/17 CS162 ©UCB Fall 2017 Lec 7.40 Page 10
11 . Too Much Milk: Solution #1 Too Much Milk: Solution #1½ • Use a note to avoid buying too much milk: • Clearly the Note is not quite blocking enough – Leave a note before buying (kind of “lock”) – Let’s try to fix this by placing note first – Remove note after buying (kind of “unlock”) • Another try at previous solution: – Don’t buy if note (wait) • Suppose a computer tries this (remember, only memory read/write leave Note; are atomic): if (noMilk) { if (noMilk) { if (noNote) { if (noNote) { leave Note; leave Note; buy milk; buy milk; } remove note; } } } remove note; • Result? – Still too much milk but only occasionally! • What happens here? – Thread can get context switched after checking milk and note but before – Well, with human, probably nothing bad buying milk! – With computer: no one ever buys milk • Solution makes problem worse since fails intermittently – Makes it really hard to debug… – Must work despite what the dispatcher does! 9/18/17 CS162 ©UCB Fall 2017 Lec 7.41 9/18/17 CS162 ©UCB Fall 2017 Lec 7.42 Too Much Milk Solution #2 Too Much Milk Solution #2: problem! • How about labeled notes? – Now we can leave note before checking • Algorithm looks like this: Thread A Thread B leave note A; leave note B; if (noNote B) { if (noNoteA) { if (noMilk) { if (noMilk) { buy Milk; buy Milk; } } } } remove note A; remove note B; • Does this work? • Possible for neither thread to buy milk – Context switches at exactly the wrong times can lead each to think that the other is going to buy • Really insidious: • I thought you had the milk! But I thought you had the milk! – Extremely unlikely that this would happen, but will at worse possible time • This kind of lockup is called “starvation!” – Probably something like this in UNIX 9/18/17 CS162 ©UCB Fall 2017 Lec 7.43 9/18/17 CS162 ©UCB Fall 2017 Lec 7.44 Page 11
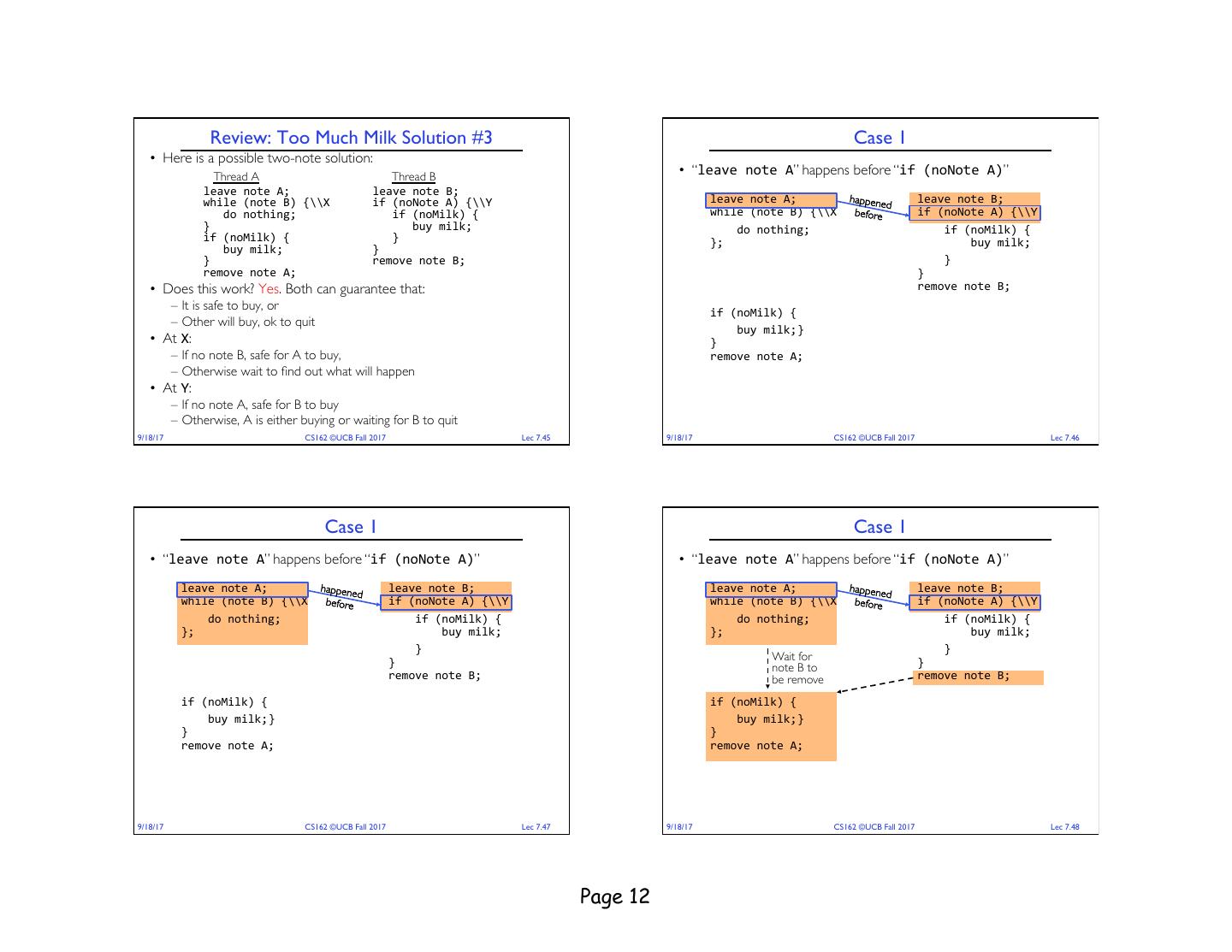
12 . Review: Too Much Milk Solution #3 Case 1 • Here is a possible two-note solution: Thread A Thread B • “leave note A” happens before “if (noNote A)” leave note A; leave note B; while (note B) {\\X if (noNote A) {\\Y leave note A; happene leave note B; d do nothing; if (noMilk) { while (note B) {\\X before if (noNote A) {\\Y } buy milk; do nothing; if (noMilk) { if (noMilk) { } }; buy milk; buy milk; } } remove note B; } remove note A; } • Does this work? Yes. Both can guarantee that: remove note B; – It is safe to buy, or if (noMilk) { – Other will buy, ok to quit buy milk; } • At X: } – If no note B, safe for A to buy, remove note A; – Otherwise wait to find out what will happen • At Y: – If no note A, safe for B to buy – Otherwise, A is either buying or waiting for B to quit 9/18/17 CS162 ©UCB Fall 2017 Lec 7.45 9/18/17 CS162 ©UCB Fall 2017 Lec 7.46 Case 1 Case 1 • “leave note A” happens before “if (noNote A)” • “leave note A” happens before “if (noNote A)” leave note A; happene leave note B; leave note A; happene leave note B; d d while (note B) {\\X before if (noNote A) {\\Y while (note B) {\\X before if (noNote A) {\\Y do nothing; if (noMilk) { do nothing; if (noMilk) { }; buy milk; }; buy milk; } } Wait for } note B to } remove note B; be remove remove note B; if (noMilk) { if (noMilk) { buy milk; } buy milk; } } } remove note A; remove note A; 9/18/17 CS162 ©UCB Fall 2017 Lec 7.47 9/18/17 CS162 ©UCB Fall 2017 Lec 7.48 Page 12
13 . Case 2 Case 2 • “if (noNote A)” happens before “leave note A” • “if (noNote A)” happens before “leave note A” leave note B; leave note B; ned if (noNote A) {\\Y ned if (noNote A) {\\Y happe e happe e leave note A; befor if (noMilk) { leave note A; befor if (noMilk) { while (note B) {\\X buy milk; while (note B) {\\X buy milk; do nothing; } do nothing; } }; } }; } remove note B; remove note B; if (noMilk) { if (noMilk) { buy milk; } buy milk; } } } remove note A; remove note A; 9/18/17 CS162 ©UCB Fall 2017 Lec 7.49 9/18/17 CS162 ©UCB Fall 2017 Lec 7.50 Case 2 Review: Solution #3 discussion • Our solution protects a single “Critical-Section” piece of code for each • “if (noNote A)” happens before “leave note A” thread: if (noMilk) { leave note B; buy milk; ned if (noNote A) {\\Y } happe e leave note A; befor if (noMilk) { • Solution #3 works, but it’s really unsatisfactory while (note B) {\\X buy milk; – Really complex – even for this simple an example do nothing; } } » Hard to convince yourself that this really works }; remove note B; – A’s code is different from B’s – what if lots of threads? Wait for note B to » Code would have to be slightly different for each thread be remove – While A is waiting, it is consuming CPU time if (noMilk) { » This is called “busy-waiting” buy milk; } } • There’s a better way remove note A; – Have hardware provide higher-level primitives than atomic load & store – Build even higher-level programming abstractions on this hardware support 9/18/17 CS162 ©UCB Fall 2017 Lec 7.51 9/18/17 CS162 ©UCB Fall 2017 Lec 7.52 Page 13
14 . Too Much Milk: Solution #4 Where are we going with synchronization? • Suppose we have some sort of implementation of a lock – lock.Acquire() – wait until lock is free, then grab Programs Shared Programs – lock.Release() – Unlock, waking up anyone waiting – These must be atomic operations – if two threads are waiting for the Higher- lock and both see it’s free, only one succeeds to grab the lock level Locks Semaphores Monitors Send/Receive API • Then, our milk problem is easy: milklock.Acquire(); Hardware Load/Store Disable Ints Test&Set Compare&Swap if (nomilk) buy milk; milklock.Release(); • We are going to implement various higher-level synchronization • Once again, section of code between Acquire() and primitives using atomic operations Release() called a “Critical Section” – Everything is pretty painful if only atomic primitives are load and store • Of course, you can make this even simpler: suppose you are out of – Need to provide primitives useful at user-level ice cream instead of milk – Skip the test since you always need more ice cream ;-) 9/18/17 CS162 ©UCB Fall 2017 Lec 7.53 9/18/17 CS162 ©UCB Fall 2017 Lec 7.54 Summary • Concurrent threads are a very useful abstraction – Allow transparent overlapping of computation and I/O – Allow use of parallel processing when available • Concurrent threads introduce problems when accessing shared data – Programs must be insensitive to arbitrary interleavings – Without careful design, shared variables can become completely inconsistent • Important concept: Atomic Operations – An operation that runs to completion or not at all – These are the primitives on which to construct various synchronization primitives 9/18/17 CS162 ©UCB Fall 2017 Lec 7.55 Page 14
3秒后跳转登录页面
去登陆

