













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Chord和Berkeley数据分析软件栈
介绍了分布式系统中共识机制和为了确保系统的可靠性,特别是当数据量极具变大,集群引入更多机器,如何确保数据的均衡,提出一致性哈希算法解释。最后介绍了伯克利的大数据分析软件栈的基本软件架构。
展开查看详情
1 . Outline CS162 • Quorum consensus Operating Systems and Systems Programming Lecture 24 • Chord Chord and Berkeley Data Analytics Stack (part I) • Mesos November 20th, 2017 Prof. Ion Stoica http://cs162.eecs.Berkeley.edu 11/19/17 CS162 © UCB Fall 2017 Lec 24.2 Quorum Consensus Quorum Consensus Example • N=3, W=2, R=2 • Improve put() and get() operation performance • Replica set for K14: {N1, N3, N4} • Assume put() on N3 fails • Define a replica set of size N – put() waits for acknowledgements from at least W replicas put(K14, V14) – get() waits for responses from at least R replicas put 4) V1 (K1 – W+R > N AC , 14 CK 4, V K t(K A pu 14) • Why does it work? – There is at least one node that contains the update K14 V14 K14 V14 • Why might you use W+R > N+1? N1 N2 N3 N4 11/19/17 CS162 © UCB Fall 2017 Lec 24.3 11/19/17 CS162 © UCB Fall 2017 Lec 24.4 Page 1
2 . Quorum Consensus Example Outline • Now, issuing get() to any two nodes out of three will • Quorum consensus return the answer • Chord ) get(K14) 14 • Mesos NIL t(K 14 ge V K14 V14 K14 V14 N1 N2 N3 N4 11/19/17 CS162 © UCB Fall 2017 Lec 24.5 11/19/17 CS162 © UCB Fall 2017 Lec 24.6 Scaling Up Directory – Challenges Scaling Up Directory – Strawman Solution • Directory contains a number of entries equal to number • Assume a system with m nodes of (key, value) tuples in the system • Store (key, value) on node i = key mod M + 1 • No need to keep any metadata! • Can be tens or hundreds of billions of entries in the • Challenge: what happened if you take away a node or add a system! new node? … 1 2 3 M 11/19/17 CS162 © UCB Fall 2017 Lec 24.7 11/19/17 CS162 © UCB Fall 2017 Lec 24.8 Page 2
3 . Scaling Up Directory – Consistent Hashing Key to Node Mapping Example • Associate to each node a unique id in an uni-dimensional space 0..2m-1 63 0 • m = 6 à ID space: 0..63 4 – Partition this space across m machines • Node 8 maps keys [5,8] 58 8 – Assume keys are in same uni-dimensional space • Node 15 maps keys [9,15] – Each (Key, Value) is stored at the node with the smallest • Node 20 maps keys [16, ID larger than Key 20] 14 V14 • … 15 • Node 4 maps keys [59, 4] 44 20 35 32 11/19/17 CS162 © UCB Fall 2017 Lec 24.9 11/19/17 CS162 © UCB Fall 2017 Lec 24.10 Scaling Up Directory Chord: Distributed Lookup (Directory) Service • With consistent hashing, directory contains only a number of entries equal to number of nodes • Key design decision – Much smaller than number of tuples – Decouple correctness from efficiency • Next challenge: every query still needs to contact the directory • Properties • Solution: distributed directory (a.k.a. lookup) service: – Each node needs to know about O(log(M)), where M is the total – Given a key, find the node storing value associated to the key number of nodes – Guarantees that a tuple is found in O(log(M)) steps • Key idea: route request from node to node until reaching the node storing the request’s key • Many other lookup services: CAN, Tapestry, Pastry, Kademlia, … • Key advantage: totally distributed – No point of failure; no hot spot 11/19/17 CS162 © UCB Fall 2017 Lec 24.11 11/19/17 CS162 © UCB Fall 2017 Lec 24.12 Page 3
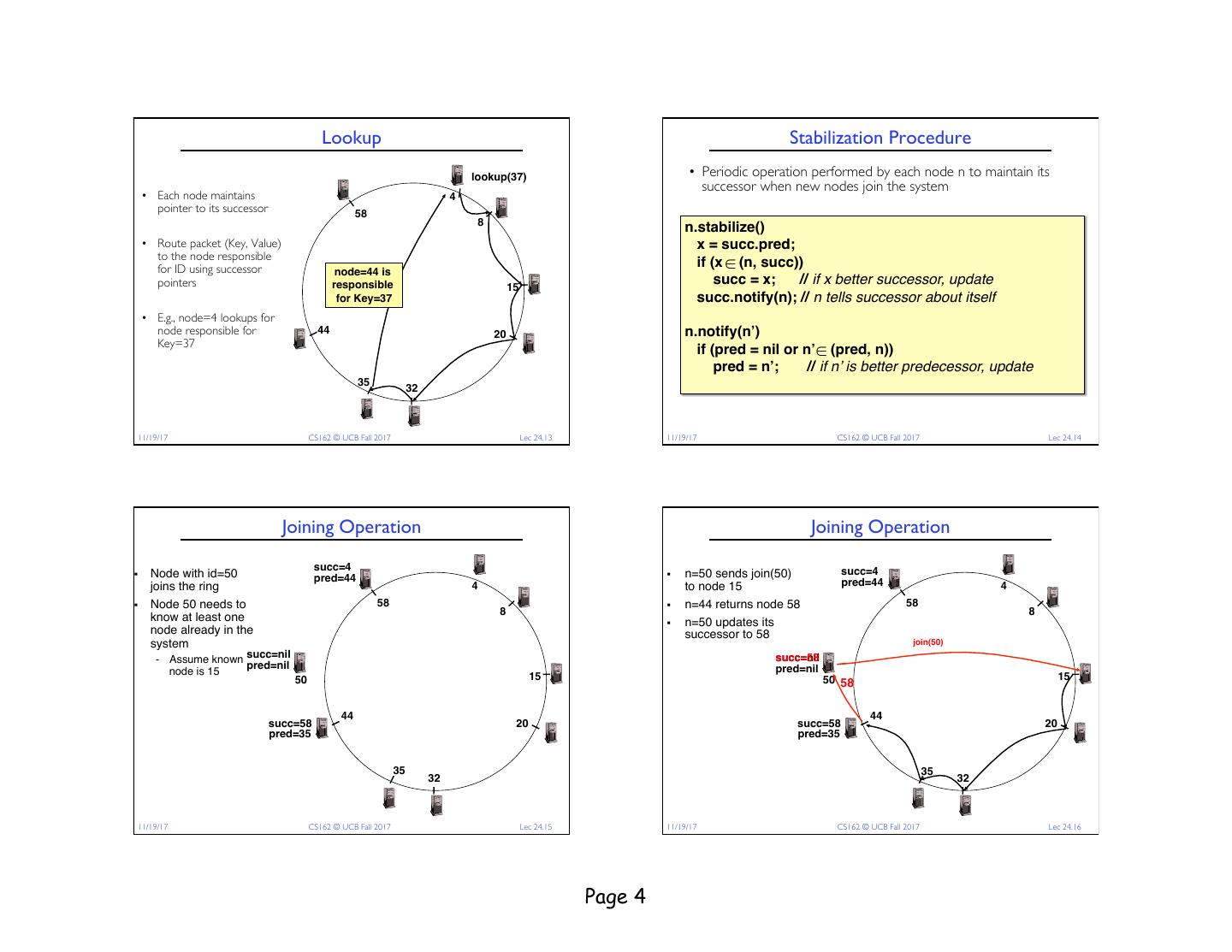
4 . Lookup Stabilization Procedure lookup(37) • Periodic operation performed by each node n to maintain its successor when new nodes join the system • Each node maintains 4 pointer to its successor 58 8 n.stabilize() • Route packet (Key, Value) x = succ.pred; to the node responsible for ID using successor if (x ∈ (n, succ)) node=44 is pointers responsible 15 succ = x; // if x better successor, update for Key=37 succ.notify(n); // n tells successor about itself • E.g., node=4 lookups for node responsible for € 44 20 n.notify(n’) Key=37 if (pred = nil or n’ ∈ (pred, n)) pred = n’; // if n’ is better predecessor, update 35 32 € 11/19/17 CS162 © UCB Fall 2017 Lec 24.13 11/19/17 CS162 © UCB Fall 2017 Lec 24.14 Joining Operation Joining Operation succ=4 succ=4 § Node with id=50 pred=44 § n=50 sends join(50) joins the ring 4 to node 15 pred=44 4 § Node 50 needs to 58 § n=44 returns node 58 58 8 8 know at least one § n=50 updates its node already in the successor to 58 system join(50) - Assume known succ=nil succ=58 succ=nil pred=nil pred=nil node is 15 50 15 50 58 15 44 44 succ=58 20 succ=58 20 pred=35 pred=35 35 35 32 32 11/19/17 CS162 © UCB Fall 2017 Lec 24.15 11/19/17 CS162 © UCB Fall 2017 Lec 24.16 Page 4
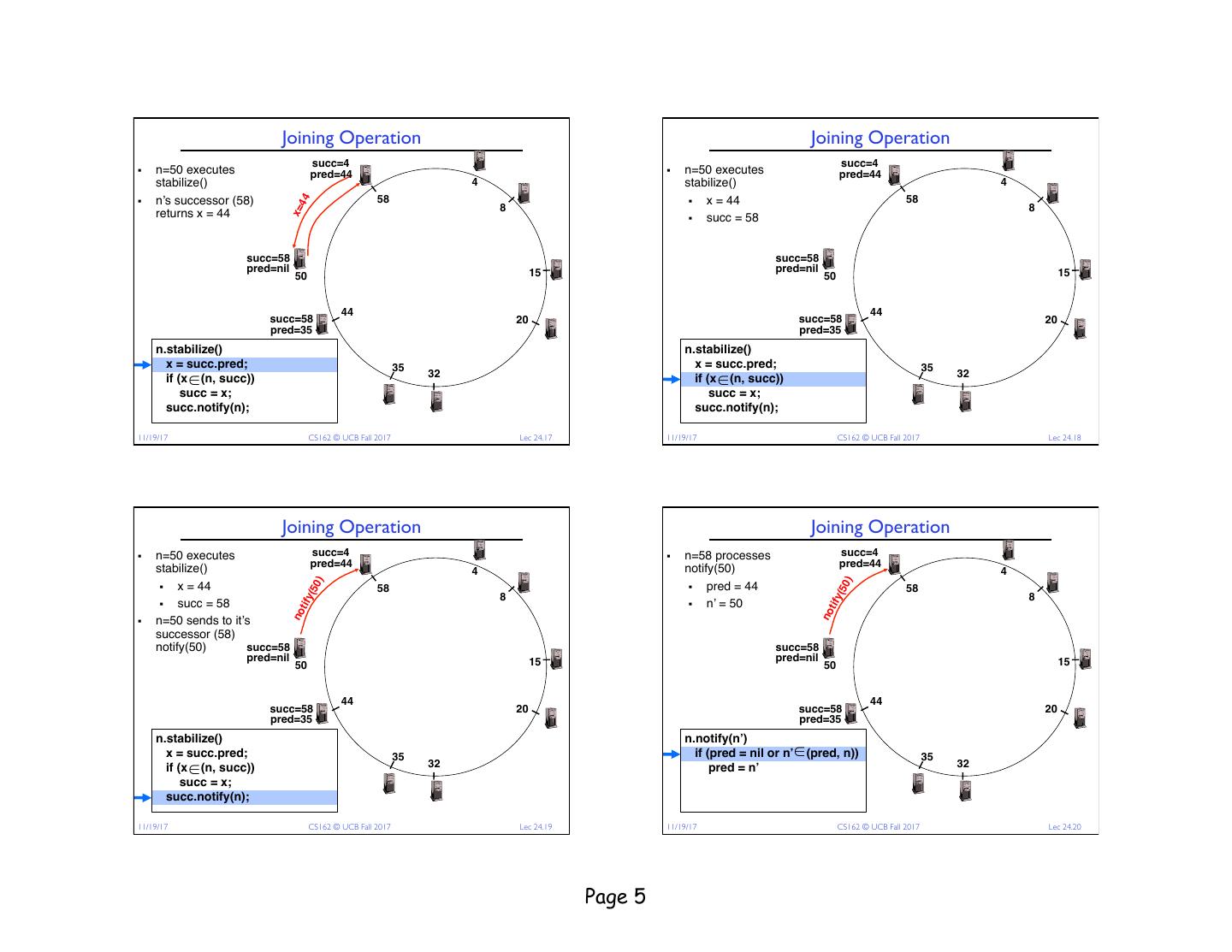
5 . Joining Operation Joining Operation succ=4 succ=4 § n=50 executes pred=44 § n=50 executes pred=44 stabilize() 4 stabilize() 4 § n’s successor (58) 58 § x = 44 58 44 8 8 x= returns x = 44 § succ = 58 succ=58 succ=58 pred=nil 15 pred=nil 15 50 50 44 44 succ=58 20 succ=58 20 pred=35 pred=35 n.stabilize() n.stabilize() x = succ.pred; 35 x = succ.pred; 35 if (x ∈ (n, succ)) 32 if (x ∈ (n, succ)) 32 succ = x; succ = x; succ.notify(n); succ.notify(n); €11/19/17 CS162 © UCB Fall 2017 Lec 24.17 €11/19/17 CS162 © UCB Fall 2017 Lec 24.18 Joining Operation Joining Operation § n=50 executes succ=4 § n=58 processes succ=4 stabilize() pred=44 notify(50) pred=44 4 4 ) ) § x = 44 § pred = 44 (50 (50 58 58 8 8 tify tify § succ = 58 § n’ = 50 no no § n=50 sends to it’s successor (58) notify(50) succ=58 succ=58 pred=nil 15 pred=nil 15 50 50 44 44 succ=58 20 succ=58 20 pred=35 pred=35 n.stabilize() n.notify(n’) x = succ.pred; 35 if (pred = nil or n’ ∈ (pred, n)) 35 if (x ∈ (n, succ)) 32 pred = n’ 32 succ = x; succ.notify(n); € €11/19/17 CS162 © UCB Fall 2017 Lec 24.19 11/19/17 CS162 © UCB Fall 2017 Lec 24.20 Page 5
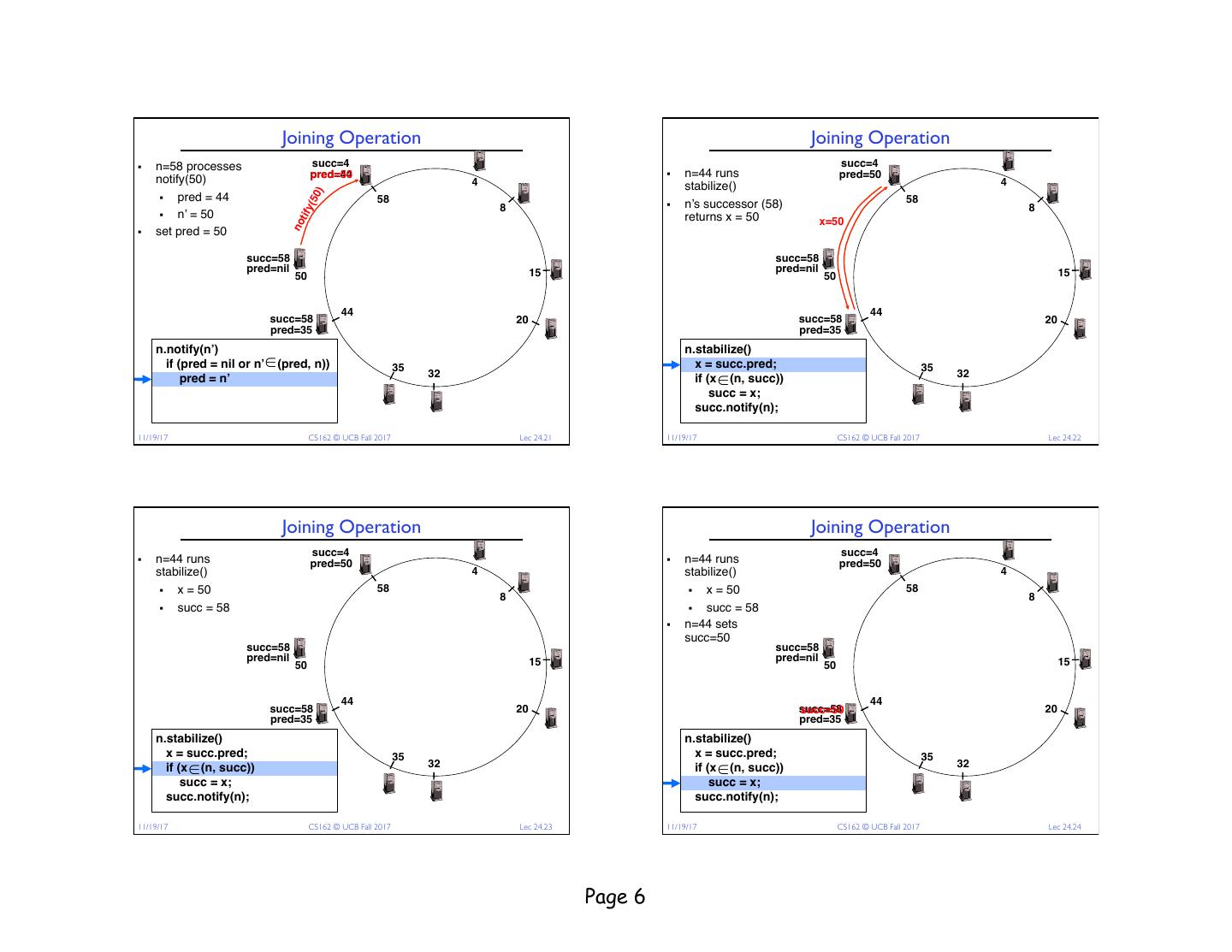
6 . Joining Operation Joining Operation § n=58 processes succ=4 succ=4 notify(50) pred=44 pred=50 § n=44 runs pred=50 4 stabilize() 4 ) § pred = 44 (50 58 § n’s successor (58) 58 8 8 tify § n’ = 50 returns x = 50 x=50 no § set pred = 50 succ=58 succ=58 pred=nil 15 pred=nil 15 50 50 44 44 succ=58 20 succ=58 20 pred=35 pred=35 n.notify(n’) n.stabilize() if (pred = nil or n’ ∈ (pred, n)) 35 x = succ.pred; 35 pred = n’ 32 if (x ∈ (n, succ)) 32 succ = x; succ.notify(n); € 11/19/17 CS162 © UCB Fall 2017 Lec 24.21 €11/19/17 CS162 © UCB Fall 2017 Lec 24.22 Joining Operation Joining Operation succ=4 succ=4 § n=44 runs pred=50 § n=44 runs pred=50 stabilize() 4 stabilize() 4 § x = 50 58 § x = 50 58 8 8 § succ = 58 § succ = 58 § n=44 sets succ=50 succ=58 succ=58 pred=nil 15 pred=nil 15 50 50 44 44 succ=58 20 succ=58 succ=50 20 pred=35 pred=35 n.stabilize() n.stabilize() x = succ.pred; 35 x = succ.pred; 35 if (x ∈ (n, succ)) 32 if (x ∈ (n, succ)) 32 succ = x; succ = x; succ.notify(n); succ.notify(n); €11/19/17 CS162 © UCB Fall 2017 Lec 24.23 €11/19/17 CS162 © UCB Fall 2017 Lec 24.24 Page 6
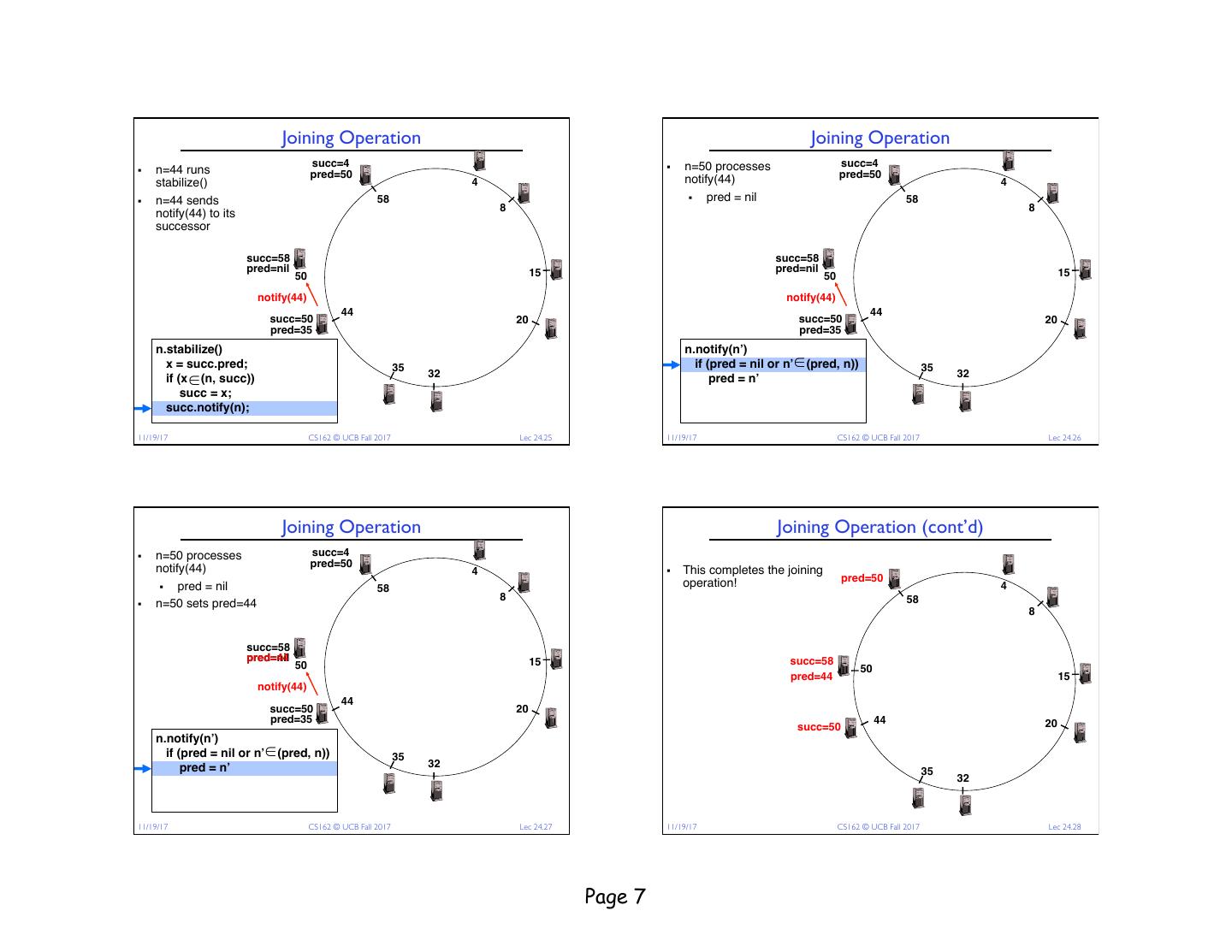
7 . Joining Operation Joining Operation succ=4 § n=50 processes succ=4 § n=44 runs pred=50 pred=50 stabilize() 4 notify(44) 4 § n=44 sends 58 § pred = nil 58 8 8 notify(44) to its successor succ=58 succ=58 pred=nil 15 pred=nil 15 50 50 notify(44) notify(44) 44 44 succ=50 20 succ=50 20 pred=35 pred=35 n.stabilize() n.notify(n’) x = succ.pred; 35 if (pred = nil or n’ ∈ (pred, n)) 35 if (x ∈ (n, succ)) 32 pred = n’ 32 succ = x; succ.notify(n); € €11/19/17 CS162 © UCB Fall 2017 Lec 24.25 11/19/17 CS162 © UCB Fall 2017 Lec 24.26 Joining Operation Joining Operation (cont’d) § n=50 processes succ=4 notify(44) pred=50 4 § This completes the joining operation! pred=50 § pred = nil 58 4 8 58 § n=50 sets pred=44 8 succ=58 pred=nil pred=44 15 succ=58 50 50 pred=44 15 notify(44) 44 succ=50 20 pred=35 44 20 succ=50 n.notify(n’) if (pred = nil or n’ ∈ (pred, n)) 35 pred = n’ 32 35 32 € 11/19/17 CS162 © UCB Fall 2017 Lec 24.27 11/19/17 CS162 © UCB Fall 2017 Lec 24.28 Page 7
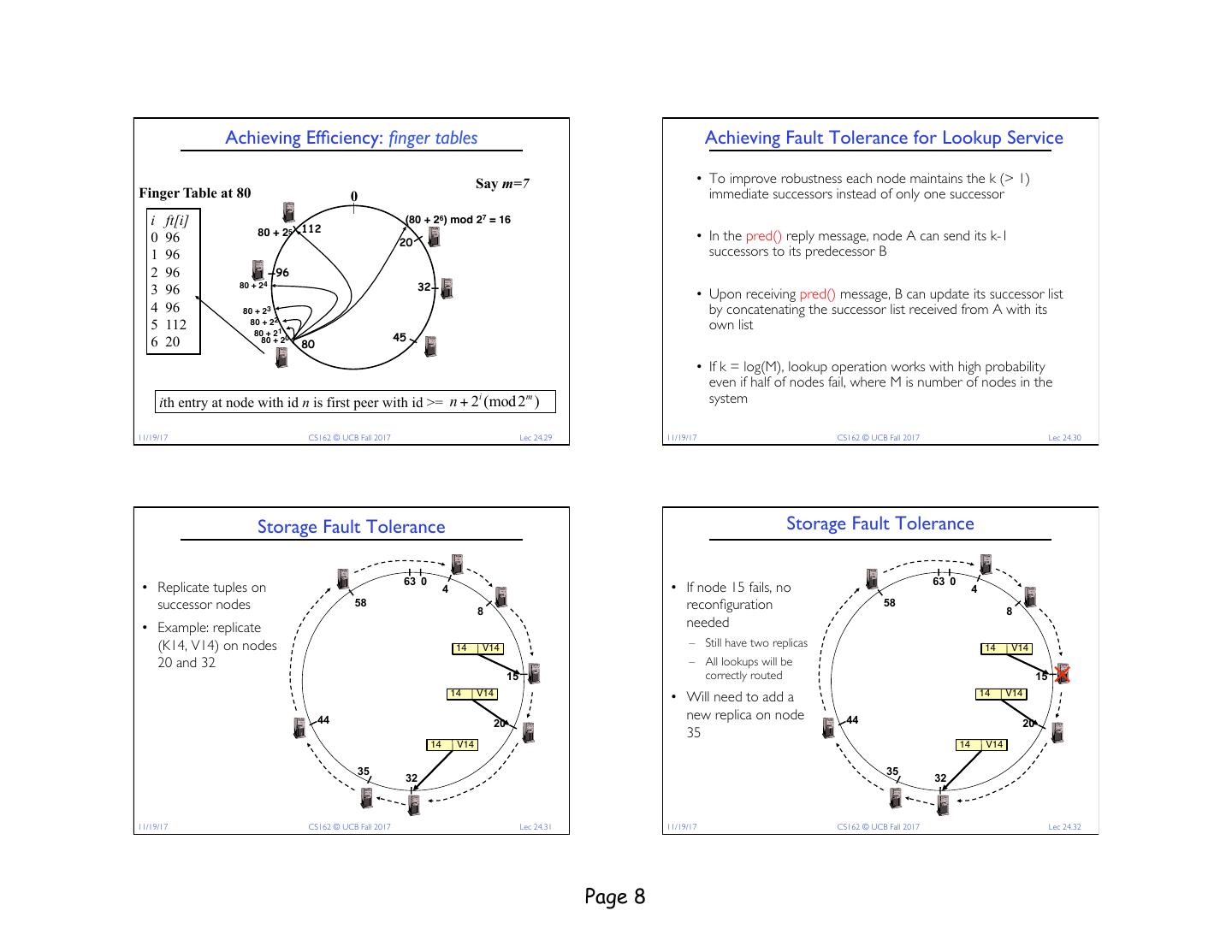
8 . Achieving Efficiency: finger tables Achieving Fault Tolerance for Lookup Service Say m=7 • To improve robustness each node maintains the k (> 1) Finger Table at 80 0 immediate successors instead of only one successor i ft[i] (80 + 26) mod 27 = 16 80 + 25 112 • In the pred() reply message, node A can send its k-1 0 96 20 1 96 successors to its predecessor B 2 96 96 3 96 80 + 24 32 • Upon receiving pred() message, B can update its successor list 4 96 80 + 23 by concatenating the successor list received from A with its 5 112 80 + 22 80 + 21 own list 6 20 80 + 20 45 80 • If k = log(M), lookup operation works with high probability even if half of nodes fail, where M is number of nodes in the i m ith entry at node with id n is first peer with id >= n + 2 (mod 2 ) system 11/19/17 CS162 © UCB Fall 2017 Lec 24.29 11/19/17 CS162 © UCB Fall 2017 Lec 24.30 Storage Fault Tolerance Storage Fault Tolerance 63 0 63 0 • Replicate tuples on 4 • If node 15 fails, no 4 successor nodes 58 8 reconfiguration 58 8 • Example: replicate needed (K14, V14) on nodes 14 V14 – Still have two replicas 14 V14 20 and 32 – All lookups will be 15 correctly routed 15 14 V14 • Will need to add a 14 V14 44 new replica on node 44 20 20 35 14 V14 14 V14 35 35 32 32 11/19/17 CS162 © UCB Fall 2017 Lec 24.31 11/19/17 CS162 © UCB Fall 2017 Lec 24.32 Page 8
9 . Administrivia • Midterm 3 coming up on Wen 11/29 6:30-8PM – All topics up to and including Lecture 24 » Focus will be on Lectures 17 – 25 and associated readings, and Projects 3 » But expect 20-30% questions from materials from Lectures 1-16 – Closed book – 2 sides hand-written notes both sides BREAK 11/19/17 CS162 © UCB Fall 2017 Lec 24.33 11/19/17 CS162 © UCB Fall 2017 Lec 24.34 Outline Data Deluge • Quorum consensus • Billions of users connected through the net – WWW, FB, twitter, cell phones, … – 80% of the data on FB was produced last year • Chord – FB building Exabyte (260 ≅ 1018) data centers • Mesos • It’s all happening online – could record every: – Click, ad impression, billing event, server request, transaction, network msg, fault, fast forward, pause, skip, … • User Generated Content (Web & Mobile) – Facebook, Instagram, Yelp, TripAdvisor, Twitter, YouTube, … 11/19/17 CS162 © UCB Fall 2017 Lec 24.35 11/19/17 CS162 © UCB Fall 2017 Lec 24.36 Page 9
10 . Data Grows Faster than Moore’s Law The Big Data Solution: Cloud Computing • One machine can not process or even store all the data! Projected Growth 60 • Solution: distribute data over cluster of cheap machines Increase over 2010 50 Moore's Law 40 Particle Accel. 30 DNA Sequencers Lots of hard drives … and CPUs … and memory! 20 Cloud Computing 10 0 • Cloud Computing provides: 2010 2011 2012 2013 2014 2015 – Illusion of infinite resources – Short-term, on-demand resource allocation – Can be much less expensive than owning computers And Moore’s law is ending!! – Access to latest technologies (SSDs, GPUs, …) 11/19/17 CS162 © UCB Fall 2017 Lec 24.37 11/19/17 CS162 © UCB Fall 2017 Lec 24.38 What Can You do with Big Data? The Berkeley AMPLab Alogorithms • January 2011 – 2016 – 8 faculty – > 50 students AMP – 3 software engineer team Machines People • Organized for collaboration Crowdsourcing + Physical modeling + Sensing + Data Assimilation AMPCamp (since 2012) = http://traffic.berkeley.edu 3 day retreats 400+ campers (twice a year) (100s companies) 11/19/17 CS162 © UCB Fall 2017 Lec 24.39 11/19/17 CS162 © UCB Fall 2017 Lec 24.40 Page 10
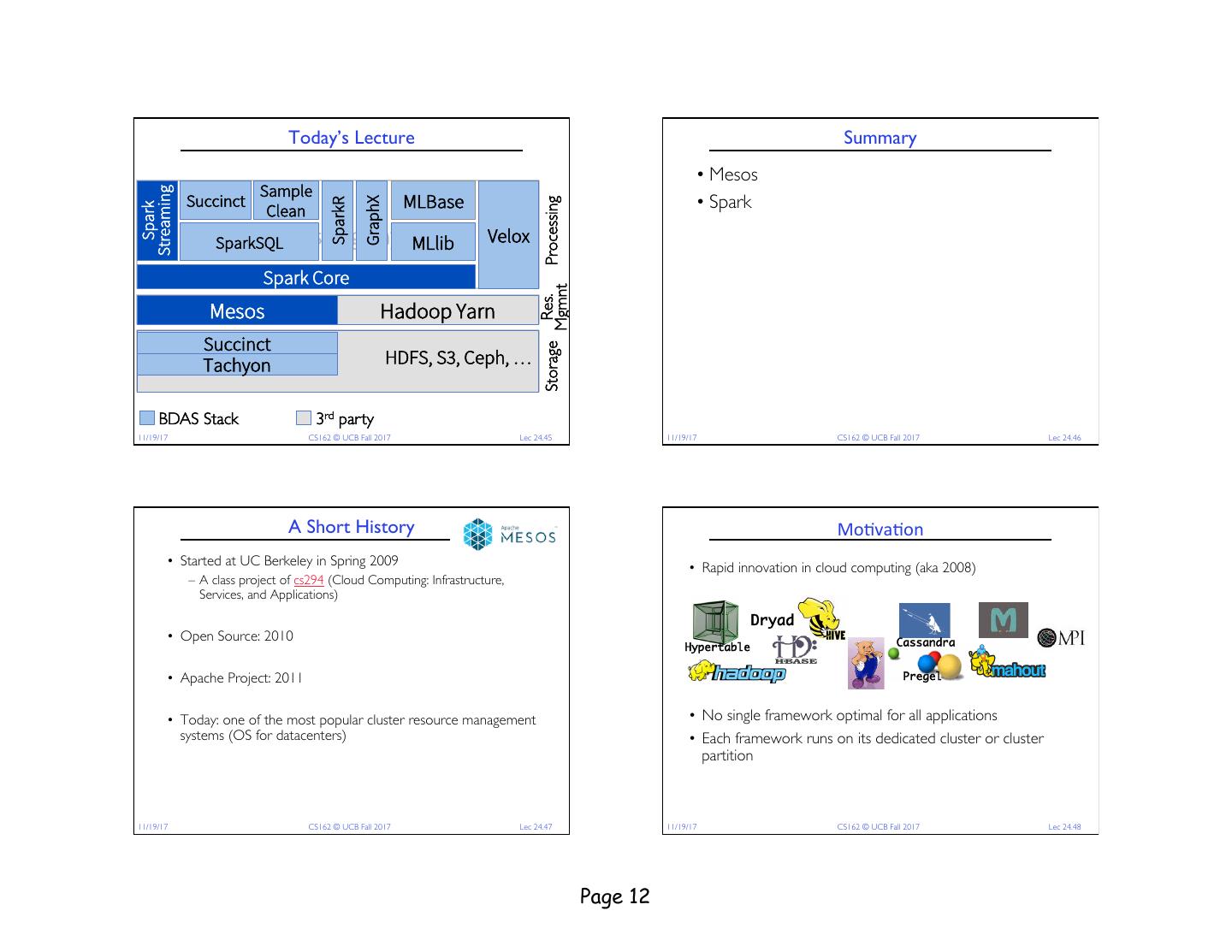
11 . The Berkeley AMPLab Generic Big Data Stack • Governmental and industrial funding: Processing Layer Resource Management Layer Goal: Next generation of open source data Storage Layer analytics stack for industry & academia: Berkeley Data Analytics Stack (BDAS) 11/19/17 CS162 © UCB Fall 2017 Lec 24.41 11/19/17 CS162 © UCB Fall 2017 Lec 24.42 Hadoop Stack BDAS Stack Sample Streaming Succinct MLBase GraphX SparkR Processing Processing Hive Pig Clean Spark Impala Giraph Storm Velox Processing Layer … Processing LayerMLlib SparkSQL Velox HadoopMR Spark Core Mgmnt Mgmnt Res. Res. Resource Management Yarn Layer Resource Management Mesos LayerYarn Hadoop Succinct Storage Storage Storage HDFSLayer HDFS, S3, Ceph, … TachyonStorage Layer BDAS Stack 3rd party 11/19/17 CS162 © UCB Fall 2017 Lec 24.43 11/19/17 CS162 © UCB Fall 2017 Lec 24.44 Page 11
12 . Today’s Lecture Summary • Mesos Sample Streaming Succinct MLBase • Spark GraphX SparkR Processing Clean Spark Velox Processing LayerMLlib SparkSQL Velox Spark Core Mgmnt Res. Resource Management Mesos LayerYarn Hadoop Succinct Storage HDFS, S3, Ceph, … TachyonStorage Layer BDAS Stack 3rd party 11/19/17 CS162 © UCB Fall 2017 Lec 24.45 11/19/17 CS162 © UCB Fall 2017 Lec 24.46 A Short History Mo#va#on • Started at UC Berkeley in Spring 2009 • Rapid innovation in cloud computing (aka 2008) – A class project of cs294 (Cloud Computing: Infrastructure, Services, and Applications) Dryad • Open Source: 2010 Cassandra Hypertable • Apache Project: 2011 Pregel • Today: one of the most popular cluster resource management • No single framework optimal for all applications systems (OS for datacenters) • Each framework runs on its dedicated cluster or cluster partition 11/19/17 CS162 © UCB Fall 2017 Lec 24.47 11/19/17 CS162 © UCB Fall 2017 Lec 24.48 Page 12
13 . Computa#on Model: Frameworks One Framework Per Cluster Challenges 50%# • Inefficient resource usage • A framework (e.g., Hadoop, MPI) manages one or more jobs in a 25%# computer cluster – E.g., Hadoop cannot use available resources from Pregel’s cluster Hadoop 0%# • A job consists of one or more tasks – No opportunity for stat. multiplexing 50%# • A task (e.g., map, reduce) is implemented by one or more processes running on a single machine Pregel 25%# • Hard to share data 0%# cluster – Copy or access remotely, expensive Executor Executor (e.g., taskTask 1 (e.g., taskTask 2 Job 1: tasks 1, 2, 3, 4 Tracker) task 5 Traker) task 6 Framework Job 2: tasks 5, 6, 7 • Hard to cooperate Hadoop Scheduler (e.g., – E.g., Not easy for Pregel to use graphs Executor Job Tracker) Executor generated by Hadoop (e.g., taskTask 3 Pregel (e.g., Task Tracker) task 7 task 4 Tracker) Need to run multiple frameworks on same cluster 11/19/17 CS162 © UCB Fall 2017 Lec 24.49 11/19/17 CS162 © UCB Fall 2017 Lec 24.50 Solu#on: Apache Mesos Fine Grained Resource Sharing • Common resource sharing layer • Task granularity both in time & space – abstracts (“virtualizes”) resources to frameworks – Multiplex node/time between tasks belonging to different jobs/frameworks – enable diverse frameworks to share cluster • Tasks typically short; median ~= 10 sec, minutes • Why fine grained? Hadoop MPI – Improve data locality Hadoop MPI Mesos – Easier to handle node failures Uniprograming Multiprograming 11/19/17 CS162 © UCB Fall 2017 Lec 24.51 11/19/17 CS162 © UCB Fall 2017 Lec 24.52 Page 13
14 . Mesos Goals Approach: Global Scheduler • High utilization of resources Organization policies Resource availability • Support diverse frameworks (existing & future) Global Job requirements Scheduler • Scalability to 10,000’s of nodes • Response time • Throughput • Availability • Reliability in face of node failures • … • Focus of this talk: resource management & scheduling 11/19/17 CS162 © UCB Fall 2017 Lec 24.53 11/19/17 CS162 © UCB Fall 2017 Lec 24.54 Approach: Global Scheduler Approach: Global Scheduler Organization policies Organization policies Resource availability Resource availability Global Global Job requirements Job requirements Scheduler Scheduler Job execution plan Job execution plan • Task DAG Estimates • Inputs/outputs • Task durations • Input sizes • Transfer sizes 11/19/17 CS162 © UCB Fall 2017 Lec 24.55 11/19/17 CS162 © UCB Fall 2017 Lec 24.56 Page 14
15 . Approach: Global Scheduler Our Approach: Distributed Scheduler Organization policies Resource availability Organization Global policies Mesos Framework Framework Task Job requirements Task schedule Framework Scheduler Master Scheduler scheduler schedule Job execution plan Resource Fwk scheduler availability schedule Estimates • Advantages: can achieve optimal schedule • Advantages: • Disadvantages: – Simple à easier to scale and make resilient – Complexity à hard to scale and ensure resilience – Easy to port existing frameworks, support new ones – Hard to anticipate future frameworks’ requirements • Disadvantages: – Need to refactor existing frameworks – Distributed scheduling decision à not optimal 11/19/17 CS162 © UCB Fall 2017 Lec 24.57 11/19/17 CS162 © UCB Fall 2017 Lec 24.58 Resource Offers Mesos Architecture: Example Slaves con#nuously send status updates • Unit of allocation: resource offer about resources – Vector of available resources on a node Framework executors Framework scheduler launch tasks and may selects resources and – E.g., node1: <1CPU, 1GB>, node2: <4CPU, 16GB> Slave S1 persist across tasks provides tasks Hadoop task 1 Executor S1 ; • Master sends resource offers to frameworks MPI executor task 1 :<8 Hadoop B>] 8CPU, 8GB CPU ,4G ]) ,8G task 2CPU ,4GB> B> 1:<4 Mesos Master CPU JobTracker 1:[S < 1: CPU 4 Slave S2 ,2GB k :< • Frameworks select which offers to accept and which tasks to run tas k 1 S1 <6CPU,4GB> <8CPU,8GB> <2CPU,2GB> > (tas k2:[S2 :<2 ( tas Hadoop task 2 S S2 CPU<4CPU,12GB> 1:<6 <8CPU,16GB> , S3:,<4G CCPPU, , 8GB> Executor S2:<8CPU,16GB> task 2:<4CPU,4GB>168BC> 4 1G6BGB>) S3 (S<16CPU,16GB> 1:< PPUU, >, C , 8CPU, 16GB S2:<8 16GB> Alloca#on ) Slave S3 Module ([ta > GB :S1: MPI sk1 ,16 Push task scheduling to frameworks S3: < 16CPU Pluggable scheduler to <4C JobTracker PU, 2GB ]) pick framework to 16CPU, 16GB send an offer to 11/19/17 CS162 © UCB Fall 2017 Lec 24.59 11/19/17 CS162 © UCB Fall 2017 Lec 24.60 Page 15
16 . Why does it Work? Dynamic Resource Sharing • 100 node cluster • A framework can just wait for an offer that matches its constraints or preferences! – Reject offers it does not like Accept: both S2 Reject: S1 doesn’t and S3 store the • Example: Hadoop’s job input is blue file store blue file blue file S1 …>]; :[S2:< Hadoop (task1 3:<..>]) (Job tracker) ta s k2 :[S Mesos S(S 1:< …… 2:< > …>) S2 >,S3:< master …> 2:<:<…> task1 task S3 11/19/17 CS162 © UCB Fall 2017 Lec 24.61 11/19/17 CS162 © UCB Fall 2017 Lec 24.62 Apache Mesos Today Summary (1/2) • Hundreds of of contributors • Quarum consensus: – N replicase • Hundreds of deployments in productions – Write to W replicas, read from R, where W + R > N – E.g., Twitter, GE, Apple – Tolerate one failure – Managing 10K node datacenterts! • Chord: • Mesosphere, startup to commercialize Apache Spark – Highly scalable distributed lookup protocol – Each node needs to know about O(log(M)), where M is the total number of nodes – Guarantees that a tuple is found in O(log(M)) steps – Highly resilient: works with high probability even if half of nodes fail 11/19/17 CS162 © UCB Fall 2017 Lec 24.63 11/19/17 CS162 © UCB Fall 2017 Lec 24.64 Page 16
17 . Summary (2/2) • Mesos: large scale resource management systems: – Two-level schedulers – First level: performance isolation across multiple frameworks, models – Second level: frameworks decide which tasks to schedule, when, and where 11/19/17 CS162 © UCB Fall 2017 Lec 24.65 Page 17
3秒后跳转登录页面
去登陆

