






- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
缓存, 请求分页系统
缓存就是数据交换的缓冲区(称作Cache),由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。高速缓存是当今许多使计算机快速运行的技术的基础,缓存的应用:内存位置,地址转换,页面,文件夹,文件名,网络路由等。
展开查看详情
1 . Recall: Caching Concept CS162 Operating Systems and Systems Programming Lecture 14 Caching (Finished), Demand Paging • Cache: a repository for copies that can be accessed more quickly than the original – Make frequent case fast and infrequent case less dominant October 11th, 2017 • Caching underlies many techniques used today to make computers fast Neeraja J. Yadwadkar – Can cache: memory locations, address translations, pages, file blocks, http://cs162.eecs.Berkeley.edu file names, network routes, etc… 11/11/17 CS162 ©UCB Fall 17 Lec 14.2 Recall: In Machine Structures (eg. 61C) … Caching Applied to Address Translation • Caching is the key to memory system performance 100ns Virtual TLB Physical Main Address Cached? Address Memory CPU Yes Physical Processor (DRAM) No Memory Access time = 100ns ve Sa sult Re Main Translate Second Memory (MMU) Level Processor Cache (DRAM) (SRAM) Data Read or Write (untranslated) 10ns 100ns • Question is one of page locality: does it exist? Average Access time=(Hit Rate x HitTime) + (Miss Rate x MissTime) – Instruction accesses spend a lot of time on the same page (since accesses sequential) HitRate + MissRate = 1 – Stack accesses have definite locality of reference HitRate = 90% => Avg. Access Time=(0.9 x 10) + (0.1 x 100)=19ns – Data accesses have less page locality, but still some… HitRate = 99% => Avg. Access Time=(0.99 x 10) + (0.01 x 100)=10.9 ns • Can we have a TLB hierarchy? – Sure: multiple levels at different sizes/speeds 11/11/17 CS162 ©UCB Fall 17 Lec 14.3 11/11/17 CS162 ©UCB Fall 17 Lec 14.4 Page 1
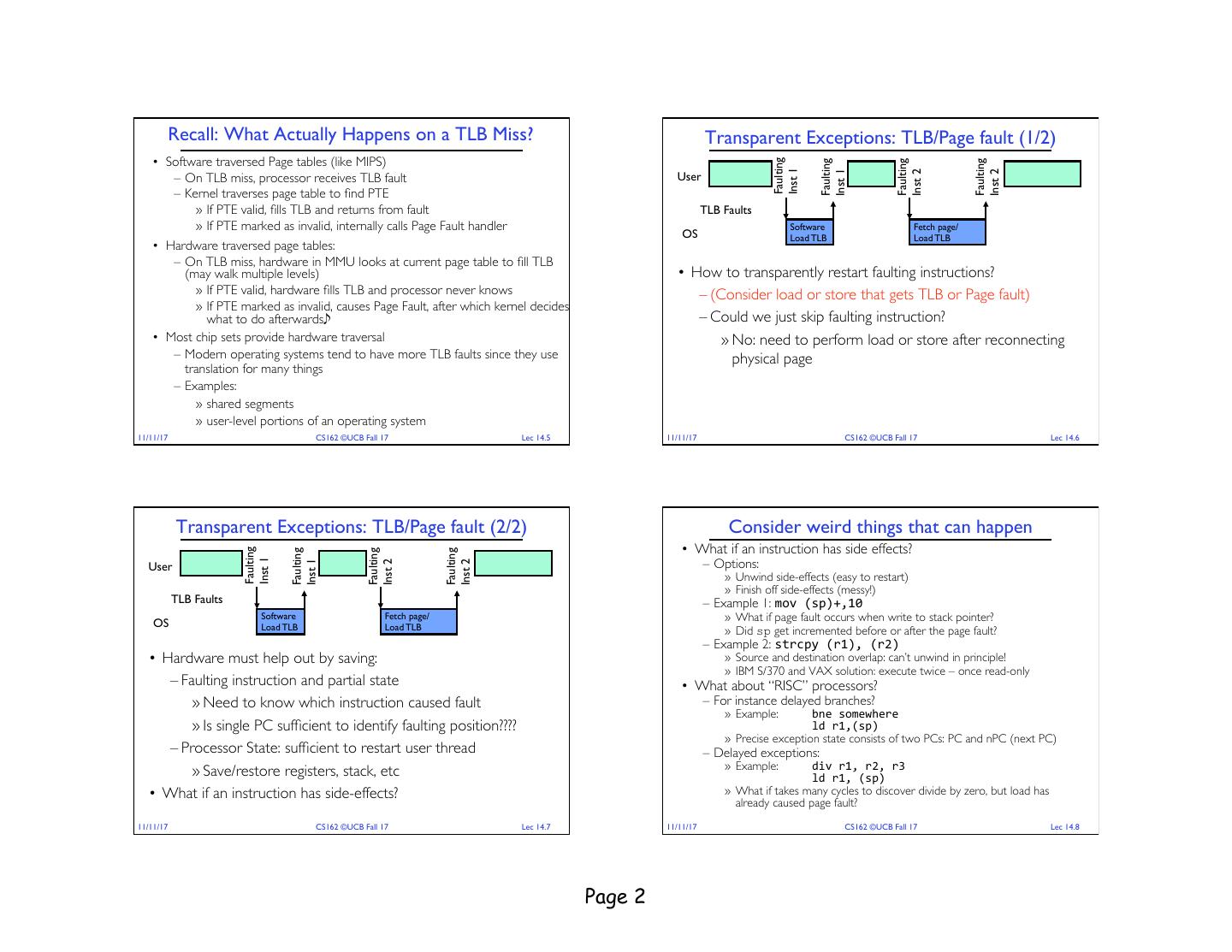
2 . Recall: What Actually Happens on a TLB Miss? Transparent Exceptions: TLB/Page fault (1/2) • Software traversed Page tables (like MIPS) Faulting Faulting Faulting Faulting Inst 1 Inst 1 Inst 2 Inst 2 – On TLB miss, processor receives TLB fault User – Kernel traverses page table to find PTE » If PTE valid, fills TLB and returns from fault TLB Faults » If PTE marked as invalid, internally calls Page Fault handler Software Fetch page/ OS Load TLB Load TLB • Hardware traversed page tables: – On TLB miss, hardware in MMU looks at current page table to fill TLB (may walk multiple levels) • How to transparently restart faulting instructions? » If PTE valid, hardware fills TLB and processor never knows – (Consider load or store that gets TLB or Page fault) » If PTE marked as invalid, causes Page Fault, after which kernel decides what to do afterwards – Could we just skip faulting instruction? • Most chip sets provide hardware traversal » No: need to perform load or store after reconnecting – Modern operating systems tend to have more TLB faults since they use physical page translation for many things – Examples: » shared segments » user-level portions of an operating system 11/11/17 CS162 ©UCB Fall 17 Lec 14.5 11/11/17 CS162 ©UCB Fall 17 Lec 14.6 Transparent Exceptions: TLB/Page fault (2/2) Consider weird things that can happen • What if an instruction has side effects? Faulting Faulting Faulting Faulting – Options: Inst 1 Inst 1 Inst 2 Inst 2 User » Unwind side-effects (easy to restart) » Finish off side-effects (messy!) TLB Faults – Example 1: mov (sp)+,10 OS Software Fetch page/ » What if page fault occurs when write to stack pointer? Load TLB Load TLB » Did sp get incremented before or after the page fault? – Example 2: strcpy (r1), (r2) • Hardware must help out by saving: » Source and destination overlap: can’t unwind in principle! » IBM S/370 and VAX solution: execute twice – once read-only – Faulting instruction and partial state • What about “RISC” processors? » Need to know which instruction caused fault – For instance delayed branches? » Example: bne somewhere » Is single PC sufficient to identify faulting position???? ld r1,(sp) » Precise exception state consists of two PCs: PC and nPC (next PC) – Processor State: sufficient to restart user thread – Delayed exceptions: » Save/restore registers, stack, etc » Example: div r1, r2, r3 ld r1, (sp) • What if an instruction has side-effects? » What if takes many cycles to discover divide by zero, but load has already caused page fault? 11/11/17 CS162 ©UCB Fall 17 Lec 14.7 11/11/17 CS162 ©UCB Fall 17 Lec 14.8 Page 2
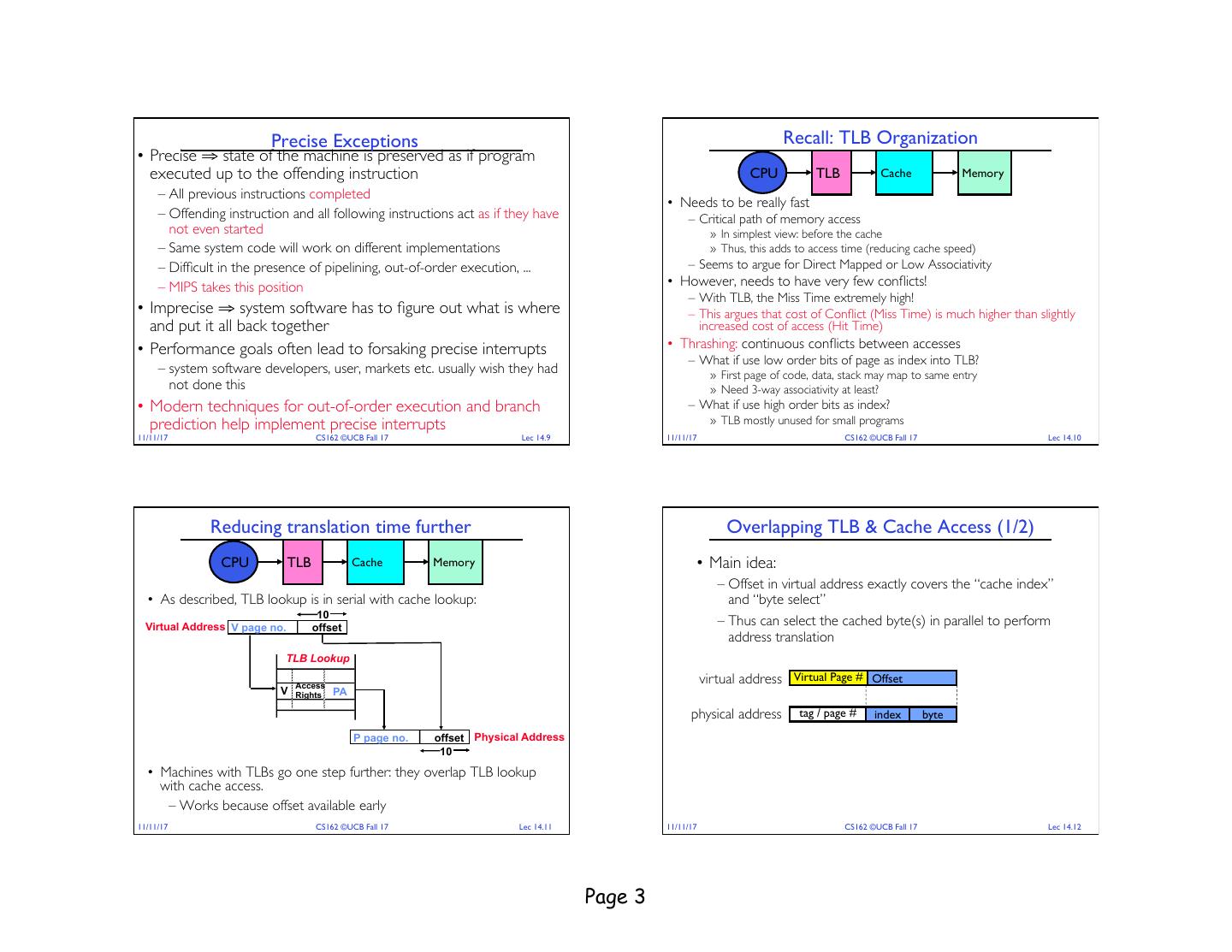
3 . Precise Exceptions Recall: TLB Organization • Precise ⇒ state of the machine is preserved as if program executed up to the offending instruction CPU TLB Cache Memory – All previous instructions completed • Needs to be really fast – Offending instruction and all following instructions act as if they have – Critical path of memory access not even started » In simplest view: before the cache – Same system code will work on different implementations » Thus, this adds to access time (reducing cache speed) – Difficult in the presence of pipelining, out-of-order execution, ... – Seems to argue for Direct Mapped or Low Associativity – MIPS takes this position • However, needs to have very few conflicts! – With TLB, the Miss Time extremely high! • Imprecise ⇒ system software has to figure out what is where – This argues that cost of Conflict (Miss Time) is much higher than slightly and put it all back together increased cost of access (Hit Time) • Performance goals often lead to forsaking precise interrupts • Thrashing: continuous conflicts between accesses – What if use low order bits of page as index into TLB? – system software developers, user, markets etc. usually wish they had » First page of code, data, stack may map to same entry not done this » Need 3-way associativity at least? • Modern techniques for out-of-order execution and branch – What if use high order bits as index? prediction help implement precise interrupts » TLB mostly unused for small programs 11/11/17 CS162 ©UCB Fall 17 Lec 14.9 11/11/17 CS162 ©UCB Fall 17 Lec 14.10 Reducing translation time further Overlapping TLB & Cache Access (1/2) CPU TLB Cache Memory • Main idea: – Offset in virtual address exactly covers the “cache index” • As described, TLB lookup is in serial with cache lookup: and “byte select” 10 Virtual Address V page no. offset – Thus can select the cached byte(s) in parallel to perform address translation TLB Lookup Access virtual address Virtual Page # Offset V Rights PA physical address tag / page # index byte P page no. offset Physical Address 10 • Machines with TLBs go one step further: they overlap TLB lookup with cache access. – Works because offset available early 11/11/17 CS162 ©UCB Fall 17 Lec 14.11 11/11/17 CS162 ©UCB Fall 17 Lec 14.12 Page 3
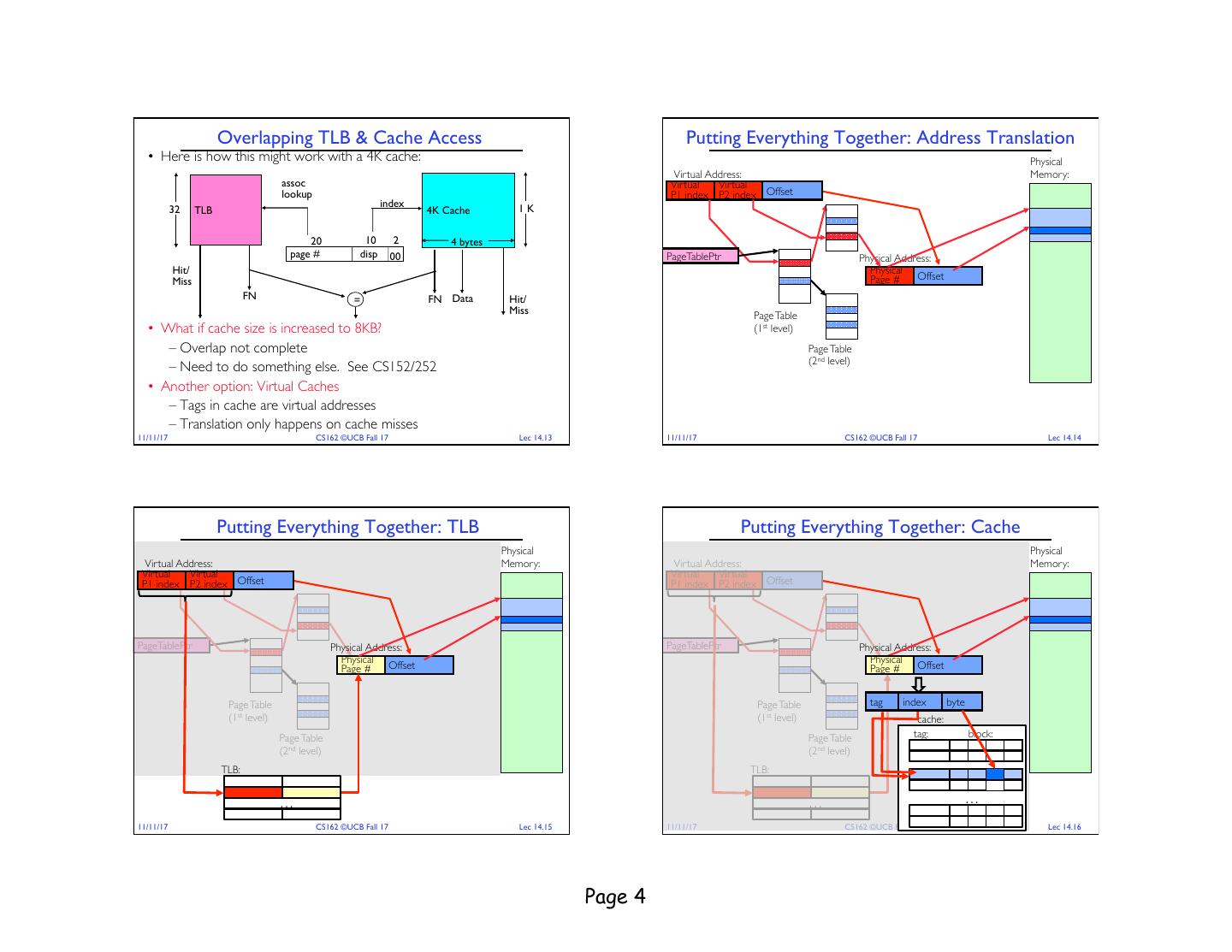
4 . Overlapping TLB & Cache Access Putting Everything Together: Address Translation • Here is how this might work with a 4K cache: Physical Virtual Address: Memory: assoc Virtual Virtual lookup P1 index P2 index Offset index 32 TLB 4K Cache 1K 20 10 2 4 bytes page # disp 00 PageTablePtr Physical Address: Hit/ Physical Miss Page # Offset FN = FN Data Hit/ Miss Page Table • What if cache size is increased to 8KB? (1st level) – Overlap not complete Page Table (2nd level) – Need to do something else. See CS152/252 • Another option: Virtual Caches – Tags in cache are virtual addresses – Translation only happens on cache misses 11/11/17 CS162 ©UCB Fall 17 Lec 14.13 11/11/17 CS162 ©UCB Fall 17 Lec 14.14 Putting Everything Together: TLB Putting Everything Together: Cache Physical Physical Virtual Address: Memory: Virtual Address: Memory: Virtual Virtual Virtual Virtual P1 index P2 index Offset P1 index P2 index Offset PageTablePtr Physical Address: PageTablePtr Physical Address: Physical Physical Page # Offset Page # Offset Page Table Page Table tag index byte (1st level) (1st level) cache: Page Table Page Table tag: block: (2nd level) (2nd level) TLB: TLB: … … … 11/11/17 CS162 ©UCB Fall 17 Lec 14.15 11/11/17 CS162 ©UCB Fall 17 Lec 14.16 Page 4
5 . Next Up: What happens when … Process virtual address physical address page# instruction MMU frame# PT offset retry exception page fault frame# Operating System offset update PT entry Page Fault Handler load page from disk BREAK scheduler 11/11/17 CS162 ©UCB Fall 17 Lec 14.17 11/11/17 CS162 ©UCB Fall 17 Lec 14.18 Where are all places that caching arises in OSes? Impact of caches on Operating Systems (1/2) • Direct use of caching techniques • Indirect - dealing with cache effects (e.g., sync state across levels) – TLB (cache of PTEs) – Maintaining the correctness of various caches – Paged virtual memory (memory as cache for disk) – E.g., TLB consistency: – File systems (cache disk blocks in memory) – DNS (cache hostname => IP address translations) » With PT across context switches ? – Web proxies (cache recently accessed pages) » Across updates to the PT ? • Process scheduling • Which pages to keep in memory? – Which and how many processes are active ? Priorities ? – All-important “Policy” aspect of virtual memory – Large memory footprints versus small ones ? – Will spend a bit more time on this in a moment – Shared pages mapped into VAS of multiple processes ? 11/11/17 CS162 ©UCB Fall 17 Lec 14.19 11/11/17 CS162 ©UCB Fall 17 Lec 14.20 Page 5
6 . Impact of caches on Operating Systems (2/2) Working Set Model • As a program executes it transitions through a sequence of • Impact of thread scheduling on cache performance “working sets” consisting of varying sized subsets of the address – Rapid interleaving of threads (small quantum) may degrade space cache performance » Increase average memory access time (AMAT) !!! Address • Designing operating system data structures for cache performance Time 11/11/17 CS162 ©UCB Fall 17 Lec 14.21 11/11/17 CS162 ©UCB Fall 17 Lec 14.22 Cache Behavior under WS model Another model of Locality: Zipf 1 P access(rank) = 1/rank 20% 1 Popularity (% accesses) Estimated Hit Rate 15% 0.8 new working set fits Hit Rate 0.6 10% pop a=1 0.4 5% 0.2 Hit Rate(cache) 0% 0 1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 0 Rank Cache Size • Likelihood of accessing item of rank r is α 1/ra • Amortized by fraction of time the Working Set is active • Although rare to access items below the top few, there are so many • Transitions from one WS to the next that it yields a “heavy tailed” distribution • Capacity, Conflict, Compulsory misses • Substantial value from even a tiny cache • Applicable to memory caches and pages. Others ? • Substantial misses from even a very large cache 11/11/17 CS162 ©UCB Fall 17 Lec 14.23 11/11/17 CS162 ©UCB Fall 17 Lec 14.24 Page 6
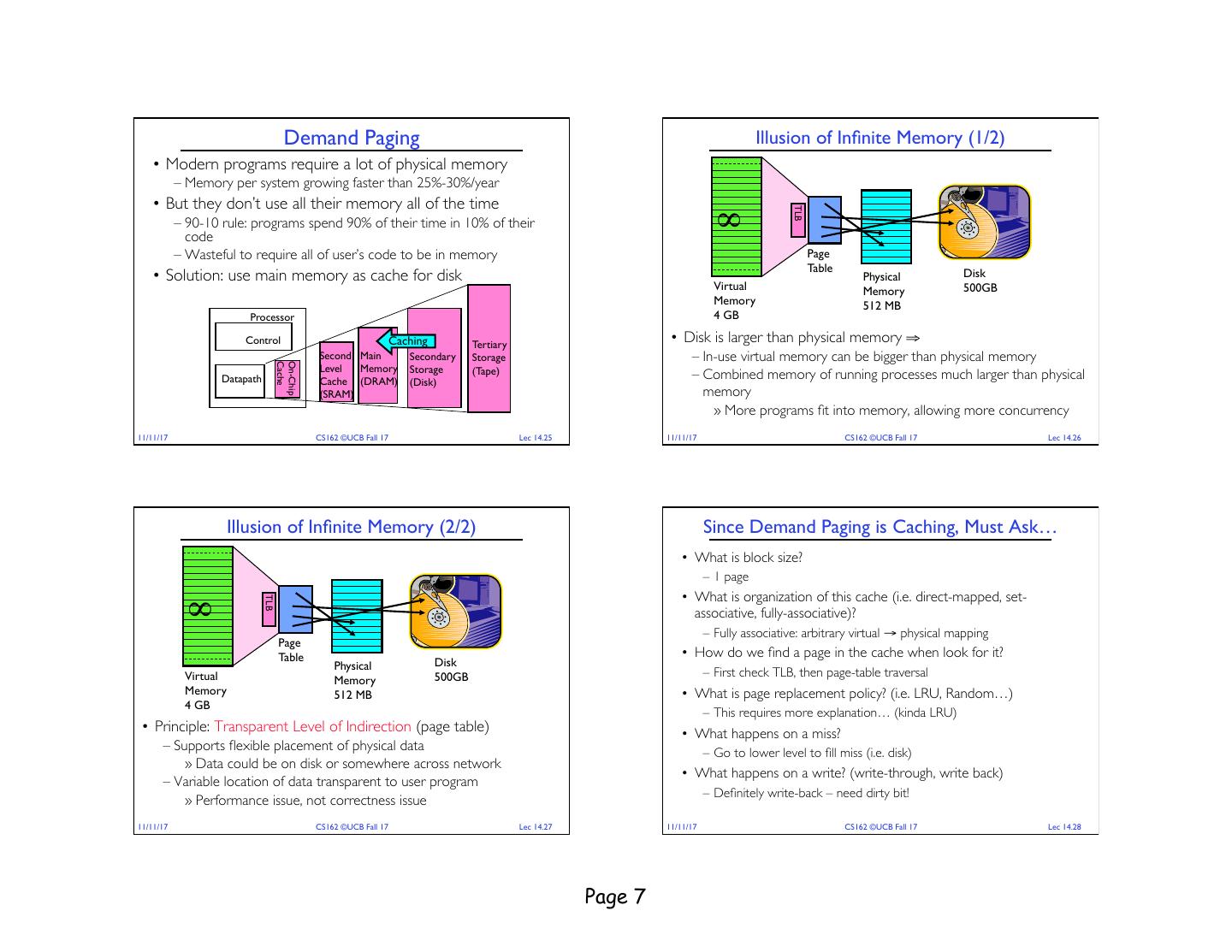
7 . Demand Paging Illusion of Infinite Memory (1/2) • Modern programs require a lot of physical memory – Memory per system growing faster than 25%-30%/year • But they don’t use all their memory all of the time TLB – 90-10 rule: programs spend 90% of their time in 10% of their code ∞ – Wasteful to require all of user’s code to be in memory Page Table • Solution: use main memory as cache for disk Physical Disk Virtual Memory 500GB Memory 512 MB Processor 4 GB Control Caching Tertiary • Disk is larger than physical memory ⇒ Second Main Secondary Storage – In-use virtual memory can be bigger than physical memory Cache On-Chip Level Memory Storage (Tape) Datapath Cache (DRAM) (Disk) – Combined memory of running processes much larger than physical (SRAM) memory » More programs fit into memory, allowing more concurrency 11/11/17 CS162 ©UCB Fall 17 Lec 14.25 11/11/17 CS162 ©UCB Fall 17 Lec 14.26 Illusion of Infinite Memory (2/2) Since Demand Paging is Caching, Must Ask… • What is block size? – 1 page • What is organization of this cache (i.e. direct-mapped, set- TLB ∞ associative, fully-associative)? – Fully associative: arbitrary virtual → physical mapping Page Table • How do we find a page in the cache when look for it? Physical Disk Virtual 500GB – First check TLB, then page-table traversal Memory Memory 512 MB • What is page replacement policy? (i.e. LRU, Random…) 4 GB – This requires more explanation… (kinda LRU) • Principle: Transparent Level of Indirection (page table) • What happens on a miss? – Supports flexible placement of physical data – Go to lower level to fill miss (i.e. disk) » Data could be on disk or somewhere across network • What happens on a write? (write-through, write back) – Variable location of data transparent to user program – Definitely write-back – need dirty bit! » Performance issue, not correctness issue 11/11/17 CS162 ©UCB Fall 17 Lec 14.27 11/11/17 CS162 ©UCB Fall 17 Lec 14.28 Page 7
8 . Recall: What is in a Page Table Entry Demand Paging Mechanisms • What is in a Page Table Entry (or PTE)? • PTE helps us implement demand paging – Pointer to next-level page table or to actual page – Valid ⇒ Page in memory, PTE points at physical page – Permission bits: valid, read-only, read-write, write-only – Not Valid ⇒ Page not in memory; use info in PTE to find it on disk • Example: Intel x86 architecture PTE: when necessary – Address same format previous slide (10, 10, 12-bit offset) • Suppose user references page with invalid PTE? – Intermediate page tables called “Directories” – Memory Management Unit (MMU) traps to OS Page Frame Number Free » Resulting trap is a “Page Fault” PCD PWT 0 L D A UW P (Physical Page Number) (OS) – What does OS do on a Page Fault?: 31-12 11-9 8 7 6 5 4 3 2 1 0 » Choose an old page to replace P: Present (same as “valid” bit in other architectures) » If old page modified (“D=1”), write contents back to disk W: Writeable » Change its PTE and any cached TLB to be invalid U: User accessible » Load new page into memory from disk PWT: Page write transparent: external cache write-through » Update page table entry, invalidate TLB for new entry PCD: Page cache disabled (page cannot be cached) » Continue thread from original faulting location A: Accessed: page has been accessed recently – TLB for new page will be loaded when thread continued! D: Dirty (PTE only): page has been modified recently – While pulling pages off disk for one process, OS runs another process L: L=1⇒4MB page (directory only). from ready queue Bottom 22 bits of virtual address serve as offset » Suspended process sits on wait queue 11/11/17 CS162 ©UCB Fall 17 Lec 14.29 11/11/17 CS162 ©UCB Fall 17 Lec 14.30 Summary: Steps in Handling a Page Fault Summary • A cache of translations called a “Translation Lookaside Buffer” (TLB) – Relatively small number of PTEs and optional process IDs (< 512) – Fully Associative (Since conflict misses expensive) – On TLB miss, page table must be traversed and if located PTE is invalid, cause Page Fault – On change in page table, TLB entries must be invalidated – TLB is logically in front of cache (need to overlap with cache access) • Precise Exception specifies a single instruction for which: – All previous instructions have completed (committed state) – No following instructions nor actual instruction have started • Can manage caches in hardware or software or both – Goal is highest hit rate, even if it means more complex cache management 11/11/17 CS162 ©UCB Fall 17 Lec 14.31 11/11/17 CS162 ©UCB Fall 17 Lec 14.32 Page 8
3秒后跳转登录页面
去登陆

