










































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
03 编译原理---词法分析
这一节是南京大学计算机系许畅所讲授编译原理之词法分析。这一节的主要内容有词法分析器的作用以及为什么要设立独立的词法分析器,还有词法单元、模式、词素,词法单元的规约 (正则表达式),词法单元的识别 (状态转换图),词法分析器生成工具及设计,有穷自动机。
展开查看详情
1 .第三章 词法分析 许畅 南京大学计算机系 2018年春季
2 .内容 词法分析器的作用 词法单元的规约 (正则表达式) 词法单元的识别 (状态转换图) 词法分析器生成工具及设计 有穷自动机 2
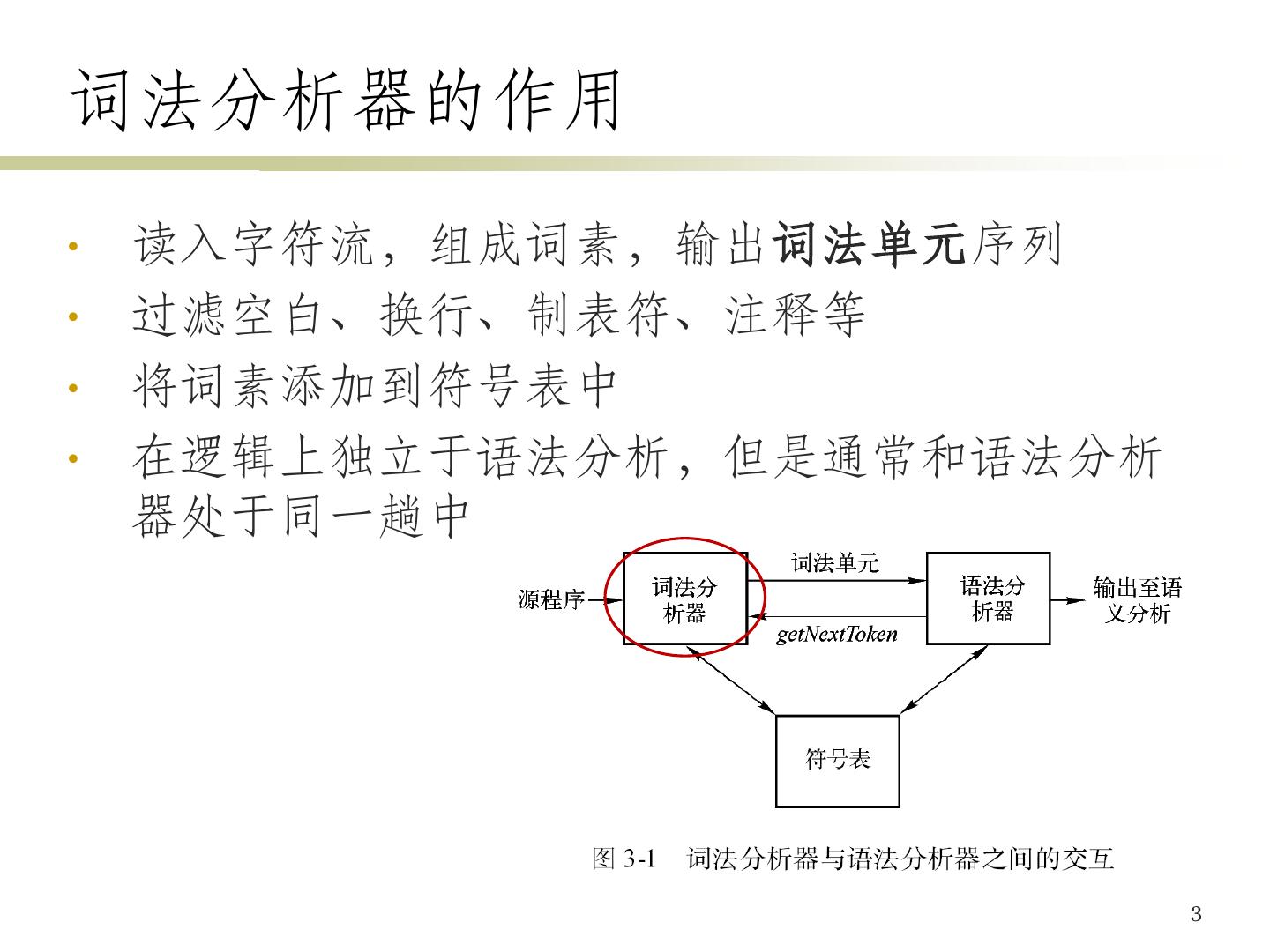
3 .词法分析器的作用 • 读入字符流,组成词素,输出词法单元序列 • 过滤空白、换行、制表符、注释等 • 将词素添加到符号表中 • 在逻辑上独立于语法分析,但是通常和语法分析 器处于同一趟中 3
4 .为什么要设立独立的词法分析器? 简化编译器的设计 词法分析器可以首先完成一些简单的处理工作 提高编译器效率 相对于语法分析,词法分析过程简单,可高效实现 (下 推自动机 vs. 有穷自动机) 增强编译器的可移植性 4
5 .词法单元、模式、词素 • 词法单元 (Token) – <词法单元名、属性值 (可选) > – 单元名是表示词法单位种类的抽象符号,语法分析器 通过单元名即可确定词法单元序列的结构 – 属性值通常用于语义分析之后的阶段 • 模式 (Pattern) – 描述了一类词法单元的词素可能具有的形式 • 词素 (Lexeme) – 源程序中的字符序列 – 它和某个词法单元的模式匹配,被词法分析器识别为 该词法单元的实例 5
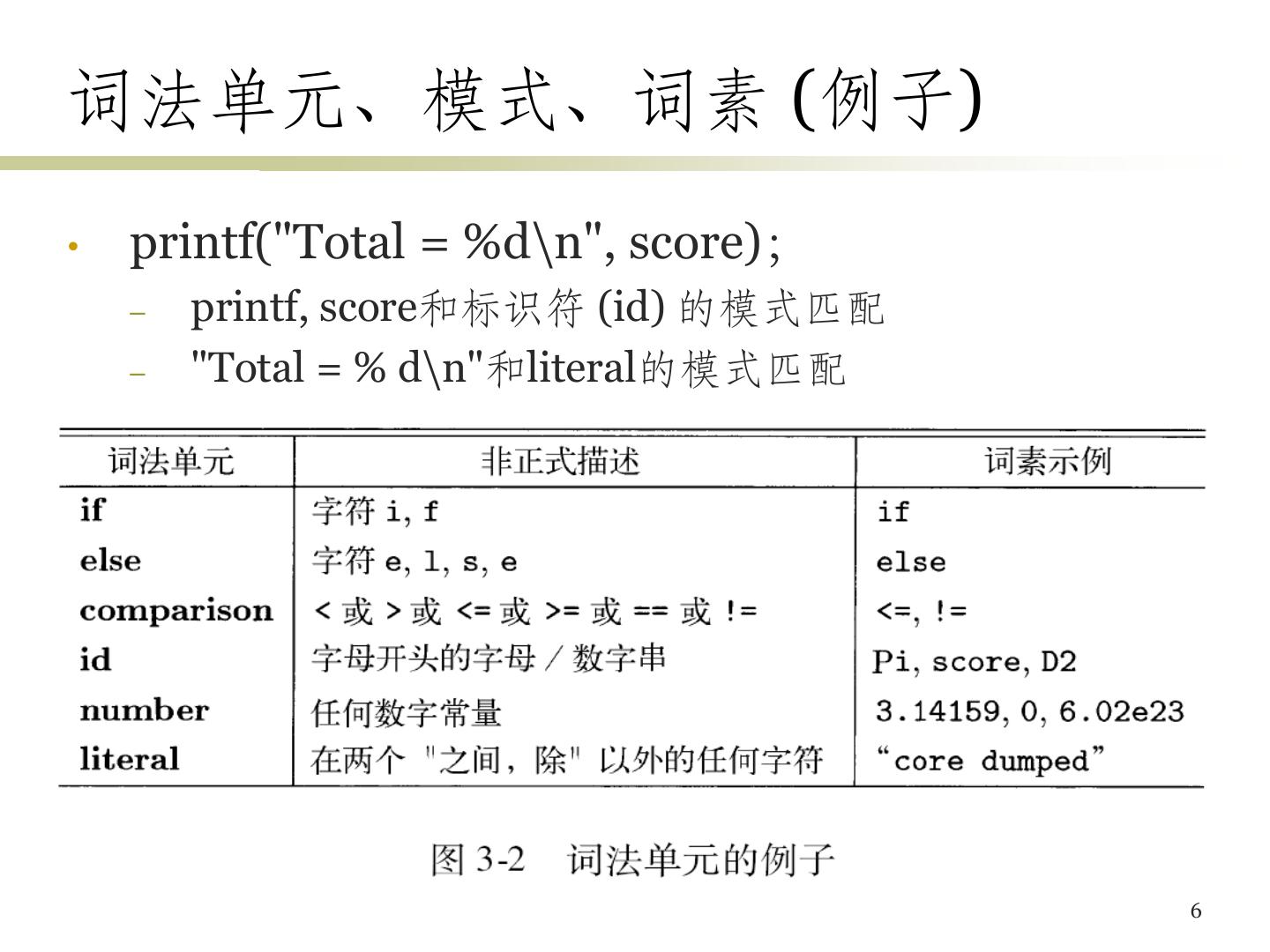
6 .词法单元、模式、词素 (例子) • printf("Total = %d\n", score); – printf, score和标识符 (id) 的模式匹配 – "Total = % d\n"和literal的模式匹配 6
7 .词法单元的属性 一个模式匹配多个词素时,必须通过属性来传递 附加的信息 属性值将被用于语义分析、代码生成等阶段 不同的目的需要不同的属性 属性值通常是一个结构化数据 如词法单元id的属性 词素、类型、第一次出现的位置、… 7
8 .内容 词法分析器的作用 词法单元的规约 (正则表达式) 词法单元的识别 (状态转换图) 词法分析器生成工具及设计 有穷自动机 8
9 .词法单元的规约 正则表达式可以高效、简洁地描述处理词法单元 时用到的模式类型 内容 串和语言 语言上的运算 正则表达式和正则定义 正则表达式的扩展 9
10 .串和语言 (1) • 字母表 (Alphabet) :一个有穷的符号集合 – 符号典型例子:字母、数字、标点符号 – 例子:{0,1}, ASCII, Unicode – 在理论上,我们可以把任意的有限集合看作字母表 • 字母表上的串 (String) 是该表中符号的有穷序列 – 串s的长度,即 |s|,是指s中符号出现的次数 – 空串:长度为0的串,ε • 语言 (Language) 是某个给定字母表上的串的可数 集合 10
11 .串和语言 (2) • 和串有关的术语 (以banana为例) – 前缀:从串的尾部删除0个或多个符号后得到的串 (ban、banana、ε) – 后缀:从串的开始处删除0个或多个符号后得到的串 (nana、banana、ε) – 子串:删除串的某个前缀和某个后缀得到的串 (banana、nan、ε) – 真前缀、真后缀、真子串:既不等于原串,也不等于 空串的前缀、后缀、子串 (前面例子的红色部分) – 子序列:从原串中删除0个或者多个符号后得到的串 (baan) 11
12 .串和语言 (3) 串的运算 连接 (Concatenation):x和y的连接是把y附加到x的后 面而形成的串,记作xy x = dog,y = house,xy = doghouse 指数运算 (幂运算):s0 = ε,s1 = s,si = si-1s x = dog,x0 = ε,x1 = dog,x3 = dogdogdog 12
13 .串和语言 (4) 语言的运算 语言是某个给定字母表上的串的可数集合 + 13
14 .串和语言 (5) 例子 L = {A, B , ……, Z, a, b, ……, z} D = {0, 1, ……, 9} L D = {A, B, ……, Z, a, b, ……, z, 0, 1, ……, 9} LD:520个长度为2的串的集合 (字母 + 数字) L4:所有由四个字母构成的串的集合 L*:所有字母构成的集合,包括ε L (L D)*:? D+:? 14
15 .正则表达式 字母表Σ上的正则表达式的定义 • 基本部分 – ε是一个正则表达式,L(ε) = {ε} – 如果a是Σ上的一个符号,那么a是正则表达式,L(a) = {a} • 归纳步骤 – 选择:(r)|(s),L((r)|(s)) = L(r) L(s) – 连接:(r)(s),L((r)(s)) = L(r)L(s) – 闭包:(r)*,L((r)*) = (L(r))* – 括号:(r),L((r)) = L(r) • 运算的优先级:* > 连接 > |,如(a) | ((b)*(c)) = a | b*c • 正则集合:可以用一个正则表达式定义的语言 15
16 .正则表达式的例子 Σ = {a, b} L(a | b) = {a, b} L((a | b) (a | b)) = {aa, ab, ba, bb} L(a*) = {ε, a, aa, aaa, aaaa, …} L((a | b)*) = {ε, a, b, aa, ab, ba, bb, aaa, aab, …} L(a | a*b) = {a, b, ab, aab, aaab, …} 16
17 .正则定义 (1) • 为了书写方便,可以给正则表达式命名,且可以 通过名字使用正则表达式 • 正则定义是如下形式的定义序列 d1 r1 d2 r2 … dn rn • 其中 – di不在Σ中,且各不相同 – 每个ri是字母表Σ {d1, d2, …, di-1}上的正则表达式;这 保证了不会出现递归定义 18
18 .正则定义的例子 C语言标识符的正则定义 letter_ A | B | … | Z | a | b | … | z | _ digit 0 | 1 | … | 9 id letter_ ( letter_ | digit )* id对应的正则表达式为 (A | B | … | Z | a | b | … | z | _) ( (A | B | … | Z | a | b | … | z | _) | (0 | 1 | … | 9) )* 20
19 .正则表达式的扩展 • 基本运算符:选择、连接、Kleene闭包 • 扩展的运算符 – 一个或多个实例:单目后缀+ • r+等价于r r* – 零个或一个实例:? • r?等价于ε | r – 字符类 • [a1a2…an]等价于a1 | a2 | … | an • [ae]等价于a | b | c | d | e • 使正则表达式更简洁,但不会使其描述能力增强 21
20 .内容 词法分析器的作用 词法单元的规约 (正则表达式) 词法单元的识别 (状态转换图) 词法分析器生成工具及设计 有穷自动机 22
21 .词法单元的识别 词法分析器要求能够检查输入字符串,在其前缀 中找出和某个模式匹配的词素 首先通过正则定义来描述各种词法单元的模式 定义ws (blank | tab | newline)+来消除空白 当词法分析器识别出这个模式时,不返回词法单元, 继续识别其它模式 23
22 .24
23 .状态转换图 词法分析器的重要组件之一 状态转换图 (Transition diagram) 状态 (State):表示在识别词素时可能出现的情况 状态看作是已处理部分的总结 某些状态为接受状态或最终状态,表明已找到词素 加上*的接受状态表示最后读入的符号不在词素中 开始状态 (初始状态):用Start边表示 边 (Edge):从一个状态指向另一个状态 边的标号是一个或多个符号 当前状态为s,下一个输入符号为a,就沿着从s离开,标号为a 的边到达下一个状态 25
24 .状态转换图的例子 26
25 .保留字和标识符的识别 在很多时候,保留字也符合标识符的模式 识别标识符的状态转换图也会识别保留字 解决方法 在符号表中先填保留字,并指明它们不是普通标识符 为保留字建立独立的、高优先级的状态转换图 27
26 .其它的状态转换图 28
27 .词法分析器的体系结构 • 从转换图构造词法分析器的方法 – 变量State记录当前状态 – 一个switch根据State的值转到相应的代码 – 每个状态对应于一段代码 • 这段代码根据读入的符号,确定下一个状态 • 如果找不到相应的边,则调用fail()进行错误恢复 – 进入某个接受状态时,返回相应的词法单元 • 注意状态有*标记时,需要回退forward指针 • 实际是模拟转换图的运行 29
28 .Relop对应的代码概要 30
29 .内容 词法分析器的作用 词法单元的规约 (正则表达式) 词法单元的识别 (状态转换图) 词法分析器生成工具及设计 有穷自动机 32
3秒后跳转登录页面
去登陆

