










































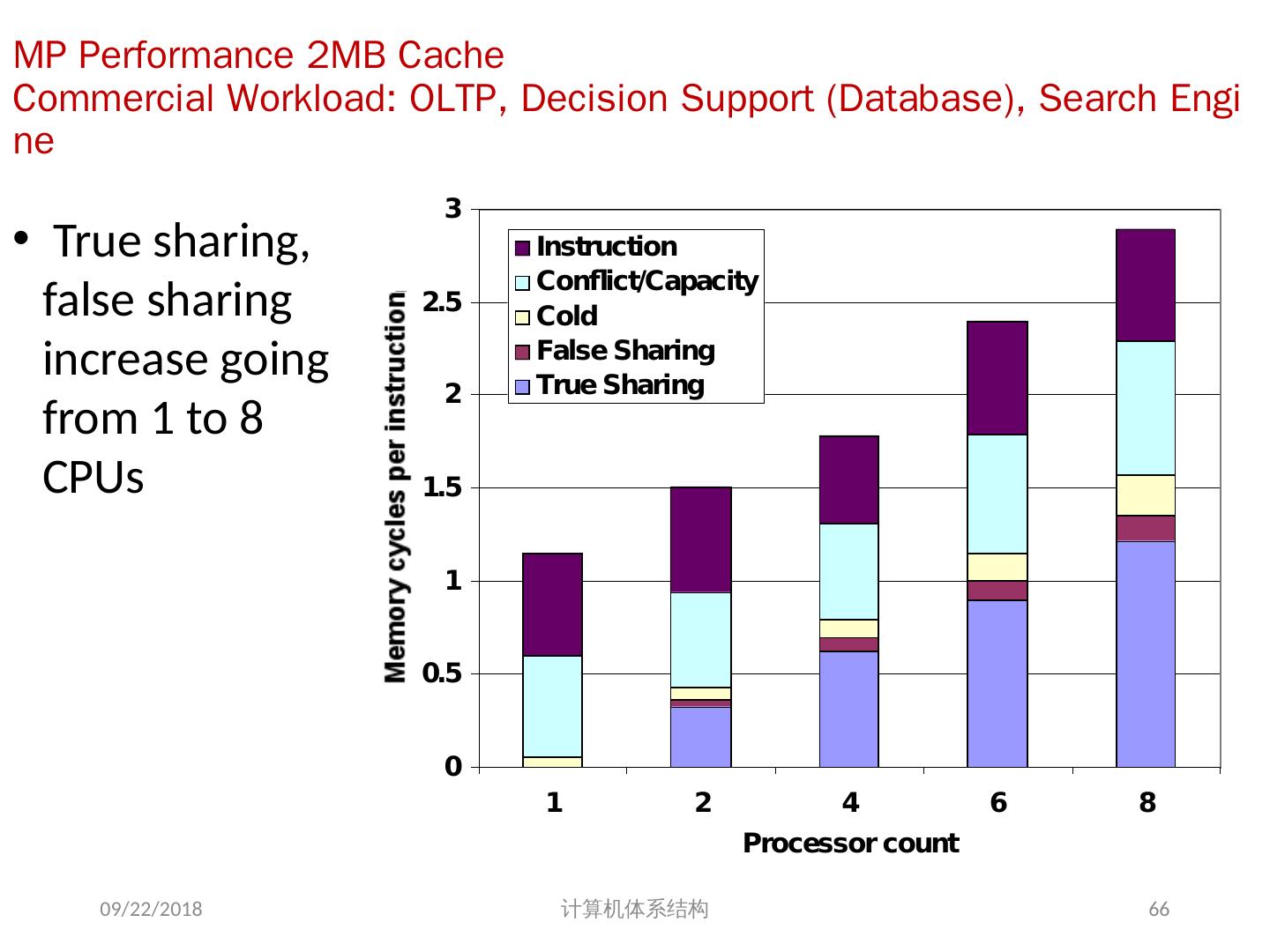


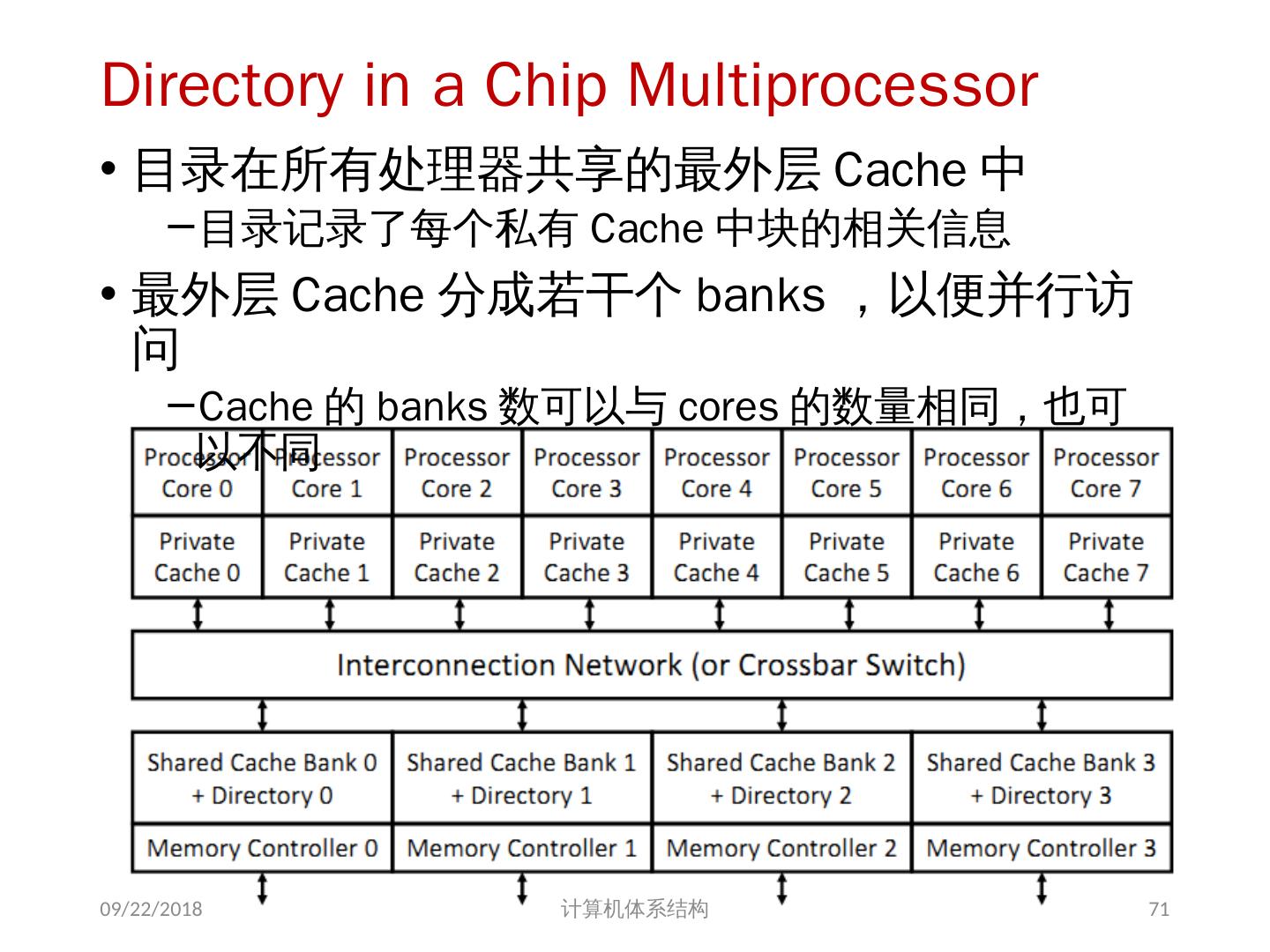











































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
07 计算机体系结构--多处理器及线程级并行
这一节是中国科学技术大学周学海教授所讲授的计算机体系结构中的多处理器及线程级并行部分。这一节的主要内容有:关于多处理及多线程级的引言 ;集中式共享存储器体系结构 ;分布式共享存储器体系结构 ;存储同一性 ;同步与通信等。在这一节中,作者列举出了几个非常重要的模型,对我们的学习有非常重要的意义。
展开查看详情
1 .计算机体系结构 周学海 xhzhou@ustc.edu.cn 0551-63601556, 63492149 中国科学技术大学 2018/6/6 计算机体系结构 1
2 .第 7 章 多处理器及线程级并行 7.1 引言 7.2 集中式共享存储器体系结构 7.3 分布式共享存储器体系结构 7.4 存储同一性 7.5 同步与通信 2018/6/6 计算机体系结构 2
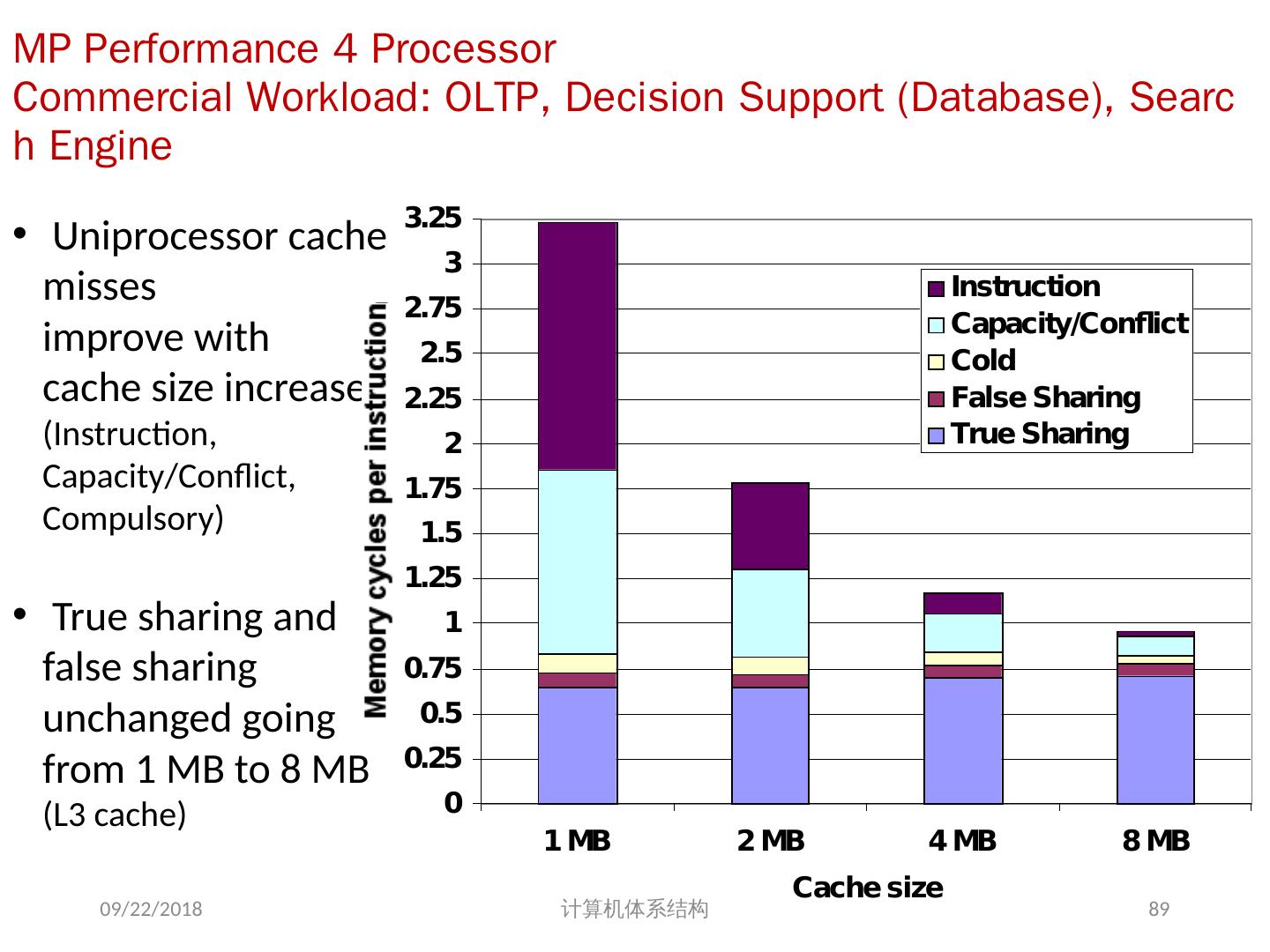
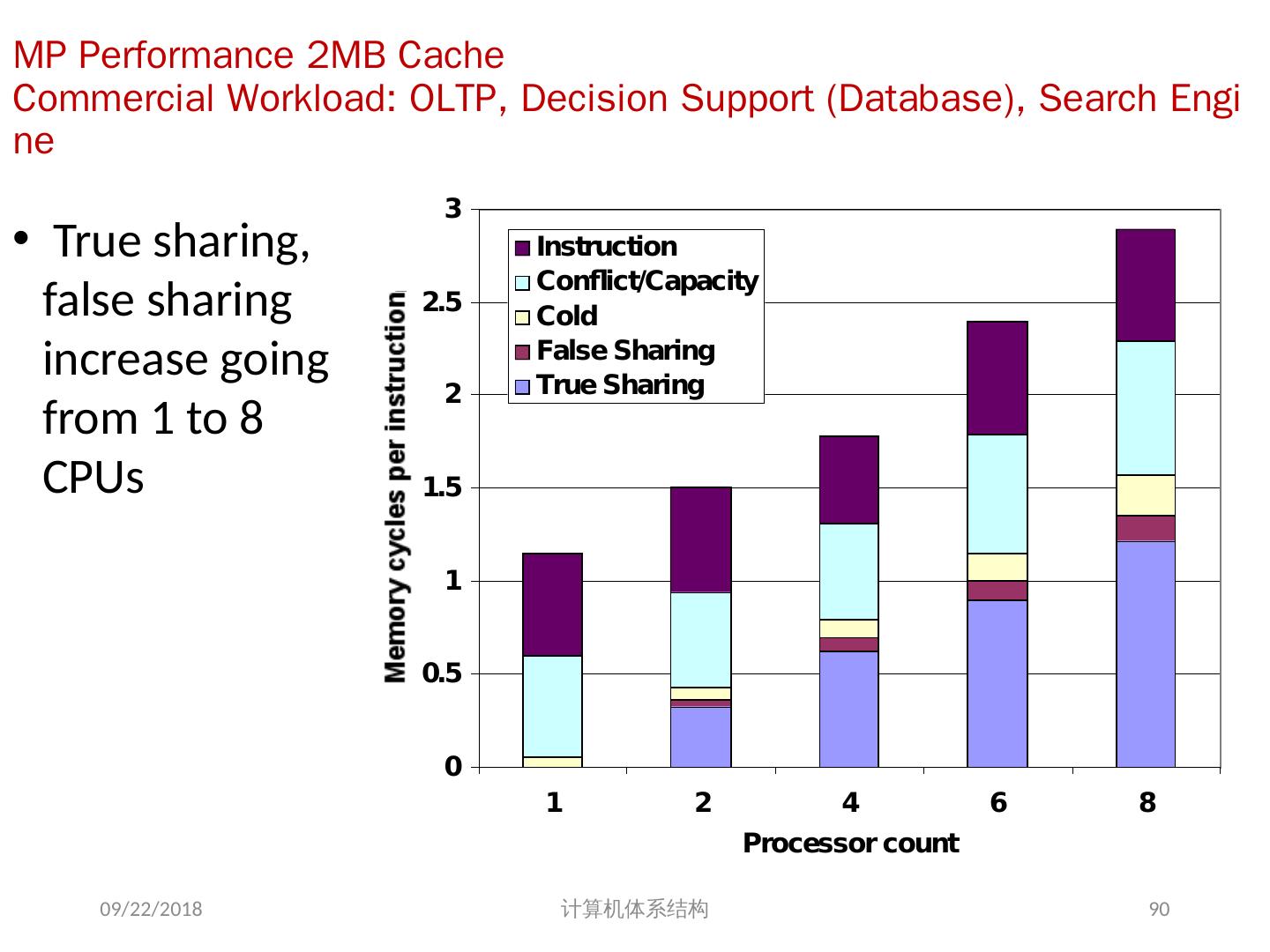
3 .7.1 、引言 自 1985 年以来,体系结构的改进使性能迅速提高,但通过复杂度和硅技术的提高而得到的性能的提高正在减小; 单(核)处理器的发展正在走向尽头? 挖掘 ILP 并行收益日益减小 功耗问题 获得超过单处理器的性能,最直接的方法就是把多个处理器连在一起; 并行计算机在未来将会发挥更大的作用 并行计算机应用软件已有缓慢但稳定的发展。 2018/6/6 计算机体系结构 3
4 .并行计算机体系结构的分类 1 、按照 Flynn 分类法,可把计算机分成 单指令流单数据流( SISD ) 单指令流多数据流( SIMD ) 多指令流单数据流( MISD ) 多指令流多数据流( MIMD ) 2 、 MIMD 已成为通用多处理器体系结构的选择,原因: MIMD 具有灵活性。 MIMD 可以充分利用商品化微处理器在性能价格比方面的优势。 2018/6/6 计算机体系结构 4
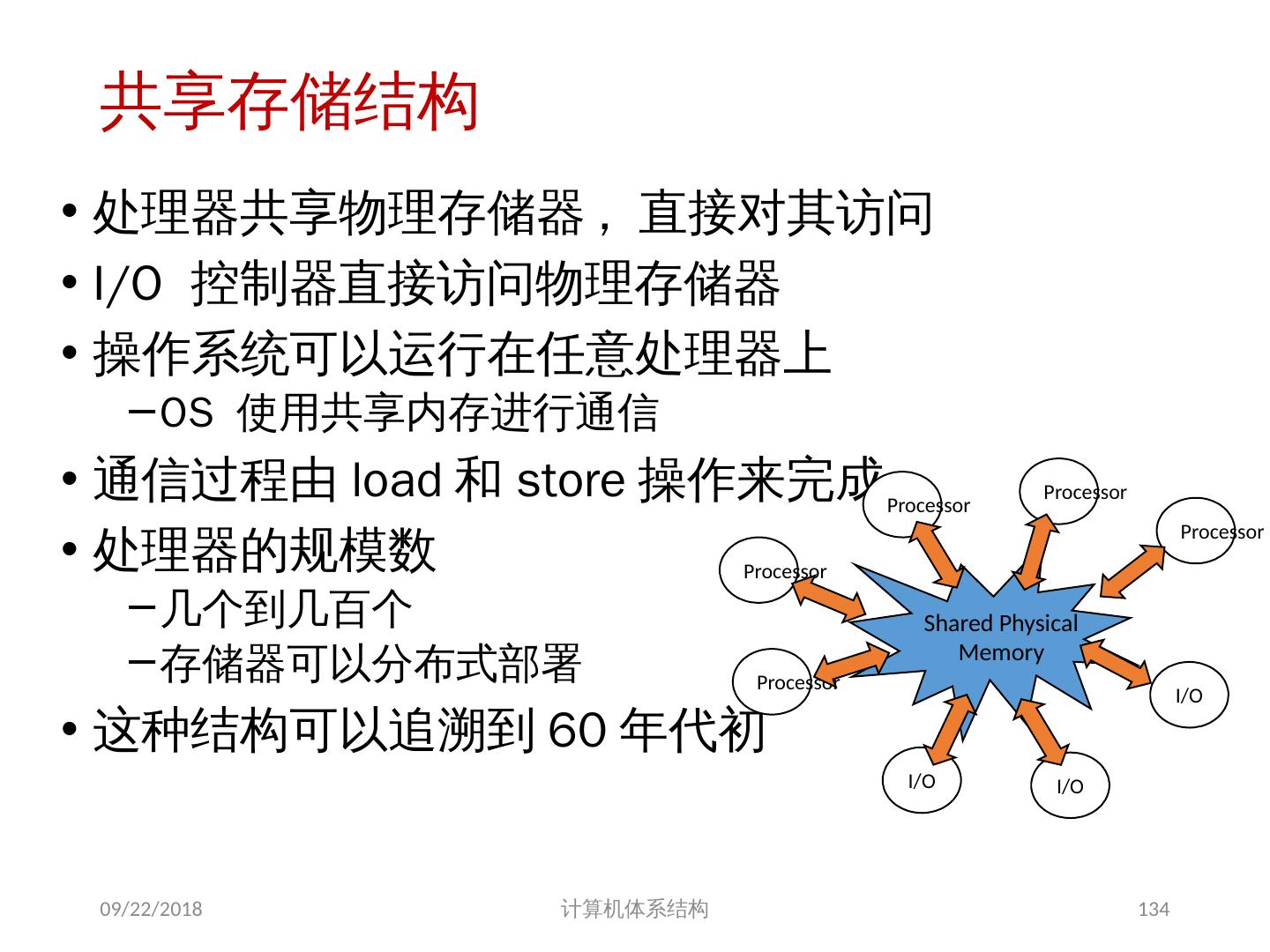
5 .通信模型和存储器的结构模型 1. 两种地址空间的组织方案 (1) 共享存储(多处理机): 物理上分离的多个存储器可作为一个逻辑上共享的存储空间进行编址 (2) 非共享存储(多计算机): 整个地址空间由多个独立的地址空间构成,它们在逻辑上也是独立的,远程的处理器不能对其直接寻址。 每一个处理器 - 存储器模块实际上是一个单独的计算机,这种机器也称为多计算机。 2018/6/6 计算机体系结构 5
6 .两种通信模型 2. 两种通信模型 (1) 共享地址空间的机器 利用 Load/Store 指令的地址隐含地进行数据通讯 (2) 多个地址空间的机器 通过处理器间显式地传递消息完成 这种机器常称为消息传递机器。 2018/6/6 计算机体系结构 6
7 .不同通信机制的优点 1 、共享存储器通信的主要优点 当处理器通信方式复杂或程序执行动态变化时易于编程,同时在简化编译器设计方面也占有优势。 当通信数据较小时,通信开销较低,带宽利用较好。 通过硬件控制的 Cache 减少了远程通信的频度,减少了通信延迟以及对共享数据的访问冲突。 2 、消息传递通信机制的主要优点 硬件较简单。 通信是显式的,从而引起编程者和编译程序的注意,着重处理开销大的通信。 2018/6/6 计算机体系结构 7
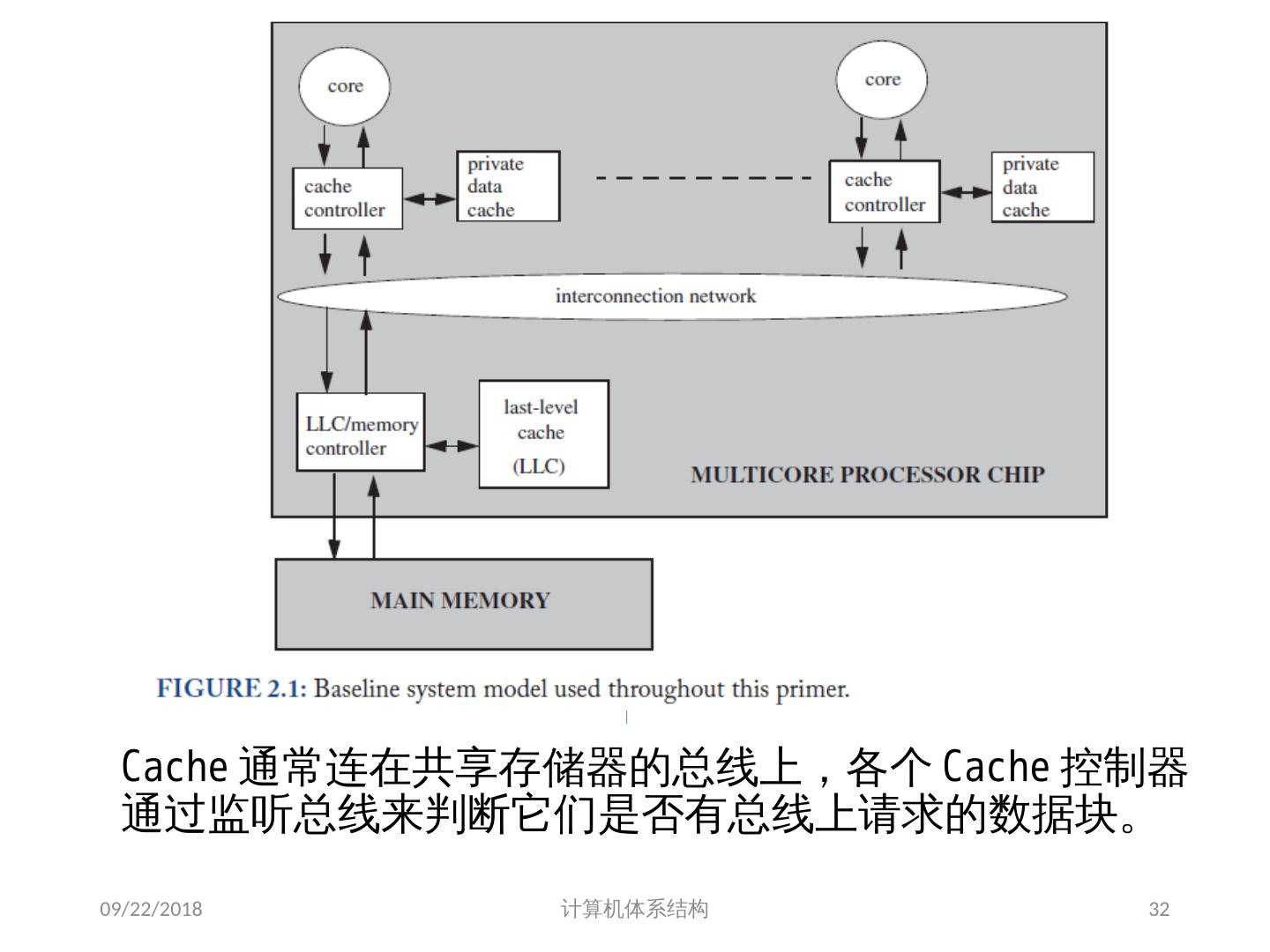
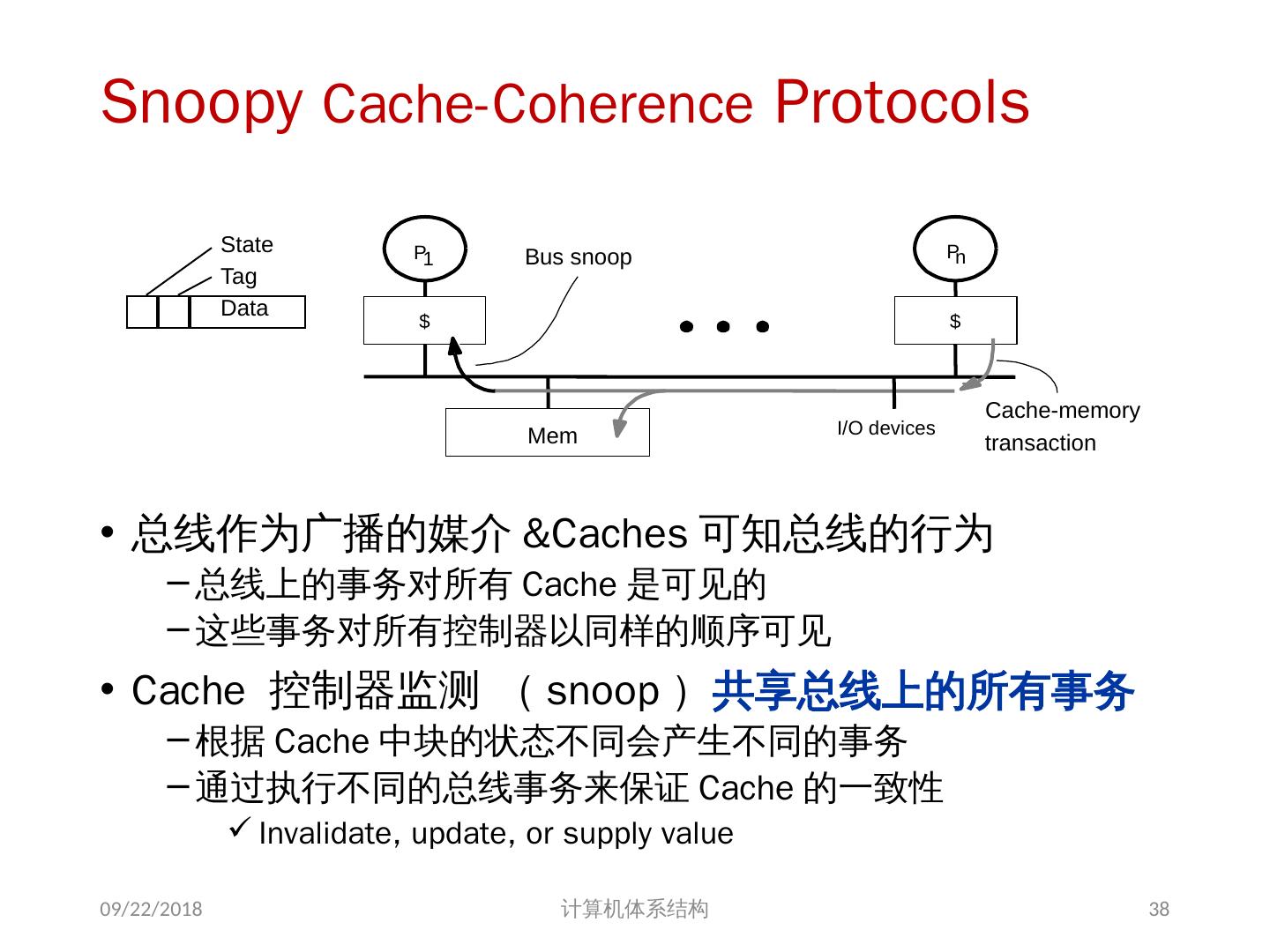
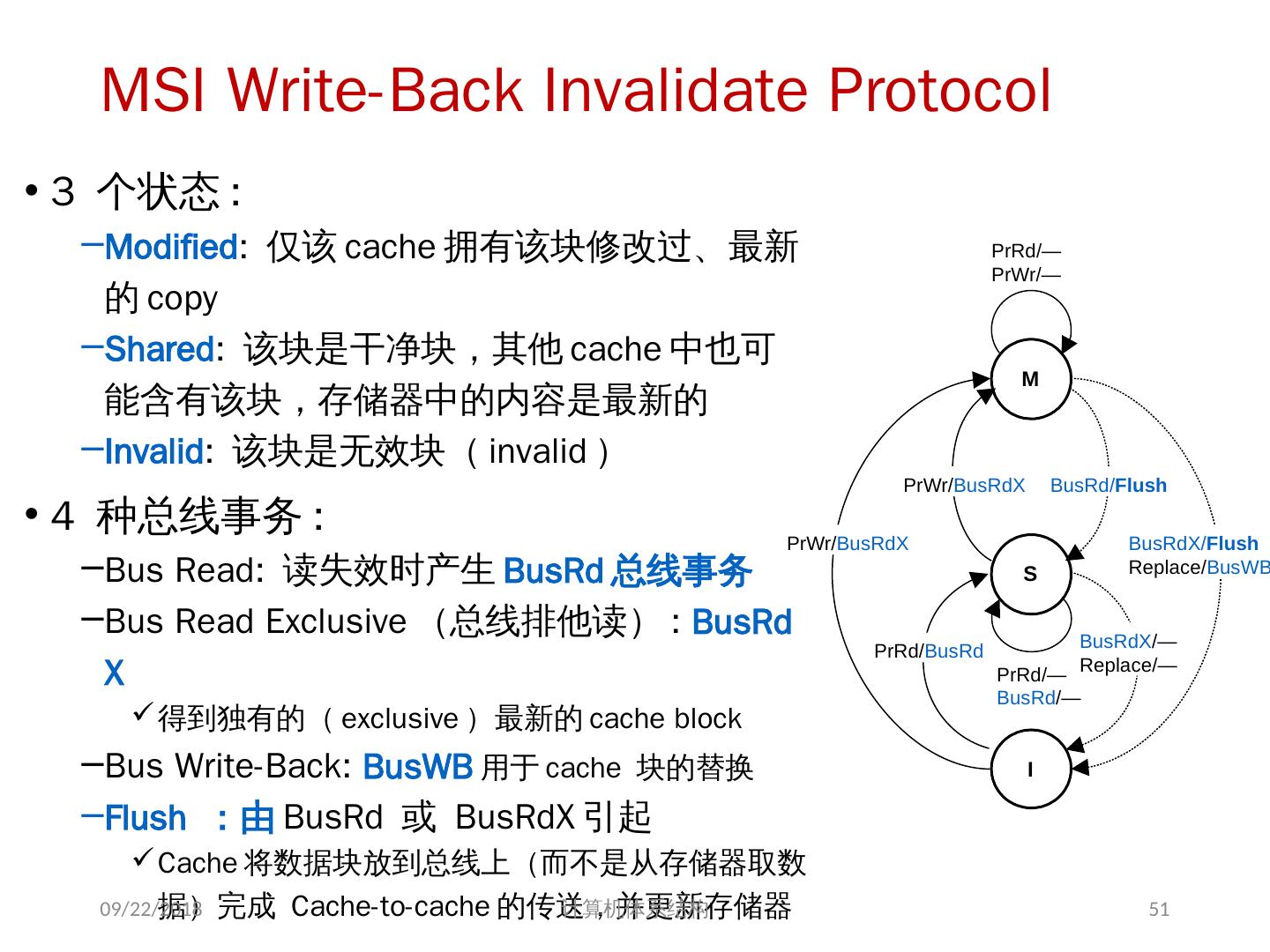
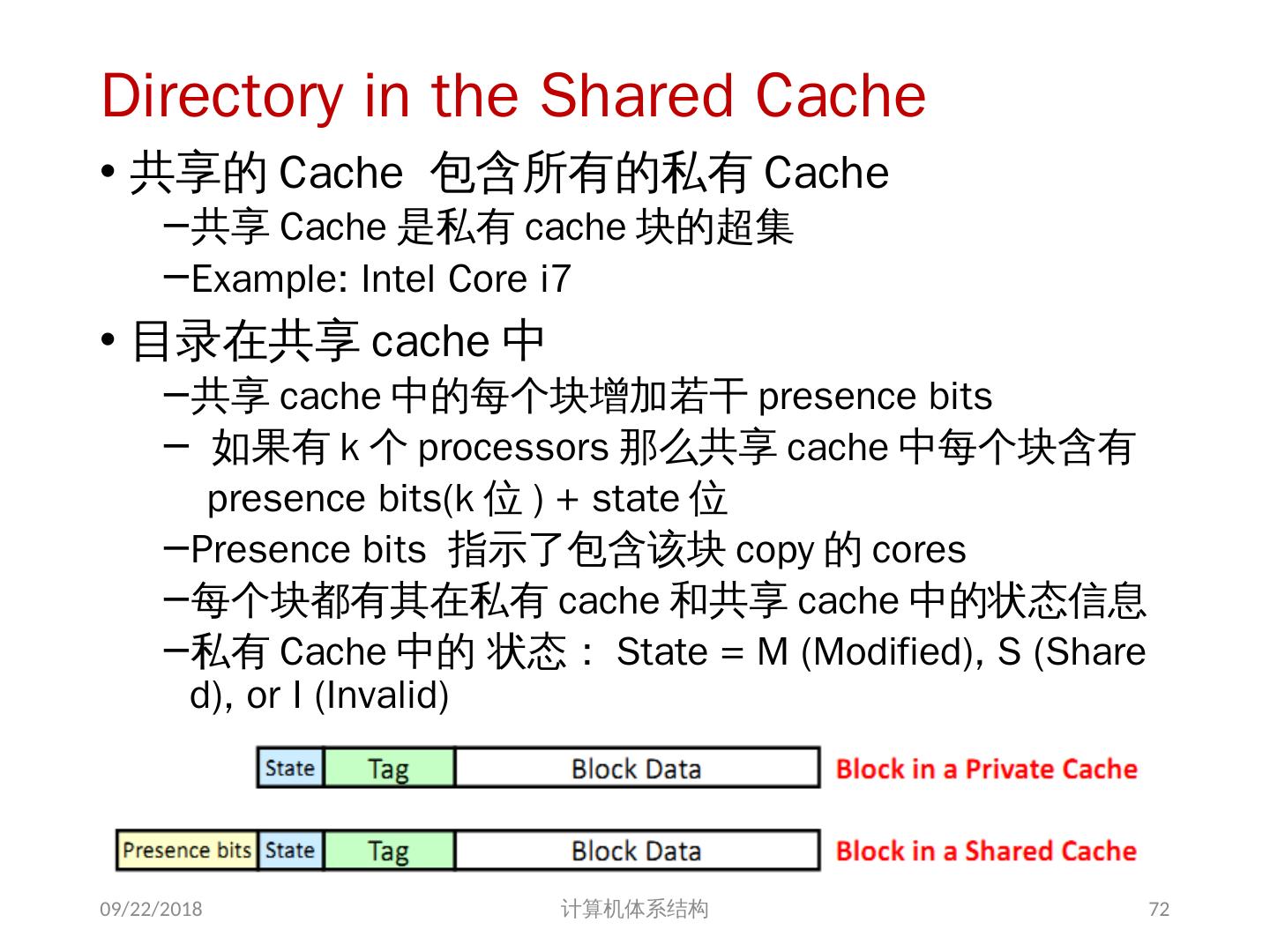
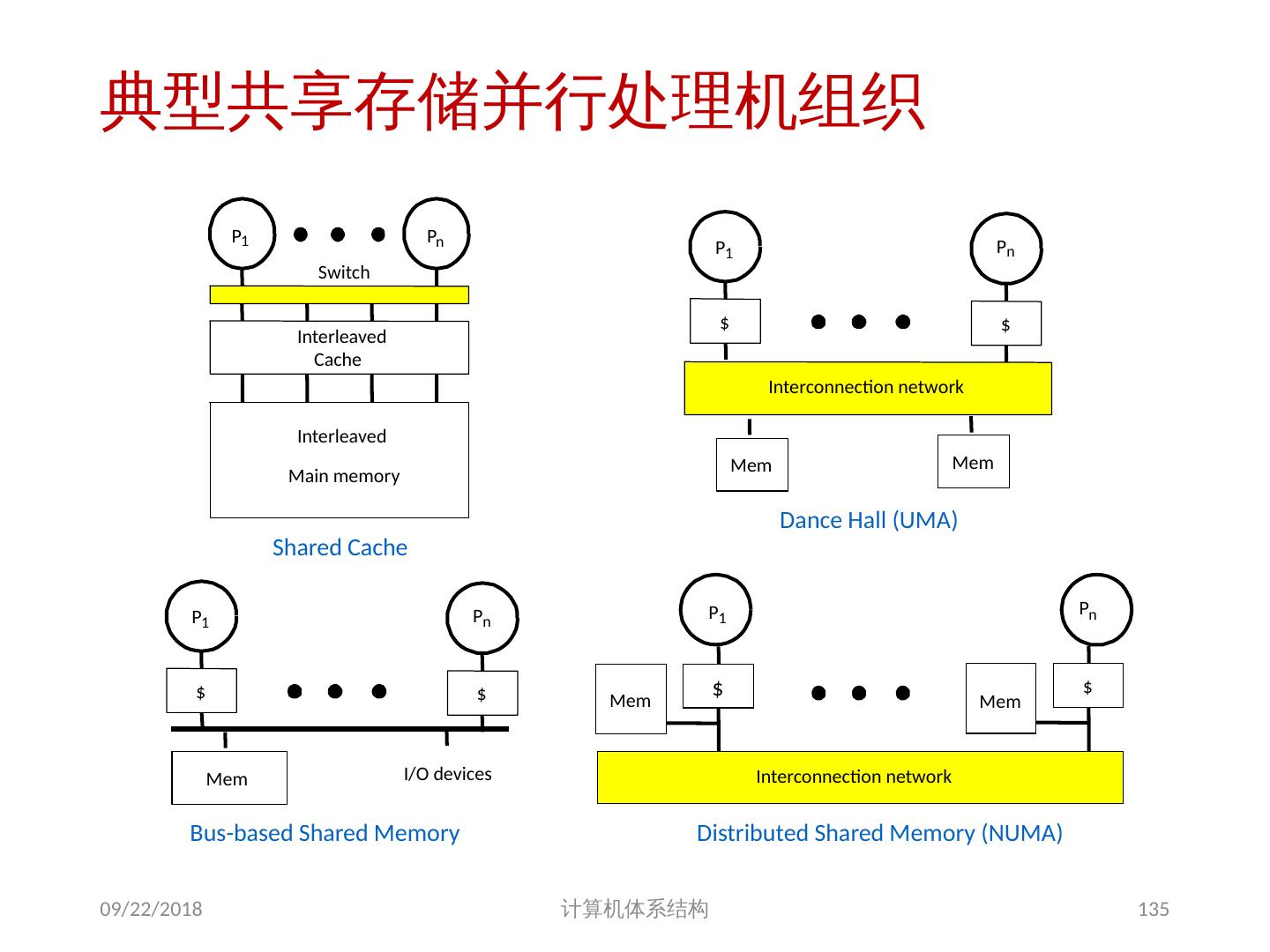
8 .基于共享存储的 MIMD 机器分类 根据多处理机系统中存储器组织 以及 处理器个数的多少,可分为两类 集中式共享存储器结构( SMP ) symmetric (shared-memory) multiprocessors 这类机器有时被称为 UMA(uniform memory access) 机器 适合处理器个数 < 32 特点: 多个处理器( core )共享 集中 式存储器 所有处理器访问存储器的延时是 相等 的 所有处理器共享一个地址空间 2018/6/6 计算机体系结构 8
9 .2018/6/6 计算机体系结构 9 集中式共享存储多处理器系统
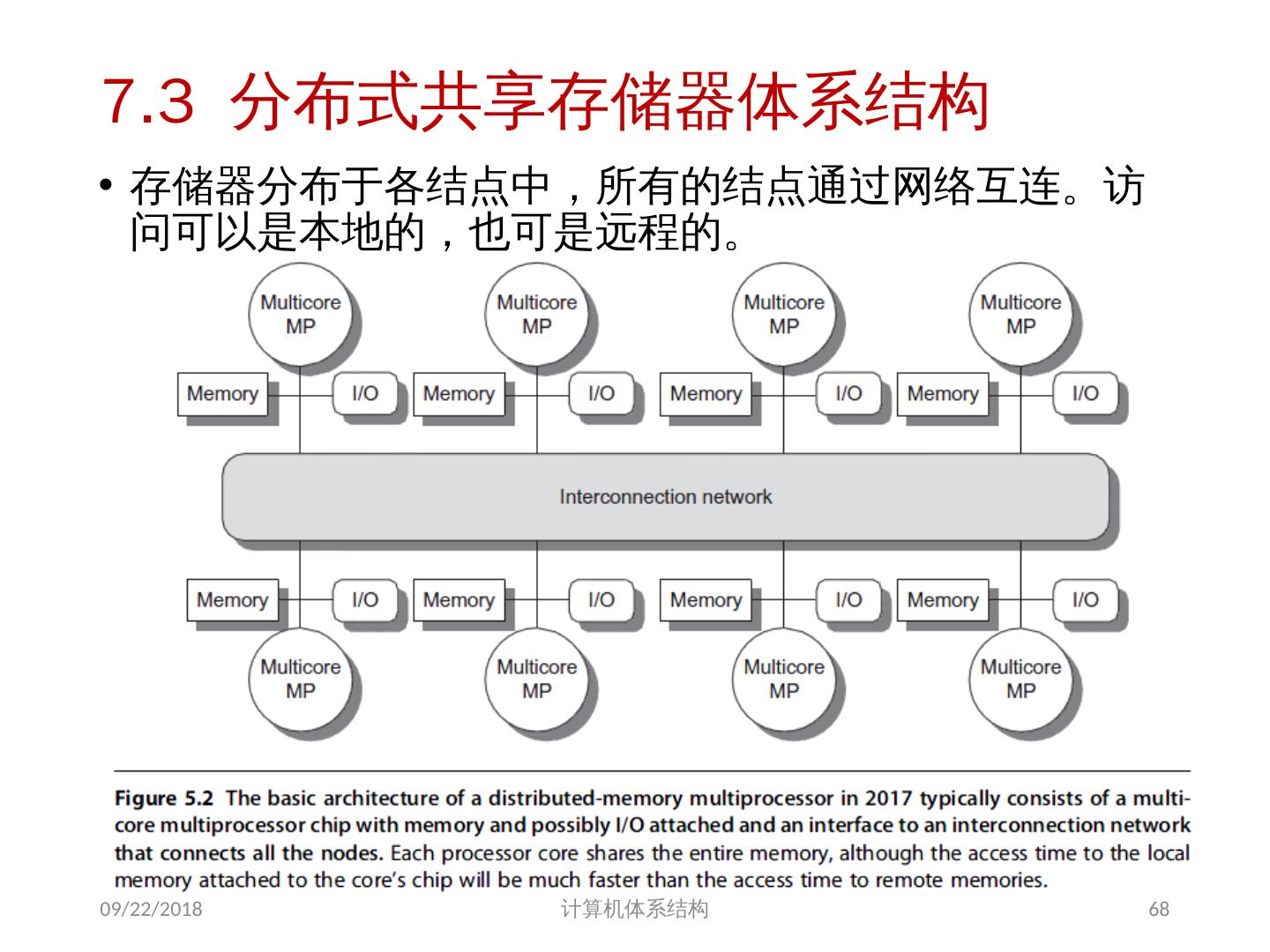
10 .分布式共享存储器结构 分布式共享存储器结构( DSM ) : Distributed Shared Memory 这类机器的结构被称为分布式共享存储器或可缩放共享存储器体系结构。 DSM 机器被称为 NUMA(non-uniform memory access) 机器 特点: 每个结点包含:处理器、存储器、 I/O 处理器访问数据的延时,取决于数据所在的位置 ( 不相等) 分布式存储器结构需要高带宽的互连 所有处理器共享一个地址空间 2018/6/6 计算机体系结构 10
11 .分布式共享存储多处理器系统 2018/6/6 计算机体系结构 11
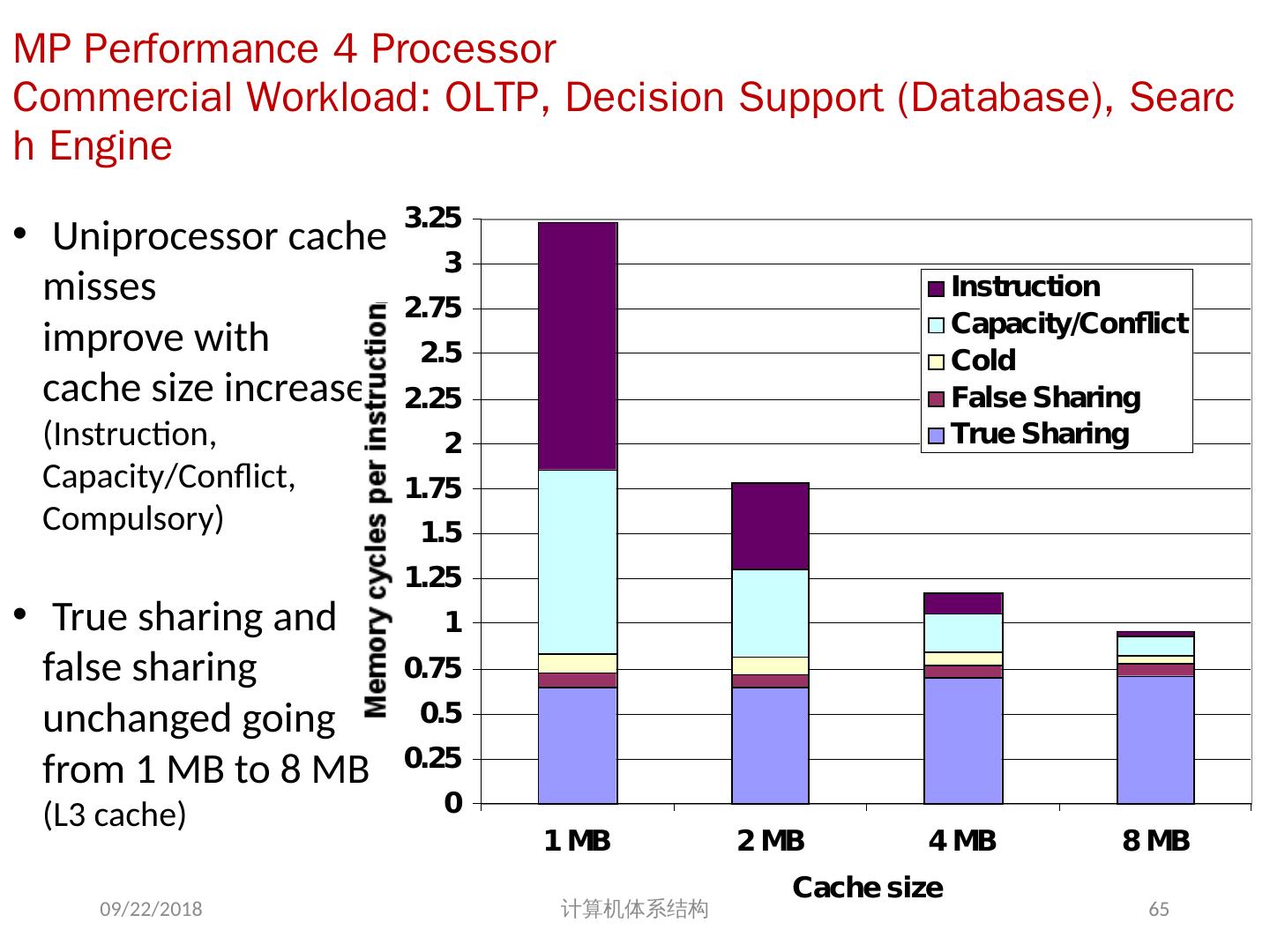
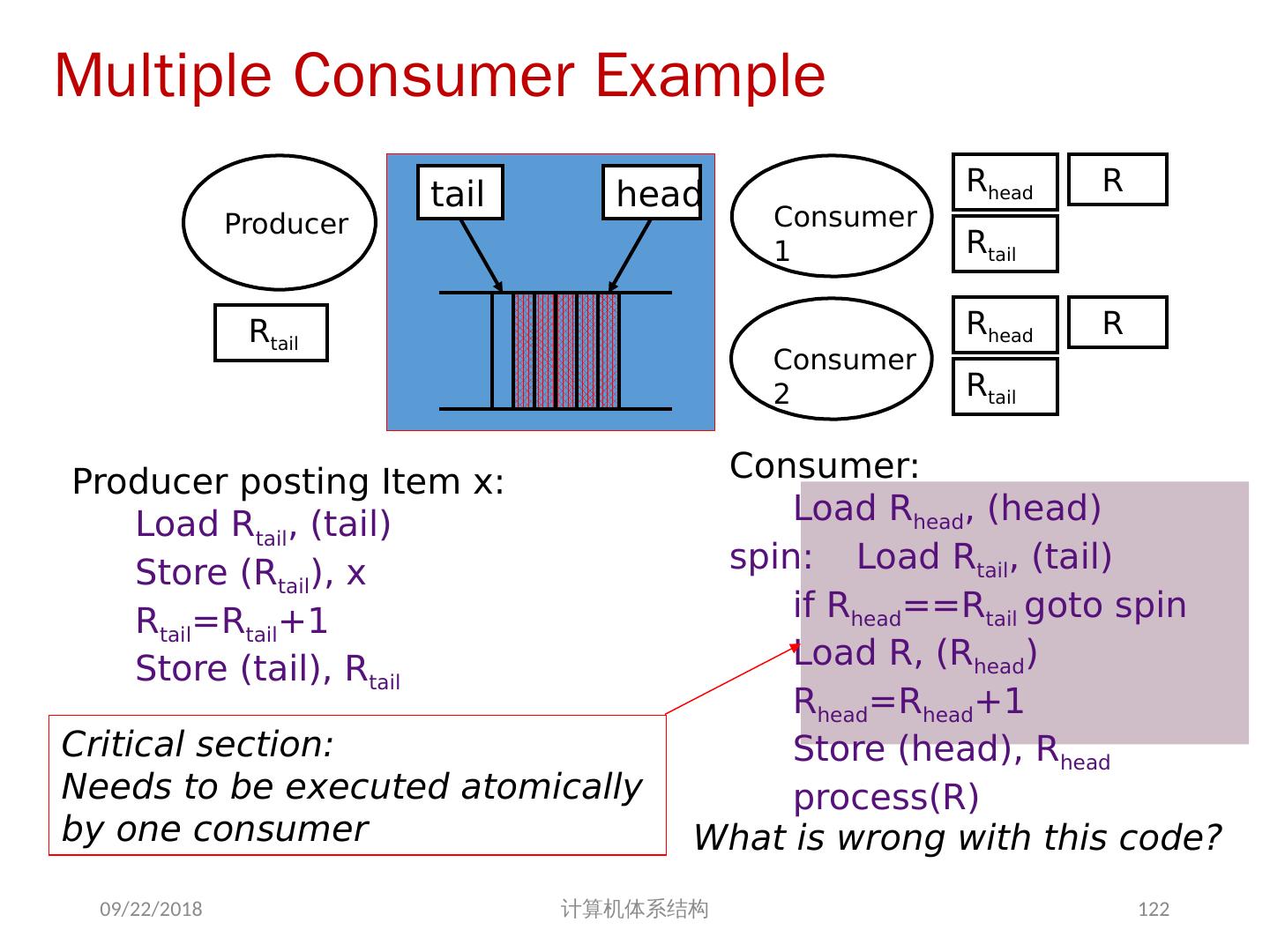
12 .并行处理面临的挑战 并行处理面临的挑战性问题: 程序中有限的并行性 相对较高的通信开销 共享存储的一个基本问题:存储器访问的序问题 挑战之一 : 有限的并行性使机器要达到好的加速比十分困难 2018/6/6 计算机体系结构 12 例 7.1 如果想用 100 个处理器达到 80 的加速比, 求原计算程序中串行部分所占比例。
13 .2018/6/6 计算机体系结构 13 80 = 1 并行比例 100 + ( 1 -并行比例) 1 可加速部分比例 理论加速比 + ( 1 -可加速部分比例) 例 7.1 如果想用 100 个处理器达到 80 的加速比, 求原计算程序中串行部分所占比例。 解 根据 Amdahl 定律加速比为: 得出:并行比例= 0.9975 可以看出要用 100 个处理器达到 80 的加速比,串行计算的部分只能占 0.25% 。
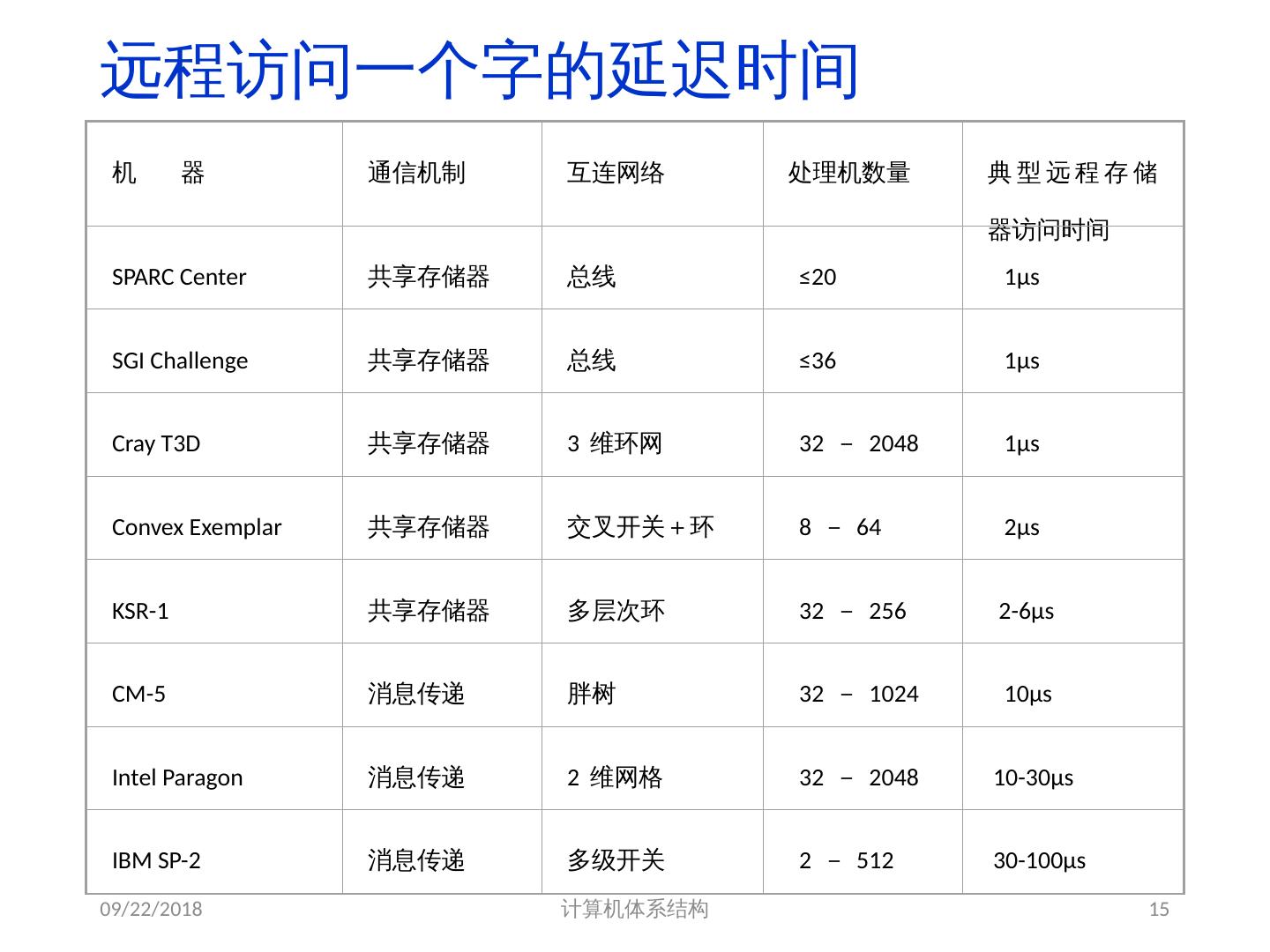
14 .挑战之二: 多处理机中远程访问的较大延迟。 在现有的机器中,处理器之间的数据通信大约需要 35 ~ >500 个时钟周期。 同一芯片中 core 之间的延迟 35~50cycles 不同芯片间 core 之间的延迟 100~>500 cycles 相关因素:处理器数量、通信机制、互连网络等 2018/6/6 计算机体系结构 14
15 .远程访问一个字的延迟时间 2018/6/6 计算机体系结构 15 机 器 通信机制 互连网络 处理机数量 典型远程存储器访问时间 SPARC Center 共享存储器 总线 ≤20 1μs SGI Challenge 共享存储器 总线 ≤36 1μs Cray T3D 共享存储器 3 维环网 32 - 2048 1μs Convex Exemplar 共享存储器 交叉开关+环 8 - 64 2μs KSR-1 共享存储器 多层次环 32 - 256 2-6μs CM-5 消息传递 胖树 32 - 1024 10μs Intel Paragon 消息传递 2 维网格 32 - 2048 10-30μs IBM SP-2 消息传递 多级开关 2 - 512 30-100μs
16 .例 7.2 一台 32 个处理器的计算机,对远程存储器访问时间为 100ns 。除了通信以外,假设计算中的访问均命中局部存储器。当发出一个远程请求时,本处理器挂起。处理器时钟周期为 0.25ns ,如果指令基本的 CPI 为 0.5( 设所有访存均命中 Cache) ,求在没有远程访问的状态下与有 0.2% 的指令需要远程访问的状态下,前者比后者快多少 ? 2018/6/6 计算机体系结构 16
17 .解 有 0.2% 远程访问的机器的实际 CPI 为: CPI =基本 CPI +远程访问率 × 远程访问开销 = 0.5 + 0.2%× 远程访问开销 远程访问开销=远程访问时间 / 时钟时间 = 100ns/0.25ns = 400 个时钟周期 ∴ CPI = 0.5 + 0.2%×400 = 1.3 它为只有局部访问的机器的 1.3 / 0.5 = 2.6 倍, 因此在没有远程访问的状态下的机器速度是有 0.2% 远程访问的机器速度的 2.6 倍。 2018/6/6 计算机体系结构 17
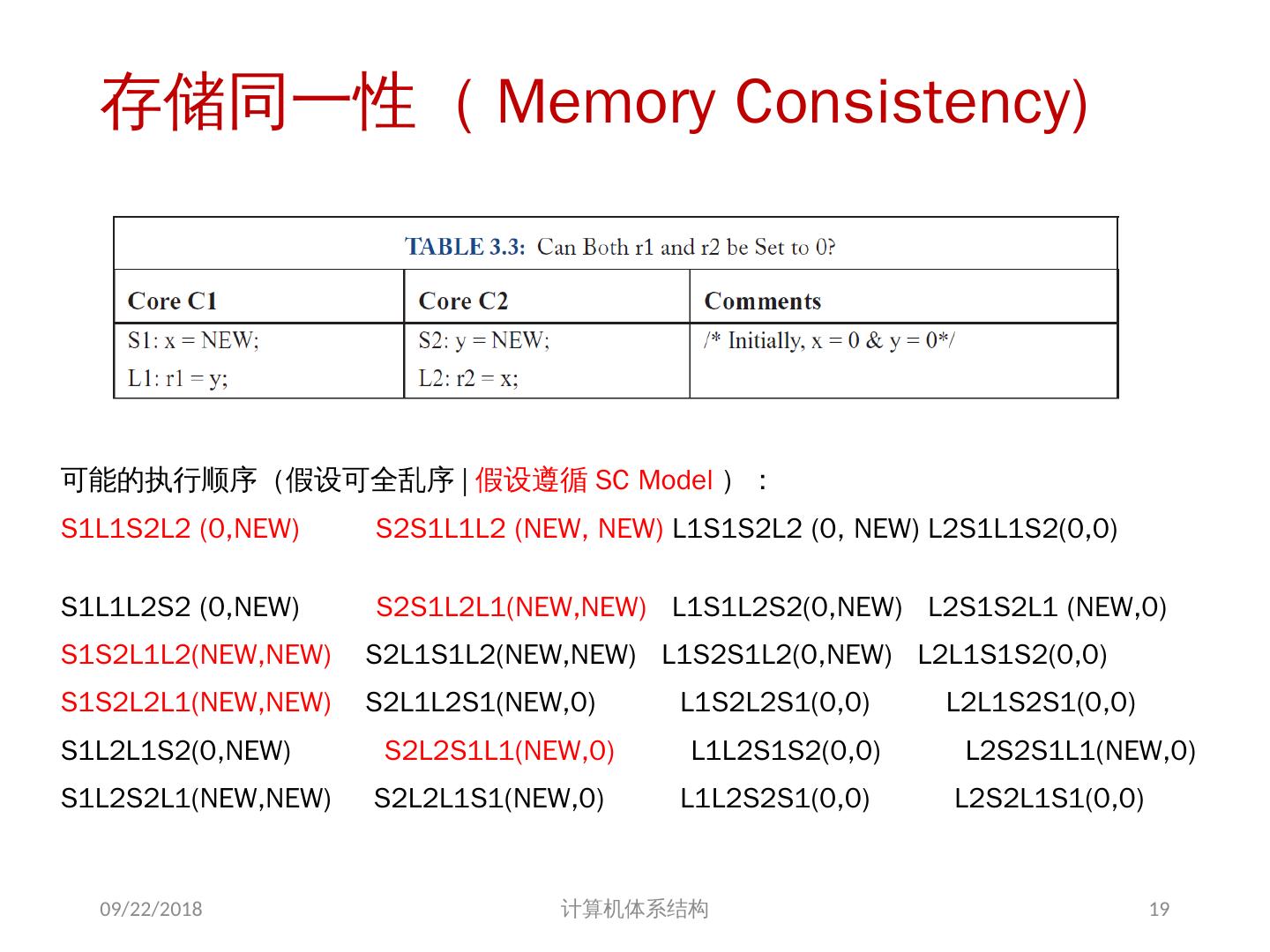
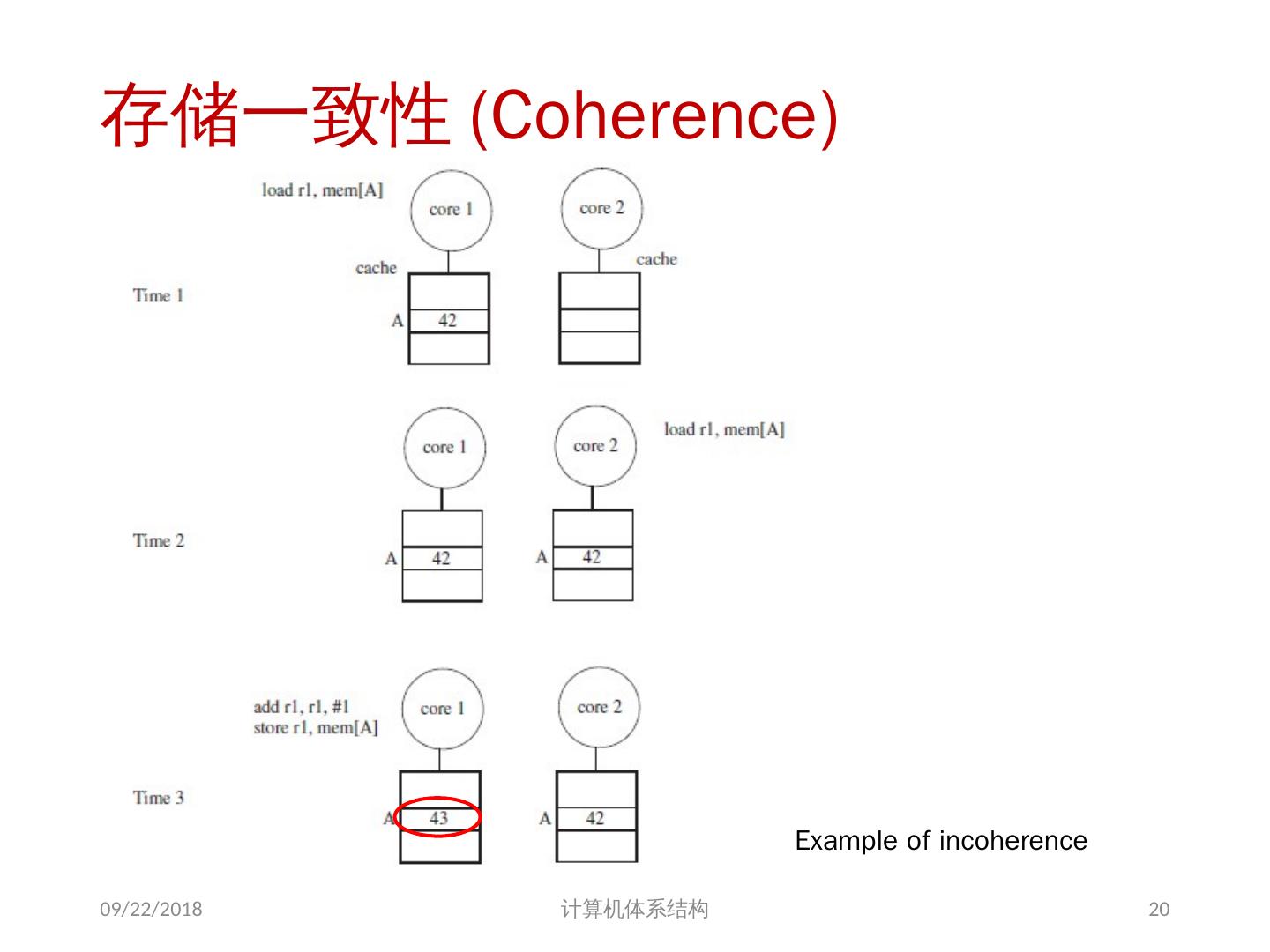
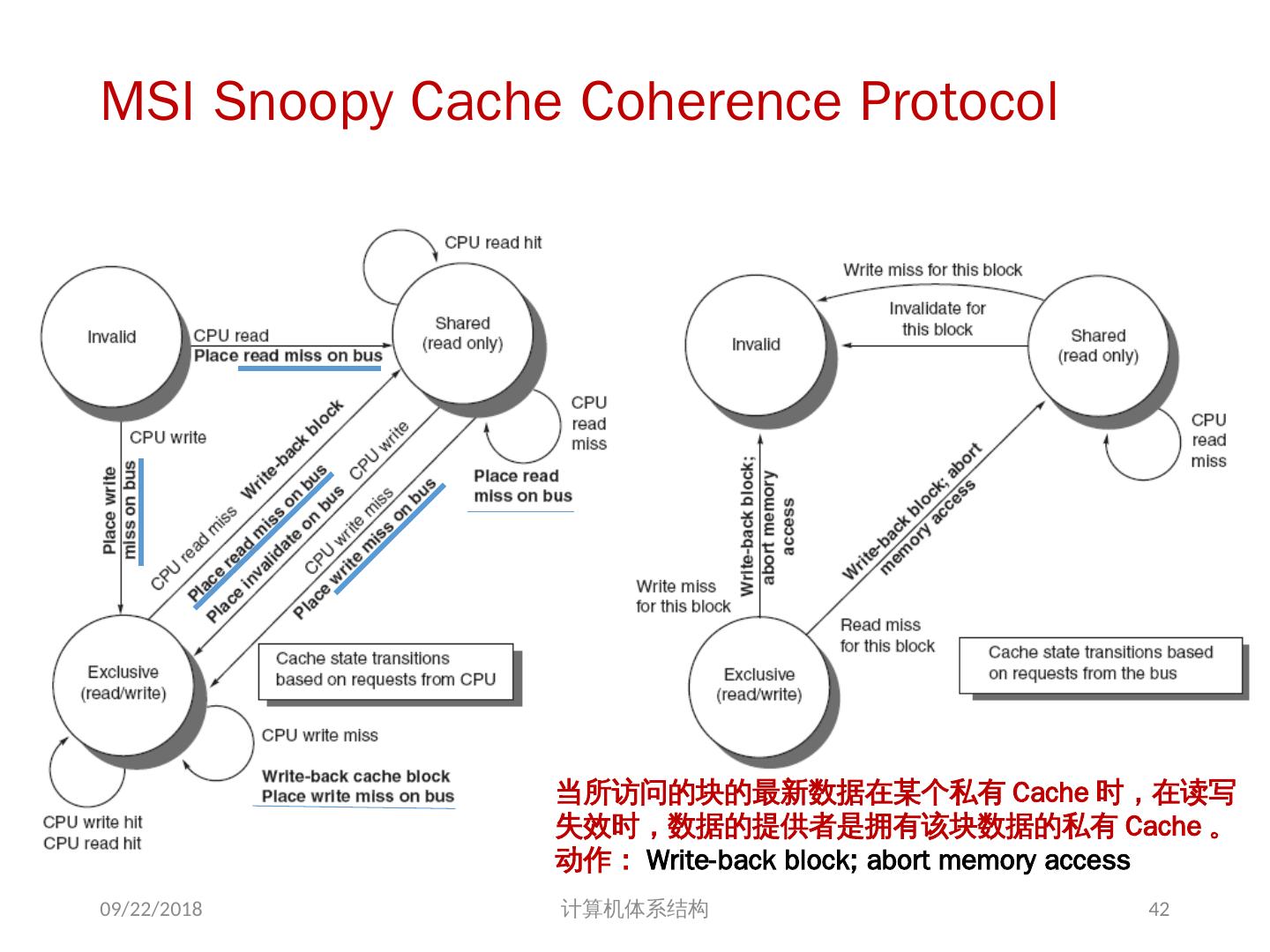
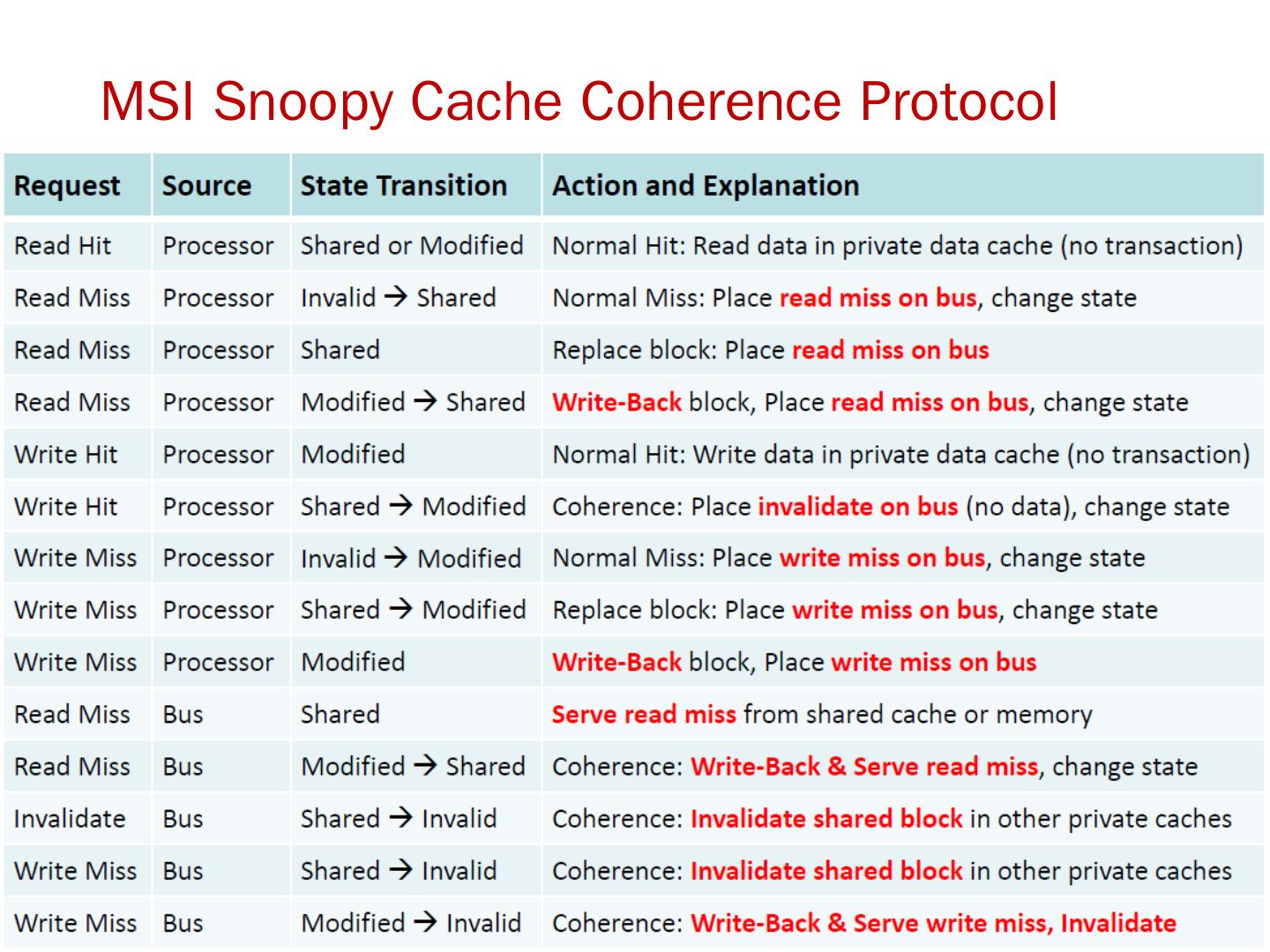
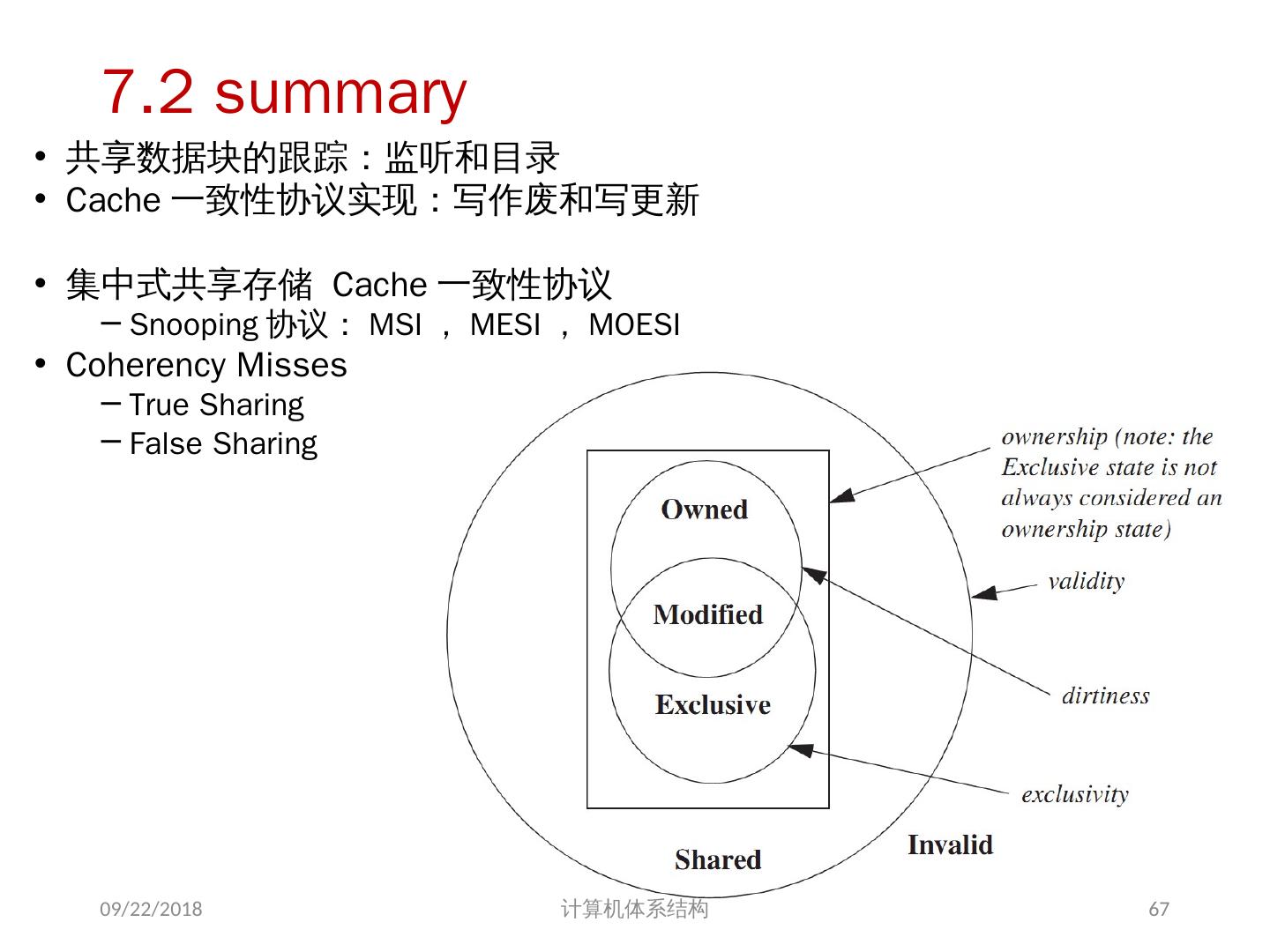
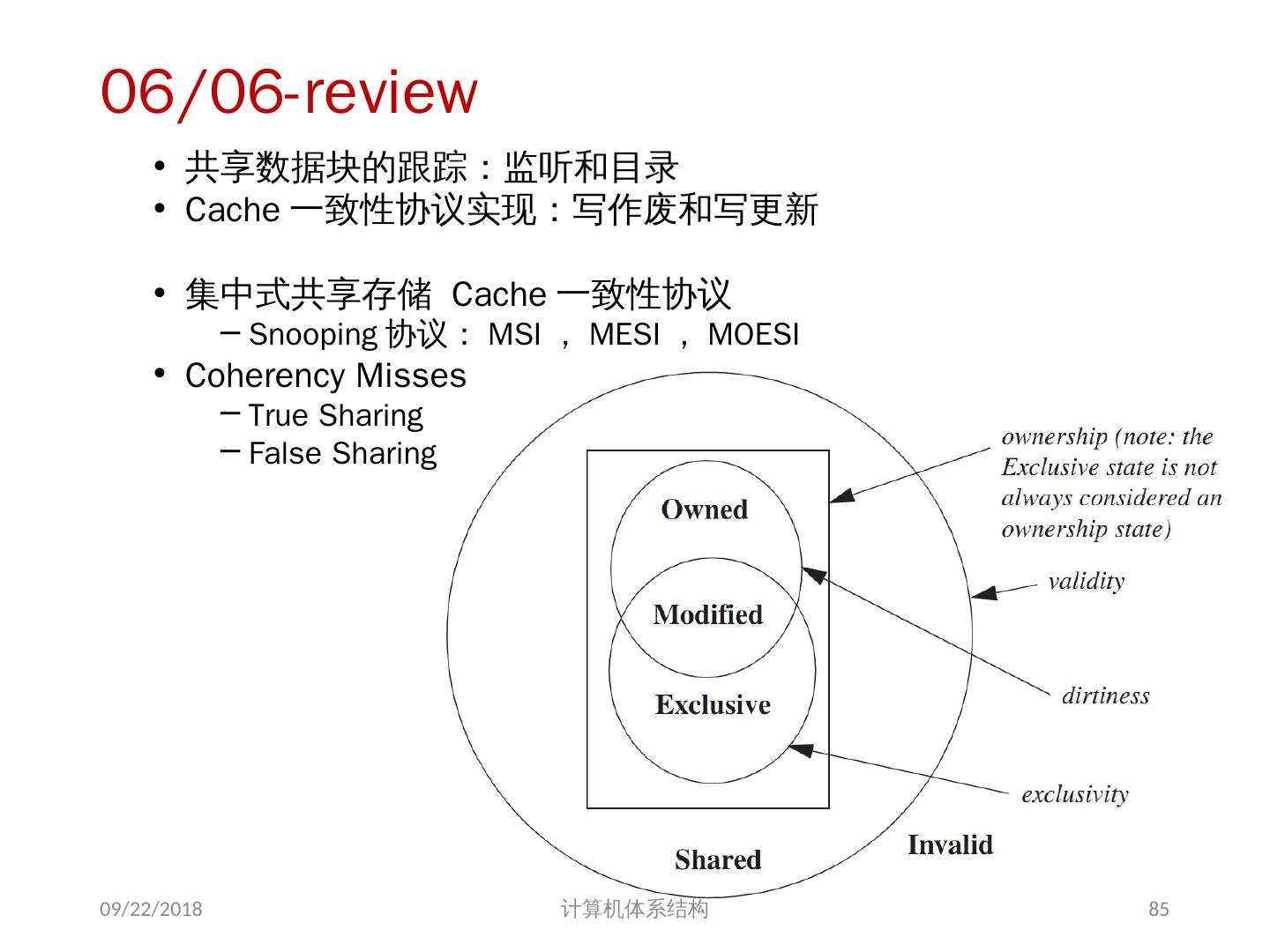
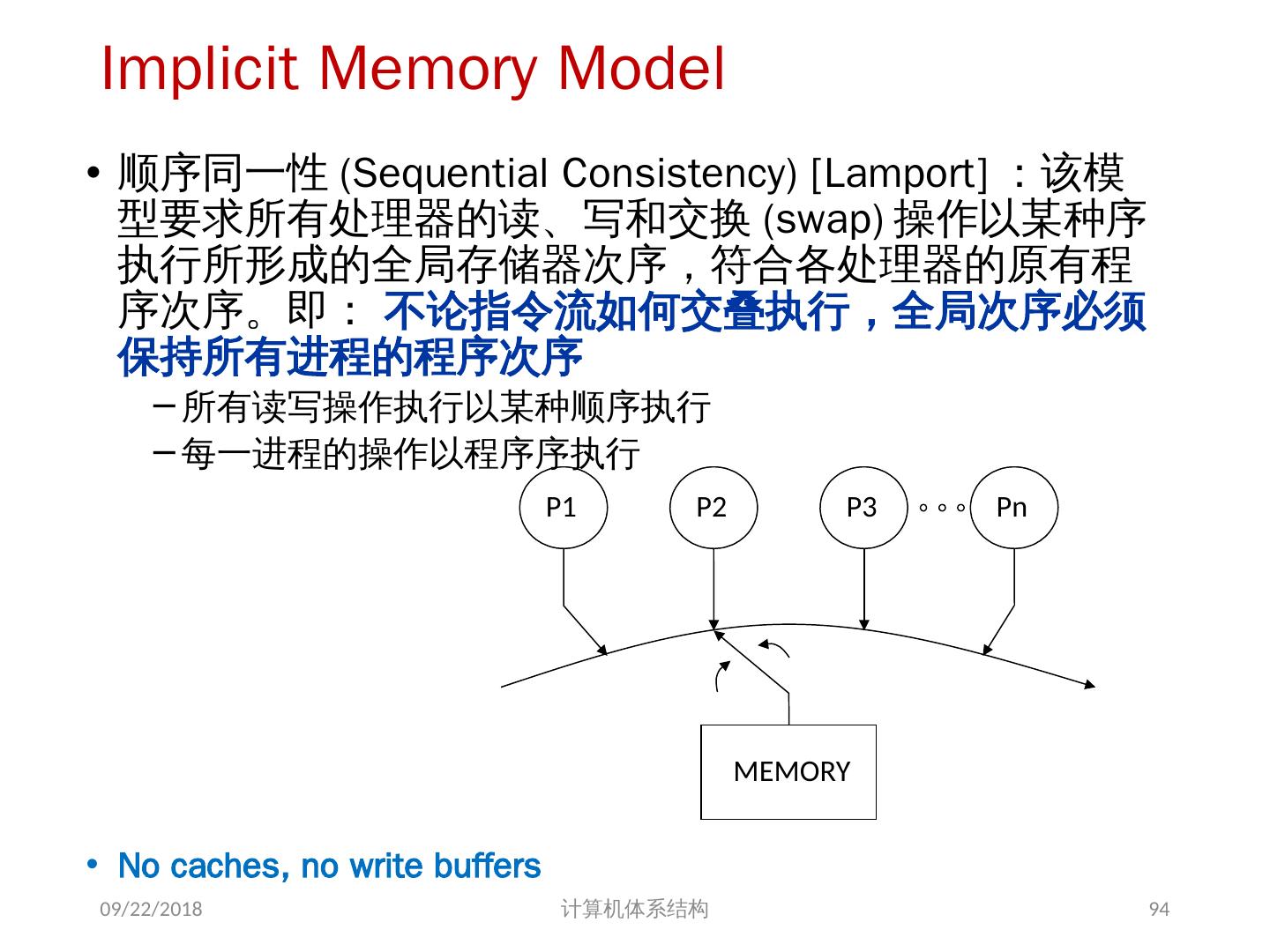
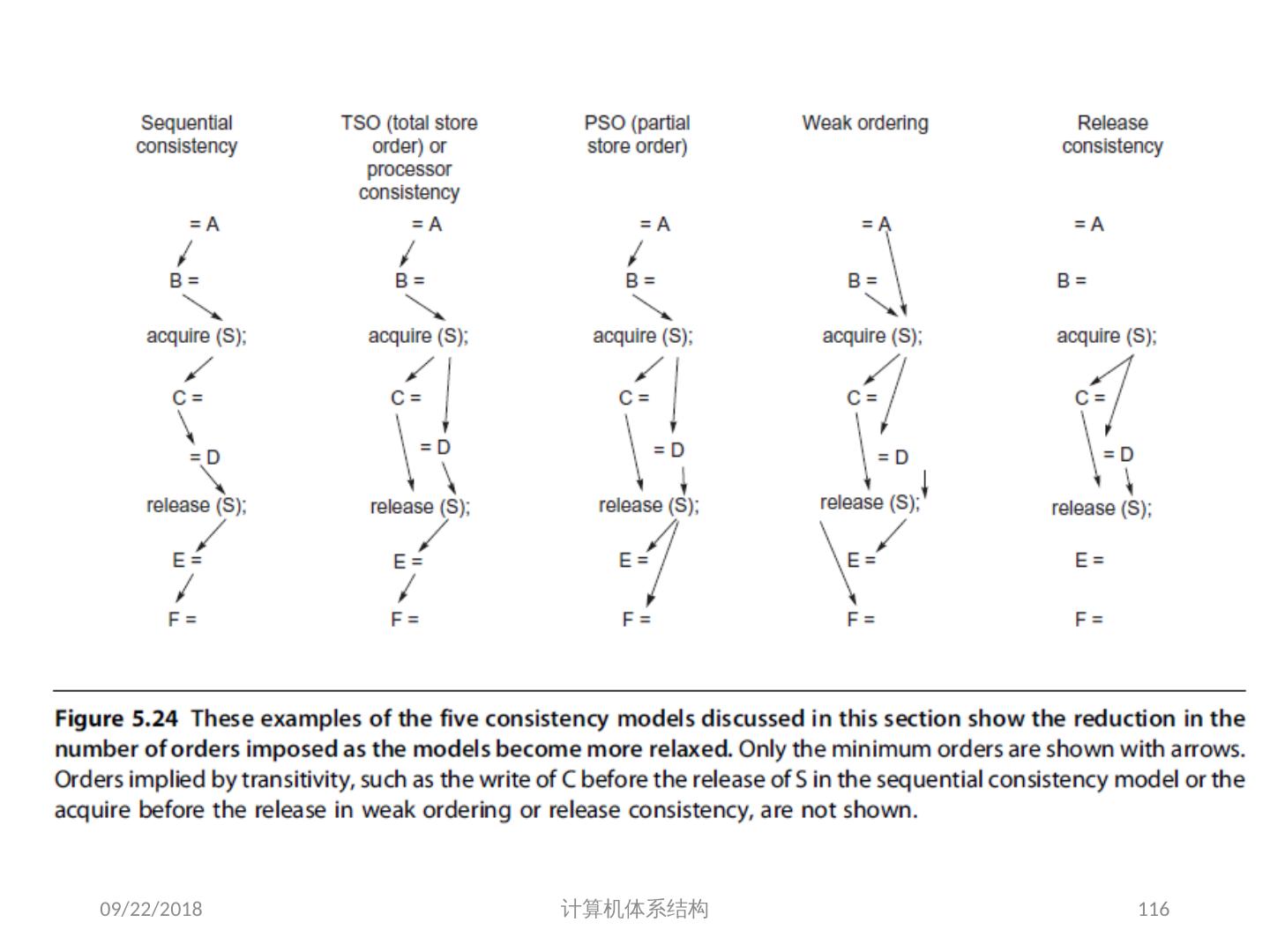
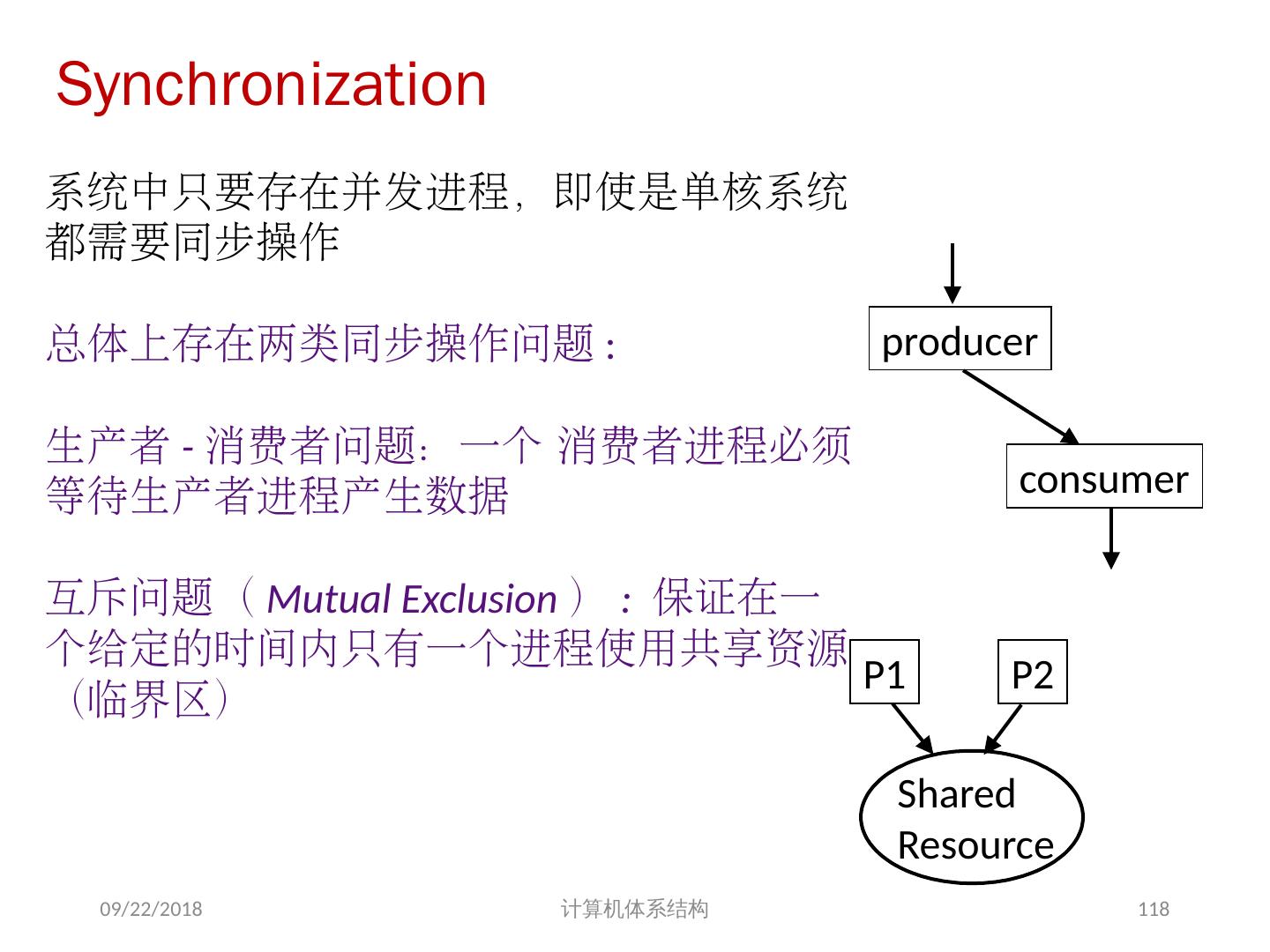
18 .存储器访问的序问题 存储同一性( Consistency ): 不同处理器发出的 所有存储器操作 的顺序问题(即针对不同存储单元或相同存储单元) 访问所有存储单元的 全序问题 存储一致性( Coherence ): 不同处理器访问 相同存储单元 时的访问顺序问题 访问每个 Cache 块的 局部序问题 其他参考文献: 2018/6/6 计算机体系结构 18 Sorin D, Hill M, Wood D. A Primer on Memory Consistency and Cache Coherence[J]. 2011, 6(3):212.
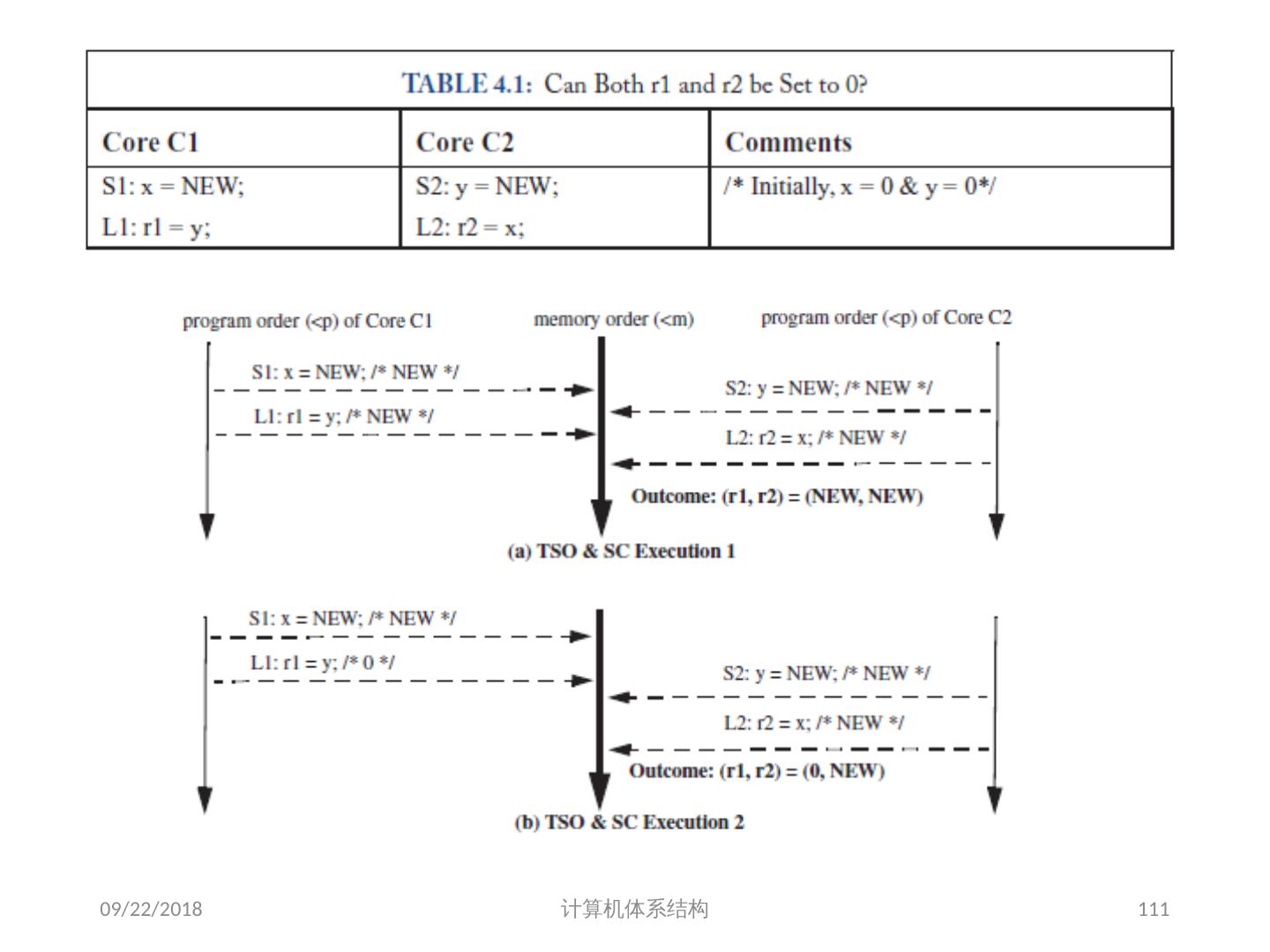
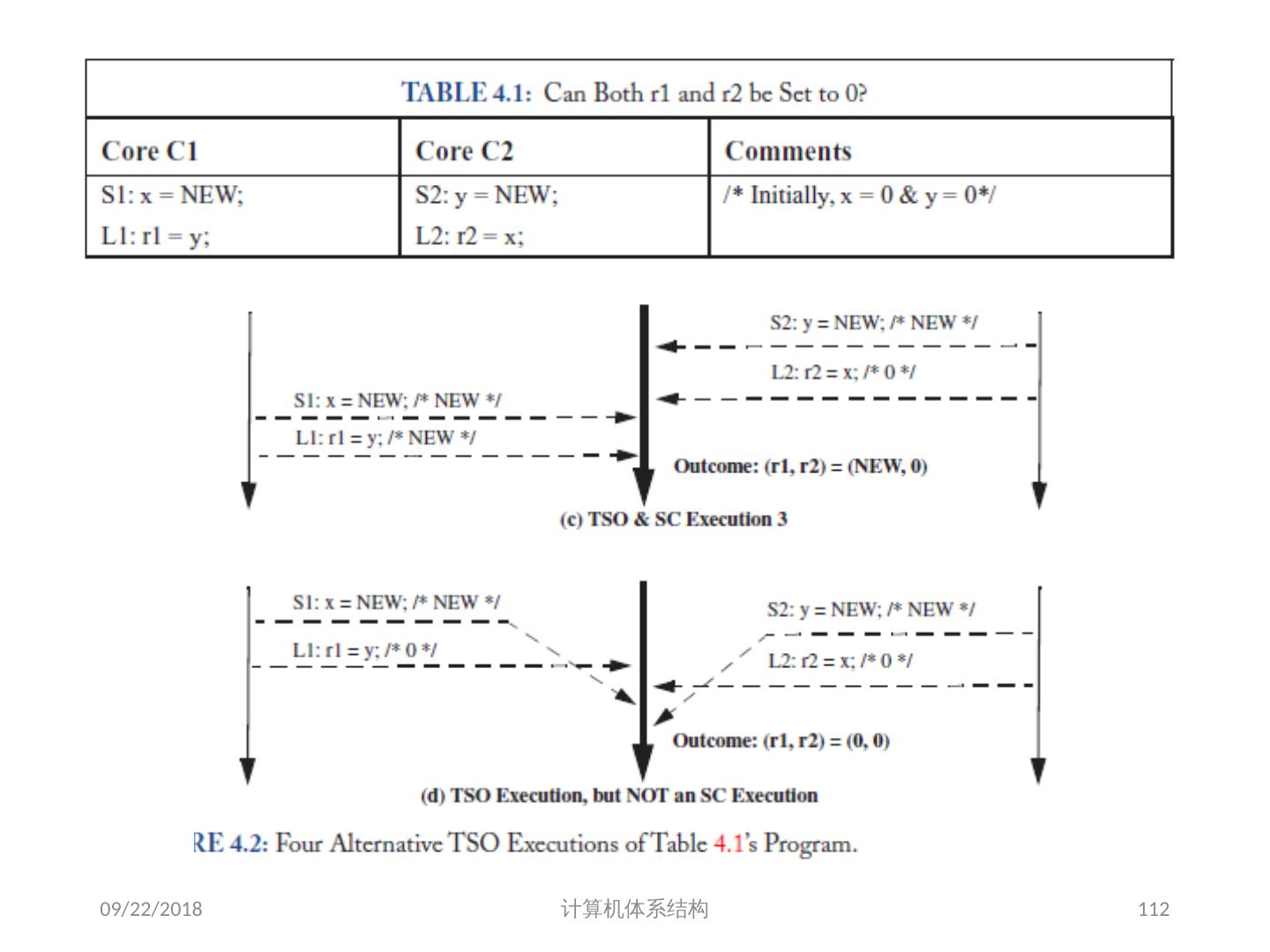
19 .存储同一性( Memory Consistency) 可能的执行顺序(假设可全乱序 | 假设遵循 SC Model ): S1L1S2L2 (0,NEW) S2S1L1L2 (NEW, NEW) L1S1S2L2 (0, NEW) L2S1L1S2(0,0) S1L1L2S2 (0,NEW) S2S1L2L1(NEW,NEW) L1S1L2S2(0,NEW) L2S1S2L1 (NEW,0) S1S2L1L2(NEW,NEW) S2L1S1L2(NEW,NEW) L1S2S1L2(0,NEW) L2L1S1S2(0,0) S1S2L2L1(NEW,NEW) S2L1L2S1(NEW,0) L1S2L2S1(0,0) L2L1S2S1(0,0) S1L2L1S2(0,NEW) S2L2S1L1(NEW,0) L1L2S1S2(0,0) L2S2S1L1(NEW,0) S1L2S2L1(NEW,NEW) S2L2L1S1(NEW,0) L1L2S2S1(0,0) L2S2L1S1(0,0) 2018/6/6 计算机体系结构 19
20 .存储一致性 (Coherence) Example of incoherence 2018/6/6 计算机体系结构 20
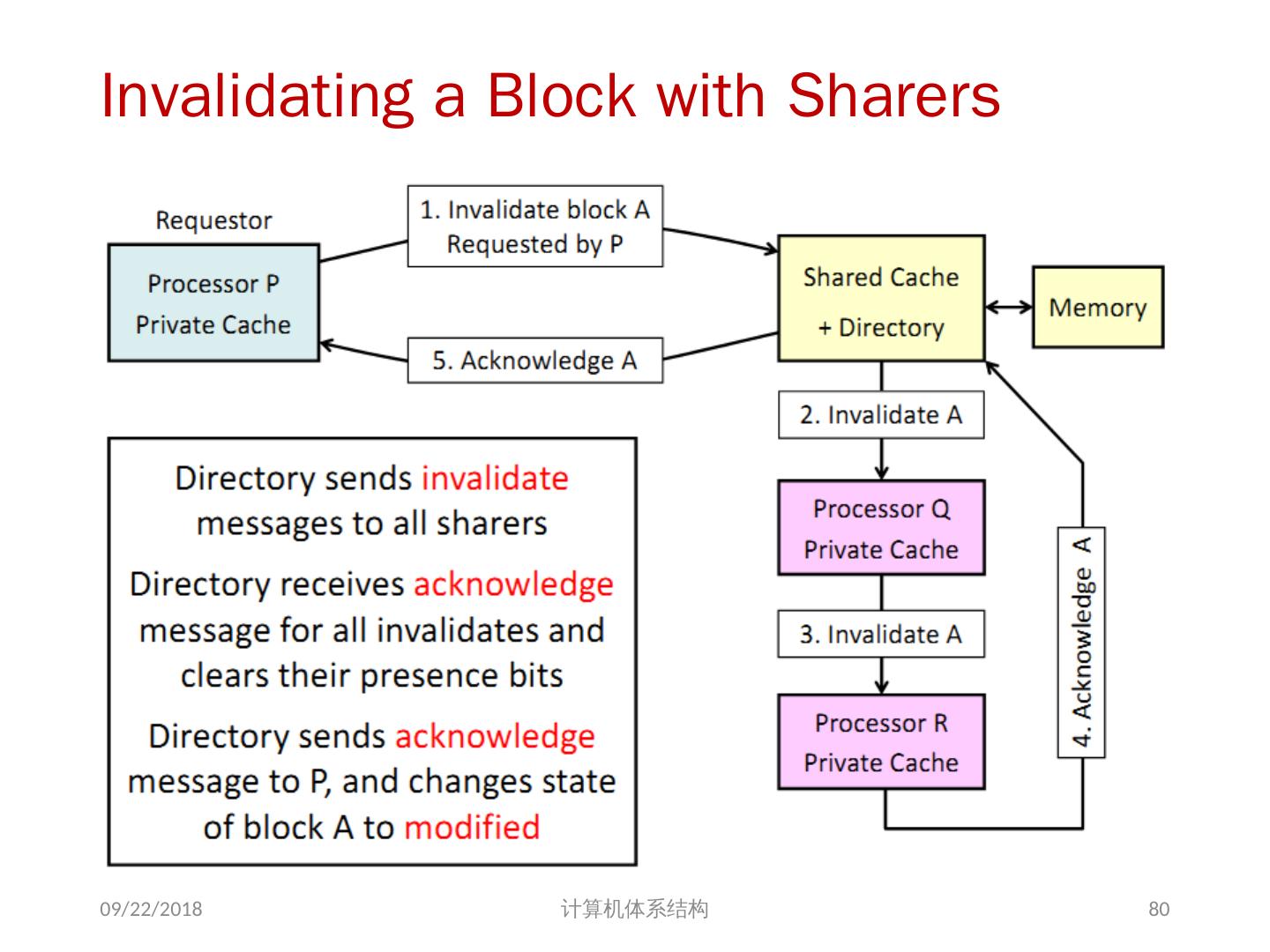
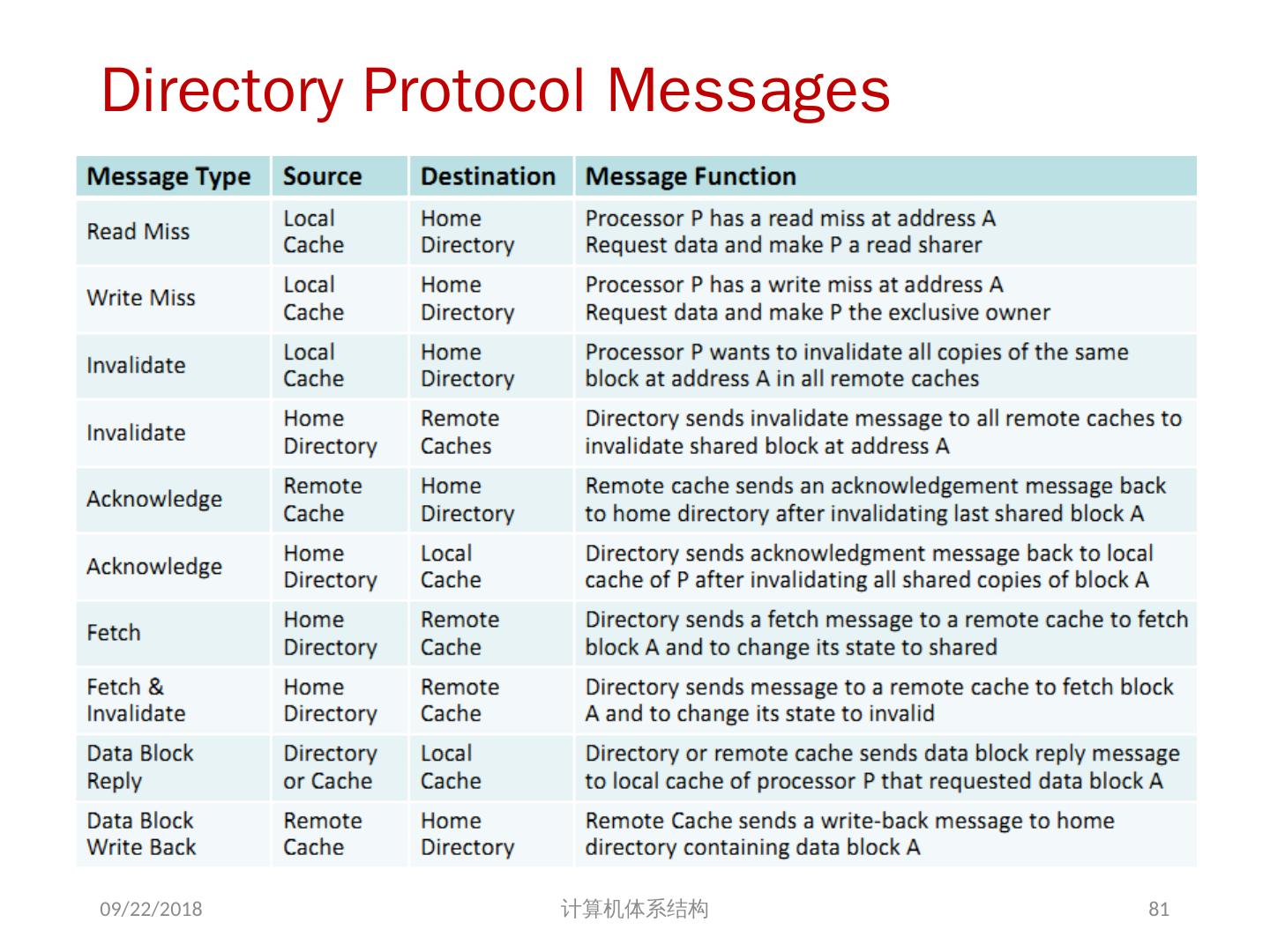
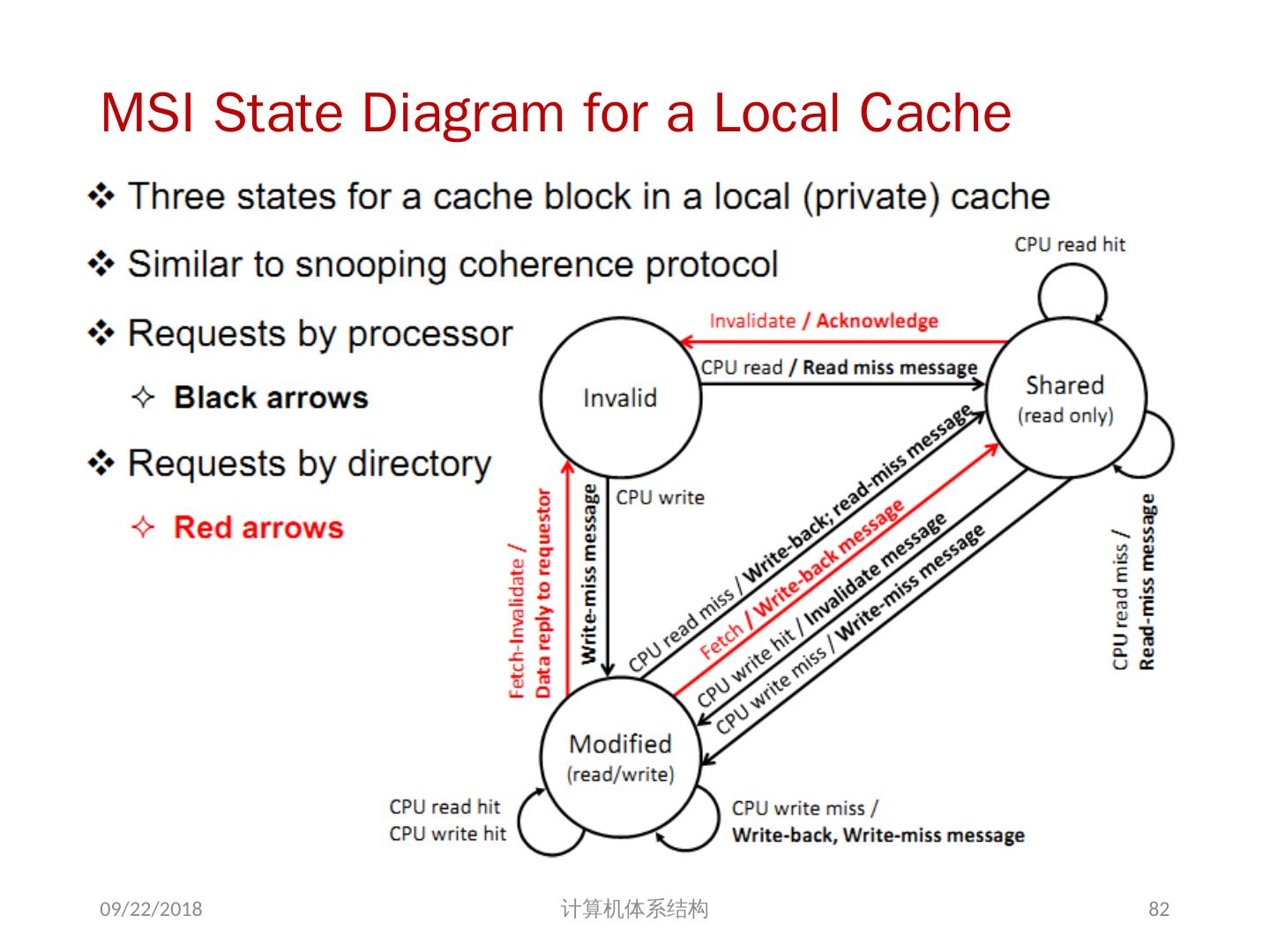
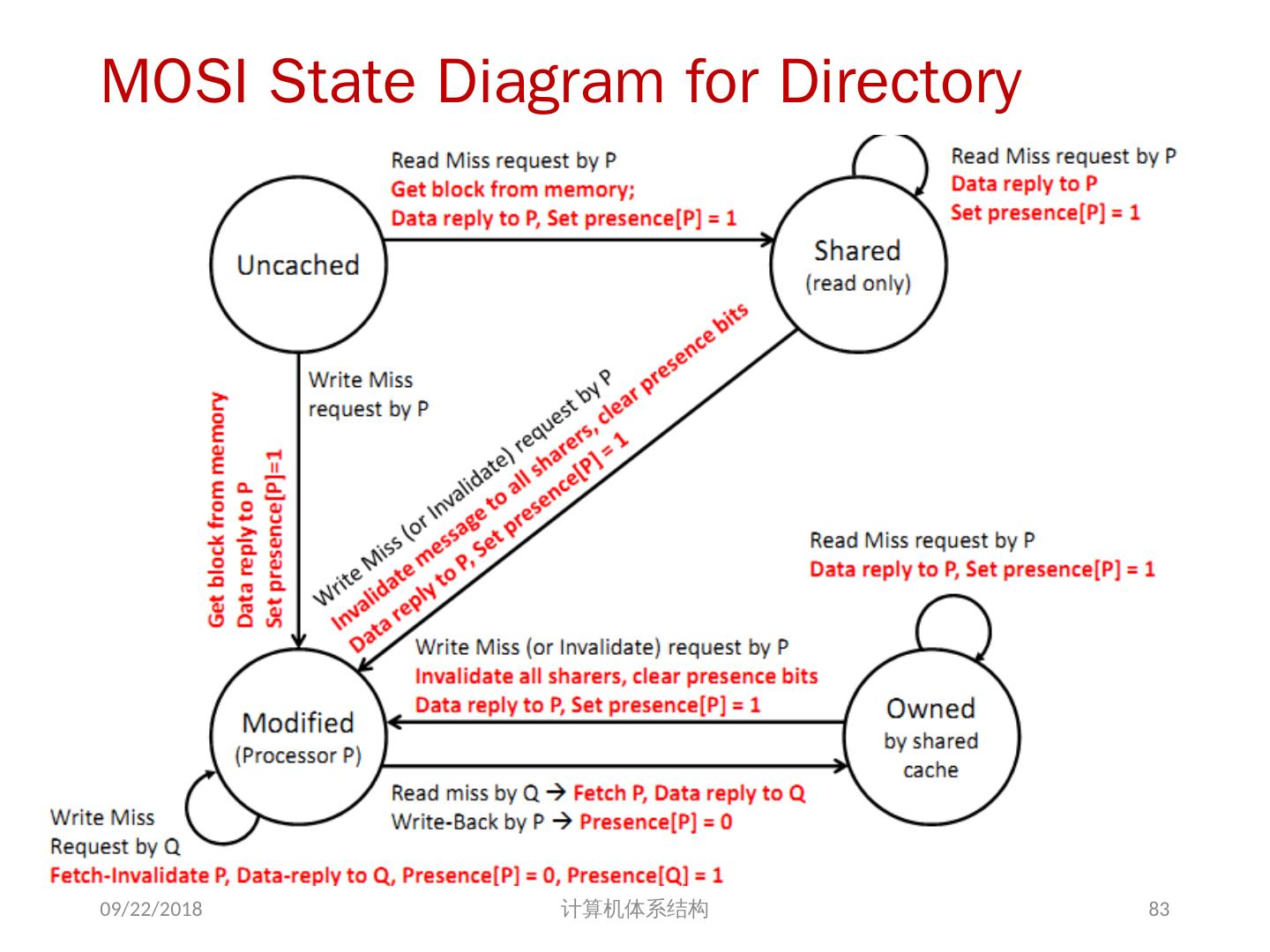
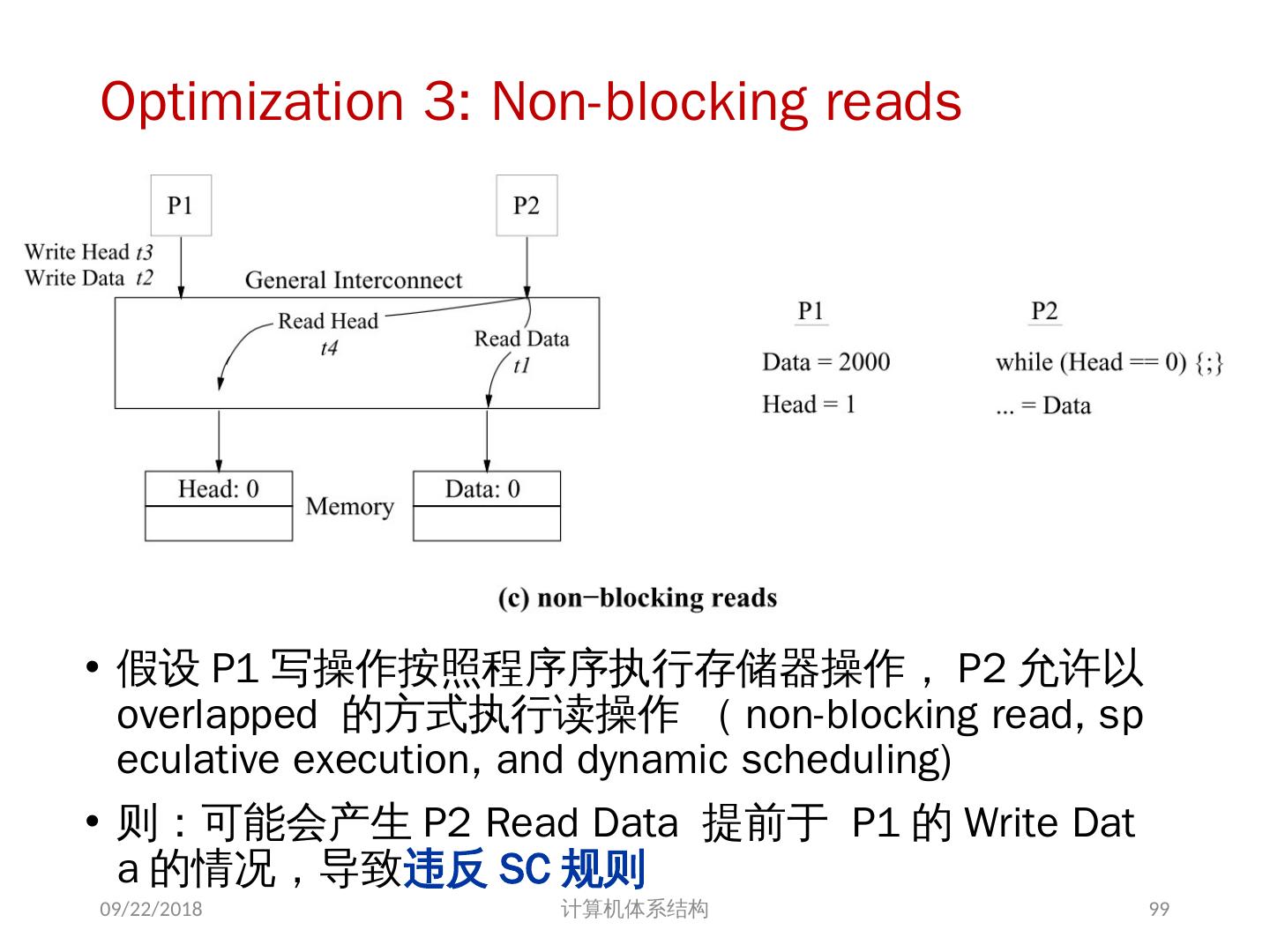
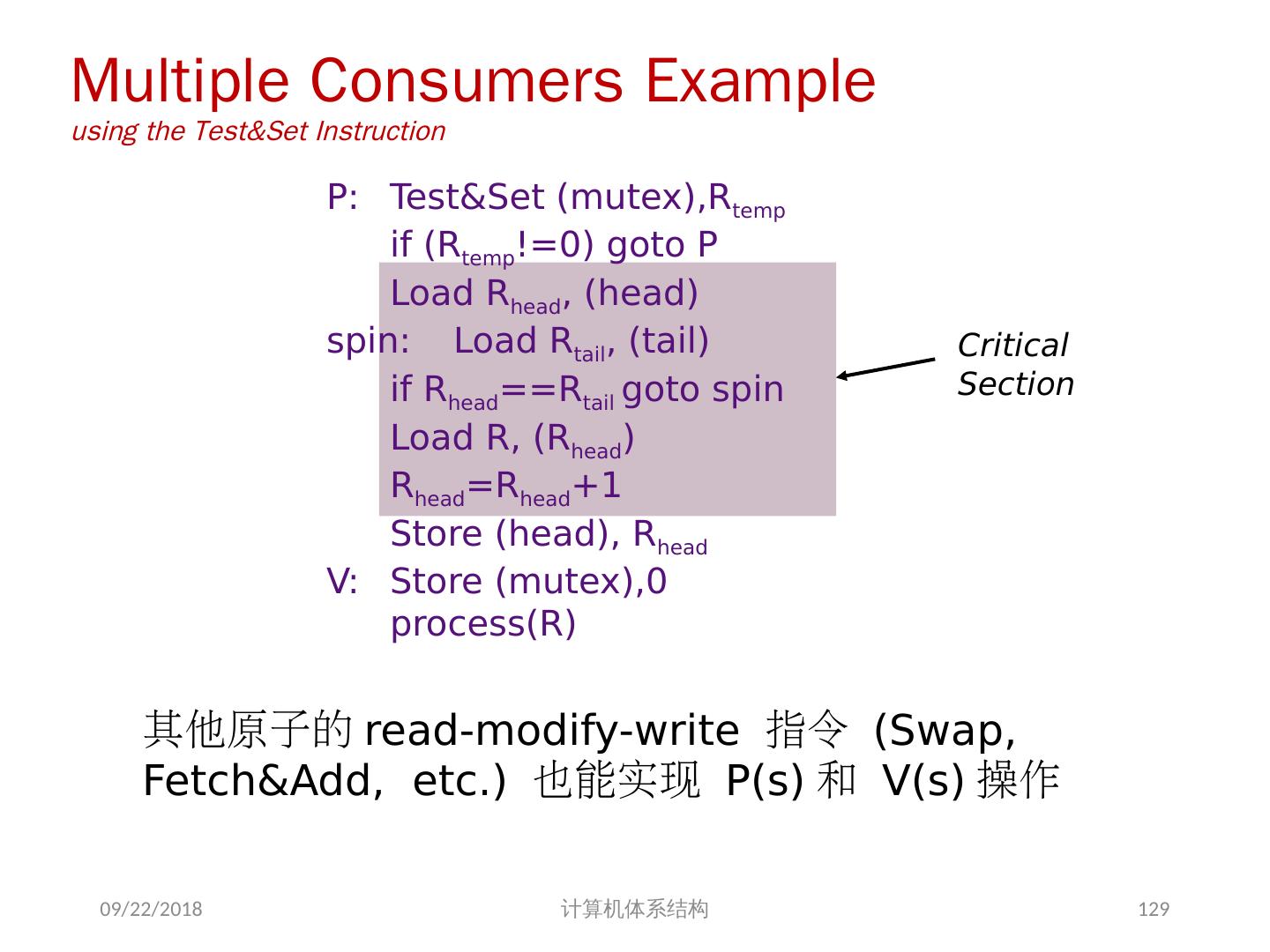
21 .问题的解决 并行性不足: 通过采用并行性更好的算法来解决 远程访问延迟的降低: 靠体系结构支持和编程技术 共享存储器访问 Cache 一致性协议 存储同一性模型 2018/6/6 计算机体系结构 21
22 .05/25-review : GPU 分支处理 与向量结构类似 , 但 GPU 使用内部的屏蔽字 (masks) 分支同步堆栈 保存分支的路径地址 保存该路径的 SIMD lane 屏蔽字 (mask) 即指示哪些车道可以提交结果 指令标记 (instruction markers ) 管理何时分支( divergence )到多个执行路径,何时路径汇合 (converge) 2018/6/6 计算机体系结构 22
23 .05/25-review : TLP 简介 并行计算机体系结构: SISD, SIMD, MISD, MIMD MIMD 的通信模型及存储器结构 地址空间的组织模式:共享存储 ( 多处理机 ) vs. 非共享存储 ( 多计算机 ) 通信模型: LOAD /STORE 指令 vs. 消息传递 共享存储的 MIMD 结构 集中式共享存储( SMP ) vs. 分布式共享存储( DSM ) 共享存储器结构的存储器行为 Cache 一致性问题 (Coherence) :使得多处理机系统的 Cache 像单处理机的 Cache 一样对程序员而言是透明的 存储器同一性问题 (Consistency) :在多线程并发执行的情况下,提供一些规则来定义正确的共享存储器行为。通常允许有多种运行顺序 2018/6/6 计算机体系结构 23
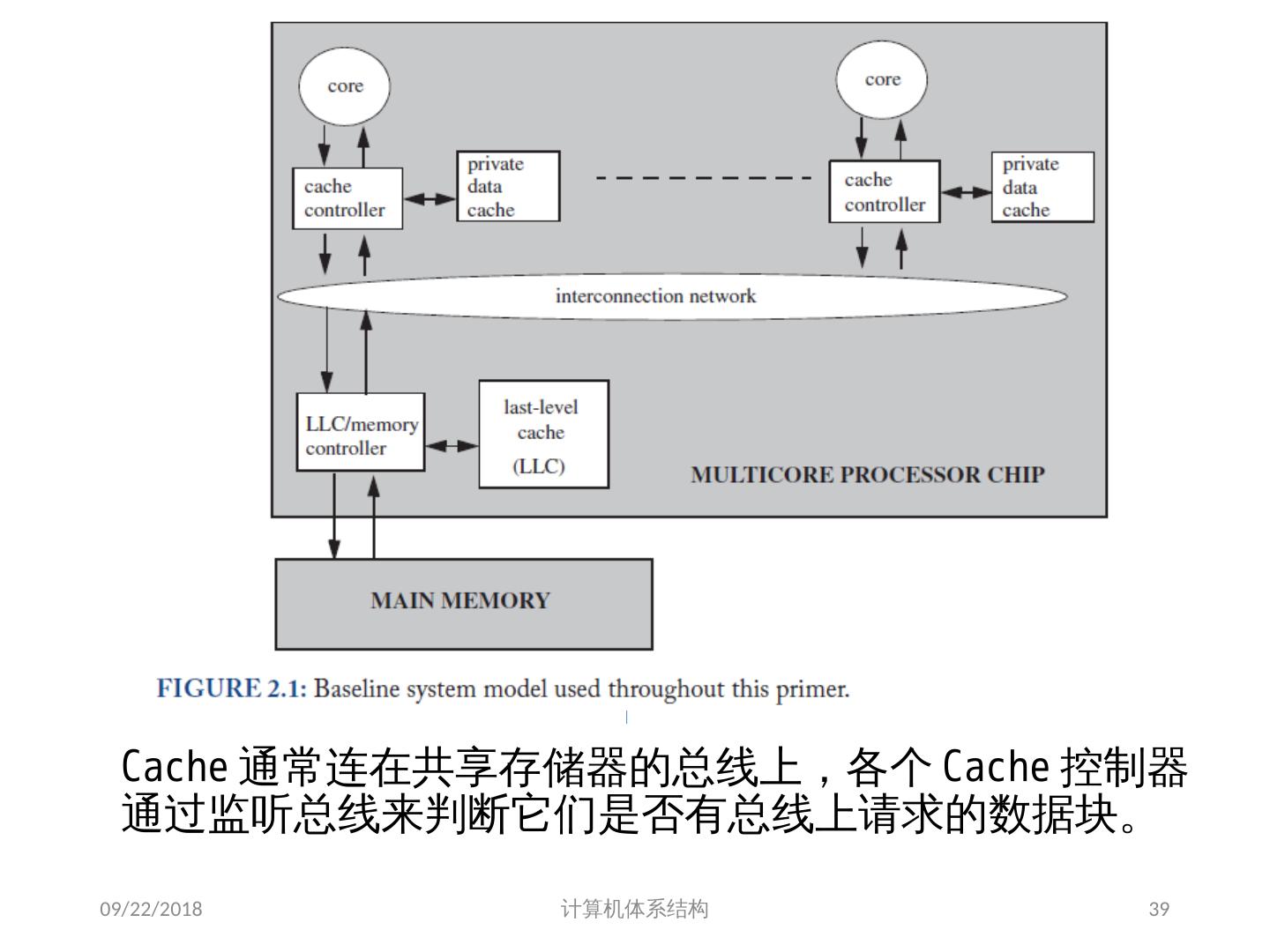
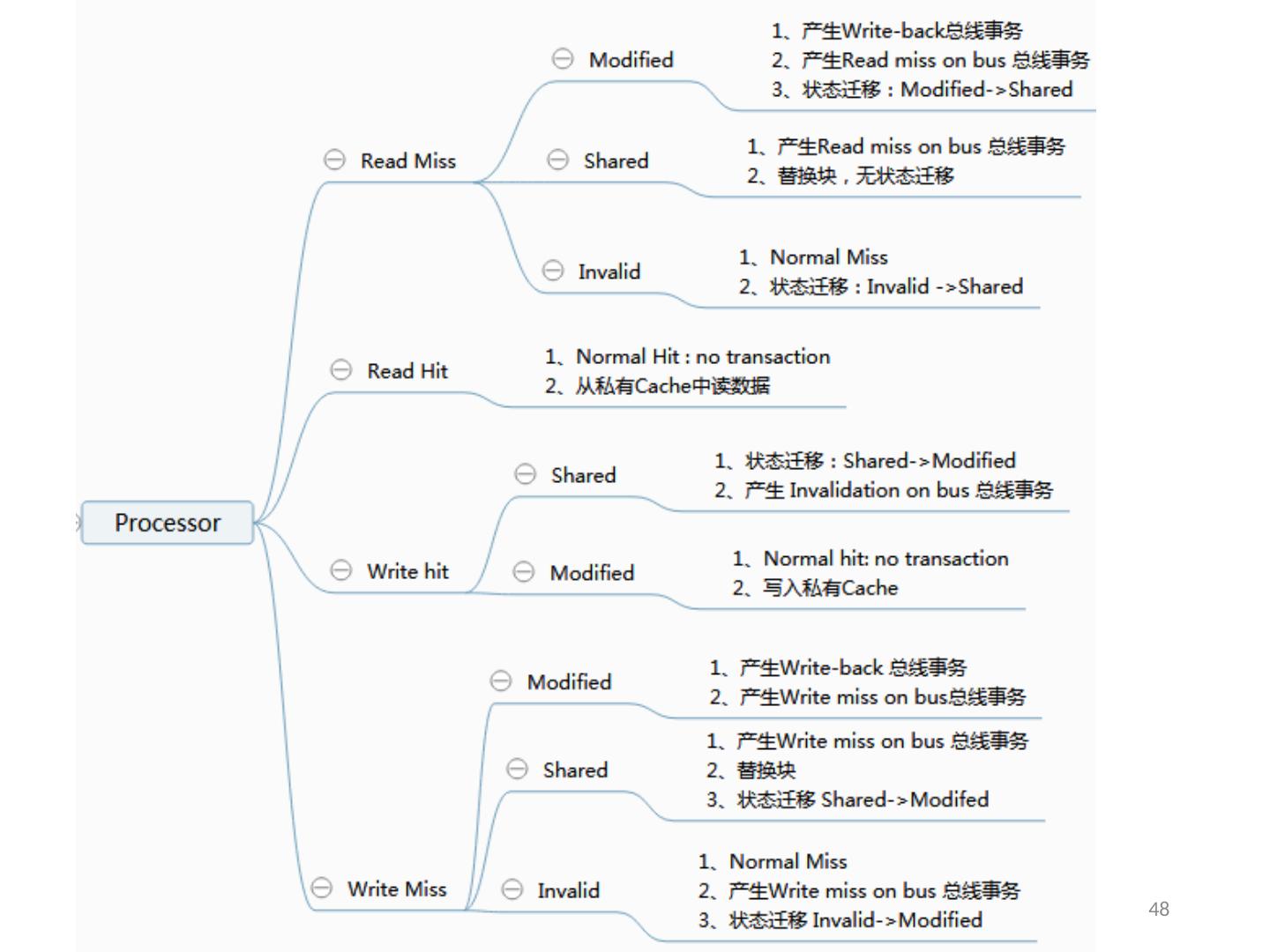
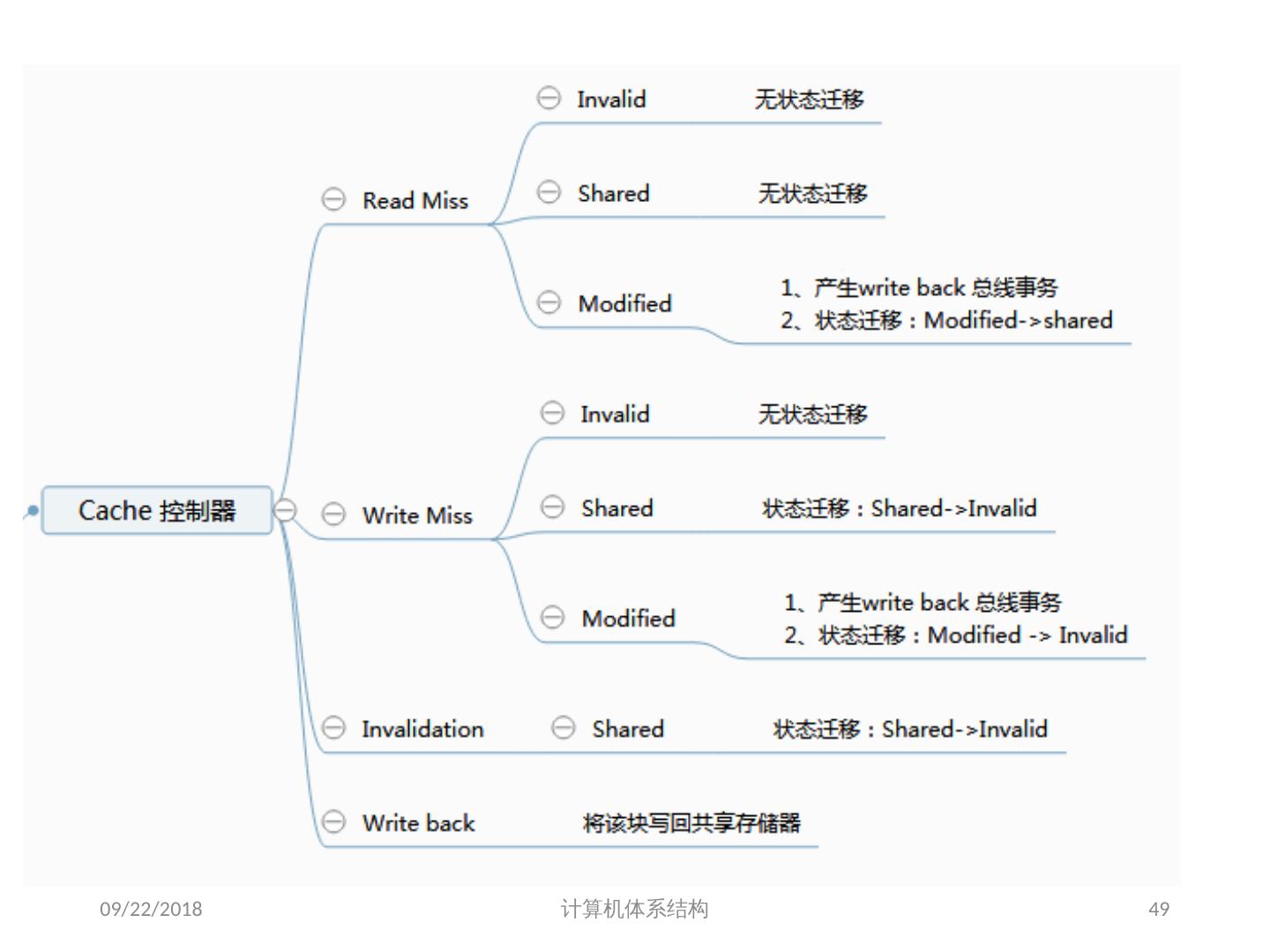
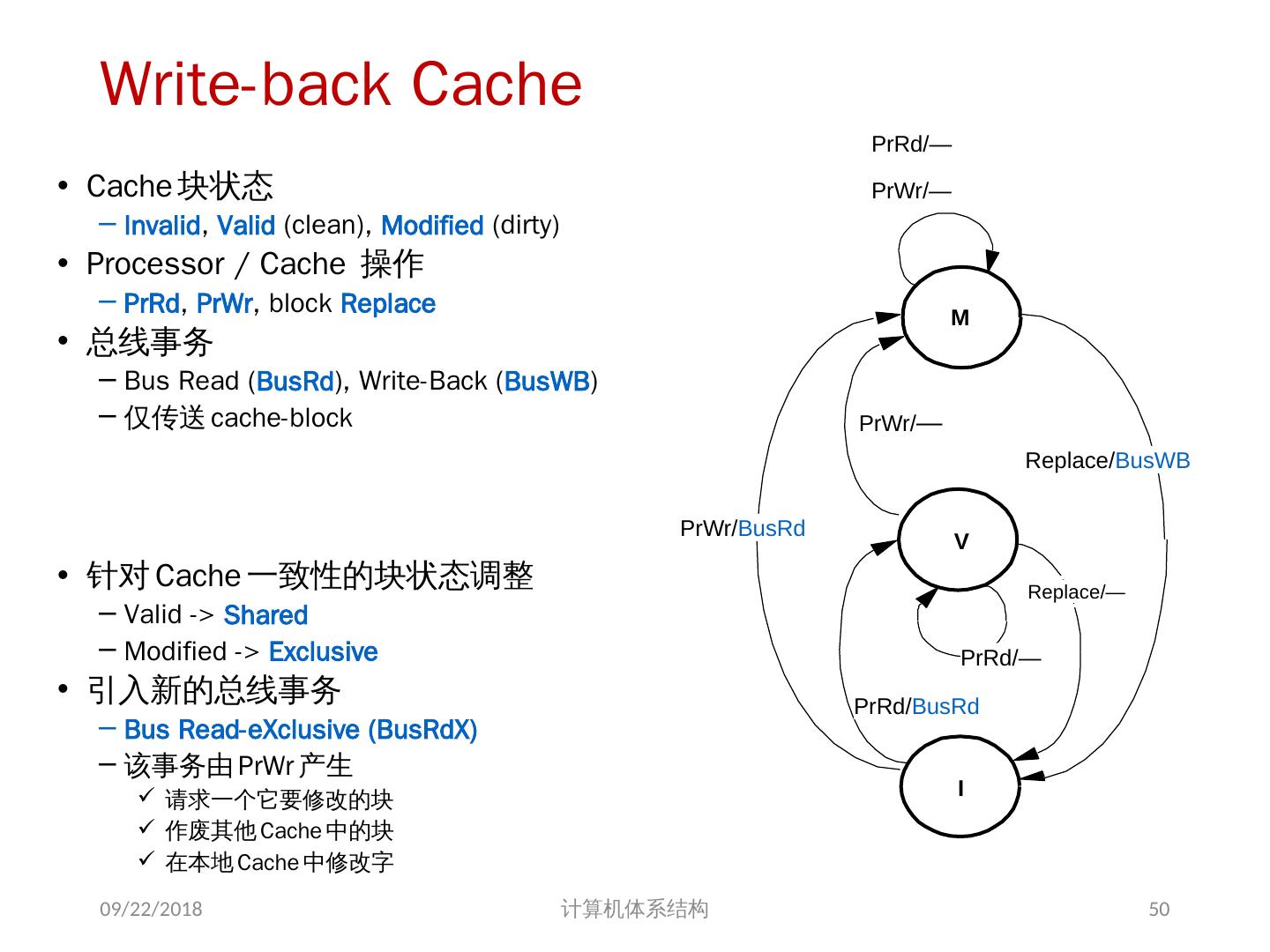
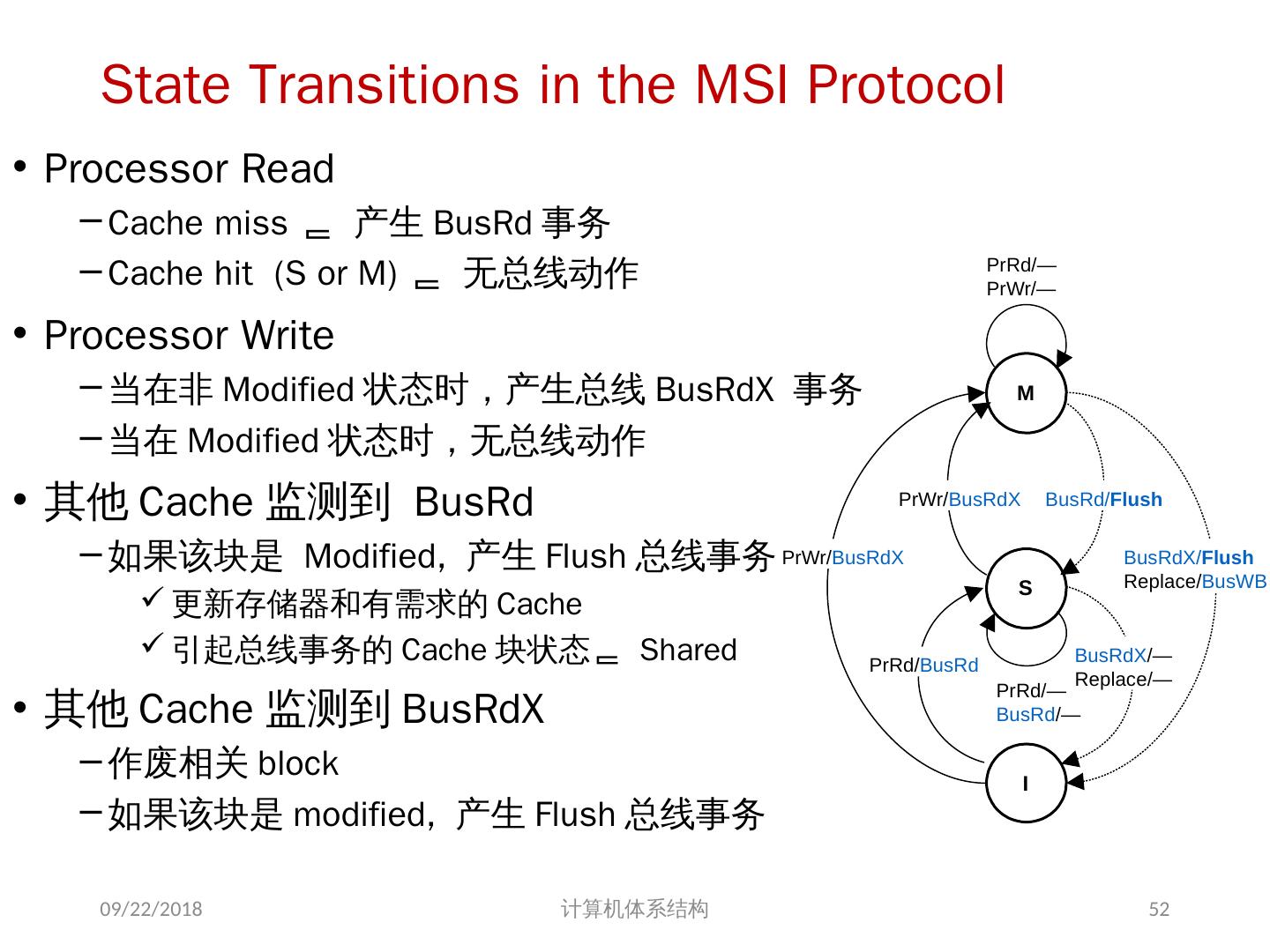
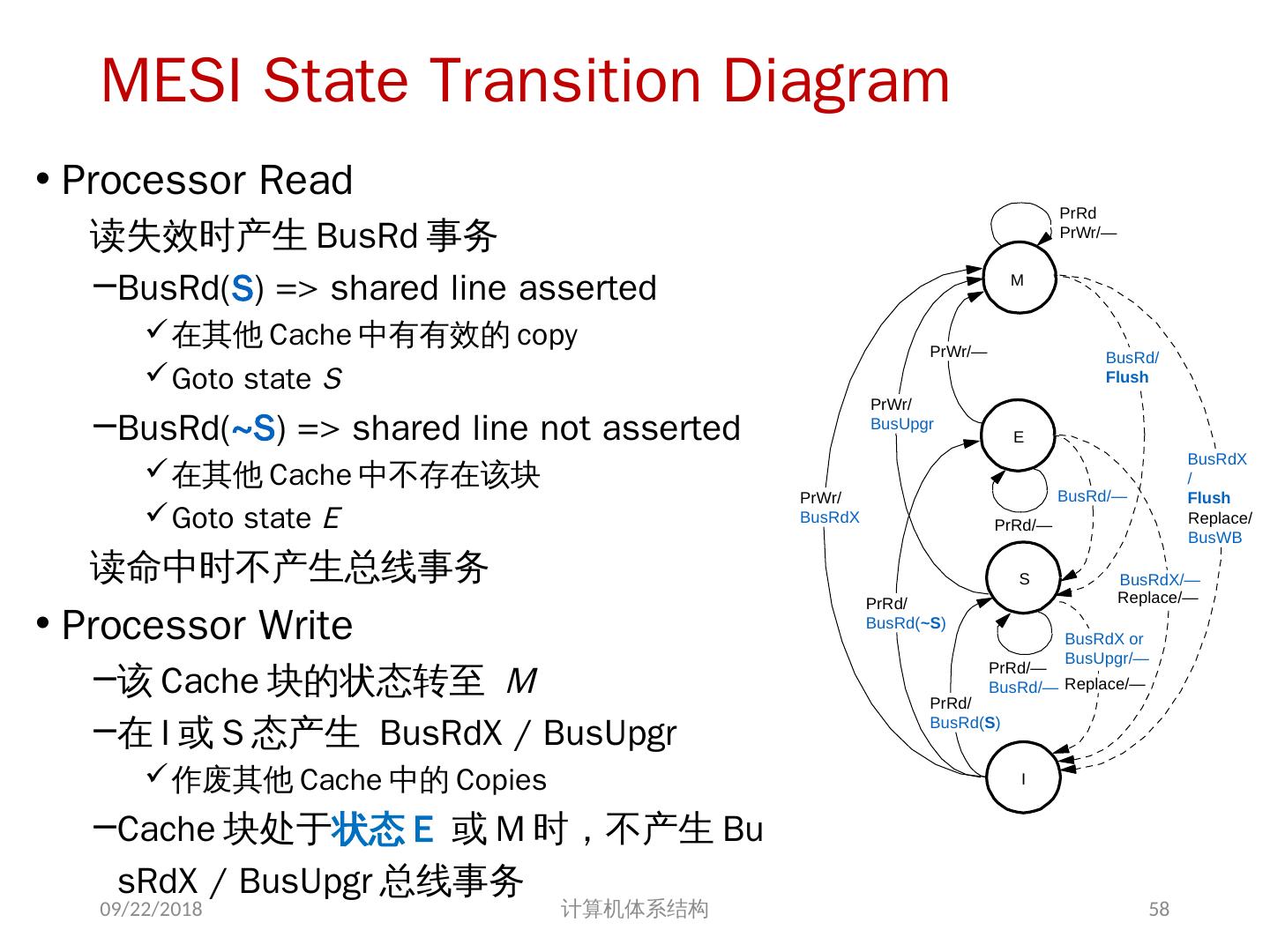
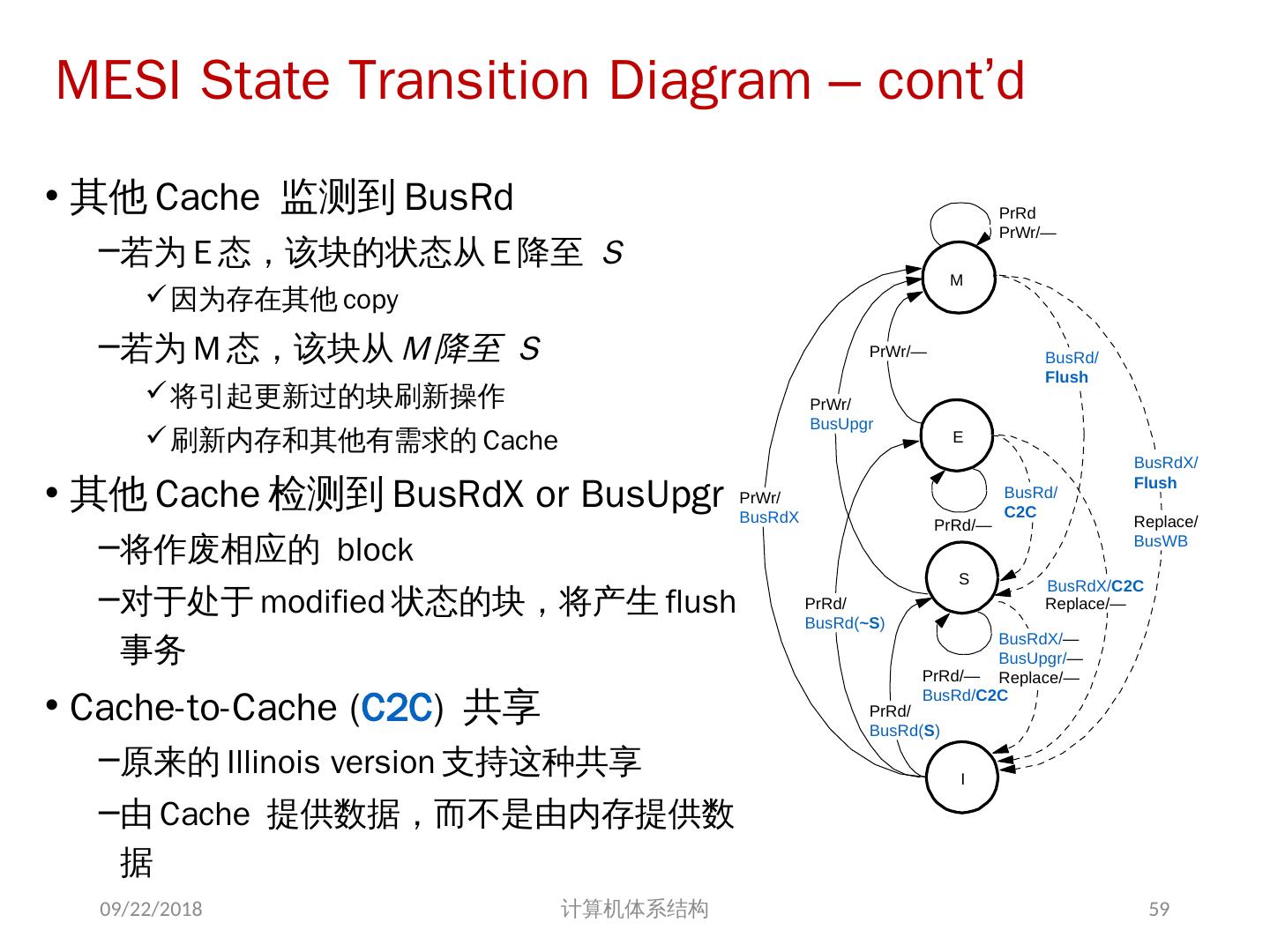
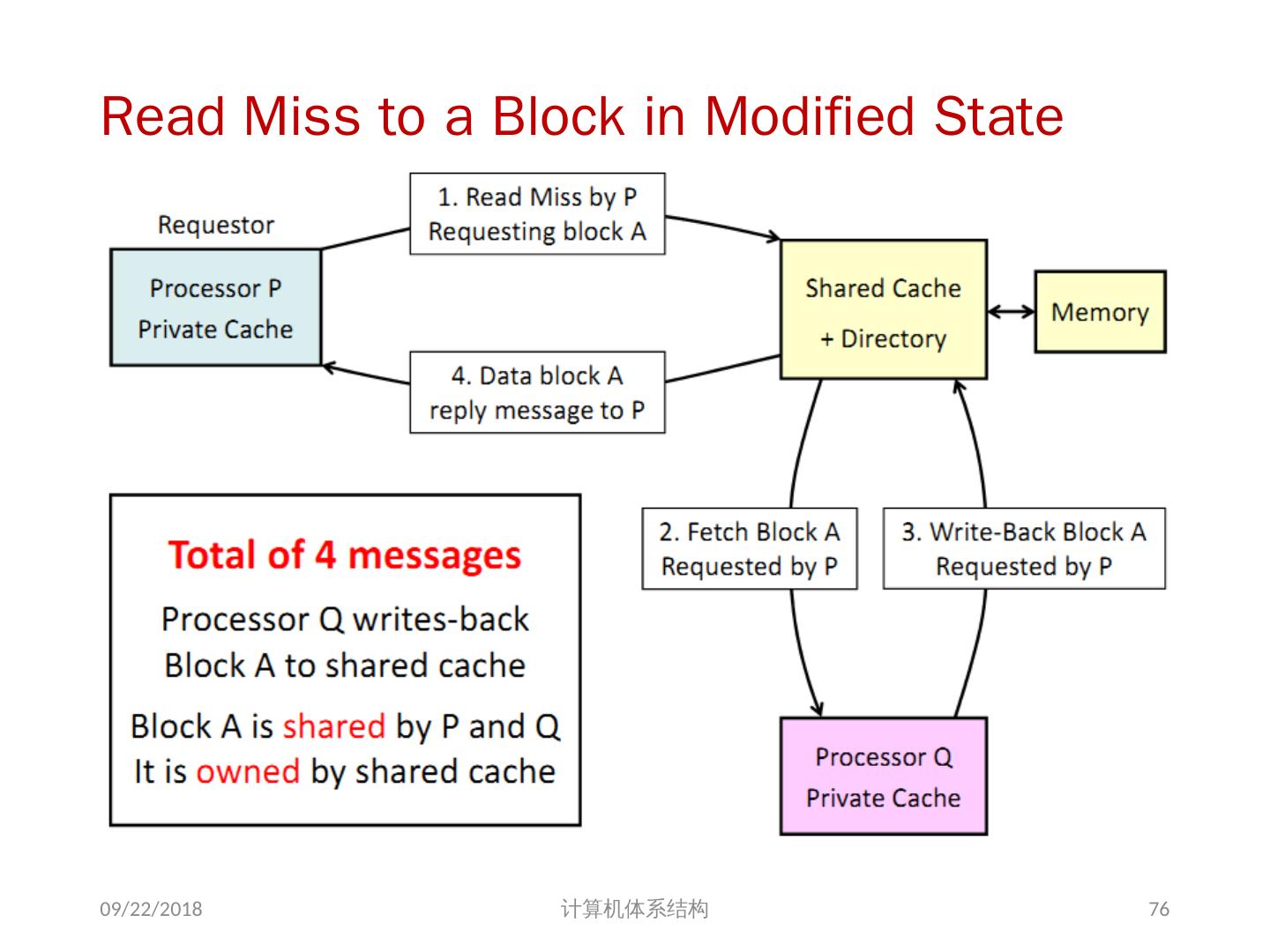
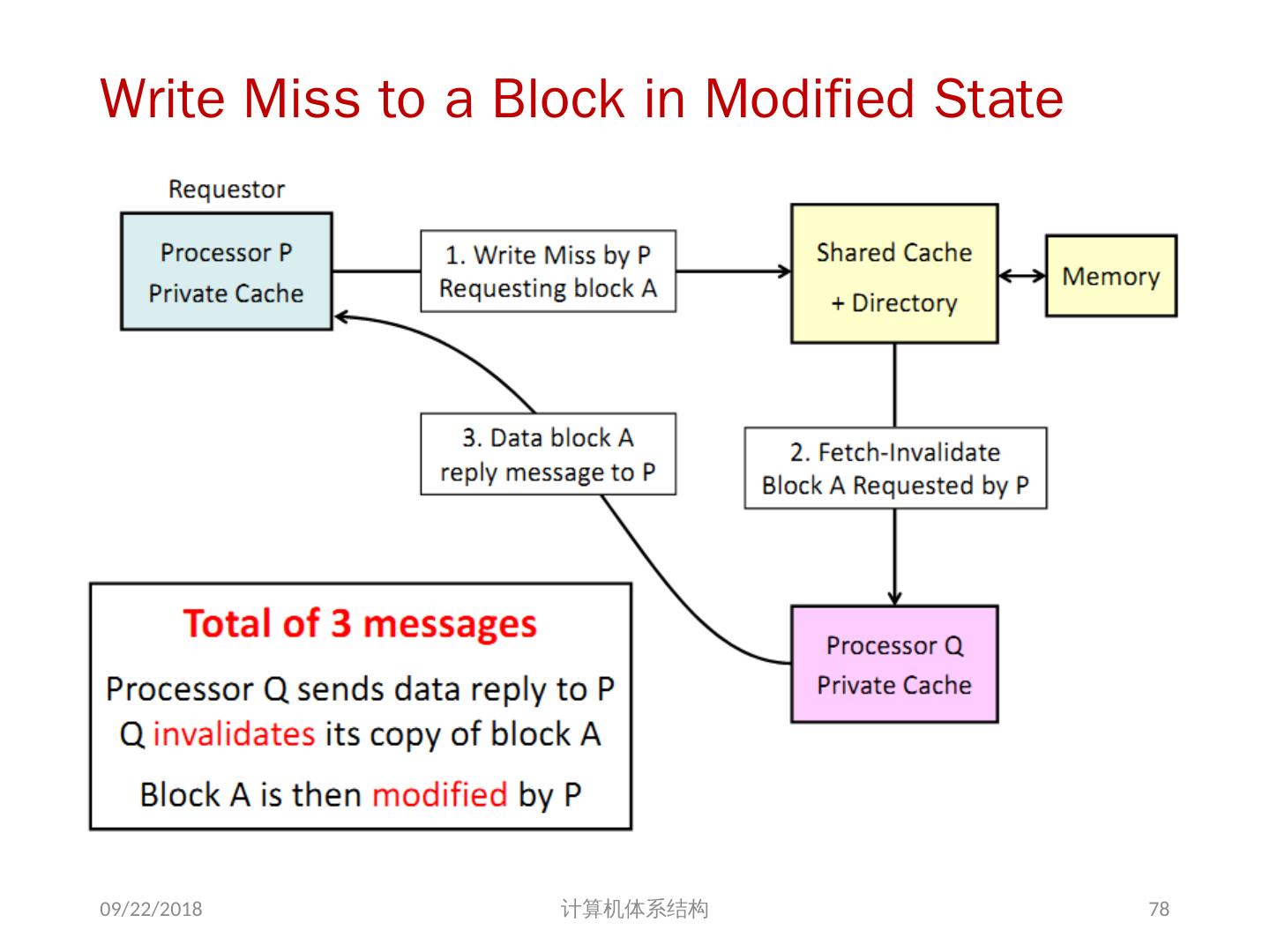
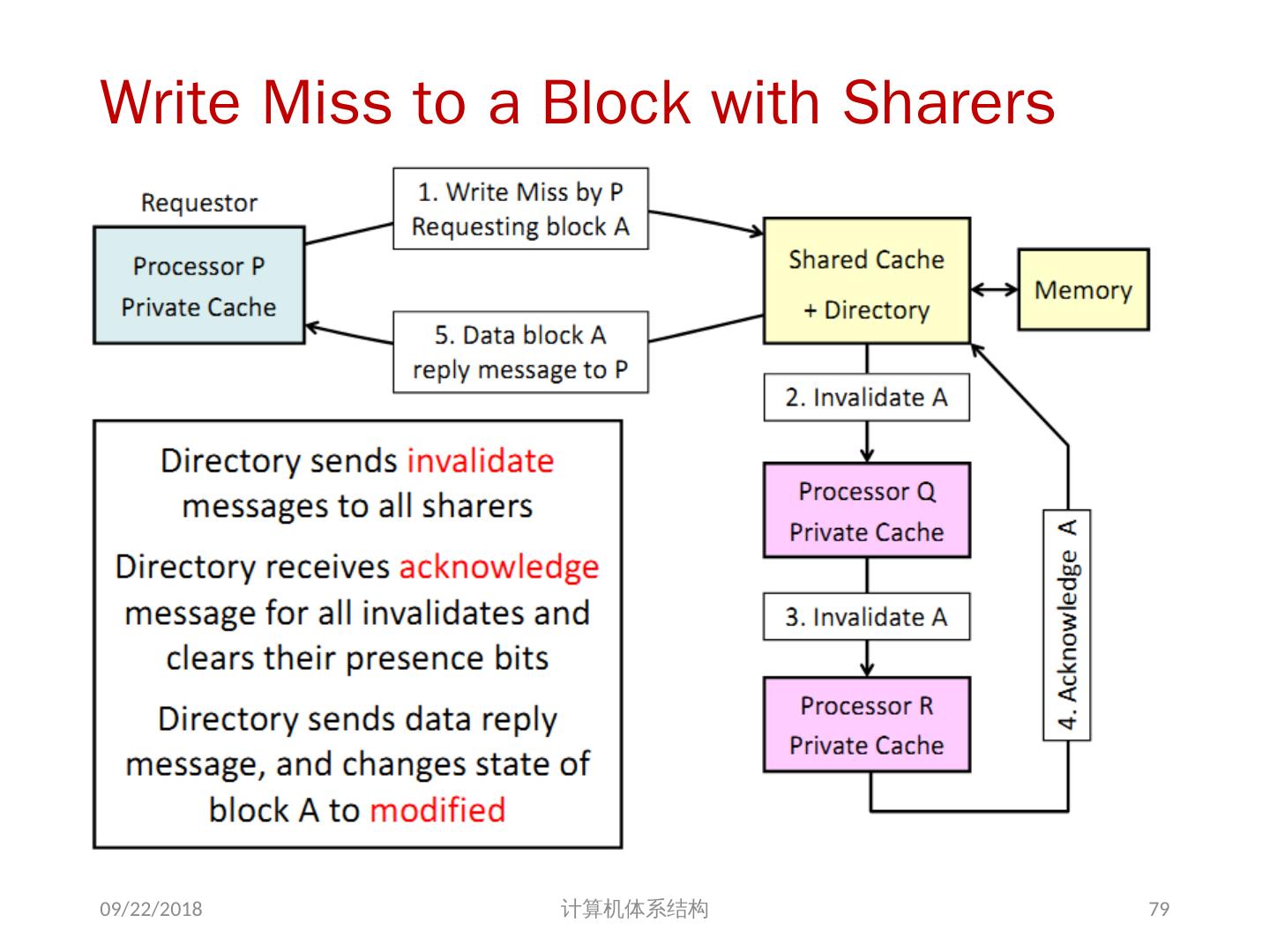
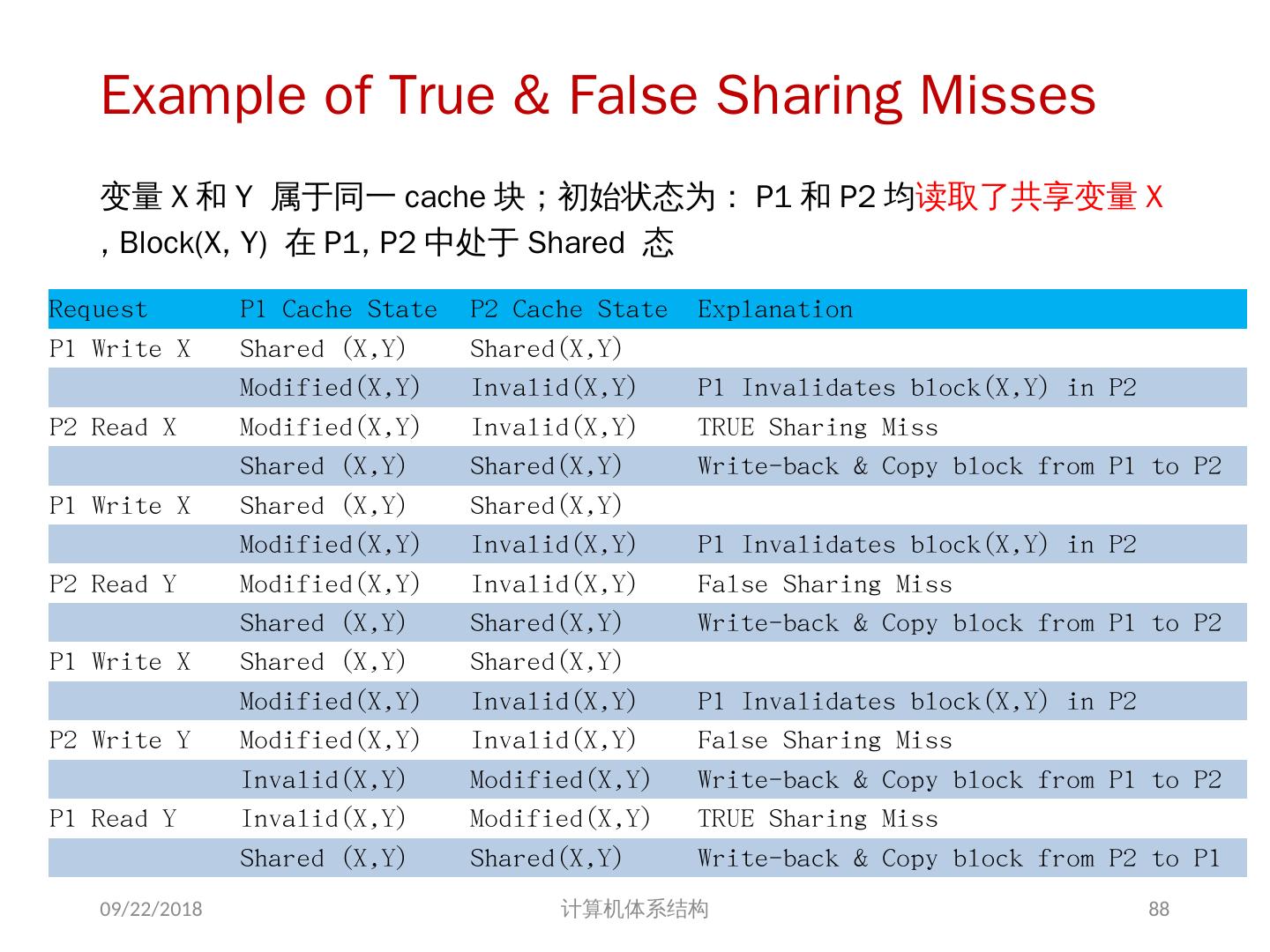
24 .7.2 集中式共享存储器体系结构 多个处理器共享一个存储器。 当处理器规模较小时,这种机器十分经济。 支持对共享数据和私有数据的 Cache 缓存。 私有数据供一个单独的处理器使用,而共享数据供多个处理器使用。 共享数据进入 Cache 产生了一个新的问题: Cache 的一致性问题 2018/6/6 计算机体系结构 24
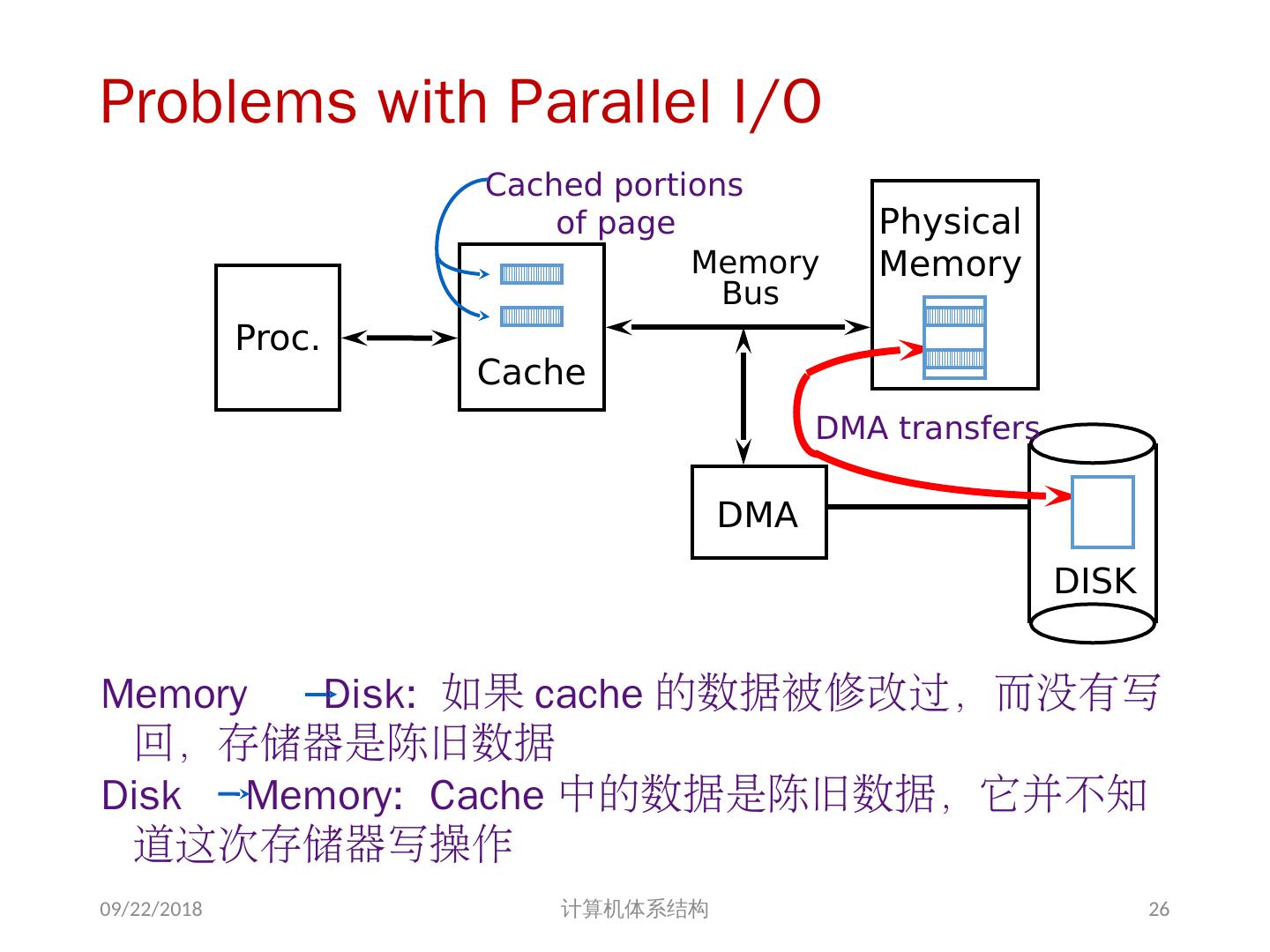
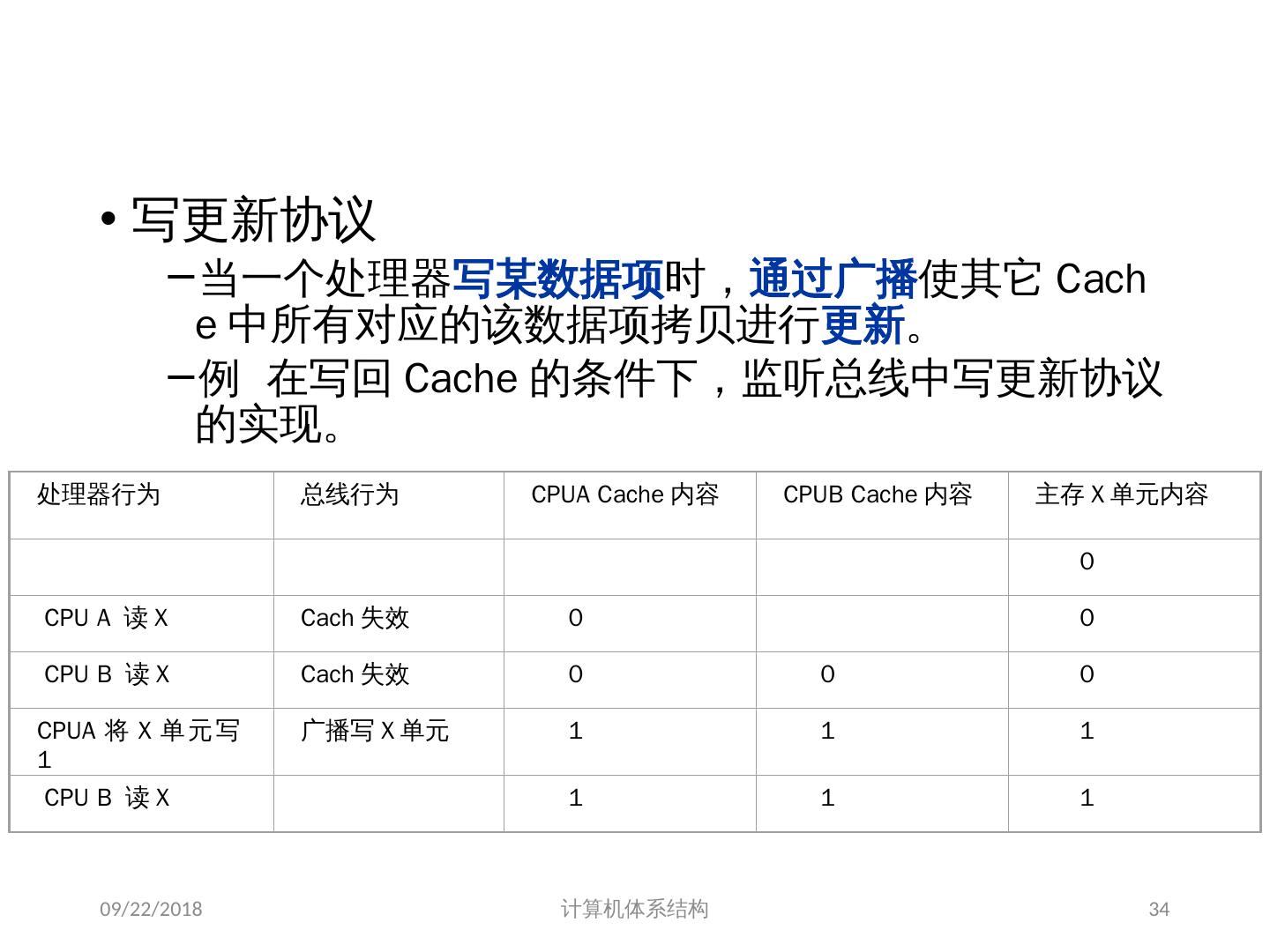
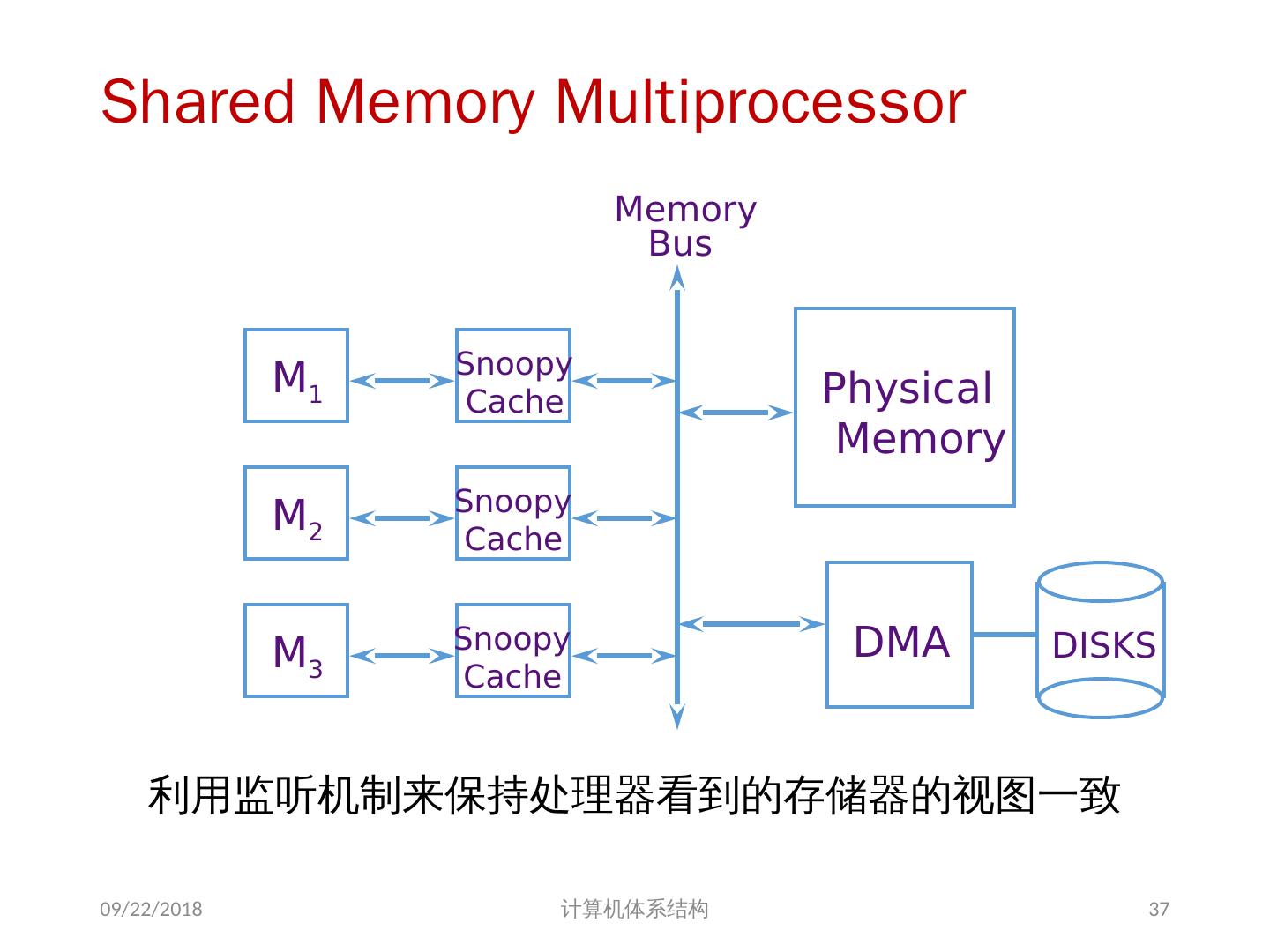
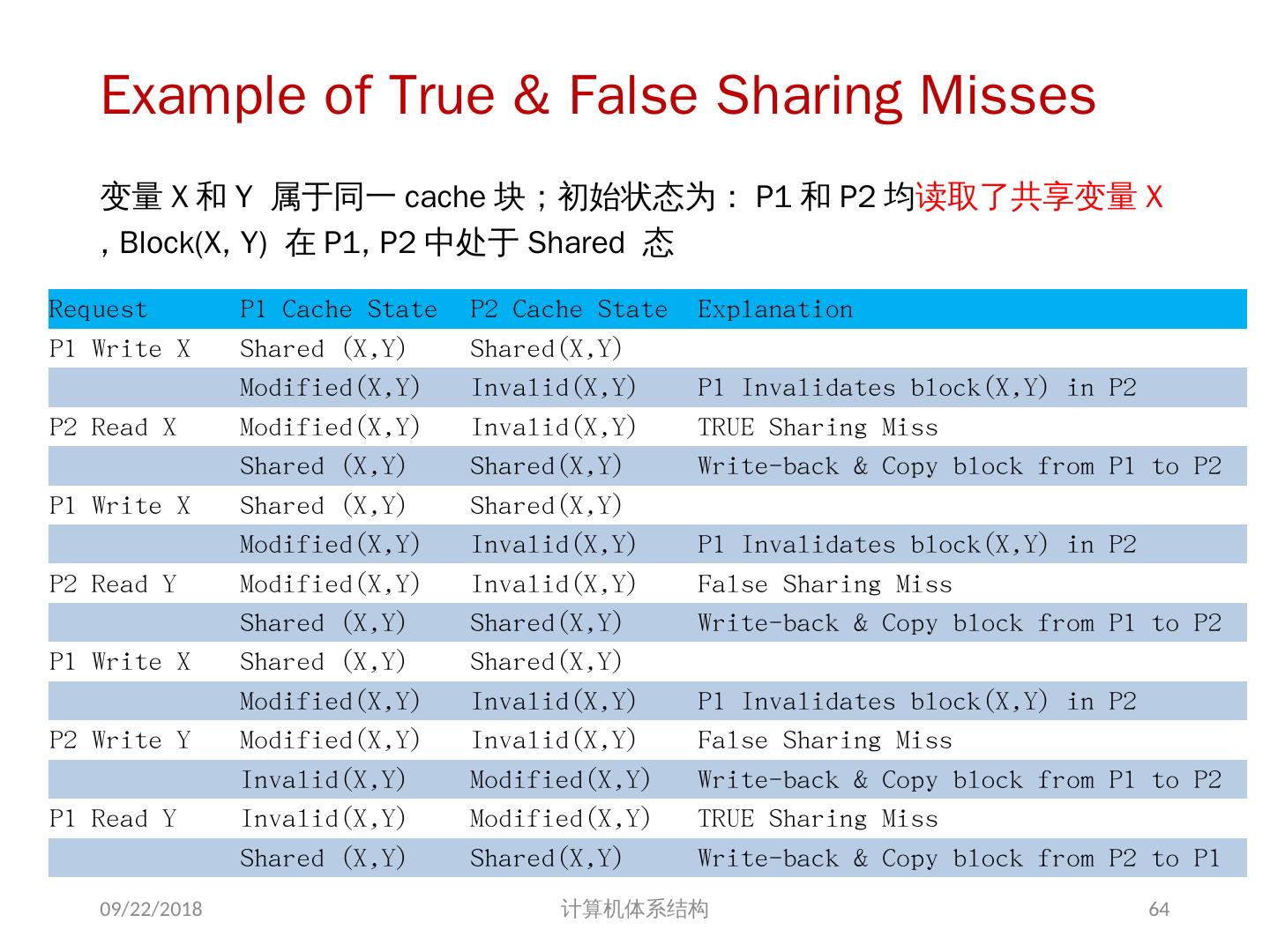
25 .1、 多处理机的一致性 不一致产生的原因( Cache 一致性问题) I / O 操作 Cache 中的内容可能与由 I / O 子系统输入输出形成的存储器对应部分的内容不同。 共享数据 不同处理器的 Cache 都保存有对应存储器单元的内容 2018/6/6 计算机体系结构 25
26 .Problems with Parallel I/O Memory Disk: 如果 cache 的数据被修改过,而没有写回,存储器是陈旧数据 Disk Memory: Cache 中的数据是陈旧数据,它并不知道这次存储器写操作 2018/6/6 计算机体系结构 DISK DMA Physical Memory Proc. Cache Memory Bus Cached portions of page DMA transfers 26
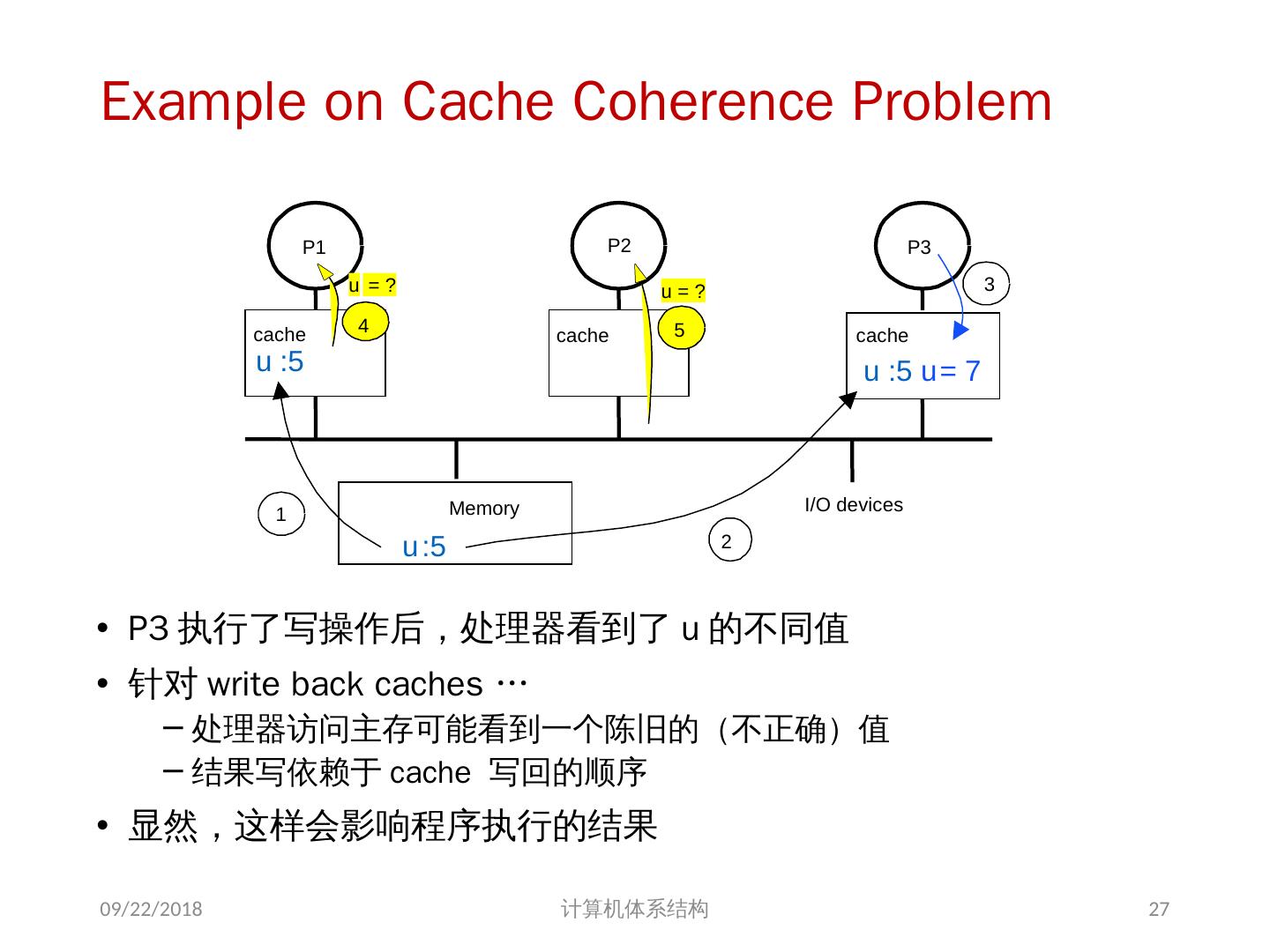
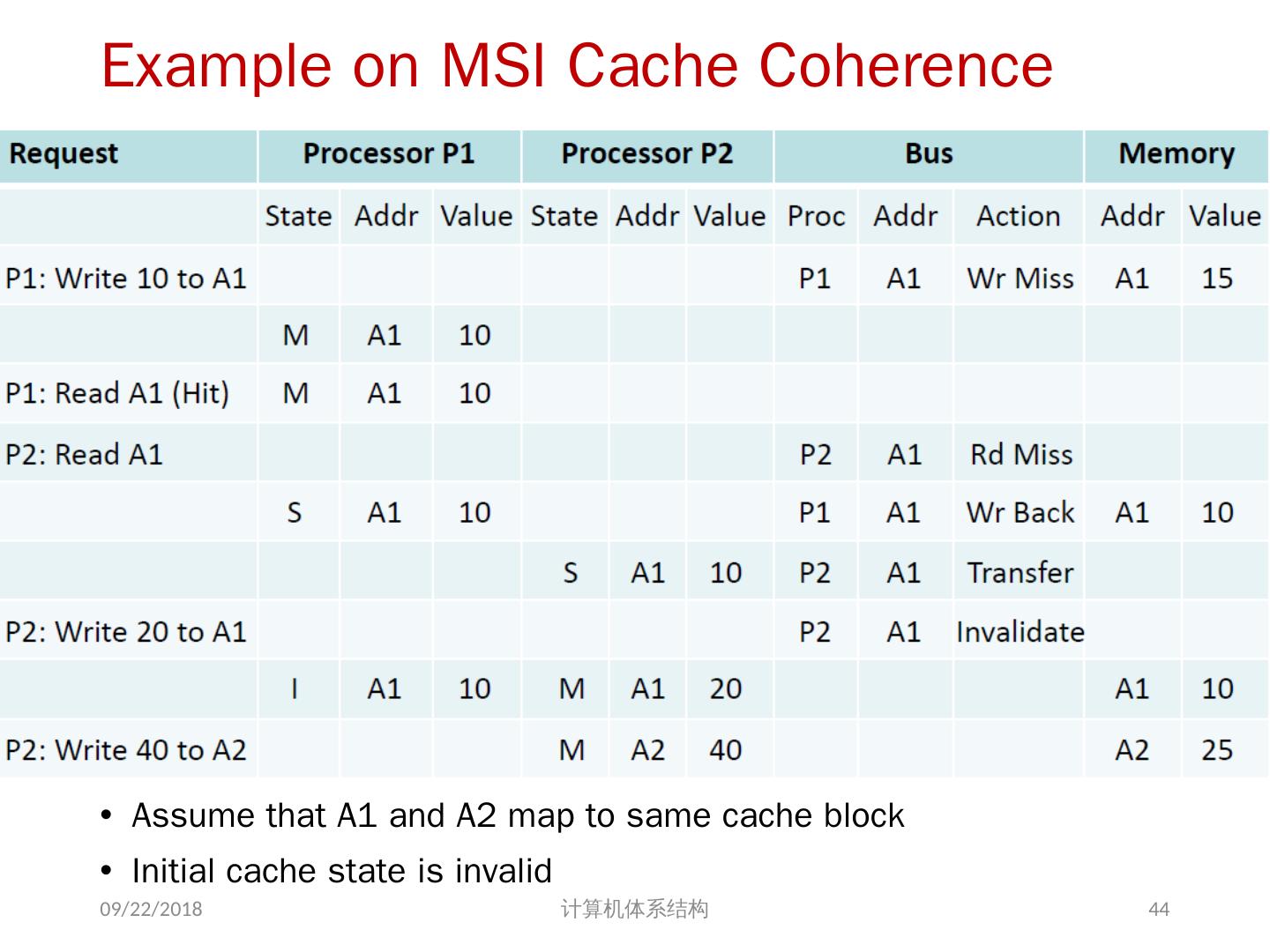
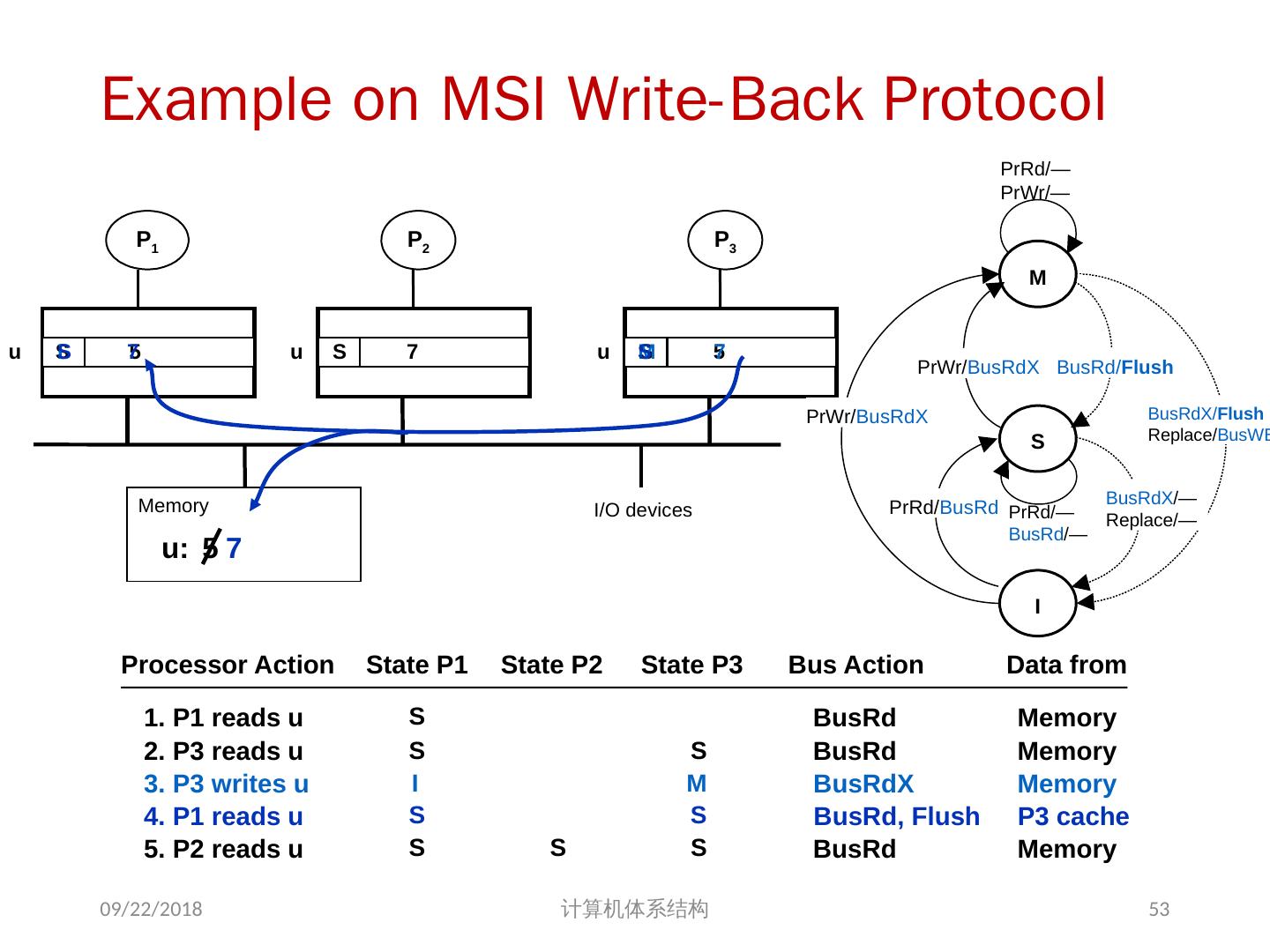
27 .Example on Cache Coherence Problem P3 执行了写操作后,处理器看到了 u 的不同值 针对 w rite back caches … 处理器访问主存可能看到一个陈旧的(不正确)值 结果写依赖于 cache 写回的顺序 显然,这样会影响程序执行的结果 2018/6/6 计算机体系结构 I/O devices Memory P1 cache P2 P3 5 u = ? 4 u = ? u :5 2 u :5 3 u = 7 1 u :5 cache cache 27
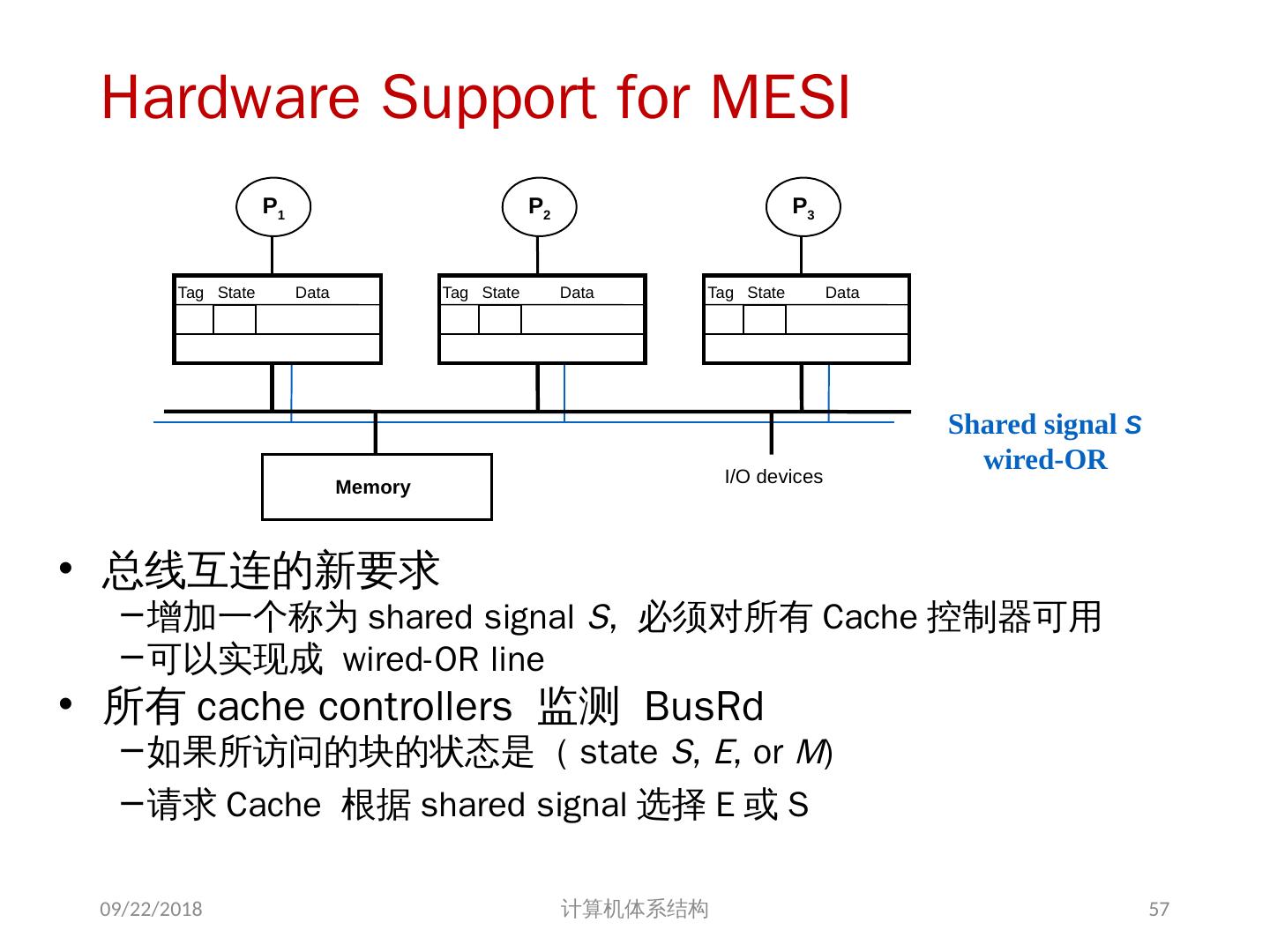
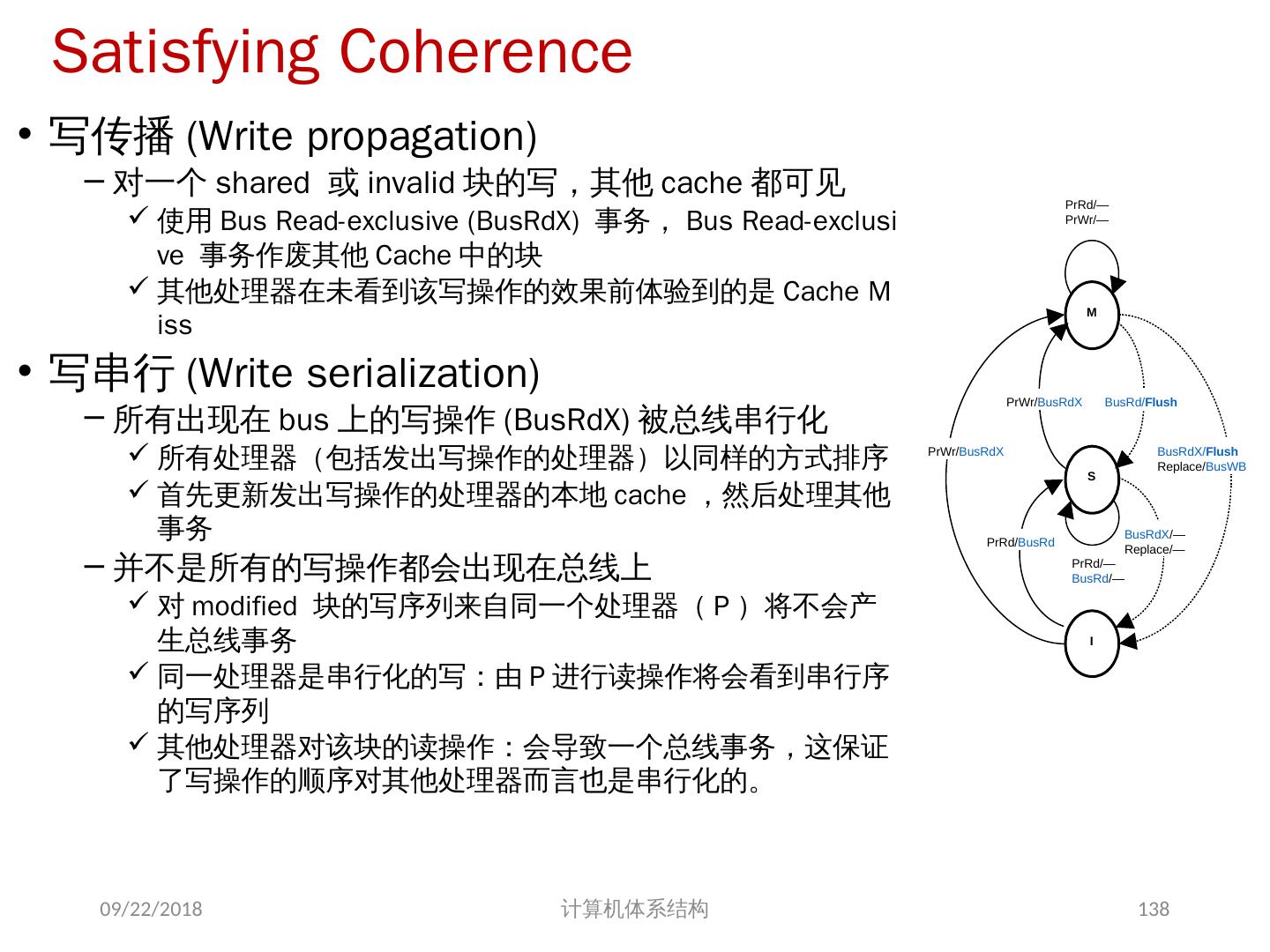
28 .存储系统是一致的 如果对某个数据项的任何读操作均可得到其最新写入的值,则认为这个存储系统是一致的(非正式定义) 如果存储系统行为满足条件: 处理器 P 对 X 进行一次写之后又对 X 进行读,读和写之间没有其它处理器对 X 进行写,则读的返回值总是写进的值。 一个处理器对 X 进行写之后,另一处理器对 X 进行读,读和写之间无其它写,则读 X 的返回值应为写进的值 对同一单元的写是顺序化的,即任意两个处理器对同一单元的两次写,从所有处理器看来顺序都应是相同的 2 个条件 直到所有的处理器均看到了写的结果,一次写操作才算完成 (写传播) 允许处理器无序读,但必须以程序序进行写 (写串行化) 2018/6/6 计算机体系结构 28
29 .另一种描述: 2018/6/6 计算机体系结构 29 一致性不变量 1 、 Single-Writer, Multiple-Read (SWMR). 对于任意单元 A ,任何时刻,仅存在一个核对其进行读写,或者多个核进行读操作 2 、 Data-Value Invariant. 一阶段开始时某一内存单元的值 等于 上一阶段结束时该内存单元的值。
3秒后跳转登录页面
去登陆

