
































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
06 计算机体系结构--数据级并行
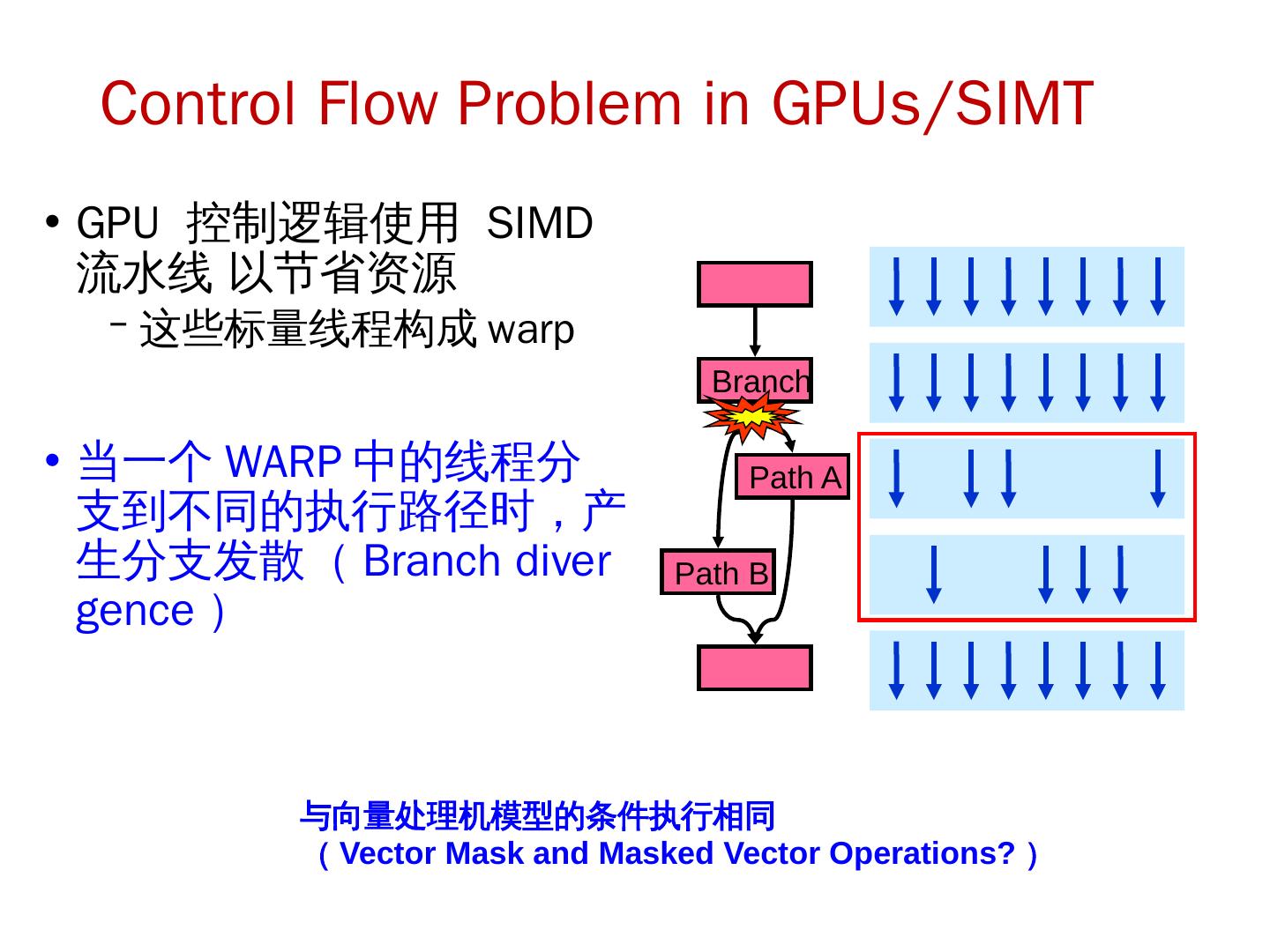
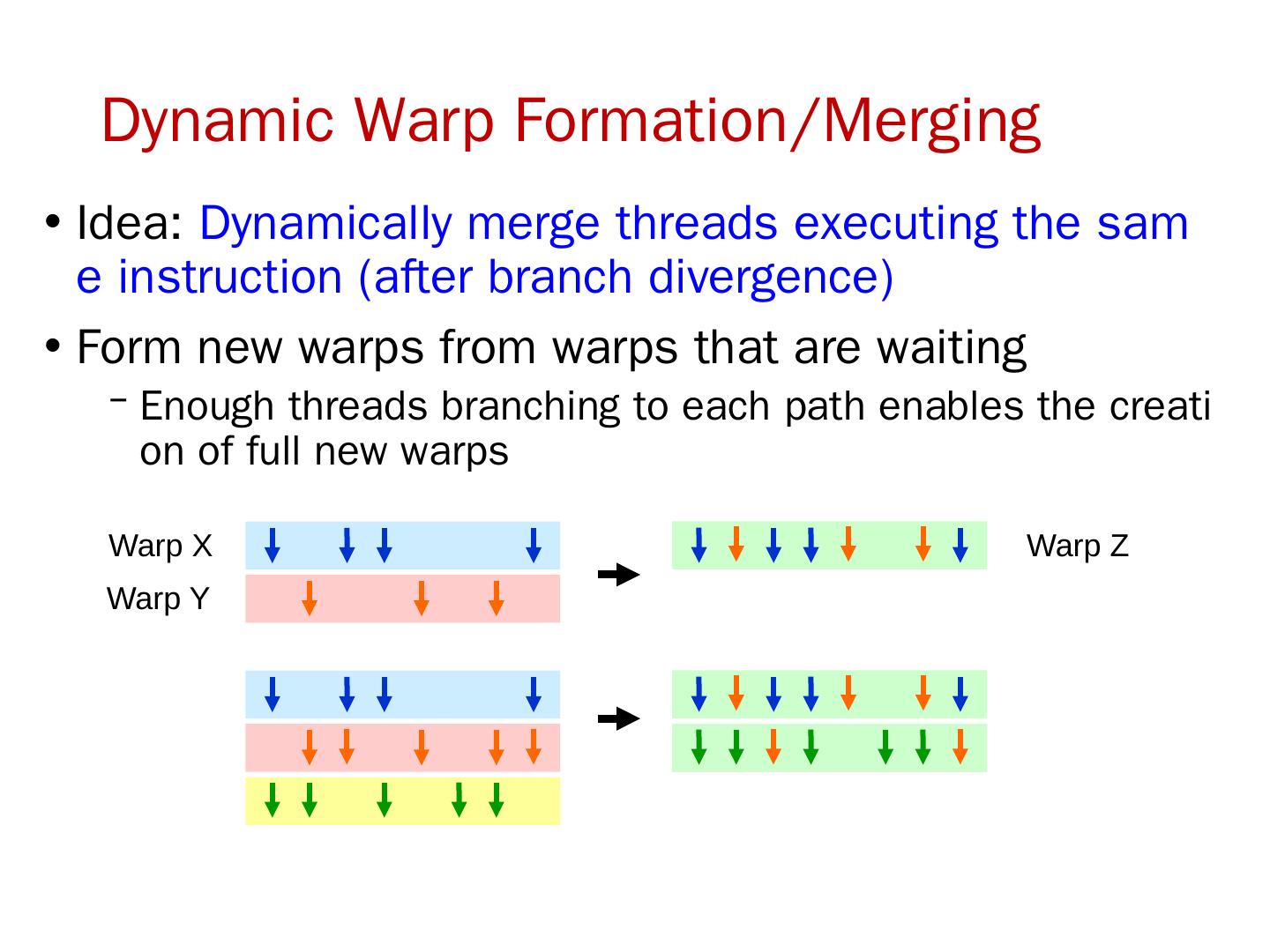
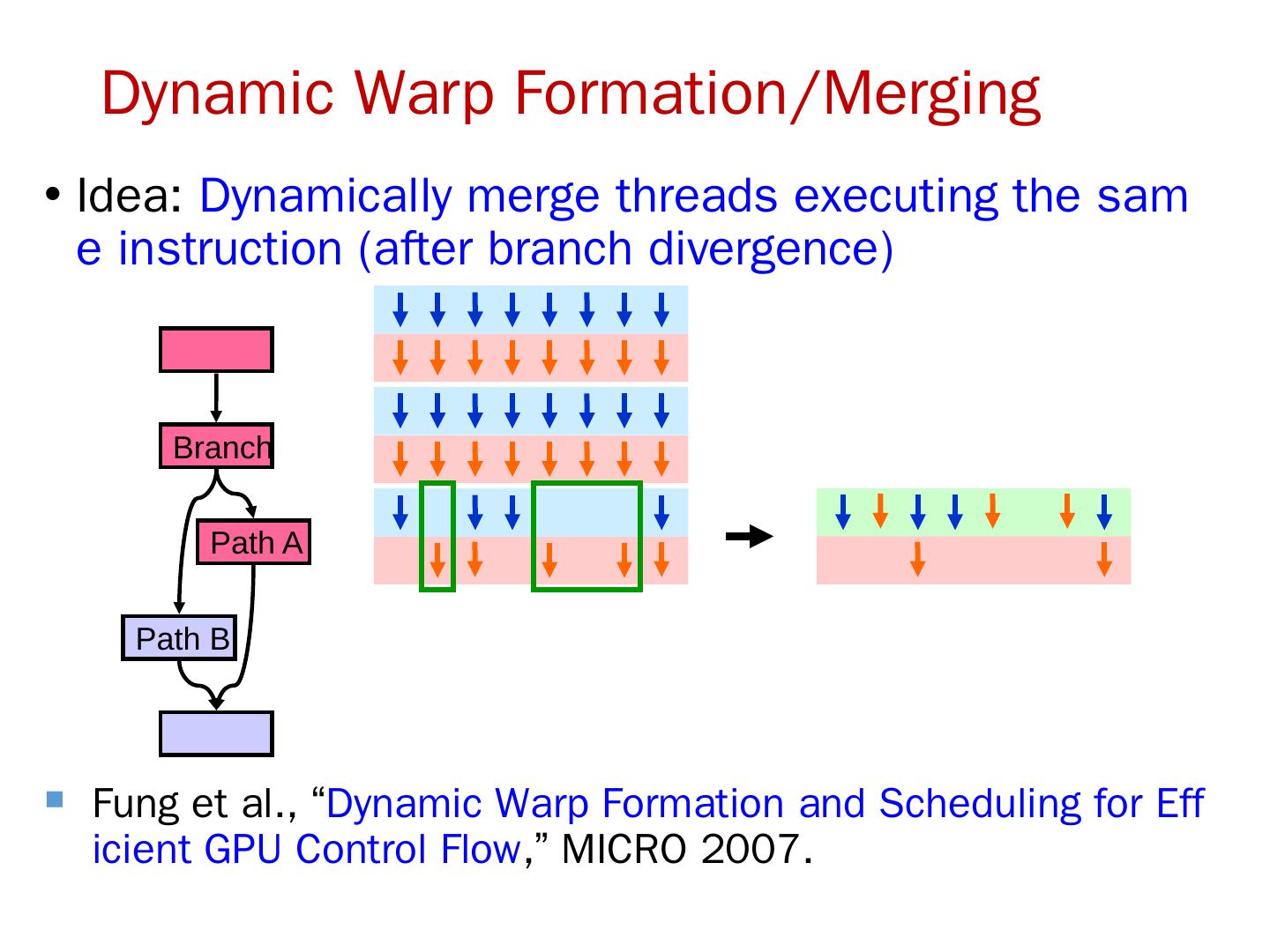
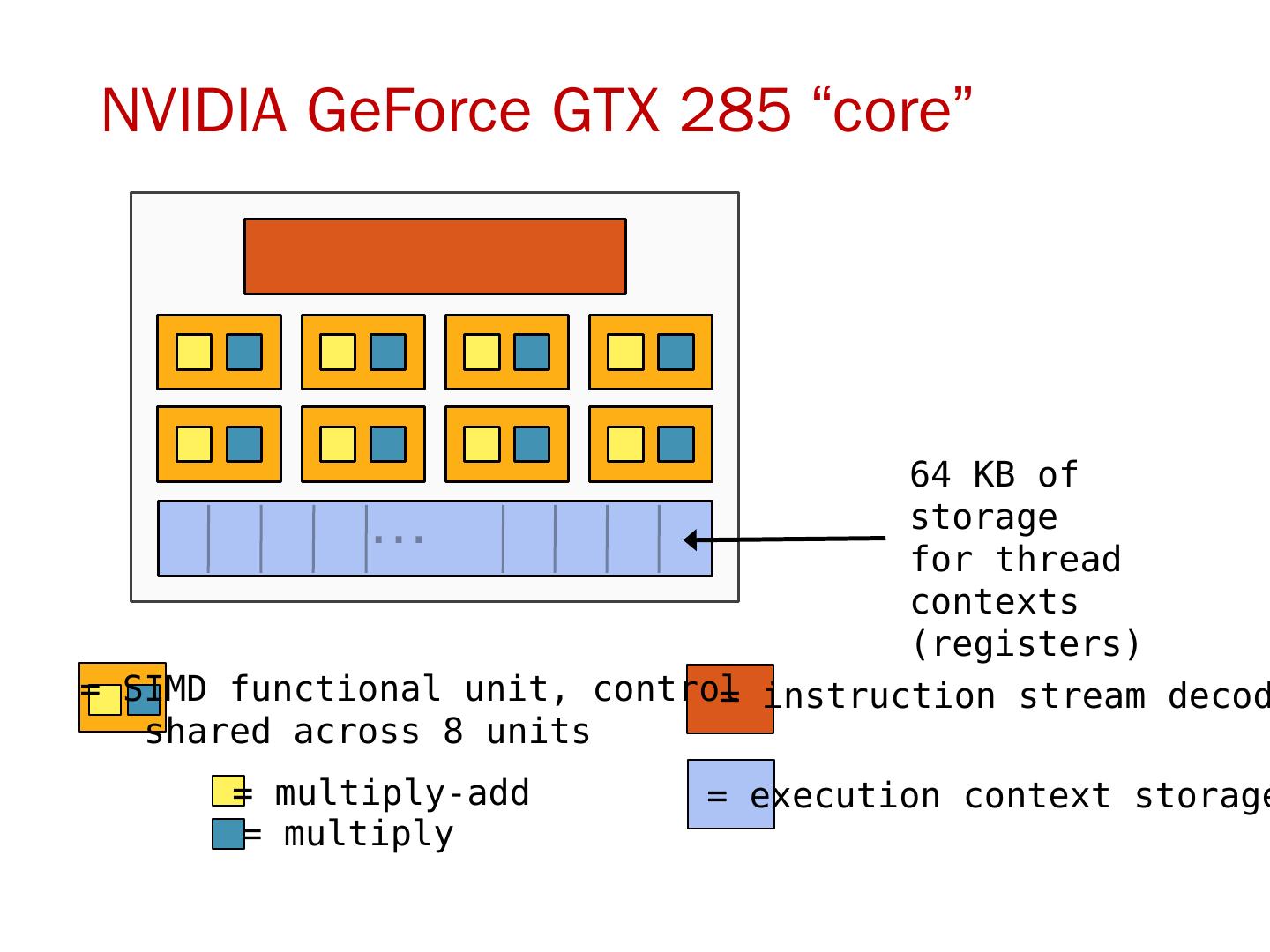
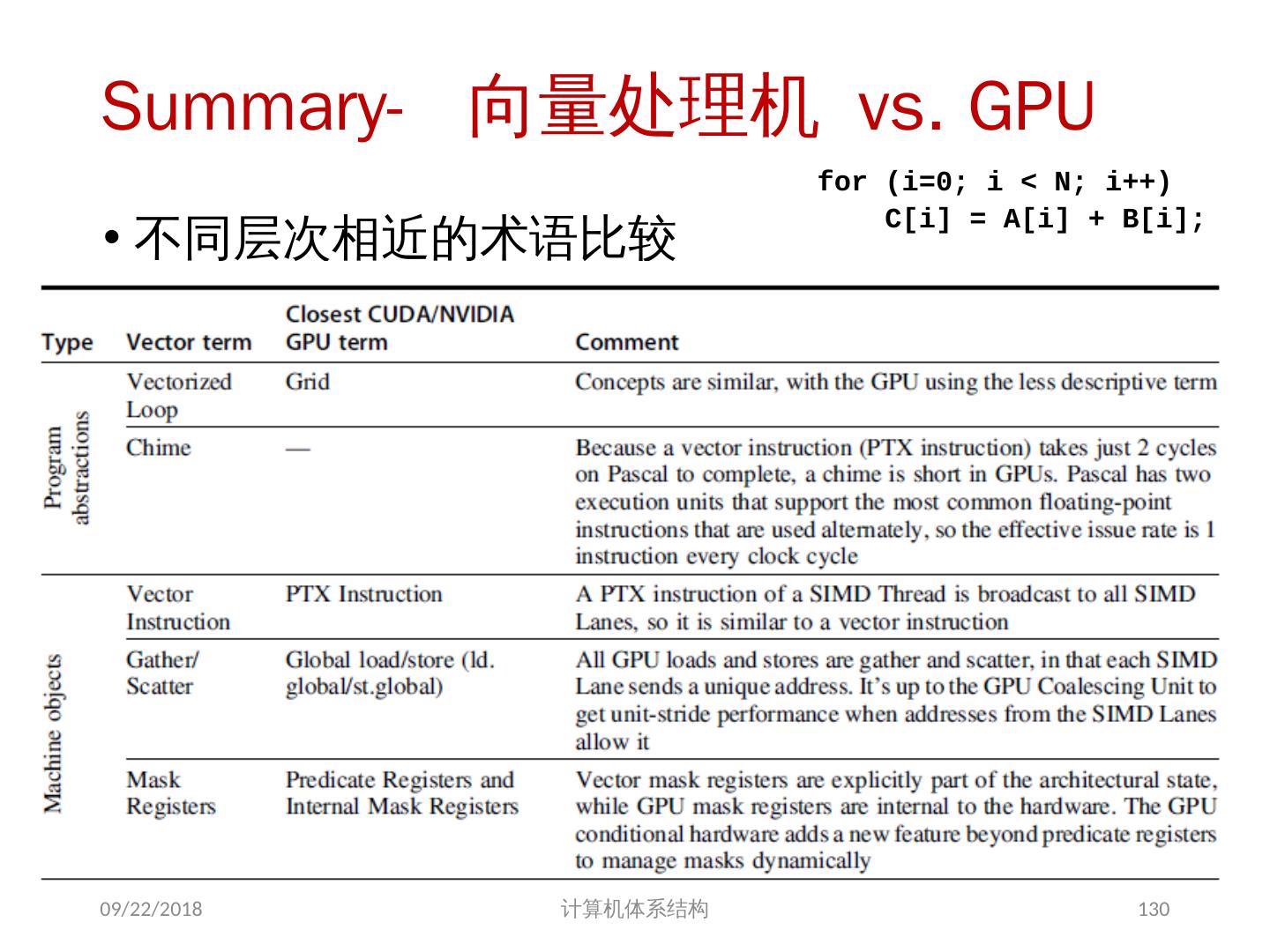
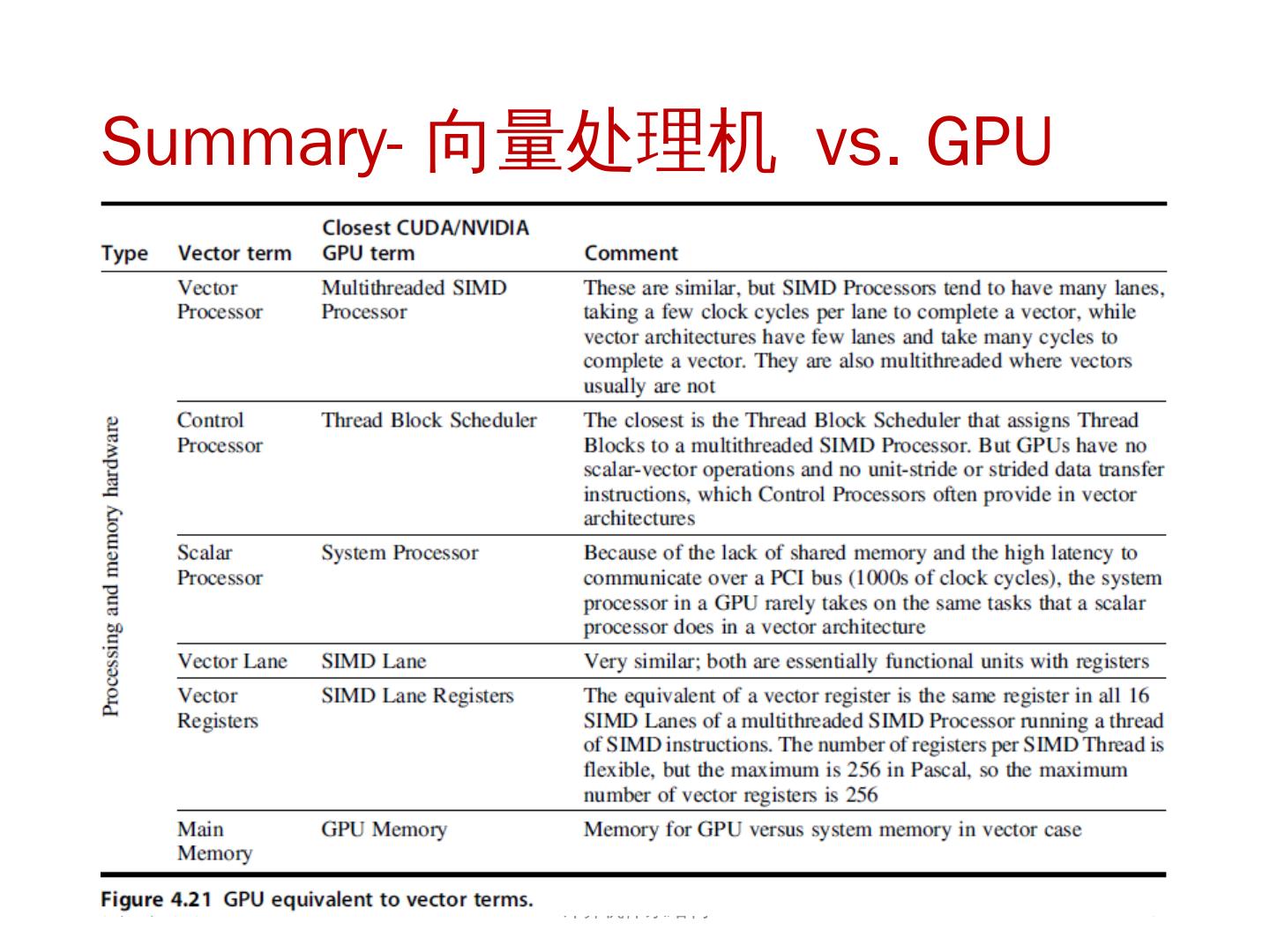
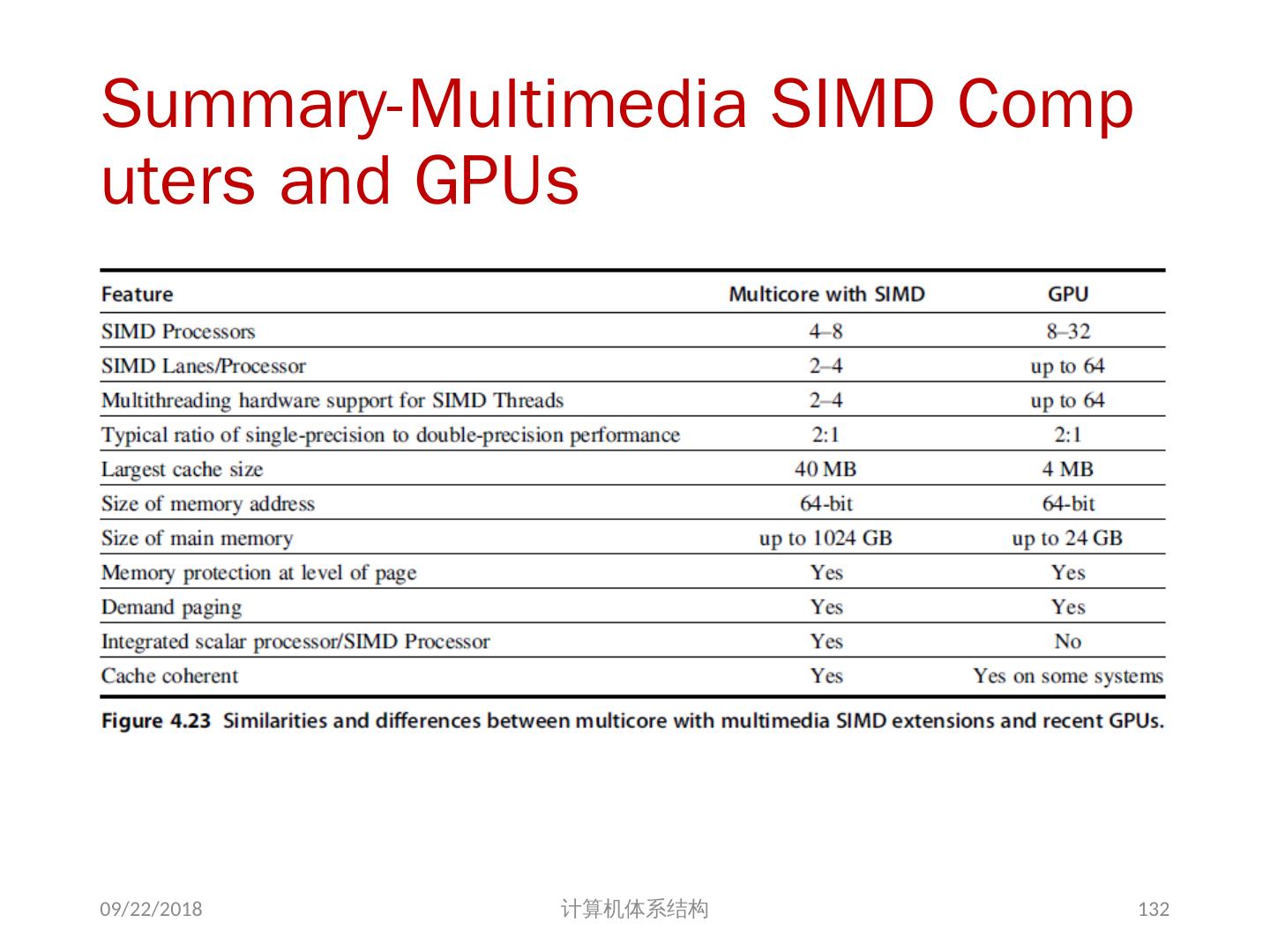
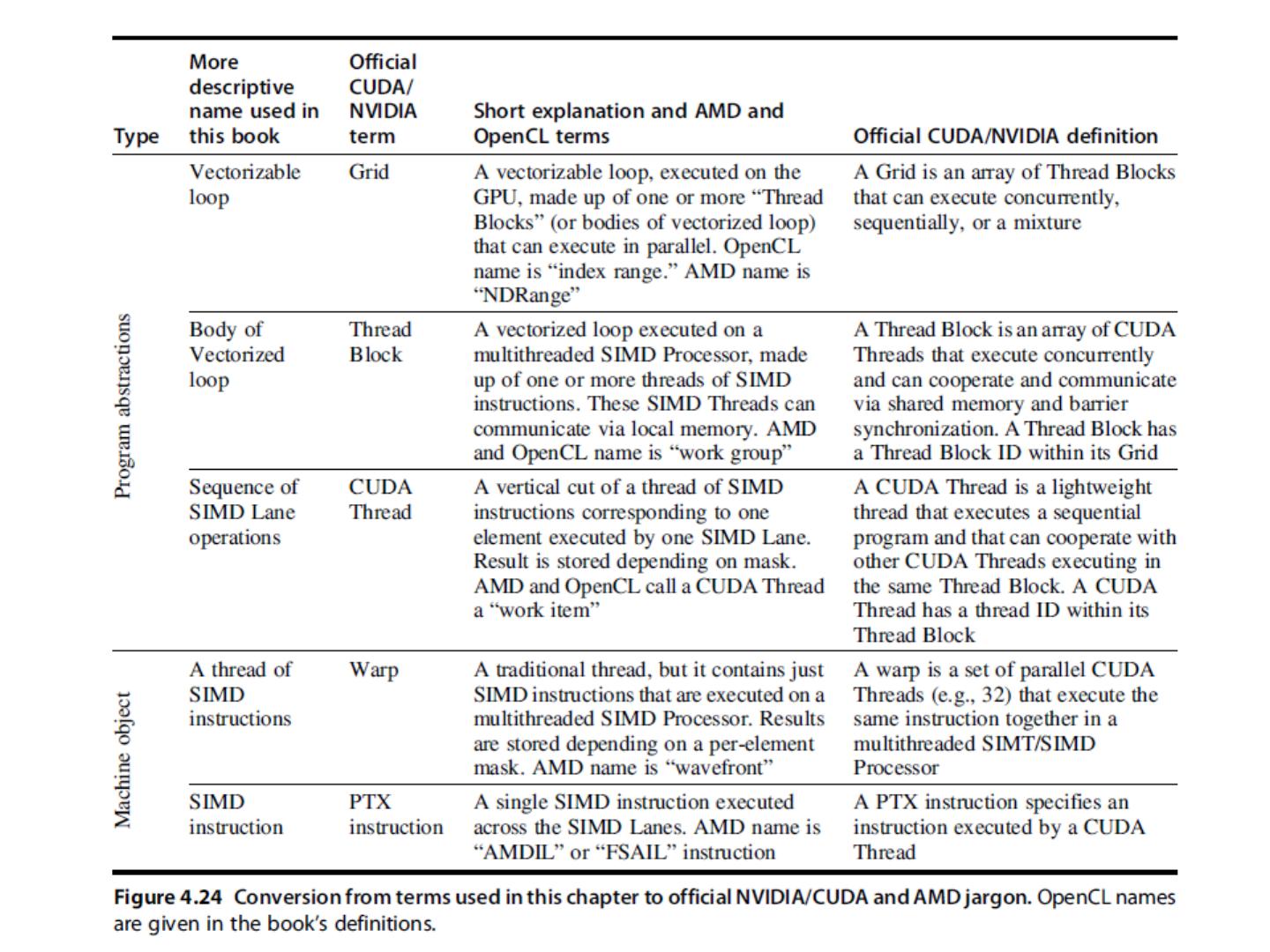
这一节是中国科学技术大学周学海教授所讲授的计算机体系结构的数据级并行部分。这一节的主要内容有:SIMD结构;向量体系结构;以及GPU。在SIMD结构中主要讲了三个部分:向量体系结构 多媒体SIMD指令集扩展 图形处理单元。这里的指的是在向量,SIMD,GPU结构中的并行。
展开查看详情
1 .计算机体系结构 周学海 xhzhou@ustc.edu.cn 0551-63606864 中国科学技术大学
2 .第 6 章 Data-Level Parallelism in Vector, SIMD, and GPU Architectures SIMD 结构 向量体系结构 多媒体 SIMD 指令集扩展 图形处理单元 向量体系结构 GPU 2018/5/23 计算机体系结构 2
3 .传统指令级并行技术的问题 提高性能的传统方法(挖掘 ILP )的主要缺陷 : 程序内在的并行性 提高流水线的时钟频率 : 提高时钟频率,有时导致 CPI 随着增加 (branches, other hazards) 指令预取和译码 : 有时在每个时钟周期很难预取和译码多条指令 提高 Cache 命中率 : 在有些计算量较大的应用中(科学计算 ) 需要大量的数据,其局部性较差,有些程序处理的是连续的媒体流( multimedia), 其局部性也较差。 2018/5/23 计算机体系结构 3
4 .Introduction SIMD 结构可有效地挖掘数据级并行 : 基于矩阵运算的科学计算 图像和声音处理 SIMD 比 MIMD 更节能 针对每组数据操作仅需要取指一次 SIMD 对 PMD( personal mobile devices) 更具吸引力 SIMD 允许程序员继续以串行模式思维 2018/5/23 计算机体系结构 4
5 .SIMD Parallelism 向量体系结构 多媒体 SIMD 指令集 扩展 Graphics Processor Units (GPUs) For x86 processors: 每年增加 2cores/chip SIMD 宽度每 4 年翻一番 SIMD 潜在加速比是 MIMD 的 2 倍 2018/5/23 计算机体系结构 5
6 .2018/5/23 计算机体系结构 6
7 .Supercomputers Supercomputer 的定义 : 对于给定任务而言世界上最快的机器 任何造价超过 3 千万美元的机器 计算能力达到每秒万亿次的机器 由 Seymour Cray 设计的机器 CDC6600 (Cray, 1964) 被认为是第一台超级计算机 2018/5/23 计算机体系结构 7
8 .CDC 6600 Seymour Cray, 1963 A fast pipelined machine with 60-bit words 128 Kword main memory capacity, 32 banks Ten functional units (parallel, unpipelined) Floating Point: adder, 2 multipliers, divider Integer: adder, 2 incrementers, ... Hardwired control (no microcoding) Scoreboard for dynamic scheduling of instructions Ten Peripheral Processors for Input/Output a fast multi-threaded 12-bit integer ALU Very fast clock, 10 MHz (FP add in 4 clocks) >400,000 transistors, 750 sq. ft., 5 tons, 150 kW, novel freon-based technology for cooling Fastest machine in world for 5 years (until 7600) over 100 sold ($7-10M each) 2018/5/23 8 计算机体系结构
9 .CDC 6600 Seymour Cray, 1963 A fast pipelined machine with 60-bit words 128 Kword main memory capacity, 32 banks Ten functional units (parallel, unpipelined) Floating Point: adder, 2 multipliers, divider Integer: adder, 2 incrementers, ... Hardwired control (no microcoding) Scoreboard for dynamic scheduling of instructions Ten Peripheral Processors for Input/Output a fast multi-threaded 12-bit integer ALU Very fast clock, 10 MHz (FP add in 4 clocks) >400,000 transistors, 750 sq. ft., 5 tons, 150 kW, novel freon-based technology for cooling Fastest machine in world for 5 years (until 7600) over 100 sold ($7-10M each) 2018/5/23 8 计算机体系结构
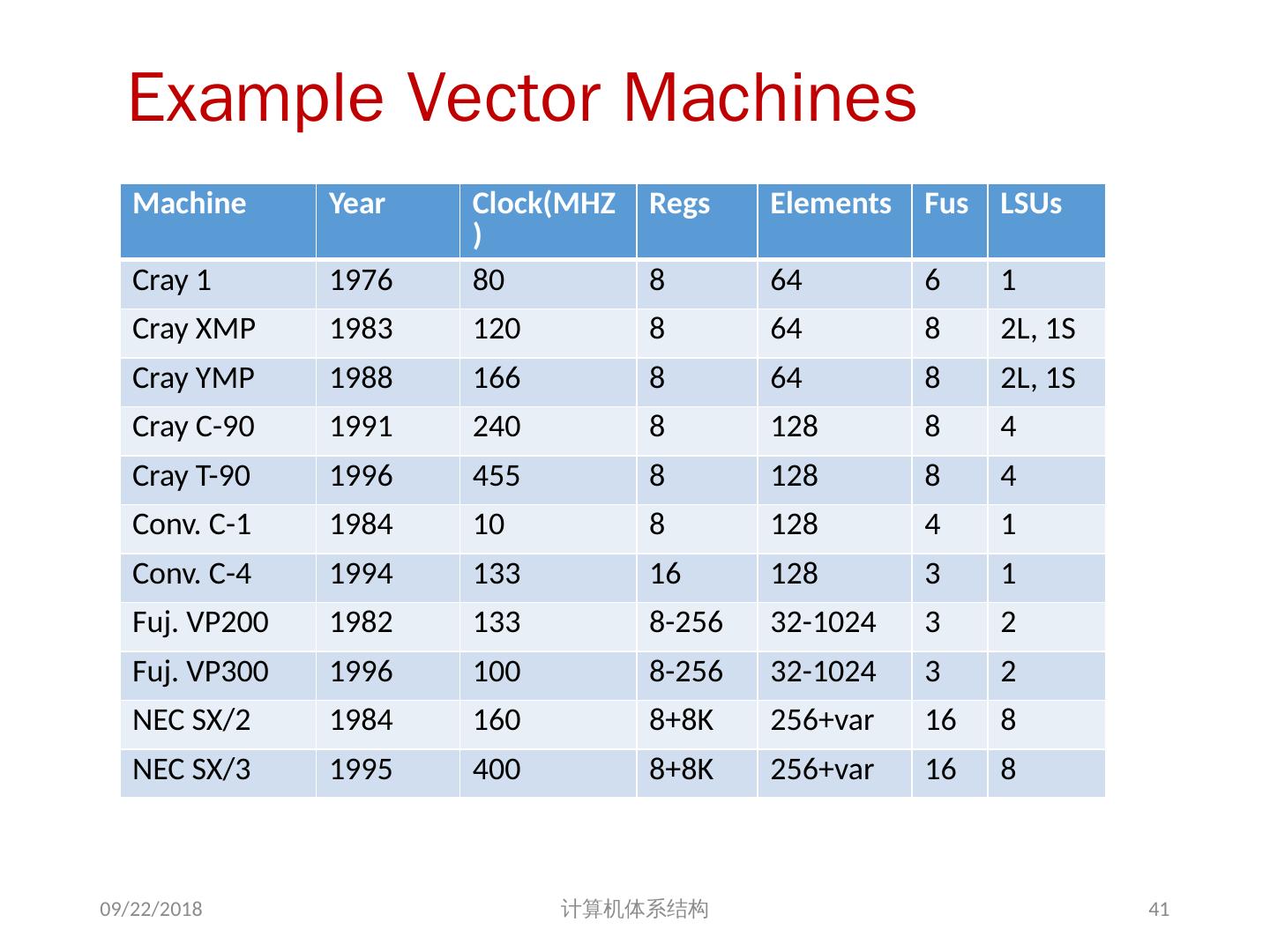
10 .Supercomputer Applications 典型应用领域 军事研究领域(核武器研制、密码学) 科学研究 天气预报 石油勘探 工业设计 (car crash simulation) 生物信息学 密码学 均涉及大量的数据集处理 70-80 年代 Supe rcomputer = Vector Machine 2018/5/23 计算机体系结构 10
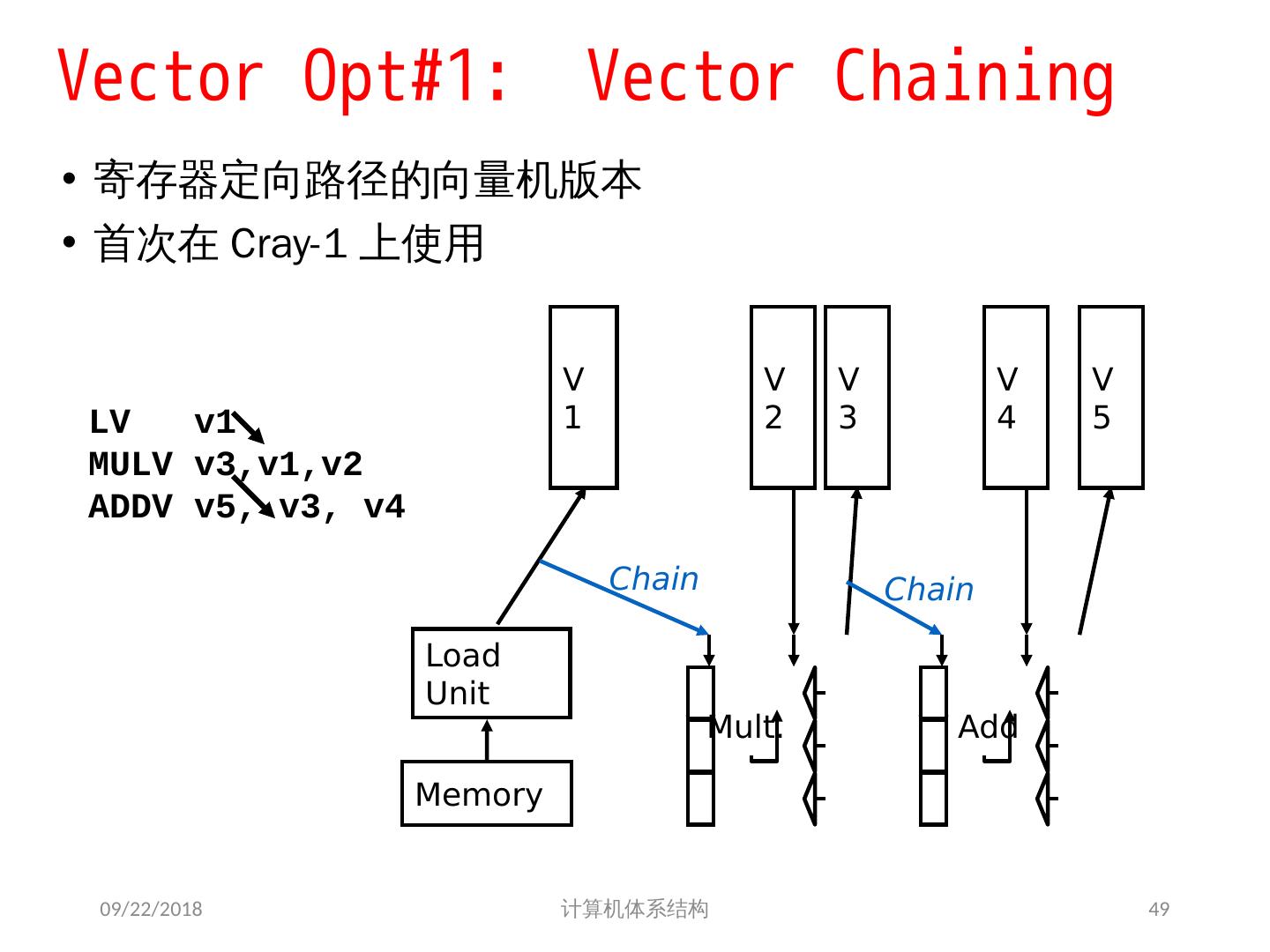
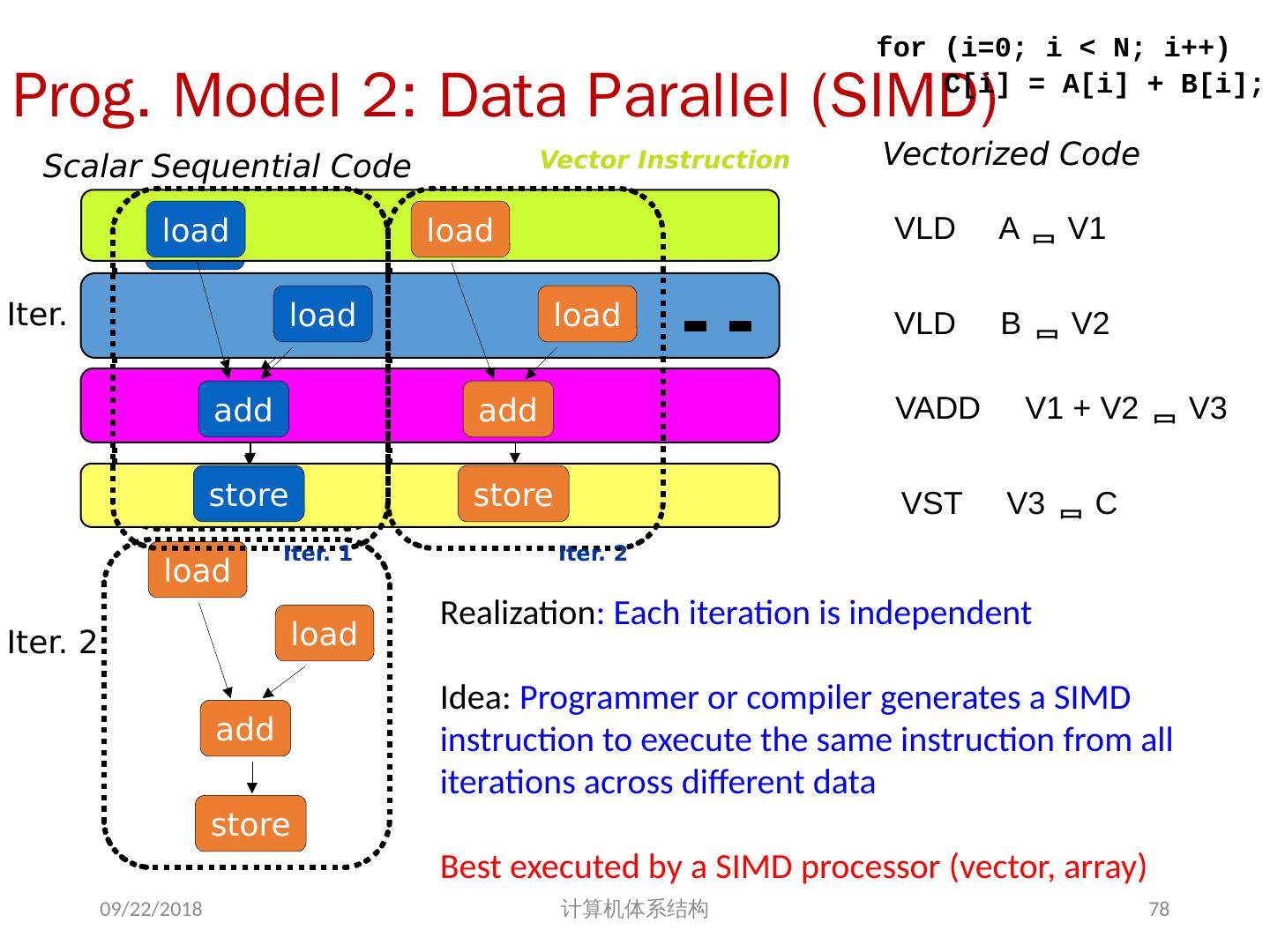
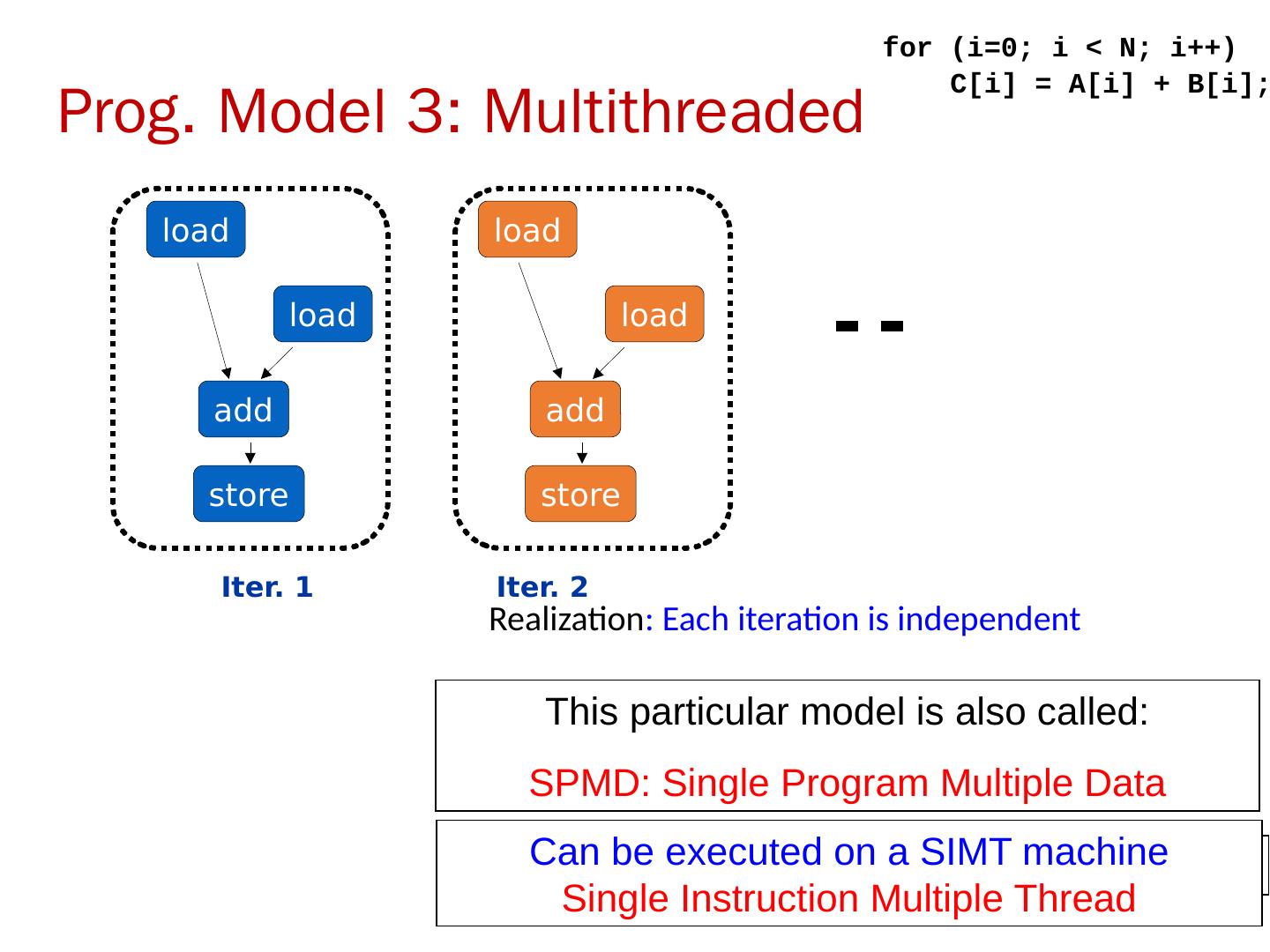
11 .Alternative Model:Vector Processing 向量处理机具有更高层次的操作,一条向量指令可以处理 N 个或 N 对操作数(处理对象是向量) 2018/5/23 计算机体系结构 + r1 r2 r3 add r3, r1, r2 SCALAR (1 operation) v1 v2 v3 + vector length add.vv v3, v1, v2 VECTOR (N operations) 11
12 .向量处理机的基本特性 基本思想:两个向量的对应分量进行运算,产生一个结果向量。 简单的一条向量指令包含了多个操作 => fewer instruction fetches 每一结果独立于前面的结果 长流水线,编译器保证操作间没有相关性 硬件仅需检测两条向量指令间的相关性 较高的时钟频率 向量指令以已知的模式访问存储器 可有效发挥多体交叉存储器的优势 可通过重叠减少存储器操作的延时 64 elements 不需要数据 Cache! ( 仅使用指令 cache) 在流水线控制中减少了控制相关 2018/5/23 计算机体系结构 12
13 .向量处理机的基本结构 memory-memory vector processors: 所有的向量操作是存储器到存储器 vector-register processors: 除了 load 和 store 操作外,所有的操作是向量寄存器与向量寄存器间的操作 向量机的 Load/Store 结构 1980 年以后的所有的向量处理机都是这种结构 : Cray, Convex, Fujitsu, Hitachi, NEC 我们也主要针对这种结构 2018/5/23 计算机体系结构 13
14 .Vector Memory-Memory versus Vector Register Machines 存储器 - 存储器型向量机所有指令操作的操作数来源于存储器 第一台向量机 CDC Star-100 (‘73) and TI ASC (‘71), 是存储器 - 存储器型机器 Cray-1 (’76) 是第一台寄存器型向量机 2018/5/23 计算机体系结构 for (i=0; i<N; i++) { C[i] = A[i] + B[i]; D[i] = A[i] - B[i]; } Example Source Code ADDV C, A, B SUBV D, A, B Vector Memory-Memory Code LV V1, A LV V2, B ADDV V3, V1, V2 SV V3, C SUBV V4, V1, V2 SV V4, D Vector Register Code
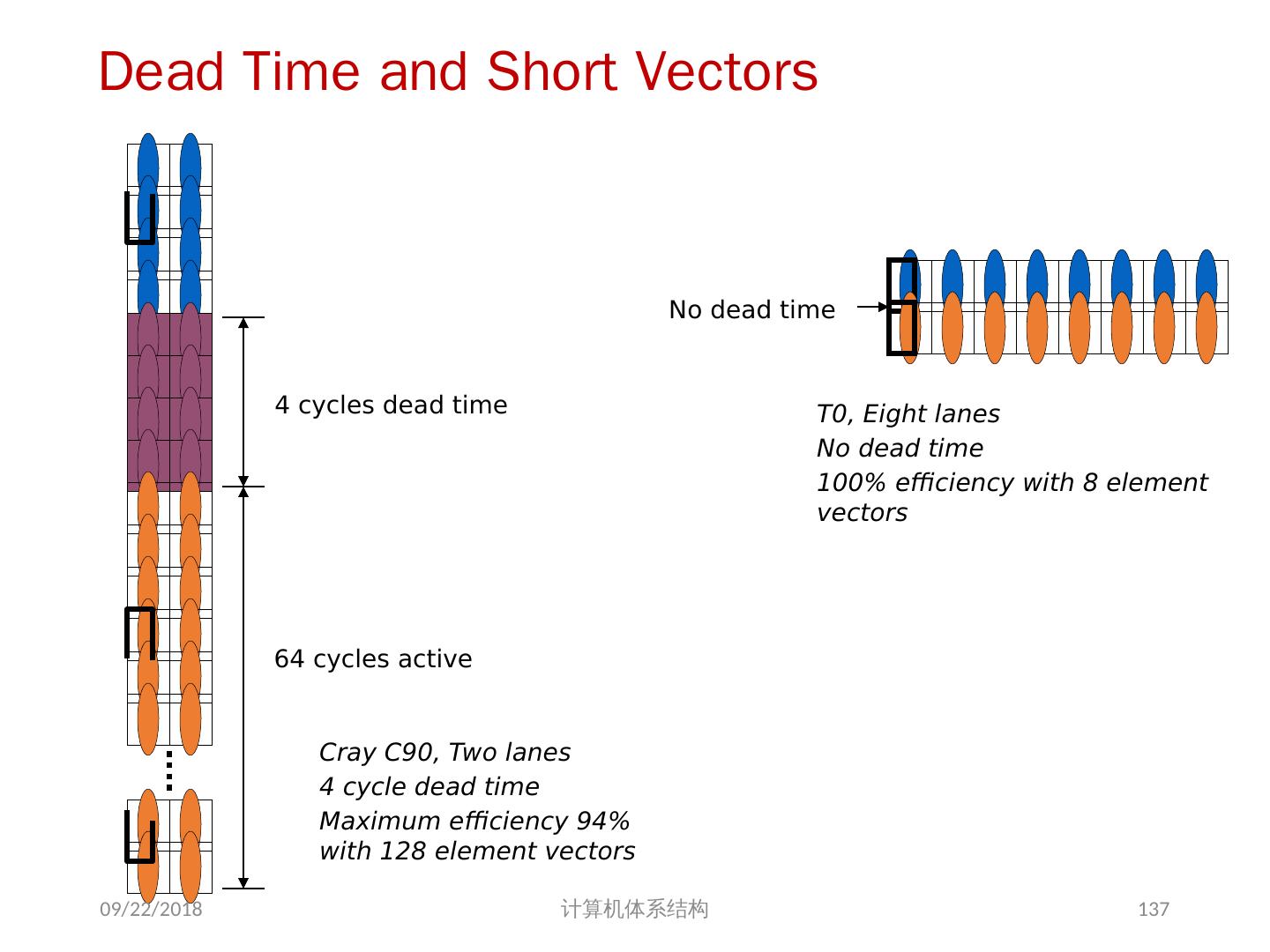
15 .Vector Memory-Memory vs. Vector Register Machines 存储器 - 存储器型向量机 (VMMA) 需要更高的存储器带宽 All operands must be read in and out of memory VMMA 结构使得多个向量操作 重叠执行较困难 Must check dependencies on memory addresses VMMA 启动时间更长 CDC Star-100 在向量元素小于 100 时,标量代码的性能高于向量化代码 For Cray-1, vector/scalar 均衡点在 2 个元素 CDC Cray-1 后续的机器 (Cyber-205, ETA-10) 都是寄存器型向量机 2018/5/23 计算机体系结构 15
16 .Vector Supercomputers Cray-1 的变体( 1976 ) : Scalar Unit : Load/Store Architecture Vector Extension Vector Registers Vector Instructions Implementation 硬布线逻辑控制 高效流水化的功能部件 多体交叉存储系统 无 Data Cache 不支持 Virtual Memory 2018/5/23 计算机体系结构 16
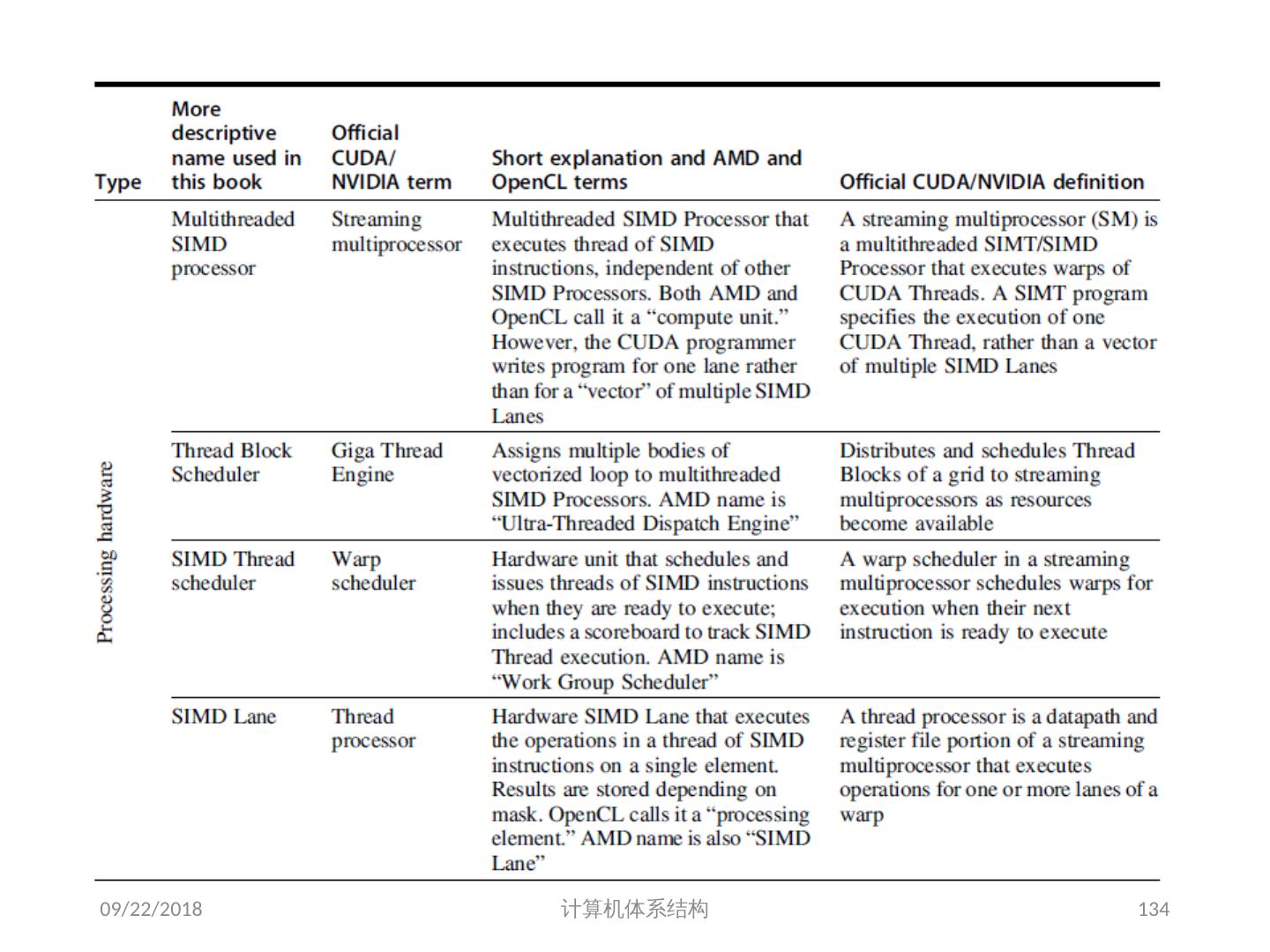
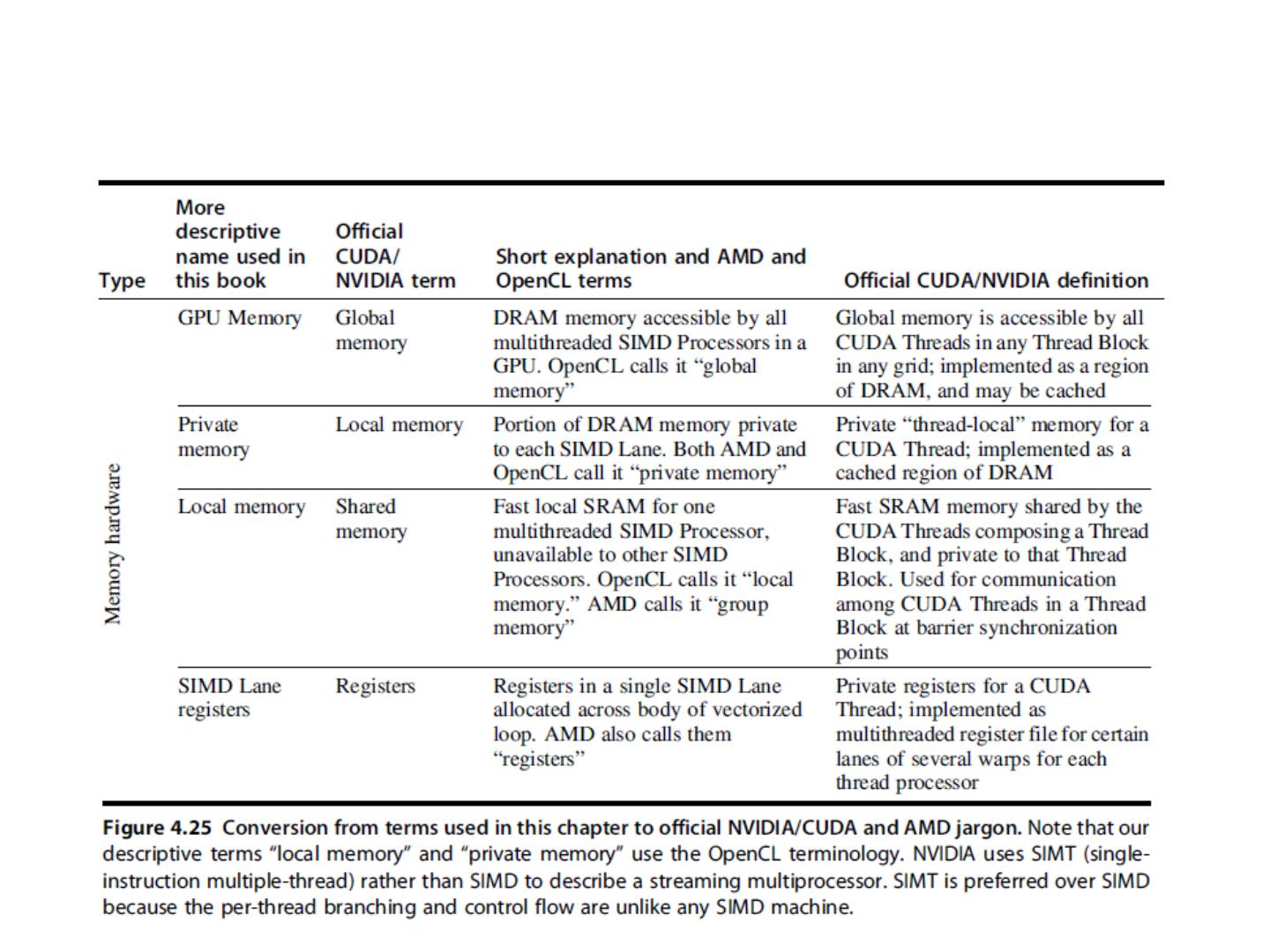
17 .Vector Instruction Set Advantages 格式紧凑 一条指令包含 N 个操作 表达能力强 , 一条指令能告诉硬件 : N 个操作之间无相关性 使用同样的功能部件 访问不相交的寄存器 与前面的操作以相同模式访问寄存器 访问存储器中的连续块 (unit-stride load/store) 以已知的模式访问存储器 (strided load/store) 可扩展性好 可以在多个并行的流水线上运行同样的代码 (lanes) 2018/5/23 计算机体系结构 17
18 .Vector Instructions Instr. Operands Operation Comment ADD V V1,V2,V3 V1=V2+V3 vector + vector ADD S V V1, F0 ,V2 V1= F0 +V2 scalar + vector MULTV V1,V2,V3 V1=V2xV3 vector x vector MULSV V1,F0,V2 V1=F0xV2 scalar x vector LV V1,R1 V1=M[R1..R1+63] load, stride=1 LV WS V1,R1,R2 V1=M[R1..R1+ 63*R2 ] load, stride=R2 LV I V1,R1,V2 V1=M[R1 +V2i ,i=0..63] indir.("gather") CeqV VM,V1,V2 VMASKi = (V1i=V2i)? comp. setmask MOV VLR ,R1 Vec. Len. Reg. = R1 set vector length MOV VM ,R1 Vec. Mask = R1 set vector mask 2018/5/23 18 计算机体系结构
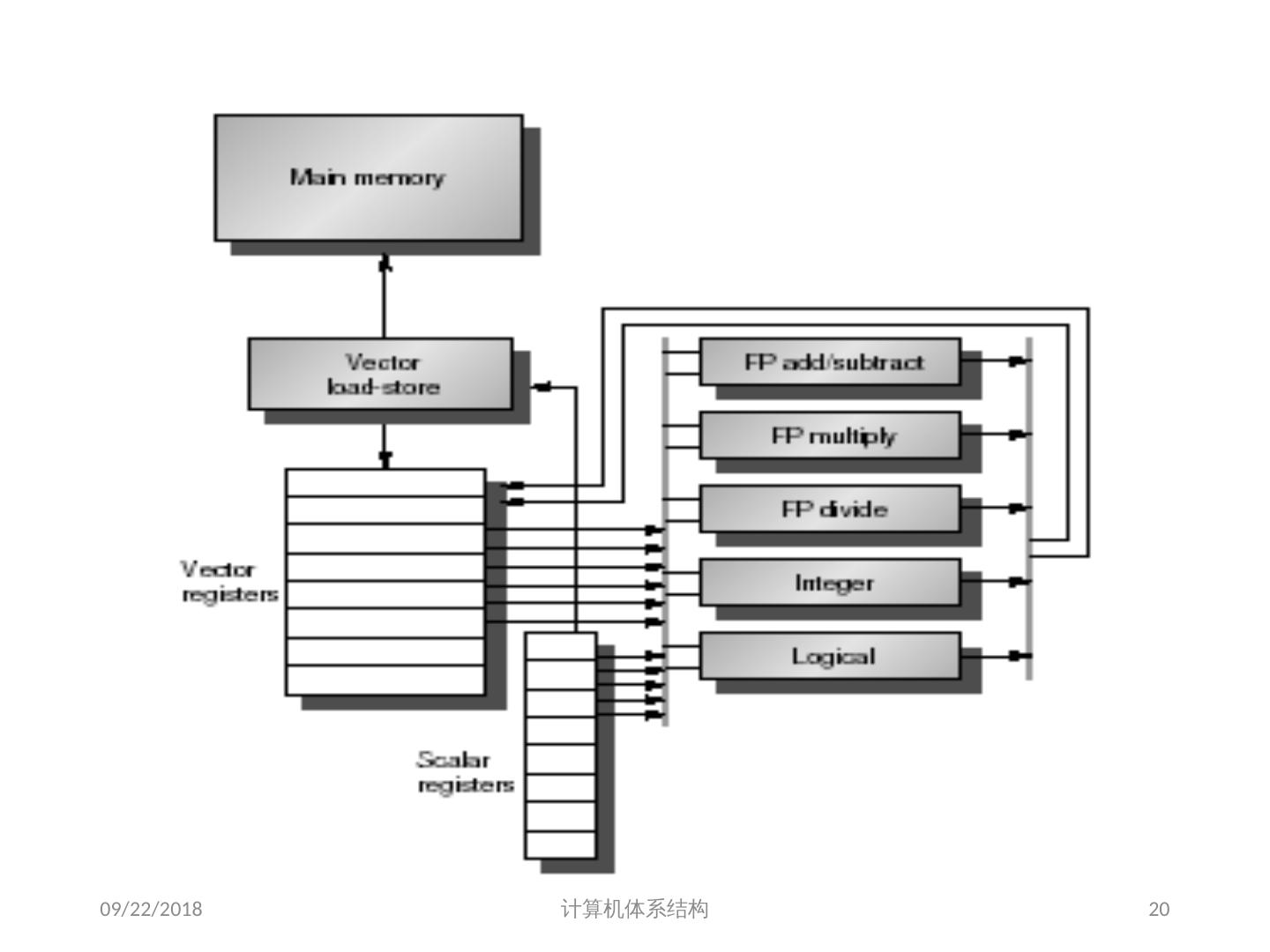
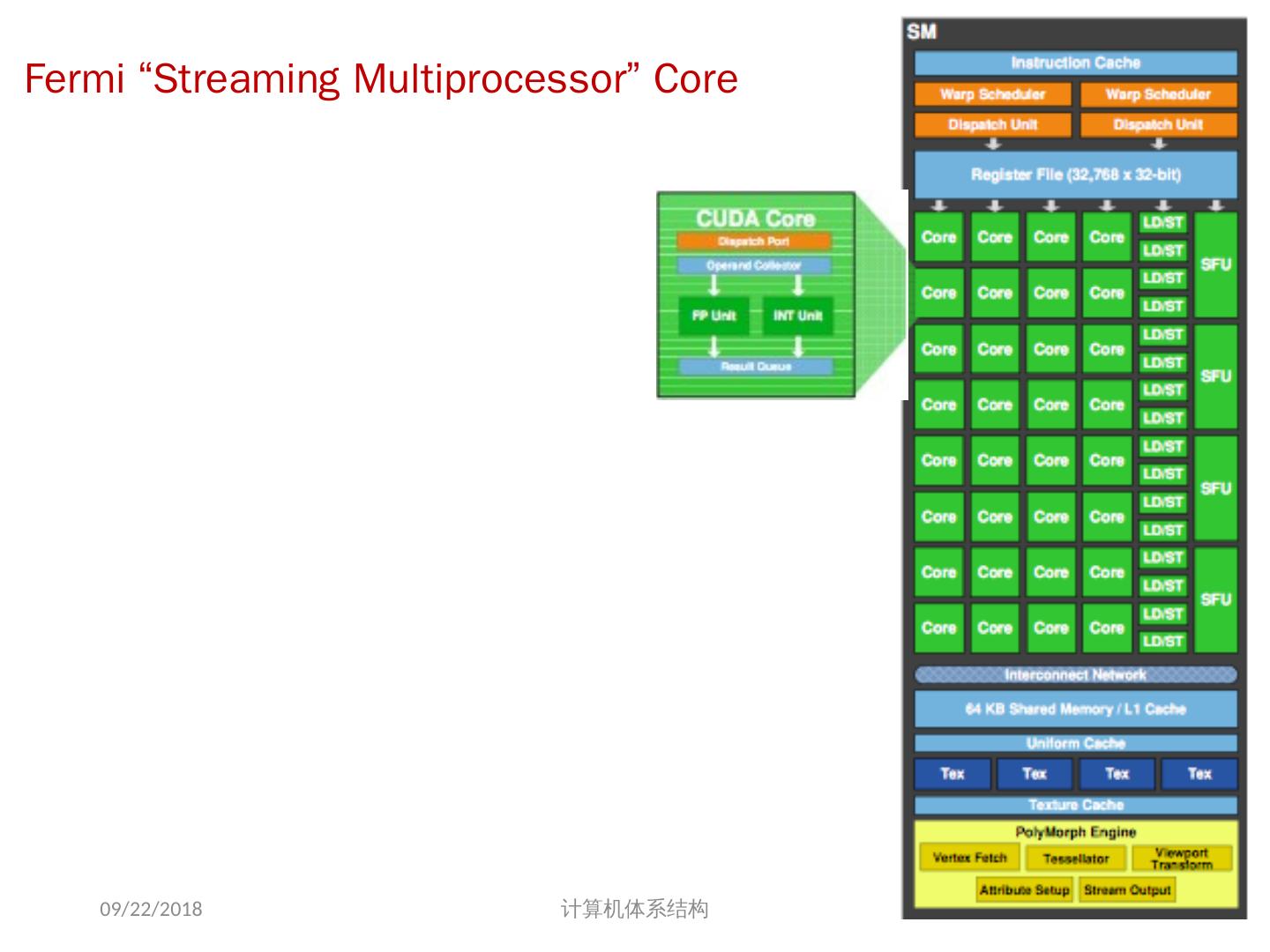
19 .向量处理机的基本组成单元 Vector Register : 固定长度的一块区域,存放单个向量 至少2个读端口和一个写端口(一般最少 16 个读端口, 8 个写端口) 典型的有 8-32 向量寄存器,每个寄存器存放64到128个64位元素 Vector Functional Units (FUs) : 全流水化的,每一个 clock 启动一个新的操作 一般4到8个 FUs: FP add, FP mult, FP reciprocal (1/X), integer add, logical, shift; 可能有些重复设置的部件 Vector Load-Store Units (LSUs) : 全流水化地 load 或 store 一个向量,可能会配置多个 LSU 部件 Scalar registers : 存放单个元素用于标量处理或存储地址 用交叉开关连接( Cross-bar) FUs , LSUs, registers 2018/5/23 计算机体系结构 19
20 .2018/5/23 20 计算机体系结构
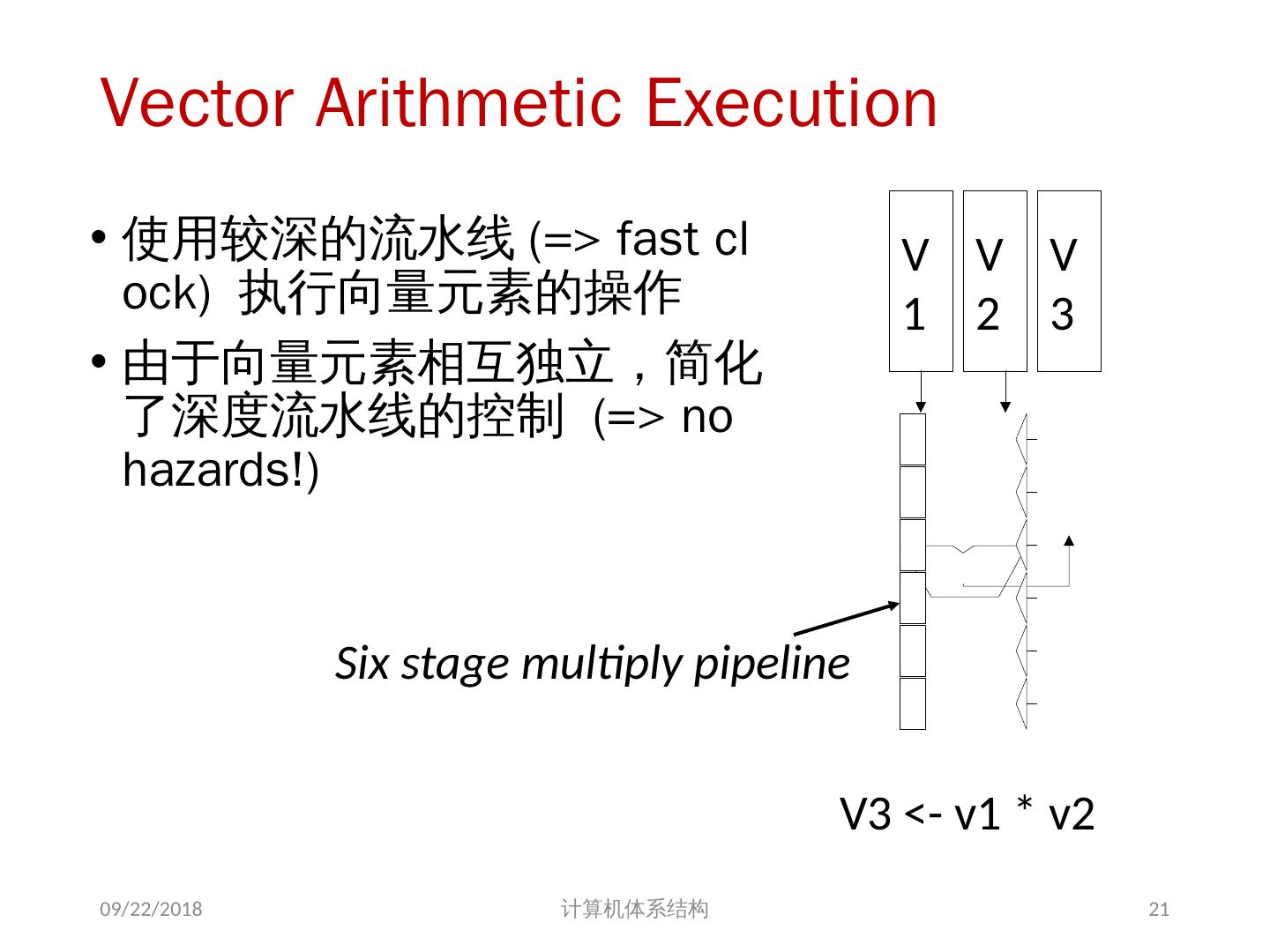
21 .Vector Arithmetic Execution 使用较深的流水线 (=> fast clock) 执行向量元素的操作 由于向量元素相互独立,简化了深度流水线的控制 (=> no hazards!) 2018/5/23 计算机体系结构 V1 V2 V3 V3 <- v1 * v2 Six stage multiply pipeline 21
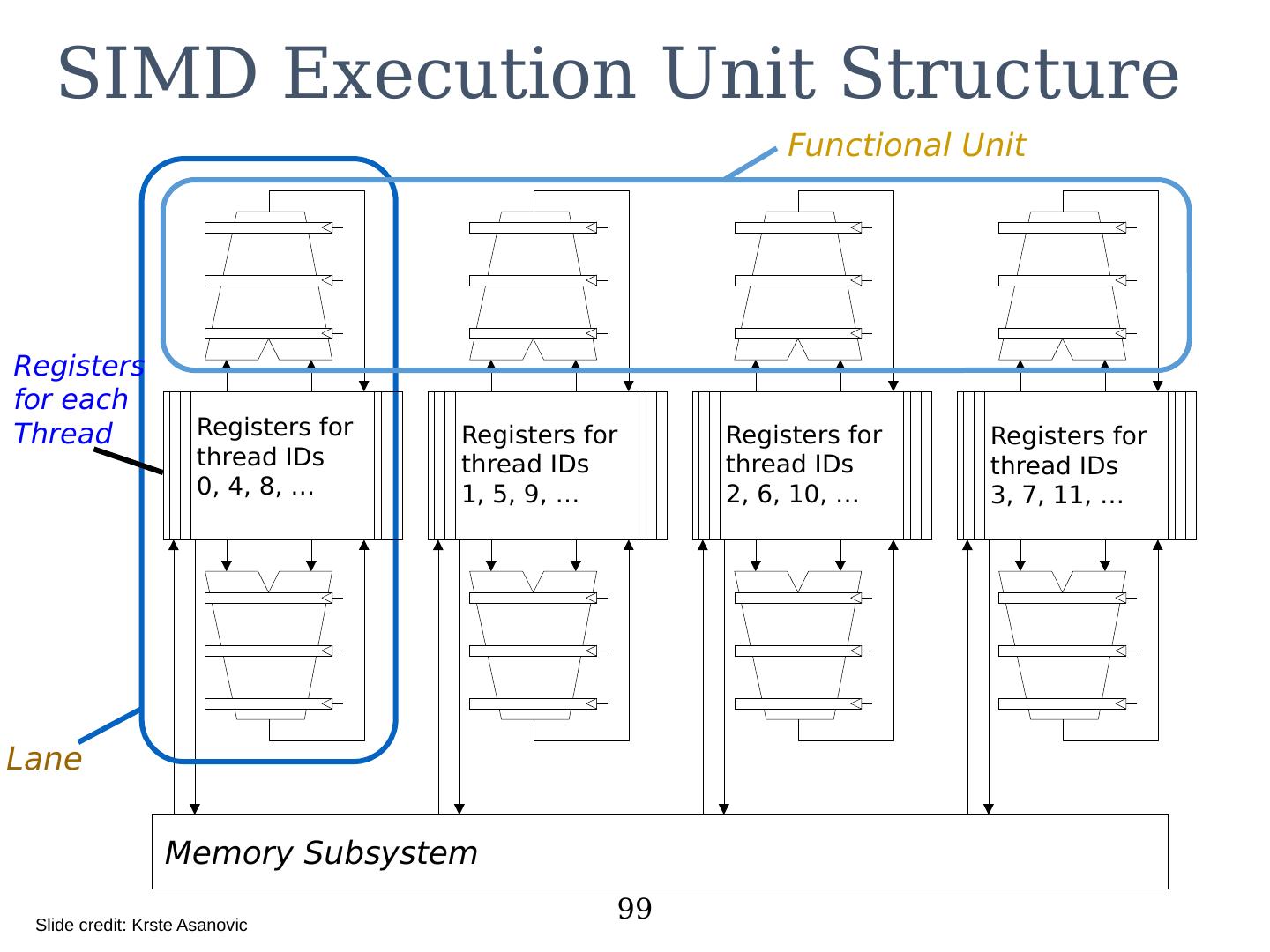
22 .Vector Unit Structure 22 Lane Functional Unit Vector Registers Memory Subsystem Elements 0, 4, 8, … Elements 1, 5, 9, … Elements 2, 6, 10, … Elements 3, 7, 11, … 2018/5/23 计算机体系结构
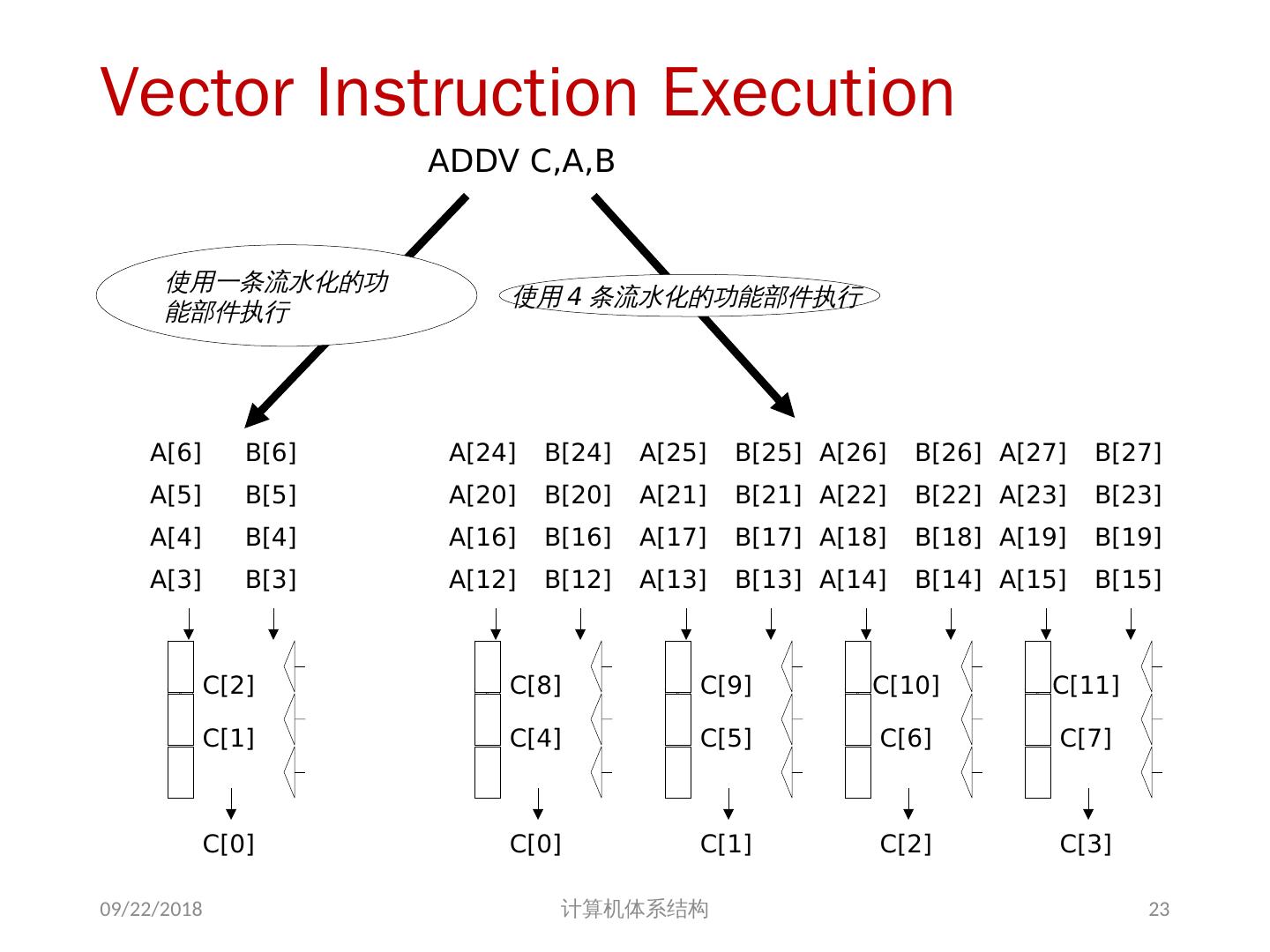
23 .Vector Instruction Execution 2018/5/23 计算机体系结构 ADDV C,A,B C[1] C[2] C[0] A[3] B[3] A[4] B[4] A[5] B[5] A[6] B[6] 使用一条流水化的功能部件执行 C[4] C[8] C[0] A[12] B[12] A[16] B[16] A[20] B[20] A[24] B[24] C[5] C[9] C[1] A[13] B[13] A[17] B[17] A[21] B[21] A[25] B[25] C[6] C[10] C[2] A[14] B[14] A[18] B[18] A[22] B[22] A[26] B[26] C[7] C[11] C[3] A[15] B[15] A[19] B[19] A[23] B[23] A[27] B[27] 使用 4 条流水化的功能部件执行 23
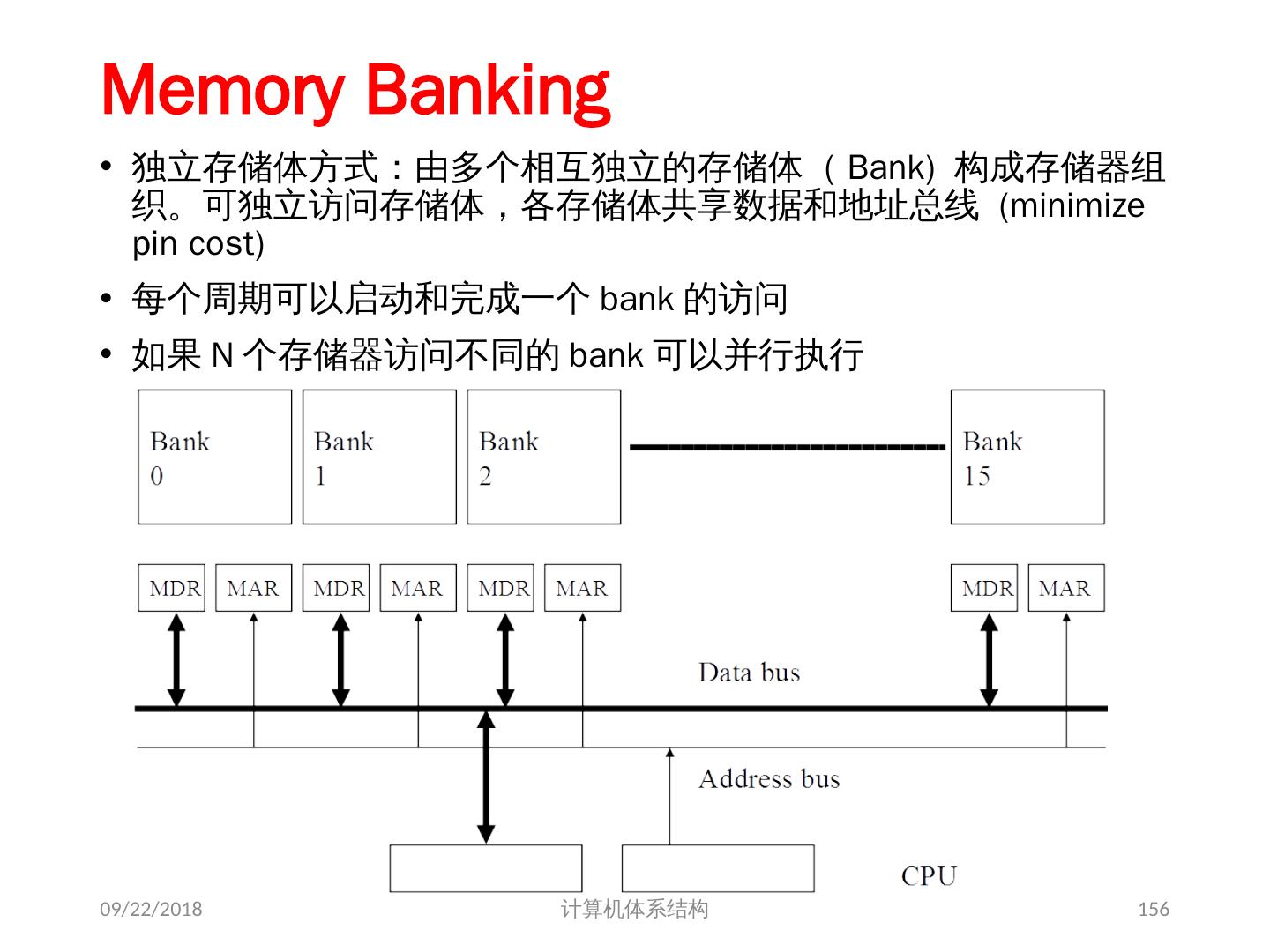
24 .Interleaved Vector Memory System 24 0 1 2 3 4 5 6 7 8 9 A B C D E F + Base Stride Vector Registers Memory Banks Address Generator Cray-1, 16 banks, 4 cycle bank busy time, 12 cycle latency Bank busy time : Time before bank ready to accept next request 2018/5/23 计算机体系结构
25 .T0 Vector Microprocessor (UCB/ICSI, 1995) 25 Lane Vector register elements striped over lanes [0] [8] [16] [24] [1] [9] [17] [25] [2] [10] [18] [26] [3] [11] [19] [27] [4] [12] [20] [28] [5] [13] [21] [29] [6] [14] [22] [30] [7] [15] [23] [31] 2018/5/23 计算机体系结构
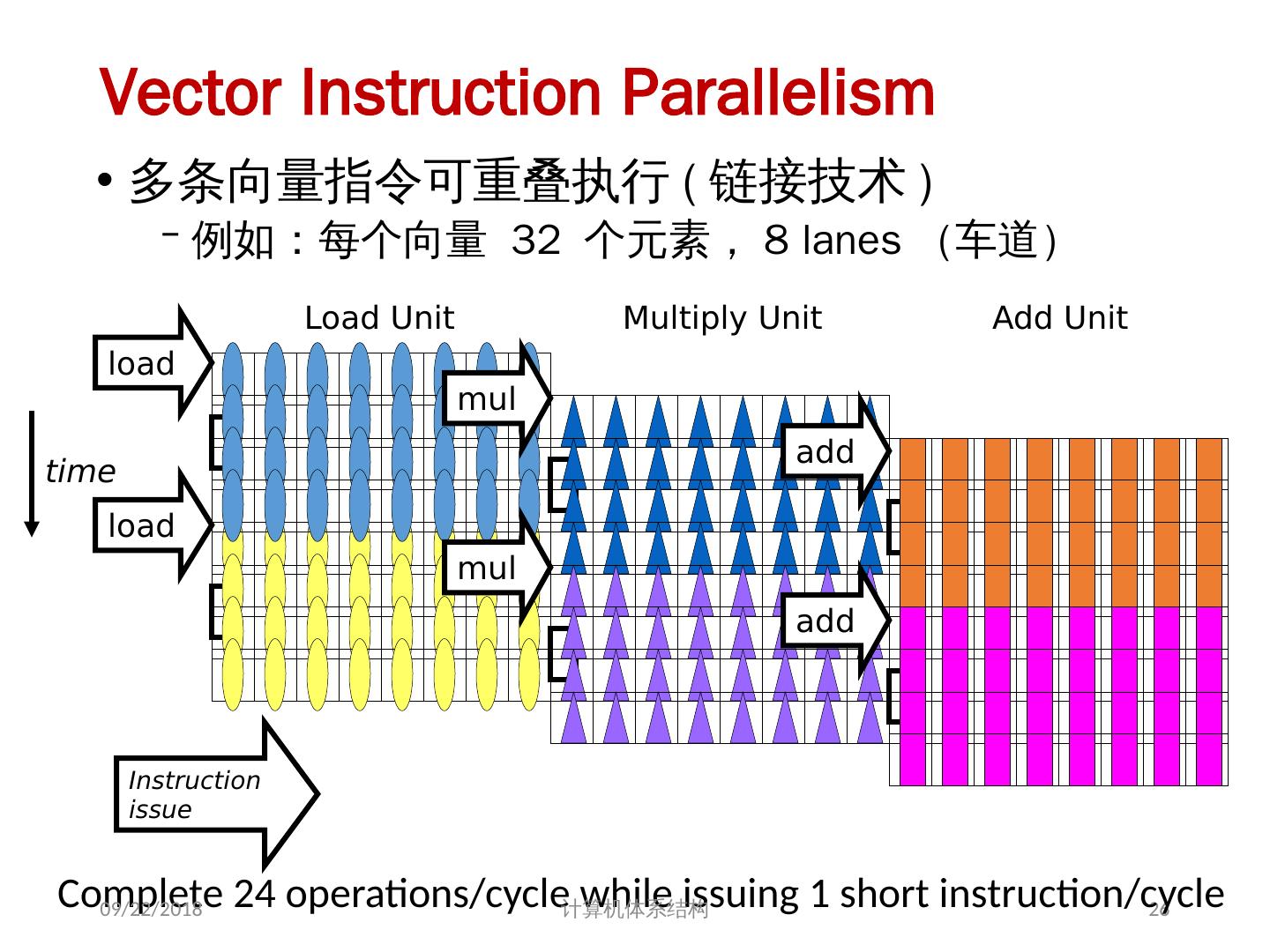
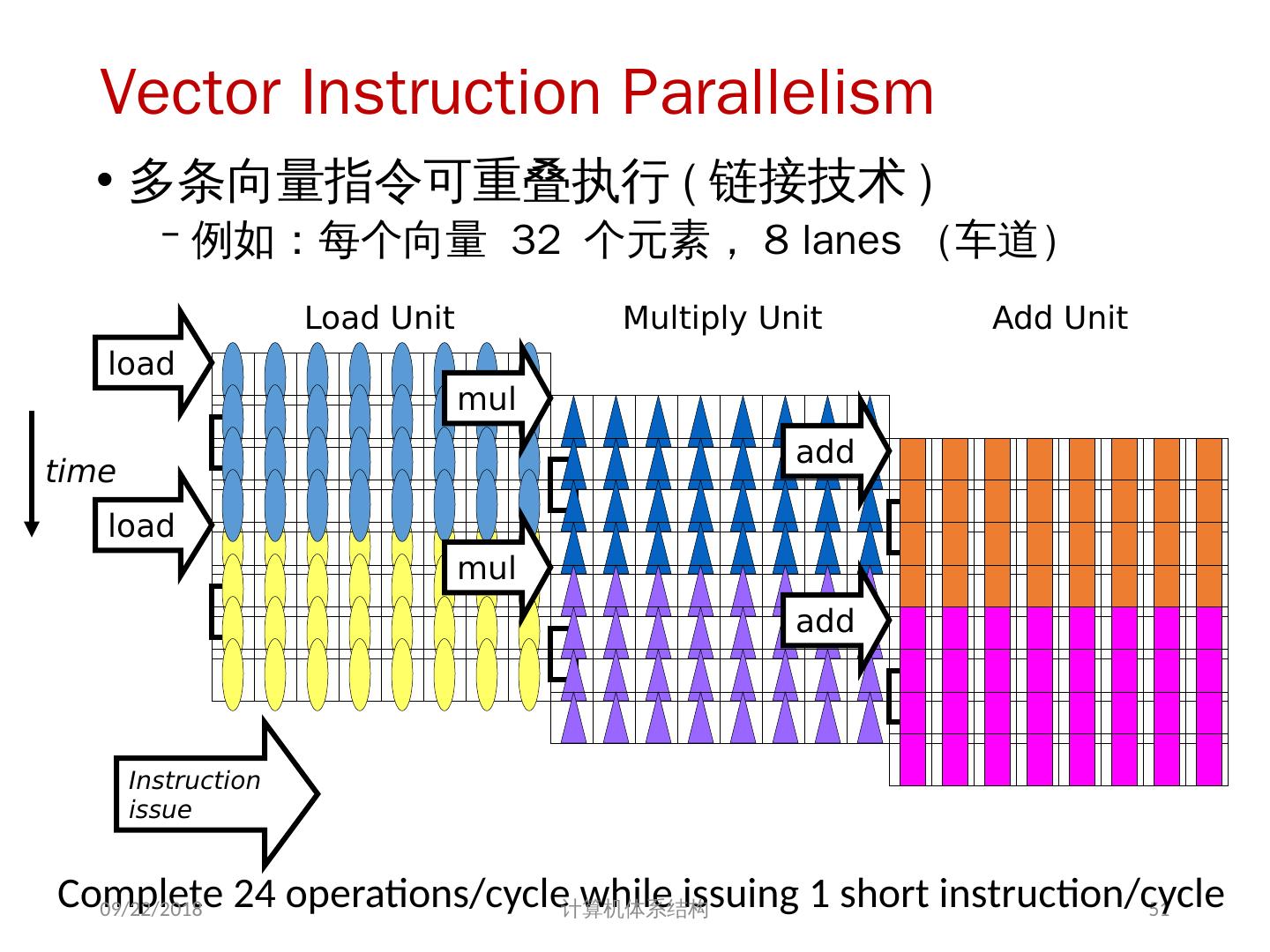
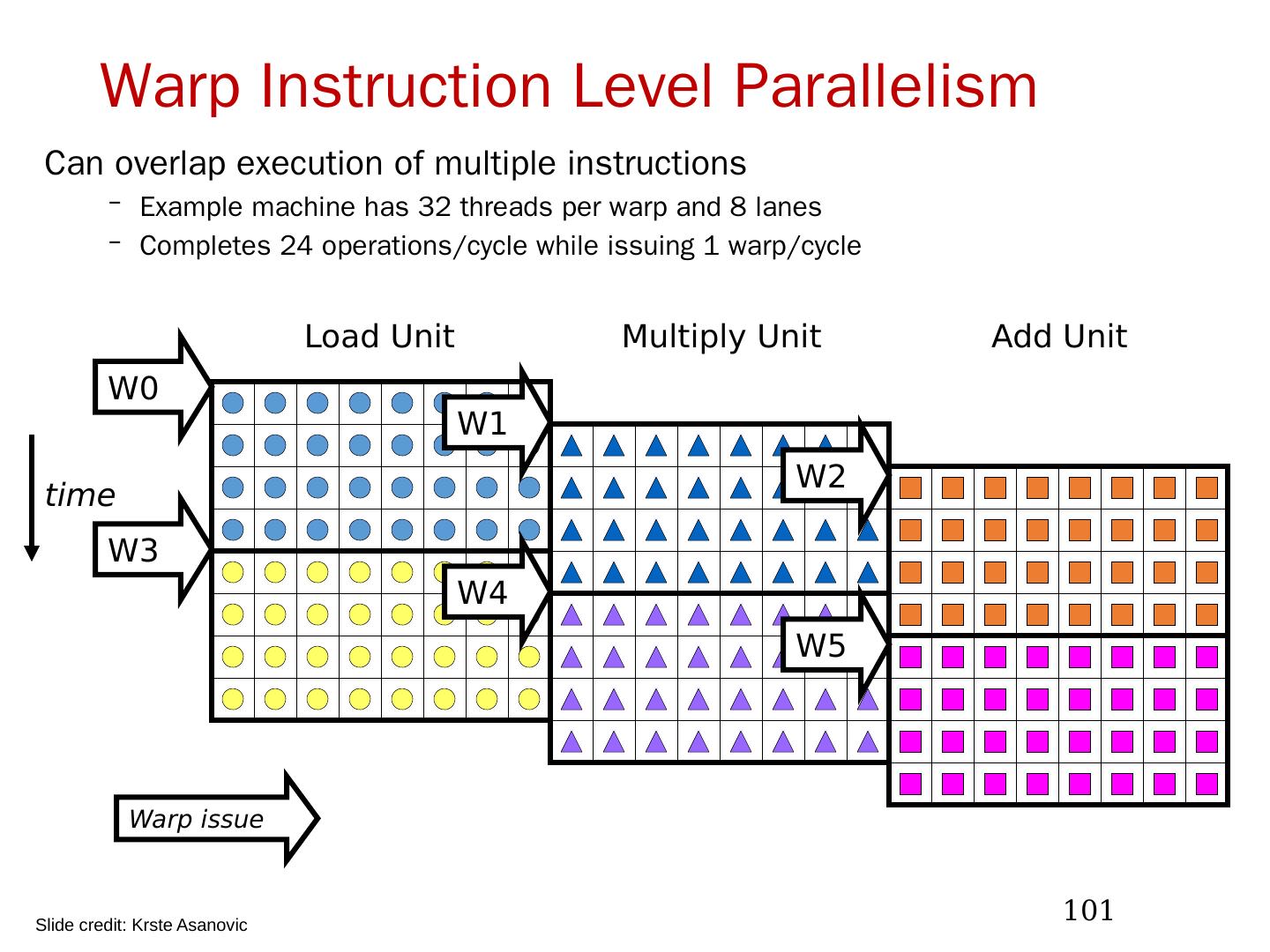
26 .Vector Instruction Parallelism 多条向量指令可重叠执行 ( 链接技术 ) 例如:每个向量 32 个元素, 8 lanes (车道) 26 load load mul mul add add Load Unit Multiply Unit Add Unit time Instruction issue Complete 24 operations/cycle while issuing 1 short instruction/cycle 2018/5/23 计算机体系结构
27 .-Review 向量处理机 基本结构 VSIW (ISA) 向量处理机的基本组成 向量运算部件的执行方式 - 流水线方式 向量部件结构 - 多“道”结构 - 多条运算流水线 多体交叉存储系统 向量指令并行执行 向量处理机 性能评估 向量指令流执行时间 : Convey, Chimes, Start-up time 其他指标: R , N 1/2 , N V 2018/5/23 计算机体系结构 27
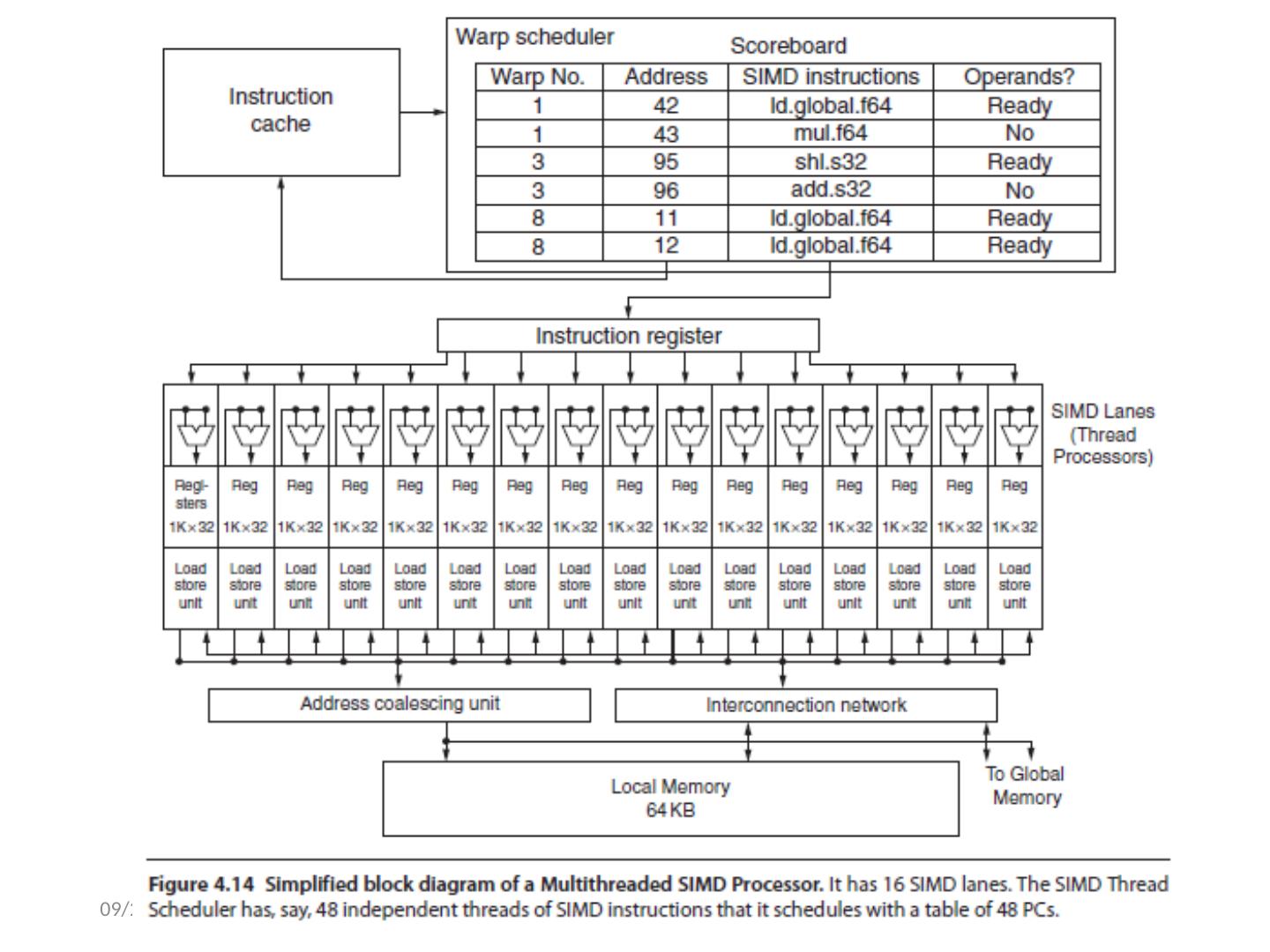
28 .05/16-review: Multithreading 28 Time (processor cycle) Superscalar Fine-Grained Coarse-Grained Multiprocessing Simultaneous Multithreading Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Idle slot 2018/5/23 计算机体系结构
29 .问题 试从挖掘 ILP 角度比较 CMP , FGMT , CGMT 以及 SMT 2018/5/23 计算机体系结构 29
3秒后跳转登录页面
去登陆

