


























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
08 编译原理---代码生成
这一节是南京大学计算机系许畅所讲授的编译原理中的代码生成。这一节的主要内容有:代码生成器的设计 目标语言 目标代码中的地址 基本块和流图 基本块优化 代码生成器 寄存器分配 代码生成器的位置 寻址模式 活动记录的静态分配等。在这一节中,作者举出了很多例子,需要我们仔细分析。
展开查看详情
1 .第八章 代码生成 许畅 南京大学计算机系 2018年春季
2 .主要内容 代码生成器的设计 目标语言 目标代码中的地址 基本块和流图 基本块优化 代码生成器 寄存器分配 2
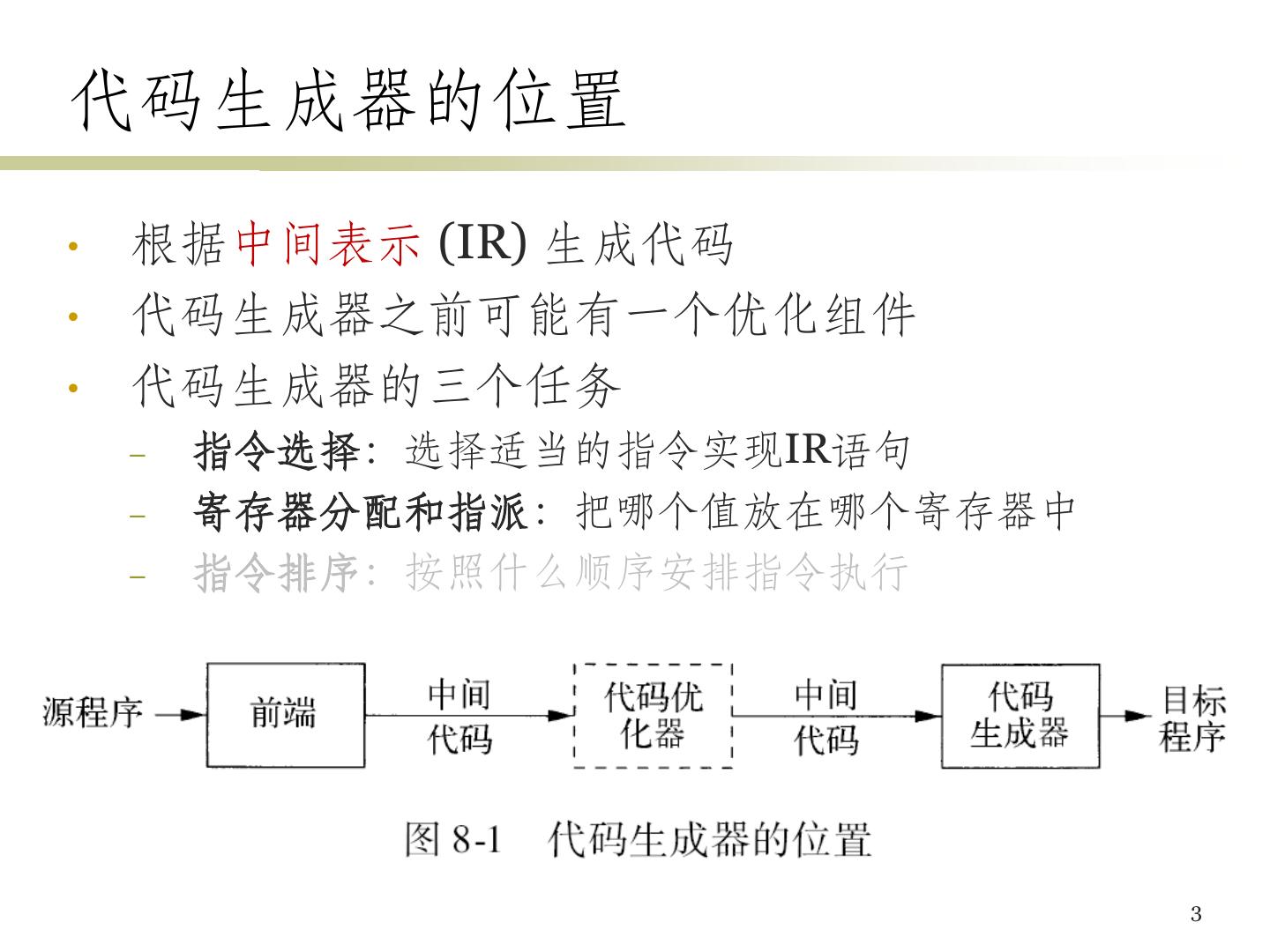
3 .代码生成器的位置 • 根据中间表示 (IR) 生成代码 • 代码生成器之前可能有一个优化组件 • 代码生成器的三个任务 – 指令选择:选择适当的指令实现IR语句 – 寄存器分配和指派:把哪个值放在哪个寄存器中 – 指令排序:按照什么顺序安排指令执行 3
4 .要解决的问题 正确性:正确的机器指令 易于实现、测试和维护 输入IR的选择 四元式、三元式、字节代码、堆栈机代码、后缀表示、 抽象语法树、DAG图、… 输出 RISC、CISC 可重定向代码、汇编语言 4
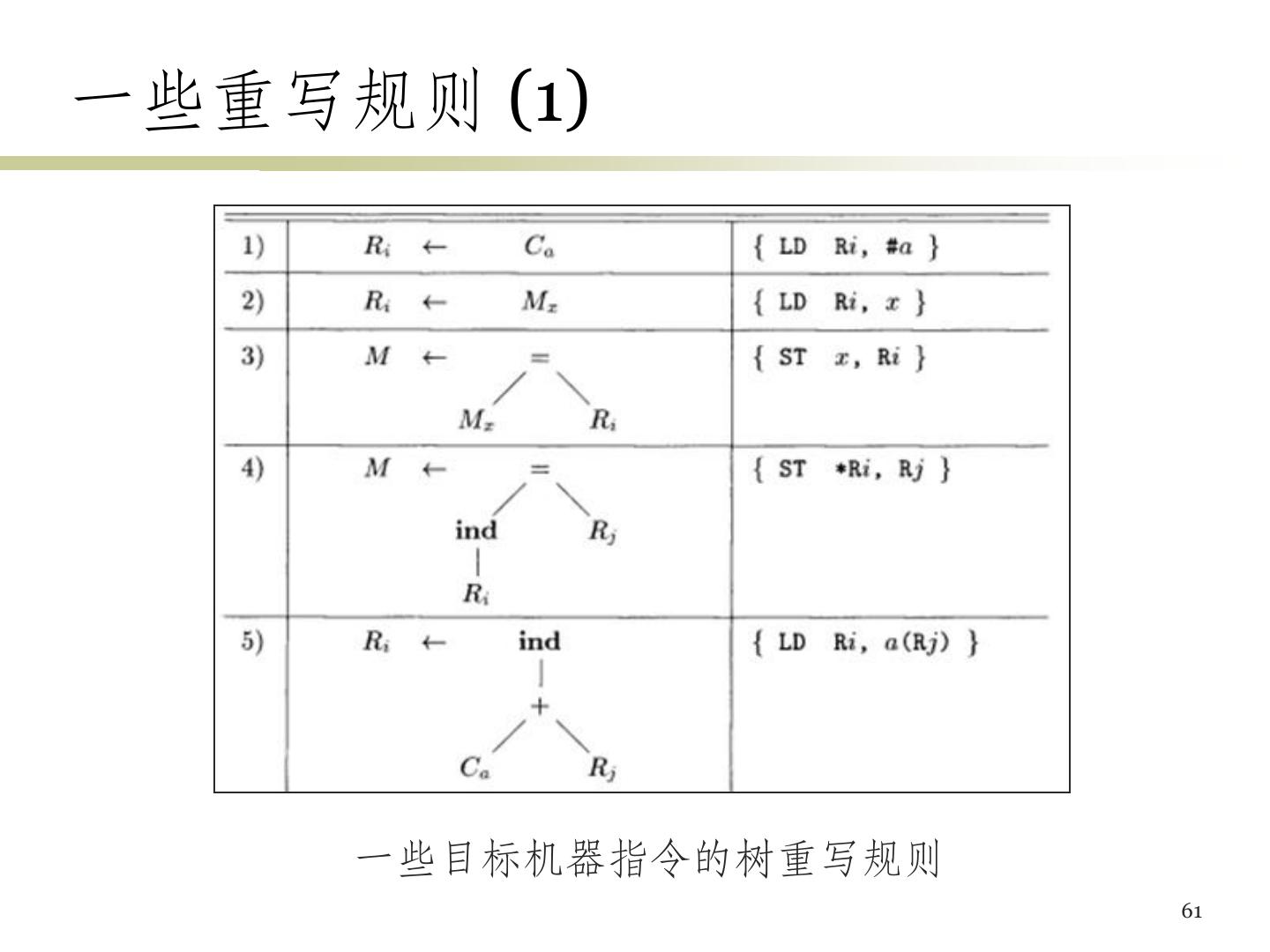
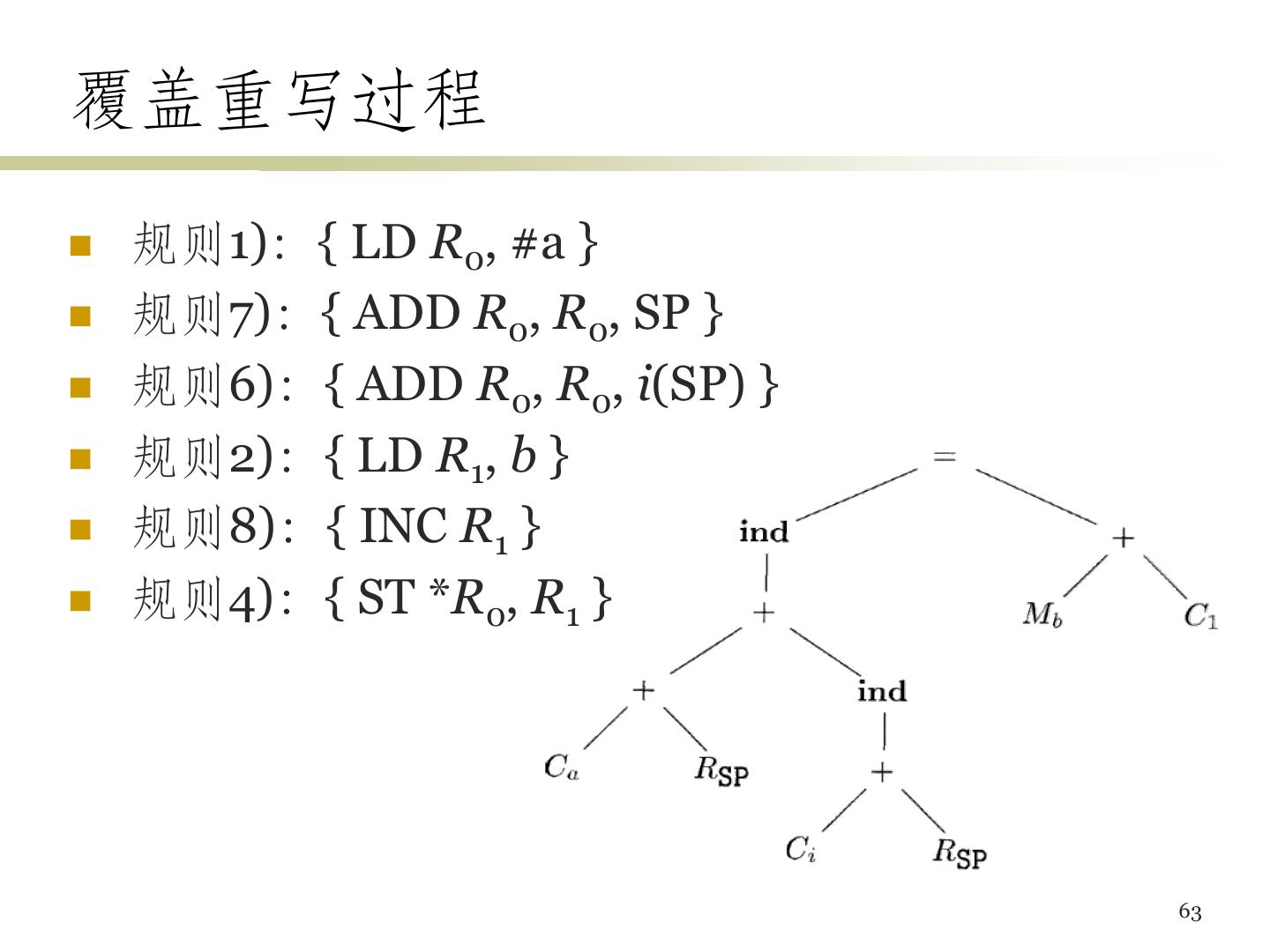
5 .目标机模型 • 使用三地址机器的模型 • 指令 – 加载:LD dst, addr (把地址addr中的内容加载到dst所 指的寄存器) – 保存:ST x, r (把寄存器r中的内容保存到x中) – 计算:OP dst, src1, src2 (把src1和src2中的值运算后将 结果存放到dst中) – 无条件跳转:BR L (控制流转向标号L的指令) – 条件跳转:Bcond r, L (对r中的值进行测试,如果为真 则转向L) 5
6 .寻址模式 变量x:指向分配x的内存位置 a(r):地址是a的左值加上寄存器r中的值 constant(r):寄存器r中内容加上前面的常数即其 地址 *r:寄存器r的内容所表示的位置上存放的内容位 置 *constant(r):寄存器r中内容加上常量所代表的 位置上的内容所表示的位置 常量#constant 6
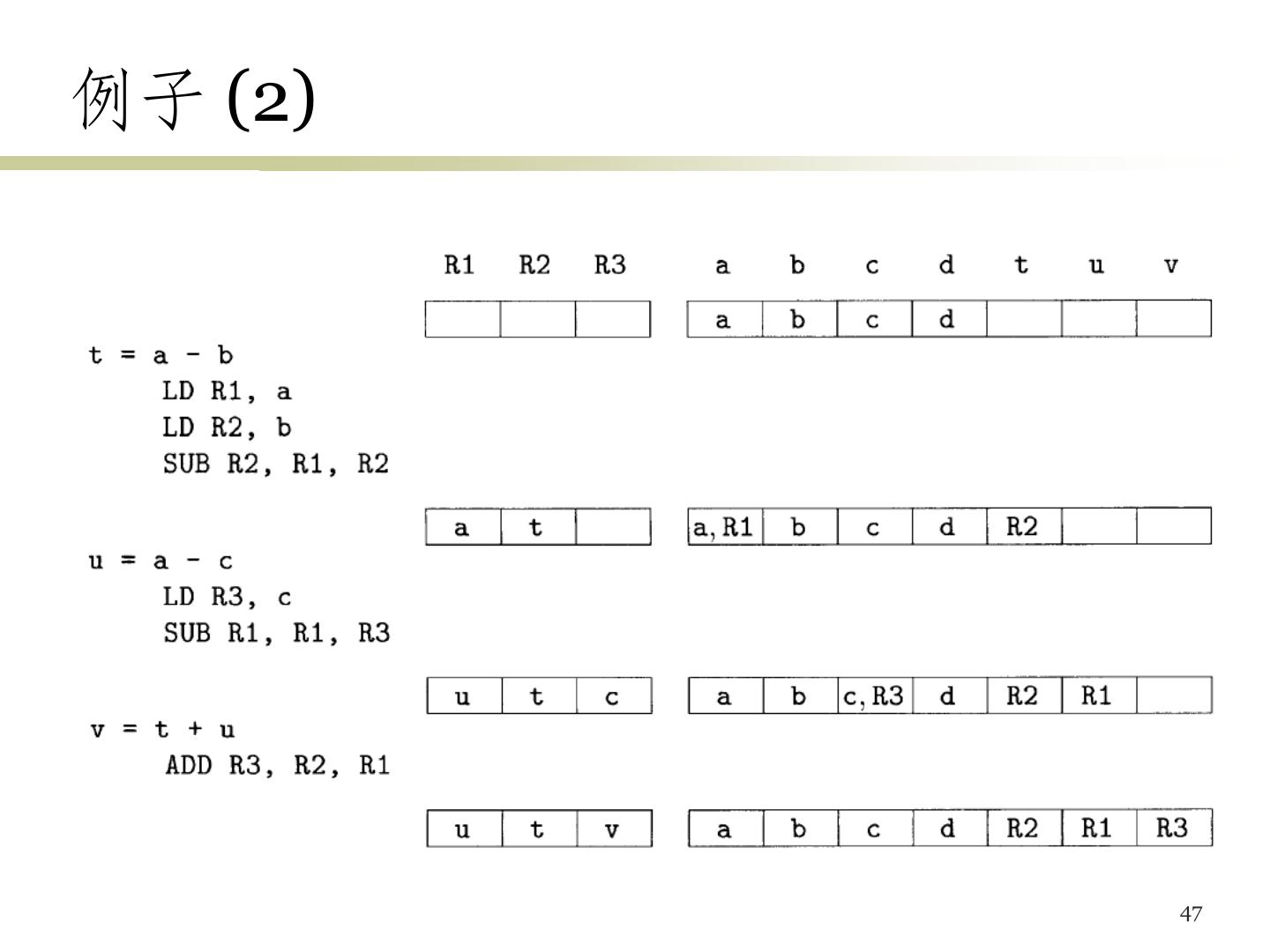
7 .例子 (1) • x=y–z – LD R1, y // R1 = y – LD R2, z // R2 = z – SUB R1, R1, R2 // R1 = R1 – R2 – ST x, R1 // x = R1 • b = a[i] – LD R1, i // R1 = i – MUL R1, R1, 8 // R1 = R1 * 8 (8字节长元素) – LD R2, a(R1) // R2 = content(a + content(R1)) – ST b, R2 // b = R2 7
8 .例子 (2) a[j] = c LD R1, c // R1 = c LD R2, j // R2 = j MUL R2, R2, 8 // R2 = R2 * 8 (8字节长元素) ST a(R2), R1 // content(a + content(R2)) = R1 x = *p LD R1, p // R1 = p LD R2, 0(R1) // R2 = content(0 + content(R1)) ST x, R2 // x = R2 8
9 .例子 (3) *p = y LD R1, p // R1 = p LD R2, y // R2 = y ST 0(R1), R2 // content(0 + content(R1)) = R2 if x < y goto L LD R1, x // R1 = x LD R2, y // R2 = y SUB R1, R1, R2 // R1 = R1 – R2 BLTZ R1, M // if R1 < 0 jump to M 9
10 .程序及指令的代价 • 不同的目的有不同的度量 – 最短编译时间、运行时间、目标程序大小、能耗 • 不可判定一个目标程序是否最优 • 假设每个指令有固定的代价,设定为1加上运算分 量寻址模式的代价 – LD R0, R1:代价为1 – LD R0, M:代价是2 – LD R1, *100(R2):代价为2 10
11 .目标代码中的地址 如何为过程调用和返回生成代码? – 静态分配 (活动记录) – 栈式分配 (活动记录) 如何将IR中的名字 (过程名或变量名) 转换成为目 标代码中的地址? – 不同区域中的名字采用不同的寻址方式 11
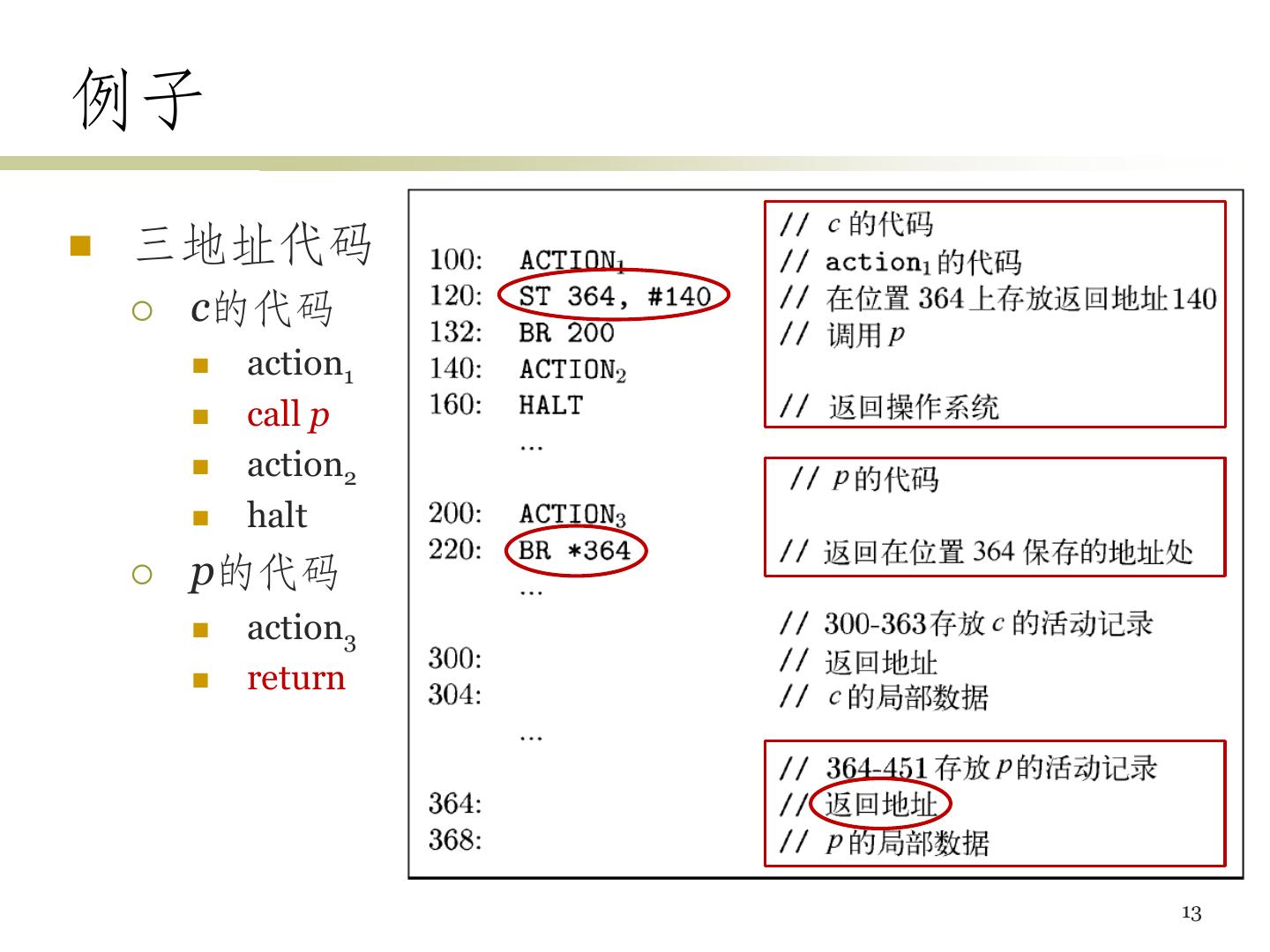
12 .活动记录的静态分配 每个过程静态地分配一个数据区域,其开始位置 用staticArea表示 call callee的实现 ST callee.staticArea, #here + 20 // 存放返回地址 BR callee.codeArea callee中的语句return BR *callee.staticArea 12
13 .例子 三地址代码 c的代码 action1 call p action2 halt p的代码 action3 return 13
14 .活动记录的栈式分配 • 寄存器SP指向栈顶 • 第一个过程 (main) 初始化栈区 • 过程调用指令序列 – ADD SP, SP, #caller.recordSize // 增大栈指针 – ST 0(SP), #here + 16 // 保存返回地址 – BR callee.codeArea // 转移到被调用者 • 返回指令序列 – BR *0(SP) // 被调用者执行,返回调用者 – SUB SP, SP, #caller.recordSize // 调用者减小栈指针 14
15 .例子 m调用q,q调用p 15
16 .名字的运行时刻地址 在三地址语句中使用名字 (实际上是指向符号表条 目) 来引用变量 语句x = 0 如果x分配在静态区域,且静态区开始位置为static static[12] = 0 LD 112, #0 // static = 100 如果x分配在栈区,且相对地址为12,则 LD 12(SP), #0 16
17 .基本块和流图 • 中间代码的流图表示法 – 中间代码划分成为基本块 (Basic block) • 控制流只能从基本块的第一条指令进入 • 除基本块的最后一条指令外,控制流不会跳转/停机 – 流图的结点是基本块,流图的边指明了哪些基本块可 以跟在一个基本块之后运行 • 流图可以作为优化的基础 – 它指出了基本块之间的控制流 – 可以根据流图了解到一个值是否会被使用等信息 17
18 .划分基本块的算法 • 输入:三地址指令序列 • 输出:基本块的列表 • 方法 – 确定首指令leader (基本块的第一个指令) • 第一个三地址指令 • 任意一个 (条件或无条件) 转移指令的目标指令 • 紧跟在一个 (条件或无条件) 转移指令之后的指令 – 确定基本块 • 每个首指令对应于一个基本块:从首指令开始到下一个首指令 18
19 .基本块划分的例子 • 第一个指令 – 1 • 跳转指令的目标指令 – 3, 2, 13 • 跳转指令的下一条指令 – 10, 12 • 基本块 – 1-1, 2-2, 3-9, 10-11, 12- 12, 13-17 19
20 .后续使用信息 • 变量值的使用 – 三地址语句i向变量x赋值,如果另一个语句j的运算分 量为x,且从i开始有一条路径到达j,且路径上没有对x 赋值,那么j就使用了i处计算得到的x的值 – 我们说变量x在语句i后的程序点上活跃 • 程序执行完语句i时,x中存放的值将被后面的语句使用 • 不活跃是指变量的值不会被使用,而不是变量不会被使用 • 这些信息可以用于代码生成 – 如果x在i处不活跃,且x占用了一个寄存器,我们可以 把这个寄存器用于其它目的 20
21 .确定基本块中的活跃性、后续使用 • 输入 • 基本块B,开始时B中的所有非临时变量都是活跃的 • 输出 • 各个语句i上变量的活跃性、后续使用信息 • 方法 – 从B的最后一个语句开始反向扫描 – 对于每个语句i:x = y + z • 令语句i和x、y、z的当前活跃性信息/使用信息关联 • 在符号表中,设置x为“不活跃”和“无后续使用” • 在符号表中,设置y和z为“活跃”,并指明它们的下一次使用 设置为语句i 21
22 .例子 • i, j, a非临时变量 (出口处活跃),其 余变量不活跃 – 8) i, j, a活跃,j在8上被使用 – 7) i, j, a, t4活跃,a和t4被7使用 – 6) i, j, a, t3活跃,t4不活跃,t3被6使用 – 5) i, j, a, t2活跃,t4, t3不活跃,t2被5 使用 – 4) i, j, a, t1活跃,t4, t3, t2不活跃,t1和 j被4使用 – 3) i, j, a活跃,t4, t3, t2, t1不活跃,i被3 使用 22
23 .流图的构造 • 流图的结点是基本块 • 两个结点B和C之间有一条有向边 iff 基本块C的第一个 指令可能在B的最后一个指令之后执行 • 存在边的原因 – B的结尾指令是一条跳转到C的开头的条件/无条件语句 – C紧跟在B之后,且B的结尾不是无条件跳转语句 • 我们称B是C的前驱,C是B的后继 • 入口/出口结点 – 不和任何中间指令对应;入口到第一条指令有一条边; 任何可能最后执行的基本块到出口有一条边 23
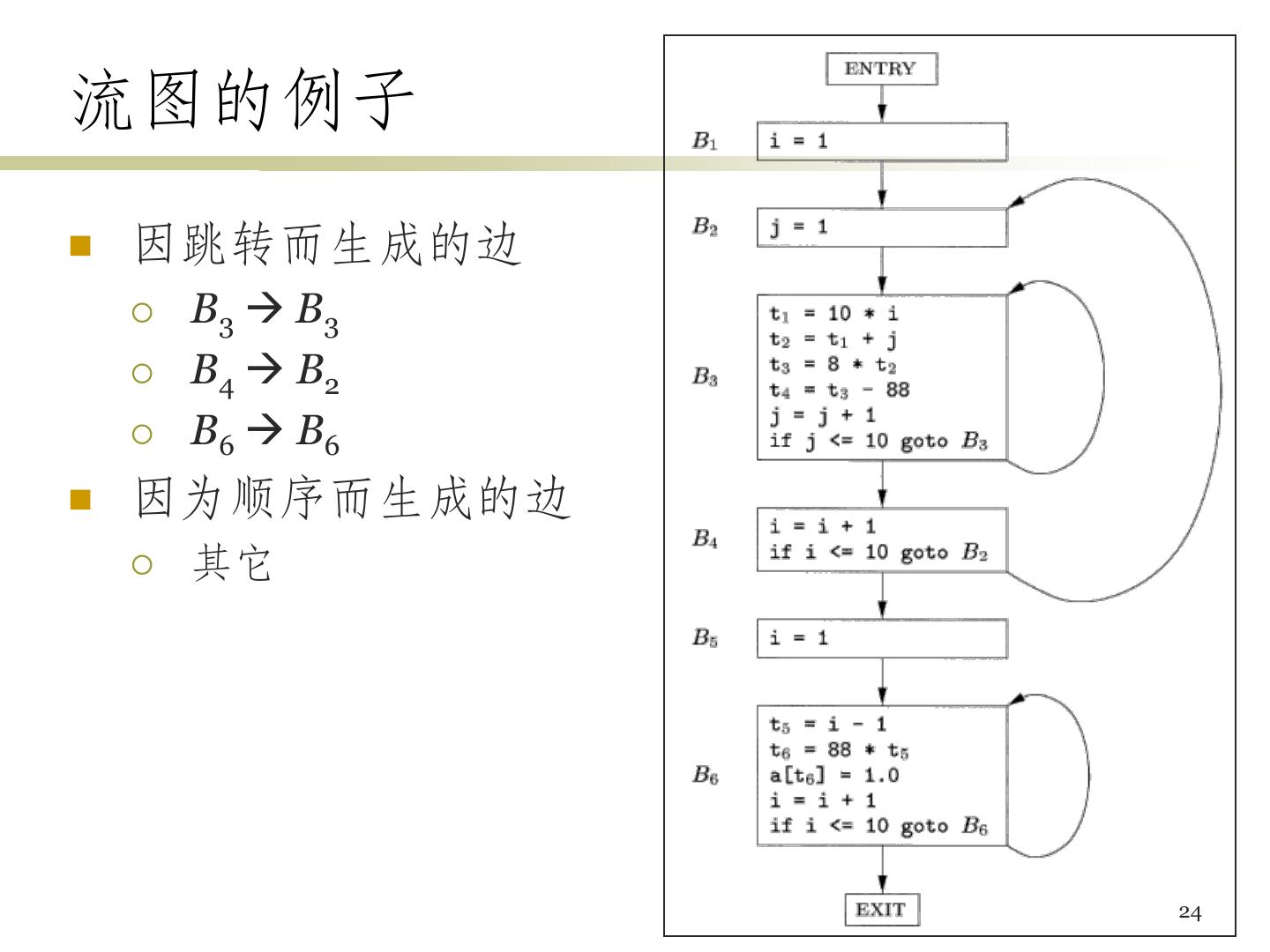
24 .流图的例子 因跳转而生成的边 B3 B3 B4 B2 B6 B6 因为顺序而生成的边 其它 24
25 .循环 • 程序的大部分运行时间花费在循环上,因此循环 是识别的重点 (优化的目标) • 循环的定义 – 循环L是一个结点集合 – 存在一个循环入口 (Loop entry) 结点,是唯一的、前 驱可以在循环L之外的结点,到达其余结点的路径必然 先经过这个入口结点 – 其余结点都存在到达入口结点的非空路径,且路径都 在L中 25
26 .循环的例子 • 循环 – {B3} – {B2, B3, B4} – {B6} • 对于{B2, B3, B4}的解释 • B2为入口结点 • B1, B5, B6不在循环内 – 到达B1可不经过B2 – B5, B6没有到达B2的结点 26
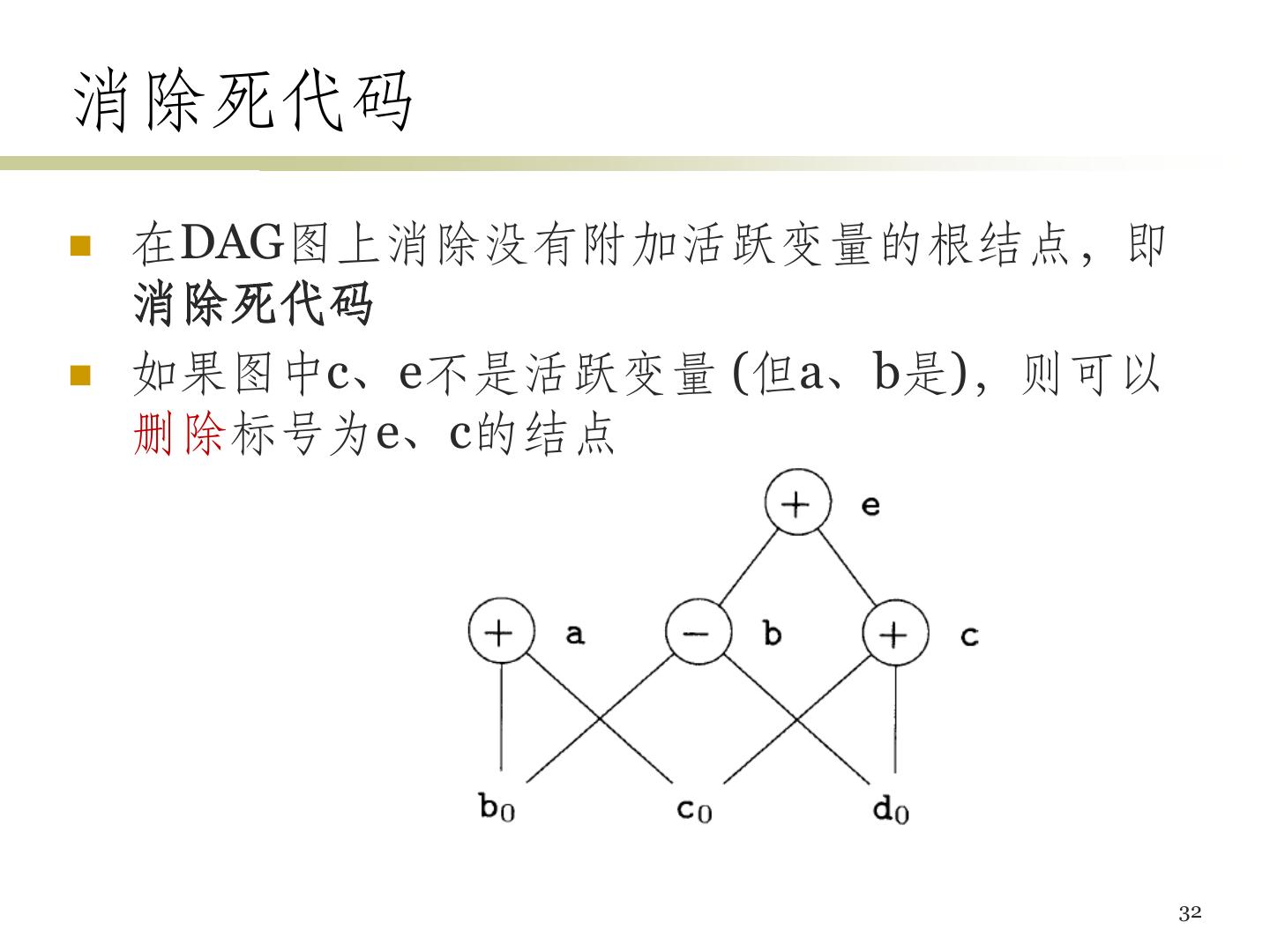
27 .基本块的优化 • 针对基本块的优化可以有很好的效果 (局部优化) • DAG图可反映变量及其值对其他变量的依赖关系 • 构造方法 – 每个变量都有一个对应的DAG结点表示其初始值 – 每个语句s有一个相关的结点N,代表此计算得到的值 • N的子结点对应于 (得到其运算分量当前值的) 其它语句 • N的标号是s中的运算符,同时还有一组变量被关联到N,表示 s是最晚对这些变量进行定值的语句 27
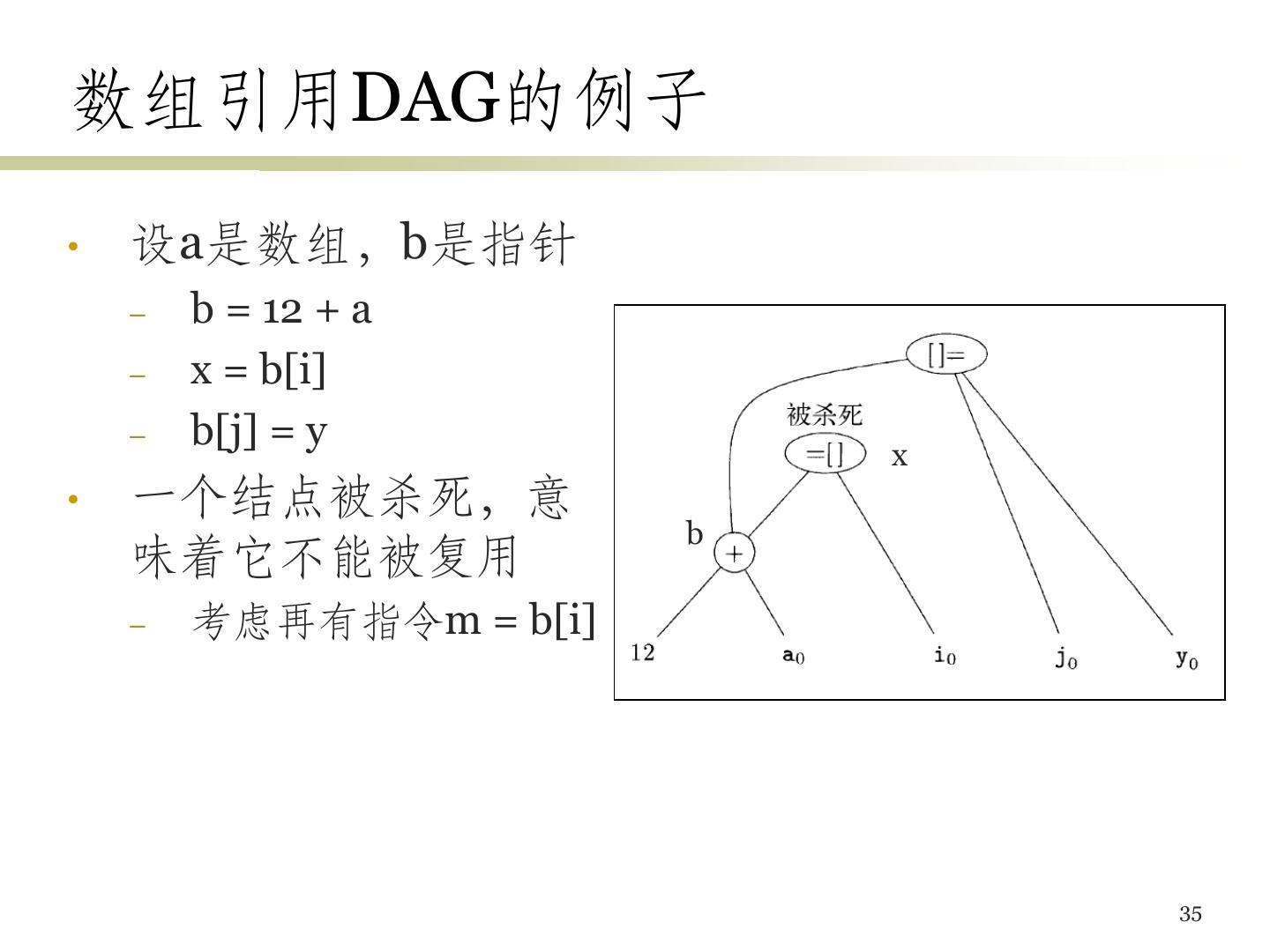
28 .DAG图的构造 • 为基本块中出现的每个变量建立结点 (表示初始 值),各变量和相应结点关联 • 顺序扫描各三地址指令,进行如下处理 • 指令x = y op z – 为该指令建立结点N,标号为op,令x和N关联 – N的子结点为y、z当前关联的结点 • 指令x = y – 假设y关联到N,那么x现在也关联到N • 扫描结束后,对所有在出口处活跃的变量x,将x 所关联的结点设置为输出结点 28
29 .例子 • 指令序列 – a=b+c – b=a–d – c=b+c • 过程 – 结点b0、c0和d0对应于b、c和d的初始值 – a = b + c:构造第一个加法结点,a与之关联 – b = a – d:构造减法结点,b与之关联 – c = b + c:构造第二个加法结点,c与之关联 (注意第一 个子结点对应于减法结点) 29
3秒后跳转登录页面
去登陆

